
1. Introdução
Neste codelab, você vai aprender a usar o SDK do Python da API Análises de conversação (CA) com uma fonte de dados do BigQuery. Você vai aprender a criar um novo agente, aproveitar o gerenciamento de estado da conversa e enviar e transmitir respostas da API.
Pré-requisitos
- Conhecimentos básicos sobre o Google Cloud e o console do Google Cloud
- Habilidades básicas na interface de linha de comando e no Cloud Shell
- Proficiência básica em programação Python
O que você vai aprender
- Como usar o SDK da API Análises de conversação para Python com uma fonte de dados do BigQuery
- Como criar um agente usando a API CA
- Como aproveitar o gerenciamento de estado da conversa
- Como enviar e transmitir respostas da API
O que é necessário
- Uma conta do Google Cloud e um projeto na nuvem do Google Cloud
- Um navegador da Web, como o Chrome
2. Configuração e requisitos
Escolher um projeto
- Faça login no Console do Google Cloud e crie um novo projeto ou reutilize um existente. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma.

- O Nome do projeto é o nome de exibição para os participantes do projeto. É uma string de caracteres não usada pelas APIs do Google e pode ser atualizada quando você quiser.
- O ID do projeto precisa ser exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Cloud gera automaticamente uma string exclusiva. Em geral, não importa o que seja. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, normalmente identificado como
PROJECT_ID. Se você não gostar do ID gerado, crie outro aleatório. Se preferir, teste o seu e confira se ele está disponível. Ele não pode ser mudado após essa etapa e permanece durante o projeto. - Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
- Em seguida, ative o faturamento no console do Cloud para usar os recursos/APIs do Cloud. A execução deste codelab não vai ser muito cara, se tiver algum custo. Para encerrar os recursos e evitar cobranças além deste tutorial, exclua os recursos criados ou exclua o projeto. Novos usuários do Google Cloud estão qualificados para o programa de US$ 300 de avaliação sem custos.
Inicie o Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No Console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:
O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
3. Antes de começar
Ative as APIs necessárias
Para usar os serviços do Google Cloud, primeiro é necessário ativar as APIs respectivas no seu projeto. Neste codelab, você vai usar os seguintes serviços do Google Cloud:
- API Data Analytics com Gemini
- Gemini para o Google Cloud
- API BigQuery
Para ativar esses serviços, execute os seguintes comandos no terminal do Cloud Shell:
gcloud services enable geminidataanalytics.googleapis.com
gcloud services enable cloudaicompanion.googleapis.com
gcloud services enable bigquery.googleapis.com
Instalar pacotes Python
Antes de iniciar qualquer projeto em Python, é recomendável criar um ambiente virtual. Isso isola as dependências do projeto, evitando conflitos com outros projetos ou com os pacotes globais do Python no sistema. Nesta seção, você vai instalar o uv do pip, já que o Cloud Shell já tem o pip disponível.
Instalar o pacote uv
pip install uv
Verificar se o uv está instalado corretamente
uv --version
Saída esperada
Se você vir uma linha de saída com "uv", siga para a próxima etapa. O número da versão pode variar:

Criar ambiente virtual e instalar pacotes
uv init ca-api-codelab
cd ca-api-codelab
uv venv --python 3.12
uv add google-cloud-geminidataanalytics pandas altair
uv pip list | grep -E 'altair|pandas|google-cloud-geminidataanalytics'
Saída esperada
Se você vir linhas de saída com os três pacotes, siga para a próxima etapa. Os números de versão podem variar:

Começar a usar o Python
uv run python
Na tela, você verá algo assim:

4. Criar um agente
Agora que o ambiente de desenvolvimento está configurado e pronto, é hora de criar a base para a API Gemini Data Analytics. O SDK simplifica esse processo, exigindo apenas algumas configurações essenciais para criar seu agente.
