
1. Einführung
In diesem Codelab erfahren Sie, wie Sie das Python SDK für die Conversational Analytics (CA) API mit einer BigQuery-Datenquelle verwenden. Sie erfahren, wie Sie einen neuen Agent erstellen, wie Sie die Verwaltung des Konversationsstatus nutzen und wie Sie Antworten über die API senden und streamen.
Voraussetzungen
- Grundlegende Kenntnisse von Google Cloud und der Google Cloud Console
- Grundkenntnisse in der Befehlszeile und Cloud Shell
- Grundlegende Kenntnisse der Programmierung mit Python
Lerninhalte
- Verwendung des Python SDK für die Conversational Analytics API mit einer BigQuery-Datenquelle
- Neuen Agent mit der CA API erstellen
- Unterhaltungsstatus verwalten
- Anfragen senden und Antworten von der API streamen
Voraussetzungen
- Ein Google Cloud-Konto und ein Google Cloud-Projekt
- Ein Webbrowser wie Chrome
2. Einrichtung und Anforderungen
Projekt auswählen
- Melden Sie sich in der Google Cloud Console an und erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eines erstellen.

- Der Projektname ist der Anzeigename für die Teilnehmer dieses Projekts. Es handelt sich um einen String, der nicht von Google APIs verwendet wird. Sie können sie jederzeit aktualisieren.
- Die Projekt-ID ist für alle Google Cloud-Projekte eindeutig und unveränderlich (kann nach dem Festlegen nicht mehr geändert werden). In der Cloud Console wird automatisch ein eindeutiger String generiert. Normalerweise ist es nicht wichtig, wie dieser String aussieht. In den meisten Codelabs müssen Sie auf Ihre Projekt-ID verweisen (in der Regel als
PROJECT_IDangegeben). Wenn Ihnen die generierte ID nicht gefällt, können Sie eine andere zufällige ID generieren. Alternativ können Sie es mit einem eigenen Namen versuchen und sehen, ob er verfügbar ist. Sie kann nach diesem Schritt nicht mehr geändert werden und bleibt für die Dauer des Projekts bestehen. - Zur Information: Es gibt einen dritten Wert, die Projektnummer, die von einigen APIs verwendet wird. Weitere Informationen zu diesen drei Werten
- Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Cloud-Ressourcen/-APIs zu verwenden. Die Durchführung dieses Codelabs kostet wenig oder gar nichts. Wenn Sie Ressourcen herunterfahren möchten, um Kosten zu vermeiden, die über diese Anleitung hinausgehen, können Sie die erstellten Ressourcen oder das Projekt löschen. Neue Google Cloud-Nutzer können am kostenlosen Testzeitraum mit einem Guthaben von 300$ teilnehmen.
Cloud Shell starten
Während Sie Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Codelab Google Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console rechts oben in der Symbolleiste auf das Cloud Shell-Symbol:
Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Anschließend sehen Sie in etwa Folgendes:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
3. Hinweis
Aktivieren der erforderlichen APIs
Wenn Sie Google Cloud-Dienste verwenden möchten, müssen Sie zuerst die entsprechenden APIs für Ihr Projekt aktivieren. In diesem Codelab verwenden Sie die folgenden Google Cloud-Dienste:
- Data Analytics API with Gemini
- Gemini für Google Cloud
- BigQuery API
Führen Sie zum Aktivieren dieser Dienste die folgenden Befehle im Cloud Shell-Terminal aus:
gcloud services enable geminidataanalytics.googleapis.com
gcloud services enable cloudaicompanion.googleapis.com
gcloud services enable bigquery.googleapis.com
Python-Pakete installieren
Bevor Sie ein Python-Projekt starten, sollten Sie eine virtuelle Umgebung erstellen. Dadurch werden die Abhängigkeiten des Projekts isoliert und Konflikte mit anderen Projekten oder den globalen Python-Paketen des Systems vermieden. In diesem Abschnitt installieren Sie uv über pip, da pip in Cloud Shell bereits verfügbar ist.
