
1. Введение
В настоящее время BigQuery Graph, BigQuery Conversational Analytics и BigQuery Agent Analytics SDK находятся в режиме предварительного просмотра в Google Cloud. Плагин BigQuery Agent Analytics доступен в режиме общего доступа (GA). В примерах этого практического занятия используются синтетические данные.
Поскольку автономные агенты искусственного интеллекта берут на себя все больше оперативных обязанностей (оценка заявок на кредиты, управление маркетинговыми бюджетами, утверждение запросов на доступ), организациям необходимо иметь возможность проверять и объяснять принимаемые ими решения. Восстановление точного контекста, рассмотренных альтернатив и окончательного обоснования решения агента имеет важное значение для соблюдения нормативных требований, управления рисками и обеспечения оперативного доверия.
В этом практическом занятии используется SDK BigQuery Agent Analytics для преобразования необработанных журналов событий агентов в контекстный граф агентов — граф решений агентов, доступный для запросов в BigQuery Graph, — по расписанию, без использования внешней графовой базы данных или конвейера ETL.
Ключевые термины
- Траектория принятия решений агентом — данные об уровне принятия решений, полученные в результате собственных запусков агента: варианты, которые он взвешивал, данные, с которыми он взаимодействовал, и результат, которого он достиг.
- Граф контекста агента — типизированный, доступный для запросов граф в BigQuery Graph, в который материализуются эти трассировки. Это экземпляр концепции графа контекста отрасли (устойчивый, связанный со временем слой контекста принятия решений, который агенты как создают, так и используют) в рамках одного агента; квалификатор «Агент» ограничивает его областью действия только запусками ваших собственных агентов, а не контекстным слоем в масштабах всего предприятия.
В этом практическом занятии bqaa context-graph извлекает траектории принятия решений агентом из ваших agent_events и преобразует их в граф контекста агента, который можно запрашивать с помощью GQL — следуя отраслевому шаблону, где графы контекста строятся на основе траекторий принятия решений.
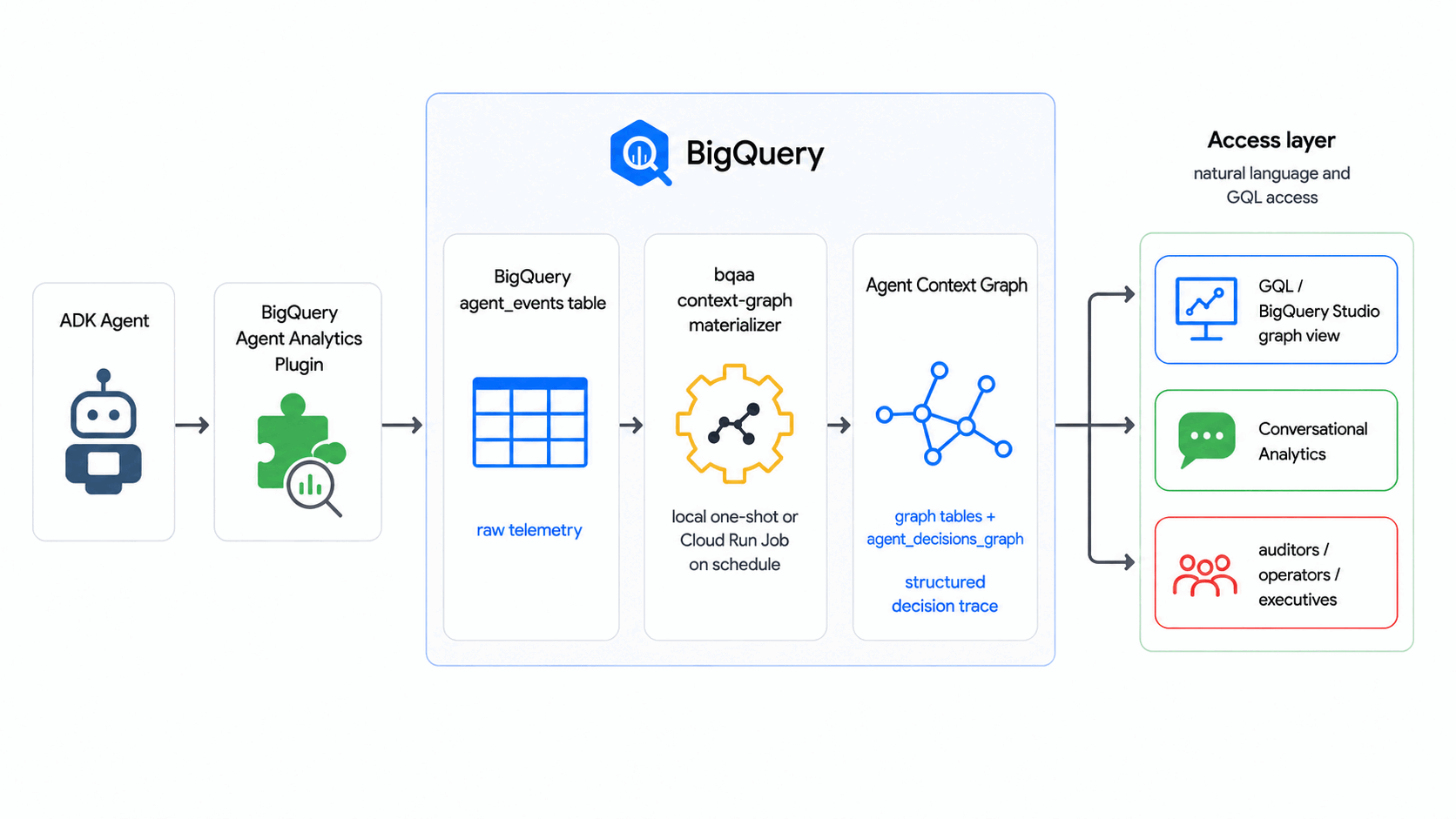
Что вы построите
- Граф контекста агента (с использованием BigQuery Graph), моделирующий типичный процесс принятия решений агентом: поступает запрос, агент взвешивает варианты, и принимается решение.
