
1. Giới thiệu
Trong lớp học lập trình này, bạn sẽ tìm hiểu cách sử dụng SDK Python API Phân tích đàm thoại (CA) với một nguồn dữ liệu BigQuery. Bạn sẽ tìm hiểu cách tạo một tác nhân mới, cách tận dụng tính năng quản lý trạng thái cuộc trò chuyện, cũng như cách gửi và truyền trực tuyến các phản hồi từ API.
Điều kiện tiên quyết
- Hiểu biết cơ bản về Google Cloud và bảng điều khiển Cloud
- Kỹ năng cơ bản về giao diện dòng lệnh và Cloud Shell
- Có kiến thức cơ bản về lập trình Python
Kiến thức bạn sẽ học được
- Cách sử dụng SDK Python của API Phân tích đàm thoại với nguồn dữ liệu BigQuery
- Cách tạo một nhân viên hỗ trợ mới bằng API CA
- Cách tận dụng tính năng quản lý trạng thái cuộc trò chuyện
- Cách gửi và truyền trực tuyến các phản hồi từ API
Bạn cần có
- Tài khoản Google Cloud và dự án trên Google Cloud
- Một trình duyệt web như Chrome
2. Thiết lập và yêu cầu
Chọn một dự án
- Đăng nhập vào Google Cloud Console rồi tạo một dự án mới hoặc sử dụng lại một dự án hiện có. Nếu chưa có tài khoản Gmail hoặc Google Workspace, bạn phải tạo một tài khoản.

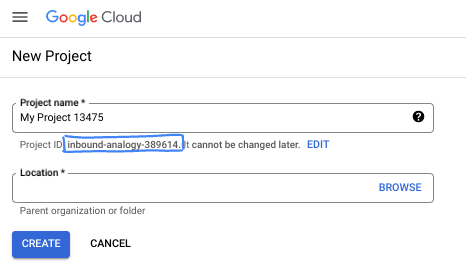
- Tên dự án là tên hiển thị của những người tham gia dự án này. Đây là một chuỗi ký tự mà các API của Google không sử dụng. Bạn luôn có thể cập nhật thông tin này.
- Mã dự án là mã duy nhất trên tất cả các dự án trên Google Cloud và không thể thay đổi (bạn không thể thay đổi mã này sau khi đã đặt). Cloud Console sẽ tự động tạo một chuỗi duy nhất; thường thì bạn không cần quan tâm đến chuỗi này. Trong hầu hết các lớp học lập trình, bạn sẽ cần tham chiếu đến Mã dự án (thường được xác định là
PROJECT_ID). Nếu không thích mã nhận dạng được tạo, bạn có thể tạo một mã nhận dạng ngẫu nhiên khác. Hoặc bạn có thể thử tên người dùng của riêng mình để xem tên đó có được chấp nhận hay không. Bạn không thể thay đổi tên này sau bước này và tên này sẽ tồn tại trong suốt thời gian của dự án. - Để bạn nắm được thông tin, có một giá trị thứ ba là Số dự án mà một số API sử dụng. Tìm hiểu thêm về cả 3 giá trị này trong tài liệu.
- Tiếp theo, bạn cần bật tính năng thanh toán trong Cloud Console để sử dụng các tài nguyên/API trên đám mây. Việc thực hiện lớp học lập trình này sẽ không tốn nhiều chi phí, nếu có. Để tắt các tài nguyên nhằm tránh bị tính phí ngoài phạm vi hướng dẫn này, bạn có thể xoá các tài nguyên đã tạo hoặc xoá dự án. Người dùng mới của Google Cloud đủ điều kiện tham gia chương trình Dùng thử miễn phí trị giá 300 USD.
Khởi động Cloud Shell
Mặc dù có thể vận hành Google Cloud từ xa trên máy tính xách tay, nhưng trong lớp học lập trình này, bạn sẽ sử dụng Google Cloud Shell, một môi trường dòng lệnh chạy trên Cloud.
Trên Bảng điều khiển Google Cloud, hãy nhấp vào biểu tượng Cloud Shell trên thanh công cụ ở trên cùng bên phải:
Quá trình này chỉ mất vài phút để cung cấp và kết nối với môi trường. Khi quá trình này kết thúc, bạn sẽ thấy như sau:

Máy ảo này được trang bị tất cả các công cụ phát triển mà bạn cần. Nó cung cấp một thư mục chính có dung lượng 5 GB và chạy trên Google Cloud, giúp tăng cường đáng kể hiệu suất mạng và hoạt động xác thực. Bạn có thể thực hiện mọi thao tác trong lớp học lập trình này trong trình duyệt. Bạn không cần cài đặt bất cứ thứ gì.
