
1. Introducción
Obtener estadísticas a partir de los datos suele requerir mucho tiempo, esfuerzo y experiencia en SQL. En este codelab, explorarás el Catálogo de agentes de BigQuery, una nueva plataforma que ofrece estadísticas instantáneas basadas en IA a través de agentes de datos conversacionales.
Crearás un agente de datos seleccionado, lo que te permitirá ir más allá de la simple conversión de texto a SQL. Aprenderás a enriquecer el agente con contexto empresarial, instrucciones del sistema y búsquedas verificadas para garantizar resultados muy precisos. Por último, publicarás este agente para que lo usen otras personas de tu organización.
Requisitos previos
- Conocimientos básicos de Google Cloud
Qué aprenderás
- Cómo navegar por el catálogo de agentes de BigQuery
- Cómo crear un agente personalizado y definir fuentes de conocimiento
- Cómo usar Gemini para generar metadatos semánticos
- Cómo agregar instrucciones del sistema y consultas verificadas para guiar al agente
- Cómo publicar y compartir agentes
Requisitos
- Una cuenta y un proyecto de Google Cloud
- Conocimientos básicos de BigQuery y SQL
- Un navegador web, como Chrome
2. Configuración y requisitos
Elige un proyecto
- Accede a Google Cloud Console y crea un proyecto nuevo o reutiliza uno existente. Si aún no tienes una cuenta de Gmail o de Google Workspace, debes crear una.

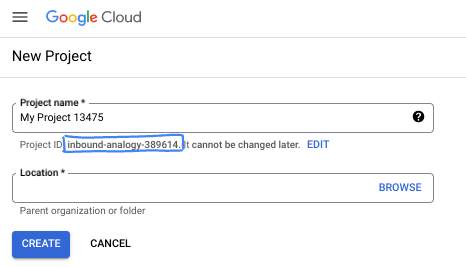
- El Nombre del proyecto es el nombre visible de los participantes de este proyecto. Es una cadena de caracteres que no se utiliza en las APIs de Google. Puedes actualizarla cuando quieras.
- El ID del proyecto es único en todos los proyectos de Google Cloud y es inmutable (no se puede cambiar después de configurarlo). La consola de Cloud genera automáticamente una cadena única. Por lo general, no importa cuál sea. En la mayoría de los codelabs, deberás hacer referencia al ID de tu proyecto (suele identificarse como
PROJECT_ID). Si no te gusta el ID que se generó, podrías generar otro aleatorio. También puedes probar uno propio y ver si está disponible. No se puede cambiar después de este paso y se usa el mismo durante todo el proyecto. - Recuerda que hay un tercer valor, un número de proyecto, que usan algunas APIs. Obtén más información sobre estos tres valores en la documentación.
- A continuación, deberás habilitar la facturación en la consola de Cloud para usar las APIs o los recursos de Cloud. Ejecutar este codelab no costará mucho, tal vez nada. Para cerrar recursos y evitar que se generen cobros más allá de este instructivo, puedes borrar los recursos que creaste o borrar el proyecto. Los usuarios nuevos de Google Cloud son aptos para participar en el programa Prueba gratuita de $300.
3. Antes de comenzar
Cómo otorgarte los roles necesarios
Navega a la página de IAM del proyecto y otórgate el rol de Propietario del agente de datos de Gemini Data Analytics:
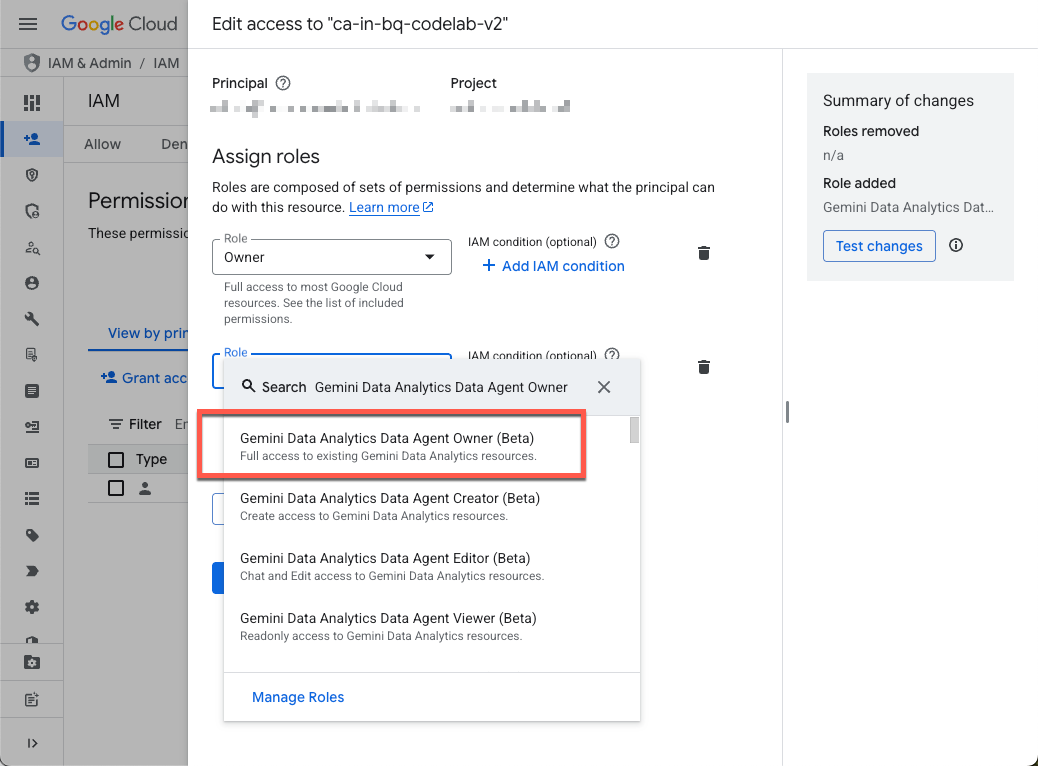
Este rol te otorga permiso para crear, editar, compartir y borrar todos los agentes de datos del proyecto.
Habilite las API necesarias
Usa el menú de navegación de la barra lateral o el menú de búsqueda en la parte superior de la página para navegar a BigQuery > Agents.
