
1. Introduzione
In questo codelab imparerai a creare un agente AI sofisticato utilizzando Google Agent Development Kit (ADK). Seguiremo un percorso evolutivo naturale, partendo da un agente conversazionale di base e aggiungendo progressivamente funzionalità specializzate.
L'agente che stiamo creando è un assistente personale, progettato per aiutarti nelle attività quotidiane come la gestione del calendario, i promemoria, la ricerca e la compilazione di note, il tutto creato da zero utilizzando ADK, Gemini e Vertex AI.
Al termine di questo lab avrai un agente completamente funzionante e le conoscenze necessarie per estenderlo in base alle tue esigenze.
Prerequisiti
- Conoscenza di base del linguaggio di programmazione Python
- Conoscenza di base della console Google Cloud per gestire le risorse cloud
Obiettivi didattici
- Provisioning dell'infrastruttura cloud di Google per gli agenti AI.
- Implementazione della memoria a lungo termine persistente utilizzando Vertex AI Memory Bank.
- Costruzione di una gerarchia di subagenti specializzati.
- Integrazione di database esterni e dell'ecosistema Google Workspace.
Che cosa ti serve
Questo workshop può essere svolto interamente in Google Cloud Shell, che include tutte le dipendenze necessarie (gcloud CLI, editor di codice, Go, Gemini CLI) preinstallate.
In alternativa, se preferisci lavorare sulla tua macchina, avrai bisogno di quanto segue:
- Python (versione 3.12 o successive)
- Un editor di codice o un IDE (come VS Code o
vim). - Un terminale per eseguire i comandi Python e
gcloud. - Consigliato: un agente di programmazione come Gemini CLI o Antigravity
Tecnologie chiave
Qui puoi trovare maggiori informazioni sulle tecnologie che utilizzeremo:
2. Configurazione dell'ambiente
Scegli una delle seguenti opzioni: Configurazione dell'ambiente autonomo se vuoi eseguire questo codelab sulla tua macchina oppure Avvia Cloud Shell se vuoi eseguire questo codelab interamente nel cloud.
Configurazione dell'ambiente autonomo
- Accedi alla console Google Cloud e crea un nuovo progetto o riutilizzane uno esistente. Se non hai ancora un account Gmail o Google Workspace, devi crearne uno.

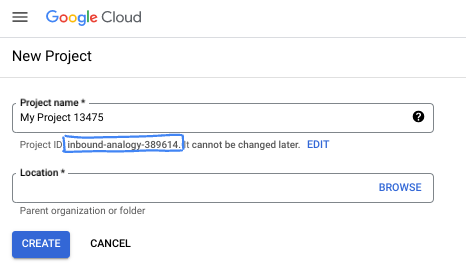
- Il nome del progetto è il nome visualizzato per i partecipanti a questo progetto. È una stringa di caratteri non utilizzata dalle API di Google. Puoi sempre aggiornarlo.
- L'ID progetto è univoco in tutti i progetti Google Cloud ed è immutabile (non può essere modificato dopo l'impostazione). La console Cloud genera automaticamente una stringa univoca, di solito non ti interessa di cosa si tratta. Nella maggior parte dei codelab, dovrai fare riferimento all'ID progetto (in genere identificato come
PROJECT_ID). Se l'ID generato non ti piace, puoi generarne un altro casuale. In alternativa, puoi provare a crearne uno e vedere se è disponibile. Non può essere modificato dopo questo passaggio e rimane per tutta la durata del progetto. - Per tua informazione, esiste un terzo valore, un numero di progetto, utilizzato da alcune API. Scopri di più su tutti e tre questi valori nella documentazione.
- Successivamente, devi abilitare la fatturazione in Cloud Console per utilizzare le risorse/API Cloud. Completare questo codelab non costa molto, se non nulla. Per arrestare le risorse ed evitare addebiti oltre a quelli previsti in questo tutorial, puoi eliminare le risorse che hai creato o il progetto. I nuovi utenti di Google Cloud possono beneficiare del programma prova senza costi di 300$.
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:
Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere un risultato simile a questo:

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
3. Configurazione del progetto
Prima di scrivere il codice, dobbiamo eseguire il provisioning dell'infrastruttura e delle autorizzazioni necessarie in Google Cloud.
Imposta le variabili di ambiente
Apri il terminale e imposta le seguenti variabili di ambiente:
export PROJECT_ID=`gcloud config get project`
export LOCATION=us-central1
Abilita le API richieste
L'agente richiede l'accesso a diversi servizi Google Cloud. Esegui questo comando per abilitarle:
gcloud services enable \
aiplatform.googleapis.com \
calendar-json.googleapis.com \
sqladmin.googleapis.com
Eseguire l'autenticazione con le credenziali predefinite dell'applicazione
Per comunicare con i servizi Google Cloud dal tuo ambiente, dobbiamo autenticarci con le credenziali predefinite dell'applicazione (ADC).
Esegui questo comando per assicurarti che le credenziali predefinite dell'applicazione siano attive e aggiornate:
gcloud auth application-default login
4. Crea l'agente di base
Ora dobbiamo inizializzare la directory in cui archivieremo il codice sorgente del progetto:
# setup project directory
mkdir -p adk_ea_codelab && cd adk_ea_codelab
# prepare virtual environment
uv init
# install dependencies
uv add google-adk google-api-python-client tzlocal python-dotenv
uv add cloud-sql-python-connector[pg8000] sqlalchemy
Iniziamo stabilendo l'identità dell'agente e le funzionalità conversazionali di base. Nell'ADK, la classe Agent definisce la personalità dell'agente e le sue istruzioni.
Questo è il momento in cui potresti pensare a un nome agente. Mi piace che i miei agenti abbiano nomi propri come Aida o Sharon, perché penso che li aiuti a dare loro un po' di "personalità", ma puoi anche semplicemente chiamare l'agente in base a ciò che fa, ad esempio "assistente_dirigente", "agente_di_viaggi" o "esecutore_di_codice".
