
1. 簡介
BigQuery Graph、BigQuery 對話式數據分析和 BigQuery Agent Analytics SDK 目前在 Google Cloud 處於預先發布版。BigQuery Agent Analytics 外掛程式已正式發布。本程式碼研究室中的範例使用合成資料。
隨著自主 AI 代理承擔更多營運責任 (評估貸款申請、管理行銷預算、核准存取要求),機構必須能夠稽核及說明其決策。重建代理程式決策的確切脈絡、考慮的替代方案和最終理由,對於法規遵循、風險管理和作業信任至關重要。
本程式碼研究室會使用 BigQuery Agent Analytics SDK,將原始代理程式事件記錄轉換為「代理程式環境圖」,也就是 BigQuery 代理程式決策圖中的可查詢圖表,並排定時間執行這項作業,不必使用任何外部圖表資料庫或 ETL 管道。
重要詞彙
- 代理程式決策追蹤記錄:從代理程式的執行作業中擷取的決策層級證據,包括代理程式評估的選項、存取的資料,以及最終結果。
- 代理程式內容圖表:BigQuery 圖表中的可查詢型別圖表,這些追蹤記錄會具體化為該圖表。這是產業脈絡圖概念的代理範圍執行個體 (代理產生及使用的決策脈絡的持久時間連結層);「代理」限定符會將其範圍限定為您自己的代理執行,而非企業範圍的脈絡層。
在本程式碼研究室中,bqaa context-graph 會從 agent_events 擷取代理程式的決策追蹤記錄,並將其具體化為可使用 GQL 查詢的代理程式內容圖表,這符合業界從決策追蹤記錄建構內容圖表的模式。
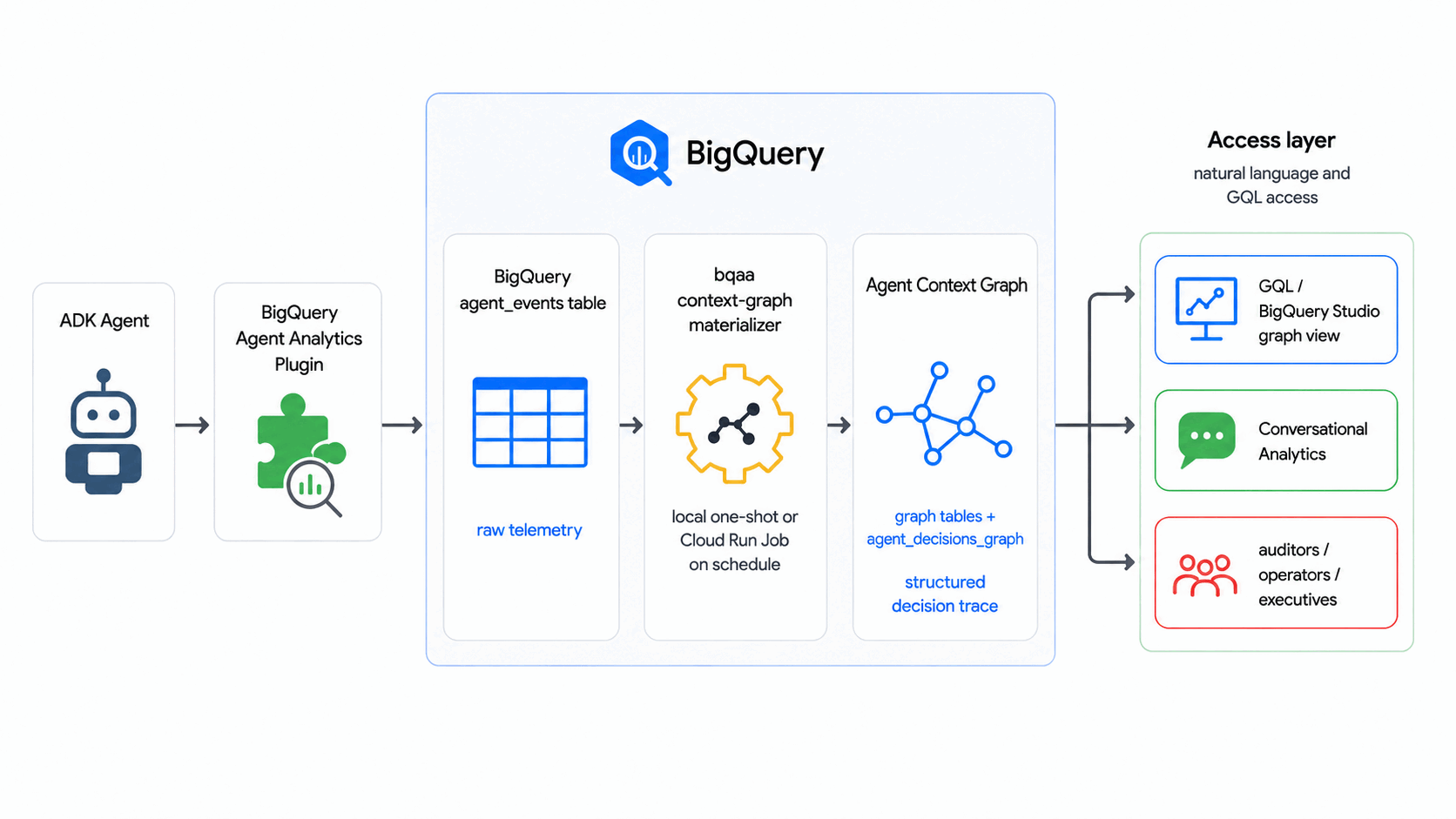
建構項目
- 代理程式內容圖 (含 BigQuery 圖),可模擬一般代理程式決策流程:收到要求、代理程式權衡選項、確定結果。
- 已填入內容的
agent_events表格,其中包含合成事件語料庫。 - 工作
bqaa context-graph執行作業,可根據這些事件填入圖表。 - 稽核樣式的 GQL 查詢,可追蹤單一決策的端對端流程。
課程內容
- BigQuery Agent Analytics 外掛程式如何寫入
agent_events。 - 如何只透過兩個宣告式構件 (資料表 DDL 和
CREATE PROPERTY GRAPH結構定義) 定義內容圖表。 - 如何對 BigQuery 圖表執行
bqaa context-graph。 - 如何使用 GQL 查詢圖形。
- SDK 支援的實際工作環境等級功能,適用於企業部署作業。
軟硬體需求
- 已啟用計費功能的 Google Cloud 專案。
- 該專案的「擁有者」或「編輯者」角色。您將建立 BigQuery 資料集並授予 IAM。
- 已安裝並驗證
gcloudCLI,或可存取 Cloud Shell。 - Python 3.10 以上版本。
- 熟悉 BigQuery SQL。不需要具備 GQL 知識。
這個程式碼研究室適合各種程度的開發人員,包括剛接觸 BigQuery Graph 的使用者。
本程式碼研究室建立的資源費用極低,最後一個步驟會拆除所有項目,因此您不會因閒置資料集而產生費用。
預計時間:完成本程式碼研究室約需 35 分鐘。
2. 事前準備
選擇專案和區域
開啟 Cloud Shell 或本機終端機:
export PROJECT_ID="your-project-id"
export REGION="us-central1"
export DATASET="agent_analytics_demo"
gcloud config set project "$PROJECT_ID"