- Заполненная таблица
agent_eventsсинтетическим корпусом событий. - Рабочий пример
bqaa context-graph, заполняющий граф на основе этих событий. - Запрос GQL в стиле аудита, отслеживающий принятие одного решения от начала до конца.
Что вы узнаете
- Как плагин BigQuery Agent Analytics записывает данные в
agent_events. - Как контекстный граф определяется всего двумя декларативными артефактами — DDL-скриптом таблицы и схемой
CREATE PROPERTY GRAPH. - Как запустить
bqaa context-graphдля работы с графом BigQuery. - Как выполнить запрос к графу с помощью GQL.
- Функционал SDK, предназначенный для использования в корпоративной среде, обеспечивает возможности производственного уровня.
Что вам понадобится
- Проект Google Cloud с включенной функцией выставления счетов.
- Вам потребуется роль владельца или редактора в этом проекте. Вы создадите набор данных BigQuery и предоставите права доступа по протоколу IAM.
- Для работы требуется установленный и прошедший аутентификацию интерфейс командной строки
gcloudили доступ к Cloud Shell. - Python 3.10 или новее.
- Знание BigQuery SQL обязательно. Знание GQL не требуется.
Этот практический семинар предназначен для разработчиков всех уровней, включая тех, кто только начинает работать с BigQuery Graph.
Ресурсы, созданные в этом практическом занятии, стоят очень недорого, а на заключительном этапе все удаляется, поэтому вам не придется платить за простаивающий набор данных.
Ориентировочная продолжительность: выполнение этого практического задания займет приблизительно 35 минут.
2. Прежде чем начать
Выберите проект и регион.
Откройте Cloud Shell или локальный терминал:
export PROJECT_ID="your-project-id"
export REGION="us-central1"
export DATASET="agent_analytics_demo"
gcloud config set project "$PROJECT_ID"
Единственная переменная DATASET содержит как исходную таблицу agent_events , так и материализованные таблицы графов. Использование одного набора данных упрощает выполнение практического задания. В производственных средах события и графы часто разделяются на отдельные наборы данных, чтобы IAM можно было предоставлять с ограничением по каждому набору данных.
Включите необходимые API.
Выполните следующую команду , чтобы включить API, используемые в этом практическом занятии:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com \
--project="$PROJECT_ID"
API aiplatform.googleapis.com необходим, поскольку путь извлечения данных по умолчанию в SDK вызывает функцию AI.GENERATE из BigQuery. Если вы позже переключитесь на детерминированное извлечение данных с помощью --extraction-mode=compiled-only , этот API больше не потребуется.
Создайте набор данных BigQuery.
Создайте набор данных , который будет содержать как исходную таблицу agent_events , так и материализованные таблицы графов:
bq --location=US mk --dataset "$PROJECT_ID:$DATASET"
Вы должны увидеть сообщение об успешном завершении:
Dataset 'your-project-id:agent_analytics_demo' successfully created.
Если набор данных уже существует, команда выдаст безобидную ошибку. Оставьте его на месте.
3. Установите SDK.
Настройте виртуальное окружение Python и установите SDK из PyPI:
python3 -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install bigquery-agent-analytics
Пакет bigquery-agent-analytics подключает клиентскую библиотеку BigQuery, поэтому для выполнения всего практического задания вам потребуется установить только его.
Проверьте установку:
bqaa context-graph --help | head -8
Вы должны увидеть баннер командной строки.
Аутентификация
Если вы работаете на рабочей станции:
gcloud auth login
gcloud auth application-default login
Пользователи Cloud Shell могут пропустить этот шаг; учетные данные уже настроены.
4. Получите артефакты кодовой лаборатории.
Для выполнения практического задания необходимы всего два готовых к использованию артефакта: DDL-файл таблицы (таблицы физического графа) и схема графа свойств ( CREATE PROPERTY GRAPH ). Вам не нужно создавать ни один из них самостоятельно; практическое задание использует их как есть, а в файле README в папке с артефактами объясняется, как адаптировать их для вашей собственной области принятия решений.