3. Trước khi bắt đầu
Bật các API bắt buộc
Để sử dụng các dịch vụ của Google Cloud, trước tiên, bạn phải kích hoạt các API tương ứng cho dự án của mình. Bạn sẽ sử dụng các dịch vụ sau đây của Google Cloud trong lớp học lập trình này:
- Data Analytics API với Gemini
- Gemini cho Google Cloud
- API BigQuery
Để bật các dịch vụ này, hãy chạy các lệnh sau trong thiết bị đầu cuối Cloud Shell:
gcloud services enable geminidataanalytics.googleapis.com
gcloud services enable cloudaicompanion.googleapis.com
gcloud services enable bigquery.googleapis.com
Cài đặt các gói Python
Trước khi bắt đầu bất kỳ dự án Python nào, bạn nên tạo một môi trường ảo. Điều này giúp tách biệt các phần phụ thuộc của dự án, ngăn chặn xung đột với các dự án khác hoặc các gói Python chung của hệ thống. Trong phần này, bạn sẽ cài đặt uv từ pip, vì Cloud Shell đã có pip.
Cài đặt gói uv
pip install uv
Xác minh xem uv đã được cài đặt đúng cách hay chưa
uv --version
Kết quả đầu ra dự kiến
Nếu thấy một dòng đầu ra có uv, bạn có thể chuyển sang bước tiếp theo. Xin lưu ý rằng số phiên bản có thể khác nhau:

Tạo môi trường ảo và cài đặt các gói
uv init ca-api-codelab
cd ca-api-codelab
uv venv --python 3.12
uv add google-cloud-geminidataanalytics pandas altair
uv pip list | grep -E 'altair|pandas|google-cloud-geminidataanalytics'
Kết quả đầu ra dự kiến
Nếu thấy các dòng đầu ra có 3 gói, bạn có thể chuyển sang bước tiếp theo. Xin lưu ý rằng số phiên bản có thể khác nhau:

Start Python
uv run python
Màn hình của bạn sẽ có dạng như sau:

4. Tạo một nhân viên hỗ trợ
Giờ đây, khi môi trường phát triển của bạn đã được thiết lập và sẵn sàng, đã đến lúc đặt nền tảng cho Gemini Data Analytics API. SDK giúp đơn giản hoá quy trình này, chỉ yêu cầu một vài cấu hình thiết yếu để tạo tác nhân.
Đặt biến
Nhập gói geminidataanalytics và đặt các biến môi trường:
import os
from google.cloud import geminidataanalytics
data_agent_client = geminidataanalytics.DataAgentServiceClient()
location = "global"
billing_project = os.environ.get('DEVSHELL_PROJECT_ID')
data_agent_id = "google_trends_analytics_agent"
Đặt chỉ dẫn hệ thống cho trợ lý
CA API đọc siêu dữ liệu BigQuery để hiểu rõ hơn về ngữ cảnh của các bảng và cột đang được tham chiếu. Vì tập dữ liệu công khai này không có nội dung mô tả cột, nên bạn có thể cung cấp thêm ngữ cảnh cho tác nhân dưới dạng một chuỗi có định dạng YAML. Hãy tham khảo tài liệu để biết các phương pháp hay nhất và mẫu cần sử dụng:
system_instruction = """
system_instruction:
- You are a data analyst specializing in the Google Trends dataset.
- When querying, always use the 'week' column for date-based filtering. This needs to be a Sunday. If you are doing week over week comparison, make sure you specify a date that is a Sunday.
- The following columns should be ignored in all queries 'dma_id', 'refresh_date'
- The 'dma_name' column represents the city and state for about 210 metro areas in the USA.
tables:
top_terms:
description: "Represents the 25 most popular search terms by weekly search volume in a given US metro area (DMA)."
fields:
term: "The search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's popularity rank from 1 (most popular) to 25."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
dma_name: "The name of the US metro area, e.g., 'New York NY'."
top_rising_terms:
description: "Represents the 25 fastest-growing ('breakout') search terms by momentum in a given US metro area (DMA)."
fields:
term: "The surging search query string."
week: "The start date of the week (Sunday) for which the ranking is valid."
rank: "The term's breakout rank from 1 (top rising) to 25."
percent_gain: "The percentage growth in search volume compared to the previous period."
dma_name: "The name of the US metro area, e.g., 'Los Angeles CA'."
score: "Relative search interest, where 100 is the peak popularity for the term in that week."
join_instructions:
goal: "Find terms that are simultaneously popular and rising in the same week and metro area."
method: "INNER JOIN the two tables on their common keys."