uv-Paket installieren
pip install uv
Prüfen, ob uv korrekt installiert ist
uv --version
Erwartete Ausgabe
Wenn Sie eine Ausgaberzeile mit „uv“ sehen, können Sie mit dem nächsten Schritt fortfahren. Die Versionsnummer kann variieren:

Virtuelle Umgebung erstellen und Pakete installieren
uv init ca-api-codelab
cd ca-api-codelab
uv venv --python 3.12
uv add google-cloud-geminidataanalytics pandas altair
uv pip list | grep -E 'altair|pandas|google-cloud-geminidataanalytics'
Erwartete Ausgabe
Wenn Sie Ausgabelinien mit den drei Paketen sehen, können Sie mit dem nächsten Schritt fortfahren. Die Versionsnummern können variieren:

Python starten
uv run python
Auf Ihrem Bildschirm sollte nun Folgendes angezeigt werden:

4. Agent erstellen
Nachdem Sie Ihre Entwicklungsumgebung eingerichtet haben, können Sie mit der Vorbereitung der Gemini Data Analytics API beginnen. Das SDK vereinfacht diesen Prozess, da nur wenige grundlegende Konfigurationen erforderlich sind, um einen Agent zu erstellen.
Variablen festlegen
Importieren Sie das geminidataanalytics-Paket und legen Sie die Umgebungsvariablen fest:
import os
from google.cloud import geminidataanalytics
data_agent_client = geminidataanalytics.DataAgentServiceClient()
location = "global"
billing_project = os.environ.get('DEVSHELL_PROJECT_ID')
data_agent_id = "google_trends_analytics_agent"
Systemanweisungen für den Agenten festlegen
Die CA API liest BigQuery-Metadaten, um mehr Kontext zu den referenzierten Tabellen und Spalten zu erhalten. Da dieses öffentliche Dataset keine Spaltenbeschreibungen enthält, können Sie dem Agenten zusätzlichen Kontext als YAML-formatierte Zeichenfolge bereitstellen. Hier finden Sie die Dokumentation mit Best Practices und einer Vorlage:
system_instruction = """
system_instruction:
- You are a data analyst specializing in the Google Trends dataset.
- When querying, always use the 'week' column for date-based filtering. This needs to be a Sunday. If you are doing week over week comparison, make sure you specify a date that is a Sunday.
- The following columns should be ignored in all queries 'dma_id', 'refresh_date'
- The 'dma_name' column represents the city and state for about 210 metro areas in the USA.
tables:
top_terms:
description: "Represents the 25 most popular search terms by weekly search volume in a given US metro area (DMA)."
fields:
term: "The search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's popularity rank from 1 (most popular) to 25."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
dma_name: "The name of the US metro area, e.g., 'New York NY'."
top_rising_terms:
description: "Represents the 25 fastest-growing ('breakout') search terms by momentum in a given US metro area (DMA)."
fields:
term: "The surging search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's breakout rank from 1 (top rising) to 25."
percent_gain: "The percentage growth in search volume compared to the previous period."
dma_name: "The name of the US metro area, e.g., 'Los Angeles CA'."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
join_instructions:
goal: "Find terms that are simultaneously popular and rising in the same week and metro area."
method: "INNER JOIN the two tables on their common keys."
keys:
- "term"
- "week"
- "dma_name"
golden_queries:
- natural_language_query: "Find all terms in the 'New York NY' area that were in both the top 25 and top 25 rising lists for the week of July 6th, 2025, and show their ranks and percent gain."
sql_query: |
SELECT
top.term,
top.rank AS top_25_rank,
rising.rank AS rising_25_rank,
rising.percent_gain
FROM
`bigquery-public-data.google_trends.top_terms` AS top
INNER JOIN
`bigquery-public-data.google_trends.top_rising_terms` AS rising
ON
top.term = rising.term
AND top.week = rising.week
AND top.dma_name = rising.dma_name
WHERE
top.week = '2025-07-06'
AND top.dma_name = 'New York NY'
ORDER BY
top.rank;
"""
BigQuery-Tabellendatenquellen festlegen
Jetzt können Sie die Datenquellen für die BigQuery-Tabelle festlegen. Die CA API akzeptiert BigQuery-Tabellen in einem Array:
# BigQuery table data sources
bq_top = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_terms"
)
bq_rising = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_rising_terms"
)
datasource_references = geminidataanalytics.DatasourceReferences(
bq=geminidataanalytics.BigQueryTableReferences(table_references=[bq_top, bq_rising]))
Kontext für zustandsorientierte Chats festlegen
Sie können den neuen KI-Agenten mit dem veröffentlichten Kontext erstellen. Dieser umfasst die Systemanweisungen, Datenquellenverweise und alle anderen Optionen.
