
1. Wprowadzenie
Z tego ćwiczenia dowiesz się, jak utworzyć zaawansowanego agenta AI za pomocą pakietu Google Agent Development Kit (ADK). Będziemy podążać naturalną ścieżką rozwoju, zaczynając od podstawowego agenta konwersacyjnego i stopniowo dodając do niego specjalistyczne funkcje.
Tworzony przez nas agent to asystent wykonawczy, który pomoże Ci w codziennych zadaniach, takich jak zarządzanie kalendarzem, przypominanie o zadaniach, wyszukiwanie informacji i sporządzanie notatek. Wszystkie te funkcje zostały stworzone od podstaw przy użyciu pakietu ADK, Gemini i Vertex AI.
Po ukończeniu tego modułu będziesz mieć w pełni działającego agenta i wiedzę potrzebną do dostosowania go do własnych potrzeb.
Wymagania wstępne
- podstawowa wiedza o programowaniu w języku programowania Python,
- Podstawowa znajomość konsoli Google Cloud do zarządzania zasobami w chmurze
Czego się nauczysz
- aprowizowanie infrastruktury w chmurze Google dla agentów AI;
- Wdrażanie trwałej pamięci długoterminowej z wykorzystaniem Vertex AI Banku zapamiętanych informacji.
- Tworzenie hierarchii wyspecjalizowanych subagentów.
- integrowanie zewnętrznych baz danych z ekosystemem Google Workspace;
Czego potrzebujesz
Te warsztaty można w całości przeprowadzić w Google Cloud Shell, które ma wstępnie zainstalowane wszystkie niezbędne zależności (interfejs gcloud CLI, edytor kodu, Go, interfejs wiersza poleceń Gemini).
Możesz też pracować na własnym urządzeniu. W tym celu potrzebujesz:
- Python (wersja 3.12 lub nowsza)
- Edytor kodu lub IDE (np. VS Code lub
vim). - terminal do wykonywania poleceń Pythona i
gcloud; - Zalecane: agent do kodowania, np. interfejs wiersza poleceń Gemini lub Antigravity.
Kluczowe technologie
Więcej informacji o technologiach, z których będziemy korzystać, znajdziesz tutaj:
2. Konfiguracja środowiska
Wybierz jedną z tych opcji: Self-paced environment setup (Konfiguracja środowiska we własnym tempie), jeśli chcesz uruchomić ten samouczek na własnym komputerze, lub Start Cloud Shell (Uruchom Cloud Shell), jeśli chcesz uruchomić go w chmurze.
Samodzielne konfigurowanie środowiska
- Zaloguj się w konsoli Google Cloud i utwórz nowy projekt lub użyj istniejącego. Jeśli nie masz jeszcze konta Gmail ani Google Workspace, musisz je utworzyć.

- Nazwa projektu to wyświetlana nazwa uczestników tego projektu. Jest to ciąg znaków, który nie jest używany przez interfejsy API Google. Zawsze możesz ją zaktualizować.
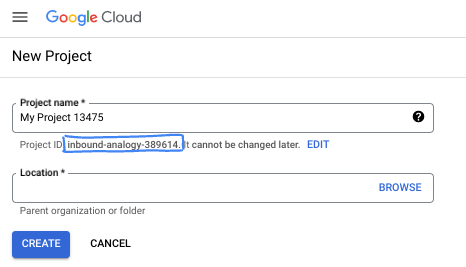
- Identyfikator projektu jest unikalny we wszystkich projektach Google Cloud i nie można go zmienić po ustawieniu. Konsola Cloud automatycznie generuje unikalny ciąg znaków. Zwykle nie musisz się tym przejmować. W większości ćwiczeń z programowania musisz odwoływać się do identyfikatora projektu (zwykle oznaczanego jako
PROJECT_ID). Jeśli wygenerowany identyfikator Ci się nie podoba, możesz wygenerować inny losowy identyfikator. Możesz też spróbować własnej nazwy i sprawdzić, czy jest dostępna. Po tym kroku nie można go zmienić i pozostaje on taki przez cały czas trwania projektu. - Warto wiedzieć, że istnieje trzecia wartość, numer projektu, której używają niektóre interfejsy API. Więcej informacji o tych 3 wartościach znajdziesz w dokumentacji.
- Następnie musisz włączyć płatności w konsoli Cloud, aby korzystać z zasobów i interfejsów API Google Cloud. Wykonanie tego laboratorium nie będzie kosztować dużo, a może nawet nic. Aby wyłączyć zasoby i uniknąć naliczania opłat po zakończeniu tego samouczka, możesz usunąć utworzone zasoby lub projekt. Nowi użytkownicy Google Cloud mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Uruchom Cloud Shell
Z Google Cloud można korzystać zdalnie na laptopie, ale w tym ćwiczeniu użyjesz Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:
Uzyskanie dostępu do środowiska i połączenie się z nim powinno zająć tylko kilka chwil. Po zakończeniu powinno wyświetlić się coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym laboratorium możesz wykonać w przeglądarce. Nie musisz niczego instalować.
3. Konfiguracja projektu
Zanim zaczniemy pisać kod, musimy udostępnić w Google Cloud niezbędną infrastrukturę i uprawnienia.
Ustawianie zmiennych środowiskowych
Otwórz terminal i ustaw te zmienne środowiskowe:
export PROJECT_ID=`gcloud config get project`
export LOCATION=us-central1
Włącz wymagane interfejsy API
Twój agent wymaga dostępu do kilku usług Google Cloud. W tym celu uruchom to polecenie:
gcloud services enable \
aiplatform.googleapis.com \
calendar-json.googleapis.com \
sqladmin.googleapis.com
Uwierzytelnianie za pomocą domyślnego uwierzytelniania aplikacji
Aby komunikować się z usługami Google Cloud w Twoim środowisku, musimy uwierzytelnić się za pomocą domyślnego uwierzytelniania aplikacji (ADC).
Uruchom to polecenie, aby sprawdzić, czy domyślne uwierzytelnianie aplikacji jest aktywne i aktualne:
gcloud auth application-default login
4. Tworzenie agenta podstawowego
Teraz musimy zainicjować katalog, w którym będziemy przechowywać kod źródłowy projektu:
# setup project directory
mkdir -p adk_ea_codelab && cd adk_ea_codelab
# prepare virtual environment
uv init
# install dependencies
uv add google-adk google-api-python-client tzlocal python-dotenv
uv add cloud-sql-python-connector[pg8000] sqlalchemy
Zaczynamy od ustalenia tożsamości agenta i jego podstawowych możliwości konwersacyjnych. W pakiecie ADK klasa Agent definiuje personę agenta i jego instrukcje.
W tym momencie warto zastanowić się nad nazwą agenta. Chcę, aby moi agenci mieli odpowiednie imiona, takie jak Aida czy Sharon, ponieważ uważam, że pomaga to nadać im „osobowość”. Możesz jednak po prostu nazwać agenta zgodnie z jego funkcją, np. „asystent_wykonawczy”, „agent_turystyczny” lub „wykonawca_kodu”.