keys:
- "term"
- "week"
- "dma_name"
golden_queries:
- natural_language_query: "Find all terms in the 'New York NY' area that were in both the top 25 and top 25 rising lists for the week of July 6th, 2025, and show their ranks and percent gain."
sql_query: |
SELECT
top.term,
top.rank AS top_25_rank,
rising.rank AS rising_25_rank,
rising.percent_gain
FROM
`bigquery-public-data.google_trends.top_terms` AS top
INNER JOIN
`bigquery-public-data.google_trends.top_rising_terms` AS rising
ON
top.term = rising.term
AND top.week = rising.week
AND top.dma_name = rising.dma_name
WHERE
top.week = '2025-07-06'
AND top.dma_name = 'New York NY'
ORDER BY
top.rank;
"""
Thiết lập nguồn dữ liệu Bảng BigQuery
Giờ đây, bạn có thể thiết lập nguồn dữ liệu bảng BigQuery. CA API chấp nhận các bảng BigQuery trong một mảng:
# BigQuery table data sources
bq_top = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_terms"
)
bq_rising = geminidataanalytics.BigQueryTableReference(
project_id="bigquery-public-data", dataset_id="google_trends", table_id="top_rising_terms"
)
datasource_references = geminidataanalytics.DatasourceReferences(
bq=geminidataanalytics.BigQueryTableReferences(table_references=[bq_top, bq_rising]))
Đặt bối cảnh cho cuộc trò chuyện có trạng thái
Bạn có thể tạo tác nhân mới bằng bối cảnh đã xuất bản. Bối cảnh này kết hợp các chỉ dẫn hệ thống, các tham chiếu nguồn dữ liệu và mọi lựa chọn khác.
Xin lưu ý rằng bạn có chức năng tạo stagingContext để kiểm thử và xác thực các thay đổi trước khi xuất bản. Điều này cho phép nhà phát triển thêm tính năng kiểm soát phiên bản vào một tác nhân dữ liệu bằng cách chỉ định contextVersion trong yêu cầu trò chuyện. Trong lớp học lập trình này, bạn sẽ chỉ xuất bản trực tiếp:
# Context setup for stateful chat
published_context = geminidataanalytics.Context(
system_instruction=system_instruction,
datasource_references=datasource_references,
options=geminidataanalytics.ConversationOptions(
analysis=geminidataanalytics.AnalysisOptions(
python=geminidataanalytics.AnalysisOptions.Python(
enabled=False
)
)
),
)
data_agent = geminidataanalytics.DataAgent(
data_analytics_agent=geminidataanalytics.DataAnalyticsAgent(
published_context=published_context
),
)
# Create the agent
data_agent_client.create_data_agent(request=geminidataanalytics.CreateDataAgentRequest(
parent=f"projects/{billing_project}/locations/{location}",
data_agent_id=data_agent_id,
data_agent=data_agent,
))
Sau khi tạo tác nhân, bạn sẽ thấy kết quả tương tự như bên dưới:

Nhận tác nhân
Hãy kiểm thử nhân viên hỗ trợ để đảm bảo nhân viên hỗ trợ đã được tạo:
# Test the agent
request = geminidataanalytics.GetDataAgentRequest(
name=data_agent_client.data_agent_path(
billing_project, location, data_agent_id)
)
response = data_agent_client.get_data_agent(request=request)
print(response)
Bạn sẽ thấy siêu dữ liệu trên nhân viên hỗ trợ mới. Thông tin này sẽ bao gồm những nội dung như thời gian tạo và ngữ cảnh của tác nhân trong các hướng dẫn và nguồn dữ liệu của hệ thống.
5. Tạo cuộc trò chuyện
Giờ đây, bạn đã sẵn sàng tạo cuộc trò chuyện đầu tiên! Trong lớp học lập trình này, bạn sẽ sử dụng một tham chiếu cuộc trò chuyện cho cuộc trò chuyện có trạng thái với trợ lý ảo.
