
1. 简介
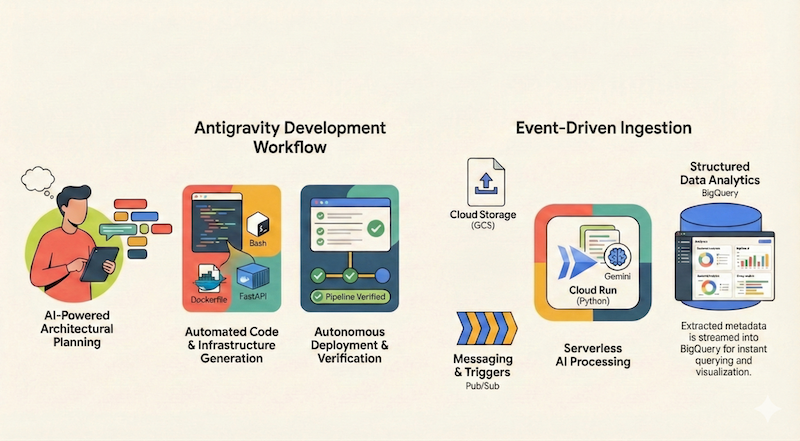
在此 Codelab 中,您将学习如何使用 Google Antigravity 设计、构建和部署无服务器应用到 Google Cloud。我们将构建一个无服务器且由事件驱动的文档流水线,该流水线可从 Google Cloud Storage (GCS) 注入文件,使用 Cloud Run 和 Gemini 处理这些文件,并将它们的元数据流式传输到 BigQuery。
学习内容
- 如何使用 Antigravity 进行建筑规划和设计。
- 使用 AI 智能体生成基础设施即代码(shell 脚本)。
- 构建并部署基于 Python 的 Cloud Run 服务。
- 集成 Vertex AI 上的 Gemini,以进行多模态文档分析。
- 使用 Antigravity 的 Walkthrough 制品验证端到端流水线。
所需条件
- 已安装 Google Antigravity。
- 启用了结算功能的 Google Cloud 项目。
- 已安装 gcloud CLI 并通过身份验证。
2. 应用概览
在开始使用 Antigravity 设计和实现应用之前,我们先来简要说明一下要构建的应用。
我们希望构建一个无服务器且由事件驱动的文档流水线,该流水线可从 Google Cloud Storage (GCS) 注入文件,使用 Cloud Run 和 Gemini 处理这些文件,并将它们的元数据流式传输到 BigQuery。
此应用的高级架构图可能如下所示:
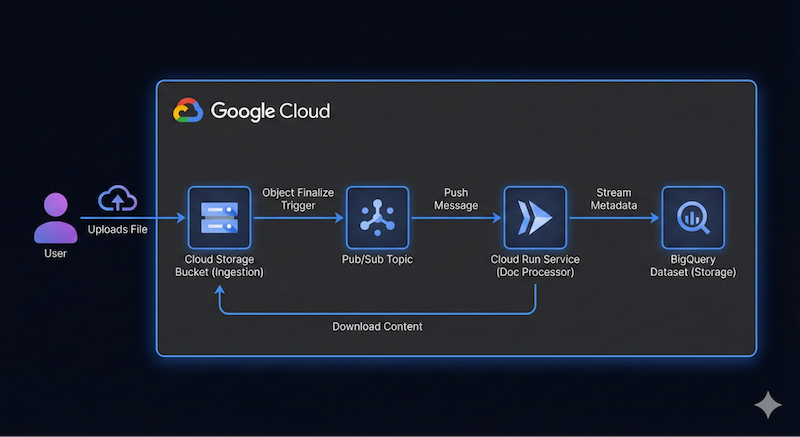
不必过于精确。Antigravity 可以帮助我们逐步确定架构细节。不过,最好先确定要构建的内容。您提供的细节越多,Antigravity 在架构和代码方面给出的结果就越好。
3. 规划架构
我们已准备好使用 Antigravity 开始规划架构细节!
