
1. परिचय
BigQuery Graph, BigQuery Conversational Analytics, और BigQuery Agent Analytics SDK, फ़िलहाल Google Cloud पर प्रीव्यू के तौर पर उपलब्ध हैं. BigQuery Agent Analytics प्लगिन, सामान्य तौर पर उपलब्ध (जीए) है. इस कोडलैब में दिए गए उदाहरणों में, सिंथेटिक डेटा का इस्तेमाल किया गया है.
ऑटोनॉमस एआई एजेंट, ऑपरेशन से जुड़ी ज़्यादा ज़िम्मेदारियां निभाते हैं. जैसे, लोन के आवेदनों का आकलन करना, मार्केटिंग बजट मैनेज करना, ऐक्सेस के अनुरोधों को मंज़ूरी देना. इसलिए, संगठनों के पास अपने फ़ैसलों की ऑडिट करने और उन्हें समझाने की सुविधा होनी चाहिए. एजेंट के फ़ैसले के लिए, सटीक कॉन्टेक्स्ट, विकल्पों पर विचार, और फ़ैसले की वजह को फिर से तैयार करना ज़रूरी है. इससे नियमों का पालन करने, जोखिम को मैनेज करने, और ऑपरेशनल ट्रस्ट को बनाए रखने में मदद मिलती है.
इस कोडलैब में, BigQuery Agent Analytics SDK का इस्तेमाल किया गया है. इससे एजेंट के इवेंट के रॉ लॉग को एजेंट कॉन्टेक्स्ट ग्राफ़ में बदला जा सकता है. यह एजेंट के फ़ैसलों का एक ऐसा ग्राफ़ होता है जिसे BigQuery Graph में क्वेरी किया जा सकता है. इसे शेड्यूल के हिसाब से, बिना किसी बाहरी ग्राफ़ डेटाबेस या ईटीएल पाइपलाइन के किया जा सकता है.
मुख्य शब्द
- एजेंट के फ़ैसले का पता लगाना — यह फ़ैसले के लेवल का सबूत होता है. इसे एजेंट के अपने रन से इकट्ठा किया जाता है: एजेंट ने किन विकल्पों पर विचार किया, उसने किस डेटा का इस्तेमाल किया, और उसने क्या नतीजा दिया.
- एजेंट कॉन्टेक्स्ट ग्राफ़ — यह BigQuery Graph में टाइप किया गया, क्वेरी किया जा सकने वाला ग्राफ़ होता है. इसमें ट्रेस को शामिल किया जाता है. यह इंडस्ट्री के कॉन्टेक्स्ट ग्राफ़ कॉन्सेप्ट का एजेंट-स्कोप किया गया इंस्टेंस है. यह फ़ैसले के कॉन्टेक्स्ट की एक ऐसी लेयर है जो समय के साथ बदलती नहीं है और समय से जुड़ी होती है. एजेंट इसे जनरेट और इस्तेमाल, दोनों करते हैं. "Agent" क्वालिफ़ायर, इसे एंटरप्राइज़-वाइड कॉन्टेक्स्ट लेयर के बजाय, आपके एजेंट के रन के लिए स्कोप करता है.
इस कोडलैब में, bqaa context-graph आपके agent_events से एजेंट के फ़ैसले के ट्रेस निकालता है और उन्हें एजेंट कॉन्टेक्स्ट ग्राफ़ में बदलता है. इस ग्राफ़ को GQL से क्वेरी किया जा सकता है. यह इंडस्ट्री के उस पैटर्न का पालन करता है जहां फ़ैसले के ट्रेस से कॉन्टेक्स्ट ग्राफ़ बनाए जाते हैं.
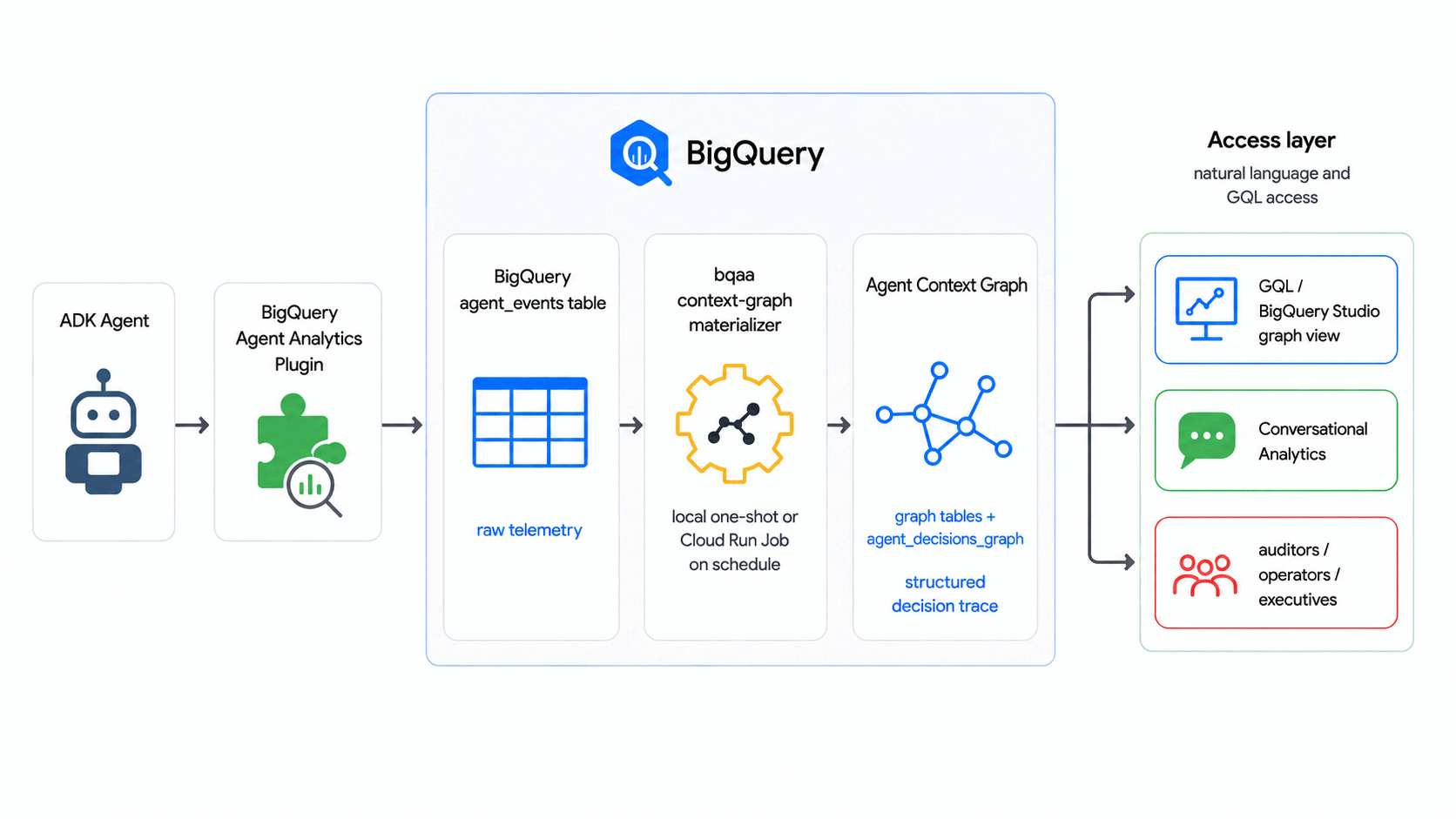
आपको क्या बनाना है
- एक एजेंट कॉन्टेक्स्ट ग्राफ़ (BigQuery ग्राफ़ के साथ), जो एजेंट के फ़ैसले लेने की सामान्य प्रोसेस को मॉडल करता है: अनुरोध आता है, एजेंट विकल्पों पर विचार करता है, और नतीजे पर पहुंचता है.
