
1. 소개
BigQuery 그래프, BigQuery 대화형 분석, BigQuery 에이전트 애널리틱스 SDK는 현재 Google Cloud에서 미리보기로 제공됩니다. BigQuery 에이전트 분석 플러그인이 정식 버전으로 제공됩니다. 이 Codelab의 예에서는 합성 데이터를 사용합니다.
자율 AI 에이전트가 더 많은 운영 책임 (대출 신청 평가, 마케팅 예산 관리, 액세스 요청 승인)을 맡게 되면서 조직은 이러한 결정을 감사하고 설명할 수 있어야 합니다. 에이전트의 결정에 대한 정확한 컨텍스트, 고려된 대안, 최종 근거를 재구성하는 것은 규정 준수, 위험 관리, 운영 신뢰에 필수적입니다.
이 Codelab에서는 BigQuery 에이전트 애널리틱스 SDK를 사용하여 외부 그래프 데이터베이스나 ETL 파이프라인 없이 일정에 따라 원시 에이전트 이벤트 로그를 에이전트 컨텍스트 그래프(에이전트 결정의 BigQuery 그래프에서 쿼리 가능한 그래프)로 변환합니다.
핵심 용어
- 에이전트 결정 추적 - 에이전트 자체 실행에서 가져온 결정 수준 증거: 고려한 옵션, 사용한 데이터, 커밋한 결과
- 에이전트 컨텍스트 그래프: 이러한 트레이스가 구체화되는 BigQuery 그래프의 유형이 지정되고 쿼리 가능한 그래프입니다. 이는 에이전트가 생성하고 소비하는 지속적이고 시간으로 연결된 결정 컨텍스트 레이어인 업계 컨텍스트 그래프 개념의 에이전트 범위 인스턴스입니다. 'Agent' 한정자는 엔터프라이즈 전체 컨텍스트 레이어가 아닌 자체 에이전트 실행으로 범위를 지정합니다.
이 Codelab에서 bqaa context-graph는 agent_events에서 에이전트의 결정 추적을 추출하고 이를 GQL로 쿼리할 수 있는 에이전트 컨텍스트 그래프로 구체화합니다. 이는 컨텍스트 그래프가 결정 추적에서 빌드되는 업계 패턴을 따릅니다.
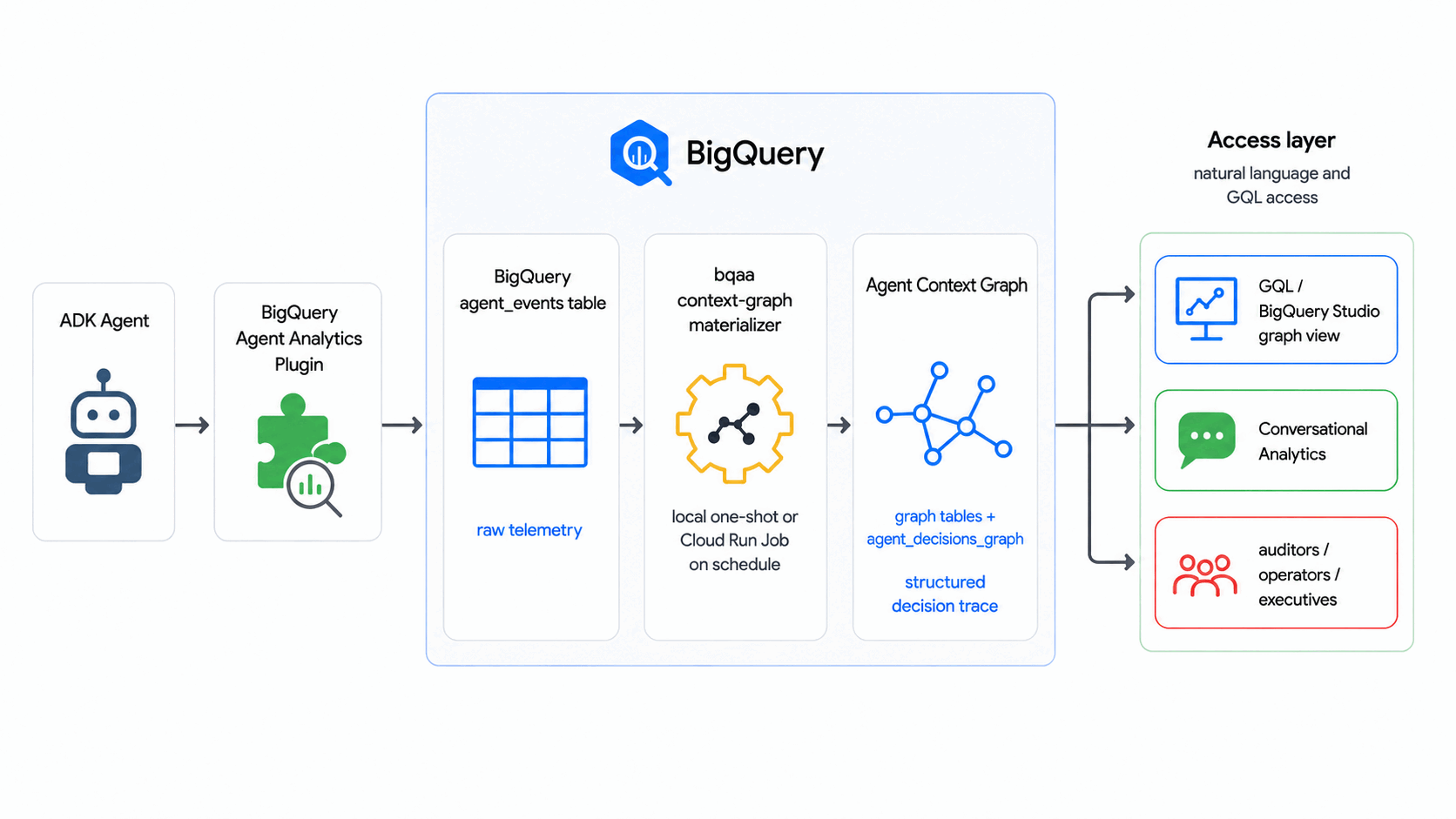
빌드할 항목
- 일반적인 에이전트 결정 흐름을 모델링하는 에이전트 컨텍스트 그래프 (BigQuery 그래프 사용): 요청이 들어오면 에이전트가 옵션을 고려하고 결과가 커밋됩니다.