Haz clic en Habilita la API de Data Analytics with Gemini:
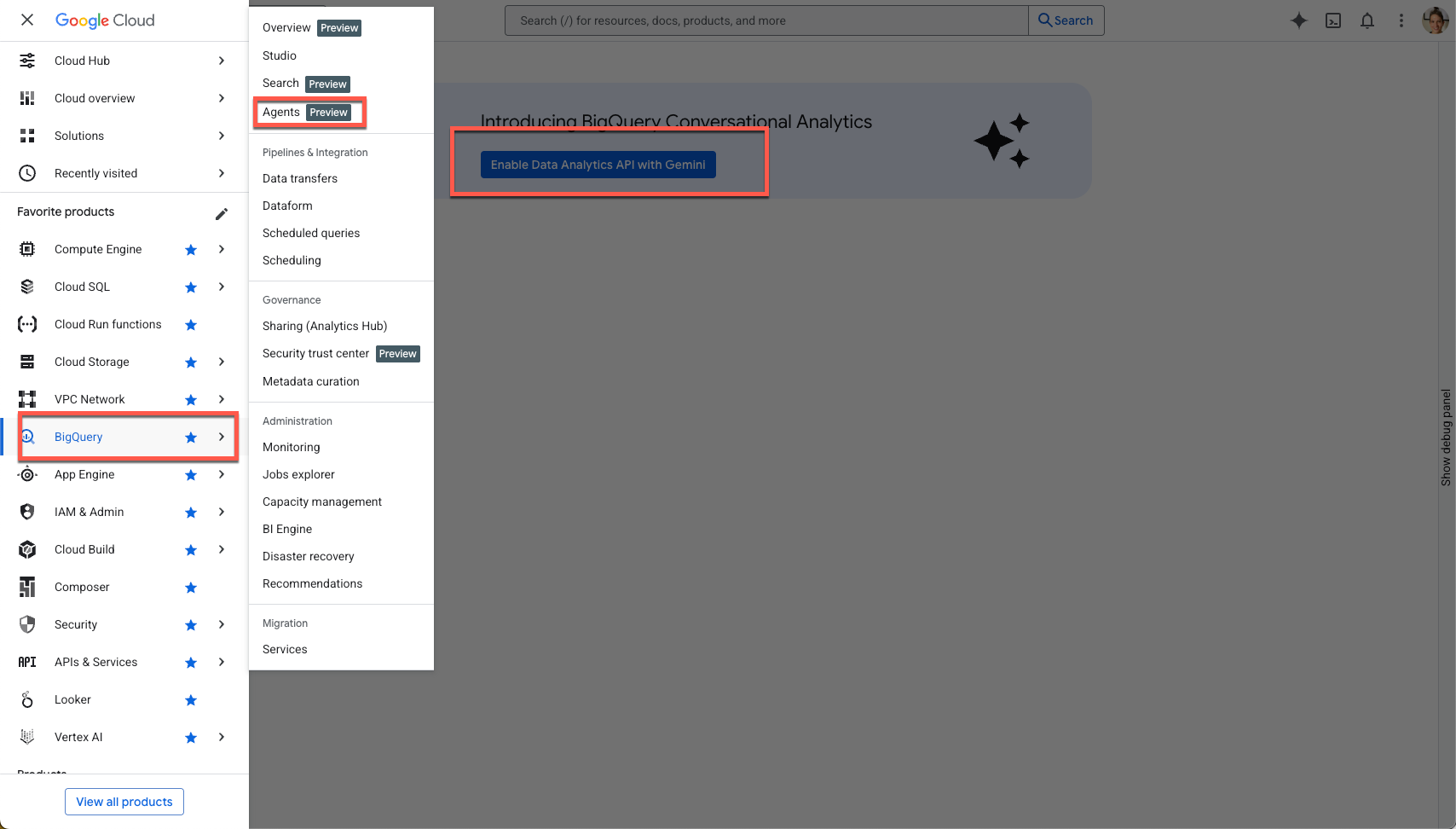
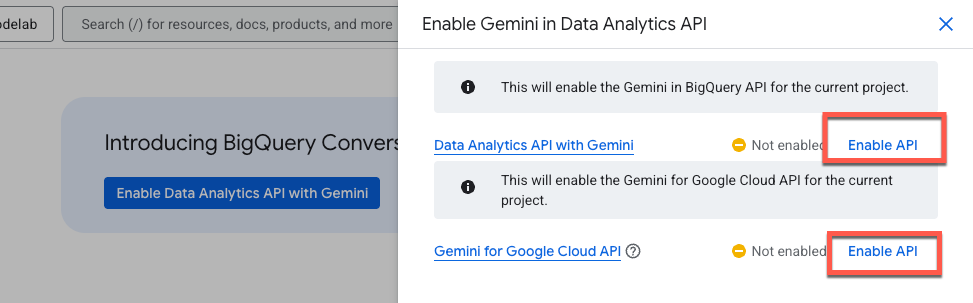
Habilita la API de Gemini in BigQuery y la API de Gemini for Google Cloud:
Ahora deberías ver la página del agente nuevo:
4. Crea un agente
Creemos tu primer agente de datos con el conjunto de datos públicos internacionales de Google Trends. Este conjunto de datos es útil para hacer preguntas sobre qué términos de búsqueda son tendencia a nivel internacional y cómo se comparan esos intereses históricamente.
Comencemos asignándole un nombre y una breve descripción a tu agente. Esta descripción se usa únicamente para que otros usuarios comprendan el propósito del agente.
Nombre del agente
Google Trends Agent
Descripción del agente
Data agent for the Google Trends International Top Terms public dataset
Fuentes de conocimiento
Ahora, agrega las fuentes de conocimiento. Una fuente de conocimiento es una tabla, una vista o una UDF de BigQuery que el agente puede usar para responder preguntas.
Para esta demostración, agrega solo una tabla para simplificar las cosas. Sin embargo, ten en cuenta que puedes agregar hasta 50 fuentes de conocimiento por agente para controlar situaciones de datos más complejas.
