
1. Introduction
Dans cet atelier de programmation, vous allez apprendre à utiliser le SDK Python de l'API Conversational Analytics (CA) avec une source de données BigQuery. Vous apprendrez à créer un agent, à tirer parti de la gestion de l'état de la conversation, et à envoyer et diffuser des réponses à partir de l'API.
Prérequis
- Connaissances de base de Google Cloud et de la console Google Cloud
- Compétences de base concernant l'interface de ligne de commande et Cloud Shell
- Maîtrise de base de la programmation Python
Points abordés
- Utiliser le SDK Python de l'API Conversational Analytics avec une source de données BigQuery
- Créer un agent à l'aide de l'API CA
- Utiliser la gestion de l'état de la conversation
- Envoyer et diffuser des réponses depuis l'API
Prérequis
- Un compte Google Cloud et un projet Google Cloud
- Un navigateur Web tel que Chrome
2. Préparation
Choisir un projet
- Connectez-vous à la console Google Cloud, puis créez un projet ou réutilisez un projet existant. Si vous n'avez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.

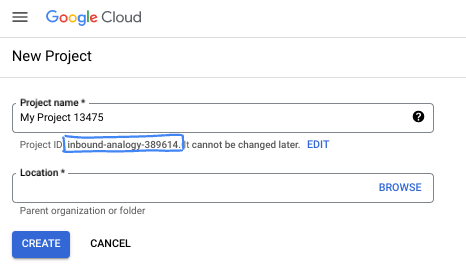
- Le nom du projet est le nom à afficher pour les participants au projet. Il s'agit d'une chaîne de caractères non utilisée par les API Google. Vous pourrez toujours le modifier.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Cloud génère automatiquement une chaîne unique (en général, vous n'y accordez d'importance particulière). Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet (généralement identifié par
PROJECT_ID). Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire. Vous pouvez également en spécifier un et voir s'il est disponible. Après cette étape, l'ID n'est plus modifiable et restera donc le même pour toute la durée du projet. - Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
- Vous devez ensuite activer la facturation dans la console Cloud pour utiliser les ressources/API Cloud. L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Pour désactiver les ressources et éviter ainsi que des frais ne vous soient facturés après ce tutoriel, vous pouvez supprimer le projet ou les ressources que vous avez créées. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300 $.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :
Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
3. Avant de commencer
Activer les API requises
Pour utiliser les services Google Cloud, vous devez d'abord activer leurs API respectives pour votre projet. Dans cet atelier de programmation, vous utiliserez les services Google Cloud suivants :
- API Data Analytics avec Gemini
- Gemini pour Google Cloud
- API BigQuery
Pour activer ces services, exécutez les commandes suivantes dans le terminal Cloud Shell :
gcloud services enable geminidataanalytics.googleapis.com
gcloud services enable cloudaicompanion.googleapis.com
gcloud services enable bigquery.googleapis.com
Installer des packages Python
Avant de commencer un projet Python, il est recommandé de créer un environnement virtuel. Cela isole les dépendances du projet, ce qui évite les conflits avec d'autres projets ou les packages Python globaux du système. Dans cette section, vous allez installer uv à partir de pip, car Cloud Shell dispose déjà de pip.
Installer le package uv
pip install uv
Vérifier si uv est correctement installé
uv --version
Résultat attendu
Si une ligne de résultat contient "uv", vous pouvez passer à l'étape suivante. Notez que le numéro de version peut varier :

Créer un environnement virtuel et installer des packages
uv init ca-api-codelab
cd ca-api-codelab
uv venv --python 3.12
uv add google-cloud-geminidataanalytics pandas altair
uv pip list | grep -E 'altair|pandas|google-cloud-geminidataanalytics'
Résultat attendu
Si des lignes de sortie s'affichent avec les trois packages, vous pouvez passer à l'étape suivante. Notez que les numéros de version peuvent varier :

Démarrer Python
uv run python
Votre écran doit désormais ressembler à ce qui suit :

4. Créer un agent
Maintenant que votre environnement de développement est configuré et prêt, il est temps de poser les bases de l'API Gemini Data Analytics. Le SDK simplifie ce processus et ne nécessite que quelques configurations essentielles pour créer votre agent.
