
1. Introduzione
In questo codelab imparerai a utilizzare l'SDK Python dell'API Conversational Analytics (CA) con un'origine dati BigQuery. Imparerai a creare un nuovo agente, a sfruttare la gestione dello stato della conversazione e a inviare e trasmettere in streaming le risposte dall'API.
Prerequisiti
- Una conoscenza di base di Google Cloud e della console Google Cloud
- Competenze di base nell'interfaccia a riga di comando e in Cloud Shell
- Una conoscenza di base della programmazione in Python
Cosa imparerai a fare
- Come utilizzare l'SDK Python dell'API Conversational Analytics con un'origine dati BigQuery
- Come creare un nuovo agente utilizzando l'API CA
- Come sfruttare la gestione dello stato della conversazione
- Come inviare e trasmettere in streaming le risposte dall'API
Che cosa ti serve
- Un account Google Cloud e un progetto Google Cloud
- Un browser web come Chrome
2. Configurazione e requisiti
Scegliere un progetto
- Accedi alla console Google Cloud e crea un nuovo progetto o riutilizzane uno esistente. Se non hai ancora un account Gmail o Google Workspace, devi crearne uno.

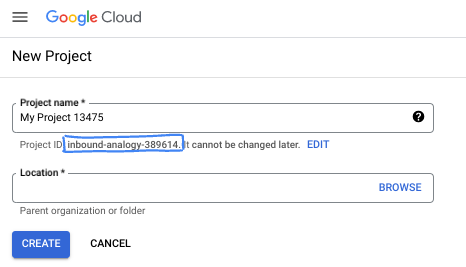
- Il nome del progetto è il nome visualizzato per i partecipanti a questo progetto. È una stringa di caratteri non utilizzata dalle API di Google. Puoi sempre aggiornarlo.
- L'ID progetto è univoco in tutti i progetti Google Cloud ed è immutabile (non può essere modificato dopo l'impostazione). La console Cloud genera automaticamente una stringa univoca, di solito non ti interessa di cosa si tratta. Nella maggior parte dei codelab, dovrai fare riferimento all'ID progetto (in genere identificato come
PROJECT_ID). Se l'ID generato non ti piace, puoi generarne un altro casuale. In alternativa, puoi provare a crearne uno e vedere se è disponibile. Non può essere modificato dopo questo passaggio e rimane per tutta la durata del progetto. - Per tua informazione, esiste un terzo valore, un numero di progetto, utilizzato da alcune API. Scopri di più su tutti e tre questi valori nella documentazione.
- Successivamente, devi abilitare la fatturazione in Cloud Console per utilizzare le risorse/API Cloud. Completare questo codelab non costa molto, se non nulla. Per arrestare le risorse ed evitare addebiti oltre a quelli previsti in questo tutorial, puoi eliminare le risorse che hai creato o il progetto. I nuovi utenti di Google Cloud possono beneficiare del programma prova senza costi di 300$.
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:
Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere un risultato simile a questo:

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
3. Prima di iniziare
Abilita le API richieste
Per utilizzare i servizi Google Cloud, devi prima attivare le rispettive API per il tuo progetto. In questo codelab utilizzerai i seguenti servizi Google Cloud:
- API Data Analytics con Gemini
- Gemini per Google Cloud
- API BigQuery
Per abilitare questi servizi, esegui questi comandi nel terminale Cloud Shell:
gcloud services enable geminidataanalytics.googleapis.com
gcloud services enable cloudaicompanion.googleapis.com
gcloud services enable bigquery.googleapis.com
Installare pacchetti Python
Prima di iniziare qualsiasi progetto Python, è buona prassi creare un ambiente virtuale. In questo modo, le dipendenze del progetto vengono isolate, evitando conflitti con altri progetti o con i pacchetti Python globali del sistema. In questa sezione installerai uv da pip, poiché Cloud Shell ha già pip disponibile.
