
1. Introducción
En este codelab, aprenderás a usar el SDK de Python de la API de Conversational Analytics (CA) con una fuente de datos de BigQuery. Aprenderás a crear un agente nuevo, a aprovechar la administración del estado de la conversación y a enviar y transmitir respuestas desde la API.
Requisitos previos
- Conocimientos básicos de Google Cloud y la consola de Google Cloud
- Habilidades básicas de la interfaz de línea de comandos y de Cloud Shell
- Conocimiento básico de programación en Python
Qué aprenderás
- Cómo usar el SDK de Python de la API de Conversational Analytics con una fuente de datos de BigQuery
- Cómo crear un agente nuevo con la API de CA
- Cómo aprovechar la administración del estado de la conversación
- Cómo enviar y transmitir respuestas desde la API
Requisitos
- Una cuenta y un proyecto de Google Cloud
- Un navegador web, como Chrome
2. Configuración y requisitos
Elige un proyecto
- Accede a Google Cloud Console y crea un proyecto nuevo o reutiliza uno existente. Si aún no tienes una cuenta de Gmail o de Google Workspace, debes crear una.

- El Nombre del proyecto es el nombre visible de los participantes de este proyecto. Es una cadena de caracteres que no se utiliza en las APIs de Google. Puedes actualizarla cuando quieras.
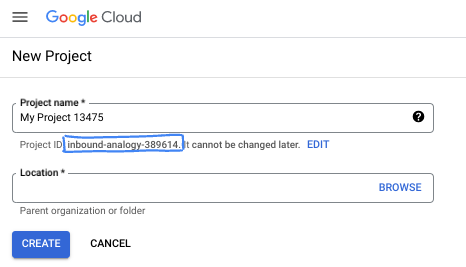
- El ID del proyecto es único en todos los proyectos de Google Cloud y es inmutable (no se puede cambiar después de configurarlo). La consola de Cloud genera automáticamente una cadena única. Por lo general, no importa cuál sea. En la mayoría de los codelabs, deberás hacer referencia al ID de tu proyecto (suele identificarse como
PROJECT_ID). Si no te gusta el ID que se generó, podrías generar otro aleatorio. También puedes probar uno propio y ver si está disponible. No se puede cambiar después de este paso y se usa el mismo durante todo el proyecto. - Recuerda que hay un tercer valor, un número de proyecto, que usan algunas APIs. Obtén más información sobre estos tres valores en la documentación.
- A continuación, deberás habilitar la facturación en la consola de Cloud para usar las APIs o los recursos de Cloud. Ejecutar este codelab no costará mucho, tal vez nada. Para cerrar recursos y evitar que se generen cobros más allá de este instructivo, puedes borrar los recursos que creaste o borrar el proyecto. Los usuarios nuevos de Google Cloud son aptos para participar en el programa Prueba gratuita de $300.
Inicia Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En Google Cloud Console, haz clic en el ícono de Cloud Shell en la barra de herramientas en la parte superior derecha:
El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
3. Antes de comenzar
Habilite las API necesarias
Para usar los servicios de Google Cloud, primero debes activar sus respectivas APIs para tu proyecto. En este codelab, usarás los siguientes servicios de Google Cloud:
- API de Data Analytics with Gemini
- Gemini para Google Cloud
- API de BigQuery
Para habilitar estos servicios, ejecuta los siguientes comandos en la terminal de Cloud Shell:
gcloud services enable geminidataanalytics.googleapis.com
gcloud services enable cloudaicompanion.googleapis.com
gcloud services enable bigquery.googleapis.com
Instala paquetes de Python
Antes de comenzar cualquier proyecto de Python, es una buena práctica crear un entorno virtual. Esto aísla las dependencias del proyecto y evita conflictos con otros proyectos o con los paquetes globales de Python del sistema. En esta sección, instalarás uv desde pip, ya que Cloud Shell ya tiene pip disponible.