單一 DATASET 變數會同時保留原始 agent_events 資料表和具體化的圖形資料表。使用單一資料集可簡化程式碼研究室。實際工作環境部署作業通常會將事件和圖表分割成不同的資料集,以便針對每個資料集授予 IAM。
啟用必用的 API。
執行下列指令,啟用本程式碼研究室使用的 API:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com \
--project="$PROJECT_ID"
由於 SDK 的預設擷取路徑會呼叫 BigQuery 的 AI.GENERATE 函式,因此需要 aiplatform.googleapis.com API。如果您之後改用 --extraction-mode=compiled-only 進行確定性擷取,就不再需要這個 API。
建立 BigQuery 資料集
建立資料集,用來存放原始 agent_events 資料表和具體化圖表資料表:
bq --location=US mk --dataset "$PROJECT_ID:$DATASET"
畫面上應會顯示成功訊息:
Dataset 'your-project-id:agent_analytics_demo' successfully created.
如果資料集已存在,指令會無害地發生錯誤。請勿移動。
3. 安裝 SDK
設定 Python 虛擬環境,並從 PyPI 安裝 SDK:
python3 -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install bigquery-agent-analytics
bigquery-agent-analytics 套件會提取 BigQuery 用戶端程式庫,因此您只需要安裝這個套件,即可完成整個程式碼研究室。
驗證安裝狀態:
bqaa context-graph --help | head -8
畫面上應會顯示 CLI 橫幅。
驗證
如果使用工作站:
gcloud auth login
gcloud auth application-default login
Cloud Shell 使用者可以略過這個步驟,因為系統已設定憑證。
4. 取得程式碼研究室構件
本程式碼研究室只需要兩個現成可用的構件:資料表 DDL (實體圖表資料表) 和屬性圖表結構定義 (CREATE PROPERTY GRAPH)。您不需要自行編寫,程式碼研究室會直接使用這些構件,而構件資料夾中的 README 則說明如何根據自己的決策網域調整這些構件。
屬性圖表結構定義是圖表內容的單一可靠資料來源。您只需將其套用至 BigQuery 一次,之後部署的圖表本身就是合約。實體化時,bqaa context-graph 會從 BigQuery 的 INFORMATION_SCHEMA.PROPERTY_GRAPHS 讀回圖表的定義 (以及所參照資料表的結構定義),藉此判斷要擷取哪些實體和關係,以及要將這些實體和關係寫入何處,因此系統絕不會將 SQL 檔案傳遞至實體化工具。
本程式碼研究室內容完整,因此不必下載任何項目。下列指令會將內容圖 DDL 寫入工作目錄。內容與 examples/context_graph/codelab/ 中出貨的構件相同。
建立工作目錄:
mkdir -p ~/context-graph-codelab
cd ~/context-graph-codelab
撰寫內容圖表 DDL (context_graph_ddl.sql)。在下一個步驟中套用檔案時,系統會填入 ${PROJECT_ID} / ${DATASET} 標記。
cat > context_graph_ddl.sql <<'SQL'
-- Node and edge table DDL for the context-graph codelab.