Définir les variables
Importez le package geminidataanalytics et définissez nos variables d'environnement :
import os
from google.cloud import geminidataanalytics
data_agent_client = geminidataanalytics.DataAgentServiceClient()
location = "global"
billing_project = os.environ.get('DEVSHELL_PROJECT_ID')
data_agent_id = "google_trends_analytics_agent"
Définir des instructions système pour l'agent
L'API CA lit les métadonnées BigQuery pour obtenir plus de contexte sur les tables et les colonnes référencées. Étant donné que ce jeu de données public ne comporte aucune description de colonne, vous pouvez fournir un contexte supplémentaire à l'agent sous forme de chaîne au format YAML. Consultez la documentation pour connaître les bonnes pratiques et obtenir un modèle à utiliser :
system_instruction = """
system_instruction:
- You are a data analyst specializing in the Google Trends dataset.
- When querying, always use the 'week' column for date-based filtering. This needs to be a Sunday. If you are doing week over week comparison, make sure you specify a date that is a Sunday.
- The following columns should be ignored in all queries 'dma_id', 'refresh_date'
- The 'dma_name' column represents the city and state for about 210 metro areas in the USA.
tables:
top_terms:
description: "Represents the 25 most popular search terms by weekly search volume in a given US metro area (DMA)."
fields:
term: "The search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's popularity rank from 1 (most popular) to 25."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
dma_name: "The name of the US metro area, e.g., 'New York NY'."
top_rising_terms:
description: "Represents the 25 fastest-growing ('breakout') search terms by momentum in a given US metro area (DMA)."
fields:
term: "The surging search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's breakout rank from 1 (top rising) to 25."
percent_gain: "The percentage growth in search volume compared to the previous period."
dma_name: "The name of the US metro area, e.g., 'Los Angeles CA'."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
join_instructions:
goal: "Find terms that are simultaneously popular and rising in the same week and metro area."
method: "INNER JOIN the two tables on their common keys."
keys:
- "term"
- "week"
- "dma_name"
golden_queries:
- natural_language_query: "Find all terms in the 'New York NY' area that were in both the top 25 and top 25 rising lists for the week of July 6th, 2025, and show their ranks and percent gain."
sql_query: |
SELECT
top.term,
top.rank AS top_25_rank,
rising.rank AS rising_25_rank,
rising.percent_gain
FROM
`bigquery-public-data.google_trends.top_terms` AS top
INNER JOIN
`bigquery-public-data.google_trends.top_rising_terms` AS rising
ON
top.term = rising.term
AND top.week = rising.week
AND top.dma_name = rising.dma_name
WHERE
top.week = '2025-07-06'
AND top.dma_name = 'New York NY'
ORDER BY
top.rank;
"""
Définir les sources de données de table BigQuery
Vous pouvez maintenant définir les sources de données des tables BigQuery. L'API CA accepte les tables BigQuery dans un tableau :
# BigQuery table data sources
bq_top = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_terms"
)
bq_rising = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_rising_terms"
)
datasource_references = geminidataanalytics.DatasourceReferences(
bq=geminidataanalytics.BigQueryTableReferences(table_references=[bq_top, bq_rising]))
Définir le contexte pour un chat avec état
Vous pouvez créer l'agent avec le contexte publié, qui regroupe les instructions système, les références aux sources de données et toutes les autres options.
