
1. Introduction
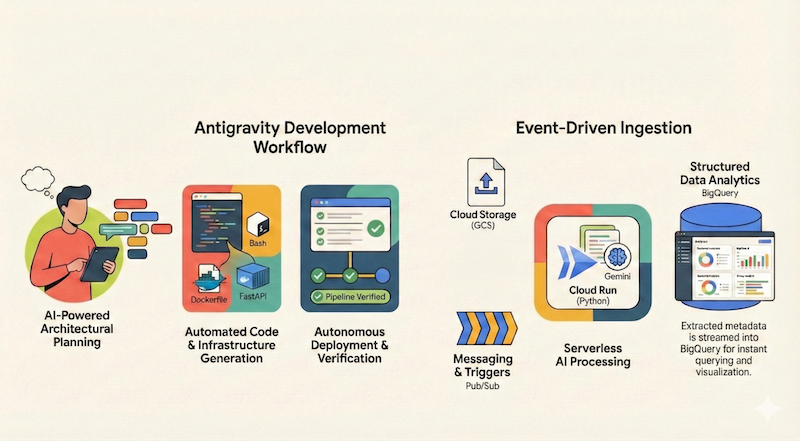
Dans cet atelier de programmation, vous allez apprendre à utiliser Google Antigravity pour concevoir, créer et déployer une application sans serveur sur Google Cloud. Nous allons créer un pipeline de documents sans serveur et basé sur les événements qui ingère des fichiers depuis Google Cloud Storage (GCS), les traite à l'aide de Cloud Run et de Gemini, et diffuse leurs métadonnées dans BigQuery.
Points abordés
- Utiliser Antigravity pour la planification et la conception architecturales
- Générez de l'infrastructure as code (scripts shell) avec un agent IA.
- Créez et déployez un service Cloud Run basé sur Python.
- Intégrez Gemini sur Vertex AI pour l'analyse multimodale de documents.
- Vérifiez le pipeline de bout en bout à l'aide de l'artefact "Walkthrough" d'Antigravity.
Prérequis
- Avoir installé Google Antigravity
- Projet Google Cloud avec facturation activée
- gcloud CLI installée et authentifiée.
2. Présentation de l'application
Avant de nous lancer dans l'architecture et l'implémentation de l'application à l'aide d'Antigravity, commençons par définir l'application que nous souhaitons créer pour nous-mêmes.
Nous souhaitons créer un pipeline de documents sans serveur et axé sur les événements qui ingère des fichiers depuis Google Cloud Storage (GCS), les traite à l'aide de Cloud Run et de Gemini, et diffuse leurs métadonnées dans BigQuery.
Voici un exemple de diagramme d'architecture de haut niveau pour cette application :
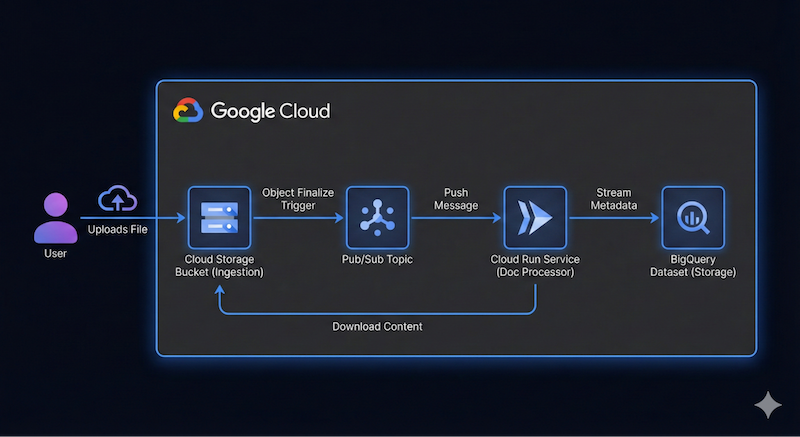
Il n'est pas nécessaire d'être précis. Antigravity peut nous aider à déterminer les détails de l'architecture au fur et à mesure. Toutefois, il est utile d'avoir une idée de ce que vous voulez construire. Plus vous fournirez de détails, meilleurs seront les résultats d'Antigravity en termes d'architecture et de code.
3. Planifier l'architecture
Nous sommes prêts à commencer à planifier les détails de l'architecture avec Antigravity.