Installare il pacchetto uv
pip install uv
Verificare se uv è installato correttamente
uv --version
Output previsto
Se vedi una riga di output con uv, puoi procedere al passaggio successivo. Tieni presente che il numero di versione può variare:

Creare un ambiente virtuale e installare i pacchetti
uv init ca-api-codelab
cd ca-api-codelab
uv venv --python 3.12
uv add google-cloud-geminidataanalytics pandas altair
uv pip list | grep -E 'altair|pandas|google-cloud-geminidataanalytics'
Output previsto
Se vedi righe di output con i tre pacchetti, puoi procedere al passaggio successivo. Tieni presente che i numeri di versione possono variare:

Avvia Python
uv run python
La schermata visualizzata dovrebbe essere simile a questa:

4. Crea un agente
Ora che l'ambiente di sviluppo è configurato e pronto, è il momento di creare le basi per l'API Gemini Data Analytics. L'SDK semplifica questa procedura, richiedendo solo alcune configurazioni essenziali per creare l'agente.
Impostare le variabili
Importa il pacchetto geminidataanalytics e imposta le variabili di ambiente:
import os
from google.cloud import geminidataanalytics
data_agent_client = geminidataanalytics.DataAgentServiceClient()
location = "global"
billing_project = os.environ.get('DEVSHELL_PROJECT_ID')
data_agent_id = "google_trends_analytics_agent"
Imposta le istruzioni di sistema per l'agente
L'API CA legge i metadati BigQuery per ottenere maggiori informazioni sulle tabelle e sulle colonne a cui viene fatto riferimento. Poiché questo set di dati pubblico non ha descrizioni delle colonne, puoi fornire un contesto aggiuntivo all'agente come stringa in formato YAML. Per le best practice e un modello da utilizzare, consulta la documentazione:
system_instruction = """
system_instruction:
- You are a data analyst specializing in the Google Trends dataset.
- When querying, always use the 'week' column for date-based filtering. This needs to be a Sunday. If you are doing week over week comparison, make sure you specify a date that is a Sunday.
- The following columns should be ignored in all queries 'dma_id', 'refresh_date'
- The 'dma_name' column represents the city and state for about 210 metro areas in the USA.
tables:
top_terms:
description: "Represents the 25 most popular search terms by weekly search volume in a given US metro area (DMA)."
fields:
term: "The search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's popularity rank from 1 (most popular) to 25."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
dma_name: "The name of the US metro area, e.g., 'New York NY'."
top_rising_terms:
description: "Represents the 25 fastest-growing ('breakout') search terms by momentum in a given US metro area (DMA)."
fields:
term: "The surging search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's breakout rank from 1 (top rising) to 25."
percent_gain: "The percentage growth in search volume compared to the previous period."
dma_name: "The name of the US metro area, e.g., 'Los Angeles CA'."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
join_instructions:
goal: "Find terms that are simultaneously popular and rising in the same week and metro area."
method: "INNER JOIN the two tables on their common keys."
keys:
- "term"
- "week"
- "dma_name"
golden_queries:
- natural_language_query: "Find all terms in the 'New York NY' area that were in both the top 25 and top 25 rising lists for the week of July 6th, 2025, and show their ranks and percent gain."
sql_query: |
SELECT
top.term,
top.rank AS top_25_rank,
rising.rank AS rising_25_rank,
rising.percent_gain
FROM
`bigquery-public-data.google_trends.top_terms` AS top
INNER JOIN
`bigquery-public-data.google_trends.top_rising_terms` AS rising
ON
top.term = rising.term
AND top.week = rising.week
AND top.dma_name = rising.dma_name
WHERE
top.week = '2025-07-06'
AND top.dma_name = 'New York NY'
ORDER BY
top.rank;
"""
Imposta le origini dati della tabella BigQuery
Ora puoi impostare le origini dati della tabella BigQuery. L'API CA accetta tabelle BigQuery in un array:
# BigQuery table data sources
bq_top = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_terms"
)
bq_rising = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_rising_terms"
)
datasource_references = geminidataanalytics.DatasourceReferences(
bq=geminidataanalytics.BigQueryTableReferences(table_references=[bq_top, bq_rising]))
Impostare il contesto per la chat stateful
Puoi creare il nuovo agente con il contesto pubblicato che riunisce le istruzioni di sistema, i riferimenti alle origini dati e qualsiasi altra opzione.