Notez que vous pouvez créer un stagingContext pour tester et valider les modifications avant de les publier. Cela permet à un développeur d'ajouter un système de gestion des versions à un agent de données en spécifiant contextVersion dans la demande de chat. Pour cet atelier de programmation, vous allez simplement publier directement :
# Context setup for stateful chat
published_context = geminidataanalytics.Context(
system_instruction=system_instruction,
datasource_references=datasource_references,
options=geminidataanalytics.ConversationOptions(
analysis=geminidataanalytics.AnalysisOptions(
python=geminidataanalytics.AnalysisOptions.Python(
enabled=False
)
)
),
)
data_agent = geminidataanalytics.DataAgent(
data_analytics_agent=geminidataanalytics.DataAnalyticsAgent(
published_context=published_context
),
)
# Create the agent
data_agent_client.create_data_agent(request=geminidataanalytics.CreateDataAgentRequest(
parent=f"projects/{billing_project}/locations/{location}",
data_agent_id=data_agent_id,
data_agent=data_agent,
))
Une fois l'agent créé, un résultat semblable à celui ci-dessous doit s'afficher :

Obtenir l'agent
Testons l'agent pour nous assurer qu'il a bien été créé :
# Test the agent
request = geminidataanalytics.GetDataAgentRequest(
name=data_agent_client.data_agent_path(
billing_project, location, data_agent_id)
)
response = data_agent_client.get_data_agent(request=request)
print(response)
Les métadonnées de votre nouvel agent devraient s'afficher. Cela inclut des éléments tels que l'heure de création et le contexte de l'agent concernant les instructions système et les sources de données.
5. Créer une conversation
Vous êtes maintenant prêt à créer votre première conversation. Pour cet atelier de programmation, vous allez utiliser une référence de conversation pour un chat avec état avec votre agent.
Pour information, l'API CA propose différentes façons de discuter avec différentes options de gestion des états et des agents. Voici un bref récapitulatif des trois approches :
État | Historique des conversations | Agent | Code | Description | |
Discuter en utilisant une référence à une conversation | Avec état | API gérée | Oui | Poursuit une conversation avec état en envoyant un message de chat qui fait référence à une conversation existante et au contexte de l'agent associé. Pour les conversations multitours, Google Cloud stocke et gère l'historique de la conversation. | |
Discuter en utilisant une référence à un agent de données | Sans état | Géré par l'utilisateur | Oui | Envoie un message de chat sans état qui se réfère à un agent de données enregistré pour le contexte. Pour les conversations multitours, votre application doit gérer et fournir l'historique de la conversation à chaque requête. | |
Discuter en utilisant le contexte intégré | Sans état | Géré par l'utilisateur | Non | Envoie un message de chat sans état en fournissant tout le contexte directement dans la requête, sans utiliser d'agent de données enregistré. Pour les conversations multitours, votre application doit gérer et fournir l'historique de la conversation à chaque requête. |
Vous allez créer une fonction pour configurer votre conversation et fournir un ID unique pour celle-ci :
def setup_conversation(conversation_id: str):
data_chat_client = geminidataanalytics.DataChatServiceClient()
conversation = geminidataanalytics.Conversation(
agents=[data_chat_client.data_agent_path(
billing_project, location, data_agent_id)],
)
request = geminidataanalytics.CreateConversationRequest(
parent=f"projects/{billing_project}/locations/{location}",
conversation_id=conversation_id,
conversation=conversation,
)
try:
data_chat_client.get_conversation(name=data_chat_client.conversation_path(
billing_project, location, conversation_id))
print(f"Conversation '{conversation_id}' already exists.")
except Exception:
response = data_chat_client.create_conversation(request=request)
print("Conversation created successfully:")
print(response)
conversation_id = "my_first_conversation"
setup_conversation(conversation_id=conversation_id)
Un message indiquant que la conversation a bien été créée doit s'afficher.
