
۱. مقدمه
در این آزمایشگاه کد، شما یاد خواهید گرفت که چگونه یک عامل هوش مصنوعی پیشرفته با استفاده از کیت توسعه عامل گوگل (ADK) بسازید. ما یک مسیر تکاملی طبیعی را دنبال خواهیم کرد، که از یک عامل محاورهای بنیادی شروع میشود و به تدریج قابلیتهای تخصصی را لایهبندی میکند.
عاملی که ما در حال ساخت آن هستیم یک دستیار اجرایی است که برای کمک به شما در انجام کارهای روزانه مانند مدیریت تقویم، یادآوری وظایف، انجام تحقیقات و گردآوری یادداشتها طراحی شده است و همه اینها از ابتدا با استفاده از ADK، Gemini و Vertex AI ساخته شده است.
در پایان این آزمایش، شما یک عامل کاملاً کارآمد و دانش لازم برای گسترش آن به نیازهای خود را خواهید داشت.
پیشنیازها
- دانش پایه زبان برنامه نویسی پایتون
- آشنایی اولیه با کنسول گوگل کلود برای مدیریت منابع ابری
آنچه یاد خواهید گرفت
- تأمین زیرساختهای گوگل کلود برای عاملهای هوش مصنوعی.
- پیادهسازی حافظه بلندمدت پایدار با استفاده از بانک حافظه هوش مصنوعی Vertex
- ساخت سلسله مراتبی از زیرعاملهای تخصصی.
- ادغام پایگاههای داده خارجی و اکوسیستم Google Workspace.
آنچه نیاز دارید
این کارگاه آموزشی را میتوان بهطور کامل در Google Cloud Shell انجام داد، که شامل تمام وابستگیهای لازم (gcloud CLI، ویرایشگر کد، Go، Gemini CLI) از پیش نصبشده است .
از طرف دیگر ، اگر ترجیح میدهید روی دستگاه خودتان کار کنید، به موارد زیر نیاز خواهید داشت:
- پایتون (نسخه ۳.۱۲ یا بالاتر)
- یک ویرایشگر کد یا IDE (مانند VS Code یا
vim). - یک ترمینال برای اجرای دستورات پایتون و
gcloud. - توصیه میشود: یک عامل کدنویسی مانند Gemini CLI یا Antigravity
فناوریهای کلیدی
در اینجا میتوانید اطلاعات بیشتری در مورد فناوریهایی که ما استفاده خواهیم کرد، بیابید:
۲. تنظیمات محیطی
یکی از گزینههای زیر را انتخاب کنید: اگر میخواهید این آزمایشگاه کد را روی دستگاه خودتان اجرا کنید، تنظیمات محیط خودآموز را انتخاب کنید ، یا اگر میخواهید این آزمایشگاه کد را کاملاً در فضای ابری اجرا کنید ، Cloud Shell را راهاندازی کنید .
تنظیم محیط خودتنظیم
- وارد کنسول گوگل کلود شوید و یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. اگر از قبل حساب جیمیل یا گوگل ورک اسپیس ندارید، باید یکی ایجاد کنید .

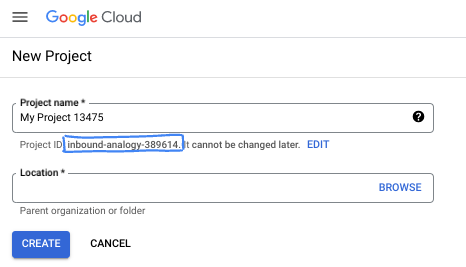
- نام پروژه، نام نمایشی برای شرکتکنندگان این پروژه است. این یک رشته کاراکتری است که توسط APIهای گوگل استفاده نمیشود. شما همیشه میتوانید آن را بهروزرسانی کنید.
- شناسه پروژه در تمام پروژههای گوگل کلود منحصر به فرد است و تغییرناپذیر است (پس از تنظیم، قابل تغییر نیست). کنسول کلود به طور خودکار یک رشته منحصر به فرد تولید میکند؛ معمولاً برای شما مهم نیست که چه باشد. در اکثر آزمایشگاههای کد، باید شناسه پروژه خود را (که معمولاً با عنوان
PROJECT_IDشناخته میشود) ارجاع دهید. اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید. به عنوان یک جایگزین، میتوانید شناسه خودتان را امتحان کنید و ببینید که آیا در دسترس است یا خیر. پس از این مرحله قابل تغییر نیست و در طول پروژه باقی میماند. - برای اطلاع شما، یک مقدار سوم، شماره پروژه ، وجود دارد که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
- در مرحله بعد، برای استفاده از منابع/API های ابری، باید پرداخت صورتحساب را در کنسول ابری فعال کنید . اجرای این آزمایشگاه کد هزینه زیادی نخواهد داشت، اگر اصلاً هزینهای داشته باشد. برای خاموش کردن منابع به منظور جلوگیری از پرداخت صورتحساب پس از این آموزش، میتوانید منابعی را که ایجاد کردهاید یا پروژه را حذف کنید. کاربران جدید Google Cloud واجد شرایط برنامه آزمایشی رایگان ۳۰۰ دلاری هستند.
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:
آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
۳. راهاندازی پروژه
قبل از نوشتن کد، باید زیرساختها و مجوزهای لازم را در Google Cloud فراهم کنیم.
تنظیم متغیرهای محیطی
ترمینال را باز کنید و متغیرهای محیطی زیر را تنظیم کنید:
export PROJECT_ID=`gcloud config get project`
export LOCATION=us-central1
فعال کردن API های مورد نیاز
نماینده شما نیاز به دسترسی به چندین سرویس Google Cloud دارد. برای فعال کردن آنها، دستور زیر را اجرا کنید:
gcloud services enable \
aiplatform.googleapis.com \
calendar-json.googleapis.com \
sqladmin.googleapis.com
احراز هویت با اعتبارنامههای پیشفرض برنامه
برای ارتباط با سرویسهای گوگل کلود از محیط شما، باید با استفاده از اعتبارنامههای پیشفرض برنامه (ADC) احراز هویت کنیم.
برای اطمینان از فعال و بهروز بودن اعتبارنامههای پیشفرض برنامه، دستور زیر را اجرا کنید:
gcloud auth application-default login
۴. عامل پایه را ایجاد کنید
حالا باید دایرکتوری که قرار است کد منبع پروژه در آن ذخیره شود را مقداردهی اولیه کنیم:
# setup project directory
mkdir -p adk_ea_codelab && cd adk_ea_codelab
# prepare virtual environment
uv init
# install dependencies
uv add google-adk google-api-python-client tzlocal python-dotenv
uv add cloud-sql-python-connector[pg8000] sqlalchemy
ما با تعیین هویت عامل و قابلیتهای مکالمهای اولیه شروع میکنیم. در ADK، کلاس عامل، شخصیت عامل و دستورالعملهای آن را تعریف میکند.
الان زمانی است که شاید بخواهید در مورد نام یک نماینده فکر کنید. من دوست دارم نمایندگانم نامهای مناسبی مانند آیدا یا شارون داشته باشند، زیرا فکر میکنم به آنها شخصیت میدهد، اما میتوانید به سادگی نماینده را با کاری که انجام میدهد، مانند "دستیار_اجرایی"، "نماینده_مسافرت" یا "مجری_کد" نیز صدا بزنید.