Antigravity excelle dans la planification de systèmes complexes. Au lieu d'écrire du code immédiatement, nous pouvons commencer par définir l'architecture de haut niveau et utiliser l'une des fonctionnalités pour aider Antigravity à évaluer notre demande, à nous poser des questions complémentaires, puis à planifier et à implémenter.
En supposant que vous ayez lancé Antigravity, nous allons créer un projet pour cet atelier de programmation.
Cliquez sur l'icône Nouveau projet à côté de l'atelier Projects, puis sur New Project, comme indiqué ci-dessous :

L'option Add Folder s'affiche, comme illustré ci-dessous :
Cliquez sur le bouton Ajouter un dossier pour ajouter un dossier à votre projet. Sur mon ordinateur, j'ai créé un dossier google-cloud-serverless-app et je l'ai ajouté à ce projet.
Une conversation s'ouvre dans l'espace de travail google-cloud-serverless-app.
Cliquez sur l'icône de paramètres principal ⚙️ en bas à gauche de l'écran, puis accédez aux paramètres spécifiques au projet. Définissez Agent Settings / Security Preset sur Default et Agent Behaviour / Artifact Review Policy sur Always Ask, comme indiqué ci-dessous :
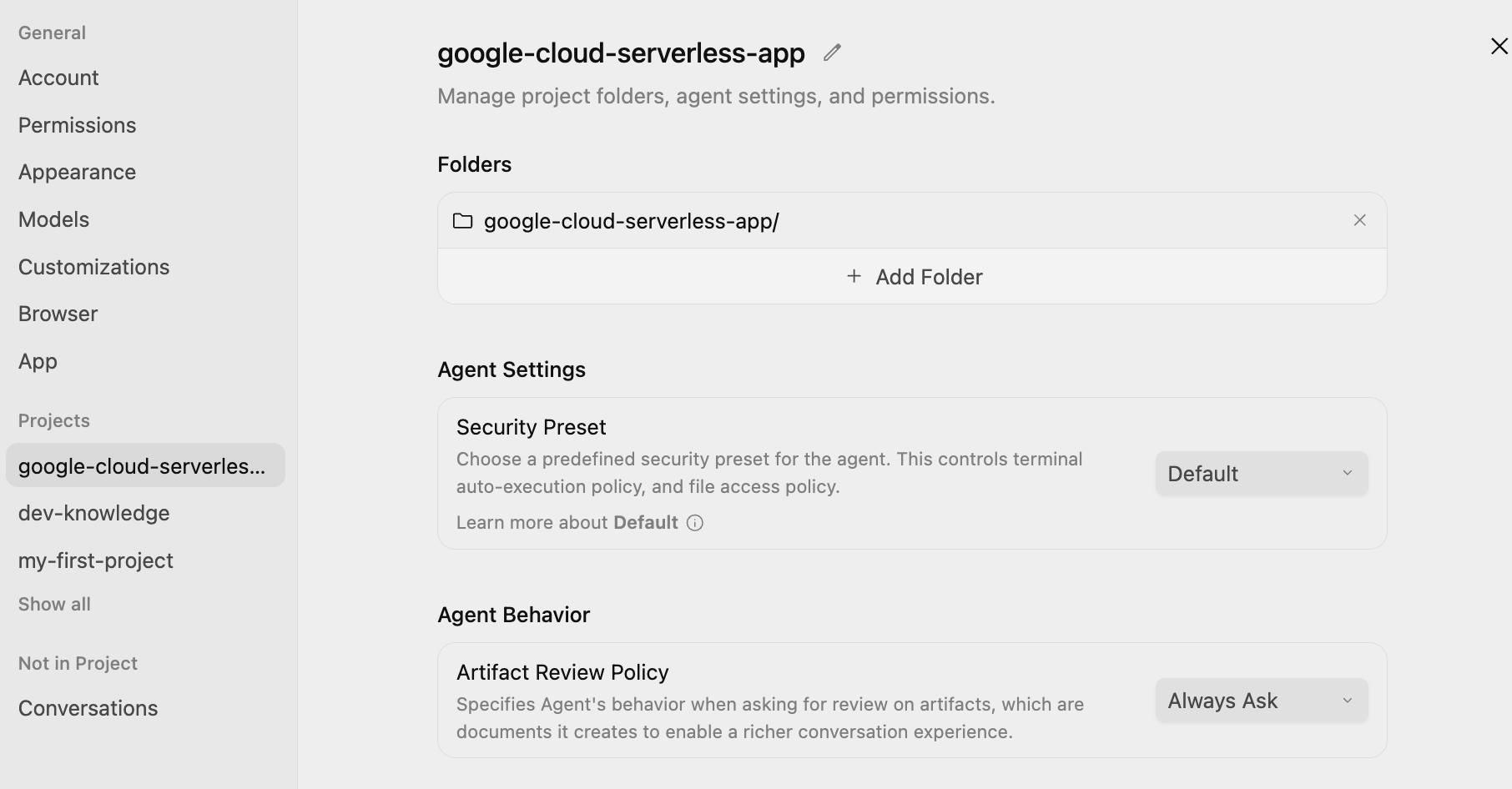
Vous pourrez ainsi examiner et approuver le plan à chaque étape avant que l'agent ne l'exécute.