Sie können einen stagingContext erstellen, um Änderungen vor der Veröffentlichung zu testen und zu validieren. So kann ein Entwickler einem Daten-Agent die Versionsverwaltung hinzufügen, indem er die contextVersion in der Chatanfrage angibt. In diesem Codelab veröffentlichen Sie die App direkt:
# Context setup for stateful chat
published_context = geminidataanalytics.Context(
system_instruction=system_instruction,
datasource_references=datasource_references,
options=geminidataanalytics.ConversationOptions(
analysis=geminidataanalytics.AnalysisOptions(
python=geminidataanalytics.AnalysisOptions.Python(
enabled=False
)
)
),
)
data_agent = geminidataanalytics.DataAgent(
data_analytics_agent=geminidataanalytics.DataAnalyticsAgent(
published_context=published_context
),
)
# Create the agent
data_agent_client.create_data_agent(request=geminidataanalytics.CreateDataAgentRequest(
parent=f"projects/{billing_project}/locations/{location}",
data_agent_id=data_agent_id,
data_agent=data_agent,
))
Nachdem Sie den Agent erstellt haben, sollte die Ausgabe in etwa so aussehen:

Agent abrufen
Lassen Sie uns den Agenten testen, um sicherzugehen, dass er erstellt wurde:
# Test the agent
request = geminidataanalytics.GetDataAgentRequest(
name=data_agent_client.data_agent_path(
billing_project, location, data_agent_id)
)
response = data_agent_client.get_data_agent(request=request)
print(response)
Die Metadaten sollten für den neuen KI‑Agenten angezeigt werden. Dazu gehören beispielsweise die Erstellungszeit und der Kontext des KI-Agents in Bezug auf Systemanweisungen und Datenquellen.
5. Unterhaltung erstellen
Jetzt können Sie Ihr erstes Gespräch erstellen. In diesem Codelab verwenden Sie einen Unterhaltungsverweis für einen zustandsorientierten Chat mit Ihrem KI-Agenten.
Die CA API bietet verschiedene Möglichkeiten für den Chat mit unterschiedlichen Status- und Agentenverwaltungsoptionen. Hier eine kurze Zusammenfassung der drei Ansätze:
Bundesland | Unterhaltungsverlauf | Agentenmodus | Code | Beschreibung | |
Mit Unterhaltungsverweis chatten | Zustandsorientiert | API verwaltet | Ja | Setzt eine zustandsorientierte Unterhaltung fort, indem eine Chatnachricht gesendet wird, die auf eine vorhandene Unterhaltung und den zugehörigen KI-Agentenkontext verweist. Bei Multi-Turn-Unterhaltungen speichert und verwaltet Google Cloud den Unterhaltungsverlauf. | |
Mit KI-Datenagentenverweis chatten | Zustandslos | Vom Nutzer verwaltet | Ja | Sendet eine zustandslose Chatnachricht, die zur Kontextualisierung auf einen gespeicherten KI-Datenagenten verweist. Bei Multi-Turn-Unterhaltungen muss Ihre Anwendung den Unterhaltungsverlauf verwalten und bei jeder Anfrage bereitstellen. | |
Mit Inline-Kontext chatten | Zustandslos | Vom Nutzer verwaltet | Nein | Sendet eine zustandslose Chatnachricht, indem der gesamte Kontext direkt in der Anfrage angegeben wird, ohne einen gespeicherten KI-Datenagenten zu verwenden. Bei Multi-Turn-Unterhaltungen muss Ihre Anwendung den Unterhaltungsverlauf verwalten und bei jeder Anfrage bereitstellen. |
Sie erstellen eine Funktion, um die Unterhaltung einzurichten und eine eindeutige ID für die Unterhaltung bereitzustellen:
def setup_conversation(conversation_id: str):
data_chat_client = geminidataanalytics.DataChatServiceClient()
conversation = geminidataanalytics.Conversation(
agents=[data_chat_client.data_agent_path(
billing_project, location, data_agent_id)],
)
request = geminidataanalytics.CreateConversationRequest(
parent=f"projects/{billing_project}/locations/{location}",
conversation_id=conversation_id,
conversation=conversation,
)
try:
data_chat_client.get_conversation(name=data_chat_client.conversation_path(
billing_project, location, conversation_id))
print(f"Conversation '{conversation_id}' already exists.")
except Exception:
response = data_chat_client.create_conversation(request=request)
print("Conversation created successfully:")
print(response)
conversation_id = "my_first_conversation"
setup_conversation(conversation_id=conversation_id)
Es sollte eine Meldung angezeigt werden, dass die Unterhaltung erfolgreich erstellt wurde.