Схема графа свойств является единственным источником достоверной информации о содержании графа. Вы применяете её к BigQuery один раз; с этого момента сам развернутый граф становится контрактом . При материализации bqaa context-graph считывает определение графа из INFORMATION_SCHEMA.PROPERTY_GRAPHS BigQuery (вместе со схемами таблиц, на которые он ссылается), чтобы определить, какие сущности и связи нужно извлечь и куда их записать — поэтому в материализатор никогда не передаётся SQL-файл.
Данный учебный модуль является самодостаточным, поэтому ничего скачивать не нужно. Приведенная ниже команда записывает DDL-код контекстного графа в рабочую директорию. Его содержимое идентично содержимому файлов, поставляемых в examples/context_graph/codelab/ .
Создайте рабочую директорию:
mkdir -p ~/context-graph-codelab
cd ~/context-graph-codelab
Напишите DDL-скрипт контекстного графа ( context_graph_ddl.sql ). Маркеры ${PROJECT_ID} / ${DATASET} заполнятся при применении файла на следующем шаге.
cat > context_graph_ddl.sql <<'SQL'
-- Node and edge table DDL for the context-graph codelab.
--
-- `bqaa context-graph` writes into these tables on every run.
-- `session_id` and `extracted_at` are SDK metadata columns that
-- `bqaa context-graph` fills automatically; they are required on
-- every table behind the graph.
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_request` (
request_id STRING, request_text STRING, requested_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_option` (
option_id STRING, option_label STRING, confidence FLOAT64,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_outcome` (
outcome_id STRING, status STRING, rationale STRING, decided_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.evaluates_option` (
request_id STRING, option_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.resulted_in` (
request_id STRING, outcome_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
-- Graph DDL for the context-graph codelab.
--
-- Models a generic agent decision flow:
-- DecisionRequest -> evaluatesOption -> DecisionOption
-- DecisionRequest -> resultedIn -> DecisionOutcome
CREATE OR REPLACE PROPERTY GRAPH `${PROJECT_ID}.${DATASET}.agent_decisions_graph`
NODE TABLES (
`${PROJECT_ID}.${DATASET}.decision_request` AS decision_request
KEY (request_id)
LABEL DecisionRequest PROPERTIES (request_id, request_text, requested_at),
`${PROJECT_ID}.${DATASET}.decision_option` AS decision_option
KEY (option_id)
LABEL DecisionOption PROPERTIES (option_id, option_label, confidence),
`${PROJECT_ID}.${DATASET}.decision_outcome` AS decision_outcome
KEY (outcome_id)
LABEL DecisionOutcome PROPERTIES (outcome_id, status, rationale, decided_at)
)
EDGE TABLES (
`${PROJECT_ID}.${DATASET}.evaluates_option` AS evaluates_option
KEY (request_id, option_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (option_id) REFERENCES decision_option (option_id)
LABEL evaluatesOption,
`${PROJECT_ID}.${DATASET}.resulted_in` AS resulted_in
