
1. Pengantar
Dalam codelab ini, Anda akan mempelajari cara menggunakan SDK Python Conversational Analytics (CA) API dengan sumber data BigQuery. Anda akan mempelajari cara membuat agen baru, cara memanfaatkan pengelolaan status percakapan, serta cara mengirim dan melakukan streaming respons dari API.
Prasyarat
- Pemahaman dasar tentang Google Cloud dan konsol Google Cloud
- Keterampilan dasar dalam antarmuka command line dan Cloud Shell
- Kemahiran dasar dalam pemrograman Python
Yang akan Anda pelajari
- Cara menggunakan Conversational Analytics API Python SDK dengan sumber data BigQuery
- Cara membuat agen baru menggunakan CA API
- Cara memanfaatkan pengelolaan status percakapan
- Cara mengirim dan melakukan streaming respons dari API
Yang Anda butuhkan
- Akun Google Cloud dan project Google Cloud
- Browser web seperti Chrome
2. Penyiapan dan persyaratan
Pilih project
- Login ke Google Cloud Console dan buat project baru atau gunakan kembali project yang sudah ada. Jika belum memiliki akun Gmail atau Google Workspace, Anda harus membuatnya.

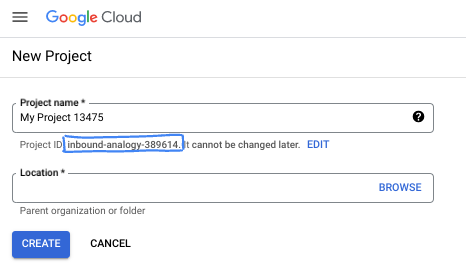
- Project name adalah nama tampilan untuk peserta project ini. String ini adalah string karakter yang tidak digunakan oleh Google API. Anda dapat memperbaruinya kapan saja.
- Project ID bersifat unik di semua project Google Cloud dan tidak dapat diubah (tidak dapat diubah setelah ditetapkan). Cloud Console otomatis membuat string unik; biasanya Anda tidak mementingkan kata-katanya. Di sebagian besar codelab, Anda harus merujuk Project ID-nya (umumnya diidentifikasi sebagai
PROJECT_ID). Jika tidak suka dengan ID yang dibuat, Anda dapat membuat ID acak lainnya. Atau, Anda dapat mencobanya sendiri, dan lihat apakah ID tersebut tersedia. ID tidak dapat diubah setelah langkah ini dan tersedia selama durasi project. - Sebagai informasi, ada nilai ketiga, Project Number, yang digunakan oleh beberapa API. Pelajari lebih lanjut ketiga nilai ini di dokumentasi.
- Selanjutnya, Anda harus mengaktifkan penagihan di Konsol Cloud untuk menggunakan resource/API Cloud. Menjalankan operasi dalam codelab ini tidak akan memakan banyak biaya, bahkan mungkin tidak sama sekali. Guna mematikan resource agar tidak menimbulkan penagihan di luar tutorial ini, Anda dapat menghapus resource yang dibuat atau menghapus project-nya. Pengguna baru Google Cloud memenuhi syarat untuk mengikuti program Uji Coba Gratis senilai $300 USD.
Mulai Cloud Shell
Meskipun Google Cloud dapat dioperasikan dari jarak jauh menggunakan laptop Anda, dalam codelab ini, Anda akan menggunakan Google Cloud Shell, lingkungan command line yang berjalan di Cloud.
Dari Google Cloud Console, klik ikon Cloud Shell di toolbar kanan atas:
Hanya perlu waktu beberapa saat untuk penyediaan dan terhubung ke lingkungan. Jika sudah selesai, Anda akan melihat tampilan seperti ini:

Mesin virtual ini berisi semua alat pengembangan yang Anda perlukan. Layanan ini menawarkan direktori beranda tetap sebesar 5 GB dan beroperasi di Google Cloud, sehingga sangat meningkatkan performa dan autentikasi jaringan. Semua pekerjaan Anda dalam codelab ini dapat dilakukan di browser. Anda tidak perlu menginstal apa pun.
