
1. Einführung
In diesem Codelab erfahren Sie, wie Sie mit Google Antigravity eine serverlose Anwendung für Google Cloud entwerfen, erstellen und bereitstellen. Wir erstellen eine serverlose und ereignisgesteuerte Dokumentpipeline, die Dateien aus Google Cloud Storage (GCS) aufnimmt, sie mit Cloud Run und Gemini verarbeitet und ihre Metadaten in BigQuery streamt.
Lerninhalte
- Antigravity für die Architekturplanung und das Design verwenden
- Mit einem KI-Agenten Infrastruktur als Code (Shell-Skripts) generieren
- Cloud Run-Dienst auf Python-Basis erstellen und bereitstellen.
- Gemini auf Vertex AI für die multimodale Dokumentanalyse einbinden
- Überprüfen Sie die End-to-End-Pipeline mit dem Walkthrough-Artefakt von Antigravity.
Voraussetzungen
- Google Antigravity ist installiert.
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion
- Die gcloud CLI muss installiert und authentifiziert sein.
2. Übersicht über die App
Bevor wir mit der Architektur und Implementierung der Anwendung mit Antigravity beginnen, wollen wir uns erst einmal ansehen, welche Anwendung wir erstellen möchten.
Wir möchten eine serverlose und ereignisgesteuerte Dokumentpipeline erstellen, die Dateien aus Google Cloud Storage (GCS) aufnimmt, sie mit Cloud Run und Gemini verarbeitet und ihre Metadaten in BigQuery streamt.
Ein Architekturdiagramm auf hoher Ebene für diese Anwendung könnte so aussehen:
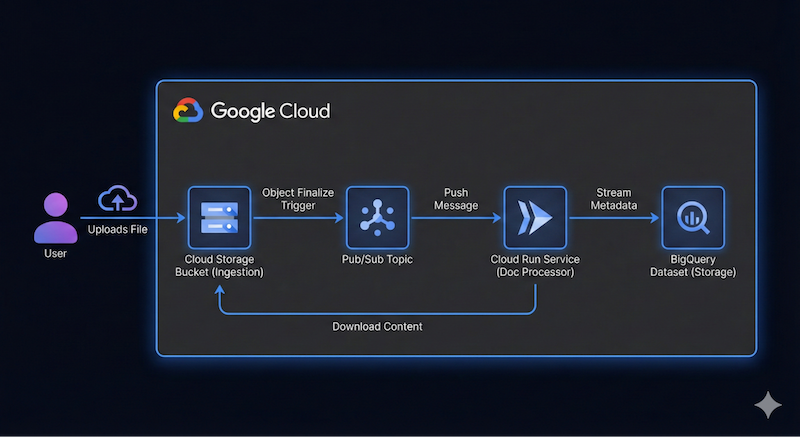
Das muss nicht präzise sein. Antigravity kann uns helfen, die Architekturdetails im Laufe der Zeit zu ermitteln. Es ist jedoch hilfreich, eine Vorstellung davon zu haben, was Sie erstellen möchten. Je mehr Details Sie angeben können, desto bessere Ergebnisse erhalten Sie von Antigravity in Bezug auf Architektur und Code.
3. Architektur planen
Wir sind bereit, mit Antigravity die Architekturdetails zu planen.
Antigravity ist hervorragend für die Planung komplexer Systeme geeignet. Anstatt sofort Code zu schreiben, können wir mit der Definition der Architektur auf hoher Ebene beginnen und eine der Funktionen verwenden, damit Antigravity unsere Anfrage bewerten, uns weiterführende Fragen stellen und dann mit der Planung und Implementierung fortfahren kann.
Angenommen, Sie haben Antigravity gestartet. Wir erstellen nun ein neues Projekt für dieses Codelab.
Klicken Sie neben dem Projects-Lab auf das Symbol für ein neues Projekt und dann auf New Project, wie unten dargestellt:

Dadurch wird die Option Add Folder wie unten dargestellt angezeigt:
Klicken Sie auf die Schaltfläche Ordner hinzufügen, um Ihrem Projekt einen Ordner hinzuzufügen. Auf meinem Computer habe ich einen Ordner google-cloud-serverless-app erstellt und ihn diesem Projekt hinzugefügt.
Dadurch wird eine Unterhaltung im Arbeitsbereich google-cloud-serverless-app geöffnet.
