
1. 简介
BigQuery Graph、BigQuery 对话式分析和 BigQuery Agent Analytics SDK 目前在 Google Cloud 上处于预览状态。BigQuery Agent Analytics 插件现已正式发布 (GA)。此 Codelab 中的示例使用合成数据。
随着自主 AI 智能体承担更多运营责任(评估贷款申请、管理营销预算、批准访问请求),组织必须能够审核并解释其决策。重构智能体决策的确切背景、考虑的替代方案和最终理由对于合规性、风险管理和运营信任至关重要。
此 Codelab 使用 BigQuery Agent Analytics SDK 将原始智能体事件日志转换为 Agent Context Graph(BigQuery Graph 中可查询的智能体决策图),并按计划执行此转换,而无需任何外部图数据库或 ETL 流水线。
关键词
- 智能体决策轨迹 - 从智能体自身运行中提取的决策级证据:智能体权衡的选项、触及的数据以及最终确定的结果。
- 代理上下文图 - BigQuery Graph 中可查询的类型化图,这些轨迹会具体化到该图中。它是行业情境图概念(智能体生成和使用的持久性、时间关联的决策情境层)的代理范围实例;“代理”限定符将其范围限定为您自己的代理运行,而不是企业范围的情境层。
在此 Codelab 中,bqaa context-graph 会从您的 agent_events 中提取代理的决策轨迹,并将其具体化为可使用 GQL 查询的代理上下文图,这符合行业模式,即根据决策轨迹构建上下文图。
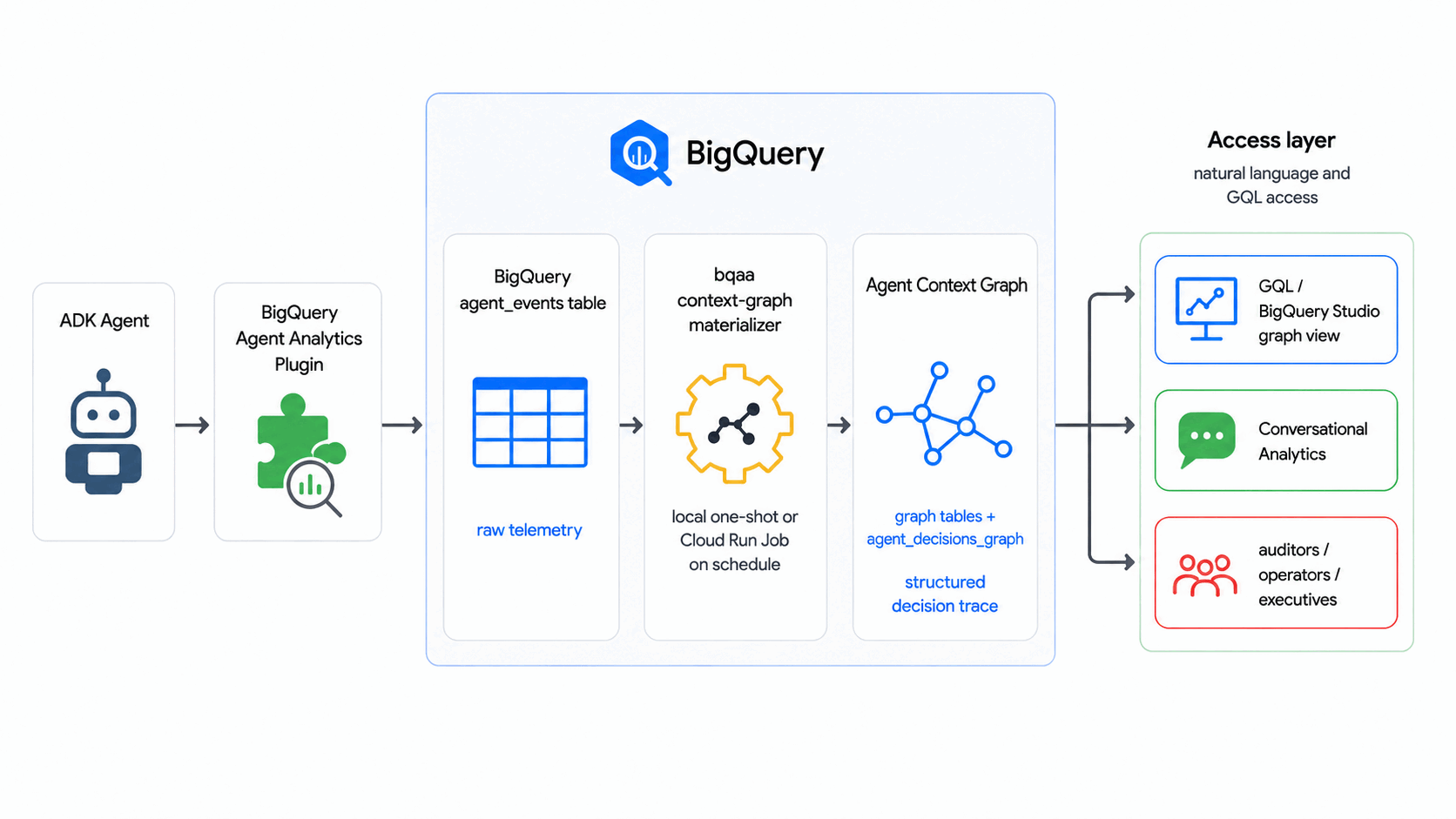
构建内容
- 一个代理上下文图(使用 BigQuery Graph),用于对通用代理决策流程进行建模:收到请求后,代理会权衡各种选项,然后确定结果。
- 包含合成事件语料库的已填充
agent_events表。 - 一个有效的
bqaa context-graph运行,用于填充基于这些事件的图表。 - 一种审核风格的 GQL 查询,可用于端到端地跟踪单个决策。
学习内容
- BigQuery Agent Analytics 插件如何写入
agent_events。 - 如何仅通过两个声明性制品(表 DDL 和
CREATE PROPERTY GRAPH架构)来定义上下文图。 - 如何针对 BigQuery 图运行
bqaa context-graph。 - 如何使用 GQL 查询图。
- SDK 支持的企业部署生产级功能。
所需条件
- 启用了结算功能的 Google Cloud 项目。
- 相应项目的 Owner 或 Editor 角色。您将创建一个 BigQuery 数据集并授予 IAM。
- 已安装并经过身份验证的
gcloudCLI,或对 Cloud Shell 的访问权限。 - Python 3.10 或更高版本。
- 熟悉 BigQuery SQL。无需具备 GQL 知识。
本 Codelab 适用于各种水平的开发者,包括刚开始使用 BigQuery Graph 的开发者。
在此 Codelab 中创建的资源费用非常低,并且最后一步会拆除所有内容,因此您不会因闲置数据集而被收取费用。
预计时长:完成此 Codelab 大约需要 35 分钟。
2. 准备工作
选择项目和区域
打开 Cloud Shell 或本地终端:
export PROJECT_ID="your-project-id"
export REGION="us-central1"
export DATASET="agent_analytics_demo"
gcloud config set project "$PROJECT_ID"