دستور adk create را اجرا کنید تا یک عامل تکراری ایجاد شود:
# replace with your desired agent name
uv run adk create executive_assistant
لطفاً gemini-2.5-flash به عنوان مدل و Vertex AI را به عنوان backend انتخاب کنید. شناسه پروژه پیشنهادی را دوباره بررسی کنید که همان شناسهای باشد که برای این آزمایش ایجاد کردهاید و برای تأیید، Enter را بزنید. برای منطقه Google Cloud، میتوانید پیشفرض ( us-central1 ) را بپذیرید. ترمینال شما شبیه به این خواهد بود:
daniela_petruzalek@cloudshell:~/adk_ea_codelab (your-project-id)$ uv run adk create executive_assistant Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [your-project-id]: Enter Google Cloud region [us-central1]: Agent created in /home/daniela_petruzalek/adk_ea_codelab/executive_assistant: - .env - __init__.py - agent.py daniela_petruzalek@cloudshell:~/adk_ea_codelab (your-project-id)$
پس از اتمام، دستور قبلی پوشهای با نام عامل (مثلاً executive_assistant ) ایجاد میکند که شامل چند فایل از جمله فایل agent.py با تعریف اولیه عامل است:
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
اگر میخواهید با این عامل تعامل داشته باشید، میتوانید با اجرای uv run adk web در خط فرمان و باز کردن رابط کاربری توسعه در مرورگر خود این کار را انجام دهید. چیزی شبیه به این را خواهید دید:
$ uv run adk web ... INFO: Started server process [1244] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
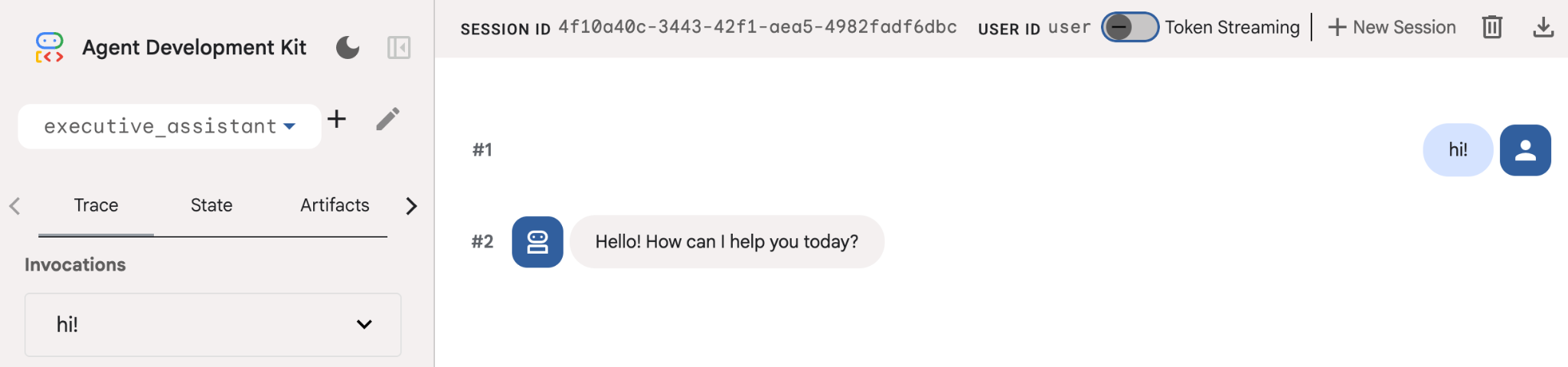
حتی اگر این عامل بسیار ابتدایی باشد، انجام این کار حداقل یک بار برای اطمینان از عملکرد صحیح تنظیمات قبل از شروع ویرایش عامل مفید است. تصویر زیر یک تعامل ساده با استفاده از رابط کاربری توسعه را نشان میدهد:
حالا، بیایید تعریف عامل را با شخصیت دستیار اجرایی خود تغییر دهیم. کد زیر را کپی کنید و محتویات agent.py را جایگزین کنید. نام عامل و شخصیت را با تنظیمات برگزیده خود تطبیق دهید.
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant',
instruction='''
You are an elite, warm, and highly efficient AI partner.
Your primary goal is to help the user manage their tasks, schedule, and research.
Always be direct, concise, and high-signal.
''',
)
لطفاً توجه داشته باشید که ویژگی name، نام داخلی عامل را تعریف میکند، در حالی که در دستورالعملها میتوانید نام دوستانهتری را به عنوان بخشی از شخصیت آنها برای تعامل با کاربر نهایی نیز به آن بدهید. نام داخلی بیشتر برای مشاهدهپذیری و تحویل در سیستمهای چندعاملی با استفاده از ابزار transfer_to_agent استفاده میشود. شما خودتان با این ابزار سر و کار نخواهید داشت، ADK به طور خودکار آن را هنگام اعلام یک یا چند عامل فرعی ثبت میکند.
برای اجرای عاملی که تازه ایجاد کردیم، از adk web استفاده کنید:
uv run adk web
رابط کاربری ADK را در مرورگر باز کنید و به دستیار جدیدتان سلام کنید!
۵. با استفاده از بانک حافظه هوش مصنوعی ورتکس، حافظه پایدار اضافه کنید
یک دستیار واقعی باید تنظیمات برگزیده و تعاملات گذشته را به خاطر بسپارد تا یک تجربه شخصیسازیشده و یکپارچه ارائه دهد. در این مرحله، ما بانک حافظه موتور عامل هوش مصنوعی ورتکس را ادغام خواهیم کرد، یک ویژگی هوش مصنوعی ورتکس که به صورت پویا خاطرات بلندمدت را بر اساس مکالمات کاربر ایجاد میکند.
بانک حافظه به عامل شما اجازه میدهد تا اطلاعات شخصیسازیشدهای را که در چندین جلسه قابل دسترسی هستند، ایجاد کند و پیوستگی بین جلسات را برقرار سازد. در پشت صحنه، توالی زمانی پیامها را در یک جلسه مدیریت میکند و میتواند از بازیابی جستجوی شباهت برای ارائه مرتبطترین خاطرات به عامل برای زمینه فعلی استفاده کند.
مقداردهی اولیه سرویس حافظه
ADK از Vertex AI برای ذخیره و بازیابی خاطرات بلندمدت استفاده میکند. شما باید یک "موتور حافظه" را در پروژه خود راهاندازی کنید. این اساساً یک نمونه Reasoning Engine است که برای عمل به عنوان یک بانک حافظه پیکربندی شده است.
اسکریپت زیر را با نام setup_memory.py ایجاد کنید:
setup_memory.py
import vertexai
import os
PROJECT_ID=os.getenv("PROJECT_ID")
LOCATION=os.getenv("LOCATION")
client = vertexai.Client(project=PROJECT_ID, location=LOCATION)
# Create Reasoning Engine for Memory Bank
agent_engine = client.agent_engines.create()
# You will need this resource name to give it to ADK
print(agent_engine.api_resource.name)
اکنون setup_memory.py را اجرا کنید تا موتور استدلال برای بانک حافظه آماده شود:
uv run python setup_memory.py
خروجی شما باید شبیه به این باشد:
$ uv run python setup.py projects/1234567890/locations/us-central1/reasoningEngines/1234567890
نام منبع موتور را در یک متغیر محیطی ذخیره کنید:
export ENGINE_ID="<insert the resource name above>"
حالا باید کد را برای استفاده از حافظه پایدار بهروزرسانی کنیم. محتوای agent.py را با موارد زیر جایگزین کنید:
عامل.py
from google.adk.agents.llm_agent import Agent
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Update root_agent with memory tools and callback
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='Executive Assistant with Persistent Memory',
instruction='''
You are an elite AI partner with long-term memory.
Use load_memory to find context about the user when needed.
Always be direct, concise, and high-signal.
