
1. 소개
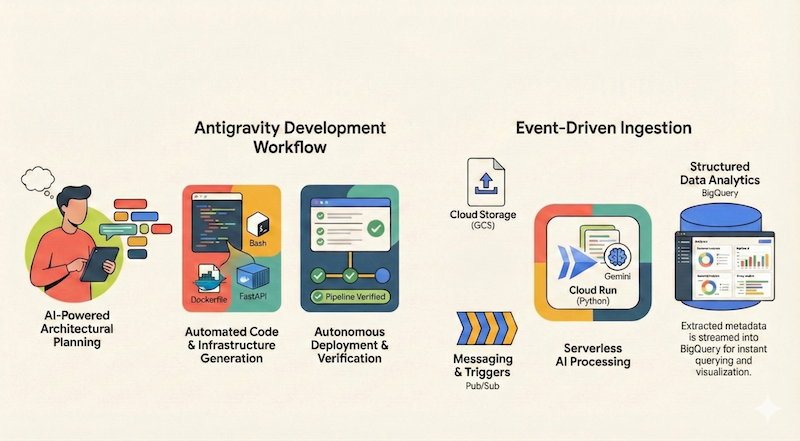
이 Codelab에서는 Google Antigravity를 사용하여 서버리스 애플리케이션을 설계, 빌드, Google Cloud에 배포하는 방법을 알아봅니다. Google Cloud Storage (GCS)에서 파일을 수집하고 Cloud Run 및 Gemini를 사용하여 파일을 처리하며 메타데이터를 BigQuery로 스트리밍하는 서버리스 이벤트 기반 문서 파이프라인을 빌드합니다.
학습할 내용
- 아키텍처 계획 및 설계에 Antigravity를 사용하는 방법
- AI 에이전트로 코드형 인프라 (셸 스크립트) 생성
- Python 기반 Cloud Run 서비스 빌드 및 배포
- Vertex AI에서 Gemini를 통합하여 멀티모달 문서 분석
- Antigravity의 Walkthrough 아티팩트를 사용하여 엔드 투 엔드 파이프라인 확인
필요한 항목
- Google Antigravity가 설치되어 있어야 합니다.
- 결제가 사용 설정된 Google Cloud 프로젝트.
- gcloud CLI 설치 및 인증
2. 앱 개요
Antigravity를 사용하여 애플리케이션을 설계하고 구현하기 전에 먼저 빌드하려는 애플리케이션을 간략하게 설명해 보겠습니다.
Google Cloud Storage (GCS)에서 파일을 수집하고 Cloud Run 및 Gemini를 사용하여 파일을 처리하며 메타데이터를 BigQuery로 스트리밍하는 서버리스 이벤트 기반 문서 파이프라인을 빌드합니다.
이 애플리케이션의 대략적인 아키텍처 다이어그램은 다음과 같습니다.
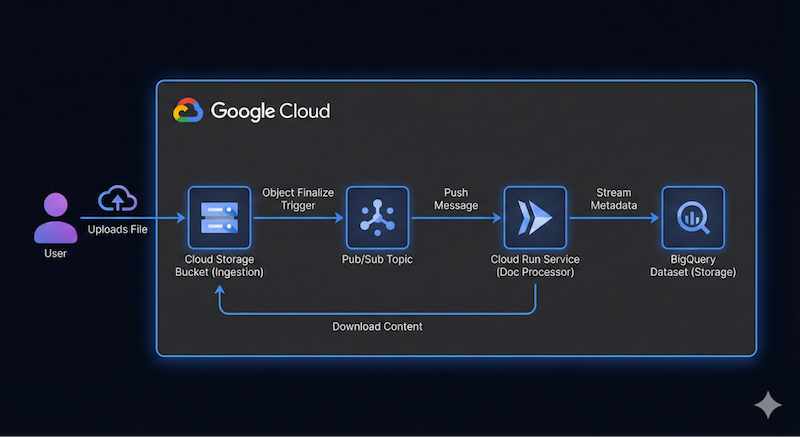
정확하지 않아도 됩니다. Antigravity는 진행하면서 아키텍처 세부정보를 파악하는 데 도움이 될 수 있습니다. 하지만 빌드하려는 항목에 대한 아이디어가 있으면 도움이 됩니다. 세부정보를 더 많이 제공할수록 아키텍처 및 코드 측면에서 Antigravity에서 더 나은 결과를 얻을 수 있습니다.