- 합성 이벤트 코퍼스가 포함된
agent_events테이블 - 이러한 이벤트에서 그래프를 채우는 작업
bqaa context-graph실행 - 단일 결정을 엔드 투 엔드로 추적하는 감사 스타일 GQL 쿼리입니다.
학습할 내용
- BigQuery 에이전트 분석 플러그인이
agent_events에 쓰는 방식 - 선언적 아티팩트인 테이블 DDL과
CREATE PROPERTY GRAPH스키마만으로 컨텍스트 그래프가 정의되는 방식 - BigQuery 그래프에 대해
bqaa context-graph를 실행하는 방법 - GQL을 사용하여 그래프를 쿼리하는 방법
- SDK가 엔터프라이즈 배포를 위해 지원하는 프로덕션 등급 기능입니다.
필요한 항목
- 결제가 사용 설정된 Google Cloud 프로젝트.
- 해당 프로젝트의 소유자 또는 편집자 역할 BigQuery 데이터 세트를 만들고 IAM을 부여합니다.
gcloudCLI가 설치되고 인증되었거나 Cloud Shell에 액세스할 수 있어야 합니다.- Python 3.10 이상
- BigQuery SQL에 대한 지식 GQL 지식은 필요하지 않습니다.
이 Codelab은 BigQuery 그래프를 처음 사용하는 사용자를 비롯한 모든 수준의 개발자를 대상으로 합니다.
이 Codelab에서 만든 리소스는 비용이 거의 들지 않으며 마지막 단계에서 모든 항목을 삭제하므로 유휴 데이터 세트에 대한 요금이 청구되지 않습니다.
예상 소요 시간: 이 Codelab을 완료하는 데는 약 35분이 소요됩니다.
2. 시작하기 전에
프로젝트 및 리전 선택
Cloud Shell 또는 로컬 터미널을 엽니다.
export PROJECT_ID="your-project-id"
export REGION="us-central1"
export DATASET="agent_analytics_demo"
gcloud config set project "$PROJECT_ID"
단일 DATASET 변수는 원시 agent_events 테이블과 구체화된 그래프 테이블을 모두 보유합니다. 하나의 데이터 세트를 사용하면 Codelab이 간단해집니다. 프로덕션 배포에서는 IAM이 데이터 세트별로 좁게 부여될 수 있도록 이벤트와 그래프를 별도의 데이터 세트로 분할하는 경우가 많습니다.
필요한 API 사용 설정
다음 명령어를 실행하여 이 Codelab에서 사용하는 API를 사용 설정합니다.
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com \
--project="$PROJECT_ID"
SDK의 기본 추출 경로가 BigQuery의 AI.GENERATE 함수를 호출하므로 aiplatform.googleapis.com API가 필요합니다. 나중에 --extraction-mode=compiled-only를 사용하여 결정적 추출로 전환하는 경우 이 API는 더 이상 필요하지 않습니다.
BigQuery 데이터 세트 만들기
원시 agent_events 테이블과 구체화된 그래프 테이블을 모두 포함할 데이터 세트를 만듭니다.
bq --location=US mk --dataset "$PROJECT_ID:$DATASET"
다음과 같은 성공 메시지가 표시됩니다.
Dataset 'your-project-id:agent_analytics_demo' successfully created.
데이터 세트가 이미 있으면 명령어가 무해한 오류를 발생시킵니다. 제자리에 둡니다.
3. SDK 설치
Python 가상 환경을 설정하고 PyPI에서 SDK를 설치합니다.
python3 -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install bigquery-agent-analytics
bigquery-agent-analytics 패키지는 BigQuery 클라이언트 라이브러리를 가져오므로 이 설치가 전체 Codelab에 필요한 유일한 설치입니다.
설치 확인:
bqaa context-graph --help | head -8
CLI 배너가 표시됩니다.
인증
워크스테이션을 사용하는 경우:
gcloud auth login
gcloud auth application-default login
Cloud Shell 사용자는 이 단계를 건너뛸 수 있습니다. 사용자 인증 정보가 이미 구성되어 있기 때문입니다.
