
1. Введение
В этом практическом занятии вы научитесь использовать Python SDK для API Conversational Analytics (CA) с источником данных BigQuery. Вы узнаете, как создать нового агента, как использовать управление состоянием диалога, а также как отправлять и передавать ответы из API.
Предварительные требования
- Базовое понимание Google Cloud и консоли Google Cloud.
- Базовые навыки работы с командной строкой и Cloud Shell.
- Базовые навыки программирования на Python.
Что вы узнаете
- Как использовать Python SDK для API анализа разговоров с источником данных BigQuery
- Как создать нового агента с помощью API CA
- Как использовать управление состоянием диалога
- Как отправлять и передавать ответы от API
Что вам понадобится
- Аккаунт Google Cloud и проект Google Cloud
- Веб-браузер, например Chrome.
2. Настройка и требования
Выберите проект
- Войдите в консоль Google Cloud и создайте новый проект или используйте существующий. Если у вас еще нет учетной записи Gmail или Google Workspace, вам необходимо ее создать .

- Название проекта — это отображаемое имя участников данного проекта. Это строка символов, не используемая API Google. Вы всегда можете его изменить.
- Идентификатор проекта уникален для всех проектов Google Cloud и является неизменяемым (его нельзя изменить после установки). Консоль Cloud автоматически генерирует уникальную строку; обычно вам неважно, какая она. В большинстве практических заданий вам потребуется указать идентификатор вашего проекта (обычно обозначается как
PROJECT_ID). Если сгенерированный идентификатор вас не устраивает, вы можете сгенерировать другой случайный идентификатор. В качестве альтернативы вы можете попробовать свой собственный и посмотреть, доступен ли он. После этого шага его нельзя изменить, и он сохраняется на протяжении всего проекта. - К вашему сведению, существует третье значение — номер проекта , которое используется некоторыми API. Подробнее обо всех трех значениях можно узнать в документации .
- Далее вам потребуется включить оплату в консоли Cloud для использования ресурсов/API Cloud. Выполнение этого практического задания не потребует больших затрат, если вообще потребует. Чтобы отключить ресурсы и избежать дополнительных расходов после завершения этого урока, вы можете удалить созданные ресурсы или удалить проект. Новые пользователи Google Cloud имеют право на бесплатную пробную версию стоимостью 300 долларов США .
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
В консоли Google Cloud нажмите на значок Cloud Shell на панели инструментов в правом верхнем углу:
Подготовка и подключение к среде займут всего несколько минут. После завершения вы должны увидеть что-то подобное:

Эта виртуальная машина содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Вся работа в этом практическом задании может выполняться в браузере. Вам не нужно ничего устанавливать.
3. Прежде чем начать
Включите необходимые API.
Для использования сервисов Google Cloud необходимо сначала активировать соответствующие API для вашего проекта. В этом практическом задании вы будете использовать следующие сервисы Google Cloud:
- API для анализа данных с помощью Gemini
- Gemini для Google Cloud
- API BigQuery
Для включения этих служб выполните следующие команды в терминале Cloud Shell:
gcloud services enable geminidataanalytics.googleapis.com
gcloud services enable cloudaicompanion.googleapis.com
gcloud services enable bigquery.googleapis.com
Установите пакеты Python.
Перед началом любого проекта на Python рекомендуется создать виртуальное окружение. Это изолирует зависимости проекта, предотвращая конфликты с другими проектами или глобальными пакетами Python в системе. В этом разделе вы установите uv из pip, поскольку в Cloud Shell pip уже доступен.
Установить UV-пакет
pip install uv
Проверьте правильность установки UV-модуля.
uv --version
Ожидаемый результат
Если вы видите строку вывода с uv, вы можете перейти к следующему шагу. Обратите внимание, что номер версии может отличаться:

Создайте виртуальную среду и установите пакеты.
uv init ca-api-codelab
cd ca-api-codelab
uv venv --python 3.12
uv add google-cloud-geminidataanalytics pandas altair
uv pip list | grep -E 'altair|pandas|google-cloud-geminidataanalytics'
Ожидаемый результат
Если вы видите строки вывода с указанием всех трех пакетов, вы можете перейти к следующему шагу. Обратите внимание, что номера версий могут отличаться:

Запуск Python
uv run python
На вашем экране должно выглядеть примерно так:

4. Создайте агента.