Esegui il comando adk create per avviare un agente boilerplate:
# replace with your desired agent name
uv run adk create executive_assistant
Scegli gemini-2.5-flash come modello e Vertex AI come backend. Verifica che l'ID progetto suggerito sia quello che hai creato per questo lab e premi Invio per confermare. Per la regione Google Cloud, puoi accettare il valore predefinito (us-central1). Il terminale avrà un aspetto simile a questo:
daniela_petruzalek@cloudshell:~/adk_ea_codelab (your-project-id)$ uv run adk create executive_assistant Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [your-project-id]: Enter Google Cloud region [us-central1]: Agent created in /home/daniela_petruzalek/adk_ea_codelab/executive_assistant: - .env - __init__.py - agent.py daniela_petruzalek@cloudshell:~/adk_ea_codelab (your-project-id)$
Al termine, il comando precedente creerà una cartella con il nome dell'agente (ad es. executive_assistant) con alcuni file, incluso un file agent.py con la definizione di base dell'agente:
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Se vuoi interagire con questo agente, puoi farlo eseguendo uv run adk web nella riga di comando e aprendo l'interfaccia utente di sviluppo nel browser. Visualizzerai un riquadro simile al seguente:
$ uv run adk web ... INFO: Started server process [1244] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
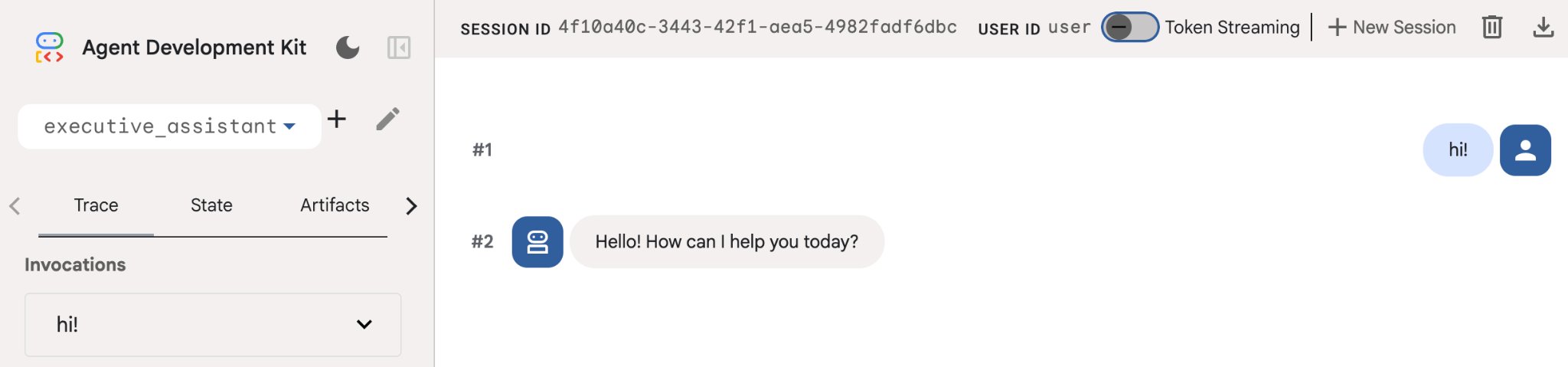
Anche se questo agente è piuttosto semplice, è utile farlo almeno una volta per assicurarsi che la configurazione funzioni correttamente prima di iniziare a modificarlo. Lo screenshot seguente mostra una semplice interazione utilizzando la UI di sviluppo:
Ora modifichiamo la definizione dell'agente con la persona del nostro assistente esecutivo. Copia il codice riportato di seguito e sostituisci i contenuti di agent.py. Adatta il nome e la personalità dell'agente alle tue preferenze.
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant',
instruction='''
You are an elite, warm, and highly efficient AI partner.
Your primary goal is to help the user manage their tasks, schedule, and research.
Always be direct, concise, and high-signal.
''',
)
Tieni presente che la proprietà name definisce il nome interno dell'agente, mentre nelle istruzioni puoi anche assegnargli un nome più amichevole come parte della sua persona per le interazioni con l'utente finale. Il nome interno viene utilizzato principalmente per l'osservabilità e i trasferimenti nei sistemi multi-agente che utilizzano lo strumento transfer_to_agent. Non dovrai occuparti personalmente di questo strumento, ADK lo registra automaticamente quando dichiari uno o più subagenti.
Per eseguire l'agente che abbiamo appena creato, utilizza adk web:
uv run adk web
Apri la UI dell'ADK nel browser e saluta il tuo nuovo assistente.
5. Aggiungere la memoria persistente con Vertex AI Memory Bank
Un vero assistente deve ricordare le preferenze e le interazioni passate per offrire un'esperienza personalizzata e senza interruzioni. In questo passaggio, integreremo Vertex AI Agent Engine Memory Bank, una funzionalità di Vertex AI che genera dinamicamente ricordi a lungo termine in base alle conversazioni degli utenti.
Memory Bank consente all'agente di creare informazioni personalizzate accessibili in più sessioni, stabilendo la continuità tra le sessioni. Dietro le quinte, gestisce la sequenza cronologica dei messaggi in una sessione e può utilizzare il recupero della ricerca per somiglianza per fornire all'agente i ricordi più pertinenti per il contesto attuale.
Inizializza il servizio di memoria
L'ADK utilizza Vertex AI per archiviare e recuperare i ricordi a lungo termine. Devi inizializzare un "Memory Engine" nel tuo progetto. Si tratta essenzialmente di un'istanza del motore di ragionamento configurata per fungere da Memory Bank.
Crea il seguente script come setup_memory.py:
setup_memory.py
import vertexai
import os
PROJECT_ID=os.getenv("PROJECT_ID")
LOCATION=os.getenv("LOCATION")
client = vertexai.Client(project=PROJECT_ID, location=LOCATION)
# Create Reasoning Engine for Memory Bank
agent_engine = client.agent_engines.create()
# You will need this resource name to give it to ADK
print(agent_engine.api_resource.name)
Ora esegui setup_memory.py per eseguire il provisioning del motore di ragionamento per la banca di memoria:
uv run python setup_memory.py
L'output dovrebbe essere simile a questo:
$ uv run python setup.py projects/1234567890/locations/us-central1/reasoningEngines/1234567890
Salva il nome della risorsa del motore in una variabile di ambiente:
export ENGINE_ID="<insert the resource name above>"
Ora dobbiamo aggiornare il codice per utilizzare la memoria persistente. Sostituisci i contenuti di agent.py con quanto segue:
agent.py
from google.adk.agents.llm_agent import Agent
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Update root_agent with memory tools and callback
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='Executive Assistant with Persistent Memory',
instruction='''
You are an elite AI partner with long-term memory.
Use load_memory to find context about the user when needed.
Always be direct, concise, and high-signal.
''',
tools=[PreloadMemoryTool(), load_memory_tool],
after_agent_callback=auto_save_session_to_memory_callback,
)
PreloadMemoryTool inserisce automaticamente il contesto pertinente delle conversazioni passate in ogni richiesta (utilizzando il recupero della ricerca per similarità), mentre load_memory_tool consente al modello di eseguire query esplicite in Memory Bank per i fatti, se necessario. Questa combinazione fornisce al tuo agente un contesto profondo e persistente.