KEY (request_id, outcome_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (outcome_id) REFERENCES decision_outcome (outcome_id)
LABEL resultedIn
);
SQL
Убедитесь, что файл находится на месте:
ls
Вы должны увидеть один файл:
context_graph_ddl.sql
Описанный ими алгоритм принятия решений включает три типа узлов и два разнородных ребра:
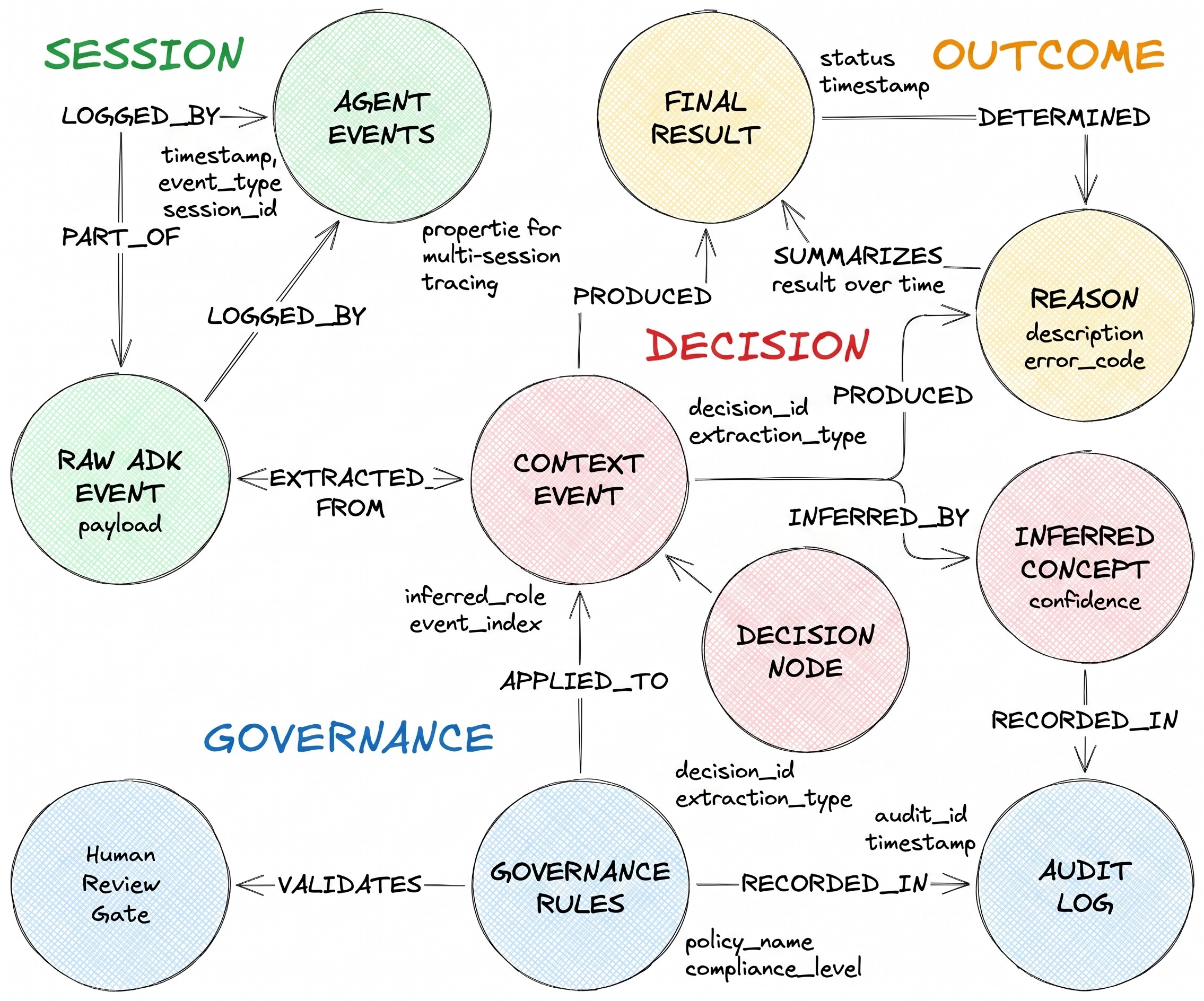
DecisionRequest — это вопрос, полученный агентом. DecisionOption — это один из вариантов, рассмотренных агентом. DecisionOutcome фиксирует сделанный выбор и его обоснование.
5. Примените схему графа свойств.
bqaa context-graph записывает данные в таблицы BigQuery, поэтому они должны существовать до первого запуска. context_graph_ddl.sql сначала создает пять таблиц, а затем граф свойств, который на них ссылается (BigQuery отклоняет команду CREATE PROPERTY GRAPH , указывающую на таблицы, которые еще не существуют), поэтому одна команда apply настраивает все:
envsubst < context_graph_ddl.sql | bq query --use_legacy_sql=false
Вы должны увидеть пять результатов CREATE TABLE и один результат CREATE PROPERTY GRAPH . DDL-скрипт идемпотентен; вы можете безопасно запустить его повторно.
Это единственная работа со схемой, которую вы выполняете, — и единственное время, когда используются эти SQL-файлы. BigQuery теперь записывает определение вашего графа, а bqaa context-graph считывает его обратно из INFORMATION_SCHEMA.PROPERTY_GRAPHS по имени. Нет отдельного файла для передачи материализатору, и то, что вы запрашиваете с помощью GQL, и то, что материализуется, никогда не будут расходиться: это один и тот же развернутый граф.
6. Сгенерируйте примеры событий агента.
В рабочей среде плагин BigQuery Agent Analytics автоматически фиксирует события во время работы вашего агента ADK. Этот фрагмент кода приведен только для ознакомления — в данном практическом занятии его не нужно запускать:
from google.adk.plugins import BigQueryAgentAnalyticsPlugin
plugin = BigQueryAgentAnalyticsPlugin(
project_id="your-project-id",
dataset_id="agent_analytics_demo",
)
runner = Runner(agent=root_agent, plugins=[plugin])
Для этого практического занятия вы используете небольшой генератор синтетических событий, который записывает строки одинаковой структуры непосредственно в agent_events . Запустите его:
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--sessions 5
Команда выводит отчет в формате JSON. Для 5 сессий вы должны увидеть значения "events_generated": 30 , "events_inserted": 30 и "ok": true .
Предварительный просмотр корпуса с первого взгляда — количество сессий, количество событий и их временной диапазон — в одной строке:
bq query --use_legacy_sql=false \
"SELECT COUNT(DISTINCT session_id) AS sessions, COUNT(*) AS events, MIN(timestamp) AS earliest_event, MAX(timestamp) AS latest_event FROM \`$PROJECT_ID.$DATASET.agent_events\`"
При стандартном запуске с 5 сессиями отображается 5 сессий и 30 событий, охватывающих несколько минут. (В приведенном ниже реалистичном сценарии тот же запрос выдает около 100 сессий примерно за три дня.)