Теперь, когда ваша среда разработки настроена и готова, пришло время заложить основу для API Gemini Data Analytics. SDK упрощает этот процесс, требуя всего нескольких основных настроек для создания вашего агента.
Задайте переменные
Импортируйте пакет geminidataanalytics и установите переменные среды:
import os
from google.cloud import geminidataanalytics
data_agent_client = geminidataanalytics.DataAgentServiceClient()
location = "global"
billing_project = os.environ.get('DEVSHELL_PROJECT_ID')
data_agent_id = "google_trends_analytics_agent"
Установите системные инструкции для агента.
API центра сертификации считывает метаданные BigQuery, чтобы получить дополнительную информацию о таблицах и столбцах, на которые имеются ссылки. Поскольку этот общедоступный набор данных не содержит описаний столбцов, вы можете предоставить агенту дополнительную информацию в виде строки в формате YAML. Рекомендации и шаблон для использования см. в документации :
system_instruction = """
system_instruction:
- You are a data analyst specializing in the Google Trends dataset.
- When querying, always use the 'week' column for date-based filtering. This needs to be a Sunday. If you are doing week over week comparison, make sure you specify a date that is a Sunday.
- The following columns should be ignored in all queries 'dma_id', 'refresh_date'
- The 'dma_name' column represents the city and state for about 210 metro areas in the USA.
tables:
top_terms:
description: "Represents the 25 most popular search terms by weekly search volume in a given US metro area (DMA)."
fields:
term: "The search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's popularity rank from 1 (most popular) to 25."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
dma_name: "The name of the US metro area, e.g., 'New York NY'."
top_rising_terms:
description: "Represents the 25 fastest-growing ('breakout') search terms by momentum in a given US metro area (DMA)."
fields:
term: "The surging search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's breakout rank from 1 (top rising) to 25."
percent_gain: "The percentage growth in search volume compared to the previous period."
dma_name: "The name of the US metro area, e.g., 'Los Angeles CA'."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
join_instructions:
goal: "Find terms that are simultaneously popular and rising in the same week and metro area."
method: "INNER JOIN the two tables on their common keys."
keys:
- "term"
- "week"
- "dma_name"
golden_queries:
- natural_language_query: "Find all terms in the 'New York NY' area that were in both the top 25 and top 25 rising lists for the week of July 6th, 2025, and show their ranks and percent gain."
sql_query: |
SELECT
top.term,
top.rank AS top_25_rank,
rising.rank AS rising_25_rank,
rising.percent_gain
FROM
`bigquery-public-data.google_trends.top_terms` AS top
INNER JOIN
`bigquery-public-data.google_trends.top_rising_terms` AS rising
ON
top.term = rising.term
AND top.week = rising.week
AND top.dma_name = rising.dma_name
WHERE
top.week = '2025-07-06'
AND top.dma_name = 'New York NY'
ORDER BY
top.rank;
"""
Настройка источников данных для таблиц BigQuery
Теперь вы можете настроить источники данных для таблиц BigQuery. API CA принимает таблицы BigQuery в виде массива:
# BigQuery table data sources
bq_top = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_terms"
)
bq_rising = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_rising_terms"
)
datasource_references = geminidataanalytics.DatasourceReferences(
bq=geminidataanalytics.BigQueryTableReferences(table_references=[bq_top, bq_rising]))
Задайте контекст для чата с сохранением состояния.
Вы можете создать нового агента с опубликованным контекстом , который объединяет системные инструкции, ссылки на источники данных и любые другие параметры .
