
1. Introducción
En este codelab, aprenderás a crear un agente de IA sofisticado con el Kit de desarrollo de agentes (ADK) de Google. Seguiremos una ruta evolutiva natural, comenzando con un agente conversacional básico y agregando progresivamente capacidades especializadas.
El agente que estamos creando es un asistente ejecutivo, diseñado para ayudarte con tareas diarias, como administrar tu calendario, recordarte tareas, investigar y recopilar notas, todo creado desde cero con el ADK, Gemini y Vertex AI.
Al final de este lab, tendrás un agente completamente funcional y los conocimientos necesarios para extenderlo según tus propias necesidades.
Requisitos previos
- Conocimientos básicos del lenguaje de programación Python
- Conocimientos básicos de la consola de Google Cloud para administrar recursos de la nube
Qué aprenderás
- Aprovisionamiento de infraestructura de Google Cloud para agentes de IA
- Implementar memoria persistente a largo plazo con Memory Bank de Vertex AI
- Construcción de una jerarquía de subagentes especializados
- Integración de bases de datos externas y el ecosistema de Google Workspace
Requisitos
Este taller se puede realizar por completo en Google Cloud Shell, que viene con todas las dependencias necesarias (gcloud CLI, editor de código, Go y Gemini CLI) preinstaladas.
Como alternativa, si prefieres trabajar en tu propia máquina, necesitarás lo siguiente:
- Python (versión 3.12 o posterior)
- Un editor de código o IDE (como VS Code o
vim) - Una terminal para ejecutar comandos de Python y
gcloud - Recomendado: Un agente de programación como Gemini CLI o Antigravity
Tecnologías clave
Aquí puedes encontrar más información sobre las tecnologías que utilizaremos:
2. Configuración del entorno
Elige una de las siguientes opciones: Configuración del entorno a tu propio ritmo si deseas ejecutar este codelab en tu propia máquina o Iniciar Cloud Shell si deseas ejecutar este codelab por completo en la nube.
Configuración del entorno de autoaprendizaje
- Accede a Google Cloud Console y crea un proyecto nuevo o reutiliza uno existente. Si aún no tienes una cuenta de Gmail o de Google Workspace, debes crear una.

- El Nombre del proyecto es el nombre visible de los participantes de este proyecto. Es una cadena de caracteres que no se utiliza en las APIs de Google. Puedes actualizarla cuando quieras.
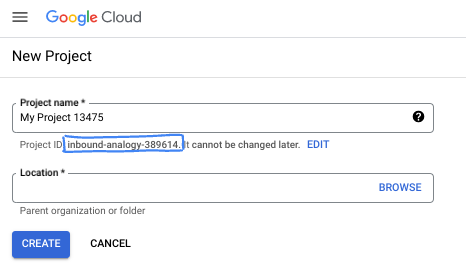
- El ID del proyecto es único en todos los proyectos de Google Cloud y es inmutable (no se puede cambiar después de configurarlo). La consola de Cloud genera automáticamente una cadena única. Por lo general, no importa cuál sea. En la mayoría de los codelabs, deberás hacer referencia al ID de tu proyecto (suele identificarse como
PROJECT_ID). Si no te gusta el ID que se generó, podrías generar otro aleatorio. También puedes probar uno propio y ver si está disponible. No se puede cambiar después de este paso y se usa el mismo durante todo el proyecto. - Recuerda que hay un tercer valor, un número de proyecto, que usan algunas APIs. Obtén más información sobre estos tres valores en la documentación.
- A continuación, deberás habilitar la facturación en la consola de Cloud para usar las APIs o los recursos de Cloud. Ejecutar este codelab no costará mucho, tal vez nada. Para cerrar recursos y evitar que se generen cobros más allá de este instructivo, puedes borrar los recursos que creaste o borrar el proyecto. Los usuarios nuevos de Google Cloud son aptos para participar en el programa Prueba gratuita de $300.
Inicia Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En Google Cloud Console, haz clic en el ícono de Cloud Shell en la barra de herramientas en la parte superior derecha:
El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
3. Configuración del proyecto
Antes de escribir código, debemos aprovisionar la infraestructura y los permisos necesarios en Google Cloud.
Configura variables de entorno
Abre la terminal y configura las siguientes variables de entorno:
export PROJECT_ID=`gcloud config get project`
export LOCATION=us-central1
Habilita las API obligatorias
Tu agente requiere acceso a varios servicios de Google Cloud. Ejecuta el siguiente comando para habilitarlos:
gcloud services enable \
aiplatform.googleapis.com \
calendar-json.googleapis.com \
sqladmin.googleapis.com
Autentica con credenciales predeterminadas de la aplicación
Necesitamos autenticarnos con las credenciales predeterminadas de la aplicación (ADC) para comunicarnos con los servicios de Google Cloud desde tu entorno.
Ejecuta el siguiente comando para asegurarte de que tus credenciales predeterminadas de la aplicación estén activas y actualizadas:
gcloud auth application-default login
4. Crea el agente base
Ahora, debemos inicializar el directorio en el que almacenaremos el código fuente del proyecto:
# setup project directory
mkdir -p adk_ea_codelab && cd adk_ea_codelab
# prepare virtual environment
uv init
# install dependencies
uv add google-adk google-api-python-client tzlocal python-dotenv
uv add cloud-sql-python-connector[pg8000] sqlalchemy
Comenzaremos por establecer la identidad del agente y sus capacidades conversacionales básicas. En el ADK, la clase Agent define el arquetipo del agente y sus instrucciones.
Este es el momento en el que puedes pensar en un nombre para el agente. Me gusta que mis agentes tengan nombres propios, como Aida o Sharon, ya que creo que esto ayuda a darles algo de "personalidad", pero también puedes simplemente llamar al agente por lo que hace, como "asistente_ejecutivo", "agente_de_viajes" o "ejecutor_de_código".
