
1. Wprowadzenie
BigQuery Graph, analityka konwersacyjna BigQuery i pakiet SDK do analizy agenta BigQuery są obecnie dostępne w wersji podglądowej w Google Cloud. Wtyczka BigQuery Agent Analytics jest ogólnie dostępna (GA). Przykłady w tych ćwiczeniach z programowania wykorzystują dane syntetyczne.
W miarę jak autonomiczne agenty AI przejmują coraz więcej obowiązków operacyjnych (ocenianie wniosków o kredyt, zarządzanie budżetami marketingowymi, zatwierdzanie próśb o dostęp), organizacje muszą mieć możliwość kontrolowania i wyjaśniania ich decyzji. Odtworzenie dokładnego kontekstu, rozważanych alternatyw i ostatecznego uzasadnienia decyzji agenta ma kluczowe znaczenie dla zapewnienia zgodności z przepisami, zarządzania ryzykiem i zaufania operacyjnego.
W tym samouczku używamy pakietu BigQuery Agent Analytics SDK do przekształcania nieprzetworzonych dzienników zdarzeń agenta w graf kontekstu agenta – graf zapytań w BigQuery Graph dotyczący decyzji agenta – zgodnie z harmonogramem, bez zewnętrznej bazy danych grafów ani potoku ETL.
Kluczowe terminy
- Ślad decyzji agenta – dowody na poziomie decyzji pochodzące z własnych uruchomień agenta: rozważane opcje, wykorzystane dane i osiągnięty wynik.
- Wykres kontekstu agenta – typowany wykres, na którym można wykonywać zapytania, w BigQuery Graph, do którego są materializowane te ślady. Jest to instancja koncepcji wykresu kontekstu branży w zakresie agenta (trwała, powiązana z czasem warstwa kontekstu decyzyjnego, którą agenci tworzą i wykorzystują). Kwalifikator „Agent” ogranicza ją do uruchomień Twoich agentów, a nie do warstwy kontekstu obejmującej całe przedsiębiorstwo.
W tym laboratorium bqaa context-graph wyodrębnia ślady decyzji agenta z agent_events i przekształca je w graf kontekstu agenta, o który możesz wysyłać zapytania w GQL. Jest to zgodne z wzorcem branżowym, w którym grafy kontekstu są tworzone na podstawie śladów decyzji.
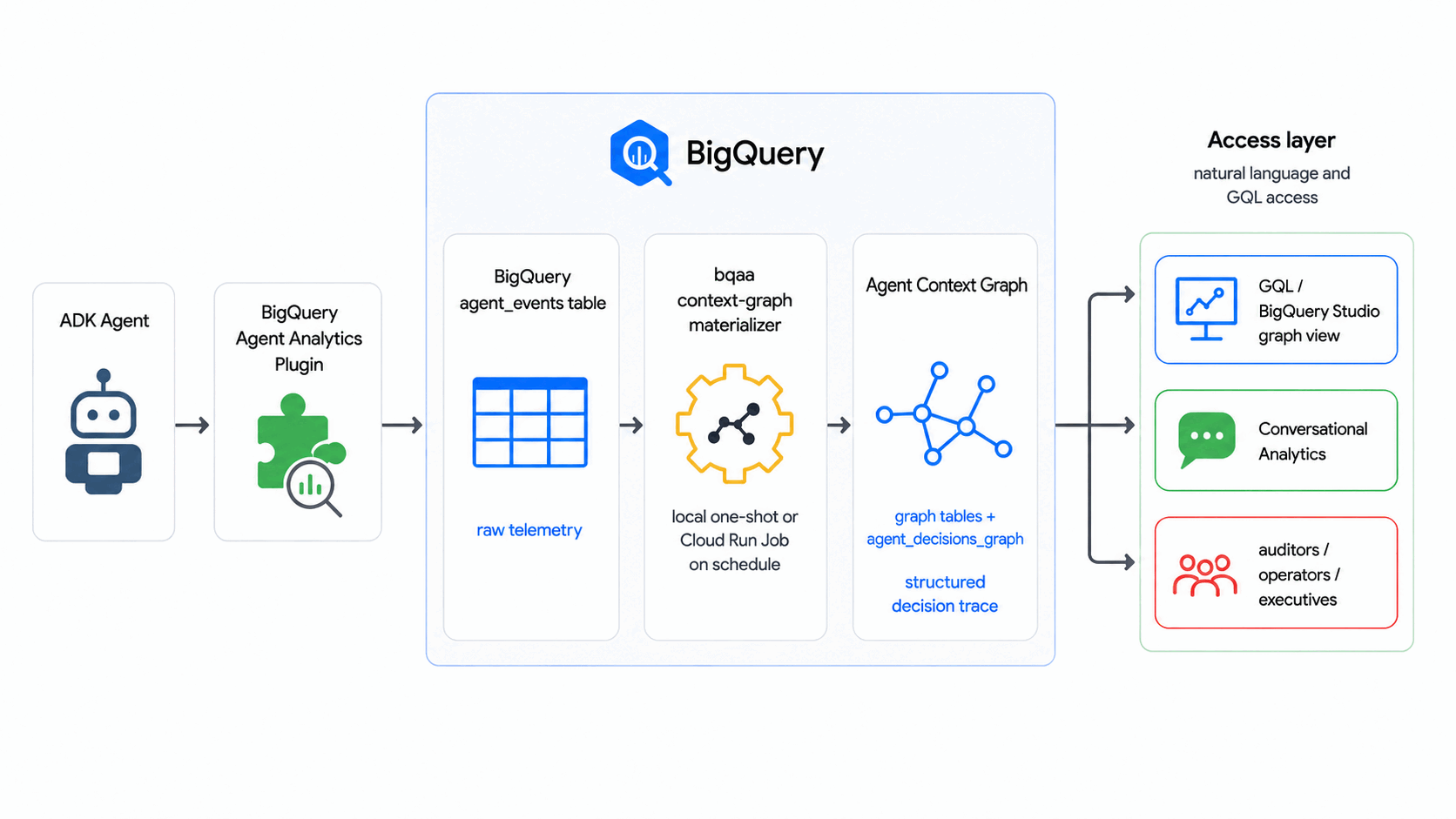
Co utworzysz
- Wykres kontekstu agenta (z wykresem BigQuery), który modeluje ogólny proces decyzyjny agenta: przychodzi żądanie, agent rozważa opcje i podejmuje decyzję.
