
۱. مقدمه
در این آزمایشگاه کد، نحوه استفاده از API تحلیل مکالمهای (CA) پایتون SDK را با منبع داده BigQuery خواهید آموخت. نحوه ایجاد یک عامل جدید، نحوه استفاده از مدیریت وضعیت مکالمه و نحوه ارسال و پخش پاسخها از API را خواهید آموخت.
پیشنیازها
- درک اولیه از گوگل کلود و کنسول گوگل کلود
- مهارتهای پایه در رابط خط فرمان و Cloud Shell
- تسلط اولیه به برنامه نویسی پایتون
آنچه یاد خواهید گرفت
- نحوه استفاده از API تحلیل مکالمهای پایتون SDK با منبع داده BigQuery
- نحوه ایجاد یک عامل جدید با استفاده از API CA
- چگونه از مدیریت وضعیت مکالمه بهره ببریم
- نحوه ارسال و پخش پاسخها از API
آنچه نیاز دارید
- یک حساب کاربری گوگل کلود و پروژه گوگل کلود
- یک مرورگر وب مانند کروم
۲. تنظیمات و الزامات
Choose a project
- وارد کنسول گوگل کلود شوید و یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. اگر از قبل حساب جیمیل یا گوگل ورک اسپیس ندارید، باید یکی ایجاد کنید .

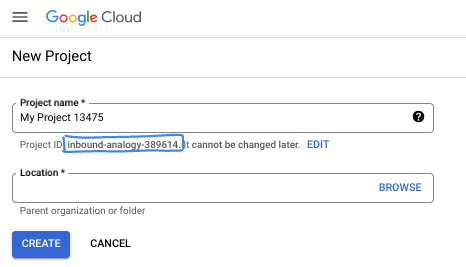
- نام پروژه، نام نمایشی برای شرکتکنندگان این پروژه است. این یک رشته کاراکتری است که توسط APIهای گوگل استفاده نمیشود. شما همیشه میتوانید آن را بهروزرسانی کنید.
- شناسه پروژه در تمام پروژههای گوگل کلود منحصر به فرد است و تغییرناپذیر است (پس از تنظیم، قابل تغییر نیست). کنسول کلود به طور خودکار یک رشته منحصر به فرد تولید میکند؛ معمولاً برای شما مهم نیست که چه باشد. در اکثر آزمایشگاههای کد، باید شناسه پروژه خود را (که معمولاً با عنوان
PROJECT_IDشناخته میشود) ارجاع دهید. اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید. به عنوان یک جایگزین، میتوانید شناسه خودتان را امتحان کنید و ببینید که آیا در دسترس است یا خیر. پس از این مرحله قابل تغییر نیست و در طول پروژه باقی میماند. - برای اطلاع شما، یک مقدار سوم، شماره پروژه ، وجود دارد که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
- در مرحله بعد، برای استفاده از منابع/API های ابری، باید پرداخت صورتحساب را در کنسول ابری فعال کنید . اجرای این آزمایشگاه کد هزینه زیادی نخواهد داشت، اگر اصلاً هزینهای داشته باشد. برای خاموش کردن منابع به منظور جلوگیری از پرداخت صورتحساب پس از این آموزش، میتوانید منابعی را که ایجاد کردهاید یا پروژه را حذف کنید. کاربران جدید Google Cloud واجد شرایط برنامه آزمایشی رایگان ۳۰۰ دلاری هستند.
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:
آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
۳. قبل از شروع
فعال کردن API های مورد نیاز
برای استفاده از سرویسهای گوگل کلود، ابتدا باید APIهای مربوط به آنها را برای پروژه خود فعال کنید. در این آزمایشگاه کد، از سرویسهای گوگل کلود زیر استفاده خواهید کرد:
- Data Analytics API with Gemini
- جمینی برای گوگل کلود
- رابط برنامهنویسی کاربردی بیگکوئری
برای فعال کردن این سرویسها، دستورات زیر را در ترمینال Cloud Shell اجرا کنید:
gcloud services enable geminidataanalytics.googleapis.com
gcloud services enable cloudaicompanion.googleapis.com
gcloud services enable bigquery.googleapis.com
نصب بستههای پایتون
قبل از شروع هر پروژه پایتون، ایجاد یک محیط مجازی تمرین خوبی است. این کار وابستگیهای پروژه را ایزوله میکند و از تداخل با سایر پروژهها یا بستههای پایتون سراسری سیستم جلوگیری میکند. در این بخش، uv از طریق pip نصب خواهید کرد، زیرا Cloud Shell از قبل pip را در دسترس دارد.