4. Codelab 아티팩트 가져오기
Codelab에는 표 DDL (물리적 그래프 표)과 속성 그래프 스키마 (CREATE PROPERTY GRAPH)라는 두 개의 바로 사용할 수 있는 아티팩트만 있으면 됩니다. 직접 작성하지 않아도 됩니다. Codelab에서 그대로 사용하며 아티팩트 폴더의 README에 자체 결정 도메인에 맞게 조정하는 방법이 설명되어 있습니다.
속성 그래프 스키마는 그래프에 포함된 내용에 대한 단일 정보 소스입니다. BigQuery에 한 번 적용하면 이후부터는 배포된 그래프 자체가 계약이 됩니다. 구체화할 때 bqaa context-graph는 BigQuery의 INFORMATION_SCHEMA.PROPERTY_GRAPHS에서 그래프의 정의를 다시 읽어 (참조하는 테이블의 스키마와 함께) 추출할 엔티티와 관계, 그리고 이를 쓸 위치를 파악하므로 SQL 파일이 구체화 도구에 전달되지 않습니다.
이 Codelab은 독립적이므로 다운로드할 항목이 없습니다. 아래 명령어는 컨텍스트 그래프 DDL을 작업 디렉터리에 작성합니다. 해당 콘텐츠는 examples/context_graph/codelab/에 제공된 아티팩트와 동일합니다.
작업 디렉터리를 만듭니다.
mkdir -p ~/context-graph-codelab
cd ~/context-graph-codelab
컨텍스트 그래프 DDL 작성 (context_graph_ddl.sql). 다음 단계에서 파일을 적용하면 ${PROJECT_ID} / ${DATASET} 마커가 채워집니다.
cat > context_graph_ddl.sql <<'SQL'
-- Node and edge table DDL for the context-graph codelab.
--
-- `bqaa context-graph` writes into these tables on every run.
-- `session_id` and `extracted_at` are SDK metadata columns that
-- `bqaa context-graph` fills automatically; they are required on
-- every table behind the graph.
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_request` (
request_id STRING, request_text STRING, requested_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_option` (
option_id STRING, option_label STRING, confidence FLOAT64,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_outcome` (
outcome_id STRING, status STRING, rationale STRING, decided_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.evaluates_option` (
request_id STRING, option_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.resulted_in` (
request_id STRING, outcome_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
-- Graph DDL for the context-graph codelab.
--
-- Models a generic agent decision flow:
-- DecisionRequest -> evaluatesOption -> DecisionOption
-- DecisionRequest -> resultedIn -> DecisionOutcome
CREATE OR REPLACE PROPERTY GRAPH `${PROJECT_ID}.${DATASET}.agent_decisions_graph`
NODE TABLES (
`${PROJECT_ID}.${DATASET}.decision_request` AS decision_request
KEY (request_id)
LABEL DecisionRequest PROPERTIES (request_id, request_text, requested_at),
`${PROJECT_ID}.${DATASET}.decision_option` AS decision_option
KEY (option_id)
LABEL DecisionOption PROPERTIES (option_id, option_label, confidence),
`${PROJECT_ID}.${DATASET}.decision_outcome` AS decision_outcome
KEY (outcome_id)
LABEL DecisionOutcome PROPERTIES (outcome_id, status, rationale, decided_at)
)
EDGE TABLES (
`${PROJECT_ID}.${DATASET}.evaluates_option` AS evaluates_option
KEY (request_id, option_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (option_id) REFERENCES decision_option (option_id)
LABEL evaluatesOption,
`${PROJECT_ID}.${DATASET}.resulted_in` AS resulted_in
KEY (request_id, outcome_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (outcome_id) REFERENCES decision_outcome (outcome_id)
LABEL resultedIn
);
SQL
파일이 있는지 확인합니다.
ls
다음과 같은 파일이 표시됩니다.
context_graph_ddl.sql
이들이 설명하는 결정 흐름에는 세 가지 노드 유형과 두 가지 이질적인 에지가 있습니다.