- Wypełniona tabela
agent_eventsz syntetycznym korpusem zdarzeń. - działające
bqaa context-graphuruchomienie, które wypełnia wykres danymi z tych zdarzeń. - Zapytanie GQL w stylu kontroli, które śledzi pojedynczą decyzję od początku do końca.
Czego się nauczysz
- Jak wtyczka BigQuery Agent Analytics zapisuje dane w
agent_events. - Jak wykres kontekstu jest definiowany przez 2 elementy deklaratywne – DDL tabeli i schemat
CREATE PROPERTY GRAPH. - Jak uruchomić
bqaa context-graphna wykresie BigQuery. - Jak wysyłać zapytania do grafu za pomocą GQL.
- Możliwości pakietu SDK w wersji produkcyjnej, które są obsługiwane w przypadku wdrożeń w firmach.
Czego potrzebujesz
- Projekt Google Cloud z włączonymi płatnościami.
- rolę właściciela lub edytującego w tym projekcie. Utworzysz zbiór danych BigQuery i przyznasz uprawnienia IAM.
- Zainstalowany i uwierzytelniony interfejs wiersza poleceń
gcloudlub dostęp do Cloud Shell. - Python 3.10 lub nowszy.
- znajomość SQL BigQuery; Znajomość GQL nie jest wymagana.
Te ćwiczenia są przeznaczone dla programistów na wszystkich poziomach zaawansowania, w tym dla osób, które dopiero zaczynają korzystać z BigQuery Graph.
Zasoby utworzone w tym ćwiczeniu są bardzo tanie, a w ostatnim kroku wszystko jest usuwane, więc nie będziesz obciążany(-a) opłatami za nieużywany zbiór danych.
Szacowany czas trwania: ukończenie tego laboratorium zajmuje około 35 minut.
2. Zanim zaczniesz
Wybierz projekt i region
Otwórz Cloud Shell lub terminal lokalny:
export PROJECT_ID="your-project-id"
export REGION="us-central1"
export DATASET="agent_analytics_demo"
gcloud config set project "$PROJECT_ID"
Pojedyncza zmienna DATASET zawiera zarówno nieprzetworzoną tabelę agent_events, jak i zmaterializowane tabele wykresów. Użycie jednego zbioru danych uprości codelab. Wdrożenia produkcyjne często dzielą zdarzenia i wykres na osobne zbiory danych, aby można było przyznawać uprawnienia IAM w wąskim zakresie dla każdego zbioru danych.
Włączanie wymaganych interfejsów API
Uruchom to polecenie, aby włączyć interfejsy API używane w tym laboratorium:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com \
--project="$PROJECT_ID"
Interfejs aiplatform.googleapis.com API jest wymagany, ponieważ domyślna ścieżka wyodrębniania w pakiecie SDK wywołuje funkcję AI.GENERATE BigQuery. Jeśli później przejdziesz na deterministyczne wyodrębnianie za pomocą interfejsu --extraction-mode=compiled-only, ten interfejs API nie będzie już potrzebny.
Tworzenie zbioru danych BigQuery
Utwórz zbiór danych, który będzie zawierać zarówno tabelę z surowymi danymi agent_events, jak i zmaterializowane tabele grafu:
bq --location=US mk --dataset "$PROJECT_ID:$DATASET"
Powinien wyświetlić się komunikat o powodzeniu:
Dataset 'your-project-id:agent_analytics_demo' successfully created.
Jeśli zbiór danych już istnieje, polecenie zakończy się bez błędów. Pozostaw go na miejscu.
3. Instalowanie pakietu SDK
Skonfiguruj środowisko wirtualne Pythona i zainstaluj pakiet SDK z PyPI:
python3 -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install bigquery-agent-analytics
Pakiet bigquery-agent-analytics pobiera bibliotekę klienta BigQuery, więc jest to jedyna instalacja potrzebna do ukończenia całego samouczka.
Sprawdź instalację:
bqaa context-graph --help | head -8
Powinien pojawić się baner interfejsu wiersza poleceń.
Uwierzytelnij
Jeśli korzystasz ze stacji roboczej:
gcloud auth login
gcloud auth application-default login
Użytkownicy Cloud Shell mogą pominąć ten krok, ponieważ dane logowania są już skonfigurowane.