Проверьте, завершились ли события:
bq query --use_legacy_sql=false \
"SELECT event_type, COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY event_type ORDER BY n DESC"
Вы должны увидеть 25 строк TOOL_COMPLETED и 5 строк AGENT_COMPLETED (каждая сессия генерирует один submit_request , три evaluate_option , один commit_outcome и один закрывающий AGENT_COMPLETED — пять событий инструмента плюс один завершающий агент на сессию). Строки AGENT_COMPLETED — это завершающие агенты сессий, которые используются в качестве ключей bqaa context-graph для обнаружения событий терминала.
Дополнительно: данные в реалистичном масштабе.
Представленный выше корпус из 5 сессий намеренно очень мал, чтобы первый запуск был быстрым и дешевым. Если вам нужны данные, приближенные к реальным производственным — данные от множества агентов и пользователей, распределенные на несколько дней, с неудачными, потерянными и усеченными сессиями — используйте decision-realistic . По умолчанию он включает 100 сессий за 72 часа; путь первого запуска, описанный выше, остается неизменным.
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--scenario decision-realistic \
--sessions 100 \
--seed 42
В JSON-отчете session_outcome_counts показывает примерно следующее: {"success": 70, "failed": 10, "orphaned": 10, "truncated": 10} .
Подтвердите распределение результатов, классифицируя каждую сессию по ее строкам (orphaned = нет AGENT_COMPLETED ; failed = AGENT_COMPLETED со status = 'error' ; truncated = любая строка с is_truncated = true ; в противном случае success). Первый проход классифицирует каждую сессию, затем второй агрегирует результаты по каждому исходу:
bq query --use_legacy_sql=false \
"WITH per_session AS (SELECT session_id, CASE WHEN COUNTIF(event_type = 'AGENT_COMPLETED') = 0 THEN 'orphaned' WHEN COUNTIF(event_type = 'AGENT_COMPLETED' AND status = 'error') > 0 THEN 'failed' WHEN COUNTIF(is_truncated) > 0 THEN 'truncated' ELSE 'success' END AS outcome FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY session_id) SELECT outcome, COUNT(*) AS sessions FROM per_session GROUP BY outcome ORDER BY outcome"
Вы должны увидеть примерно 70 успешных, 10 неудачных, 10 потерянных и 10 усеченных сессий (плюс 5 успешных сессий из корпуса первого запуска, если вы заполнили его ранее в том же наборе данных).
Десять «осиротевших» сессий так и не выдали сообщение AGENT_COMPLETED , поэтому стандартный запуск bqaa context-graph пропускает их (он материализует только сессии, закрытые в результате события терминала). Чтобы отображать их как session_orphaned вместо того, чтобы молча повторять попытки бесконечно, добавьте --max-session-age-hours при запуске — см. --max-session-age-hours в разделе «Перевод в продакшн» .
7. Материализуйте контекстный граф.
bqaa context-graph считывает необработанные данные agent_events , а затем определяет, что нужно извлечь непосредственно из развернутого графа : он считывает определение CREATE PROPERTY GRAPH которое вы применили в параметре Apply the property graph schema back from BigQuery's INFORMATION_SCHEMA.PROPERTY_GRAPHS , объединяет его со схемами таблиц, на которые он ссылается, определяет сущности, связи и типы столбцов, а также заполняет таблицы графа. Вы указываете на развернутый граф по имени с помощью --graph agent_decisions_graph — передавать SQL-файл не нужно.
Бегать
bqaa context-graph locally:
bqaa context-graph \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--graph agent_decisions_graph \
--lookback-hours 24 \
--format json
Вы должны увидеть структурированный JSON-отчет:
{
"run_id": "...",
"sessions_discovered": 5,
"sessions_materialized": 5,
"sessions_failed": 0,
"rows_materialized": {
"DecisionRequest": 5,
"DecisionOption": 15,
"DecisionOutcome": 5
},
"ok": true
}
ok: true указывает, что bqaa context-graph обнаружил пять завершенных сессий, извлек поток принятия решений из каждой с помощью AI.GENERATE и записал соответствующие строки в таблицы графа. Детерминированное извлечение ( --extraction-mode=compiled-only , рассматривается ниже) возвращает ту же структуру отчета — те же поля, тот же параметр ok: true — просто пропускает вызовы AI.GENERATE .
Устранение неполадок: пустая выгрузка
Если вы видите ok: false с error_code = "empty_extraction" , наиболее распространенная причина заключается в том, что API aiplatform.googleapis.com еще не запущен, или в вашей учетной записи отсутствуют roles/aiplatform.user . Подождите минуту и повторите попытку или предоставьте роль:
USER_EMAIL=$(gcloud auth list --filter=status:ACTIVE --format="value(account)")
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="user:$USER_EMAIL" --role="roles/aiplatform.user"
Затем повторно выполните указанную выше команду bqaa context-graph .