Ora, per avviare l'agente con il supporto della memoria, devi trasmettergli memory_service_uri quando esegui adk web:
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
Prova a fornire agli agenti alcuni fatti che ti riguardano, poi torna con un'altra sessione per chiedere informazioni su di loro. Ad esempio, digli il tuo nome:
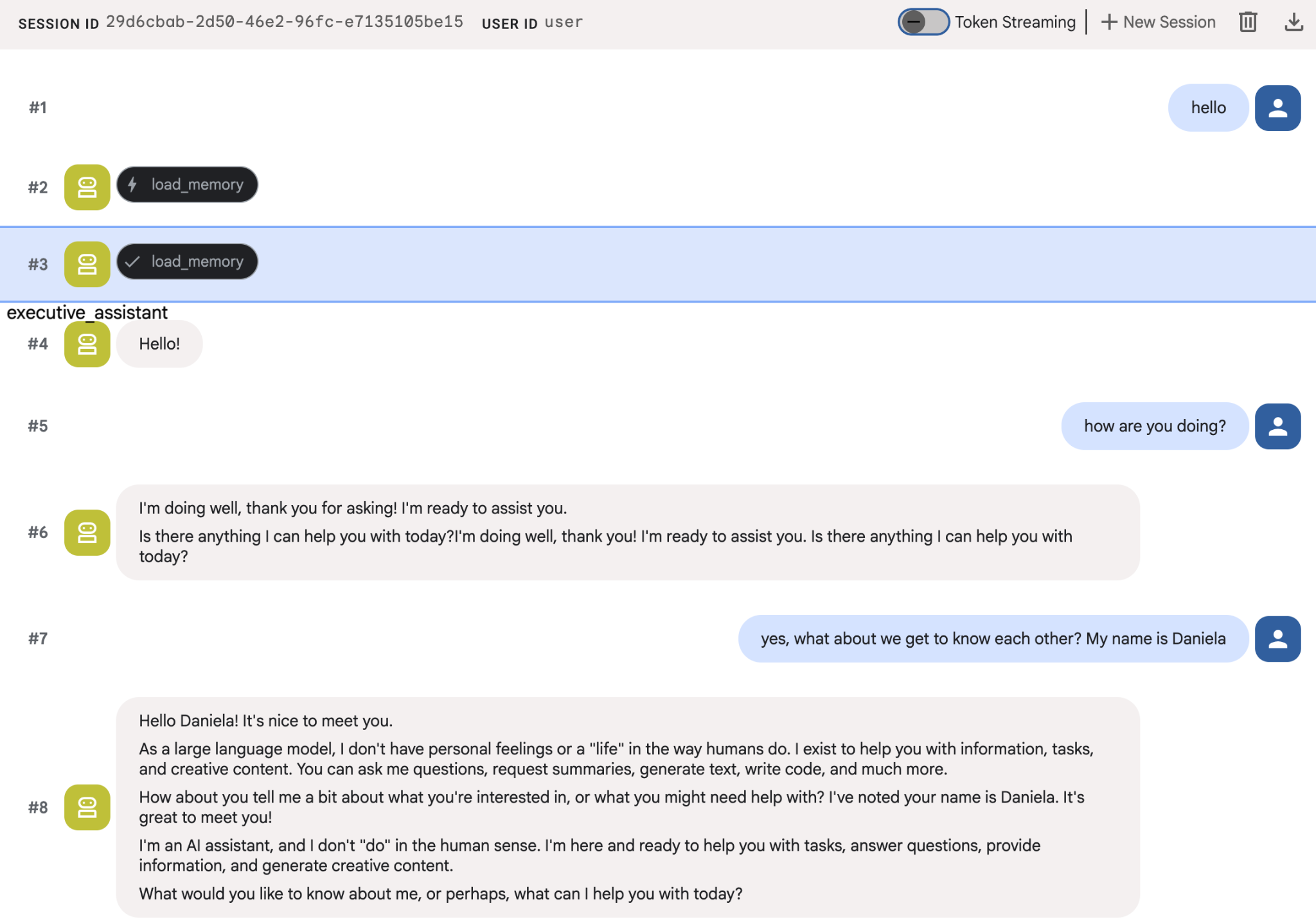
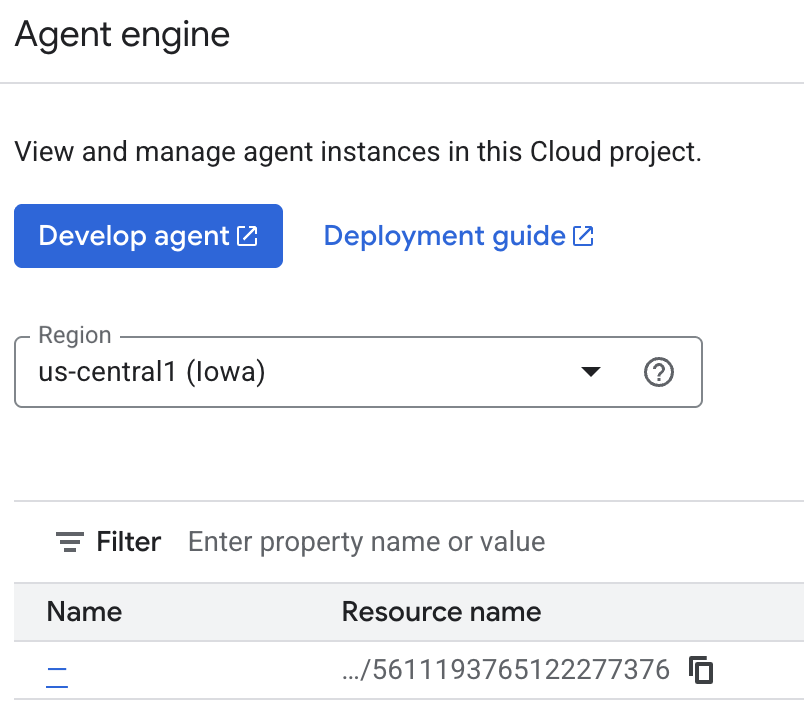
Puoi esaminare le memorie che l'agente salva nella console cloud. Vai alla pagina di prodotto per "Agent Engine" (utilizza la barra di ricerca).