4. Pobieranie artefaktów z ćwiczeń z programowania
W tym celu potrzebne są tylko 2 gotowe artefakty: DDL tabeli (tabele grafu fizycznego) i schemat grafu właściwości (CREATE PROPERTY GRAPH). Nie musisz ich tworzyć samodzielnie. W tym przewodniku używamy ich w takiej postaci, w jakiej są. Plik README w folderze artefaktów zawiera wyjaśnienie, jak dostosować je do własnej domeny decyzyjnej.
Schemat wykresu właściwości jest jedynym źródłem wiarygodnych informacji o tym, co zawiera wykres. Stosujesz go w BigQuery tylko raz, a potem wdrożony wykres jest umową. Podczas materializacji funkcja bqaa context-graph odczytuje definicję wykresu z tabeli INFORMATION_SCHEMA.PROPERTY_GRAPHS w BigQuery (wraz ze schematami tabel, do których się odwołuje), aby określić, które jednostki i relacje należy wyodrębnić i gdzie je zapisać. W ten sposób do materializatora nigdy nie jest przekazywany plik SQL.
Te warsztaty są samodzielne, więc nie musisz niczego pobierać. Poniższe polecenie zapisuje DDL wykresu kontekstu w katalogu roboczym. Jego zawartość jest identyczna z artefaktami dostarczanymi w examples/context_graph/codelab/.
Utwórz katalog roboczy:
mkdir -p ~/context-graph-codelab
cd ~/context-graph-codelab
Napisz DDL wykresu kontekstowego (context_graph_ddl.sql). Markery ${PROJECT_ID} / ${DATASET} zostaną wypełnione, gdy w następnym kroku zastosujesz plik.
cat > context_graph_ddl.sql <<'SQL'
-- Node and edge table DDL for the context-graph codelab.
--
-- `bqaa context-graph` writes into these tables on every run.
-- `session_id` and `extracted_at` are SDK metadata columns that
-- `bqaa context-graph` fills automatically; they are required on
-- every table behind the graph.
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_request` (
request_id STRING, request_text STRING, requested_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_option` (
option_id STRING, option_label STRING, confidence FLOAT64,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_outcome` (
outcome_id STRING, status STRING, rationale STRING, decided_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.evaluates_option` (
request_id STRING, option_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.resulted_in` (
request_id STRING, outcome_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
-- Graph DDL for the context-graph codelab.
--
-- Models a generic agent decision flow:
-- DecisionRequest -> evaluatesOption -> DecisionOption
-- DecisionRequest -> resultedIn -> DecisionOutcome
CREATE OR REPLACE PROPERTY GRAPH `${PROJECT_ID}.${DATASET}.agent_decisions_graph`
NODE TABLES (
`${PROJECT_ID}.${DATASET}.decision_request` AS decision_request
KEY (request_id)
LABEL DecisionRequest PROPERTIES (request_id, request_text, requested_at),
`${PROJECT_ID}.${DATASET}.decision_option` AS decision_option
KEY (option_id)
LABEL DecisionOption PROPERTIES (option_id, option_label, confidence),
`${PROJECT_ID}.${DATASET}.decision_outcome` AS decision_outcome
KEY (outcome_id)
LABEL DecisionOutcome PROPERTIES (outcome_id, status, rationale, decided_at)
)
EDGE TABLES (
`${PROJECT_ID}.${DATASET}.evaluates_option` AS evaluates_option