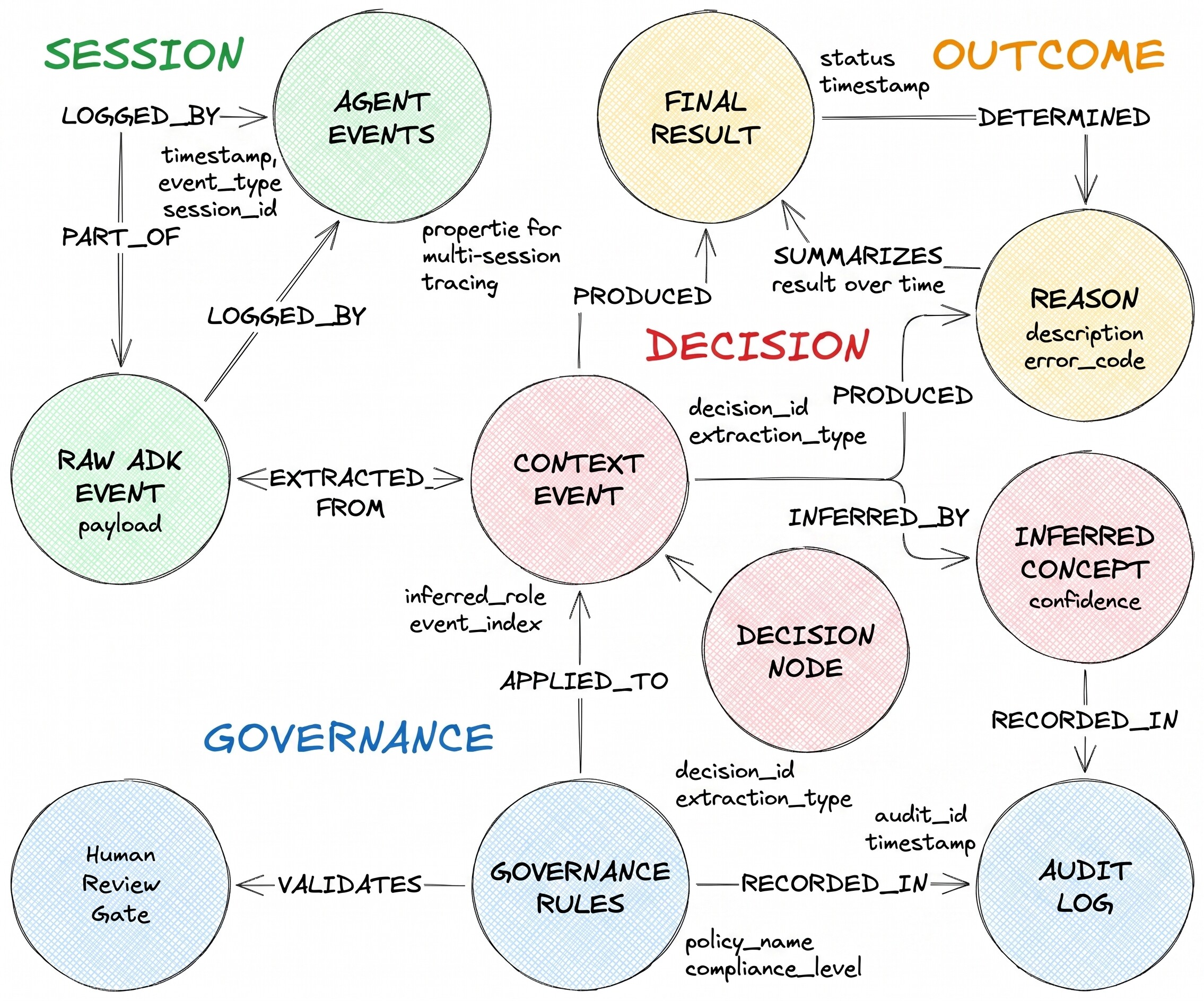
DecisionRequest은 에이전트가 받은 질문입니다. DecisionOption은 에이전트가 고려한 대안 중 하나입니다. DecisionOutcome는 커밋된 선택사항과 근거를 기록합니다.
5. 속성 그래프 스키마 적용
bqaa context-graph는 BigQuery 테이블에 쓰므로 첫 번째 실행 전에 테이블이 있어야 합니다. context_graph_ddl.sql는 먼저 5개의 테이블을 만든 다음 이를 참조하는 속성 그래프를 만듭니다 (BigQuery는 아직 존재하지 않는 테이블을 가리키는 CREATE PROPERTY GRAPH을 거부함). 따라서 단일 적용으로 모든 것을 설정합니다.
envsubst < context_graph_ddl.sql | bq query --use_legacy_sql=false
CREATE TABLE 결과 5개와 CREATE PROPERTY GRAPH 결과 1개가 표시됩니다. DDL은 멱등성이 있으므로 안전하게 다시 실행할 수 있습니다.
이것이 수행하는 유일한 스키마 작업이며 이러한 SQL 파일이 사용되는 유일한 시간입니다. 이제 BigQuery에서 그래프의 정의를 기록하고 bqaa context-graph는 이름으로 INFORMATION_SCHEMA.PROPERTY_GRAPHS에서 다시 읽습니다. 머티얼라이저에 전달할 별도의 파일이 없으며 GQL로 쿼리하는 내용과 구체화되는 내용은 절대 달라질 수 없습니다. 배포된 그래프가 동일하기 때문입니다.
6. 샘플 에이전트 이벤트 생성
프로덕션에서는 ADK 에이전트가 실행될 때 BigQuery 에이전트 분석 플러그인이 이벤트를 자동으로 캡처합니다. 이 스니펫은 참고용이며 이 Codelab에서는 실행하지 않습니다.
from google.adk.plugins import BigQueryAgentAnalyticsPlugin
plugin = BigQueryAgentAnalyticsPlugin(
project_id="your-project-id",
dataset_id="agent_analytics_demo",
)
runner = Runner(agent=root_agent, plugins=[plugin])
이 Codelab에서는 동일한 모양의 행을 agent_events에 직접 쓰는 작은 합성 이벤트 생성기를 사용합니다. 에이전트 실행:
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--sessions 5
이 명령어는 JSON 보고서를 출력합니다. 5개 세션의 경우 "events_generated": 30, "events_inserted": 30, "ok": true가 표시됩니다.
한 행에서 코퍼스(세션 수, 이벤트 수, 기간)를 한눈에 미리 봅니다.
bq query --use_legacy_sql=false \
"SELECT COUNT(DISTINCT session_id) AS sessions, COUNT(*) AS events, MIN(timestamp) AS earliest_event, MAX(timestamp) AS latest_event FROM \`$PROJECT_ID.$DATASET.agent_events\`"
기본 5세션 실행의 경우 몇 분에 걸쳐 5개의 세션과 30개의 이벤트가 표시됩니다. (아래의 현실적인 시나리오를 시드하면 동일한 쿼리에서 약 3일 동안 약 100개의 세션이 보고됩니다.)