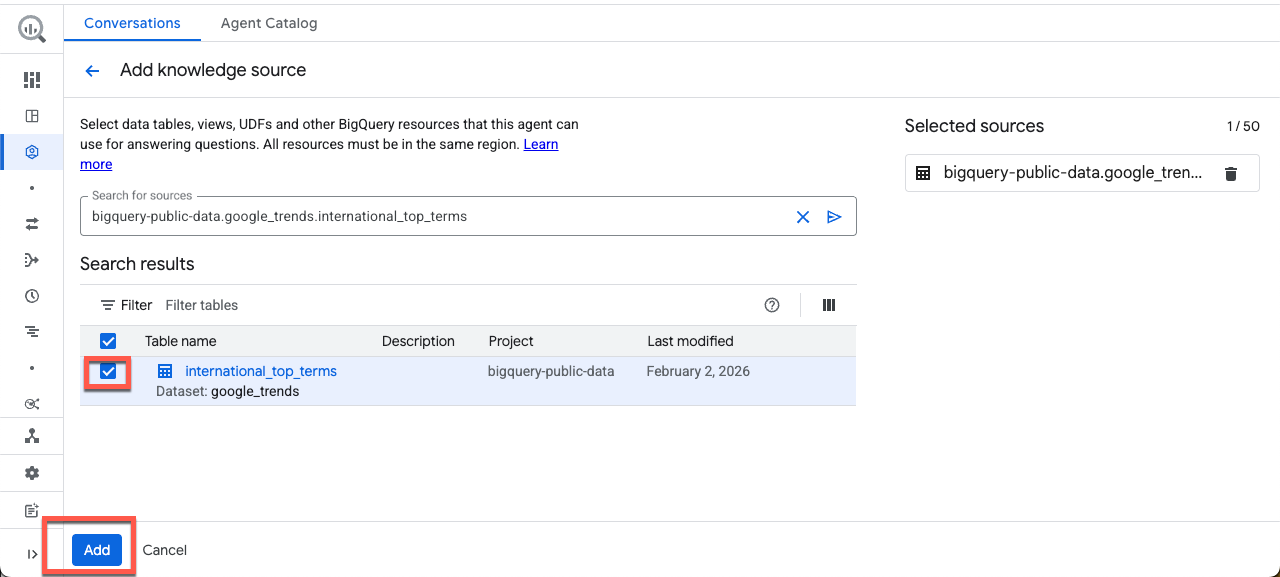
Ingresa la siguiente tabla en el cuadro de búsqueda, marca la casilla y haz clic en Agregar:
bigquery-public-data.google_trends.international_top_terms
Contexto estructurado
Para mejorar la precisión del agente de datos, agrega contexto estructurado a la tabla y las columnas. Haz clic en Customise:

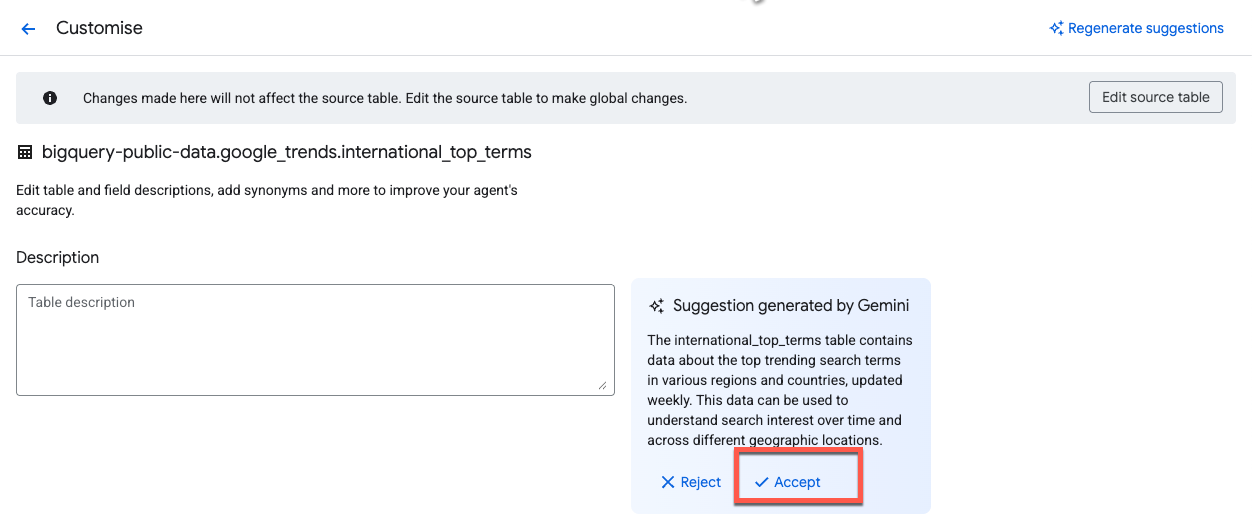
Gemini genera automáticamente sugerencias para las descripciones. Haz clic en Aceptar junto a la descripción de la tabla:
Para aplicar descripciones a todas las columnas, marca Seleccionar todas las filas y, luego, haz clic en Aceptar sugerencias:
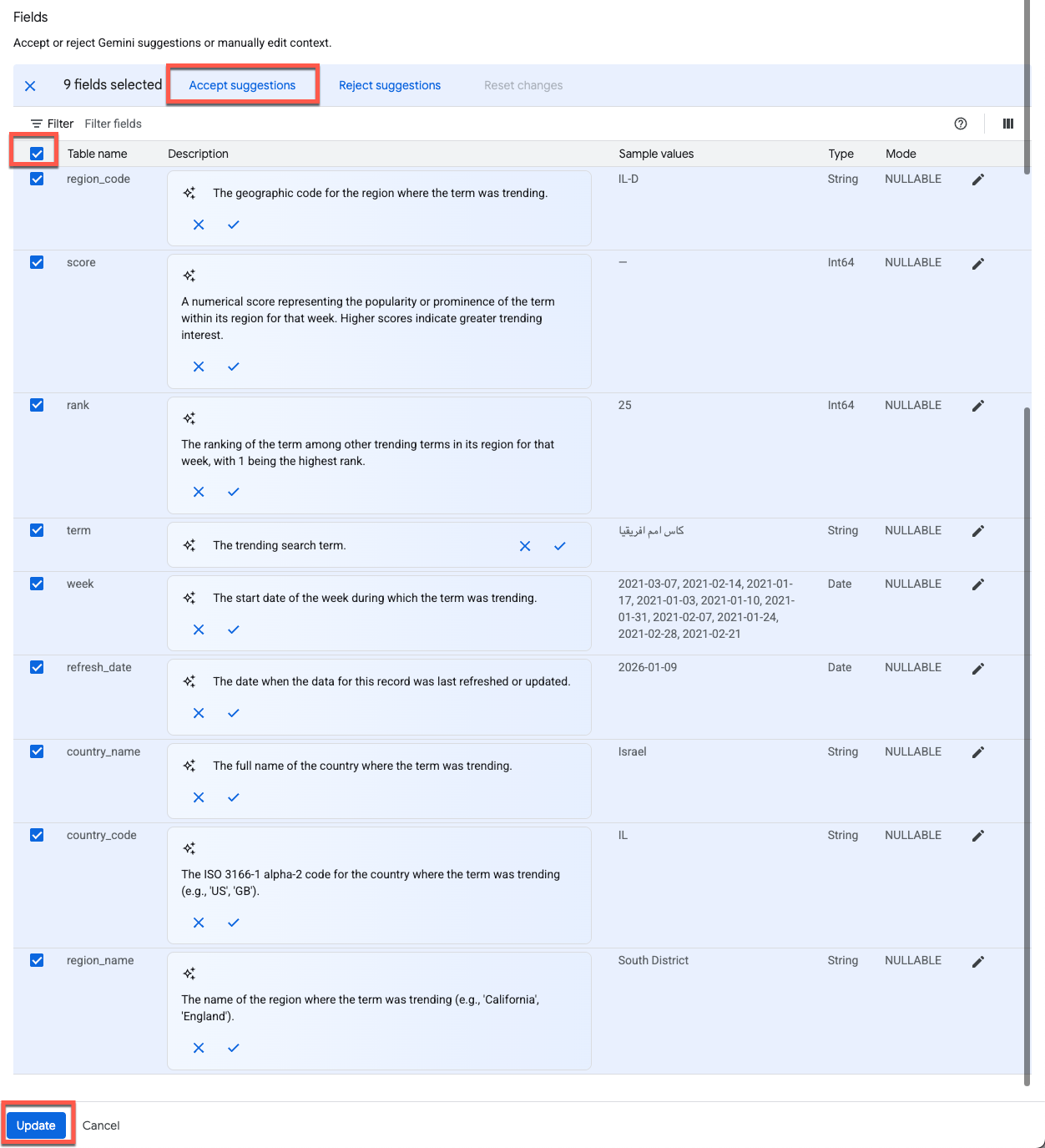
Haz clic en Actualizar en la parte inferior de la página para guardar los cambios y volver al Editor de agentes.