نصب پکیج یووی
pip install uv
تأیید کنید که آیا uv به درستی نصب شده است یا خیر
uv --version
خروجی مورد انتظار
اگر یک خط خروجی با uv مشاهده کردید، میتوانید به مرحله بعدی بروید. توجه داشته باشید که شماره نسخه ممکن است متفاوت باشد:

ایجاد محیط مجازی و نصب بستهها
uv init ca-api-codelab
cd ca-api-codelab
uv venv --python 3.12
uv add google-cloud-geminidataanalytics pandas altair
uv pip list | grep -E 'altair|pandas|google-cloud-geminidataanalytics'
خروجی مورد انتظار
اگر خطوط خروجی شامل سه بسته را مشاهده کردید، میتوانید به مرحله بعدی بروید. توجه داشته باشید که شماره نسخهها ممکن است متفاوت باشد:

شروع پایتون
uv run python
صفحه نمایش شما باید به این شکل باشد:

۴. یک نماینده ایجاد کنید
اکنون که محیط توسعه شما راهاندازی و آماده شده است، زمان آن رسیده است که پایه و اساس API تجزیه و تحلیل دادههای Gemini را بنا کنید. SDK این فرآیند را ساده میکند و برای ایجاد عامل شما فقط به چند پیکربندی اساسی نیاز دارد.
متغیرها را تنظیم کنید
بسته geminidataanalytics را وارد کنید و متغیرهای محیطی ما را تنظیم کنید:
import os
from google.cloud import geminidataanalytics
data_agent_client = geminidataanalytics.DataAgentServiceClient()
location = "global"
billing_project = os.environ.get('DEVSHELL_PROJECT_ID')
data_agent_id = "google_trends_analytics_agent"
دستورالعملهای سیستم را برای عامل تنظیم کنید
رابط برنامهنویسی کاربردی CA، فرادادههای BigQuery را میخواند تا اطلاعات بیشتری در مورد جداول و ستونهایی که به آنها ارجاع داده میشود، به دست آورد. از آنجایی که این مجموعه داده عمومی هیچ توضیحی برای ستونها ندارد، میتوانید اطلاعات بیشتری را به عنوان یک رشته با فرمت YAML در اختیار عامل قرار دهید. برای بهترین شیوهها و الگوی مورد استفاده، به مستندات مراجعه کنید:
system_instruction = """
system_instruction:
- You are a data analyst specializing in the Google Trends dataset.
- When querying, always use the 'week' column for date-based filtering. This needs to be a Sunday. If you are doing week over week comparison, make sure you specify a date that is a Sunday.
- The following columns should be ignored in all queries 'dma_id', 'refresh_date'
- The 'dma_name' column represents the city and state for about 210 metro areas in the USA.
tables:
top_terms:
description: "Represents the 25 most popular search terms by weekly search volume in a given US metro area (DMA)."
fields:
term: "The search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's popularity rank from 1 (most popular) to 25."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
dma_name: "The name of the US metro area, e.g., 'New York NY'."
top_rising_terms:
description: "Represents the 25 fastest-growing ('breakout') search terms by momentum in a given US metro area (DMA)."
fields:
term: "The surging search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's breakout rank from 1 (top rising) to 25."
percent_gain: "The percentage growth in search volume compared to the previous period."
dma_name: "The name of the US metro area, e.g., 'Los Angeles CA'."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
join_instructions:
goal: "Find terms that are simultaneously popular and rising in the same week and metro area."
method: "INNER JOIN the two tables on their common keys."
keys:
- "term"
- "week"
- "dma_name"
golden_queries:
- natural_language_query: "Find all terms in the 'New York NY' area that were in both the top 25 and top 25 rising lists for the week of July 6th, 2025, and show their ranks and percent gain."