KEY (request_id, option_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (option_id) REFERENCES decision_option (option_id)
LABEL evaluatesOption,
`${PROJECT_ID}.${DATASET}.resulted_in` AS resulted_in
KEY (request_id, outcome_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (outcome_id) REFERENCES decision_outcome (outcome_id)
LABEL resultedIn
);
SQL
Sprawdź, czy plik jest na miejscu:
ls
Powinien być widoczny 1 plik:
context_graph_ddl.sql
Opisany przez nich przepływ decyzji ma 3 typy węzłów i 2 heterogeniczne krawędzie:
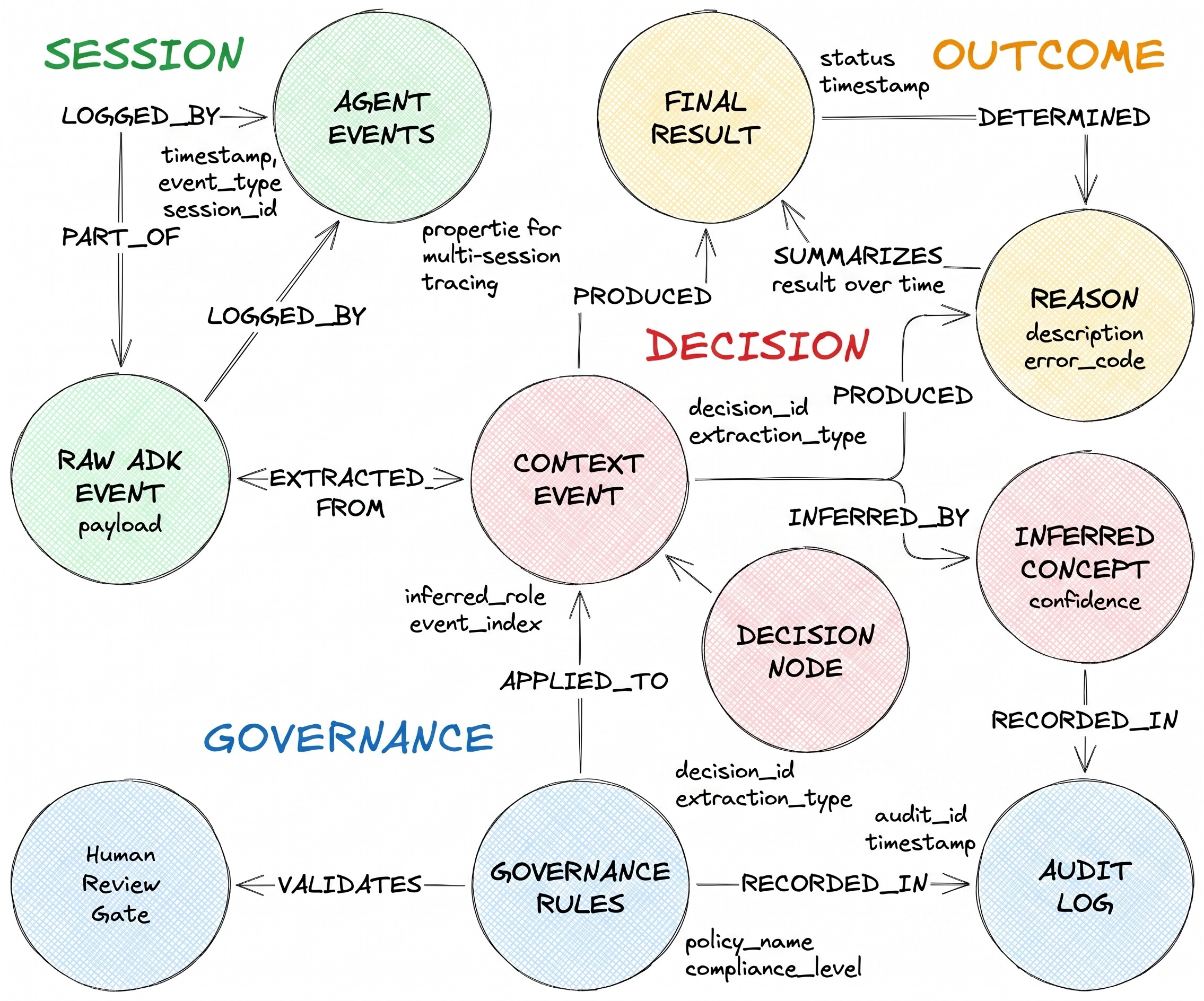
DecisionRequest to pytanie, które otrzymał agent. DecisionOption to jedna z alternatyw rozważanych przez agenta. DecisionOutcome rejestruje wybraną opcję i uzasadnienie.
5. Zastosuj schemat wykresu właściwości
bqaa context-graph zapisuje dane w tabelach BigQuery, więc muszą one istnieć przed pierwszym uruchomieniem. context_graph_ddl.sql najpierw tworzy 5 tabel, a potem wykres właściwości, który się do nich odwołuje (BigQuery odrzuca CREATE PROPERTY GRAPH, który wskazuje tabele, które jeszcze nie istnieją), więc jedno zastosowanie konfiguruje wszystko:
envsubst < context_graph_ddl.sql | bq query --use_legacy_sql=false
Powinno się wyświetlić 5 wyników CREATE TABLE i 1 wynik CREATE PROPERTY GRAPH. DDL jest idempotentny, więc możesz go bezpiecznie uruchamiać ponownie.
To jedyna praca ze schematem, jaką wykonujesz, i jedyny moment, w którym używane są te pliki SQL. BigQuery zapisuje teraz definicję wykresu, a bqaa context-graph odczytuje ją z INFORMATION_SCHEMA.PROPERTY_GRAPHS według nazwy. Nie ma osobnego pliku, który można przekazać do materializatora, a to, o co pytasz za pomocą GQL, i to, co jest materializowane, nigdy nie mogą się od siebie różnić: to ten sam wdrożony wykres.
6. Generowanie przykładowych zdarzeń agenta
W środowisku produkcyjnym wtyczka BigQuery Agent Analytics automatycznie rejestruje zdarzenia podczas działania agenta ADK. Ten fragment kodu służy tylko jako punkt odniesienia. Nie uruchamiaj go w tym ćwiczeniu:
from google.adk.plugins import BigQueryAgentAnalyticsPlugin
plugin = BigQueryAgentAnalyticsPlugin(
project_id="your-project-id",
dataset_id="agent_analytics_demo",
)
runner = Runner(agent=root_agent, plugins=[plugin])
W tym ćwiczeniu użyjesz małego syntetycznego generatora zdarzeń, który zapisuje wiersze o tym samym kształcie bezpośrednio w agent_events. Stosowanie:
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--sessions 5
Polecenie wyświetla raport JSON. W przypadku 5 sesji powinny być widoczne wartości "events_generated": 30, "events_inserted": 30 i "ok": true.
Szybki podgląd korpusu – w jednym wierszu możesz sprawdzić liczbę sesji i zdarzeń oraz zakres czasu, w którym wystąpiły:
bq query --use_legacy_sql=false \
"SELECT COUNT(DISTINCT session_id) AS sessions, COUNT(*) AS events, MIN(timestamp) AS earliest_event, MAX(timestamp) AS latest_event FROM \`$PROJECT_ID.$DATASET.agent_events\`"
W przypadku domyślnego uruchomienia 5 sesji wyświetla 5 sesji i 30 zdarzeń w ciągu kilku minut. (W realistycznym scenariuszu poniżej to samo zapytanie generuje około 100 sesji w ciągu mniej więcej 3 dni).