--
-- `bqaa context-graph` writes into these tables on every run.
-- `session_id` and `extracted_at` are SDK metadata columns that
-- `bqaa context-graph` fills automatically; they are required on
-- every table behind the graph.
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_request` (
request_id STRING, request_text STRING, requested_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_option` (
option_id STRING, option_label STRING, confidence FLOAT64,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.decision_outcome` (
outcome_id STRING, status STRING, rationale STRING, decided_at TIMESTAMP,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.evaluates_option` (
request_id STRING, option_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
CREATE TABLE IF NOT EXISTS `${PROJECT_ID}.${DATASET}.resulted_in` (
request_id STRING, outcome_id STRING,
session_id STRING, extracted_at TIMESTAMP
);
-- Graph DDL for the context-graph codelab.
--
-- Models a generic agent decision flow:
-- DecisionRequest -> evaluatesOption -> DecisionOption
-- DecisionRequest -> resultedIn -> DecisionOutcome
CREATE OR REPLACE PROPERTY GRAPH `${PROJECT_ID}.${DATASET}.agent_decisions_graph`
NODE TABLES (
`${PROJECT_ID}.${DATASET}.decision_request` AS decision_request
KEY (request_id)
LABEL DecisionRequest PROPERTIES (request_id, request_text, requested_at),
`${PROJECT_ID}.${DATASET}.decision_option` AS decision_option
KEY (option_id)
LABEL DecisionOption PROPERTIES (option_id, option_label, confidence),
`${PROJECT_ID}.${DATASET}.decision_outcome` AS decision_outcome
KEY (outcome_id)
LABEL DecisionOutcome PROPERTIES (outcome_id, status, rationale, decided_at)
