
1. परिचय
डेटा से अहम जानकारी पाने में अक्सर काफ़ी समय और मेहनत लगती है. साथ ही, इसके लिए एसक्यूएल की अच्छी जानकारी होना भी ज़रूरी है. इस कोडलैब में, BigQuery के एजेंट कैटलॉग के बारे में बताया जाएगा. यह एक नया प्लैटफ़ॉर्म है, जो बातचीत करने वाले डेटा एजेंट की मदद से, एआई पर आधारित अहम जानकारी तुरंत उपलब्ध कराता है.
इसमें, डेटा एजेंट बनाकर, टेक्स्ट-टू-एसक्यूएल कन्वर्ज़न से आगे बढ़कर काम किया जा सकता है. इसमें, एजेंट को कारोबारी संदर्भ, सिस्टम के निर्देश, और पुष्टि की गई क्वेरी की जानकारी देकर, सटीक नतीजे पाने का तरीका बताया जाएगा. इसके बाद, इस एजेंट को पब्लिश किया जाएगा, ताकि आपके संगठन के अन्य लोग इसका इस्तेमाल कर सकें.
ज़रूरी शर्तें
- Google Cloud की बुनियादी जानकारी
आपको क्या सीखने को मिलेगा
- BigQuery के एजेंट कैटलॉग पर नेविगेट करने का तरीका
- कस्टम एजेंट बनाने और नॉलेज सोर्स तय करने का तरीका
- सिमैंटिक मेटाडेटा जनरेट करने के लिए, Gemini का इस्तेमाल करने का तरीका
- एजेंट को निर्देश देने के लिए, सिस्टम के निर्देश और पुष्टि की गई क्वेरी जोड़ने का तरीका
- एजेंट पब्लिश और शेयर करने का तरीका
आपको क्या चाहिए
- Google Cloud खाता और Google Cloud प्रोजेक्ट
- BigQuery और एसक्यूएल की बुनियादी जानकारी
- Chrome जैसा वेब ब्राउज़र
2. सेटअप और ज़रूरी शर्तें
कोई प्रोजेक्ट चुनें
- Google Cloud Console में साइन इन करें और नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. अगर आपके पास Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.

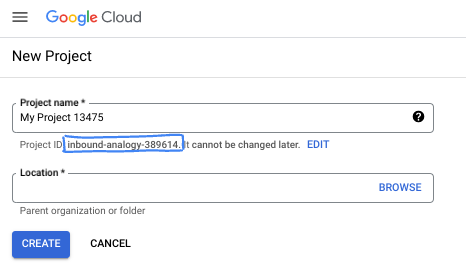
- प्रोजेक्ट का नाम , इस प्रोजेक्ट में शामिल लोगों के लिए डिसप्ले नेम होता है. यह एक कैरेक्टर स्ट्रिंग है, जिसका इस्तेमाल Google API नहीं करते. इसे कभी भी अपडेट किया जा सकता है.
- प्रोजेक्ट आईडी , Google Cloud के सभी प्रोजेक्ट के लिए यूनीक होता है. इसे बदला नहीं जा सकता. यानी, सेट करने के बाद इसे बदला नहीं जा सकता. Cloud Console, अपने-आप एक यूनीक स्ट्रिंग जनरेट करता है. आम तौर पर, आपको इस बारे में चिंता करने की ज़रूरत नहीं होती कि यह स्ट्रिंग क्या है. ज़्यादातर कोडलैब में, आपको अपने प्रोजेक्ट आईडी का रेफ़रंस देना होगा. इसे आम तौर पर
PROJECT_IDके तौर पर पहचाना जाता है. अगर आपको जनरेट किया गया आईडी पसंद नहीं है, तो कोई दूसरा रैंडम आईडी जनरेट किया जा सकता है. इसके अलावा, अपना आईडी भी आज़माया जा सकता है और देखा जा सकता है कि यह उपलब्ध है या नहीं. इस चरण के बाद, इसे बदला नहीं जा सकता. यह प्रोजेक्ट की पूरी अवधि के लिए यही रहेगा. - आपकी जानकारी के लिए बता दें कि एक तीसरी वैल्यू भी होती है, जो प्रोजेक्ट नंबर है. इसका इस्तेमाल कुछ एपीआई करते हैं. इन तीनों वैल्यू के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
- इसके बाद, Cloud के संसाधनों/एपीआई का इस्तेमाल करने के लिए, आपको Cloud Console में बिलिंग चालू करनी होगी. इस कोडलैब को पूरा करने में ज़्यादा खर्च नहीं आएगा. इस ट्यूटोरियल के बाद बिलिंग से बचने के लिए, बनाए गए संसाधनों को मिटाया जा सकता है या प्रोजेक्ट को मिटाया जा सकता है. Google Cloud के नए उपयोगकर्ताओं को, 300 डॉलर का क्रेडिट मिलेगा, ताकि वे मुफ़्त में आज़मा सकें.
3. शुरू करने से पहले
ज़रूरी रोल असाइन करना
प्रोजेक्ट के IAM पेज पर जाएं और खुद को Gemini Data Analytics के डेटा एजेंट का मालिक रोल असाइन करें:
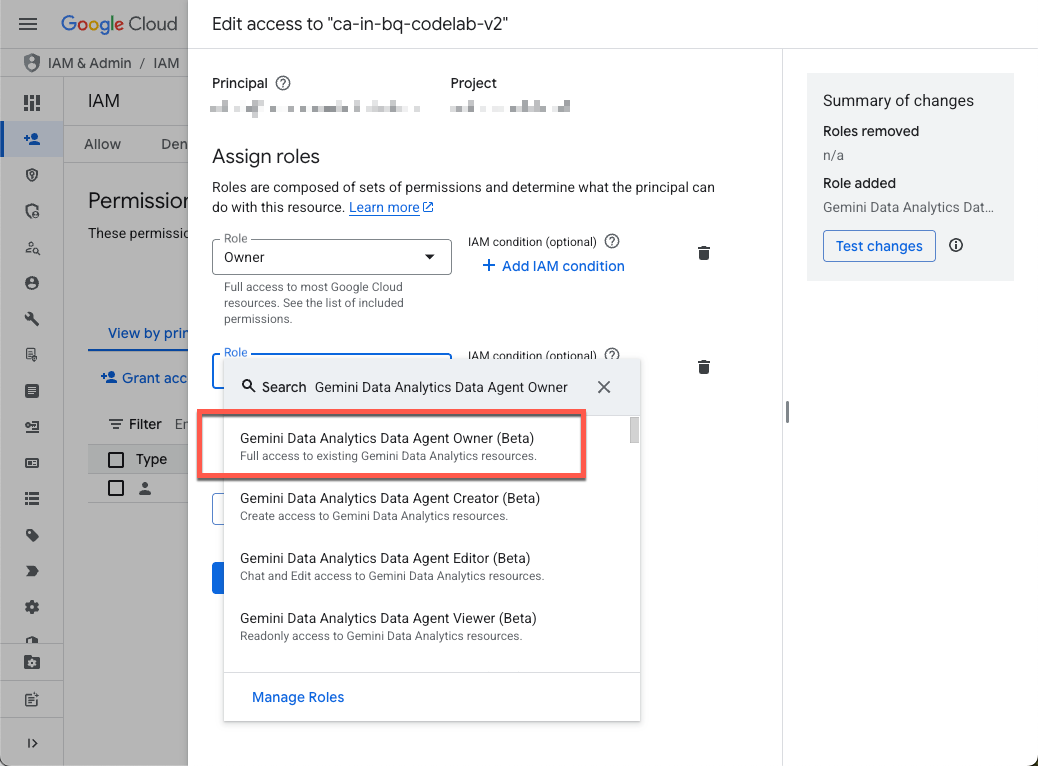
इस रोल से, आपको प्रोजेक्ट में सभी डेटा एजेंट बनाने, उनमें बदलाव करने, उन्हें शेयर करने, और मिटाने की अनुमति मिलती है.