Sprawdź, czy zdarzenia zostały zarejestrowane:
bq query --use_legacy_sql=false \
"SELECT event_type, COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY event_type ORDER BY n DESC"
Powinno się wyświetlić 25 wierszy TOOL_COMPLETED i 5 wierszy AGENT_COMPLETED (każda sesja generuje 1 zdarzenie submit_request, 3 zdarzenia evaluate_option, 1 zdarzenie commit_outcome i 1 zdarzenie zamykające AGENT_COMPLETED – 5 zdarzeń narzędzia i 1 zdarzenie zakończenia sesji agenta). Wiersze AGENT_COMPLETED to zakończenia sesji, które bqaa context-graph kluczuje w celu wykrywania zdarzeń końcowych.
Opcjonalnie: dane w skali rzeczywistej
Powyższy korpus 5 sesji jest celowo bardzo mały, aby pierwsze uruchomienie było szybkie i tanie. Jeśli chcesz uzyskać dane w formacie produkcyjnym – wielu agentów i użytkowników rozproszonych w ciągu kilku dni, z sesjami zakończonymi niepowodzeniem, osieroconymi i obciętymi – użyj scenariusza decision-realistic. Domyślnie jest to 100 sesji w ciągu 72 godzin. Ścieżka pierwszego uruchomienia powyżej pozostaje bez zmian.
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--scenario decision-realistic \
--sessions 100 \
--seed 42
W session_outcome_counts raportu JSON widać, że jest to mniej więcej {"success": 70, "failed": 10, "orphaned": 10, "truncated": 10}.
Sprawdź rozkład wyników, klasyfikując każdą sesję na podstawie jej wierszy (osierocona = brak AGENT_COMPLETED; nieudana = AGENT_COMPLETED z status = 'error'; skrócona = dowolny wiersz z is_truncated = true; w przeciwnym razie udana). W pierwszym kroku każda sesja jest klasyfikowana, a w drugim następuje agregacja według wyniku:
bq query --use_legacy_sql=false \
"WITH per_session AS (SELECT session_id, CASE WHEN COUNTIF(event_type = 'AGENT_COMPLETED') = 0 THEN 'orphaned' WHEN COUNTIF(event_type = 'AGENT_COMPLETED' AND status = 'error') > 0 THEN 'failed' WHEN COUNTIF(is_truncated) > 0 THEN 'truncated' ELSE 'success' END AS outcome FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY session_id) SELECT outcome, COUNT(*) AS sessions FROM per_session GROUP BY outcome ORDER BY outcome"
Powinno się wyświetlić około 70 udanych, 10 nieudanych, 10 osieroconych i 10 obciętych sesji (plus 5 udanych sesji z korpusu pierwszego uruchomienia, jeśli został on wcześniej zainicjowany w tym samym zbiorze danych).
10 osieroconych sesji nigdy nie wyemitowało zdarzenia AGENT_COMPLETED, więc domyślne uruchomienie bqaa context-graph je pomija (realizuje tylko sesje z zamkniętym zdarzeniem końcowym). Aby wyświetlać je jako session_orphaned zamiast bezgłośnie ponawiać próbę w nieskończoność, dodaj --max-session-age-hours podczas stosowania – patrz --max-session-age-hours w sekcji Wdrażanie w środowisku produkcyjnym.
7. Utwórz wykres kontekstu
bqaa context-graph odczytuje surowe agent_events, a następnie określa, co wyodrębnić bezpośrednio z wdrożonego wykresu: odczytuje definicję CREATE PROPERTY GRAPH zastosowaną w sekcji Stosowanie schematu wykresu właściwości z INFORMATION_SCHEMA.PROPERTY_GRAPHS BigQuery, łączy ją ze schematami tabel, do których się odwołuje, określa encje, relacje i typy kolumn oraz wypełnia tabele wykresu. Wskazujesz wdrożony wykres według nazwy za pomocą --graph agent_decisions_graph – nie ma pliku SQL do przekazania.
Uruchom
bqaa context-graph lokalnie:
bqaa context-graph \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--graph agent_decisions_graph \
--lookback-hours 24 \
--format json
Powinien pojawić się raport w formacie JSON:
{
"run_id": "...",
"sessions_discovered": 5,
"sessions_materialized": 5,
"sessions_failed": 0,
"rows_materialized": {
"DecisionRequest": 5,
"DecisionOption": 15,
"DecisionOutcome": 5
},
"ok": true
}
ok: true oznacza, że bqaa context-graph znalazł 5 ukończonych sesji, wyodrębnił z nich przepływ decyzji za pomocą AI.GENERATE i zapisał odpowiednie wiersze w tabelach wykresu. Ekstrakcja deterministyczna (--extraction-mode=compiled-only, opisana poniżej) zwraca ten sam kształt raportu – te same pola, te same ok: true – po prostu pomija wywołania AI.GENERATE.
Rozwiązywanie problemów: puste wyodrębnianie
Jeśli widzisz ok: false z error_code = "empty_extraction", najczęstszą przyczyną jest to, że interfejs API aiplatform.googleapis.com nie został jeszcze rozpowszechniony lub na Twoim koncie brakuje roles/aiplatform.user. Zaczekaj minutę i spróbuj jeszcze raz lub przyznaj rolę:
USER_EMAIL=$(gcloud auth list --filter=status:ACTIVE --format="value(account)")
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="user:$USER_EMAIL" --role="roles/aiplatform.user"
Następnie ponownie uruchom polecenie bqaa context-graph.