Убедитесь, что график содержит строки:
bq query --use_legacy_sql=false \
"SELECT COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.decision_request\`"
Вы должны увидеть пять строк. В общей сложности за пять сессий это 25 узлов графа — 5 DecisionRequest , 15 DecisionOption и 5 DecisionOutcome — соединенных 15 ребрами evaluatesOption и 5 ребрами resultedIn (одна сеть решений на сессию).
Два способа извлечения решений из событий
bqaa context-graph предлагает два пути извлечения данных. Выберите тот, который соответствует вашей рабочей нагрузке:
- Извлечение по умолчанию. Самый простой способ. Использует
AI.GENERATEиз BigQuery для чтения содержимого событий и определения сущностей и связей. Работает с любым форматом событий без дополнительного кода. Именно это используется в практическом задании. - Детерминированное извлечение (
--extraction-mode=compiled-only). Более экономичный и удобный для аудита вариант. Использует небольшой эталонный экстрактор на Python, который вы пишете один раз для своей предметной области. Никаких вызовов Vertex AI, никаких комиссий за каждый токен, полностью воспроизводимый результат. В производственных средах этот вариант выбирают, когда важна предсказуемость затрат или строгая воспроизводимость.
Руководство по развертыванию контекстного графа является справочным материалом для обоих вариантов, включая подробную информацию об IAM и о том, как создать экстрактор ссылок.
8. Запрос трассировки принятия решения.
После заполнения графика вы можете напрямую ответить на вопрос аудита. Возьмем конкретный вопрос: «Какие варианты рассматривал агент для каждого запроса и как он его решил?» В GQL это единый обход запроса, его вариантов и результата.
Запишите запрос в файл ( traversal.sql ). Маркер ${DATASET} будет заполнен при выполнении запроса на следующем шаге:
cat > traversal.sql <<'SQL'
SELECT *
FROM GRAPH_TABLE (
${DATASET}.agent_decisions_graph
MATCH
(req:DecisionRequest) -[eo:evaluatesOption]-> (opt:DecisionOption),
(req) -[ri:resultedIn]-> (out:DecisionOutcome)
COLUMNS (
req.request_id AS request,
req.request_text AS question,
opt.option_label AS considered,
opt.confidence AS score,
out.status AS outcome,
out.rationale AS rationale
)
);
SQL
Запустите его:
envsubst < traversal.sql | bq query --use_legacy_sql=false --max_rows=20
Вы должны увидеть пятнадцать строк: по три варианта на каждый запрос, всего пять запросов. В каждой строке отображается запрос, вариант, рассмотренный агентом, его оценка достоверности, окончательный результат и обоснование.