Instala el paquete uv
pip install uv
Verifica si uv está instalado correctamente
uv --version
Resultado esperado
Si ves una línea de salida con uv, puedes continuar con el siguiente paso. Ten en cuenta que el número de versión puede variar:

Crea un entorno virtual y, luego, instala paquetes
uv init ca-api-codelab
cd ca-api-codelab
uv venv --python 3.12
uv add google-cloud-geminidataanalytics pandas altair
uv pip list | grep -E 'altair|pandas|google-cloud-geminidataanalytics'
Resultado esperado
Si ves líneas de salida con los tres paquetes, puedes continuar con el siguiente paso. Ten en cuenta que los números de versión pueden variar:

Cómo iniciar Python
uv run python
En la pantalla debería ver lo siguiente:

4. Crea un agente
Ahora que tu entorno de desarrollo está configurado y listo, es momento de sentar las bases de la API de Gemini Data Analytics. El SDK simplifica este proceso, ya que solo requiere algunas configuraciones esenciales para crear tu agente.
Establecer las variables
Importa el paquete geminidataanalytics y establece nuestras variables de entorno:
import os
from google.cloud import geminidataanalytics
data_agent_client = geminidataanalytics.DataAgentServiceClient()
location = "global"
billing_project = os.environ.get('DEVSHELL_PROJECT_ID')
data_agent_id = "google_trends_analytics_agent"
Establece instrucciones del sistema para el agente
La API de CA lee los metadatos de BigQuery para obtener más contexto sobre las tablas y las columnas a las que se hace referencia. Dado que este conjunto de datos públicos no tiene descripciones de columnas, puedes proporcionar contexto adicional al agente como una cadena con formato YAML. Consulta la documentación para conocer las prácticas recomendadas y una plantilla que puedes usar:
system_instruction = """
system_instruction:
- You are a data analyst specializing in the Google Trends dataset.
- When querying, always use the 'week' column for date-based filtering. This needs to be a Sunday. If you are doing week over week comparison, make sure you specify a date that is a Sunday.
- The following columns should be ignored in all queries 'dma_id', 'refresh_date'
- The 'dma_name' column represents the city and state for about 210 metro areas in the USA.
tables:
top_terms:
description: "Represents the 25 most popular search terms by weekly search volume in a given US metro area (DMA)."
fields:
term: "The search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's popularity rank from 1 (most popular) to 25."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
dma_name: "The name of the US metro area, e.g., 'New York NY'."
top_rising_terms:
description: "Represents the 25 fastest-growing ('breakout') search terms by momentum in a given US metro area (DMA)."
fields:
term: "The surging search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's breakout rank from 1 (top rising) to 25."
percent_gain: "The percentage growth in search volume compared to the previous period."
dma_name: "The name of the US metro area, e.g., 'Los Angeles CA'."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
join_instructions:
goal: "Find terms that are simultaneously popular and rising in the same week and metro area."
method: "INNER JOIN the two tables on their common keys."
keys:
- "term"
- "week"
- "dma_name"
golden_queries:
- natural_language_query: "Find all terms in the 'New York NY' area that were in both the top 25 and top 25 rising lists for the week of July 6th, 2025, and show their ranks and percent gain."
sql_query: |
SELECT
top.term,
top.rank AS top_25_rank,
rising.rank AS rising_25_rank,
rising.percent_gain
FROM
`bigquery-public-data.google_trends.top_terms` AS top
INNER JOIN
`bigquery-public-data.google_trends.top_rising_terms` AS rising
ON
top.term = rising.term
AND top.week = rising.week
AND top.dma_name = rising.dma_name
WHERE
top.week = '2025-07-06'
AND top.dma_name = 'New York NY'
ORDER BY
top.rank;
"""
Configura las fuentes de datos de la tabla de BigQuery
Ahora puedes configurar las fuentes de datos de la tabla de BigQuery. La API de CA acepta tablas de BigQuery en un array:
# BigQuery table data sources
bq_top = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_terms"
)
bq_rising = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_rising_terms"
)
datasource_references = geminidataanalytics.DatasourceReferences(
bq=geminidataanalytics.BigQueryTableReferences(table_references=[bq_top, bq_rising]))
Cómo establecer el contexto para el chat con estado
Puedes crear el nuevo agente con el contexto publicado, que reúne las instrucciones del sistema, las referencias de la fuente de datos y cualquier otra opción.