6. Hilfsfunktionen hinzufügen
Sie sind fast bereit, mit dem Agent zu chatten. Bevor wir das tun, fügen wir einige Hilfsfunktionen hinzu, um die Nachrichten zu formatieren, damit sie leichter zu lesen sind, und um die Visualisierungen zu rendern. Die CA API sendet eine vega-Spezifikation, die Sie mit dem altair-Paket darstellen können:
# Utility functions for streaming and formatting responses
import altair as alt
import http.server
import pandas as pd
import proto
import socketserver
import threading
_server_thread = None
_httpd = None
# Prints a formatted section title
def display_section_title(text):
print(f"\n--- {text.upper()} ---")
# Handles and displays data responses
def handle_data_response(resp):
if "query" in resp:
query = resp.query
display_section_title("Retrieval query")
print(f"Query name: {query.name}")
print(f"Question: {query.question}")
print("Data sources:")
for datasource in query.datasources:
display_datasource(datasource)
elif "generated_sql" in resp:
display_section_title("SQL generated")
print(resp.generated_sql)
elif "result" in resp:
display_section_title("Data retrieved")
fields = [field.name for field in resp.result.schema.fields]
d = {field: [] for field in fields}
for el in resp.result.data:
for field in fields:
d[field].append(el[field])
print(pd.DataFrame(d))
# Starts a local web server to preview charts
def preview_in_browser(port: int = 8080):
"""Starts a web server in a background thread and waits for user to stop it."""
global _server_thread, _httpd
if _server_thread and _server_thread.is_alive():
print(
f"\n--> A new chart was generated. Refresh your browser at http://localhost:{port}")
return
Handler = http.server.SimpleHTTPRequestHandler
socketserver.TCPServer.allow_reuse_address = True
try:
_httpd = socketserver.TCPServer(("", port), Handler)
except OSError as e:
print(f"❌ Could not start server on port {port}: {e}")
return
_server_thread = threading.Thread(target=_httpd.serve_forever)
_server_thread.daemon = False
_server_thread.start()
print("\n" + "=" * 60)
print(" 📈 CHART READY - PREVIEW IN BROWSER ".center(60))
print("=" * 60)
print(
f"1. In the Cloud Shell toolbar, click 'Web Preview' and select port {port}.")
print(f"2. Or, open your local browser to http://localhost:{port}")
print("=" * 60)
try:
input(
"\n--> Press Enter here after viewing all charts to shut down the server...\n\n")
finally:
print("Shutting down server...")
_httpd.shutdown()
_server_thread.join()
_httpd, _server_thread = None, None
print("Server stopped.")