''',
tools=[PreloadMemoryTool(), load_memory_tool],
after_agent_callback=auto_save_session_to_memory_callback,
)
ابزار PreloadMemoryTool به طور خودکار زمینه مرتبط را از مکالمات گذشته به هر درخواست تزریق میکند (با استفاده از بازیابی جستجوی شباهت)، در حالی که load_memory_tool به مدل اجازه میدهد تا در صورت نیاز، به طور صریح از بانک حافظه برای حقایق پرس و جو کند. این ترکیب زمینه عمیق و پایداری را به عامل شما میدهد!
حالا برای راهاندازی عامل خود با پشتیبانی از حافظه، باید هنگام اجرای adk web، memory_service_uri را به آن منتقل کنید:
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
سعی کنید چند نکته در مورد خودتان به ماموران بگویید و سپس با یک جلسه دیگر برگردید و در مورد آنها سوال کنید. برای مثال، نام خود را به او بگویید:
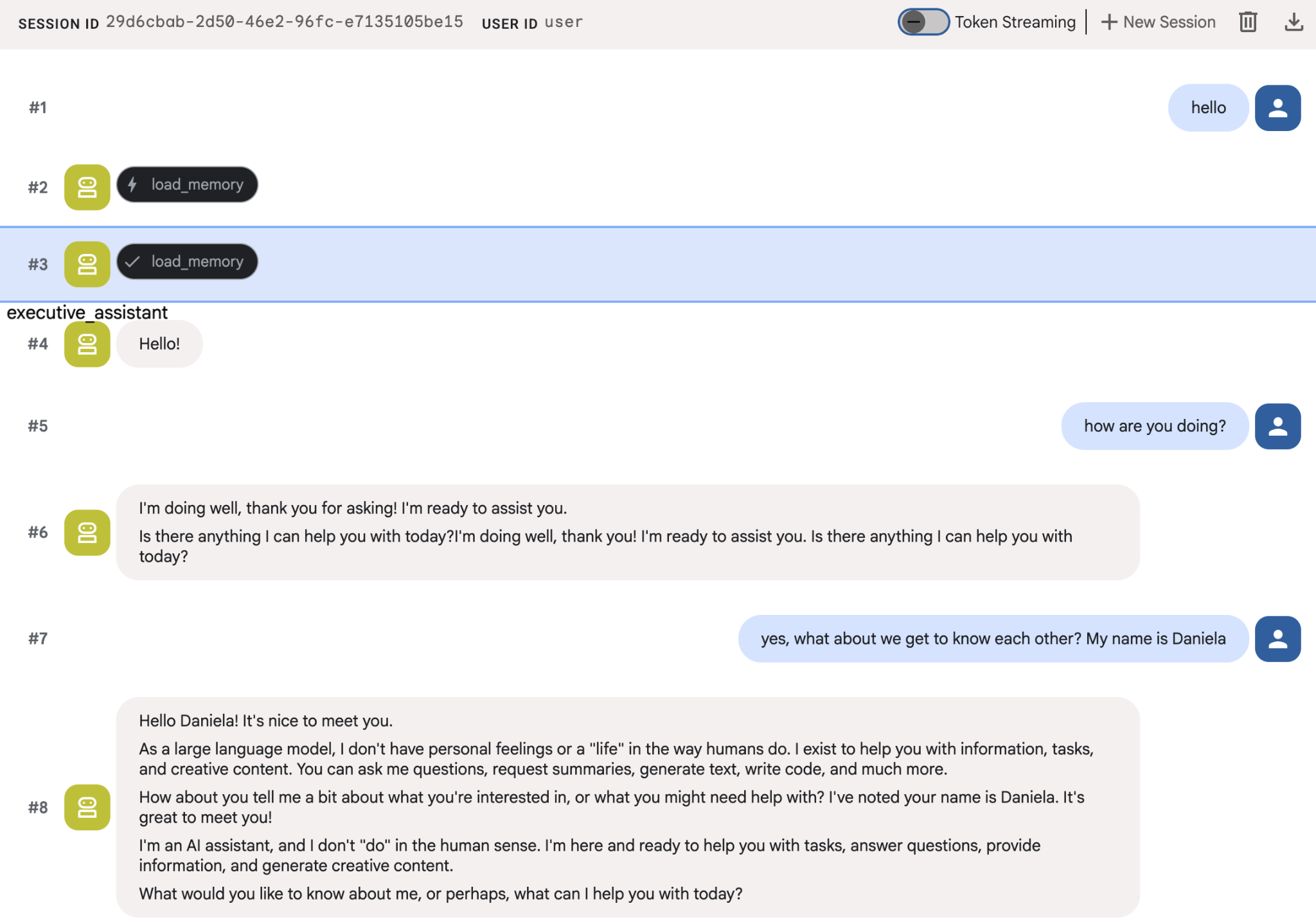
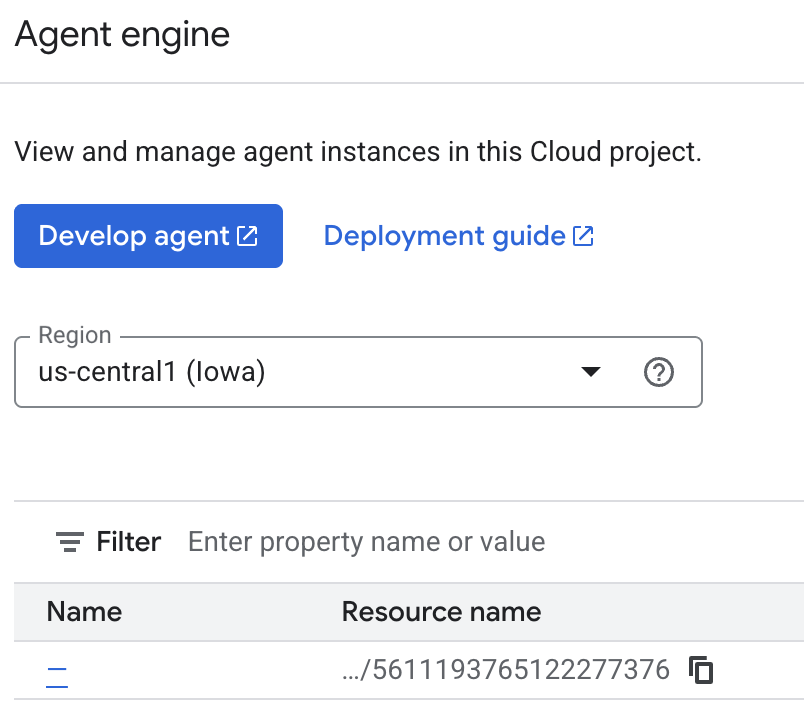
میتوانید خاطراتی را که عامل در کنسول ابری ذخیره میکند، بررسی کنید. به صفحه محصول «موتور عامل» بروید (از نوار جستجو استفاده کنید)

سپس روی نام موتور عامل خود کلیک کنید (مطمئن شوید که منطقه درست را انتخاب کردهاید):
و سپس به برگه خاطرات بروید:
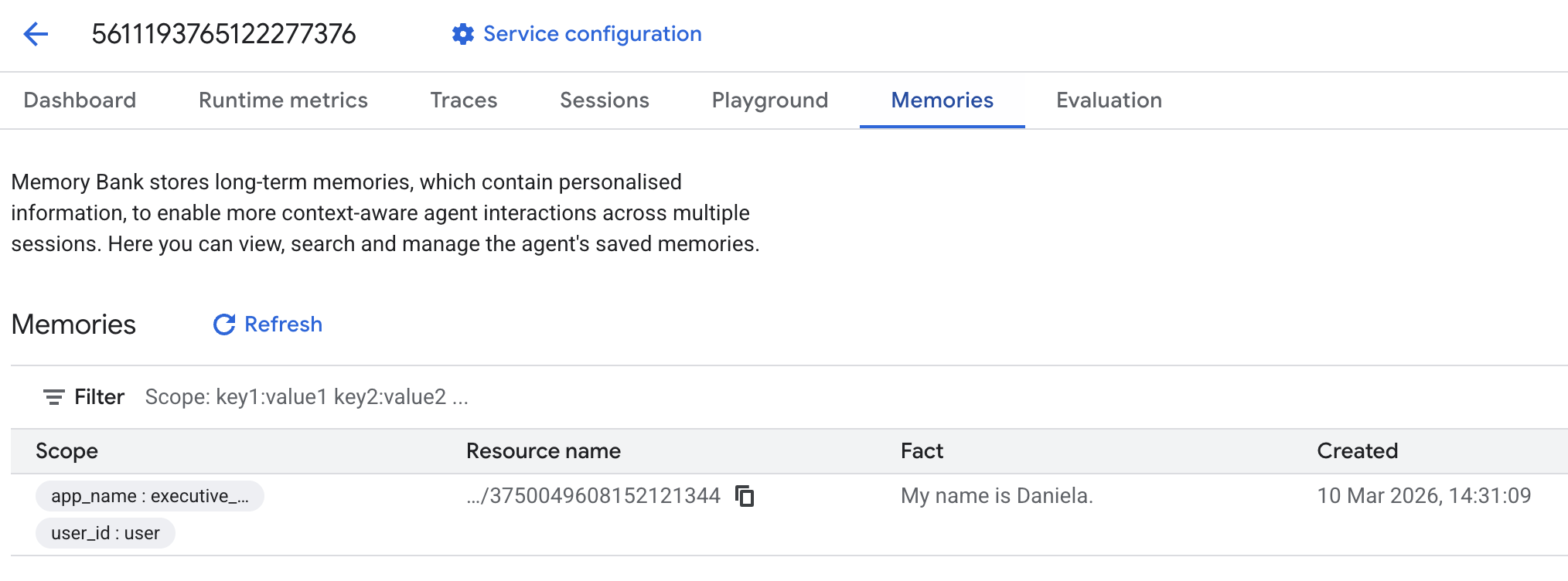
باید ببینی که چند تا خاطره اضافه شده.
۶. قابلیتهای تحقیق وب را اضافه کنید
برای ارائه اطلاعات با کیفیت بالا، نماینده ما باید تحقیقات عمیقی انجام دهد که فراتر از یک عبارت جستجوی واحد است. با واگذاری تحقیق به یک نماینده فرعی متخصص، ما پاسخگویی شخصیت اصلی را حفظ میکنیم در حالی که محقق در پسزمینه به جمعآوری دادههای پیچیده میپردازد.
در این مرحله، ما یک LoopAgent را برای دستیابی به «عمق تحقیق» پیادهسازی میکنیم - که به عامل اجازه میدهد تا به طور مکرر جستجو کند، یافتهها را ارزیابی کند و پرسوجوهای خود را اصلاح کند تا زمانی که تصویر کاملی داشته باشد. ما همچنین با الزام استنادهای درونخطی برای همه یافتهها، دقت فنی را اعمال میکنیم و اطمینان حاصل میکنیم که هر ادعا توسط یک لینک منبع پشتیبانی میشود.
ایجاد متخصص تحقیق (research.py)
در اینجا ما یک عامل پایه مجهز به ابزار جستجوی گوگل تعریف میکنیم و آن را در یک LoopAgent قرار میدهیم. پارامتر max_iterations به عنوان یک کنترلکننده عمل میکند و تضمین میکند که عامل در صورت وجود هرگونه خللی در درک خود، جستجو را تا ۳ بار تکرار کند.
research.py
from google.adk.agents.llm_agent import Agent
from google.adk.agents.loop_agent import LoopAgent
from google.adk.tools.google_search_tool import GoogleSearchTool
from google.adk.tools.tool_context import ToolContext