이벤트가 발생했는지 확인합니다.
bq query --use_legacy_sql=false \
"SELECT event_type, COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY event_type ORDER BY n DESC"
TOOL_COMPLETED 행 25개와 AGENT_COMPLETED 행 5개가 표시됩니다 (각 세션에서 submit_request 1개, evaluate_option 3개, commit_outcome 1개, 종료 AGENT_COMPLETED 1개, 즉 세션당 도구 이벤트 5개와 에이전트 종료자 1개가 발생함). AGENT_COMPLETED 행은 터미널 이벤트 감지를 위해 bqaa context-graph 키가 켜지는 세션 종료자입니다.
선택사항: 현실적인 규모의 데이터
위의 5세션 코퍼스는 첫 번째 실행이 빠르고 저렴하도록 의도적으로 작게 설정되어 있습니다. 실제와 유사한 데이터(여러 날에 걸쳐 분산된 여러 에이전트와 사용자, 실패한 세션, 고아 세션, 잘린 세션)가 필요한 경우 decision-realistic 시나리오를 사용하세요. 기본값은 72시간 동안 100세션입니다. 위의 첫 실행 경로는 변경되지 않습니다.
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--scenario decision-realistic \
--sessions 100 \
--seed 42
JSON 보고서의 session_outcome_counts는 대략 {"success": 70, "failed": 10, "orphaned": 10, "truncated": 10}인 혼합을 보여줍니다.
행에서 각 세션을 분류하여 결과 분포를 확인합니다 (고아 = AGENT_COMPLETED 없음, 실패 = status = 'error'이 있는 AGENT_COMPLETED, 잘림 = is_truncated = true이 있는 행, 그 외에는 성공). 첫 번째 패스에서는 각 세션을 분류하고 두 번째 패스에서는 결과별로 집계합니다.
bq query --use_legacy_sql=false \
"WITH per_session AS (SELECT session_id, CASE WHEN COUNTIF(event_type = 'AGENT_COMPLETED') = 0 THEN 'orphaned' WHEN COUNTIF(event_type = 'AGENT_COMPLETED' AND status = 'error') > 0 THEN 'failed' WHEN COUNTIF(is_truncated) > 0 THEN 'truncated' ELSE 'success' END AS outcome FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY session_id) SELECT outcome, COUNT(*) AS sessions FROM per_session GROUP BY outcome ORDER BY outcome"
성공 70개, 실패 10개, 고아 10개, 잘림 10개가 표시됩니다 (이전에 동일한 데이터 세트에서 시딩한 경우 첫 실행 코퍼스에서 성공한 세션 5개 포함).
고아 세션 10개가 AGENT_COMPLETED를 내보내지 않았으므로 기본 bqaa context-graph 실행에서 이를 건너뜁니다 (종료 이벤트가 닫힌 세션만 구체화됨). 무한대로 자동으로 다시 시도하는 대신 session_orphaned로 표시하려면 운영할 때 --max-session-age-hours를 추가하세요(프로덕션으로 가져가기의 --max-session-age-hours 참고).
7. 컨텍스트 그래프 구체화
bqaa context-graph는 원시 agent_events를 읽은 다음 배포된 그래프에서 추출할 항목을 직접 파생합니다. 즉, 속성 그래프 스키마 적용에서 적용한 CREATE PROPERTY GRAPH 정의를 BigQuery의 INFORMATION_SCHEMA.PROPERTY_GRAPHS에서 다시 읽고, 참조하는 테이블의 스키마와 조인하고, 엔티티, 관계, 열 유형을 파악하고, 그래프 테이블을 채웁니다. --graph agent_decisions_graph를 사용하여 배포된 그래프를 이름으로 가리킵니다. 전달할 SQL 파일이 없습니다.
실행
bqaa context-graph 로컬:
bqaa context-graph \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--graph agent_decisions_graph \
--lookback-hours 24 \
--format json
구조화된 JSON 보고서가 표시됩니다.
{
"run_id": "...",
"sessions_discovered": 5,
"sessions_materialized": 5,
"sessions_failed": 0,
"rows_materialized": {
"DecisionRequest": 5,
"DecisionOption": 15,
"DecisionOutcome": 5
},
"ok": true
}
ok: true는 완료된 세션이 5개 발견되었고, AI.GENERATE를 통해 각 세션에서 결정 흐름이 추출되었으며, 해당 행이 그래프 테이블에 작성되었음을 나타냅니다.bqaa context-graph 결정적 추출(--extraction-mode=compiled-only, 아래 설명)은 AI.GENERATE 호출을 건너뛰기만 하고 동일한 보고서 모양(동일한 필드, 동일한 ok: true)을 반환합니다.
문제 해결: 추출이 비어 있음
ok: false에 error_code = "empty_extraction"이 표시되는 경우 가장 일반적인 원인은 aiplatform.googleapis.com API가 아직 전파되지 않았거나 계정에 roles/aiplatform.user이 누락되었기 때문입니다. 1분 정도 기다린 후 다시 시도하거나 역할을 부여합니다.