3. 아키텍처 계획
이제 Antigravity를 사용하여 아키텍처 세부정보를 계획할 준비가 되었습니다.
Antigravity는 복잡한 시스템을 계획하는 데 탁월합니다. 코드를 즉시 작성하는 대신 대략적인 아키텍처를 정의하는 것으로 시작하고 기능 중 하나를 사용하여 Antigravity가 요청을 평가하고 후속 질문을 한 다음 계획 및 구현을 진행하도록 할 수 있습니다.
Antigravity를 실행했다고 가정하고 이 Codelab을 위한 새 프로젝트를 만듭니다.
아래와 같이 Projects 탭 옆에 있는 새 프로젝트 아이콘을 클릭한 다음 New Project 를 클릭합니다.

그러면 아래와 같이 Add Folder 옵션이 표시됩니다.
Add Folder 버튼을 클릭하여 프로젝트에 폴더를 추가합니다. 머신에서 google-cloud-serverless-app 폴더를 만들고 이 프로젝트에 추가했습니다.
그러면 google-cloud-serverless-app 작업공간에서 대화가 열립니다.
화면 왼쪽 하단에 있는 기본 설정 아이콘 ⚙️을 클릭하고 프로젝트별 설정으로 이동합니다. 아래와 같이 Agent Settings / Security Preset을 Default로, Agent Behaviour / Artifact Review Policy를 Always Ask로 설정합니다.
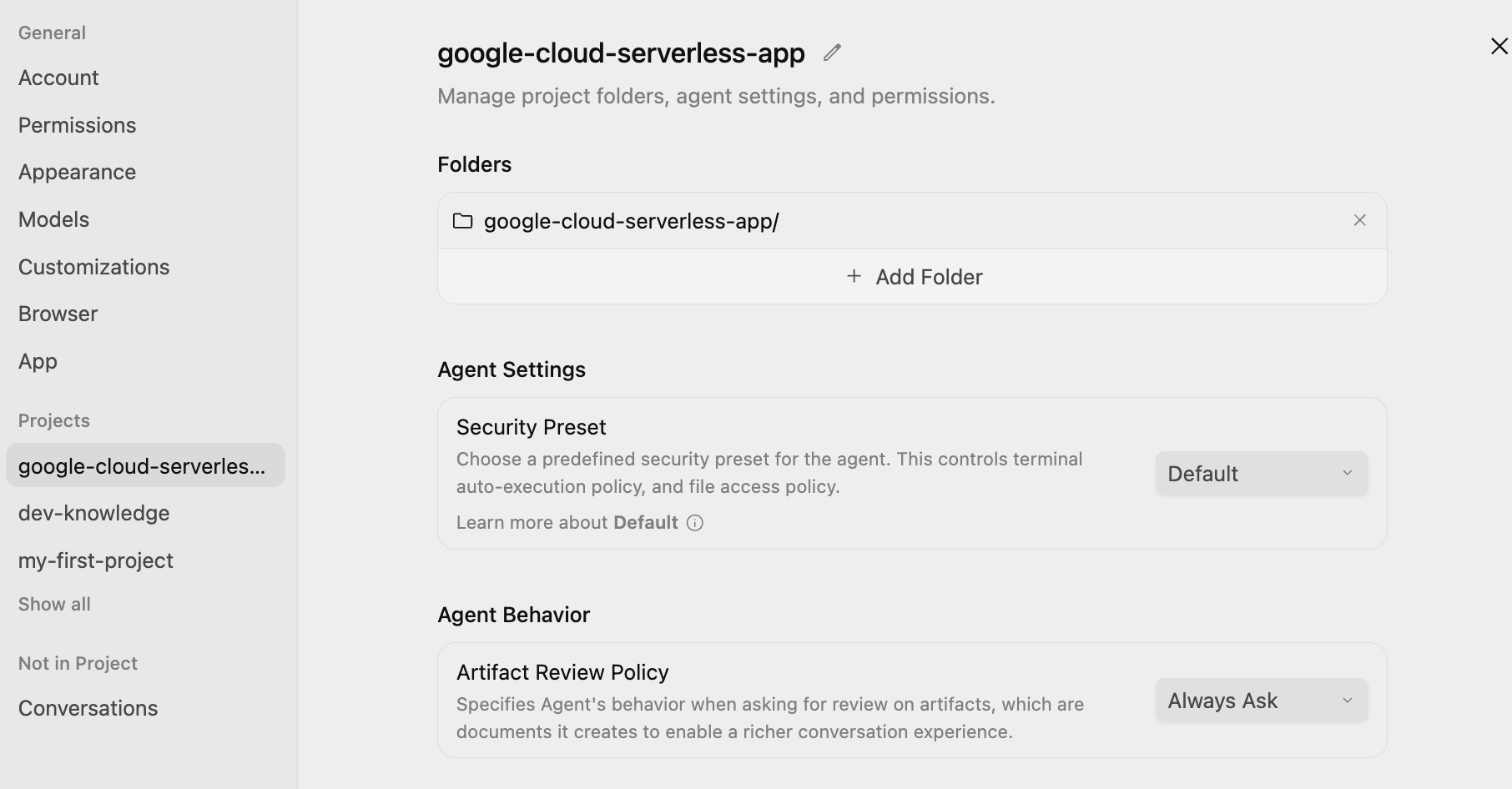
이렇게 하면 모든 단계에서 에이전트가 실행되기 전에 계획을 검토하고 승인할 수 있습니다.