单个 DATASET 变量同时包含原始 agent_events 表和具体化图表。使用一个数据集可简化 Codelab。生产部署通常会将事件和图表拆分为单独的数据集,以便按数据集授予 IAM。
启用所需的 API
运行以下命令,以启用此 Codelab 使用的 API:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com \
--project="$PROJECT_ID"
由于 SDK 的默认提取路径会调用 BigQuery 的 AI.GENERATE 函数,因此需要 aiplatform.googleapis.com API。如果您稍后改用 --extraction-mode=compiled-only 进行确定性提取,则不再需要此 API。
创建 BigQuery 数据集
创建数据集,用于存放原始 agent_events 表和具体化图表:
bq --location=US mk --dataset "$PROJECT_ID:$DATASET"
您应该会看到一条成功消息:
Dataset 'your-project-id:agent_analytics_demo' successfully created.
如果数据集已存在,该命令会无害地出错。保持原样。
3. 安装 SDK
设置 Python 虚拟环境并从 PyPI 安装 SDK:
python3 -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install bigquery-agent-analytics
bigquery-agent-analytics 软件包会拉取 BigQuery 客户端库,因此这是整个 Codelab 中唯一需要安装的软件包。
验证安装:
bqaa context-graph --help | head -8
您应该会看到 CLI 横幅。
身份验证
如果您使用的是工作站:
gcloud auth login
gcloud auth application-default login
Cloud Shell 用户可以跳过此步骤,因为凭据已配置完毕。
4. 获取 Codelab 制品
此 Codelab 仅需两个可直接使用的制品:表 DDL(物理图表)和属性图表架构 (CREATE PROPERTY GRAPH)。您无需自行创建这两个制品;此 Codelab 将按原样使用它们,并且制品文件夹中的 README 会说明如何根据您自己的决策领域调整它们。
属性图表架构是图表包含哪些内容的唯一可信来源。您只需将该许可应用于 BigQuery 一次;此后,部署的图本身就是合同。在具体化时,bqaa context-graph 会从 BigQuery 的 INFORMATION_SCHEMA.PROPERTY_GRAPHS 中读取图的定义(以及它引用的表的架构),以确定要提取哪些实体和关系以及将它们写入何处,因此永远不会将 SQL 文件传递给具体化程序。
此 Codelab 是独立的,因此无需下载任何内容。以下命令会将上下文图 DDL 写入工作目录。其内容与 examples/context_graph/codelab/ 中随附的制品完全相同。
创建工作目录:
mkdir -p ~/context-graph-codelab
cd ~/context-graph-codelab
编写上下文图 DDL (context_graph_ddl.sql)。在下一步中应用文件时,系统会填充 ${PROJECT_ID} / ${DATASET} 标记。
cat > context_graph_ddl.sql <<'SQL'
-- Node and edge table DDL for the context-graph codelab.