def exit_loop(tool_context: ToolContext):
"""Call this function ONLY when no further research is needed, signaling the iterative process should end."""
print(f" [Tool Call] exit_loop triggered by {tool_context.agent_name}")
tool_context.actions.escalate = True
# Return empty dict as tools should typically return JSON-serializable output
return {}
# --- RESEARCH LOGIC ---
_research_worker = Agent(
model='gemini-2.5-flash',
name='research_worker',
description='Worker agent that performs a single research step.',
instruction='''
Use google_search to find facts and synthesize them for the user.
Critically evaluate your findings. If the data is incomplete or you need more context, prepare to search again in the next iteration.
You must include the links you found as references in your response, formatting them like citations in a research paper (e.g., [1], [2]).
Use the exit_loop tool to terminate the research early if no further research is needed.
If you need to ask the user for clarifications, call the exit_loop function early to interrupt the research cycle.
''',
tools=[GoogleSearchTool(bypass_multi_tools_limit=True), exit_loop],
)
# The LoopAgent iterates the worker up to 3 times for deeper research
research_agent = LoopAgent(
name='research_specialist',
description='Deep web research specialist.',
sub_agents=[_research_worker],
max_iterations=3,
)
بهروزرسانی عامل ریشه (agent.py)
research_agent را وارد کنید و آن را به عنوان ابزاری به Sharon اضافه کنید:
عامل.py
from google.adk.agents.llm_agent import Agent
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import our new sub agent
from .research import research_agent
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Update root_agent with memory tools and callback
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='Executive Assistant with persistent memory and research capabilities',
instruction='''
You are an elite AI partner with long-term memory.
1. Use load_memory to recall facts.
2. Delegate research tasks to the research_specialist.
Always be direct, concise, and high-signal.
''',
tools=[PreloadMemoryTool(), load_memory_tool],
sub_agents=[research_agent],
after_agent_callback=auto_save_session_to_memory_callback,
)
برای آزمایش عامل تحقیق، دوباره adk web را اجرا کنید.
