
1. Introduction
Dans cet atelier de programmation, vous allez apprendre à créer un agent IA sophistiqué à l'aide du Google Agent Development Kit (ADK). Nous suivrons un cheminement évolutif naturel, en commençant par un agent conversationnel de base et en ajoutant progressivement des fonctionnalités spécialisées.
L'agent que nous allons créer est un assistant de direction. Il est conçu pour vous aider dans vos tâches quotidiennes, comme gérer votre agenda, vous rappeler des tâches, faire des recherches et compiler des notes. Il sera entièrement créé à partir de l'ADK, de Gemini et de Vertex AI.
À la fin de cet atelier, vous disposerez d'un agent entièrement fonctionnel et des connaissances nécessaires pour l'adapter à vos propres besoins.
Prérequis
- Connaissances de base du langage de programmation Python
- Connaissances de base de la console Google Cloud pour gérer les ressources cloud
Points abordés
- Provisionner l'infrastructure Google Cloud pour les agents d'IA.
- Implémentation d'une mémoire à long terme persistante à l'aide de Vertex AI Memory Bank.
- Construire une hiérarchie de sous-agents spécialisés.
- Intégration de bases de données externes et de l'écosystème Google Workspace.
Prérequis
Cet atelier peut être entièrement réalisé dans Google Cloud Shell, qui est préinstallé avec toutes les dépendances nécessaires (gcloud CLI, éditeur de code, Go, Gemini CLI).
Sinon, si vous préférez travailler sur votre propre machine, vous aurez besoin des éléments suivants :
- Python (version 3.12 ou ultérieure)
- Un éditeur de code ou un IDE (comme VS Code ou
vim). - Un terminal permettant d'exécuter des commandes Python et
gcloud. - Recommandé : un agent de codage tel que Gemini CLI ou Antigravity
Technologies clés
Vous trouverez ici plus d'informations sur les technologies que nous allons utiliser :
2. Configuration de l'environnement
Choisissez l'une des options suivantes : Configurer l'environnement à votre rythme si vous souhaitez exécuter cet atelier de programmation sur votre propre machine, ou Démarrer Cloud Shell si vous souhaitez exécuter cet atelier de programmation entièrement dans le cloud.
Configuration de l'environnement au rythme de chacun
- Connectez-vous à la console Google Cloud, puis créez un projet ou réutilisez un projet existant. (Si vous ne possédez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.)

- Le nom du projet est le nom à afficher pour les participants au projet. Il s'agit d'une chaîne de caractères non utilisée par les API Google. Vous pourrez toujours le modifier.
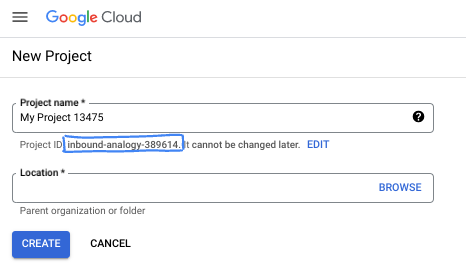
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Cloud génère automatiquement une chaîne unique (en général, vous n'y accordez d'importance particulière). Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet (généralement identifié par
PROJECT_ID). Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire. Vous pouvez également en spécifier un et voir s'il est disponible. Après cette étape, l'ID n'est plus modifiable et restera donc le même pour toute la durée du projet. - Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
- Vous devez ensuite activer la facturation dans la console Cloud pour utiliser les ressources/API Cloud. L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Pour désactiver les ressources et éviter ainsi que des frais ne vous soient facturés après ce tutoriel, vous pouvez supprimer le projet ou les ressources que vous avez créées. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300 $.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :
Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
3. Configuration du projet
Avant d'écrire du code, nous devons provisionner l'infrastructure et les autorisations nécessaires dans Google Cloud.
Définir des variables d'environnement
Ouvrez le terminal et définissez les variables d'environnement suivantes :
export PROJECT_ID=`gcloud config get project`
export LOCATION=us-central1
Activer les API requises
Votre agent a besoin d'accéder à plusieurs services Google Cloud. Exécutez la commande suivante pour les activer :
gcloud services enable \
aiplatform.googleapis.com \
calendar-json.googleapis.com \
sqladmin.googleapis.com
S'authentifier avec les identifiants par défaut de l'application
Nous devons nous authentifier à l'aide des identifiants par défaut de l'application (ADC) pour communiquer avec les services Google Cloud depuis votre environnement.
Exécutez la commande suivante pour vous assurer que vos identifiants par défaut de l'application sont actifs et à jour :
gcloud auth application-default login
4. Créer l'agent de base
Nous devons maintenant initialiser le répertoire dans lequel nous allons stocker le code source du projet :
# setup project directory
mkdir -p adk_ea_codelab && cd adk_ea_codelab
# prepare virtual environment
uv init
# install dependencies
uv add google-adk google-api-python-client tzlocal python-dotenv
uv add cloud-sql-python-connector[pg8000] sqlalchemy
Nous commençons par établir l'identité de l'agent et ses capacités conversationnelles de base. Dans l'ADK, la classe Agent définit le persona de l'agent et ses instructions.
C'est le moment de réfléchir au nom de l'agent. J'aime que mes agents aient des noms propres comme Aida ou Sharon, car je pense que cela les aide à avoir une certaine "personnalité". Mais vous pouvez aussi simplement appeler l'agent par ce qu'il fait, comme "assistant_de_direction", "agent_de_voyage" ou "executeur_de_code".
