
1. परिचय
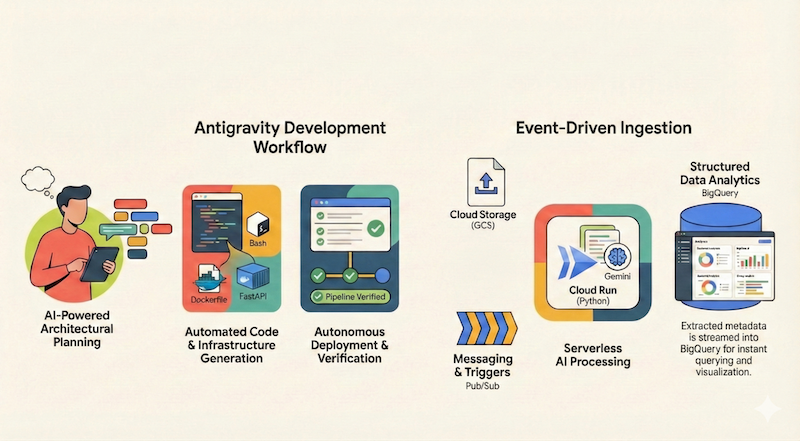
इस कोडलैब में, आपको Google Antigravity का इस्तेमाल करके, Google Cloud पर बिना सर्वर के काम करने वाला ऐप्लिकेशन डिज़ाइन, बनाने, और डिप्लॉय करने का तरीका बताया जाएगा. हम सर्वरलेस और इवेंट-ड्रिवन दस्तावेज़ पाइपलाइन बनाएंगे. यह Google Cloud Storage (GCS) से फ़ाइलें इनजेस्ट करेगी, Cloud Run और Gemini का इस्तेमाल करके उन्हें प्रोसेस करेगी, और उनके मेटाडेटा को BigQuery में स्ट्रीम करेगी.
आपको क्या सीखने को मिलेगा
- आर्किटेक्चरल प्लानिंग और डिज़ाइन के लिए, Antigravity का इस्तेमाल कैसे करें.
- एआई एजेंट की मदद से, इंफ़्रास्ट्रक्चर ऐज़ कोड (शेल स्क्रिप्ट) जनरेट करें.
- Python पर आधारित Cloud Run सेवा बनाएं और उसे डिप्लॉय करें.
- मल्टीमॉडल दस्तावेज़ों का विश्लेषण करने के लिए, Vertex AI पर Gemini को इंटिग्रेट करें.
- Antigravity के Walkthrough आर्टफ़ैक्ट का इस्तेमाल करके, एंड-टू-एंड पाइपलाइन की पुष्टि करें.
आपको इन चीज़ों की ज़रूरत होगी
- Google Antigravity इंस्टॉल हो.
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट.
- gcloud सीएलआई इंस्टॉल किया गया हो और उसकी पुष्टि की गई हो.
2. ऐप्लिकेशन की खास जानकारी
Antigravity का इस्तेमाल करके ऐप्लिकेशन को डिज़ाइन और लागू करने से पहले, आइए हम उस ऐप्लिकेशन के बारे में खास जानकारी दें जिसे हमें बनाना है.
हमें सर्वरलेस और इवेंट-ड्रिवन दस्तावेज़ पाइपलाइन बनानी है. यह पाइपलाइन, Google Cloud Storage (GCS) से फ़ाइलें लेती है, Cloud Run और Gemini का इस्तेमाल करके उन्हें प्रोसेस करती है, और उनके मेटाडेटा को BigQuery में स्ट्रीम करती है.
इस ऐप्लिकेशन के लिए, आर्किटेक्चर का डायग्राम कुछ ऐसा दिख सकता है:
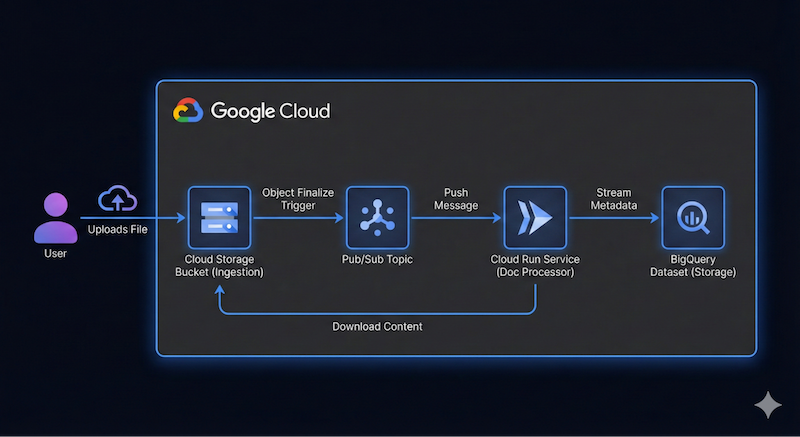
यह सटीक होना ज़रूरी नहीं है. Antigravity की मदद से, हम आर्किटेक्चर की जानकारी का पता लगा सकते हैं. हालांकि, आपको यह पता होना चाहिए कि आपको क्या बनाना है. जितनी ज़्यादा जानकारी दी जाएगी, Antigravity से आर्किटेक्चर और कोड के मामले में उतने ही बेहतर नतीजे मिलेंगे.
3. आर्किटेक्चर प्लान करना
हम Antigravity की मदद से, आर्किटेक्चर की जानकारी की योजना बनाने के लिए तैयार हैं!