Prompt
Nous sommes maintenant prêts à fournir notre première invite de commande à Antigravity. Nous allons utiliser une commande à barre oblique /grill-me pour évaluer notre requête.
Saisissez /grill-me, puis saisissez la requête suivante et cliquez sur le bouton "Envoyer" :
/grill-me
I want to build a serverless event-driven document processing pipeline on Google Cloud.
Architecture:
- Ingestion: Users upload files to a Cloud Storage bucket.
- Trigger: File uploads trigger a Pub/Sub message.
- Processor: A Python-based Cloud Run service receives the message, processes the file (simulated OCR), and extracts metadata.
- Storage: Stream the metadata (filename, date, tags, word_count) into a BigQuery dataset.
La commande /grill-me pose un certain nombre de questions complémentaires auxquelles vous pouvez essayer de répondre du mieux que vous pouvez. Il suggère également des réponses recommandées que vous pouvez utiliser si vous le souhaitez.
Vous trouverez ci-dessous un exemple d'exécution de ma commande /grill-me :
How would you provision and manage the Google Cloud infrastructure resources (Cloud Storage buckets, Pub/Sub topics, BigQuery datasets, Cloud Run service)?
gcloud CLI Setup Script - Shell scripts running gcloud CLI commands to create resources step-by-step
How should the Cloud Storage upload events trigger and reach your Python Cloud Run service?
(Recommended) Native Cloud Storage Pub/Sub Notifications + Pub/Sub Push subscription to Cloud Run (direct, lightweight, standard event-driven approach)
Which Python web framework would you prefer for the Cloud Run processing service?
Flask (with Gunicorn) - Standard, lightweight, and very common for simple Cloud Run services
How should the OCR and metadata extraction logic be implemented in the Cloud Run service?
(Recommended) Full local simulation - If it's a .txt file, read the contents, count words, and extract tags. For other files, generate mock OCR metadata and simulated word count. No external API calls.
Which BigQuery insertion method should the Cloud Run service use to store metadata?
(Recommended) BigQuery table.insert_rows() (Legacy Streaming API) - Extremely simple to code, clean error handling, perfect for simulation and low-to-medium volumes.
How should security/authentication be configured for the Cloud Run service?
Unauthenticated Cloud Run - Allow public requests to the Cloud Run service URL (simpler setup, but insecure for production).
What schema would you like to define for the BigQuery metadata table?
(Recommended) Extended Schema - Include filename, bucket, size, content_type, word_count, tags (as a REPEATED STRING array), ocr_text_preview, and process_timestamp.
How should the Cloud Run service handle processing failures (e.g., file not found, BigQuery write error)?
(Recommended) Fail-Fast with Retry - Log error to standard output (Cloud Logging) and return HTTP 500 to Pub/Sub, so that Pub/Sub automatically retries the message delivery.
What testing tools should we generate to verify the pipeline's functionality?
(Recommended) Both - Include a local test script (sending mock Pub/Sub POST requests to the local Flask server) and a Cloud-integrated test script (uploading a real file to GCS and verifying BigQuery).
Notez que j'ai demandé à Antigravity de :
- Script gcloud CLI simple pour provisionner des ressources
- Notifications Pub/Sub Cloud Storage natives + abonnement push Pub/Sub à Cloud Run
- Utiliser Flask (avec Gunicorn) pour le framework
- Utilisez simplement la simulation locale avec un fichier texte pour les données au lieu des données OCR en direct.
- Utiliser table.insert_rows() de BigQuery pour insérer des lignes dans BigQuery
- Déploiement Cloud Run non authentifié
et d'autres options recommandées.