Exécutez la commande adk create pour lancer un agent boilerplate :
# replace with your desired agent name
uv run adk create executive_assistant
Veuillez choisir gemini-2.5-flash comme modèle et Vertex AI comme backend. Vérifiez que l'ID de projet suggéré est bien celui que vous avez créé pour cet atelier, puis appuyez sur Entrée pour confirmer. Pour la région Google Cloud, vous pouvez accepter la valeur par défaut (us-central1). Votre terminal ressemblera à ceci :
daniela_petruzalek@cloudshell:~/adk_ea_codelab (your-project-id)$ uv run adk create executive_assistant Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [your-project-id]: Enter Google Cloud region [us-central1]: Agent created in /home/daniela_petruzalek/adk_ea_codelab/executive_assistant: - .env - __init__.py - agent.py daniela_petruzalek@cloudshell:~/adk_ea_codelab (your-project-id)$
Une fois la commande précédente exécutée, un dossier portant le nom de l'agent (par exemple, executive_assistant) est créé. Il contient plusieurs fichiers, dont un fichier agent.py avec la définition de base de l'agent :
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Si vous souhaitez interagir avec cet agent, vous pouvez le faire en exécutant uv run adk web sur la ligne de commande et en ouvrant l'UI de développement dans votre navigateur. Le résultat qui s'affiche doit ressembler à ceci :
$ uv run adk web ... INFO: Started server process [1244] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
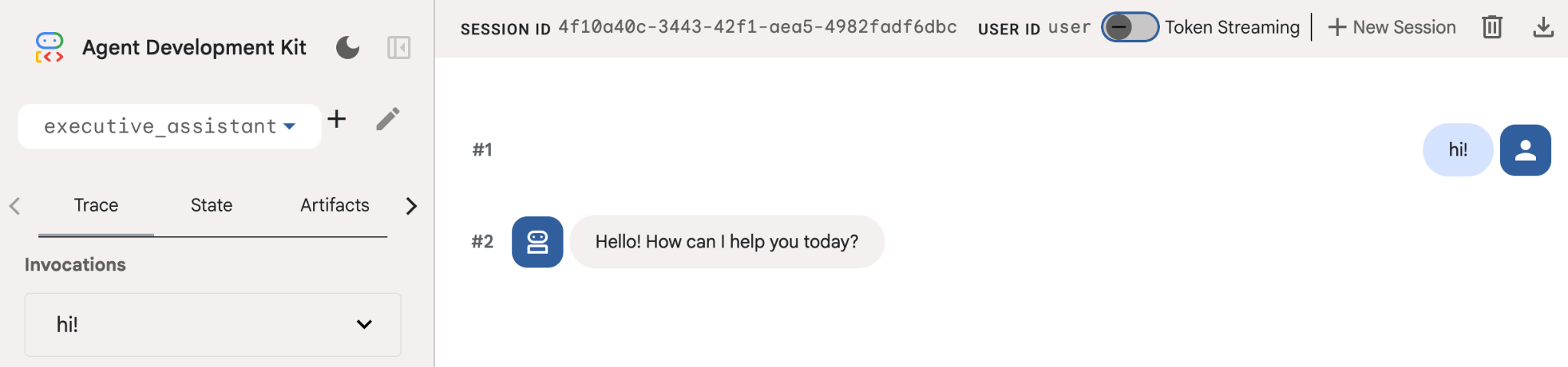
Même si cet agent est assez basique, il est utile de le faire au moins une fois pour s'assurer que la configuration fonctionne correctement avant de commencer à le modifier. La capture d'écran ci-dessous montre une interaction simple à l'aide de l'UI de développement :
Modifions maintenant la définition de l'agent avec notre persona d'assistant exécutif. Copiez le code ci-dessous et remplacez le contenu de agent.py. Adaptez le nom et le persona de l'agent à vos préférences.
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant',
instruction='''
You are an elite, warm, and highly efficient AI partner.
Your primary goal is to help the user manage their tasks, schedule, and research.
Always be direct, concise, and high-signal.
''',
)
Veuillez noter que la propriété "name" définit le nom interne de l'agent. Dans les instructions, vous pouvez également lui donner un nom plus convivial dans le cadre de sa personnalité pour les interactions avec l'utilisateur final. Le nom interne est principalement utilisé pour l'observabilité et les transferts dans les systèmes multi-agents à l'aide de l'outil transfer_to_agent. Vous n'aurez pas à gérer cet outil vous-même. ADK l'enregistre automatiquement lorsque vous déclarez un ou plusieurs sous-agents.
Pour exécuter l'agent que nous venons de créer, utilisez adk web :
uv run adk web
Ouvrez l'interface utilisateur ADK dans le navigateur et saluez votre nouvel assistant !
5. Ajouter une mémoire persistante avec Vertex AI Memory Bank
Un véritable assistant doit mémoriser les préférences et les interactions passées pour offrir une expérience fluide et personnalisée. Dans cette étape, nous allons intégrer Vertex AI Agent Engine Memory Bank, une fonctionnalité Vertex AI qui génère dynamiquement des souvenirs à long terme en fonction des conversations des utilisateurs.
La banque de mémoire permet à votre agent de créer des informations personnalisées accessibles sur plusieurs sessions, ce qui assure la continuité entre les sessions. En arrière-plan, il gère la séquence chronologique des messages d'une session et peut utiliser la récupération par recherche de similarité pour fournir à l'agent les souvenirs les plus pertinents pour le contexte actuel.
Initialiser le service Infos mémorisées
L'ADK utilise Vertex AI pour stocker et récupérer les souvenirs à long terme. Vous devez initialiser un "Memory Engine" dans votre projet. Il s'agit essentiellement d'une instance Reasoning Engine configurée pour servir de banque de mémoire.
Créez le script suivant sous le nom setup_memory.py :
setup_memory.py
import vertexai
import os
PROJECT_ID=os.getenv("PROJECT_ID")
LOCATION=os.getenv("LOCATION")
client = vertexai.Client(project=PROJECT_ID, location=LOCATION)
# Create Reasoning Engine for Memory Bank
agent_engine = client.agent_engines.create()
# You will need this resource name to give it to ADK
print(agent_engine.api_resource.name)
Exécutez maintenant setup_memory.py pour provisionner le moteur de raisonnement pour la banque de mémoire :
uv run python setup_memory.py
Le résultat doit ressembler à ceci :
$ uv run python setup.py projects/1234567890/locations/us-central1/reasoningEngines/1234567890
Enregistrez le nom de ressource du moteur dans une variable d'environnement :
export ENGINE_ID="<insert the resource name above>"
Nous devons maintenant mettre à jour le code pour utiliser la mémoire persistante. Remplacez le contenu du bloc agent.py par le code suivant :
agent.py
from google.adk.agents.llm_agent import Agent
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Update root_agent with memory tools and callback
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='Executive Assistant with Persistent Memory',
instruction='''
You are an elite AI partner with long-term memory.
Use load_memory to find context about the user when needed.
Always be direct, concise, and high-signal.
''',
tools=[PreloadMemoryTool(), load_memory_tool],
after_agent_callback=auto_save_session_to_memory_callback,
)
PreloadMemoryTool injecte automatiquement le contexte pertinent des conversations passées dans chaque requête (à l'aide de la récupération par recherche de similarité), tandis que load_memory_tool permet au modèle d'interroger explicitement la Memory Bank pour obtenir des faits si nécessaire. Cette combinaison donne à votre agent un contexte profond et persistant.