ज़रूरी एपीआई चालू करना
BigQuery > एजेंट पर जाने के लिए, साइडबार नेविगेशन मेन्यू या पेज पर सबसे ऊपर मौजूद खोज मेन्यू का इस्तेमाल करें.
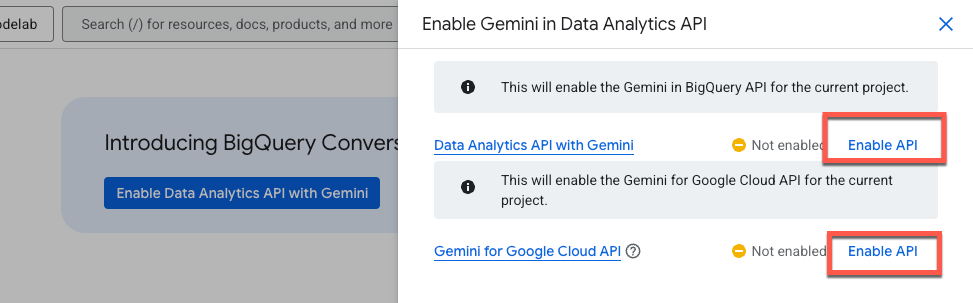
**Gemini के साथ Data Analytics API चालू करें** पर क्लिक करें:
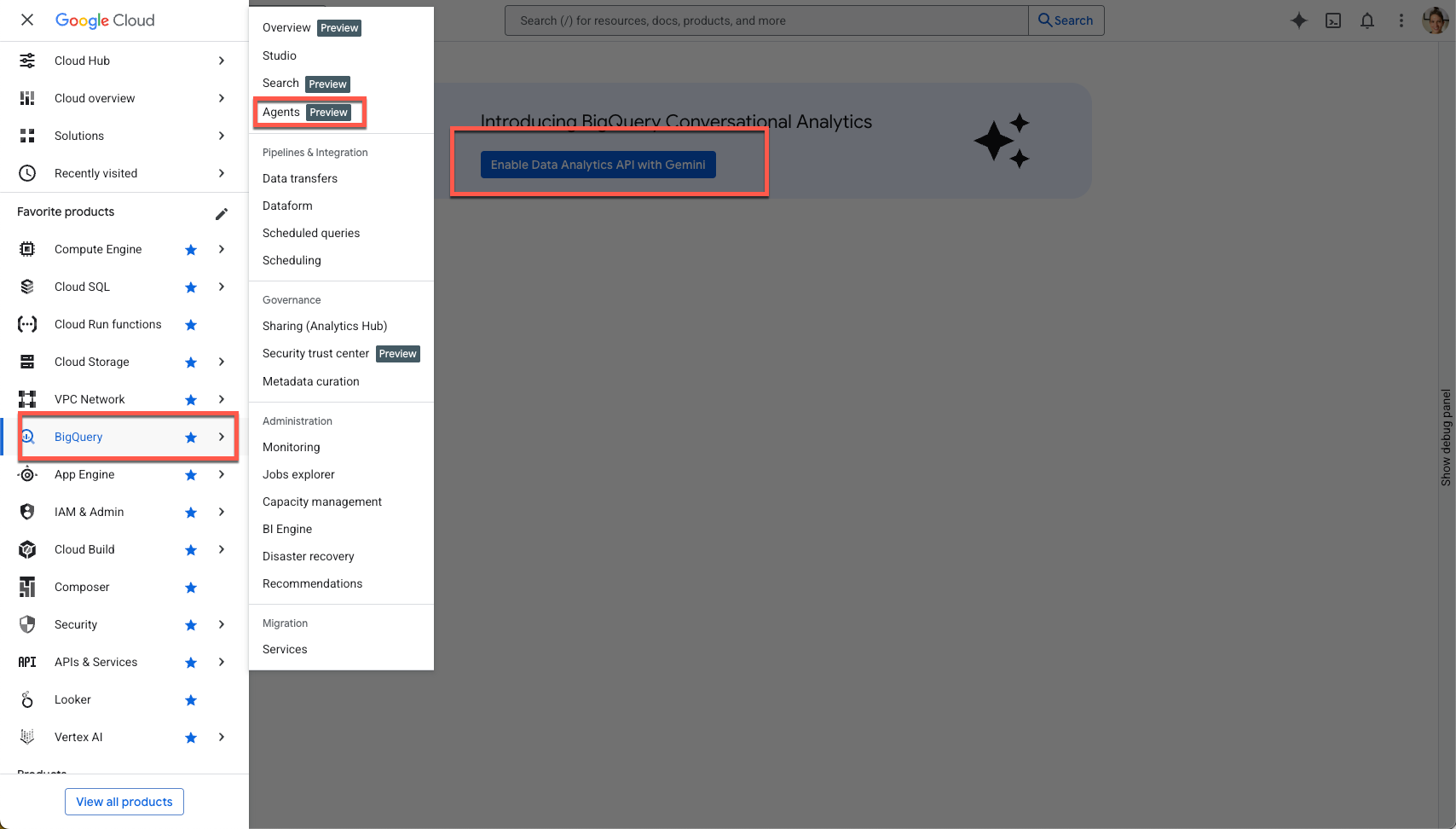
**BigQuery API में Gemini** और **Google Cloud API के लिए Gemini** , दोनों को चालू करें:
अब आपको एजेंट का नया पेज दिखेगा:
4. कोई एजेंट बनाएं
आइए, Google Trends के अंतरराष्ट्रीय सार्वजनिक डेटासेट का इस्तेमाल करके, अपना पहला डेटा एजेंट बनाएं. यह डेटासेट, इन सवालों के जवाब पाने में मददगार है कि अंतरराष्ट्रीय स्तर पर किन खोज शब्दों का ट्रेंड है और ऐतिहासिक तौर पर इन रुचियों की तुलना कैसे की जाती है.
आइए, सबसे पहले अपने एजेंट को कोई नाम और छोटा ब्यौरा दें. इस ब्यौरे का इस्तेमाल सिर्फ़ अन्य लोग, एजेंट के मकसद को समझने के लिए करते हैं.
एजेंट का नाम
Google Trends Agent
एजेंट की जानकारी
Data agent for the Google Trends International Top Terms public dataset
नॉलेज सोर्स
अब नॉलेज सोर्स जोड़ें. नॉलेज सोर्स, BigQuery की कोई टेबल, व्यू या यूडीएफ़ होता है. इसका इस्तेमाल एजेंट, सवालों के जवाब देने के लिए कर सकता है.
इस डेमो के लिए, सिर्फ़ एक टेबल जोड़ें, ताकि चीज़ें आसान रहें. हालांकि, ध्यान रखें कि ज़्यादा जटिल डेटा के लिए, हर एजेंट में 50 तक नॉलेज सोर्स जोड़े जा सकते हैं.