Обратите внимание, что у вас есть возможность создать stagingContext для тестирования и проверки изменений перед публикацией. Это позволяет разработчику добавить версионирование в агент данных, указав contextVersion в запросе чата. В этом практическом задании вы просто опубликуете изменения напрямую:
# Context setup for stateful chat
published_context = geminidataanalytics.Context(
system_instruction=system_instruction,
datasource_references=datasource_references,
options=geminidataanalytics.ConversationOptions(
analysis=geminidataanalytics.AnalysisOptions(
python=geminidataanalytics.AnalysisOptions.Python(
enabled=False
)
)
),
)
data_agent = geminidataanalytics.DataAgent(
data_analytics_agent=geminidataanalytics.DataAnalyticsAgent(
published_context=published_context
),
)
# Create the agent
data_agent_client.create_data_agent(request=geminidataanalytics.CreateDataAgentRequest(
parent=f"projects/{billing_project}/locations/{location}",
data_agent_id=data_agent_id,
data_agent=data_agent,
))
После создания агента вы должны увидеть результат, похожий на приведенный ниже:

Найдите агента
Давайте проверим агента, чтобы убедиться, что он создан:
# Test the agent
request = geminidataanalytics.GetDataAgentRequest(
name=data_agent_client.data_agent_path(
billing_project, location, data_agent_id)
)
response = data_agent_client.get_data_agent(request=request)
print(response)
Вы должны увидеть метаданные вашего нового агента. Они будут включать в себя такие данные, как время создания, контекст агента, системные инструкции и источники данных.
5. Начните разговор
Теперь вы готовы создать свой первый диалог! Для этого практического занятия вы будете использовать пример диалога для чата с сохранением состояния с вашим агентом.
Для справки, API CA предлагает различные способы взаимодействия с различными вариантами управления состоянием и агентами. Вот краткое описание 3 подходов:
Состояние | История разговоров | Агент | Код | Описание | |
Общайтесь, используя ссылку на диалог. | Состояние | API управляется | Да | Продолжает диалог с сохранением состояния, отправляя сообщение в чате, которое ссылается на существующий диалог и связанный с ним контекст агента. Для многоэтапных диалогов Google Cloud хранит и управляет историей разговоров. | |
Общайтесь, используя справочную информацию об агенте данных. | Лица без гражданства | Управление пользователем | Да | Отправляет сообщение чата без сохранения состояния, которое ссылается на сохраненные данные агента для контекста. Для многоходовых диалогов ваше приложение должно управлять историей разговора и предоставлять ее с каждым запросом. | |
Общение с использованием контекстного ввода | Лица без гражданства | Управление пользователем | Нет | Отправляет сообщение чата без сохранения состояния, предоставляя весь контекст непосредственно в запросе, без использования агента сохранения данных. Для многоходовых диалогов ваше приложение должно управлять историей разговора и предоставлять её с каждым запросом. |
Вам потребуется создать функцию для настройки диалога и присвоения ему уникального идентификатора:
def setup_conversation(conversation_id: str):
data_chat_client = geminidataanalytics.DataChatServiceClient()
conversation = geminidataanalytics.Conversation(
agents=[data_chat_client.data_agent_path(
billing_project, location, data_agent_id)],
)
request = geminidataanalytics.CreateConversationRequest(
parent=f"projects/{billing_project}/locations/{location}",
conversation_id=conversation_id,
conversation=conversation,
)
try:
data_chat_client.get_conversation(name=data_chat_client.conversation_path(
billing_project, location, conversation_id))
print(f"Conversation '{conversation_id}' already exists.")
except Exception:
response = data_chat_client.create_conversation(request=request)
print("Conversation created successfully:")
print(response)
conversation_id = "my_first_conversation"
setup_conversation(conversation_id=conversation_id)
Вы должны увидеть сообщение о том, что беседа успешно создана.