Plan de mise en œuvre et liste de tâches
Antigravity va maintenant se mettre au travail et générer un plan d'implémentation. Il vous le soumet pour examen en vous envoyant un message semblable à celui ci-dessous :
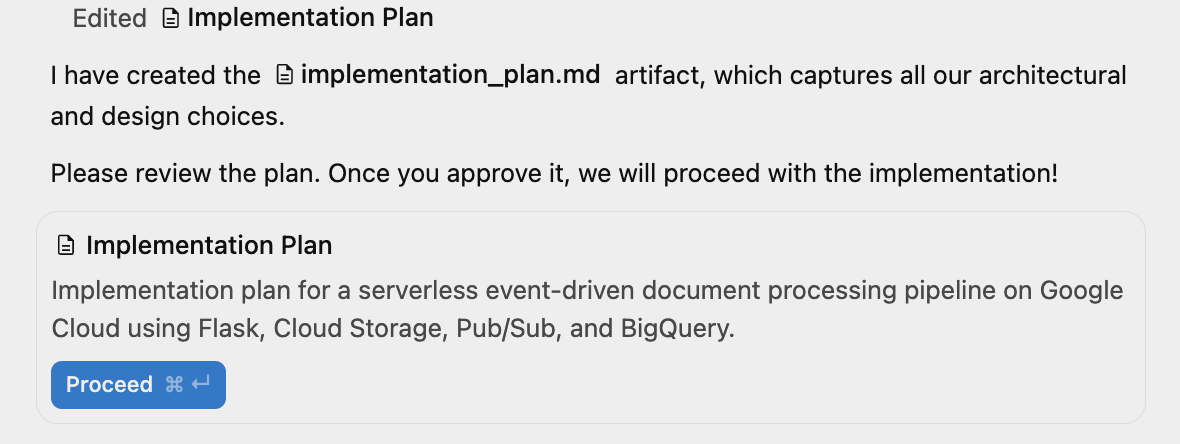
Vous pouvez cliquer sur le bouton bascule du volet auxiliaire en haut à droite de la fenêtre pour afficher les artefacts générés, qui ne sont pour l'instant que le plan d'implémentation.
Ce plan décrit :
- Infrastructure : bucket GCS, thème Pub/Sub, ensemble de données BigQuery.
- Processeur : application Python/Flask, Dockerfile, exigences.
- Intégration : notifications GCS → Pub/Sub → Cloud Run.
Le résultat doit ressembler à ceci : Vous trouverez ci-dessous une liste partielle du plan d'implémentation sur notre machine :
Event-Driven Document Processing Pipeline Implementation Plan
This implementation plan describes the components and setup scripts required to build a serverless event-driven document processing pipeline on Google Cloud.
User Review Required
Please review the proposed architecture, components, and default configuration. If you agree, please approve the plan so we can proceed with creating the files and implementation.
IMPORTANT
Security Notice: As requested, the Cloud Run service is configured to allow unauthenticated invocations (--allow-unauthenticated) for simpler testing and development.
Error Handling: The service returns an HTTP 500 error code for failures to trigger Pub/Sub retries.
GCP Configuration: The provisioning scripts will use standard environment variables (e.g., GCP_PROJECT, GCP_REGION) that default to the active configuration of your local gcloud CLI.
Proposed Components and Files
The project will be organized as follows:
google-cloud-serverless-app/
├── src/
│ ├── __init__.py
│ ├── app.py # Flask app entrypoint and routes
│ ├── processor.py # Simulated OCR and metadata extraction engine
│ ├── gcs_helper.py # Helper functions to read files from Cloud Storage
│ └── bq_helper.py # Helper functions to write metadata to BigQuery
├── requirements.txt # Python dependencies
├── Dockerfile # Docker configuration for Cloud Run
├── deploy.sh # gcloud CLI provisioning and deployment script
├── test_local.sh # Script to test the Flask app locally with mock Pub/Sub events
├── test_cloud.sh # Script to upload a real file to GCS and query BigQuery
└── README.md # Setup and execution guide
Lisez-le attentivement. C'est l'occasion de nous faire part de vos commentaires sur l'implémentation. Vous pouvez cliquer sur n'importe quelle partie du plan d'implémentation et ajouter des commentaires. Une fois que vous avez ajouté des commentaires, veillez à envoyer pour examen toutes les modifications que vous souhaitez voir apportées, en particulier concernant le nom, l'ID du projet Google Cloud, la région, etc.