--
-- `bqaa context-graph` writes into these tables on every run.
-- `session_id` and `extracted_at` are SDK metadata columns that
-- `bqaa context-graph` fills automatically; they are required on
-- every table behind the graph.
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_request` (
request_id STRING, request_text STRING, requested_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_option` (
option_id STRING, option_label STRING, confidence FLOAT64,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_outcome` (
outcome_id STRING, status STRING, rationale STRING, decided_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.evaluates_option` (
request_id STRING, option_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.resulted_in` (
request_id STRING, outcome_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
-- Graph DDL for the context-graph codelab.
--
-- Models a generic agent decision flow:
-- DecisionRequest -> evaluatesOption -> DecisionOption
-- DecisionRequest -> resultedIn -> DecisionOutcome
CREATE OR REPLACE PROPERTY GRAPH `${PROJECT_ID}.${DATASET}.agent_decisions_graph`
NODE TABLES (
`${PROJECT_ID}.${DATASET}.decision_request` AS decision_request
KEY (request_id)
LABEL DecisionRequest PROPERTIES (request_id, request_text, requested_at),
`${PROJECT_ID}.${DATASET}.decision_option` AS decision_option
KEY (option_id)
LABEL DecisionOption PROPERTIES (option_id, option_label, confidence),
`${PROJECT_ID}.${DATASET}.decision_outcome` AS decision_outcome
KEY (outcome_id)
LABEL DecisionOutcome PROPERTIES (outcome_id, status, rationale, decided_at)
)