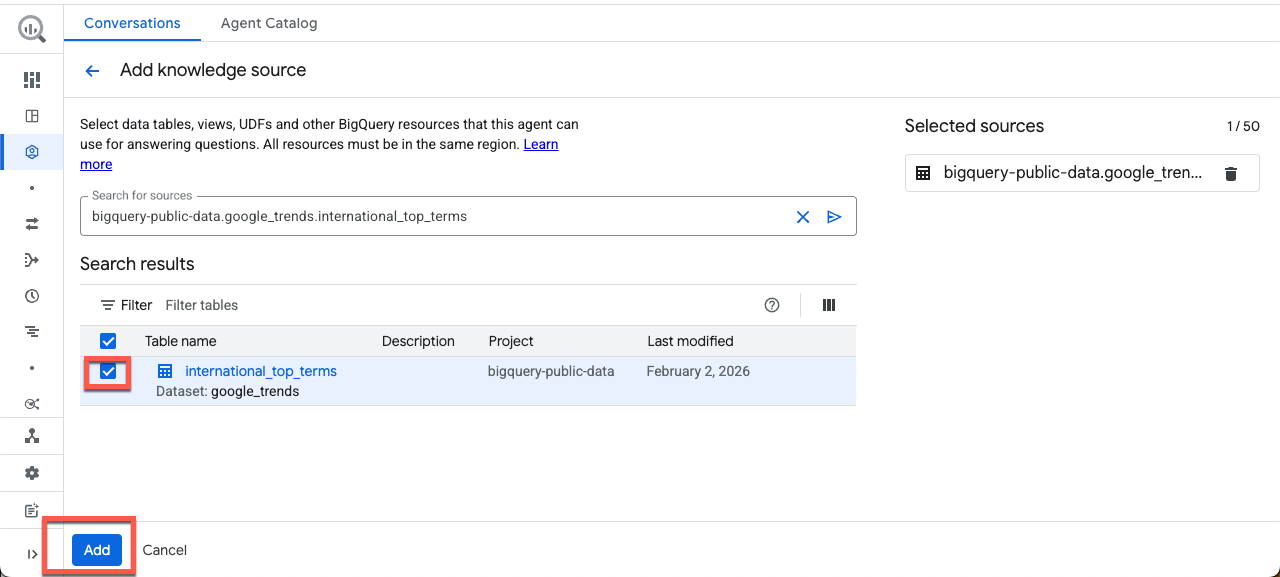
खोज बॉक्स में यह टेबल डालें, बॉक्स को चुनें, और जोड़ें पर क्लिक करें:
bigquery-public-data.google_trends.international_top_terms
स्ट्रक्चर्ड कॉन्टेक्स्ट
डेटा एजेंट की सटीकता को बेहतर बनाने के लिए, टेबल और कॉलम में स्ट्रक्चर्ड कॉन्टेक्स्ट जोड़ें. Customise पर क्लिक करें:

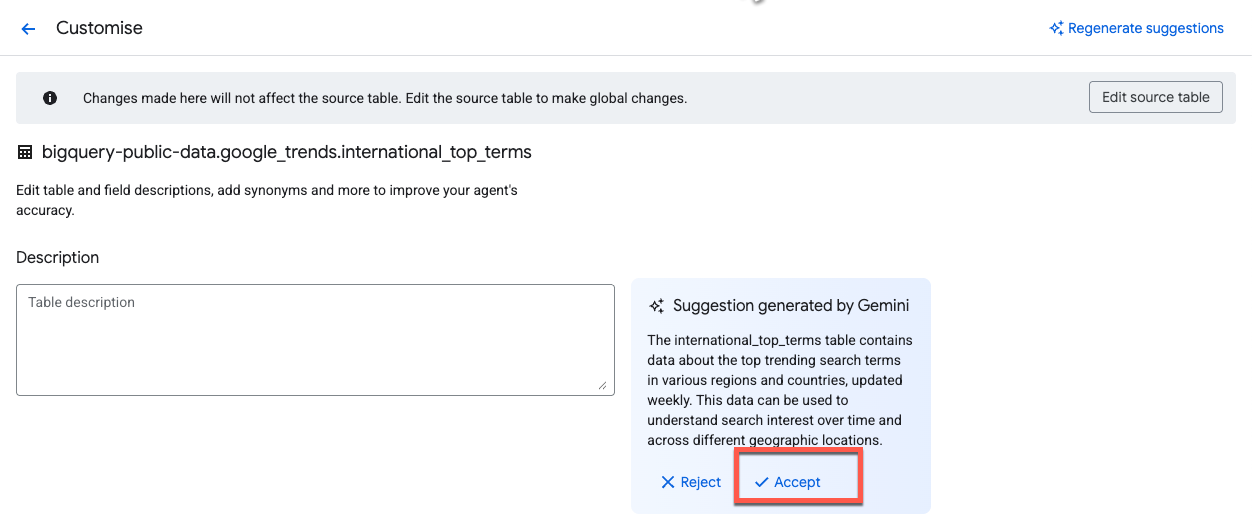
Gemini, ब्यौरे के लिए सुझाव अपने-आप जनरेट करता है. टेबल के ब्यौरे के बगल में मौजूद, स्वीकार करें पर क्लिक करें:
सभी कॉलम पर ब्यौरे लागू करने के लिए, सभी लाइनें चुनें को चुनें. इसके बाद, सुझाव स्वीकार करें पर क्लिक करें:
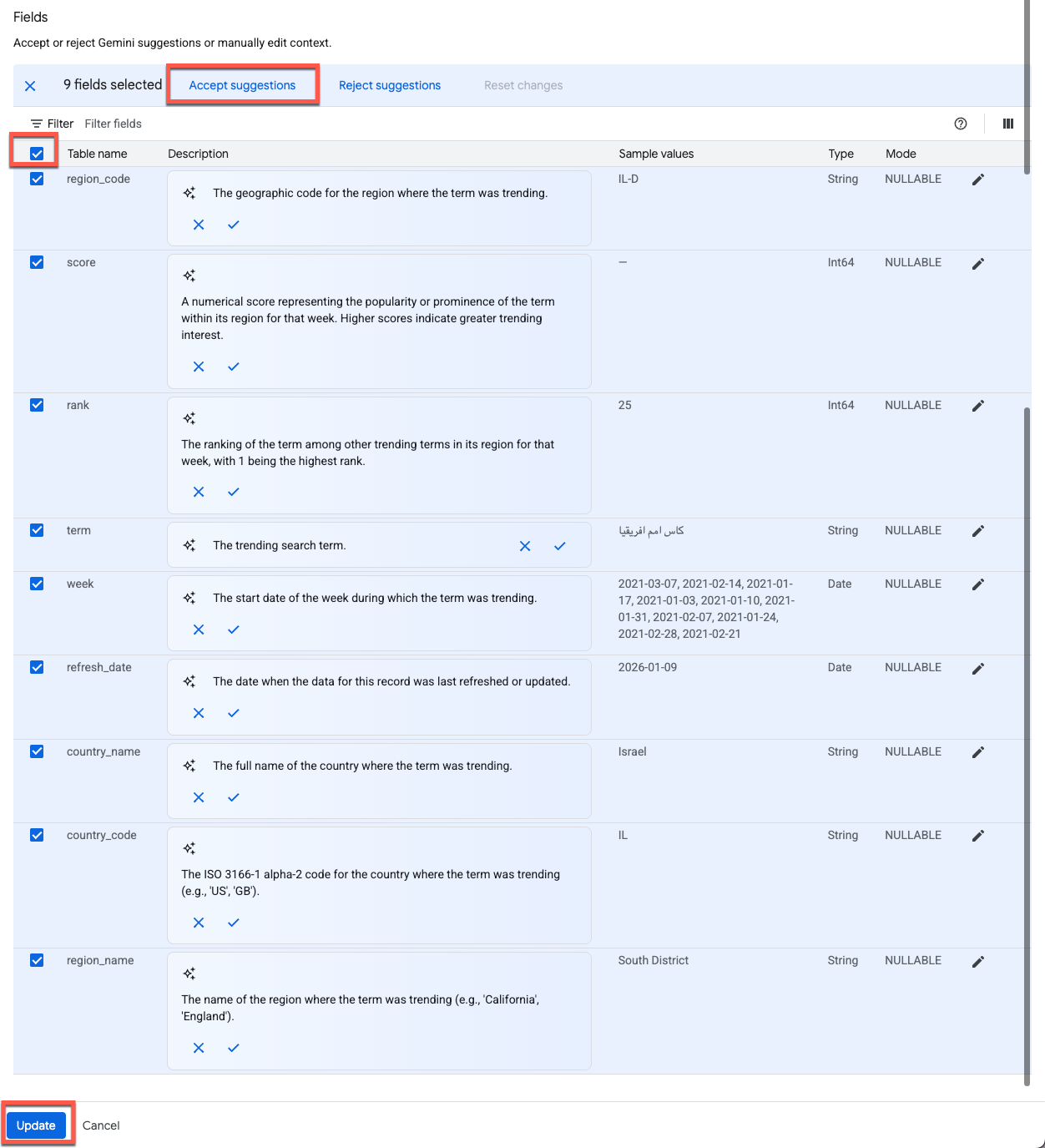
बदलाव सेव करने और एजेंट एडिटर पर वापस जाने के लिए, पेज पर सबसे नीचे मौजूद अपडेट करें पर क्लिक करें.