Une fois que tout semble correct, autorisez l'agent à poursuivre le plan d'implémentation en cliquant sur le bouton Proceed.
Il va maintenant créer un autre artefact, le plan de tâches, qui contient un ensemble de tâches créées par Antigravity. L'agent les exécutera une par une. Vous trouverez ci-dessous un exemple de liste de tâches :
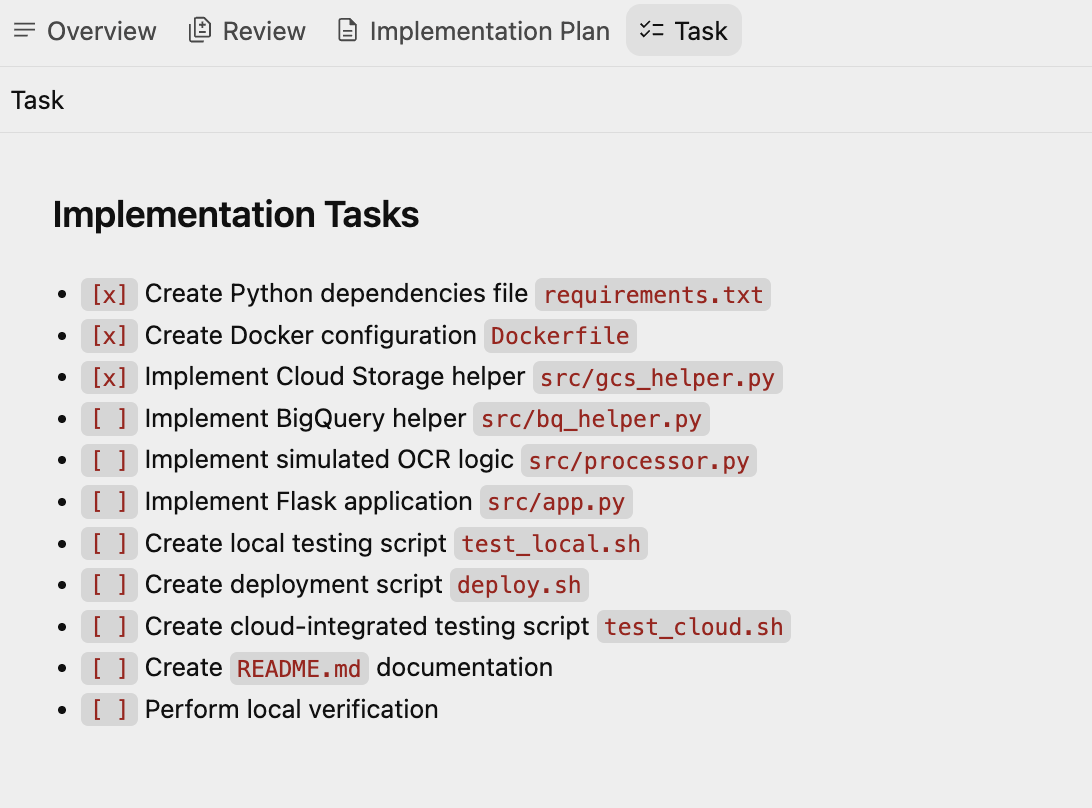
4. Générer l'application
Une fois le plan approuvé, Antigravity commence à générer les fichiers requis pour l'application, des scripts de provisionnement au code de l'application.
Antigravity crée un dossier et commence à créer les fichiers nécessaires au projet. Si vous consultez les artefacts, vous remarquerez que plusieurs fichiers (code source, fichiers de script, etc.) sont générés.