Để tham khảo, CA API cung cấp nhiều cách để trò chuyện với các lựa chọn quản lý trạng thái và tác nhân khác nhau. Sau đây là nội dung tóm tắt ngắn gọn về 3 phương pháp này:
Trạng thái | Nhật ký trò chuyện | Tác nhân | Mã | Mô tả | |
Trò chuyện bằng cách sử dụng thông tin tham khảo trong cuộc trò chuyện | Lưu trạng thái | API được quản lý | Có | Tiếp tục một cuộc trò chuyện có trạng thái bằng cách gửi một tin nhắn trò chuyện tham chiếu đến một cuộc trò chuyện hiện có và ngữ cảnh tác nhân được liên kết. Đối với các cuộc trò chuyện nhiều lượt, Google Cloud sẽ lưu trữ và quản lý nhật ký trò chuyện. | |
Trò chuyện bằng cách sử dụng thông tin tham khảo về tác nhân dữ liệu | Không có trạng thái | Do người dùng quản lý | Có | Gửi một tin nhắn trò chuyện không trạng thái tham chiếu đến một tác nhân dữ liệu đã lưu để biết ngữ cảnh. Đối với các cuộc trò chuyện nhiều lượt, ứng dụng của bạn phải quản lý và cung cấp nhật ký trò chuyện trong mỗi yêu cầu. | |
Trò chuyện bằng cách sử dụng bối cảnh cùng dòng | Không có trạng thái | Do người dùng quản lý | Không | Gửi tin nhắn trò chuyện không trạng thái bằng cách cung cấp tất cả ngữ cảnh ngay trong yêu cầu mà không cần sử dụng tác nhân dữ liệu đã lưu. Đối với các cuộc trò chuyện nhiều lượt, ứng dụng của bạn phải quản lý và cung cấp nhật ký trò chuyện trong mỗi yêu cầu. |
Bạn sẽ tạo một hàm để thiết lập cuộc trò chuyện và cung cấp một mã nhận dạng duy nhất cho cuộc trò chuyện:
def setup_conversation(conversation_id: str):
data_chat_client = geminidataanalytics.DataChatServiceClient()
conversation = geminidataanalytics.Conversation(
agents=[data_chat_client.data_agent_path(
billing_project, location, data_agent_id)],
)
request = geminidataanalytics.CreateConversationRequest(
parent=f"projects/{billing_project}/locations/{location}",
conversation_id=conversation_id,
conversation=conversation,
)
try:
data_chat_client.get_conversation(name=data_chat_client.conversation_path(
billing_project, location, conversation_id))
print(f"Conversation '{conversation_id}' already exists.")
except Exception:
response = data_chat_client.create_conversation(request=request)
print("Conversation created successfully:")
print(response)
conversation_id = "my_first_conversation"
setup_conversation(conversation_id=conversation_id)
Bạn sẽ thấy một thông báo cho biết cuộc trò chuyện đã được tạo thành công.
6. Thêm các hàm tiện ích
Bạn sắp có thể bắt đầu trò chuyện với nhân viên hỗ trợ. Trước khi thực hiện, hãy thêm một số hàm tiện ích để giúp định dạng các thông báo sao cho dễ đọc hơn và cũng hiển thị các hình ảnh trực quan. CA API sẽ gửi một quy cách vega mà bạn có thể vẽ bằng gói altair:
# Utility functions for streaming and formatting responses
import altair as alt
import http.server
import pandas as pd
import proto
import socketserver
import threading
_server_thread = None
_httpd = None
# Prints a formatted section title
def display_section_title(text):
print(f"\n--- {text.upper()} ---")
# Handles and displays data responses
def handle_data_response(resp):
if "query" in resp:
query = resp.query
display_section_title("Retrieval query")
print(f"Query name: {query.name}")
print(f"Question: {query.question}")
print("Data sources:")
for datasource in query.datasources:
display_datasource(datasource)
elif "generated_sql" in resp:
display_section_title("SQL generated")
print(resp.generated_sql)
elif "result" in resp:
display_section_title("Data retrieved")
fields = [field.name for field in resp.result.schema.fields]
d = {field: [] for field in fields}
for el in resp.result.data:
for field in fields:
d[field].append(el[field])
print(pd.DataFrame(d))
# Starts a local web server to preview charts
def preview_in_browser(port: int = 8080):
"""Starts a web server in a background thread and waits for user to stop it."""
global _server_thread, _httpd
if _server_thread and _server_thread.is_alive():
print(
f"\n--> A new chart was generated. Refresh your browser at http://localhost:{port}")
return
Handler = http.server.SimpleHTTPRequestHandler
socketserver.TCPServer.allow_reuse_address = True
try:
_httpd = socketserver.TCPServer(("", port), Handler)
except OSError as e:
print(f"❌ Could not start server on port {port}: {e}")
return
_server_thread = threading.Thread(target=_httpd.serve_forever)
_server_thread.daemon = False
_server_thread.start()
print("\n" + "=" * 60)
print(" 📈 CHART READY - PREVIEW IN BROWSER ".center(60))
print("=" * 60)
print(
f"1. In the Cloud Shell toolbar, click 'Web Preview' and select port {port}.")
print(f"2. Or, open your local browser to http://localhost:{port}")
print("=" * 60)
try:
input(
"\n--> Press Enter here after viewing all charts to shut down the server...\n\n")
finally:
print("Shutting down server...")