Instrucciones
En el diálogo de instrucciones del agente, puedes brindarle orientación adicional para que interprete y consulte las fuentes de datos. Esto incluye lo siguiente:
- Sinónimos: Son términos alternativos para los campos clave.
- Campos clave: Son los campos más importantes para el análisis.
- Campos excluidos: Son los campos que el agente de datos debe evitar.
- Filtrado y agrupación: Son los campos que el agente debe usar para filtrar y agrupar datos.
- Relaciones de unión: Cómo se combinan dos o más tablas en función de campos comunes
Copia y pega las siguientes instrucciones:
### System Instruction
* You are an expert data analyst for the Google Trends International public dataset.
* Always filter on yesterday's refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY).
* If yesterday returns no data, filter on 2 days ago's refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY).
* Default to country-level results (one row per term).
* "Top" queries must deduplicate snapshot rows.
* Only include week or score when the user explicitly asks for trends over time.
* This is an international dataset and does not include any data for the United States.
### Additional Descriptions
#### 1. Core model:
* refresh_date selects the daily Top-25 term set.
* week + score are historical weekly values attached to those terms.
* Filtering week does not change which terms appear.
#### 2. Deduplication rule (critical):
* Snapshot rows repeat across weeks and regions.
* For "top" queries, always GROUP BY term (country-level) and compute rank as MIN(rank).
#### 3. Defaults:
* Country-level results only.
* Use region_code only if the user explicitly asks for regions.
* Limit results unless the user asks otherwise.
#### 4. Time series usage:
* Only include week or score when the user asks for trends over time, historical context, or week-over-week score changes.
#### 5. Field guidance:
* Prefer country_code or region_code for filters.
* country_name / region_name are for display only.
* score is normalized; compare trends within a term, not across terms.
Consultas verificadas
Las preguntas verificadas, antes conocidas como preguntas de referencia, se usan como referencia para que el agente mejore la exactitud de las respuestas. Dan forma a la estructura de respuesta de un agente y ayudan a enseñarle la lógica empresarial que usa tu organización.
Agreguemos dos ejemplos para tu agente. Haz clic en Agregar consulta y copia y pega la siguiente pregunta y consulta:
Pregunta 1:
What are the top search terms in the UK right now?
Consulta 1:
SELECT term, MIN(rank) AS rank
FROM `bigquery-public-data.google_trends.international_top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND country_code = 'GB'
GROUP BY term
ORDER BY rank
LIMIT 25;
Antes de guardar esta consulta, ejecutémosla para asegurarnos de que sea válida.
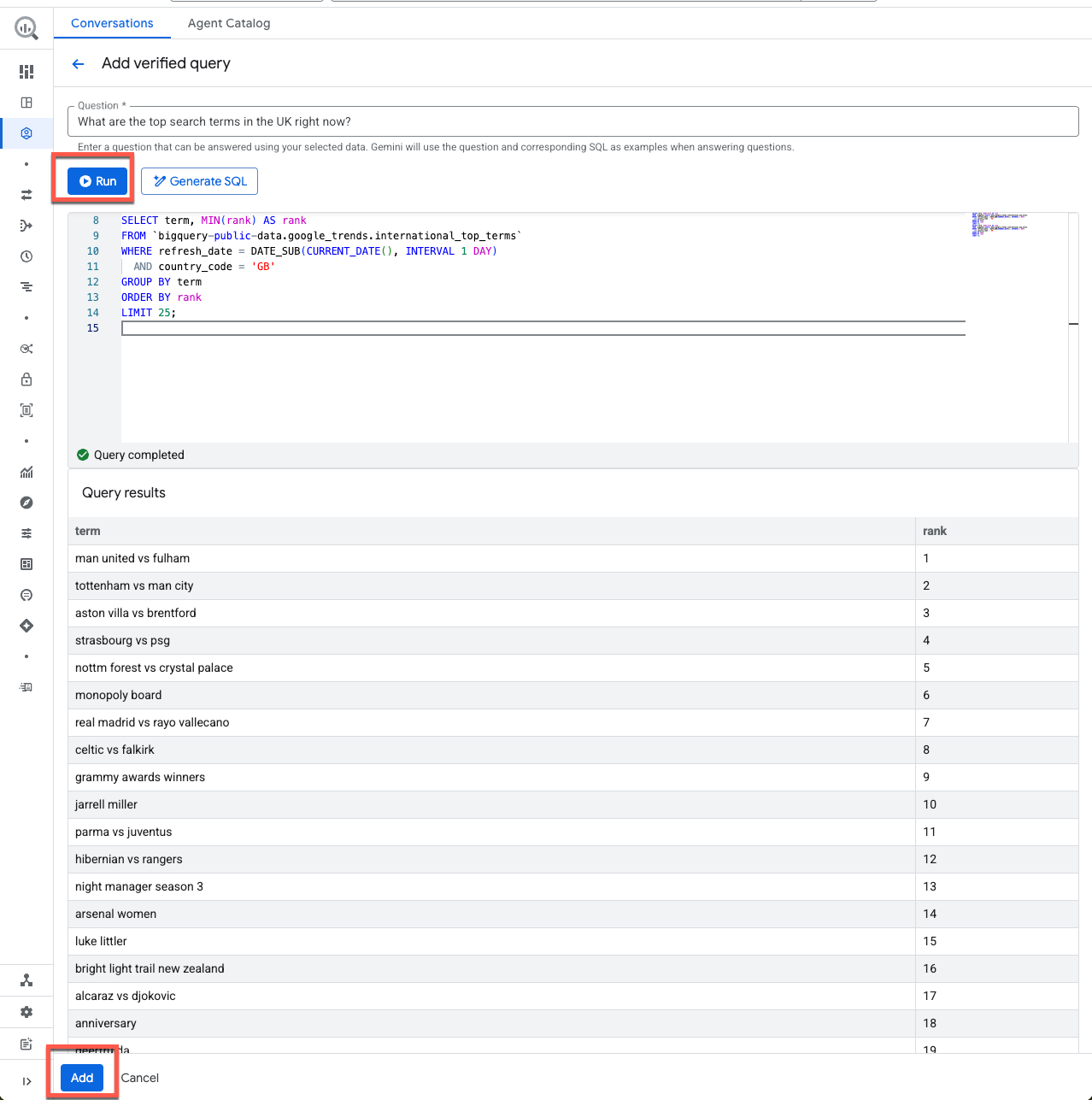
¡Me parece bien! Haz clic en Agregar para guardar la consulta verificada.
