
1. Introduction
Obtenir des insights à partir de données nécessite souvent beaucoup de temps, d'efforts et une expertise approfondie en SQL. Dans cet atelier de programmation, vous allez découvrir le catalogue d'agents de BigQuery, une nouvelle plate-forme qui fournit des insights instantanés basés sur l'IA via des agents de données conversationnels.
Vous irez au-delà de la simple conversion de texte en SQL en créant un agent de données organisé. Vous apprendrez à enrichir l'agent avec un contexte métier, des instructions système et des requêtes validées pour garantir des résultats très précis. Enfin, vous publierez cet agent pour que d'autres membres de votre organisation puissent l'utiliser.
Prérequis
- Connaissances de base concernant Google Cloud
Points abordés
- Parcourir le catalogue d'agents BigQuery
- Créer un agent personnalisé et définir des sources de connaissances
- Utiliser Gemini pour générer des métadonnées sémantiques
- Ajouter des instructions système et des requêtes validées pour guider l'agent
- Publier et partager des agents
Prérequis
- Un compte Google Cloud et un projet Google Cloud
- Connaissances de base sur BigQuery et SQL
- Un navigateur Web tel que Chrome
2. Préparation
Sélectionner un projet
- Connectez-vous à la console Google Cloud, puis créez un projet ou réutilisez un projet existant. (Si vous ne possédez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.)

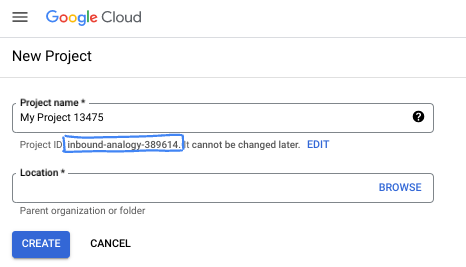
- Le nom du projet est le nom à afficher pour les participants au projet. Il s'agit d'une chaîne de caractères non utilisée par les API Google. Vous pouvez modifier ce nom à tout moment.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Cloud génère automatiquement une chaîne unique (en général, vous n'y accordez d'importance particulière). Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet (généralement identifié par
PROJECT_ID). Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire. Vous pouvez également en spécifier un et voir s'il est disponible. Après cette étape, l'ID n'est plus modifiable et restera donc le même pour toute la durée du projet. - Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
- Vous devez ensuite activer la facturation dans la console Cloud pour utiliser les ressources/API Cloud. L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Pour désactiver les ressources et éviter ainsi que des frais ne vous soient facturés après ce tutoriel, vous pouvez supprimer le projet ou les ressources que vous avez créées. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300$.
3. Avant de commencer
Accorder à votre compte les rôles requis
Accédez à la page IAM du projet et accordez-vous le rôle Propriétaire d'agent des données des analyses de données Gemini :
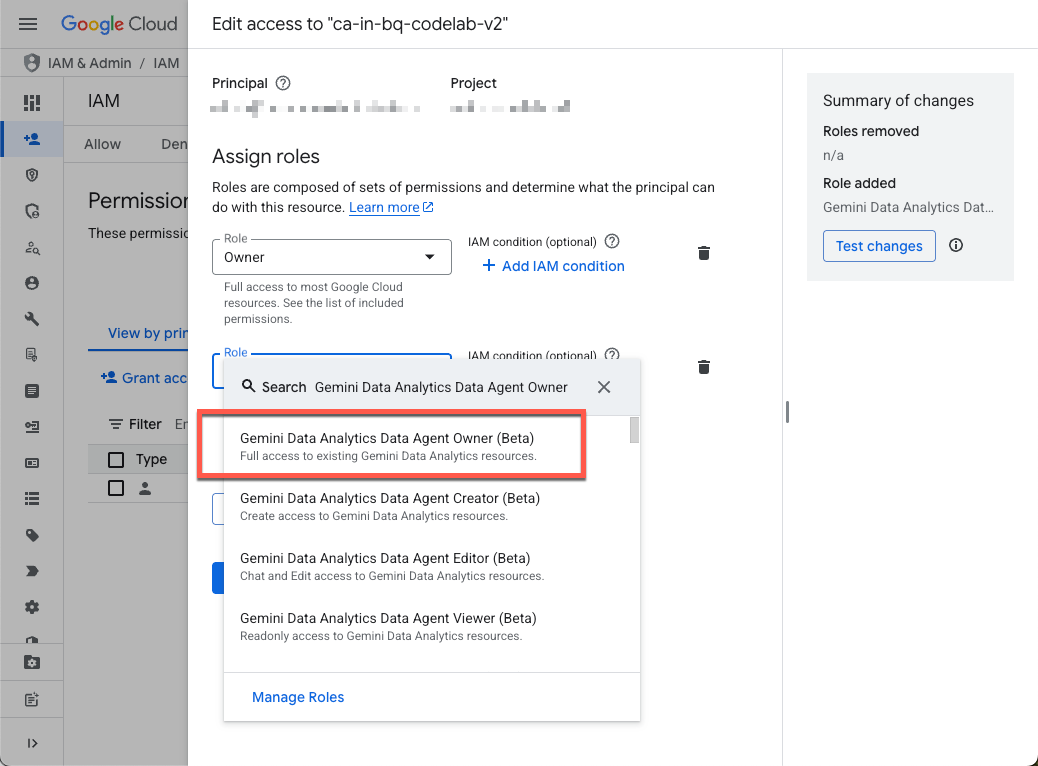
Ce rôle vous autorise à créer, modifier, partager et supprimer tous les agents de données du projet.
Activer les API requises
Utilisez le menu de navigation de la barre latérale ou le menu de recherche en haut de la page pour accéder à BigQuery > Agents.
