
1. Wprowadzenie
Z tego przewodnika dowiesz się, jak używać pakietu Conversational Analytics (CA) API Python SDK ze źródłem danych BigQuery. Dowiesz się, jak utworzyć nowego agenta, jak korzystać z zarządzania stanem rozmowy oraz jak wysyłać i przesyłać strumieniowo odpowiedzi z interfejsu API.
Wymagania wstępne
- Podstawowa wiedza o Google Cloud i konsoli Google Cloud
- Podstawowe umiejętności w zakresie interfejsu wiersza poleceń i Cloud Shell
- podstawowa znajomość programowania w Pythonie,
Czego się nauczysz
- Instrukcje: Jak używać pakietu SDK Python interfejsu analityki konwersacyjnej ze źródłem danych BigQuery
- Jak utworzyć nowego agenta za pomocą interfejsu API CA
- Jak wykorzystać zarządzanie stanem rozmowy
- Wysyłanie i strumieniowanie odpowiedzi z interfejsu API
Czego potrzebujesz
- konto Google Cloud i projekt w chmurze Google Cloud,
- przeglądarka, np. Chrome;
2. Konfiguracja i wymagania
Wybierz projekt
- Zaloguj się w konsoli Google Cloud i utwórz nowy projekt lub użyj istniejącego. Jeśli nie masz jeszcze konta Gmail ani Google Workspace, musisz je utworzyć.

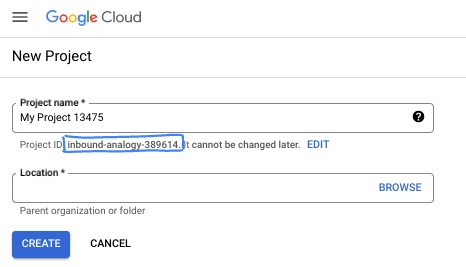
- Nazwa projektu to wyświetlana nazwa uczestników tego projektu. Jest to ciąg znaków, który nie jest używany przez interfejsy API Google. Zawsze możesz ją zaktualizować.
- Identyfikator projektu jest unikalny we wszystkich projektach Google Cloud i nie można go zmienić po ustawieniu. Konsola Cloud automatycznie generuje unikalny ciąg znaków. Zwykle nie musisz się tym przejmować. W większości ćwiczeń z programowania musisz odwoływać się do identyfikatora projektu (zwykle oznaczanego jako
PROJECT_ID). Jeśli wygenerowany identyfikator Ci się nie podoba, możesz wygenerować inny losowy identyfikator. Możesz też spróbować własnej nazwy i sprawdzić, czy jest dostępna. Po tym kroku nie można go zmienić i pozostaje on taki przez cały czas trwania projektu. - Warto wiedzieć, że istnieje też trzecia wartość, numer projektu, której używają niektóre interfejsy API. Więcej informacji o tych 3 wartościach znajdziesz w dokumentacji.
- Następnie musisz włączyć płatności w konsoli Cloud, aby korzystać z zasobów i interfejsów API Google Cloud. Wykonanie tego laboratorium nie będzie kosztować dużo, a może nawet nic. Aby wyłączyć zasoby i uniknąć naliczania opłat po zakończeniu tego samouczka, możesz usunąć utworzone zasoby lub projekt. Nowi użytkownicy Google Cloud mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Uruchamianie Cloud Shell
Z Google Cloud można korzystać zdalnie na laptopie, ale w tym module praktycznym będziesz używać Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:
Uzyskanie dostępu do środowiska i połączenie się z nim powinno zająć tylko kilka chwil. Po zakończeniu powinno wyświetlić się coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym laboratorium możesz wykonać w przeglądarce. Nie musisz niczego instalować.
3. Zanim zaczniesz
Włącz wymagane interfejsy API
Aby korzystać z usług Google Cloud, musisz najpierw aktywować odpowiednie interfejsy API w swoim projekcie. W tym laboratorium będziesz korzystać z tych usług Google Cloud:
- API Data Analytics z Gemini
- Gemini dla Google Cloud
- BigQuery API
Aby włączyć te usługi, uruchom w terminalu Cloud Shell te polecenia:
gcloud services enable geminidataanalytics.googleapis.com
gcloud services enable cloudaicompanion.googleapis.com
gcloud services enable bigquery.googleapis.com
Instalowanie pakietów Pythona
Przed rozpoczęciem dowolnego projektu w Pythonie warto utworzyć środowisko wirtualne. Izoluje to zależności projektu, zapobiegając konfliktom z innymi projektami lub globalnymi pakietami Pythona w systemie. W tej sekcji zainstalujesz uv za pomocą narzędzia pip, ponieważ jest ono już dostępne w Cloud Shell.