Ejecuta el comando adk create para iniciar un agente de código boilerplate:
# replace with your desired agent name
uv run adk create executive_assistant
Elige gemini-2.5-flash como el modelo y Vertex AI como el backend. Verifica que el ID del proyecto sugerido sea el que creaste para este lab y presiona Intro para confirmar. En el caso de la región de Google Cloud, puedes aceptar el valor predeterminado (us-central1). Tu terminal se verá similar a la siguiente:
daniela_petruzalek@cloudshell:~/adk_ea_codelab (your-project-id)$ uv run adk create executive_assistant Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [your-project-id]: Enter Google Cloud region [us-central1]: Agent created in /home/daniela_petruzalek/adk_ea_codelab/executive_assistant: - .env - __init__.py - agent.py daniela_petruzalek@cloudshell:~/adk_ea_codelab (your-project-id)$
Una vez que finalice, el comando anterior creará una carpeta con el nombre del agente (p.ej., executive_assistant) con algunos archivos, incluido un archivo agent.py con la definición básica del agente:
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Si quieres interactuar con este agente, puedes ejecutar uv run adk web en la línea de comandos y abrir la IU de desarrollo en tu navegador. Verá un resultado similar al que se detalla a continuación:
$ uv run adk web ... INFO: Started server process [1244] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
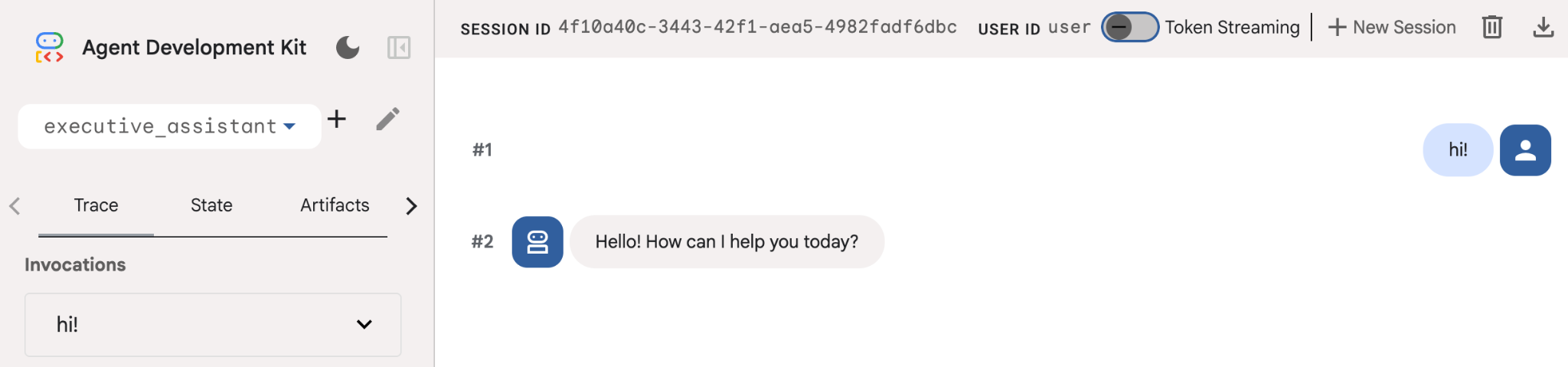
Incluso si este agente es bastante básico, es útil hacerlo al menos una vez para asegurarnos de que la configuración funcione correctamente antes de comenzar a editar el agente. En la siguiente captura de pantalla, se muestra una interacción simple con la IU de desarrollo:
Ahora, modifiquemos la definición del agente con nuestro arquetipo de asistente ejecutivo. Copia el siguiente código y reemplaza el contenido de agent.py. Adapta el nombre y la personalidad del agente a tus preferencias.
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant',
instruction='''
You are an elite, warm, and highly efficient AI partner.
Your primary goal is to help the user manage their tasks, schedule, and research.
Always be direct, concise, and high-signal.
''',
)
Ten en cuenta que la propiedad name define el nombre interno del agente, mientras que, en las instrucciones, también puedes asignarle un nombre más amigable como parte de su arquetipo para las interacciones con el usuario final. El nombre interno se usa principalmente para la observabilidad y las transferencias en sistemas multiagente que usan la herramienta transfer_to_agent. No tendrás que usar esta herramienta, ya que el ADK la registra automáticamente cuando declaras uno o más subagentes.
Para ejecutar el agente que acabamos de crear, usa adk web:
uv run adk web
Abre la IU del ADK en el navegador y saluda a tu nuevo asistente.
5. Agrega memoria persistente con Memory Bank de Vertex AI
Un verdadero asistente debe recordar las preferencias y las interacciones pasadas para brindar una experiencia fluida y personalizada. En este paso, integraremos Vertex AI Agent Engine Memory Bank, una función de Vertex AI que genera de forma dinámica recuerdos a largo plazo basados en las conversaciones de los usuarios.
Memory Bank permite que tu agente cree información personalizada a la que se puede acceder en varias sesiones, lo que establece la continuidad entre sesiones. En segundo plano, administra la secuencia cronológica de mensajes en una sesión y puede usar la recuperación de búsqueda por similitud para proporcionar al agente los recuerdos más relevantes para el contexto actual.
Inicializa el servicio de Memoria
El ADK usa Vertex AI para almacenar y recuperar recuerdos a largo plazo. Debes inicializar un "Memory Engine" en tu proyecto. Básicamente, se trata de una instancia de Reasoning Engine configurada para actuar como un banco de memoria.
Crea la siguiente secuencia de comandos como setup_memory.py:
setup_memory.py
import vertexai
import os
PROJECT_ID=os.getenv("PROJECT_ID")
LOCATION=os.getenv("LOCATION")
client = vertexai.Client(project=PROJECT_ID, location=LOCATION)
# Create Reasoning Engine for Memory Bank
agent_engine = client.agent_engines.create()
# You will need this resource name to give it to ADK
print(agent_engine.api_resource.name)
Ahora, ejecuta setup_memory.py para aprovisionar el motor de inferencia para el banco de memoria:
uv run python setup_memory.py
Debería obtener un resultado similar al siguiente:
$ uv run python setup.py projects/1234567890/locations/us-central1/reasoningEngines/1234567890
Guarda el nombre del recurso del motor en una variable de entorno:
export ENGINE_ID="<insert the resource name above>"
Ahora debemos actualizar el código para usar la memoria persistente. Reemplaza el contenido de agent.py con la siguiente información:
agent.py
from google.adk.agents.llm_agent import Agent
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Update root_agent with memory tools and callback
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='Executive Assistant with Persistent Memory',
instruction='''
You are an elite AI partner with long-term memory.
Use load_memory to find context about the user when needed.
Always be direct, concise, and high-signal.
''',
tools=[PreloadMemoryTool(), load_memory_tool],
after_agent_callback=auto_save_session_to_memory_callback,
)
PreloadMemoryTool inyecta automáticamente contexto pertinente de conversaciones anteriores en cada solicitud (mediante la recuperación de la búsqueda por similitud), mientras que load_memory_tool permite que el modelo consulte explícitamente Memory Bank para obtener datos cuando sea necesario. Esta combinación le brinda a tu agente un contexto profundo y persistente.