_httpd.shutdown()
_server_thread.join()
_httpd, _server_thread = None, None
print("Server stopped.")
# Handles chart responses
def handle_chart_response(resp, chart_generated_flag: list):
def _value_to_dict(v):
if isinstance(v, proto.marshal.collections.maps.MapComposite):
return {k: _value_to_dict(v[k]) for k in v}
elif isinstance(v, proto.marshal.collections.RepeatedComposite):
return [_value_to_dict(el) for el in v]
return v
if "query" in resp:
print(resp.query.instructions)
elif "result" in resp:
vega_config_dict = _value_to_dict(resp.result.vega_config)
chart = alt.Chart.from_dict(vega_config_dict)
chart_filename = "index.html"
chart.save(chart_filename)
if chart_generated_flag:
chart_generated_flag[0] = True
# Displays the schema of a data source
def display_schema(data):
fields = getattr(data, "fields")
df = pd.DataFrame({
"Column": [f.name for f in fields],
"Type": [f.type for f in fields],
"Description": [getattr(f, "description", "-") for f in fields],
"Mode": [f.mode for f in fields],
})
print(df)
# Displays information about a BigQuery data source
def display_datasource(datasource):
table_ref = datasource.bigquery_table_reference
source_name = f"{table_ref.project_id}.{table_ref.dataset_id}.{table_ref.table_id}"
print(source_name)
display_schema(datasource.schema)
# Handles and displays schema resolution responses
def handle_schema_response(resp):
if "query" in resp:
print(resp.query.question)
elif "result" in resp:
display_section_title("Schema resolved")
print("Data sources:")
for datasource in resp.result.datasources:
display_datasource(datasource)
# Handles and prints simple text responses
def handle_text_response(resp):
parts = resp.parts
print("".join(parts))
# Processes and displays different types of system messages
def show_message(msg, chart_generated_flag: list):
m = msg.system_message
if "text" in m:
handle_text_response(getattr(m, "text"))
elif "schema" in m:
handle_schema_response(getattr(m, "schema"))
elif "data" in m:
handle_data_response(getattr(m, "data"))
elif "chart" in m:
handle_chart_response(getattr(m, "chart"), chart_generated_flag)
print("\n")
7. Tạo hàm trò chuyện
Bước cuối cùng là tạo một hàm trò chuyện mà bạn có thể dùng lại và gọi hàm show_message cho từng đoạn trong luồng phản hồi:
def stream_chat_response(question: str):
"""
Sends a chat request, processes the streaming response, and if a chart
was generated, starts the preview server and waits for it to be closed.
"""
data_chat_client = geminidataanalytics.DataChatServiceClient()
chart_generated_flag = [False]
messages = [
geminidataanalytics.Message(
user_message=geminidataanalytics.UserMessage(text=question)
)
]
conversation_reference = geminidataanalytics.ConversationReference(
conversation=data_chat_client.conversation_path(
billing_project, location, conversation_id
),
data_agent_context=geminidataanalytics.DataAgentContext(
data_agent=data_chat_client.data_agent_path(
billing_project, location, data_agent_id
),
),
)
request = geminidataanalytics.ChatRequest(
parent=f"projects/{billing_project}/locations/{location}",
messages=messages,
conversation_reference=conversation_reference,
)
stream = data_chat_client.chat(request=request)
for response in stream:
show_message(response, chart_generated_flag)
if chart_generated_flag[0]:
preview_in_browser()
Hàm stream_chat_response hiện đã được xác định và sẵn sàng sử dụng với câu lệnh của bạn.