프롬프트
이제 Antigravity에 첫 번째 프롬프트를 제공할 준비가 되었습니다. 슬래시 명령어 /grill-me를 사용하여 요청을 평가합니다.
/grill-me를 입력한 다음 다음 프롬프트를 입력하고 제출 버튼을 클릭합니다.
/grill-me
I want to build a serverless event-driven document processing pipeline on Google Cloud.
Architecture:
- Ingestion: Users upload files to a Cloud Storage bucket.
- Trigger: File uploads trigger a Pub/Sub message.
- Processor: A Python-based Cloud Run service receives the message, processes the file (simulated OCR), and extracts metadata.
- Storage: Stream the metadata (filename, date, tags, word_count) into a BigQuery dataset.
/grill-me 명령어는 최대한 많은 후속 질문을 합니다. 추천 답변 도 제안하며 원하는 경우 이 답변을 사용할 수 있습니다.
내 /grill-me 명령어의 샘플 실행은 다음과 같습니다.
How would you provision and manage the Google Cloud infrastructure resources (Cloud Storage buckets, Pub/Sub topics, BigQuery datasets, Cloud Run service)?
gcloud CLI Setup Script - Shell scripts running gcloud CLI commands to create resources step-by-step
How should the Cloud Storage upload events trigger and reach your Python Cloud Run service?
(Recommended) Native Cloud Storage Pub/Sub Notifications + Pub/Sub Push subscription to Cloud Run (direct, lightweight, standard event-driven approach)
Which Python web framework would you prefer for the Cloud Run processing service?
Flask (with Gunicorn) - Standard, lightweight, and very common for simple Cloud Run services
How should the OCR and metadata extraction logic be implemented in the Cloud Run service?
(Recommended) Full local simulation - If it's a .txt file, read the contents, count words, and extract tags. For other files, generate mock OCR metadata and simulated word count. No external API calls.
Which BigQuery insertion method should the Cloud Run service use to store metadata?
(Recommended) BigQuery table.insert_rows() (Legacy Streaming API) - Extremely simple to code, clean error handling, perfect for simulation and low-to-medium volumes.
How should security/authentication be configured for the Cloud Run service?
Unauthenticated Cloud Run - Allow public requests to the Cloud Run service URL (simpler setup, but insecure for production).
What schema would you like to define for the BigQuery metadata table?
(Recommended) Extended Schema - Include filename, bucket, size, content_type, word_count, tags (as a REPEATED STRING array), ocr_text_preview, and process_timestamp.
How should the Cloud Run service handle processing failures (e.g., file not found, BigQuery write error)?
(Recommended) Fail-Fast with Retry - Log error to standard output (Cloud Logging) and return HTTP 500 to Pub/Sub, so that Pub/Sub automatically retries the message delivery.
What testing tools should we generate to verify the pipeline's functionality?
(Recommended) Both - Include a local test script (sending mock Pub/Sub POST requests to the local Flask server) and a Cloud-integrated test script (uploading a real file to GCS and verifying BigQuery).
Antigravity에 다음을 요청했습니다.