Poi fai clic sul nome del motore dell'agente (assicurati di selezionare la regione corretta):
Poi vai alla scheda Ricordi:
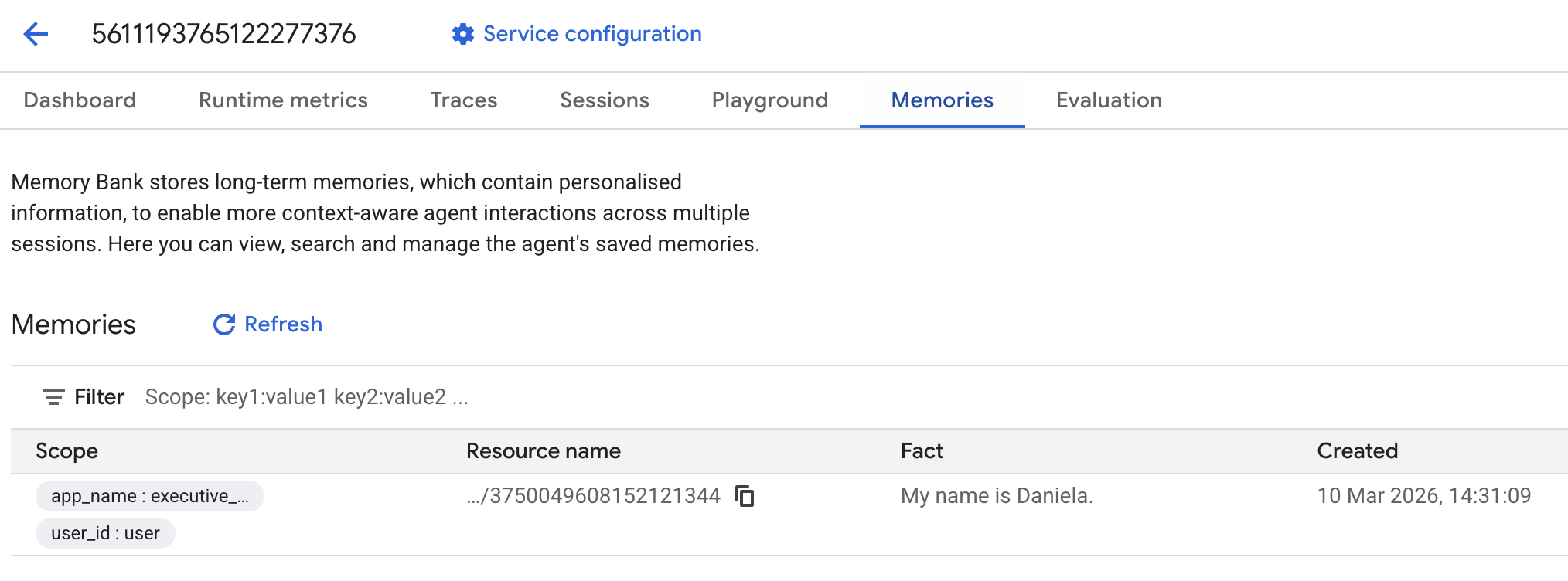
Dovresti vedere alcuni ricordi aggiunti.
6. Aggiungere funzionalità di ricerca sul web
Per fornire informazioni di alta qualità, il nostro agente deve eseguire indagini approfondite che vanno oltre una singola query di ricerca. Delegando la ricerca a un sub-agente specializzato, manteniamo la reattività della persona principale mentre il ricercatore gestisce la raccolta di dati complessi in background.
In questo passaggio, implementiamo un LoopAgent per ottenere una "ricerca approfondita", consentendo all'agente di cercare, valutare i risultati e perfezionare le query in modo iterativo finché non ha un quadro completo. Inoltre, applichiamo il rigore tecnico richiedendo citazioni in linea per tutti i risultati, garantendo che ogni affermazione sia supportata da un link alla fonte.
Crea lo specialista della ricerca (research.py)
Qui definiamo un agente di base dotato dello strumento Ricerca Google e lo inseriamo in un LoopAgent. Il parametro max_iterations funge da regolatore, garantendo che l'agente esegua l'iterazione della ricerca fino a tre volte se rimangono lacune nella sua comprensione.
research.py
from google.adk.agents.llm_agent import Agent
from google.adk.agents.loop_agent import LoopAgent
from google.adk.tools.google_search_tool import GoogleSearchTool
from google.adk.tools.tool_context import ToolContext
def exit_loop(tool_context: ToolContext):
"""Call this function ONLY when no further research is needed, signaling the iterative process should end."""
print(f" [Tool Call] exit_loop triggered by {tool_context.agent_name}")
tool_context.actions.escalate = True
# Return empty dict as tools should typically return JSON-serializable output
return {}
# --- RESEARCH LOGIC ---
_research_worker = Agent(
model='gemini-2.5-flash',
name='research_worker',
description='Worker agent that performs a single research step.',
instruction='''
Use google_search to find facts and synthesize them for the user.
Critically evaluate your findings. If the data is incomplete or you need more context, prepare to search again in the next iteration.
You must include the links you found as references in your response, formatting them like citations in a research paper (e.g., [1], [2]).
Use the exit_loop tool to terminate the research early if no further research is needed.
If you need to ask the user for clarifications, call the exit_loop function early to interrupt the research cycle.
''',
tools=[GoogleSearchTool(bypass_multi_tools_limit=True), exit_loop],
)
# The LoopAgent iterates the worker up to 3 times for deeper research
research_agent = LoopAgent(
name='research_specialist',
description='Deep web research specialist.',
sub_agents=[_research_worker],
max_iterations=3,
)
Aggiorna l'agente root (agent.py)
Importa research_agent e aggiungilo come strumento a Sharon:
agent.py
from google.adk.agents.llm_agent import Agent
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import our new sub agent
from .research import research_agent
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Update root_agent with memory tools and callback
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='Executive Assistant with persistent memory and research capabilities',
instruction='''
You are an elite AI partner with long-term memory.
1. Use load_memory to recall facts.
2. Delegate research tasks to the research_specialist.
Always be direct, concise, and high-signal.
''',
tools=[PreloadMemoryTool(), load_memory_tool],
sub_agents=[research_agent],
after_agent_callback=auto_save_session_to_memory_callback,
)
Avvia di nuovo adk web per testare l'agente di ricerca.
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
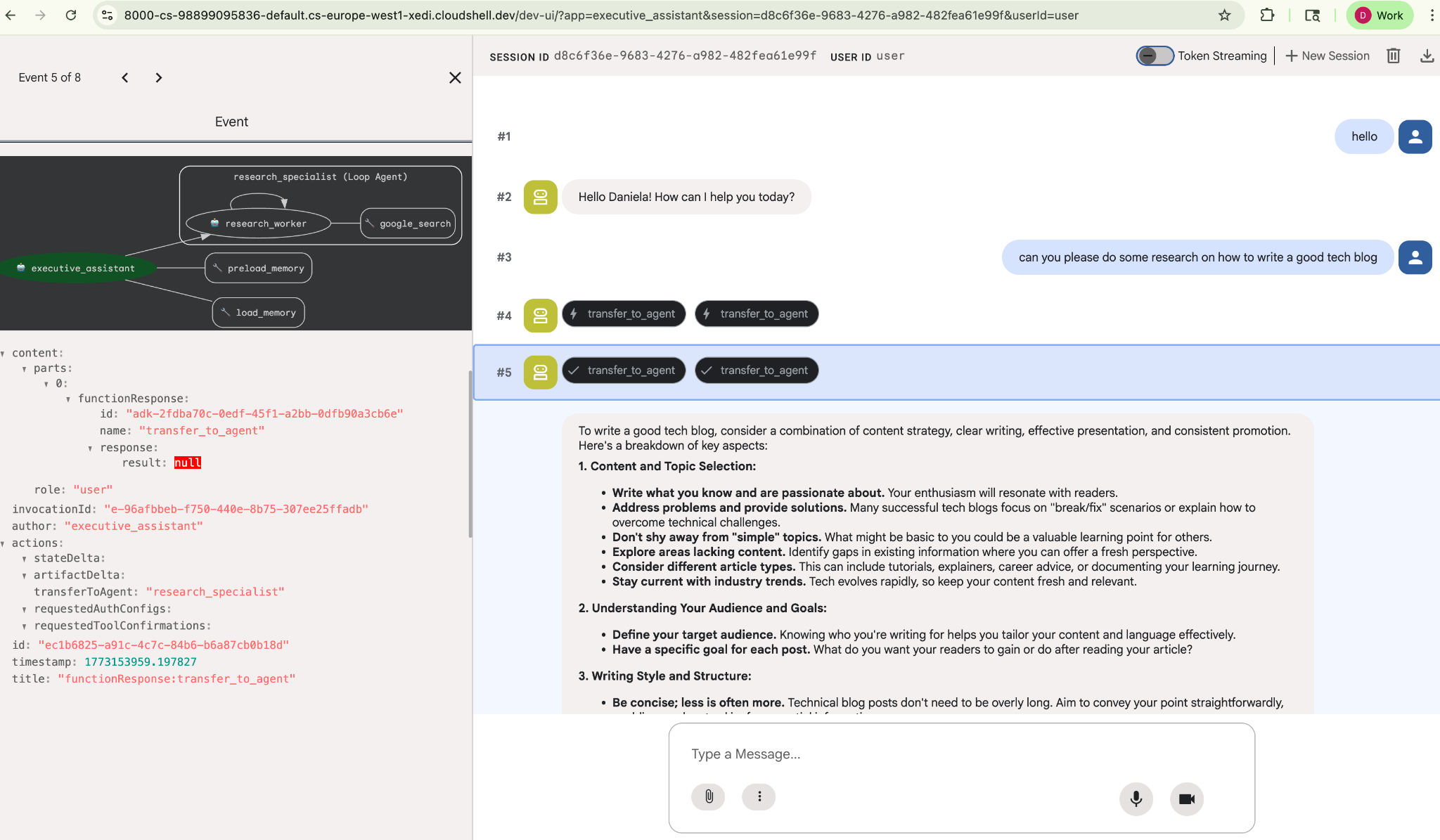
Assegna un semplice compito di ricerca, ad esempio "come scrivere un buon blog tecnologico?"