8. Bắt đầu trò chuyện
Câu hỏi 1
Giờ đây, bạn đã sẵn sàng bắt đầu đặt câu hỏi! Hãy xem tác nhân này có thể làm gì để bắt đầu:
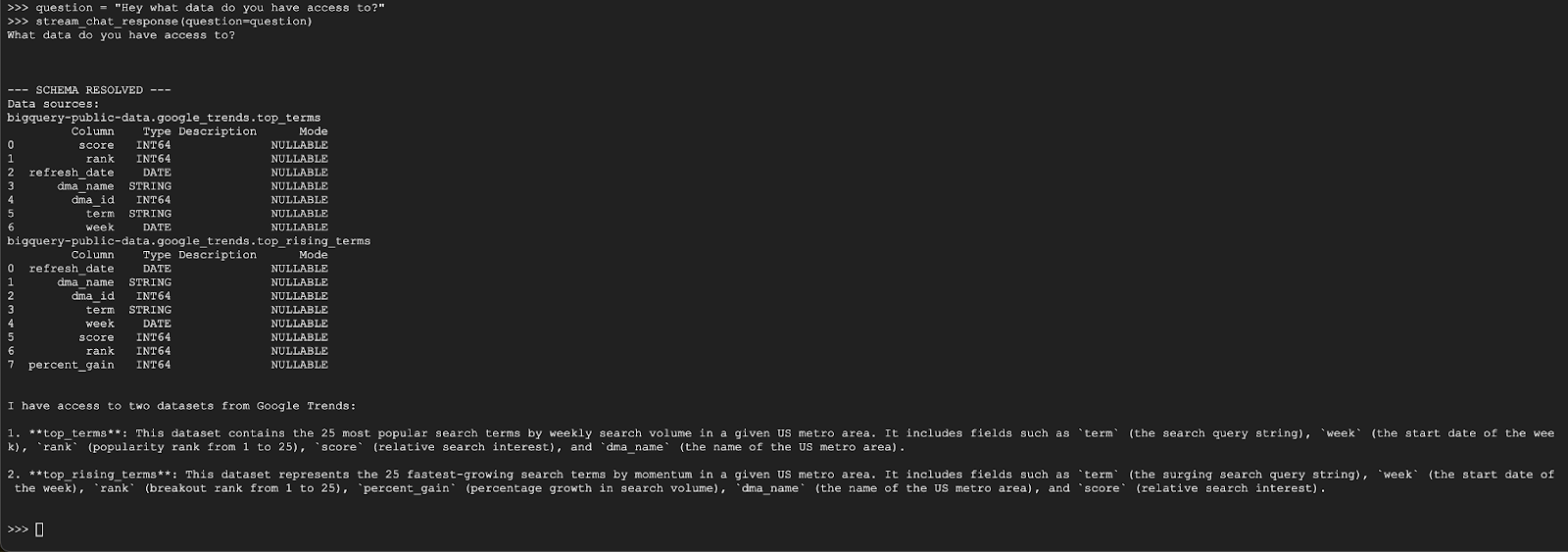
question = "Hey what data do you have access to?"
stream_chat_response(question=question)
Nhân viên hỗ trợ sẽ trả lời bằng nội dung tương tự như dưới đây:
Câu hỏi 2
Tuyệt vời! Hãy thử tìm thêm thông tin về các cụm từ tìm kiếm phổ biến mới nhất:
question = "What are the top 20 most popular search terms last week in NYC based on rank? Display each term and score as a column chart"
stream_chat_response(question=question)
Quá trình này sẽ mất chút thời gian để chạy. Bạn sẽ thấy tác nhân chạy qua nhiều bước và truyền trực tuyến các nội dung cập nhật, từ việc truy xuất giản đồ và siêu dữ liệu, viết truy vấn SQL, nhận kết quả, chỉ định hướng dẫn trực quan hoá và tóm tắt kết quả.