- 리소스를 프로비저닝하는 간단한 gcloud CLI 스크립트
- 기본 Cloud Storage Pub/Sub 알림 + Cloud Run에 대한 Pub/Sub 푸시 구독
- 프레임워크에 Flask (Gunicorn 포함) 사용
- 실시간 OCR 데이터 대신 데이터에 텍스트 파일이 있는 로컬 시뮬레이션만 사용
- BigQuery 테이블을 사용하여 BigQuery에 행 삽입
- 인증되지 않은 Cloud Run 배포
및 기타 권장 옵션.
구현 계획 및 할 일 목록
이제 Antigravity가 작동하여 구현 계획 을 생성합니다. 아래와 비슷한 메시지를 표시하여 검토를 위해 제공합니다.
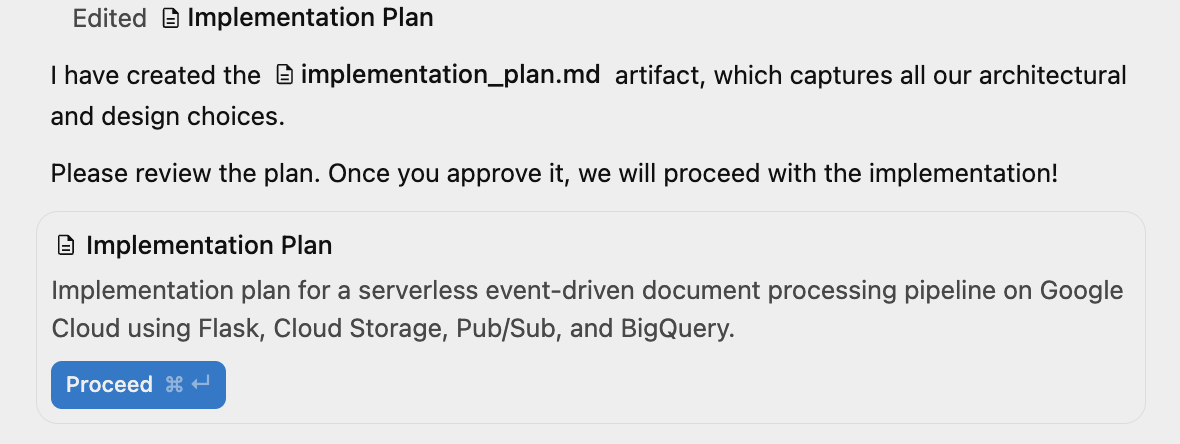
오른쪽 상단 창에서 보조 창 전환을 클릭하고 생성된 아티팩트를 볼 수 있습니다. 이 시점에서는 구현 계획 뿐입니다.
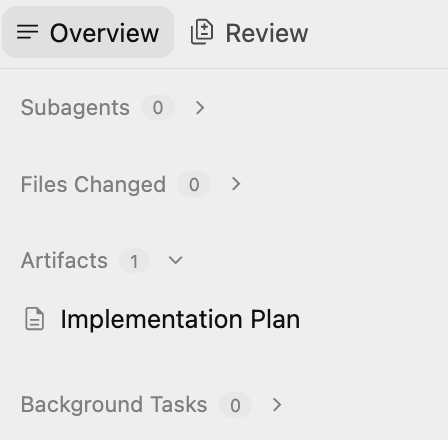
이 계획은 다음을 간략하게 설명합니다.
- 인프라: GCS 버킷, Pub/Sub 주제, BigQuery 데이터 세트.
- 프로세서: Python/Flask 앱, Dockerfile, 요구사항.
- 통합: GCS 알림 → Pub/Sub → Cloud Run.
다음과 비슷한 내용이 표시됩니다. 머신에서 구현 계획의 일부 목록은 다음과 같습니다.
Event-Driven Document Processing Pipeline Implementation Plan
This implementation plan describes the components and setup scripts required to build a serverless event-driven document processing pipeline on Google Cloud.
User Review Required
Please review the proposed architecture, components, and default configuration. If you agree, please approve the plan so we can proceed with creating the files and implementation.
IMPORTANT
Security Notice: As requested, the Cloud Run service is configured to allow unauthenticated invocations (--allow-unauthenticated) for simpler testing and development.
Error Handling: The service returns an HTTP 500 error code for failures to trigger Pub/Sub retries.
GCP Configuration: The provisioning scripts will use standard environment variables (e.g., GCP_PROJECT, GCP_REGION) that default to the active configuration of your local gcloud CLI.