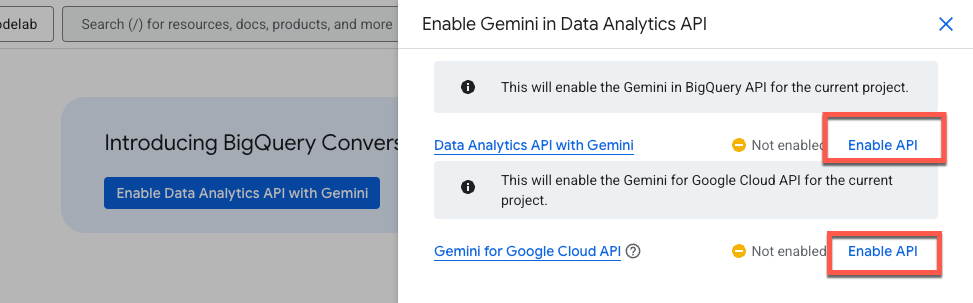
Cliquez sur Activer l'API Data Analytics avec Gemini :
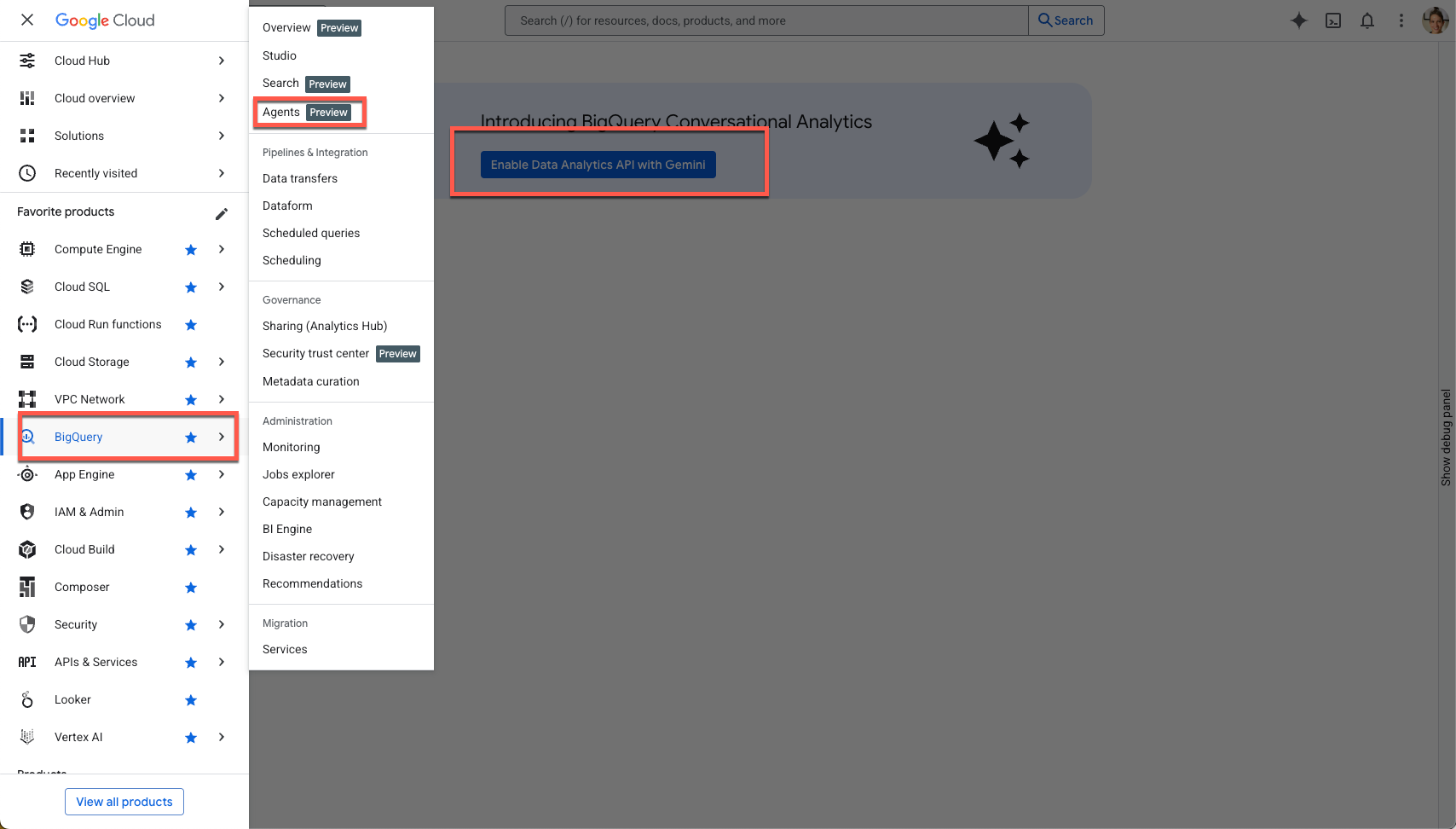
Activez l'API Gemini dans BigQuery et l'API Gemini pour Google Cloud :
La nouvelle page de l'agent doit s'afficher :
4. Créer un agent
Créons votre premier agent de données à l'aide de l'ensemble de données public international Google Trends. Cet ensemble de données est utile pour poser des questions sur les termes de recherche les plus populaires à l'international et sur l'évolution de ces intérêts au fil du temps.
Commençons par donner un nom et une brève description à votre agent. Cette description permet aux autres utilisateurs de comprendre l'objectif de l'agent.
Agent Name (Nom de l'agent)
Google Trends Agent
Description de l'agent
Data agent for the Google Trends International Top Terms public dataset
Sources de connaissances
Ajoutez maintenant les sources de connaissances. Une source de connaissances est une table, une vue ou une UDF BigQuery que l'agent peut utiliser pour répondre aux questions.