Antigravity, जटिल सिस्टम की प्लानिंग करने में माहिर है. हम तुरंत कोड लिखने के बजाय, सबसे पहले हाई-लेवल आर्किटेक्चर तय कर सकते हैं. इसके बाद, किसी एक सुविधा का इस्तेमाल करके, Antigravity को हमारे अनुरोध का आकलन करने में मदद कर सकते हैं. साथ ही, उससे फ़ॉलो अप सवाल पूछ सकते हैं. इसके बाद, हम प्लानिंग और लागू करने की प्रोसेस शुरू कर सकते हैं.
मान लें कि आपने Antigravity लॉन्च कर दिया है. अब हम इस कोडलैब के लिए एक नया प्रोजेक्ट बनाएंगे.
Projects लैब के बगल में मौजूद, नए प्रोजेक्ट के आइकॉन पर क्लिक करें. इसके बाद, नीचे दिखाए गए तरीके से New Project पर क्लिक करें:

इससे, नीचे दिखाए गए Add Folder विकल्प दिखेगा:
अपने प्रोजेक्ट में कोई फ़ोल्डर जोड़ने के लिए, फ़ोल्डर जोड़ें बटन पर क्लिक करें. मैंने अपनी मशीन पर google-cloud-serverless-app फ़ोल्डर बनाया और उसे इस प्रोजेक्ट में जोड़ा.
इससे google-cloud-serverless-app वर्कस्पेस में बातचीत खुल जाती है.
स्क्रीन पर सबसे नीचे बाईं ओर मौजूद, मुख्य सेटिंग आइकॉन ⚙️ पर क्लिक करें. इसके बाद, प्रोजेक्ट से जुड़ी सेटिंग पर जाएं. Agent Settings / Security Preset को Default और Agent Behaviour / Artifact Review Policy को Always Ask पर सेट करें. जैसा कि यहां दिखाया गया है:
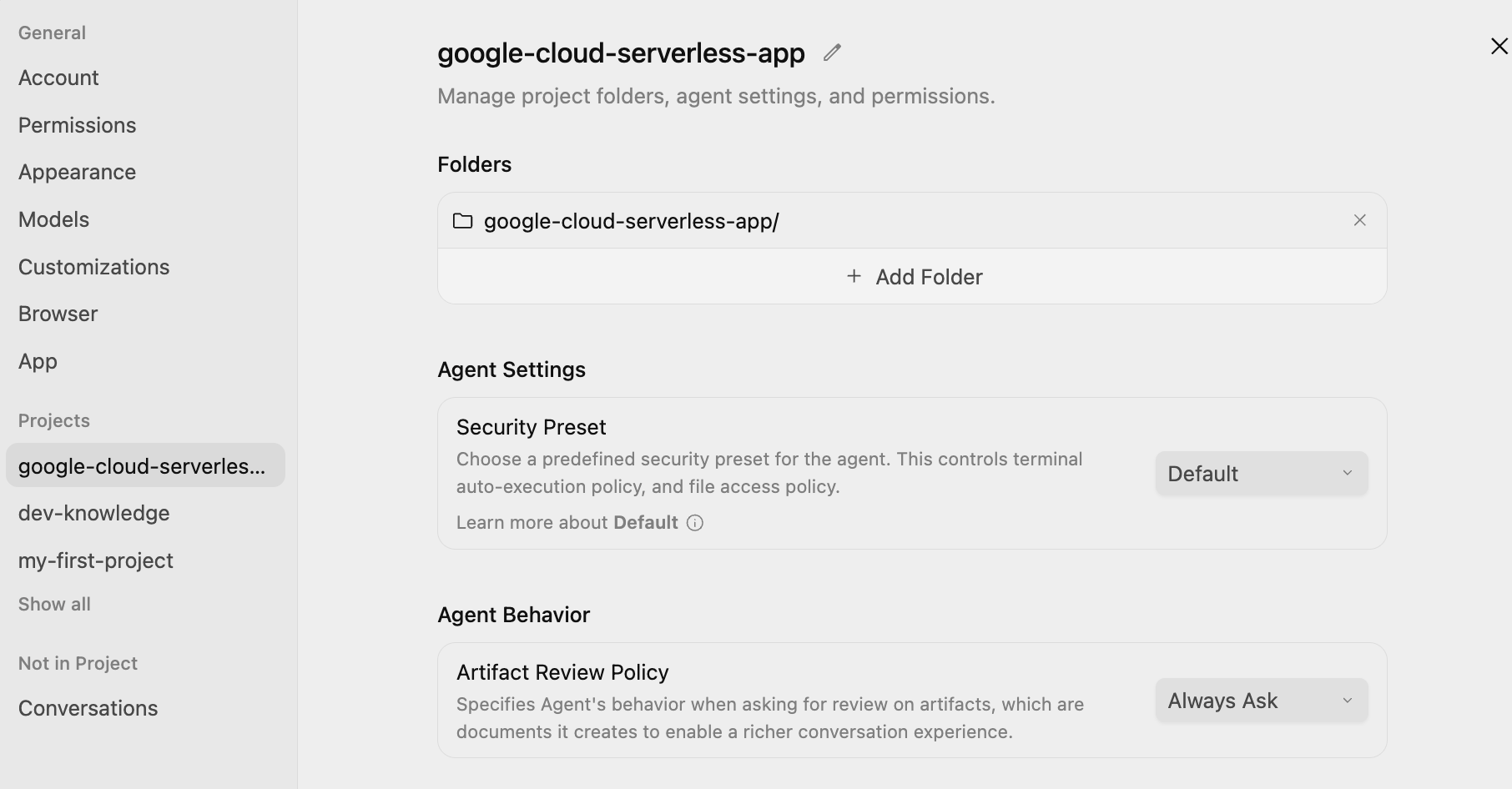
इससे यह पक्का किया जा सकेगा कि एजेंट के प्लान को लागू करने से पहले, आपको हर चरण में उसकी समीक्षा करने और उसे मंज़ूरी देने का मौका मिले.