Klicken Sie links unten auf dem Bildschirm auf das Symbol für die Haupteinstellungen ⚙️ und rufen Sie die projektspezifischen Einstellungen auf. Legen Sie Agent Settings / Security Preset auf Default und Agent Behaviour / Artifact Review Policy auf Always Ask fest, wie unten dargestellt:
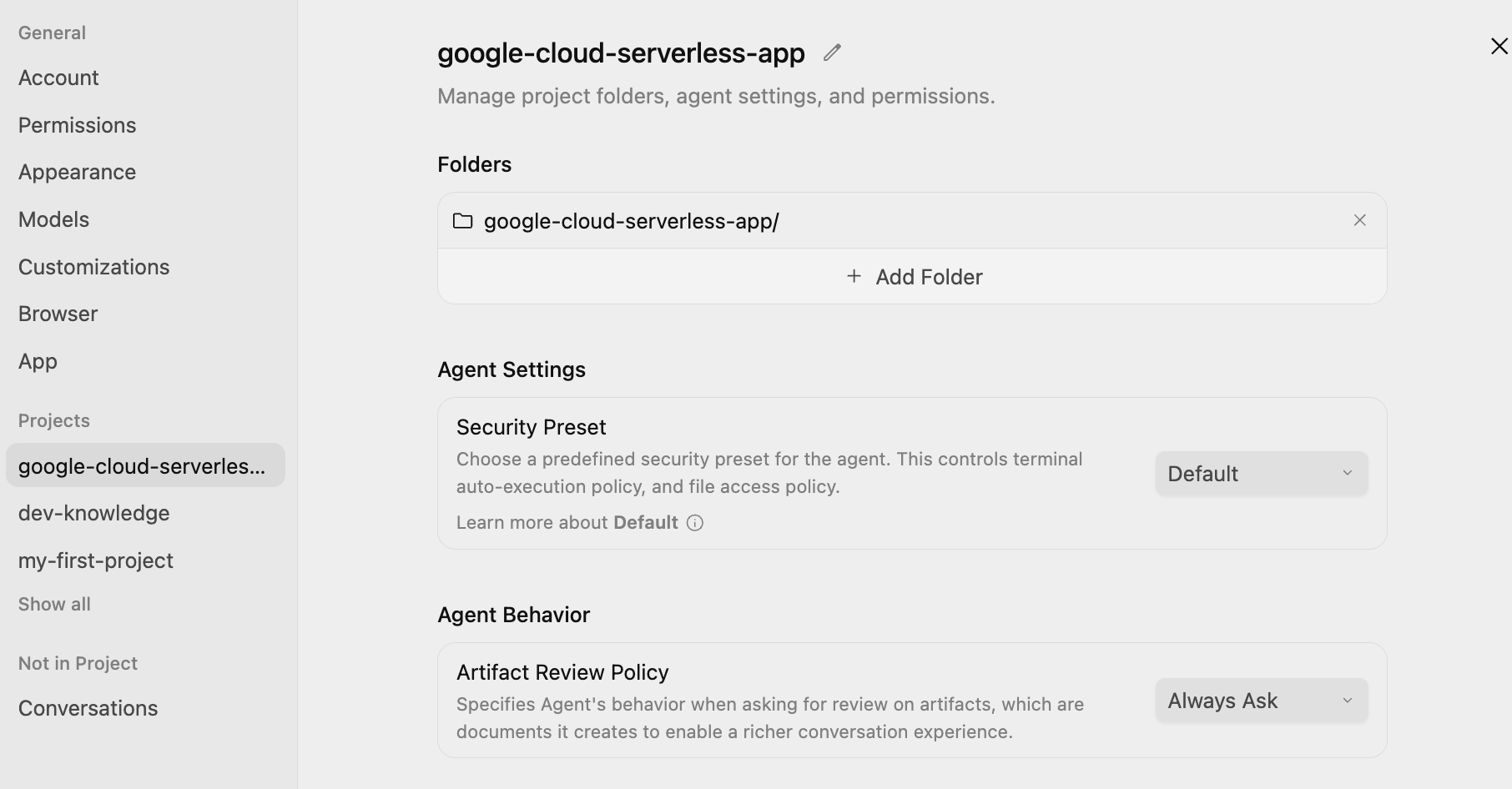
So können Sie den Plan in jedem Schritt überprüfen und genehmigen, bevor der KI-Agent ihn ausführt.
Prompt
Jetzt können wir Antigravity unseren ersten Prompt geben. Wir verwenden einen Slash-Befehl /grill-me, um unsere Anfrage zu bewerten.
Geben Sie /grill-me ein, geben Sie dann den folgenden Prompt ein und klicken Sie auf die Schaltfläche „Senden“:
/grill-me
I want to build a serverless event-driven document processing pipeline on Google Cloud.
Architecture:
- Ingestion: Users upload files to a Cloud Storage bucket.
- Trigger: File uploads trigger a Pub/Sub message.
- Processor: A Python-based Cloud Run service receives the message, processes the file (simulated OCR), and extracts metadata.