Proposed Components and Files
The project will be organized as follows:
google-cloud-serverless-app/
├── src/
│ ├── __init__.py
│ ├── app.py # Flask app entrypoint and routes
│ ├── processor.py # Simulated OCR and metadata extraction engine
│ ├── gcs_helper.py # Helper functions to read files from Cloud Storage
│ └── bq_helper.py # Helper functions to write metadata to BigQuery
├── requirements.txt # Python dependencies
├── Dockerfile # Docker configuration for Cloud Run
├── deploy.sh # gcloud CLI provisioning and deployment script
├── test_local.sh # Script to test the Flask app locally with mock Pub/Sub events
├── test_cloud.sh # Script to upload a real file to GCS and query BigQuery
└── README.md # Setup and execution guide
주의 깊게 읽어보세요. 구현에 대한 의견을 제공할 수 있는 기회입니다. 구현 계획의 아무 부분이나 클릭하고 의견을 추가할 수 있습니다. 의견을 추가한 후 특히 이름 지정, Google Cloud 프로젝트 ID, 리전 등에 관해 원하는 변경사항을 검토를 위해 제출해야 합니다.
모든 것이 괜찮아 보이면 Proceed 버튼을 클릭하여 에이전트가 구현 계획을 진행할 수 있는 권한을 부여합니다.
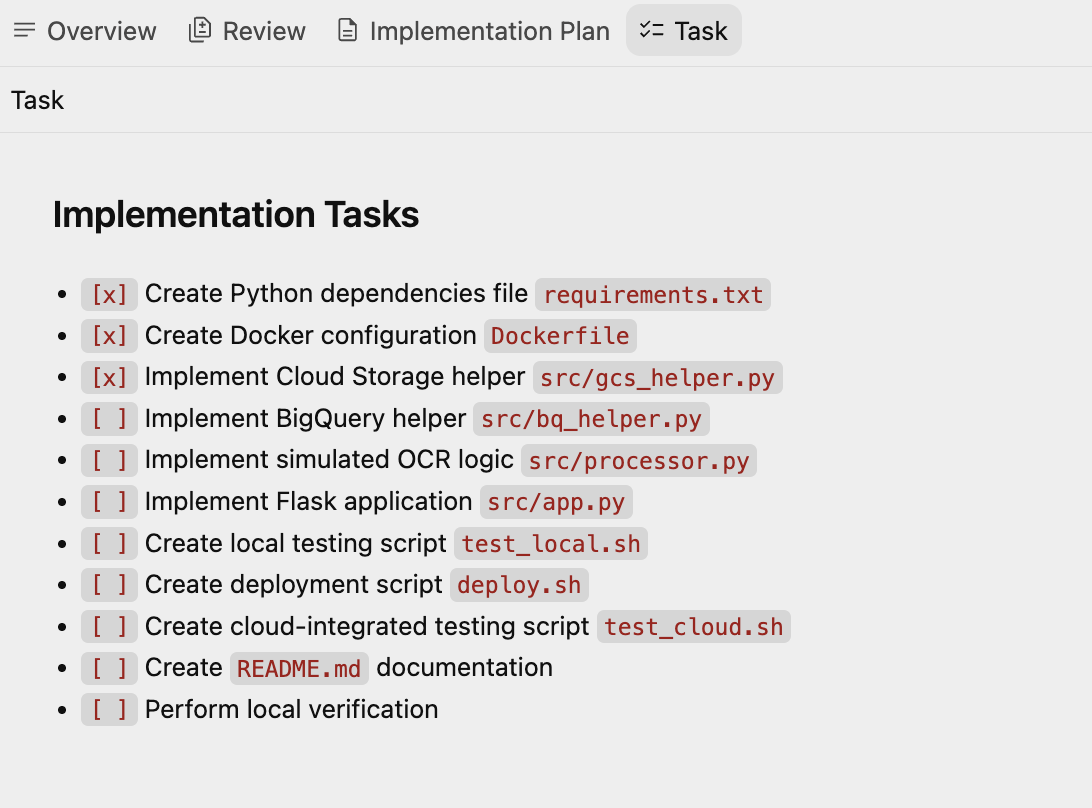
이제 Antigravity에서 만든 작업 집합이 포함된 다른 아티팩트 작업 계획을 만듭니다. 에이전트는 하나씩 살펴보고 실행합니다. 샘플 할 일 목록은 다음과 같습니다.