प्रॉम्प्ट
अब हम Antigravity को पहला प्रॉम्प्ट देने के लिए तैयार हैं. हम अपने अनुरोध का आकलन करने के लिए, स्लैश कमांड /grill-me का इस्तेमाल करने जा रहे हैं.
/grill-me टाइप करें. इसके बाद, यह प्रॉम्प्ट डालें और सबमिट करें बटन पर क्लिक करें:
/grill-me
I want to build a serverless event-driven document processing pipeline on Google Cloud.
Architecture:
- Ingestion: Users upload files to a Cloud Storage bucket.
- Trigger: File uploads trigger a Pub/Sub message.
- Processor: A Python-based Cloud Run service receives the message, processes the file (simulated OCR), and extracts metadata.
- Storage: Stream the metadata (filename, date, tags, word_count) into a BigQuery dataset.
/grill-me कमांड, फ़ॉलो अप के तौर पर कई सवाल पूछती है. अपनी जानकारी के हिसाब से, इन सवालों के जवाब दिए जा सकते हैं. यह कमांड, सुझाए गए जवाब भी दिखाती है. अगर आपको लगता है कि ये जवाब सही हैं, तो इन्हें चुना जा सकता है.
/grill-me कमांड के सैंपल रन का उदाहरण यहां दिया गया है:
How would you provision and manage the Google Cloud infrastructure resources (Cloud Storage buckets, Pub/Sub topics, BigQuery datasets, Cloud Run service)?
gcloud CLI Setup Script - Shell scripts running gcloud CLI commands to create resources step-by-step
How should the Cloud Storage upload events trigger and reach your Python Cloud Run service?
(Recommended) Native Cloud Storage Pub/Sub Notifications + Pub/Sub Push subscription to Cloud Run (direct, lightweight, standard event-driven approach)
Which Python web framework would you prefer for the Cloud Run processing service?
Flask (with Gunicorn) - Standard, lightweight, and very common for simple Cloud Run services
How should the OCR and metadata extraction logic be implemented in the Cloud Run service?
(Recommended) Full local simulation - If it's a .txt file, read the contents, count words, and extract tags. For other files, generate mock OCR metadata and simulated word count. No external API calls.
Which BigQuery insertion method should the Cloud Run service use to store metadata?
(Recommended) BigQuery table.insert_rows() (Legacy Streaming API) - Extremely simple to code, clean error handling, perfect for simulation and low-to-medium volumes.
How should security/authentication be configured for the Cloud Run service?
Unauthenticated Cloud Run - Allow public requests to the Cloud Run service URL (simpler setup, but insecure for production).
What schema would you like to define for the BigQuery metadata table?
(Recommended) Extended Schema - Include filename, bucket, size, content_type, word_count, tags (as a REPEATED STRING array), ocr_text_preview, and process_timestamp.
How should the Cloud Run service handle processing failures (e.g., file not found, BigQuery write error)?
(Recommended) Fail-Fast with Retry - Log error to standard output (Cloud Logging) and return HTTP 500 to Pub/Sub, so that Pub/Sub automatically retries the message delivery.
What testing tools should we generate to verify the pipeline's functionality?
(Recommended) Both - Include a local test script (sending mock Pub/Sub POST requests to the local Flask server) and a Cloud-integrated test script (uploading a real file to GCS and verifying BigQuery).
ध्यान दें कि मैंने Antigravity से यह पूछा है कि:
- संसाधन उपलब्ध कराने के लिए, gcloud सीएलआई की एक सामान्य स्क्रिप्ट
- Cloud Storage की Pub/Sub सूचनाएं + Cloud Run के लिए Pub/Sub पुश सदस्यता
- फ़्रेमवर्क के लिए Flask (Gunicorn के साथ) का इस्तेमाल करें
- लाइव ओसीआर डेटा के बजाय, डेटा के लिए टेक्स्ट फ़ाइल के साथ सिर्फ़ लोकल सिम्युलेशन का इस्तेमाल करें
- BigQuery में पंक्तियां डालने के लिए, BigQuery table.insert_rows() का इस्तेमाल करें
- बिना पुष्टि किया गया Cloud Run डिप्लॉयमेंट
और अन्य सुझाए गए विकल्प.