Antigravity 擅长规划复杂系统。我们可以先定义高级架构,而不是立即编写代码,然后使用其中一项功能来帮助 Antigravity 评估我们的请求、向我们提出后续问题,然后继续进行规划和实施。
假设您已启动 Antigravity,我们将为此 Codelab 创建一个新项目。
点击 Projects 实验旁边的“新建项目”图标,然后点击 New Project,如下所示:

此时会显示 Add Folder 选项,如下所示:
点击添加文件夹按钮,向项目添加文件夹。在我的电脑上,我创建了一个 google-cloud-serverless-app 文件夹,并将其添加到了此项目中。
这会在 google-cloud-serverless-app 工作区中打开对话。
点击屏幕左下角的主设置图标 ⚙️,然后前往项目专用设置。将 Agent Settings / Security Preset 设置为 Default,并将 Agent Behaviour / Artifact Review Policy 设置为 Always Ask,如下所示:
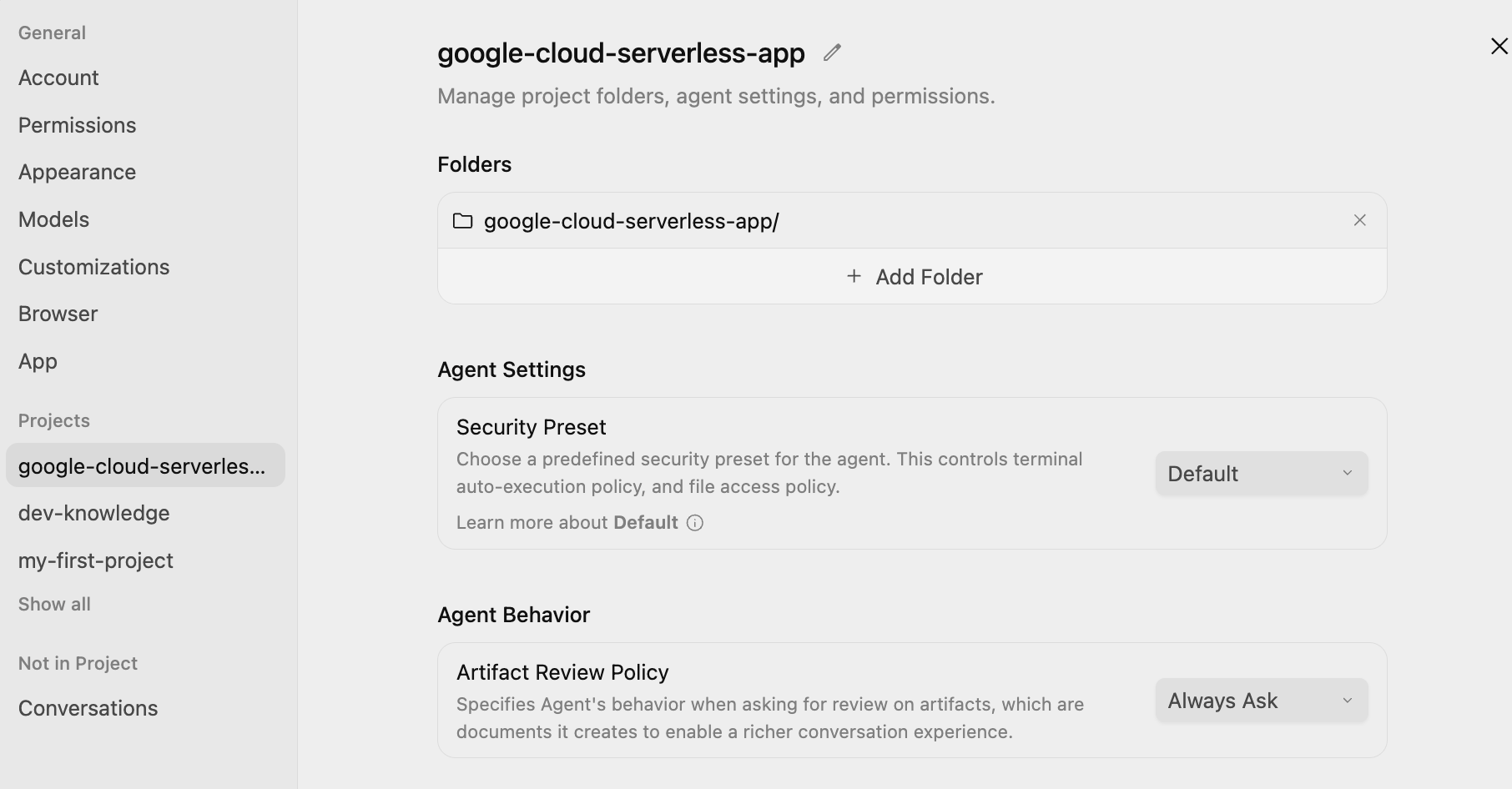
这样可确保在每个步骤中,您都能在智能体执行计划之前查看并批准该计划。
提示
现在,我们可以向 Antigravity 提供第一个提示了。我们将使用斜杠命令 /grill-me 来评估我们的请求。
输入 /grill-me,然后输入以下提示,并点击提交按钮:
/grill-me
I want to build a serverless event-driven document processing pipeline on Google Cloud.