)
EDGE TABLES (
`${PROJECT_ID}.${DATASET}.evaluates_option` AS evaluates_option
KEY (request_id, option_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (option_id) REFERENCES decision_option (option_id)
LABEL evaluatesOption,
`${PROJECT_ID}.${DATASET}.resulted_in` AS resulted_in
KEY (request_id, outcome_id)
SOURCE KEY (request_id) REFERENCES decision_request (request_id)
DESTINATION KEY (outcome_id) REFERENCES decision_outcome (outcome_id)
LABEL resultedIn
);
SQL
確認檔案位置:
ls
您應該會看到一個檔案:
context_graph_ddl.sql
他們描述的決策流程有三種節點類型和兩個異質邊緣:
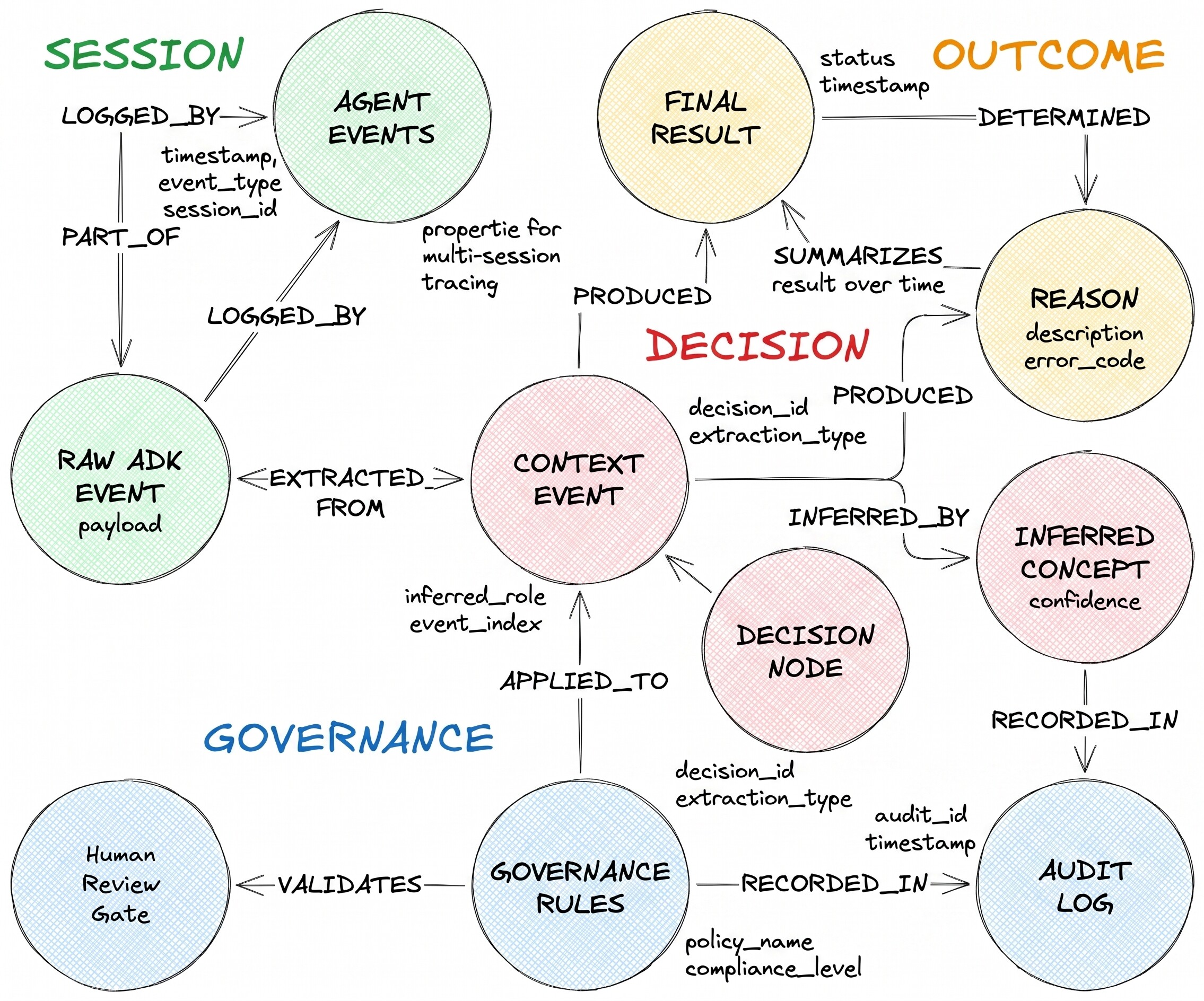
DecisionRequest 是代理程式收到的問題。DecisionOption 是代理人考慮的替代方案之一。DecisionOutcome 會記錄已確定的選擇和理由。
5. 套用屬性圖結構定義
bqaa context-graph 會寫入 BigQuery 資料表,因此必須在第一次執行前存在。context_graph_ddl.sql 會先建立五個資料表,然後建立參照這些資料表的屬性圖 (BigQuery 會拒絕指向尚不存在資料表的 CREATE PROPERTY GRAPH),因此單一套用會設定所有項目:
envsubst < context_graph_ddl.sql | bq query --use_legacy_sql=false
您應該會看到五個 CREATE TABLE 結果和一個 CREATE PROPERTY GRAPH 結果。DDL 具有冪等性,因此可以安全地重新執行。
這就是您唯一需要進行的結構定義作業,也是唯一會使用這些 SQL 檔案的時機。BigQuery 現在會記錄圖表的定義,而 bqaa context-graph 會依名稱從 INFORMATION_SCHEMA.PROPERTY_GRAPHS 讀取定義。沒有要傳遞給具體化工具的個別檔案,而且您使用 GQL 查詢的內容與具體化的內容絕不會不同,因為兩者是相同的已部署圖形。
6. 產生範例代理程式事件
在正式環境中,BigQuery Agent Analytics 外掛程式會在 ADK 代理執行時自動擷取事件。這個程式碼片段僅供參考,您不會在本程式碼研究室中運作執行:
from google.adk.plugins import BigQueryAgentAnalyticsPlugin
plugin = BigQueryAgentAnalyticsPlugin(
project_id="your-project-id",
dataset_id="agent_analytics_demo",
)
runner = Runner(agent=root_agent, plugins=[plugin])
在本程式碼研究室中,您會使用小型合成事件產生器,將相同形狀的資料列直接寫入 agent_events。執行:
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--sessions 5