EDGE TABLES (
`${PROJECT_ID}.${DATASET}.evaluates_option` AS evaluates_option
KEY (request_id, option_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (option_id) REFERENCES decision_option (option_id)
LABEL evaluatesOption,
`${PROJECT_ID}.${DATASET}.resulted_in` AS resulted_in
KEY (request_id, outcome_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (outcome_id) REFERENCES decision_outcome (outcome_id)
LABEL resultedIn
);
SQL
确认文件已就位:
ls
您应该会看到一个文件:
context_graph_ddl.sql
他们描述的决策流程包含三种节点类型和两条异构边:
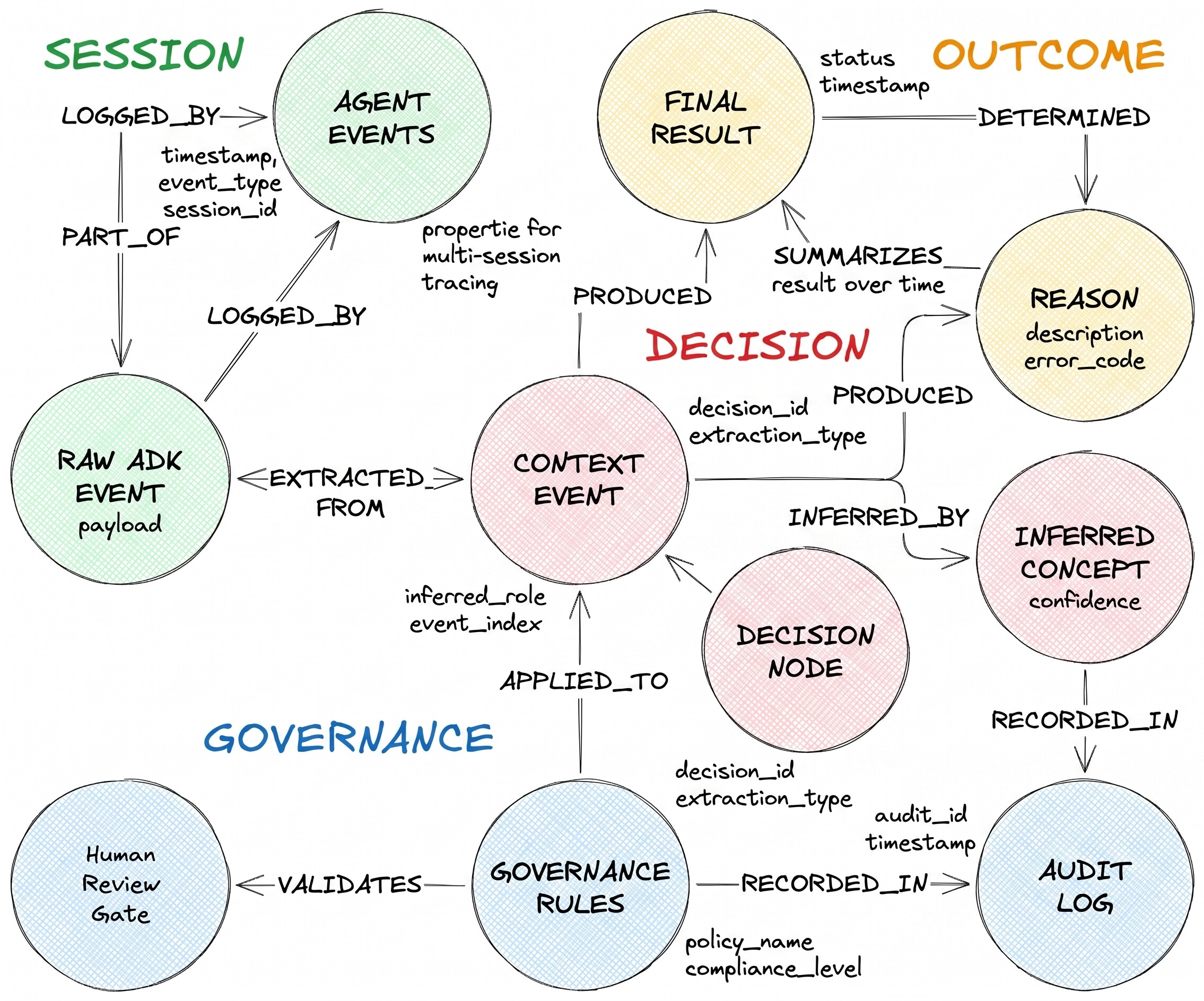
DecisionRequest 是智能体收到的问题。DecisionOption 是代理考虑的一种替代方案。DecisionOutcome 记录已确定的选择和理由。
5. 应用属性图表架构
bqaa context-graph 会写入 BigQuery 表,因此这些表必须在首次运行之前存在。context_graph_ddl.sql 先创建五个表,然后创建引用这些表的属性图(BigQuery 会拒绝指向尚不存在的表的 CREATE PROPERTY GRAPH),因此单个 apply 会设置所有内容:
envsubst < context_graph_ddl.sql | bq query --use_legacy_sql=false
您应该会看到 5 个 CREATE TABLE 结果和 1 个 CREATE PROPERTY GRAPH 结果。DDL 是幂等的,您可以安全地重新运行它。
这是您唯一需要完成的架构工作,也是唯一需要使用这些 SQL 文件的时候。BigQuery 现在会记录图的定义,并按名称从 INFORMATION_SCHEMA.PROPERTY_GRAPHS 中读取该定义。bqaa context-graph没有单独的文件可传递给实体化器,并且您使用 GQL 查询的内容与实体化的内容永远不会分离:它们是相同的已部署图。
6. 生成示例代理事件
在生产环境中,BigQuery Agent Analytics 插件会在 ADK 智能体运行时自动捕获事件。此代码段仅供参考,您在此 Codelab 中不会运行它:
from google.adk.plugins import BigQueryAgentAnalyticsPlugin
plugin = BigQueryAgentAnalyticsPlugin(
project_id="your-project-id",
dataset_id="agent_analytics_demo",
)
runner = Runner(agent=root_agent, plugins=[plugin])
在此 Codelab 中,您将使用一个小型合成事件生成器,该生成器会将相同形状的行直接写入 agent_events。运行该文件:
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--sessions 5