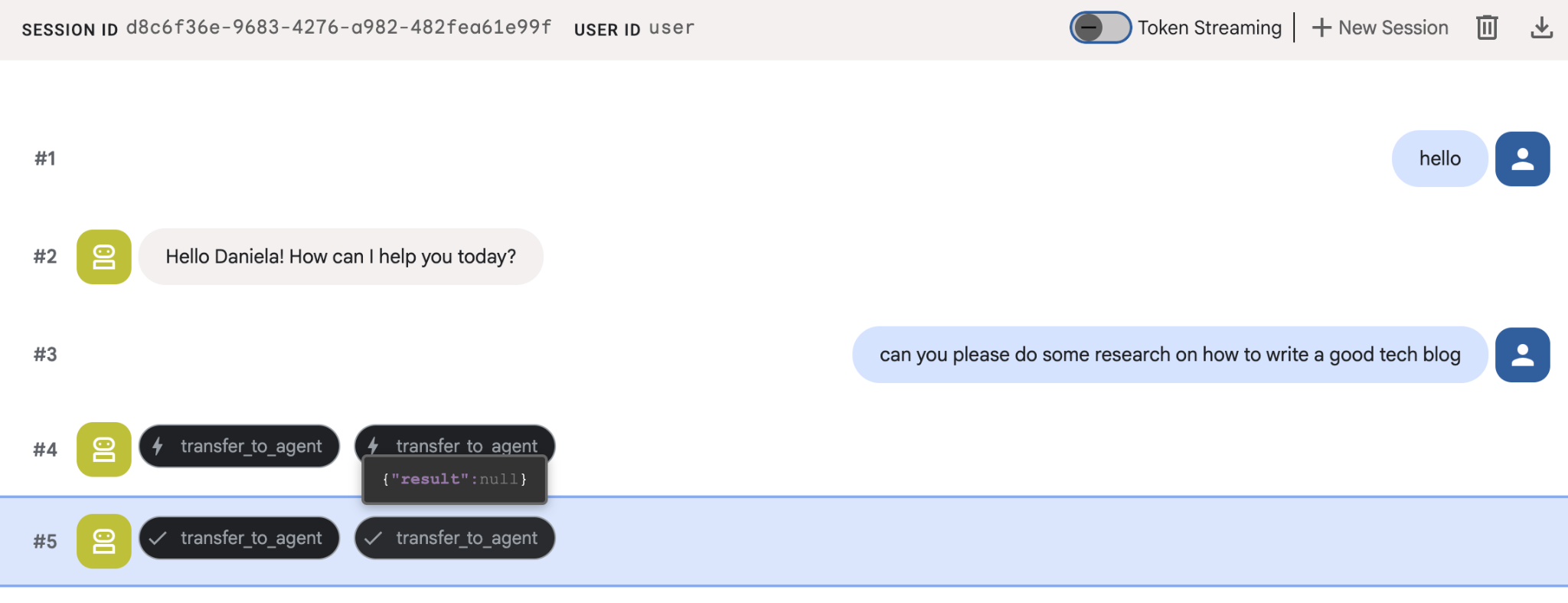
Potresti aver notato che l'agente ha ricordato il mio nome anche se si tratta di una nuova sessione. Prendi nota anche della chiamata allo strumento "transfer_to_agent": questo è lo strumento che trasferisce l'attività al nostro nuovo agente di ricerca.
Ora passiamo alla gestione delle attività.
7. Aggiungi la gestione delle attività con Cloud SQL
Sebbene l'agente abbia una memoria a lungo termine, non è adatto a dati granulari e strutturati come una lista di cose da fare. Per le attività, utilizziamo un database relazionale tradizionale. Utilizzeremo SQLAlchemy e un database Google Cloud SQL (PostgreSQL). Prima di poter scrivere il codice, dobbiamo eseguire il provisioning dell'infrastruttura.
Esegui il provisioning dell'infrastruttura
Esegui questi comandi per creare il database. Nota: la creazione dell'istanza richiede circa 5-10 minuti. Puoi procedere al passaggio successivo mentre l'operazione viene eseguita in background.
# 1. Define instance variables
export INSTANCE_NAME="assistant-db"
export USER_EMAIL=$(gcloud config get-value account)
# 2. Create the Cloud SQL instance
gcloud sql instances create $INSTANCE_NAME \
--database-version=POSTGRES_18 \
--tier=db-f1-micro \
--region=us-central1 \
--edition=ENTERPRISE
# 3. Create the database for our tasks
gcloud sql databases create tasks --instance=$INSTANCE_NAME
Il provisioning dell'istanza del database richiederà alcuni minuti. Potrebbe essere un buon momento per prendere una tazza di caffè o tè o aggiornare il codice mentre aspetti che termini, ma non dimenticare di tornare indietro e completare il controllo dell'accesso.
Configura il controllo dell'accesso
Ora dobbiamo configurare il tuo account utente in modo che abbia accesso al database. Esegui questi comandi nel terminale:
# change this to your favorite password
export DB_PASS="correct-horse-battery-staple"
# Create a regular database user
gcloud sql users create assistant_user \
--instance=$INSTANCE_NAME \
--password=$DB_PASS
Aggiorna la configurazione dell'ambiente
L'ADK carica la configurazione da un file .env in fase di runtime. Aggiorna l'ambiente dell'agente con i dettagli di connessione al database.