definir variáveis
Importe o pacote geminidataanalytics e defina as variáveis de ambiente:
import os
from google.cloud import geminidataanalytics
data_agent_client = geminidataanalytics.DataAgentServiceClient()
location = "global"
billing_project = os.environ.get('DEVSHELL_PROJECT_ID')
data_agent_id = "google_trends_analytics_agent"
Definir instruções do sistema para o agente
A API CA lê metadados do BigQuery para ter mais contexto sobre as tabelas e colunas referenciadas. Como esse conjunto de dados público não tem descrições de colunas, você pode fornecer mais contexto ao agente como uma string formatada em YAML. Consulte a documentação para conferir práticas recomendadas e um modelo para usar:
system_instruction = """
system_instruction:
- You are a data analyst specializing in the Google Trends dataset.
- When querying, always use the 'week' column for date-based filtering. This needs to be a Sunday. If you are doing week over week comparison, make sure you specify a date that is a Sunday.
- The following columns should be ignored in all queries 'dma_id', 'refresh_date'
- The 'dma_name' column represents the city and state for about 210 metro areas in the USA.
tables:
top_terms:
description: "Represents the 25 most popular search terms by weekly search volume in a given US metro area (DMA)."
fields:
term: "The search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's popularity rank from 1 (most popular) to 25."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
dma_name: "The name of the US metro area, e.g., 'New York NY'."
top_rising_terms:
description: "Represents the 25 fastest-growing ('breakout') search terms by momentum in a given US metro area (DMA)."
fields:
term: "The surging search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's breakout rank from 1 (top rising) to 25."
percent_gain: "The percentage growth in search volume compared to the previous period."
dma_name: "The name of the US metro area, e.g., 'Los Angeles CA'."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
join_instructions:
goal: "Find terms that are simultaneously popular and rising in the same week and metro area."
method: "INNER JOIN the two tables on their common keys."
keys:
- "term"
- "week"
- "dma_name"
golden_queries:
- natural_language_query: "Find all terms in the 'New York NY' area that were in both the top 25 and top 25 rising lists for the week of July 6th, 2025, and show their ranks and percent gain."
sql_query: |
SELECT
top.term,
top.rank AS top_25_rank,
rising.rank AS rising_25_rank,
rising.percent_gain
FROM
`bigquery-public-data.google_trends.top_terms` AS top
INNER JOIN
`bigquery-public-data.google_trends.top_rising_terms` AS rising
ON
top.term = rising.term
AND top.week = rising.week
AND top.dma_name = rising.dma_name
WHERE
top.week = '2025-07-06'
AND top.dma_name = 'New York NY'
ORDER BY
top.rank;
"""
Definir fontes de dados da tabela do BigQuery
Agora você pode definir as fontes de dados da tabela do BigQuery. A API CA aceita tabelas do BigQuery em uma matriz:
# BigQuery table data sources
bq_top = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_terms"
)
bq_rising = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_rising_terms"
)
datasource_references = geminidataanalytics.DatasourceReferences(
bq=geminidataanalytics.BigQueryTableReferences(table_references=[bq_top, bq_rising]))
Definir o contexto para conversa com estado
É possível criar o novo agente com o contexto publicado, que reúne as instruções do sistema, as referências de fontes de dados e outras opções.