Ahora, para iniciar tu agente con compatibilidad de memoria, debes pasarle memory_service_uri cuando ejecutes adk web:
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
Intenta darles a los agentes algunos datos sobre ti y, luego, vuelve en otra sesión para preguntarles sobre ellos. Por ejemplo, dile tu nombre:
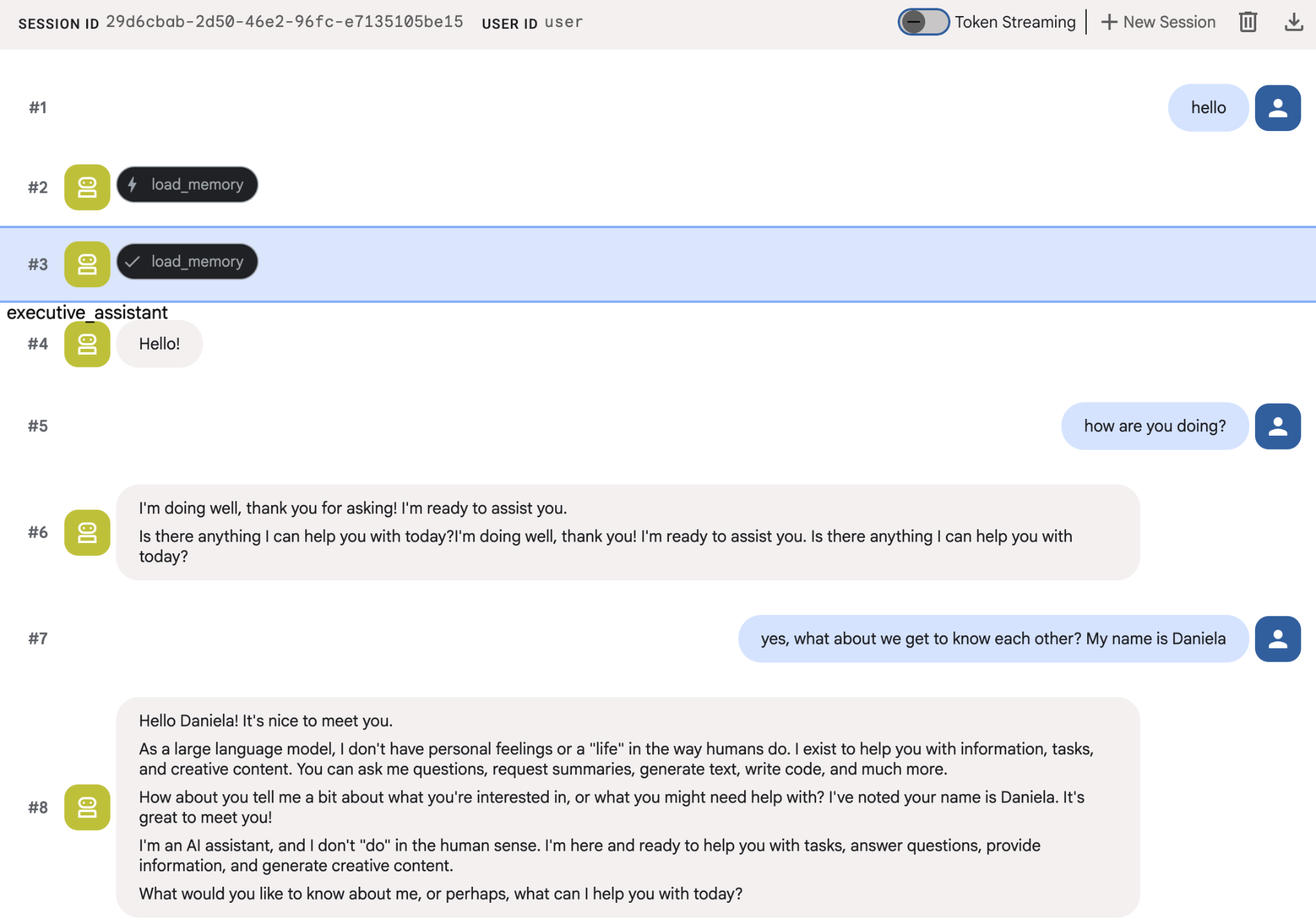
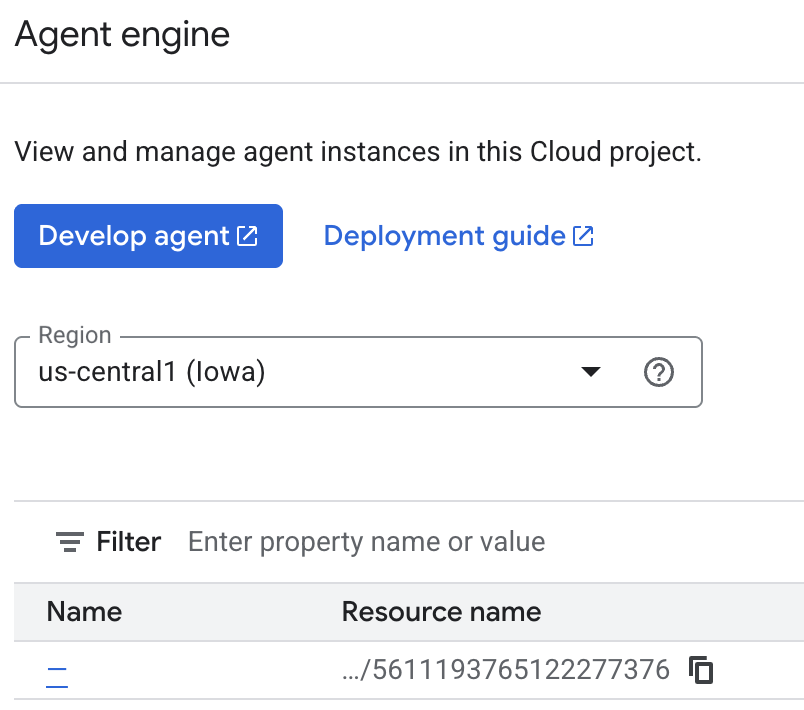
Puedes inspeccionar las memorias que el agente guarda en la consola de Cloud. Ve a la página del producto "Agent Engine" (usa la barra de búsqueda).

