
1. Introdução
Neste codelab, você vai aprender a criar um agente de IA sofisticado usando o Kit de Desenvolvimento de Agente (ADK) do Google. Vamos seguir um caminho evolutivo natural, começando com um agente de conversa básico e adicionando progressivamente recursos especializados.
O agente que estamos criando é um assistente executivo, projetado para ajudar você com tarefas diárias, como gerenciar sua agenda, lembrar de tarefas, fazer pesquisas e compilar observações. Tudo isso foi criado do zero usando o ADK, o Gemini e a Vertex AI.
Ao final deste laboratório, você terá um agente totalmente funcional e o conhecimento necessário para estendê-lo às suas próprias necessidades.
Pré-requisitos
- Conhecimento básico da linguagem de programação Python
- Conhecimento básico do console do Google Cloud para gerenciar recursos da nuvem
O que você vai aprender
- Provisionamento da infraestrutura em nuvem do Google Cloud para agentes de IA.
- Implementar a memória de longo prazo persistente usando o Vertex AI Memory Bank.
- Construir uma hierarquia de subagentes especializados.
- Integração de bancos de dados externos e do ecossistema do Google Workspace.
O que é necessário
Este workshop pode ser feito inteiramente no Google Cloud Shell, que já vem com todas as dependências necessárias (CLI gcloud, editor de código, Go, CLI do Gemini) pré-instaladas.
Como alternativa, se você preferir trabalhar na sua própria máquina, vai precisar do seguinte:
- Python (versão 3.12 ou mais recente)
- Um editor de código ou ambiente de desenvolvimento integrado (como VS Code ou
vim). - Um terminal para executar comandos do Python e
gcloud. - Recomendado:um agente de programação como a CLI do Gemini ou o Antigravity
Principais tecnologias
Confira mais informações sobre as tecnologias que vamos usar:
2. Configuração do ambiente
Escolha uma das seguintes opções: Configuração do ambiente no seu ritmo se quiser executar este codelab na sua própria máquina ou Iniciar o Cloud Shell se quiser executar este codelab totalmente na nuvem.
Configuração de ambiente autoguiada
- Faça login no Console do Google Cloud e crie um novo projeto ou reutilize um existente. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma.

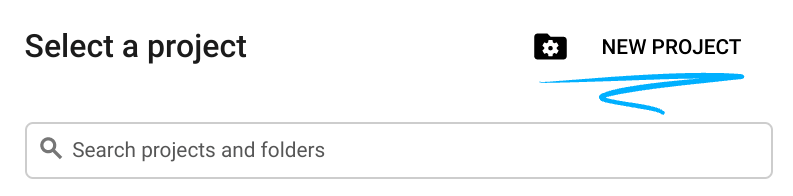
- O Nome do projeto é o nome de exibição para os participantes do projeto. É uma string de caracteres não usada pelas APIs do Google e pode ser atualizada quando você quiser.
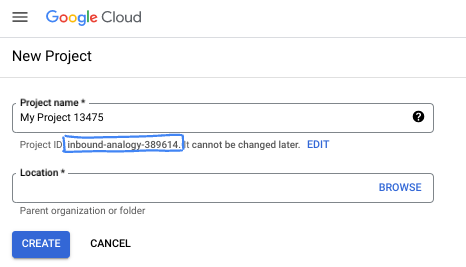
- O ID do projeto precisa ser exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Cloud gera automaticamente uma string exclusiva. Em geral, não importa o que seja. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, normalmente identificado como
PROJECT_ID. Se você não gostar do ID gerado, crie outro aleatório. Se preferir, teste o seu e confira se ele está disponível. Ele não pode ser mudado após essa etapa e permanece durante o projeto. - Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
- Em seguida, ative o faturamento no console do Cloud para usar os recursos/APIs do Cloud. A execução deste codelab não vai ser muito cara, se tiver algum custo. Para encerrar os recursos e evitar cobranças além deste tutorial, exclua os recursos criados ou exclua o projeto. Novos usuários do Google Cloud estão qualificados para o programa de US$ 300 de avaliação sem custos.
Inicie o Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No Console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:
O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
3. Configuração do projeto
Antes de escrever o código, precisamos provisionar a infraestrutura e as permissões necessárias no Google Cloud.
Definir variáveis de ambiente
Abra o terminal e defina as seguintes variáveis de ambiente:
export PROJECT_ID=`gcloud config get project`
export LOCATION=us-central1
Ativar APIs obrigatórias
Seu agente precisa de acesso a vários serviços do Google Cloud. Execute este comando para fazer isso:
gcloud services enable \
aiplatform.googleapis.com \
calendar-json.googleapis.com \
sqladmin.googleapis.com
Autenticar com o Application Default Credentials
Precisamos fazer a autenticação com o Application Default Credentials (ADC) para nos comunicar com os serviços do Google Cloud no seu ambiente.
Execute o comando a seguir para garantir que as Application Default Credentials estejam ativas e atualizadas:
gcloud auth application-default login
4. Criar o agente de base
Agora, precisamos inicializar o diretório em que vamos armazenar o código-fonte do projeto:
# setup project directory
mkdir -p adk_ea_codelab && cd adk_ea_codelab
# prepare virtual environment
uv init
# install dependencies
uv add google-adk google-api-python-client tzlocal python-dotenv
uv add cloud-sql-python-connector[pg8000] sqlalchemy
Começamos estabelecendo a identidade do agente e as funcionalidades básicas de conversa. No ADK, a classe "Agent" define o perfil do agente e as instruções dele.