Pour cette démonstration, n'ajoutez qu'une seule table pour plus de simplicité. Toutefois, n'oubliez pas que vous pouvez ajouter jusqu'à 50 sources de connaissances par agent pour gérer des scénarios de données plus complexes.
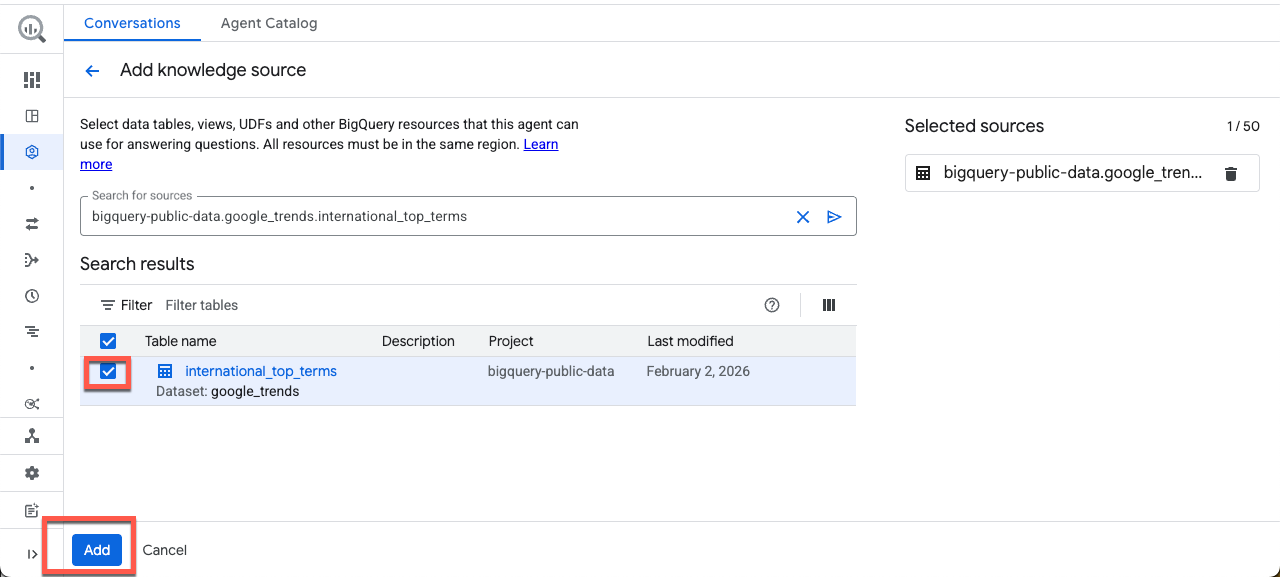
Saisissez la table suivante dans la zone de recherche, cochez la case, puis cliquez sur Ajouter :
bigquery-public-data.google_trends.international_top_terms
Contexte structuré
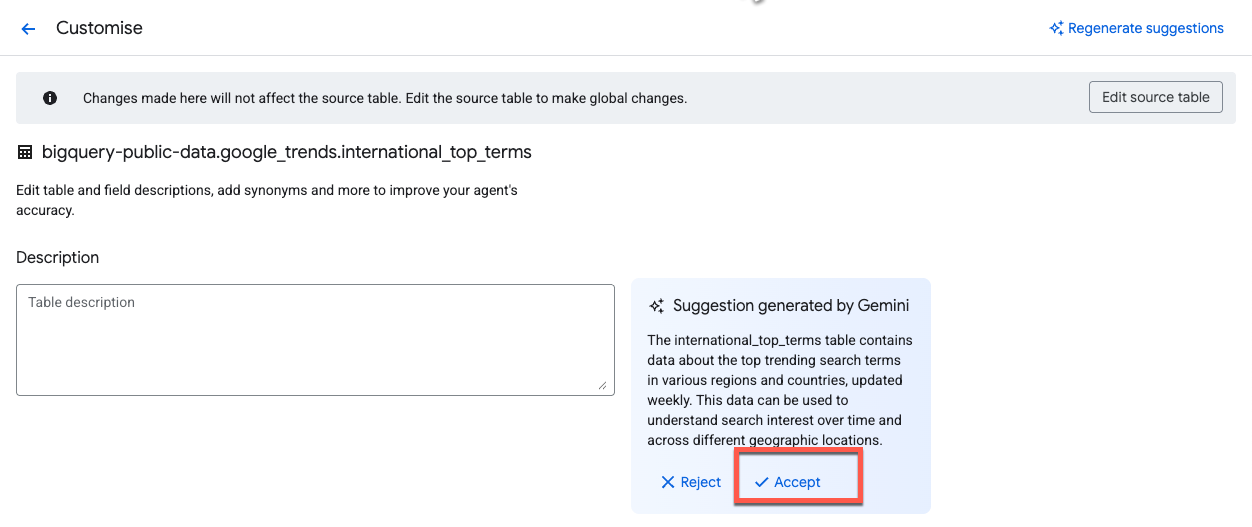
Pour améliorer la précision de l'agent de données, ajoutez un contexte structuré à la table et aux colonnes. Cliquez sur Customise :

Gemini génère automatiquement des suggestions de descriptions. Cliquez sur Accepter à côté de la description de la table :
Pour appliquer des descriptions à toutes les colonnes, cochez Sélectionner toutes les lignes , puis cliquez sur Accepter les suggestions :
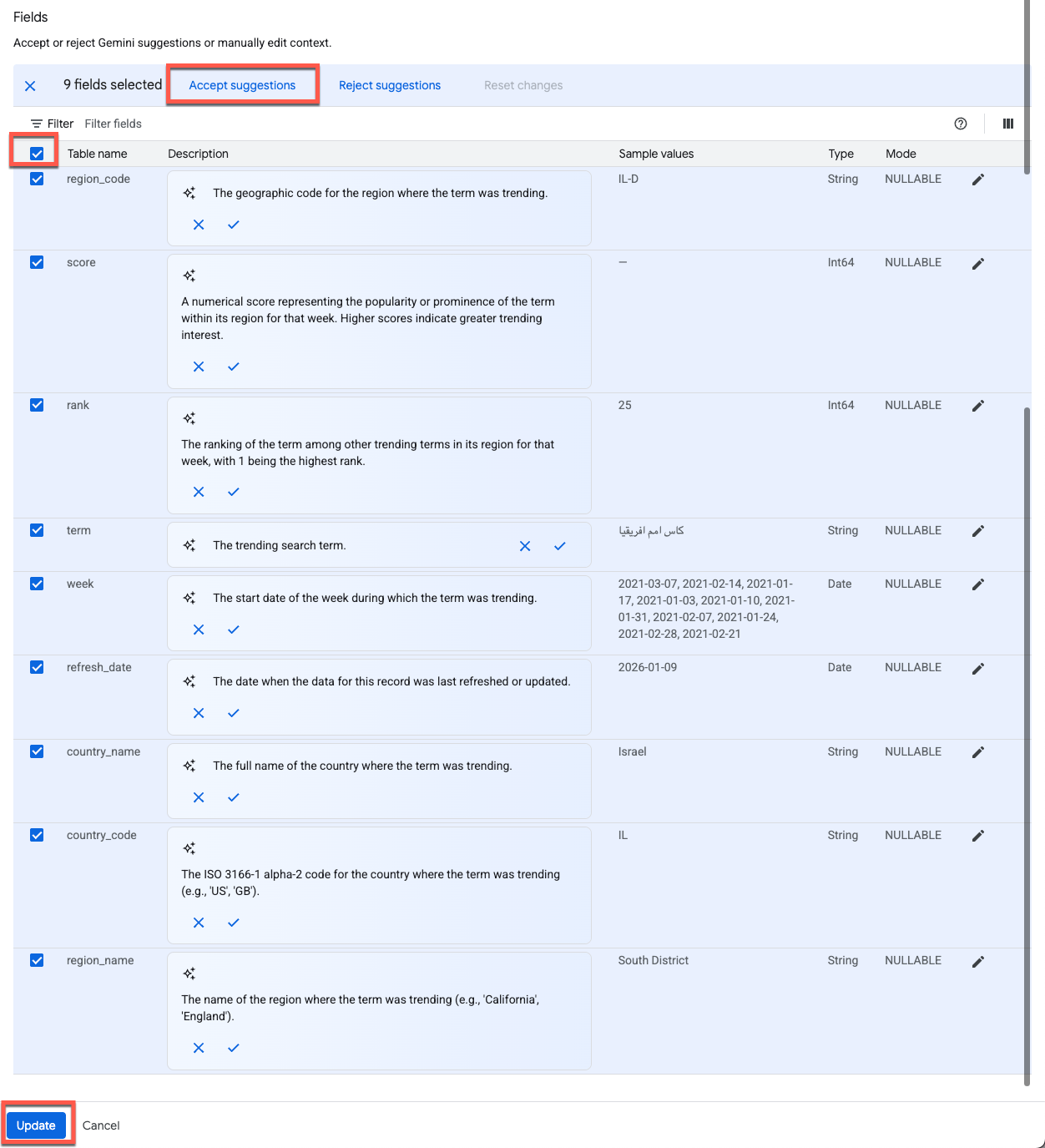
Cliquez sur Mettre à jour en bas de la page pour enregistrer les modifications et revenir à l'éditeur d'agent.