Чтобы получить полную картину отдельного решения, отфильтруйте результаты по request_id , чтобы получить необходимый группе аудита набор строк: поступивший вопрос, рассмотренные варианты (с оценками) и обоснование принятого решения.
Визуализируйте граф в BigQuery Studio.
BigQuery Studio также может визуально отображать граф. Откройте BigQuery Studio в консоли BigQuery, выполните приведенный ниже запрос к пути, затем переключитесь на вкладку «График» в панели результатов, чтобы увидеть схему принятия решений. При использовании корпуса реалистичного масштаба это позволит вам получить визуальную карту запросов, вариантов и результатов:
GRAPH agent_analytics_demo.agent_decisions_graph
MATCH p = (a)-[e]->(b)
RETURN TO_JSON(p) AS path_json
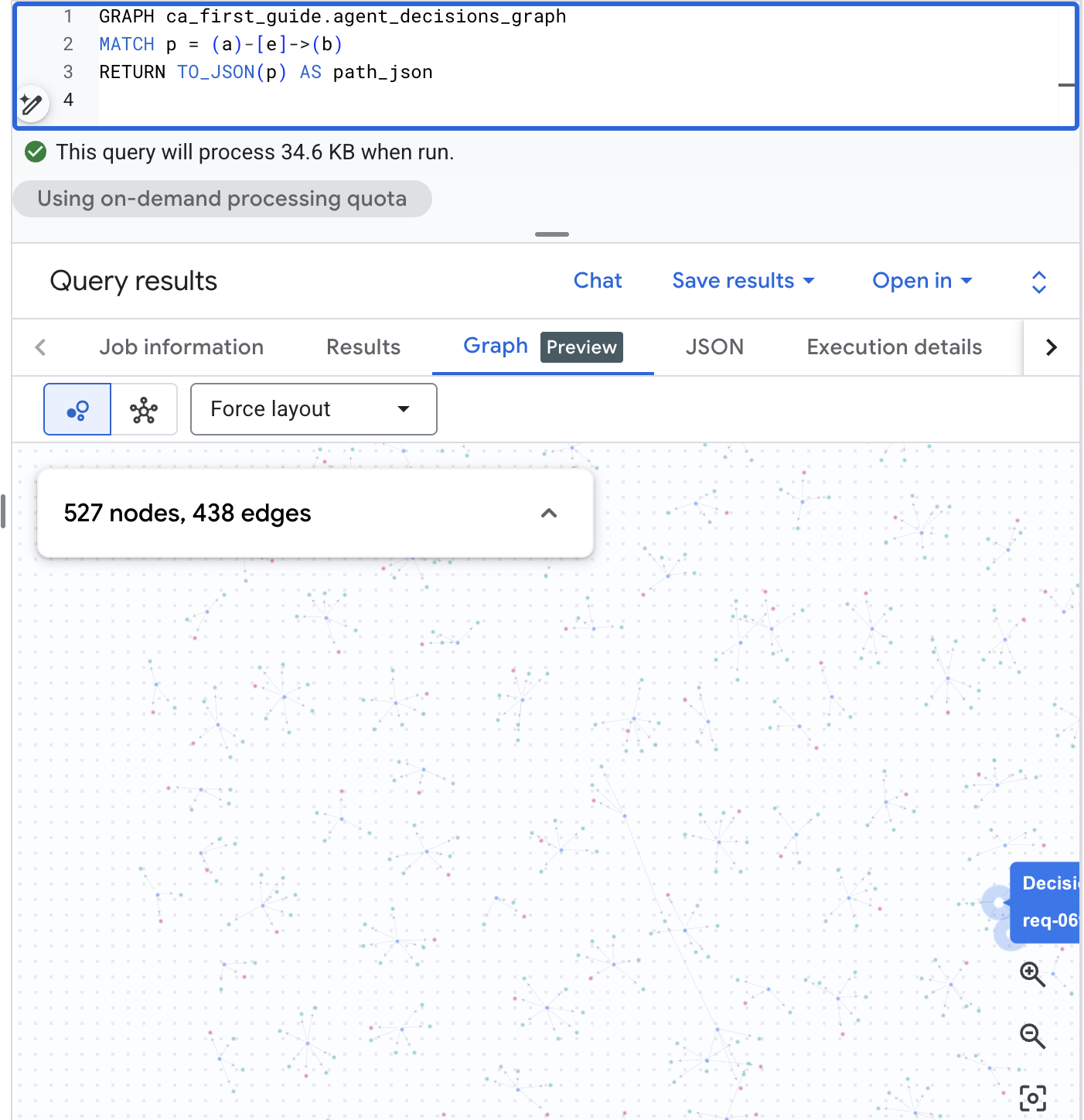
Задайте тот же вопрос простыми словами.
Не каждый, кто читает аудиторские запросы, использует GQL. С помощью BigQuery Conversational Analytics (Preview) ваша команда по соблюдению нормативных требований может задавать аналогичные вопросы на естественном языке и получать в ответ структурированную карточку ответа — без необходимости изучать синтаксис запросов и объединения таблиц.
Зарегистрируйте объект agent_decisions_graph (вместе с таблицами agent_events и decision) в качестве источника данных для анализа разговорной речи, а затем задайте вопрос аудита напрямую:
Вопрос для аудита (простым языком): «Какие запросы так и не достигли запланированного результата?»
Аналитическая служба обработки разговоров анализирует граф, пишет за вас SQL-запросы и отвечает простым языком, предоставляя подтверждающую таблицу — в данном случае, демонстрируя, что каждый записанный запрос достиг запланированного результата:
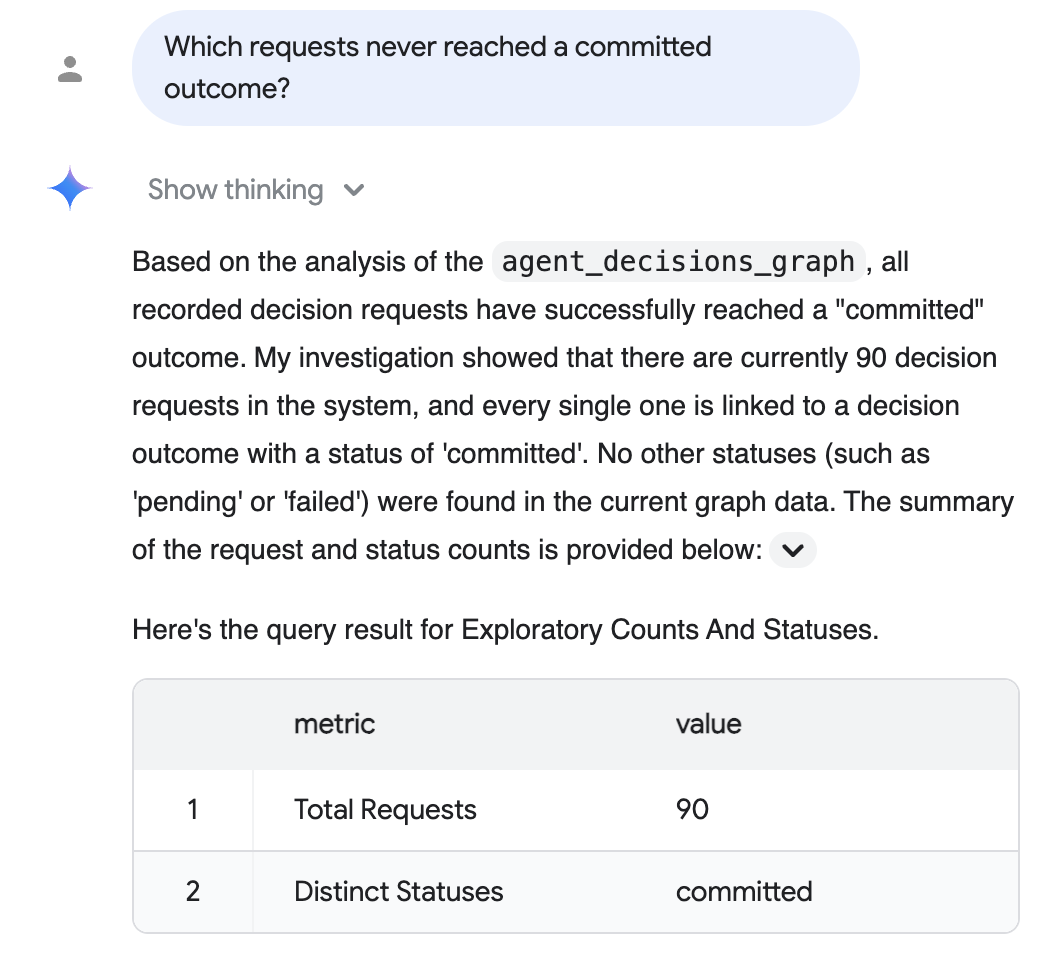
Приведенный выше ответ отражает реальный корпус данных, полученный на дополнительном этапе обработки реальных данных (90 материализованных запросов, все подтверждены); ваши точные цифры зависят от того, какой корпус вы использовали в качестве исходного, а при запуске по умолчанию с 5 сессиями отображается пять таких корпусов.
Инструкции по настройке см. в документации по анализу диалогов .
9. Довести до производства.
Приведенный выше локальный запуск использует поведение по умолчанию, которое уже охватывает основные аспекты реальных развертываний: каждый запуск оставляет след аудита (структурированное облачное логирование плюс строка для каждого запуска в таблице состояний вашего набора данных), временные сбои автоматически повторяются, а прогресс продвигается только после полностью успешно завершенных сессий, поэтому двойной подсчет исключен.