Tieni presente che hai la funzionalità per creare stagingContext per testare e convalidare le modifiche prima della pubblicazione. In questo modo, uno sviluppatore può aggiungere il controllo delle versioni a un agente dati specificando contextVersion nella richiesta di chat. Per questo codelab, pubblicherai direttamente:
# Context setup for stateful chat
published_context = geminidataanalytics.Context(
system_instruction=system_instruction,
datasource_references=datasource_references,
options=geminidataanalytics.ConversationOptions(
analysis=geminidataanalytics.AnalysisOptions(
python=geminidataanalytics.AnalysisOptions.Python(
enabled=False
)
)
),
)
data_agent = geminidataanalytics.DataAgent(
data_analytics_agent=geminidataanalytics.DataAnalyticsAgent(
published_context=published_context
),
)
# Create the agent
data_agent_client.create_data_agent(request=geminidataanalytics.CreateDataAgentRequest(
parent=f"projects/{billing_project}/locations/{location}",
data_agent_id=data_agent_id,
data_agent=data_agent,
))
Dopo aver creato l'agente, dovresti vedere un output simile al seguente:

Recuperare l'agente
Testiamo l'agente per assicurarci che sia stato creato:
# Test the agent
request = geminidataanalytics.GetDataAgentRequest(
name=data_agent_client.data_agent_path(
billing_project, location, data_agent_id)
)
response = data_agent_client.get_data_agent(request=request)
print(response)
Dovresti visualizzare i metadati del nuovo agente. Ciò includerà elementi come l'ora di creazione e il contesto dell'agente nelle istruzioni di sistema e nelle origini dati.
5. Crea una conversazione
Ora puoi creare la tua prima conversazione. Per questo codelab, utilizzerai un riferimento alla conversazione per una chat stateful con il tuo agente.
Per riferimento, l'API CA offre vari modi per chattare con diverse opzioni di gestione di stati e agenti. Ecco un breve riepilogo dei tre approcci:
Stato | Cronologia conversazione | Agent | Code | Descrizione | |
Chattare utilizzando un riferimento alla conversazione | Stateful | API gestita | Sì | Continua una conversazione stateful inviando un messaggio di chat che fa riferimento a una conversazione esistente e al relativo contesto dell'agente. Per le conversazioni multi-turno, Google Cloud archivia e gestisce la cronologia della conversazione. | |
Chattare utilizzando un riferimento dell'agente dei dati | Stateless | Gestita dall'utente | Sì | Invia un messaggio di chat stateless che fa riferimento a un agente di dati salvato per il contesto. Per le conversazioni multi-turno, la tua applicazione deve gestire e fornire la cronologia della conversazione a ogni richiesta. | |
Chattare utilizzando il contesto in linea | Stateless | Gestita dall'utente | No | Invia un messaggio di chat stateless fornendo tutto il contesto direttamente nella richiesta, senza utilizzare un agente di dati salvato. Per le conversazioni multi-turno, la tua applicazione deve gestire e fornire la cronologia della conversazione a ogni richiesta. |
Creerai una funzione per configurare la conversazione e fornire un ID univoco per la conversazione:
def setup_conversation(conversation_id: str):
data_chat_client = geminidataanalytics.DataChatServiceClient()
conversation = geminidataanalytics.Conversation(
agents=[data_chat_client.data_agent_path(
billing_project, location, data_agent_id)],
)
request = geminidataanalytics.CreateConversationRequest(
parent=f"projects/{billing_project}/locations/{location}",
conversation_id=conversation_id,
conversation=conversation,
)
try:
data_chat_client.get_conversation(name=data_chat_client.conversation_path(
billing_project, location, conversation_id))
print(f"Conversation '{conversation_id}' already exists.")
except Exception:
response = data_chat_client.create_conversation(request=request)
print("Conversation created successfully:")
print(response)
conversation_id = "my_first_conversation"
setup_conversation(conversation_id=conversation_id)
Dovresti visualizzare un messaggio che conferma la creazione della conversazione.