這項指令會列印 JSON 報表。5 個工作階段應會顯示 "events_generated": 30、"events_inserted": 30 和 "ok": true。
在同一列中一覽語料庫,包括工作階段數、事件數和時間範圍:
bq query --use_legacy_sql=false \
"SELECT COUNT(DISTINCT session_id) AS sessions, COUNT(*) AS events, MIN(timestamp) AS earliest_event, MAX(timestamp) AS latest_event FROM \`$PROJECT_ID.$DATASET.agent_events\`"
如果是預設的 5 個工作階段,這會顯示 5 個工作階段和 30 個事件,時間跨度為幾分鐘。(請根據下方的實際情況提供種子,並在約三天內產生約 100 個工作階段的相同查詢報表)。
確認事件是否已登陸:
bq query --use_legacy_sql=false \
"SELECT event_type, COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY event_type ORDER BY n DESC"
您應該會看到 25 個 TOOL_COMPLETED 列和 5 個 AGENT_COMPLETED 列 (每個工作階段會發出一個 submit_request、三個 evaluate_option、一個 commit_outcome 和一個結尾 AGENT_COMPLETED,也就是每個工作階段五個工具事件加上一個代理終止符)。AGENT_COMPLETED 列是工作階段終止符,bqaa context-graph 鍵則用於偵測終止事件。
選用:實際規模的資料
上述 5 個工作階段的語料庫刻意縮小,因此第一次執行時速度快且成本低。如要取得生產環境形狀的資料 (多個代理和使用者分散在幾天內,且有失敗、孤立和截斷的工作階段),請使用 decision-realistic 案例。預設值為 72 小時內 100 個工作階段,上述首次執行路徑維持不變。
bqaa seed-events \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--scenario decision-realistic \
--sessions 100 \
--seed 42
JSON 報表的 session_outcome_counts 會顯示組合,大約是 {"success": 70, "failed": 10, "orphaned": 10, "truncated": 10}。
從資料列分類每個工作階段,確認結果分布情形 (孤立 = 無 AGENT_COMPLETED;失敗 = AGENT_COMPLETED 含有 status = 'error';截斷 = 任何含有 is_truncated = true 的資料列;否則為成功)。第一階段會分類每個工作階段,第二階段則會依結果匯總:
bq query --use_legacy_sql=false \
"WITH per_session AS (SELECT session_id, CASE WHEN COUNTIF(event_type = 'AGENT_COMPLETED') = 0 THEN 'orphaned' WHEN COUNTIF(event_type = 'AGENT_COMPLETED' AND status = 'error') > 0 THEN 'failed' WHEN COUNTIF(is_truncated) > 0 THEN 'truncated' ELSE 'success' END AS outcome FROM \`$PROJECT_ID.$DATASET.agent_events\` GROUP BY session_id) SELECT outcome, COUNT(*) AS sessions FROM per_session GROUP BY outcome ORDER BY outcome"