Instalowanie pakietu uv
pip install uv
Sprawdzanie, czy narzędzie uv jest prawidłowo zainstalowane
uv --version
Oczekiwane dane wyjściowe:
Jeśli zobaczysz w danych wyjściowych wiersz z uv, możesz przejść do następnego kroku. Pamiętaj, że numer wersji może się różnić:

Tworzenie środowiska wirtualnego i instalowanie pakietów
uv init ca-api-codelab
cd ca-api-codelab
uv venv --python 3.12
uv add google-cloud-geminidataanalytics pandas altair
uv pip list | grep -E 'altair|pandas|google-cloud-geminidataanalytics'
Oczekiwane dane wyjściowe:
Jeśli zobaczysz w wierszach wyjściowych te 3 pakiety, możesz przejść do następnego kroku. Pamiętaj, że numery wersji mogą się różnić:

Rozpocznij naukę Pythona
uv run python
Ekran powinien wyglądać tak:

4. Utwórz agenta
Środowisko programistyczne jest już skonfigurowane i gotowe do użycia. Czas więc stworzyć podstawy interfejsu Gemini Data Analytics API. Pakiet SDK upraszcza ten proces, wymagając tylko kilku podstawowych konfiguracji do utworzenia agenta.
Ustawianie zmiennych
Zaimportuj pakiet geminidataanalytics i ustaw zmienne środowiskowe:
import os
from google.cloud import geminidataanalytics
data_agent_client = geminidataanalytics.DataAgentServiceClient()
location = "global"
billing_project = os.environ.get('DEVSHELL_PROJECT_ID')
data_agent_id = "google_trends_analytics_agent"
Ustawianie instrukcji systemowych dla agenta
Interfejs CA API odczytuje metadane BigQuery, aby uzyskać więcej informacji o tabelach i kolumnach, do których się odwołuje. Ten publiczny zbiór danych nie zawiera opisów kolumn, więc możesz podać dodatkowe informacje o agencie w postaci ciągu znaków w formacie YAML. Sprawdzone metody i szablon znajdziesz w dokumentacji:
system_instruction = """
system_instruction:
- You are a data analyst specializing in the Google Trends dataset.
- When querying, always use the 'week' column for date-based filtering. This needs to be a Sunday. If you are doing week over week comparison, make sure you specify a date that is a Sunday.
- The following columns should be ignored in all queries 'dma_id', 'refresh_date'
- The 'dma_name' column represents the city and state for about 210 metro areas in the USA.
tables:
top_terms:
description: "Represents the 25 most popular search terms by weekly search volume in a given US metro area (DMA)."
fields:
term: "The search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's popularity rank from 1 (most popular) to 25."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
dma_name: "The name of the US metro area, e.g., 'New York NY'."
top_rising_terms:
description: "Represents the 25 fastest-growing ('breakout') search terms by momentum in a given US metro area (DMA)."
fields:
term: "The surging search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's breakout rank from 1 (top rising) to 25."
percent_gain: "The percentage growth in search volume compared to the previous period."
dma_name: "The name of the US metro area, e.g., 'Los Angeles CA'."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
join_instructions:
goal: "Find terms that are simultaneously popular and rising in the same week and metro area."
method: "INNER JOIN the two tables on their common keys."
keys:
- "term"
- "week"
- "dma_name"
golden_queries:
- natural_language_query: "Find all terms in the 'New York NY' area that were in both the top 25 and top 25 rising lists for the week of July 6th, 2025, and show their ranks and percent gain."