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
به آن یک کار تحقیقاتی ساده بدهید، مثلاً «چگونه یک وبلاگ فناوری خوب بنویسیم؟»
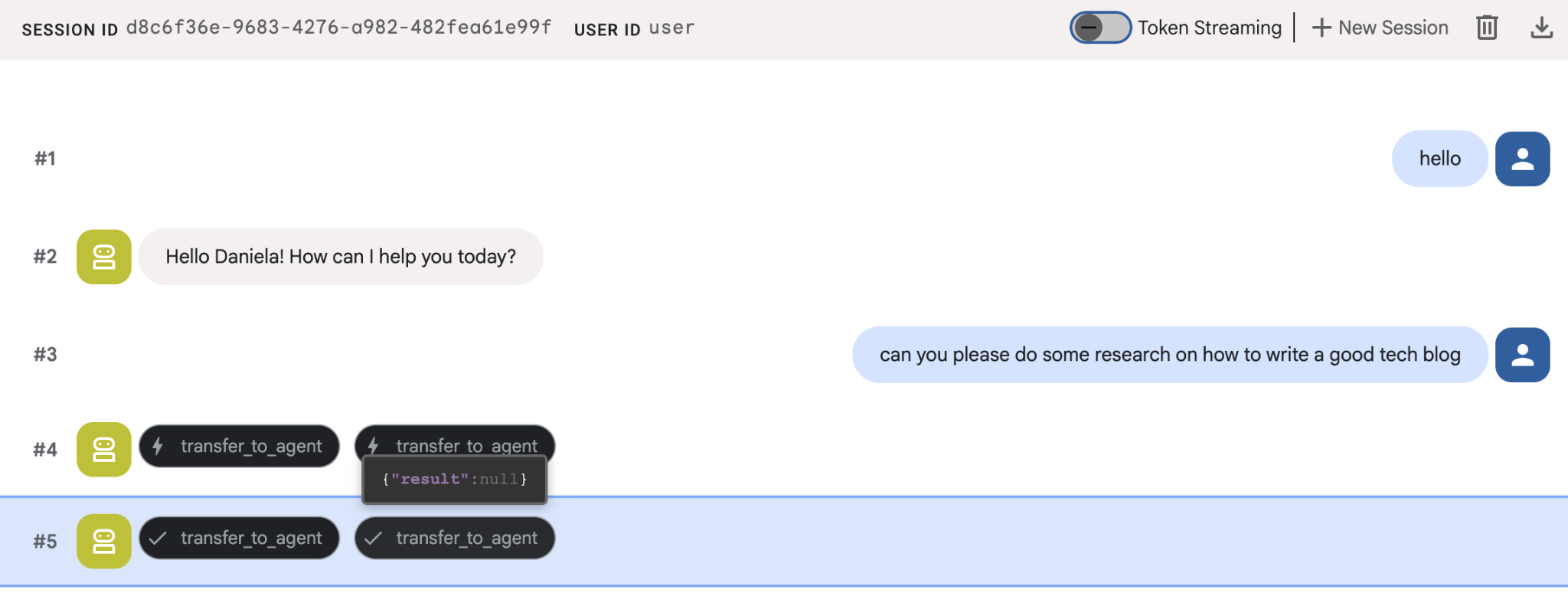
شاید متوجه شده باشید که با وجود اینکه این یک جلسه جدید است، عامل نام من را به خاطر سپرده است. لطفاً به فراخوانی ابزار "transfer_to_agent" نیز توجه کنید: این ابزاری است که وظیفه را به عامل تحقیقاتی جدید ما واگذار میکند.
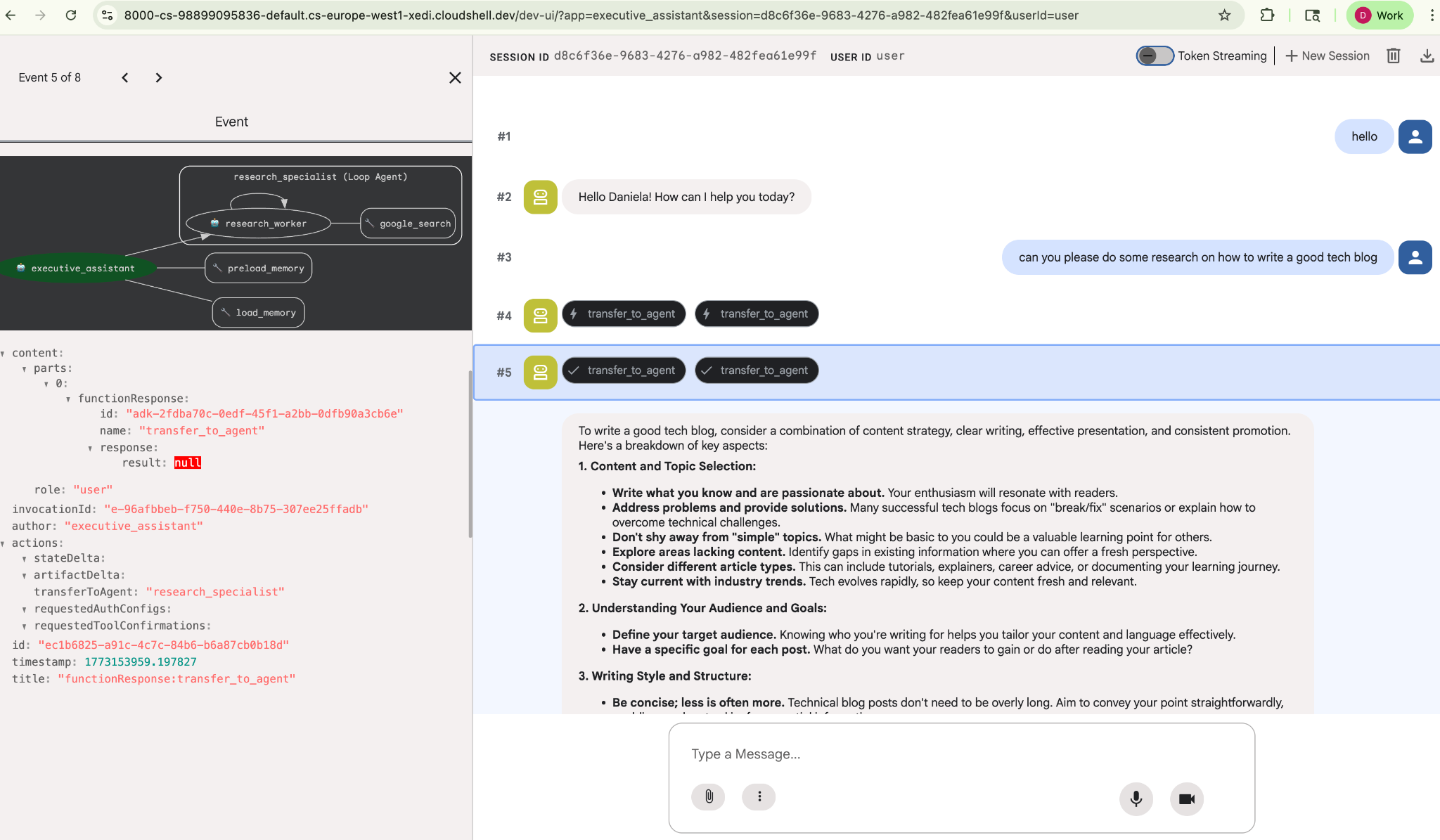
حالا، بیایید به سراغ مدیریت وظایف برویم.
۷. مدیریت وظایف را با Cloud SQL اضافه کنید
اگرچه این عامل حافظه بلندمدت دارد، اما برای دادههای جزئی و ساختاریافته مانند فهرست کارها (To-Do List) مناسب نیست. برای وظایف، ما از یک پایگاه داده رابطهای سنتی استفاده میکنیم. ما قصد داریم از SQLAlchemy و یک پایگاه داده Google Cloud SQL (PostgreSQL) استفاده کنیم. قبل از اینکه بتوانیم کد بنویسیم، باید زیرساخت را فراهم کنیم.
تأمین زیرساختها
این دستورات را برای ایجاد پایگاه داده خود اجرا کنید. توجه: ایجاد نمونه حدود ۵ تا ۱۰ دقیقه طول میکشد. میتوانید در حالی که این مرحله در پسزمینه در حال اجرا است، به مرحله بعدی بروید.
# 1. Define instance variables
export INSTANCE_NAME="assistant-db"
export USER_EMAIL=$(gcloud config get-value account)
# 2. Create the Cloud SQL instance
gcloud sql instances create $INSTANCE_NAME \
--database-version=POSTGRES_18 \
--tier=db-f1-micro \
--region=us-central1 \
--edition=ENTERPRISE
# 3. Create the database for our tasks
gcloud sql databases create tasks --instance=$INSTANCE_NAME
آمادهسازی نمونه پایگاه داده چند دقیقه طول میکشد. این ممکن است زمان مناسبی برای نوشیدن یک فنجان قهوه یا چای یا بهروزرسانی کد در حین انتظار برای اتمام آن باشد، فقط فراموش نکنید که برگردید و کنترل دسترسی را تمام کنید!
