
1. はじめに
現在、BigQuery Graph、BigQuery 会話型分析、BigQuery Agent アナリティクス SDK は Google Cloud でプレビュー版として提供されています。BigQuery Agent Analytics プラグインは一般提供(GA)されています。この Codelab の例では、合成データを使用します。
自律型 AI エージェントが運用上の責任(融資申請の評価、マーケティング予算の管理、アクセス リクエストの承認など)を担うようになるにつれて、組織は意思決定を監査して説明できるようになる必要があります。エージェントの意思決定の正確なコンテキスト、検討された代替案、最終的な根拠を再構築することは、コンプライアンス、リスク管理、運用上の信頼にとって不可欠です。
この Codelab では、BigQuery Agent Analytics SDK を使用して、外部のグラフ データベースや ETL パイプラインを使用せずに、スケジュールに基づいて、エージェントの意思決定のクエリ可能なグラフであるエージェント コンテキスト グラフ にエージェントの生イベントログを変換します。
主な用語
- エージェントの意思決定トレース: エージェント自身の実行から抽出された意思決定レベルの証拠。エージェントが検討したオプション、アクセスしたデータ、コミットした結果。
- エージェント コンテキスト グラフ : これらのトレースが具体化される BigQuery Graph の型付きのクエリ可能なグラフ。これは、業界の コンテキスト グラフ の概念(エージェントが生成して使用する意思決定コンテキストの永続的な時間リンク レイヤ)のエージェント スコープのインスタンスです。「エージェント」 修飾子は、エンタープライズ全体のコンテキスト レイヤではなく、独自のエージェントの実行にスコープを設定します。
この Codelab では、bqaa context-graph は agent_events からエージェントの意思決定トレースを抽出し、GQL でクエリできるエージェント コンテキスト グラフに具体化します。これは、意思決定トレースからコンテキスト グラフを構築する業界パターンに従っています。
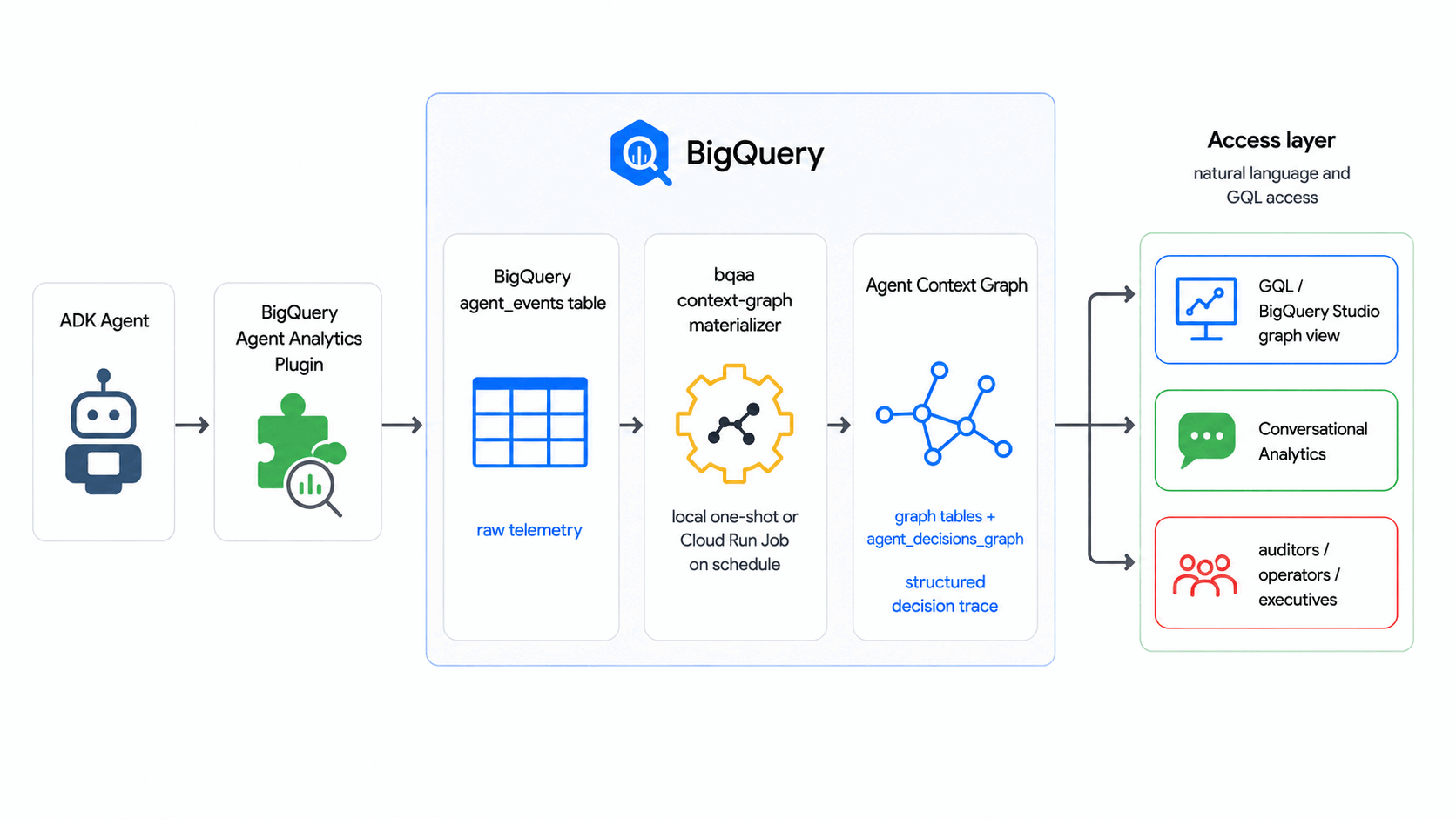
作成するアプリの概要
- 汎用エージェントの意思決定フローをモデル化したエージェント コンテキスト グラフ(BigQuery Graph を使用)。リクエストが届き、エージェントがオプションを検討し、結果がコミットされます。
- 合成イベント コーパスが入力された
agent_eventsテーブル。 - これらのイベントからグラフを入力する
bqaa context-graphの実行。 - 単一の意思決定をエンドツーエンドで追跡する監査スタイルの GQL クエリ。
学習内容
- BigQuery Agent Analytics プラグインが
agent_eventsに書き込む方法。 - コンテキスト グラフが、テーブル DDL と
CREATE PROPERTY GRAPHスキーマという 2 つの宣言型アーティファクトのみで定義される方法。 - BigQuery Graph に対して