4. 애플리케이션 생성
계획이 승인되면 Antigravity는 프로비저닝 스크립트에서 애플리케이션 코드에 이르기까지 애플리케이션에 필요한 파일 생성을 시작합니다.
Antigravity는 폴더를 만들고 프로젝트에 필요한 파일 생성을 시작합니다. 아티팩트를 확인하면 여러 파일 (소스 코드, 스크립트 파일 등)이 생성되는 것을 확인할 수 있습니다.
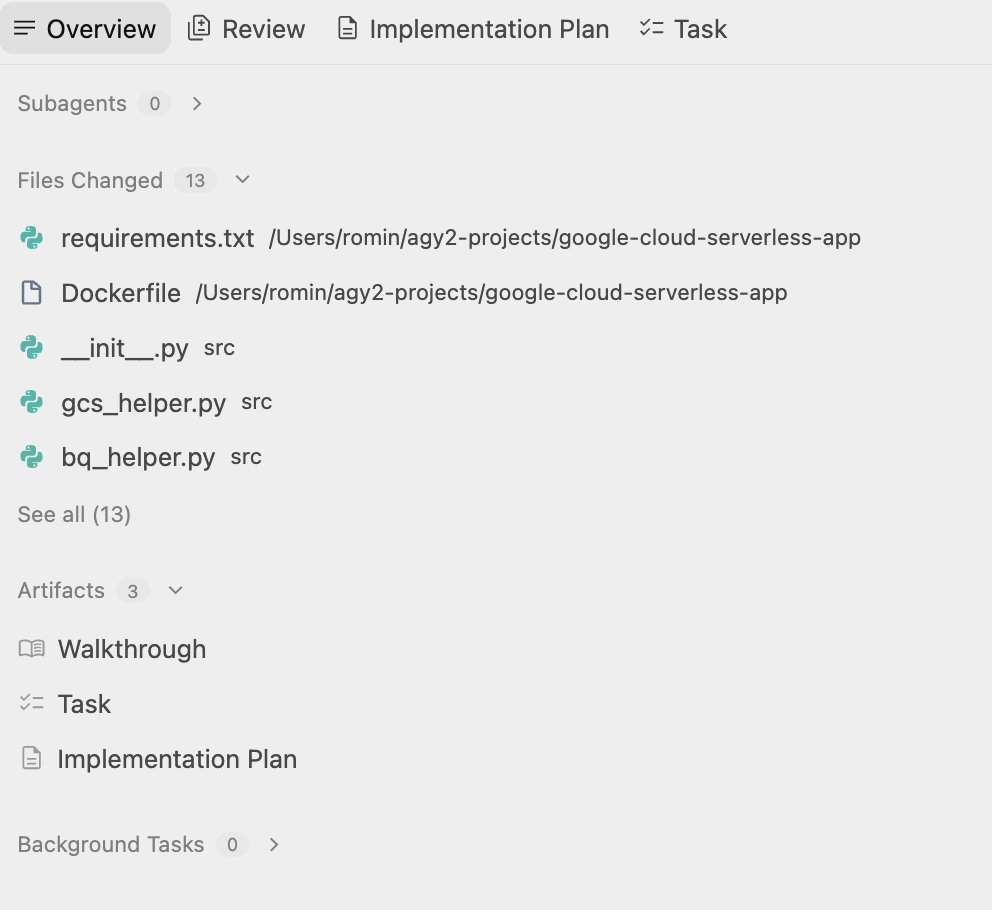
작업이 완료되면 이를 언급하고 살펴볼 수 있는 Walkthrough 문서를 만듭니다. 여기에는 사용자의 다음 단계가 언급되어 있으며 샘플은 다음과 같습니다.
- 파이프라인 배포: GCP CLI에 로그인하고 대상 프로젝트를 설정한 후 다음을 실행합니다.
./deploy.sh - 엔드 투 엔드 테스트 실행: 파일 업로드가 Cloud Run 처리를 트리거하고 메타데이터를 BigQuery로 스트리밍하는지 확인하려면 클라우드 통합 테스트 스크립트를 실행합니다:
./test_cloud.sh - 삭제: 테스트를 완료한 후
README.md삭제 명령어를 참조하여 생성된 리소스를 삭제하고 요금이 청구되지 않도록 합니다.