Architecture:
- Ingestion: Users upload files to a Cloud Storage bucket.
- Trigger: File uploads trigger a Pub/Sub message.
- Processor: A Python-based Cloud Run service receives the message, processes the file (simulated OCR), and extracts metadata.
- Storage: Stream the metadata (filename, date, tags, word_count) into a BigQuery dataset.
/grill-me 命令会提出一些后续问题,您可以尽您所知地尝试回答这些问题。它还会建议推荐答案,您可以根据需要选择使用。
下面展示了 /grill-me 命令的运行示例:
How would you provision and manage the Google Cloud infrastructure resources (Cloud Storage buckets, Pub/Sub topics, BigQuery datasets, Cloud Run service)?
gcloud CLI Setup Script - Shell scripts running gcloud CLI commands to create resources step-by-step
How should the Cloud Storage upload events trigger and reach your Python Cloud Run service?
(Recommended) Native Cloud Storage Pub/Sub Notifications + Pub/Sub Push subscription to Cloud Run (direct, lightweight, standard event-driven approach)
Which Python web framework would you prefer for the Cloud Run processing service?
Flask (with Gunicorn) - Standard, lightweight, and very common for simple Cloud Run services
How should the OCR and metadata extraction logic be implemented in the Cloud Run service?
(Recommended) Full local simulation - If it's a .txt file, read the contents, count words, and extract tags. For other files, generate mock OCR metadata and simulated word count. No external API calls.
Which BigQuery insertion method should the Cloud Run service use to store metadata?
(Recommended) BigQuery table.insert_rows() (Legacy Streaming API) - Extremely simple to code, clean error handling, perfect for simulation and low-to-medium volumes.
How should security/authentication be configured for the Cloud Run service?
Unauthenticated Cloud Run - Allow public requests to the Cloud Run service URL (simpler setup, but insecure for production).
What schema would you like to define for the BigQuery metadata table?
(Recommended) Extended Schema - Include filename, bucket, size, content_type, word_count, tags (as a REPEATED STRING array), ocr_text_preview, and process_timestamp.
How should the Cloud Run service handle processing failures (e.g., file not found, BigQuery write error)?
(Recommended) Fail-Fast with Retry - Log error to standard output (Cloud Logging) and return HTTP 500 to Pub/Sub, so that Pub/Sub automatically retries the message delivery.
What testing tools should we generate to verify the pipeline's functionality?
(Recommended) Both - Include a local test script (sending mock Pub/Sub POST requests to the local Flask server) and a Cloud-integrated test script (uploading a real file to GCS and verifying BigQuery).