该命令会输出 JSON 报告。对于 5 个会话,您应该会看到 "events_generated": 30、"events_inserted": 30 和 "ok": true。
在一行中快速预览语料库,包括会话数、事件数以及它们的时间范围:
bq query --use_legacy_sql=false \
"SELECT COUNT(DISTINCT session_id) AS sessions, COUNT(*) AS events, MIN(timestamp) AS earliest_event, MAX(timestamp) AS latest_event FROM \`$PROJECT_ID.$DATASET.agent_events\`"
对于默认的 5 次会话运行,此图表会显示 5 次会话和 30 个事件,这些事件分布在几分钟内。(以下是实际场景的种子,同一查询报告了大约 3 天内的大约 100 次会话。)
验证事件是否已到达:
bq query --use_legacy_sql=false \
"SELECT event_type, COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY event_type ORDER BY n DESC"
您应该会看到 25 个 TOOL_COMPLETED 行和 5 个 AGENT_COMPLETED 行(每个会话会发出一个 submit_request、三个 evaluate_option、一个 commit_outcome 和一个关闭 AGENT_COMPLETED - 每个会话有 5 个工具事件和一个代理终止符)。AGENT_COMPLETED 行是会话终止符,用于检测终端事件的 bqaa context-graph 键。
可选:真实规模的数据
上述 5 个会话的语料库有意设置得很小,以便首次运行快速且经济实惠。如果您需要生成类似实际环境的数据(即多个代理和用户分布在几天内,包含失败、孤立和截断的会话),请使用 decision-realistic 方案。默认值为 72 小时内 100 个会话;上述首次运行路径保持不变。
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--scenario decision-realistic \
--sessions 100 \
--seed 42
JSON 报告的 session_outcome_counts 显示了混合比例,约为 {"success": 70, "failed": 10, "orphaned": 10, "truncated": 10}。
通过对每个会话的行进行分类来确认结果分布(孤立 = 无 AGENT_COMPLETED;失败 = AGENT_COMPLETED 且有 status = 'error';截断 = 任何行有 is_truncated = true;否则为成功)。第一个传递会分类每个会话,然后第二个传递会按结果进行汇总:
bq query --use_legacy_sql=false \
"WITH per_session AS (SELECT session_id, CASE WHEN COUNTIF(event_type = 'AGENT_COMPLETED') = 0 THEN 'orphaned' WHEN COUNTIF(event_type = 'AGENT_COMPLETED' AND status = 'error') > 0 THEN 'failed' WHEN COUNTIF(is_truncated) > 0 THEN 'truncated' ELSE 'success' END AS outcome FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY session_id) SELECT outcome, COUNT(*) AS sessions FROM per_session GROUP BY outcome ORDER BY outcome"