Instructions
La boîte de dialogue des instructions de l'agent vous permet de fournir à l'agent des conseils supplémentaires pour interpréter et interroger les sources de données. Par exemple :
- Synonymes : termes alternatifs pour les champs clés.
- Champs clés : champs les plus importants pour l'analyse.
- Champs exclus : champs que l'agent de données doit exclure.
- Filtrage et regroupement : champs que l'agent doit utiliser pour filtrer et regrouper les données.
- Relations de jointure : façon dont deux tables ou plus sont combinées en fonction de champs communs.
Copiez et collez les instructions suivantes :
### System Instruction
* You are an expert data analyst for the Google Trends International public dataset.
* Always filter on yesterday's refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY).
* If yesterday returns no data, filter on 2 days ago's refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY).
* Default to country-level results (one row per term).
* "Top" queries must deduplicate snapshot rows.
* Only include week or score when the user explicitly asks for trends over time.
* This is an international dataset and does not include any data for the United States.
### Additional Descriptions
#### 1. Core model:
* refresh_date selects the daily Top-25 term set.
* week + score are historical weekly values attached to those terms.
* Filtering week does not change which terms appear.
#### 2. Deduplication rule (critical):
* Snapshot rows repeat across weeks and regions.
* For "top" queries, always GROUP BY term (country-level) and compute rank as MIN(rank).
#### 3. Defaults:
* Country-level results only.
* Use region_code only if the user explicitly asks for regions.
* Limit results unless the user asks otherwise.
#### 4. Time series usage:
* Only include week or score when the user asks for trends over time, historical context, or week-over-week score changes.
#### 5. Field guidance:
* Prefer country_code or region_code for filters.
* country_name / region_name are for display only.
* score is normalized; compare trends within a term, not across terms.
Requêtes validées
Les requêtes validées, auparavant appelées requêtes en or, sont utilisées comme référence pour l'agent afin d'améliorer la précision des réponses. Elles façonnent la structure de réponse d'un agent et l'aident à comprendre la logique métier utilisée par votre organisation.
Ajoutons deux exemples pour votre agent. Cliquez sur Ajouter une requête, puis copiez et collez la question et la requête suivantes :
Question 1 :
What are the top search terms in the UK right now?
Requête 1 :
SELECT term, MIN(rank) AS rank
FROM `bigquery-public-data.google_trends.international_top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND country_code = 'GB'
GROUP BY term
ORDER BY rank
LIMIT 25;
Avant d'enregistrer cette requête, exécutons-la pour nous assurer qu'elle est valide.
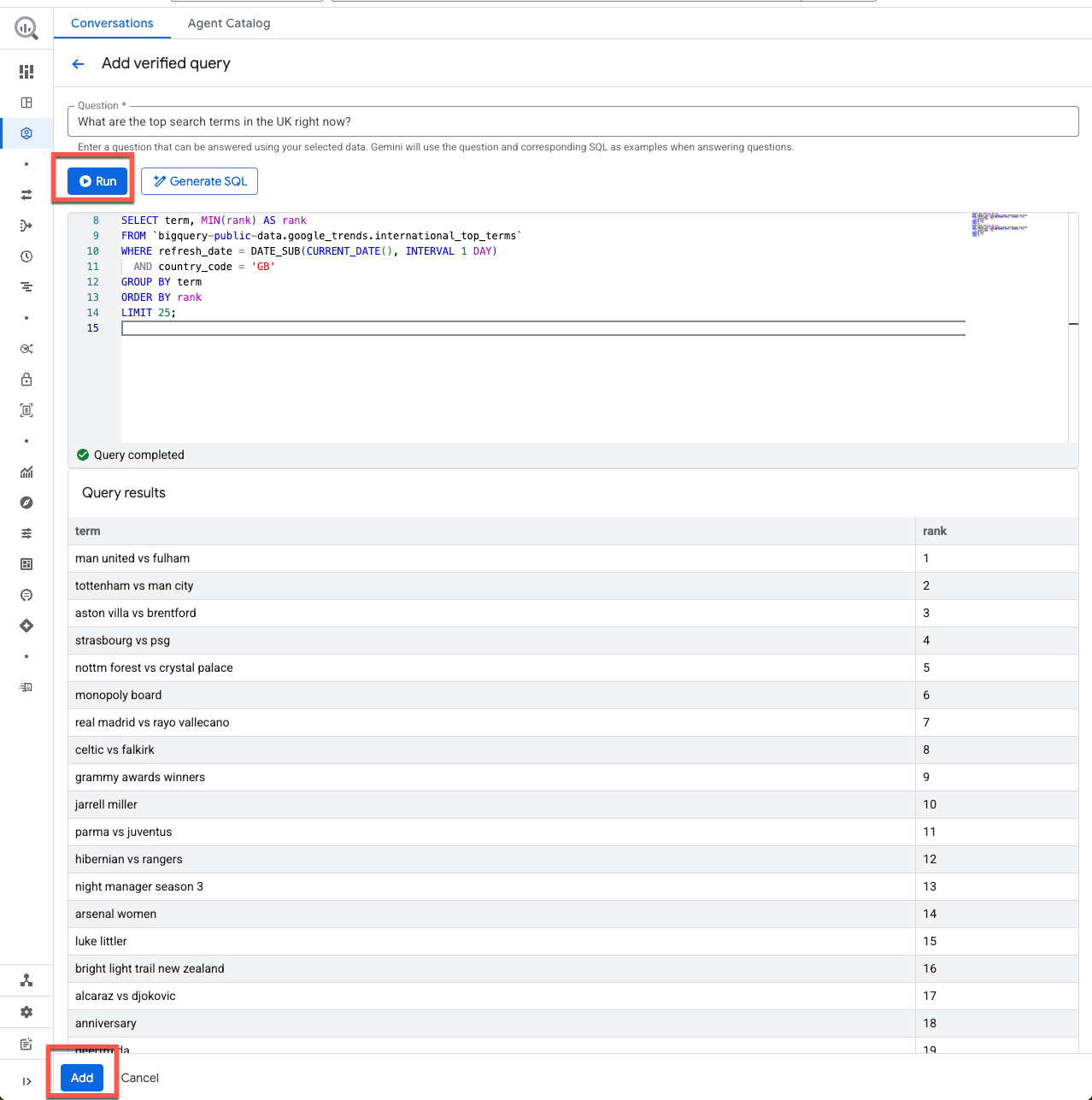
Cela me semble correct. Cliquez sur Ajouter pour enregistrer la requête validée.
Ajoutons un autre exemple pour un cas d'utilisation plus complexe. Cliquez sur Gérer les requêtes , puis ajoutez :
Question 2 :
Show the last 12 weeks of interest for the current top 5 terms in Auckland.