6. Ajouter des fonctions utilitaires
Vous êtes presque prêt à discuter avec l'agent. Avant de commencer, ajoutons quelques fonctions utilitaires pour mettre en forme les messages afin de les rendre plus lisibles et pour afficher les visualisations. L'API CA enverra une spécification vega que vous pourrez représenter à l'aide du package altair :
# Utility functions for streaming and formatting responses
import altair as alt
import http.server
import pandas as pd
import proto
import socketserver
import threading
_server_thread = None
_httpd = None
# Prints a formatted section title
def display_section_title(text):
print(f"\n--- {text.upper()} ---")
# Handles and displays data responses
def handle_data_response(resp):
if "query" in resp:
query = resp.query
display_section_title("Retrieval query")
print(f"Query name: {query.name}")
print(f"Question: {query.question}")
print("Data sources:")
for datasource in query.datasources:
display_datasource(datasource)
elif "generated_sql" in resp:
display_section_title("SQL generated")
print(resp.generated_sql)
elif "result" in resp:
display_section_title("Data retrieved")
fields = [field.name for field in resp.result.schema.fields]
d = {field: [] for field in fields}
for el in resp.result.data:
for field in fields:
d[field].append(el[field])
print(pd.DataFrame(d))
# Starts a local web server to preview charts
def preview_in_browser(port: int = 8080):
"""Starts a web server in a background thread and waits for user to stop it."""
global _server_thread, _httpd
if _server_thread and _server_thread.is_alive():
print(
f"\n--> A new chart was generated. Refresh your browser at http://localhost:{port}")
return
Handler = http.server.SimpleHTTPRequestHandler
socketserver.TCPServer.allow_reuse_address = True
try:
_httpd = socketserver.TCPServer(("", port), Handler)
except OSError as e:
print(f"❌ Could not start server on port {port}: {e}")
return
_server_thread = threading.Thread(target=_httpd.serve_forever)
_server_thread.daemon = False
_server_thread.start()
print("\n" + "=" * 60)
print(" 📈 CHART READY - PREVIEW IN BROWSER ".center(60))
print("=" * 60)
print(
f"1. In the Cloud Shell toolbar, click 'Web Preview' and select port {port}.")
print(f"2. Or, open your local browser to http://localhost:{port}")
print("=" * 60)
try:
input(
"\n--> Press Enter here after viewing all charts to shut down the server...\n\n")
finally:
print("Shutting down server...")
_httpd.shutdown()
_server_thread.join()
_httpd, _server_thread = None, None
print("Server stopped.")
# Handles chart responses
def handle_chart_response(resp, chart_generated_flag: list):
def _value_to_dict(v):
if isinstance(v, proto.marshal.collections.maps.MapComposite):
return {k: _value_to_dict(v[k]) for k in v}
elif isinstance(v, proto.marshal.collections.RepeatedComposite):
return [_value_to_dict(el) for el in v]
return v
if "query" in resp:
print(resp.query.instructions)
elif "result" in resp:
vega_config_dict = _value_to_dict(resp.result.vega_config)
chart = alt.Chart.from_dict(vega_config_dict)
chart_filename = "index.html"
chart.save(chart_filename)
if chart_generated_flag:
chart_generated_flag[0] = True
# Displays the schema of a data source
def display_schema(data):
fields = getattr(data, "fields")
df = pd.DataFrame({
"Column": [f.name for f in fields],
"Type": [f.type for f in fields],
"Description": [getattr(f, "description", "-") for f in fields],
"Mode": [f.mode for f in fields],
})
print(df)
# Displays information about a BigQuery data source
def display_datasource(datasource):
table_ref = datasource.bigquery_table_reference
source_name = f"{table_ref.project_id}.{table_ref.dataset_id}.{table_ref.table_id}"
print(source_name)
display_schema(datasource.schema)
# Handles and displays schema resolution responses
def handle_schema_response(resp):
if "query" in resp:
print(resp.query.question)
elif "result" in resp:
display_section_title("Schema resolved")
print("Data sources:")
for datasource in resp.result.datasources:
display_datasource(datasource)
# Handles and prints simple text responses
def handle_text_response(resp):
parts = resp.parts
print("".join(parts))
# Processes and displays different types of system messages
def show_message(msg, chart_generated_flag: list):
m = msg.system_message
if "text" in m:
handle_text_response(getattr(m, "text"))
elif "schema" in m:
handle_schema_response(getattr(m, "schema"))
elif "data" in m:
handle_data_response(getattr(m, "data"))
elif "chart" in m:
handle_chart_response(getattr(m, "chart"), chart_generated_flag)
print("\n")
7. Créer une fonctionnalité de chat
La dernière étape consiste à créer une fonction de chat que vous pouvez réutiliser et à appeler la fonction show_message pour chaque bloc du flux de réponse :
def stream_chat_response(question: str):
"""
Sends a chat request, processes the streaming response, and if a chart
was generated, starts the preview server and waits for it to be closed.