लागू करने का प्लान और टास्क की सूची
अब Antigravity काम करना शुरू कर देगा और लागू करने का प्लान जनरेट करेगा. यह प्लान आपकी समीक्षा के लिए उपलब्ध कराया जाएगा. इसके लिए, आपको नीचे दिए गए मैसेज जैसा मैसेज मिलेगा:
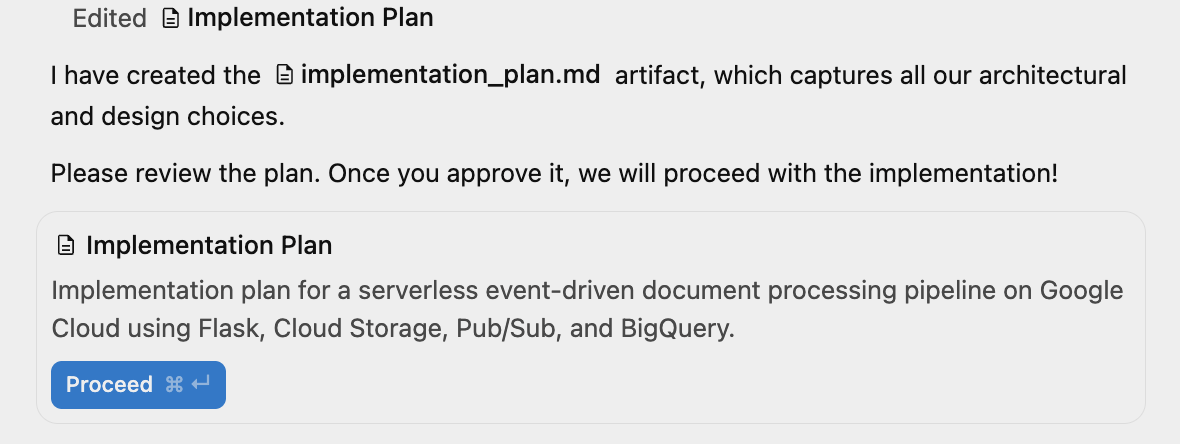
सबसे ऊपर दाईं ओर मौजूद विंडो में, ऑक्ज़िलरी पैन टॉगल पर क्लिक करके जनरेट किए गए आर्टफ़ैक्ट देखे जा सकते हैं. फ़िलहाल, यह सिर्फ़ लागू करने की योजना है.
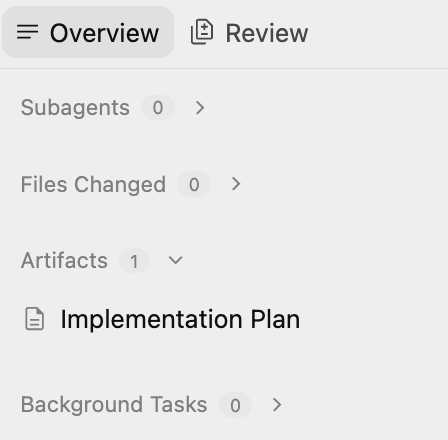
इस प्लान में ये बातें बताई गई हैं:
- बुनियादी ढांचा: GCS बकेट, Pub/Sub विषय, BigQuery डेटासेट.
- प्रोसेसर: Python/Flask ऐप्लिकेशन, Dockerfile, Requirements.
- इंटिग्रेशन: GCS सूचनाएं → Pub/Sub → Cloud Run.
आपको कुछ ऐसा दिखेगा. हमारी मशीन पर लागू करने के प्लान की आंशिक सूची यहां दिखाई गई है:
Event-Driven Document Processing Pipeline Implementation Plan
This implementation plan describes the components and setup scripts required to build a serverless event-driven document processing pipeline on Google Cloud.
User Review Required
Please review the proposed architecture, components, and default configuration. If you agree, please approve the plan so we can proceed with creating the files and implementation.
IMPORTANT
Security Notice: As requested, the Cloud Run service is configured to allow unauthenticated invocations (--allow-unauthenticated) for simpler testing and development.
Error Handling: The service returns an HTTP 500 error code for failures to trigger Pub/Sub retries.
GCP Configuration: The provisioning scripts will use standard environment variables (e.g., GCP_PROJECT, GCP_REGION) that default to the active configuration of your local gcloud CLI.
Proposed Components and Files
The project will be organized as follows:
google-cloud-serverless-app/
├── src/
│ ├── __init__.py
│ ├── app.py # Flask app entrypoint and routes
│ ├── processor.py # Simulated OCR and metadata extraction engine
│ ├── gcs_helper.py # Helper functions to read files from Cloud Storage
│ └── bq_helper.py # Helper functions to write metadata to BigQuery
├── requirements.txt # Python dependencies
├── Dockerfile # Docker configuration for Cloud Run
├── deploy.sh # gcloud CLI provisioning and deployment script
├── test_local.sh # Script to test the Flask app locally with mock Pub/Sub events
├── test_cloud.sh # Script to upload a real file to GCS and query BigQuery
└── README.md # Setup and execution guide
इसे ध्यान से पढ़ें. आपके पास इस सुविधा को लागू करने के बारे में सुझाव/राय देने या शिकायत करने का मौका है. लागू करने के प्लान के किसी भी हिस्से पर क्लिक करके, टिप्पणियां जोड़ी जा सकती हैं. कुछ टिप्पणियां जोड़ने के बाद, उन बदलावों को समीक्षा के लिए सबमिट करना न भूलें जिन्हें आपको देखना है. खास तौर पर, नाम, Google Cloud प्रोजेक्ट आईडी, क्षेत्र वगैरह से जुड़े बदलाव.
जब आपको सब कुछ ठीक लगे, तब एजेंट को लागू करने के प्लान के साथ आगे बढ़ने की अनुमति दें. इसके लिए, Proceed बटन पर क्लिक करें.