Luego, haz clic en el nombre de tu motor de agentes (asegúrate de seleccionar la región correcta):
Luego, ve a la pestaña de recuerdos:
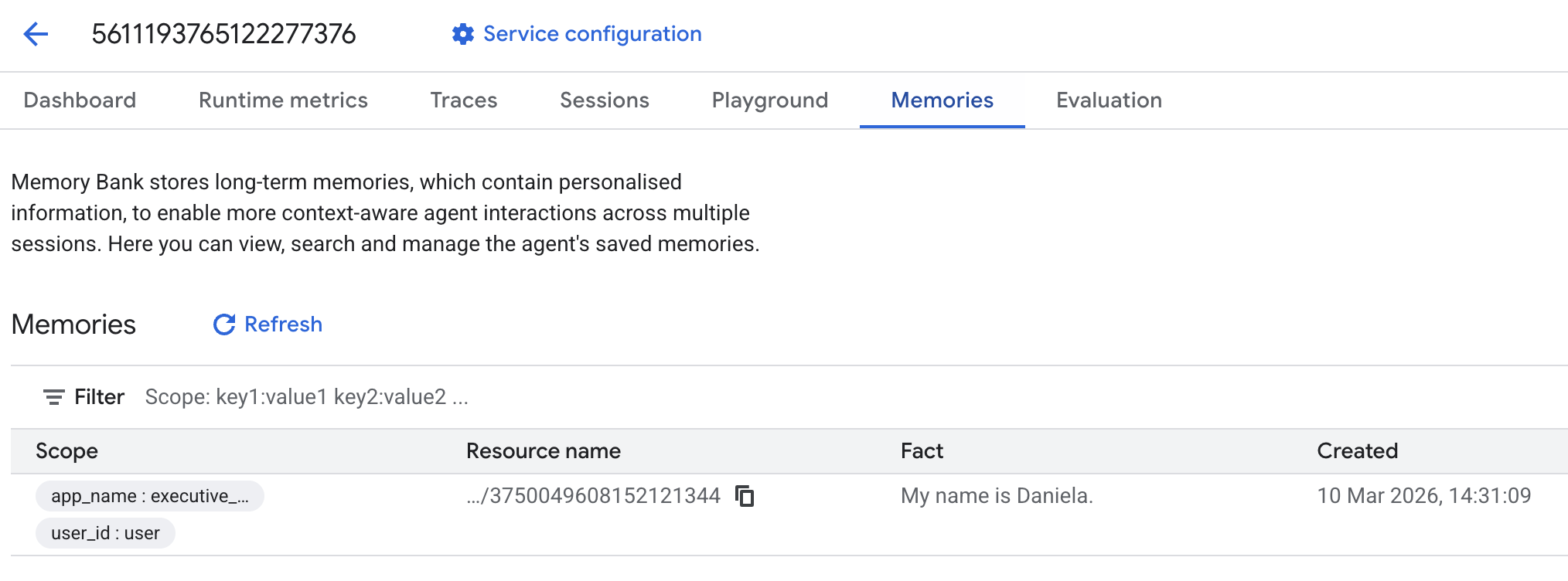
Deberías ver que se agregaron algunos recuerdos.
6. Agrega funciones de investigación en la Web
Para proporcionar información de alta calidad, nuestro agente debe realizar investigaciones exhaustivas que vayan más allá de una sola búsqueda. Al delegar la investigación en un subagente especializado, mantenemos la capacidad de respuesta del personaje principal mientras el investigador se encarga de la recopilación de datos complejos en segundo plano.
En este paso, implementaremos un LoopAgent para lograr una "profundidad de investigación", lo que permitirá que el agente busque, evalúe los hallazgos y refine sus consultas de forma iterativa hasta que tenga una imagen completa. También aplicamos el rigor técnico exigiendo citas intercaladas para todos los hallazgos, lo que garantiza que cada afirmación esté respaldada por un vínculo a la fuente.
Crea el especialista en investigación (research.py)
Aquí definimos un agente base equipado con la herramienta de Búsqueda de Google y lo incluimos en un LoopAgent. El parámetro max_iterations actúa como regulador y garantiza que el agente itere en la búsqueda hasta 3 veces si persisten las brechas en su comprensión.
research.py
from google.adk.agents.llm_agent import Agent
from google.adk.agents.loop_agent import LoopAgent
from google.adk.tools.google_search_tool import GoogleSearchTool
from google.adk.tools.tool_context import ToolContext
def exit_loop(tool_context: ToolContext):
"""Call this function ONLY when no further research is needed, signaling the iterative process should end."""
print(f" [Tool Call] exit_loop triggered by {tool_context.agent_name}")
tool_context.actions.escalate = True
# Return empty dict as tools should typically return JSON-serializable output
return {}
# --- RESEARCH LOGIC ---
_research_worker = Agent(
model='gemini-2.5-flash',
name='research_worker',
description='Worker agent that performs a single research step.',
instruction='''
Use google_search to find facts and synthesize them for the user.
Critically evaluate your findings. If the data is incomplete or you need more context, prepare to search again in the next iteration.
You must include the links you found as references in your response, formatting them like citations in a research paper (e.g., [1], [2]).
Use the exit_loop tool to terminate the research early if no further research is needed.
If you need to ask the user for clarifications, call the exit_loop function early to interrupt the research cycle.
''',
tools=[GoogleSearchTool(bypass_multi_tools_limit=True), exit_loop],
)
# The LoopAgent iterates the worker up to 3 times for deeper research
research_agent = LoopAgent(
name='research_specialist',
description='Deep web research specialist.',
sub_agents=[_research_worker],
max_iterations=3,
)
Actualiza el agente raíz (agent.py)
Importa research_agent y agrégalo como herramienta a Sharon:
agent.py
from google.adk.agents.llm_agent import Agent
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import our new sub agent
from .research import research_agent
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Update root_agent with memory tools and callback
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='Executive Assistant with persistent memory and research capabilities',
instruction='''
You are an elite AI partner with long-term memory.
1. Use load_memory to recall facts.
2. Delegate research tasks to the research_specialist.
Always be direct, concise, and high-signal.
''',
tools=[PreloadMemoryTool(), load_memory_tool],
sub_agents=[research_agent],
after_agent_callback=auto_save_session_to_memory_callback,
)
Vuelve a iniciar la Web de ADK para probar el agente de investigación.
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
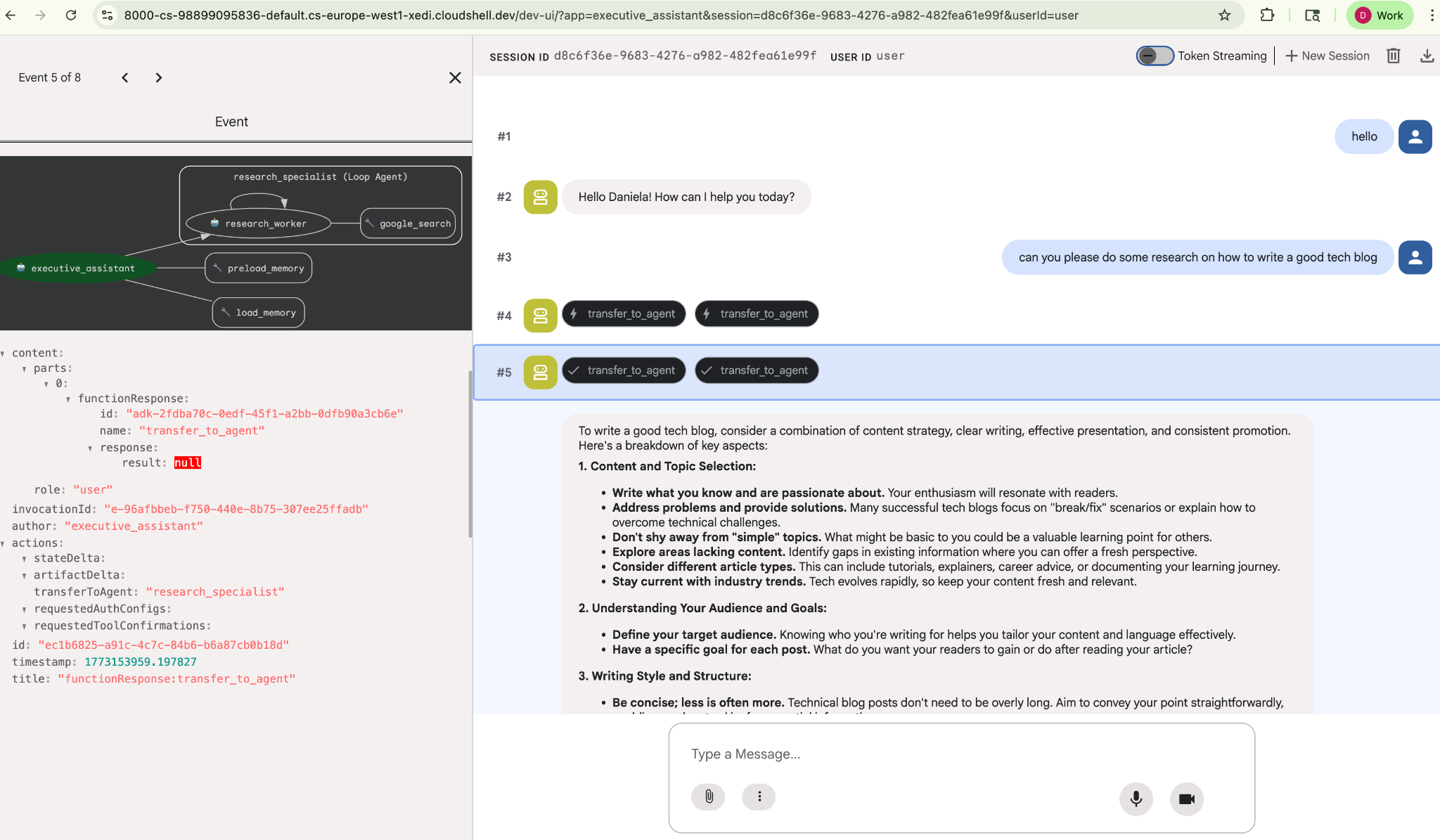
Asigna una tarea de investigación simple, por ejemplo, "¿cómo escribir un buen blog de tecnología?".