sql_query: |
SELECT
top.term,
top.rank AS top_25_rank,
rising.rank AS rising_25_rank,
rising.percent_gain
FROM
`bigquery-public-data.google_trends.top_terms` AS top
INNER JOIN
`bigquery-public-data.google_trends.top_rising_terms` AS rising
ON
top.term = rising.term
AND top.week = rising.week
AND top.dma_name = rising.dma_name
WHERE
top.week = '2025-07-06'
AND top.dma_name = 'New York NY'
ORDER BY
top.rank;
"""
منابع داده جدول BigQuery را تنظیم کنید
حالا میتوانید منابع داده جدول BigQuery را تنظیم کنید. رابط برنامهنویسی کاربردی CA، جداول BigQuery را در یک آرایه میپذیرد:
# BigQuery table data sources
bq_top = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_terms"
)
bq_rising = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_rising_terms"
)
datasource_references = geminidataanalytics.DatasourceReferences(
bq=geminidataanalytics.BigQueryTableReferences(table_references=[bq_top, bq_rising]))
تنظیم زمینه برای چت با وضعیت
شما میتوانید عامل جدید را با زمینه منتشر شده ایجاد کنید که دستورالعملهای سیستم، ارجاعات به منبع داده و هر گزینه دیگری را گرد هم میآورد.
توجه داشته باشید که شما قابلیت ایجاد stagingContext را برای آزمایش و اعتبارسنجی تغییرات قبل از انتشار دارید. این به یک توسعهدهنده اجازه میدهد تا با مشخص کردن contextVersion در درخواست چت، نسخهبندی را به یک عامل داده اضافه کند. برای این codelab، شما مستقیماً منتشر خواهید کرد:
# Context setup for stateful chat
published_context = geminidataanalytics.Context(
system_instruction=system_instruction,
datasource_references=datasource_references,
options=geminidataanalytics.ConversationOptions(
analysis=geminidataanalytics.AnalysisOptions(
python=geminidataanalytics.AnalysisOptions.Python(
enabled=False
)
)
),
)
data_agent = geminidataanalytics.DataAgent(
data_analytics_agent=geminidataanalytics.DataAnalyticsAgent(
published_context=published_context
),
)
# Create the agent
data_agent_client.create_data_agent(request=geminidataanalytics.CreateDataAgentRequest(
parent=f"projects/{billing_project}/locations/{location}",
data_agent_id=data_agent_id,
data_agent=data_agent,
))
پس از ایجاد عامل، باید خروجی مشابه زیر را مشاهده کنید:

نماینده را دریافت کنید
بیایید عامل را آزمایش کنیم تا مطمئن شویم که ایجاد شده است:
# Test the agent
request = geminidataanalytics.GetDataAgentRequest(
name=data_agent_client.data_agent_path(
billing_project, location, data_agent_id)
)
response = data_agent_client.get_data_agent(request=request)
print(response)
شما باید فرادادههای مربوط به عامل جدید خود را مشاهده کنید. این شامل مواردی مانند زمان ایجاد شده و زمینه عامل در دستورالعملهای سیستم و منابع داده خواهد بود.
۵. یک مکالمه ایجاد کنید
اکنون آمادهاید تا اولین مکالمه خود را ایجاد کنید! برای این آزمایشگاه کد، از یک مرجع مکالمه برای یک چت با وضعیت (stateful chat) با عامل خود استفاده خواهید کرد.
برای مرجع، رابط برنامهنویسی کاربردی CA روشهای مختلفی برای چت با گزینههای مختلف مدیریت وضعیت و عامل ارائه میدهد. در اینجا خلاصهای سریع از ۳ رویکرد ارائه شده است:
ایالت | تاریخچه مکالمه | عامل | کد | توضیحات | |
با استفاده از مرجع مکالمه چت کنید | دولتی | API مدیریت شده | بله | با ارسال یک پیام چت که به مکالمه موجود و زمینه عامل مرتبط با آن اشاره دارد، مکالمهای با وضعیت مشخص را ادامه میدهد. برای مکالمات چند نوبتی، Google Cloud تاریخچه مکالمه را ذخیره و مدیریت میکند. | |
با استفاده از مرجع عامل داده چت کنید | بیتابعیت | مدیریت شده توسط کاربر | بله | یک پیام چت بدون وضعیت ارسال میکند که به یک عامل داده ذخیره شده برای زمینه ارجاع میدهد. برای مکالمات چند نوبتی، برنامه شما باید تاریخچه مکالمات را مدیریت و با هر درخواست ارائه دهد. | |
چت با استفاده از متن درون خطی | بیتابعیت | مدیریت شده توسط کاربر | خیر | با ارائه تمام متن به طور مستقیم در درخواست، بدون استفاده از عامل داده ذخیره شده، یک پیام چت بدون وضعیت ارسال میکند. برای مکالمات چند نوبتی، برنامه شما باید تاریخچه مکالمات را با هر درخواست مدیریت و ارائه کند. |
شما یک تابع برای تنظیم مکالمه خود ایجاد خواهید کرد و یک شناسه منحصر به فرد برای مکالمه ارائه خواهید داد:
def setup_conversation(conversation_id: str):
data_chat_client = geminidataanalytics.DataChatServiceClient()
conversation = geminidataanalytics.Conversation(
agents=[data_chat_client.data_agent_path(
billing_project, location, data_agent_id)],
)
request = geminidataanalytics.CreateConversationRequest(
parent=f"projects/{billing_project}/locations/{location}",
conversation_id=conversation_id,
conversation=conversation,
)
try:
data_chat_client.get_conversation(name=data_chat_client.conversation_path(
billing_project, location, conversation_id))
print(f"Conversation '{conversation_id}' already exists.")