您应该会看到大约 70 个成功会话、10 个失败会话、10 个孤立会话和 10 个截断会话(如果您之前在同一数据集中播种了第一个运行语料库,则还会有 5 个成功会话)。
这 10 个孤立会话从未发出 AGENT_COMPLETED,因此默认的 bqaa context-graph 运行会跳过它们(它仅具体化以终端事件关闭的会话)。如需将它们显示为 session_orphaned,而不是永远静默重试,请在高效运转时添加 --max-session-age-hours - 请参阅投入生产中的 --max-session-age-hours。
7. 实现上下文图
bqaa context-graph 读取原始 agent_events,然后直接从已部署的图表中推导出要提取的内容:它从 BigQuery 的 INFORMATION_SCHEMA.PROPERTY_GRAPHS 中读取您在应用属性图架构中应用的 CREATE PROPERTY GRAPH 定义,将其与所引用表的架构联接,确定实体、关系和列类型,并填充图表。您可以使用 --graph agent_decisions_graph 按名称指向已部署的图表,无需传递 SQL 文件。
运行
bqaa context-graph 本地:
bqaa context-graph \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--graph agent_decisions_graph \
--lookback-hours 24 \
--format json
您应该会看到结构化的 JSON 报告:
{
"run_id": "...",
"sessions_discovered": 5,
"sessions_materialized": 5,
"sessions_failed": 0,
"rows_materialized": {
"DecisionRequest": 5,
"DecisionOption": 15,
"DecisionOutcome": 5
},
"ok": true
}
ok: true 表示 bqaa context-graph 找到了 5 个已完成的会话,通过 AI.GENERATE 从每个会话中提取了决策流,并将相应的行写入了图表表格。确定性提取(--extraction-mode=compiled-only,下文会介绍)会返回相同的报告形状(相同的字段、相同的 ok: true),只是会跳过 AI.GENERATE 调用。
问题排查:提取结果为空
如果您看到 ok: false 和 error_code = "empty_extraction",最常见的原因是 aiplatform.googleapis.com API 尚未传播,或者您的账号缺少 roles/aiplatform.user。请稍等片刻,然后重试,或授予相应角色:
USER_EMAIL=$(gcloud auth list --filter=status:ACTIVE --format="value(account)")
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="user:$USER_EMAIL" --role="roles/aiplatform.user"
然后,重新运行上述 bqaa context-graph 命令。