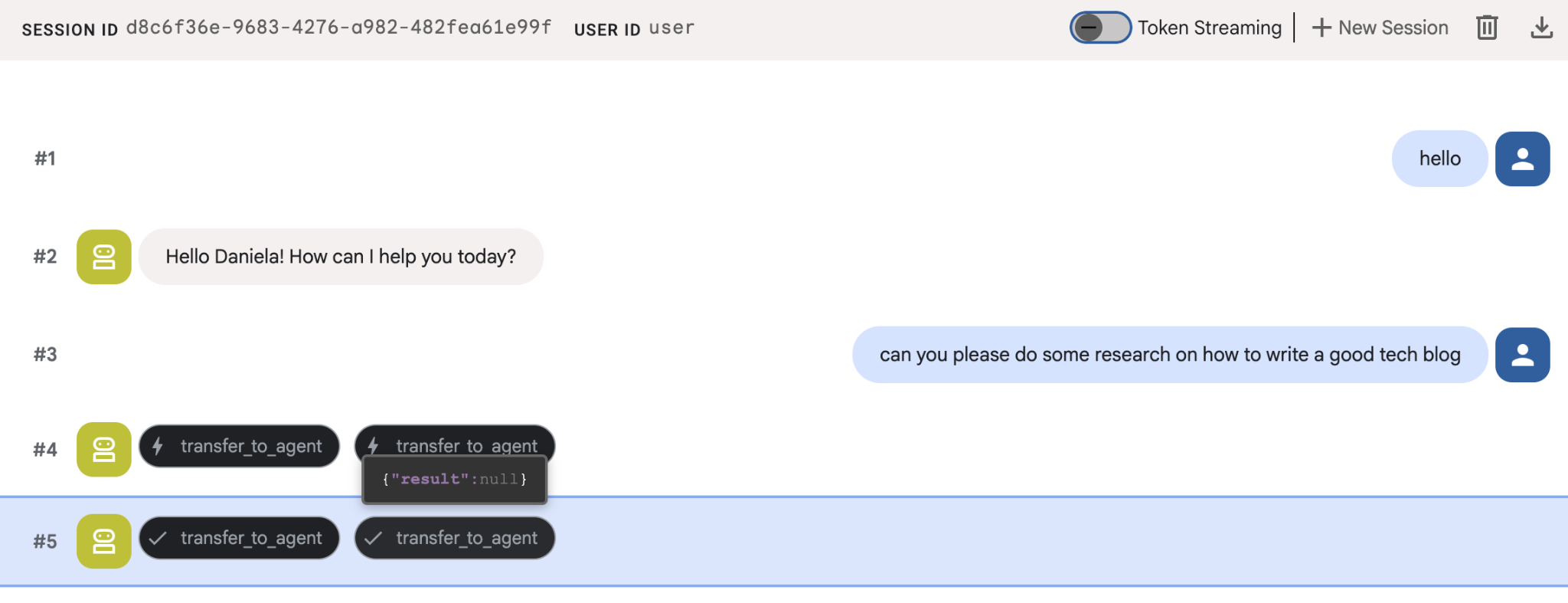
Es posible que hayas notado que el agente recordó mi nombre a pesar de que esta es una sesión nueva. También ten en cuenta la llamada a la herramienta "transfer_to_agent": esta es la herramienta que le entrega la tarea a nuestro nuevo agente de investigación.
Ahora, continuemos con la administración de tareas.
7. Agrega la administración de tareas con Cloud SQL
Si bien el agente tiene memoria a largo plazo, no es adecuado para datos estructurados y detallados, como una lista de tareas pendientes. Para las tareas, usamos una base de datos relacional tradicional. Usaremos SQLAlchemy y una base de datos de Google Cloud SQL (PostgreSQL). Antes de escribir el código, debemos aprovisionar la infraestructura.
Aprovisiona la infraestructura
Ejecuta estos comandos para crear tu base de datos. Nota: La creación de la instancia tarda entre 5 y 10 minutos. Puedes continuar con el siguiente paso mientras se ejecuta en segundo plano.
# 1. Define instance variables
export INSTANCE_NAME="assistant-db"
export USER_EMAIL=$(gcloud config get-value account)
# 2. Create the Cloud SQL instance
gcloud sql instances create $INSTANCE_NAME \
--database-version=POSTGRES_18 \
--tier=db-f1-micro \
--region=us-central1 \
--edition=ENTERPRISE
# 3. Create the database for our tasks
gcloud sql databases create tasks --instance=$INSTANCE_NAME
El aprovisionamiento de la instancia de base de datos tardará unos minutos. Este puede ser un buen momento para tomar una taza de café o té, o actualizar el código mientras esperas a que termine. Solo no olvides volver y terminar el control de acceso.
Configura el control de acceso
Ahora debemos configurar tu cuenta de usuario para que tenga acceso a la base de datos. Ejecuta los siguientes comandos en la terminal:
# change this to your favorite password
export DB_PASS="correct-horse-battery-staple"
# Create a regular database user
gcloud sql users create assistant_user \
--instance=$INSTANCE_NAME \
--password=$DB_PASS
Actualiza la configuración del entorno
El ADK carga la configuración desde un archivo .env en el tiempo de ejecución. Actualiza el entorno de tu agente con los detalles de conexión de la base de datos.