- Storage: Stream the metadata (filename, date, tags, word_count) into a BigQuery dataset.
Mit dem Befehl /grill-me werden einige weiterführende Fragen gestellt, die Sie nach bestem Wissen beantworten können. Außerdem werden empfohlene Antworten vorgeschlagen, die Sie verwenden können.
Unten sehen Sie einen Beispielaufruf meines /grill-me-Befehls:
How would you provision and manage the Google Cloud infrastructure resources (Cloud Storage buckets, Pub/Sub topics, BigQuery datasets, Cloud Run service)?
gcloud CLI Setup Script - Shell scripts running gcloud CLI commands to create resources step-by-step
How should the Cloud Storage upload events trigger and reach your Python Cloud Run service?
(Recommended) Native Cloud Storage Pub/Sub Notifications + Pub/Sub Push subscription to Cloud Run (direct, lightweight, standard event-driven approach)
Which Python web framework would you prefer for the Cloud Run processing service?
Flask (with Gunicorn) - Standard, lightweight, and very common for simple Cloud Run services
How should the OCR and metadata extraction logic be implemented in the Cloud Run service?
(Recommended) Full local simulation - If it's a .txt file, read the contents, count words, and extract tags. For other files, generate mock OCR metadata and simulated word count. No external API calls.
Which BigQuery insertion method should the Cloud Run service use to store metadata?
(Recommended) BigQuery table.insert_rows() (Legacy Streaming API) - Extremely simple to code, clean error handling, perfect for simulation and low-to-medium volumes.
How should security/authentication be configured for the Cloud Run service?
Unauthenticated Cloud Run - Allow public requests to the Cloud Run service URL (simpler setup, but insecure for production).
What schema would you like to define for the BigQuery metadata table?
(Recommended) Extended Schema - Include filename, bucket, size, content_type, word_count, tags (as a REPEATED STRING array), ocr_text_preview, and process_timestamp.
How should the Cloud Run service handle processing failures (e.g., file not found, BigQuery write error)?
(Recommended) Fail-Fast with Retry - Log error to standard output (Cloud Logging) and return HTTP 500 to Pub/Sub, so that Pub/Sub automatically retries the message delivery.
What testing tools should we generate to verify the pipeline's functionality?
(Recommended) Both - Include a local test script (sending mock Pub/Sub POST requests to the local Flask server) and a Cloud-integrated test script (uploading a real file to GCS and verifying BigQuery).
Ich habe Antigravity gebeten, Folgendes zu berücksichtigen:
- Einfaches gcloud-Befehlszeilenscript zum Bereitstellen von Ressourcen
- Native Cloud Storage Pub/Sub-Benachrichtigungen + Pub/Sub-Push-Abo für Cloud Run
- Flask (mit Gunicorn) als Framework verwenden
- Verwenden Sie einfach die lokale Simulation mit einer Textdatei für die Daten anstelle von Live-OCR-Daten.
- Mit BigQuery table.insert_rows() Zeilen in BigQuery einfügen
- Nicht authentifizierte Cloud Run-Bereitstellung
und andere empfohlene Optionen.
Implementierungsplan und Aufgabenliste
Antigravity generiert nun einen Implementierungsplan und stellt ihn Ihnen zur Überprüfung zur Verfügung. Sie erhalten eine Nachricht wie die folgende:
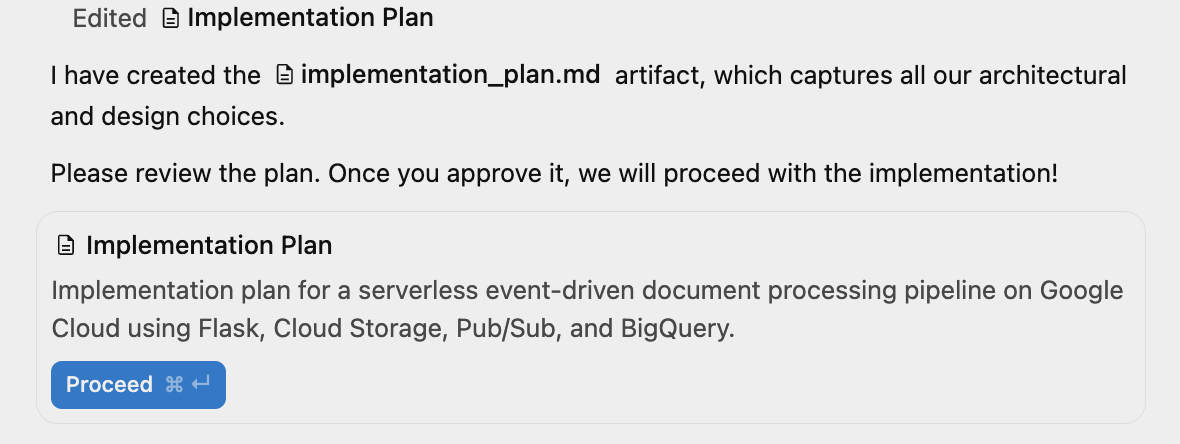
Klicken Sie oben rechts im Fenster auf die Ein/Aus-Schaltfläche für den Zusatzbereich, um die generierten Artefakte aufzurufen. Derzeit ist das nur der Implementierungsplan.