É nessa hora que você pode pensar em um nome para o agente. Gosto que meus agentes tenham nomes próprios, como Aida ou Sharon, porque acho que isso ajuda a dar a eles alguma "personalidade". Mas você também pode simplesmente chamar o agente pelo que ele faz, como "executive_assistant", "travel_agent" ou "code_executor".
Execute o comando adk create para criar um agente modelo:
# replace with your desired agent name
uv run adk create executive_assistant
Escolha gemini-2.5-flash como o modelo e a Vertex AI como o back-end. Verifique se o ID do projeto sugerido é o que você criou para este laboratório e pressione "Enter" para confirmar. Para a região do Google Cloud, aceite o padrão (us-central1). Seu terminal vai ficar parecido com isto:
daniela_petruzalek@cloudshell:~/adk_ea_codelab (your-project-id)$ uv run adk create executive_assistant Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [your-project-id]: Enter Google Cloud region [us-central1]: Agent created in /home/daniela_petruzalek/adk_ea_codelab/executive_assistant: - .env - __init__.py - agent.py daniela_petruzalek@cloudshell:~/adk_ea_codelab (your-project-id)$
Quando terminar, o comando anterior vai criar uma pasta com o nome do agente (por exemplo, executive_assistant) com alguns arquivos, incluindo um arquivo agent.py com a definição básica do agente:
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Para interagir com esse agente, execute uv run adk web na linha de comando e abra a interface de desenvolvimento no navegador. Você verá algo como:
$ uv run adk web ... INFO: Started server process [1244] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
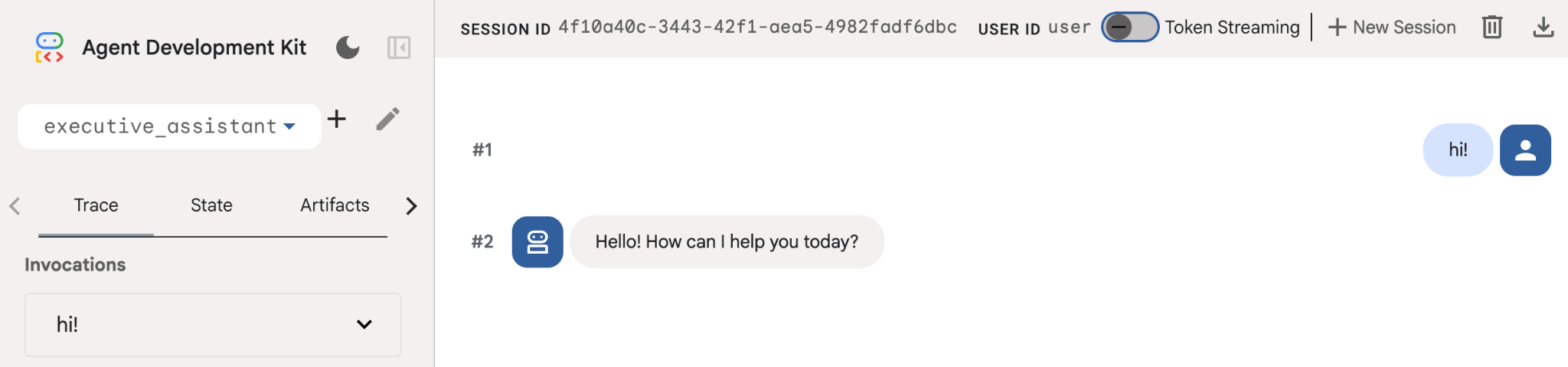
Mesmo que esse agente seja bem básico, é útil fazer isso pelo menos uma vez para garantir que a configuração esteja funcionando corretamente antes de começarmos a editar o agente. A captura de tela abaixo mostra uma interação simples usando a interface de desenvolvimento:
Agora, vamos modificar a definição do agente com o perfil de assistente executivo. Copie o código abaixo e substitua o conteúdo de agent.py. Adapte o nome e o perfil do agente às suas preferências.
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant',
instruction='''
You are an elite, warm, and highly efficient AI partner.
Your primary goal is to help the user manage their tasks, schedule, and research.
Always be direct, concise, and high-signal.
''',
)
A propriedade "name" define o nome interno do agente, mas nas instruções você também pode dar um nome mais amigável como parte da personalidade dele para as interações com o usuário final. O nome interno é usado principalmente para observabilidade e transferências em sistemas multiagente usando a ferramenta transfer_to_agent. Você não vai lidar com essa ferramenta diretamente. O ADK a registra automaticamente quando você declara um ou mais subagentes.
Para executar o agente que acabamos de criar, use adk web:
uv run adk web
Abra a interface do ADK no navegador e diga olá para seu novo assistente.
5. Adicionar memória persistente com o Memory Bank da Vertex AI
Um verdadeiro assistente precisa lembrar preferências e interações anteriores para oferecer uma experiência personalizada e sem problemas. Nesta etapa, vamos integrar o Vertex AI Agent Engine Memory Bank, um recurso da Vertex AI que gera dinamicamente memórias de longo prazo com base nas conversas dos usuários.
Com o Memory Bank, seu agente pode criar informações personalizadas acessíveis em várias sessões, estabelecendo a continuidade entre elas. Nos bastidores, ele gerencia a sequência cronológica de mensagens em uma sessão e pode usar a recuperação de pesquisa por similaridade para fornecer ao agente as memórias mais relevantes para o contexto atual.
Inicializar o serviço de memória
O ADK usa a Vertex AI para armazenar e recuperar memórias de longo prazo. Você precisa inicializar um "Memory Engine" no seu projeto. Essa é essencialmente uma instância do Reasoning Engine configurada para funcionar como um Memory Bank.