您應該會看到大約 70 個成功、10 個失敗、10 個孤立和 10 個截斷的項目 (如果您先前在同一個資料集中植入第一個執行階段的語料庫,還會看到 5 個成功的項目)。
這 10 個孤立工作階段從未發出 AGENT_COMPLETED,因此預設 bqaa context-graph 執行會略過這些工作階段 (只會具體化終止事件關閉的工作階段)。如要將這些錯誤顯示為 session_orphaned,而不是永遠默默重試,請在運作執行時新增 --max-session-age-hours,詳情請參閱「投入實際工作環境」一文中的 --max-session-age-hours。
7. 具體化脈絡圖
bqaa context-graph 會讀取原始 agent_events,然後直接從已部署的圖表衍生要擷取的內容:它會從 BigQuery 的 INFORMATION_SCHEMA.PROPERTY_GRAPHS 讀取您在「套用屬性圖表結構定義」中套用的 CREATE PROPERTY GRAPH 定義,並將其與所參照資料表的結構定義聯結,計算出實體、關係和資料欄類型,然後填入圖表資料表。您可以使用 --graph agent_decisions_graph 依名稱指向已部署的圖表,不必傳遞 SQL 檔案。
跑步
bqaa context-graph 本機:
bqaa context-graph \
--project-id "$PROJECT_ID" \
--dataset-id "$DATASET" \
--graph agent_decisions_graph \
--lookback-hours 24 \
--format json
您應該會看到結構化的 JSON 報告:
{
"run_id": "...",
"sessions_discovered": 5,
"sessions_materialized": 5,
"sessions_failed": 0,
"rows_materialized": {
"DecisionRequest": 5,
"DecisionOption": 15,
"DecisionOutcome": 5
},
"ok": true
}
ok: true 表示 bqaa context-graph 找到五個已完成的會話,透過 AI.GENERATE 從每個會話中擷取決策流程,並將對應的資料列寫入圖表資料表。確定性擷取 (--extraction-mode=compiled-only,下文會說明) 會傳回相同的報表形狀 (相同欄位、相同 ok: true),只是會略過 AI.GENERATE 呼叫。
疑難排解:擷取內容為空
如果看到 ok: false 和 error_code = "empty_extraction",最常見的原因是 aiplatform.googleapis.com API 尚未生效,或是帳戶缺少 roles/aiplatform.user。請稍候再試,或授予角色:
USER_EMAIL=$(gcloud auth list --filter=status:ACTIVE --format="value(account)")
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="user:$USER_EMAIL" --role="roles/aiplatform.user"
接著重新執行上述 bqaa context-graph 指令。