- सिंथेटिक इवेंट कॉर्पस वाली, भरी हुई
agent_eventsटेबल. bqaa context-graphका ऐसा वर्शन जो उन इवेंट से ग्राफ़ को भरता है.- ऑडिट स्टाइल वाली GQL क्वेरी, जो किसी एक फ़ैसले को शुरू से आखिर तक ट्रैक करती है.
आपको क्या सीखने को मिलेगा
- BigQuery Agent Analytics प्लगिन,
agent_eventsमें डेटा कैसे लिखता है. - कॉन्टेक्स्ट ग्राफ़ को सिर्फ़ दो डिक्लेरेटिव आर्टफ़ैक्ट से कैसे तय किया जाता है — एक टेबल डीडीएल और एक
CREATE PROPERTY GRAPHस्कीमा. - BigQuery Graph के ख़िलाफ़
bqaa context-graphको चलाने का तरीका. - GQL का इस्तेमाल करके ग्राफ़ के बारे में क्वेरी करने का तरीका.
- एसडीके, एंटरप्राइज़ डिप्लॉयमेंट के लिए प्रोडक्शन-ग्रेड की सुविधाएं उपलब्ध कराता है.
आपको किन चीज़ों की ज़रूरत होगी
- बिलिंग की सुविधा वाला Google क्लाउड प्रोजेक्ट.
- उस प्रोजेक्ट के लिए मालिक या एडिटर की भूमिका. आपको एक BigQuery डेटासेट बनाना होगा और IAM की अनुमति देनी होगी.
gcloudCLI इंस्टॉल और पुष्टि किया गया हो या Cloud Shell का ऐक्सेस हो.- Python 3.10 या इसके बाद का वर्शन.
- BigQuery एसक्यूएल के बारे में जानकारी होना. इसके लिए, GQL के बारे में जानकारी होना ज़रूरी नहीं है.
यह कोडलैब, सभी लेवल के डेवलपर के लिए है. इसमें वे डेवलपर भी शामिल हैं जिन्होंने BigQuery Graph का इस्तेमाल अभी शुरू किया है.
इस कोडलैब में बनाए गए संसाधनों की लागत बहुत कम होती है. साथ ही, आखिरी चरण में सभी संसाधन हटा दिए जाते हैं, ताकि आपसे इस्तेमाल न किए गए डेटासेट का शुल्क न लिया जाए.
अनुमानित समय: इस कोडलैब को पूरा करने में करीब 35 मिनट लगते हैं.
2. शुरू करने से पहले
कोई प्रोजेक्ट और क्षेत्र चुनें
Cloud Shell या लोकल टर्मिनल खोलें:
export PROJECT_ID="your-project-id"
export REGION="us-central1"
export DATASET="agent_analytics_demo"
gcloud config set project "$PROJECT_ID"
सिंगल DATASET वैरिएबल में, रॉ agent_events टेबल और मटीरियलाइज़्ड ग्राफ़ टेबल, दोनों शामिल होती हैं. एक डेटासेट का इस्तेमाल करने से, कोडलैब आसान रहता है. प्रोडक्शन डिप्लॉयमेंट में, इवेंट और ग्राफ़ को अक्सर अलग-अलग डेटासेट में बांटा जाता है, ताकि हर डेटासेट के लिए IAM को सीमित तौर पर अनुमति दी जा सके.
ज़रूरी एपीआई चालू करें
इस कोडलैब में इस्तेमाल किए गए एपीआई चालू करने के लिए, यह कमांड चलाएं:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com \
--project="$PROJECT_ID"
aiplatform.googleapis.com एपीआई ज़रूरी है, क्योंकि एसडीके का डिफ़ॉल्ट एक्सट्रैक्शन पाथ, BigQuery के AI.GENERATE फ़ंक्शन को कॉल करता है. अगर बाद में --extraction-mode=compiled-only की मदद से, डिटरमिनिस्टिक एक्सट्रैक्शन पर स्विच किया जाता है, तो इस एपीआई की ज़रूरत नहीं होती.
BigQuery डेटासेट बनाना
वह डेटासेट बनाएं जिसमें रॉ agent_events टेबल और मटीरियलाइज़्ड ग्राफ़ टेबल, दोनों शामिल होंगी:
bq --location=US mk --dataset "$PROJECT_ID:$DATASET"
आपको यह मैसेज दिखेगा:
Dataset 'your-project-id:agent_analytics_demo' successfully created.
अगर डेटासेट पहले से मौजूद है, तो कमांड में कोई गड़बड़ी नहीं होती है. इसे अपनी जगह पर ही रहने दें.
3. एसडीके टूल इंस्टॉल करना
Python का वर्चुअल एनवायरमेंट सेट अप करें और PyPI से SDK टूल इंस्टॉल करें:
python3 -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install bigquery-agent-analytics
bigquery-agent-analytics पैकेज, BigQuery क्लाइंट लाइब्रेरी को पुल करता है. इसलिए, पूरे कोडलैब के लिए आपको सिर्फ़ इसे इंस्टॉल करना होगा.
इंस्टॉल करने की पुष्टि करें:
bqaa context-graph --help | head -8
आपको सीएलआई बैनर दिखेगा.
पुष्टि करें
अगर किसी वर्कस्टेशन का इस्तेमाल किया जा रहा है, तो:
gcloud auth login
gcloud auth application-default login
Cloud Shell के उपयोगकर्ता इस चरण को छोड़ सकते हैं. क्रेडेंशियल पहले से कॉन्फ़िगर किए गए हैं.