bqaa context-graphを実行する方法。 - GQL を使用してグラフをクエリする方法。
- SDK がエンタープライズ デプロイメントでサポートする本番環境グレードの機能。
必要なもの
- 課金を有効にした Google Cloud プロジェクト
- そのプロジェクトに対するオーナーまたは編集者のロール。BigQuery データセットを作成し、IAM を付与します。
gcloudCLI がインストールされ、認証されていること、または Cloud Shell にアクセスできること。- Python 3.10 以降。
- BigQuery SQL に精通していること。GQL の知識は必要ありません。
この Codelab は、BigQuery Graph を初めて使用する方を含め、あらゆるレベルのデベロッパーを対象としています。
この Codelab で作成するリソースの費用はごくわずかです。最後のステップですべてが削除されるため、アイドル状態のデータセットに対して課金されることはありません。
所要時間: この Codelab の所要時間はおよそ 35 分です。
2. 始める前に
プロジェクトとリージョンを選択する
Cloud Shell またはローカル ターミナルを開きます。
export PROJECT_ID="your-project-id"
export REGION="us-central1"
export DATASET="agent_analytics_demo"
gcloud config set project "$PROJECT_ID"
単一の DATASET 変数には、未加工の agent_events テーブルと具体化されたグラフテーブルの両方が保持されます。1 つのデータセットを使用すると、Codelab を簡単にできます。本番環境のデプロイでは、イベントとグラフを別々のデータセットに分割して、データセットごとに IAM を絞り込むことがよくあります。
必要な API を有効にする
次のコマンドを実行 して、この Codelab で使用する API を有効にします。
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com \
--project="$PROJECT_ID"
SDK のデフォルトの抽出パスは BigQuery の AI.GENERATE 関数を呼び出すため、aiplatform.googleapis.com API が必要です。--extraction-mode=compiled-only を使用して決定論的抽出に切り替えた場合、この API は不要になります。
BigQuery データセットを作成する
未加工の agent_events テーブルと具体化されたグラフテーブルの両方を保持するデータセットを作成 します。
bq --location=US mk --dataset "$PROJECT_ID:$DATASET"
成功メッセージが表示されます。
Dataset 'your-project-id:agent_analytics_demo' successfully created.