Uruchom polecenie adk create, aby uruchomić agenta z kodem początkowym:
# replace with your desired agent name
uv run adk create executive_assistant
Wybierz gemini-2.5-flash jako model i Vertex AI jako backend. Sprawdź, czy sugerowany identyfikator projektu to ten, który został utworzony na potrzeby tego modułu, i naciśnij Enter, aby potwierdzić. W przypadku regionu Google Cloud możesz zaakceptować wartość domyślną (us-central1). Twój terminal będzie wyglądać podobnie do tego:
daniela_petruzalek@cloudshell:~/adk_ea_codelab (your-project-id)$ uv run adk create executive_assistant Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [your-project-id]: Enter Google Cloud region [us-central1]: Agent created in /home/daniela_petruzalek/adk_ea_codelab/executive_assistant: - .env - __init__.py - agent.py daniela_petruzalek@cloudshell:~/adk_ea_codelab (your-project-id)$
Po zakończeniu poprzednie polecenie utworzy folder z nazwą agenta (np. executive_assistant), który będzie zawierać kilka plików, w tym plik agent.py z podstawową definicją agenta:
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Jeśli chcesz korzystać z tego agenta, możesz to zrobić, uruchamiając uv run adk web w wierszu poleceń i otwierając interfejs programistyczny w przeglądarce. Zobaczysz coś takiego:
$ uv run adk web ... INFO: Started server process [1244] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
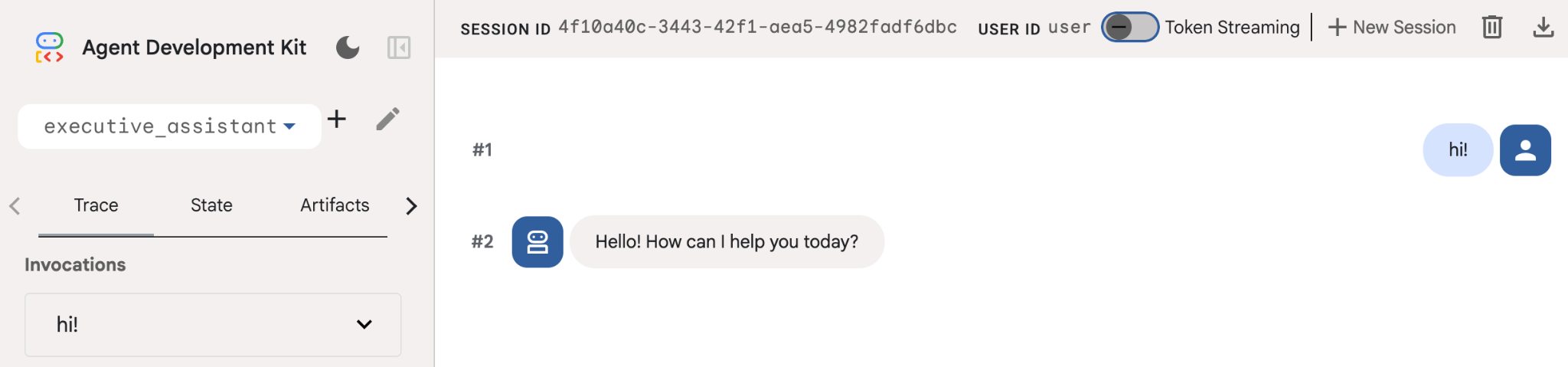
Nawet jeśli ten agent jest dość prosty, warto to zrobić przynajmniej raz, aby upewnić się, że konfiguracja działa prawidłowo, zanim zaczniemy go edytować. Na zrzucie ekranu poniżej widać prostą interakcję z użyciem interfejsu programistycznego:
Teraz zmodyfikujmy definicję agenta, aby uwzględnić w niej osobowość asystenta dyrektora. Skopiuj poniższy kod i zastąp nim zawartość pliku agent.py. Dostosuj nazwę i osobowość agenta do swoich preferencji.
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant',
instruction='''
You are an elite, warm, and highly efficient AI partner.
Your primary goal is to help the user manage their tasks, schedule, and research.
Always be direct, concise, and high-signal.
''',
)
Pamiętaj, że właściwość name określa wewnętrzną nazwę agenta, ale w instrukcjach możesz też podać bardziej przyjazną nazwę w ramach jego persony na potrzeby interakcji z użytkownikiem. Nazwa wewnętrzna jest używana głównie do dostrzegalności i przekazywania informacji w systemach z wieloma agentami korzystających z narzędzia transfer_to_agent. Nie musisz samodzielnie korzystać z tego narzędzia. Pakiet ADK automatycznie rejestruje je, gdy zadeklarujesz co najmniej 1 sub-agenta.
Aby uruchomić utworzonego właśnie agenta, użyj polecenia adk web:
uv run adk web
Otwórz interfejs ADK w przeglądarce i przywitaj się z nowym asystentem.
5. Dodawanie pamięci trwałej za pomocą Vertex AI Memory Bank
Prawdziwy asystent musi pamiętać preferencje i wcześniejsze interakcje, aby zapewnić płynną i spersonalizowaną obsługę. W tym kroku zintegrujemy bank zapamiętanych informacji w Vertex AI Agent Engine, czyli funkcję Vertex AI, która dynamicznie generuje długoterminowe zapamiętane informacje na podstawie rozmów z użytkownikami.
Bank zapamiętanych informacji umożliwia agentowi tworzenie spersonalizowanych informacji dostępnych w wielu sesjach, co zapewnia ciągłość między sesjami. Za kulisami zarządza chronologiczną sekwencją wiadomości w sesji i może używać wyszukiwania podobieństw, aby dostarczać agentowi najbardziej odpowiednie wspomnienia w bieżącym kontekście.
Inicjowanie usługi Pamięć
ADK używa Vertex AI do przechowywania i pobierania długotrwałych wspomnień. W projekcie musisz zainicjować „Memory Engine”. Jest to w zasadzie instancja silnika rozumowania skonfigurowana do działania jako Bank zapamiętanych informacji.
Utwórz ten skrypt jako setup_memory.py:
setup_memory.py
import vertexai
import os
PROJECT_ID=os.getenv("PROJECT_ID")
LOCATION=os.getenv("LOCATION")
client = vertexai.Client(project=PROJECT_ID, location=LOCATION)
# Create Reasoning Engine for Memory Bank
agent_engine = client.agent_engines.create()
# You will need this resource name to give it to ADK
print(agent_engine.api_resource.name)
Teraz uruchom polecenie setup_memory.py, aby udostępnić silnik rozumowania dla banku pamięci:
uv run python setup_memory.py
Dane wyjściowe powinny wyglądać podobnie do tych:
$ uv run python setup.py projects/1234567890/locations/us-central1/reasoningEngines/1234567890
Zapisz nazwę zasobu silnika w zmiennej środowiskowej:
export ENGINE_ID="<insert the resource name above>"
Teraz musimy zaktualizować kod, aby korzystać z pamięci trwałej. Zastąp zawartość pliku agent.py tym kodem:
agent.py
from google.adk.agents.llm_agent import Agent
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Update root_agent with memory tools and callback
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='Executive Assistant with Persistent Memory',
instruction='''
You are an elite AI partner with long-term memory.
Use load_memory to find context about the user when needed.
Always be direct, concise, and high-signal.
''',
tools=[PreloadMemoryTool(), load_memory_tool],
after_agent_callback=auto_save_session_to_memory_callback,
)
PreloadMemoryTool automatycznie wstrzykuje do każdego żądania odpowiedni kontekst z poprzednich rozmów (za pomocą wyszukiwania podobieństw), a load_memory_tool umożliwia modelowi w razie potrzeby wysyłanie do Banku zapamiętanych informacji zapytań o fakty. Ta kombinacja zapewnia agentowi głęboki, trwały kontekst.