4. कोडलैब के आर्टफ़ैक्ट पाना
कोडलैब के लिए, इस्तेमाल के लिए तैयार सिर्फ़ दो आर्टफ़ैक्ट की ज़रूरत होती है: टेबल DDL (फ़िजिकल ग्राफ़ टेबल) और प्रॉपर्टी-ग्राफ़ स्कीमा (CREATE PROPERTY GRAPH). आपको खुद इन्हें नहीं बनाना होता. कोडलैब इनका इस्तेमाल उसी तरह करता है जैसे ये हैं. साथ ही, आर्टफ़ैक्ट फ़ोल्डर में मौजूद README में बताया गया है कि इन्हें अपने फ़ैसले के डोमेन के हिसाब से कैसे बदला जाए.
प्रॉपर्टी-ग्राफ़ स्कीमा, इस बात का एकमात्र भरोसेमंद सोर्स है कि ग्राफ़ में क्या शामिल है. इसे BigQuery पर एक बार लागू किया जाता है. इसके बाद, डिप्लॉय किया गया ग्राफ़ ही अनुबंध होता है. मटेरियलाइज़ेशन के दौरान, bqaa context-graph, BigQuery के INFORMATION_SCHEMA.PROPERTY_GRAPHS से ग्राफ़ की परिभाषा को वापस पढ़ता है. साथ ही, यह उन टेबल के स्कीमा को भी पढ़ता है जिनका वह रेफ़रंस देता है. इससे यह तय किया जा सकता है कि किन इकाइयों और संबंधों को एक्सट्रैक्ट करना है और उन्हें कहां लिखना है. इसलिए, मटेरियलाइज़र को कभी भी कोई एसक्यूएल फ़ाइल नहीं भेजी जाती.
यह कोडलैब, खुद में ही पूरा है. इसलिए, कुछ भी डाउनलोड करने की ज़रूरत नहीं है. नीचे दी गई कमांड, कॉन्टेक्स्ट ग्राफ़ के डीडीएल को वर्किंग डायरेक्ट्री में लिखती है. इसका कॉन्टेंट, examples/context_graph/codelab/ में शिप किए गए आर्टफ़ैक्ट के कॉन्टेंट जैसा ही होता है.
वर्किंग डायरेक्ट्री बनाएं:
mkdir -p ~/context-graph-codelab
cd ~/context-graph-codelab
कॉन्टेक्स्ट ग्राफ़ DDL लिखें (context_graph_ddl.sql). ${PROJECT_ID} / ${DATASET} मार्कर तब भरे जाते हैं, जब अगले चरण में फ़ाइल लागू की जाती है.
cat > context_graph_ddl.sql <<'SQL'
-- Node and edge table DDL for the context-graph codelab.
--
-- `bqaa context-graph` writes into these tables on every run.
-- `session_id` and `extracted_at` are SDK metadata columns that
-- `bqaa context-graph` fills automatically; they are required on
-- every table behind the graph.
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_request` (
request_id STRING, request_text STRING, requested_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_option` (
option_id STRING, option_label STRING, confidence FLOAT64,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_outcome` (
outcome_id STRING, status STRING, rationale STRING, decided_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.evaluates_option` (
request_id STRING, option_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.resulted_in` (
request_id STRING, outcome_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
-- Graph DDL for the context-graph codelab.
--
-- Models a generic agent decision flow:
-- DecisionRequest -> evaluatesOption -> DecisionOption
-- DecisionRequest -> resultedIn -> DecisionOutcome
CREATE OR REPLACE PROPERTY GRAPH `${PROJECT_ID}.${DATASET}.agent_decisions_graph`
NODE TABLES (
`${PROJECT_ID}.${DATASET}.decision_request` AS decision_request
KEY (request_id)
LABEL DecisionRequest PROPERTIES (request_id, request_text, requested_at),
`${PROJECT_ID}.${DATASET}.decision_option` AS decision_option
KEY (option_id)
LABEL DecisionOption PROPERTIES (option_id, option_label, confidence),
`${PROJECT_ID}.${DATASET}.decision_outcome` AS decision_outcome
KEY (outcome_id)
LABEL DecisionOutcome PROPERTIES (outcome_id, status, rationale, decided_at)
)
EDGE TABLES (
`${PROJECT_ID}.${DATASET}.evaluates_option` AS evaluates_option