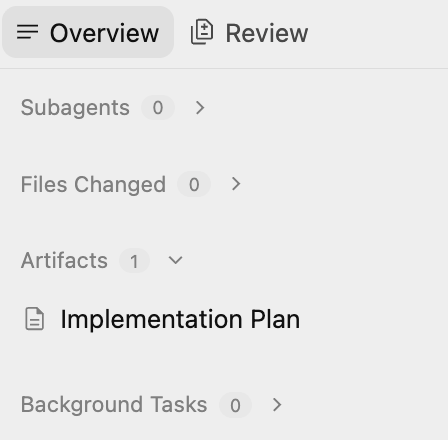
Dieser Plan enthält folgende Informationen:
- Infrastruktur: GCS-Bucket, Pub/Sub-Thema, BigQuery-Dataset.
- Prozessor: Python/Flask-App, Dockerfile, Anforderungen.
- Integration: GCS-Benachrichtigungen → Pub/Sub → Cloud Run.
Die Ausgabe sollte in etwa so aussehen. Unten sehen Sie einen Auszug aus dem Implementierungsplan auf unserem Computer:
Event-Driven Document Processing Pipeline Implementation Plan
This implementation plan describes the components and setup scripts required to build a serverless event-driven document processing pipeline on Google Cloud.
User Review Required
Please review the proposed architecture, components, and default configuration. If you agree, please approve the plan so we can proceed with creating the files and implementation.
IMPORTANT
Security Notice: As requested, the Cloud Run service is configured to allow unauthenticated invocations (--allow-unauthenticated) for simpler testing and development.
Error Handling: The service returns an HTTP 500 error code for failures to trigger Pub/Sub retries.
GCP Configuration: The provisioning scripts will use standard environment variables (e.g., GCP_PROJECT, GCP_REGION) that default to the active configuration of your local gcloud CLI.
Proposed Components and Files
The project will be organized as follows:
google-cloud-serverless-app/
├── src/
│ ├── __init__.py
│ ├── app.py # Flask app entrypoint and routes
│ ├── processor.py # Simulated OCR and metadata extraction engine
│ ├── gcs_helper.py # Helper functions to read files from Cloud Storage
│ └── bq_helper.py # Helper functions to write metadata to BigQuery
├── requirements.txt # Python dependencies
├── Dockerfile # Docker configuration for Cloud Run
├── deploy.sh # gcloud CLI provisioning and deployment script
├── test_local.sh # Script to test the Flask app locally with mock Pub/Sub events
├── test_cloud.sh # Script to upload a real file to GCS and query BigQuery
└── README.md # Setup and execution guide
Lesen Sie sie sorgfältig durch. Hier haben Sie die Möglichkeit, Feedback zur Implementierung zu geben. Sie können auf einen beliebigen Teil des Implementierungsplans klicken und Kommentare hinzufügen. Nachdem Sie einige Kommentare hinzugefügt haben, müssen Sie alle Änderungen, die Sie vornehmen möchten, zur Überprüfung einreichen, insbesondere in Bezug auf die Benennung, die Google Cloud-Projekt-ID, die Region usw.
Wenn alles in Ordnung ist, erteilen Sie dem Kundenservicemitarbeiter die Berechtigung, mit dem Implementierungsplan fortzufahren, indem Sie auf die Schaltfläche Proceed klicken.