Pour lancer votre agent avec la prise en charge de la mémoire, vous devez lui transmettre memory_service_uri lorsque vous exécutez adk web :
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
Essayez de donner quelques informations sur vous aux agents, puis revenez dans une autre session pour leur poser des questions à ce sujet. Par exemple, dites-lui votre nom :
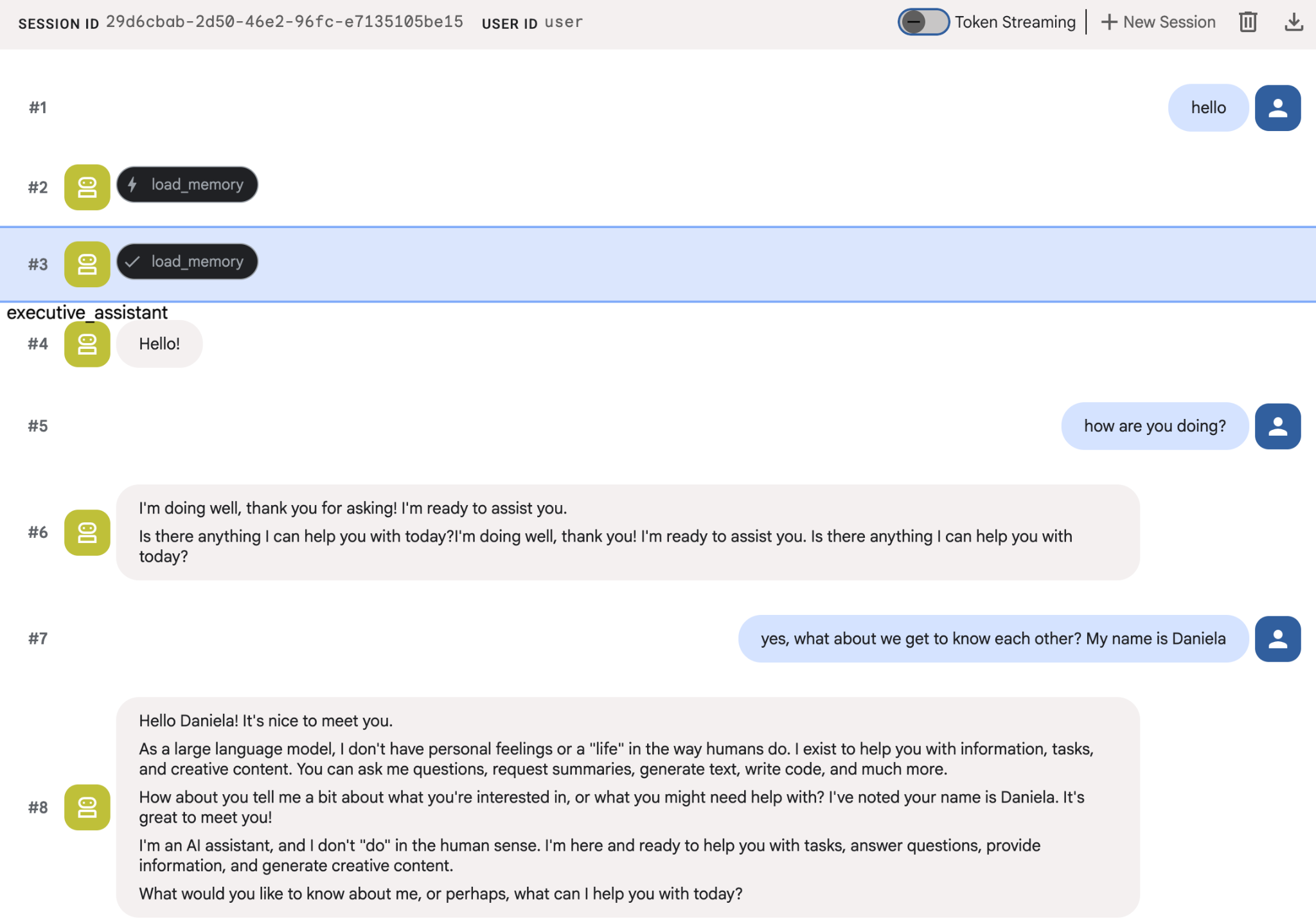
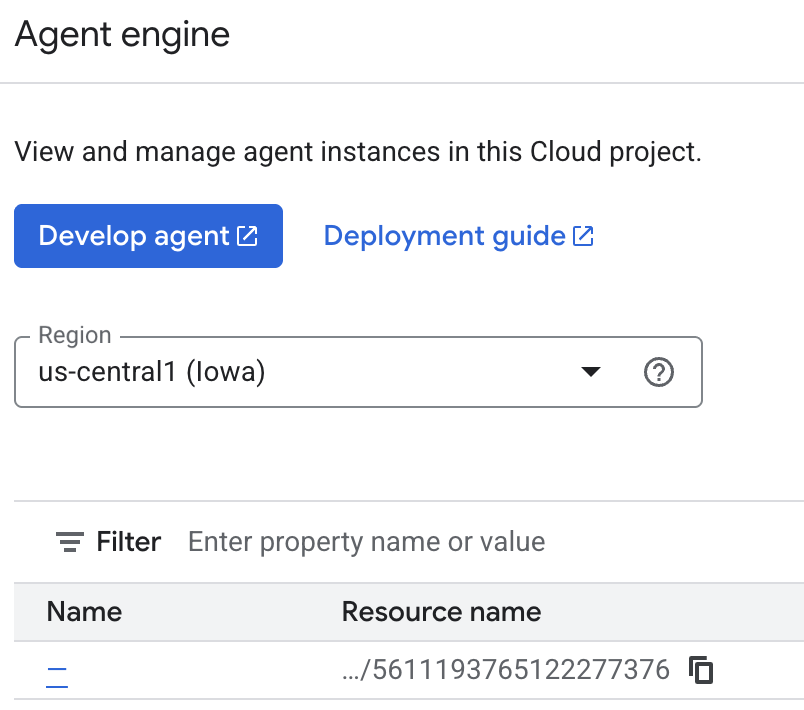
Vous pouvez inspecter les souvenirs que l'agent enregistre dans la console Cloud. Accédez à la page produit "Agent Engine" (utilisez la barre de recherche).

Cliquez ensuite sur le nom de votre moteur d'agent (assurez-vous de sélectionner la bonne région) :
Accédez ensuite à l'onglet "Souvenirs" :
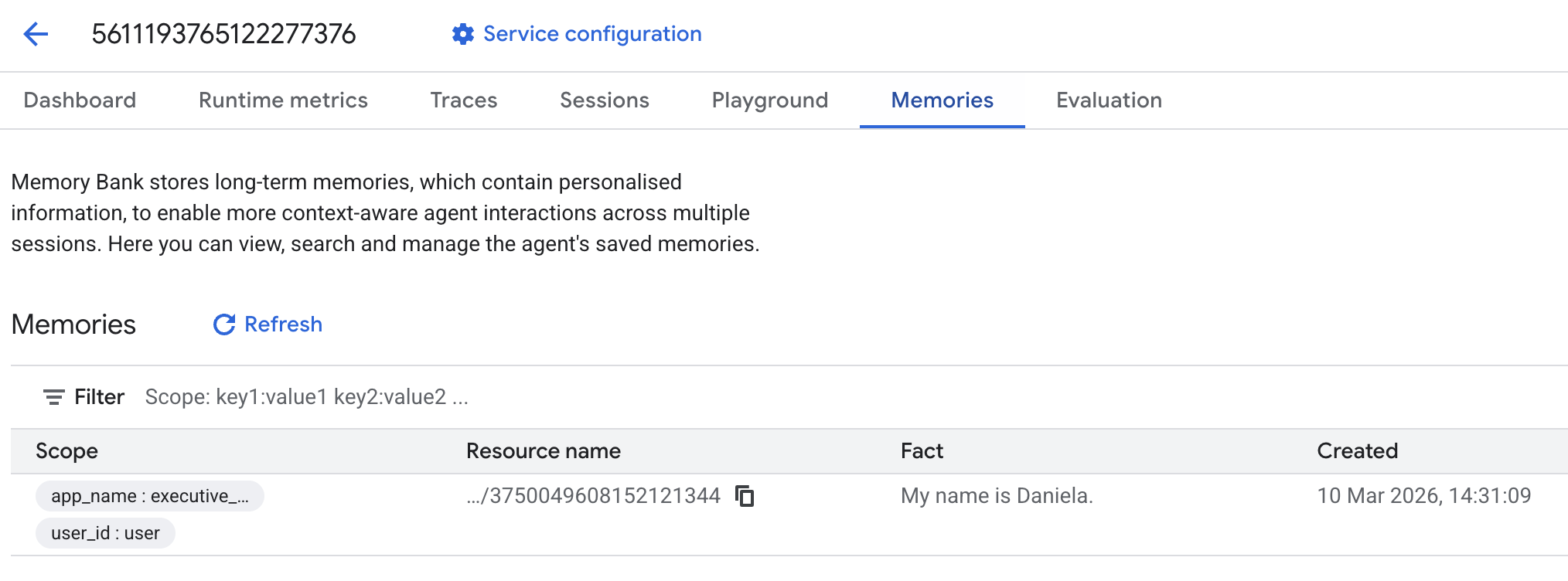
Vous devriez voir des souvenirs ajoutés.