请注意,我让 Antigravity 按照以下方式回答:
- 用于预配资源的简单 gcloud CLI 脚本
- 原生 Cloud Storage Pub/Sub 通知 + Pub/Sub 推送订阅到 Cloud Run
- 使用 Flask(搭配 Gunicorn)作为框架
- 只需使用本地模拟功能,并使用文本文件作为数据源,而不是使用实时 OCR 数据
- 使用 BigQuery table.insert_rows() 将行插入到 BigQuery 中
- 未经身份验证的 Cloud Run 部署
以及其他推荐选项。
实施计划和任务列表
Antigravity 现在将开始工作,并生成实施方案。系统会显示类似以下内容的消息,供您查看:
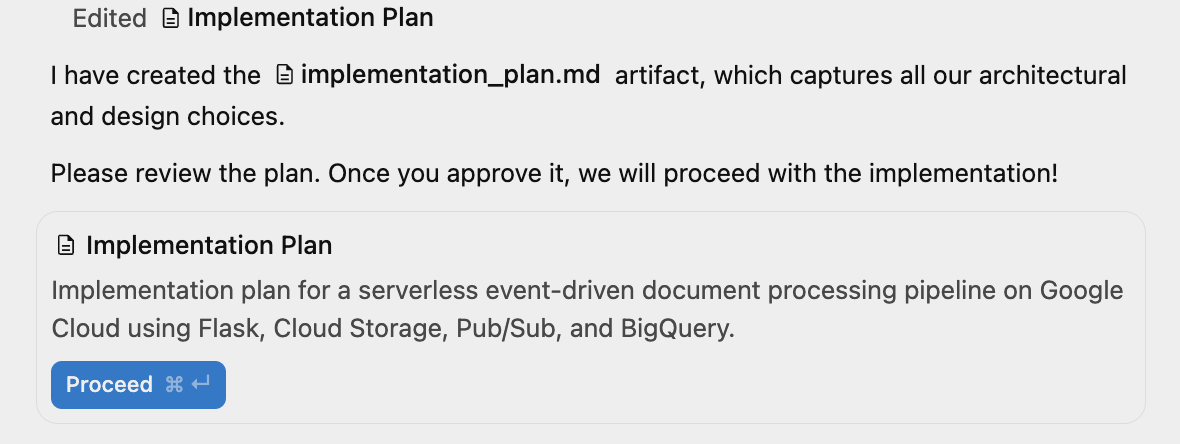
您可以点击右上角窗口中的“辅助窗格”切换开关,查看生成的制品,目前只有实施计划。
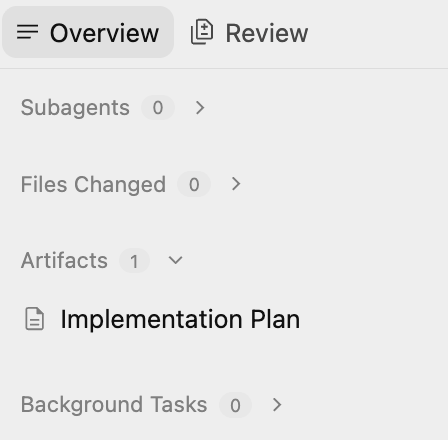
本计划概述了以下内容:
- 基础架构:GCS 存储分区、Pub/Sub 主题、BigQuery 数据集。
- 处理器:Python/Flask 应用、Dockerfile、要求。
- 集成:GCS 通知 → Pub/Sub → Cloud Run。
您应该会看到类似以下内容。下面显示的是我们机器上的部分实施计划列表:
Event-Driven Document Processing Pipeline Implementation Plan
This implementation plan describes the components and setup scripts required to build a serverless event-driven document processing pipeline on Google Cloud.
User Review Required
Please review the proposed architecture, components, and default configuration. If you agree, please approve the plan so we can proceed with creating the files and implementation.
IMPORTANT
Security Notice: As requested, the Cloud Run service is configured to allow unauthenticated invocations (--allow-unauthenticated) for simpler testing and development.
Error Handling: The service returns an HTTP 500 error code for failures to trigger Pub/Sub retries.
GCP Configuration: The provisioning scripts will use standard environment variables (e.g., GCP_PROJECT, GCP_REGION) that default to the active configuration of your local gcloud CLI.