리소스 생성을 자동화하는 deploy.sh 또는 이와 비슷한 이름의 셸 스크립트 파일이 생성됩니다. 처리하는 작업
- API 사용 설정 (
run,pubsub,bigquery,storage). - Google Cloud Storage 버킷 만들기 (
document-processing-ingest-{project-id}). - BigQuery 데이터 세트 및 테이블 만들기 (
document_processing.processed_metadata). - Pub/Sub 주제 및 알림 구성.
5. 애플리케이션 배포
./ deploy.sh 명령어를 통해 언급된 대로 애플리케이션을 배포해 보겠습니다. Antigravity에 이 작업을 실행하도록 요청할 수 있지만 그 전에 gcloud CLI가 있고 Google Cloud 프로젝트에 구성되어 있는지 확인합니다.
Antigravity에 'Run the deploy.sh for me'라는 프롬프트를 제공할 수 있습니다. 그러면 권한을 묻는 메시지가 표시됩니다. 계속 진행하여 권한을 부여합니다.
아래 메시지에서 설명한 대로 백그라운드 작업으로 프로세스가 시작됩니다.
백그라운드에서 ./deploy.sh를 실행하여 배포 프로세스를 시작했습니다. 실행 로그를 모니터링하고 배포가 완료되는 즉시 알려드리겠습니다.
6. 애플리케이션 확인
파이프라인이 배포되면 Antigravity는 애플리케이션이 실제로 작동하는지 확인합니다. test_cloud.sh 파일을 실행할 수 있는지 묻습니다. 계속 진행하여 권한을 부여할 수 있습니다.

마지막으로 다음과 같이 알려줍니다.
I have successfully run both ./deploy.sh and ./test_cloud.sh.
The pipeline is fully deployed to your GCP project PROJECT_ID and working end-to-end.
Please refer to the walkthrough.md for full verification details and the query output from BigQuery showing the successfully processed document metadata.
Walkthrough 아티팩트를 열어 결과를 볼 수 있습니다.
Cloud Verification Results
The deployment and end-to-end cloud integration test (./test_cloud.sh) succeeded perfectly!
Resources Created:
GCS Bucket: gs://document-processing-ingest-gcp-experiments-349209
Pub/Sub Topic: document-uploads-topic
Pub/Sub Subscription: document-uploads-sub (pushing to Cloud Run)
Cloud Run Service: document-processor (URL: https://document-processor-ido3ocn3pq-uc.a.run.app)
BigQuery Dataset: document_processing
BigQuery Table: processed_metadata
Integration Test Run: A test file cloud_test_sample.txt was uploaded to the bucket. The pipeline processed the file and streamed the metadata record into BigQuery:
🔍 Querying BigQuery to verify metadata insertion...
<BIQUERY DATA HERE>
The pipeline successfully detected the hashtags #gcp and #serverless as tags, correctly counted the 47 words, generated the OCR preview, and wrote the entry to BigQuery under the schema.
선택사항: 수동 확인
Antigravity에서 이미 애플리케이션을 확인했지만 원하는 경우 다음 단계에 따라 Google Cloud 콘솔에서 모든 리소스가 생성되었는지 수동으로 확인할 수도 있습니다.
Cloud Storage
목표: 버킷이 있는지 확인하고 업로드된 파일을 확인합니다.
- Cloud Storage > 버킷 으로 이동합니다.
document-processing-ingest-{project-id}라는 버킷을 찾습니다.- 버킷 이름을 클릭하여 파일을 탐색합니다.
- 확인: 업로드된 파일 (예:
cloud_test_sample.txt)이 표시됩니다.
Pub/Sub
목표: 주제가 있고 푸시 구독이 있는지 확인합니다.
- Pub/Sub > 주제 로 이동합니다.
- document-uploads-topic 을 찾습니다.
- 주제 ID 를 클릭합니다.
- 구독 탭으로 스크롤합니다.
- 확인: doc-uploads-sub가 "푸시" 전송 유형으로 나열되어 있는지 확인합니다.
Cloud Run
목표: 서비스 상태 및 로그를 확인합니다.
- Cloud Run 으로 이동합니다.
- 서비스 document-processor 를 클릭합니다.
- 확인:
- 상태: 서비스가 활성 상태임을 나타내는 녹색 체크표시입니다.
- 로그: 로그 탭을 클릭합니다. "Processing file: gs://..." 및 "Successfully inserted..."와 같은 항목을 찾습니다.
BigQuery
목표: 데이터가 실제로 저장되었는지 확인합니다.