6. Ajouter des fonctionnalités de recherche sur le Web
Pour fournir des informations de haute qualité, notre agent doit effectuer des recherches approfondies qui vont au-delà d'une simple requête de recherche. En déléguant la recherche à un sous-agent spécialisé, nous maintenons la réactivité de la persona principale pendant que le chercheur gère la collecte de données complexes en arrière-plan.
Dans cette étape, nous allons implémenter un LoopAgent pour atteindre une "profondeur de recherche". Cela permettra à l'agent de rechercher, d'évaluer les résultats et d'affiner ses requêtes de manière itérative jusqu'à ce qu'il obtienne une image complète. Nous appliquons également une rigueur technique en exigeant des citations en ligne pour tous les résultats, ce qui garantit que chaque affirmation est étayée par un lien vers une source.
Créer le spécialiste de la recherche (research.py)
Nous définissons ici un agent de base équipé de l'outil de recherche Google et l'encapsulons dans un LoopAgent. Le paramètre "max_iterations" sert de régulateur. Il permet à l'agent d'itérer sur la recherche jusqu'à trois fois si des lacunes subsistent dans sa compréhension.
research.py
from google.adk.agents.llm_agent import Agent
from google.adk.agents.loop_agent import LoopAgent
from google.adk.tools.google_search_tool import GoogleSearchTool
from google.adk.tools.tool_context import ToolContext
def exit_loop(tool_context: ToolContext):
"""Call this function ONLY when no further research is needed, signaling the iterative process should end."""
print(f" [Tool Call] exit_loop triggered by {tool_context.agent_name}")
tool_context.actions.escalate = True
# Return empty dict as tools should typically return JSON-serializable output
return {}
# --- RESEARCH LOGIC ---
_research_worker = Agent(
model='gemini-2.5-flash',
name='research_worker',
description='Worker agent that performs a single research step.',
instruction='''
Use google_search to find facts and synthesize them for the user.
Critically evaluate your findings. If the data is incomplete or you need more context, prepare to search again in the next iteration.
You must include the links you found as references in your response, formatting them like citations in a research paper (e.g., [1], [2]).
Use the exit_loop tool to terminate the research early if no further research is needed.
If you need to ask the user for clarifications, call the exit_loop function early to interrupt the research cycle.
''',
tools=[GoogleSearchTool(bypass_multi_tools_limit=True), exit_loop],
)
# The LoopAgent iterates the worker up to 3 times for deeper research
research_agent = LoopAgent(
name='research_specialist',
description='Deep web research specialist.',
sub_agents=[_research_worker],
max_iterations=3,
)
Mettre à jour l'agent racine (agent.py)
Importez l'agent de recherche et ajoutez-le en tant qu'outil à Sharon :
agent.py
from google.adk.agents.llm_agent import Agent
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import our new sub agent
from .research import research_agent
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Update root_agent with memory tools and callback
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='Executive Assistant with persistent memory and research capabilities',
instruction='''
You are an elite AI partner with long-term memory.
1. Use load_memory to recall facts.
2. Delegate research tasks to the research_specialist.
Always be direct, concise, and high-signal.
''',
tools=[PreloadMemoryTool(), load_memory_tool],
sub_agents=[research_agent],
after_agent_callback=auto_save_session_to_memory_callback,
)
Relancez adk web pour tester l'agent de recherche.
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
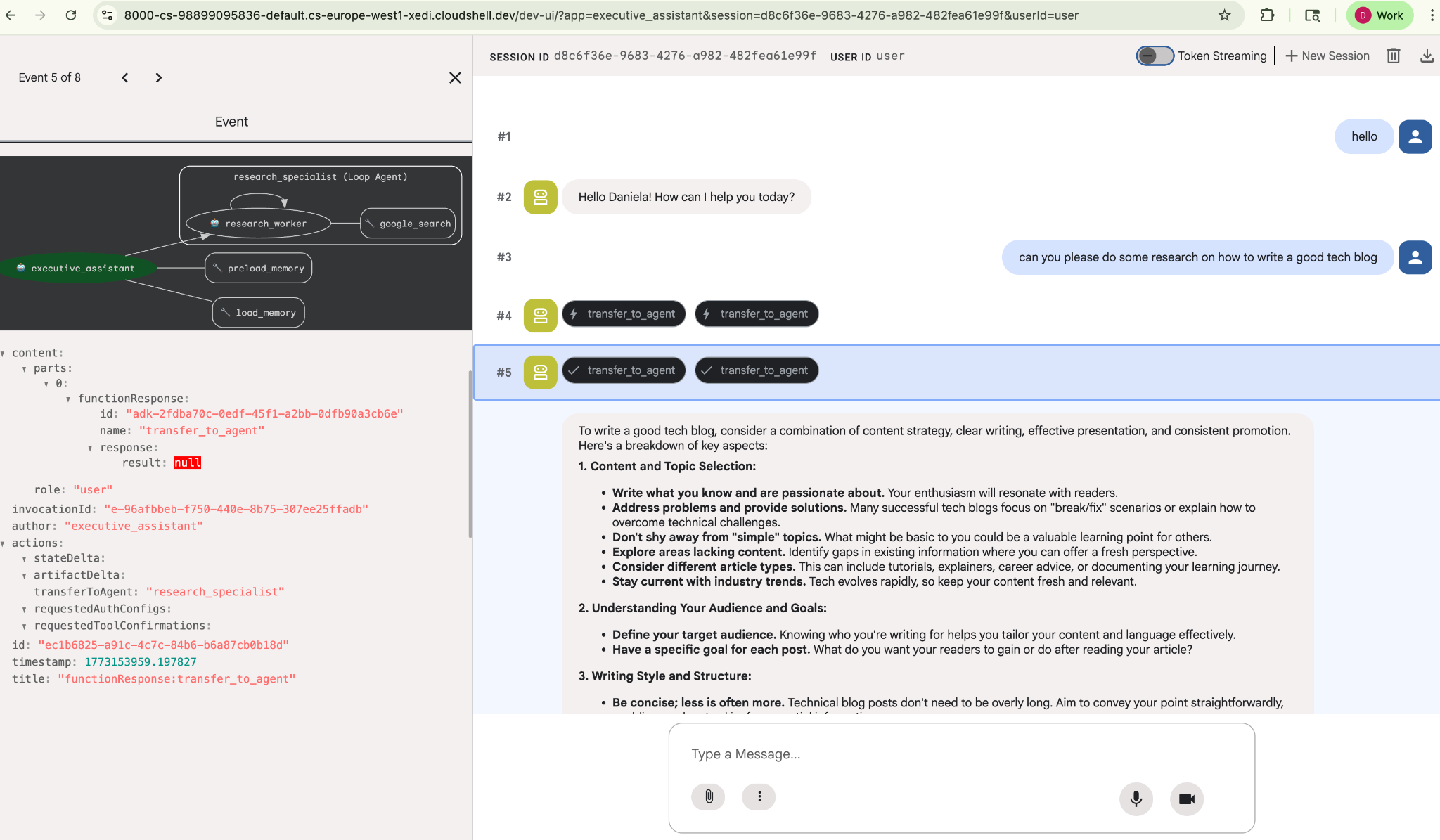
Donnez-lui une tâche de recherche simple, par exemple "comment écrire un bon blog technique ?".