Aby uruchomić agenta z obsługą pamięci, musisz przekazać mu parametr memory_service_uri podczas uruchamiania adk web:
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
Podaj agentom kilka informacji o sobie, a potem w innej sesji zadaj im pytania na ten temat. Na przykład podaj swoje imię:
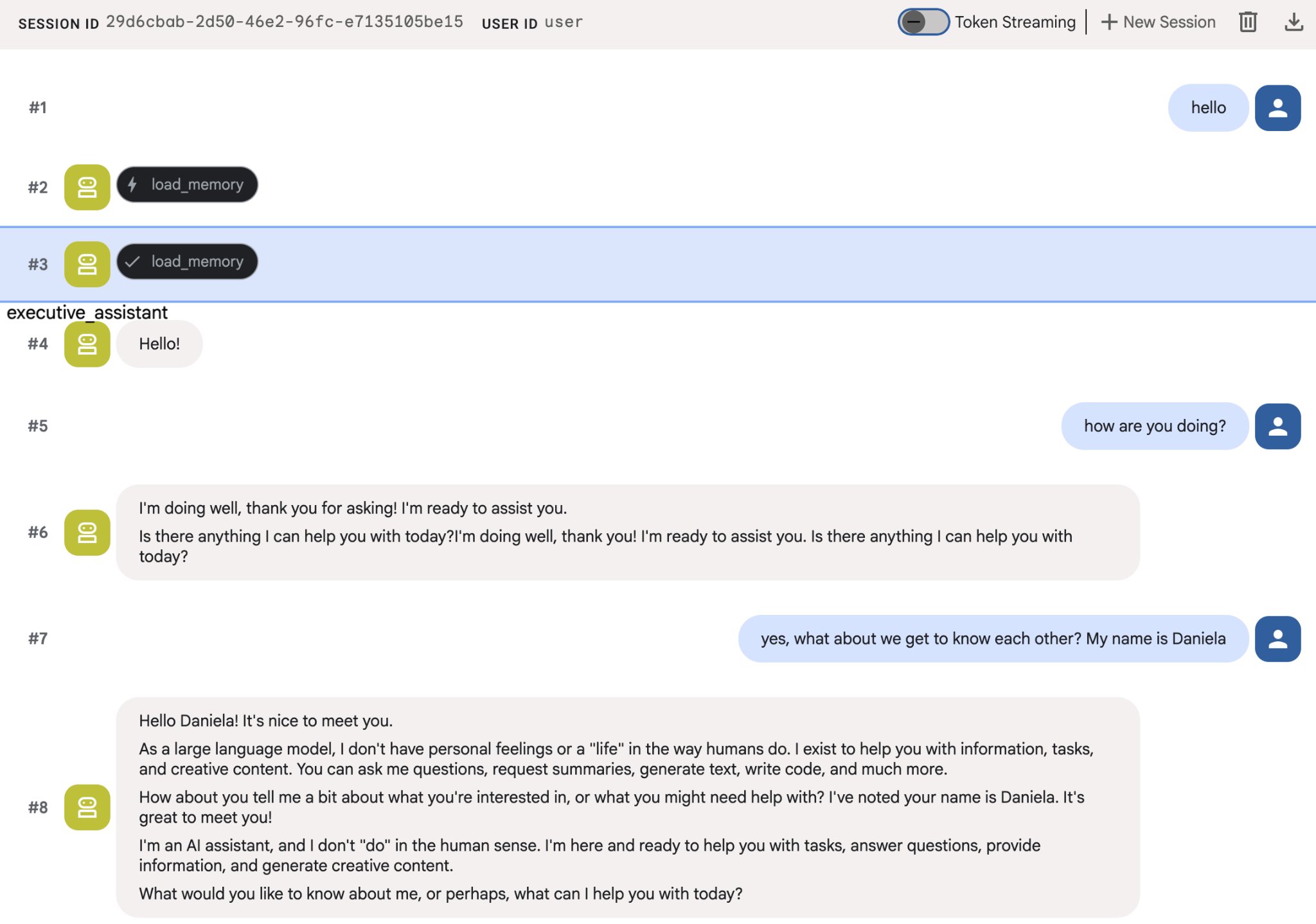
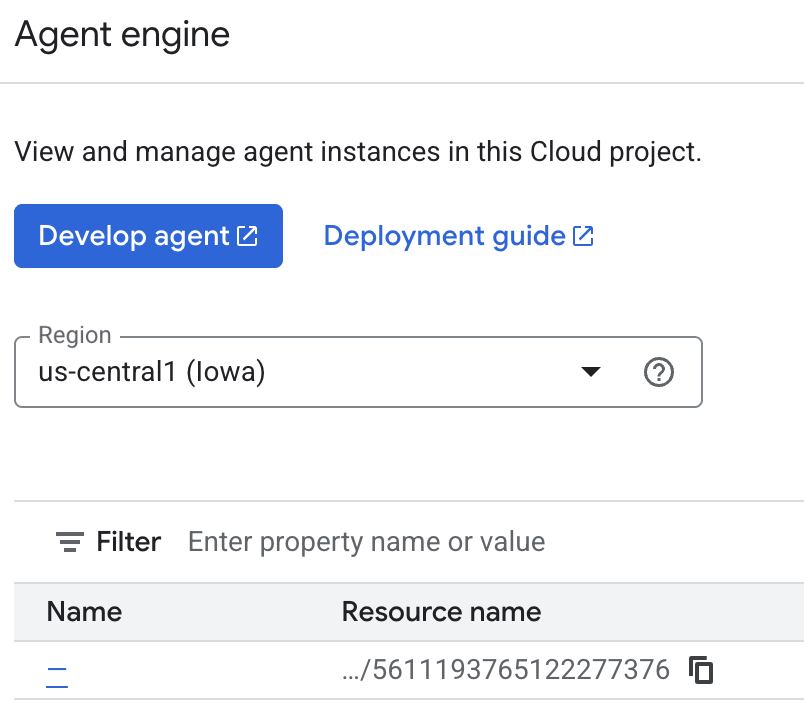
Zapamiętane informacje zapisywane przez agenta możesz sprawdzić w konsoli w chmurze. Otwórz stronę produktu „Agent Engine” (użyj paska wyszukiwania).