Crie o seguinte script como setup_memory.py:
setup_memory.py
import vertexai
import os
PROJECT_ID=os.getenv("PROJECT_ID")
LOCATION=os.getenv("LOCATION")
client = vertexai.Client(project=PROJECT_ID, location=LOCATION)
# Create Reasoning Engine for Memory Bank
agent_engine = client.agent_engines.create()
# You will need this resource name to give it to ADK
print(agent_engine.api_resource.name)
Agora execute setup_memory.py para provisionar o mecanismo de raciocínio para o Memory Bank:
uv run python setup_memory.py
O resultado será semelhante a este:
$ uv run python setup.py projects/1234567890/locations/us-central1/reasoningEngines/1234567890
Salve o nome do recurso do mecanismo em uma variável de ambiente:
export ENGINE_ID="<insert the resource name above>"
Agora precisamos atualizar o código para usar a memória persistente. Substitua o conteúdo de agent.py pelo seguinte:
agent.py
from google.adk.agents.llm_agent import Agent
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Update root_agent with memory tools and callback
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='Executive Assistant with Persistent Memory',
instruction='''
You are an elite AI partner with long-term memory.
Use load_memory to find context about the user when needed.
Always be direct, concise, and high-signal.
''',
tools=[PreloadMemoryTool(), load_memory_tool],
after_agent_callback=auto_save_session_to_memory_callback,
)