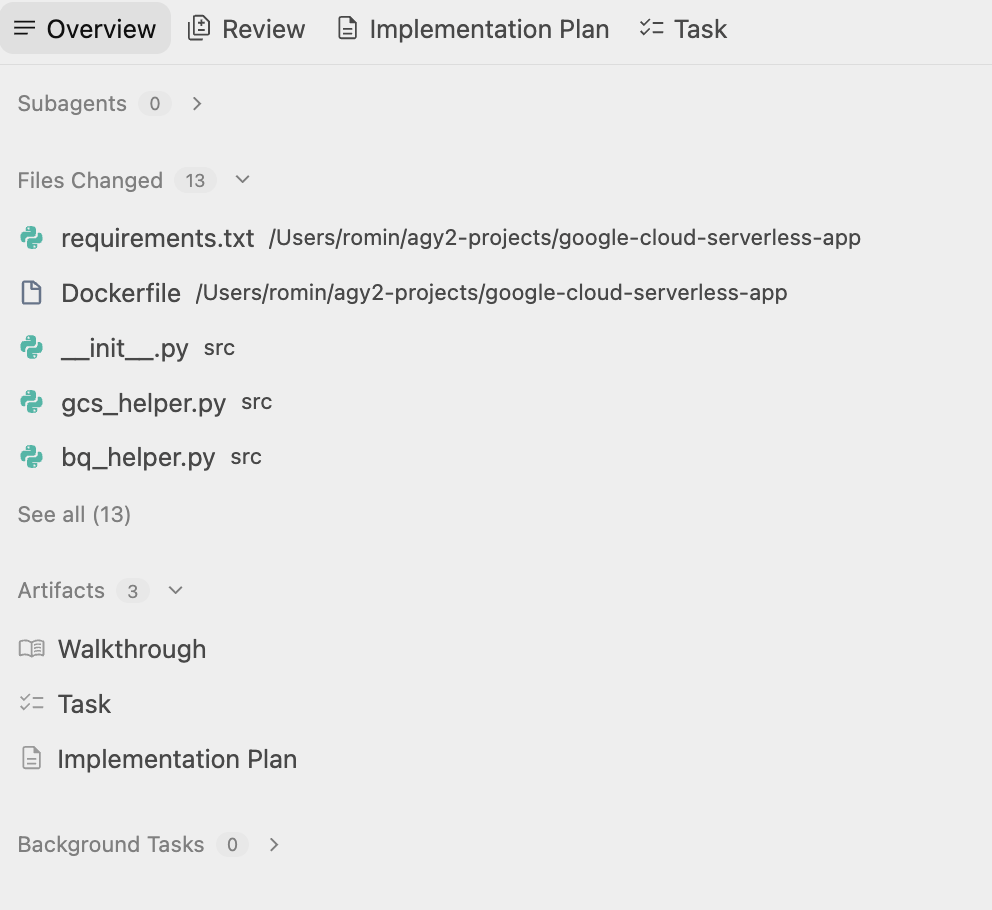
Une fois son travail terminé, il vous le mentionnera et créera un document Procédure pas à pas que vous pourrez consulter. Voici un exemple qui mentionne l'étape suivante pour l'utilisateur :
- Déployez le pipeline : assurez-vous d'être connecté à la CLI GCP et d'avoir défini votre projet cible, puis exécutez la commande suivante :
./deploy.sh. - Exécuter le test de bout en bout : exécutez le script de test d'intégration Cloud pour vérifier qu'un import de fichier déclenche le traitement Cloud Run et transmet les métadonnées à BigQuery :
./test_cloud.sh - Nettoyage : une fois les tests terminés, consultez les commandes de nettoyage
README.mdpour supprimer les ressources créées et éviter des frais.
Un fichier de script shell nommé deploy.sh ou un nom similaire est généré. Il automatise la création de ressources. Ce qu'elle gère :
- Activation des API (
run,pubsub,bigquery,storage). - Créez le bucket Google Cloud Storage (
document-processing-ingest-{project-id}). - Créer l'ensemble de données et la table BigQuery (
document_processing.processed_metadata). - Configurer les sujets et les notifications Pub/Sub
5. Déployer l'application
Déployons l'application comme indiqué à l'aide de la commande ./ deploy.sh. Nous pouvons demander à Antigravity de l'exécuter pour nous, mais avant cela, assurez-vous que gcloud CLI est présent et configuré pour le projet Google Cloud.
Nous pouvons demander à Antigravity d'exécuter deploy.sh pour nous. Vous serez alors invité à accorder l'autorisation. Allez-y, essayez.