Ten en cuenta que tienes la funcionalidad para crear un stagingContext para probar y validar los cambios antes de publicarlos. Esto permite que un desarrollador agregue control de versiones a un agente de datos especificando contextVersion en la solicitud de chat. En este codelab, publicarás directamente:
# Context setup for stateful chat
published_context = geminidataanalytics.Context(
system_instruction=system_instruction,
datasource_references=datasource_references,
options=geminidataanalytics.ConversationOptions(
analysis=geminidataanalytics.AnalysisOptions(
python=geminidataanalytics.AnalysisOptions.Python(
enabled=False
)
)
),
)
data_agent = geminidataanalytics.DataAgent(
data_analytics_agent=geminidataanalytics.DataAnalyticsAgent(
published_context=published_context
),
)
# Create the agent
data_agent_client.create_data_agent(request=geminidataanalytics.CreateDataAgentRequest(
parent=f"projects/{billing_project}/locations/{location}",
data_agent_id=data_agent_id,
data_agent=data_agent,
))
Después de crear el agente, deberías ver un resultado similar al siguiente:

Obtén el agente
Probemos el agente para asegurarnos de que se haya creado:
# Test the agent
request = geminidataanalytics.GetDataAgentRequest(
name=data_agent_client.data_agent_path(
billing_project, location, data_agent_id)
)
response = data_agent_client.get_data_agent(request=request)
print(response)
Deberías ver los metadatos en tu nuevo agente. Esto incluirá elementos como la hora de creación y el contexto del agente en las instrucciones del sistema y las fuentes de datos.
5. Cómo crear una conversación
Ya puedes crear tu primera conversación. En este codelab, usarás una referencia de conversación para un chat con estado con tu agente.
Como referencia, la API de CA ofrece varias formas de chatear con diferentes opciones de administración de estados y agentes. A continuación, se incluye un breve resumen de los 3 enfoques:
Estado | Historial de conversaciones | Agent | Código | Descripción | |
Chatea con una referencia de conversación | Con estado | API administrada | Sí | Continúa una conversación con estado enviando un mensaje de chat que hace referencia a una conversación existente y a su contexto del agente asociado. En el caso de las conversaciones de varios turnos, Google Cloud almacena y administra el historial de conversaciones. | |
Chatea con una referencia de agente de datos | Sin estado | Administrada por el usuario | Sí | Envía un mensaje de chat sin estado que hace referencia a un agente de datos guardado para el contexto. En el caso de las conversaciones de varios turnos, tu aplicación debe administrar y proporcionar el historial de conversaciones con cada solicitud. | |
Chatea con contexto intercalado | Sin estado | Administrada por el usuario | No | Envía un mensaje de chat sin estado proporcionando todo el contexto directamente en la solicitud, sin usar un agente de datos guardado. En el caso de las conversaciones de varios turnos, tu aplicación debe administrar y proporcionar el historial de conversaciones con cada solicitud. |
Crearás una función para configurar tu conversación y proporcionar un ID único para ella:
def setup_conversation(conversation_id: str):
data_chat_client = geminidataanalytics.DataChatServiceClient()
conversation = geminidataanalytics.Conversation(
agents=[data_chat_client.data_agent_path(
billing_project, location, data_agent_id)],
)
request = geminidataanalytics.CreateConversationRequest(
parent=f"projects/{billing_project}/locations/{location}",
conversation_id=conversation_id,
conversation=conversation,
)
try:
data_chat_client.get_conversation(name=data_chat_client.conversation_path(
billing_project, location, conversation_id))
print(f"Conversation '{conversation_id}' already exists.")
except Exception:
response = data_chat_client.create_conversation(request=request)
print("Conversation created successfully:")
print(response)
conversation_id = "my_first_conversation"
setup_conversation(conversation_id=conversation_id)
Deberías ver un mensaje que indica que la conversación se creó correctamente.