except Exception:
response = data_chat_client.create_conversation(request=request)
print("Conversation created successfully:")
print(response)
conversation_id = "my_first_conversation"
setup_conversation(conversation_id=conversation_id)
شما باید پیامی مبنی بر موفقیت آمیز بودن ایجاد مکالمه مشاهده کنید.
۶. توابع کاربردی را اضافه کنید
شما تقریباً آماده شروع چت با عامل هستید. قبل از انجام این کار، بیایید چند تابع کاربردی اضافه کنیم تا به قالببندی پیامها کمک کنیم تا خواندن و همچنین رندر کردن تجسمها آسانتر شود. رابط برنامهنویسی کاربردی CA، مشخصات vega را ارسال میکند که میتوانید با استفاده از بسته altair آن را ترسیم کنید:
# Utility functions for streaming and formatting responses
import altair as alt
import http.server
import pandas as pd
import proto
import socketserver
import threading
_server_thread = None
_httpd = None
# Prints a formatted section title
def display_section_title(text):
print(f"\n--- {text.upper()} ---")
# Handles and displays data responses
def handle_data_response(resp):
if "query" in resp:
query = resp.query
display_section_title("Retrieval query")
print(f"Query name: {query.name}")
print(f"Question: {query.question}")
print("Data sources:")
for datasource in query.datasources:
display_datasource(datasource)
elif "generated_sql" in resp:
display_section_title("SQL generated")
print(resp.generated_sql)
elif "result" in resp:
display_section_title("Data retrieved")
fields = [field.name for field in resp.result.schema.fields]
d = {field: [] for field in fields}
for el in resp.result.data:
for field in fields:
d[field].append(el[field])
print(pd.DataFrame(d))
# Starts a local web server to preview charts
def preview_in_browser(port: int = 8080):
"""Starts a web server in a background thread and waits for user to stop it."""
global _server_thread, _httpd
if _server_thread and _server_thread.is_alive():
print(
f"\n--> A new chart was generated. Refresh your browser at http://localhost:{port}")
return
Handler = http.server.SimpleHTTPRequestHandler
socketserver.TCPServer.allow_reuse_address = True
try:
_httpd = socketserver.TCPServer(("", port), Handler)
except OSError as e:
print(f"❌ Could not start server on port {port}: {e}")
return
_server_thread = threading.Thread(target=_httpd.serve_forever)
_server_thread.daemon = False
_server_thread.start()
print("\n" + "=" * 60)
print(" 📈 CHART READY - PREVIEW IN BROWSER ".center(60))
print("=" * 60)
print(
f"1. In the Cloud Shell toolbar, click 'Web Preview' and select port {port}.")
print(f"2. Or, open your local browser to http://localhost:{port}")
print("=" * 60)
try:
input(
"\n--> Press Enter here after viewing all charts to shut down the server...\n\n")
finally:
print("Shutting down server...")
_httpd.shutdown()
_server_thread.join()
_httpd, _server_thread = None, None
print("Server stopped.")