Następnie kliknij nazwę silnika agenta (upewnij się, że wybierasz właściwy region):
Następnie otwórz kartę Wspomnienia:
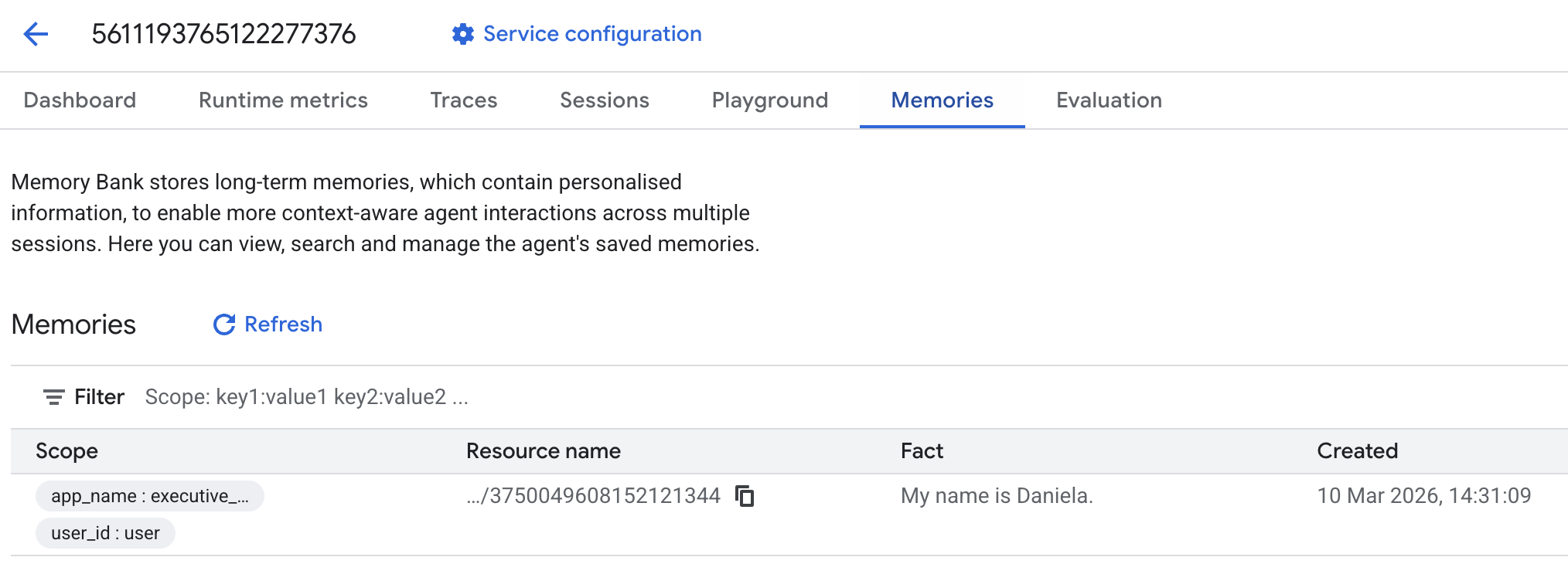
Powinny pojawić się dodane wspomnienia.
6. Dodawanie funkcji wyszukiwania w internecie
Aby dostarczać wysokiej jakości informacje, nasz agent musi przeprowadzać szczegółowe badania, które wykraczają poza jedno zapytanie. Przekazując zadanie badawcze wyspecjalizowanemu sub-agentowi, zachowujemy responsywność głównej persony, podczas gdy badacz zajmuje się w tle złożonym zbieraniem danych.
W tym kroku wdrażamy LoopAgent, aby osiągnąć „głębię wyszukiwania”, czyli umożliwić agentowi iteracyjne wyszukiwanie, ocenianie wyników i doprecyzowywanie zapytań, dopóki nie uzyska pełnego obrazu. Dbamy też o dokładność techniczną, wymagając cytatów w tekście w przypadku wszystkich wyników, dzięki czemu każde stwierdzenie jest poparte linkiem do źródła.
Utwórz specjalistę ds. badań (research.py)
Definiujemy tutaj podstawowego agenta wyposażonego w narzędzie wyszukiwarki Google i zawieramy go w agencie LoopAgent. Parametr max_iterations działa jako regulator, który zapewnia, że agent będzie powtarzać wyszukiwanie maksymalnie 3 razy, jeśli nadal będzie miał problemy ze zrozumieniem.
research.py
from google.adk.agents.llm_agent import Agent
from google.adk.agents.loop_agent import LoopAgent
from google.adk.tools.google_search_tool import GoogleSearchTool
from google.adk.tools.tool_context import ToolContext
def exit_loop(tool_context: ToolContext):
"""Call this function ONLY when no further research is needed, signaling the iterative process should end."""
print(f" [Tool Call] exit_loop triggered by {tool_context.agent_name}")
tool_context.actions.escalate = True
# Return empty dict as tools should typically return JSON-serializable output
return {}
# --- RESEARCH LOGIC ---
_research_worker = Agent(
model='gemini-2.5-flash',
name='research_worker',
description='Worker agent that performs a single research step.',
instruction='''
Use google_search to find facts and synthesize them for the user.
Critically evaluate your findings. If the data is incomplete or you need more context, prepare to search again in the next iteration.
You must include the links you found as references in your response, formatting them like citations in a research paper (e.g., [1], [2]).
Use the exit_loop tool to terminate the research early if no further research is needed.
If you need to ask the user for clarifications, call the exit_loop function early to interrupt the research cycle.
''',
tools=[GoogleSearchTool(bypass_multi_tools_limit=True), exit_loop],
)
# The LoopAgent iterates the worker up to 3 times for deeper research
research_agent = LoopAgent(
name='research_specialist',
description='Deep web research specialist.',
sub_agents=[_research_worker],
max_iterations=3,
)
Aktualizowanie agenta głównego (agent.py)
Zaimportuj agenta research_agent i dodaj go jako narzędzie do Sharon:
agent.py
from google.adk.agents.llm_agent import Agent
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import our new sub agent
from .research import research_agent
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Update root_agent with memory tools and callback
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='Executive Assistant with persistent memory and research capabilities',
instruction='''
You are an elite AI partner with long-term memory.
1. Use load_memory to recall facts.
2. Delegate research tasks to the research_specialist.
Always be direct, concise, and high-signal.
''',
tools=[PreloadMemoryTool(), load_memory_tool],
sub_agents=[research_agent],
after_agent_callback=auto_save_session_to_memory_callback,
)
Ponownie uruchom adk web, aby przetestować agenta badawczego.