Sprawdź, czy graf zawiera wiersze:
bq query --use_legacy_sql=false \
"SELECT COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.decision_request\`"
Powinno być widocznych 5 wierszy. W 5 sesjach jest łącznie 25 węzłów wykresu – 5 DecisionRequest, 15 DecisionOption i 5 DecisionOutcome – połączonych 15 krawędziami evaluatesOption i 5 krawędziami resultedIn (po jednej sieci decyzyjnej na sesję).
2 sposoby wyodrębniania decyzji ze zdarzeń
bqaa context-graph oferuje 2 ścieżki wyodrębniania. Wybierz opcję, która pasuje do Twojego zbioru zadań:
- Domyślne wyodrębnianie Najłatwiejsza ścieżka. Korzysta z
AI.GENERATEBigQuery do odczytywania treści zdarzeń oraz wnioskowania o podmiotach i relacjach. Działa w przypadku dowolnego kształtu zdarzenia bez dodatkowego kodu. Jest to metoda używana w tym laboratorium. - Ekstrakcja deterministyczna (
--extraction-mode=compiled-only) – tańsza i łatwiejsza do kontrolowania. Wykorzystuje mały ekstraktor referencyjny w Pythonie, który piszesz raz dla swojej domeny. Brak wywołań Vertex AI, brak opłat za token, w pełni powtarzalne dane wyjściowe. Wdrożenia produkcyjne wybierają tę opcję, gdy ważna jest przewidywalność kosztów lub ścisła powtarzalność.
Przewodnik po wdrażaniu wykresu kontekstowego zawiera informacje o obu ścieżkach, w tym szczegóły dotyczące uprawnień i sposób tworzenia ekstraktora odwołań.
8. Wysyłanie zapytań dotyczących śladu decyzji
Po wypełnieniu wykresu możesz bezpośrednio odpowiedzieć na pytanie kontrolne. Weźmy konkretne pytanie: „Jakie opcje rozważył agent w przypadku każdego żądania i jak je rozwiązał?” W GQL jest to pojedyncze przejście przez żądanie, jego opcje i wynik.
Zapisz zapytanie w pliku (traversal.sql). Znak ${DATASET} zostanie wypełniony, gdy uruchomisz zapytanie w następnym kroku:
cat > traversal.sql <<'SQL'
SELECT *
FROM GRAPH_TABLE (
${DATASET}.agent_decisions_graph
MATCH
(req:DecisionRequest) -[eo:evaluatesOption]-> (opt:DecisionOption),
(req) -[ri:resultedIn]-> (out:DecisionOutcome)
COLUMNS (
req.request_id AS request,
req.request_text AS question,
opt.option_label AS considered,
opt.confidence AS score,
out.status AS outcome,
out.rationale AS rationale
)
);
SQL
Stosowanie:
envsubst < traversal.sql | bq query --use_legacy_sql=false --max_rows=20
Powinno być widocznych 15 wierszy: 3 opcje na żądanie i 5 żądań. Każdy wiersz zawiera żądanie, opcję rozważaną przez agenta, jej poziom ufności, ostateczny wynik i uzasadnienie.