Als Nächstes wird ein weiteres Artefakt, der Task Plan (Aufgabenplan), erstellt, der eine Reihe von Aufgaben enthält, die von Antigravity erstellt wurden. Der Agent geht sie einzeln durch und führt sie aus. Unten sehen Sie eine Beispielaufgabenliste:
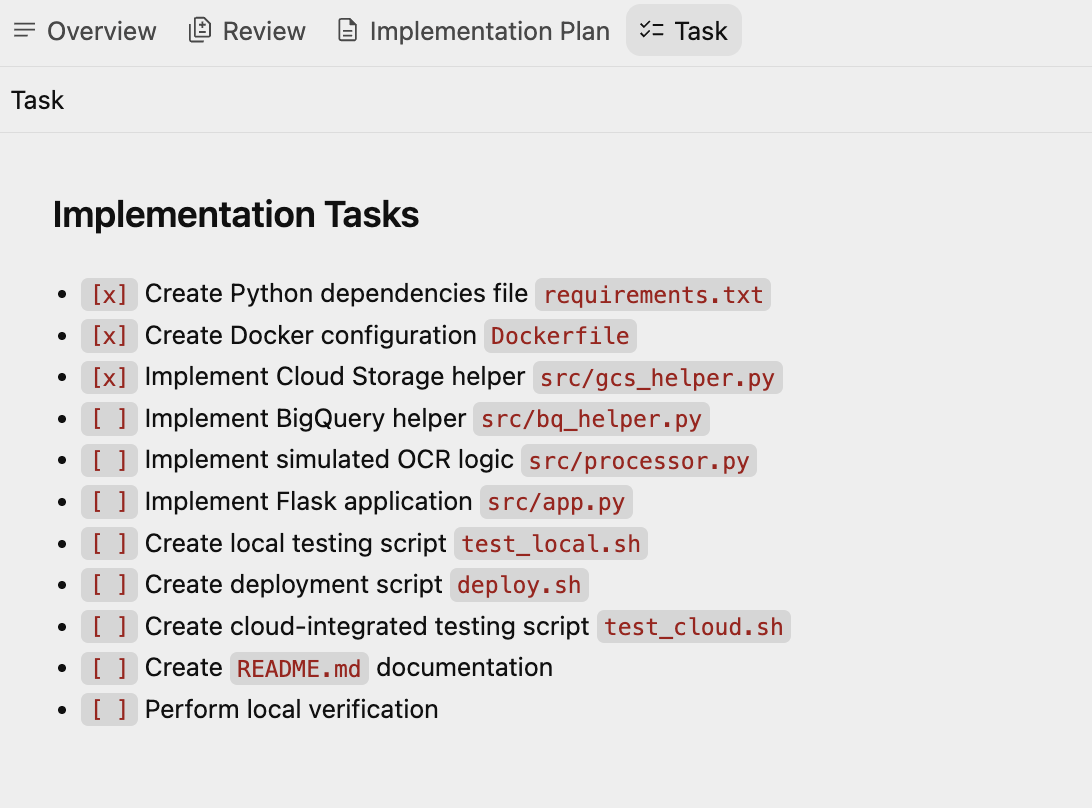
4. Anwendung generieren
Sobald der Plan genehmigt wurde, beginnt Antigravity mit der Generierung der für die Anwendung erforderlichen Dateien, von Bereitstellungsskripten bis hin zum Anwendungscode.
Antigravity erstellt einen Ordner und beginnt mit der Erstellung der für das Projekt erforderlichen Dateien. Wenn Sie die Artefakte prüfen, werden Sie feststellen, dass mehrere Dateien (Quellcode, Skriptdateien usw.) generiert werden.
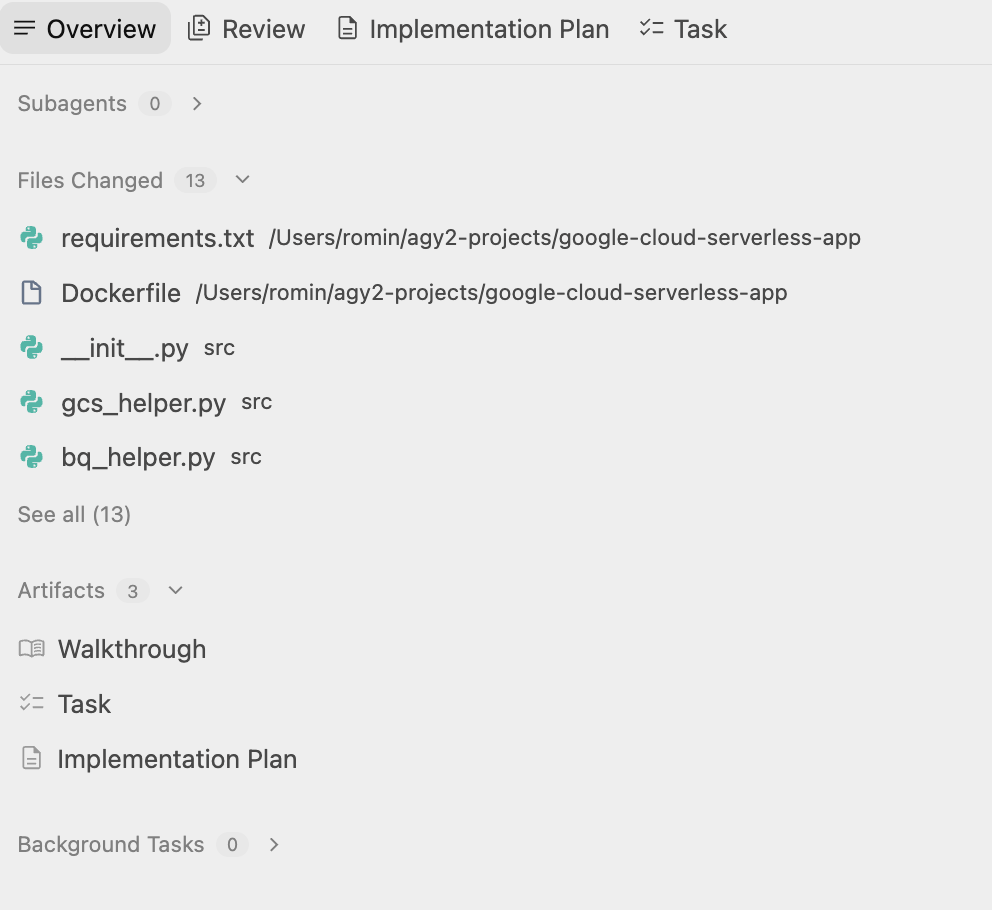
Wenn die Aufgabe abgeschlossen ist, wird das erwähnt und ein Walkthrough-Dokument erstellt, das Sie sich ansehen können. Darin wird der nächste Schritt für den Nutzer erwähnt. Ein Beispiel finden Sie unten:
- Pipeline bereitstellen: Achten Sie darauf, dass Sie sich in der GCP CLI angemeldet und Ihr Zielprojekt festgelegt haben. Führen Sie dann
./deploy.shaus. - End-to-End-Test ausführen: Führen Sie das Cloud-Integrations-Testskript aus, um zu prüfen, ob durch einen Dateiupload die Cloud Run-Verarbeitung ausgelöst und Metadaten in BigQuery gestreamt werden:
./test_cloud.sh - Bereinigen:Wenn Sie die Tests abgeschlossen haben, verwenden Sie die
README.md-Bereinigungsbefehle, um die erstellten Ressourcen zu entfernen und Gebühren zu vermeiden.
Es wird ein Shell-Script mit dem Namen deploy.sh oder einem ähnlichen Namen generiert, das die Ressourcenerstellung automatisiert. Es kümmert sich um:
- Aktivieren von APIs (
run,pubsub,bigquery,storage). - Erstellen Sie den Google Cloud Storage-Bucket (
document-processing-ingest-{project-id}). - BigQuery-Dataset und ‑Tabelle erstellen (
document_processing.processed_metadata). - Pub/Sub-Themen und ‑Benachrichtigungen konfigurieren
5. Anwendung bereitstellen
Wir stellen die Anwendung wie oben beschrieben über den Befehl ./ deploy.sh bereit. Wir können Antigravity bitten, dies für uns auszuführen. Bevor wir das tun, müssen wir jedoch sicherstellen, dass die gcloud CLI vorhanden und für das Google Cloud-Projekt konfiguriert ist.
Wir können Antigravity auffordern, „deploy.sh für mich auszuführen“. Sie werden dann um Erlaubnis gebeten. Gib das bitte ein.
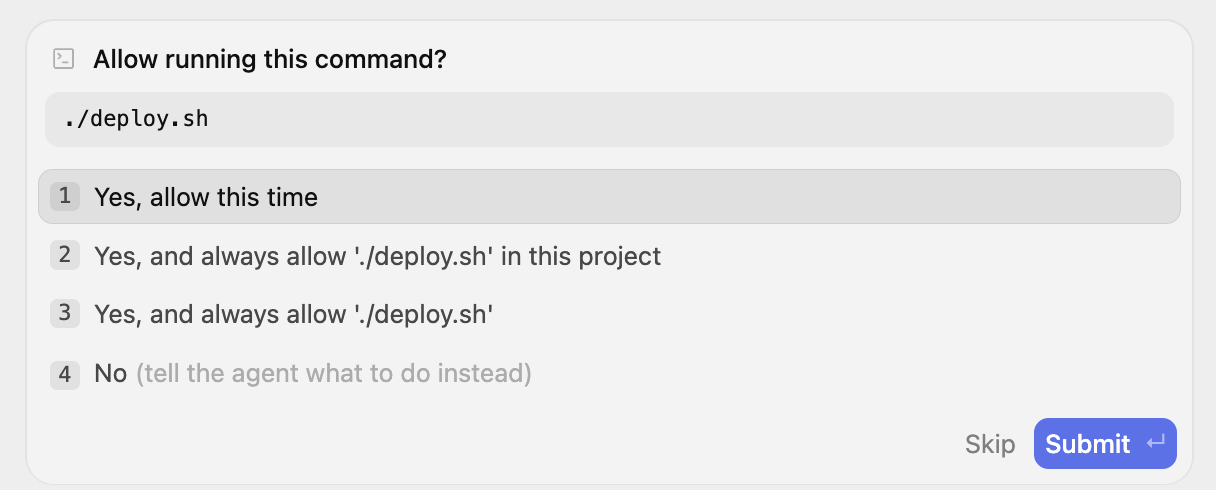
Der Prozess wird als Hintergrundaufgabe gestartet, wie in der folgenden Meldung erläutert:
Ich habe den Bereitstellungsprozess gestartet, indem ich ./deploy.sh im Hintergrund ausgeführt habe. Ich behalte die Ausführungsprotokolle im Blick und informiere dich, sobald die Bereitstellung abgeschlossen ist.