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
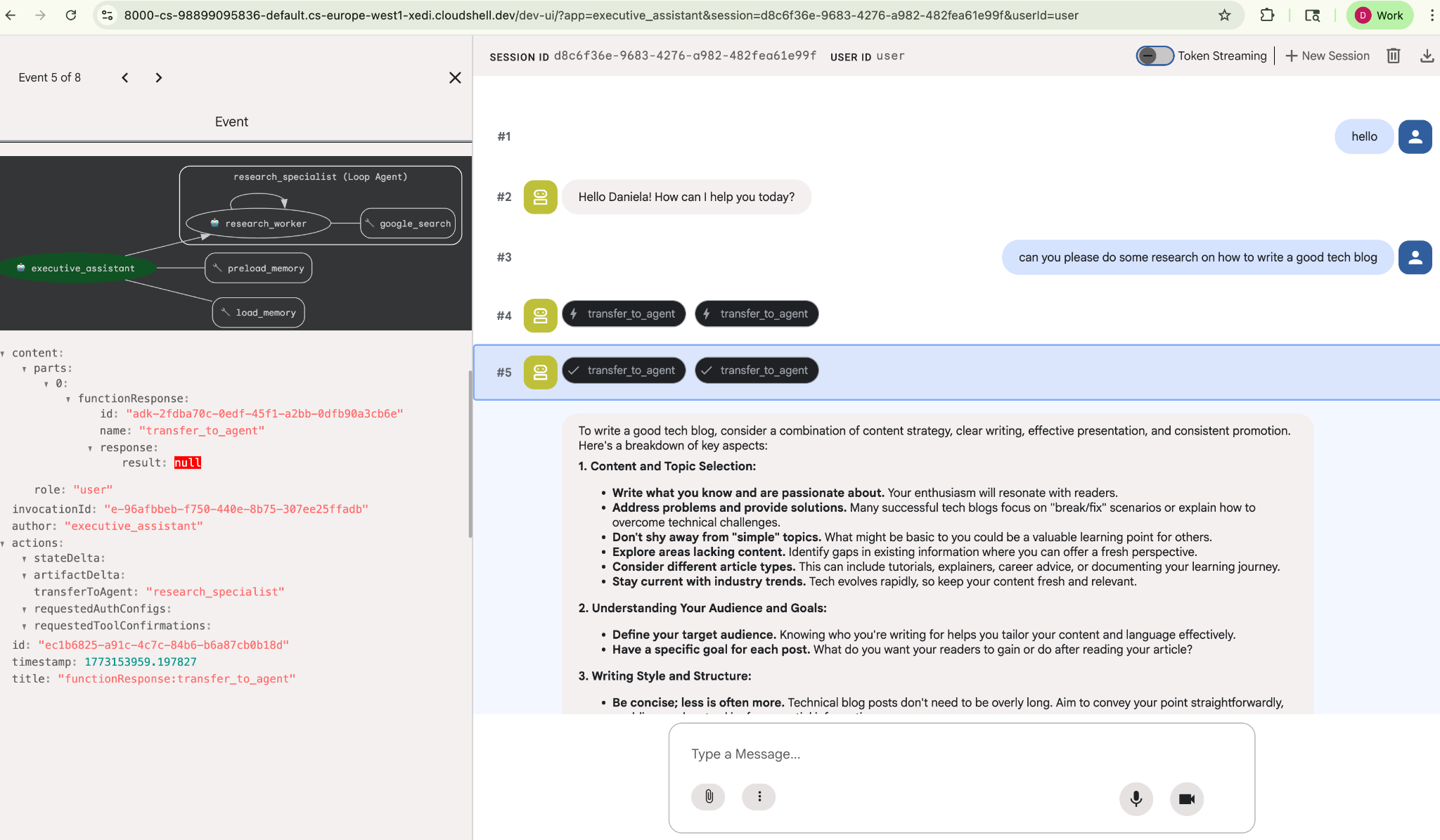
Zleć mu proste zadanie badawcze, np. „jak napisać dobrego bloga o technologii?”.
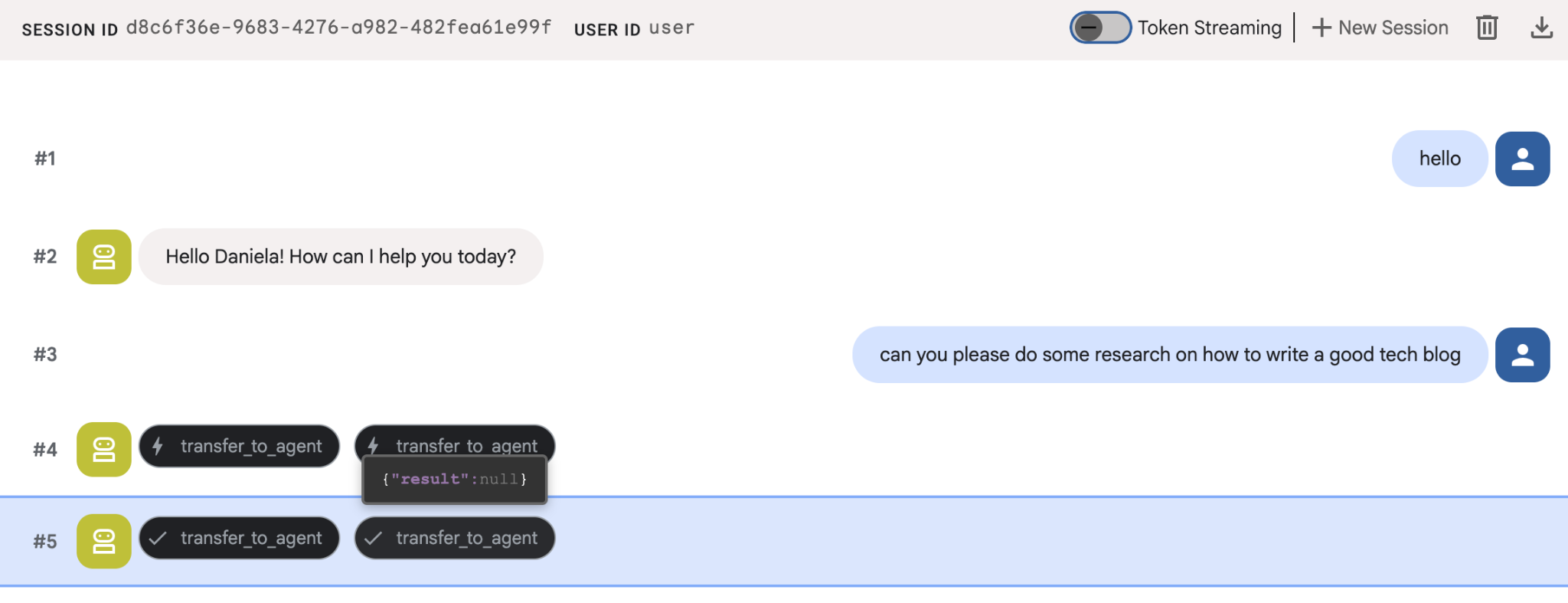
Możesz zauważyć, że agent zapamiętał moje imię, mimo że jest to nowa sesja. Zwróć też uwagę na wywołanie narzędzia „transfer_to_agent”: to ono przekazuje zadanie naszemu nowemu agentowi badawczemu.
Przejdźmy teraz do zarządzania zadaniami.
7. Dodawanie zarządzania zadaniami za pomocą Cloud SQL
Chociaż agent ma pamięć długotrwałą, nie nadaje się do szczegółowych, uporządkowanych danych, takich jak lista zadań. W przypadku zadań używamy tradycyjnej relacyjnej bazy danych. Będziemy używać SQLAlchemy i bazy danych Google Cloud SQL (PostgreSQL). Zanim napiszemy kod, musimy przygotować infrastrukturę.
Aprowizowanie infrastruktury
Aby utworzyć bazę danych, uruchom te polecenia. Uwaga: tworzenie instancji trwa około 5–10 minut. Podczas gdy to się dzieje w tle, możesz przejść do następnego kroku.
# 1. Define instance variables
export INSTANCE_NAME="assistant-db"
export USER_EMAIL=$(gcloud config get-value account)
# 2. Create the Cloud SQL instance
gcloud sql instances create $INSTANCE_NAME \
--database-version=POSTGRES_18 \
--tier=db-f1-micro \
--region=us-central1 \
--edition=ENTERPRISE
# 3. Create the database for our tasks
gcloud sql databases create tasks --instance=$INSTANCE_NAME
Obsługa administracyjna instancji bazy danych potrwa kilka minut. To dobry moment, aby napić się kawy lub herbaty albo zaktualizować kod w oczekiwaniu na zakończenie procesu. Nie zapomnij jednak wrócić i dokończyć konfiguracji kontroli dostępu.