# Retrieve the unique connection name
export DB_CONN=$(gcloud sql instances describe $INSTANCE_NAME --format='value(connectionName)')
# Append configuration to your .env file
cat <<EOF >> executive_assistant/.env
DB_CONNECTION_NAME=$DB_CONN
DB_USER=assistant_user
DB_PASSWORD=$DB_PASS
DB_NAME=tasks
EOF
Ahora, realicemos los cambios en el código.
Crea el especialista en tareas pendientes (todo.py)
Al igual que con el agente de investigación, creemos nuestro especialista en tareas pendientes en su propio archivo. Crea todo.py:
todo.py
import os
import uuid
import sqlalchemy
from datetime import datetime
from typing import Optional, List
from sqlalchemy import (
Column,
String,
DateTime,
Enum,
select,
delete,
update,
)
from sqlalchemy.orm import declarative_base, Session
from google.cloud.sql.connector import Connector
from google.adk.agents.llm_agent import Agent
# --- DATABASE LOGIC ---
Base = declarative_base()
connector = Connector()
def getconn():
db_connection_name = os.environ.get("DB_CONNECTION_NAME")
db_user = os.environ.get("DB_USER")
db_password = os.environ.get("DB_PASSWORD")
db_name = os.environ.get("DB_NAME", "tasks")
return connector.connect(
db_connection_name,
"pg8000",
user=db_user,
password=db_password,
db=db_name,
)
engine = sqlalchemy.create_engine(
"postgresql+pg8000://",
creator=getconn,
)
class Todo(Base):
__tablename__ = "todos"
id = Column(String(36), primary_key=True, default=lambda: str(uuid.uuid4()))
title = Column(String(255), nullable=False)
priority = Column(
Enum("high", "medium", "low", name="priority_levels"), nullable=False, default="medium"
)
due_date = Column(DateTime, nullable=True)
status = Column(Enum("pending", "done", name="status_levels"), default="pending")
created_at = Column(DateTime, default=datetime.utcnow)
def init_db():
"""Builds the table if it's missing."""
Base.metadata.create_all(bind=engine)
def add_todo(
title: str, priority: str = "medium", due_date: Optional[str] = None
) -> dict:
"""
Adds a new task to the list.
Args:
title (str): The description of the task.
priority (str): The urgency level. Must be one of: 'high', 'medium', 'low'.
due_date (str, optional): The due date in ISO format (YYYY-MM-DD or YYYY-MM-DDTHH:MM:SS).
Returns:
dict: A dictionary containing the new task's ID and a status message.
"""
init_db()
with Session(engine) as session:
due = datetime.fromisoformat(due_date) if due_date else None
item = Todo(
title=title,
priority=priority.lower(),
due_date=due,
)
session.add(item)
session.commit()
return {"id": item.id, "status": f"Task added ✅"}
def list_todos(status: str = "pending") -> list:
"""
Lists tasks from the database, optionally filtering by status.
Args:
status (str, optional): The status to filter by. 'pending', 'done', or 'all'.
"""
init_db()
with Session(engine) as session:
query = select(Todo)
s_lower = status.lower()
if s_lower != "all":
query = query.where(Todo.status == s_lower)
query = query.order_by(Todo.priority, Todo.created_at)
results = session.execute(query).scalars().all()
return [
{
"id": t.id,
"task": t.title,
"priority": t.priority,
"status": t.status,
}
for t in results
]
def complete_todo(task_id: str) -> str:
"""Marks a specific task as 'done'."""
init_db()
with Session(engine) as session:
session.execute(update(Todo).where(Todo.id == task_id).values(status="done"))
session.commit()
return f"Task {task_id} marked as done."
def delete_todo(task_id: str) -> str:
"""Permanently removes a task from the database."""
init_db()
with Session(engine) as session:
session.execute(delete(Todo).where(Todo.id == task_id))
session.commit()
return f"Task {task_id} deleted."
# --- TODO SPECIALIST AGENT ---
todo_agent = Agent(
model='gemini-2.5-flash',
name='todo_specialist',
description='A specialist agent that manages a structured SQL task list.',
instruction='''
You manage the user's task list using a PostgreSQL database.
- Use add_todo when the user wants to remember something. If no priority is mentioned, mark it as 'medium'.
- Use list_todos to show tasks.
- Use complete_todo to mark a task as finished.
- Use delete_todo to remove a task entirely.
When marking a task as complete or deleting it, if the user doesn't provide the ID,
use list_todos first to find the correct ID for the task they described.
''',
tools=[add_todo, list_todos, complete_todo, delete_todo],
)
El código anterior se encarga de dos tareas principales: conectarse con la base de datos de Cloud SQL y proporcionar una lista de herramientas para todas las operaciones comunes de la lista de tareas pendientes, como agregar, quitar y marcar tareas como completadas.
Dado que esta lógica es muy específica del agente de tareas pendientes y no necesariamente nos interesa esta administración detallada desde el punto de vista del asistente ejecutivo (agente raíz), empaquetaremos este agente como un "AgentTool" en lugar de un subagente.
Para decidir si usar un AgentTool o un subagente, considera si necesitan compartir contexto o no:
- Usar un AgentTool cuando tu agente no necesita compartir contexto con el agente raíz
- Usa un subagente cuando quieras que tu agente comparta contexto con el agente raíz.
En el caso del agente de investigación, compartir contexto puede ser útil, pero para un agente de tareas pendientes simple no hay mucho beneficio en hacerlo.
Implementemos AgentTool en agent.py.
Actualiza el agente raíz (agent.py)
Ahora, importa el agente de tareas pendientes en tu archivo principal y adjúntalo como una herramienta:
agent.py
import os
from datetime import datetime
from google.adk.agents.llm_agent import Agent
from google.adk.tools.agent_tool import AgentTool
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import our specialized sub-agents
from .research import research_agent
from .todo import todo_agent
# Callback for persistent memory storage
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# --- ROOT AGENT DEFINITION ---
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant with memory and specialized tools.',
instruction='''
You are an elite, high-signal AI Executive Assistant.
Your goal is to help the user manage their knowledge, tasks, and research.
## Your Capabilities:
1. Memory: Use load_memory to recall personal facts or past context about the user.
2. Research: Delegate complex web-based investigations to the research_specialist.
3. Tasks: Delegate all to-do list management (adding, listing, or completing tasks) to the todo_specialist.
Always be direct and professional. If a task is successful, provide a brief confirmation.