6. Добавить вспомогательные функции
Вы почти готовы начать общение с агентом. Прежде чем это сделать, давайте добавим несколько вспомогательных функций, которые помогут отформатировать сообщения для удобства чтения, а также отобразить визуализации. API CA отправит спецификацию веги , которую вы сможете построить с помощью пакета altair:
# Utility functions for streaming and formatting responses
import altair as alt
import http.server
import pandas as pd
import proto
import socketserver
import threading
_server_thread = None
_httpd = None
# Prints a formatted section title
def display_section_title(text):
print(f"\n--- {text.upper()} ---")
# Handles and displays data responses
def handle_data_response(resp):
if "query" in resp:
query = resp.query
display_section_title("Retrieval query")
print(f"Query name: {query.name}")
print(f"Question: {query.question}")
print("Data sources:")
for datasource in query.datasources:
display_datasource(datasource)
elif "generated_sql" in resp:
display_section_title("SQL generated")
print(resp.generated_sql)
elif "result" in resp:
display_section_title("Data retrieved")
fields = [field.name for field in resp.result.schema.fields]
d = {field: [] for field in fields}
for el in resp.result.data:
for field in fields:
d[field].append(el[field])
print(pd.DataFrame(d))
# Starts a local web server to preview charts
def preview_in_browser(port: int = 8080):
"""Starts a web server in a background thread and waits for user to stop it."""
global _server_thread, _httpd
if _server_thread and _server_thread.is_alive():
print(
f"\n--> A new chart was generated. Refresh your browser at http://localhost:{port}")
return
Handler = http.server.SimpleHTTPRequestHandler
socketserver.TCPServer.allow_reuse_address = True
try:
_httpd = socketserver.TCPServer(("", port), Handler)
except OSError as e:
print(f"❌ Could not start server on port {port}: {e}")
return
_server_thread = threading.Thread(target=_httpd.serve_forever)
_server_thread.daemon = False
_server_thread.start()
print("\n" + "=" * 60)
print(" 📈 CHART READY - PREVIEW IN BROWSER ".center(60))
print("=" * 60)
print(
f"1. In the Cloud Shell toolbar, click 'Web Preview' and select port {port}.")
print(f"2. Or, open your local browser to http://localhost:{port}")
print("=" * 60)
try:
input(
"\n--> Press Enter here after viewing all charts to shut down the server...\n\n")
finally:
print("Shutting down server...")
_httpd.shutdown()
_server_thread.join()
_httpd, _server_thread = None, None
print("Server stopped.")
# Handles chart responses
def handle_chart_response(resp, chart_generated_flag: list):
def _value_to_dict(v):
if isinstance(v, proto.marshal.collections.maps.MapComposite):
return {k: _value_to_dict(v[k]) for k in v}
elif isinstance(v, proto.marshal.collections.RepeatedComposite):
return [_value_to_dict(el) for el in v]
return v
if "query" in resp:
print(resp.query.instructions)
elif "result" in resp:
vega_config_dict = _value_to_dict(resp.result.vega_config)
chart = alt.Chart.from_dict(vega_config_dict)
chart_filename = "index.html"
chart.save(chart_filename)
if chart_generated_flag:
chart_generated_flag[0] = True
# Displays the schema of a data source
def display_schema(data):
fields = getattr(data, "fields")
df = pd.DataFrame({
"Column": [f.name for f in fields],
"Type": [f.type for f in fields],
"Description": [getattr(f, "description", "-") for f in fields],
"Mode": [f.mode for f in fields],
})
print(df)
# Displays information about a BigQuery data source
def display_datasource(datasource):
table_ref = datasource.bigquery_table_reference
source_name = f"{table_ref.project_id}.{table_ref.dataset_id}.{table_ref.table_id}"
print(source_name)
display_schema(datasource.schema)
# Handles and displays schema resolution responses
def handle_schema_response(resp):
if "query" in resp:
print(resp.query.question)
elif "result" in resp:
display_section_title("Schema resolved")
print("Data sources:")
for datasource in resp.result.datasources:
display_datasource(datasource)
# Handles and prints simple text responses
def handle_text_response(resp):
parts = resp.parts
print("".join(parts))
# Processes and displays different types of system messages
def show_message(msg, chart_generated_flag: list):
m = msg.system_message
if "text" in m:
handle_text_response(getattr(m, "text"))
elif "schema" in m:
handle_schema_response(getattr(m, "schema"))
elif "data" in m:
handle_data_response(getattr(m, "data"))
elif "chart" in m:
handle_chart_response(getattr(m, "chart"), chart_generated_flag)
print("\n")
7. Создайте функцию чата.