KEY (request_id, option_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (option_id) REFERENCES decision_option (option_id)
LABEL evaluatesOption,
`${PROJECT_ID}.${DATASET}.resulted_in` AS resulted_in
KEY (request_id, outcome_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (outcome_id) REFERENCES decision_outcome (outcome_id)
LABEL resultedIn
);
SQL
पुष्टि करें कि फ़ाइल मौजूद है:
ls
आपको एक फ़ाइल दिखेगी:
context_graph_ddl.sql
उन्होंने जिस फ़ैसले के फ़्लो के बारे में बताया है उसमें तीन नोड टाइप और दो हेटेरोज़ीनियस एज हैं:
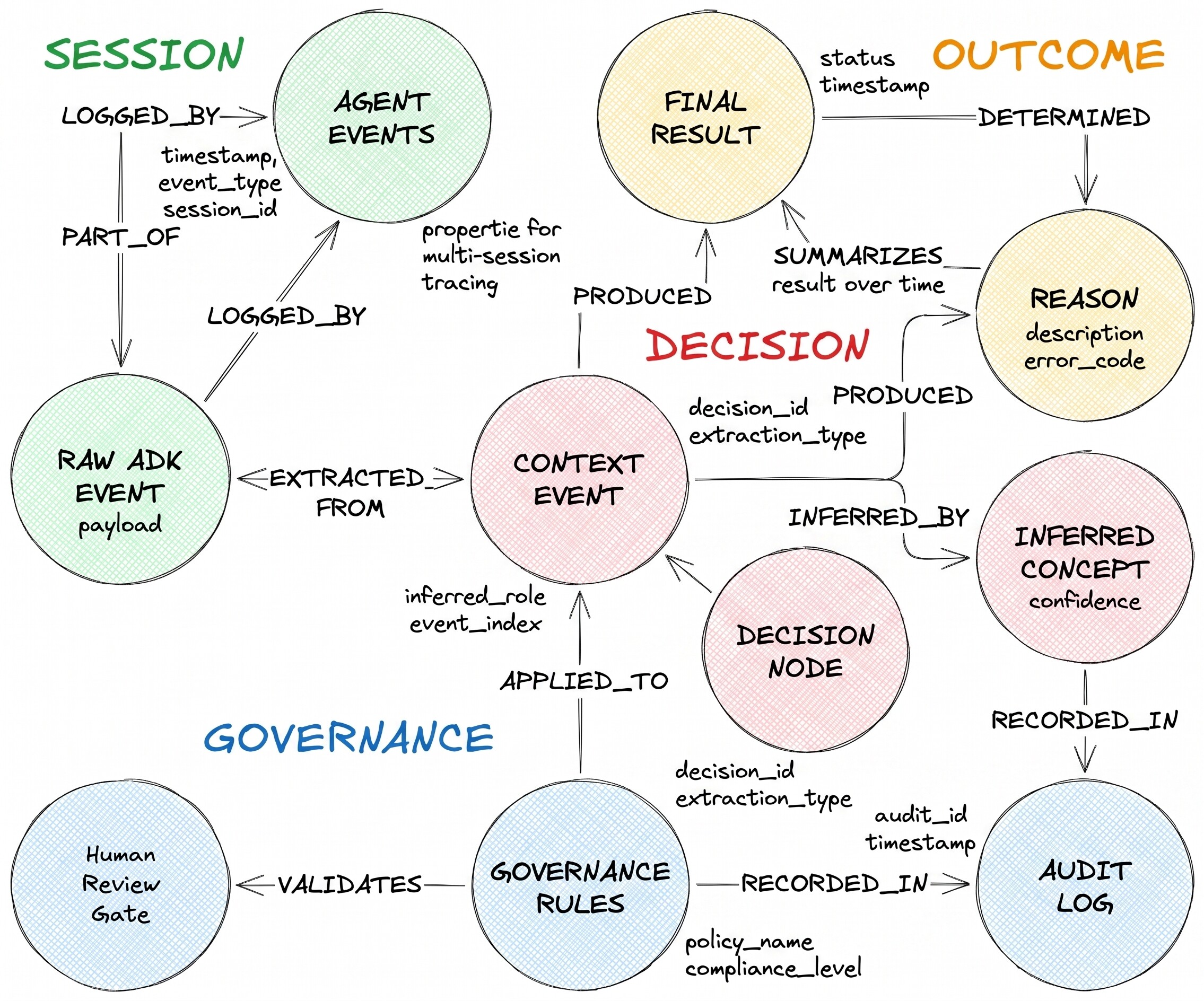
DecisionRequest वह सवाल है जो एजेंट को मिला है. DecisionOption एक ऐसा विकल्प है जिस पर एजेंट ने विचार किया है. DecisionOutcome, चुने गए विकल्प और उसके पीछे की वजह को रिकॉर्ड करता है.
5. प्रॉपर्टी ग्राफ़ स्कीमा लागू करना
bqaa context-graph, BigQuery टेबल में डेटा लिखता है. इसलिए, पहली बार चलाने से पहले इन टेबल का मौजूद होना ज़रूरी है. context_graph_ddl.sql सबसे पहले पांच टेबल बनाता है. इसके बाद, प्रॉपर्टी ग्राफ़ बनाता है, जो उन्हें रेफ़रंस करता है. BigQuery, ऐसी CREATE PROPERTY GRAPH को अस्वीकार कर देता है जो ऐसी टेबल की ओर इशारा करती हैं जो अभी तक मौजूद नहीं हैं. इसलिए, एक बार लागू करने से सब कुछ सेट अप हो जाता है:
envsubst < context_graph_ddl.sql | bq query --use_legacy_sql=false
आपको पांच CREATE TABLE नतीजे और एक CREATE PROPERTY GRAPH नतीजा दिखेगा. डीडीएल, आइडमपोटेंट होता है. इसे सुरक्षित तरीके से फिर से चलाया जा सकता है.
आपको सिर्फ़ इतना स्कीमा बनाना होता है. साथ ही, इन SQL फ़ाइलों का इस्तेमाल सिर्फ़ इसी समय किया जाता है. BigQuery अब आपके ग्राफ़ की परिभाषा को रिकॉर्ड करता है. साथ ही, bqaa context-graph इसे नाम के हिसाब से INFORMATION_SCHEMA.PROPERTY_GRAPHS से वापस पढ़ता है. मटेरियलाइज़र को पास करने के लिए कोई अलग फ़ाइल नहीं होती. साथ ही, GQL से क्वेरी किए गए डेटा और मटेरियलाइज़ किए गए डेटा में कभी कोई अंतर नहीं होता. ये दोनों, एक ही डिप्लॉय किए गए ग्राफ़ होते हैं.
6. सैंपल एजेंट इवेंट जनरेट करना
प्रोडक्शन में, BigQuery Agent Analytics प्लगिन आपके एडीके एजेंट के चलने पर इवेंट अपने-आप कैप्चर करता है. यह स्निपेट सिर्फ़ रेफ़रंस के लिए है. आपको इसे इस कोडलैब में नहीं चलाना है:
from google.adk.plugins import BigQueryAgentAnalyticsPlugin
plugin = BigQueryAgentAnalyticsPlugin(
project_id="your-project-id",
dataset_id="agent_analytics_demo",
)
runner = Runner(agent=root_agent, plugins=[plugin])
इस कोडलैब के लिए, आपको एक छोटे सिंथेटिक इवेंट जनरेटर का इस्तेमाल करना होगा. यह जनरेटर, एक ही तरह की लाइनों को सीधे agent_events में लिखता है. इसे चलाएं:
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--sessions 5
यह कमांड, JSON रिपोर्ट प्रिंट करती है. आपको पांच सेशन के लिए "events_generated": 30, "events_inserted": 30, और "ok": true दिखना चाहिए.
एक ही लाइन में कॉर्पस की झलक देखें. इसमें यह जानकारी शामिल होती है: कितने सेशन, कितने इवेंट, और उनकी समयसीमा:
bq query --use_legacy_sql=false \
"SELECT COUNT(DISTINCT session_id) AS sessions, COUNT(*) AS events, MIN(timestamp) AS earliest_event, MAX(timestamp) AS latest_event FROM \`$PROJECT_ID.$DATASET.agent_events\`"
डिफ़ॉल्ट रूप से पांच सेशन के लिए, यह पांच सेशन और कुछ मिनटों के 30 इवेंट दिखाता है. (नीचे दिए गए रियलिस्टिक उदाहरण को शामिल करें. साथ ही, इसी क्वेरी की रिपोर्ट में, करीब तीन दिनों में ~100 सेशन शामिल करें.)