USER_EMAIL=$(gcloud auth list --filter=status:ACTIVE --format="value(account)")
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="user:$USER_EMAIL" --role="roles/aiplatform.user"
그런 다음 위의 bqaa context-graph 명령어를 다시 실행합니다.
그래프에 행이 있는지 확인합니다.
bq query --use_legacy_sql=false \
"SELECT COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.decision_request\`"
5개의 행이 표시됩니다. 5개 세션에 걸쳐 총 25개의 그래프 노드(5개의 DecisionRequest, 15개의 DecisionOption, 5개의 DecisionOutcome)가 15개의 evaluatesOption 에지와 5개의 resultedIn 에지(세션당 하나의 결정 웹)로 연결됩니다.
이벤트에서 결정을 추출하는 두 가지 방법
bqaa context-graph는 두 가지 추출 경로를 제공합니다. 워크로드에 맞는 항목을 선택합니다.
- 기본 추출. 가장 쉬운 방법입니다. BigQuery의
AI.GENERATE를 사용하여 이벤트 콘텐츠를 읽고 엔티티와 관계를 추론합니다. 추가 코드 없이 모든 이벤트 모양에 대해 작동합니다. Codelab에서 사용하는 방식입니다. - 결정적 추출 (
--extraction-mode=compiled-only): 비용이 저렴하고 감사 친화적인 경로입니다. 도메인에 대해 한 번 작성하는 작은 Python 참조 추출기를 사용합니다. Vertex AI 호출 없음, 토큰당 요금 없음, 완전히 재현 가능한 출력 비용 예측 가능성 또는 엄격한 재현성이 중요한 경우 프로덕션 배포에서 이 옵션을 선택합니다.
컨텍스트 그래프 배포 가이드는 IAM 세부정보와 참조 추출기를 작성하는 방법을 비롯한 두 경로의 참조입니다.
8. 결정 추적 쿼리
그래프가 채워지면 감사 질문에 바로 답변할 수 있습니다. 구체적인 질문을 해 보세요. '각 요청에 대해 상담사가 어떤 옵션을 고려했고 어떻게 해결했나요?' GQL에서는 요청, 옵션, 결과에 대한 단일 순회입니다.
파일에 쿼리 작성 (traversal.sql). 다음 단계에서 실행하면 ${DATASET} 마커가 채워집니다.
cat > traversal.sql <<'SQL'
SELECT *
FROM GRAPH_TABLE (
${DATASET}.agent_decisions_graph
MATCH
(req:DecisionRequest) -[eo:evaluatesOption]-> (opt:DecisionOption),
(req) -[ri:resultedIn]-> (out:DecisionOutcome)
COLUMNS (
req.request_id AS request,
req.request_text AS question,
opt.option_label AS considered,
opt.confidence AS score,
out.status AS outcome,
out.rationale AS rationale
)
);
SQL
실행:
envsubst < traversal.sql | bq query --use_legacy_sql=false --max_rows=20
15개의 행이 표시됩니다. 요청당 3개의 옵션, 5개의 요청이 있습니다. 각 행에는 요청, 상담사가 고려한 옵션, 신뢰도 점수, 최종 결과, 근거가 표시됩니다.
단일 결정의 전체 그림을 보려면 request_id로 필터링하여 감사팀에 필요한 행 집합(들어온 질문, 가중치가 적용된 옵션(점수 포함), 커밋된 근거)을 가져옵니다.
BigQuery Studio에서 그래프 시각화
BigQuery Studio에서 그래프를 시각적으로 렌더링할 수도 있습니다. BigQuery 콘솔에서 BigQuery Studio를 열고 아래의 경로 쿼리를 실행한 다음 결과 창을 그래프 탭으로 전환하여 결정 웹을 확인합니다. 현실적인 규모의 코퍼스를 사용하면 요청, 옵션, 결과의 시각적 지도를 확인할 수 있습니다.