O PreloadMemoryTool injeta automaticamente o contexto relevante de conversas anteriores em cada solicitação (usando a recuperação de pesquisa por similaridade), enquanto o load_memory_tool permite que o modelo consulte explicitamente o Memory Bank para fatos quando necessário. Essa combinação oferece ao seu agente um contexto profundo e persistente.
Agora, para iniciar seu agente com suporte à memória, transmita o memory_service_uri ao executar adk web:
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
Dê aos agentes alguns fatos sobre você e depois volte em uma sessão diferente para perguntar sobre eles. Por exemplo, diga seu nome:
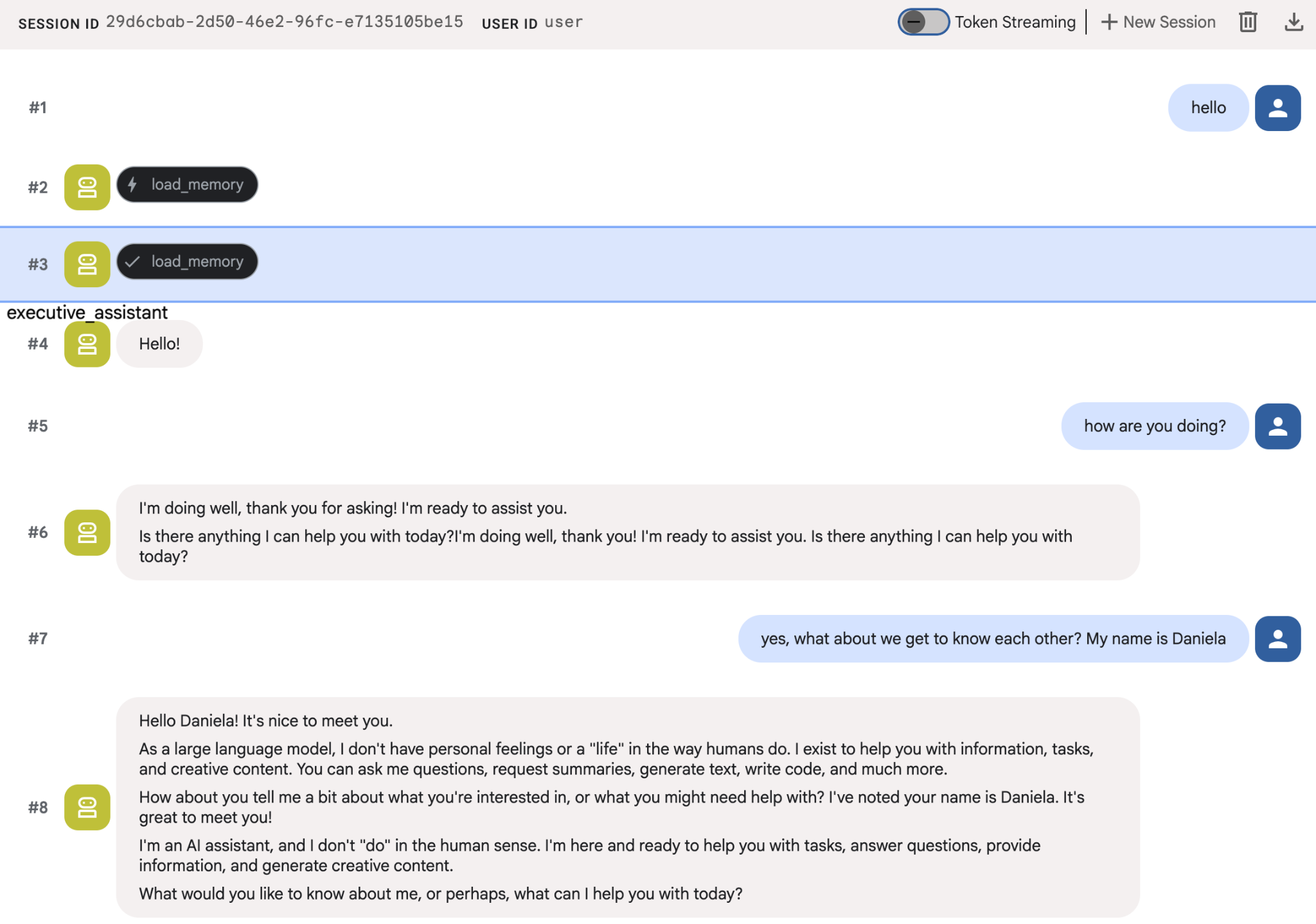
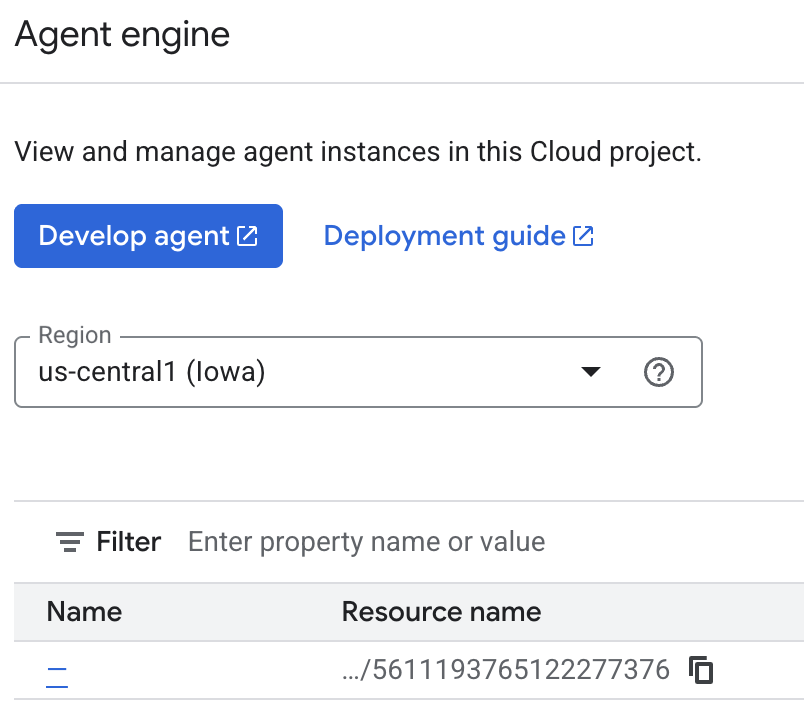
É possível inspecionar as memórias que o agente está salvando no console do Cloud. Acesse a página do produto "Agent Engine" (use a barra de pesquisa).

Em seguida, clique no nome do seu mecanismo de agente (confira se você selecionou a região certa):
Em seguida, acesse a guia "Recordações":
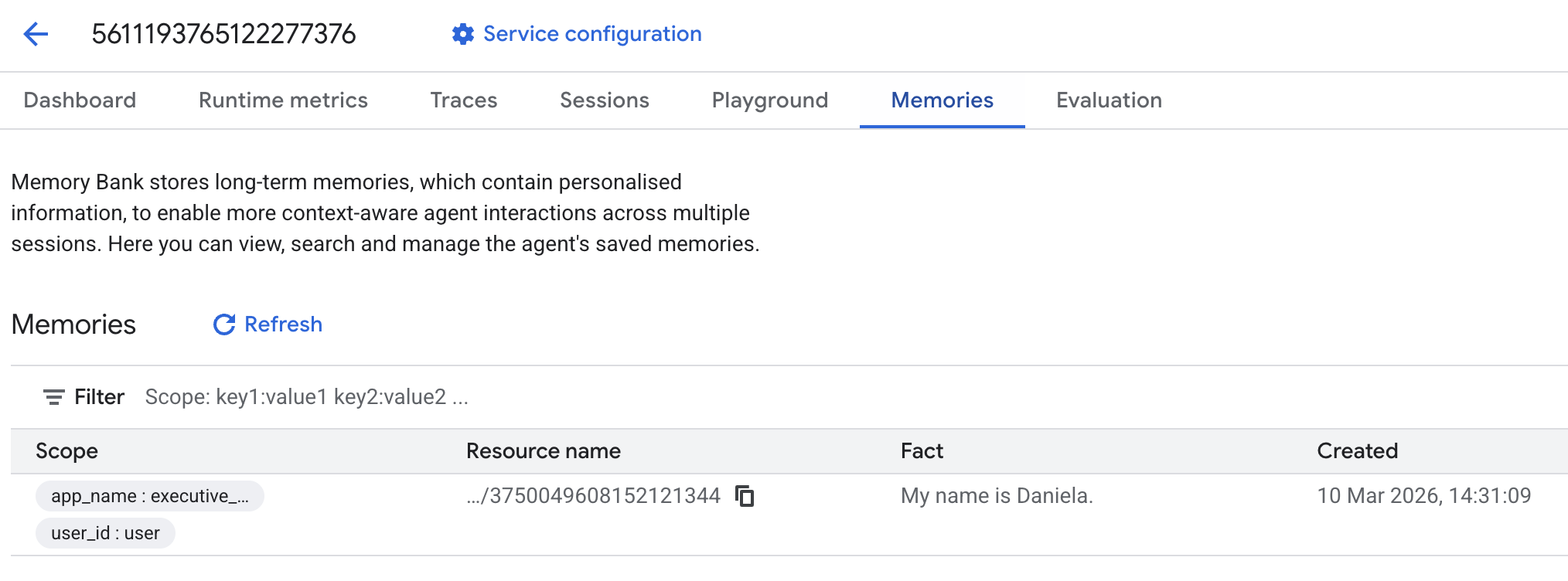
Algumas recordações vão aparecer.
6. Adicionar recursos de pesquisa na Web
Para fornecer informações de alta qualidade, nosso agente precisa realizar investigações detalhadas que vão além de uma única consulta de pesquisa. Ao delegar a pesquisa a um subagente especializado, mantemos a capacidade de resposta da persona principal enquanto o pesquisador lida com a coleta de dados complexos em segundo plano.