निर्देश
एजेंट के निर्देशों वाले डायलॉग में, एजेंट को डेटा सोर्स को समझने और उनसे क्वेरी करने के लिए अतिरिक्त निर्देश दिए जा सकते हैं. इसमें ये शामिल हैं:
- समानार्थी शब्द: मुख्य फ़ील्ड के लिए वैकल्पिक शब्द.
- मुख्य फ़ील्ड: विश्लेषण के लिए सबसे ज़रूरी फ़ील्ड.
- शामिल न किए गए फ़ील्ड: ऐसे फ़ील्ड जिनका इस्तेमाल डेटा एजेंट को नहीं करना चाहिए.
- फ़िल्टर करना और ग्रुप बनाना: ऐसे फ़ील्ड जिनका इस्तेमाल एजेंट को डेटा फ़िल्टर करने और ग्रुप बनाने के लिए करना चाहिए.
- जॉइन रिलेशनशिप: कॉमन फ़ील्ड के आधार पर, दो या इससे ज़्यादा टेबल को कैसे जोड़ा जाता है.
यहां दिए गए निर्देशों को कॉपी करके चिपकाएं:
### System Instruction
* You are an expert data analyst for the Google Trends International public dataset.
* Always filter on yesterday's refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY).
* If yesterday returns no data, filter on 2 days ago's refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY).
* Default to country-level results (one row per term).
* "Top" queries must deduplicate snapshot rows.
* Only include week or score when the user explicitly asks for trends over time.
* This is an international dataset and does not include any data for the United States.
### Additional Descriptions
#### 1. Core model:
* refresh_date selects the daily Top-25 term set.
* week + score are historical weekly values attached to those terms.
* Filtering week does not change which terms appear.
#### 2. Deduplication rule (critical):
* Snapshot rows repeat across weeks and regions.
* For "top" queries, always GROUP BY term (country-level) and compute rank as MIN(rank).
#### 3. Defaults:
* Country-level results only.
* Use region_code only if the user explicitly asks for regions.
* Limit results unless the user asks otherwise.
#### 4. Time series usage:
* Only include week or score when the user asks for trends over time, historical context, or week-over-week score changes.
#### 5. Field guidance:
* Prefer country_code or region_code for filters.
* country_name / region_name are for display only.
* score is normalized; compare trends within a term, not across terms.
पुष्टि की गई क्वेरी
पुष्टि की गई क्वेरी को पहले गोल्डन क्वेरी के तौर पर जाना जाता था. इनका इस्तेमाल, एजेंट के रेफ़रंस के तौर पर किया जाता है, ताकि जवाब सटीक हों. इनसे एजेंट के जवाब का स्ट्रक्चर तय होता है. साथ ही, इनसे एजेंट को आपके संगठन में इस्तेमाल किए जाने वाले कारोबारी नियम को समझने में मदद मिलती है.
आइए, आपके एजेंट के लिए दो उदाहरण जोड़ें. **क्वेरी जोड़ें** पर क्लिक करें. इसके बाद, यहां दिया गया सवाल और क्वेरी कॉपी करके चिपकाएं:
पहला सवाल:
What are the top search terms in the UK right now?
पहली क्वेरी:
SELECT term, MIN(rank) AS rank
FROM `bigquery-public-data.google_trends.international_top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND country_code = 'GB'
GROUP BY term
ORDER BY rank
LIMIT 25;
इस क्वेरी को सेव करने से पहले, आइए इसे चलाकर देखें, ताकि यह पक्का किया जा सके कि यह मान्य है.
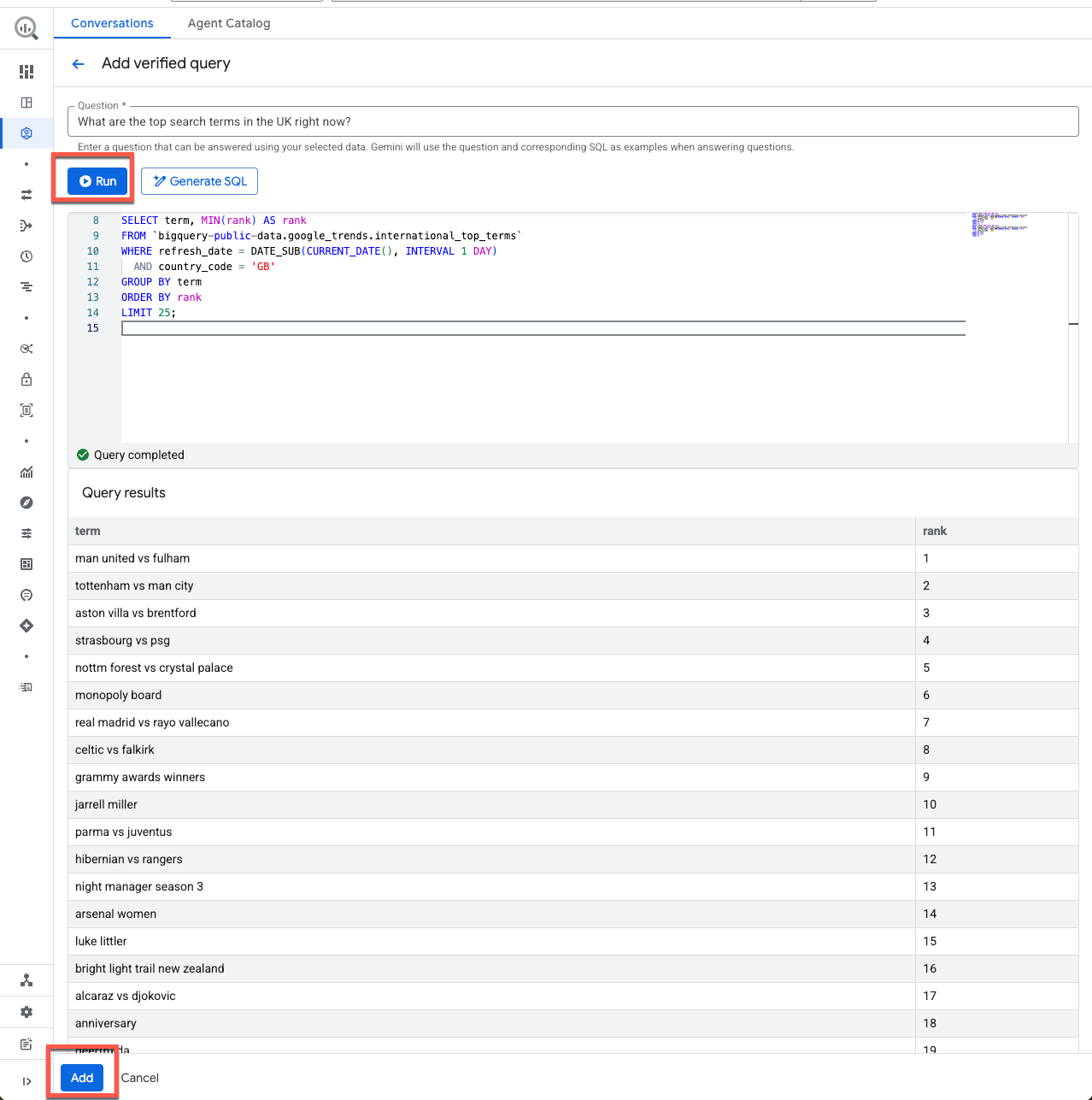
मुझे यह ठीक लग रहा है! पुष्टि की गई क्वेरी सेव करने के लिए, जोड़ें पर क्लिक करें.
आइए, ज़्यादा जटिल इस्तेमाल के लिए एक और उदाहरण जोड़ें. क्वेरी मैनेज करें पर क्लिक करें और यह जोड़ें:
दूसरा सवाल:
Show the last 12 weeks of interest for the current top 5 terms in Auckland.