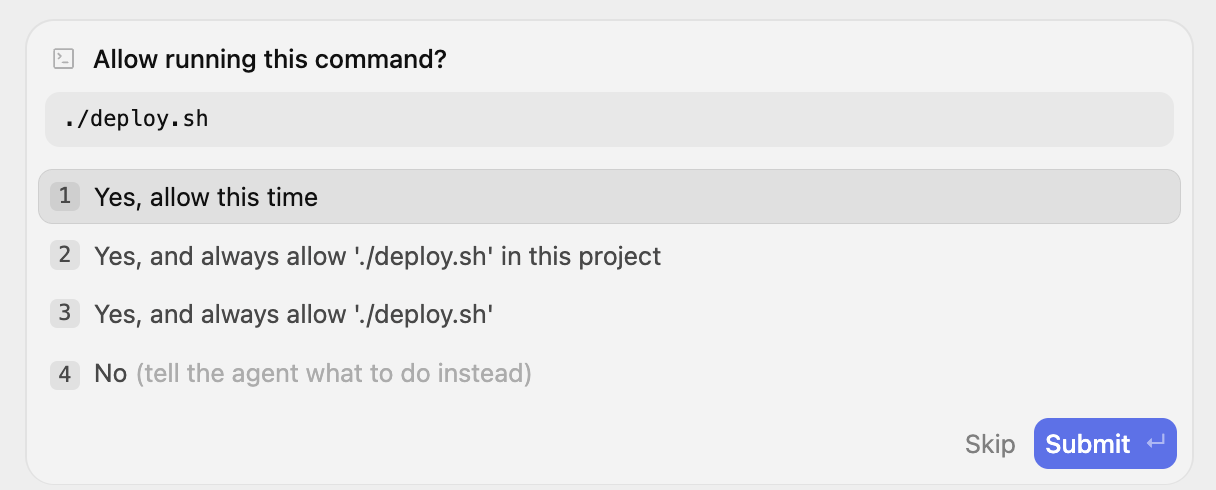
Il lance le processus en tant que tâche en arrière-plan, comme l'indique le message ci-dessous :
J'ai lancé le processus de déploiement en exécutant ./deploy.sh en arrière-plan. Je vais surveiller les journaux d'exécution et vous informer dès que le déploiement sera terminé.
6. Valider l'application
Une fois le pipeline déployé, Antigravity vérifie que l'application fonctionne correctement. Il nous demande s'il peut exécuter le fichier test_cloud.sh. Nous pouvons lui accorder l'autorisation.

Il nous indique enfin ce qui suit :
I have successfully run both ./deploy.sh and ./test_cloud.sh.
The pipeline is fully deployed to your GCP project PROJECT_ID and working end-to-end.
Please refer to the walkthrough.md for full verification details and the query output from BigQuery showing the successfully processed document metadata.
Nous pouvons ouvrir l'artefact "Procédure pas à pas" pour afficher les résultats :
Cloud Verification Results
The deployment and end-to-end cloud integration test (./test_cloud.sh) succeeded perfectly!
Resources Created:
GCS Bucket: gs://document-processing-ingest-gcp-experiments-349209
Pub/Sub Topic: document-uploads-topic
Pub/Sub Subscription: document-uploads-sub (pushing to Cloud Run)
Cloud Run Service: document-processor (URL: https://document-processor-ido3ocn3pq-uc.a.run.app)
BigQuery Dataset: document_processing
BigQuery Table: processed_metadata
Integration Test Run: A test file cloud_test_sample.txt was uploaded to the bucket. The pipeline processed the file and streamed the metadata record into BigQuery:
🔍 Querying BigQuery to verify metadata insertion...
<BIQUERY DATA HERE>
The pipeline successfully detected the hashtags #gcp and #serverless as tags, correctly counted the 47 words, generated the OCR preview, and wrote the entry to BigQuery under the schema.
Facultatif : Validation manuelle
Même si Antigravity a déjà vérifié l'application, vous pouvez également vérifier manuellement dans la console Google Cloud que toutes les ressources ont été créées, si vous le souhaitez, en suivant ces étapes.
Cloud Storage
Objectif : Vérifier que le bucket existe et rechercher les fichiers importés.
- Accédez à Cloud Storage > Buckets.
- Recherchez le bucket nommé
document-processing-ingest-{project-id}. - Cliquez sur le nom du bucket pour parcourir les fichiers.
- Vérifiez que les fichiers importés s'affichent (par exemple,
cloud_test_sample.txt).
Pub/Sub
Objectif : Vérifiez que le sujet existe et qu'il dispose d'un abonnement push.
- Accédez à Pub/Sub > Sujets.
- Recherchez document-uploads-topic.
- Cliquez sur l'ID du sujet.
- Faites défiler la page jusqu'à l'onglet Abonnements.
- Vérifiez que doc-uploads-sub est listé avec le type de distribution Push.
Cloud Run
Objectif : Vérifier l'état et les journaux du service.
- Accédez à Cloud Run.
- Cliquez sur le service document-processor.