Réponse 2 :
WITH top5 AS (
SELECT term, MIN(rank) AS rank
FROM `bigquery-public-data.google_trends.international_top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND country_code = 'NZ'
AND region_code = 'NZ-AUK'
GROUP BY 1
ORDER BY 2
LIMIT 5
),
series AS (
SELECT term, week, score,
ROW_NUMBER() OVER (PARTITION BY term ORDER BY week DESC) AS rn
FROM `bigquery-public-data.google_trends.international_top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND country_code = 'NZ'
AND region_code = 'NZ-AUK'
AND term IN (SELECT term FROM top5)
)
SELECT week, term, score
FROM series
WHERE rn <= 12
ORDER BY 1 DESC, 3
Avant de passer à la section suivante, examinons les suggestions générées par Gemini :
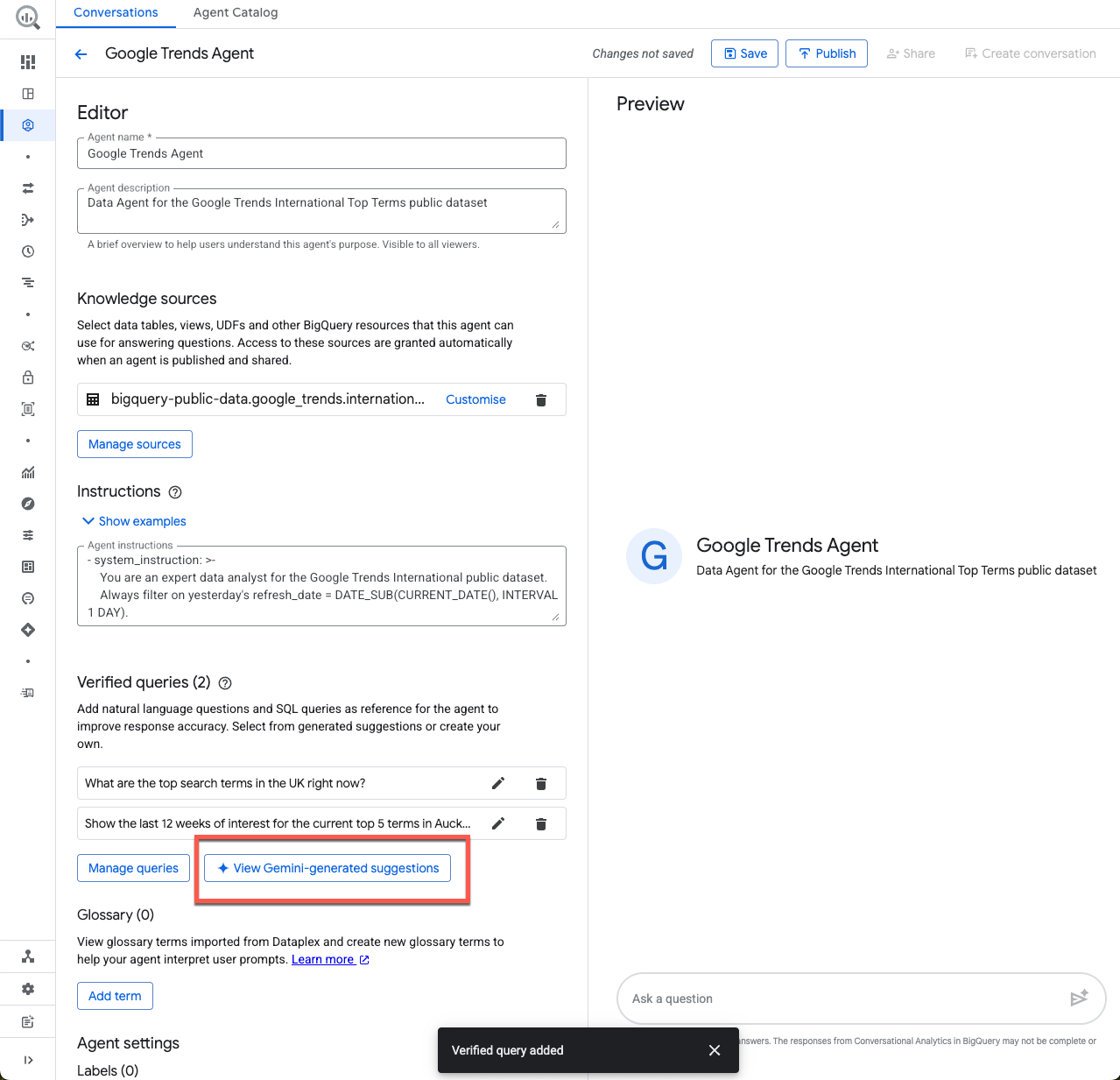
Vous pouvez voir ici quelques requêtes validées suggérées. Lorsque vous créerez un agent à l'avenir, ce sera un excellent point de départ. Veillez simplement à valider toutes les requêtes que vous ajoutez.
Glossaire
Ajoutons un terme au glossaire. Si votre entreprise utilise Dataplex, ces termes sont importés directement à partir du glossaire d'entreprise dans Dataplex Universal Catalog.
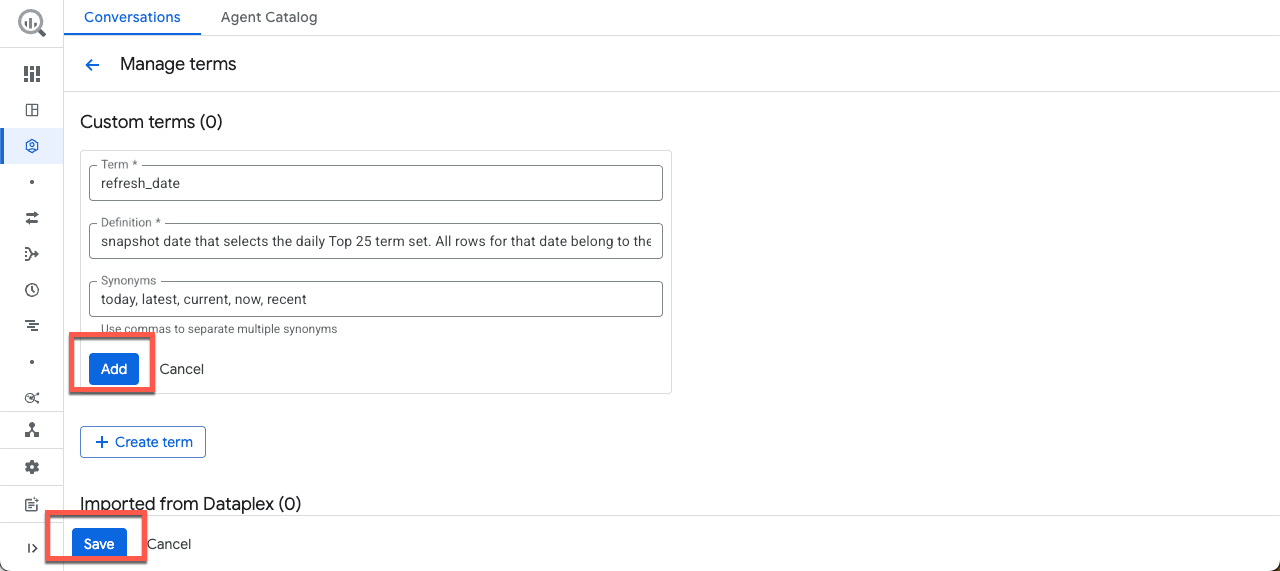
Cliquez sur Ajouter un terme, puis copiez et collez l'exemple suivant :
Term :
refresh_date
Définition :
Snapshot date that selects the daily Top 25 term set. All rows for that date belong to the same "what's trending now" snapshot. Attach Historical week and score values after this selection.