6. Agrega funciones de utilidad
Ya casi está todo listo para comenzar a chatear con el agente. Antes de hacerlo, agreguemos algunas funciones de utilidad para ayudar a formatear los mensajes de modo que sean más fáciles de leer y también renderizar las visualizaciones. La API de la AC enviará una especificación de Vega que puedes graficar con el paquete Altair:
# Utility functions for streaming and formatting responses
import altair as alt
import http.server
import pandas as pd
import proto
import socketserver
import threading
_server_thread = None
_httpd = None
# Prints a formatted section title
def display_section_title(text):
print(f"\n--- {text.upper()} ---")
# Handles and displays data responses
def handle_data_response(resp):
if "query" in resp:
query = resp.query
display_section_title("Retrieval query")
print(f"Query name: {query.name}")
print(f"Question: {query.question}")
print("Data sources:")
for datasource in query.datasources:
display_datasource(datasource)
elif "generated_sql" in resp:
display_section_title("SQL generated")
print(resp.generated_sql)
elif "result" in resp:
display_section_title("Data retrieved")
fields = [field.name for field in resp.result.schema.fields]
d = {field: [] for field in fields}
for el in resp.result.data:
for field in fields:
d[field].append(el[field])
print(pd.DataFrame(d))
# Starts a local web server to preview charts
def preview_in_browser(port: int = 8080):
"""Starts a web server in a background thread and waits for user to stop it."""
global _server_thread, _httpd
if _server_thread and _server_thread.is_alive():
print(
f"\n--> A new chart was generated. Refresh your browser at http://localhost:{port}")
return
Handler = http.server.SimpleHTTPRequestHandler
socketserver.TCPServer.allow_reuse_address = True
try:
_httpd = socketserver.TCPServer(("", port), Handler)
except OSError as e:
print(f"❌ Could not start server on port {port}: {e}")
return
_server_thread = threading.Thread(target=_httpd.serve_forever)
_server_thread.daemon = False
_server_thread.start()
print("\n" + "=" * 60)
print(" 📈 CHART READY - PREVIEW IN BROWSER ".center(60))
print("=" * 60)
print(
f"1. In the Cloud Shell toolbar, click 'Web Preview' and select port {port}.")
print(f"2. Or, open your local browser to http://localhost:{port}")
print("=" * 60)
try:
input(
"\n--> Press Enter here after viewing all charts to shut down the server...\n\n")
finally:
print("Shutting down server...")
_httpd.shutdown()
_server_thread.join()
_httpd, _server_thread = None, None
print("Server stopped.")
# Handles chart responses
def handle_chart_response(resp, chart_generated_flag: list):
def _value_to_dict(v):
if isinstance(v, proto.marshal.collections.maps.MapComposite):
return {k: _value_to_dict(v[k]) for k in v}
elif isinstance(v, proto.marshal.collections.RepeatedComposite):
return [_value_to_dict(el) for el in v]
return v
if "query" in resp:
print(resp.query.instructions)
elif "result" in resp:
vega_config_dict = _value_to_dict(resp.result.vega_config)
chart = alt.Chart.from_dict(vega_config_dict)
chart_filename = "index.html"
chart.save(chart_filename)
if chart_generated_flag:
chart_generated_flag[0] = True
# Displays the schema of a data source
def display_schema(data):
fields = getattr(data, "fields")
df = pd.DataFrame({
"Column": [f.name for f in fields],
"Type": [f.type for f in fields],
"Description": [getattr(f, "description", "-") for f in fields],
"Mode": [f.mode for f in fields],
})
print(df)
# Displays information about a BigQuery data source
def display_datasource(datasource):
table_ref = datasource.bigquery_table_reference
source_name = f"{table_ref.project_id}.{table_ref.dataset_id}.{table_ref.table_id}"
print(source_name)
display_schema(datasource.schema)
# Handles and displays schema resolution responses
def handle_schema_response(resp):
if "query" in resp:
print(resp.query.question)
elif "result" in resp:
display_section_title("Schema resolved")
print("Data sources:")
for datasource in resp.result.datasources:
display_datasource(datasource)
# Handles and prints simple text responses
def handle_text_response(resp):
parts = resp.parts
print("".join(parts))
# Processes and displays different types of system messages
def show_message(msg, chart_generated_flag: list):
m = msg.system_message
if "text" in m:
handle_text_response(getattr(m, "text"))
elif "schema" in m:
handle_schema_response(getattr(m, "schema"))
elif "data" in m:
handle_data_response(getattr(m, "data"))
elif "chart" in m:
handle_chart_response(getattr(m, "chart"), chart_generated_flag)
print("\n")
7. Crea una función de chat
El paso final es crear una función de chat que puedas reutilizar y llamar a la función show_message para cada fragmento del flujo de respuesta:
def stream_chat_response(question: str):
"""
Sends a chat request, processes the streaming response, and if a chart
was generated, starts the preview server and waits for it to be closed.