Nesta etapa, vamos implementar um LoopAgent para alcançar a "profundidade da pesquisa", permitindo que o agente pesquise, avalie descobertas e refine as consultas de forma iterativa até ter um panorama completo. Também exigimos rigor técnico com citações inline para todas as descobertas, garantindo que cada declaração seja respaldada por um link de origem.
Criar o especialista em pesquisa (research.py)
Aqui, definimos um agente básico equipado com a ferramenta da Pesquisa Google e o incluímos em um LoopAgent. O parâmetro "max_iterations" funciona como um regulador, garantindo que o agente itere na pesquisa até três vezes se houver lacunas no entendimento.
research.py
from google.adk.agents.llm_agent import Agent
from google.adk.agents.loop_agent import LoopAgent
from google.adk.tools.google_search_tool import GoogleSearchTool
from google.adk.tools.tool_context import ToolContext
def exit_loop(tool_context: ToolContext):
"""Call this function ONLY when no further research is needed, signaling the iterative process should end."""
print(f" [Tool Call] exit_loop triggered by {tool_context.agent_name}")
tool_context.actions.escalate = True
# Return empty dict as tools should typically return JSON-serializable output
return {}
# --- RESEARCH LOGIC ---
_research_worker = Agent(
model='gemini-2.5-flash',
name='research_worker',
description='Worker agent that performs a single research step.',
instruction='''
Use google_search to find facts and synthesize them for the user.
Critically evaluate your findings. If the data is incomplete or you need more context, prepare to search again in the next iteration.
You must include the links you found as references in your response, formatting them like citations in a research paper (e.g., [1], [2]).
Use the exit_loop tool to terminate the research early if no further research is needed.
If you need to ask the user for clarifications, call the exit_loop function early to interrupt the research cycle.
''',
tools=[GoogleSearchTool(bypass_multi_tools_limit=True), exit_loop],
)
# The LoopAgent iterates the worker up to 3 times for deeper research
research_agent = LoopAgent(
name='research_specialist',
description='Deep web research specialist.',
sub_agents=[_research_worker],
max_iterations=3,
)
Atualizar o agente raiz (agent.py)
Importe o research_agent e adicione-o como uma ferramenta para Sharon:
agent.py
from google.adk.agents.llm_agent import Agent
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import our new sub agent
from .research import research_agent
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Update root_agent with memory tools and callback
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='Executive Assistant with persistent memory and research capabilities',
instruction='''
You are an elite AI partner with long-term memory.
1. Use load_memory to recall facts.
2. Delegate research tasks to the research_specialist.
Always be direct, concise, and high-signal.
''',
tools=[PreloadMemoryTool(), load_memory_tool],
sub_agents=[research_agent],
after_agent_callback=auto_save_session_to_memory_callback,
)
Inicie o adk web novamente para testar o agente de pesquisa.
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
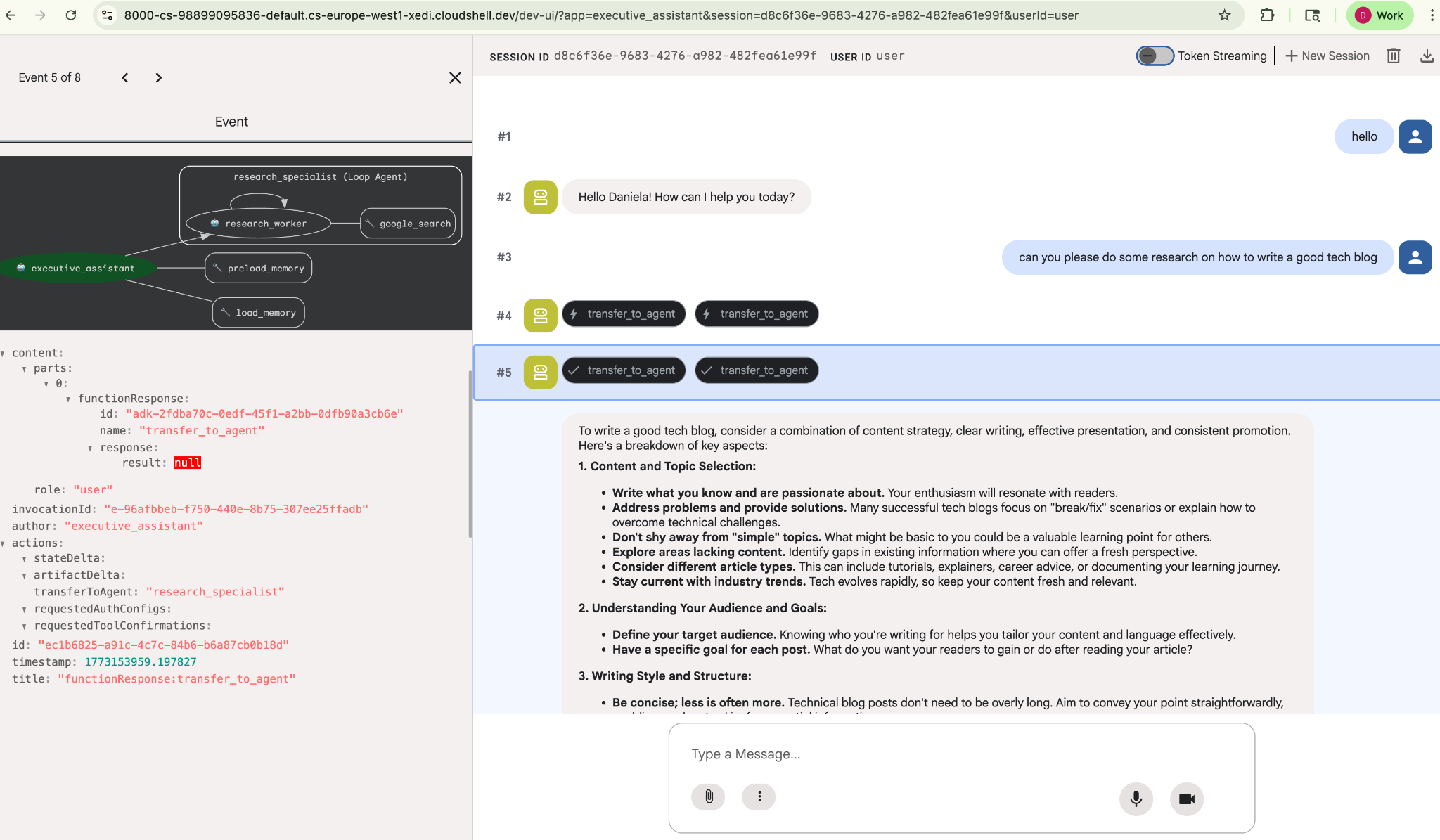
Dê a ele uma tarefa de pesquisa simples, por exemplo, "como escrever um bom blog de tecnologia?"