# Retrieve the unique connection name
export DB_CONN=$(gcloud sql instances describe $INSTANCE_NAME --format='value(connectionName)')
# Append configuration to your .env file
cat <<EOF >> executive_assistant/.env
DB_CONNECTION_NAME=$DB_CONN
DB_USER=assistant_user
DB_PASSWORD=$DB_PASS
DB_NAME=tasks
EOF
Ora procediamo con le modifiche al codice.
Crea lo specialista delle attività da fare (todo.py)
Come per l'agente di ricerca, creiamo il nostro esperto di cose da fare nel suo file. Crea todo.py:
todo.py
import os
import uuid
import sqlalchemy
from datetime import datetime
from typing import Optional, List
from sqlalchemy import (
Column,
String,
DateTime,
Enum,
select,
delete,
update,
)
from sqlalchemy.orm import declarative_base, Session
from google.cloud.sql.connector import Connector
from google.adk.agents.llm_agent import Agent
# --- DATABASE LOGIC ---
Base = declarative_base()
connector = Connector()
def getconn():
db_connection_name = os.environ.get("DB_CONNECTION_NAME")
db_user = os.environ.get("DB_USER")
db_password = os.environ.get("DB_PASSWORD")
db_name = os.environ.get("DB_NAME", "tasks")
return connector.connect(
db_connection_name,
"pg8000",
user=db_user,
password=db_password,
db=db_name,
)
engine = sqlalchemy.create_engine(
"postgresql+pg8000://",
creator=getconn,
)
class Todo(Base):
__tablename__ = "todos"
id = Column(String(36), primary_key=True, default=lambda: str(uuid.uuid4()))
title = Column(String(255), nullable=False)
priority = Column(
Enum("high", "medium", "low", name="priority_levels"), nullable=False, default="medium"
)
due_date = Column(DateTime, nullable=True)
status = Column(Enum("pending", "done", name="status_levels"), default="pending")
created_at = Column(DateTime, default=datetime.utcnow)
def init_db():
"""Builds the table if it's missing."""
Base.metadata.create_all(bind=engine)
def add_todo(
title: str, priority: str = "medium", due_date: Optional[str] = None
) -> dict:
"""
Adds a new task to the list.
Args:
title (str): The description of the task.
priority (str): The urgency level. Must be one of: 'high', 'medium', 'low'.
due_date (str, optional): The due date in ISO format (YYYY-MM-DD or YYYY-MM-DDTHH:MM:SS).
Returns:
dict: A dictionary containing the new task's ID and a status message.
"""
init_db()
with Session(engine) as session:
due = datetime.fromisoformat(due_date) if due_date else None
item = Todo(
title=title,
priority=priority.lower(),
due_date=due,
)
session.add(item)
session.commit()
return {"id": item.id, "status": f"Task added ✅"}
def list_todos(status: str = "pending") -> list:
"""
Lists tasks from the database, optionally filtering by status.
Args:
status (str, optional): The status to filter by. 'pending', 'done', or 'all'.
"""
init_db()
with Session(engine) as session:
query = select(Todo)
s_lower = status.lower()
if s_lower != "all":
query = query.where(Todo.status == s_lower)
query = query.order_by(Todo.priority, Todo.created_at)
results = session.execute(query).scalars().all()
return [
{
"id": t.id,
"task": t.title,
"priority": t.priority,
"status": t.status,
}
for t in results
]
def complete_todo(task_id: str) -> str:
"""Marks a specific task as 'done'."""
init_db()
with Session(engine) as session:
session.execute(update(Todo).where(Todo.id == task_id).values(status="done"))
session.commit()
return f"Task {task_id} marked as done."
def delete_todo(task_id: str) -> str:
"""Permanently removes a task from the database."""
init_db()
with Session(engine) as session:
session.execute(delete(Todo).where(Todo.id == task_id))
session.commit()
return f"Task {task_id} deleted."
# --- TODO SPECIALIST AGENT ---
todo_agent = Agent(
model='gemini-2.5-flash',
name='todo_specialist',
description='A specialist agent that manages a structured SQL task list.',
instruction='''
You manage the user's task list using a PostgreSQL database.
- Use add_todo when the user wants to remember something. If no priority is mentioned, mark it as 'medium'.
- Use list_todos to show tasks.
- Use complete_todo to mark a task as finished.
- Use delete_todo to remove a task entirely.
When marking a task as complete or deleting it, if the user doesn't provide the ID,
use list_todos first to find the correct ID for the task they described.
''',
tools=[add_todo, list_todos, complete_todo, delete_todo],
)
Il codice riportato sopra è responsabile di due attività principali: la connessione al database Cloud SQL e la fornitura di un elenco di strumenti per tutte le operazioni comuni delle liste di cose da fare, tra cui l'aggiunta, la rimozione e il contrassegno come completate.
Poiché questa logica è molto specifica per l'agente Elenco di cose da fare e non ci interessa necessariamente questa gestione granulare dal punto di vista dell'assistente personale (agente principale), questo agente verrà incluso in un "AgentTool" anziché in un agente secondario.
Per decidere se utilizzare un AgentTool o un subagente, valuta se è necessario condividere il contesto:
- utilizzare un AgentTool quando l'agente non ha bisogno di condividere il contesto con l'agente principale
- utilizzare un agente secondario quando vuoi che l'agente condivida il contesto con l'agente principale
Nel caso dell'agente di ricerca, la condivisione del contesto può essere utile, ma per un semplice agente di attività da svolgere non è molto vantaggiosa.
Implementiamo AgentTool in agent.py.
Aggiorna l'agente root (agent.py)
Ora importa todo_agent nel file principale e collegalo come strumento:
agent.py
import os
from datetime import datetime
from google.adk.agents.llm_agent import Agent
from google.adk.tools.agent_tool import AgentTool
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import our specialized sub-agents
from .research import research_agent
from .todo import todo_agent
# Callback for persistent memory storage
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# --- ROOT AGENT DEFINITION ---
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant with memory and specialized tools.',
instruction='''
You are an elite, high-signal AI Executive Assistant.
Your goal is to help the user manage their knowledge, tasks, and research.
## Your Capabilities:
1. Memory: Use load_memory to recall personal facts or past context about the user.
2. Research: Delegate complex web-based investigations to the research_specialist.
3. Tasks: Delegate all to-do list management (adding, listing, or completing tasks) to the todo_specialist.
Always be direct and professional. If a task is successful, provide a brief confirmation.