3. Sebelum memulai
Mengaktifkan API yang diperlukan
Untuk menggunakan layanan Google Cloud, Anda harus mengaktifkan API masing-masing layanan terlebih dahulu untuk project Anda. Anda akan menggunakan layanan Google Cloud berikut dalam codelab ini:
- Data Analytics API with Gemini
- Gemini untuk Google Cloud
- BigQuery API
Untuk mengaktifkan layanan ini, jalankan perintah berikut di terminal Cloud Shell:
gcloud services enable geminidataanalytics.googleapis.com
gcloud services enable cloudaicompanion.googleapis.com
gcloud services enable bigquery.googleapis.com
Menginstal paket Python
Sebelum memulai project Python, sebaiknya buat lingkungan virtual. Tindakan ini mengisolasi dependensi project, sehingga mencegah konflik dengan project lain atau paket Python global sistem. Di bagian ini, Anda akan menginstal uv dari pip, karena Cloud Shell sudah memiliki pip.
Instal paket uv
pip install uv
Memastikan apakah uv diinstal dengan benar
uv --version
Output yang diharapkan
Jika Anda melihat baris output dengan uv, Anda dapat melanjutkan ke langkah berikutnya. Perhatikan bahwa nomor versi dapat bervariasi:

Membuat lingkungan virtual dan menginstal paket
uv init ca-api-codelab
cd ca-api-codelab
uv venv --python 3.12
uv add google-cloud-geminidataanalytics pandas altair
uv pip list | grep -E 'altair|pandas|google-cloud-geminidataanalytics'
Output yang diharapkan
Jika Anda melihat baris output dengan tiga paket, Anda dapat melanjutkan ke langkah berikutnya. Perhatikan bahwa nomor versi dapat bervariasi:

Mulai Python
uv run python
Layar Anda akan terlihat seperti ini:

4. Buat agen
Setelah lingkungan pengembangan disiapkan dan siap, kini saatnya meletakkan dasar untuk Gemini Data Analytics API. SDK menyederhanakan proses ini, hanya memerlukan beberapa konfigurasi penting untuk membuat agen Anda.
Menetapkan variabel
Impor paket geminidataanalytics dan tetapkan variabel lingkungan kita:
import os
from google.cloud import geminidataanalytics
data_agent_client = geminidataanalytics.DataAgentServiceClient()
location = "global"
billing_project = os.environ.get('DEVSHELL_PROJECT_ID')
data_agent_id = "google_trends_analytics_agent"
Menetapkan petunjuk sistem untuk agen
CA API membaca metadata BigQuery untuk mendapatkan lebih banyak konteks tentang tabel dan kolom yang dirujuk. Karena kumpulan data publik ini tidak memiliki deskripsi kolom, Anda dapat memberikan konteks tambahan kepada agen sebagai string berformat YAML. Lihat dokumentasi untuk mengetahui praktik terbaik dan template yang dapat digunakan:
system_instruction = """
system_instruction:
- You are a data analyst specializing in the Google Trends dataset.
- When querying, always use the 'week' column for date-based filtering. This needs to be a Sunday. If you are doing week over week comparison, make sure you specify a date that is a Sunday.
- The following columns should be ignored in all queries 'dma_id', 'refresh_date'
- The 'dma_name' column represents the city and state for about 210 metro areas in the USA.
tables:
top_terms:
description: "Represents the 25 most popular search terms by weekly search volume in a given US metro area (DMA)."
fields:
term: "The search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's popularity rank from 1 (most popular) to 25."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
dma_name: "The name of the US metro area, e.g., 'New York NY'."
top_rising_terms:
description: "Represents the 25 fastest-growing ('breakout') search terms by momentum in a given US metro area (DMA)."
fields:
term: "The surging search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's breakout rank from 1 (top rising) to 25."
percent_gain: "The percentage growth in search volume compared to the previous period."
dma_name: "The name of the US metro area, e.g., 'Los Angeles CA'."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
join_instructions:
goal: "Find terms that are simultaneously popular and rising in the same week and metro area."
method: "INNER JOIN the two tables on their common keys."
keys:
- "term"
- "week"
- "dma_name"
golden_queries:
- natural_language_query: "Find all terms in the 'New York NY' area that were in both the top 25 and top 25 rising lists for the week of July 6th, 2025, and show their ranks and percent gain."