Proposed Components and Files
The project will be organized as follows:
google-cloud-serverless-app/
├── src/
│ ├── __init__.py
│ ├── app.py # Flask app entrypoint and routes
│ ├── processor.py # Simulated OCR and metadata extraction engine
│ ├── gcs_helper.py # Helper functions to read files from Cloud Storage
│ └── bq_helper.py # Helper functions to write metadata to BigQuery
├── requirements.txt # Python dependencies
├── Dockerfile # Docker configuration for Cloud Run
├── deploy.sh # gcloud CLI provisioning and deployment script
├── test_local.sh # Script to test the Flask app locally with mock Pub/Sub events
├── test_cloud.sh # Script to upload a real file to GCS and query BigQuery
└── README.md # Setup and execution guide
请仔细阅读该计划。这是您提供实施反馈意见的机会。您可以点击实施计划的任何部分并添加评论。添加一些评论后,请务必提交您希望看到的任何更改以供审核,尤其是在命名、Google Cloud 项目 ID、区域等方面。
一切就绪后,点击 Proceed 按钮,向智能体授予权限以继续执行实施方案。
现在,它继续创建另一个制品任务计划,其中包含 Antigravity 创建的一组任务。代理会逐一检查这些任务并执行它们。示例任务列表如下所示:
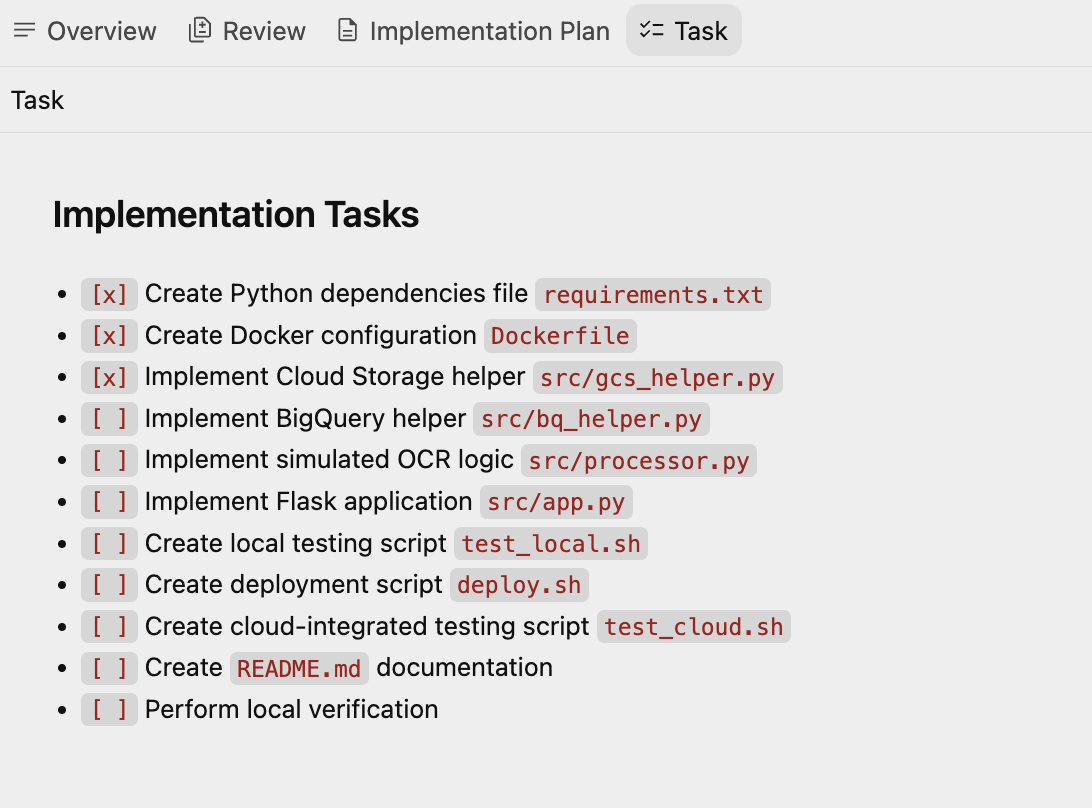
4. 生成应用
方案获得批准后,Antigravity 会开始生成应用所需的文件,从配置脚本到应用代码。
Antigravity 将创建一个文件夹,并开始创建项目所需的文件。如果您查看工件,会发现系统生成了多个文件(源代码、脚本文件等)。