दूसरा जवाब:
WITH top5 AS (
SELECT term, MIN(rank) AS rank
FROM `bigquery-public-data.google_trends.international_top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND country_code = 'NZ'
AND region_code = 'NZ-AUK'
GROUP BY 1
ORDER BY 2
LIMIT 5
),
series AS (
SELECT term, week, score,
ROW_NUMBER() OVER (PARTITION BY term ORDER BY week DESC) AS rn
FROM `bigquery-public-data.google_trends.international_top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND country_code = 'NZ'
AND region_code = 'NZ-AUK'
AND term IN (SELECT term FROM top5)
)
SELECT week, term, score
FROM series
WHERE rn <= 12
ORDER BY 1 DESC, 3
अगले सेक्शन पर जाने से पहले, आइए Gemini से जनरेट किए गए सुझाव देखें:
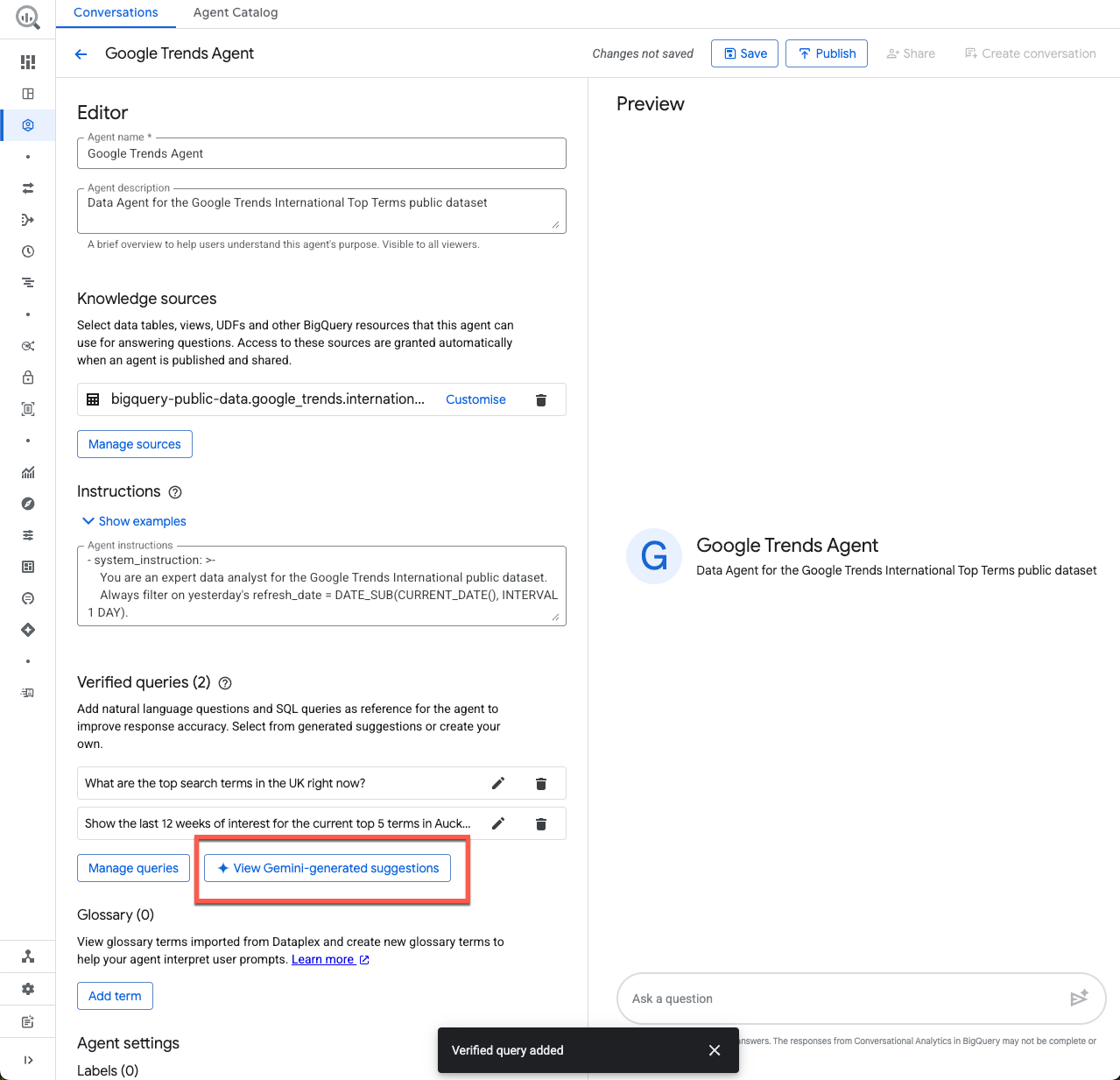
यहां, पुष्टि की गई कुछ क्वेरी के सुझाव देखे जा सकते हैं. आने वाले समय में, नया एजेंट बनाते समय यह एक अच्छा शुरुआती पॉइंट हो सकता है. बस यह पक्का करें कि जोड़ी गई हर क्वेरी मान्य हो!
शब्दावली
आइए, ग्लॉसरी में एक शब्द जोड़ें. अगर आपका कारोबार Dataplex का इस्तेमाल करता है, तो ये शब्द सीधे तौर पर Dataplex Universal Catalog में मौजूद कारोबारी ग्लॉसरी से इंपोर्ट किए जाते हैं.
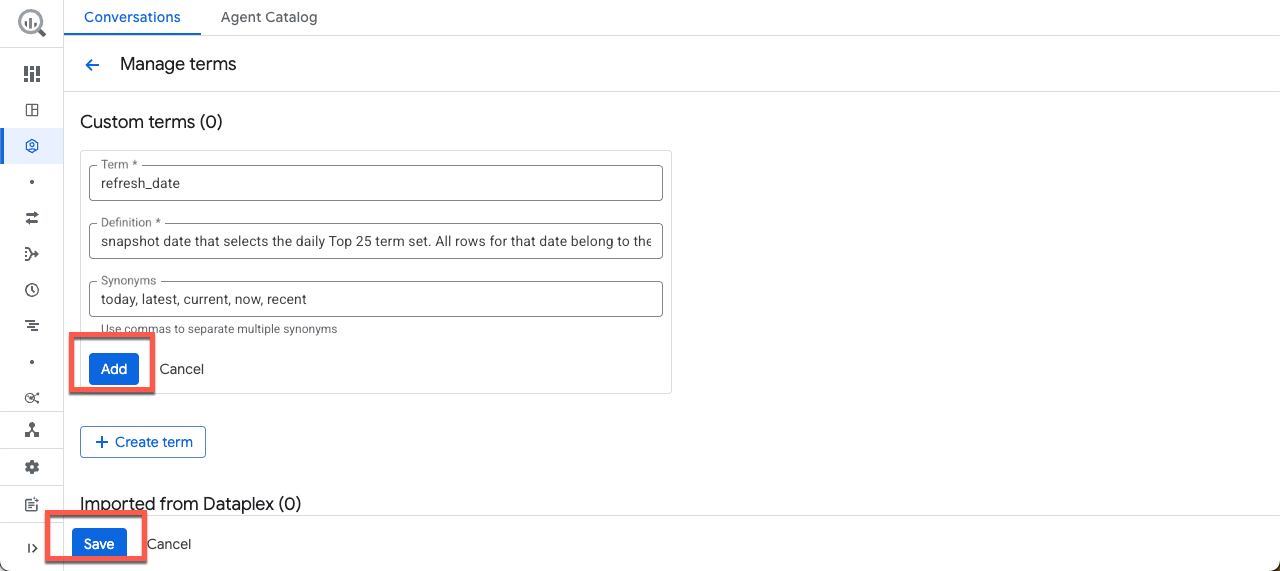
**शब्द जोड़ें** पर क्लिक करें. इसके बाद, यहां दिया गया उदाहरण कॉपी करके चिपकाएं:
शब्द:
refresh_date
परिभाषा:
Snapshot date that selects the daily Top 25 term set. All rows for that date belong to the same "what's trending now" snapshot. Attach Historical week and score values after this selection.