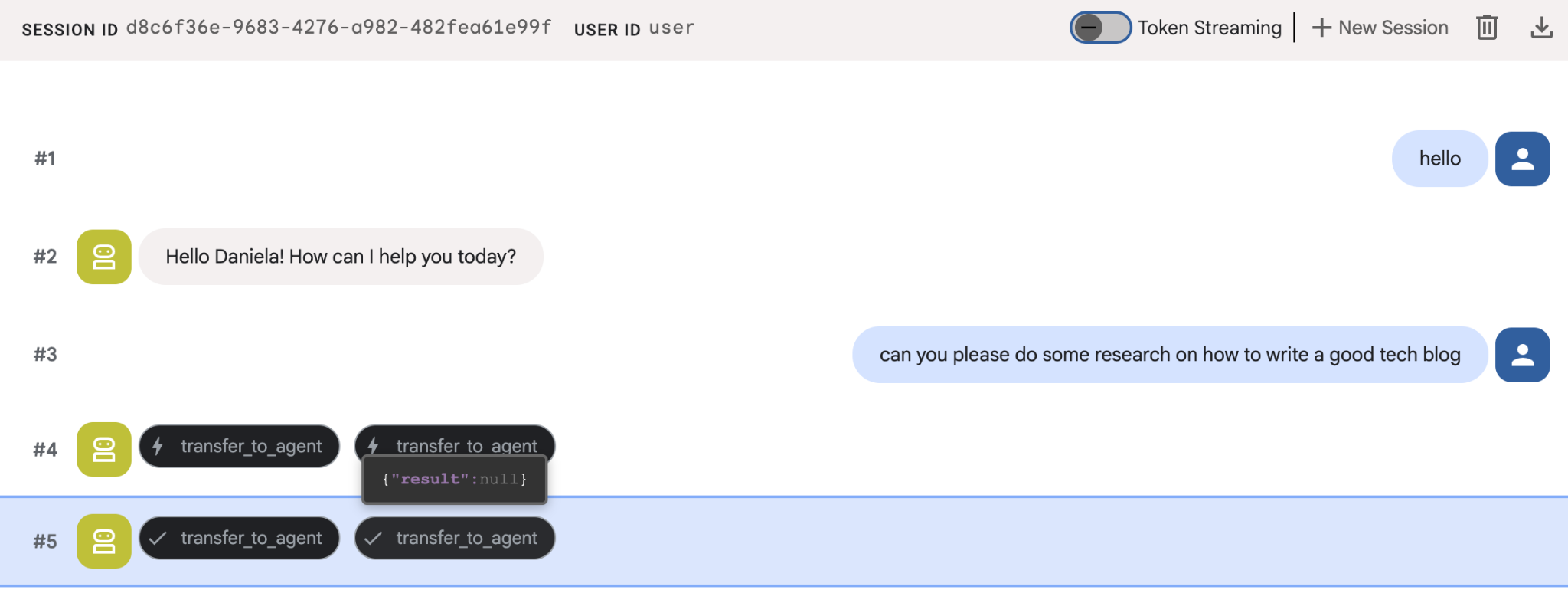
Você deve ter notado que o agente lembrou meu nome, mesmo que esta seja uma nova sessão. Observe também a chamada de ferramenta "transfer_to_agent": ela transfere a tarefa para nosso novo agente de pesquisa.
Agora vamos continuar com o gerenciamento de tarefas.
7. Adicionar gerenciamento de tarefas com o Cloud SQL
Embora o agente tenha memória de longo prazo, ele não é adequado para dados granulares e estruturados, como uma lista de tarefas. Para tarefas, usamos um banco de dados relacional tradicional. Vamos usar o SQLAlchemy e um banco de dados do Google Cloud SQL (PostgreSQL). Antes de escrever o código, precisamos provisionar a infraestrutura.
Provisionar a infraestrutura
Execute estes comandos para criar seu banco de dados. Observação:a criação da instância leva de 5 a 10 minutos. Você pode continuar para a próxima etapa enquanto isso é executado em segundo plano.