データセットがすでに存在する場合、コマンドは無害なエラーになります。そのままにしておきます。
3. SDK のインストール
Python 仮想環境を設定し、PyPI からSDK をインストール します。
python3 -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install bigquery-agent-analytics
bigquery-agent-analytics パッケージは BigQuery クライアント ライブラリをプルするため、Codelab 全体で必要なインストールはこれだけです。
インストールを確認します。
bqaa context-graph --help | head -8
CLI バナーが表示されます。
認証
ワークステーションを使用している場合:
gcloud auth login
gcloud auth application-default login
Cloud Shell ユーザーは、この手順をスキップできます。認証情報はすでに構成されています。
4. Codelab アーティファクトを取得する
この Codelab には、すぐに使用できる 2 つのアーティファクト(テーブル DDL (物理グラフテーブル)とプロパティ グラフ スキーマ (CREATE PROPERTY GRAPH))が必要です。どちらも自分で作成する必要はありません。Codelab ではそのまま使用します。アーティファクト フォルダの README には、独自の意思決定ドメインに合わせて調整する方法が記載されています。
プロパティ グラフ スキーマは、グラフに含まれる内容の唯一の情報源です。 BigQuery に 1 回適用すると、デプロイされたグラフ自体が契約 になります。具体化すると、bqaa context-graph は BigQuery の INFORMATION_SCHEMA.PROPERTY_GRAPHS からグラフの定義(参照するテーブルのスキーマを含む)を読み取り、抽出するエンティティとリレーションシップ、書き込む場所を特定します。そのため、SQL ファイルは具体化ツールに渡されません。
この Codelab は自己完結型であるため、ダウンロードするものはありません。次のコマンドは、コンテキスト グラフ DDL を作業ディレクトリに書き込みます。その内容は、examples/context_graph/codelab/ に同梱されているアーティファクトと同じです。
作業ディレクトリを作成します。
mkdir -p ~/context-graph-codelab
cd ~/context-graph-codelab
コンテキスト グラフ DDL (context_graph_ddl.sql)を記述します。次のステップでファイルを適用すると、${PROJECT_ID} / ${DATASET} マーカーが入力されます。
cat > context_graph_ddl.sql <<'SQL'
-- Node and edge table DDL for the context-graph codelab.
--
-- `bqaa context-graph` writes into these tables on every run.
-- `session_id` and `extracted_at` are SDK metadata columns that
-- `bqaa context-graph` fills automatically; they are required on
-- every table behind the graph.
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_request` (
request_id STRING, request_text STRING, requested_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_option` (
option_id STRING, option_label STRING, confidence FLOAT64,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_outcome` (
outcome_id STRING, status STRING, rationale STRING, decided_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.evaluates_option` (
request_id STRING, option_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.resulted_in` (