अब यह एक और आर्टफ़ैक्ट टास्क प्लान बनाता है. इसमें ऐसे टास्क का सेट होता है जिन्हें Antigravity ने बनाया है. एजेंट, एक-एक करके इन कार्रवाइयों को पूरा करेगा. काम की सूची का एक सैंपल यहां दिखाया गया है:
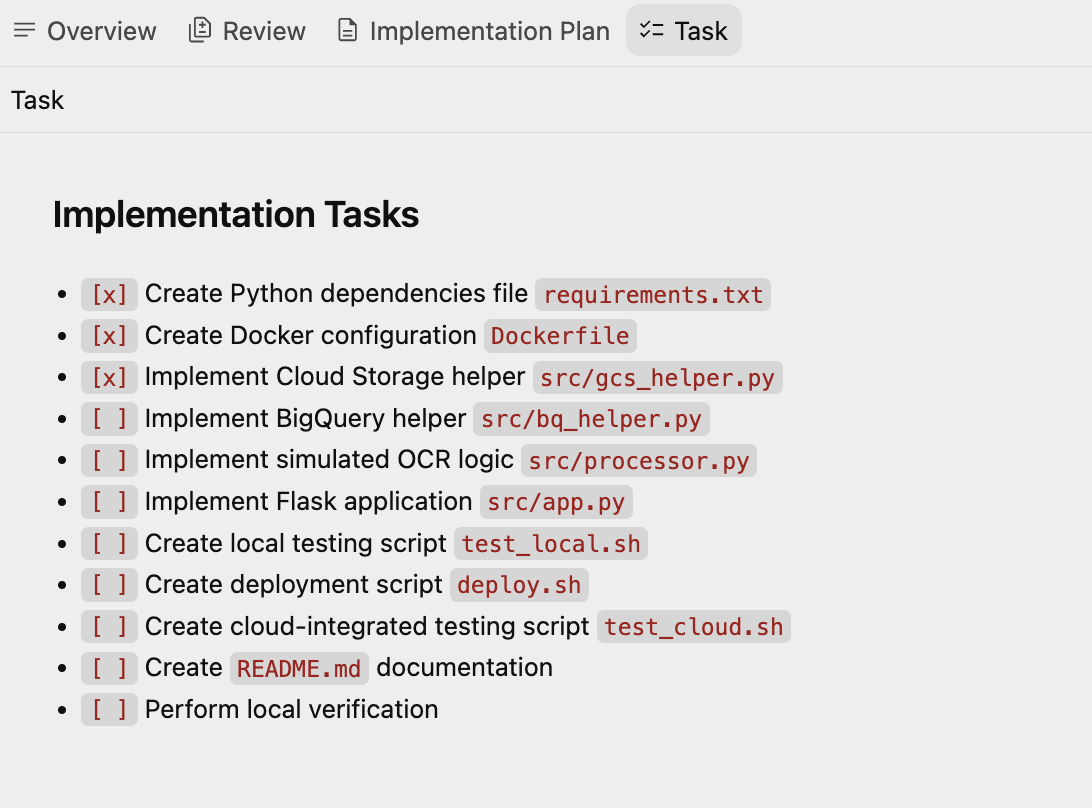
4. ऐप्लिकेशन जनरेट करो
प्लान को मंज़ूरी मिलने के बाद, Antigravity ऐप्लिकेशन के लिए ज़रूरी फ़ाइलें जनरेट करना शुरू कर देता है. इनमें प्रोविज़निंग स्क्रिप्ट से लेकर ऐप्लिकेशन कोड तक शामिल हैं.
Antigravity एक फ़ोल्डर बनाएगा और प्रोजेक्ट के लिए ज़रूरी फ़ाइलें बनाना शुरू कर देगा. आर्टफ़ैक्ट की जांच करने पर, आपको कई फ़ाइलें (सोर्स कोड, स्क्रिप्ट फ़ाइलें वगैरह) जनरेट होती दिखेंगी.
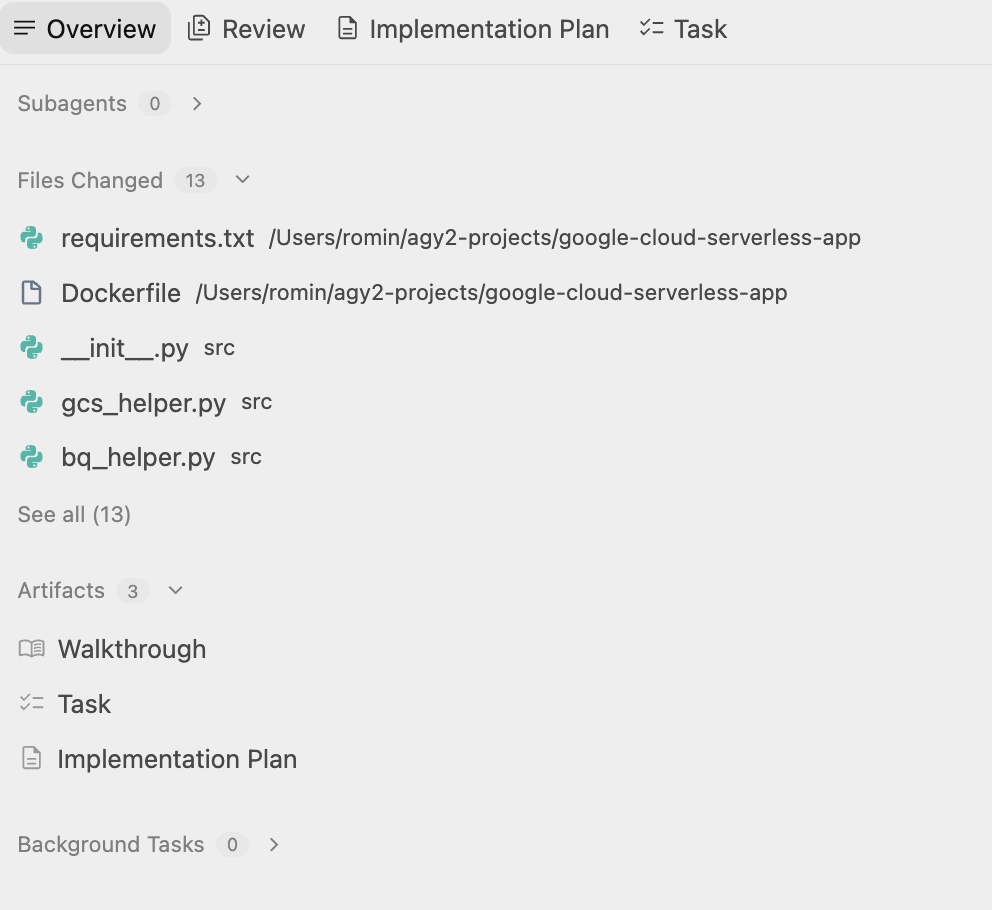
जब यह प्रोसेस पूरी हो जाएगी, तो आपको इसकी सूचना मिलेगी. साथ ही, एक वॉकट्रू दस्तावेज़ बनाया जाएगा, जिसे देखा जा सकता है. इसमें उपयोगकर्ता के लिए अगला चरण बताया गया है. इसका एक उदाहरण यहां दिया गया है:
- पाइपलाइन डिप्लॉय करें: पक्का करें कि आपने GCP CLI में लॉग इन किया हो और टारगेट प्रोजेक्ट सेट किया हो. इसके बाद, यह कमांड चलाएं:
./deploy.sh - एंड-टू-एंड टेस्ट चलाएं: क्लाउड इंटिग्रेशन टेस्ट स्क्रिप्ट को एक्ज़ीक्यूट करें. इससे यह पुष्टि की जा सकेगी कि फ़ाइल अपलोड करने पर, Cloud Run प्रोसेसिंग ट्रिगर होती है और BigQuery को मेटाडेटा स्ट्रीम किया जाता है:
./test_cloud.sh - क्लीन अप: टेस्टिंग पूरी होने के बाद, बनाए गए संसाधनों को हटाने के लिए
README.mdक्लीन-अप कमांड का इस्तेमाल करें. इससे आपको शुल्क नहीं देना पड़ेगा.
आपको deploy.sh या इसी तरह के नाम वाली शेल स्क्रिप्ट फ़ाइल जनरेट हुई दिखेगी. इससे संसाधन बनाने की प्रोसेस अपने-आप पूरी हो जाती है. यह इन चीज़ों को मैनेज करता है:
- एपीआई चालू करना (
run,pubsub,bigquery,storage). - Google Cloud Storage बकेट (
document-processing-ingest-{project-id}) बनाया जा रहा है. - BigQuery डेटासेट और टेबल बनाना (
document_processing.processed_metadata). - Pub/Sub विषयों और सूचनाओं को कॉन्फ़िगर करना.
5. ऐप्लिकेशन डिप्लॉय करना
आइए, ./ deploy.sh कमांड का इस्तेमाल करके, ऐप्लिकेशन को डिप्लॉय करें. हम Antigravity से यह काम करने के लिए कह सकते हैं. हालांकि, इससे पहले पक्का करें कि gcloud CLI मौजूद हो और Google Cloud प्रोजेक्ट के लिए कॉन्फ़िगर किया गया हो.
हम Antigravity को यह प्रॉम्प्ट दे सकते हैं कि "मेरे लिए deploy.sh चलाओ". ऐसा करने पर, आपसे अनुमति मांगी जाएगी. आगे बढ़ें और वह जानकारी दें.
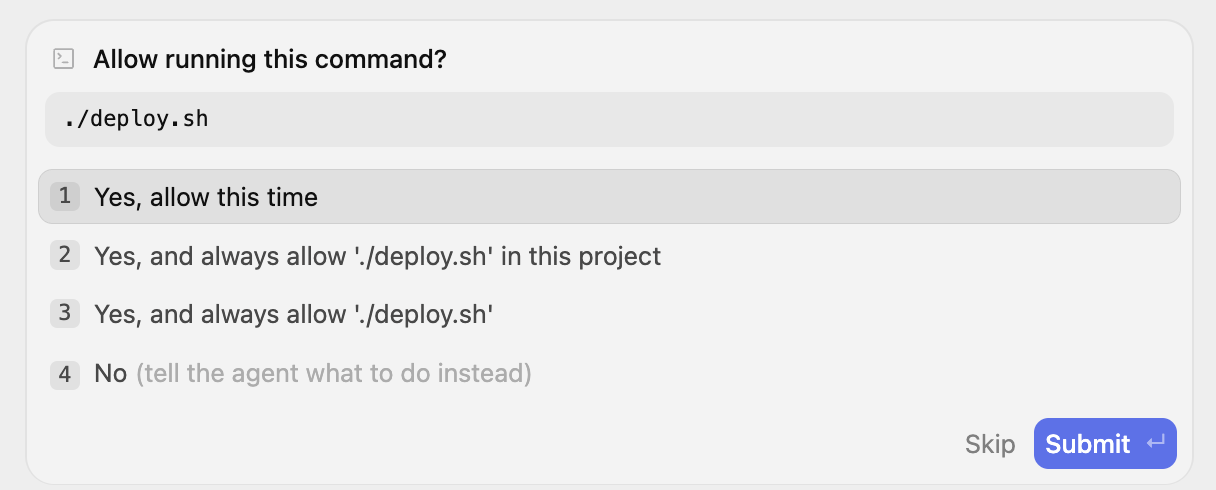
यह प्रोसेस को बैकग्राउंड टास्क के तौर पर शुरू करता है. इसके बारे में यहां दिए गए मैसेज में बताया गया है:
मैंने बैकग्राउंड में ./deploy.sh चलाकर, डिप्लॉयमेंट की प्रोसेस शुरू कर दी है. मैं एक्ज़ीक्यूशन लॉग पर नज़र रखूंगा और डिप्लॉयमेंट पूरा होने पर आपको इसकी सूचना दूंगा!