6. Anwendung überprüfen
Sobald die Pipeline bereitgestellt ist, prüft Antigravity, ob die Anwendung tatsächlich funktioniert. Wir werden gefragt, ob die Datei „test_cloud.sh“ ausgeführt werden darf. Wir können die Berechtigung erteilen.

Daraus lässt sich Folgendes ableiten:
I have successfully run both ./deploy.sh and ./test_cloud.sh.
The pipeline is fully deployed to your GCP project PROJECT_ID and working end-to-end.
Please refer to the walkthrough.md for full verification details and the query output from BigQuery showing the successfully processed document metadata.
Wir können das Walkthrough-Artefakt öffnen, um die Ergebnisse anzusehen:
Cloud Verification Results
The deployment and end-to-end cloud integration test (./test_cloud.sh) succeeded perfectly!
Resources Created:
GCS Bucket: gs://document-processing-ingest-gcp-experiments-349209
Pub/Sub Topic: document-uploads-topic
Pub/Sub Subscription: document-uploads-sub (pushing to Cloud Run)
Cloud Run Service: document-processor (URL: https://document-processor-ido3ocn3pq-uc.a.run.app)
BigQuery Dataset: document_processing
BigQuery Table: processed_metadata
Integration Test Run: A test file cloud_test_sample.txt was uploaded to the bucket. The pipeline processed the file and streamed the metadata record into BigQuery:
🔍 Querying BigQuery to verify metadata insertion...
<BIQUERY DATA HERE>
The pipeline successfully detected the hashtags #gcp and #serverless as tags, correctly counted the 47 words, generated the OCR preview, and wrote the entry to BigQuery under the schema.
Optional: Manuelle Bestätigung
Auch wenn Antigravity die Anwendung bereits überprüft hat, können Sie in der Google Cloud Console manuell prüfen, ob alle Ressourcen erstellt wurden. Gehen Sie dazu so vor:
Cloud Storage
Ziel: Prüfen, ob der Bucket vorhanden ist, und nach hochgeladenen Dateien suchen.
- Rufen Sie Cloud Storage > Buckets auf.
- Suchen Sie den Bucket mit dem Namen
document-processing-ingest-{project-id}. - Klicken Sie auf den Bucket-Namen, um Dateien zu durchsuchen.
- Prüfen: Sie sollten Ihre hochgeladenen Dateien sehen, z.B.
cloud_test_sample.txt.
Pub/Sub
Ziel: Prüfen Sie, ob das Thema vorhanden ist und ein Push-Abo hat.
- Wechseln Sie zu Pub/Sub > Themen.
- Suchen Sie nach document-uploads-topic.
- Klicken Sie auf die Themen-ID.
- Scrolle nach unten zum Tab Abos.
- Prüfen Sie, ob doc-uploads-sub mit dem Zustellungstyp Push aufgeführt ist.
Cloud Run
Ziel: Dienststatus und ‑protokolle prüfen.
- Rufen Sie Cloud Run auf.
- Klicken Sie auf den Dienst document-processor.
- Bestätigen:
- „Health“ (Integrität): Ein grünes Häkchen zeigt an, dass der Dienst aktiv ist.
- Logs: Klicken Sie auf den Tab „Logs“. Suchen Sie nach Einträgen wie Processing file: gs://... (Datei wird verarbeitet: gs://...) und Successfully inserted... (Erfolgreich eingefügt...).
BigQuery
Ziel: Prüfen, ob die Daten tatsächlich gespeichert werden.
- Rufen Sie BigQuery > SQL-Arbeitsbereich auf.
- Maximieren Sie im Bereich „Explorer“ Ihr Projekt > Dataset „document_processing“.
- Klicken Sie auf die Tabelle processed_metadata.