request_id STRING, outcome_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
-- Graph DDL for the context-graph codelab.
--
-- Models a generic agent decision flow:
-- DecisionRequest -> evaluatesOption -> DecisionOption
-- DecisionRequest -> resultedIn -> DecisionOutcome
CREATE OR REPLACE PROPERTY GRAPH `${PROJECT_ID}.${DATASET}.agent_decisions_graph`
NODE TABLES (
`${PROJECT_ID}.${DATASET}.decision_request` AS decision_request
KEY (request_id)
LABEL DecisionRequest PROPERTIES (request_id, request_text, requested_at),
`${PROJECT_ID}.${DATASET}.decision_option` AS decision_option
KEY (option_id)
LABEL DecisionOption PROPERTIES (option_id, option_label, confidence),
`${PROJECT_ID}.${DATASET}.decision_outcome` AS decision_outcome
KEY (outcome_id)
LABEL DecisionOutcome PROPERTIES (outcome_id, status, rationale, decided_at)
)
EDGE TABLES (
`${PROJECT_ID}.${DATASET}.evaluates_option` AS evaluates_option
KEY (request_id, option_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (option_id) REFERENCES decision_option (option_id)
LABEL evaluatesOption,
`${PROJECT_ID}.${DATASET}.resulted_in` AS resulted_in
KEY (request_id, outcome_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (outcome_id) REFERENCES decision_outcome (outcome_id)
LABEL resultedIn
);
SQL
ファイルが配置されていることを確認します。
ls
1 つのファイルが表示されます。
context_graph_ddl.sql
記述されている意思決定フローには、3 つのノードタイプと 2 つの異種エッジがあります。
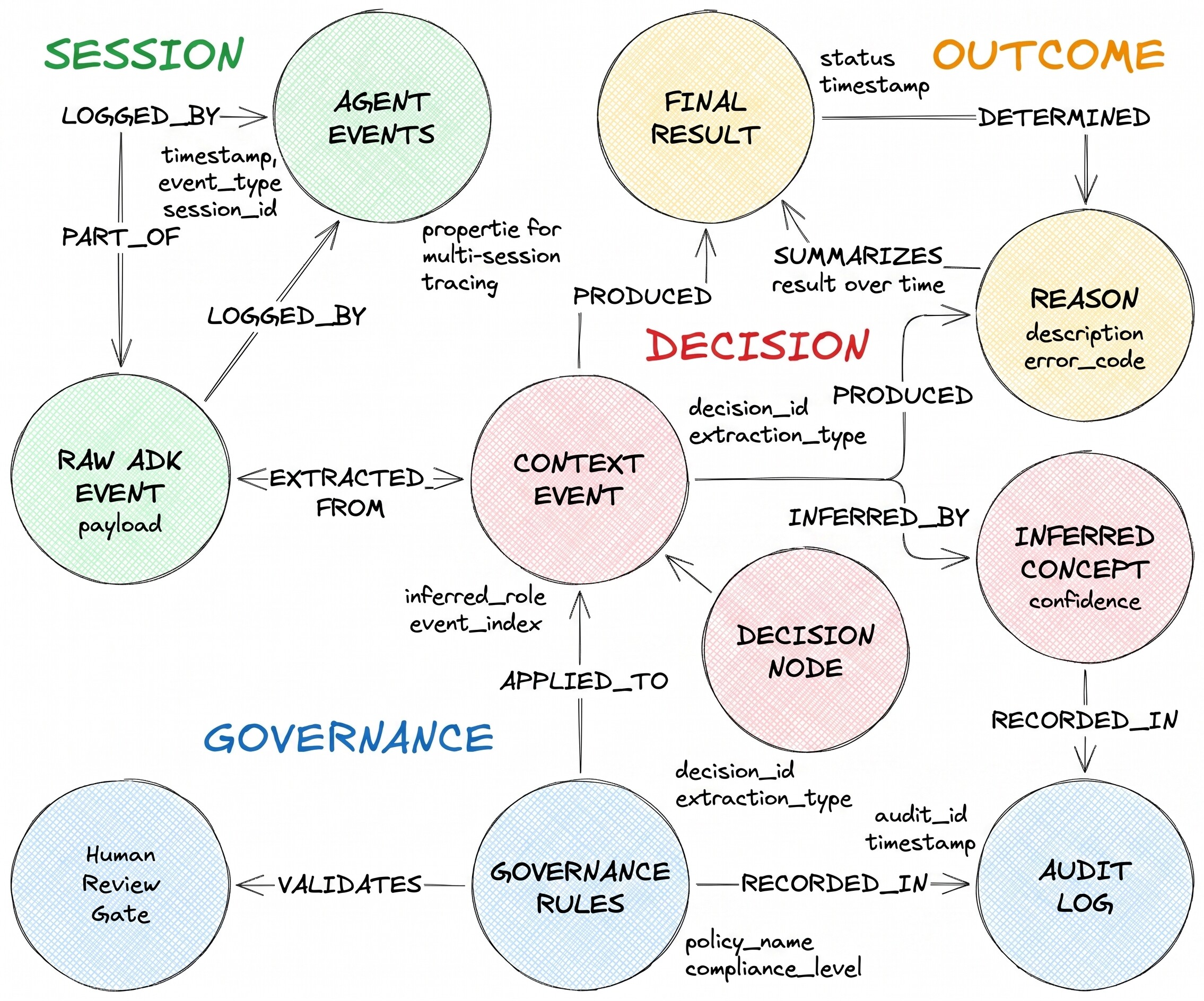
DecisionRequest はエージェントが受け取った質問です。DecisionOption は、エージェントが検討した代替案の 1 つです。DecisionOutcome は、コミットされた選択と根拠を記録します。
5. プロパティ グラフ スキーマを適用する
bqaa context-graph は BigQuery テーブルに書き込むため、最初の実行の前に存在する必要があります。context_graph_ddl.sql は、最初に 5 つのテーブルを作成し、次にそれらを参照するプロパティ グラフを作成します(BigQuery は、まだ存在しないテーブルを指す CREATE PROPERTY GRAPH を拒否します)。そのため、1 回の適用 ですべてが設定されます。
envsubst < context_graph_ddl.sql | bq query --use_legacy_sql=false
5 つの CREATE TABLE の結果と 1 つの CREATE PROPERTY GRAPH の結果が表示されます。DDL はべき等であるため、安全に再実行できます。
これが唯一のスキーマ作業であり、これらの SQL ファイルが使用されるのはこのときだけです。BigQuery はグラフの定義を記録し、bqaa context-graph は名前で INFORMATION_SCHEMA.PROPERTY_GRAPHS から読み取ります。具体化ツールに渡す個別のファイルはなく、GQL でクエリするものと具体化されるものがずれることはありません。これらは同じデプロイされたグラフです。