sql_query: |
SELECT
top.term,
top.rank AS top_25_rank,
rising.rank AS rising_25_rank,
rising.percent_gain
FROM
`bigquery-public-data.google_trends.top_terms` AS top
INNER JOIN
`bigquery-public-data.google_trends.top_rising_terms` AS rising
ON
top.term = rising.term
AND top.week = rising.week
AND top.dma_name = rising.dma_name
WHERE
top.week = '2025-07-06'
AND top.dma_name = 'New York NY'
ORDER BY
top.rank;
"""
Menetapkan sumber data Tabel BigQuery
Sekarang Anda dapat menetapkan sumber data tabel BigQuery. CA API menerima tabel BigQuery dalam array:
# BigQuery table data sources
bq_top = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_terms"
)
bq_rising = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_rising_terms"
)
datasource_references = geminidataanalytics.DatasourceReferences(
bq=geminidataanalytics.BigQueryTableReferences(table_references=[bq_top, bq_rising]))
Menetapkan konteks untuk chat stateful
Anda dapat membuat agen baru dengan konteks yang dipublikasikan yang menggabungkan petunjuk sistem, referensi sumber data, dan opsi lainnya.
Perhatikan bahwa Anda memiliki fungsi untuk membuat stagingContext guna menguji dan memvalidasi perubahan sebelum dipublikasikan. Hal ini memungkinkan developer menambahkan pembuatan versi ke agen data dengan menentukan contextVersion dalam permintaan chat. Untuk codelab ini, Anda hanya akan memublikasikan secara langsung:
# Context setup for stateful chat
published_context = geminidataanalytics.Context(
system_instruction=system_instruction,
datasource_references=datasource_references,
options=geminidataanalytics.ConversationOptions(
analysis=geminidataanalytics.AnalysisOptions(
python=geminidataanalytics.AnalysisOptions.Python(
enabled=False
)
)
),
)
data_agent = geminidataanalytics.DataAgent(
data_analytics_agent=geminidataanalytics.DataAnalyticsAgent(
published_context=published_context
),
)
# Create the agent
data_agent_client.create_data_agent(request=geminidataanalytics.CreateDataAgentRequest(
parent=f"projects/{billing_project}/locations/{location}",
data_agent_id=data_agent_id,
data_agent=data_agent,
))
Anda akan melihat output yang mirip dengan di bawah setelah membuat agen:

Mendapatkan Agen
Mari kita uji agen untuk memastikan agen telah dibuat:
# Test the agent
request = geminidataanalytics.GetDataAgentRequest(
name=data_agent_client.data_agent_path(
billing_project, location, data_agent_id)
)
response = data_agent_client.get_data_agent(request=request)
print(response)
Anda akan melihat metadata di agen baru Anda. Hal ini akan mencakup hal-hal seperti waktu pembuatan dan konteks agen pada petunjuk sistem dan sumber data.
5. Buat percakapan
Sekarang Anda siap membuat percakapan pertama Anda. Untuk codelab ini, Anda akan menggunakan referensi percakapan untuk chat stateful dengan agen Anda.
Sebagai referensi, CA API menawarkan berbagai cara untuk memulai percakapan dengan berbagai opsi pengelolaan agen dan status. Berikut ringkasan singkat 3 pendekatan tersebut:
Status | Histori Percakapan | Agent | Kode | Deskripsi | |
Memulai percakapan dengan menggunakan referensi percakapan | Stateful | API yang dikelola | Ya | Melanjutkan percakapan stateful dengan mengirim pesan chat yang mereferensikan percakapan yang ada dan konteks agen terkait. Untuk percakapan multi-giliran, Google Cloud menyimpan dan mengelola histori percakapan. | |
Melakukan percakapan dengan menggunakan referensi agen data | Stateless | Dikelola pengguna | Ya | Mengirim pesan chat stateless yang mereferensikan agen data tersimpan untuk konteks. Untuk percakapan bolak-balik, aplikasi Anda harus mengelola dan memberikan histori percakapan dengan setiap permintaan. | |
Melakukan percakapan menggunakan konteks inline | Stateless | Dikelola pengguna | Tidak | Mengirim pesan chat stateless dengan memberikan semua konteks langsung dalam permintaan, tanpa menggunakan agen data tersimpan. Untuk percakapan bolak-balik, aplikasi Anda harus mengelola dan memberikan histori percakapan dengan setiap permintaan. |
Anda akan membuat fungsi untuk menyiapkan percakapan dan memberikan ID unik untuk percakapan:
def setup_conversation(conversation_id: str):
data_chat_client = geminidataanalytics.DataChatServiceClient()
conversation = geminidataanalytics.Conversation(
agents=[data_chat_client.data_agent_path(
billing_project, location, data_agent_id)],
)
request = geminidataanalytics.CreateConversationRequest(
parent=f"projects/{billing_project}/locations/{location}",
conversation_id=conversation_id,
conversation=conversation,
)
try:
data_chat_client.get_conversation(name=data_chat_client.conversation_path(
billing_project, location, conversation_id))
print(f"Conversation '{conversation_id}' already exists.")