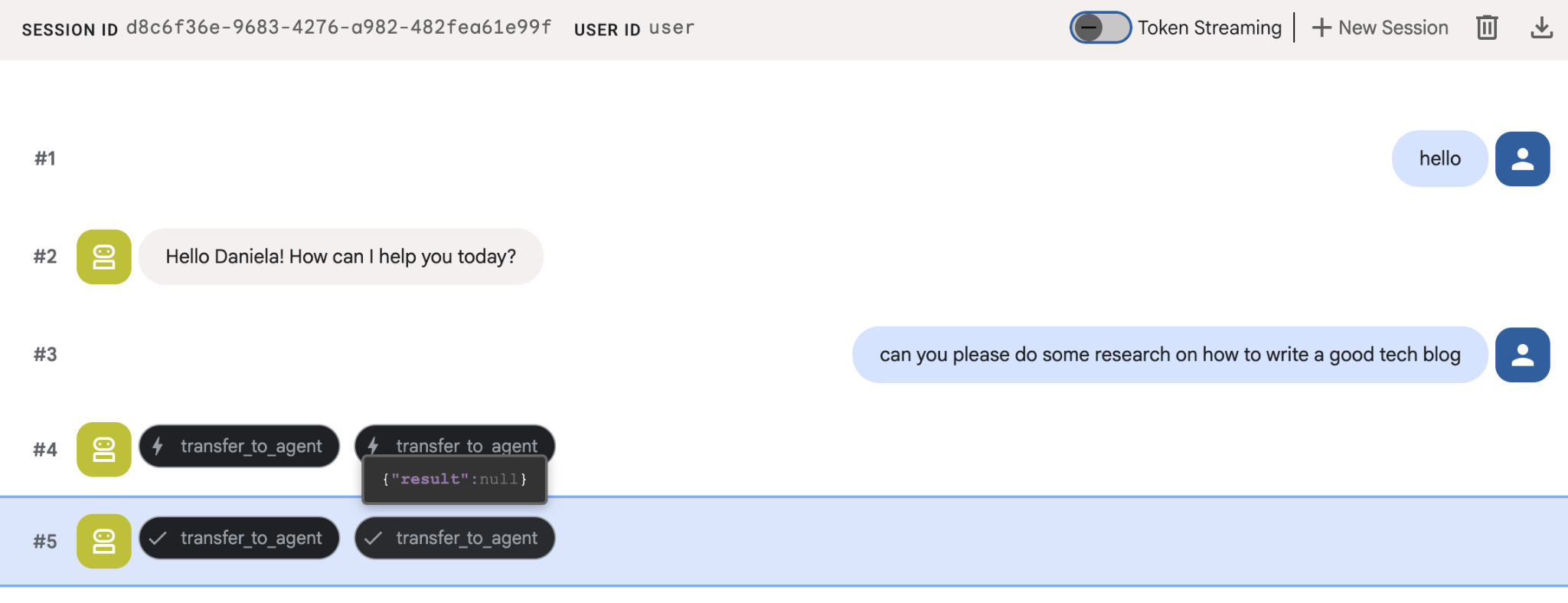
Vous avez peut-être remarqué que l'agent se souvenait de mon nom, même s'il s'agit d'une nouvelle session. Veuillez également noter l'appel d'outil "transfer_to_agent" : il s'agit de l'outil qui transmet la tâche à notre nouvel agent de recherche.
Passons maintenant à la gestion des tâches.
7. Ajouter la gestion des tâches avec Cloud SQL
Bien que l'agent dispose d'une mémoire à long terme, il ne convient pas aux données structurées et précises comme une liste de tâches. Pour les tâches, nous utilisons une base de données relationnelle traditionnelle. Nous allons utiliser SQLAlchemy et une base de données Google Cloud SQL (PostgreSQL). Avant de pouvoir écrire le code, nous devons provisionner l'infrastructure.
Provisionner l'infrastructure
Exécutez ces commandes pour créer votre base de données. Remarque : La création de l'instance prend environ 5 à 10 minutes. Vous pouvez passer à l'étape suivante pendant que cette opération s'exécute en arrière-plan.
# 1. Define instance variables
export INSTANCE_NAME="assistant-db"
export USER_EMAIL=$(gcloud config get-value account)
# 2. Create the Cloud SQL instance
gcloud sql instances create $INSTANCE_NAME \
--database-version=POSTGRES_18 \
--tier=db-f1-micro \
--region=us-central1 \
--edition=ENTERPRISE
# 3. Create the database for our tasks
gcloud sql databases create tasks --instance=$INSTANCE_NAME
Le provisionnement de l'instance de base de données prendra quelques minutes. C'est peut-être le moment de prendre un café ou un thé, ou de mettre à jour le code en attendant la fin de l'opération. N'oubliez pas de revenir pour terminer le contrôle des accès !
Configurer le contrôle des accès
Nous devons maintenant configurer votre compte utilisateur pour qu'il ait accès à la base de données. Exécutez les commandes suivantes dans le terminal :
# change this to your favorite password
export DB_PASS="correct-horse-battery-staple"
# Create a regular database user
gcloud sql users create assistant_user \
--instance=$INSTANCE_NAME \
--password=$DB_PASS
Mettre à jour la configuration de l'environnement
L'ADK charge la configuration à partir d'un fichier .env au moment de l'exécution. Mettez à jour l'environnement de votre agent avec les informations de connexion à la base de données.