6. ऐप्लिकेशन की पुष्टि करना
पाइपलाइन डिप्लॉय होने के बाद, Antigravity यह पुष्टि करता है कि ऐप्लिकेशन सही तरीके से काम कर रहा है या नहीं. यह हमसे पूछता है कि क्या वह test_cloud.sh फ़ाइल को चला सकता है. हम इसे अनुमति दे सकते हैं.

इससे हमें यह जानकारी मिलती है:
I have successfully run both ./deploy.sh and ./test_cloud.sh.
The pipeline is fully deployed to your GCP project PROJECT_ID and working end-to-end.
Please refer to the walkthrough.md for full verification details and the query output from BigQuery showing the successfully processed document metadata.
नतीजे देखने के लिए, हम वॉकट्रू आर्टफ़ैक्ट खोल सकते हैं:
Cloud Verification Results
The deployment and end-to-end cloud integration test (./test_cloud.sh) succeeded perfectly!
Resources Created:
GCS Bucket: gs://document-processing-ingest-gcp-experiments-349209
Pub/Sub Topic: document-uploads-topic
Pub/Sub Subscription: document-uploads-sub (pushing to Cloud Run)
Cloud Run Service: document-processor (URL: https://document-processor-ido3ocn3pq-uc.a.run.app)
BigQuery Dataset: document_processing
BigQuery Table: processed_metadata
Integration Test Run: A test file cloud_test_sample.txt was uploaded to the bucket. The pipeline processed the file and streamed the metadata record into BigQuery:
🔍 Querying BigQuery to verify metadata insertion...
<BIQUERY DATA HERE>
The pipeline successfully detected the hashtags #gcp and #serverless as tags, correctly counted the 47 words, generated the OCR preview, and wrote the entry to BigQuery under the schema.
ज़रूरी नहीं: मैन्युअल तरीके से पुष्टि करना
Antigravity ने ऐप्लिकेशन की पुष्टि कर दी है. हालांकि, अगर आपको Google Cloud Console में जाकर यह देखना है कि सभी संसाधन बनाए गए हैं या नहीं, तो यह तरीका अपनाएं.
Cloud Storage
लक्ष्य: पुष्टि करें कि बकेट मौजूद है और अपलोड की गई फ़ाइलों की जांच करें.
- Cloud Storage > बकेट पर जाएं.
document-processing-ingest-{project-id}नाम वाले बकेट का पता लगाएं.- फ़ाइलें ब्राउज़ करने के लिए, बकेट के नाम पर क्लिक करें.
- पुष्टि करें: आपको अपनी अपलोड की गई फ़ाइलें दिखनी चाहिए. जैसे,
cloud_test_sample.txt.
Pub/Sub
लक्ष्य: पुष्टि करें कि विषय मौजूद है और उसके लिए पुश नोटिफ़िकेशन पाने की सुविधा चालू है.
- Pub/Sub > विषय पर जाएं.
- document-uploads-topic ढूंढें.
- विषय का आईडी पर क्लिक करें.
- नीचे की ओर स्क्रोल करके, सदस्यताएं टैब पर जाएं.
- पुष्टि करें: पक्का करें कि doc-uploads-sub को "पुश करें" डिलीवरी टाइप के साथ सूची में शामिल किया गया हो.
Cloud Run
लक्ष्य: सेवा की स्थिति और लॉग की जांच करें.
- Cloud Run पर जाएं.
- सेवा document-processor पर क्लिक करें.
- पुष्टि करें:
- स्वास्थ्य: हरे रंग का सही का निशान, यह दिखाता है कि सेवा चालू है.
- लॉग: लॉग टैब पर क्लिक करें. "Processing file: gs://..." और "Successfully inserted..." जैसी एंट्री ढूंढें.
BigQuery
लक्ष्य: पुष्टि करना कि डेटा वाकई में सेव किया गया है.
- BigQuery > SQL फ़ाइल फ़ोल्डर पर जाएं.
- एक्सप्लोरर पैनल में, project > document_processing dataset को बड़ा करें.
- processed_metadata टेबल पर क्लिक करें.
- क्वेरी टैब पर क्लिक करें और SELECT * स्टेटमेंट का इस्तेमाल करके, टेबल की सभी लाइनें वापस पाएं.
- पुष्टि करें: आपको filename, process_timestamp, tags, और word_count वाली लाइनें दिखनी चाहिए.
7. ऐप्लिकेशन के बारे में ज़्यादा जानें
इस समय, आपके पास बुनियादी ऐप्लिकेशन उपलब्ध है और वह चल रहा है. इस ऐप्लिकेशन को आगे बढ़ाने से पहले, कुछ समय निकालकर कोड को एक्सप्लोर करें. आर्टफ़ैक्ट देखे जा सकते हैं. इनमें जनरेट की गई कोड फ़ाइलें दिखेंगी.