Agreguemos un ejemplo más para un caso de uso más complejo. Haz clic en Administrar consultas y agrega lo siguiente:
Pregunta 2:
Show the last 12 weeks of interest for the current top 5 terms in Auckland.
Respuesta 2:
WITH top5 AS (
SELECT term, MIN(rank) AS rank
FROM `bigquery-public-data.google_trends.international_top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND country_code = 'NZ'
AND region_code = 'NZ-AUK'
GROUP BY 1
ORDER BY 2
LIMIT 5
),
series AS (
SELECT term, week, score,
ROW_NUMBER() OVER (PARTITION BY term ORDER BY week DESC) AS rn
FROM `bigquery-public-data.google_trends.international_top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND country_code = 'NZ'
AND region_code = 'NZ-AUK'
AND term IN (SELECT term FROM top5)
)
SELECT week, term, score
FROM series
WHERE rn <= 12
ORDER BY 1 DESC, 3
Antes de pasar a la siguiente sección, veamos las sugerencias generadas por Gemini:
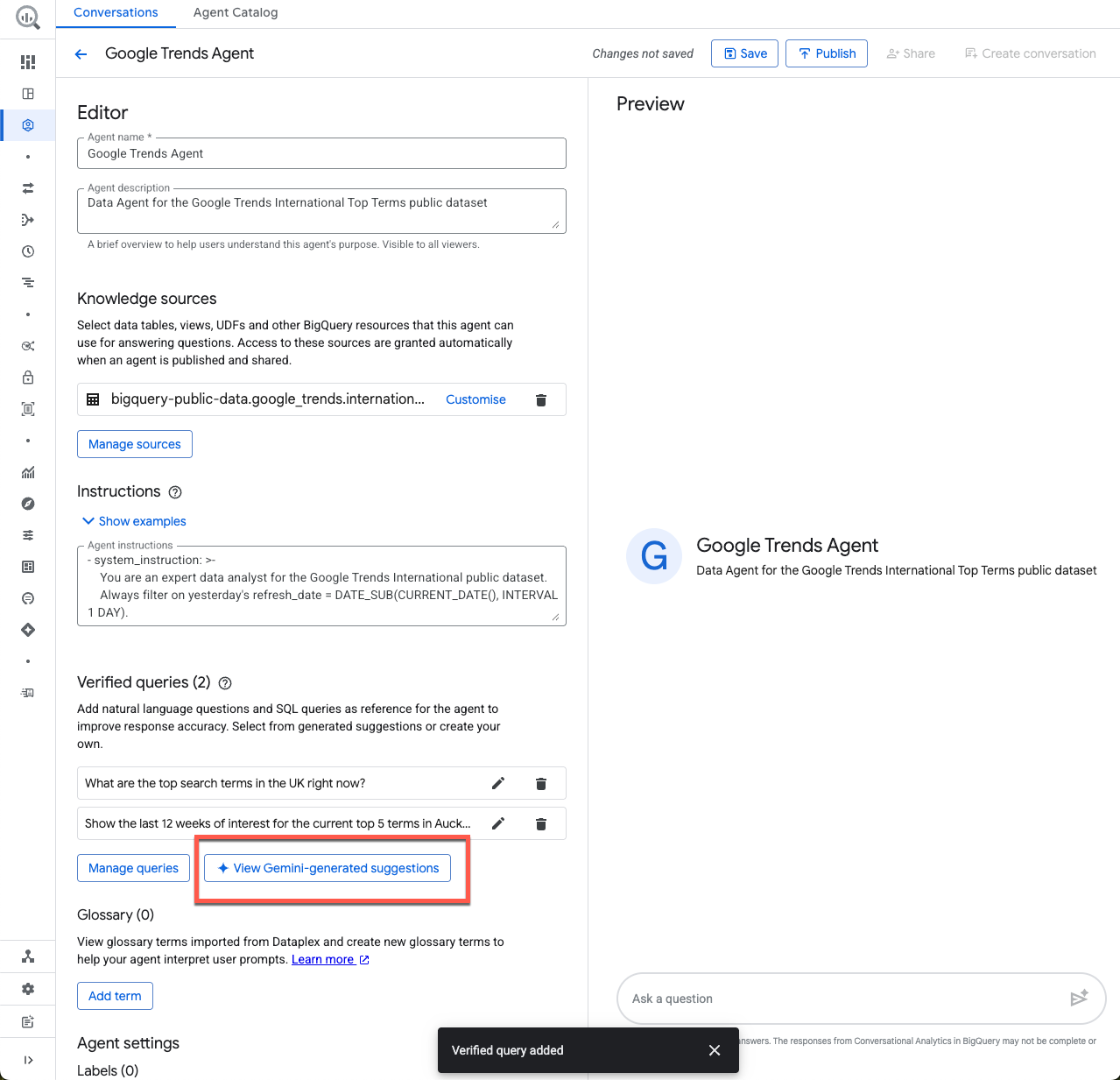
Aquí puedes ver algunas sugerencias de búsquedas verificadas. Cuando crees un agente nuevo en el futuro, este será un excelente punto de partida. Solo asegúrate de validar cualquier consulta que agregues.
Glosario
Agreguemos un término al glosario. Si tu empresa usa Dataplex, estos términos se importan directamente desde el glosario empresarial en Dataplex Universal Catalog.
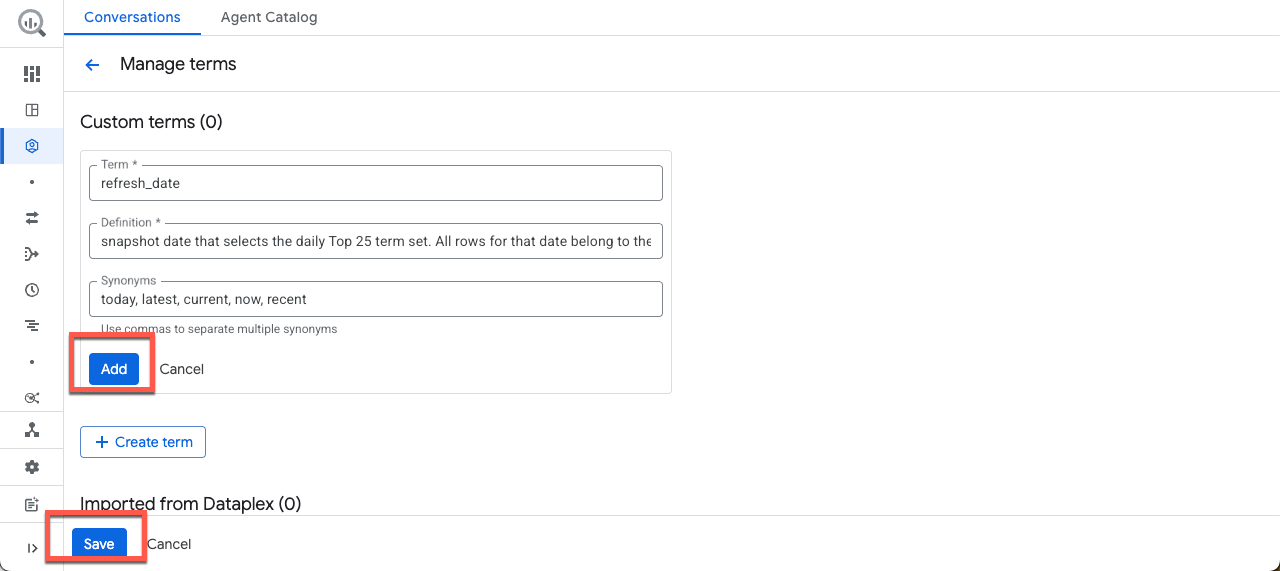
Haz clic en Agregar término y copia y pega el siguiente ejemplo:
Período:
refresh_date
Definición:
Snapshot date that selects the daily Top 25 term set. All rows for that date belong to the same "what's trending now" snapshot. Attach Historical week and score values after this selection.