Skonfiguruj kontrolę dostępu
Teraz musimy skonfigurować Twoje konto użytkownika, aby uzyskać dostęp do bazy danych. Uruchom w terminalu te polecenia:
# change this to your favorite password
export DB_PASS="correct-horse-battery-staple"
# Create a regular database user
gcloud sql users create assistant_user \
--instance=$INSTANCE_NAME \
--password=$DB_PASS
Aktualizowanie konfiguracji środowiska
ADK wczytuje konfigurację z pliku .env w czasie działania. Zaktualizuj środowisko agenta, podając szczegóły połączenia z bazą danych.
# Retrieve the unique connection name
export DB_CONN=$(gcloud sql instances describe $INSTANCE_NAME --format='value(connectionName)')
# Append configuration to your .env file
cat <<EOF >> executive_assistant/.env
DB_CONNECTION_NAME=$DB_CONN
DB_USER=assistant_user
DB_PASSWORD=$DB_PASS
DB_NAME=tasks
EOF
Teraz wprowadźmy zmiany w kodzie.
Tworzenie specjalisty ds. spraw do załatwienia (todo.py)
Podobnie jak w przypadku agenta badawczego utwórzmy specjalistę ds. zadań do wykonania w osobnym pliku. Utwórz todo.py:
todo.py
import os
import uuid
import sqlalchemy
from datetime import datetime
from typing import Optional, List
from sqlalchemy import (
Column,
String,
DateTime,
Enum,
select,
delete,
update,
)
from sqlalchemy.orm import declarative_base, Session
from google.cloud.sql.connector import Connector
from google.adk.agents.llm_agent import Agent
# --- DATABASE LOGIC ---
Base = declarative_base()
connector = Connector()
def getconn():
db_connection_name = os.environ.get("DB_CONNECTION_NAME")
db_user = os.environ.get("DB_USER")
db_password = os.environ.get("DB_PASSWORD")
db_name = os.environ.get("DB_NAME", "tasks")
return connector.connect(
db_connection_name,
"pg8000",
user=db_user,
password=db_password,
db=db_name,
)
engine = sqlalchemy.create_engine(
"postgresql+pg8000://",
creator=getconn,
)
class Todo(Base):
__tablename__ = "todos"
id = Column(String(36), primary_key=True, default=lambda: str(uuid.uuid4()))
title = Column(String(255), nullable=False)
priority = Column(
Enum("high", "medium", "low", name="priority_levels"), nullable=False, default="medium"
)
due_date = Column(DateTime, nullable=True)
status = Column(Enum("pending", "done", name="status_levels"), default="pending")
created_at = Column(DateTime, default=datetime.utcnow)
def init_db():
"""Builds the table if it's missing."""
Base.metadata.create_all(bind=engine)
def add_todo(
title: str, priority: str = "medium", due_date: Optional[str] = None
) -> dict:
"""
Adds a new task to the list.
Args:
title (str): The description of the task.
priority (str): The urgency level. Must be one of: 'high', 'medium', 'low'.
due_date (str, optional): The due date in ISO format (YYYY-MM-DD or YYYY-MM-DDTHH:MM:SS).
Returns:
dict: A dictionary containing the new task's ID and a status message.
"""
init_db()
with Session(engine) as session:
due = datetime.fromisoformat(due_date) if due_date else None
item = Todo(
title=title,
priority=priority.lower(),
due_date=due,
)
session.add(item)
session.commit()
return {"id": item.id, "status": f"Task added ✅"}
def list_todos(status: str = "pending") -> list:
"""
Lists tasks from the database, optionally filtering by status.
Args:
status (str, optional): The status to filter by. 'pending', 'done', or 'all'.
"""
init_db()
with Session(engine) as session:
query = select(Todo)
s_lower = status.lower()
if s_lower != "all":
query = query.where(Todo.status == s_lower)
query = query.order_by(Todo.priority, Todo.created_at)
results = session.execute(query).scalars().all()
return [
{
"id": t.id,
"task": t.title,
"priority": t.priority,
"status": t.status,
}
for t in results
]
def complete_todo(task_id: str) -> str:
"""Marks a specific task as 'done'."""
init_db()
with Session(engine) as session:
session.execute(update(Todo).where(Todo.id == task_id).values(status="done"))
session.commit()
return f"Task {task_id} marked as done."
def delete_todo(task_id: str) -> str:
"""Permanently removes a task from the database."""
init_db()
with Session(engine) as session:
session.execute(delete(Todo).where(Todo.id == task_id))
session.commit()
return f"Task {task_id} deleted."
# --- TODO SPECIALIST AGENT ---
todo_agent = Agent(
model='gemini-2.5-flash',
name='todo_specialist',
description='A specialist agent that manages a structured SQL task list.',
instruction='''
You manage the user's task list using a PostgreSQL database.
- Use add_todo when the user wants to remember something. If no priority is mentioned, mark it as 'medium'.
- Use list_todos to show tasks.
- Use complete_todo to mark a task as finished.
- Use delete_todo to remove a task entirely.
When marking a task as complete or deleting it, if the user doesn't provide the ID,
use list_todos first to find the correct ID for the task they described.
''',
tools=[add_todo, list_todos, complete_todo, delete_todo],
)
Powyższy kod odpowiada za 2 główne działania: łączenie z bazą danych Cloud SQL i udostępnianie listy narzędzi do wszystkich typowych operacji na liście zadań, w tym dodawania, usuwania i oznaczania zadań jako wykonanych.
Ta logika jest bardzo specyficzna dla agenta zadań do wykonania i niekoniecznie zależy nam na tak szczegółowym zarządzaniu z punktu widzenia asystenta (agenta głównego), dlatego spakujemy tego agenta jako „AgentTool”, a nie jako agenta podrzędnego.
Aby zdecydować, czy użyć AgentTool czy subagenta, zastanów się, czy muszą oni udostępniać kontekst:
- używać narzędzia AgentTool, gdy agent nie musi udostępniać kontekstu agentowi głównemu;
- używać subagenta, gdy chcesz, aby agent udostępniał kontekst agentowi głównemu;
W przypadku agenta badawczego udostępnianie kontekstu może być przydatne, ale w przypadku prostego agenta do wykonania zadań nie przynosi to większych korzyści.
Zaimplementujmy funkcję AgentTool w języku agent.py.
Aktualizowanie agenta głównego (agent.py)
Teraz zaimportuj agenta todo_agent do głównego pliku i dołącz go jako narzędzie:
agent.py
import os
from datetime import datetime
from google.adk.agents.llm_agent import Agent
from google.adk.tools.agent_tool import AgentTool
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import our specialized sub-agents
from .research import research_agent
from .todo import todo_agent
# Callback for persistent memory storage
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# --- ROOT AGENT DEFINITION ---
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant with memory and specialized tools.',
instruction='''
You are an elite, high-signal AI Executive Assistant.
Your goal is to help the user manage their knowledge, tasks, and research.
## Your Capabilities:
1. Memory: Use load_memory to recall personal facts or past context about the user.
2. Research: Delegate complex web-based investigations to the research_specialist.
3. Tasks: Delegate all to-do list management (adding, listing, or completing tasks) to the todo_specialist.
Always be direct and professional. If a task is successful, provide a brief confirmation.