GRAPH agent_analytics_demo.agent_decisions_graph
MATCH p = (a)-[e]->(b)
RETURN TO_JSON(p) AS path_json
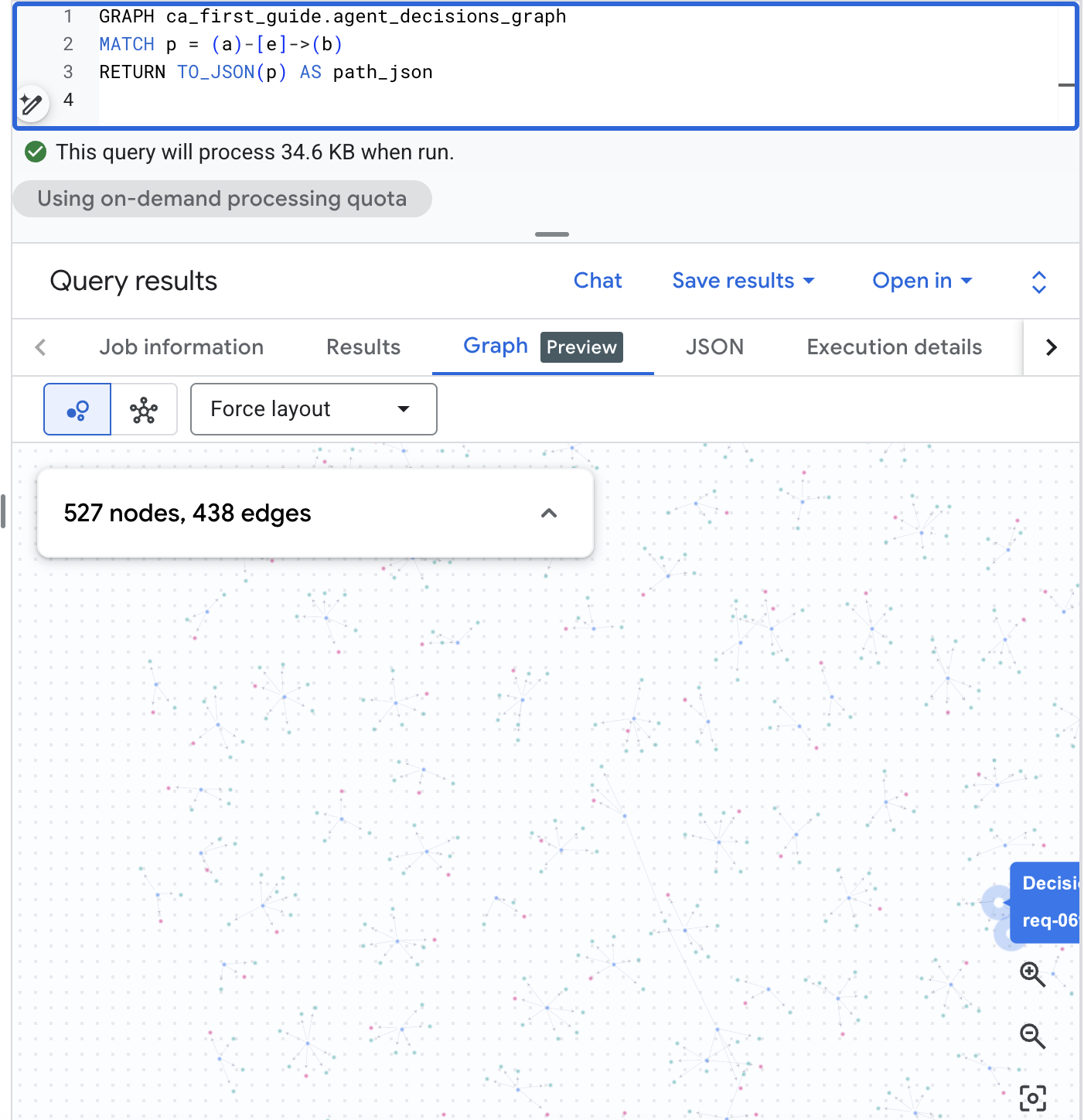
간단한 영어로 동일한 질문을 합니다.
모든 감사 리더가 GQL을 작성하는 것은 아닙니다. BigQuery 대화형 분석 (미리보기)을 사용하면 규정 준수팀에서 자연어로 동일한 종류의 질문을 하고 구조화된 답변 카드를 받을 수 있습니다. 쿼리 구문이나 조인을 배울 필요가 없습니다.
agent_decisions_graph (agent_events 및 결정 테이블과 함께)을 대화형 분석 데이터 소스로 등록한 다음 감사 질문을 직접 합니다.
감사 질문 (일반 영어): '약속된 결과에 도달하지 못한 요청은 무엇인가요?'
대화형 분석은 그래프를 기반으로 추론하고, SQL을 작성하고, 지원 테이블과 함께 일반 영어로 대답합니다. 여기서는 기록된 모든 요청이 약속된 결과에 도달했습니다.
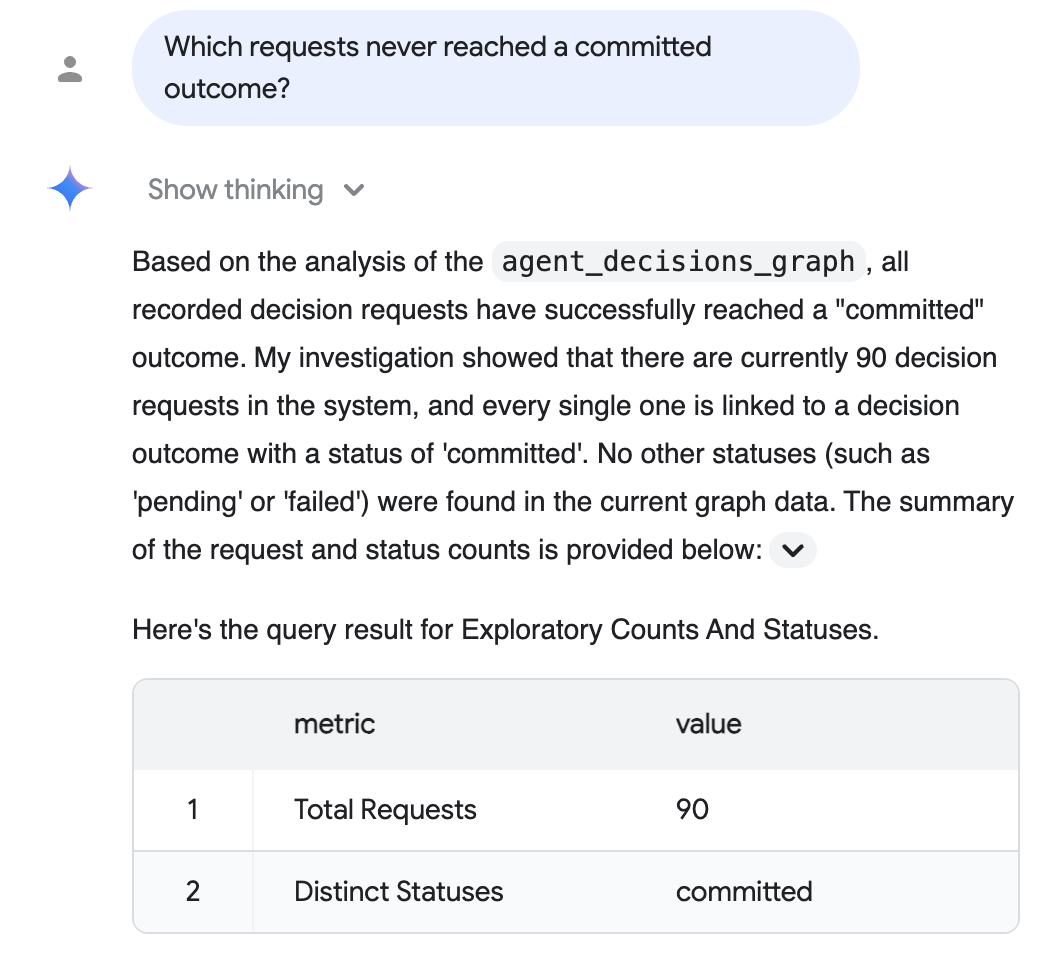
위의 대답은 선택사항인 현실적인 규모의 데이터 단계의 현실적인 규모의 코퍼스 (구체화된 요청 90개, 모두 커밋됨)를 반영합니다. 정확한 숫자는 시드한 코퍼스에 따라 달라지며 기본 5세션 실행에는 5개가 표시됩니다.
설정은 대화형 분석 문서를 참고하세요.
9. 프로덕션으로 전환
위의 로컬 실행은 기본 동작을 사용하며, 이는 이미 실제 배포의 기본사항을 다룹니다. 모든 실행은 감사 추적 (구조화된 Cloud Logging과 데이터 세트의 상태 테이블에 있는 실행별 행)을 남기고, 일시적인 실패는 자동으로 재시도되며, 진행 상황은 완전히 성공한 세션에서만 진행되므로 중복 계산이 없습니다.
프로덕션 컨트롤(결정적 추출(--extraction-mode=compiled-only), 정체된 세션 감지(--max-session-age-hours), 이전 창의 원샷 재생(--backfill --from / --to, 라이브 일정에 방해되지 않도록 일반 새로고침과 별도로 추적됨), 실행별 배치 경계(--max-sessions))은 필요할 때 사용하는 선택 플래그입니다. 컨텍스트 그래프 배포 가이드에는 전체 IAM 매트릭스와 권장 일정과 함께 각 항목이 문서화되어 있습니다.