確認圖表有資料列:
bq query --use_legacy_sql=false \
"SELECT COUNT(*) AS n FROM \`$PROJECT_ID.$DATASET.decision_request\`"
您應該會看到五列。這五個工作階段總共是 25 個圖表節點 (5 個 DecisionRequest、15 個 DecisionOption 和 5 個 DecisionOutcome),以及 15 個 evaluatesOption 邊緣和 5 個 resultedIn 邊緣 (每個工作階段一個決策網)。
從事件中擷取決策的兩種方式
bqaa context-graph 提供兩種擷取路徑。請選擇符合工作負載需求的方案:
- 預設擷取。最簡單的途徑。使用 BigQuery 的
AI.GENERATE讀取事件內容,並推斷實體和關係。可針對任何事件形狀運作,無需額外程式碼。本程式碼研究室會使用這個版本。 - 確定性擷取 (
--extraction-mode=compiled-only)。這是成本較低且適合稽核的路徑。使用您為網域編寫的小型 Python 參照擷取器。無須呼叫 Vertex AI,不需支付權杖費用,輸出內容完全可重現。如果成本可預測性或嚴格重現性很重要,則生產環境部署作業會選擇這個選項。
脈絡圖部署指南是這兩種路徑的參考資料,包括 IAM 詳細資料和如何編寫參照擷取器。
8. 查詢決策追蹤記錄
圖表填入資料後,您就可以直接回答稽核問題。舉例來說:「針對每項要求,服務專員權衡了哪些選項,以及如何解決問題?」在 GQL 中,這是指在要求、選項和結果之間進行單一遍歷。
將查詢寫入檔案 (traversal.sql)。在下一個步驟中執行查詢時,系統會填入 ${DATASET} 標記:
cat > traversal.sql <<'SQL'
SELECT *
FROM GRAPH_TABLE (
${DATASET}.agent_decisions_graph
MATCH
(req:DecisionRequest) -[eo:evaluatesOption]-> (opt:DecisionOption),
(req) -[ri:resultedIn]-> (out:DecisionOutcome)
COLUMNS (
req.request_id AS request,
req.request_text AS question,
opt.option_label AS considered,
opt.confidence AS score,
out.status AS outcome,
out.rationale AS rationale
)
);
SQL
運作執行:
envsubst < traversal.sql | bq query --use_legacy_sql=false --max_rows=20
您應該會看到十五列:每個要求有三個選項,共五個要求。每列都會顯示要求、代理程式考慮的選項、信賴分數、最終結果和基本原理。
如要瞭解單一決策的完整情況,請依 request_id 篩選,取得稽核團隊所需的資料列集:收到的問題、權衡的選項 (附帶分數) 和提交的理由。
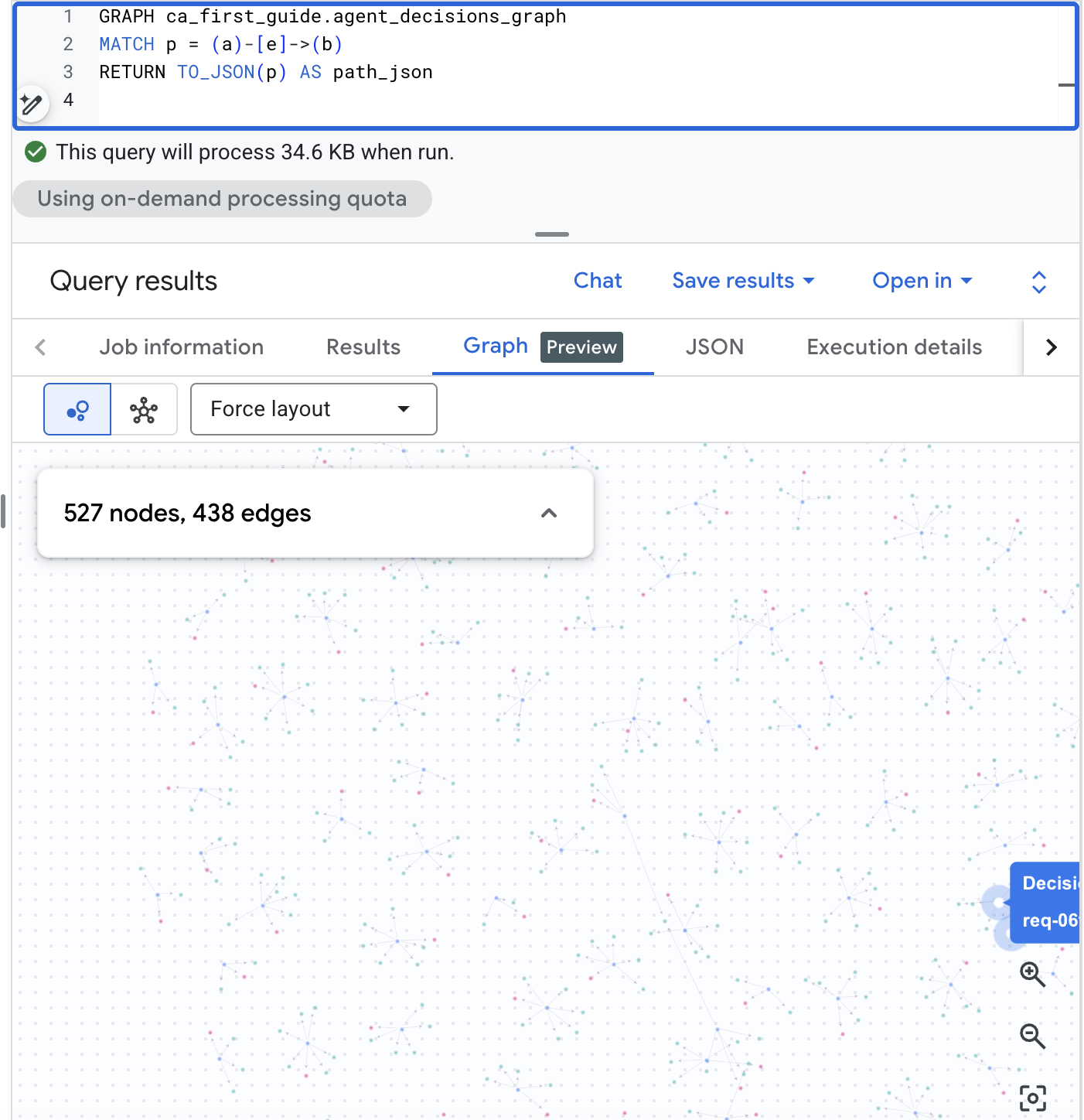
在 BigQuery Studio 中以圖表呈現
BigQuery Studio 也能以視覺化方式呈現圖表。在 BigQuery 控制台中開啟 BigQuery Studio,執行下列路徑查詢,然後將結果窗格切換至「圖表」分頁,即可查看決策網。有了這個真實規模的語料庫,您就能取得要求、選項和結果的視覺化地圖:
GRAPH agent_analytics_demo.agent_decisions_graph