Aby uzyskać pełny obraz pojedynczej decyzji, przefiltruj dane według request_id, aby uzyskać zestaw wierszy potrzebny zespołowi audytowemu: pytanie, które wpłynęło, opcje, które zostały rozważone (z ocenami), oraz uzasadnienie, które zostało zatwierdzone.
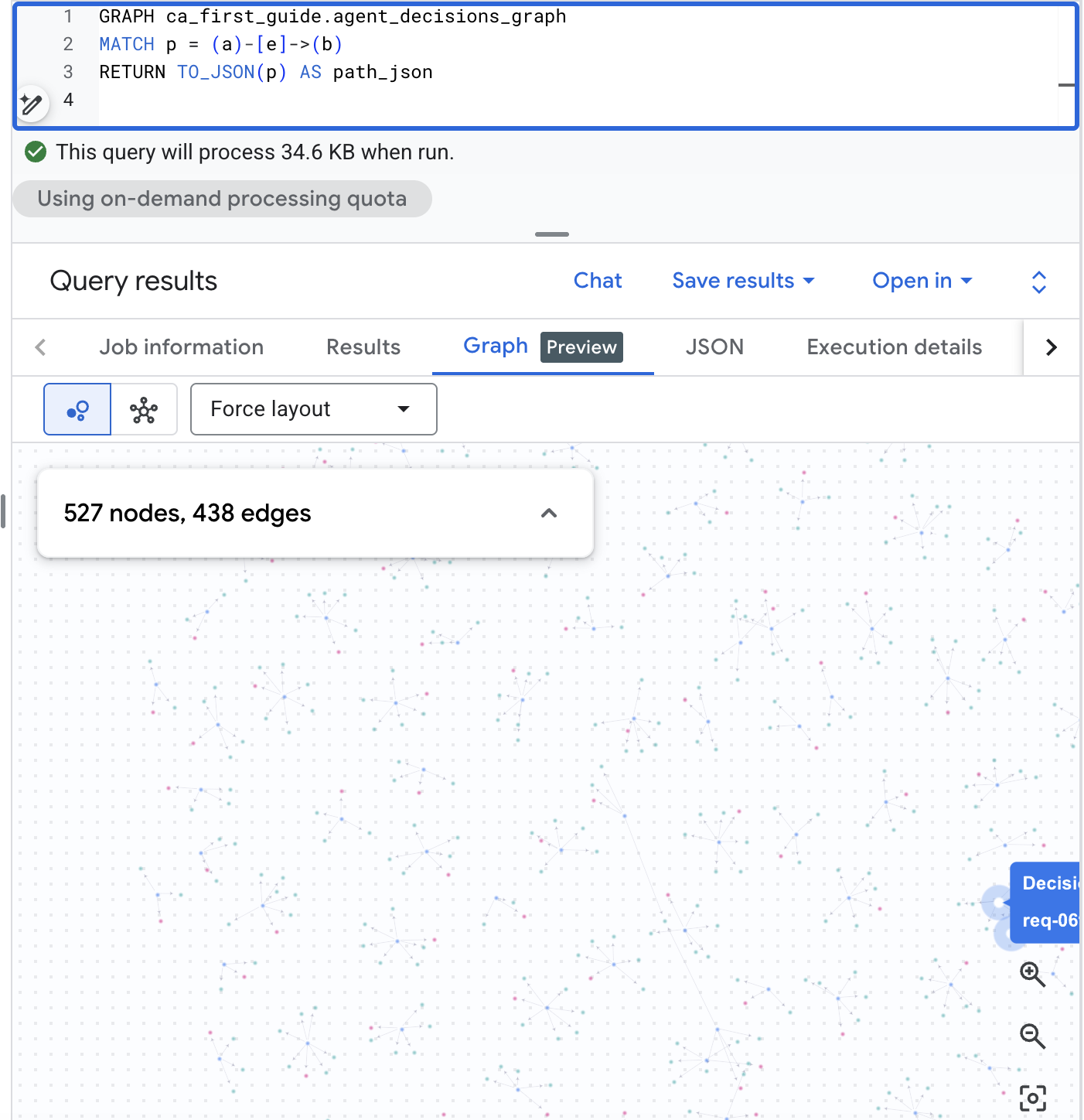
Wizualizacja wykresu w BigQuery Studio
BigQuery Studio może też wizualnie renderować wykres. Otwórz BigQuery Studio w konsoli BigQuery, uruchom poniższe zapytanie o ścieżkę, a następnie przełącz panel wyników na kartę Wykres, aby zobaczyć sieć decyzyjną. Dzięki korpusowi o realistycznej skali uzyskasz wizualną mapę żądań, opcji i wyników:
GRAPH agent_analytics_demo.agent_decisions_graph
MATCH p = (a)-[e]->(b)
RETURN TO_JSON(p) AS path_json
Zadaj to samo pytanie w prostym języku angielskim
Nie każdy czytelnik kontroli pisze w GQL. Dzięki analityce konwersacyjnej BigQuery (wersja zapoznawcza) Twój zespół ds. zgodności może zadawać pytania w języku naturalnym i otrzymywać w odpowiedzi kartę ze strukturalnymi informacjami – bez konieczności używania składni zapytań czy łączenia tabel.
Zarejestruj agent_decisions_graph (wraz z agent_events i tabelami decyzyjnymi) jako źródło danych analityki konwersacyjnej, a następnie zadaj pytanie kontrolne bezpośrednio:
Pytanie kontrolne (w języku naturalnym): „Które żądania nigdy nie osiągnęły ostatecznego wyniku?”
Analityka konwersacyjna analizuje wykres, zapisuje za Ciebie kod SQL i odpowiada w prostym języku angielskim, podając tabelę pomocniczą, która w tym przypadku pokazuje, że każde zarejestrowane żądanie osiągnęło oczekiwany rezultat:
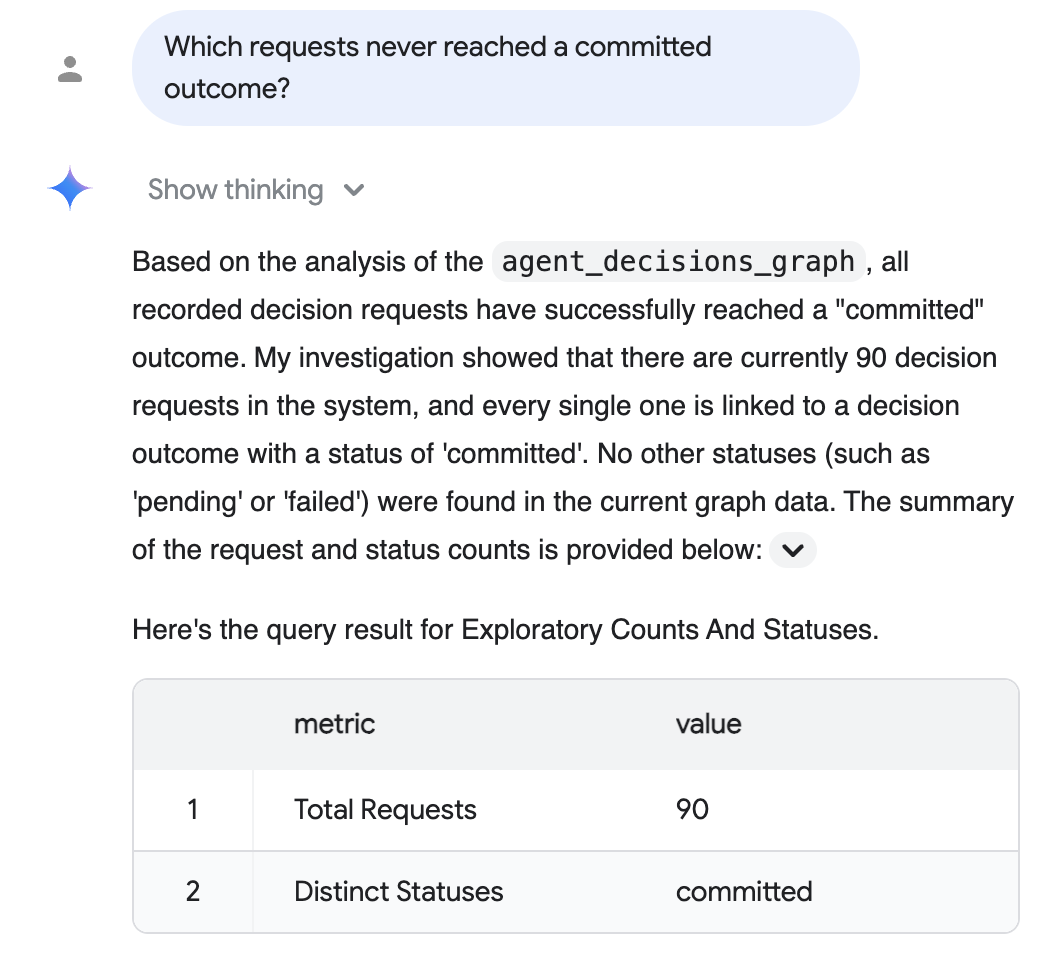
Odpowiedź powyżej odzwierciedla korpus o realistycznej skali z opcjonalnego kroku dane o realistycznej skali (90 zrealizowanych żądań, wszystkie zatwierdzone). Dokładne liczby zależą od tego, który korpus został użyty. Domyślne 5 sesji pokazuje 5.
Informacje o konfiguracji znajdziesz w dokumentacji analityki konwersacyjnej.
9. Wdrażanie w środowisku produkcyjnym
Powyższe lokalne uruchomienie korzysta z domyślnego działania, które obejmuje już podstawowe elementy rzeczywistych wdrożeń: każde uruchomienie pozostawia ślad kontrolny (strukturalne logowanie w Cloud Logging plus wiersz w tabeli stanu w zbiorze danych), przejściowe błędy są automatycznie ponawiane, a postęp jest rejestrowany tylko w przypadku w pełni zakończonych sesji, więc nie ma podwójnego zliczania.