समानार्थी शब्द:
today, latest, current, now, recent
इसके बाद, जोड़ें पर क्लिक करें. फिर, सेव करें पर क्लिक करें.
एजेंट से जुड़ी सेटिंग
सेटिंग सेक्शन में, लेबल और बिल किए गए ज़्यादा से ज़्यादा बाइट को कॉन्फ़िगर किया जा सकता है.
लेबल
लेबल, की-वैल्यू पेयर होते हैं. इनका इस्तेमाल, Google Cloud के संसाधनों को लॉजिकल ग्रुप में व्यवस्थित करने के लिए किया जाता है. इस लैब को फ़ोकस में रखने के लिए, लेबल को खाली छोड़ दें.
बिल किए गए ज़्यादा से ज़्यादा बाइट
यह पक्का करने के लिए कि आपसे गलती से कोई महंगी क्वेरी जनरेट न हो जाए, आइए हर क्वेरी के लिए, बिल किए गए ज़्यादा से ज़्यादा बाइट की सीमा सेट करें. अगर एजेंट की क्वेरी, इस सीमा से ज़्यादा बाइट प्रोसेस करती है, तो क्वेरी को अस्वीकार कर दिया जाता है. हालांकि, इसके लिए कोई शुल्क नहीं लिया जाता. यह वैल्यू डालें:
10000000000
1,00,00,00,000 बाइट, करीब 9.3 जीबी के बराबर है. अगर कोई वैल्यू तय नहीं की जाती है, तो बिल किए गए ज़्यादा से ज़्यादा बाइट, डिफ़ॉल्ट रूप से प्रोजेक्ट के लिए हर दिन की क्वेरी के इस्तेमाल के कोटे के हिसाब से सेट हो जाते हैं.
5. अपने एजेंट को सेव और शेयर करना
झलक देखें
अब हम तैयार हैं! आगे बढ़ने से पहले, आइए अपने एजेंट को टेस्ट करें. स्क्रीन की दाईं ओर, कॉन्फ़िगरेशन में बदलाव करते समय, एजेंट को डाइनैमिक तरीके से टेस्ट किया जा सकता है. झलक में, आपके दिए गए नए मेटाडेटा का इस्तेमाल अपने-आप होता है. इसके लिए, बदलावों को सेव या पब्लिश करने की ज़रूरत नहीं होती.
आइए, यह सवाल पूछें कि एजेंट के पास किस डेटा का ऐक्सेस है. अपनी भाषा में कुछ सवाल पूछें:
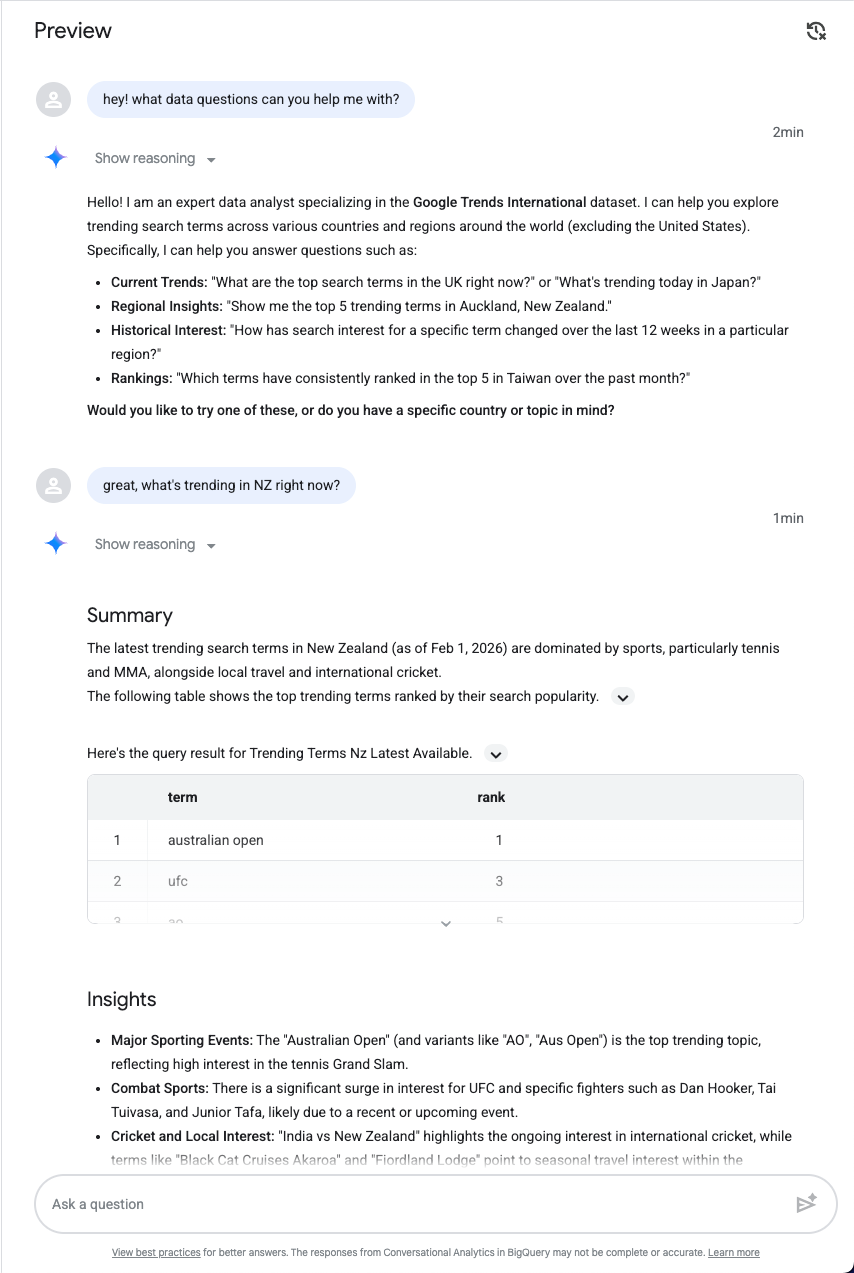
सेव करें
कुछ प्रॉम्प्ट टेस्ट करने के बाद, सेव करें पर क्लिक करें. इसके बाद, एजेंट को पब्लिश करें:
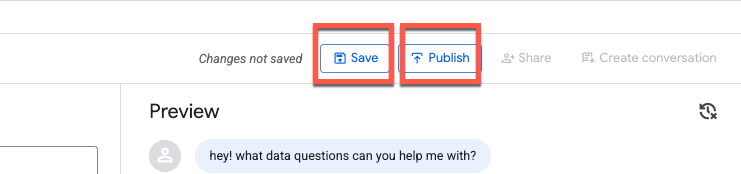
एजेंट को पब्लिश करने पर, यह BigQuery Studio, Conversational Analytics API, और Looker Studio Pro में उपलब्ध होगा. हालांकि, इसके लिए लाइसेंसिंग की ज़रूरत होगी:
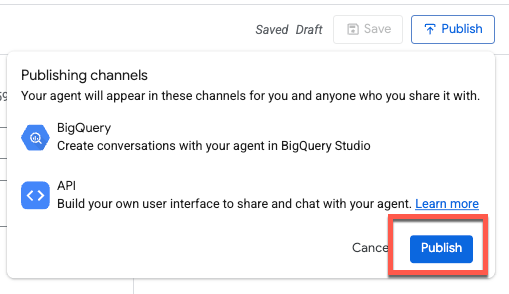
आने वाले समय में, अन्य प्लैटफ़ॉर्म और इंटिग्रेशन के लिए भी यह सुविधा उपलब्ध कराई जाएगी.
शेयर करें
आपको एक पुष्टि करने वाला मैसेज दिखेगा, जिसमें यह बताया जाएगा कि एजेंट पब्लिश कर दिया गया है. अब इस एजेंट को अन्य लोगों के साथ शेयर किया जा सकता है.