''',
tools=[
PreloadMemoryTool(),
load_memory_tool,
AgentTool(todo_agent) # Exposes the Todo Specialist as a tool
],
sub_agents=[research_agent], # Exposes the Research Specialist for direct handover
after_agent_callback=auto_save_session_to_memory_callback,
)
Esegui di nuovo adk web per testare la nuova funzionalità:
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
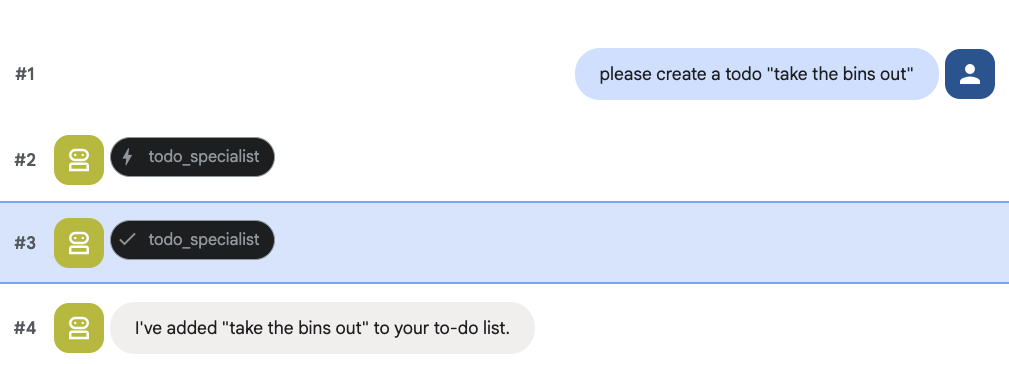
Prova a creare un'attività da svolgere:
8. Aggiungere la gestione del calendario
Infine, ci integreremo con Google Calendar in modo che l'agente possa gestire gli appuntamenti. Ai fini di questo codelab, anziché concedere all'agente l'accesso al tuo calendario personale, il che potrebbe essere potenzialmente pericoloso se non fatto nel modo giusto, creeremo un calendario indipendente da gestire.
Per prima cosa, creeremo un service account dedicato che funga da identità dell'agente. Poi, creeremo il calendario dell'agente in modo programmatico utilizzando l'account di servizio.
Esegui il provisioning del service account
Apri il terminale ed esegui questi comandi per creare l'identità e concedere al tuo account personale l'autorizzazione a rappresentarla:
export SA_NAME="ea-agent"
export SA_EMAIL="${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"
# Create the service account
gcloud iam service-accounts create $SA_NAME \
--display-name="Executive Assistant Agent"
# Allow your local user to impersonate it
gcloud iam service-accounts add-iam-policy-binding $SA_EMAIL \
--member="user:$(gcloud config get-value account)" \
--role="roles/iam.serviceAccountTokenCreator"
# Save it to the agent's environment
echo "SERVICE_ACCOUNT_EMAIL=$SA_EMAIL" >> executive_assistant/.env
Creare il calendario in modo programmatico
Scriviamo uno script per indicare al service account di creare il calendario. Crea un nuovo file denominato setup_calendar.py nella radice del progetto (accanto a setup_memory.py):
setup_calendar.py
import os
import google.auth
from googleapiclient.discovery import build
from google.auth.transport.requests import Request
from google.auth import impersonated_credentials
from dotenv import load_dotenv
load_dotenv('executive_assistant/.env')
SA_EMAIL = os.environ.get("SERVICE_ACCOUNT_EMAIL")
def setup_sa_calendar():
print(f"Authenticating to impersonate {SA_EMAIL}...")
# 1. Base credentials
creds, _ = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
creds.refresh(Request())
# 2. Impersonate the Service Account
impersonated = impersonated_credentials.Credentials(
source_credentials=creds,
target_principal=SA_EMAIL,
target_scopes=["https://www.googleapis.com/auth/calendar"],
)
service = build("calendar", "v3", credentials=impersonated)
# 3. Create the calendar
print("Creating independent Service Account calendar...")
calendar = service.calendars().insert(body={
"summary": "AI Assistant (SA Owned)",
"description": "An independent calendar managed purely by the AI."
}).execute()
calendar_id = calendar['id']
# 4. Save the ID
with open("executive_assistant/.env", "a") as f:
f.write(f"\nCALENDAR_ID={calendar_id}\n")
print(f"Setup complete! CALENDAR_ID {calendar_id} added to .env")
if __name__ == "__main__":
setup_sa_calendar()
Esegui lo script dal terminale:
uv run python setup_calendar.py
Crea lo specialista di Calendar (calendar.py)
Ora concentriamoci sull'esperto di calendario. Dotaremo questo agente di una suite completa di strumenti per il calendario: elencare, creare, aggiornare, eliminare e persino una funzionalità "Aggiunta rapida" che comprende il linguaggio naturale.
Copia il codice riportato di seguito in calendar.py.
calendar.py
import os
from datetime import datetime, timedelta, timezone
import google.auth
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from google.adk.agents.llm_agent import Agent
def _get_calendar_service():
"""Build the Google Calendar API service using Service Account Impersonation."""
from google.auth.transport.requests import Request
from google.auth import impersonated_credentials
target_principal = os.environ.get("SERVICE_ACCOUNT_EMAIL")
if not target_principal:
raise ValueError("SERVICE_ACCOUNT_EMAIL environment variable is missing.")
base_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
creds, _ = google.auth.default(scopes=base_scopes)
creds.refresh(Request())
target_scopes = ["https://www.googleapis.com/auth/calendar"]
impersonated = impersonated_credentials.Credentials(
source_credentials=creds,
target_principal=target_principal,
target_scopes=target_scopes,
)
return build("calendar", "v3", credentials=impersonated)
def _format_event(event: dict) -> dict:
"""Format a raw Calendar API event into a clean dict for the LLM."""