MATCH p = (a)-[e]->(b)
RETURN TO_JSON(p) AS path_json
以簡單的英文句子提出相同問題
並非所有稽核讀取者都會編寫 GQL。透過 BigQuery 對話式數據分析 (預先發布版),法規遵循團隊可以自然語言提出相同類型的問題,並取得結構化答案資訊卡,不必學習查詢語法,也不必瞭解聯結。
將 agent_decisions_graph (連同 agent_events 和決策表) 註冊為對話式數據分析資料來源,然後直接提出稽核問題:
稽核問題 (簡單用語): 「哪些要求從未達成已承諾的結果?」
對話式分析會根據圖表進行推論、為您編寫 SQL,並以直白的英文回覆,附上支援的表格。在下例中,表格顯示每項記錄的要求都達到預期結果:
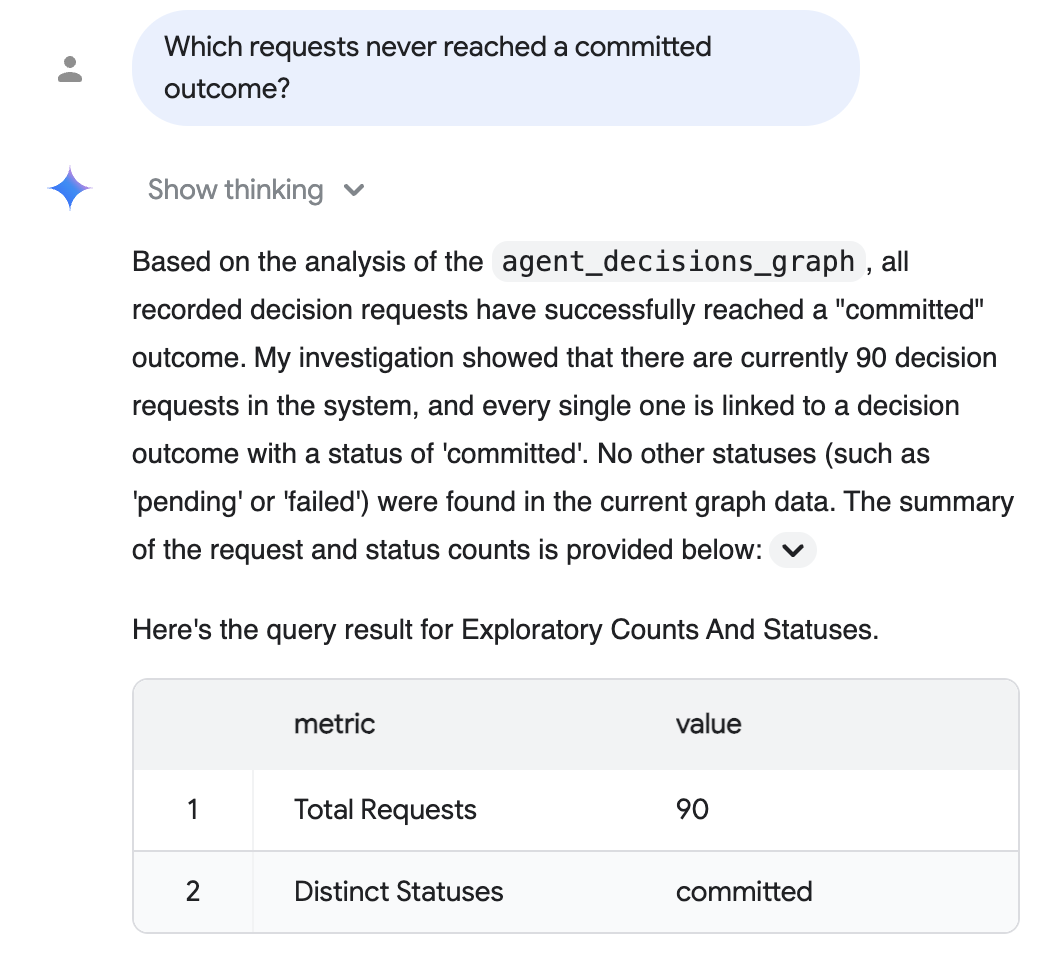
上述回覆反映了選用「realistic-scale data」(實際規模資料) 步驟中的實際規模語料庫 (90 個具體化要求,全數已提交);確切數字取決於您播種的語料庫,而預設的 5 個工作階段執行會顯示五個。
如需設定方式,請參閱對話式數據分析說明文件。
9. 實際推出
上述本機執行作業使用預設行為,已涵蓋實際部署的基本事項:每次執行都會留下稽核追蹤記錄 (結構化 Cloud Logging,以及資料集狀態表中的每項執行作業資料列)、暫時性失敗會自動重試,且進度只會在工作階段完全成功時推進,因此不會重複計算。
製作控制項 (確定性擷取 (--extraction-mode=compiled-only)、偵測卡住的工作階段 (--max-session-age-hours)、一次性重播過去的視窗 (--backfill --from / --to,與一般重新整理分開追蹤,因此不會干擾直播時間表),以及每次執行的批次界限 (--max-sessions)) 是您需要時可選擇使用的旗標。脈絡圖部署指南會記錄每個步驟,並提供完整的 IAM 矩陣和建議時間表。
10. 清理
拆除您建立的項目,以免系統對閒置資料集收費:
bq rm -r -f --dataset "$PROJECT_ID:$DATASET"
這項單一指令會一併移除資料集、代理程式事件、圖表資料表和狀態資料表。
11. 恭喜
恭喜!您已將原始代理程式事件記錄轉換為可查詢的代理程式脈絡圖,並端對端追蹤單一決策,無需外部圖形資料庫或 ETL 管道。
凡是代理程式做出重大決策的領域,都適用相同的模式:信用評估、事前授權、行銷預算調動、採購、客戶服務和內部 IT。如要建構自己的代理程式內容圖,請複製 Codelab 構件做為起點,根據您的網域調整兩個宣告式檔案 (資料表 DDL + CREATE PROPERTY GRAPH 架構),然後套用至 BigQuery - bqaa context-graph --graph 會從 INFORMATION_SCHEMA 讀取已部署的圖,並衍生其餘部分。
目前所學內容
- 如何建立 BigQuery 資料集,並套用描述代理程式決策領域的屬性圖表結構定義。
- 如何使用合成事件語料庫填入
agent_events。 - 如何執行
bqaa context-graph,從這些事件中將代理的決策追蹤記錄擷取至代理內容圖表,並從INFORMATION_SCHEMA讀回圖表定義。 - 如何使用 GQL 查詢產生的圖表,以及如何閱讀稽核風格的答案。
參考文件
- BigQuery Agent Analytics SDK 存放區
- 程式碼研究室構件和改編指南
- 脈絡圖部署指南:必要 API、IAM 矩陣、建議時間表、Cloud Monitoring 警報查詢和 Terraform 模組。
- BigQuery Graph 說明文件 (預先發布版)。
- BigQuery 對話式數據分析說明文件 (預先發布版)。