except Exception:
response = data_chat_client.create_conversation(request=request)
print("Conversation created successfully:")
print(response)
conversation_id = "my_first_conversation"
setup_conversation(conversation_id=conversation_id)
Anda akan melihat pesan bahwa percakapan telah berhasil dibuat.
6. Menambahkan fungsi utilitas
Anda hampir siap untuk memulai percakapan dengan agen. Sebelum melakukannya, mari tambahkan beberapa fungsi utilitas untuk membantu memformat pesan agar lebih mudah dibaca dan juga merender visualisasi. CA API akan mengirimkan spesifikasi vega yang dapat Anda buat plotnya menggunakan paket altair:
# Utility functions for streaming and formatting responses
import altair as alt
import http.server
import pandas as pd
import proto
import socketserver
import threading
_server_thread = None
_httpd = None
# Prints a formatted section title
def display_section_title(text):
print(f"\n--- {text.upper()} ---")
# Handles and displays data responses
def handle_data_response(resp):
if "query" in resp:
query = resp.query
display_section_title("Retrieval query")
print(f"Query name: {query.name}")
print(f"Question: {query.question}")
print("Data sources:")
for datasource in query.datasources:
display_datasource(datasource)
elif "generated_sql" in resp:
display_section_title("SQL generated")
print(resp.generated_sql)
elif "result" in resp:
display_section_title("Data retrieved")
fields = [field.name for field in resp.result.schema.fields]
d = {field: [] for field in fields}
for el in resp.result.data:
for field in fields:
d[field].append(el[field])
print(pd.DataFrame(d))
# Starts a local web server to preview charts
def preview_in_browser(port: int = 8080):
"""Starts a web server in a background thread and waits for user to stop it."""
global _server_thread, _httpd
if _server_thread and _server_thread.is_alive():
print(
f"\n--> A new chart was generated. Refresh your browser at http://localhost:{port}")
return
Handler = http.server.SimpleHTTPRequestHandler
socketserver.TCPServer.allow_reuse_address = True
try:
_httpd = socketserver.TCPServer(("", port), Handler)
except OSError as e:
print(f"❌ Could not start server on port {port}: {e}")
return
_server_thread = threading.Thread(target=_httpd.serve_forever)
_server_thread.daemon = False
_server_thread.start()
print("\n" + "=" * 60)
print(" 📈 CHART READY - PREVIEW IN BROWSER ".center(60))
print("=" * 60)
print(
f"1. In the Cloud Shell toolbar, click 'Web Preview' and select port {port}.")
print(f"2. Or, open your local browser to http://localhost:{port}")
print("=" * 60)
try:
input(
"\n--> Press Enter here after viewing all charts to shut down the server...\n\n")
finally:
print("Shutting down server...")
_httpd.shutdown()
_server_thread.join()
_httpd, _server_thread = None, None
print("Server stopped.")