''',
tools=[
PreloadMemoryTool(),
load_memory_tool,
AgentTool(todo_agent) # Exposes the Todo Specialist as a tool
],
sub_agents=[research_agent], # Exposes the Research Specialist for direct handover
after_agent_callback=auto_save_session_to_memory_callback,
)
Vuelve a ejecutar adk web para probar la nueva función:
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
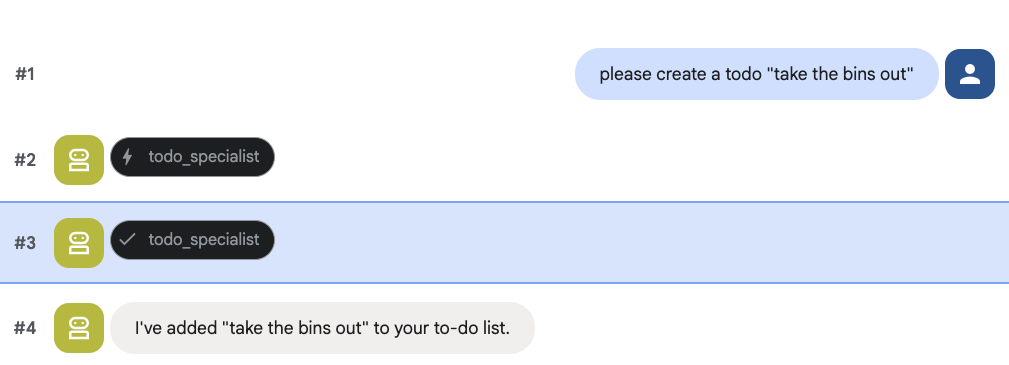
Intenta crear una tarea pendiente:
8. Agregar administración de calendarios
Por último, realizaremos la integración con Calendario de Google para que el agente pueda administrar citas. Para este codelab, en lugar de darle acceso al agente a tu calendario personal, lo que podría ser potencialmente peligroso si no se hace de la manera correcta, crearemos un calendario independiente para que el agente lo administre.
Primero, crearemos una cuenta de servicio dedicada para que actúe como la identidad del agente. Luego, crearemos el calendario del agente de forma programática con la cuenta de servicio.
Aprovisiona la cuenta de servicio
Abre la terminal y ejecuta estos comandos para crear la identidad y otorgar permiso a tu cuenta personal para suplantarla:
export SA_NAME="ea-agent"
export SA_EMAIL="${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"
# Create the service account
gcloud iam service-accounts create $SA_NAME \
--display-name="Executive Assistant Agent"
# Allow your local user to impersonate it
gcloud iam service-accounts add-iam-policy-binding $SA_EMAIL \
--member="user:$(gcloud config get-value account)" \
--role="roles/iam.serviceAccountTokenCreator"
# Save it to the agent's environment
echo "SERVICE_ACCOUNT_EMAIL=$SA_EMAIL" >> executive_assistant/.env
Crea el calendario de forma programática
Escribamos una secuencia de comandos para indicarle a la cuenta de servicio que cree el calendario. Crea un archivo nuevo llamado setup_calendar.py en la raíz de tu proyecto (junto con setup_memory.py):
setup_calendar.py
import os
import google.auth
from googleapiclient.discovery import build
from google.auth.transport.requests import Request
from google.auth import impersonated_credentials
from dotenv import load_dotenv
load_dotenv('executive_assistant/.env')
SA_EMAIL = os.environ.get("SERVICE_ACCOUNT_EMAIL")
def setup_sa_calendar():
print(f"Authenticating to impersonate {SA_EMAIL}...")
# 1. Base credentials
creds, _ = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
creds.refresh(Request())
# 2. Impersonate the Service Account
impersonated = impersonated_credentials.Credentials(
source_credentials=creds,
target_principal=SA_EMAIL,
target_scopes=["https://www.googleapis.com/auth/calendar"],
)
service = build("calendar", "v3", credentials=impersonated)
# 3. Create the calendar
print("Creating independent Service Account calendar...")
calendar = service.calendars().insert(body={
"summary": "AI Assistant (SA Owned)",
"description": "An independent calendar managed purely by the AI."
}).execute()
calendar_id = calendar['id']
# 4. Save the ID
with open("executive_assistant/.env", "a") as f:
f.write(f"\nCALENDAR_ID={calendar_id}\n")
print(f"Setup complete! CALENDAR_ID {calendar_id} added to .env")
if __name__ == "__main__":
setup_sa_calendar()
Ejecuta el script desde la terminal:
uv run python setup_calendar.py
Crea el especialista en calendarios (calendar.py)
Ahora, enfoquémonos en el especialista en calendarios. Equiparemos a este agente con un conjunto completo de herramientas de calendario: listar, crear, actualizar, borrar y hasta una función de "agregar rápido" que comprende el lenguaje natural.
Copia el siguiente código en calendar.py.
calendar.py
import os
from datetime import datetime, timedelta, timezone
import google.auth
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from google.adk.agents.llm_agent import Agent
def _get_calendar_service():
"""Build the Google Calendar API service using Service Account Impersonation."""
from google.auth.transport.requests import Request
from google.auth import impersonated_credentials
target_principal = os.environ.get("SERVICE_ACCOUNT_EMAIL")
if not target_principal:
raise ValueError("SERVICE_ACCOUNT_EMAIL environment variable is missing.")
base_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
creds, _ = google.auth.default(scopes=base_scopes)
creds.refresh(Request())
target_scopes = ["https://www.googleapis.com/auth/calendar"]
impersonated = impersonated_credentials.Credentials(
source_credentials=creds,
target_principal=target_principal,
target_scopes=target_scopes,
)
return build("calendar", "v3", credentials=impersonated)
def _format_event(event: dict) -> dict:
"""Format a raw Calendar API event into a clean dict for the LLM."""