# Retrieve the unique connection name
export DB_CONN=$(gcloud sql instances describe $INSTANCE_NAME --format='value(connectionName)')
# Append configuration to your .env file
cat <<EOF >> executive_assistant/.env
DB_CONNECTION_NAME=$DB_CONN
DB_USER=assistant_user
DB_PASSWORD=$DB_PASS
DB_NAME=tasks
EOF
Passons maintenant aux modifications du code.
Créer le spécialiste Todo (todo.py)
Comme pour l'agent de recherche, créons notre spécialiste des tâches à faire dans son propre fichier. Créez todo.py :
todo.py
import os
import uuid
import sqlalchemy
from datetime import datetime
from typing import Optional, List
from sqlalchemy import (
Column,
String,
DateTime,
Enum,
select,
delete,
update,
)
from sqlalchemy.orm import declarative_base, Session
from google.cloud.sql.connector import Connector
from google.adk.agents.llm_agent import Agent
# --- DATABASE LOGIC ---
Base = declarative_base()
connector = Connector()
def getconn():
db_connection_name = os.environ.get("DB_CONNECTION_NAME")
db_user = os.environ.get("DB_USER")
db_password = os.environ.get("DB_PASSWORD")
db_name = os.environ.get("DB_NAME", "tasks")
return connector.connect(
db_connection_name,
"pg8000",
user=db_user,
password=db_password,
db=db_name,
)
engine = sqlalchemy.create_engine(
"postgresql+pg8000://",
creator=getconn,
)
class Todo(Base):
__tablename__ = "todos"
id = Column(String(36), primary_key=True, default=lambda: str(uuid.uuid4()))
title = Column(String(255), nullable=False)
priority = Column(
Enum("high", "medium", "low", name="priority_levels"), nullable=False, default="medium"
)
due_date = Column(DateTime, nullable=True)
status = Column(Enum("pending", "done", name="status_levels"), default="pending")
created_at = Column(DateTime, default=datetime.utcnow)
def init_db():
"""Builds the table if it's missing."""
Base.metadata.create_all(bind=engine)
def add_todo(
title: str, priority: str = "medium", due_date: Optional[str] = None
) -> dict:
"""
Adds a new task to the list.
Args:
title (str): The description of the task.
priority (str): The urgency level. Must be one of: 'high', 'medium', 'low'.
due_date (str, optional): The due date in ISO format (YYYY-MM-DD or YYYY-MM-DDTHH:MM:SS).
Returns:
dict: A dictionary containing the new task's ID and a status message.
"""
init_db()
with Session(engine) as session:
due = datetime.fromisoformat(due_date) if due_date else None
item = Todo(
title=title,
priority=priority.lower(),
due_date=due,
)
session.add(item)
session.commit()
return {"id": item.id, "status": f"Task added ✅"}
def list_todos(status: str = "pending") -> list:
"""
Lists tasks from the database, optionally filtering by status.
Args:
status (str, optional): The status to filter by. 'pending', 'done', or 'all'.
"""
init_db()
with Session(engine) as session:
query = select(Todo)
s_lower = status.lower()
if s_lower != "all":
query = query.where(Todo.status == s_lower)
query = query.order_by(Todo.priority, Todo.created_at)
results = session.execute(query).scalars().all()
return [
{
"id": t.id,
"task": t.title,
"priority": t.priority,
"status": t.status,
}
for t in results
]
def complete_todo(task_id: str) -> str:
"""Marks a specific task as 'done'."""
init_db()
with Session(engine) as session:
session.execute(update(Todo).where(Todo.id == task_id).values(status="done"))
session.commit()
return f"Task {task_id} marked as done."
def delete_todo(task_id: str) -> str:
"""Permanently removes a task from the database."""
init_db()
with Session(engine) as session:
session.execute(delete(Todo).where(Todo.id == task_id))
session.commit()
return f"Task {task_id} deleted."
# --- TODO SPECIALIST AGENT ---
todo_agent = Agent(
model='gemini-2.5-flash',
name='todo_specialist',
description='A specialist agent that manages a structured SQL task list.',
instruction='''
You manage the user's task list using a PostgreSQL database.
- Use add_todo when the user wants to remember something. If no priority is mentioned, mark it as 'medium'.
- Use list_todos to show tasks.
- Use complete_todo to mark a task as finished.
- Use delete_todo to remove a task entirely.
When marking a task as complete or deleting it, if the user doesn't provide the ID,
use list_todos first to find the correct ID for the task they described.
''',
tools=[add_todo, list_todos, complete_todo, delete_todo],
)
Le code ci-dessus est responsable de deux choses principales : la connexion à la base de données Cloud SQL et la fourniture d'une liste d'outils pour toutes les opérations courantes de la liste de tâches, y compris l'ajout, la suppression et le marquage comme terminées.
Étant donné que cette logique est très spécifique à l'agent de tâches et que nous ne nous soucions pas nécessairement de cette gestion précise du point de vue de l'assistant exécutif (agent racine), nous allons regrouper cet agent en tant que "AgentTool" au lieu d'un sous-agent.
Pour choisir entre un AgentTool et un sous-agent, déterminez s'ils doivent partager le contexte ou non :
- utiliser un AgentTool lorsque votre agent n'a pas besoin de partager le contexte avec l'agent racine ;
- utiliser un sous-agent lorsque vous souhaitez que votre agent partage le contexte avec l'agent racine ;
Dans le cas de l'agent de recherche, le partage du contexte peut être utile, mais pour un simple agent de tâches, il n'y a pas grand intérêt à le faire.
Implémentons AgentTool dans agent.py.
Mettre à jour l'agent racine (agent.py)
Importez maintenant todo_agent dans votre fichier principal et associez-le en tant qu'outil :
agent.py
import os
from datetime import datetime
from google.adk.agents.llm_agent import Agent
from google.adk.tools.agent_tool import AgentTool
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import our specialized sub-agents
from .research import research_agent
from .todo import todo_agent
# Callback for persistent memory storage
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# --- ROOT AGENT DEFINITION ---
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant with memory and specialized tools.',
instruction='''
You are an elite, high-signal AI Executive Assistant.
Your goal is to help the user manage their knowledge, tasks, and research.
## Your Capabilities:
1. Memory: Use load_memory to recall personal facts or past context about the user.
2. Research: Delegate complex web-based investigations to the research_specialist.
3. Tasks: Delegate all to-do list management (adding, listing, or completing tasks) to the todo_specialist.
Always be direct and professional. If a task is successful, provide a brief confirmation.