Você pode criar um stagingContext para testar e validar as mudanças antes de publicar. Isso permite que um desenvolvedor adicione controle de versões a um agente de dados especificando o contextVersion na solicitação de chat. Neste codelab, você vai publicar diretamente:
# Context setup for stateful chat
published_context = geminidataanalytics.Context(
system_instruction=system_instruction,
datasource_references=datasource_references,
options=geminidataanalytics.ConversationOptions(
analysis=geminidataanalytics.AnalysisOptions(
python=geminidataanalytics.AnalysisOptions.Python(
enabled=False
)
)
),
)
data_agent = geminidataanalytics.DataAgent(
data_analytics_agent=geminidataanalytics.DataAnalyticsAgent(
published_context=published_context
),
)
# Create the agent
data_agent_client.create_data_agent(request=geminidataanalytics.CreateDataAgentRequest(
parent=f"projects/{billing_project}/locations/{location}",
data_agent_id=data_agent_id,
data_agent=data_agent,
))
Depois de criar o agente, você vai ver uma saída semelhante a esta:

Acessar o agente
Vamos testar o agente para garantir que ele foi criado:
# Test the agent
request = geminidataanalytics.GetDataAgentRequest(
name=data_agent_client.data_agent_path(
billing_project, location, data_agent_id)
)
response = data_agent_client.get_data_agent(request=request)
print(response)
Os metadados vão aparecer no novo agente. Isso inclui o horário de criação e o contexto do agente em instruções do sistema e fontes de dados.
5. Criar uma conversa
Agora você já pode criar sua primeira conversa! Neste codelab, você vai usar uma referência de conversa para um chat com estado com seu agente.
Para referência, a API CA oferece várias maneiras de conversar com diferentes opções de gerenciamento de estado e agente. Confira um breve resumo das três abordagens:
Estado | Histórico de conversas | Agente | Código | Descrição | |
Conversar usando uma referência de conversa | Com estado | API gerenciada | Sim | Continua uma conversa com estado enviando uma mensagem de chat que faz referência a uma conversa e ao contexto do agente associado. Para conversas com várias interações, o Google Cloud armazena e gerencia o histórico da conversa. | |
Usar uma referência de agente de dados para conversar | Sem estado | Gerenciado pelo usuário | Sim | Envia uma mensagem de chat sem estado que faz referência a um agente de dados salvo para contexto. Para conversas com várias interações, o aplicativo precisa gerenciar e fornecer o histórico da conversa com cada solicitação. | |
Conversar usando contexto inline | Sem estado | Gerenciado pelo usuário | Não | Envia uma mensagem de chat sem estado fornecendo todo o contexto diretamente na solicitação, sem usar um agente de dados salvo. Para conversas com várias interações, o aplicativo precisa gerenciar e fornecer o histórico da conversa com cada solicitação. |
Você vai criar uma função para configurar sua conversa e fornecer um ID exclusivo para ela:
def setup_conversation(conversation_id: str):
data_chat_client = geminidataanalytics.DataChatServiceClient()
conversation = geminidataanalytics.Conversation(
agents=[data_chat_client.data_agent_path(
billing_project, location, data_agent_id)],
)
request = geminidataanalytics.CreateConversationRequest(
parent=f"projects/{billing_project}/locations/{location}",
conversation_id=conversation_id,
conversation=conversation,
)
try:
data_chat_client.get_conversation(name=data_chat_client.conversation_path(
billing_project, location, conversation_id))
print(f"Conversation '{conversation_id}' already exists.")
except Exception:
response = data_chat_client.create_conversation(request=request)
print("Conversation created successfully:")
print(response)
conversation_id = "my_first_conversation"
setup_conversation(conversation_id=conversation_id)
Você vai receber uma mensagem informando que a conversa foi criada.
6. Adicionar funções utilitárias
Está quase tudo pronto para você começar a conversar com o representante. Antes disso, vamos adicionar algumas funções utilitárias para ajudar a formatar as mensagens de modo que seja mais fácil ler e renderizar as visualizações. A API CA vai enviar uma especificação vega que pode ser representada usando o pacote altair:
# Utility functions for streaming and formatting responses
import altair as alt
import http.server
import pandas as pd
import proto
import socketserver
import threading
_server_thread = None
_httpd = None
# Prints a formatted section title
def display_section_title(text):
print(f"\n--- {text.upper()} ---")
# Handles and displays data responses
def handle_data_response(resp):
if "query" in resp:
query = resp.query
display_section_title("Retrieval query")
print(f"Query name: {query.name}")
print(f"Question: {query.question}")
print("Data sources:")
for datasource in query.datasources:
display_datasource(datasource)
elif "generated_sql" in resp:
display_section_title("SQL generated")
print(resp.generated_sql)
elif "result" in resp:
display_section_title("Data retrieved")
fields = [field.name for field in resp.result.schema.fields]
d = {field: [] for field in fields}
for el in resp.result.data:
for field in fields:
d[field].append(el[field])
print(pd.DataFrame(d))
# Starts a local web server to preview charts
def preview_in_browser(port: int = 8080):
"""Starts a web server in a background thread and waits for user to stop it."""