Synonymes :
today, latest, current, now, recent
Cliquez ensuite sur Ajouter, puis sur Enregistrer.
Paramètres de l'agent
Dans la section Paramètres, vous pouvez configurer les libellés et le nombre maximal d'octets facturés.
Libellés
Les libellés sont des paires clé/valeur utilisées pour organiser les ressources Google Cloud en groupes logiques. Pour que cet atelier reste ciblé, laissez les libellés vides.
Nombre maximal d'octets facturés
Pour éviter de générer accidentellement des requêtes coûteuses, définissons une limite pour le nombre maximal d'octets facturés par requête. Si la requête de l'agent traite des octets au-delà de cette limite, elle échoue sans entraîner de frais. Saisissez la valeur suivante :
10000000000
10 000 000 000 octets correspondent à environ 9,3 Go. Si vous ne spécifiez pas de valeur, le nombre maximal d'octets facturés est défini par défaut sur le quota d'utilisation des requêtes du projet par jour query usage per day quota.
5. Enregistrer et partager votre agent
Aperçu
Tout est prêt. Testons votre agent avant de continuer. Sur le côté droit de l'écran, vous pouvez tester l'agent de manière dynamique tout en modifiant la configuration. L'aperçu utilise automatiquement les nouvelles métadonnées que vous fournissez sans enregistrer ni publier les modifications.
Demandons à quelles données l'agent a accès. N'hésitez pas à poser quelques questions avec vos propres mots :
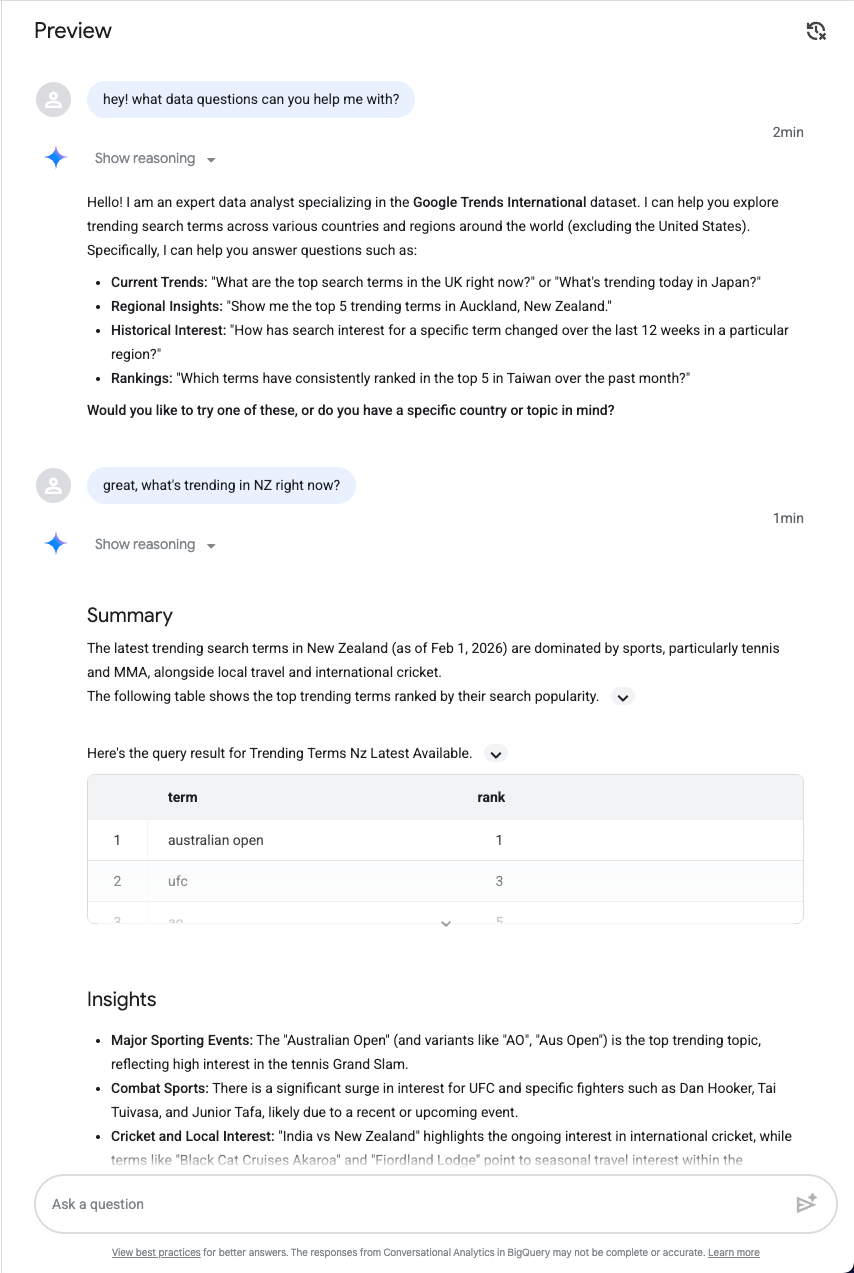
Enregistrer
Après avoir testé quelques requêtes, enregistrez l'agent, puis publiez-le :
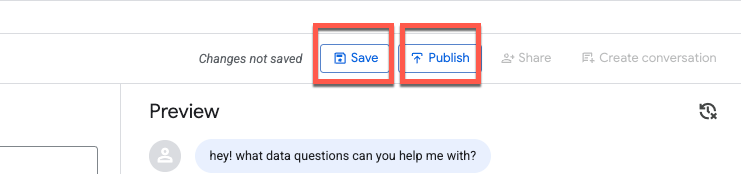
La publication de l'agent le rendra disponible dans BigQuery Studio, l'API Conversational Analytics et Looker Studio Pro (sous réserve de licence) :
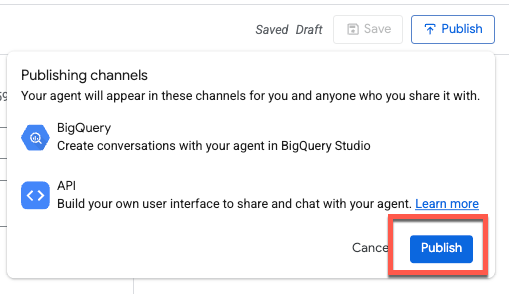
La prise en charge de surfaces et d'intégrations supplémentaires est prévue dans les prochaines versions.