# 1. Define instance variables
export INSTANCE_NAME="assistant-db"
export USER_EMAIL=$(gcloud config get-value account)
# 2. Create the Cloud SQL instance
gcloud sql instances create $INSTANCE_NAME \
--database-version=POSTGRES_18 \
--tier=db-f1-micro \
--region=us-central1 \
--edition=ENTERPRISE
# 3. Create the database for our tasks
gcloud sql databases create tasks --instance=$INSTANCE_NAME
O provisionamento da instância de banco de dados vai levar alguns minutos. Aproveite para tomar um café ou chá ou atualizar o código enquanto espera a conclusão. Não se esqueça de voltar e concluir o controle de acesso!
Configurar o controle de acesso
Agora precisamos configurar sua conta de usuário para ter acesso ao banco de dados. Execute os seguintes comandos no terminal:
# change this to your favorite password
export DB_PASS="correct-horse-battery-staple"
# Create a regular database user
gcloud sql users create assistant_user \
--instance=$INSTANCE_NAME \
--password=$DB_PASS
Atualizar a configuração do ambiente
O ADK carrega a configuração de um arquivo .env no ambiente de execução. Atualize o ambiente do agente com os detalhes da conexão do banco de dados.
# Retrieve the unique connection name
export DB_CONN=$(gcloud sql instances describe $INSTANCE_NAME --format='value(connectionName)')
# Append configuration to your .env file
cat <<EOF >> executive_assistant/.env
DB_CONNECTION_NAME=$DB_CONN
DB_USER=assistant_user
DB_PASSWORD=$DB_PASS
DB_NAME=tasks
EOF
Agora vamos fazer as mudanças no código.
Criar o especialista em tarefas pendentes (todo.py)
Assim como o agente de pesquisa, vamos criar nosso especialista em tarefas em um arquivo próprio. Crie todo.py:
todo.py
import os
import uuid
import sqlalchemy
from datetime import datetime
from typing import Optional, List
from sqlalchemy import (
Column,
String,
DateTime,
Enum,
select,
delete,
update,
)
from sqlalchemy.orm import declarative_base, Session
from google.cloud.sql.connector import Connector
from google.adk.agents.llm_agent import Agent
# --- DATABASE LOGIC ---
Base = declarative_base()
connector = Connector()
def getconn():
db_connection_name = os.environ.get("DB_CONNECTION_NAME")
db_user = os.environ.get("DB_USER")
db_password = os.environ.get("DB_PASSWORD")
db_name = os.environ.get("DB_NAME", "tasks")
return connector.connect(
db_connection_name,
"pg8000",
user=db_user,
password=db_password,
db=db_name,
)
engine = sqlalchemy.create_engine(
"postgresql+pg8000://",
creator=getconn,
)
class Todo(Base):
__tablename__ = "todos"
id = Column(String(36), primary_key=True, default=lambda: str(uuid.uuid4()))
title = Column(String(255), nullable=False)
priority = Column(
Enum("high", "medium", "low", name="priority_levels"), nullable=False, default="medium"
)
due_date = Column(DateTime, nullable=True)
status = Column(Enum("pending", "done", name="status_levels"), default="pending")
created_at = Column(DateTime, default=datetime.utcnow)
def init_db():
"""Builds the table if it's missing."""
Base.metadata.create_all(bind=engine)
def add_todo(
title: str, priority: str = "medium", due_date: Optional[str] = None
) -> dict:
"""
Adds a new task to the list.
Args:
title (str): The description of the task.
priority (str): The urgency level. Must be one of: 'high', 'medium', 'low'.
due_date (str, optional): The due date in ISO format (YYYY-MM-DD or YYYY-MM-DDTHH:MM:SS).
Returns:
dict: A dictionary containing the new task's ID and a status message.
"""
init_db()
with Session(engine) as session:
due = datetime.fromisoformat(due_date) if due_date else None
item = Todo(
title=title,
priority=priority.lower(),
due_date=due,
)
session.add(item)
session.commit()
return {"id": item.id, "status": f"Task added ✅"}
def list_todos(status: str = "pending") -> list:
"""
Lists tasks from the database, optionally filtering by status.
Args:
status (str, optional): The status to filter by. 'pending', 'done', or 'all'.
"""
init_db()
with Session(engine) as session:
query = select(Todo)
s_lower = status.lower()
if s_lower != "all":
query = query.where(Todo.status == s_lower)
query = query.order_by(Todo.priority, Todo.created_at)
results = session.execute(query).scalars().all()
return [
{
"id": t.id,
"task": t.title,
"priority": t.priority,
"status": t.status,
}
for t in results
]
def complete_todo(task_id: str) -> str:
"""Marks a specific task as 'done'."""
init_db()
with Session(engine) as session:
session.execute(update(Todo).where(Todo.id == task_id).values(status="done"))
session.commit()
return f"Task {task_id} marked as done."
def delete_todo(task_id: str) -> str:
"""Permanently removes a task from the database."""
init_db()
with Session(engine) as session:
session.execute(delete(Todo).where(Todo.id == task_id))
session.commit()
return f"Task {task_id} deleted."
# --- TODO SPECIALIST AGENT ---
todo_agent = Agent(
model='gemini-2.5-flash',
name='todo_specialist',
description='A specialist agent that manages a structured SQL task list.',
instruction='''
You manage the user's task list using a PostgreSQL database.
- Use add_todo when the user wants to remember something. If no priority is mentioned, mark it as 'medium'.
- Use list_todos to show tasks.
- Use complete_todo to mark a task as finished.
- Use delete_todo to remove a task entirely.
When marking a task as complete or deleting it, if the user doesn't provide the ID,
use list_todos first to find the correct ID for the task they described.
''',
tools=[add_todo, list_todos, complete_todo, delete_todo],
)
O código acima é responsável por duas coisas principais: conectar-se ao banco de dados do Cloud SQL e fornecer uma lista de ferramentas para todas as operações comuns de lista de tarefas, incluindo adicionar, remover e marcar como concluídas.