6. エージェント イベントのサンプルを生成する
本番環境では、BigQuery Agent Analytics プラグインは、ADK エージェントの実行時にイベントを自動的にキャプチャします。このスニペットは参考用です。この Codelab では実行しません。
from google.adk.plugins import BigQueryAgentAnalyticsPlugin
plugin = BigQueryAgentAnalyticsPlugin(
project_id="your-project-id",
dataset_id="agent_analytics_demo",
)
runner = Runner(agent=root_agent, plugins=[plugin])
この Codelab では、同じ形状の行を agent_events に直接書き込む小さな合成イベント ジェネレータを使用します。実行する:
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--sessions 5
このコマンドは JSON レポートを出力します。5 回のセッションでは、"events_generated": 30、"events_inserted": 30、"ok": true が表示されます。
1 行で、コーパスの概要(セッション数、イベント数、期間)を確認します。
bq query --use_legacy_sql=false \
"SELECT COUNT(DISTINCT session_id) AS sessions, COUNT(*) AS events, MIN(timestamp) AS earliest_event, MAX(timestamp) AS latest_event FROM \`$PROJECT_ID.$DATASET.agent_events\`"
デフォルトの 5 セッションの実行では、5 つのセッションと 30 個のイベントが数分間にわたって表示されます。(以下の現実的なシナリオをシードすると、同じクエリで約 3 日間にわたる約 100 セッションが報告されます)。
イベントが着信したことを確認します。
bq query --use_legacy_sql=false \
"SELECT event_type, COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY event_type ORDER BY n DESC"
25 個の TOOL_COMPLETED 行と 5 個の AGENT_COMPLETED 行が表示されます(各セッションは、1 つの submit_request、3 つの evaluate_option、1 つの commit_outcome、1 つの終了 AGENT_COMPLETED を生成します。つまり、セッションごとに 5 つのツールイベントと 1 つのエージェント ターミネータです)。AGENT_COMPLETED 行は、bqaa context-graph がターミナル イベントの検出に使用するセッション ターミネータです。
省略可: 現実的なスケールのデータ
上記の 5 セッションのコーパスは、最初の実行が高速かつ安価になるように意図的に小さくしています。本番環境の形状のデータ(複数のエージェントとユーザーが数日間に分散し、失敗したセッション、孤立したセッション、切り捨てられたセッションがある)が必要な場合は、decision-realistic シナリオを使用します。デフォルトでは 72 時間のウィンドウで 100 セッションになります。上記の最初の実行パスは変更されません。
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--scenario decision-realistic \
--sessions 100 \
--seed 42
JSON レポートの session_outcome_counts には、{"success": 70, "failed": 10, "orphaned": 10, "truncated": 10} のように、混合が表示されます。
各セッションを行から分類して、結果の分布を確認します(孤立 = AGENT_COMPLETED なし、失敗 = status = 'error' の AGENT_COMPLETED、切り捨て = is_truncated = true の行、それ以外は成功)。最初のパスで各セッションを分類し、2 番目のパスで結果ごとに集計します。