Partager
Un message de confirmation indiquant que l'agent a été publié doit s'afficher. Vous pouvez maintenant partager cet agent avec d'autres utilisateurs.
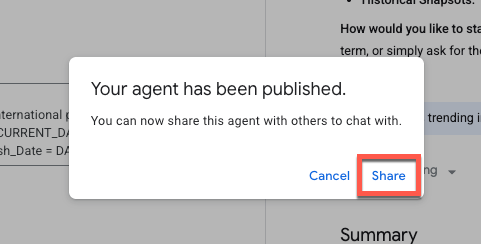
Lorsque vous partagez un agent avec d'autres utilisateurs, vous contrôlez leur niveau d'accès en leur attribuant un rôle spécifique. Ces rôles déterminent si un collaborateur peut simplement afficher votre agent ou s'il a le pouvoir de modifier et de gérer sa configuration.
Il est important de noter que ces rôles peuvent être appliqués à deux niveaux différents :
- Niveau du projet : l'attribution d'un rôle au niveau du projet fournit à l'utilisateur ces autorisations pour tous les agents de ce projet Google Cloud.
- Niveau de l'agent : pour un contrôle plus précis, vous pouvez accorder des rôles pour un agent spécifique. Cela est utile lorsque vous souhaitez qu'un utilisateur ait accès à un agent de données particulier sans voir les autres agents du projet.
Les rôles prédéfinis pour Conversational Analytics sont les suivants :
- Propriétaire d'agent des données des analyses de données Gemini (roles/geminidataanalytics.dataAgentOwner) - Créer, modifier, partager et supprimer tous les agents de données
- Créateur d'agent des données des analyses de données Gemini (roles/geminidataanalytics.dataAgentCreator) - Créer, modifier, partager et supprimer vos propres agents de données
- Éditeur d'agent des données des analyses de données Gemini (roles/geminidataanalytics.dataAgentEditor) - Accès en chat et en modification aux agents de données
- Utilisateur d'agent des données des analyses de données Gemini (roles/geminidataanalytics.dataAgentUser) - Accès en chat et en affichage aux agents de données
- Lecteur d'agent des données des analyses de données Gemini (roles/geminidataanalytics.dataAgentViewer) - Accès en affichage (lecture seule) aux agents de données
6. Créer une conversation avec un agent
Quittons l'onglet Partager et créons une conversation :
Lorsque vous cliquez sur Créer une conversation, une conversation sans titre est générée.
Demandons quels sont les termes les plus populaires en Angleterre (n'hésitez pas à remplacer ce pays par celui de votre choix) :
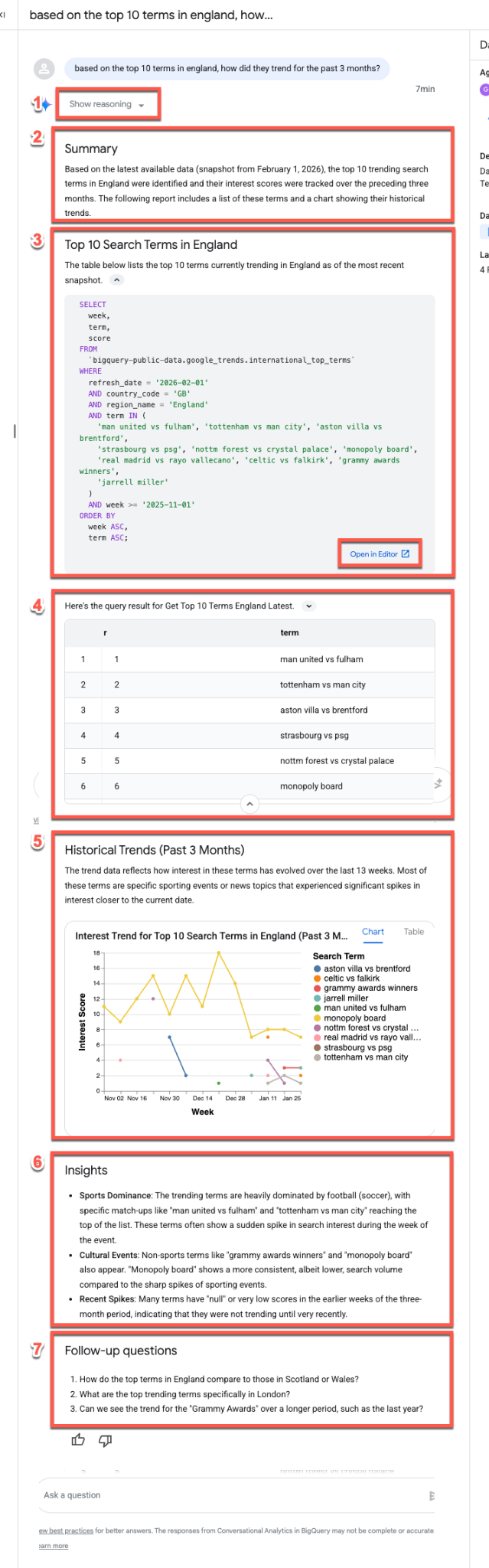
Based on the top 10 terms in England, how did they trend for the past 3 months?
Décompresser le flux de réponse
L'agent de données suit généralement le même flux de réponse lorsqu'il répond à des questions :
- Raisonnement : l'agent "réfléchit" d'abord à la requête. Développez le bouton Afficher le raisonnement pour afficher des insights détaillés sur le processus de prise de décision de l'agent.
- Résumé : l'agent génère un résumé général de la requête, du rapport obtenu et de la visualisation.
- SQL généré : développez la section Voici la requête... pour inspecter le code SQL. Cliquez sur Ouvrir dans l'éditeur pour affiner manuellement la requête dans BigQuery Studio.
- Résultats des données : l'agent présente les résultats de la requête dans un format tabulaire clair.
- Visualisation : un graphique s'affiche avec une brève description. L'agent déduit automatiquement le meilleur type de visualisation (par exemple, un graphique linéaire à plusieurs séries) pour vos données.
- Insights sur les données : l'agent résume les principales tendances et les principaux points à retenir des résultats.
- Questions de suivi : enfin, l'agent suggère des questions de suivi pertinentes pour vous aider à poursuivre votre analyse.
Compatibilité avec BigQuery ML
Demandons si l'agent de données peut exécuter des prévisions basées sur ces résultats. Cela exploite les fonctions BigQuery ML pour prédire les points futurs.