Последний шаг — создание функции чата, которую можно повторно использовать и вызывать функцию show_message для каждого фрагмента в потоке ответов:
def stream_chat_response(question: str):
"""
Sends a chat request, processes the streaming response, and if a chart
was generated, starts the preview server and waits for it to be closed.
"""
data_chat_client = geminidataanalytics.DataChatServiceClient()
chart_generated_flag = [False]
messages = [
geminidataanalytics.Message(
user_message=geminidataanalytics.UserMessage(text=question)
)
]
conversation_reference = geminidataanalytics.ConversationReference(
conversation=data_chat_client.conversation_path(
billing_project, location, conversation_id
),
data_agent_context=geminidataanalytics.DataAgentContext(
data_agent=data_chat_client.data_agent_path(
billing_project, location, data_agent_id
),
),
)
request = geminidataanalytics.ChatRequest(
parent=f"projects/{billing_project}/locations/{location}",
messages=messages,
conversation_reference=conversation_reference,
)
stream = data_chat_client.chat(request=request)
for response in stream:
show_message(response, chart_generated_flag)
if chart_generated_flag[0]:
preview_in_browser()
Функция stream_chat_response теперь определена и готова к использованию с вашими подсказками.
8. Начните общаться!
Вопрос 1
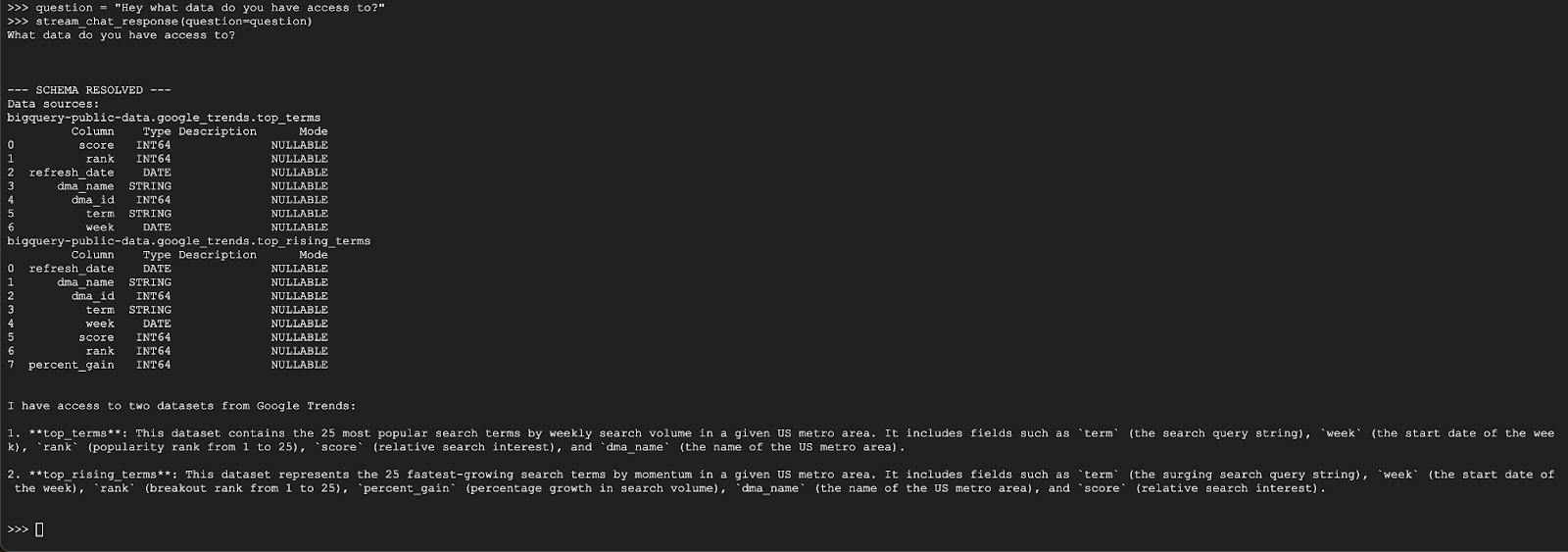
Теперь вы готовы начать задавать вопросы! Давайте для начала посмотрим, что может сделать этот агент:
question = "Hey what data do you have access to?"