bq query --use_legacy_sql=false \
"WITH per_session AS (SELECT session_id, CASE WHEN COUNTIF(event_type = 'AGENT_COMPLETED') = 0 THEN 'orphaned' WHEN COUNTIF(event_type = 'AGENT_COMPLETED' AND status = 'error') > 0 THEN 'failed' WHEN COUNTIF(is_truncated) > 0 THEN 'truncated' ELSE 'success' END AS outcome FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY session_id) SELECT outcome, COUNT(*) AS sessions FROM per_session GROUP BY outcome ORDER BY outcome"
約 70 件の成功、10 件の失敗、10 件の孤立、10 件の切り捨てが表示されます(同じデータセットで以前にシードした場合は、最初の実行コーパスからの 5 件の成功セッションも表示されます)。
10 個の孤立したセッションでは AGENT_COMPLETED が生成されなかったため、デフォルトの bqaa context-graph の実行ではスキップされます(ターミナル イベントが終了したセッションのみが具体化されます)。永久に再試行するのではなく、session_orphaned として表示するには、実行時に --max-session-age-hours を追加します。 本番環境に移行する の --max-session-age-hours をご覧ください。
7. コンテキスト グラフを具体化する
bqaa context-graph は未加工の agent_events を読み取り、デプロイされたグラフから抽出する内容を直接導出 します。CREATE PROPERTY GRAPH 定義を プロパティ グラフ スキーマを適用する で適用した BigQuery の INFORMATION_SCHEMA.PROPERTY_GRAPHS から読み取り、参照するテーブルのスキーマと結合し、エンティティ、リレーションシップ、列タイプを特定して、グラフテーブルに入力します。--graph agent_decisions_graph を使用して、デプロイされたグラフを名前で 指定します。渡す SQL ファイルはありません。
実行
ローカルでbqaa context-graph:
bqaa context-graph \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--graph agent_decisions_graph \
--lookback-hours 24 \
--format json
構造化された JSON レポートが表示されます。
{
"run_id": "...",
"sessions_discovered": 5,
"sessions_materialized": 5,
"sessions_failed": 0,
"rows_materialized": {
"DecisionRequest": 5,
"DecisionOption": 15,
"DecisionOutcome": 5
},
"ok": true
}
ok: true は、bqaa context-graph が完了した 5 つのセッションを検出し、AI.GENERATE を使用して各セッションから意思決定フローを抽出し、対応する行をグラフテーブルに書き込んだことを示します。決定論的抽出(--extraction-mode=compiled-only。後述)は、同じレポート形状(同じフィールド、同じ ok: true)を返しますが、AI.GENERATE 呼び出しはスキップします。
トラブルシューティング: 抽出が空の場合
error_code = "empty_extraction" で ok: false が表示される場合、最も一般的な原因は、aiplatform.googleapis.com API がまだ伝播されていないか、アカウントに roles/aiplatform.user がないことです。1 分待ってから再試行するか、ロールを付与します。
USER_EMAIL=$(gcloud auth list --filter=status:ACTIVE --format="value(account)")
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="user:$USER_EMAIL" --role="roles/aiplatform.user"