sql_query: |
SELECT
top.term,
top.rank AS top_25_rank,
rising.rank AS rising_25_rank,
rising.percent_gain
FROM
`bigquery-public-data.google_trends.top_terms` AS top
INNER JOIN
`bigquery-public-data.google_trends.top_rising_terms` AS rising
ON
top.term = rising.term
AND top.week = rising.week
AND top.dma_name = rising.dma_name
WHERE
top.week = '2025-07-06'
AND top.dma_name = 'New York NY'
ORDER BY
top.rank;
"""
Ustawianie źródeł danych tabeli BigQuery
Teraz możesz ustawić źródła danych tabeli BigQuery. Interfejs CA API akceptuje tabele BigQuery w postaci tablicy:
# BigQuery table data sources
bq_top = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_terms"
)
bq_rising = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_rising_terms"
)
datasource_references = geminidataanalytics.DatasourceReferences(
bq=geminidataanalytics.BigQueryTableReferences(table_references=[bq_top, bq_rising]))
Ustawianie kontekstu czatu stanowego
Możesz utworzyć nowego agenta z opublikowanym kontekstem, który łączy instrukcje systemowe, odwołania do źródeł danych i inne opcje.
Pamiętaj, że możesz utworzyć element stagingContext, aby przetestować i zweryfikować zmiany przed ich opublikowaniem. Umożliwia to deweloperowi dodanie obsługi wersji do agenta danych przez określenie parametru contextVersion w żądaniu czatu. W tym ćwiczeniu z programowania opublikujesz projekt bezpośrednio:
# Context setup for stateful chat
published_context = geminidataanalytics.Context(
system_instruction=system_instruction,
datasource_references=datasource_references,
options=geminidataanalytics.ConversationOptions(
analysis=geminidataanalytics.AnalysisOptions(
python=geminidataanalytics.AnalysisOptions.Python(
enabled=False
)
)
),
)
data_agent = geminidataanalytics.DataAgent(
data_analytics_agent=geminidataanalytics.DataAnalyticsAgent(
published_context=published_context
),
)
# Create the agent
data_agent_client.create_data_agent(request=geminidataanalytics.CreateDataAgentRequest(
parent=f"projects/{billing_project}/locations/{location}",
data_agent_id=data_agent_id,
data_agent=data_agent,
))
Po utworzeniu agenta powinny się wyświetlić dane wyjściowe podobne do tych poniżej:

Pobieranie agenta
Przetestujmy agenta, aby sprawdzić, czy został utworzony:
# Test the agent
request = geminidataanalytics.GetDataAgentRequest(
name=data_agent_client.data_agent_path(
billing_project, location, data_agent_id)
)
response = data_agent_client.get_data_agent(request=request)
print(response)
Powinny być widoczne metadane nowego agenta. Obejmuje to takie informacje jak czas utworzenia i kontekst agenta w instrukcjach systemowych i źródłach danych.
5. Utwórz rozmowę
Możesz teraz utworzyć pierwszą rozmowę. W tym laboratorium kodowym użyjesz odwołania do rozmowy w przypadku czatu stanowego z agentem.
Interfejs CA API oferuje różne sposoby czatowania z różnymi opcjami zarządzania stanem i agentami. Oto krótkie podsumowanie 3 podejść:
Stan | Historia rozmowy | Agent | Code | Opis | |
Czatowanie przy użyciu odniesienia do rozmowy | Stanowa | Zarządzanie interfejsem API | Tak | Kontynuuje rozmowę z zachowaniem stanu, wysyłając wiadomość na czacie, która odwołuje się do istniejącej rozmowy i powiązanego z nią kontekstu agenta. W przypadku rozmów wieloetapowych Google Cloud przechowuje historię rozmowy i nią zarządza. | |
Czatowanie z użyciem odwołania do agenta danych | Bezstanowy | Zarządzane przez użytkownika | Tak | Wysyła bezstanową wiadomość na czacie, która odwołuje się do zapisanego agenta danych w celu uzyskania kontekstu. W przypadku rozmów wieloetapowych aplikacja musi zarządzać historią rozmowy i przesyłać ją z każdym żądaniem. | |
Czatowanie z użyciem kontekstu wbudowanego | Bezstanowy | Zarządzane przez użytkownika | Nie | Wysyła bezstanową wiadomość na czacie, podając cały kontekst bezpośrednio w żądaniu, bez używania agenta danych zapisanych. W przypadku rozmów wieloetapowych aplikacja musi zarządzać historią rozmowy i przesyłać ją z każdym żądaniem. |
Utworzysz funkcję, która skonfiguruje rozmowę i przypisze jej unikalny identyfikator:
def setup_conversation(conversation_id: str):
data_chat_client = geminidataanalytics.DataChatServiceClient()
conversation = geminidataanalytics.Conversation(
agents=[data_chat_client.data_agent_path(
billing_project, location, data_agent_id)],
)
request = geminidataanalytics.CreateConversationRequest(
parent=f"projects/{billing_project}/locations/{location}",
conversation_id=conversation_id,
conversation=conversation,
)
try:
data_chat_client.get_conversation(name=data_chat_client.conversation_path(
billing_project, location, conversation_id))
print(f"Conversation '{conversation_id}' already exists.")