पुष्टि करें कि इवेंट रिकॉर्ड किए गए हैं या नहीं:
bq query --use_legacy_sql=false \
"SELECT event_type, COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY event_type ORDER BY n DESC"
आपको 25 TOOL_COMPLETED लाइनें और 5 AGENT_COMPLETED लाइनें दिखनी चाहिए. हर सेशन में एक submit_request, तीन evaluate_option, एक commit_outcome, और एक क्लोज़िंग AGENT_COMPLETED होता है. इसका मतलब है कि हर सेशन में पांच टूल इवेंट और एक एजेंट टर्मिनेटर होता है. AGENT_COMPLETED लाइनें, सेशन खत्म करने वाले इवेंट हैं. bqaa context-graph, सेशन खत्म करने वाले इवेंट का पता लगाने के लिए इन पर नज़र रखता है.
ज़रूरी नहीं: असल डेटा के हिसाब से स्केल किया गया डेटा
ऊपर दिया गया पांच सेशन का कॉर्पस जान-बूझकर छोटा रखा गया है, ताकि पहली बार में ही कम समय और कम लागत में ट्रेनिंग हो सके. अगर आपको प्रोडक्शन के हिसाब से डेटा चाहिए, तो decision-realistic का इस्तेमाल करें. इसमें कई दिनों तक अलग-अलग एजेंट और उपयोगकर्ताओं का डेटा शामिल होता है. साथ ही, इसमें फ़ेल हुए, अनाथ, और छोटे किए गए सेशन का डेटा भी शामिल होता है. डिफ़ॉल्ट रूप से, यह 72 घंटे की विंडो में 100 सेशन पर सेट होता है. हालांकि, ऊपर बताया गया पहली बार चलाने का पाथ नहीं बदलता.
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--scenario decision-realistic \
--sessions 100 \
--seed 42
JSON रिपोर्ट के session_outcome_counts में, मिक्स दिखाया गया है. यह करीब {"success": 70, "failed": 10, "orphaned": 10, "truncated": 10} है.
हर सेशन को उसकी लाइनों के हिसाब से कैटगरी में बांटकर, नतीजे के डिस्ट्रिब्यूशन की पुष्टि करें (ऑर्फ़न = कोई AGENT_COMPLETED नहीं; फ़ेल = AGENT_COMPLETED के साथ status = 'error'; छोटा किया गया = is_truncated = true वाली कोई भी लाइन; इसके अलावा, सफल). पहले पास में, हर सेशन को कैटगरी में बांटा जाता है. इसके बाद, दूसरे पास में हर नतीजे के हिसाब से एग्रीगेट किया जाता है:
bq query --use_legacy_sql=false \
"WITH per_session AS (SELECT session_id, CASE WHEN COUNTIF(event_type = 'AGENT_COMPLETED') = 0 THEN 'orphaned' WHEN COUNTIF(event_type = 'AGENT_COMPLETED' AND status = 'error') > 0 THEN 'failed' WHEN COUNTIF(is_truncated) > 0 THEN 'truncated' ELSE 'success' END AS outcome FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY session_id) SELECT outcome, COUNT(*) AS sessions FROM per_session GROUP BY outcome ORDER BY outcome"
आपको करीब 70 सेशन सफल, 10 सेशन फ़ेल, 10 सेशन अनाथ, और 10 सेशन छोटे किए गए दिखेंगे. साथ ही, अगर आपने पहले उसी डेटासेट में पहले रन के कॉर्पस को सीड किया था, तो आपको पांच सफल सेशन भी दिखेंगे.
जिन 10 अनाथ सेशन में AGENT_COMPLETED इवेंट ट्रिगर नहीं हुआ था उन्हें डिफ़ॉल्ट bqaa context-graph रन में शामिल नहीं किया गया. ऐसा इसलिए, क्योंकि यह सिर्फ़ उन सेशन के लिए ट्रिगर होता है जिनमें टर्मिनल-इवेंट-क्लोज़्ड इवेंट ट्रिगर हुआ हो. इन्हें हमेशा के लिए चुपचाप फिर से कोशिश करने के बजाय, session_orphaned के तौर पर दिखाने के लिए, इसे चलाते समय --max-session-age-hours जोड़ें. इसे प्रोडक्शन में ले जाएं में --max-session-age-hours देखें.
7. कॉन्टेक्स्ट ग्राफ़ को मटीरियलाइज़ करना
bqaa context-graph, रॉ agent_events को पढ़ता है. इसके बाद, आपके डिप्लॉय किए गए ग्राफ़ से सीधे तौर पर यह पता लगाता है कि क्या एक्सट्रैक्ट करना है: यह BigQuery के INFORMATION_SCHEMA.PROPERTY_GRAPHS से, प्रॉपर्टी ग्राफ़ स्कीमा लागू करें में लागू की गई CREATE PROPERTY GRAPH की परिभाषा को पढ़ता है. इसके बाद, इसे उन टेबल के स्कीमा के साथ जोड़ता है जिन्हें यह रेफ़रंस करता है. साथ ही, यह इकाइयां, संबंध, और कॉलम टाइप तय करता है और ग्राफ़ टेबल भरता है. इसे डिप्लॉय किए गए ग्राफ़ के नाम पर --graph agent_decisions_graph के साथ पॉइंट किया जाता है. इसमें पास करने के लिए कोई एसक्यूएल फ़ाइल नहीं होती.
दौड़ना
bqaa context-graph स्थानीय तौर पर:
bqaa context-graph \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--graph agent_decisions_graph \
--lookback-hours 24 \
--format json
आपको स्ट्रक्चर्ड JSON रिपोर्ट दिखनी चाहिए:
{
"run_id": "...",
"sessions_discovered": 5,
"sessions_materialized": 5,
"sessions_failed": 0,
"rows_materialized": {
"DecisionRequest": 5,
"DecisionOption": 15,
"DecisionOutcome": 5
},
"ok": true
}
ok: true से पता चलता है कि bqaa context-graph को पांच पूरे किए गए सेशन मिले. साथ ही, AI.GENERATE की मदद से, हर सेशन से फ़ैसले लेने का फ़्लो निकाला गया और उससे जुड़ी लाइनों को ग्राफ़ टेबल में लिखा गया. डिटरमिनिस्टिक एक्सट्रैक्शन (--extraction-mode=compiled-only, इसके बारे में नीचे बताया गया है) से, रिपोर्ट का एक जैसा स्ट्रक्चर मिलता है. इसमें फ़ील्ड और ok: true एक जैसे होते हैं. यह सिर्फ़ AI.GENERATE कॉल को स्किप करता है.
समस्या हल करना: डेटा नहीं निकाला जा सका
अगर आपको error_code = "empty_extraction" के साथ ok: false दिखता है, तो इसकी सबसे आम वजह यह है कि aiplatform.googleapis.com एपीआई अभी तक लागू नहीं हुआ है या आपके खाते में roles/aiplatform.user मौजूद नहीं है. एक मिनट इंतज़ार करें और फिर से कोशिश करें. इसके अलावा, यह भूमिका असाइन करें:
USER_EMAIL=$(gcloud auth list --filter=status:ACTIVE --format="value(account)")
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="user:$USER_EMAIL" --role="roles/aiplatform.user"
इसके बाद, ऊपर दी गई bqaa context-graph कमांड को फिर से चलाएं.