Управление производственными процессами — детерминированное извлечение ( --extraction-mode=compiled-only ), обнаружение зависших сессий ( --max-session-age-hours ), однократное воспроизведение предыдущего окна ( --backfill --from / --to , отслеживается отдельно от обычного обновления, чтобы не нарушать расписание в реальном времени) и ограничение пакетной обработки для каждого запуска ( --max-sessions ) — это флаги, которые вы можете включить по мере необходимости. В руководстве по развертыванию контекстного графа описан каждый из них с полной матрицей IAM и рекомендуемыми расписаниями.
10. Уборка
Удалите созданный вами набор данных , чтобы избежать выставления счетов за неиспользуемый набор данных:
bq rm -r -f --dataset "$PROJECT_ID:$DATASET"
Эта единственная команда удаляет набор данных, события агента, таблицы графов и таблицу состояний одновременно.
11. Поздравляем!
Поздравляем! Вы преобразовали необработанные журналы событий агента в доступный для запросов граф контекста агента и отследили принятие единого решения от начала до конца, без использования внешней базы данных графов или конвейера ETL.
Та же схема применима везде, где агент принимает важные решения: оценка кредитоспособности, предварительное согласование, распределение маркетингового бюджета, закупки, обслуживание клиентов и внутренние ИТ-решения. Чтобы создать собственный граф контекста агента, скопируйте артефакты из Codelab в качестве отправной точки, адаптируйте два декларативных файла (DDL таблицы + схема CREATE PROPERTY GRAPH ) к вашей предметной области и примените их к BigQuery — bqaa context-graph --graph считывает развернутый граф из INFORMATION_SCHEMA и вычисляет остальную часть.
Что вы узнали
- Как создать набор данных BigQuery и применить схему графа свойств, описывающую область принятия решений агентом.
- Как заполнить поле
agent_eventsсинтетическим корпусом событий. - Как запустить
bqaa context-graphдля извлечения трассировок решений агента в граф контекста агента из этих событий, считывая определение графа изINFORMATION_SCHEMA. - Как выполнить запрос к полученному графу в GQL и прочитать ответ в формате аудита.
Справочная документация
- Репозиторий SDK BigQuery Agent Analytics
- Артефакты Codelab и руководство по адаптации
- Руководство по развертыванию контекстного графа : необходимые API, матрица IAM, рекомендуемые расписания, запросы оповещений Cloud Monitoring и модуль Terraform.
- Документация BigQuery Graph (предварительная версия).
- Документация BigQuery по разговорной аналитике (предварительная версия).