except Exception:
response = data_chat_client.create_conversation(request=request)
print("Conversation created successfully:")
print(response)
conversation_id = "my_first_conversation"
setup_conversation(conversation_id=conversation_id)
Powinien pojawić się komunikat informujący o utworzeniu rozmowy.
6. Dodawanie funkcji narzędziowych
Już prawie możesz rozpocząć rozmowę z pracownikiem obsługi klienta. Zanim to zrobisz, dodajmy kilka funkcji użytkowych, które ułatwią formatowanie wiadomości, aby były łatwiejsze do odczytania, a także renderowanie wizualizacji. Interfejs CA API wyśle specyfikację vega, którą możesz wykreślić za pomocą pakietu altair:
# Utility functions for streaming and formatting responses
import altair as alt
import http.server
import pandas as pd
import proto
import socketserver
import threading
_server_thread = None
_httpd = None
# Prints a formatted section title
def display_section_title(text):
print(f"\n--- {text.upper()} ---")
# Handles and displays data responses
def handle_data_response(resp):
if "query" in resp:
query = resp.query
display_section_title("Retrieval query")
print(f"Query name: {query.name}")
print(f"Question: {query.question}")
print("Data sources:")
for datasource in query.datasources:
display_datasource(datasource)
elif "generated_sql" in resp:
display_section_title("SQL generated")
print(resp.generated_sql)
elif "result" in resp:
display_section_title("Data retrieved")
fields = [field.name for field in resp.result.schema.fields]
d = {field: [] for field in fields}
for el in resp.result.data:
for field in fields:
d[field].append(el[field])
print(pd.DataFrame(d))
# Starts a local web server to preview charts
def preview_in_browser(port: int = 8080):
"""Starts a web server in a background thread and waits for user to stop it."""
global _server_thread, _httpd
if _server_thread and _server_thread.is_alive():
print(
f"\n--> A new chart was generated. Refresh your browser at http://localhost:{port}")
return
Handler = http.server.SimpleHTTPRequestHandler
socketserver.TCPServer.allow_reuse_address = True
try:
_httpd = socketserver.TCPServer(("", port), Handler)
except OSError as e:
print(f"❌ Could not start server on port {port}: {e}")
return
_server_thread = threading.Thread(target=_httpd.serve_forever)
_server_thread.daemon = False
_server_thread.start()
print("\n" + "=" * 60)
print(" 📈 CHART READY - PREVIEW IN BROWSER ".center(60))
print("=" * 60)
print(
f"1. In the Cloud Shell toolbar, click 'Web Preview' and select port {port}.")
print(f"2. Or, open your local browser to http://localhost:{port}")
print("=" * 60)
try:
input(
"\n--> Press Enter here after viewing all charts to shut down the server...\n\n")
finally:
print("Shutting down server...")
_httpd.shutdown()
_server_thread.join()
_httpd, _server_thread = None, None
print("Server stopped.")