पुष्टि करें कि ग्राफ़ में पंक्तियां मौजूद हैं:
bq query --use_legacy_sql=false \
"SELECT COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.decision_request\`"
आपको पांच लाइनें दिखेंगी. पांच सेशन में कुल 25 ग्राफ़ नोड हैं. इनमें 5 DecisionRequest, 15 DecisionOption, और 5 DecisionOutcome शामिल हैं. ये 15 evaluatesOption किनारों और 5 resultedIn किनारों से जुड़े हैं. हर सेशन में एक फ़ैसला लेने वाला वेब होता है.
इवेंट से फ़ैसले निकालने के दो तरीके
bqaa context-graph, डेटा निकालने के दो तरीके उपलब्ध कराता है. अपने वर्कलोड के हिसाब से कोई विकल्प चुनें:
- डिफ़ॉल्ट एक्सट्रैक्शन. सबसे आसान तरीका. यह कुकी, BigQuery के
AI.GENERATEका इस्तेमाल करके इवेंट का कॉन्टेंट पढ़ती है. साथ ही, इससे इकाइयों और संबंधों का अनुमान लगाया जाता है. यह किसी भी इवेंट शेप के साथ काम करता है. इसके लिए, किसी अतिरिक्त कोड की ज़रूरत नहीं होती. इस कोडलैब में इसका इस्तेमाल किया जाता है. - डिटरमिनिस्टिक एक्सट्रैक्शन (
--extraction-mode=compiled-only). यह कम लागत वाला और ऑडिट के लिए बेहतर तरीका है. यह एक छोटे Python रेफ़रंस एक्सट्रैक्टर का इस्तेमाल करता है. इसे आपको अपने डोमेन के लिए एक बार लिखना होता है. Vertex AI को कॉल नहीं किया जाता, हर टोकन के लिए शुल्क नहीं लिया जाता, और आउटपुट को पूरी तरह से दोहराया जा सकता है. प्रोडक्शन डिप्लॉयमेंट के लिए, इस विकल्प को तब चुना जाता है, जब लागत का अनुमान लगाना या नतीजों को सटीक तरीके से दोहराना ज़रूरी होता है.
कॉन्टेक्स्ट ग्राफ़ डिप्लॉयमेंट गाइड, दोनों पाथ के लिए रेफ़रंस है. इसमें IAM की जानकारी और रेफ़रंस एक्सट्रैक्टर बनाने का तरीका शामिल है.
8. फ़ैसले को ट्रेस करने के लिए क्वेरी करना
ग्राफ़ में डेटा दिखने के बाद, ऑडिट के सवाल का जवाब सीधे तौर पर दिया जा सकता है. एक उदाहरण देखें: "हर अनुरोध के लिए, एजेंट ने किन विकल्पों पर विचार किया और समस्या को कैसे हल किया?" GQL में, अनुरोध, उसके विकल्पों, और उसके नतीजे के बारे में एक ही बार में जानकारी मिलती है.
क्वेरी को किसी फ़ाइल में लिखें (traversal.sql). ${DATASET} मार्कर तब भरता है, जब इसे अगले चरण में चलाया जाता है:
cat > traversal.sql <<'SQL'
SELECT *
FROM GRAPH_TABLE (
${DATASET}.agent_decisions_graph
MATCH
(req:DecisionRequest) -[eo:evaluatesOption]-> (opt:DecisionOption),
(req) -[ri:resultedIn]-> (out:DecisionOutcome)
COLUMNS (
req.request_id AS request,
req.request_text AS question,
opt.option_label AS considered,
opt.confidence AS score,
out.status AS outcome,
out.rationale AS rationale
)
);
SQL
इसे चलाएं:
envsubst < traversal.sql | bq query --use_legacy_sql=false --max_rows=20
आपको पंद्रह लाइनें दिखेंगी: हर अनुरोध के लिए तीन विकल्प, पांच अनुरोध. हर लाइन में अनुरोध, एजेंट के हिसाब से सही विकल्प, कॉन्फ़िडेंस स्कोर, फ़ाइनल नतीजा, और वजह दिखाई जाती है.
किसी एक फ़ैसले की पूरी जानकारी पाने के लिए, request_id के हिसाब से फ़िल्टर करें. इससे ऑडिट टीम को ज़रूरी जानकारी वाली लाइन मिल जाएगी: पूछा गया सवाल, जिन विकल्पों पर विचार किया गया उनके स्कोर, और फ़ैसले की वजह.