验证图表是否包含行:
bq query --use_legacy_sql=false \
"SELECT COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.decision_request\`"
您应该会看到五行。在 5 个会话中,总共有 25 个图谱节点,即 5 个 DecisionRequest、15 个 DecisionOption 和 5 个 DecisionOutcome,由 15 条 evaluatesOption 边和 5 条 resultedIn 边连接而成(每个会话一个决策网络)。
从事件中提取决策的两种方式
bqaa context-graph 提供两种提取路径。选择与您的工作负载相符的选项:
- 默认提取。最简单的路径。使用 BigQuery 的
AI.GENERATE读取事件内容并推断实体和关系。适用于任何事件形状,无需额外代码。这是 Codelab 使用的。 - 确定性提取 (
--extraction-mode=compiled-only)。成本较低且便于审核。使用您为网域编写的一次性小型 Python 参考提取器。无需调用 Vertex AI,无需按令牌收费,输出完全可重现。如果需要可预测的费用或严格的可重现性,生产部署应选择此选项。
上下文图部署指南是这两个路径的参考文档,其中包含 IAM 详细信息以及如何编写参考提取器。
8. 查询决策轨迹
填充图表后,您可以直接回答审核问题。举个具体的例子:“对于每个请求,智能体权衡了哪些选项,以及如何解决?”在 GQL 中,这是对请求、其选项及其结果的单次遍历。
将查询写入文件 (traversal.sql)。在下一步中运行查询时,系统会填充 ${DATASET} 标记:
cat > traversal.sql <<'SQL'
SELECT *
FROM GRAPH_TABLE (
${DATASET}.agent_decisions_graph
MATCH
(req:DecisionRequest) -[eo:evaluatesOption]-> (opt:DecisionOption),
(req) -[ri:resultedIn]-> (out:DecisionOutcome)
COLUMNS (
req.request_id AS request,
req.request_text AS question,
opt.option_label AS considered,
opt.confidence AS score,
out.status AS outcome,
out.rationale AS rationale
)
);
SQL
高效运转:
envsubst < traversal.sql | bq query --use_legacy_sql=false --max_rows=20
您应该会看到 15 行:每个请求有 3 个选项,总共有 5 个请求。每行都显示了请求、代理考虑的选项、置信度得分、最终结果和理由。
如需全面了解单个决策,请按 request_id 进行过滤,以获取审核团队所需的行集:收到的问题、权衡的选项(附带得分)以及已提交的理由。
在 BigQuery Studio 中直观呈现图表
BigQuery Studio 还可以直观地呈现图。在 BigQuery 控制台中打开 BigQuery Studio,运行下方的路径查询,然后将结果窗格切换到图表标签页,以查看决策网络。借助这种真实规模的语料库,您可以直观地了解请求、选项和结果:
GRAPH agent_analytics_demo.agent_decisions_graph
MATCH p = (a)-[e]->(b)