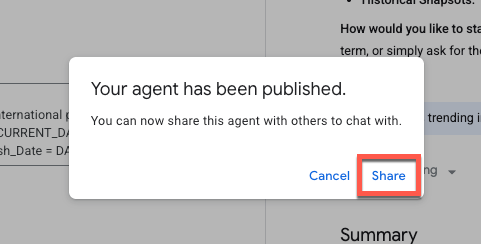
किसी एजेंट को अन्य लोगों के साथ शेयर करते समय, उन्हें कोई खास रोल असाइन करके, उनके ऐक्सेस का लेवल कंट्रोल किया जा सकता है. इन रोल से यह तय होता है कि सहयोगी सिर्फ़ आपके एजेंट को देख सकता है या उसके पास, एजेंट के कॉन्फ़िगरेशन में बदलाव करने और उसे मैनेज करने की अनुमति है.
ध्यान दें कि इन रोल को दो अलग-अलग लेवल पर लागू किया जा सकता है:
- प्रोजेक्ट लेवल: प्रोजेक्ट लेवल पर कोई रोल असाइन करने से, उपयोगकर्ता को उस Google Cloud प्रोजेक्ट में मौजूद सभी एजेंट के लिए वे अनुमतियां मिल जाती हैं.
- एजेंट लेवल: बेहतर कंट्रोल के लिए, किसी खास एजेंट के लिए रोल असाइन किए जा सकते हैं. यह तब काम आता है, जब आपको किसी उपयोगकर्ता को प्रोजेक्ट में मौजूद अन्य एजेंट दिखाए बिना, सिर्फ़ एक खास डेटा एजेंट का ऐक्सेस देना हो.
Conversational Analytics के लिए, पहले से तय रोल इस तरह हैं:
- Gemini Data Analytics के डेटा एजेंट का मालिक (roles/geminidataanalytics.dataAgentOwner) - सभी डेटा एजेंट बनाएं, उनमें बदलाव करें, उन्हें शेयर करें, और मिटाएं
- Gemini Data Analytics के डेटा एजेंट का क्रिएटर (roles/geminidataanalytics.dataAgentCreator) - अपने डेटा एजेंट बनाएं, उनमें बदलाव करें, उन्हें शेयर करें, और मिटाएं
- Gemini Data Analytics के डेटा एजेंट का एडिटर (roles/geminidataanalytics.dataAgentEditor) - डेटा एजेंट के साथ चैट करें और उनमें बदलाव करें
- Data Analytics के डेटा एजेंट का उपयोगकर्ता (roles/geminidataanalytics.dataAgentUser) - डेटा एजेंट के साथ चैट करें और उन्हें देखें
- Gemini Data Analytics के डेटा एजेंट का व्यूअर (roles/geminidataanalytics.dataAgentViewer) - डेटा एजेंट को देखें (सिर्फ़ पढ़ने की अनुमति)
6. एजेंट के साथ बातचीत शुरू करें
आइए, शेयर करें टैब से बाहर निकलें और नई बातचीत शुरू करें:
बातचीत शुरू करें पर क्लिक करने पर, बिना टाइटल वाली एक नई बातचीत जनरेट होती है.
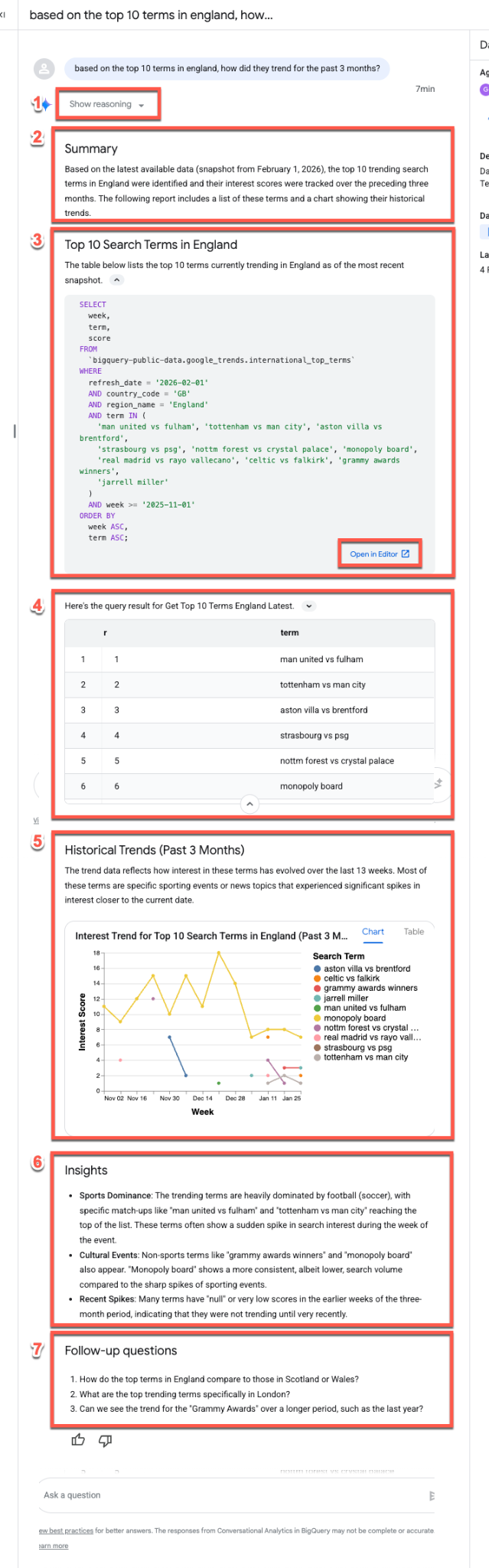
आइए, यह सवाल पूछें कि इंग्लैंड में किन शब्दों का ट्रेंड है. अपनी पसंद की जगह के हिसाब से, इसे बदला जा सकता है:
Based on the top 10 terms in England, how did they trend for the past 3 months?
जवाब की स्ट्रीम को समझना
आम तौर पर, डेटा एजेंट सवालों के जवाब देते समय, एक ही जवाब की स्ट्रीम का इस्तेमाल करता है:
- तर्क: एजेंट, सबसे पहले प्रॉम्प्ट के बारे में "सोचता" है. एजेंट के फ़ैसले लेने की प्रोसेस के बारे में चरण-दर-चरण अहम जानकारी देखने के लिए, तर्क दिखाएं बटन को बड़ा करें.
- खास जानकारी: एजेंट, क्वेरी, उससे जनरेट हुई रिपोर्ट, और विज़ुअलाइज़ेशन की खास जानकारी जनरेट करता है.
- जनरेट की गई एसक्यूएल: एसक्यूएल की जांच करने के लिए, यह क्वेरी है... सेक्शन को बड़ा करें. BigQuery Studio में क्वेरी को मैन्युअल तरीके से बेहतर बनाने के लिए, एडिटर में खोलें पर क्लिक करें.
- डेटा के नतीजे: एजेंट, क्वेरी के नतीजों को साफ़ तौर पर टेबल के फ़ॉर्मैट में दिखाता है.
- विज़ुअलाइज़ेशन: एक चार्ट, छोटे ब्यौरे के साथ दिखता है. एजेंट, आपके डेटा के लिए सबसे सही विज़ुअलाइज़ेशन टाइप (जैसे, मल्टी-सीरीज़ लाइन चार्ट) का अनुमान अपने-आप लगाता है.
- डेटा से मिली अहम जानकारी: एजेंट, नतीजों में मिले मुख्य रुझानों और अहम जानकारी की खास जानकारी देता है.
- फ़ॉलो-अप सवाल: आखिर में, एजेंट, फ़ॉलो-अप के लिए काम के सवाल सुझाता है, ताकि आपको अपना विश्लेषण जारी रखने में मदद मिल सके.