# Handles chart responses
def handle_chart_response(resp, chart_generated_flag: list):
def _value_to_dict(v):
if isinstance(v, proto.marshal.collections.maps.MapComposite):
return {k: _value_to_dict(v[k]) for k in v}
elif isinstance(v, proto.marshal.collections.RepeatedComposite):
return [_value_to_dict(el) for el in v]
return v
if "query" in resp:
print(resp.query.instructions)
elif "result" in resp:
vega_config_dict = _value_to_dict(resp.result.vega_config)
chart = alt.Chart.from_dict(vega_config_dict)
chart_filename = "index.html"
chart.save(chart_filename)
if chart_generated_flag:
chart_generated_flag[0] = True
# Displays the schema of a data source
def display_schema(data):
fields = getattr(data, "fields")
df = pd.DataFrame({
"Column": [f.name for f in fields],
"Type": [f.type for f in fields],
"Description": [getattr(f, "description", "-") for f in fields],
"Mode": [f.mode for f in fields],
})
print(df)
# Displays information about a BigQuery data source
def display_datasource(datasource):
table_ref = datasource.bigquery_table_reference
source_name = f"{table_ref.project_id}.{table_ref.dataset_id}.{table_ref.table_id}"
print(source_name)
display_schema(datasource.schema)
# Handles and displays schema resolution responses
def handle_schema_response(resp):
if "query" in resp:
print(resp.query.question)
elif "result" in resp:
display_section_title("Schema resolved")
print("Data sources:")
for datasource in resp.result.datasources:
display_datasource(datasource)
# Handles and prints simple text responses
def handle_text_response(resp):
parts = resp.parts
print("".join(parts))
# Processes and displays different types of system messages
def show_message(msg, chart_generated_flag: list):
m = msg.system_message
if "text" in m:
handle_text_response(getattr(m, "text"))
elif "schema" in m:
handle_schema_response(getattr(m, "schema"))
elif "data" in m:
handle_data_response(getattr(m, "data"))
elif "chart" in m:
handle_chart_response(getattr(m, "chart"), chart_generated_flag)
print("\n")
7. Membuat fungsi chat
Langkah terakhir adalah membuat fungsi chat yang dapat Anda gunakan kembali dan memanggil fungsi show_message untuk setiap bagian dalam aliran respons:
def stream_chat_response(question: str):
"""
Sends a chat request, processes the streaming response, and if a chart
was generated, starts the preview server and waits for it to be closed.
"""
data_chat_client = geminidataanalytics.DataChatServiceClient()
chart_generated_flag = [False]
messages = [
geminidataanalytics.Message(
user_message=geminidataanalytics.UserMessage(text=question)
)
]
conversation_reference = geminidataanalytics.ConversationReference(
conversation=data_chat_client.conversation_path(
billing_project, location, conversation_id
),
data_agent_context=geminidataanalytics.DataAgentContext(
data_agent=data_chat_client.data_agent_path(
billing_project, location, data_agent_id
),
),
)
request = geminidataanalytics.ChatRequest(
parent=f"projects/{billing_project}/locations/{location}",
messages=messages,
conversation_reference=conversation_reference,
)
stream = data_chat_client.chat(request=request)
for response in stream:
show_message(response, chart_generated_flag)
if chart_generated_flag[0]:
preview_in_browser()
Fungsi stream_chat_response kini ditentukan dan siap digunakan dengan perintah Anda.
8. Mulai Chat
Pertanyaan 1
Sekarang Anda siap untuk mulai mengajukan pertanyaan. Mari kita lihat apa yang dapat dilakukan agen ini sebagai permulaan:
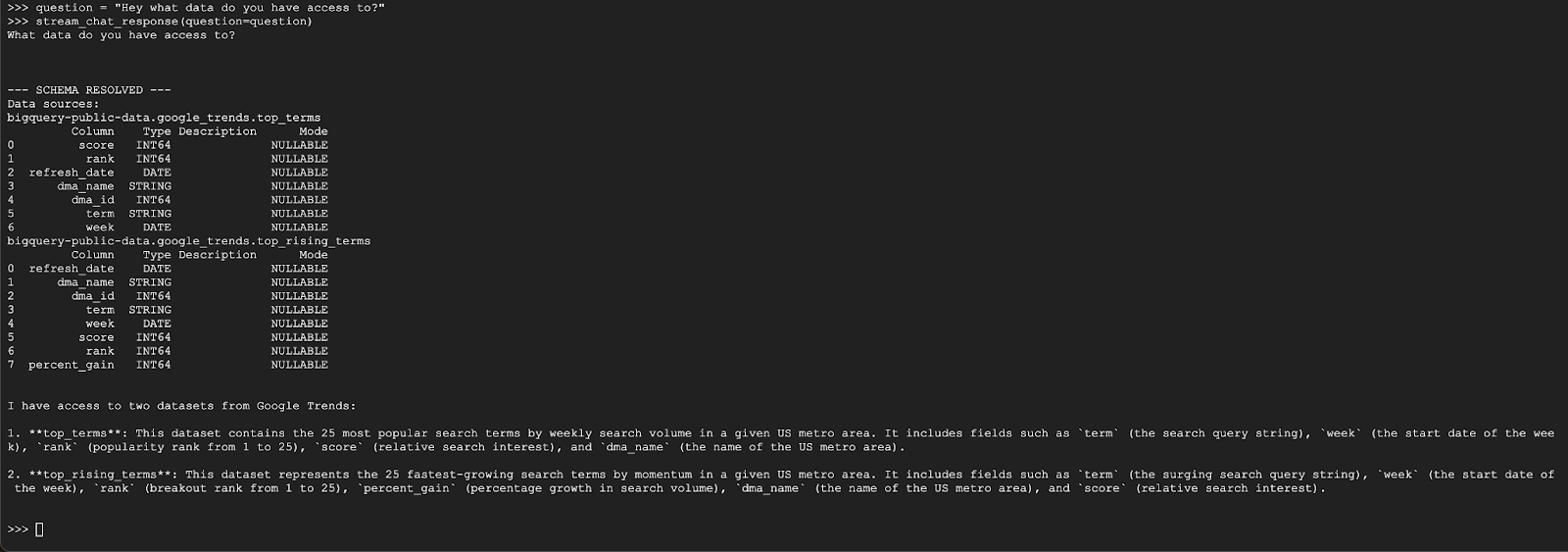
question = "Hey what data do you have access to?"