"""
data_chat_client = geminidataanalytics.DataChatServiceClient()
chart_generated_flag = [False]
messages = [
geminidataanalytics.Message(
user_message=geminidataanalytics.UserMessage(text=question)
)
]
conversation_reference = geminidataanalytics.ConversationReference(
conversation=data_chat_client.conversation_path(
billing_project, location, conversation_id
),
data_agent_context=geminidataanalytics.DataAgentContext(
data_agent=data_chat_client.data_agent_path(
billing_project, location, data_agent_id
),
),
)
request = geminidataanalytics.ChatRequest(
parent=f"projects/{billing_project}/locations/{location}",
messages=messages,
conversation_reference=conversation_reference,
)
stream = data_chat_client.chat(request=request)
for response in stream:
show_message(response, chart_generated_flag)
if chart_generated_flag[0]:
preview_in_browser()
Ahora se define la función stream_chat_response y está lista para usarse con tus instrucciones.
8. Comienza a chatear
Pregunta 1
Ya puedes comenzar a hacer preguntas. Veamos qué puede hacer este agente para empezar:
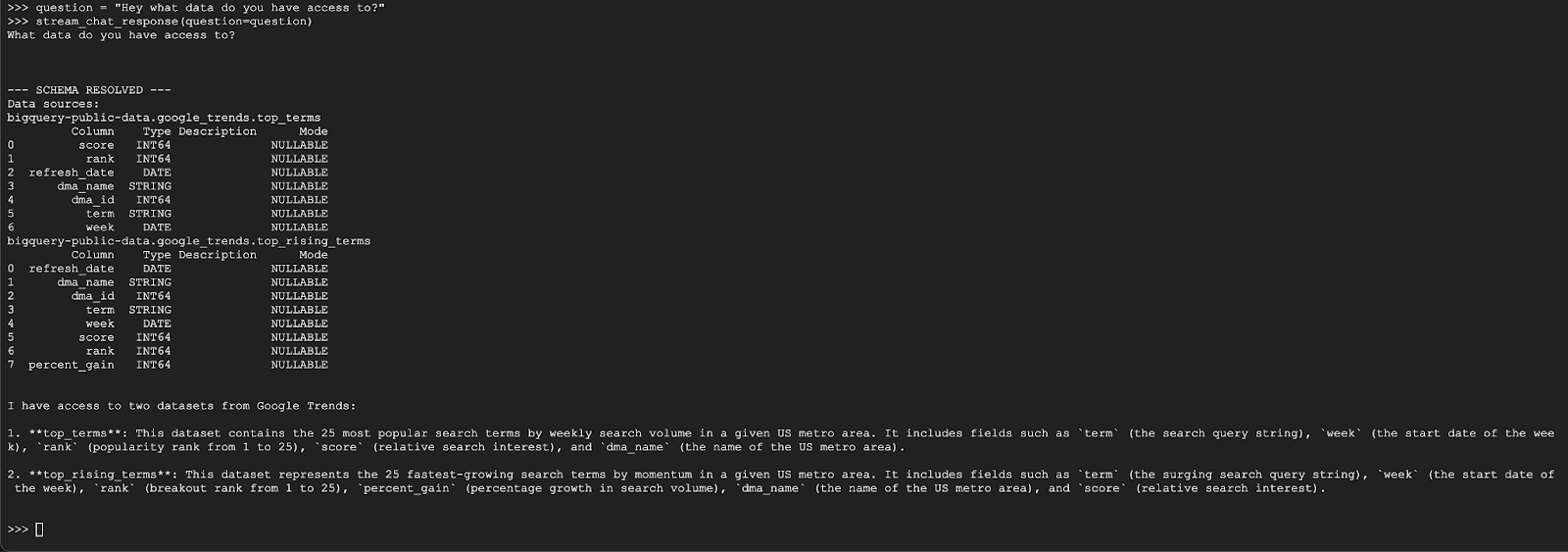
question = "Hey what data do you have access to?"