"""
data_chat_client = geminidataanalytics.DataChatServiceClient()
chart_generated_flag = [False]
messages = [
geminidataanalytics.Message(
user_message=geminidataanalytics.UserMessage(text=question)
)
]
conversation_reference = geminidataanalytics.ConversationReference(
conversation=data_chat_client.conversation_path(
billing_project, location, conversation_id
),
data_agent_context=geminidataanalytics.DataAgentContext(
data_agent=data_chat_client.data_agent_path(
billing_project, location, data_agent_id
),
),
)
request = geminidataanalytics.ChatRequest(
parent=f"projects/{billing_project}/locations/{location}",
messages=messages,
conversation_reference=conversation_reference,
)
stream = data_chat_client.chat(request=request)
for response in stream:
show_message(response, chart_generated_flag)
if chart_generated_flag[0]:
preview_in_browser()
La fonction stream_chat_response est désormais définie et prête à être utilisée avec vos requêtes.
8. Start Chattin'
Question 1
Vous pouvez maintenant commencer à poser des questions. Voyons ce que cet agent peut faire pour commencer :
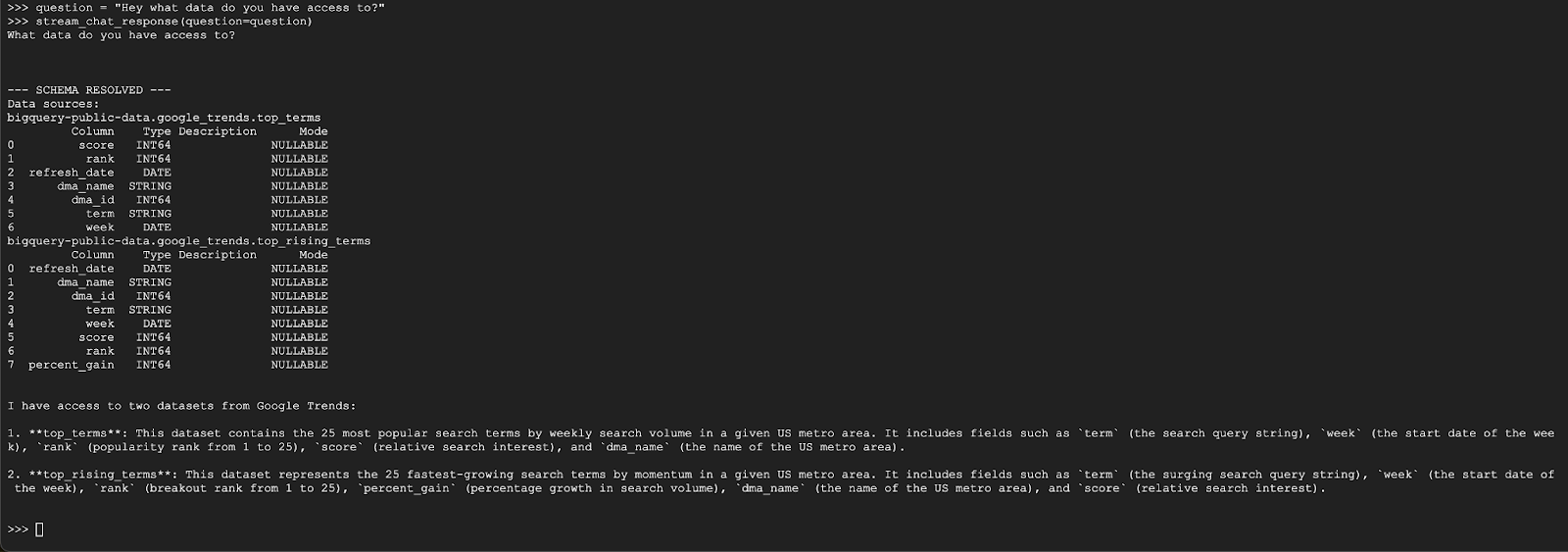
question = "Hey what data do you have access to?"