次に、上記の bqaa context-graph コマンドを再実行します。
グラフに行があることを確認します。
bq query --use_legacy_sql=false \
"SELECT COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.decision_request\`"
5 行が表示されます。5 つのセッション全体で、合計25 個のグラフノード (5 個の DecisionRequest、15 個の DecisionOption、5 個の DecisionOutcome)が、15 個の evaluatesOption エッジと 5 個の resultedIn エッジ(セッションごとに 1 つの意思決定ウェブ)で結合されています。
イベントから意思決定を抽出する 2 つの方法
bqaa context-graph には 2 つの抽出パスがあります。ワークロードに合ったものを選択します。
- デフォルトの抽出。最も簡単なパス。BigQuery の
AI.GENERATEを使用してイベント コンテンツを読み取り、エンティティとリレーションシップを推測します。追加のコードなしで、任意のイベント形状に対して機能します。これは Codelab で使用するものです。 - 決定論的抽出 (
--extraction-mode=compiled-only)。低コストで監査に適したパス。ドメイン用に 1 回作成する小さな Python リファレンス抽出ツールを使用します。Vertex AI の呼び出しなし、トークンごとの料金なし、完全に再現可能な出力。費用の予測可能性や厳密な再現性が重要な場合は、本番環境のデプロイでこれを選択します。
コンテキスト グラフのデプロイガイドは、IAM の詳細やリファレンス抽出ツールの作成方法など、両方のパスのリファレンスです。
8. 意思決定トレースをクエリする
グラフが入力されたら、監査の質問に直接回答できます。具体的な例として、「リクエストごとに、エージェントが検討したオプションと、解決方法」を考えてみましょう。GQL では、リクエスト、そのオプション、その結果を 1 回トラバースします。
クエリをファイル (traversal.sql)に書き込みます。次のステップで実行すると、${DATASET} マーカーが入力されます。
cat > traversal.sql <<'SQL'
SELECT *
FROM GRAPH_TABLE (
${DATASET}.agent_decisions_graph
MATCH
(req:DecisionRequest) -[eo:evaluatesOption]-> (opt:DecisionOption),
(req) -[ri:resultedIn]-> (out:DecisionOutcome)
COLUMNS (
req.request_id AS request,
req.request_text AS question,
opt.option_label AS considered,
opt.confidence AS score,
out.status AS outcome,
out.rationale AS rationale
)
);
SQL
実行する:
envsubst < traversal.sql | bq query --use_legacy_sql=false --max_rows=20
15 行が表示されます。リクエストごとに 3 つのオプション、5 つのリクエストです。各行には、リクエスト、エージェントが検討したオプション、信頼度スコア、最終結果、根拠が表示されます。
1 つの意思決定の全体像を把握するには、request_id でフィルタして、監査チームが必要とする行セット(受信した質問、検討されたオプション(スコア付き)、コミットされた根拠)を取得します。
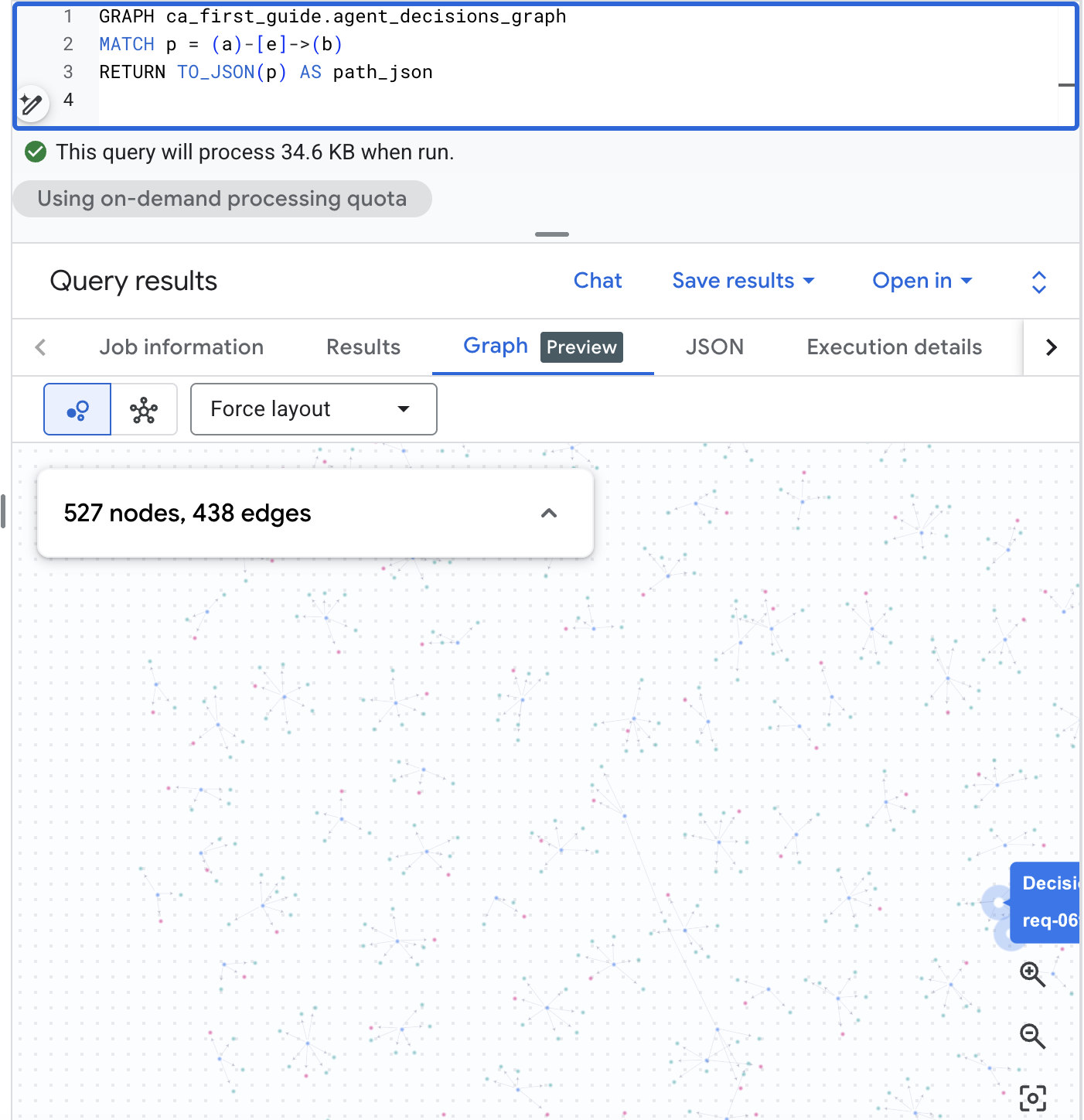
BigQuery Studio でグラフを可視化する
BigQuery Studio では、グラフを視覚的にレンダリングすることもできます。BigQuery コンソールで [BigQuery Studio] を開き、次のパスクエリを実行して、結果ペインを [グラフ] タブに切り替えて意思決定ウェブを表示します。現実的なスケールのコーパスを使用すると、リクエスト、オプション、結果のビジュアル マップが表示されます。
GRAPH agent_analytics_demo.agent_decisions_graph
MATCH p = (a)-[e]->(b)
RETURN TO_JSON(p) AS path_json
同じ質問を平易な英語で尋ねる