پیکربندی کنترل دسترسی
حالا باید حساب کاربری خود را برای دسترسی به پایگاه داده پیکربندی کنید. دستورات زیر را در ترمینال اجرا کنید:
# change this to your favorite password
export DB_PASS="correct-horse-battery-staple"
# Create a regular database user
gcloud sql users create assistant_user \
--instance=$INSTANCE_NAME \
--password=$DB_PASS
بهروزرسانی پیکربندی محیط
ADK پیکربندی را از یک فایل .env در زمان اجرا بارگذاری میکند. محیط عامل خود را با جزئیات اتصال پایگاه داده بهروزرسانی کنید.
# Retrieve the unique connection name
export DB_CONN=$(gcloud sql instances describe $INSTANCE_NAME --format='value(connectionName)')
# Append configuration to your .env file
cat <<EOF >> executive_assistant/.env
DB_CONNECTION_NAME=$DB_CONN
DB_USER=assistant_user
DB_PASSWORD=$DB_PASS
DB_NAME=tasks
EOF
حالا بیایید به سراغ ایجاد تغییرات در کد برویم.
ایجاد متخصص Todo (todo.py)
مشابه عامل تحقیق، بیایید متخصص کارهایمان را در فایل خودش ایجاد کنیم. todo.py را ایجاد کنید:
todo.py
import os
import uuid
import sqlalchemy
from datetime import datetime
from typing import Optional, List
from sqlalchemy import (
Column,
String,
DateTime,
Enum,
select,
delete,
update,
)
from sqlalchemy.orm import declarative_base, Session
from google.cloud.sql.connector import Connector
from google.adk.agents.llm_agent import Agent
# --- DATABASE LOGIC ---
Base = declarative_base()
connector = Connector()
def getconn():
db_connection_name = os.environ.get("DB_CONNECTION_NAME")
db_user = os.environ.get("DB_USER")
db_password = os.environ.get("DB_PASSWORD")
db_name = os.environ.get("DB_NAME", "tasks")
return connector.connect(
db_connection_name,
"pg8000",
user=db_user,
password=db_password,
db=db_name,
)
engine = sqlalchemy.create_engine(
"postgresql+pg8000://",
creator=getconn,
)
class Todo(Base):
__tablename__ = "todos"
id = Column(String(36), primary_key=True, default=lambda: str(uuid.uuid4()))
title = Column(String(255), nullable=False)
priority = Column(
Enum("high", "medium", "low", name="priority_levels"), nullable=False, default="medium"
)
due_date = Column(DateTime, nullable=True)
status = Column(Enum("pending", "done", name="status_levels"), default="pending")
created_at = Column(DateTime, default=datetime.utcnow)
def init_db():
"""Builds the table if it's missing."""
Base.metadata.create_all(bind=engine)
def add_todo(
title: str, priority: str = "medium", due_date: Optional[str] = None
) -> dict:
"""
Adds a new task to the list.
Args:
title (str): The description of the task.
priority (str): The urgency level. Must be one of: 'high', 'medium', 'low'.
due_date (str, optional): The due date in ISO format (YYYY-MM-DD or YYYY-MM-DDTHH:MM:SS).
Returns:
dict: A dictionary containing the new task's ID and a status message.
"""
init_db()
with Session(engine) as session:
due = datetime.fromisoformat(due_date) if due_date else None
item = Todo(
title=title,
priority=priority.lower(),
due_date=due,
)
session.add(item)
session.commit()
return {"id": item.id, "status": f"Task added ✅"}
def list_todos(status: str = "pending") -> list:
"""
Lists tasks from the database, optionally filtering by status.
Args:
status (str, optional): The status to filter by. 'pending', 'done', or 'all'.
"""
init_db()
with Session(engine) as session:
query = select(Todo)
s_lower = status.lower()
if s_lower != "all":
query = query.where(Todo.status == s_lower)
query = query.order_by(Todo.priority, Todo.created_at)
results = session.execute(query).scalars().all()
return [
{
"id": t.id,
"task": t.title,
"priority": t.priority,
"status": t.status,
}
for t in results
]
def complete_todo(task_id: str) -> str:
"""Marks a specific task as 'done'."""
init_db()
with Session(engine) as session:
session.execute(update(Todo).where(Todo.id == task_id).values(status="done"))
session.commit()
return f"Task {task_id} marked as done."
def delete_todo(task_id: str) -> str:
"""Permanently removes a task from the database."""
init_db()
with Session(engine) as session:
session.execute(delete(Todo).where(Todo.id == task_id))
session.commit()
return f"Task {task_id} deleted."
# --- TODO SPECIALIST AGENT ---
todo_agent = Agent(
model='gemini-2.5-flash',
name='todo_specialist',
description='A specialist agent that manages a structured SQL task list.',
instruction='''
You manage the user's task list using a PostgreSQL database.
- Use add_todo when the user wants to remember something. If no priority is mentioned, mark it as 'medium'.
- Use list_todos to show tasks.
- Use complete_todo to mark a task as finished.
- Use delete_todo to remove a task entirely.
When marking a task as complete or deleting it, if the user doesn't provide the ID,
use list_todos first to find the correct ID for the task they described.
''',
tools=[add_todo, list_todos, complete_todo, delete_todo],
)
کد بالا مسئول دو کار اصلی است: اتصال به پایگاه داده Cloud SQL و ارائه فهرستی از ابزارها برای تمام عملیات رایج فهرست کارها، از جمله اضافه کردن، حذف کردن و علامتگذاری آنها به عنوان تکمیلشده.
از آنجا که این منطق بسیار مختص عامل انجام کار است و ما لزوماً از دیدگاه دستیار اجرایی (عامل ریشه) به این مدیریت جزئی اهمیتی نمیدهیم، این عامل را به جای یک عامل فرعی، به عنوان یک " AgentTool " بستهبندی خواهیم کرد.
برای تصمیمگیری بین استفاده از AgentTool یا sub-agent، در نظر بگیرید که آیا آنها نیاز به اشتراکگذاری زمینه دارند یا خیر:
- وقتی عامل شما نیازی به اشتراکگذاری محتوا با عامل ریشه ندارد، از AgentTool استفاده کنید
- وقتی میخواهید عامل شما زمینه را با عامل ریشه به اشتراک بگذارد، از یک عامل فرعی استفاده کنید
در مورد عامل تحقیق، به اشتراک گذاشتن زمینه میتواند مفید باشد، اما برای یک عامل سادهی انجام کارها، انجام این کار فایدهی زیادی ندارد.
بیایید AgentTool در agent.py پیادهسازی کنیم.
بهروزرسانی عامل ریشه (agent.py)
حالا، todo_agent را به فایل اصلی خود وارد کنید و آن را به عنوان یک ابزار پیوست کنید:
عامل.py
import os
from datetime import datetime
from google.adk.agents.llm_agent import Agent
from google.adk.tools.agent_tool import AgentTool
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import our specialized sub-agents
from .research import research_agent
from .todo import todo_agent
# Callback for persistent memory storage
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# --- ROOT AGENT DEFINITION ---
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant with memory and specialized tools.',
instruction='''
You are an elite, high-signal AI Executive Assistant.
Your goal is to help the user manage their knowledge, tasks, and research.
## Your Capabilities:
1. Memory: Use load_memory to recall personal facts or past context about the user.
2. Research: Delegate complex web-based investigations to the research_specialist.
3. Tasks: Delegate all to-do list management (adding, listing, or completing tasks) to the todo_specialist.
Always be direct and professional. If a task is successful, provide a brief confirmation.