# Handles chart responses
def handle_chart_response(resp, chart_generated_flag: list):
def _value_to_dict(v):
if isinstance(v, proto.marshal.collections.maps.MapComposite):
return {k: _value_to_dict(v[k]) for k in v}
elif isinstance(v, proto.marshal.collections.RepeatedComposite):
return [_value_to_dict(el) for el in v]
return v
if "query" in resp:
print(resp.query.instructions)
elif "result" in resp:
vega_config_dict = _value_to_dict(resp.result.vega_config)
chart = alt.Chart.from_dict(vega_config_dict)
chart_filename = "index.html"
chart.save(chart_filename)
if chart_generated_flag:
chart_generated_flag[0] = True
# Displays the schema of a data source
def display_schema(data):
fields = getattr(data, "fields")
df = pd.DataFrame({
"Column": [f.name for f in fields],
"Type": [f.type for f in fields],
"Description": [getattr(f, "description", "-") for f in fields],
"Mode": [f.mode for f in fields],
})
print(df)
# Displays information about a BigQuery data source
def display_datasource(datasource):
table_ref = datasource.bigquery_table_reference
source_name = f"{table_ref.project_id}.{table_ref.dataset_id}.{table_ref.table_id}"
print(source_name)
display_schema(datasource.schema)
# Handles and displays schema resolution responses
def handle_schema_response(resp):
if "query" in resp:
print(resp.query.question)
elif "result" in resp:
display_section_title("Schema resolved")
print("Data sources:")
for datasource in resp.result.datasources:
display_datasource(datasource)
# Handles and prints simple text responses
def handle_text_response(resp):
parts = resp.parts
print("".join(parts))
# Processes and displays different types of system messages
def show_message(msg, chart_generated_flag: list):
m = msg.system_message
if "text" in m:
handle_text_response(getattr(m, "text"))
elif "schema" in m:
handle_schema_response(getattr(m, "schema"))
elif "data" in m:
handle_data_response(getattr(m, "data"))
elif "chart" in m:
handle_chart_response(getattr(m, "chart"), chart_generated_flag)
print("\n")
7. Create a chat function
مرحله آخر ایجاد یک تابع چت است که بتوانید از آن دوباره استفاده کنید و تابع show_message را برای هر بخش در جریان پاسخ فراخوانی کنید:
def stream_chat_response(question: str):
"""
Sends a chat request, processes the streaming response, and if a chart
was generated, starts the preview server and waits for it to be closed.
"""
data_chat_client = geminidataanalytics.DataChatServiceClient()
chart_generated_flag = [False]
messages = [
geminidataanalytics.Message(
user_message=geminidataanalytics.UserMessage(text=question)
)
]
conversation_reference = geminidataanalytics.ConversationReference(
conversation=data_chat_client.conversation_path(
billing_project, location, conversation_id
),
data_agent_context=geminidataanalytics.DataAgentContext(
data_agent=data_chat_client.data_agent_path(
billing_project, location, data_agent_id
),
),
)
request = geminidataanalytics.ChatRequest(
parent=f"projects/{billing_project}/locations/{location}",
messages=messages,
conversation_reference=conversation_reference,
)
stream = data_chat_client.chat(request=request)
for response in stream:
show_message(response, chart_generated_flag)
if chart_generated_flag[0]:
preview_in_browser()
تابع stream_chat_response اکنون تعریف شده و آماده استفاده با اعلانهای شماست.
۸. شروع به گپ زدن کنید
سوال ۱
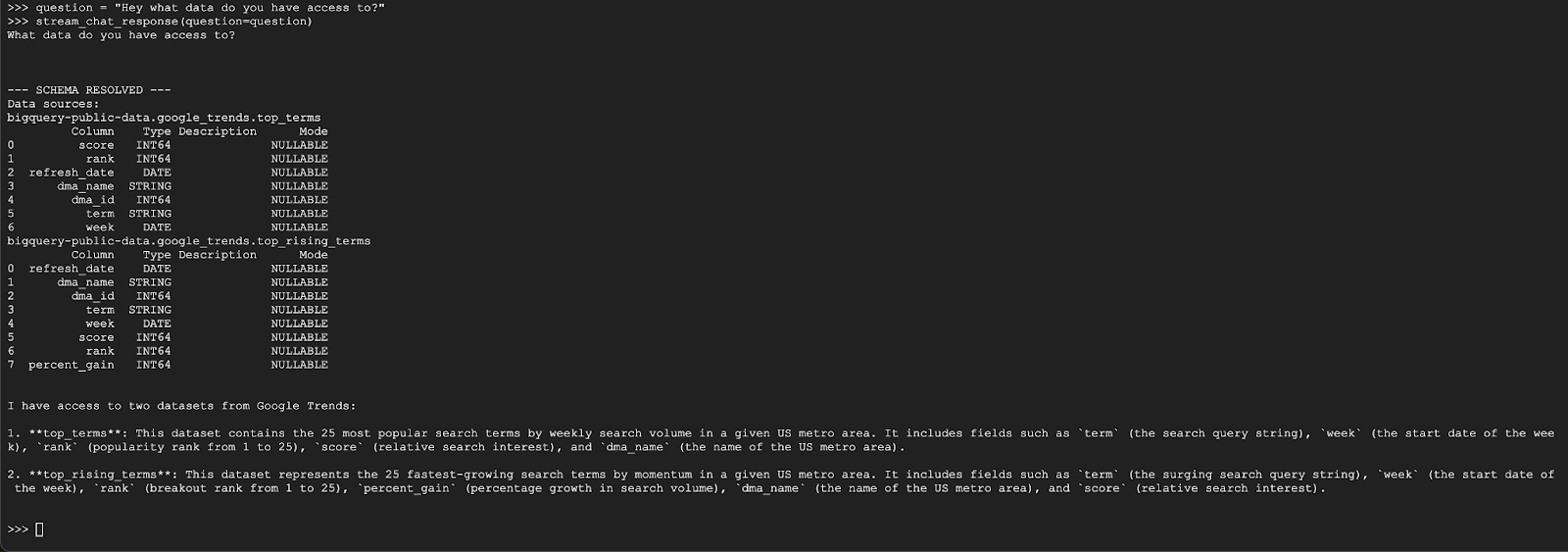
حالا آمادهاید تا سوالات خود را بپرسید! بیایید ببینیم این نماینده برای شروع چه کاری میتواند انجام دهد:
question = "Hey what data do you have access to?"