start = event.get("start", {})
end = event.get("end", {})
return {
"id": event.get("id"),
"title": event.get("summary", "(No title)"),
"start": start.get("dateTime", start.get("date")),
"end": end.get("dateTime", end.get("date")),
"location": event.get("location", ""),
"description": event.get("description", ""),
"attendees": [
{"email": a["email"], "status": a.get("responseStatus", "unknown")}
for a in event.get("attendees", [])
],
"link": event.get("htmlLink", ""),
"conference_link": (
event.get("conferenceData", {}).get("entryPoints", [{}])[0].get("uri", "")
if event.get("conferenceData")
else ""
),
"status": event.get("status", ""),
}
def list_events(days_ahead: int = 7) -> dict:
"""List upcoming calendar events."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
now = datetime.now(timezone.utc).isoformat()
end = (datetime.now(timezone.utc) + timedelta(days=days_ahead)).isoformat()
events_result = service.events().list(
calendarId=calendar_id, timeMin=now, timeMax=end,
maxResults=50, singleEvents=True, orderBy="startTime"
).execute()
events = events_result.get("items", [])
if not events:
return {"status": "success", "count": 0, "events": []}
return {"status": "success", "count": len(events), "events": [_format_event(e) for e in events]}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def create_event(title: str, start_time: str, end_time: str, description: str = "", location: str = "", attendees: str = "", add_google_meet: bool = False) -> dict:
"""Create a new calendar event."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
event_body = {
"summary": title,
"start": {"dateTime": start_time},
"end": {"dateTime": end_time},
}
if description: event_body["description"] = description
if location: event_body["location"] = location
if attendees:
email_list = [e.strip() for e in attendees.split(",") if e.strip()]
event_body["attendees"] = [{"email": e} for e in email_list]
conference_version = 0
if add_google_meet:
event_body["conferenceData"] = {
"createRequest": {"requestId": f"event-{datetime.now().strftime('%Y%m%d%H%M%S')}", "conferenceSolutionKey": {"type": "hangoutsMeet"}}
}
conference_version = 1
event = service.events().insert(calendarId=calendar_id, body=event_body, conferenceDataVersion=conference_version).execute()
return {"status": "success", "message": f"Event created ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def update_event(event_id: str, title: str = "", start_time: str = "", end_time: str = "", description: str = "") -> dict:
"""Update an existing calendar event."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
patch_body = {}
if title: patch_body["summary"] = title
if start_time: patch_body["start"] = {"dateTime": start_time}
if end_time: patch_body["end"] = {"dateTime": end_time}
if description: patch_body["description"] = description
if not patch_body: return {"status": "error", "message": "No fields to update."}
event = service.events().patch(calendarId=calendar_id, eventId=event_id, body=patch_body).execute()
return {"status": "success", "message": "Event updated ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def delete_event(event_id: str) -> dict:
"""Delete a calendar event by its ID."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
service.events().delete(calendarId=calendar_id, eventId=event_id).execute()
return {"status": "success", "message": f"Event '{event_id}' deleted ✅"}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def quick_add_event(text: str) -> dict:
"""Create an event using natural language (e.g. 'Lunch with Sarah next Monday noon')."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
event = service.events().quickAdd(calendarId=calendar_id, text=text).execute()
return {"status": "success", "message": "Event created from text ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
calendar_agent = Agent(
model='gemini-2.5-flash',
name='calendar_specialist',
description='Manages the user schedule and calendar events.',
instruction='''
You manage the user's Google Calendar.
- Use list_events to check the schedule.
- Use quick_add_event for simple, conversational scheduling requests (e.g., "Lunch tomorrow at noon").
- Use create_event for complex meetings that require attendees, specific durations, or Google Meet links.
- Use update_event to change details of an existing event.
- Use delete_event to cancel or remove an event.
CRITICAL: For update_event and delete_event, you must provide the exact `event_id`.
If the user does not provide the ID, you MUST call list_events first to find the correct `event_id` before attempting the update or deletion.
Always use the current date/time context provided by the root agent to resolve relative dates like "tomorrow".
''',
tools=[list_events, create_event, update_event, delete_event, quick_add_event],
)
Finalizza l'agente root (agent.py)
Aggiorna il file agent.py con il codice riportato di seguito:
agent.py
import os
from datetime import datetime
from zoneinfo import ZoneInfo
from google.adk.agents.llm_agent import Agent
from google.adk.tools.agent_tool import AgentTool
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import all our specialized sub-agents
from .research import research_agent
from .todo import todo_agent
from .calendar import calendar_agent
import tzlocal
# Automatically detect the local system timezone
TIMEZONE = tzlocal.get_localzone_name()
# Callback for persistent memory storage
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Callback to inject the current time into the prompt
async def setup_agent_context(callback_context, **kwargs):
now = datetime.now(ZoneInfo(TIMEZONE))
callback_context.state["current_time"] = now.strftime("%A, %Y-%m-%d %I:%M %p")
callback_context.state["timezone"] = TIMEZONE
# --- ROOT AGENT DEFINITION ---
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant with memory and specialized tools.',
instruction='''
You are an elite, high-signal AI Executive Assistant.
Your goal is to help the user manage their knowledge, tasks, research, and schedule.
## Your Capabilities:
1. Memory: Use load_memory to recall personal facts.
2. Research: Delegate complex web investigations to the research_specialist.
3. Tasks: Delegate all to-do list management to the todo_specialist.
4. Scheduling: Delegate all calendar queries to the calendar_specialist.
## 🕒 Current State
- Time: {current_time?}
- Timezone: {timezone?}
Always be direct and professional.
''',
tools=[
PreloadMemoryTool(),
load_memory_tool,
AgentTool(todo_agent),
AgentTool(calendar_agent)
],
sub_agents=[research_agent],
before_agent_callback=[setup_agent_context],
after_agent_callback=[auto_save_session_to_memory_callback],
)
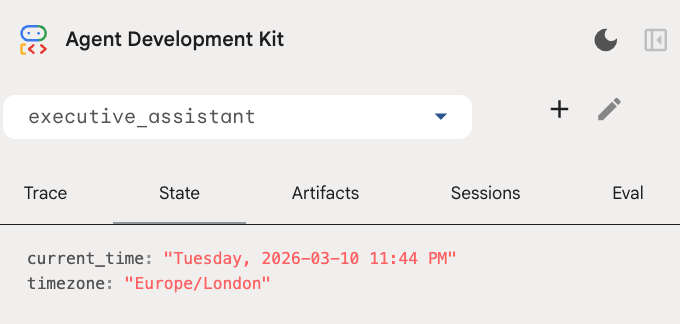
Tieni presente che, oltre allo strumento del calendario, abbiamo aggiunto anche una nuova funzione prima del callback dell'agente: setup_agent_context. Questa funzione consente all'agente di conoscere la data, l'ora e il fuso orario attuali, in modo da poter utilizzare il calendario in modo più efficiente. Funziona impostando le variabili di stato della sessione, un tipo diverso di memoria dell'agente progettato per la persistenza a breve termine.
Esegui adk web un'ultima volta per testare l'agente completo.
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
Puoi esaminare lo stato della sessione nella scheda Stato dell'interfaccia utente per sviluppatori:
Ora hai un agente che può tenere traccia degli eventi del calendario, delle liste di cose da fare, fare ricerche e ha una memoria a lungo termine.
Pulizia dopo il lab
9. Conclusione
Complimenti! Hai progettato con successo un assistente esecutivo AI multifunzionale in 5 fasi evolutive.
Argomenti trattati
- Provisioning dell'infrastruttura per gli agenti AI.
- Implementazione della memoria persistente e di sub-agenti specializzati utilizzando i componenti integrati di ADK.
- Integrazione di database esterni e API di produttività.
Passaggi successivi
Puoi continuare il tuo percorso di apprendimento esplorando altri codelab su questa piattaforma o apportando miglioramenti all'assistente esecutivo in autonomia.
Se hai bisogno di idee per i miglioramenti, puoi provare a:
- Implementa la compattazione degli eventi per ottimizzare il rendimento per le conversazioni lunghe.
- Aggiungi un servizio di artefatti per consentire all'agente di prendere appunti per te e salvarli come file
- Esegui il deployment dell'agente come servizio di backend utilizzando Google Cloud Run.
Una volta terminato il test, ricordati di eseguire la pulizia dell'ambiente per non incorrere in addebiti imprevisti sul tuo account di fatturazione.
Buona programmazione!