- Vérifiez :
- État : coche verte indiquant que le service est actif.
- Journaux : cliquez sur l'onglet "Journaux". Recherchez des entrées telles que Traitement du fichier : gs://... et Insertion réussie....
BigQuery
Objectif : valider que les données sont réellement stockées.
- Accédez à BigQuery > Espace de travail SQL.
- Dans le volet "Explorateur", développez projet > ensemble de données document_processing.
- Cliquez sur la table processed_metadata.
- Cliquez sur l'onglet Requête et récupérez toutes les lignes de la table à l'aide de l'instruction SELECT *.
- Vérifiez que des lignes contenant filename, process_timestamp, tags et word_count s'affichent.
7. Explorer l'application
À ce stade, l'application de base est provisionnée et en cours d'exécution. Avant de vous lancer dans l'extension de cette application, prenez le temps d'explorer le code. Vous pouvez afficher les artefacts et les fichiers de code générés devraient s'afficher.
Voici un bref récapitulatif des fichiers que vous pouvez voir :
deploy.sh: script principal qui provisionne toutes les ressources Google Cloud et active les API requises.appy.py: point d'entrée principal du pipeline. Cette application Python crée un serveur Web qui reçoit les messages push Pub/Sub, télécharge le fichier depuis GCS, le "traite" (simule l'OCR) et transmet les métadonnées à BigQuery.Dockerfile: définit la manière d'empaqueter l'application dans une image de conteneur.requirements.txt: liste les dépendances Python.
Vous pouvez également voir d'autres scripts et fichiers texte nécessaires aux tests et à la validation.
8. Étendre l'application
Maintenant que vous disposez d'une application de base fonctionnelle, vous pouvez continuer à l'améliorer et à l'étendre. Voici quelques idées :
Ajouter une interface
Créez une interface Web simple pour afficher les documents traités.
Essayez le prompt suivant : Create a simple Streamlit or Flask web application that connects to BigQuery. It should display a table of the processed documents (filename, upload_date, tags, word_count) and allow me to filter the results by tag
Intégration à l'IA/au ML réels
Au lieu d'un traitement OCR simulé, utilisez les modèles Gemini pour extraire, classer et traduire.
- Remplacez la logique OCR factice. Envoyez l'image ou le PDF à Gemini pour extraire le texte et les données réels. Analysez le texte extrait pour classer le type de document (facture, contrat, CV) ou extraire des entités (dates, noms, lieux).
- Détectez automatiquement la langue du document et traduisez-le en anglais avant de l'enregistrer. Vous pouvez également utiliser n'importe quelle autre langue.
Améliorer le stockage et les analyses
Vous pouvez configurer des règles de cycle de vie sur le bucket pour déplacer les anciens fichiers vers le stockage "Coldline" ou "Archive" afin de réduire les coûts.
Robustesse et sécurité
Vous pouvez rendre l'application plus robuste et sécurisée, par exemple :
- Files d'attente de lettres mortes (DLQ) : mettez à jour l'abonnement Pub/Sub pour gérer les échecs. Si le service Cloud Run ne parvient pas à traiter un fichier cinq fois, envoyez le message vers un sujet/bucket "Dead Letter" distinct pour une inspection manuelle.
- Secret Manager : si votre application a besoin de clés API ou d'une configuration sensible, stockez-les dans Secret Manager et accédez-y de manière sécurisée depuis Cloud Run au lieu de coder en dur des chaînes.
- Eventarc : passez de Pub/Sub direct à Eventarc pour un routage d'événements plus flexible, ce qui vous permet de déclencher des actions en fonction de journaux d'audit complexes ou d'autres événements de services GCP.
Bien sûr, vous pouvez trouver vos propres idées et utiliser Antigravity pour vous aider à les mettre en œuvre !
9. Conclusion
Vous avez créé un pipeline de documents évolutif, sans serveur et optimisé par l'IA en quelques minutes à l'aide de Google Antigravity. Vous avez appris à :
- Planifiez des architectures avec l'IA.
- Donnez des instructions à Antigravity et gérez-le pendant qu'il génère l'application, de la génération du code au déploiement et à la validation.
- Vérifiez les déploiements et la validation à l'aide des procédures pas à pas.
Documents de référence
- Site officiel : https://antigravity.google/
- Documentation : https://antigravity.google/docs
- Cas d'utilisation : https://antigravity.google/use-cases
- Télécharger : https://antigravity.google/download