stream_chat_response(question=question)
Агент должен ответить примерно так, как показано ниже:
Вопрос 2
Отлично, давайте попробуем найти больше информации о самых популярных поисковых запросах:
question = "What are the top 20 most popular search terms last week in NYC based on rank? Display each term and score as a column chart"
stream_chat_response(question=question)
Выполнение этого процесса займет некоторое время. Вы увидите, как агент проходит различные этапы и обновляет данные, начиная с получения схемы и метаданных, написания SQL-запроса, получения результатов, указания инструкций по визуализации и заканчивая подведением итогов.
Чтобы просмотреть диаграмму, перейдите на панель инструментов Cloud Shell, нажмите «Предварительный просмотр в веб-браузере» и выберите порт 8080:
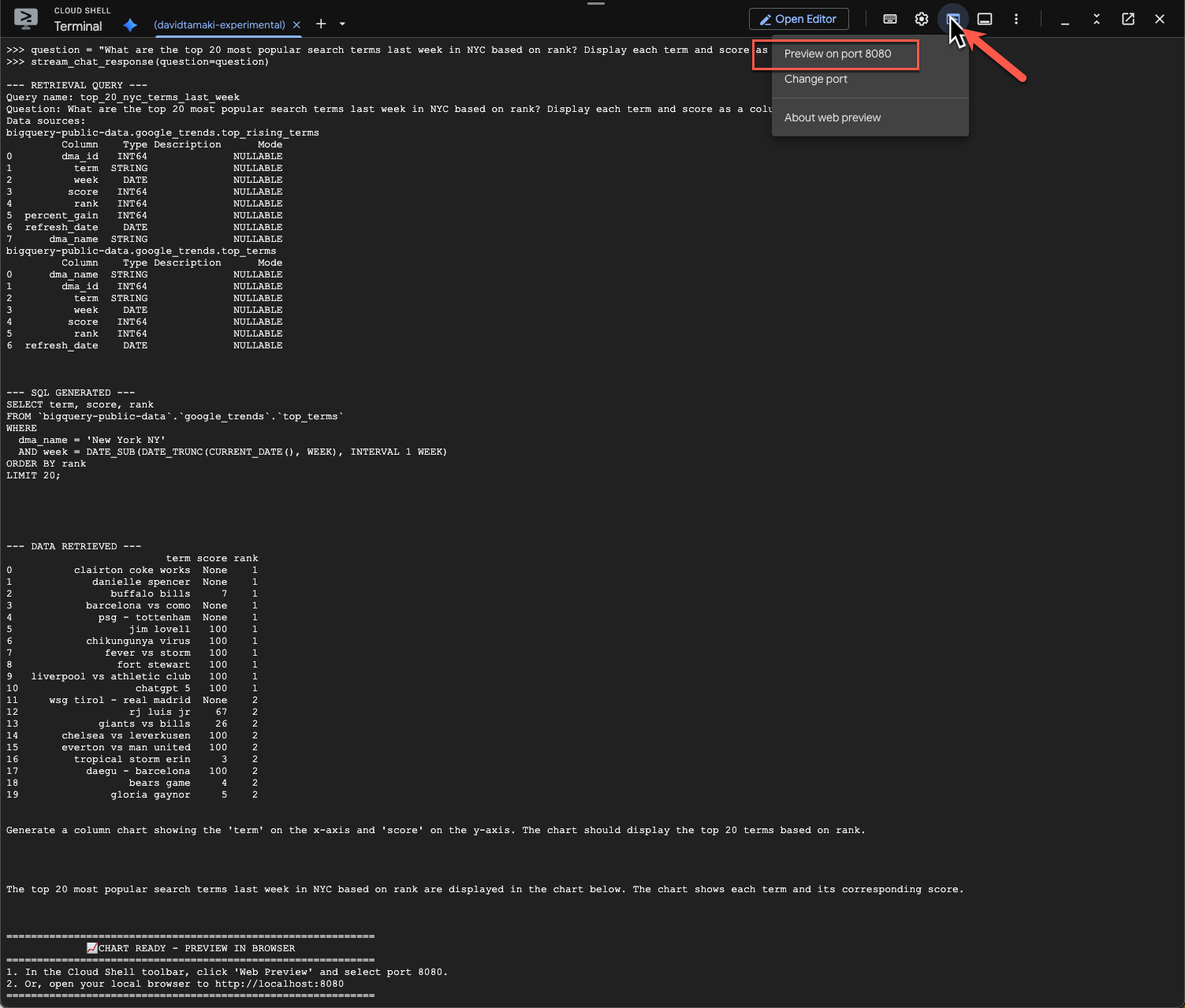
Вы должны увидеть визуализацию примерно такого вида:
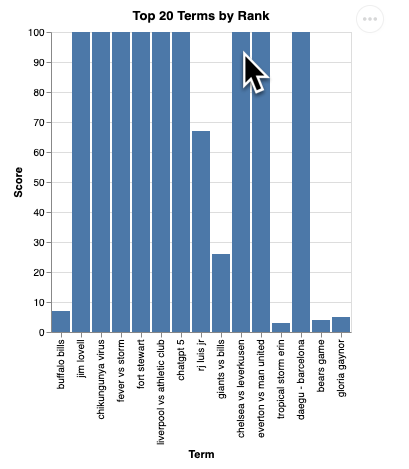
Нажмите Enter, чтобы выключить сервер и продолжить.
Вопрос 3
Давайте зададим дополнительный вопрос и углубимся в анализ полученных результатов:
question = "What was the percent gain in growth for these search terms from the week before?"
stream_chat_response(question=question)
Вы должны увидеть что-то похожее на приведенное ниже. В данном случае агент сгенерировал запрос для объединения двух таблиц, чтобы найти процентный прирост. Обратите внимание, что ваш запрос может выглядеть немного иначе:
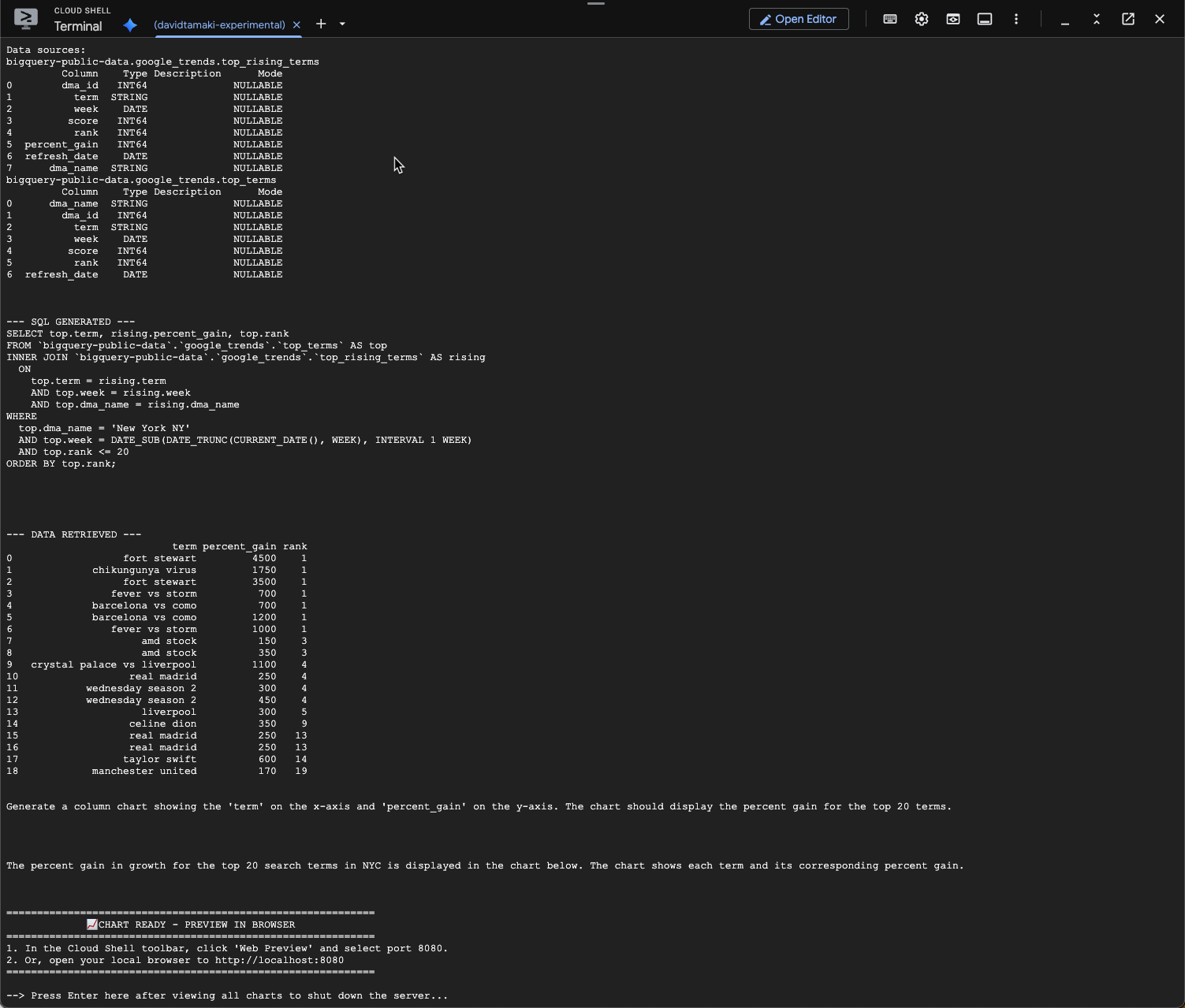
Визуально это будет выглядеть так:
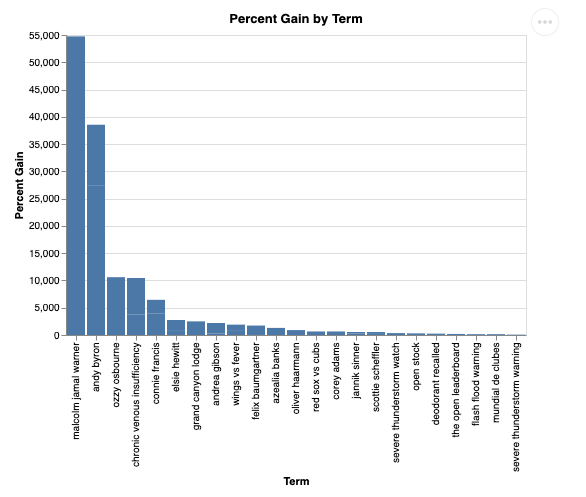
9. Уборка
Поскольку в этом практическом задании не используются длительно работающие программы, достаточно просто остановить активную сессию Python, введя exit() в терминале.
Удалите папки и файлы проекта.
Чтобы удалить код из среды Cloud Shell, используйте следующие команды:
cd ~
rm -rf ca-api-codelab
Отключить API
Чтобы отключить ранее включенные API, выполните эту команду.
gcloud services disable geminidataanalytics.googleapis.com
gcloud services disable cloudaicompanion.googleapis.com
gcloud services disable bigquery.googleapis.com
10. Заключение
Поздравляем, вы успешно создали простой агент анализа диалогов с помощью CA SDK. Для получения более подробной информации ознакомьтесь с справочными материалами!