# Handles chart responses
def handle_chart_response(resp, chart_generated_flag: list):
def _value_to_dict(v):
if isinstance(v, proto.marshal.collections.maps.MapComposite):
return {k: _value_to_dict(v[k]) for k in v}
elif isinstance(v, proto.marshal.collections.RepeatedComposite):
return [_value_to_dict(el) for el in v]
return v
if "query" in resp:
print(resp.query.instructions)
elif "result" in resp:
vega_config_dict = _value_to_dict(resp.result.vega_config)
chart = alt.Chart.from_dict(vega_config_dict)
chart_filename = "index.html"
chart.save(chart_filename)
if chart_generated_flag:
chart_generated_flag[0] = True
# Displays the schema of a data source
def display_schema(data):
fields = getattr(data, "fields")
df = pd.DataFrame({
"Column": [f.name for f in fields],
"Type": [f.type for f in fields],
"Description": [getattr(f, "description", "-") for f in fields],
"Mode": [f.mode for f in fields],
})
print(df)
# Displays information about a BigQuery data source
def display_datasource(datasource):
table_ref = datasource.bigquery_table_reference
source_name = f"{table_ref.project_id}.{table_ref.dataset_id}.{table_ref.table_id}"
print(source_name)
display_schema(datasource.schema)
# Handles and displays schema resolution responses
def handle_schema_response(resp):
if "query" in resp:
print(resp.query.question)
elif "result" in resp:
display_section_title("Schema resolved")
print("Data sources:")
for datasource in resp.result.datasources:
display_datasource(datasource)
# Handles and prints simple text responses
def handle_text_response(resp):
parts = resp.parts
print("".join(parts))
# Processes and displays different types of system messages
def show_message(msg, chart_generated_flag: list):
m = msg.system_message
if "text" in m:
handle_text_response(getattr(m, "text"))
elif "schema" in m:
handle_schema_response(getattr(m, "schema"))
elif "data" in m:
handle_data_response(getattr(m, "data"))
elif "chart" in m:
handle_chart_response(getattr(m, "chart"), chart_generated_flag)
print("\n")
7. Chatfunktion erstellen
Im letzten Schritt müssen Sie eine Chatfunktion erstellen, die Sie wiederverwenden können, und die Funktion „show_message“ für jeden Chunk im Antwortstream aufrufen:
def stream_chat_response(question: str):
"""
Sends a chat request, processes the streaming response, and if a chart
was generated, starts the preview server and waits for it to be closed.
"""
data_chat_client = geminidataanalytics.DataChatServiceClient()
chart_generated_flag = [False]
messages = [
geminidataanalytics.Message(
user_message=geminidataanalytics.UserMessage(text=question)
)
]
conversation_reference = geminidataanalytics.ConversationReference(
conversation=data_chat_client.conversation_path(
billing_project, location, conversation_id
),
data_agent_context=geminidataanalytics.DataAgentContext(
data_agent=data_chat_client.data_agent_path(
billing_project, location, data_agent_id
),
),
)
request = geminidataanalytics.ChatRequest(
parent=f"projects/{billing_project}/locations/{location}",
messages=messages,
conversation_reference=conversation_reference,
)
stream = data_chat_client.chat(request=request)
for response in stream:
show_message(response, chart_generated_flag)
if chart_generated_flag[0]:
preview_in_browser()
Die Funktion stream_chat_response ist jetzt definiert und kann mit Ihren Prompts verwendet werden.
8. Chat starten
Frage 1
Jetzt können Sie Fragen stellen. Sehen wir uns an, was dieser Agent alles kann:
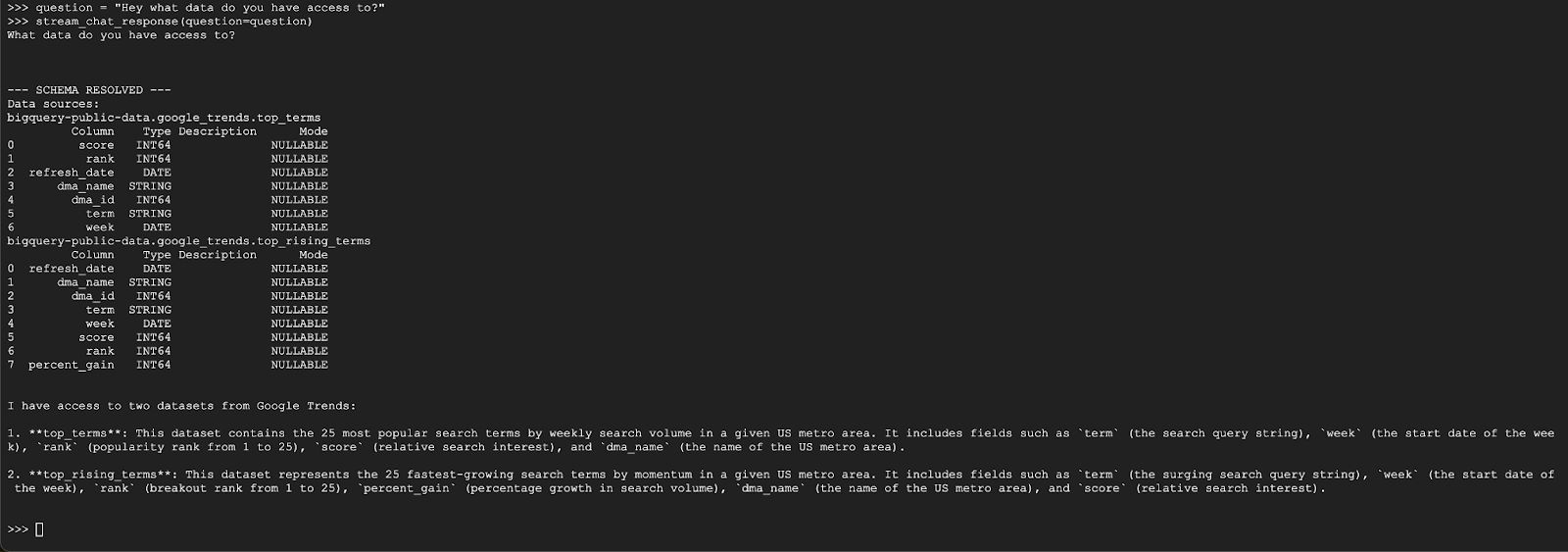
question = "Hey what data do you have access to?"