global _server_thread, _httpd
if _server_thread and _server_thread.is_alive():
print(
f"\n--> A new chart was generated. Refresh your browser at http://localhost:{port}")
return
Handler = http.server.SimpleHTTPRequestHandler
socketserver.TCPServer.allow_reuse_address = True
try:
_httpd = socketserver.TCPServer(("", port), Handler)
except OSError as e:
print(f"❌ Could not start server on port {port}: {e}")
return
_server_thread = threading.Thread(target=_httpd.serve_forever)
_server_thread.daemon = False
_server_thread.start()
print("\n" + "=" * 60)
print(" 📈 CHART READY - PREVIEW IN BROWSER ".center(60))
print("=" * 60)
print(
f"1. In the Cloud Shell toolbar, click 'Web Preview' and select port {port}.")
print(f"2. Or, open your local browser to http://localhost:{port}")
print("=" * 60)
try:
input(
"\n--> Press Enter here after viewing all charts to shut down the server...\n\n")
finally:
print("Shutting down server...")
_httpd.shutdown()
_server_thread.join()
_httpd, _server_thread = None, None
print("Server stopped.")
# Handles chart responses
def handle_chart_response(resp, chart_generated_flag: list):
def _value_to_dict(v):
if isinstance(v, proto.marshal.collections.maps.MapComposite):
return {k: _value_to_dict(v[k]) for k in v}
elif isinstance(v, proto.marshal.collections.RepeatedComposite):
return [_value_to_dict(el) for el in v]
return v
if "query" in resp:
print(resp.query.instructions)
elif "result" in resp:
vega_config_dict = _value_to_dict(resp.result.vega_config)
chart = alt.Chart.from_dict(vega_config_dict)
chart_filename = "index.html"
chart.save(chart_filename)
if chart_generated_flag:
chart_generated_flag[0] = True
# Displays the schema of a data source
def display_schema(data):
fields = getattr(data, "fields")
df = pd.DataFrame({
"Column": [f.name for f in fields],
"Type": [f.type for f in fields],
"Description": [getattr(f, "description", "-") for f in fields],
"Mode": [f.mode for f in fields],
})
print(df)
# Displays information about a BigQuery data source
def display_datasource(datasource):
table_ref = datasource.bigquery_table_reference
source_name = f"{table_ref.project_id}.{table_ref.dataset_id}.{table_ref.table_id}"
print(source_name)
display_schema(datasource.schema)
# Handles and displays schema resolution responses
def handle_schema_response(resp):
if "query" in resp:
print(resp.query.question)
elif "result" in resp:
display_section_title("Schema resolved")
print("Data sources:")
for datasource in resp.result.datasources:
display_datasource(datasource)
# Handles and prints simple text responses
def handle_text_response(resp):
parts = resp.parts
print("".join(parts))
# Processes and displays different types of system messages
def show_message(msg, chart_generated_flag: list):
m = msg.system_message
if "text" in m:
handle_text_response(getattr(m, "text"))
elif "schema" in m:
handle_schema_response(getattr(m, "schema"))
elif "data" in m:
handle_data_response(getattr(m, "data"))
elif "chart" in m:
handle_chart_response(getattr(m, "chart"), chart_generated_flag)
print("\n")
7. Criar uma função de chat
A etapa final é criar uma função de chat que pode ser reutilizada e chamar a função "show_message" para cada parte no fluxo de resposta:
def stream_chat_response(question: str):
"""
Sends a chat request, processes the streaming response, and if a chart
was generated, starts the preview server and waits for it to be closed.