# Handles chart responses
def handle_chart_response(resp, chart_generated_flag: list):
def _value_to_dict(v):
if isinstance(v, proto.marshal.collections.maps.MapComposite):
return {k: _value_to_dict(v[k]) for k in v}
elif isinstance(v, proto.marshal.collections.RepeatedComposite):
return [_value_to_dict(el) for el in v]
return v
if "query" in resp:
print(resp.query.instructions)
elif "result" in resp:
vega_config_dict = _value_to_dict(resp.result.vega_config)
chart = alt.Chart.from_dict(vega_config_dict)
chart_filename = "index.html"
chart.save(chart_filename)
if chart_generated_flag:
chart_generated_flag[0] = True
# Displays the schema of a data source
def display_schema(data):
fields = getattr(data, "fields")
df = pd.DataFrame({
"Column": [f.name for f in fields],
"Type": [f.type for f in fields],
"Description": [getattr(f, "description", "-") for f in fields],
"Mode": [f.mode for f in fields],
})
print(df)
# Displays information about a BigQuery data source
def display_datasource(datasource):
table_ref = datasource.bigquery_table_reference
source_name = f"{table_ref.project_id}.{table_ref.dataset_id}.{table_ref.table_id}"
print(source_name)
display_schema(datasource.schema)
# Handles and displays schema resolution responses
def handle_schema_response(resp):
if "query" in resp:
print(resp.query.question)
elif "result" in resp:
display_section_title("Schema resolved")
print("Data sources:")
for datasource in resp.result.datasources:
display_datasource(datasource)
# Handles and prints simple text responses
def handle_text_response(resp):
parts = resp.parts
print("".join(parts))
# Processes and displays different types of system messages
def show_message(msg, chart_generated_flag: list):
m = msg.system_message
if "text" in m:
handle_text_response(getattr(m, "text"))
elif "schema" in m:
handle_schema_response(getattr(m, "schema"))
elif "data" in m:
handle_data_response(getattr(m, "data"))
elif "chart" in m:
handle_chart_response(getattr(m, "chart"), chart_generated_flag)
print("\n")
7. Tworzenie funkcji czatu
Ostatnim krokiem jest utworzenie funkcji czatu, której możesz używać wielokrotnie, i wywołanie funkcji show_message dla każdego fragmentu w strumieniu odpowiedzi:
def stream_chat_response(question: str):
"""
Sends a chat request, processes the streaming response, and if a chart
was generated, starts the preview server and waits for it to be closed.
"""
data_chat_client = geminidataanalytics.DataChatServiceClient()
chart_generated_flag = [False]
messages = [
geminidataanalytics.Message(
user_message=geminidataanalytics.UserMessage(text=question)
)
]
conversation_reference = geminidataanalytics.ConversationReference(
conversation=data_chat_client.conversation_path(
billing_project, location, conversation_id
),
data_agent_context=geminidataanalytics.DataAgentContext(
data_agent=data_chat_client.data_agent_path(
billing_project, location, data_agent_id
),
),
)
request = geminidataanalytics.ChatRequest(
parent=f"projects/{billing_project}/locations/{location}",
messages=messages,
conversation_reference=conversation_reference,
)
stream = data_chat_client.chat(request=request)
for response in stream:
show_message(response, chart_generated_flag)
if chart_generated_flag[0]:
preview_in_browser()
Funkcja stream_chat_response jest teraz zdefiniowana i gotowa do użycia w promptach.
8. Rozpocznij czat
Pytanie 1
Możesz teraz zacząć zadawać pytania. Oto kilka przykładów tego, co może zrobić ten agent:
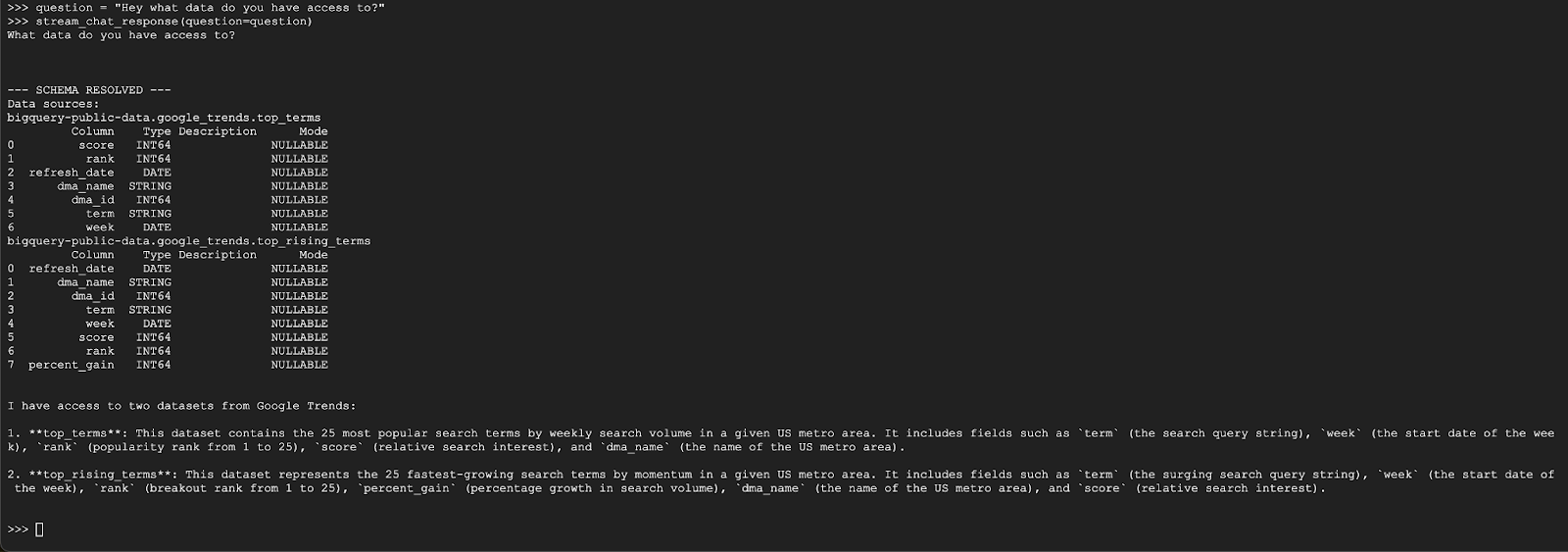
question = "Hey what data do you have access to?"