stream_chat_response(question=question)
نماینده باید چیزی شبیه به موارد زیر پاسخ دهد:
سوال ۲
عالیه، بیایید سعی کنیم اطلاعات بیشتری در مورد جدیدترین عبارات جستجوی محبوب پیدا کنیم:
question = "What are the top 20 most popular search terms last week in NYC based on rank? Display each term and score as a column chart"
stream_chat_response(question=question)
اجرای این دستور کمی زمان میبرد. شما باید ببینید که عامل مراحل مختلف و بهروزرسانیهای جریانی را طی میکند، از بازیابی طرحواره و فراداده گرفته تا نوشتن کوئری SQL، دریافت نتایج، تعیین دستورالعملهای مصورسازی و خلاصهسازی نتایج.
برای مشاهده نمودار، به نوار ابزار Cloud Shell بروید، روی «پیشنمایش وب» کلیک کنید و پورت ۸۰۸۰ را انتخاب کنید:
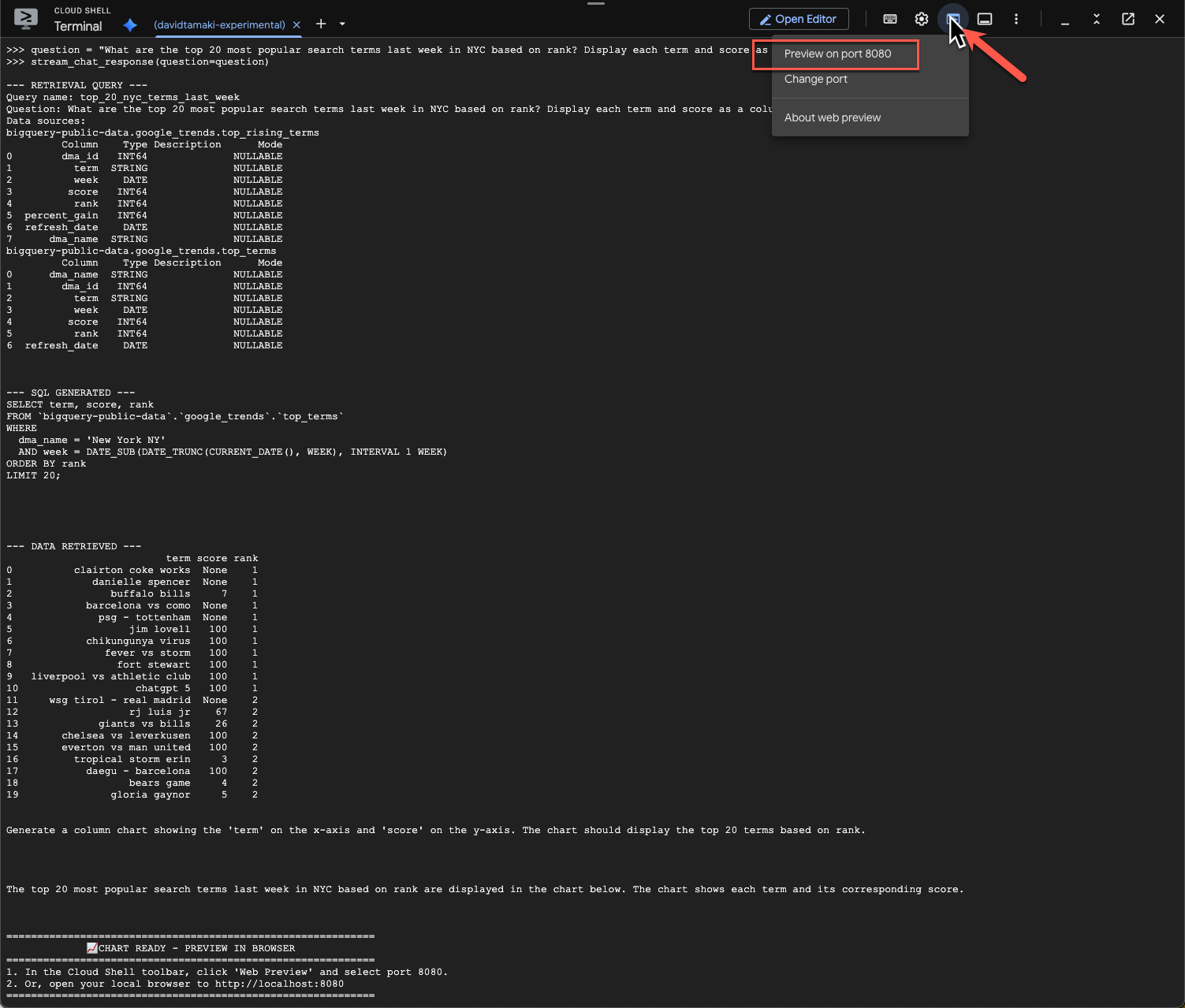
شما باید رندری از تجسم را مانند این ببینید:
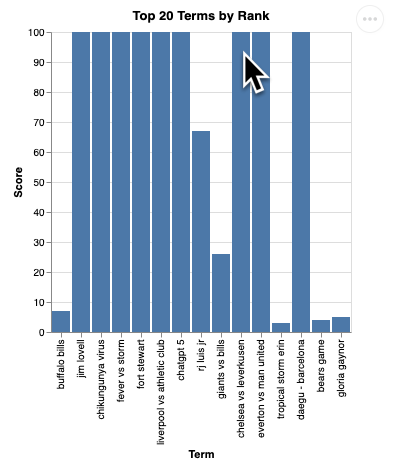
برای خاموش کردن سرور و ادامه، Enter را فشار دهید.
سوال ۳
بیایید یک سوال تکمیلی را امتحان کنیم و عمیقتر به این نتایج بپردازیم:
question = "What was the percent gain in growth for these search terms from the week before?"
stream_chat_response(question=question)
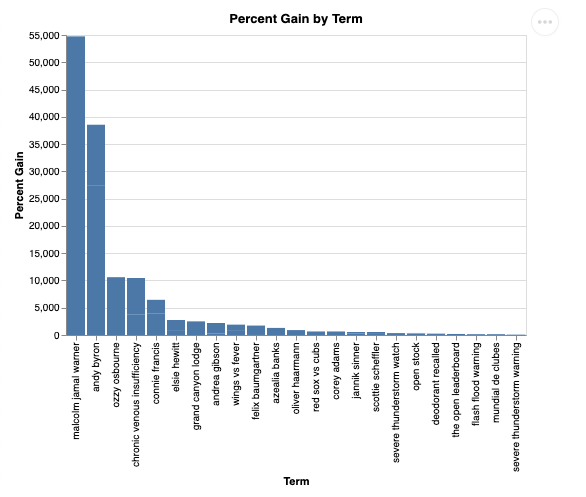
شما باید چیزی شبیه به تصویر زیر را ببینید. در این مورد، عامل یک پرسوجو برای اتصال دو جدول و یافتن درصد سود ایجاد کرده است. توجه داشته باشید که پرسوجوی شما ممکن است کمی متفاوت باشد:
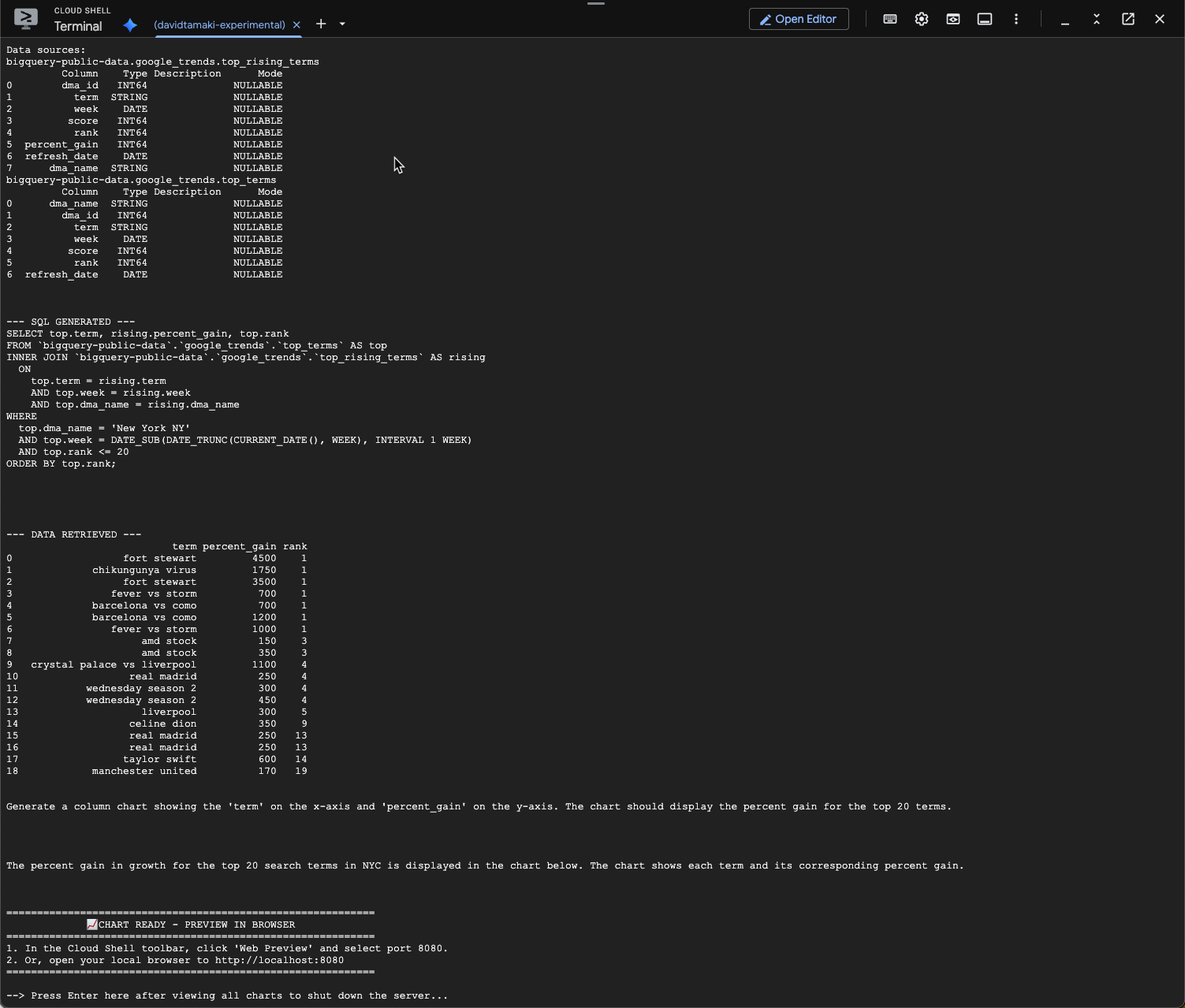
و به صورت بصری به این شکل خواهد بود:
۹. پاکسازی
از آنجایی که این آزمایشگاه کد شامل هیچ محصول طولانیمدتی نمیشود، صرفاً متوقف کردن نشست فعال پایتون با وارد کردن exit() در ترمینال کافی است.
حذف پوشهها و فایلهای پروژه
اگر میخواهید کد را از محیط Cloud Shell خود حذف کنید، از دستورات زیر استفاده کنید:
cd ~
rm -rf ca-api-codelab
غیرفعال کردن APIها
برای غیرفعال کردن APIهایی که قبلاً فعال بودند، این دستور را اجرا کنید
gcloud services disable geminidataanalytics.googleapis.com
gcloud services disable cloudaicompanion.googleapis.com
gcloud services disable bigquery.googleapis.com
۱۰. نتیجهگیری
تبریک میگویم، شما با موفقیت یک عامل تحلیل مکالمهای ساده با استفاده از CA SDK ساختید. برای کسب اطلاعات بیشتر، به منابع مراجعه کنید!