"""
data_chat_client = geminidataanalytics.DataChatServiceClient()
chart_generated_flag = [False]
messages = [
geminidataanalytics.Message(
user_message=geminidataanalytics.UserMessage(text=question)
)
]
conversation_reference = geminidataanalytics.ConversationReference(
conversation=data_chat_client.conversation_path(
billing_project, location, conversation_id
),
data_agent_context=geminidataanalytics.DataAgentContext(
data_agent=data_chat_client.data_agent_path(
billing_project, location, data_agent_id
),
),
)
request = geminidataanalytics.ChatRequest(
parent=f"projects/{billing_project}/locations/{location}",
messages=messages,
conversation_reference=conversation_reference,
)
stream = data_chat_client.chat(request=request)
for response in stream:
show_message(response, chart_generated_flag)
if chart_generated_flag[0]:
preview_in_browser()
A função stream_chat_response agora está definida e pronta para ser usada com seus comandos.
8. Começar a conversar
Pergunta 1
Agora você já pode começar a fazer perguntas. Vamos ver o que esse agente pode fazer para começar:
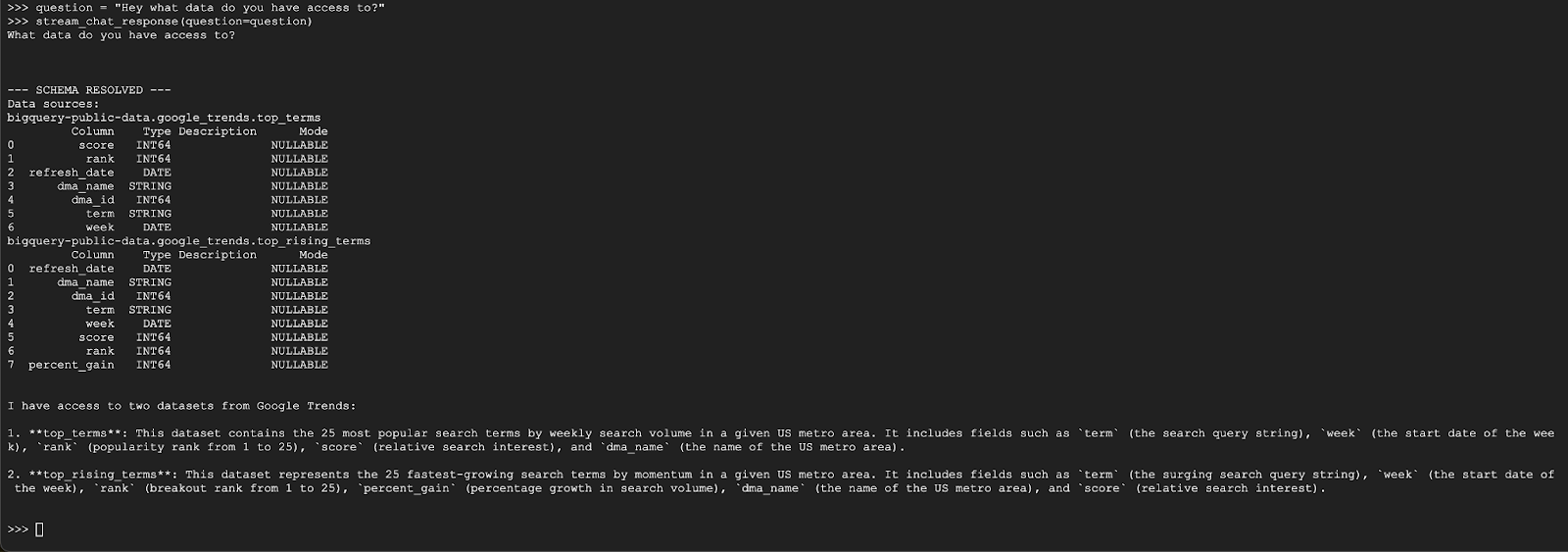
question = "Hey what data do you have access to?"