6. Aggiungere funzioni di utilità
A breve potrai iniziare a chattare con l'agente. Prima di farlo, aggiungiamo alcune funzioni di utilità per formattare i messaggi in modo che siano più facili da leggere e per visualizzare le visualizzazioni. L'API CA invierà una specifica vega che puoi tracciare utilizzando il pacchetto altair:
# Utility functions for streaming and formatting responses
import altair as alt
import http.server
import pandas as pd
import proto
import socketserver
import threading
_server_thread = None
_httpd = None
# Prints a formatted section title
def display_section_title(text):
print(f"\n--- {text.upper()} ---")
# Handles and displays data responses
def handle_data_response(resp):
if "query" in resp:
query = resp.query
display_section_title("Retrieval query")
print(f"Query name: {query.name}")
print(f"Question: {query.question}")
print("Data sources:")
for datasource in query.datasources:
display_datasource(datasource)
elif "generated_sql" in resp:
display_section_title("SQL generated")
print(resp.generated_sql)
elif "result" in resp:
display_section_title("Data retrieved")
fields = [field.name for field in resp.result.schema.fields]
d = {field: [] for field in fields}
for el in resp.result.data:
for field in fields:
d[field].append(el[field])
print(pd.DataFrame(d))
# Starts a local web server to preview charts
def preview_in_browser(port: int = 8080):
"""Starts a web server in a background thread and waits for user to stop it."""
global _server_thread, _httpd
if _server_thread and _server_thread.is_alive():
print(
f"\n--> A new chart was generated. Refresh your browser at http://localhost:{port}")
return
Handler = http.server.SimpleHTTPRequestHandler
socketserver.TCPServer.allow_reuse_address = True
try:
_httpd = socketserver.TCPServer(("", port), Handler)
except OSError as e:
print(f"❌ Could not start server on port {port}: {e}")
return
_server_thread = threading.Thread(target=_httpd.serve_forever)
_server_thread.daemon = False
_server_thread.start()
print("\n" + "=" * 60)
print(" 📈 CHART READY - PREVIEW IN BROWSER ".center(60))
print("=" * 60)
print(
f"1. In the Cloud Shell toolbar, click 'Web Preview' and select port {port}.")
print(f"2. Or, open your local browser to http://localhost:{port}")
print("=" * 60)
try:
input(
"\n--> Press Enter here after viewing all charts to shut down the server...\n\n")
finally:
print("Shutting down server...")
_httpd.shutdown()
_server_thread.join()
_httpd, _server_thread = None, None
print("Server stopped.")
# Handles chart responses
def handle_chart_response(resp, chart_generated_flag: list):
def _value_to_dict(v):
if isinstance(v, proto.marshal.collections.maps.MapComposite):
return {k: _value_to_dict(v[k]) for k in v}
elif isinstance(v, proto.marshal.collections.RepeatedComposite):
return [_value_to_dict(el) for el in v]
return v
if "query" in resp:
print(resp.query.instructions)
elif "result" in resp:
vega_config_dict = _value_to_dict(resp.result.vega_config)
chart = alt.Chart.from_dict(vega_config_dict)
chart_filename = "index.html"
chart.save(chart_filename)
if chart_generated_flag:
chart_generated_flag[0] = True
# Displays the schema of a data source
def display_schema(data):
fields = getattr(data, "fields")
df = pd.DataFrame({
"Column": [f.name for f in fields],
"Type": [f.type for f in fields],
"Description": [getattr(f, "description", "-") for f in fields],
"Mode": [f.mode for f in fields],
})
print(df)
# Displays information about a BigQuery data source
def display_datasource(datasource):
table_ref = datasource.bigquery_table_reference
source_name = f"{table_ref.project_id}.{table_ref.dataset_id}.{table_ref.table_id}"
print(source_name)
display_schema(datasource.schema)
# Handles and displays schema resolution responses
def handle_schema_response(resp):
if "query" in resp:
print(resp.query.question)
elif "result" in resp:
display_section_title("Schema resolved")
print("Data sources:")
for datasource in resp.result.datasources:
display_datasource(datasource)
# Handles and prints simple text responses
def handle_text_response(resp):
parts = resp.parts
print("".join(parts))
# Processes and displays different types of system messages
def show_message(msg, chart_generated_flag: list):
m = msg.system_message
if "text" in m:
handle_text_response(getattr(m, "text"))
elif "schema" in m:
handle_schema_response(getattr(m, "schema"))
elif "data" in m:
handle_data_response(getattr(m, "data"))
elif "chart" in m:
handle_chart_response(getattr(m, "chart"), chart_generated_flag)
print("\n")
7. Creare una funzione di chat
Il passaggio finale consiste nel creare una funzione di chat che puoi riutilizzare e chiamare la funzione show_message per ogni blocco nel flusso di risposta:
def stream_chat_response(question: str):
"""
Sends a chat request, processes the streaming response, and if a chart
was generated, starts the preview server and waits for it to be closed.