''',
tools=[
PreloadMemoryTool(),
load_memory_tool,
AgentTool(todo_agent) # Exposes the Todo Specialist as a tool
],
sub_agents=[research_agent], # Exposes the Research Specialist for direct handover
after_agent_callback=auto_save_session_to_memory_callback,
)
برای آزمایش ویژگی جدید، دوباره adk web اجرا کنید:
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
و سعی کنید یک «برای انجام دادن» ایجاد کنید:
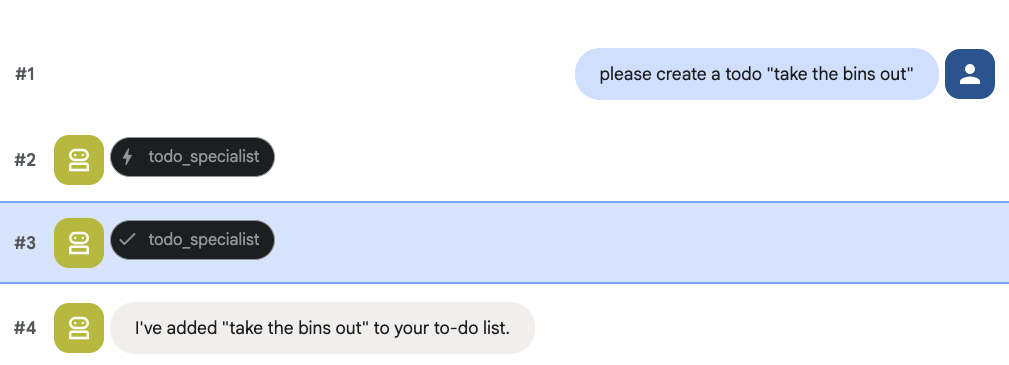
۸. مدیریت تقویم را اضافه کنید
در نهایت، ما با تقویم گوگل ادغام خواهیم شد تا اپراتور بتواند قرار ملاقاتها را مدیریت کند. به خاطر این کد، به جای اینکه به اپراتور دسترسی به تقویم شخصی خود را بدهیم، که اگر به روش صحیح انجام نشود، میتواند بالقوه خطرناک باشد، ما یک تقویم مستقل برای مدیریت اپراتور ایجاد خواهیم کرد.
ابتدا، یک حساب سرویس اختصاصی ایجاد میکنیم تا به عنوان هویت عامل عمل کند. سپس، با استفاده از حساب سرویس، تقویم عامل را به صورت برنامهنویسی ایجاد میکنیم.
ارائه حساب کاربری سرویس
ترمینال خود را باز کنید و این دستورات را اجرا کنید تا هویت ایجاد شود و به حساب شخصی خود اجازه دهید تا آن را جعل هویت کند:
export SA_NAME="ea-agent"
export SA_EMAIL="${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"
# Create the service account
gcloud iam service-accounts create $SA_NAME \
--display-name="Executive Assistant Agent"
# Allow your local user to impersonate it
gcloud iam service-accounts add-iam-policy-binding $SA_EMAIL \
--member="user:$(gcloud config get-value account)" \
--role="roles/iam.serviceAccountTokenCreator"
# Save it to the agent's environment
echo "SERVICE_ACCOUNT_EMAIL=$SA_EMAIL" >> executive_assistant/.env
ایجاد تقویم به صورت برنامهنویسیشده
بیایید اسکریپتی بنویسیم که به حساب سرویس بگوید تقویم را ایجاد کند. یک فایل جدید با نام setup_calendar.py در ریشه پروژه خود (در کنار setup_memory.py ) ایجاد کنید:
setup_calendar.py
import os
import google.auth
from googleapiclient.discovery import build
from google.auth.transport.requests import Request
from google.auth import impersonated_credentials
from dotenv import load_dotenv
load_dotenv('executive_assistant/.env')
SA_EMAIL = os.environ.get("SERVICE_ACCOUNT_EMAIL")
def setup_sa_calendar():
print(f"Authenticating to impersonate {SA_EMAIL}...")
# 1. Base credentials
creds, _ = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
creds.refresh(Request())
# 2. Impersonate the Service Account
impersonated = impersonated_credentials.Credentials(
source_credentials=creds,
target_principal=SA_EMAIL,
target_scopes=["https://www.googleapis.com/auth/calendar"],
)
service = build("calendar", "v3", credentials=impersonated)
# 3. Create the calendar
print("Creating independent Service Account calendar...")
calendar = service.calendars().insert(body={
"summary": "AI Assistant (SA Owned)",
"description": "An independent calendar managed purely by the AI."
}).execute()
calendar_id = calendar['id']
# 4. Save the ID
with open("executive_assistant/.env", "a") as f:
f.write(f"\nCALENDAR_ID={calendar_id}\n")
print(f"Setup complete! CALENDAR_ID {calendar_id} added to .env")
if __name__ == "__main__":
setup_sa_calendar()
اسکریپت را از ترمینال خود اجرا کنید:
uv run python setup_calendar.py
ایجاد متخصص تقویم (calendar.py)
حالا بیایید روی متخصص تقویم تمرکز کنیم. ما این عامل را به مجموعهای کامل از ابزارهای تقویم مجهز خواهیم کرد: فهرست کردن، ایجاد، بهروزرسانی، حذف و حتی یک ویژگی «افزودن سریع» که زبان طبیعی را درک میکند.
کد زیر را در calendar.py کپی کنید.
تقویم.py
import os
from datetime import datetime, timedelta, timezone
import google.auth
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from google.adk.agents.llm_agent import Agent
def _get_calendar_service():
"""Build the Google Calendar API service using Service Account Impersonation."""
from google.auth.transport.requests import Request
from google.auth import impersonated_credentials
target_principal = os.environ.get("SERVICE_ACCOUNT_EMAIL")
if not target_principal:
raise ValueError("SERVICE_ACCOUNT_EMAIL environment variable is missing.")
base_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
creds, _ = google.auth.default(scopes=base_scopes)
creds.refresh(Request())
target_scopes = ["https://www.googleapis.com/auth/calendar"]
impersonated = impersonated_credentials.Credentials(
source_credentials=creds,
target_principal=target_principal,
target_scopes=target_scopes,
)
return build("calendar", "v3", credentials=impersonated)
def _format_event(event: dict) -> dict:
"""Format a raw Calendar API event into a clean dict for the LLM."""