stream_chat_response(question=question)
El agente debería responder algo similar a lo siguiente:
Pregunta 2
Excelente. Intentemos encontrar más información sobre los términos de búsqueda populares más recientes:
question = "What are the top 20 most popular search terms last week in NYC based on rank? Display each term and score as a column chart"
stream_chat_response(question=question)
Este proceso tardará un poco en ejecutarse. Deberías ver que el agente ejecuta varios pasos y transmite actualizaciones, desde la recuperación del esquema y los metadatos, la escritura de la consulta de SQL, la obtención de los resultados, la especificación de las instrucciones de visualización y el resumen de los resultados.
Para ver el gráfico, ve a la barra de herramientas de Cloud Shell, haz clic en “Vista previa en la Web” y selecciona el puerto 8080:
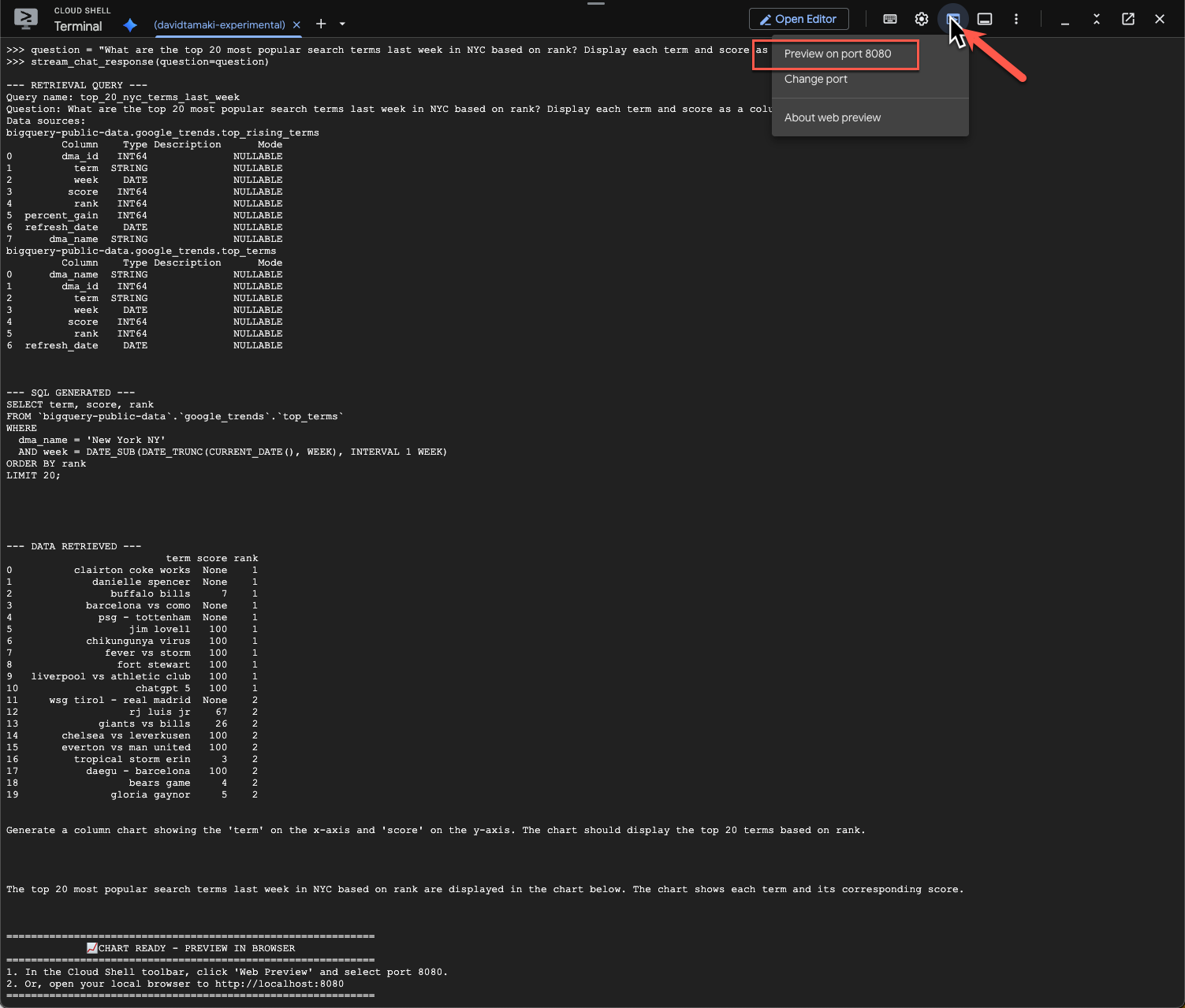
Deberías ver una renderización de la visualización como la siguiente:
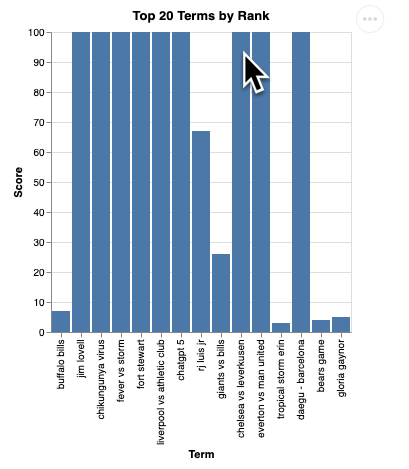
Presiona Intro para apagar el servidor y continuar.
Pregunta 3
Hagamos una pregunta de seguimiento y profundicemos en estos resultados:
question = "What was the percent gain in growth for these search terms from the week before?"
stream_chat_response(question=question)
Deberías ver un resultado similar al siguiente. En este caso, el agente generó una consulta para unir las 2 tablas y encontrar el porcentaje de ganancia. Ten en cuenta que tu búsqueda puede verse un poco diferente:
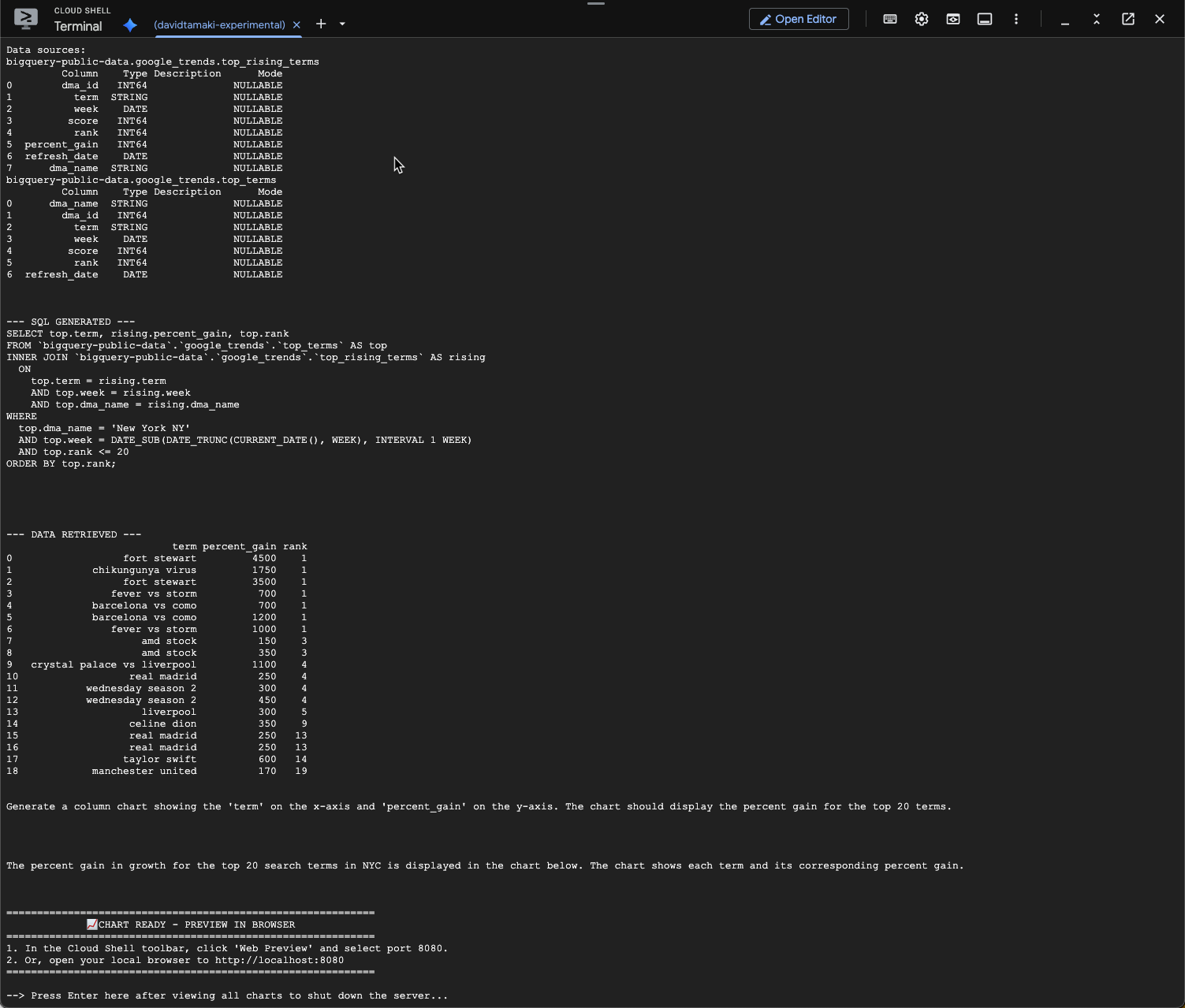
Y, visualizada, se verá de la siguiente manera:
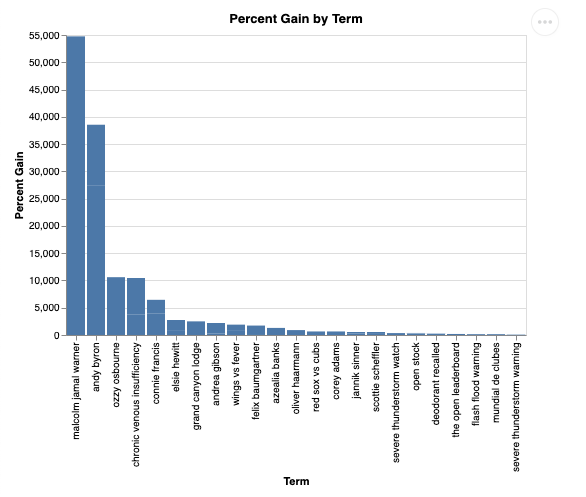
9. Limpieza
Como este codelab no involucra ningún producto de ejecución prolongada, basta con que detengas tu sesión activa de Python ingresando exit() en la terminal.
Borra las carpetas y los archivos del proyecto
Si deseas quitar el código de tu entorno de Cloud Shell, usa los siguientes comandos:
cd ~
rm -rf ca-api-codelab
Inhabilita las APIs
Para inhabilitar las APIs que se habilitaron anteriormente, ejecuta este comando:
gcloud services disable geminidataanalytics.googleapis.com
gcloud services disable cloudaicompanion.googleapis.com
gcloud services disable bigquery.googleapis.com
10. Conclusión
¡Felicitaciones! Creaste correctamente un agente de análisis conversacional simple con el SDK de CA. Consulta los materiales de referencia para obtener más información.