stream_chat_response(question=question)
Agen akan merespons dengan sesuatu yang mirip dengan di bawah ini:
Pertanyaan 2
Bagus, mari kita coba cari tahu informasi selengkapnya tentang istilah penelusuran populer terbaru:
question = "What are the top 20 most popular search terms last week in NYC based on rank? Display each term and score as a column chart"
stream_chat_response(question=question)
Proses ini akan memerlukan waktu beberapa saat. Anda akan melihat agen menjalankan berbagai langkah dan memperbarui streaming, mulai dari mengambil skema dan metadata, menulis kueri SQL, mendapatkan hasil, menentukan petunjuk visualisasi, dan meringkas hasil.
Untuk melihat diagram, buka toolbar Cloud Shell, klik 'Web Preview', lalu pilih port 8080:
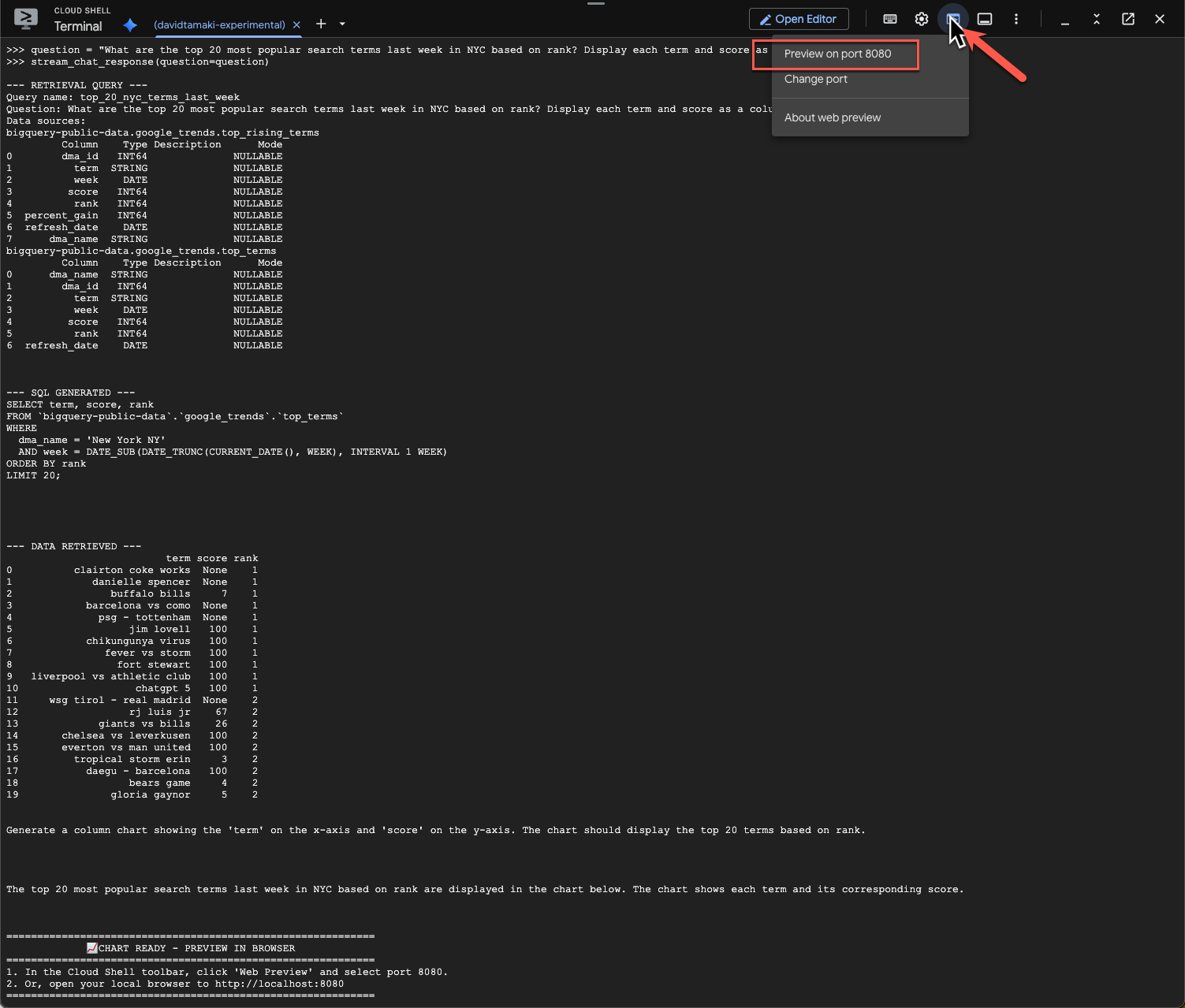
Anda akan melihat rendering visualisasi seperti ini:
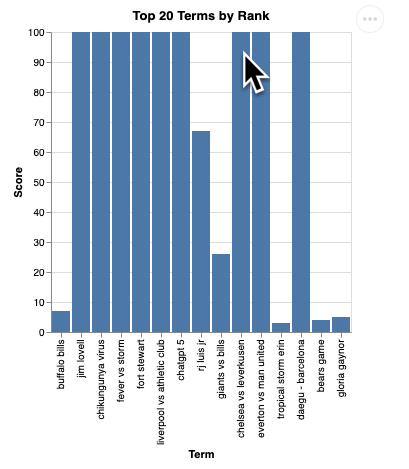
Tekan Enter untuk mematikan server dan melanjutkan.
Pertanyaan 3
Mari kita coba pertanyaan lanjutan dan pelajari lebih dalam hasil ini:
question = "What was the percent gain in growth for these search terms from the week before?"
stream_chat_response(question=question)
Anda akan melihat sesuatu yang mirip dengan di bawah ini. Dalam hal ini, agen telah membuat kueri untuk menggabungkan 2 tabel guna menemukan persentase peningkatan. Perhatikan bahwa kueri Anda mungkin terlihat sedikit berbeda:
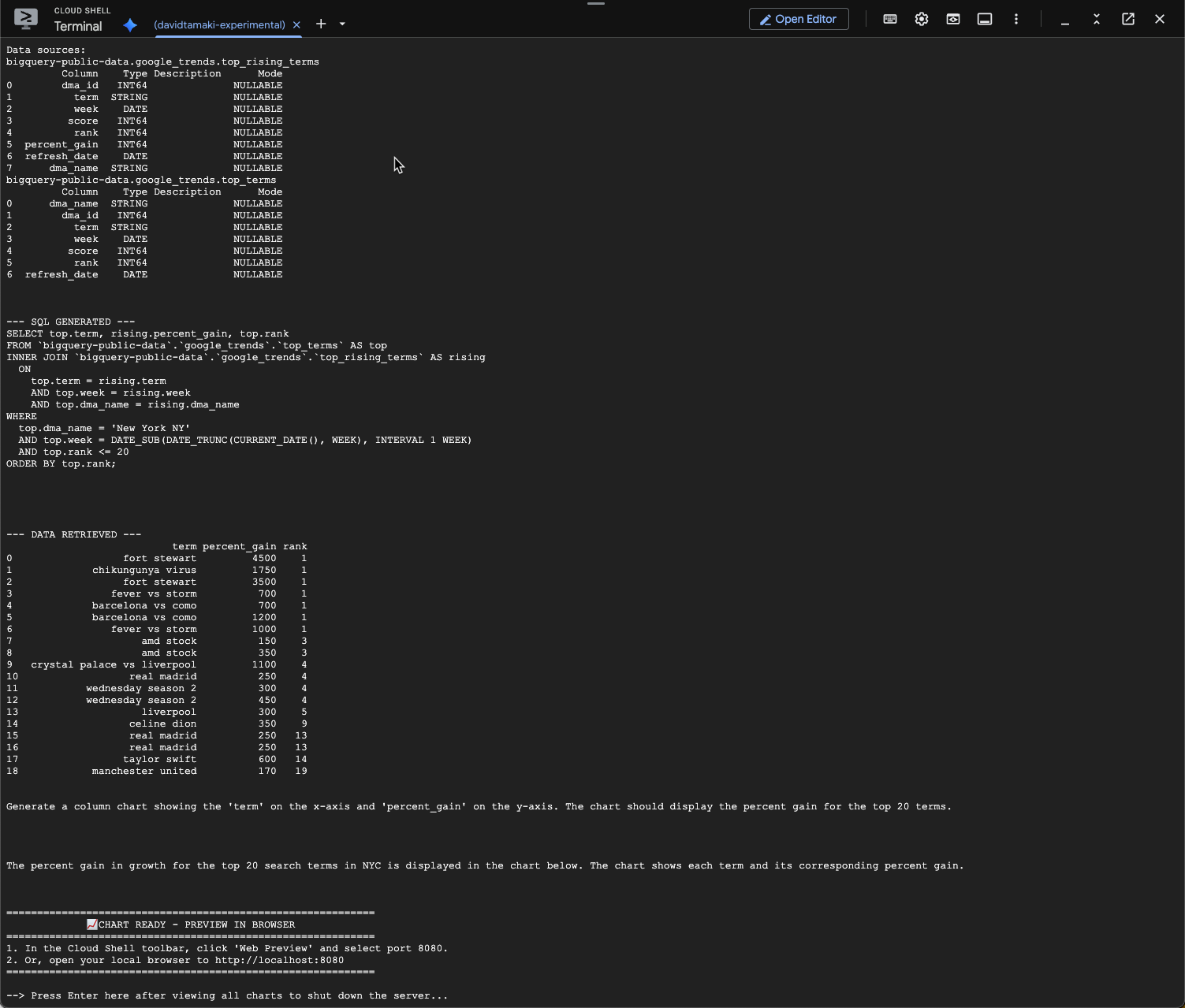
Dan jika divisualisasikan, hasilnya akan terlihat seperti ini:
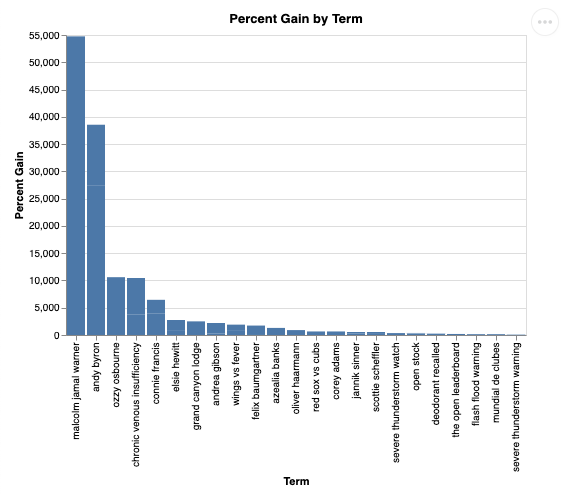
9. Pembersihan
Karena codelab ini tidak melibatkan produk yang berjalan lama, cukup hentikan sesi Python aktif Anda dengan memasukkan exit() di terminal.
Menghapus Folder dan File Project
Jika Anda ingin menghapus kode dari lingkungan Cloud Shell, gunakan perintah berikut:
cd ~
rm -rf ca-api-codelab
Menonaktifkan API
Untuk menonaktifkan API yang diaktifkan sebelumnya, jalankan perintah ini
gcloud services disable geminidataanalytics.googleapis.com
gcloud services disable cloudaicompanion.googleapis.com
gcloud services disable bigquery.googleapis.com
10. Kesimpulan
Selamat, Anda telah berhasil membuat Agen Analisis Percakapan sederhana menggunakan CA SDK. Lihat materi referensi untuk mempelajari lebih lanjut.