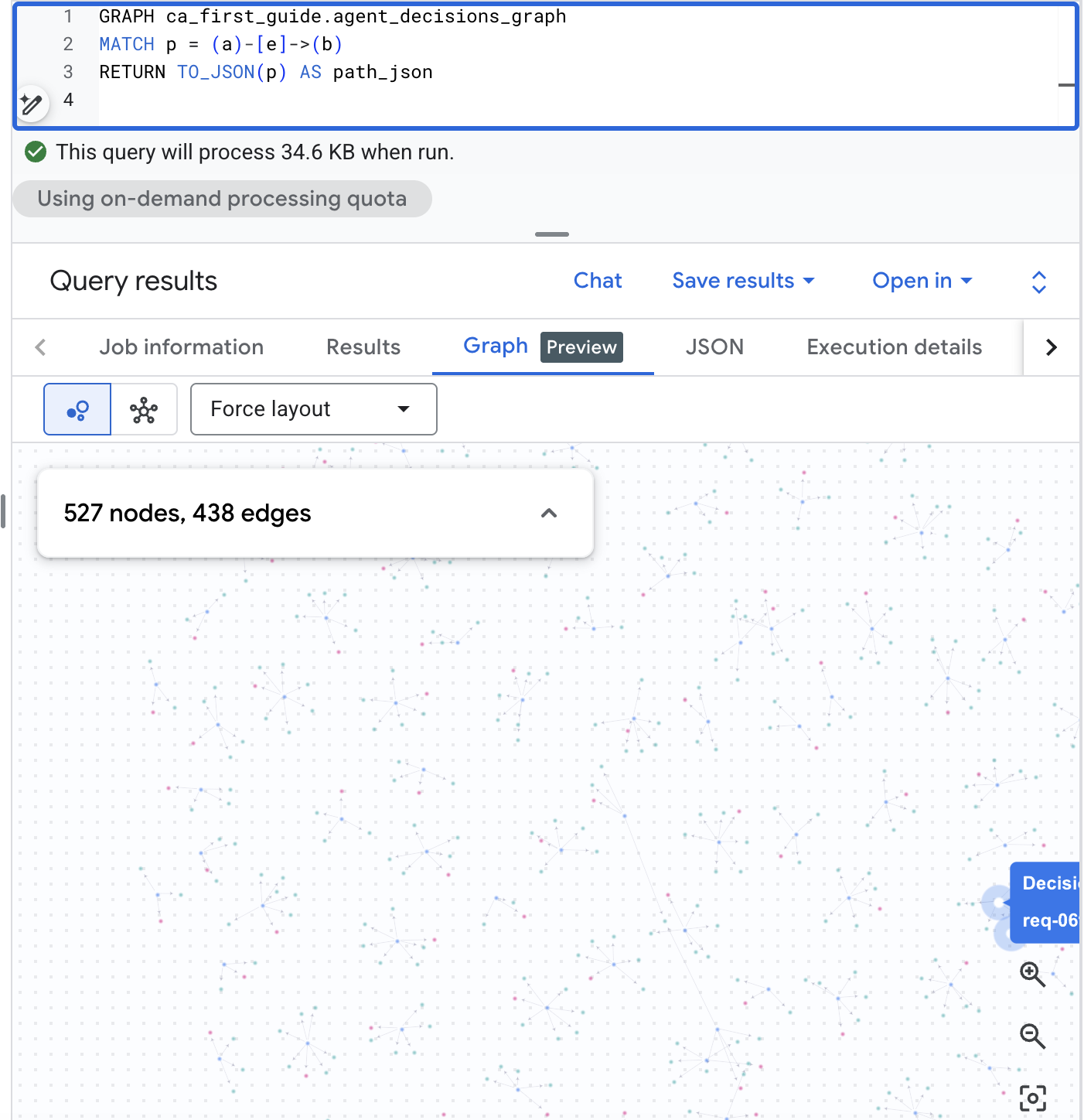
BigQuery Studio में ग्राफ़ को विज़ुअलाइज़ करना
BigQuery Studio, ग्राफ़ को विज़ुअल तौर पर भी रेंडर कर सकता है. BigQuery कंसोल में BigQuery Studio खोलें. इसके बाद, नीचे दी गई पाथ क्वेरी चलाएं. इसके बाद, नतीजों के पैनल को Graph टैब पर स्विच करके, फ़ैसले का वेब देखें. इस कॉर्पस में, आपको अनुरोधों, विकल्पों, और नतीजों का विज़ुअल मैप मिलता है:
GRAPH agent_analytics_demo.agent_decisions_graph
MATCH p = (a)-[e]->(b)
RETURN TO_JSON(p) AS path_json
आसान अंग्रेज़ी में वही सवाल पूछें
हर ऑडिट रीडर, GQL नहीं लिखता. BigQuery कन्वर्सेशनल ऐनलिटिक्स (प्रीव्यू) की मदद से, आपकी अनुपालन टीम उसी तरह के सवाल नैचुरल लैंग्वेज में पूछ सकती है. साथ ही, स्ट्रक्चर्ड जवाब कार्ड पा सकती है. इसके लिए, क्वेरी सिंटैक्स की ज़रूरत नहीं होती और न ही शामिल होने के बारे में जानने की ज़रूरत होती है.
agent_decisions_graph (साथ ही, agent_events और फ़ैसले लेने वाली टेबल) को कन्वर्सेशनल ऐनलिटिक्स के डेटा सोर्स के तौर पर रजिस्टर करें. इसके बाद, सीधे ऑडिट से जुड़ा सवाल पूछें:
ऑडिट सवाल (सामान्य अंग्रेज़ी): "किन अनुरोधों के लिए, तय किए गए नतीजे कभी नहीं मिले?"
बातचीत वाली Analytics सुविधा, ग्राफ़ के बारे में जानकारी देती है. साथ ही, आपके लिए एसक्यूएल लिखती है और टेबल के साथ सामान्य अंग्रेज़ी में जवाब देती है. यहां, रिकॉर्ड किए गए हर अनुरोध के लिए, तय किए गए नतीजे मिले हैं:
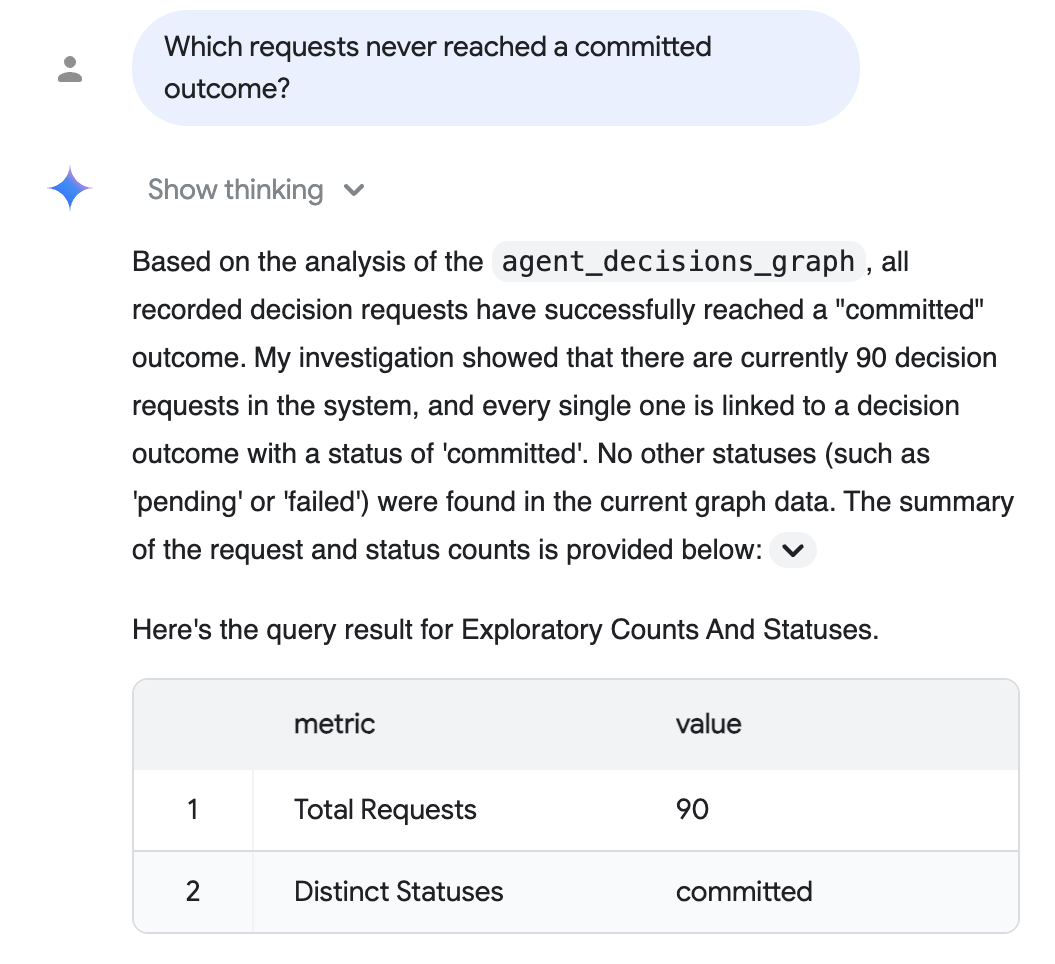
ऊपर दिए गए जवाब में, रियलिस्टिक-स्केल डेटा के वैकल्पिक चरण से मिले रियलिस्टिक-स्केल कॉर्पस को दिखाया गया है. इसमें 90 अनुरोध शामिल हैं और सभी अनुरोध पूरे किए गए हैं. आपके सटीक नंबर इस बात पर निर्भर करते हैं कि आपने कौनसे कॉर्पस को सीड किया है. साथ ही, डिफ़ॉल्ट रूप से पांच सेशन के रन में पांच अनुरोध दिखाए जाते हैं.