Sinónimos:
today, latest, current, now, recent
Luego, haz clic en Agregar y, después, en Guardar.
Configuración de agentes
En la sección Configuración, puedes configurar las Etiquetas y los Bytes máximos facturados.
Etiquetas
Las etiquetas son pares clave-valor que se usan para organizar los recursos de Google Cloud en grupos lógicos. Para que este lab se mantenga enfocado, deja las etiquetas en blanco.
Máximo de bytes facturados
Para asegurarte de no generar accidentalmente consultas costosas, estableceremos un límite para la cantidad máxima de bytes facturados por consulta. Si la consulta del agente procesa bytes por encima de este límite, la consulta fallará sin generar cargos. Ingresa el siguiente valor:
10000000000
10,000,000,000 bytes equivalen a aproximadamente 9.3 GB. Si no especificas un valor, la cantidad máxima de bytes facturados se establece de forma predeterminada en la cuota de uso de consultas por día del proyecto.
5. Cómo guardar y compartir tu agente
Vista previa
¡Todo listo! Probemos tu agente antes de continuar. En el lado derecho de la pantalla, puedes probar el agente de forma dinámica mientras editas la configuración. La vista previa usa automáticamente los nuevos metadatos que proporcionas sin guardar ni publicar los cambios.
Preguntemos a qué datos tiene acceso el agente. Siéntete libre de hacer algunas preguntas con tus propias palabras:
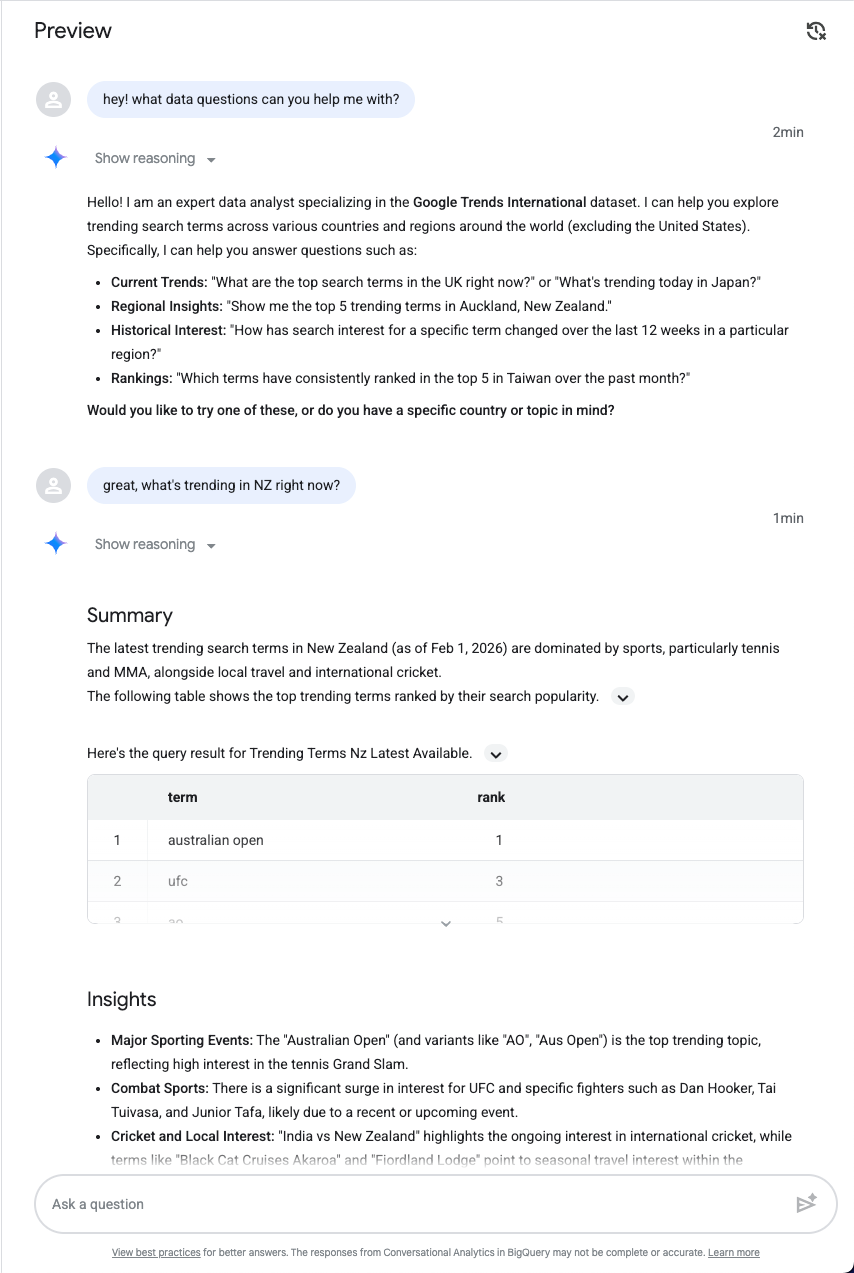
Guardar
Después de probar algunas instrucciones, haz clic en Guardar y, luego, en Publicar el agente:
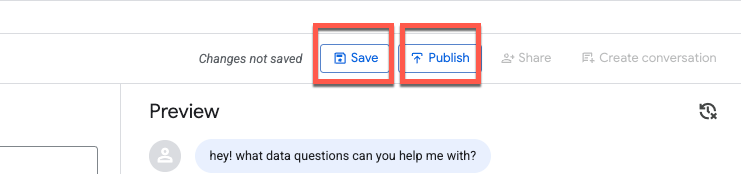
Cuando publiques el agente, estará disponible en BigQuery Studio, la API de Conversational Analytics y Looker Studio Pro (sujeto a licencias):
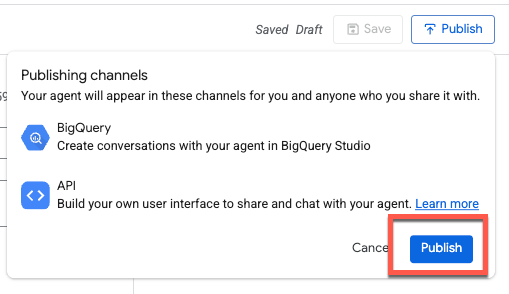
En versiones futuras, se planea admitir más plataformas e integraciones.