"""
data_chat_client = geminidataanalytics.DataChatServiceClient()
chart_generated_flag = [False]
messages = [
geminidataanalytics.Message(
user_message=geminidataanalytics.UserMessage(text=question)
)
]
conversation_reference = geminidataanalytics.ConversationReference(
conversation=data_chat_client.conversation_path(
billing_project, location, conversation_id
),
data_agent_context=geminidataanalytics.DataAgentContext(
data_agent=data_chat_client.data_agent_path(
billing_project, location, data_agent_id
),
),
)
request = geminidataanalytics.ChatRequest(
parent=f"projects/{billing_project}/locations/{location}",
messages=messages,
conversation_reference=conversation_reference,
)
stream = data_chat_client.chat(request=request)
for response in stream:
show_message(response, chart_generated_flag)
if chart_generated_flag[0]:
preview_in_browser()
La funzione stream_chat_response è ora definita e pronta per l'uso con i prompt.
8. Start Chattin'
Domanda 1
Ora puoi iniziare a fare domande. Vediamo cosa può fare questo agente per iniziare:
question = "Hey what data do you have access to?"
stream_chat_response(question=question)
L'agente dovrebbe rispondere in modo simile a quanto riportato di seguito:
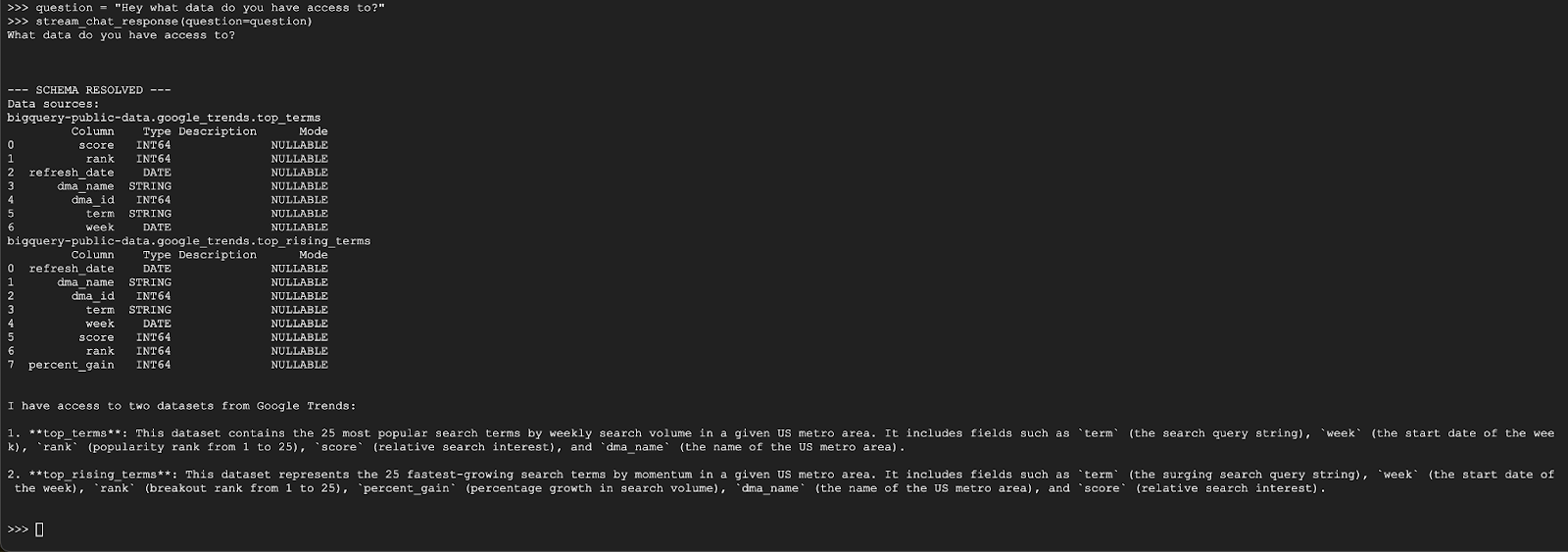
Domanda 2
Fantastico, proviamo a trovare maggiori informazioni sugli ultimi termini di ricerca più popolari:
question = "What are the top 20 most popular search terms last week in NYC based on rank? Display each term and score as a column chart"
stream_chat_response(question=question)
L'operazione richiederà del tempo. Dovresti vedere l'agente eseguire vari passaggi e trasmettere aggiornamenti in streaming, dal recupero dello schema e dei metadati alla scrittura della query SQL, all'ottenimento dei risultati, alla specifica delle istruzioni di visualizzazione e al riepilogo dei risultati.