''',
tools=[
PreloadMemoryTool(),
load_memory_tool,
AgentTool(todo_agent) # Exposes the Todo Specialist as a tool
],
sub_agents=[research_agent], # Exposes the Research Specialist for direct handover
after_agent_callback=auto_save_session_to_memory_callback,
)
Uruchom ponownie adk web, aby przetestować nową funkcję:
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
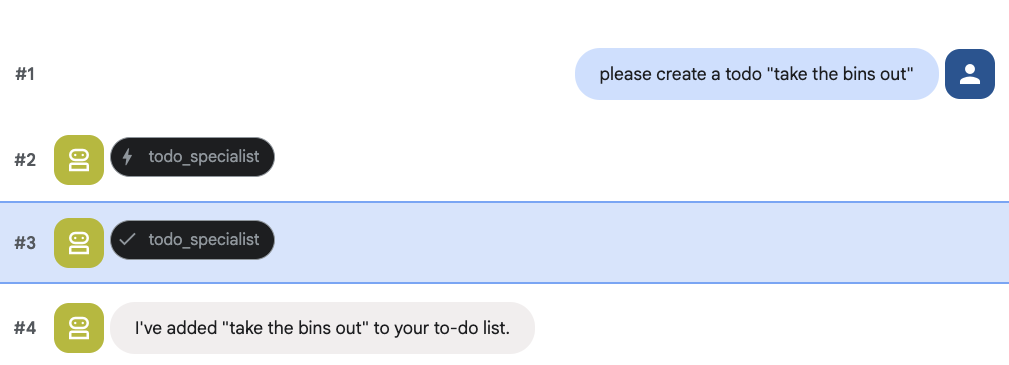
Spróbuj utworzyć zadanie do wykonania:
8. Dodawanie zarządzania kalendarzem
Na koniec zintegrujemy usługę z Kalendarzem Google, aby agent mógł zarządzać spotkaniami. Na potrzeby tego laboratorium zamiast przyznawać agentowi dostępu do Twojego kalendarza osobistego, co mogłoby być potencjalnie niebezpieczne, jeśli nie zostanie wykonane we właściwy sposób, utworzymy niezależny kalendarz, którym będzie zarządzać agent.
Najpierw utworzymy dedykowane konto usługi, które będzie tożsamością agenta. Następnie programowo utworzymy kalendarz agenta za pomocą konta usługi.
Utwórz konto usługi
Otwórz terminal i uruchom te polecenia, aby utworzyć tożsamość i przyznać swojemu kontu osobistemu uprawnienia do jej reprezentowania:
export SA_NAME="ea-agent"
export SA_EMAIL="${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"
# Create the service account
gcloud iam service-accounts create $SA_NAME \
--display-name="Executive Assistant Agent"
# Allow your local user to impersonate it
gcloud iam service-accounts add-iam-policy-binding $SA_EMAIL \
--member="user:$(gcloud config get-value account)" \
--role="roles/iam.serviceAccountTokenCreator"
# Save it to the agent's environment
echo "SERVICE_ACCOUNT_EMAIL=$SA_EMAIL" >> executive_assistant/.env
Automatyczne tworzenie kalendarza
Napiszmy skrypt, który poinformuje konto usługi o konieczności utworzenia kalendarza. Utwórz nowy plik o nazwie setup_calendar.py w katalogu głównym projektu (obok pliku setup_memory.py):
setup_calendar.py
import os
import google.auth
from googleapiclient.discovery import build
from google.auth.transport.requests import Request
from google.auth import impersonated_credentials
from dotenv import load_dotenv
load_dotenv('executive_assistant/.env')
SA_EMAIL = os.environ.get("SERVICE_ACCOUNT_EMAIL")
def setup_sa_calendar():
print(f"Authenticating to impersonate {SA_EMAIL}...")
# 1. Base credentials
creds, _ = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
creds.refresh(Request())
# 2. Impersonate the Service Account
impersonated = impersonated_credentials.Credentials(
source_credentials=creds,
target_principal=SA_EMAIL,
target_scopes=["https://www.googleapis.com/auth/calendar"],
)
service = build("calendar", "v3", credentials=impersonated)
# 3. Create the calendar
print("Creating independent Service Account calendar...")
calendar = service.calendars().insert(body={
"summary": "AI Assistant (SA Owned)",
"description": "An independent calendar managed purely by the AI."
}).execute()
calendar_id = calendar['id']
# 4. Save the ID
with open("executive_assistant/.env", "a") as f:
f.write(f"\nCALENDAR_ID={calendar_id}\n")
print(f"Setup complete! CALENDAR_ID {calendar_id} added to .env")
if __name__ == "__main__":
setup_sa_calendar()
Uruchom skrypt w terminalu:
uv run python setup_calendar.py
Utwórz specjalistę ds. kalendarza (calendar.py)
Skupmy się teraz na specjaliście ds. kalendarza. Wyposażymy tego agenta w pełny pakiet narzędzi do obsługi kalendarza: wyświetlanie, tworzenie, aktualizowanie i usuwanie wydarzeń, a nawet funkcję „szybkiego dodawania”, która rozumie język naturalny.
Skopiuj poniższy kod do pliku calendar.py.
calendar.py
import os
from datetime import datetime, timedelta, timezone
import google.auth
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from google.adk.agents.llm_agent import Agent
def _get_calendar_service():
"""Build the Google Calendar API service using Service Account Impersonation."""
from google.auth.transport.requests import Request
from google.auth import impersonated_credentials
target_principal = os.environ.get("SERVICE_ACCOUNT_EMAIL")
if not target_principal:
raise ValueError("SERVICE_ACCOUNT_EMAIL environment variable is missing.")
base_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
creds, _ = google.auth.default(scopes=base_scopes)
creds.refresh(Request())
target_scopes = ["https://www.googleapis.com/auth/calendar"]
impersonated = impersonated_credentials.Credentials(
source_credentials=creds,
target_principal=target_principal,
target_scopes=target_scopes,
)
return build("calendar", "v3", credentials=impersonated)
def _format_event(event: dict) -> dict:
"""Format a raw Calendar API event into a clean dict for the LLM."""