- Klicken Sie auf den Tab Abfrage und rufen Sie alle Zeilen aus der Tabelle mit der Anweisung SELECT * ab.
- Prüfen: Sie sollten Zeilen mit filename, process_timestamp, tags und word_count sehen.
7. Anwendung ausprobieren
An diesem Punkt ist die grundlegende App bereitgestellt und wird ausgeführt. Bevor Sie die Anwendung weiter ausbauen, sollten Sie sich den Code ansehen. Sie können die Artefakte aufrufen. Dort sollten die generierten Codedateien angezeigt werden.
Hier eine kurze Zusammenfassung der Dateien, die Sie möglicherweise sehen:
deploy.sh: Das Hauptskript, mit dem alle Google Cloud-Ressourcen bereitgestellt und die erforderlichen APIs aktiviert werden.appy.py: Der Haupteinstiegspunkt der Pipeline. Diese Python-App erstellt einen Webserver, der Pub/Sub-Push-Nachrichten empfängt, die Datei aus GCS herunterlädt, sie „verarbeitet“ (simuliert OCR) und die Metadaten in BigQuery streamt.Dockerfile: Definiert, wie die App in ein Container-Image verpackt wird.requirements.txt: Listet die Python-Abhängigkeiten auf.
Möglicherweise werden auch andere Skripts und Textdateien angezeigt, die für Tests und die Bestätigung erforderlich sind.
8. Anwendung erweitern
Nachdem Sie nun eine funktionierende Basis-App haben, können Sie sie weiterentwickeln und erweitern. Hier sind einige Ideen.
Frontend hinzufügen
Erstellen Sie eine einfache Weboberfläche, um die verarbeiteten Dokumente anzusehen.
Probieren Sie den folgenden Prompt aus: Create a simple Streamlit or Flask web application that connects to BigQuery. It should display a table of the processed documents (filename, upload_date, tags, word_count) and allow me to filter the results by tag
Integration in echte KI/ML
Verwenden Sie Gemini-Modelle zum Extrahieren, Klassifizieren und Übersetzen anstelle der simulierten OCR-Verarbeitung.
- Ersetzen Sie die Dummy-OCR-Logik. Senden Sie das Bild/PDF an Gemini, um Text und Daten zu extrahieren. Analysieren Sie den extrahierten Text, um den Dokumenttyp (Rechnung, Vertrag, Lebenslauf) zu klassifizieren oder Entitäten (Datumsangaben, Namen, Orte) zu extrahieren.
- Die Sprache des Dokuments wird automatisch erkannt und das Dokument wird vor dem Speichern ins Englische übersetzt. Sie können auch eine andere Sprache verwenden.
Speicher und Analysen optimieren
Sie können Lebenszyklusregeln für den Bucket konfigurieren, um alte Dateien in den Speicherklassen „Coldline“ oder „Archive“ zu speichern und so Kosten zu sparen.
Robustheit und Sicherheit
Sie können die App robuster und sicherer machen, indem Sie beispielsweise:
- Warteschlangen für unzustellbare Nachrichten: Aktualisieren Sie das Pub/Sub-Abo, um Fehler zu verarbeiten. Wenn der Cloud Run-Dienst eine Datei fünfmal nicht verarbeiten kann, senden Sie die Nachricht zur manuellen Überprüfung an ein separates Thema/einen separaten Bucket für unzustellbare Nachrichten.
- Secret Manager: Wenn Ihre App API-Schlüssel oder vertrauliche Konfigurationen benötigt, speichern Sie sie in Secret Manager und greifen Sie sicher über Cloud Run darauf zu, anstatt Strings fest zu codieren.
- Eventarc: Wenn Sie von direkten Pub/Sub-Push-Übertragungen zu Eventarc wechseln, erhalten Sie ein flexibleres Ereignisrouting. So können Sie Trigger auf Basis komplexer Audit-Logs oder anderer GCP-Dienstereignisse erstellen.
Natürlich können Sie auch eigene Ideen entwickeln und Antigravity nutzen, um sie umzusetzen.
9. Fazit
Sie haben mit Google Antigravity in wenigen Minuten eine skalierbare, serverlose, KI-basierte Dokumentenpipeline erstellt. Sie haben Folgendes gelernt:
- Architekturen mit KI planen
- Antigravity anweisen und verwalten, während die Anwendung generiert wird – von der Codeerstellung bis zur Bereitstellung und Validierung.
- Bereitstellungen und Validierungen mit Walkthroughs überprüfen
Referenzdokumente
- Offizielle Website : https://antigravity.google/
- Dokumentation: https://antigravity.google/docs
- Anwendungsbeispiele : https://antigravity.google/use-cases
- Download : https://antigravity.google/download