start = event.get("start", {})
end = event.get("end", {})
return {
"id": event.get("id"),
"title": event.get("summary", "(No title)"),
"start": start.get("dateTime", start.get("date")),
"end": end.get("dateTime", end.get("date")),
"location": event.get("location", ""),
"description": event.get("description", ""),
"attendees": [
{"email": a["email"], "status": a.get("responseStatus", "unknown")}
for a in event.get("attendees", [])
],
"link": event.get("htmlLink", ""),
"conference_link": (
event.get("conferenceData", {}).get("entryPoints", [{}])[0].get("uri", "")
if event.get("conferenceData")
else ""
),
"status": event.get("status", ""),
}
def list_events(days_ahead: int = 7) -> dict:
"""List upcoming calendar events."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
now = datetime.now(timezone.utc).isoformat()
end = (datetime.now(timezone.utc) + timedelta(days=days_ahead)).isoformat()
events_result = service.events().list(
calendarId=calendar_id, timeMin=now, timeMax=end,
maxResults=50, singleEvents=True, orderBy="startTime"
).execute()
events = events_result.get("items", [])
if not events:
return {"status": "success", "count": 0, "events": []}
return {"status": "success", "count": len(events), "events": [_format_event(e) for e in events]}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def create_event(title: str, start_time: str, end_time: str, description: str = "", location: str = "", attendees: str = "", add_google_meet: bool = False) -> dict:
"""Create a new calendar event."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
event_body = {
"summary": title,
"start": {"dateTime": start_time},
"end": {"dateTime": end_time},
}
if description: event_body["description"] = description
if location: event_body["location"] = location
if attendees:
email_list = [e.strip() for e in attendees.split(",") if e.strip()]
event_body["attendees"] = [{"email": e} for e in email_list]
conference_version = 0
if add_google_meet:
event_body["conferenceData"] = {
"createRequest": {"requestId": f"event-{datetime.now().strftime('%Y%m%d%H%M%S')}", "conferenceSolutionKey": {"type": "hangoutsMeet"}}
}
conference_version = 1
event = service.events().insert(calendarId=calendar_id, body=event_body, conferenceDataVersion=conference_version).execute()
return {"status": "success", "message": f"Event created ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def update_event(event_id: str, title: str = "", start_time: str = "", end_time: str = "", description: str = "") -> dict:
"""Update an existing calendar event."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
patch_body = {}
if title: patch_body["summary"] = title
if start_time: patch_body["start"] = {"dateTime": start_time}
if end_time: patch_body["end"] = {"dateTime": end_time}
if description: patch_body["description"] = description
if not patch_body: return {"status": "error", "message": "No fields to update."}
event = service.events().patch(calendarId=calendar_id, eventId=event_id, body=patch_body).execute()
return {"status": "success", "message": "Event updated ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def delete_event(event_id: str) -> dict:
"""Delete a calendar event by its ID."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
service.events().delete(calendarId=calendar_id, eventId=event_id).execute()
return {"status": "success", "message": f"Event '{event_id}' deleted ✅"}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def quick_add_event(text: str) -> dict:
"""Create an event using natural language (e.g. 'Lunch with Sarah next Monday noon')."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
event = service.events().quickAdd(calendarId=calendar_id, text=text).execute()
return {"status": "success", "message": "Event created from text ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
calendar_agent = Agent(
model='gemini-2.5-flash',
name='calendar_specialist',
description='Manages the user schedule and calendar events.',
instruction='''
You manage the user's Google Calendar.
- Use list_events to check the schedule.
- Use quick_add_event for simple, conversational scheduling requests (e.g., "Lunch tomorrow at noon").
- Use create_event for complex meetings that require attendees, specific durations, or Google Meet links.
- Use update_event to change details of an existing event.
- Use delete_event to cancel or remove an event.
CRITICAL: For update_event and delete_event, you must provide the exact `event_id`.
If the user does not provide the ID, you MUST call list_events first to find the correct `event_id` before attempting the update or deletion.
Always use the current date/time context provided by the root agent to resolve relative dates like "tomorrow".
''',
tools=[list_events, create_event, update_event, delete_event, quick_add_event],
)
Finaliza el agente raíz (agent.py)
Actualiza tu archivo agent.py con el siguiente código:
agent.py
import os
from datetime import datetime
from zoneinfo import ZoneInfo
from google.adk.agents.llm_agent import Agent
from google.adk.tools.agent_tool import AgentTool
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import all our specialized sub-agents
from .research import research_agent
from .todo import todo_agent
from .calendar import calendar_agent
import tzlocal
# Automatically detect the local system timezone
TIMEZONE = tzlocal.get_localzone_name()
# Callback for persistent memory storage
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Callback to inject the current time into the prompt
async def setup_agent_context(callback_context, **kwargs):
now = datetime.now(ZoneInfo(TIMEZONE))
callback_context.state["current_time"] = now.strftime("%A, %Y-%m-%d %I:%M %p")
callback_context.state["timezone"] = TIMEZONE
# --- ROOT AGENT DEFINITION ---
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant with memory and specialized tools.',
instruction='''
You are an elite, high-signal AI Executive Assistant.
Your goal is to help the user manage their knowledge, tasks, research, and schedule.
## Your Capabilities:
1. Memory: Use load_memory to recall personal facts.
2. Research: Delegate complex web investigations to the research_specialist.
3. Tasks: Delegate all to-do list management to the todo_specialist.
4. Scheduling: Delegate all calendar queries to the calendar_specialist.
## 🕒 Current State
- Time: {current_time?}
- Timezone: {timezone?}
Always be direct and professional.
''',
tools=[
PreloadMemoryTool(),
load_memory_tool,
AgentTool(todo_agent),
AgentTool(calendar_agent)
],
sub_agents=[research_agent],
before_agent_callback=[setup_agent_context],
after_agent_callback=[auto_save_session_to_memory_callback],
)
Ten en cuenta que, además de la herramienta de calendario, también agregamos una nueva función de devolución de llamada previa al agente: setup_agent_context. Esta función le permite al agente conocer la fecha, la hora y la zona horaria actuales para que pueda usar el calendario de manera más eficiente. Funciona configurando variables de estado de sesión, un tipo diferente de memoria del agente diseñada para la persistencia a corto plazo.
Ejecuta adk web por última vez para probar el agente completo.
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
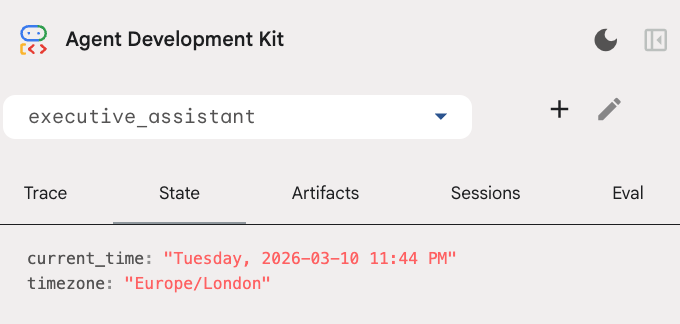
Puedes inspeccionar el estado de la sesión en la pestaña de estado de la IU para desarrolladores:
Ahora tienes un agente que puede hacer un seguimiento de los eventos del calendario y las listas de tareas, investigar y tiene memoria a largo plazo.
Limpieza después del lab
9. Conclusión
¡Felicitaciones! Diseñaste correctamente un asistente ejecutivo multifuncional potenciado por IA en 5 etapas evolutivas.
Temas abordados
- Aprovisionamiento de infraestructura para agentes de IA
- Implementar memoria persistente y subagentes especializados con elementos integrados en el ADK
- Integración de bases de datos externas y APIs de productividad
Próximos pasos
Puedes continuar tu recorrido de aprendizaje explorando otros codelabs en esta plataforma o mejorando el asistente ejecutivo por tu cuenta.
Si necesitas ideas para realizar mejoras, puedes probar lo siguiente:
- Implementa la compactación de eventos para optimizar el rendimiento en conversaciones largas.
- Agrega un servicio de artefactos para permitir que el agente tome notas por ti y las guarde como archivos.
- Implementa tu agente como un servicio de backend con Google Cloud Run.
Cuando termines de realizar las pruebas, recuerda limpiar el entorno para no incurrir en cargos inesperados en tu cuenta de facturación.
¡Suerte con la programación!