10. 삭제
유휴 데이터 세트에 대한 요금이 청구되지 않도록 생성한 항목을 해체합니다.
bq rm -r -f --dataset "$PROJECT_ID:$DATASET"
이 단일 명령어를 사용하면 데이터 세트, 에이전트 이벤트, 그래프 테이블, 상태 테이블이 함께 삭제됩니다.
11. 마무리
축하합니다. 외부 그래프 데이터베이스나 ETL 파이프라인 없이 원시 에이전트 이벤트 로그를 쿼리 가능한 에이전트 컨텍스트 그래프로 변환하고 단일 결정을 엔드 투 엔드로 추적했습니다.
에이전트가 중요한 결정을 내리는 모든 곳(신용 인수, 사전 승인, 마케팅 예산 이동, 조달, 고객 서비스, 내부 IT)에 동일한 패턴이 적용됩니다. 자체 에이전트 컨텍스트 그래프를 빌드하려면 Codelab 아티팩트를 시작점으로 복사하고, 두 선언적 파일 (표 DDL + CREATE PROPERTY GRAPH 스키마)을 도메인에 맞게 조정하고, BigQuery에 적용합니다. bqaa context-graph --graph는 배포된 그래프를 INFORMATION_SCHEMA에서 다시 읽고 나머지를 파생합니다.
학습한 내용
- BigQuery 데이터 세트를 만들고 에이전트 결정 도메인을 설명하는 속성 그래프 스키마를 적용하는 방법
- 합성 이벤트 코퍼스로
agent_events를 채우는 방법 bqaa context-graph를 실행하여 이러한 이벤트에서 에이전트의 결정 추적을 에이전트 컨텍스트 그래프로 추출하고INFORMATION_SCHEMA에서 그래프 정의를 다시 읽는 방법- GQL에서 결과 그래프를 쿼리하고 감사 스타일 답변을 읽는 방법
참조 문서
- BigQuery 에이전트 애널리틱스 SDK 저장소
- Codelab 아티팩트 및 적응 가이드
- 컨텍스트 그래프 배포 가이드: 필수 API, IAM 매트릭스, 권장 일정, Cloud Monitoring 알림 쿼리, Terraform 모듈
- BigQuery 그래프 문서 (미리보기)
- BigQuery 대화형 분석 문서 (미리보기)