stream_chat_response(question=question)
Przedstawiciel powinien odpowiedzieć w podobny sposób:
Pytanie 2
Świetnie. Spróbujmy znaleźć więcej informacji o najnowszych popularnych wyszukiwanych hasłach:
question = "What are the top 20 most popular search terms last week in NYC based on rank? Display each term and score as a column chart"
stream_chat_response(question=question)
Wykonanie tego polecenia zajmie trochę czasu. Powinny być widoczne różne kroki wykonywane przez agenta i strumieniowe aktualizacje, od pobierania schematu i metadanych, pisania zapytania SQL, uzyskiwania wyników, określania instrukcji wizualizacji po podsumowywanie wyników.
Aby wyświetlić wykres, na pasku narzędzi Cloud Shell kliknij „Podgląd w przeglądarce” i wybierz port 8080:
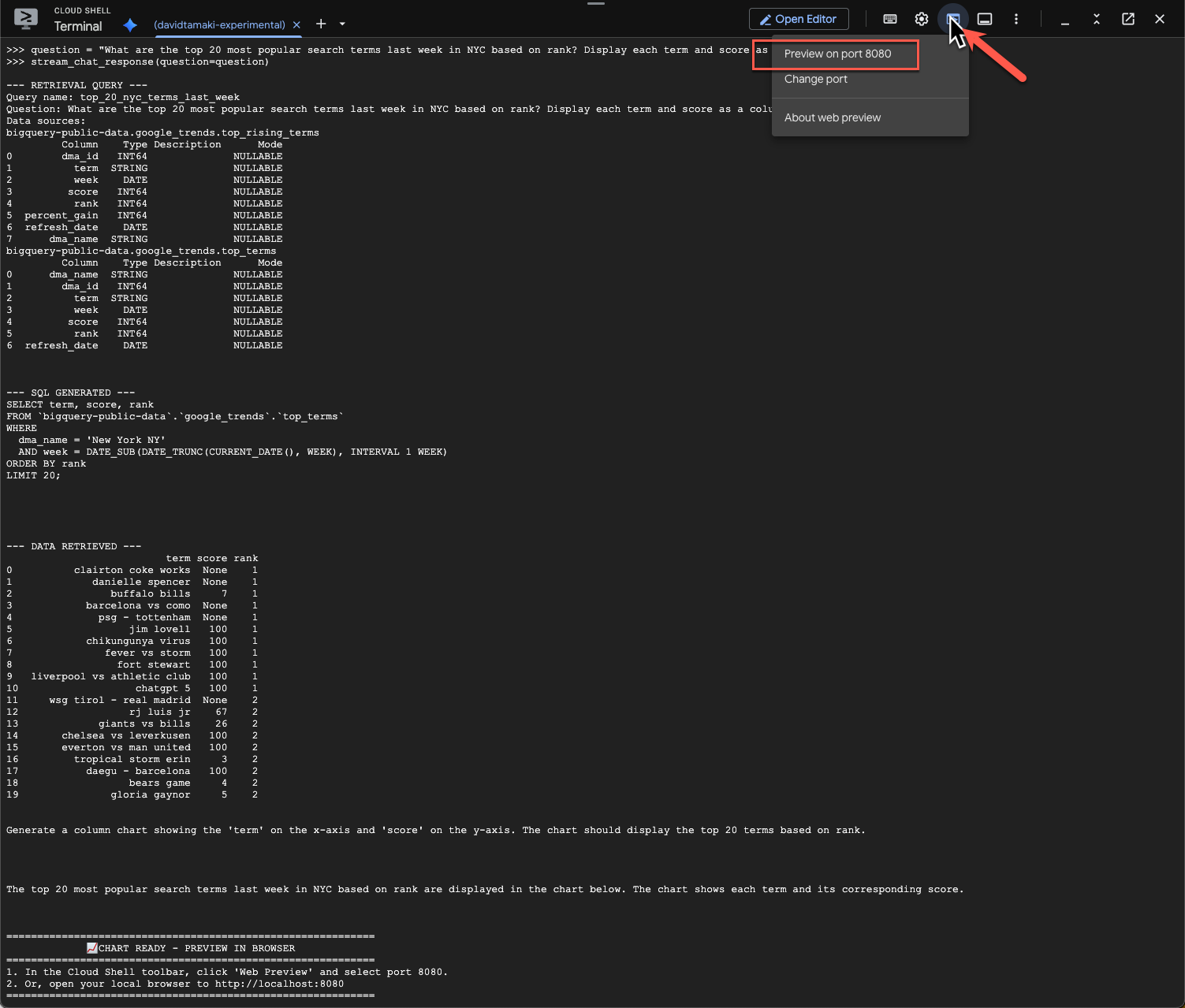
Powinna pojawić się wizualizacja podobna do tej:
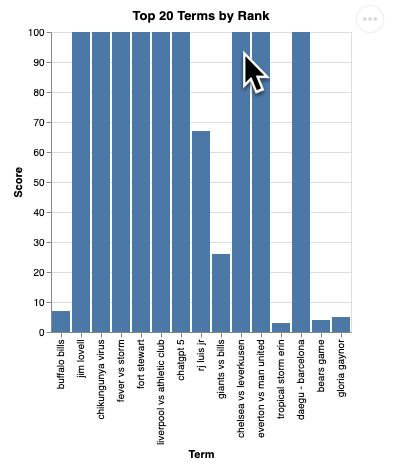
Naciśnij Enter, aby wyłączyć serwer i kontynuować.
Pytanie 3
Zadajmy dodatkowe pytanie, aby dowiedzieć się więcej o tych wynikach:
question = "What was the percent gain in growth for these search terms from the week before?"
stream_chat_response(question=question)
Powinien pojawić się ekran podobny do tego poniżej. W tym przypadku agent wygenerował zapytanie o połączenie 2 tabel w celu znalezienia procentowego wzrostu. Pamiętaj, że Twoje zapytanie może wyglądać nieco inaczej:
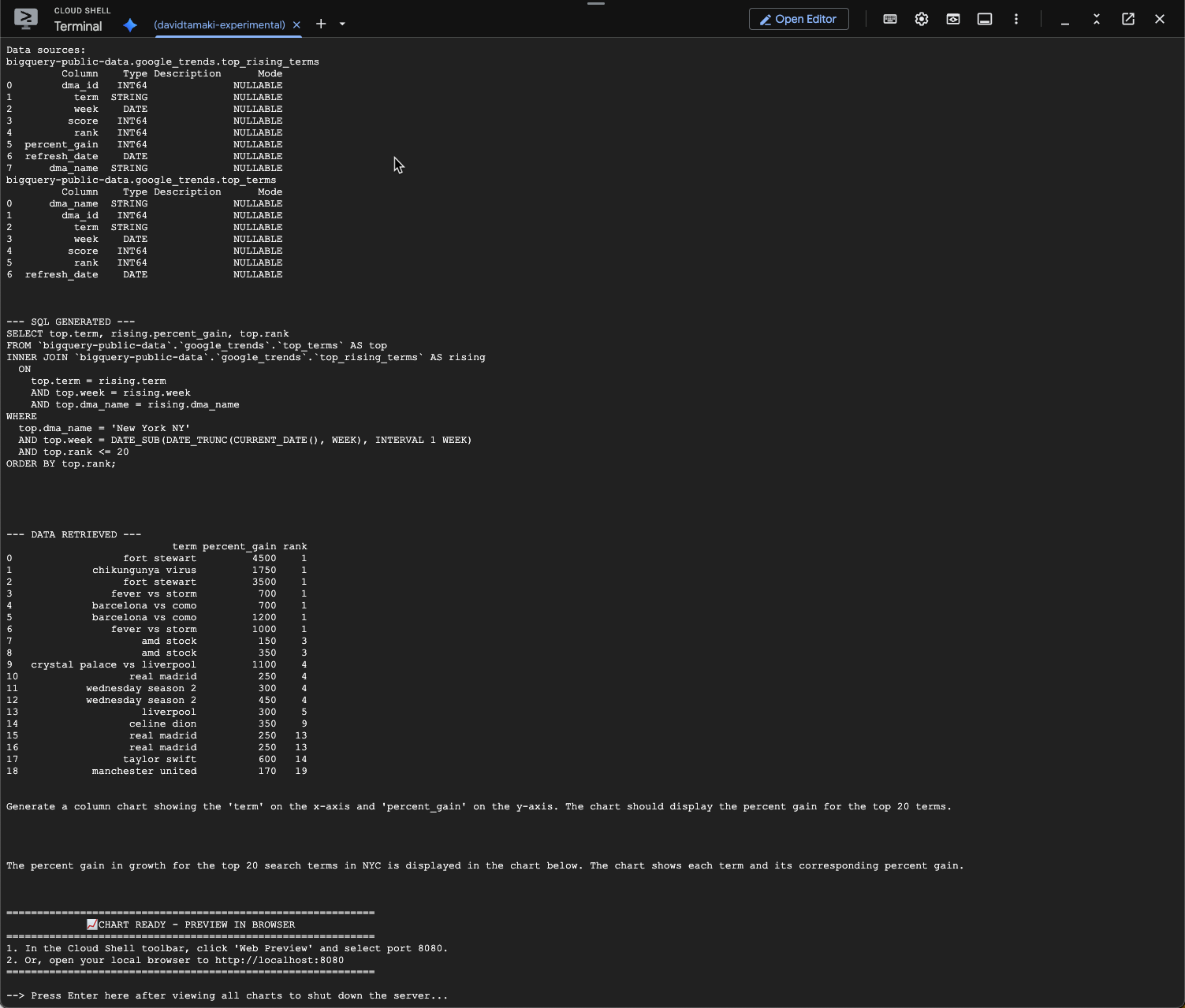
Wizualizacja będzie wyglądać tak:
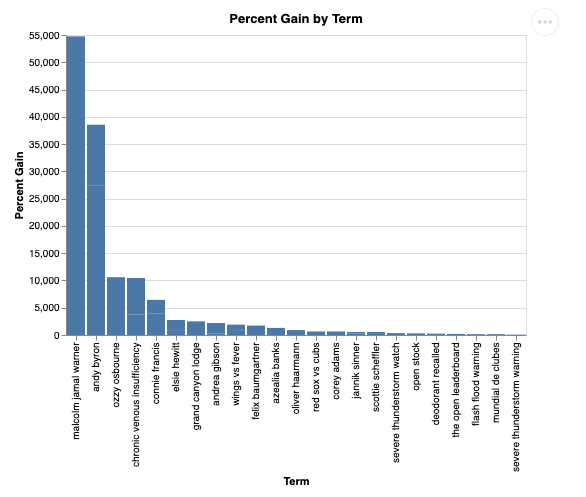
9. Czyszczenie
To laboratorium nie obejmuje żadnych długotrwałych produktów, więc wystarczy zatrzymać aktywną sesję Pythona, wpisując w terminalu exit().
Usuwanie folderów i plików projektu
Jeśli chcesz usunąć kod ze środowiska Cloud Shell, użyj tych poleceń:
cd ~
rm -rf ca-api-codelab
Wyłączanie interfejsów API
Aby wyłączyć interfejsy API, które zostały wcześniej włączone, uruchom to polecenie:
gcloud services disable geminidataanalytics.googleapis.com
gcloud services disable cloudaicompanion.googleapis.com
gcloud services disable bigquery.googleapis.com
10. Podsumowanie
Gratulacje! Udało Ci się utworzyć prostego agenta analityki konwersacyjnej za pomocą pakietu CA SDK. Więcej informacji znajdziesz w materiałach referencyjnych.