Saisissez la requête suivante (veillez à remplacer "plateau de Monopoly" par un terme pertinent pour votre requête) :
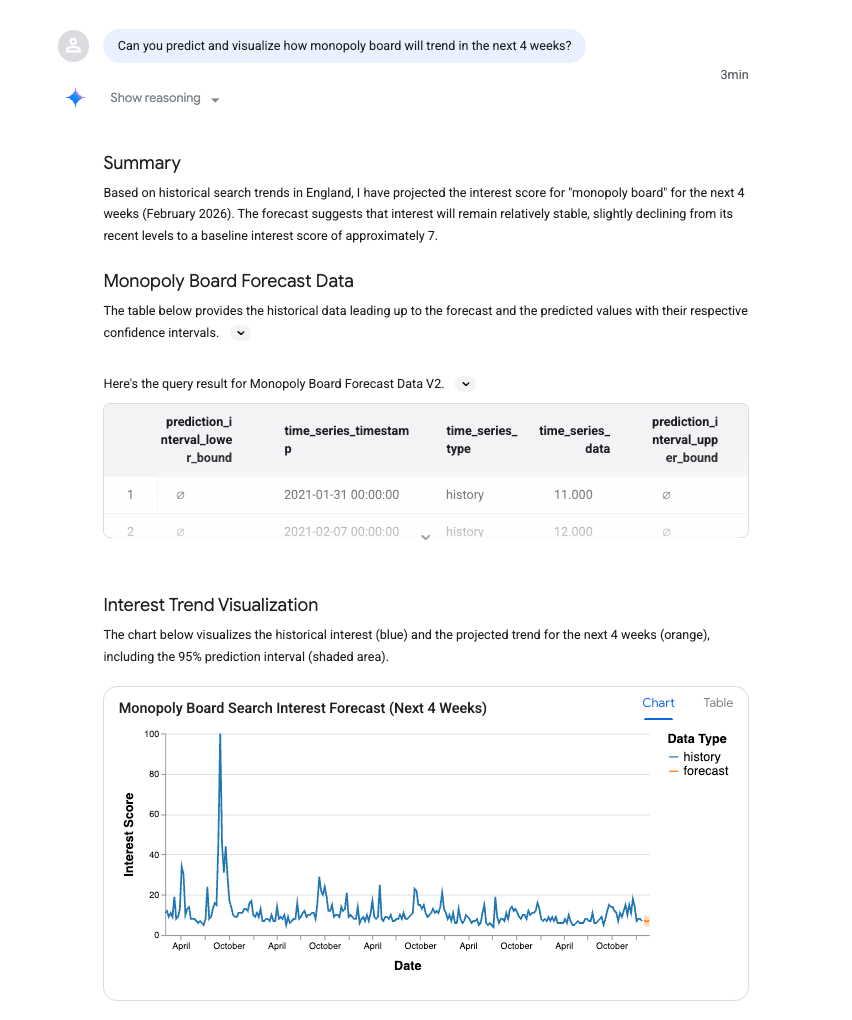
Can you predict and visualize how monopoly board will trend in the next 4 weeks?
Vous pouvez voir que AI_FORECAST a été utilisé pour prévoir une série temporelle. Rien d'étonnant, mais il est intéressant de constater un pic important en août 2021, qui coïncide avec l'ouverture de l'attraction Monopoly Lifesized à Londres.
7. Explorer le catalogue d'agents
Avant de conclure, explorons le catalogue d'agents. Cliquez sur Catalogue d'agents en haut de la fenêtre :
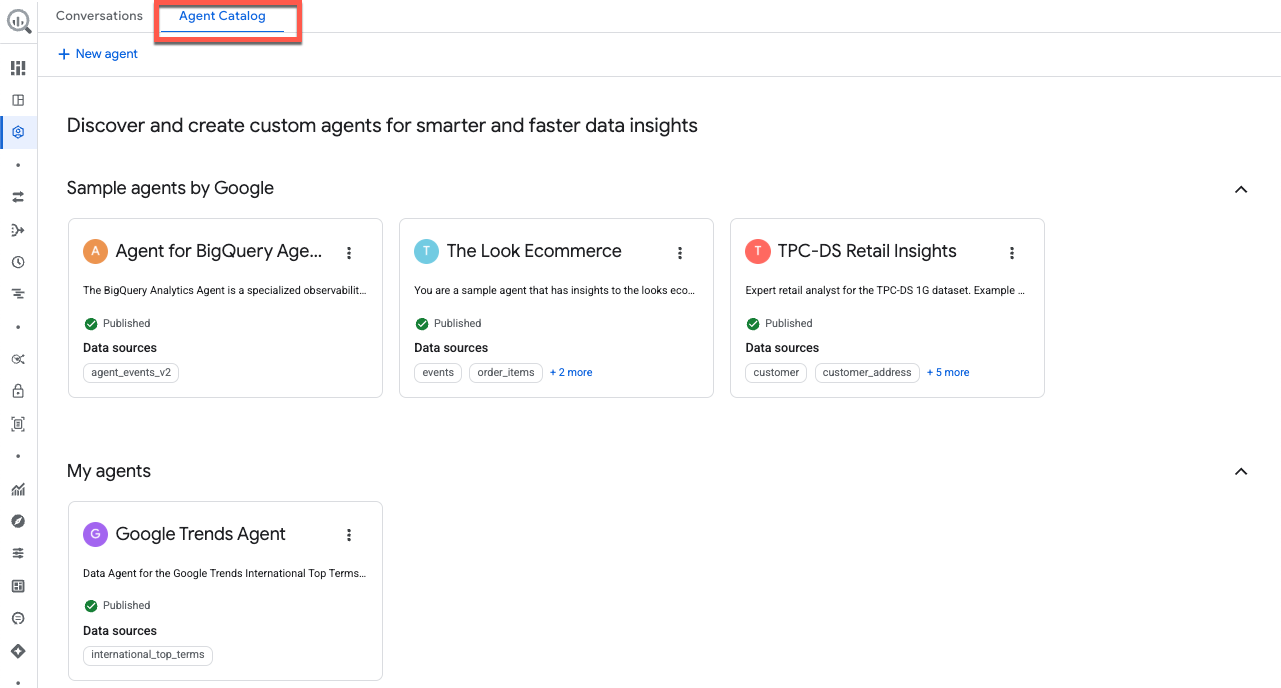
Cette page sert de hub central pour la gestion des agents de données, organisée dans les sections suivantes :
- Mes agents : vos agents actuellement publiés.
- Mes agents brouillons : les configurations que vous avez enregistrées, mais pas encore publiées.
- Partagés par d'autres membres de votre organisation : les agents créés par des collègues auxquels vous êtes autorisé à accéder.
- Exemples d'agents par Google : des exemples préconfigurés pour vous aider à démarrer.
Pour tout agent que vous gérez, vous pouvez modifier les configurations, dupliquer des agents et gérer les autorisations de partage.
8. Conclusion
Félicitations, vous avez créé un agent de données Conversational Analytics. Pour en savoir plus, consultez la documentation de référence.