''',
tools=[
PreloadMemoryTool(),
load_memory_tool,
AgentTool(todo_agent) # Exposes the Todo Specialist as a tool
],
sub_agents=[research_agent], # Exposes the Research Specialist for direct handover
after_agent_callback=auto_save_session_to_memory_callback,
)
Exécutez à nouveau adk web pour tester la nouvelle fonctionnalité :
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
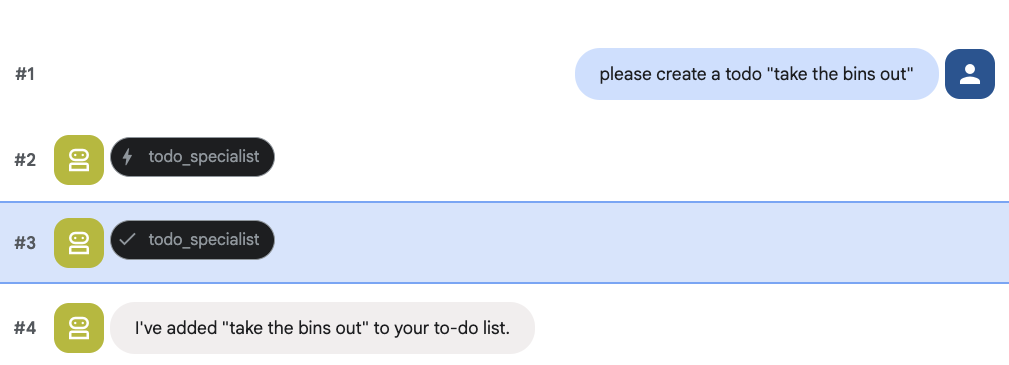
Essayez de créer une tâche :
8. Ajouter la gestion d'agenda
Enfin, nous allons l'intégrer à Google Agenda pour que l'agent puisse gérer les rendez-vous. Pour ce codelab, au lieu de donner à l'agent l'accès à votre agenda personnel, ce qui pourrait être potentiellement dangereux si cela n'est pas fait correctement, nous allons créer un agenda indépendant que l'agent pourra gérer.
Nous allons d'abord créer un compte de service dédié qui servira d'identité à l'agent. Nous allons ensuite créer le calendrier de l'agent de manière programmatique à l'aide du compte de service.
Provisionner le compte de service
Ouvrez votre terminal et exécutez les commandes suivantes pour créer l'identité et accorder à votre compte personnel l'autorisation de l'usurper :
export SA_NAME="ea-agent"
export SA_EMAIL="${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"
# Create the service account
gcloud iam service-accounts create $SA_NAME \
--display-name="Executive Assistant Agent"
# Allow your local user to impersonate it
gcloud iam service-accounts add-iam-policy-binding $SA_EMAIL \
--member="user:$(gcloud config get-value account)" \
--role="roles/iam.serviceAccountTokenCreator"
# Save it to the agent's environment
echo "SERVICE_ACCOUNT_EMAIL=$SA_EMAIL" >> executive_assistant/.env
Créer l'agenda par programmation
Écrivons un script pour indiquer au compte de service de créer l'agenda. Créez un fichier nommé setup_calendar.py à la racine de votre projet (à côté de setup_memory.py) :
setup_calendar.py
import os
import google.auth
from googleapiclient.discovery import build
from google.auth.transport.requests import Request
from google.auth import impersonated_credentials
from dotenv import load_dotenv
load_dotenv('executive_assistant/.env')
SA_EMAIL = os.environ.get("SERVICE_ACCOUNT_EMAIL")
def setup_sa_calendar():
print(f"Authenticating to impersonate {SA_EMAIL}...")
# 1. Base credentials
creds, _ = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
creds.refresh(Request())
# 2. Impersonate the Service Account
impersonated = impersonated_credentials.Credentials(
source_credentials=creds,
target_principal=SA_EMAIL,
target_scopes=["https://www.googleapis.com/auth/calendar"],
)
service = build("calendar", "v3", credentials=impersonated)
# 3. Create the calendar
print("Creating independent Service Account calendar...")
calendar = service.calendars().insert(body={
"summary": "AI Assistant (SA Owned)",
"description": "An independent calendar managed purely by the AI."
}).execute()
calendar_id = calendar['id']
# 4. Save the ID
with open("executive_assistant/.env", "a") as f:
f.write(f"\nCALENDAR_ID={calendar_id}\n")
print(f"Setup complete! CALENDAR_ID {calendar_id} added to .env")
if __name__ == "__main__":
setup_sa_calendar()
Exécutez le script depuis votre terminal :
uv run python setup_calendar.py
Créer le spécialiste de l'agenda (calendar.py)
Concentrons-nous maintenant sur le spécialiste de l'agenda. Nous équiperons cet agent d'une suite complète d'outils d'agenda : lister, créer, modifier, supprimer et même une fonctionnalité d'ajout rapide qui comprend le langage naturel.
Copiez le code ci-dessous dans calendar.py.
calendar.py
import os
from datetime import datetime, timedelta, timezone
import google.auth
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from google.adk.agents.llm_agent import Agent
def _get_calendar_service():
"""Build the Google Calendar API service using Service Account Impersonation."""
from google.auth.transport.requests import Request
from google.auth import impersonated_credentials
target_principal = os.environ.get("SERVICE_ACCOUNT_EMAIL")
if not target_principal:
raise ValueError("SERVICE_ACCOUNT_EMAIL environment variable is missing.")
base_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
creds, _ = google.auth.default(scopes=base_scopes)
creds.refresh(Request())
target_scopes = ["https://www.googleapis.com/auth/calendar"]
impersonated = impersonated_credentials.Credentials(
source_credentials=creds,
target_principal=target_principal,
target_scopes=target_scopes,
)
return build("calendar", "v3", credentials=impersonated)
def _format_event(event: dict) -> dict:
"""Format a raw Calendar API event into a clean dict for the LLM."""