stream_chat_response(question=question)
Der Kundenservicemitarbeiter sollte in etwa so antworten:
Frage 2
Okay, versuchen wir, weitere Informationen zu den neuesten beliebten Suchbegriffen zu finden:
question = "What are the top 20 most popular search terms last week in NYC based on rank? Display each term and score as a column chart"
stream_chat_response(question=question)
Dieser Vorgang dauert einige Zeit. Sie sollten sehen, wie der Agent verschiedene Schritte durchläuft und Updates streamt, z. B. zum Abrufen des Schemas und der Metadaten, zum Schreiben der SQL-Abfrage, zum Abrufen der Ergebnisse, zum Angeben von Visualisierungsanweisungen und zum Zusammenfassen der Ergebnisse.
Wenn Sie das Diagramm aufrufen möchten, klicken Sie in der Cloud Shell-Symbolleiste auf „Webvorschau“ und wählen Sie Port 8080 aus:
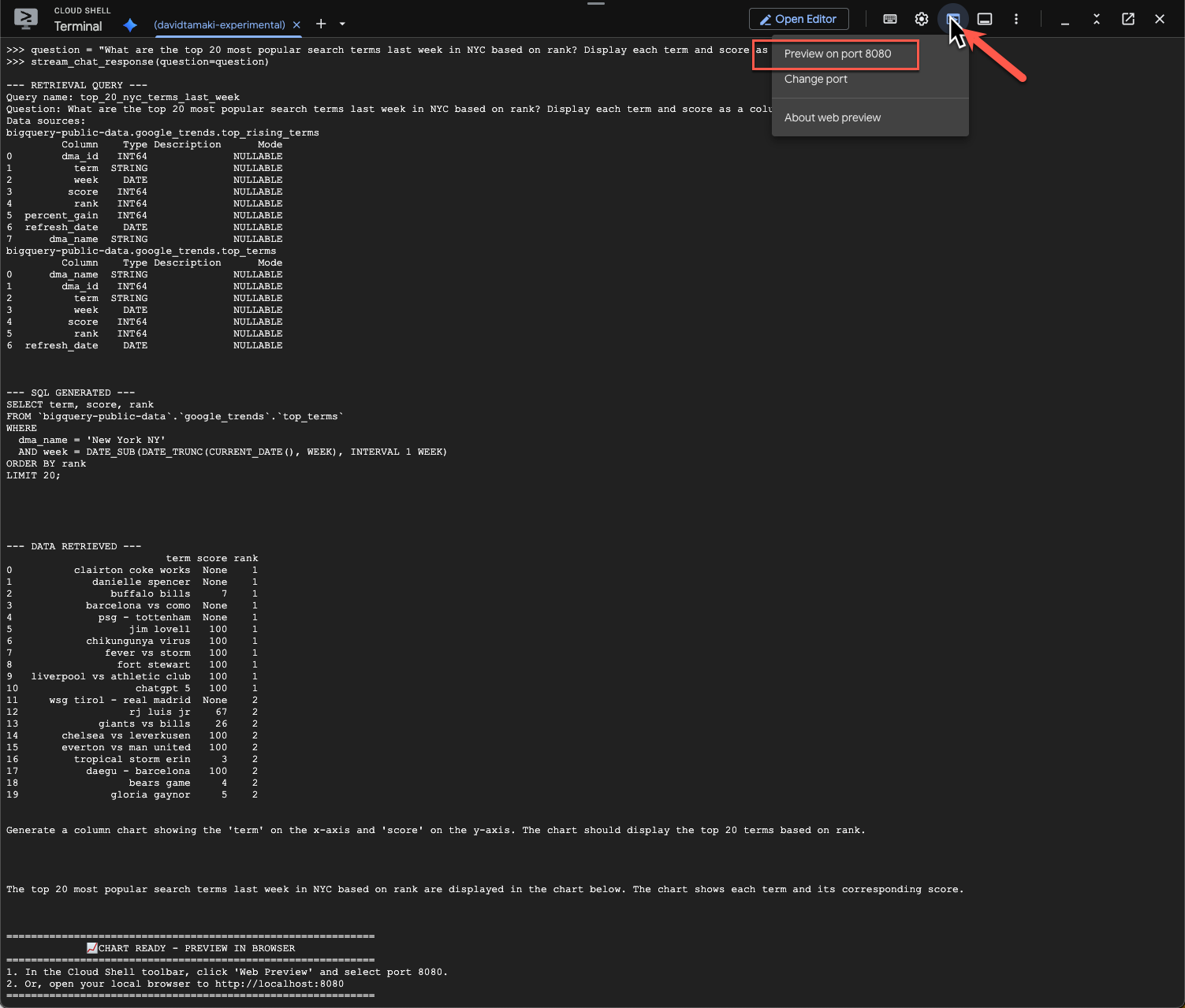
Sie sollten eine gerenderte Version der Visualisierung wie diese sehen:
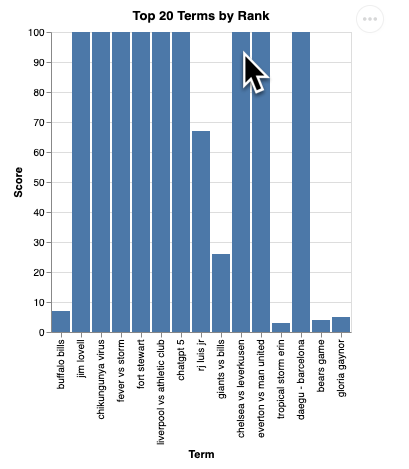
Drücken Sie die Eingabetaste, um den Server herunterzufahren und fortzufahren.
Frage 3
Stellen wir eine Folgefrage, um diese Ergebnisse genauer zu untersuchen:
question = "What was the percent gain in growth for these search terms from the week before?"
stream_chat_response(question=question)
Die Ausgabe sollte in etwa so aussehen. In diesem Fall hat der Agent eine Abfrage generiert, um die beiden Tabellen zu verknüpfen und die prozentuale Steigerung zu ermitteln. Ihre Anfrage kann leicht abweichen:
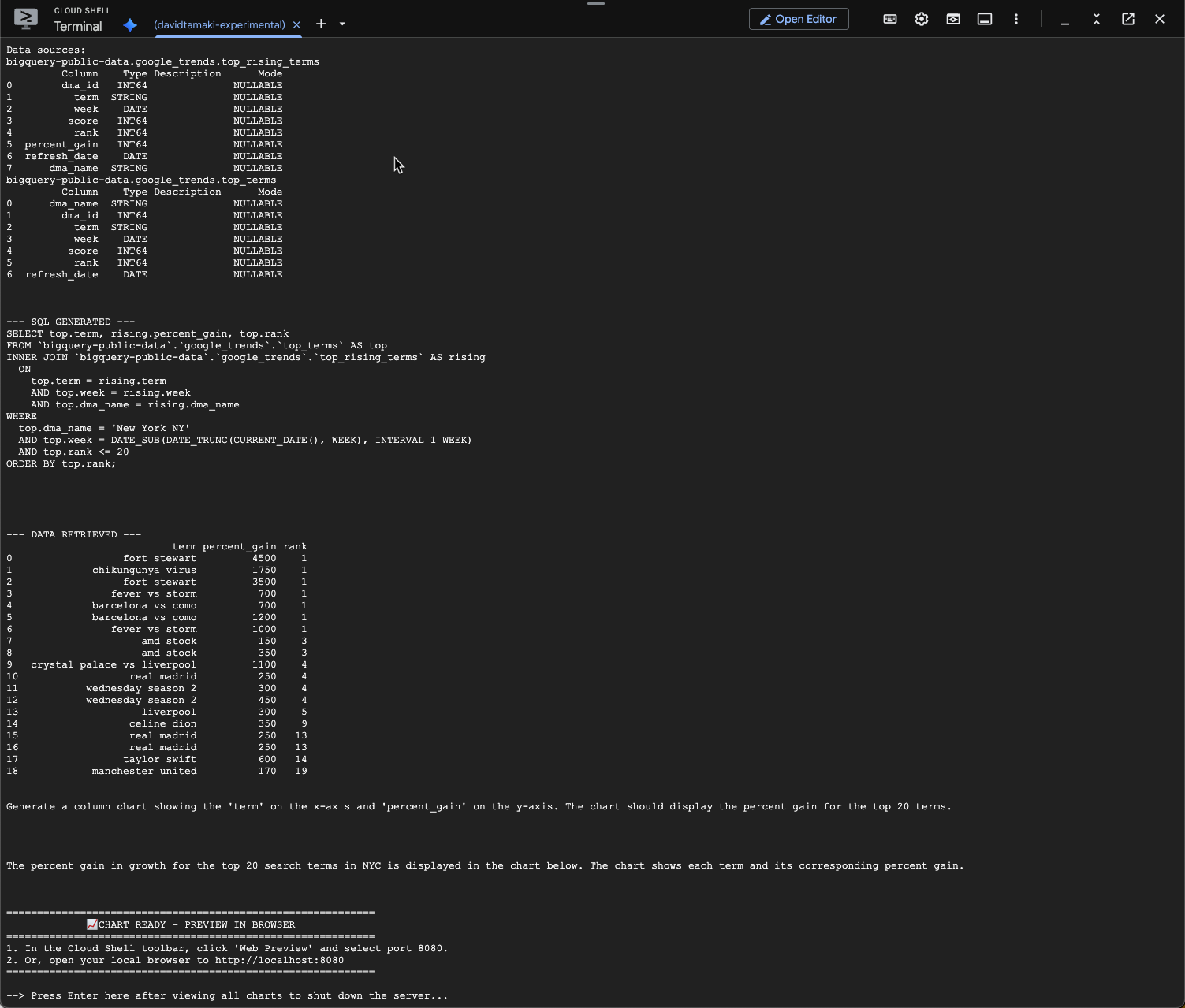
Visualisiert sieht das so aus:
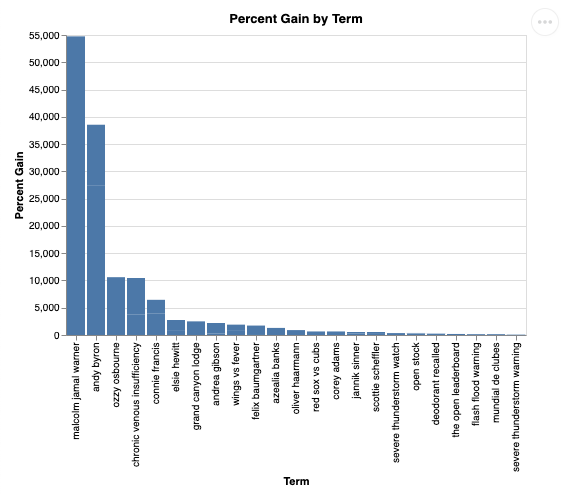
9. Bereinigen
Da in diesem Codelab keine Produkte mit langer Laufzeit verwendet werden, reicht es aus, die aktive Python-Sitzung zu beenden, indem Sie exit() in das Terminal eingeben.
Projektordner und ‑dateien löschen
Wenn Sie den Code aus Ihrer Cloud Shell-Umgebung entfernen möchten, verwenden Sie die folgenden Befehle:
cd ~
rm -rf ca-api-codelab
APIs deaktivieren
Führen Sie den folgenden Befehl aus, um die zuvor aktivierten APIs zu deaktivieren:
gcloud services disable geminidataanalytics.googleapis.com
gcloud services disable cloudaicompanion.googleapis.com
gcloud services disable bigquery.googleapis.com
10. Fazit
Herzlichen Glückwunsch! Sie haben mit dem CA SDK einen einfachen Conversational Analytics-Agenten erstellt. Weitere Informationen finden Sie in den Referenzmaterialien.