stream_chat_response(question=question)
L'agent devrait répondre quelque chose de semblable à ce qui suit :
Question 2
Super, essayons de trouver plus d'informations sur les derniers termes de recherche populaires :
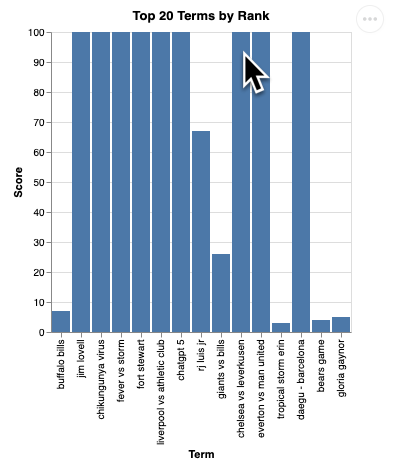
question = "What are the top 20 most popular search terms last week in NYC based on rank? Display each term and score as a column chart"
stream_chat_response(question=question)
Cette opération prendra un certain temps. L'agent devrait exécuter différentes étapes et diffuser des mises à jour, depuis la récupération du schéma et des métadonnées, l'écriture de la requête SQL, l'obtention des résultats, la spécification des instructions de visualisation et la synthèse des résultats.
Pour afficher le graphique, accédez à la barre d'outils Cloud Shell, cliquez sur "Aperçu sur le Web" et sélectionnez le port 8080 :
Vous devriez obtenir un rendu de la visualisation semblable à celui-ci :
Appuyez sur Entrée pour arrêter le serveur et continuer.
Question 3
Essayons de poser une question complémentaire pour approfondir ces résultats :
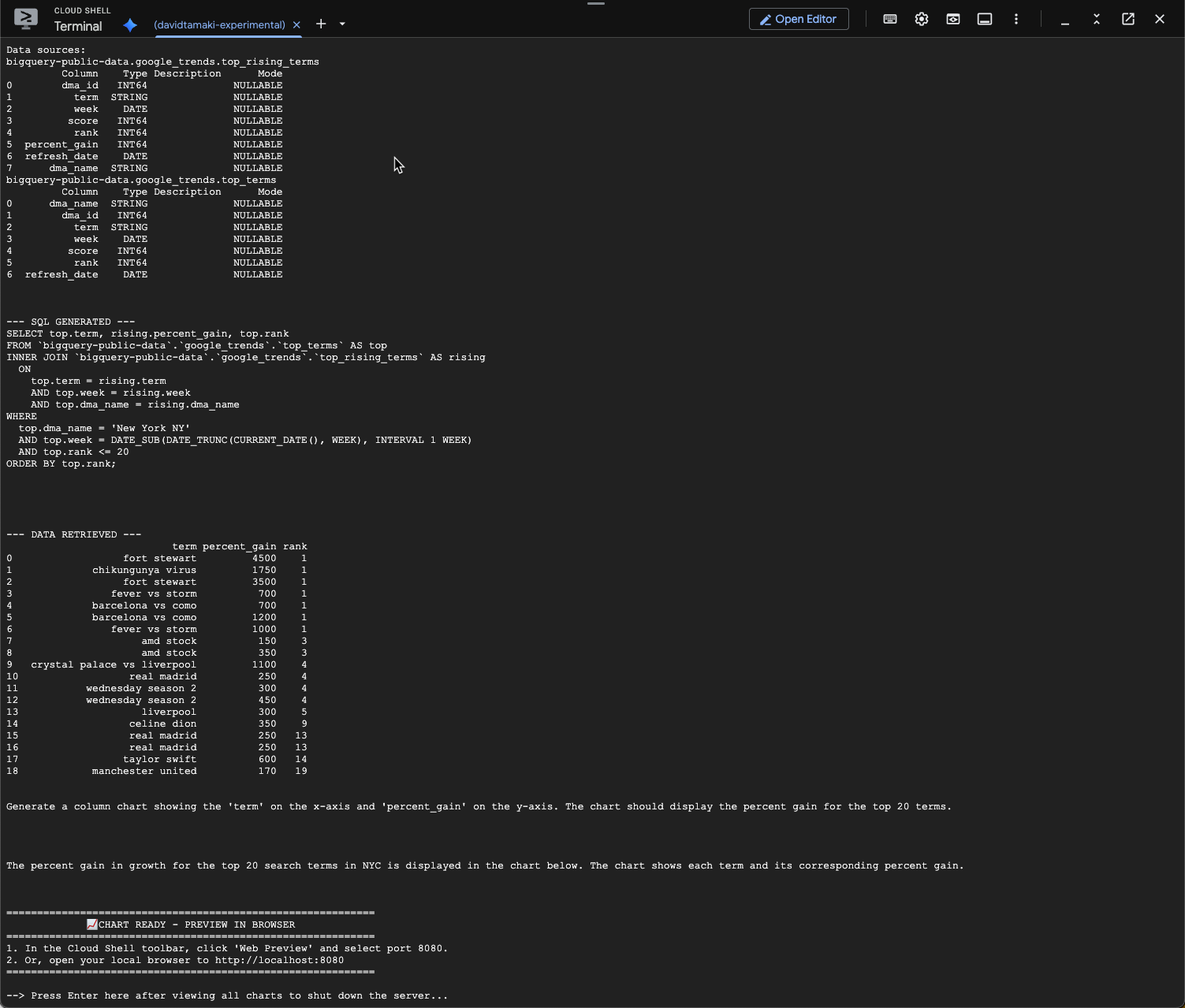
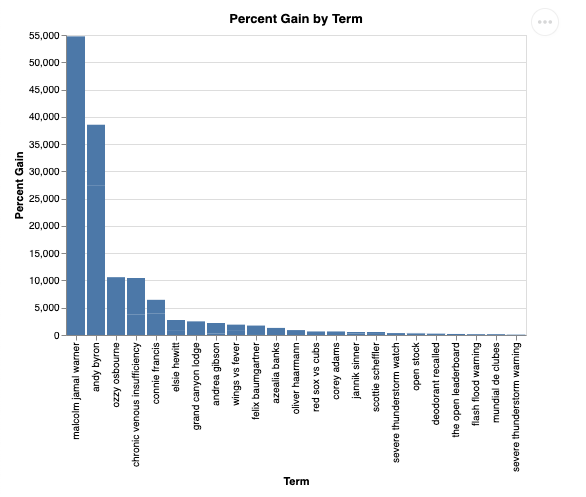
question = "What was the percent gain in growth for these search terms from the week before?"
stream_chat_response(question=question)
Le résultat doit ressembler à ceci : Dans ce cas, l'agent a généré une requête pour joindre les deux tables afin de trouver le pourcentage de gain. Notez que votre requête peut être légèrement différente :
Voici à quoi cela ressemble :
9. Nettoyage
Comme cet atelier de programmation n'implique aucun produit de longue durée, il suffit d'arrêter votre session Python active en saisissant exit() dans le terminal.
Supprimer des dossiers et des fichiers de projet
Si vous souhaitez supprimer le code de votre environnement Cloud Shell, utilisez les commandes suivantes :
cd ~
rm -rf ca-api-codelab
Désactiver les API
Pour désactiver les API qui ont été activées précédemment, exécutez cette commande :
gcloud services disable geminidataanalytics.googleapis.com
gcloud services disable cloudaicompanion.googleapis.com
gcloud services disable bigquery.googleapis.com
10. Conclusion
Félicitations, vous avez réussi à créer un agent Conversational Analytics simple à l'aide du SDK CA. Consultez les documents de référence pour en savoir plus.