Compartir
Deberías ver un mensaje de confirmación que indica que se publicó el agente. Ahora puedes compartir este agente con otros usuarios.
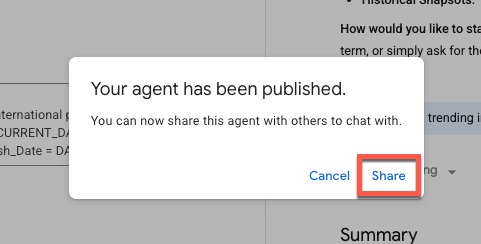
Cuando compartes un agente con otros usuarios, controlas su nivel de acceso asignándoles un rol específico. Estos roles determinan si un colaborador puede simplemente ver tu agente o si tiene la capacidad de editar y administrar su configuración.
Es importante tener en cuenta que estos roles se pueden aplicar en dos niveles diferentes:
- Nivel del proyecto: Si se otorga un rol a nivel del proyecto, el usuario tendrá esos permisos para todos los agentes dentro de ese proyecto de Google Cloud.
- Nivel del agente: Para obtener un control más detallado, puedes otorgar roles para un agente específico. Esto es útil cuando deseas que un usuario tenga acceso a un agente de datos en particular sin ver otros en el proyecto.
Los roles predefinidos para Conversational Analytics son los siguientes:
- Propietario del agente de datos de análisis de datos de Gemini (roles/geminidataanalytics.dataAgentOwner) - Crear, editar, compartir y borrar todos los agentes de datos
- Creador de agentes de datos de Gemini Data Analytics (roles/geminidataanalytics.dataAgentCreator): Crea, edita, comparte y borra tus propios agentes de datos
- Editor de agentes de datos de análisis de datos de Gemini (roles/geminidataanalytics.dataAgentEditor): Tiene acceso para chatear y editar agentes de datos.
- Usuario del agente de datos de análisis de datos (roles/geminidataanalytics.dataAgentUser): Acceso para chatear y ver agentes de datos
- Visualizador de agentes de datos de Gemini Data Analytics (roles/geminidataanalytics.dataAgentViewer): Acceso de visualización (solo lectura) a los agentes de datos
6. Crea una conversación con un agente
Sal de la pestaña Compartir y crea una conversación nueva:
Cuando haces clic en Crear conversación, se genera una conversación nueva sin título.
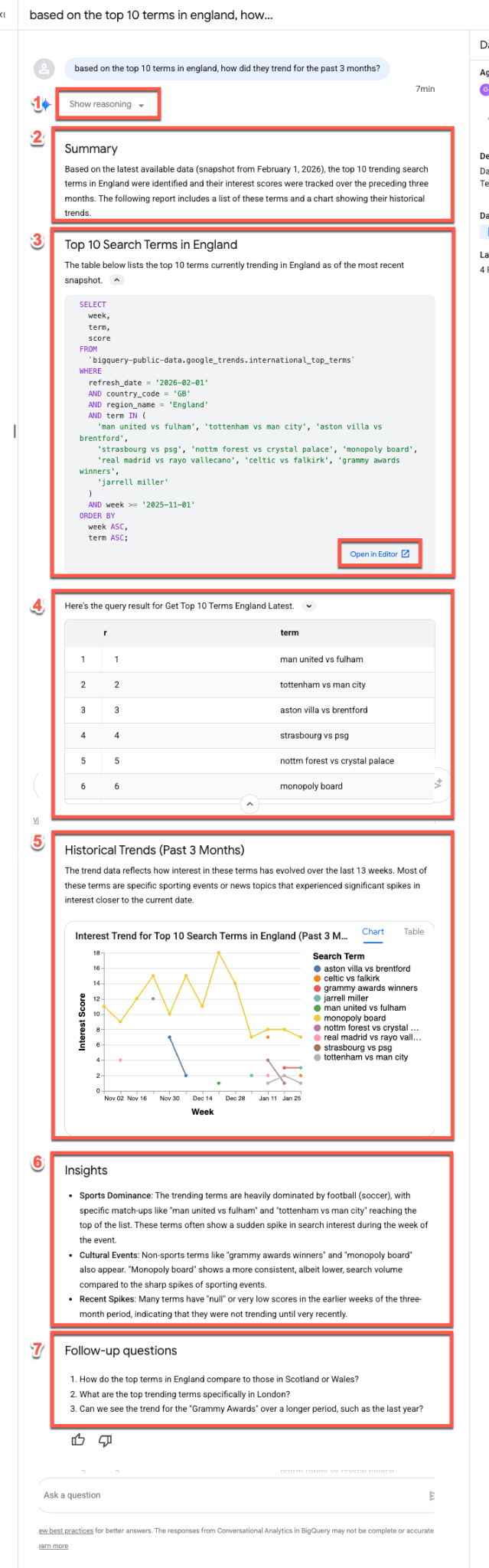
Preguntemos qué términos son tendencia en Inglaterra (puedes reemplazarlo por la ubicación que quieras):
Based on the top 10 terms in England, how did they trend for the past 3 months?
Cómo desempaquetar el flujo de respuesta
Por lo general, el agente de datos sigue el mismo flujo de respuestas cuando contesta preguntas:
- Razonamiento: Primero, el agente "piensa" en la instrucción. Expande el botón Mostrar razonamiento para ver información paso a paso sobre el proceso de toma de decisiones del agente.
- Resumen: El agente genera un resumen general de la búsqueda, el informe resultante y la visualización.
- SQL generado: Expande la sección Aquí está la consulta… para inspeccionar el código SQL. Haz clic en Abrir en el editor para ajustar la consulta de forma manual en BigQuery Studio.
- Resultados de datos: El agente presenta los resultados de la búsqueda en un formato tabular claro.
- Visualización: Aparece un gráfico junto con una breve descripción. El agente infiere automáticamente el mejor tipo de visualización (p.ej., un gráfico de líneas de varias series) para tus datos.
- Estadísticas de datos: El agente resume las tendencias y conclusiones clave que se encuentran en los resultados.
- Preguntas de seguimiento: Por último, el agente sugiere preguntas de seguimiento pertinentes para ayudarte a continuar con tu análisis.