start = event.get("start", {})
end = event.get("end", {})
return {
"id": event.get("id"),
"title": event.get("summary", "(No title)"),
"start": start.get("dateTime", start.get("date")),
"end": end.get("dateTime", end.get("date")),
"location": event.get("location", ""),
"description": event.get("description", ""),
"attendees": [
{"email": a["email"], "status": a.get("responseStatus", "unknown")}
for a in event.get("attendees", [])
],
"link": event.get("htmlLink", ""),
"conference_link": (
event.get("conferenceData", {}).get("entryPoints", [{}])[0].get("uri", "")
if event.get("conferenceData")
else ""
),
"status": event.get("status", ""),
}
def list_events(days_ahead: int = 7) -> dict:
"""List upcoming calendar events."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
now = datetime.now(timezone.utc).isoformat()
end = (datetime.now(timezone.utc) + timedelta(days=days_ahead)).isoformat()
events_result = service.events().list(
calendarId=calendar_id, timeMin=now, timeMax=end,
maxResults=50, singleEvents=True, orderBy="startTime"
).execute()
events = events_result.get("items", [])
if not events:
return {"status": "success", "count": 0, "events": []}
return {"status": "success", "count": len(events), "events": [_format_event(e) for e in events]}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def create_event(title: str, start_time: str, end_time: str, description: str = "", location: str = "", attendees: str = "", add_google_meet: bool = False) -> dict:
"""Create a new calendar event."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
event_body = {
"summary": title,
"start": {"dateTime": start_time},
"end": {"dateTime": end_time},
}
if description: event_body["description"] = description
if location: event_body["location"] = location
if attendees:
email_list = [e.strip() for e in attendees.split(",") if e.strip()]
event_body["attendees"] = [{"email": e} for e in email_list]
conference_version = 0
if add_google_meet:
event_body["conferenceData"] = {
"createRequest": {"requestId": f"event-{datetime.now().strftime('%Y%m%d%H%M%S')}", "conferenceSolutionKey": {"type": "hangoutsMeet"}}
}
conference_version = 1
event = service.events().insert(calendarId=calendar_id, body=event_body, conferenceDataVersion=conference_version).execute()
return {"status": "success", "message": f"Event created ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def update_event(event_id: str, title: str = "", start_time: str = "", end_time: str = "", description: str = "") -> dict:
"""Update an existing calendar event."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
patch_body = {}
if title: patch_body["summary"] = title
if start_time: patch_body["start"] = {"dateTime": start_time}
if end_time: patch_body["end"] = {"dateTime": end_time}
if description: patch_body["description"] = description
if not patch_body: return {"status": "error", "message": "No fields to update."}
event = service.events().patch(calendarId=calendar_id, eventId=event_id, body=patch_body).execute()
return {"status": "success", "message": "Event updated ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def delete_event(event_id: str) -> dict:
"""Delete a calendar event by its ID."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
service.events().delete(calendarId=calendar_id, eventId=event_id).execute()
return {"status": "success", "message": f"Event '{event_id}' deleted ✅"}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def quick_add_event(text: str) -> dict:
"""Create an event using natural language (e.g. 'Lunch with Sarah next Monday noon')."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
event = service.events().quickAdd(calendarId=calendar_id, text=text).execute()
return {"status": "success", "message": "Event created from text ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
calendar_agent = Agent(
model='gemini-2.5-flash',
name='calendar_specialist',
description='Manages the user schedule and calendar events.',
instruction='''
You manage the user's Google Calendar.
- Use list_events to check the schedule.
- Use quick_add_event for simple, conversational scheduling requests (e.g., "Lunch tomorrow at noon").
- Use create_event for complex meetings that require attendees, specific durations, or Google Meet links.
- Use update_event to change details of an existing event.
- Use delete_event to cancel or remove an event.
CRITICAL: For update_event and delete_event, you must provide the exact `event_id`.
If the user does not provide the ID, you MUST call list_events first to find the correct `event_id` before attempting the update or deletion.
Always use the current date/time context provided by the root agent to resolve relative dates like "tomorrow".
''',
tools=[list_events, create_event, update_event, delete_event, quick_add_event],
)
Sfinalizuj agenta głównego (agent.py)
Zaktualizuj plik agent.py za pomocą tego kodu:
agent.py
import os
from datetime import datetime
from zoneinfo import ZoneInfo
from google.adk.agents.llm_agent import Agent
from google.adk.tools.agent_tool import AgentTool
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import all our specialized sub-agents
from .research import research_agent
from .todo import todo_agent
from .calendar import calendar_agent
import tzlocal
# Automatically detect the local system timezone
TIMEZONE = tzlocal.get_localzone_name()
# Callback for persistent memory storage
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Callback to inject the current time into the prompt
async def setup_agent_context(callback_context, **kwargs):
now = datetime.now(ZoneInfo(TIMEZONE))
callback_context.state["current_time"] = now.strftime("%A, %Y-%m-%d %I:%M %p")
callback_context.state["timezone"] = TIMEZONE
# --- ROOT AGENT DEFINITION ---
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant with memory and specialized tools.',
instruction='''
You are an elite, high-signal AI Executive Assistant.
Your goal is to help the user manage their knowledge, tasks, research, and schedule.
## Your Capabilities:
1. Memory: Use load_memory to recall personal facts.
2. Research: Delegate complex web investigations to the research_specialist.
3. Tasks: Delegate all to-do list management to the todo_specialist.
4. Scheduling: Delegate all calendar queries to the calendar_specialist.
## 🕒 Current State
- Time: {current_time?}
- Timezone: {timezone?}
Always be direct and professional.
''',
tools=[
PreloadMemoryTool(),
load_memory_tool,
AgentTool(todo_agent),
AgentTool(calendar_agent)
],
sub_agents=[research_agent],
before_agent_callback=[setup_agent_context],
after_agent_callback=[auto_save_session_to_memory_callback],
)
Oprócz narzędzia kalendarza dodaliśmy też nową funkcję przed oddzwonieniem agenta: setup_agent_context. Ta funkcja informuje agenta o bieżącej dacie, godzinie i strefie czasowej, dzięki czemu może on efektywniej korzystać z kalendarza. Działa on poprzez ustawianie zmiennych stanu sesji, czyli innego rodzaju pamięci agenta przeznaczonej do krótkotrwałego przechowywania danych.
Uruchom adk web jeszcze raz, aby przetestować kompletnego agenta.
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
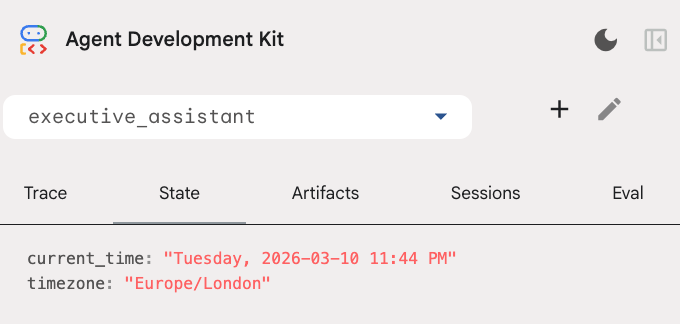
Stan sesji możesz sprawdzić na karcie stanu w interfejsie dewelopera:
Masz teraz agenta, który może śledzić wydarzenia w kalendarzu i listy zadań, prowadzić badania i ma pamięć długotrwałą.
Sprzątanie po laboratorium
9. Podsumowanie
Gratulacje! Udało Ci się zaprojektować wielofunkcyjnego asystenta AI na poziomie kierowniczym w 5 etapach rozwoju.
Co zostało omówione
- Udostępnianie infrastruktury dla agentów AI.
- Implementowanie pamięci trwałej i wyspecjalizowanych agentów podrzędnych za pomocą wbudowanych funkcji pakietu ADK.
- integrowanie zewnętrznych baz danych i interfejsów API zwiększających produktywność,
Następne kroki
Możesz kontynuować naukę, korzystając z innych ćwiczeń w tym środowisku, lub samodzielnie ulepszać asystenta wykonawczego.
Jeśli potrzebujesz pomysłów na ulepszenia, możesz spróbować:
- Wdróż kompresję zdarzeń, aby zoptymalizować skuteczność w przypadku długich rozmów.
- Dodaj usługę artefaktów, aby umożliwić agentowi robienie notatek i zapisywanie ich w plikach.
- Wdróż agenta jako usługę backendu za pomocą Google Cloud Run.
Po zakończeniu testowania pamiętaj, aby wyczyścić środowisko, co pozwoli Ci uniknąć nieoczekiwanych opłat na koncie rozliczeniowym.
Pozdrawiamy