stream_chat_response(question=question)
O agente deve responder com algo semelhante a isto:
Pergunta 2
Ótimo, vamos tentar encontrar mais informações sobre os termos de pesquisa mais recentes:
question = "What are the top 20 most popular search terms last week in NYC based on rank? Display each term and score as a column chart"
stream_chat_response(question=question)
Isso vai levar algum tempo. O agente vai executar várias etapas e transmitir atualizações, desde a recuperação do esquema e dos metadados, a gravação da consulta SQL, a obtenção dos resultados, a especificação das instruções de visualização e o resumo dos resultados.
Para ver o gráfico, acesse a barra de ferramentas do Cloud Shell, clique em "Visualização da Web" e selecione a porta 8080:
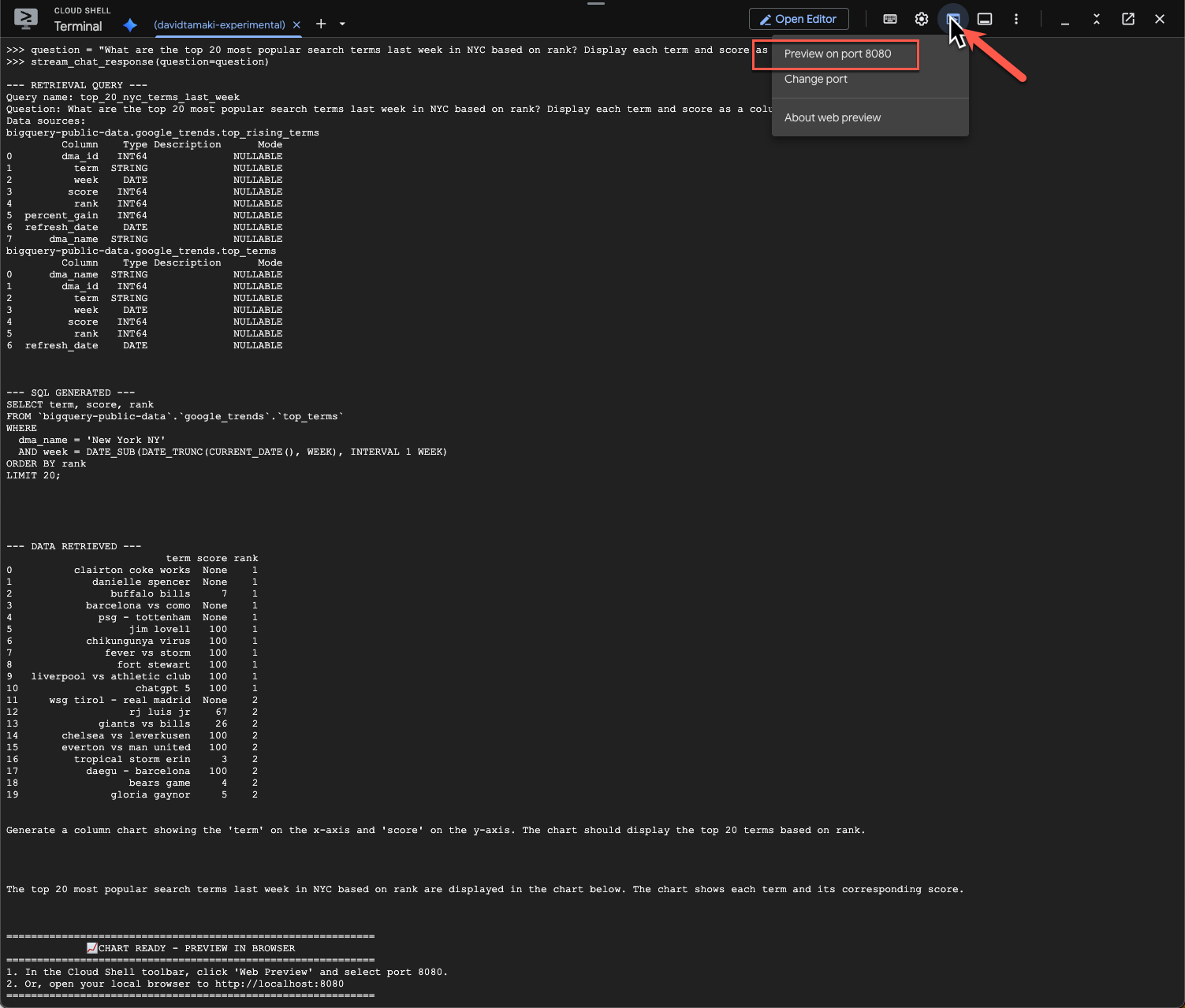
Você vai ver uma renderização da visualização assim:
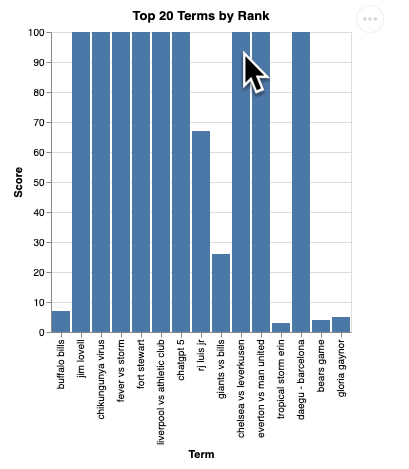
Pressione "Enter" para desligar o servidor e continuar.
Pergunta 3
Vamos tentar uma pergunta complementar e nos aprofundar nesses resultados:
question = "What was the percent gain in growth for these search terms from the week before?"
stream_chat_response(question=question)
Você vai ver algo parecido com isso. Nesse caso, o agente gerou uma consulta para unir as duas tabelas e encontrar o ganho percentual. Sua consulta pode ser um pouco diferente:
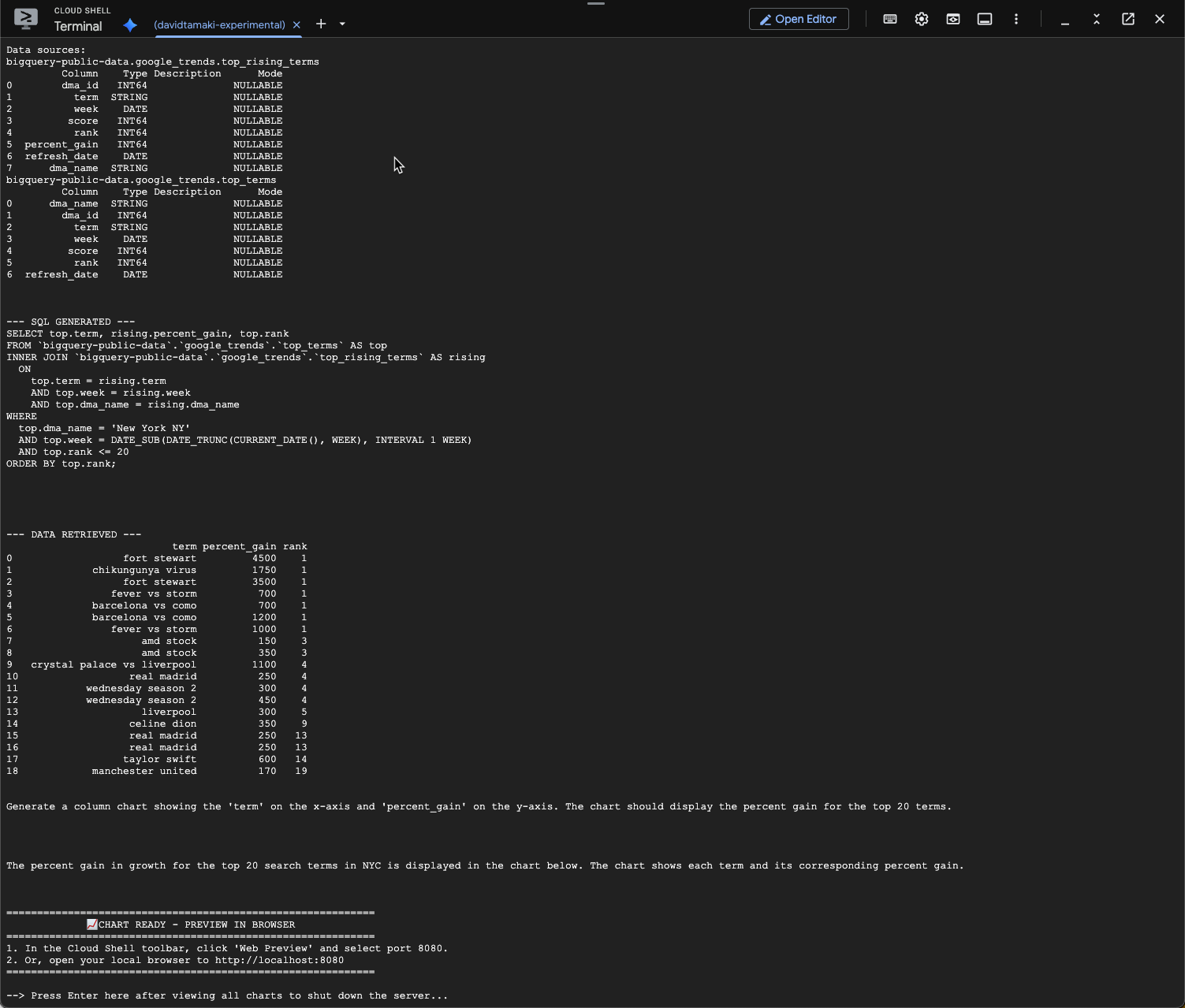
E visualizado, ele vai ficar assim:
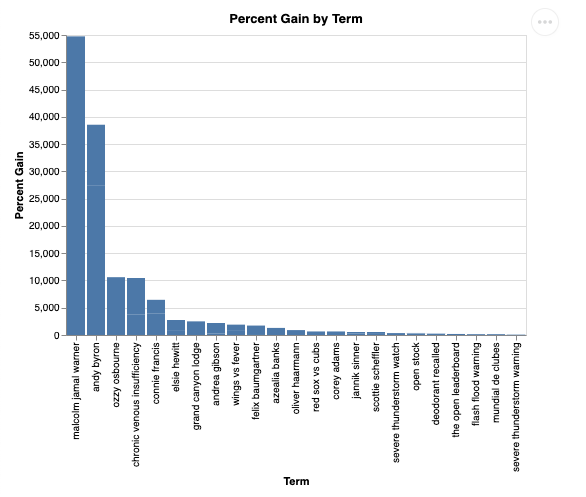
9. Limpeza
Como este codelab não envolve produtos de longa duração, basta interromper a sessão ativa do Python inserindo exit() no terminal.
Excluir pastas e arquivos do projeto
Se você quiser remover o código do seu ambiente do Cloud Shell, use os seguintes comandos:
cd ~
rm -rf ca-api-codelab
Desativar APIs
Para desativar as APIs ativadas anteriormente, execute este comando:
gcloud services disable geminidataanalytics.googleapis.com
gcloud services disable cloudaicompanion.googleapis.com
gcloud services disable bigquery.googleapis.com
10. Conclusão
Parabéns! Você criou um agente de análise de conversas simples usando o SDK do CA. Confira os materiais de referência para saber mais.