Để xem biểu đồ, hãy chuyển đến thanh công cụ Cloud Shell, nhấp vào "Xem trước trên web" rồi chọn cổng 8080:
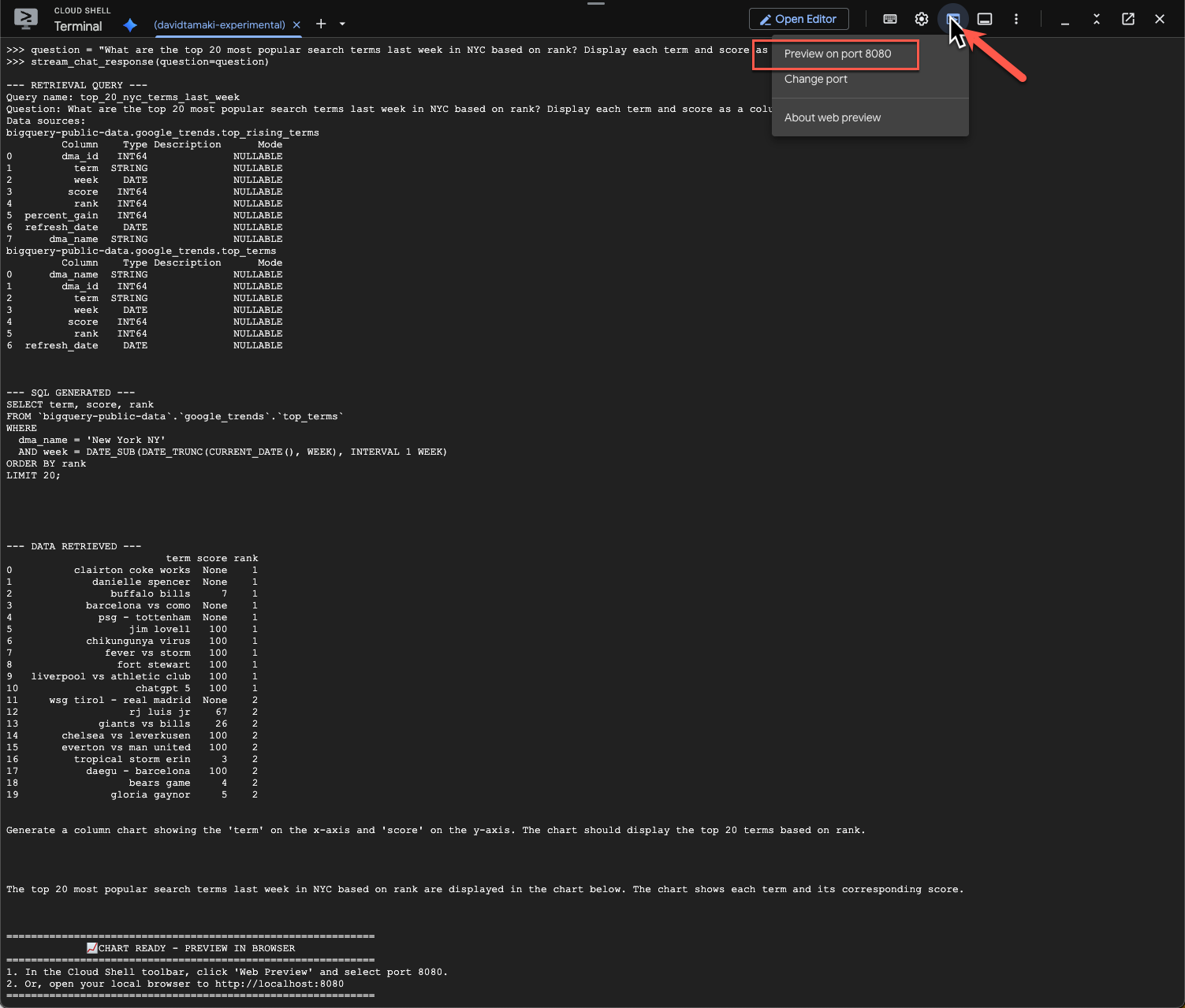
Bạn sẽ thấy một bản kết xuất của hình ảnh trực quan như sau:
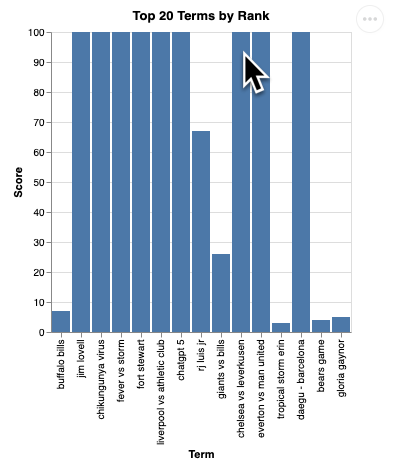
Nhấn Enter để tắt máy chủ và tiếp tục.
Câu hỏi 3
Hãy thử đặt một câu hỏi nối tiếp và tìm hiểu sâu hơn về những kết quả này:
question = "What was the percent gain in growth for these search terms from the week before?"
stream_chat_response(question=question)
Bạn sẽ thấy nội dung tương tự như bên dưới. Trong trường hợp này, tác nhân đã tạo một truy vấn để kết hợp 2 bảng nhằm tìm ra tỷ lệ phần trăm tăng. Xin lưu ý rằng truy vấn của bạn có thể hơi khác:
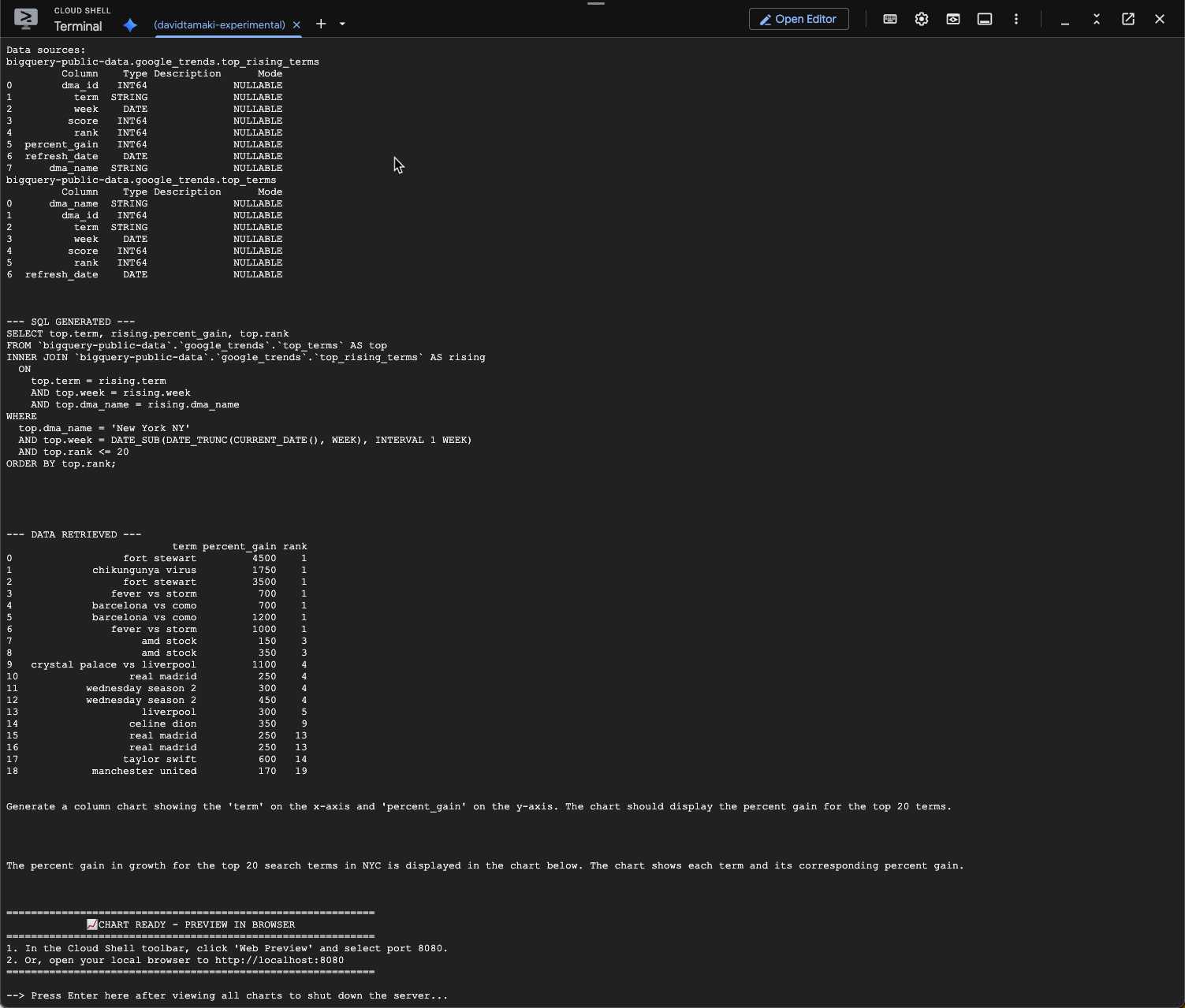