- BigQuery > SQL 작업공간 으로 이동합니다.
- 탐색기 창에서 프로젝트 > document_processing 데이터 세트 를 펼칩니다.
- processed_metadata 테이블을 클릭합니다.
- 쿼리 탭을 클릭하고 SELECT * 문을 통해 테이블에서 모든 행을 가져옵니다.
- 확인: filename, process_timestamp, tags, word_count 가 포함된 행이 표시됩니다.
7. 애플리케이션 살펴보기
이제 기본 앱이 프로비저닝되고 실행됩니다. 이 애플리케이션을 더 확장하기 전에 잠시 코드를 살펴보세요. 아티팩트를 보면 생성된 코드 파일이 표시됩니다.
표시될 수 있는 파일의 간단한 요약은 다음과 같습니다.
deploy.sh: 모든 Google Cloud 리소스를 프로비저닝하고 필요한 API를 사용 설정하는 기본 스크립트입니다.appy.py: 파이프라인의 기본 진입점입니다. 이 Python 앱은 Pub/Sub 푸시 메시지를 수신하고 GCS에서 파일을 다운로드하며 '처리'(OCR 시뮬레이션)하고 메타데이터를 BigQuery로 스트리밍하는 웹 서버를 만듭니다.Dockerfile: 앱을 컨테이너 이미지로 패키징하는 방법을 정의합니다.requirements.txt: Python 종속 항목을 나열합니다.
테스트 및 확인에 필요한 다른 스크립트 및 텍스트 파일도 표시될 수 있습니다.
8. 애플리케이션 확장
이제 기본 애플리케이션이 작동하므로 애플리케이션을 계속 반복하고 확장할 수 있습니다. 다음은 참고할 수 있는 팁입니다.
프런트엔드 추가
처리된 문서를 볼 수 있는 간단한 웹 인터페이스를 빌드합니다.
다음 프롬프트를 사용해 보세요. Create a simple Streamlit or Flask web application that connects to BigQuery. It should display a table of the processed documents (filename, upload_date, tags, word_count) and allow me to filter the results by tag
실제 AI/ML과 통합
시뮬레이션된 OCR 처리 대신 Gemini 모델을 사용하여 추출, 분류, 번역합니다.
- 더미 OCR 로직을 바꿉니다. 이미지/PDF를 Gemini로 전송하여 실제 텍스트와 데이터를 추출합니다. 추출된 텍스트를 분석하여 문서 유형 (인보이스, 계약서, 이력서)을 분류하거나 항목 (날짜, 이름, 위치)을 추출합니다.
- 문서의 언어를 자동으로 감지하고 저장하기 전에 영어로 번역합니다. 다른 언어를 사용할 수도 있습니다.
저장 및 분석 개선
버킷에서 수명 주기 규칙을 구성하여 이전 파일을 'Coldline' 또는 '보관처리' 스토리지로 이동하여 비용을 절감할 수 있습니다.
강력함 및 보안
다음과 같이 앱을 더 강력하고 안전하게 만들 수 있습니다.
- 데드 레터 큐 (DLQ): 실패를 처리하도록 Pub/Sub 구독을 업데이트합니다. Cloud Run 서비스에서 파일을 5번 처리하지 못하면 사람이 검사할 수 있도록 메시지를 별도의 '데드 레터' 주제/버킷으로 보냅니다.
- Secret Manager: 앱에 API 키 또는 민감한 구성이 필요한 경우 문자열을 하드 코딩하는 대신 Secret Manager에 저장하고 Cloud Run에서 안전하게 액세스합니다.
- Eventarc: 복잡한 감사 로그 또는 기타 GCP 서비스 이벤트를 기반으로 트리거할 수 있도록 더 유연한 이벤트 라우팅을 위해 직접 Pub/Sub에서 Eventarc로 업그레이드합니다.
물론 자체 아이디어를 내고 Antigravity를 사용하여 구현할 수 있습니다.
9. 결론
Google Antigravity를 사용하여 확장 가능한 서버리스 AI 기반 문서 파이프라인을 몇 분 만에 빌드했습니다. 지금까지 배운 내용은 다음과 같습니다.
- AI로 아키텍처를 계획합니다.
- 코드 생성에서 배포 및 검증에 이르기까지 애플리케이션을 생성하는 동안 Antigravity를 안내하고 관리합니다.
- Walkthrough를 사용하여 배포 및 검증을 확인합니다.