यहां उन फ़ाइलों के बारे में खास जानकारी दी गई है जो आपको दिख सकती हैं:
deploy.sh: यह मास्टर स्क्रिप्ट है. यह सभी Google Cloud संसाधनों को उपलब्ध कराती है और ज़रूरी एपीआई चालू करती है.appy.py: यह पाइपलाइन का मुख्य एंट्री पॉइंट है. यह Python ऐप्लिकेशन एक वेब सर्वर बनाता है. यह Pub/Sub पुश मैसेज पाता है, GCS से फ़ाइल डाउनलोड करता है, उसे "प्रोसेस" करता है (ओसीआर की प्रोसेस को सिम्युलेट करता है), और मेटाडेटा को BigQuery पर स्ट्रीम करता है.Dockerfile: इससे यह तय होता है कि ऐप्लिकेशन को कंटेनर इमेज में कैसे पैकेज किया जाए.requirements.txt: Python की डिपेंडेंसी की सूची बनाता है.
आपको जांच और पुष्टि के लिए ज़रूरी अन्य स्क्रिप्ट और टेक्स्ट फ़ाइलें भी दिख सकती हैं.
8. ऐप्लिकेशन का साइज़ बड़ा करें
अब आपके पास काम करने वाला एक बुनियादी ऐप्लिकेशन है. इसलिए, ऐप्लिकेशन को बेहतर बनाने और उसे बढ़ाने के लिए काम जारी रखा जा सकता है. यहां कुछ आइडिया दिए गए हैं.
फ़्रंटएंड जोड़ना
प्रोसेस किए गए दस्तावेज़ों को देखने के लिए, एक आसान वेब इंटरफ़ेस बनाएं.
यह प्रॉम्प्ट आज़माएँ: Create a simple Streamlit or Flask web application that connects to BigQuery. It should display a table of the processed documents (filename, upload_date, tags, word_count) and allow me to filter the results by tag
एआई/एमएल को रीयल टाइम में इंटिग्रेट करना
ओसीआर प्रोसेसिंग का सिम्युलेट करने के बजाय, Gemini के मॉडल का इस्तेमाल करके टेक्स्ट को एक्सट्रैक्ट करें, उसे कैटगरी में बांटें, और उसका अनुवाद करें.
- डमी ओसीआर लॉजिक बदलें. इमेज/PDF को Gemini पर भेजें, ताकि वह उसमें मौजूद टेक्स्ट और डेटा को निकाल सके. निकाले गए टेक्स्ट का विश्लेषण करके, दस्तावेज़ के टाइप (इनवॉइस, अनुबंध, फिर से शुरू) को कैटगरी में बांटना या इकाइयों (तारीखें, नाम, जगहें) को निकालना.
- यह सुविधा, दस्तावेज़ की भाषा का अपने-आप पता लगाती है और उसे सेव करने से पहले अंग्रेज़ी में अनुवाद करती है. हालांकि, किसी दूसरी भाषा का भी इस्तेमाल किया जा सकता है.
स्टोरेज और आंकड़ों को बेहतर बनाना
लागत बचाने के लिए, बकेट पर लाइफ़साइकल के नियम कॉन्फ़िगर किए जा सकते हैं. इससे पुरानी फ़ाइलों को "कोल्डलाइन" या "संग्रह" स्टोरेज में ले जाया जा सकता है.
मज़बूत और सुरक्षित
ऐप्लिकेशन को ज़्यादा मज़बूत और सुरक्षित बनाया जा सकता है. जैसे:
- डेड लेटर क्यू (डीएलक्यू): फ़ेलियर को मैनेज करने के लिए, Pub/Sub सदस्यता को अपडेट करें. अगर Cloud Run सेवा किसी फ़ाइल को पांच बार प्रोसेस नहीं कर पाती है, तो उस मैसेज को "डेड लेटर" वाले अलग विषय/बकेट में भेजें, ताकि कोई व्यक्ति उसकी जांच कर सके.
- Secret Manager: अगर आपके ऐप्लिकेशन को एपीआई कुंजियों या संवेदनशील कॉन्फ़िगरेशन की ज़रूरत है, तो उन्हें Secret Manager में सेव करें. साथ ही, स्ट्रिंग को हार्डकोड करने के बजाय, Cloud Run से उन्हें सुरक्षित तरीके से ऐक्सेस करें.
- Eventarc: इवेंट राउटिंग को ज़्यादा सुविधाजनक बनाने के लिए, सीधे Pub/Sub से Eventarc पर अपग्रेड करें. इससे, आपको जटिल ऑडिट लॉग या अन्य GCP सेवा इवेंट के आधार पर ट्रिगर करने की सुविधा मिलती है.
ज़रूर, आपके पास अपने आइडिया इस्तेमाल करने का विकल्प है. साथ ही, Antigravity की मदद से उन्हें लागू किया जा सकता है!
9. नतीजा
आपने Google Antigravity का इस्तेमाल करके, कुछ ही मिनटों में एक ऐसी दस्तावेज़ पाइपलाइन बनाई है जिसे ज़रूरत के हिसाब से बढ़ाया जा सकता है. यह सर्वरलेस है और एआई की मदद से काम करती है. आपने इन कामों को करने का तरीका सीखा:
- एआई की मदद से आर्किटेक्चर प्लान करें.
- Antigravity को निर्देश दें और उसे मैनेज करें. यह कोड जनरेट करने से लेकर ऐप्लिकेशन को डिप्लॉय और पुष्टि करने तक का काम करता है.
- वॉकथ्रू की मदद से, डिप्लॉयमेंट और पुष्टि की प्रोसेस की जानकारी पाएं.
रेफ़रंस दस्तावेज़
- आधिकारिक साइट : https://antigravity.google/
- दस्तावेज़: https://antigravity.google/docs
- इस्तेमाल के उदाहरण : https://antigravity.google/use-cases
- डाउनलोड करें : https://antigravity.google/download