Và khi được trực quan hoá, nó sẽ có dạng như sau:
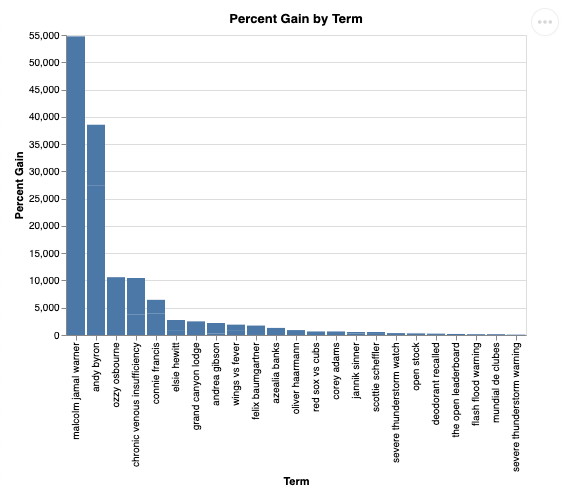
9. Dọn dẹp
Vì lớp học lập trình này không liên quan đến bất kỳ sản phẩm nào chạy trong thời gian dài, nên bạn chỉ cần dừng phiên Python đang hoạt động bằng cách nhập exit() vào thiết bị đầu cuối.
Xoá thư mục và tệp dự án
Nếu bạn muốn xoá mã khỏi môi trường Cloud Shell, hãy sử dụng các lệnh sau:
cd ~
rm -rf ca-api-codelab
Tắt API
Để tắt các API đã bật trước đó, hãy chạy lệnh này
gcloud services disable geminidataanalytics.googleapis.com
gcloud services disable cloudaicompanion.googleapis.com
gcloud services disable bigquery.googleapis.com
10. Kết luận
Xin chúc mừng! Bạn đã tạo thành công một Tác nhân Phân tích đàm thoại đơn giản bằng CA SDK. Hãy xem tài liệu tham khảo để tìm hiểu thêm!