start = event.get("start", {})
end = event.get("end", {})
return {
"id": event.get("id"),
"title": event.get("summary", "(No title)"),
"start": start.get("dateTime", start.get("date")),
"end": end.get("dateTime", end.get("date")),
"location": event.get("location", ""),
"description": event.get("description", ""),
"attendees": [
{"email": a["email"], "status": a.get("responseStatus", "unknown")}
for a in event.get("attendees", [])
],
"link": event.get("htmlLink", ""),
"conference_link": (
event.get("conferenceData", {}).get("entryPoints", [{}])[0].get("uri", "")
if event.get("conferenceData")
else ""
),
"status": event.get("status", ""),
}
def list_events(days_ahead: int = 7) -> dict:
"""List upcoming calendar events."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
now = datetime.now(timezone.utc).isoformat()
end = (datetime.now(timezone.utc) + timedelta(days=days_ahead)).isoformat()
events_result = service.events().list(
calendarId=calendar_id, timeMin=now, timeMax=end,
maxResults=50, singleEvents=True, orderBy="startTime"
).execute()
events = events_result.get("items", [])
if not events:
return {"status": "success", "count": 0, "events": []}
return {"status": "success", "count": len(events), "events": [_format_event(e) for e in events]}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def create_event(title: str, start_time: str, end_time: str, description: str = "", location: str = "", attendees: str = "", add_google_meet: bool = False) -> dict:
"""Create a new calendar event."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
event_body = {
"summary": title,
"start": {"dateTime": start_time},
"end": {"dateTime": end_time},
}
if description: event_body["description"] = description
if location: event_body["location"] = location
if attendees:
email_list = [e.strip() for e in attendees.split(",") if e.strip()]
event_body["attendees"] = [{"email": e} for e in email_list]
conference_version = 0
if add_google_meet:
event_body["conferenceData"] = {
"createRequest": {"requestId": f"event-{datetime.now().strftime('%Y%m%d%H%M%S')}", "conferenceSolutionKey": {"type": "hangoutsMeet"}}
}
conference_version = 1
event = service.events().insert(calendarId=calendar_id, body=event_body, conferenceDataVersion=conference_version).execute()
return {"status": "success", "message": f"Event created ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def update_event(event_id: str, title: str = "", start_time: str = "", end_time: str = "", description: str = "") -> dict:
"""Update an existing calendar event."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
patch_body = {}
if title: patch_body["summary"] = title
if start_time: patch_body["start"] = {"dateTime": start_time}
if end_time: patch_body["end"] = {"dateTime": end_time}
if description: patch_body["description"] = description
if not patch_body: return {"status": "error", "message": "No fields to update."}
event = service.events().patch(calendarId=calendar_id, eventId=event_id, body=patch_body).execute()
return {"status": "success", "message": "Event updated ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def delete_event(event_id: str) -> dict:
"""Delete a calendar event by its ID."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
service.events().delete(calendarId=calendar_id, eventId=event_id).execute()
return {"status": "success", "message": f"Event '{event_id}' deleted ✅"}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def quick_add_event(text: str) -> dict:
"""Create an event using natural language (e.g. 'Lunch with Sarah next Monday noon')."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
event = service.events().quickAdd(calendarId=calendar_id, text=text).execute()
return {"status": "success", "message": "Event created from text ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
calendar_agent = Agent(
model='gemini-2.5-flash',
name='calendar_specialist',
description='Manages the user schedule and calendar events.',
instruction='''
You manage the user's Google Calendar.
- Use list_events to check the schedule.
- Use quick_add_event for simple, conversational scheduling requests (e.g., "Lunch tomorrow at noon").
- Use create_event for complex meetings that require attendees, specific durations, or Google Meet links.
- Use update_event to change details of an existing event.
- Use delete_event to cancel or remove an event.
CRITICAL: For update_event and delete_event, you must provide the exact `event_id`.
If the user does not provide the ID, you MUST call list_events first to find the correct `event_id` before attempting the update or deletion.
Always use the current date/time context provided by the root agent to resolve relative dates like "tomorrow".
''',
tools=[list_events, create_event, update_event, delete_event, quick_add_event],
)
Finaliser l'agent racine (agent.py)
Mettez à jour votre fichier agent.py avec le code ci-dessous :
agent.py
import os
from datetime import datetime
from zoneinfo import ZoneInfo
from google.adk.agents.llm_agent import Agent
from google.adk.tools.agent_tool import AgentTool
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import all our specialized sub-agents
from .research import research_agent
from .todo import todo_agent
from .calendar import calendar_agent
import tzlocal
# Automatically detect the local system timezone
TIMEZONE = tzlocal.get_localzone_name()
# Callback for persistent memory storage
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Callback to inject the current time into the prompt
async def setup_agent_context(callback_context, **kwargs):
now = datetime.now(ZoneInfo(TIMEZONE))
callback_context.state["current_time"] = now.strftime("%A, %Y-%m-%d %I:%M %p")
callback_context.state["timezone"] = TIMEZONE
# --- ROOT AGENT DEFINITION ---
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant with memory and specialized tools.',
instruction='''
You are an elite, high-signal AI Executive Assistant.
Your goal is to help the user manage their knowledge, tasks, research, and schedule.
## Your Capabilities:
1. Memory: Use load_memory to recall personal facts.
2. Research: Delegate complex web investigations to the research_specialist.
3. Tasks: Delegate all to-do list management to the todo_specialist.
4. Scheduling: Delegate all calendar queries to the calendar_specialist.
## 🕒 Current State
- Time: {current_time?}
- Timezone: {timezone?}
Always be direct and professional.
''',
tools=[
PreloadMemoryTool(),
load_memory_tool,
AgentTool(todo_agent),
AgentTool(calendar_agent)
],
sub_agents=[research_agent],
before_agent_callback=[setup_agent_context],
after_agent_callback=[auto_save_session_to_memory_callback],
)
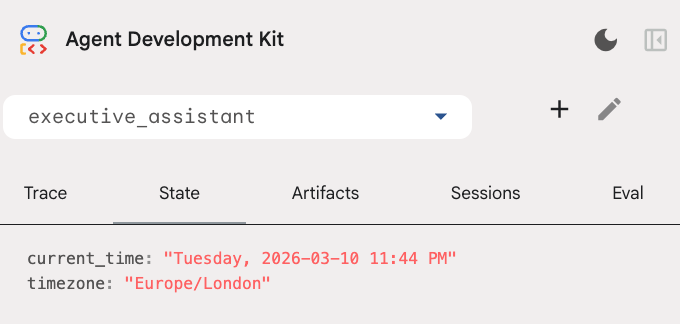
Veuillez noter qu'en plus de l'outil d'agenda, nous avons également ajouté une nouvelle fonction before agent callback : setup_agent_context. Cette fonction permet à l'agent de connaître la date, l'heure et le fuseau horaire actuels afin de pouvoir utiliser l'agenda plus efficacement. Pour ce faire, il définit des variables d'état de session, un autre type de mémoire d'agent conçu pour la persistance à court terme.
Exécutez adk web une dernière fois pour tester l'agent complet.
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
Vous pouvez inspecter l'état de la session dans l'onglet "État" de l'interface utilisateur pour les développeurs :
Vous disposez désormais d'un agent capable de suivre les événements de votre agenda et vos listes de tâches, d'effectuer des recherches et de mémoriser des informations à long terme.
Nettoyer après l'atelier
9. Conclusion
Félicitations ! Vous avez réussi à concevoir un assistant exécutif multifonctionnel basé sur l'IA en cinq étapes évolutives.
Points abordés
- Provisionner l'infrastructure pour les agents d'IA.
- Implémenter une mémoire persistante et des sous-agents spécialisés à l'aide des composants intégrés d'ADK.
- Intégrer des bases de données externes et des API de productivité.
Étapes suivantes
Vous pouvez poursuivre votre apprentissage en explorant d'autres ateliers de programmation sur cette plate-forme ou en améliorant vous-même l'assistant exécutif.
Si vous avez besoin d'idées pour améliorer votre application, vous pouvez essayer :
- Implémentez la compaction des événements pour optimiser les performances des longues conversations.
- Ajoutez un service d'artefacts pour permettre à l'agent de prendre des notes pour vous et de les enregistrer sous forme de fichiers.
- Déployez votre agent en tant que service de backend à l'aide de Google Cloud Run.
Une fois les tests terminés, n'oubliez pas de nettoyer l'environnement pour éviter des frais inattendus sur votre compte de facturation.
À vous de jouer !