RETURN TO_JSON(p) AS path_json
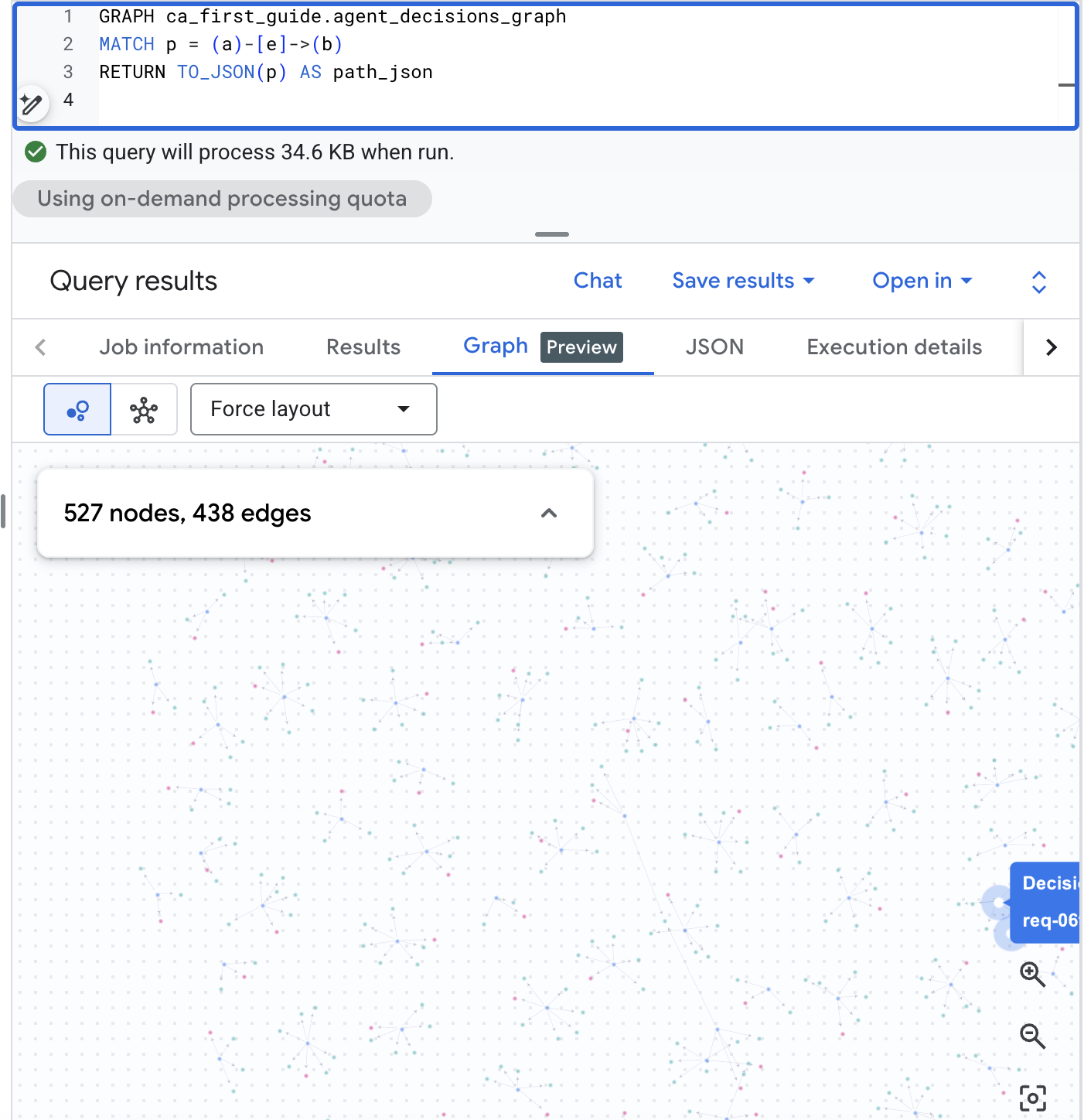
用简单直白的英语提出相同的问题
并非所有审核读者都会编写 GQL。借助 BigQuery 对话式分析(预览版),合规性团队可以采用自然语言提出同样的问题,并获得结构化的回答卡片,而无需学习查询语法或联接。
将 agent_decisions_graph(以及 agent_events 和决策表)注册为对话式分析数据源,然后直接提出审核问题:
审核问题(纯英语): “哪些请求从未达到已提交的结果?”
对话式分析功能会对图表进行推理,为您编写 SQL,并以纯英语回复,同时附上支持表格 - 在此示例中,该表格显示了每项记录的请求都达到了已提交的结果:
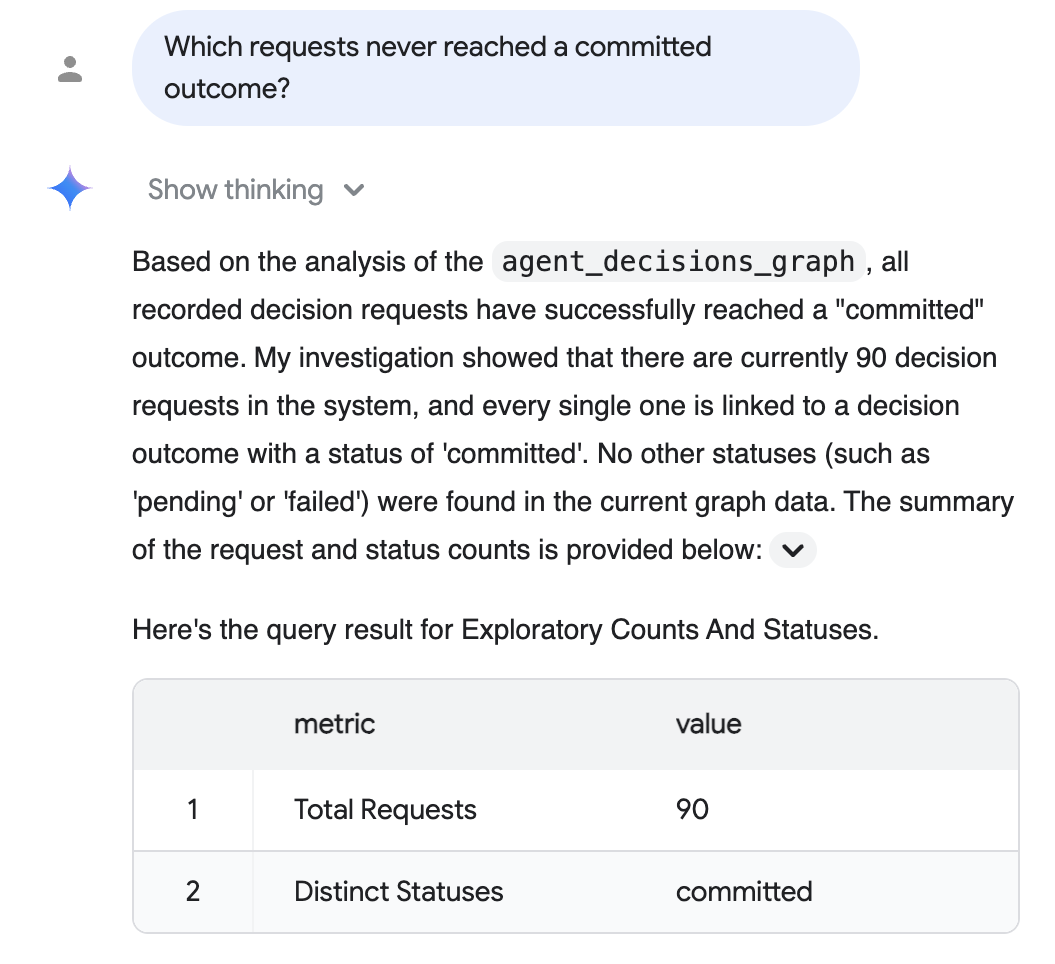
上述回答反映了可选的真实规模数据步骤中的真实规模语料库(90 个已实现请求,全部已提交);您的确切数字取决于您播种的语料库,默认的 5 会话运行显示 5 个。
如需了解设置,请参阅对话分析文档。
9. 投入生产环境
上述本地运行使用默认行为,该行为已涵盖实际部署的基础知识:每次运行都会留下审核轨迹(结构化 Cloud Logging 以及数据集中的状态表中的每运行一行)、暂时性故障会自动重试,并且只有在会话完全成功后才会推进进度,因此不会出现重复统计。
生产控制(确定性提取 [--extraction-mode=compiled-only]、卡顿会话检测 [--max-session-age-hours]、过去窗口的一次性重放 [--backfill --from / --to,与常规刷新分开跟踪,因此不会干扰直播时间表] 和每次运行的批次边界 [--max-sessions])是您在需要时选择启用的标志。上下文图部署指南记录了每个部署,其中包含完整的 IAM 矩阵和建议的时间表。
10. 清理
拆除您创建的内容,以免因闲置数据集而产生费用:
bq rm -r -f --dataset "$PROJECT_ID:$DATASET"
该单个命令会同时移除数据集、代理事件、图表表和状态表。
11. 恭喜
恭喜!您已将原始代理事件日志转换为可查询的代理上下文图,并端到端地跟踪单个决策,而无需外部图数据库或 ETL 流水线。
无论在何处,只要代理做出重大决策,都适用相同的模式:信用承保、预先授权、营销预算调整、采购、客户服务和内部 IT。如需构建您自己的代理上下文图,请复制 Codelab 制品作为起点,根据您的网域调整两个声明性文件(表 DDL + CREATE PROPERTY GRAPH 架构),然后将它们应用于 BigQuery - bqaa context-graph --graph 会从 INFORMATION_SCHEMA 读取已部署的图并推导其余部分。
您学到的内容
- 如何创建 BigQuery 数据集并应用描述代理决策领域的属性图架构。
- 如何使用合成事件语料库填充
agent_events。 - 如何运行
bqaa context-graph以从这些事件中提取智能体的决策轨迹到智能体上下文图,并从INFORMATION_SCHEMA中读回图定义。 - 如何在 GQL 中查询生成的图,以及如何读取审核风格的答案。
参考文档
- BigQuery Agent Analytics SDK 代码库
- Codelab 制品和改编指南
- 上下文图部署指南:必需的 API、IAM 矩阵、建议的时间表、Cloud Monitoring 提醒查询和 Terraform 模块。
- BigQuery 图文档(预览版)。
- BigQuery 对话式分析文档(预览版)。