BigQuery ML की सुविधा
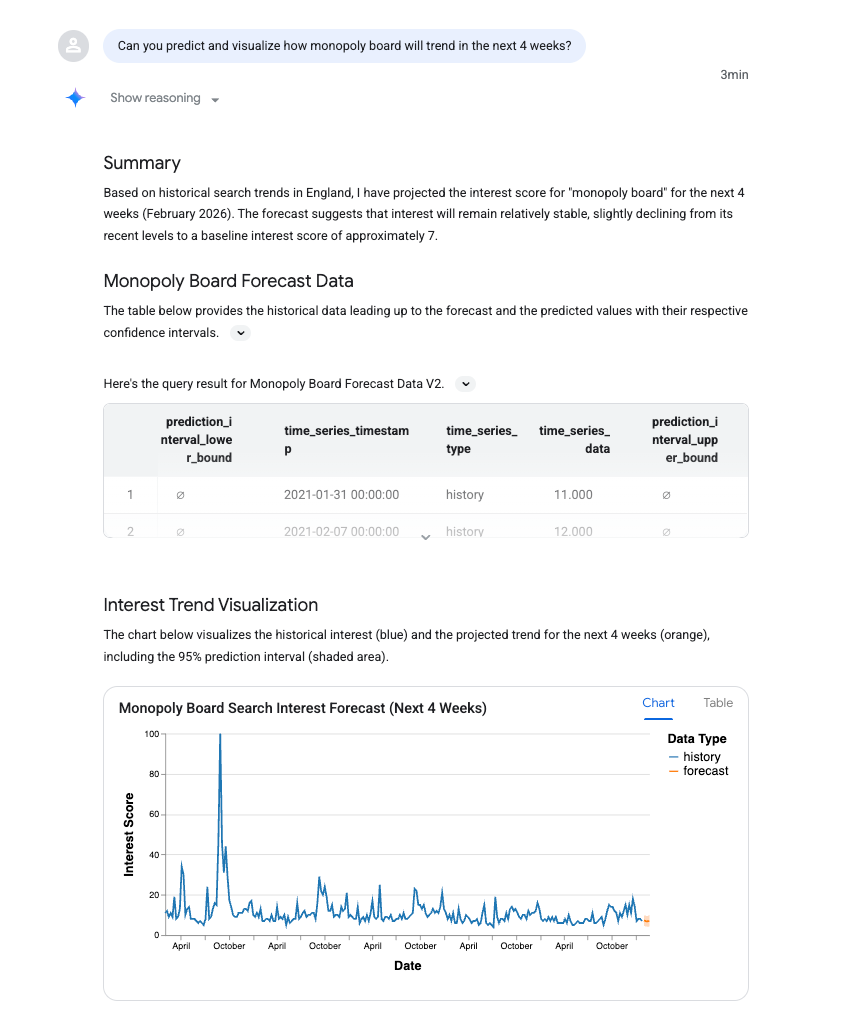
आइए, फ़ॉलो-अप करें और यह सवाल पूछें कि क्या डेटा एजेंट, इन नतीजों के आधार पर कुछ पूर्वानुमान लगा सकता है. इससे, आने वाले समय के पॉइंट का अनुमान लगाने के लिए, BigQuery ML के फ़ंक्शन का इस्तेमाल किया जाता है.
यह प्रॉम्प्ट डालें. ध्यान रखें कि "monopoly board" की जगह, अपनी क्वेरी के लिए काम का शब्द डालें:
Can you predict and visualize how monopoly board will trend in the next 4 weeks?
AI_FORECAST का इस्तेमाल, टाइम सीरीज़ का पूर्वानुमान लगाने के लिए किया गया है. हालांकि, इसमें कोई हैरानी की बात नहीं है. यह दिलचस्प है कि आपको अगस्त 2021 में एक बड़ा स्पाइक दिख रहा है. यह लंदन में Monopoly Lifesized के ग्रैंड ओपनिंग के साथ मेल खाता है!
7. एजेंट कैटलॉग एक्सप्लोर करना
आइए, खत्म करने से पहले एजेंट कैटलॉग एक्सप्लोर करें. विंडो में सबसे ऊपर मौजूद, एजेंट कैटलॉग पर क्लिक करें:
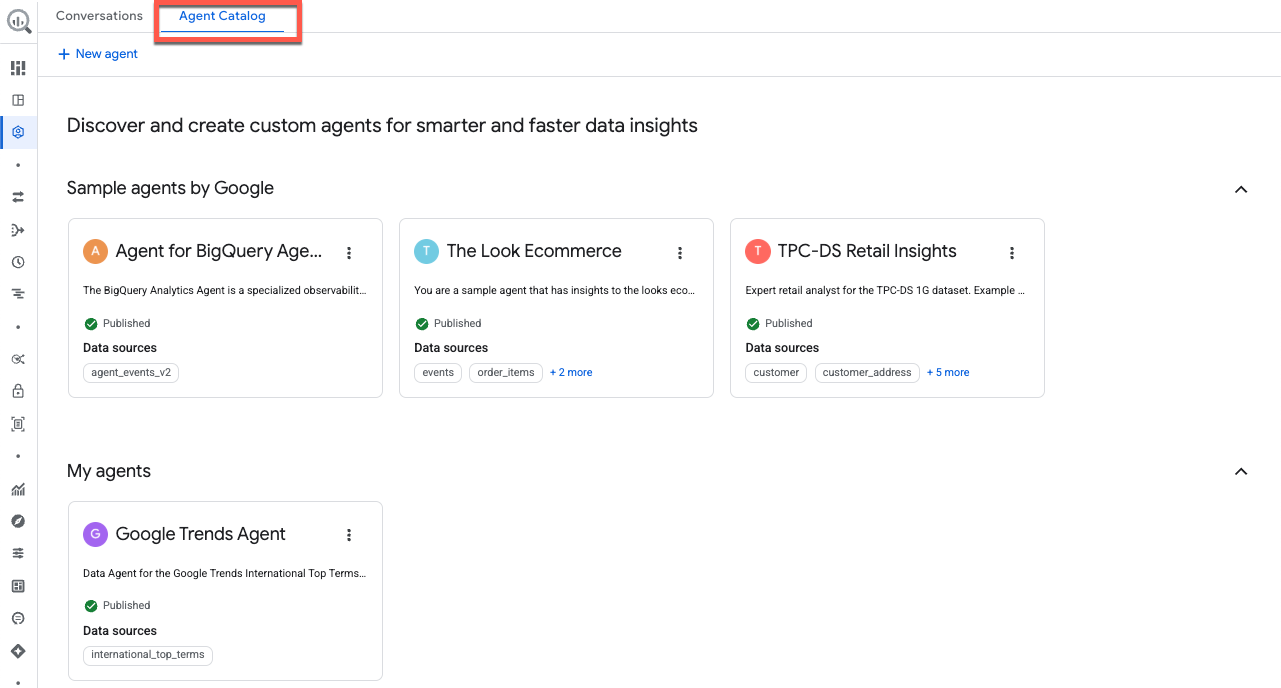
यह पेज, डेटा एजेंट को मैनेज करने के लिए आपका मुख्य हब है. इसे इन सेक्शन में व्यवस्थित किया गया है:
- मेरे एजेंट: आपके मौजूदा समय में पब्लिश किए गए एजेंट.
- मेरे ड्राफ़्ट एजेंट: वे कॉन्फ़िगरेशन जिन्हें आपने सेव किया है, लेकिन अब तक पब्लिश नहीं किया है.
- आपके संगठन के अन्य लोगों ने शेयर किए हैं: वे एजेंट जिन्हें आपके सहकर्मियों ने बनाया है और आपके पास उनका ऐक्सेस है.
- Google के सैंपल एजेंट: पहले से कॉन्फ़िगर किए गए उदाहरण, ताकि आपको शुरू करने में मदद मिल सके.
आपके पास मैनेज किए जाने वाले किसी भी एजेंट के कॉन्फ़िगरेशन में बदलाव करने, एजेंटों को डुप्लीकेट करने, और शेयर करने की अनुमतियों को मैनेज करने का विकल्प होता है.
8. नतीजा
बधाई हो, आपने Conversational Analytics का डेटा एजेंट बना लिया है. ज़्यादा जानने के लिए, रेफ़रंस के लिए दिए गए कॉन्टेंट देखें!