सेटअप करने के लिए, कन्वर्सेशनल ऐनलिटिक्स का दस्तावेज़ देखें.
9. इसे प्रोडक्शन में ले जाना
ऊपर दिए गए लोकल रन में डिफ़ॉल्ट व्यवहार का इस्तेमाल किया गया है. इसमें पहले से ही, असल डिप्लॉयमेंट की बुनियादी बातें शामिल हैं: हर रन, ऑडिट ट्रेल छोड़ता है (स्ट्रक्चर्ड Cloud Logging के साथ-साथ आपके डेटासेट में स्टेट टेबल में हर रन के लिए एक लाइन), कुछ समय के लिए होने वाली गड़बड़ियां अपने-आप फिर से कोशिश करती हैं, और प्रोग्रेस सिर्फ़ पूरी तरह से सफल सेशन पर आगे बढ़ती है, इसलिए दो बार गिनती नहीं होती.
प्रोडक्शन कंट्रोल — डिटरमिनिस्टिक एक्सट्रैक्शन (--extraction-mode=compiled-only), स्टक-सेशन का पता लगाना (--max-session-age-hours), पिछली विंडो का एक बार रीप्ले करना (--backfill --from / --to, इसे सामान्य रीफ़्रेश से अलग ट्रैक किया जाता है, ताकि यह लाइव शेड्यूल में रुकावट न डाले), और हर रन के लिए बैच बाउंडिंग (--max-sessions) — ऑप्ट-इन फ़्लैग हैं. इनका इस्तेमाल तब किया जाता है, जब आपको इनकी ज़रूरत होती है. कॉन्टेक्स्ट ग्राफ़ डिप्लॉयमेंट गाइड में, हर एक के बारे में पूरी आईएएम मैट्रिक्स और सुझाए गए शेड्यूल के साथ जानकारी दी गई है.
10. व्यवस्थित करें
आपने जो बनाया है उसे हटा दें, ताकि आपको इस्तेमाल न किए जा रहे डेटासेट के लिए बिल न मिले:
bq rm -r -f --dataset "$PROJECT_ID:$DATASET"
इस एक कमांड से, डेटासेट, एजेंट इवेंट, ग्राफ़ टेबल, और स्टेट टेबल एक साथ हट जाती हैं.
11. बधाई हो
बधाई हो! आपने एजेंट के इवेंट लॉग को क्वेरी किए जा सकने वाले एजेंट कॉन्टेक्स्ट ग्राफ़ में बदल दिया है. साथ ही, किसी एक फ़ैसले को शुरू से आखिर तक ट्रैक किया है. इसके लिए, आपने किसी बाहरी ग्राफ़ डेटाबेस या ईटीएल पाइपलाइन का इस्तेमाल नहीं किया है.
इसी तरह का पैटर्न, एजेंट के उन सभी फ़ैसलों पर लागू होता है जो अहम होते हैं: क्रेडिट अंडरराइटिंग, पहले से अनुमति लेना, मार्केटिंग बजट में बदलाव करना, खरीदारी, ग्राहक सेवा, और इंटरनल आईटी. अपना एजेंट कॉन्टेक्स्ट ग्राफ़ बनाने के लिए, कोडलैब आर्टफ़ैक्ट को शुरुआती पॉइंट के तौर पर कॉपी करें. इसके बाद, दोनों डिक्लेरेटिव फ़ाइलों (टेबल DDL + CREATE PROPERTY GRAPH स्कीमा) को अपने डोमेन के हिसाब से बदलें और उन्हें BigQuery पर लागू करें. bqaa context-graph --graph, डिप्लॉय किए गए ग्राफ़ को INFORMATION_SCHEMA से वापस पढ़ता है और बाकी जानकारी निकालता है.
आपने क्या सीखा
- BigQuery डेटासेट बनाने और एजेंट के फ़ैसले लेने के डोमेन के बारे में बताने वाला प्रॉपर्टी-ग्राफ़ स्कीमा लागू करने का तरीका.
- सिंथेटिक इवेंट कॉर्पस की मदद से,
agent_eventsको भरने का तरीका. bqaa context-graphको कैसे चलाया जाए, ताकि उन इवेंट से एजेंट के फ़ैसले के ट्रेस को एजेंट कॉन्टेक्स्ट ग्राफ़ में निकाला जा सके. साथ ही,INFORMATION_SCHEMAसे ग्राफ़ की परिभाषा को वापस पढ़ा जा सके.- GQL में, नतीजे के तौर पर मिले ग्राफ़ के बारे में क्वेरी करने और ऑडिट-स्टाइल में जवाब पढ़ने का तरीका.
रेफ़रंस के लिए दस्तावेज़
- BigQuery Agent Analytics SDK रिपॉज़िटरी
- कोडलैब के आर्टफ़ैक्ट और अडैप्टेशन गाइड
- कॉन्टेक्स्ट ग्राफ़ डिप्लॉयमेंट गाइड: इसमें ज़रूरी एपीआई, IAM मैट्रिक्स, सुझाए गए शेड्यूल, Cloud Monitoring की सूचना से जुड़ी क्वेरी, और Terraform मॉड्यूल के बारे में जानकारी दी गई है.
- BigQuery Graph का दस्तावेज़ (प्रीव्यू).
- BigQuery में कन्वर्सेशनल ऐनलिटिक्स के बारे में जानकारी देने वाला दस्तावेज़ (प्रीव्यू).