start = event.get("start", {})
end = event.get("end", {})
return {
"id": event.get("id"),
"title": event.get("summary", "(No title)"),
"start": start.get("dateTime", start.get("date")),
"end": end.get("dateTime", end.get("date")),
"location": event.get("location", ""),
"description": event.get("description", ""),
"attendees": [
{"email": a["email"], "status": a.get("responseStatus", "unknown")}
for a in event.get("attendees", [])
],
"link": event.get("htmlLink", ""),
"conference_link": (
event.get("conferenceData", {}).get("entryPoints", [{}])[0].get("uri", "")
if event.get("conferenceData")
else ""
),
"status": event.get("status", ""),
}
def list_events(days_ahead: int = 7) -> dict:
"""List upcoming calendar events."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
now = datetime.now(timezone.utc).isoformat()
end = (datetime.now(timezone.utc) + timedelta(days=days_ahead)).isoformat()
events_result = service.events().list(
calendarId=calendar_id, timeMin=now, timeMax=end,
maxResults=50, singleEvents=True, orderBy="startTime"
).execute()
events = events_result.get("items", [])
if not events:
return {"status": "success", "count": 0, "events": []}
return {"status": "success", "count": len(events), "events": [_format_event(e) for e in events]}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def create_event(title: str, start_time: str, end_time: str, description: str = "", location: str = "", attendees: str = "", add_google_meet: bool = False) -> dict:
"""Create a new calendar event."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
event_body = {
"summary": title,
"start": {"dateTime": start_time},
"end": {"dateTime": end_time},
}
if description: event_body["description"] = description
if location: event_body["location"] = location
if attendees:
email_list = [e.strip() for e in attendees.split(",") if e.strip()]
event_body["attendees"] = [{"email": e} for e in email_list]
conference_version = 0
if add_google_meet:
event_body["conferenceData"] = {
"createRequest": {"requestId": f"event-{datetime.now().strftime('%Y%m%d%H%M%S')}", "conferenceSolutionKey": {"type": "hangoutsMeet"}}
}
conference_version = 1
event = service.events().insert(calendarId=calendar_id, body=event_body, conferenceDataVersion=conference_version).execute()
return {"status": "success", "message": f"Event created ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def update_event(event_id: str, title: str = "", start_time: str = "", end_time: str = "", description: str = "") -> dict:
"""Update an existing calendar event."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
patch_body = {}
if title: patch_body["summary"] = title
if start_time: patch_body["start"] = {"dateTime": start_time}
if end_time: patch_body["end"] = {"dateTime": end_time}
if description: patch_body["description"] = description
if not patch_body: return {"status": "error", "message": "No fields to update."}
event = service.events().patch(calendarId=calendar_id, eventId=event_id, body=patch_body).execute()
return {"status": "success", "message": "Event updated ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def delete_event(event_id: str) -> dict:
"""Delete a calendar event by its ID."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
service.events().delete(calendarId=calendar_id, eventId=event_id).execute()
return {"status": "success", "message": f"Event '{event_id}' deleted ✅"}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def quick_add_event(text: str) -> dict:
"""Create an event using natural language (e.g. 'Lunch with Sarah next Monday noon')."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
event = service.events().quickAdd(calendarId=calendar_id, text=text).execute()
return {"status": "success", "message": "Event created from text ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
calendar_agent = Agent(
model='gemini-2.5-flash',
name='calendar_specialist',
description='Manages the user schedule and calendar events.',
instruction='''
You manage the user's Google Calendar.
- Use list_events to check the schedule.
- Use quick_add_event for simple, conversational scheduling requests (e.g., "Lunch tomorrow at noon").
- Use create_event for complex meetings that require attendees, specific durations, or Google Meet links.
- Use update_event to change details of an existing event.
- Use delete_event to cancel or remove an event.
CRITICAL: For update_event and delete_event, you must provide the exact `event_id`.
If the user does not provide the ID, you MUST call list_events first to find the correct `event_id` before attempting the update or deletion.
Always use the current date/time context provided by the root agent to resolve relative dates like "tomorrow".
''',
tools=[list_events, create_event, update_event, delete_event, quick_add_event],
)
نهایی کردن عامل ریشه (agent.py)
فایل agent.py خود را با کد زیر بهروزرسانی کنید:
عامل.py
import os
from datetime import datetime
from zoneinfo import ZoneInfo
from google.adk.agents.llm_agent import Agent
from google.adk.tools.agent_tool import AgentTool
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import all our specialized sub-agents
from .research import research_agent
from .todo import todo_agent
from .calendar import calendar_agent
import tzlocal
# Automatically detect the local system timezone
TIMEZONE = tzlocal.get_localzone_name()
# Callback for persistent memory storage
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Callback to inject the current time into the prompt
async def setup_agent_context(callback_context, **kwargs):
now = datetime.now(ZoneInfo(TIMEZONE))
callback_context.state["current_time"] = now.strftime("%A, %Y-%m-%d %I:%M %p")
callback_context.state["timezone"] = TIMEZONE
# --- ROOT AGENT DEFINITION ---
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant with memory and specialized tools.',
instruction='''
You are an elite, high-signal AI Executive Assistant.
Your goal is to help the user manage their knowledge, tasks, research, and schedule.
## Your Capabilities:
1. Memory: Use load_memory to recall personal facts.
2. Research: Delegate complex web investigations to the research_specialist.
3. Tasks: Delegate all to-do list management to the todo_specialist.
4. Scheduling: Delegate all calendar queries to the calendar_specialist.
## 🕒 Current State
- Time: {current_time?}
- Timezone: {timezone?}
Always be direct and professional.
''',
tools=[
PreloadMemoryTool(),
load_memory_tool,
AgentTool(todo_agent),
AgentTool(calendar_agent)
],
sub_agents=[research_agent],
before_agent_callback=[setup_agent_context],
after_agent_callback=[auto_save_session_to_memory_callback],
)
لطفاً توجه داشته باشید که علاوه بر ابزار تقویم، ما یک تابع فراخوانی قبل از عامل جدید نیز اضافه کردهایم: setup_agent_context . این تابع به عامل از تاریخ، زمان و منطقه زمانی فعلی اطلاع میدهد تا بتواند از تقویم به طور کارآمدتری استفاده کند. این تابع با تنظیم متغیرهای حالت جلسه، نوع متفاوتی از حافظه عامل که برای ماندگاری کوتاه مدت طراحی شده است، کار میکند.
برای آخرین بار adk web را اجرا کنید تا کل agent را آزمایش کنید!
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
میتوانید وضعیت جلسه را در برگه وضعیت در رابط کاربری توسعهدهنده بررسی کنید:
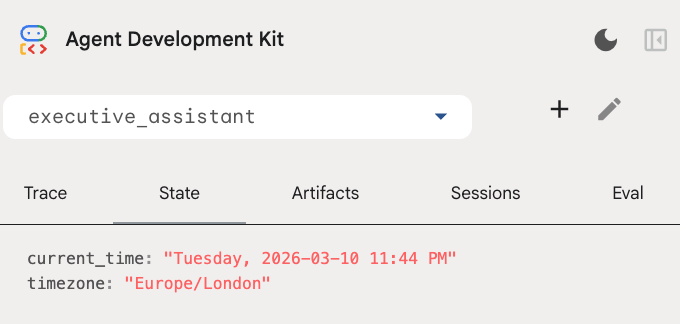
حالا شما یک عامل دارید که میتواند رویدادهای تقویم و فهرست کارها را پیگیری کند، تحقیق انجام دهد و حافظه بلندمدت داشته باشد!
نظافت بعد از آزمایشگاه
۹. نتیجهگیری
تبریک میگویم! شما با موفقیت و پس از طی ۵ مرحله تکاملی، یک دستیار اجرایی هوش مصنوعی چندمنظوره را طراحی کردهاید.
آنچه ما پوشش دادیم
- تأمین زیرساخت برای عاملهای هوش مصنوعی.
- پیادهسازی حافظه پایدار و زیرعاملهای تخصصی با استفاده از ADK داخلی.
- ادغام پایگاههای داده خارجی و APIهای بهرهوری.
مراحل بعدی
شما میتوانید با کاوش در سایر آزمایشگاههای کد در این پلتفرم، یا انجام بهبودهایی در دستیار اجرایی به تنهایی، سفر یادگیری خود را ادامه دهید.
اگر برای بهبود به ایدههایی نیاز دارید، میتوانید موارد زیر را امتحان کنید:
- برای بهینهسازی عملکرد در مکالمات طولانی، فشردهسازی رویداد را پیادهسازی کنید.
- یک سرویس مصنوعات اضافه کنید تا به عامل اجازه دهید برای شما یادداشت برداری کند و به عنوان فایل ذخیره کند
- با استفاده از Google Cloud Run، عامل خود را به عنوان یک سرویس backend مستقر کنید.
پس از انجام آزمایش، به یاد داشته باشید که محیط را تمیز کنید تا هزینههای غیرمنتظرهای به حساب صورتحساب شما وارد نشود.
کدنویسی خوبی داشته باشید!