Per visualizzare il grafico, vai alla barra degli strumenti di Cloud Shell, fai clic su "Anteprima web" e seleziona la porta 8080:
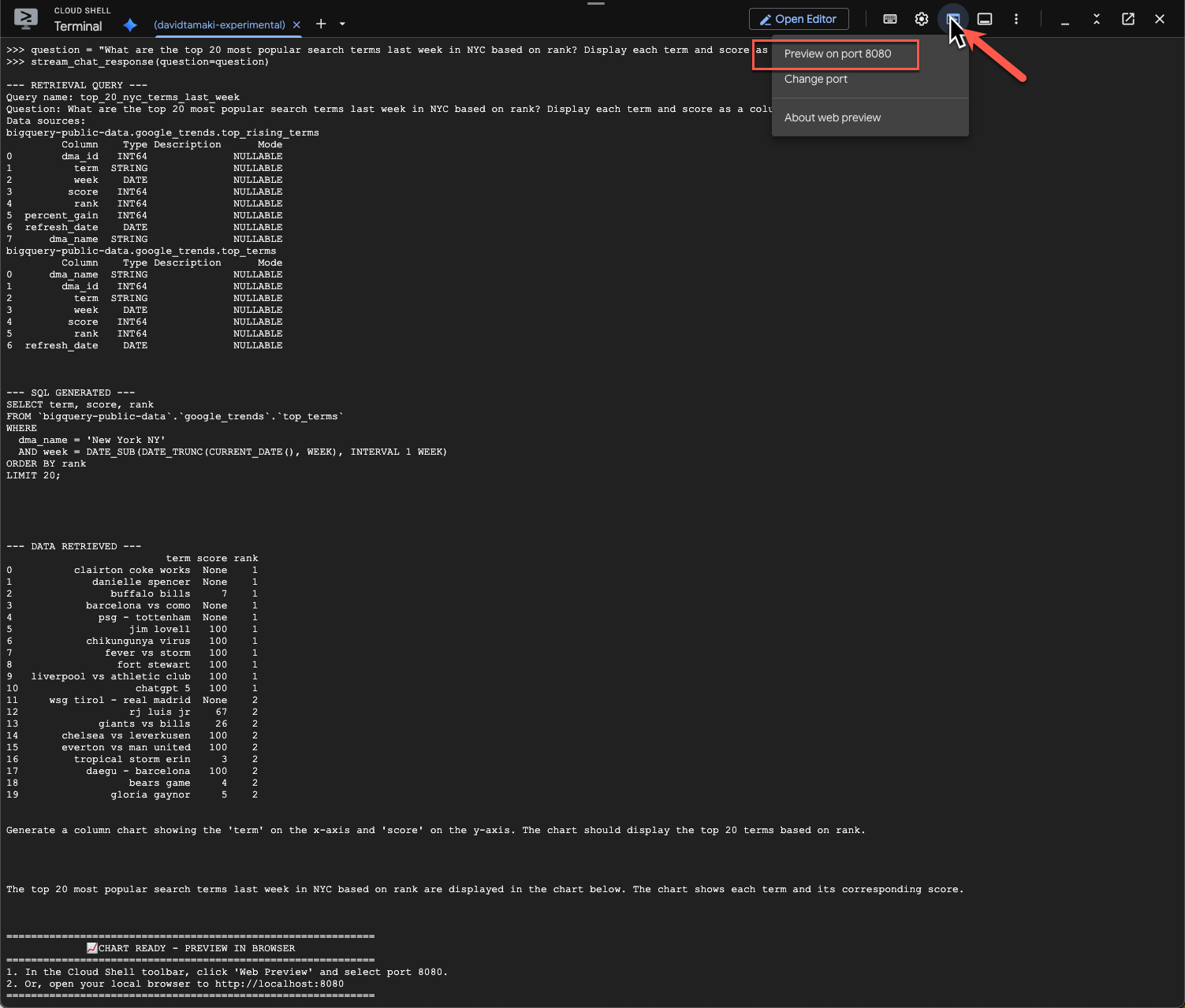
Dovresti visualizzare un rendering della visualizzazione simile a questo:
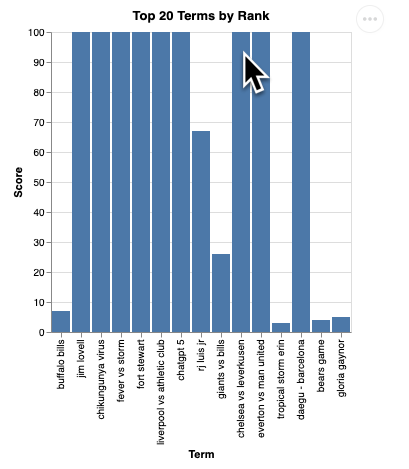
Premi Invio per spegnere il server e continuare.
Domanda 3
Proviamo a fare una domanda aggiuntiva e ad approfondire questi risultati:
question = "What was the percent gain in growth for these search terms from the week before?"
stream_chat_response(question=question)
Dovresti visualizzare un messaggio simile a quello riportato di seguito. In questo caso, l'agente ha generato una query per unire le due tabelle e trovare l'aumento percentuale. Tieni presente che la query potrebbe avere un aspetto leggermente diverso:
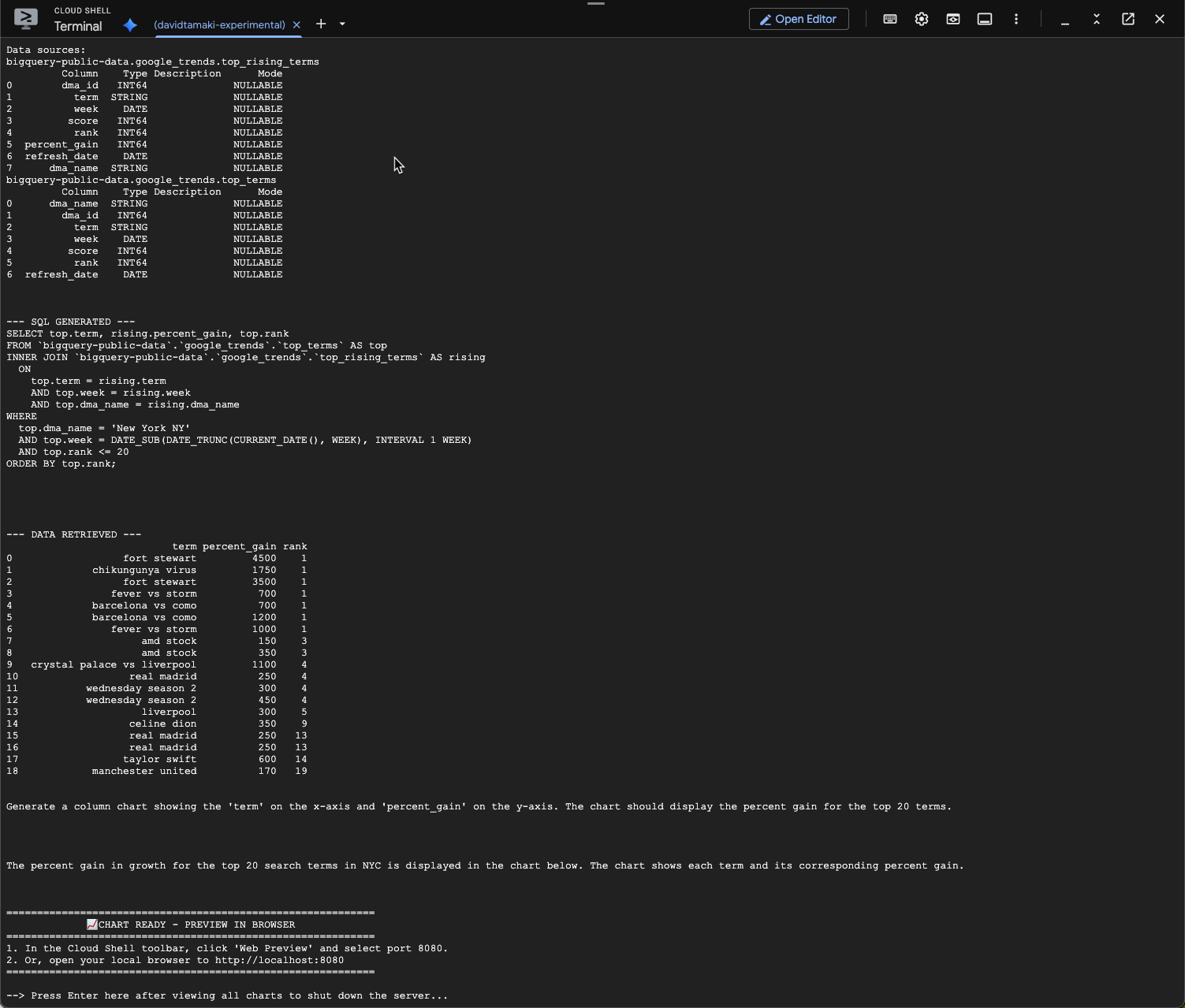
E visualizzato sarà simile a questo:
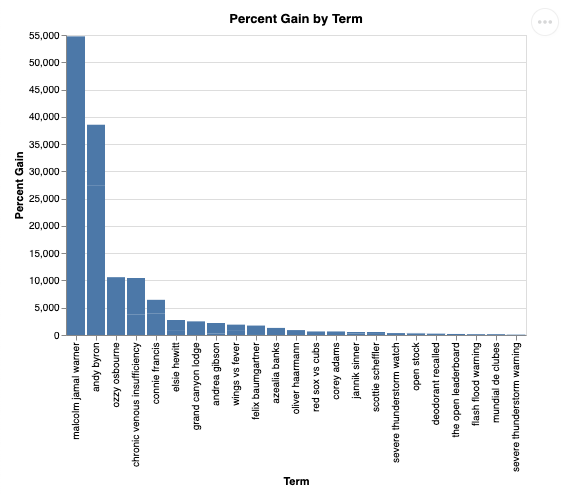
9. Esegui la pulizia
Poiché questo codelab non coinvolge prodotti a lunga esecuzione, è sufficiente interrompere la sessione Python attiva inserendo exit() nel terminale.
Eliminare cartelle e file di progetto
Se vuoi rimuovere il codice dall'ambiente Cloud Shell, utilizza i seguenti comandi:
cd ~
rm -rf ca-api-codelab
Disabilita le API
Per disattivare le API abilitate in precedenza, esegui questo comando
gcloud services disable geminidataanalytics.googleapis.com
gcloud services disable cloudaicompanion.googleapis.com
gcloud services disable bigquery.googleapis.com
10. Conclusione
Congratulazioni, hai creato correttamente un semplice agente di analisi conversazionale utilizzando l'SDK CA. Consulta i materiali di riferimento per saperne di più.