すべての監査担当者が GQL を記述するわけではありません。BigQuery 会話型分析 (プレビュー版)を使用すると、コンプライアンス チームは同じ種類の質問を自然言語で尋ねて、構造化された回答カードを取得できます。クエリ構文や結合を学習する必要はありません。
agent_decisions_graph(agent_events テーブルと意思決定テーブルを含む)を会話型分析データソースとして登録し、監査の質問を直接行います。
監査の質問(平易な英語): 「コミットされた結果に到達しなかったリクエストはどれですか?」
会話型分析はグラフに対して推論を行い、SQL を記述し、サポート テーブルを含む平易な英語で回答します。ここでは、記録されたすべてのリクエストがコミットされた結果に到達しています。
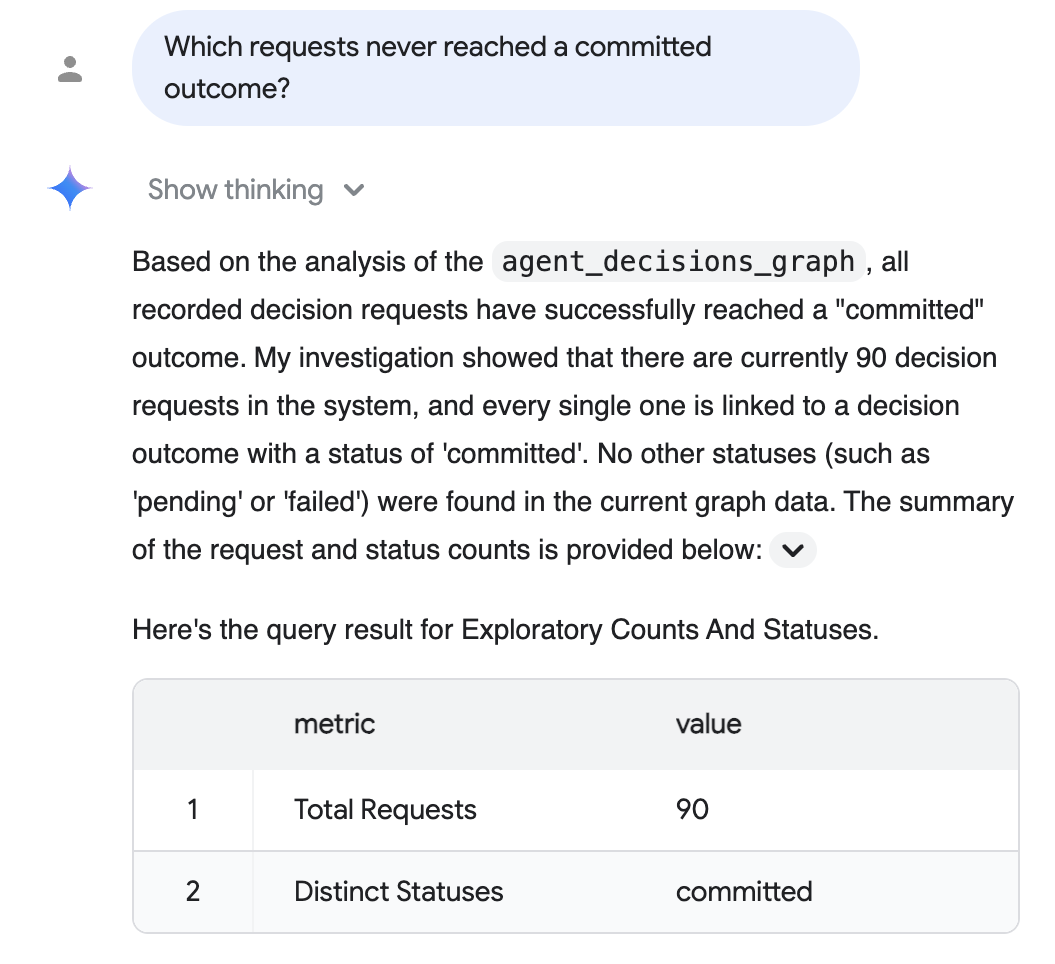
上記の回答は、省略可能な 現実的なスケールのデータ ステップの現実的なスケールのコーパス(90 件の具体化されたリクエスト、すべてコミット済み)を反映しています。正確な数は、シードしたコーパスによって異なります。デフォルトの 5 セッションの実行では 5 件が表示されます。
設定については、会話型分析のドキュメントをご覧ください。
9. 本番環境に移行する
上記のローカル実行ではデフォルトの動作を使用します。これは、実際のデプロイの基本をすでにカバーしています。実行ごとに監査証跡(構造化された Cloud Logging と、データセット内の状態テーブルの実行ごとの行)が残ります。一時的な障害は自動的に再試行されます。進行状況は完全に成功したセッションでのみ進むため、二重カウントはありません。
本番環境の制御(決定論的抽出(--extraction-mode=compiled-only)、スタック セッションの検出(--max-session-age-hours)、過去のウィンドウの 1 回限りの再生(--backfill --from / --to。通常の更新とは別に追跡されるため、ライブ スケジュールを妨げることはありません)、実行ごとのバッチ境界(--max-sessions))は、必要なときに使用するオプトイン フラグです。コンテキスト グラフのデプロイガイドには、各フラグのドキュメント、完全な IAM マトリックス、推奨スケジュールが記載されています。
10. クリーンアップ
アイドル状態のデータセットに対して課金されないように、作成したものを削除 します。
bq rm -r -f --dataset "$PROJECT_ID:$DATASET"
この単一のコマンドで、データセット、エージェント イベント、グラフテーブル、状態テーブルがまとめて削除されます。
11. 完了
おめでとうございます!外部のグラフ データベースや ETL パイプラインを使用せずに、エージェントの生イベントログをクエリ可能なエージェント コンテキスト グラフに変換し、単一の意思決定をエンドツーエンドで追跡しました。
エージェントが重要な意思決定を行う場所(クレジットの引き受け、事前承認、マーケティング予算の移動、調達、カスタマー サービス、社内 IT)には、同じパターンが適用されます。独自のエージェント コンテキスト グラフを構築するには、Codelab アーティファクトをコピーして出発地とし、2 つの宣言型ファイル(テーブル DDL + CREATE PROPERTY GRAPH スキーマ)をドメインに合わせて調整して、BigQuery に適用します。bqaa context-graph --graph は、デプロイされたグラフを INFORMATION_SCHEMA から読み取り、残りを導出します。
学習した内容
- BigQuery データセットを作成し、エージェントの意思決定ドメインを記述するプロパティ グラフ スキーマを適用する方法。
- 合成イベント コーパスで
agent_eventsを入力する方法。 bqaa context-graphを実行して、これらのイベントからエージェントの意思決定トレースをエージェント コンテキスト グラフに抽出し、INFORMATION_SCHEMAからグラフ定義を読み取る方法。- GQL で結果のグラフをクエリし、監査スタイルの回答を読み取る方法。
リファレンス ドキュメント
- BigQuery Agent アナリティクス SDK リポジトリ
- Codelab アーティファクトと適応ガイド
- コンテキスト グラフのデプロイガイド: 必要な API、IAM マトリックス、推奨スケジュール、Cloud Monitoring アラートクエリ、Terraform モジュール。
- BigQuery Graph のドキュメント(プレビュー版)。
- BigQuery 会話型分析のドキュメント(プレビュー版)。