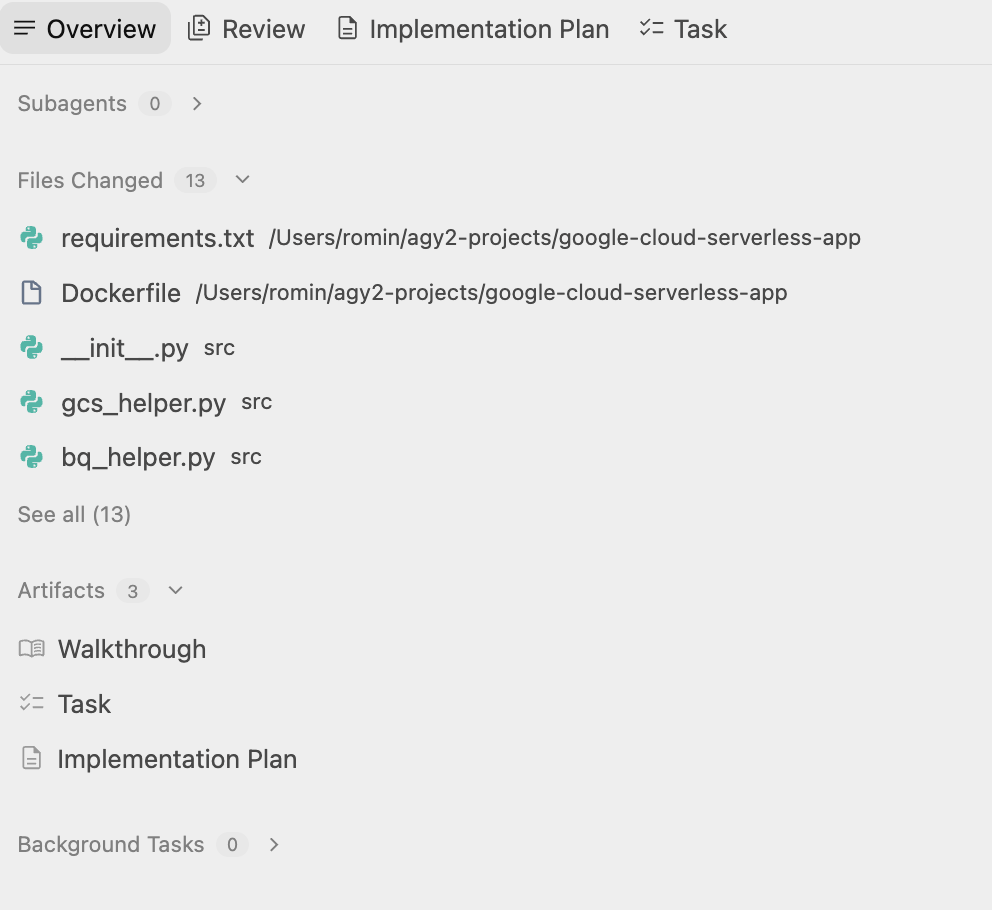
完成工作后,它会提及这一点,并创建一个您可以查看的 Walkthrough 文档。该文档会提及用户的下一步操作,示例如下:
- 部署流水线:确保您已登录 GCP CLI 并设置目标项目,然后运行:
./deploy.sh - 运行端到端测试:执行云集成测试脚本,验证文件上传是否会触发 Cloud Run 处理并将元数据流式传输到 BigQuery:
./test_cloud.sh - 清理:完成测试后,请参阅
README.md清理命令,以移除创建的资源并避免产生费用。
您会发现系统生成了一个 deploy.sh 或类似名称的 shell 脚本文件,该文件可自动创建资源。它处理:
- 启用 API(
run、pubsub、bigquery、storage)。 - 创建 Google Cloud Storage 存储分区 (
document-processing-ingest-{project-id})。 - 创建 BigQuery 数据集和表 (
document_processing.processed_metadata)。 - 配置 Pub/Sub 主题和通知。
5. 部署应用
我们来通过 ./ deploy.sh 命令部署应用。我们可以让 Antigravity 为我们运行此命令,但在执行此操作之前,请确保 gcloud CLI 已存在并已针对 Google Cloud 项目进行配置。
我们可以向 Antigravity 发出提示“Run the deploy.sh for me”(为我运行 deploy.sh)。系统会提示您授予权限。请继续操作并授予权限。
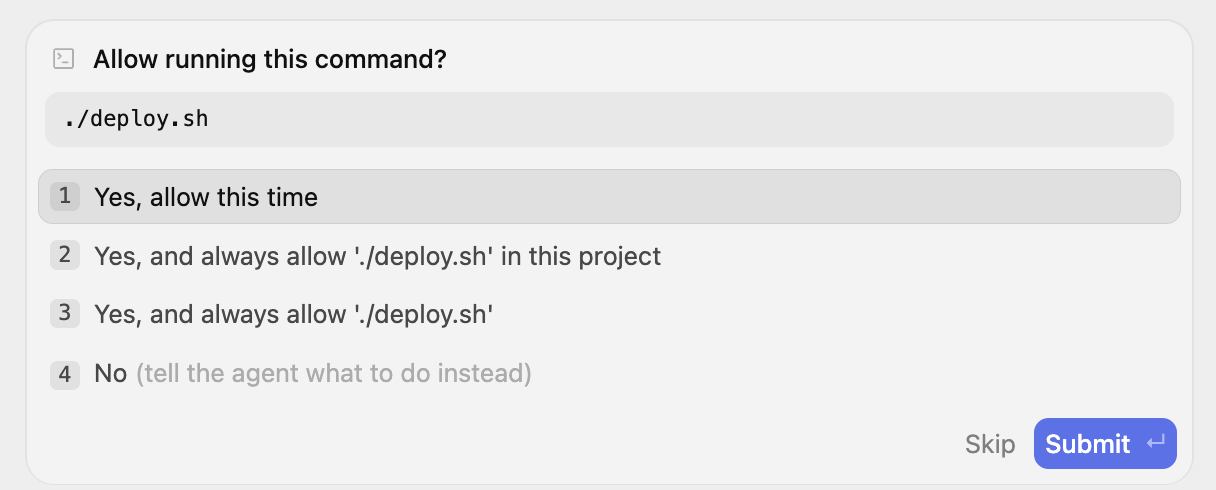
它会以后台任务的形式启动该进程,如下消息所示:
我已在后台运行 ./deploy.sh,开始部署流程。我会监控执行日志,并在部署完成后立即通知您!
6. 验证应用
流水线部署完毕后,Antigravity 会继续验证应用是否正常运行。它询问我们是否可以运行 test_cloud.sh 文件。我们可以继续操作并授予相应权限。

最后,它会告诉我们以下信息:
I have successfully run both ./deploy.sh and ./test_cloud.sh.
The pipeline is fully deployed to your GCP project PROJECT_ID and working end-to-end.
Please refer to the walkthrough.md for full verification details and the query output from BigQuery showing the successfully processed document metadata.
我们可以打开 Walkthrough 制品来查看结果:
Cloud Verification Results
The deployment and end-to-end cloud integration test (./test_cloud.sh) succeeded perfectly!
Resources Created:
GCS Bucket: gs://document-processing-ingest-gcp-experiments-349209
Pub/Sub Topic: document-uploads-topic
Pub/Sub Subscription: document-uploads-sub (pushing to Cloud Run)
Cloud Run Service: document-processor (URL: https://document-processor-ido3ocn3pq-uc.a.run.app)
BigQuery Dataset: document_processing
BigQuery Table: processed_metadata
Integration Test Run: A test file cloud_test_sample.txt was uploaded to the bucket. The pipeline processed the file and streamed the metadata record into BigQuery:
🔍 Querying BigQuery to verify metadata insertion...
<BIQUERY DATA HERE>
The pipeline successfully detected the hashtags #gcp and #serverless as tags, correctly counted the 47 words, generated the OCR preview, and wrote the entry to BigQuery under the schema.