Kontrola produkcji – deterministyczne wyodrębnianie (--extraction-mode=compiled-only), wykrywanie zablokowanych sesji (--max-session-age-hours), jednorazowe odtwarzanie poprzedniego okna (--backfill --from / --to, śledzone oddzielnie od zwykłego odświeżania, aby nie zakłócać harmonogramu transmisji na żywo) i ograniczanie partii w przypadku każdego uruchomienia (--max-sessions) – to flagi, które możesz włączyć, gdy ich potrzebujesz. Przewodnik wdrażania wykresu kontekstowego zawiera dokumentację każdego z nich wraz z pełną macierzą uprawnień i zalecanymi harmonogramami.
10. Czyszczenie danych
Usuń utworzone zasoby, aby uniknąć opłat za nieużywany zbiór danych:
bq rm -r -f --dataset "$PROJECT_ID:$DATASET"
To pojedyncze polecenie usuwa jednocześnie zbiór danych, zdarzenia agenta, tabele wykresów i tabelę stanu.
11. Gratulacje
Gratulacje! Surowe dzienniki zdarzeń agenta zostały przekształcone w wykres kontekstowy agenta, który można odpytywać. Prześledziliśmy też pojedynczą decyzję od początku do końca bez użycia zewnętrznej bazy danych wykresów ani potoku ETL.
Ten sam wzorzec dotyczy wszystkich sytuacji, w których agent podejmuje ważne decyzje: ocena zdolności kredytowej, uzyskiwanie wcześniejszej autoryzacji, przenoszenie budżetu marketingowego, zakupy, obsługa klienta i wewnętrzne usługi IT. Aby utworzyć własny wykres kontekstu agenta, skopiuj artefakty z ćwiczenia jako punkt początkowy, dostosuj 2 pliki deklaratywne (DDL tabeli i schemat CREATE PROPERTY GRAPH) do swojej domeny i zastosuj je w BigQuery – bqaa context-graph --graph odczytuje wdrożony wykres z INFORMATION_SCHEMA i wywodzi z niego resztę.
Czego się dowiedziałeś(-aś)
- Jak utworzyć zbiór danych BigQuery i zastosować schemat wykresu właściwości opisujący domenę decyzyjną agenta.
- Jak wypełnić
agent_eventssyntetycznym korpusem zdarzeń. - Jak uruchomić
bqaa context-graph, aby wyodrębnić ślady decyzji agenta do wykresu kontekstu agenta z tych zdarzeń, odczytując definicję wykresu zINFORMATION_SCHEMA. - Jak wysyłać zapytania do powstałego wykresu w języku GQL i odczytywać odpowiedź w formie audytu.
Dokumentacja
- Repozytorium pakietu BigQuery Agent Analytics SDK
- Artefakty ćwiczeń z programowania i przewodnik po dostosowywaniu
- Przewodnik wdrażania wykresu kontekstowego: wymagane interfejsy API, macierz IAM, zalecane harmonogramy, zapytania alertów Cloud Monitoring i moduł Terraform.
- Dokumentacja BigQuery Graph (wersja przedpremierowa).
- Dokumentacja analizy konwersacyjnej BigQuery (wersja podglądowa).