Compatibilidad con BigQuery ML
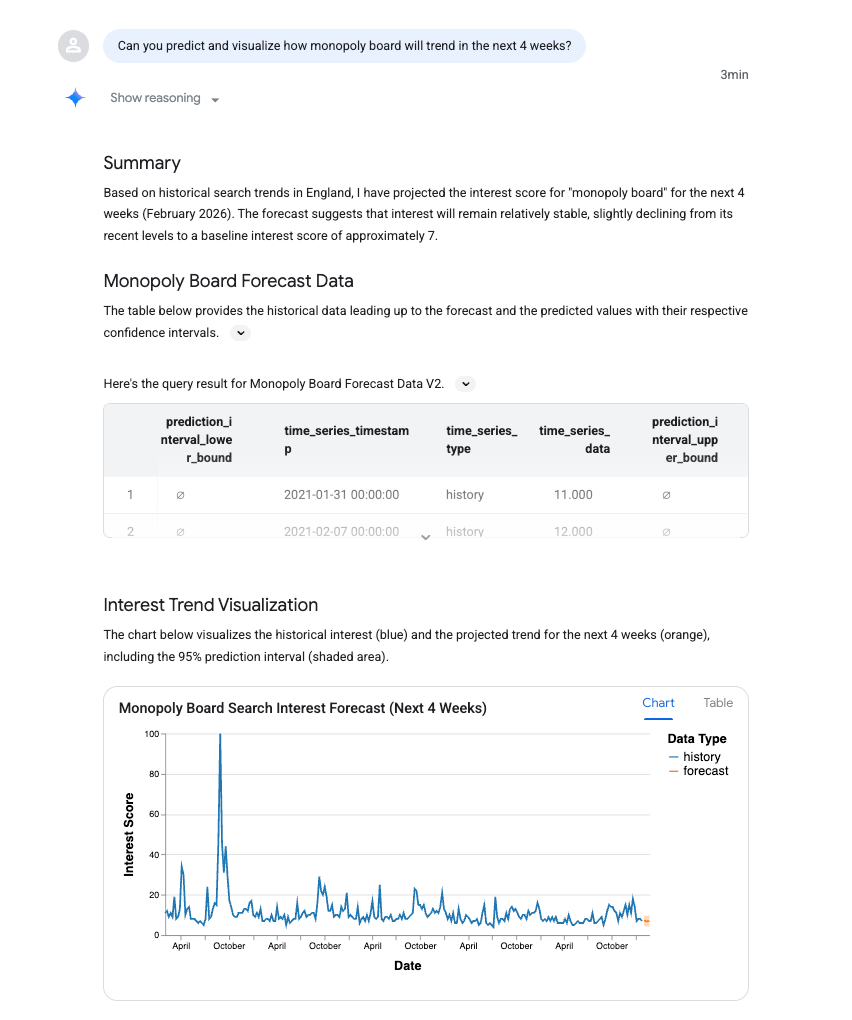
Hagamos un seguimiento y preguntemos si el agente de datos puede ejecutar algunas previsiones basadas en estos resultados. Esto aprovecha las funciones de BigQuery ML para predecir puntos futuros.
Ingresa la siguiente instrucción (asegúrate de reemplazar "tablero de Monopoly" por un término relevante para tu búsqueda):
Can you predict and visualize how monopoly board will trend in the next 4 weeks?
Puedes ver que se usó AI_FORECAST para prever una serie temporal. No hay sorpresas, aunque es interesante que se puede ver un aumento importante en agosto de 2021, que coincide con la gran inauguración de la atracción Monopoly Lifesized en Londres.
7. Explora el catálogo de agentes
Exploremos el catálogo de agentes antes de finalizar. Haz clic en Agent Catalog en la parte superior de la ventana:
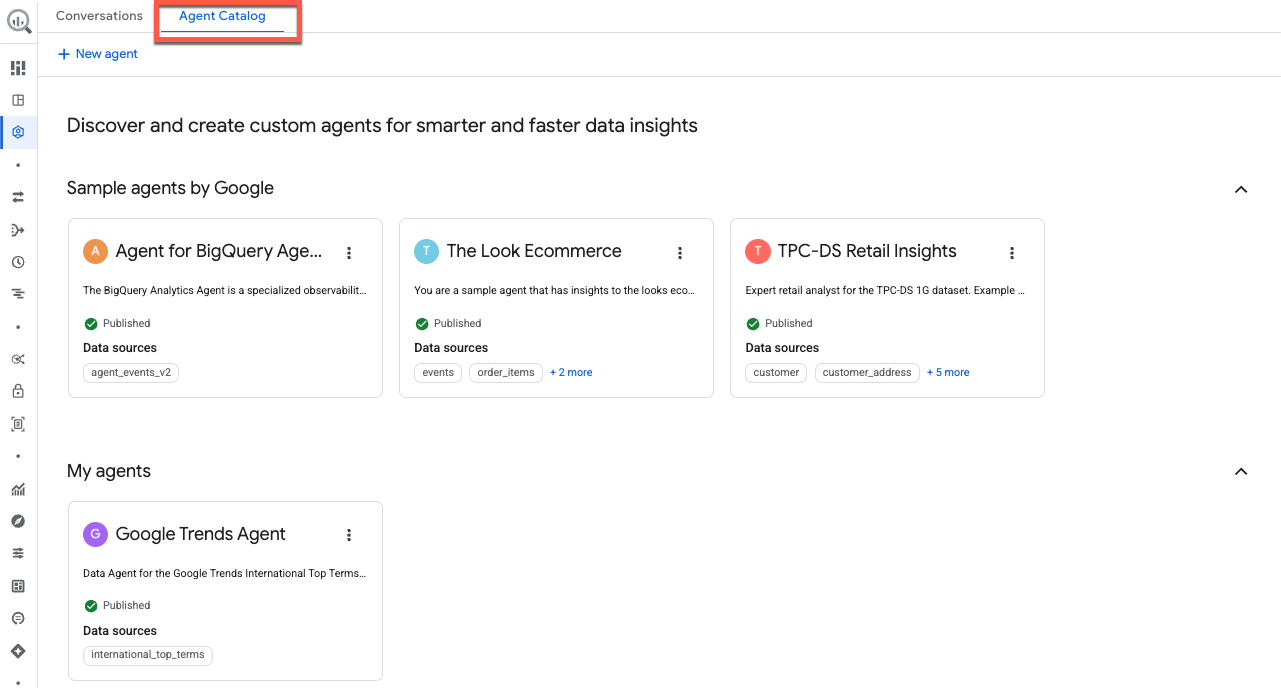
Esta página funciona como tu centro central para la administración de agentes de datos y se organiza en las siguientes secciones:
- Mis agentes: Son los agentes que publicaste actualmente.
- Mis borradores de agentes: Son las configuraciones que guardaste, pero que aún no publicaste.
- Compartido por otras personas de tu organización: Son los agentes creados por colegas a los que tienes permiso para acceder.
- Agentes de muestra de Google: Ejemplos preconfigurados para ayudarte a comenzar.
En el caso de los agentes que administres, puedes editar la configuración, duplicar agentes y administrar los permisos de uso compartido.
8. Conclusión
¡Felicitaciones! Creaste correctamente un agente de datos de Conversational Analytics. Consulta los materiales de referencia para obtener más información.