可选:手动验证
即使 Antigravity 已经验证了应用,您也可以按照以下步骤在 Google Cloud 控制台中手动检查是否已创建所有资源(如果您愿意)。
Cloud Storage
目标:验证存储分区是否存在并检查上传的文件。
- 前往 Cloud Storage > 存储分区。
- 找到名为
document-processing-ingest-{project-id}的存储分区。 - 点击相应存储分区名称即可浏览文件。
- 验证:您应该会看到已上传的文件(例如
cloud_test_sample.txt)。
Pub/Sub
目标:确认主题存在且具有推送订阅。
- 前往 Pub/Sub > 主题。
- 找到 document-uploads-topic。
- 点击主题 ID。
- 向下滚动到订阅标签页。
- 验证:确保 doc-uploads-sub 列出的传送类型为“推送”。
Cloud Run
目标:检查服务状态和日志。
- 前往 Cloud Run。
- 点击服务 document-processor。
- 验证:
- 健康状况:绿色对勾标记表示服务处于活跃状态。
- 日志:点击“日志”标签页。查找“正在处理文件:gs://...”和“已成功插入...”之类的条目。
BigQuery
目标:验证数据是否已实际存储。
- 前往 BigQuery > SQL 工作区。
- 在“探索器”窗格中,依次展开您的项目 > document_processing 数据集。
- 点击 processed_metadata 表。
- 点击查询标签页,然后通过 SELECT * 语句检索表中的所有行。
- 验证:您应该会看到包含 filename、process_timestamp、tags 和 word_count 的行。
7. 探索应用
至此,您已完成基本应用的配置并使其运行。在深入了解如何进一步扩展此应用之前,请花点时间探索代码。您可以查看制品,其中应显示生成的代码文件。
下面简要介绍了您可能会看到的文件:
deploy.sh:用于预配所有 Google Cloud 资源并启用所需 API 的主脚本。appy.py:流水线的主要入口点。此 Python 应用会创建一个 Web 服务器,该服务器接收 Pub/Sub 推送消息、从 GCS 下载文件、对文件进行“处理”(模拟 OCR)并将元数据流式传输到 BigQuery。Dockerfile:定义如何将应用打包到容器映像中。requirements.txt:列出 Python 依赖项。
您可能还会看到测试和验证所需的其他脚本和文本文件。
8. 扩展应用
现在,您已经有了一个正常运行的基本应用,可以继续迭代和扩展该应用。以下是一些建议。
添加前端
构建一个简单的 Web 界面来查看处理后的文档。
不妨试试以下提示:Create a simple Streamlit or Flask web application that connects to BigQuery. It should display a table of the processed documents (filename, upload_date, tags, word_count) and allow me to filter the results by tag
与真实的 AI/机器学习集成
使用 Gemini 模型提取、分类和翻译,而不是使用模拟 OCR 处理。
- 替换虚拟 OCR 逻辑。将图片/PDF 发送给 Gemini 以提取实际文本和数据。分析提取的文本以对文档类型(发票、合同、简历)进行分类或提取实体(日期、姓名、地点)。
- 自动检测文档的语言并将其翻译成英语,然后再存储。您也可以使用任何其他语言。
增强存储和分析功能
您可以在存储分区中配置生命周期规则,将旧文件移至“Coldline”或“Archive”存储空间,以节省费用。
稳健性和安全性
您可以提高应用的稳健性和安全性,例如:
- 死信队列 (DLQ):更新 Pub/Sub 订阅以处理失败情况。如果 Cloud Run 服务处理文件失败 5 次,则将消息发送到单独的“死信”主题/存储分区以供人工检查。
- Secret Manager:如果您的应用需要 API 密钥或敏感配置,请将其存储在 Secret Manager 中,并从 Cloud Run 安全地访问它们,而不是对字符串进行硬编码。
- Eventarc:从直接 Pub/Sub 升级到 Eventarc,以实现更灵活的事件路由,从而根据复杂的审核日志或其他 GCP 服务事件触发函数。
当然,您也可以提出自己的想法,并使用 Antigravity 帮助您实现这些想法!
9. 总结
您已成功使用 Google Antigravity 在几分钟内构建了一个可扩缩的无服务器 AI 赋能型文档流水线。您学习了如何:
- 利用 AI 规划架构。
- 在 Antigravity 从代码生成到部署和验证的过程中,对其进行指导和管理。
- 通过演练验证部署和验证。