Como essa lógica é muito específica do agente de tarefas e não necessariamente nos preocupamos com esse gerenciamento granular do ponto de vista do assistente executivo (agente raiz), vamos empacotar esse agente como um "AgentTool" em vez de um subagente.
Para decidir entre usar um AgentTool ou um subagente, considere se eles precisam compartilhar contexto ou não:
- usar um AgentTool quando o agente não precisar compartilhar contexto com o agente raiz
- use um subagente quando quiser que seu agente compartilhe contexto com o agente raiz.
No caso do agente de pesquisa, compartilhar contexto pode ser útil, mas para um agente de tarefas simples, não há muito benefício em fazer isso.
Vamos implementar o AgentTool em agent.py.
Atualizar o agente raiz (agent.py)
Agora, importe o todo_agent para o arquivo principal e anexe-o como uma ferramenta:
agent.py
import os
from datetime import datetime
from google.adk.agents.llm_agent import Agent
from google.adk.tools.agent_tool import AgentTool
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import our specialized sub-agents
from .research import research_agent
from .todo import todo_agent
# Callback for persistent memory storage
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# --- ROOT AGENT DEFINITION ---
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant with memory and specialized tools.',
instruction='''
You are an elite, high-signal AI Executive Assistant.
Your goal is to help the user manage their knowledge, tasks, and research.
## Your Capabilities:
1. Memory: Use load_memory to recall personal facts or past context about the user.
2. Research: Delegate complex web-based investigations to the research_specialist.
3. Tasks: Delegate all to-do list management (adding, listing, or completing tasks) to the todo_specialist.
Always be direct and professional. If a task is successful, provide a brief confirmation.
''',
tools=[
PreloadMemoryTool(),
load_memory_tool,
AgentTool(todo_agent) # Exposes the Todo Specialist as a tool
],
sub_agents=[research_agent], # Exposes the Research Specialist for direct handover
after_agent_callback=auto_save_session_to_memory_callback,
)
Execute adk web novamente para testar o novo recurso:
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
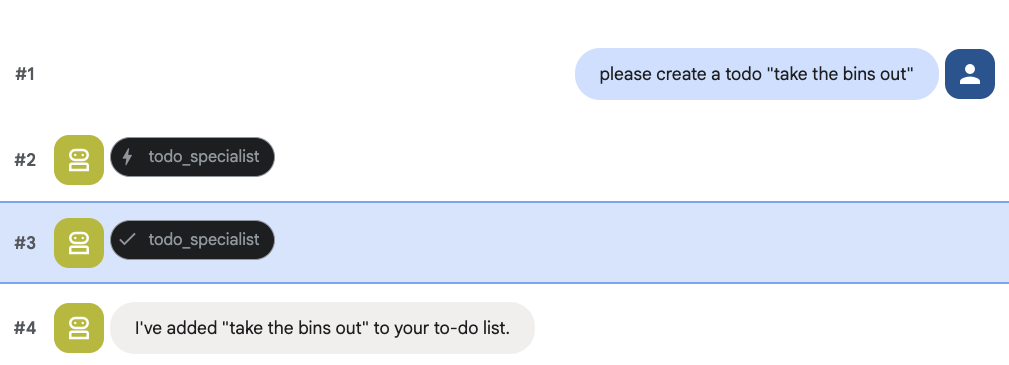
Tente criar uma tarefa:
8. Adicionar gerenciamento de agenda
Por fim, vamos integrar com o Google Agenda para que o agente possa gerenciar compromissos. Para este codelab, em vez de dar ao agente acesso à sua agenda pessoal, o que pode ser perigoso se não for feito da maneira certa, vamos criar uma agenda independente para o agente gerenciar.
Primeiro, vamos criar uma conta de serviço dedicada para atuar como a identidade do agente. Em seguida, vamos criar programaticamente o calendário do agente usando a conta de serviço.
Provisionar a conta de serviço
Abra o terminal e execute estes comandos para criar a identidade e conceder à sua conta pessoal permissão para representá-la:
export SA_NAME="ea-agent"
export SA_EMAIL="${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"
# Create the service account
gcloud iam service-accounts create $SA_NAME \
--display-name="Executive Assistant Agent"
# Allow your local user to impersonate it
gcloud iam service-accounts add-iam-policy-binding $SA_EMAIL \
--member="user:$(gcloud config get-value account)" \
--role="roles/iam.serviceAccountTokenCreator"
# Save it to the agent's environment
echo "SERVICE_ACCOUNT_EMAIL=$SA_EMAIL" >> executive_assistant/.env
Criar a agenda de maneira programática
Vamos escrever um script para dizer à conta de serviço para criar o calendário. Crie um arquivo chamado setup_calendar.py na raiz do projeto (ao lado de setup_memory.py):
setup_calendar.py
import os
import google.auth
from googleapiclient.discovery import build
from google.auth.transport.requests import Request
from google.auth import impersonated_credentials
from dotenv import load_dotenv
load_dotenv('executive_assistant/.env')
SA_EMAIL = os.environ.get("SERVICE_ACCOUNT_EMAIL")
def setup_sa_calendar():
print(f"Authenticating to impersonate {SA_EMAIL}...")
# 1. Base credentials
creds, _ = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
creds.refresh(Request())
# 2. Impersonate the Service Account
impersonated = impersonated_credentials.Credentials(
source_credentials=creds,
target_principal=SA_EMAIL,
target_scopes=["https://www.googleapis.com/auth/calendar"],
)
service = build("calendar", "v3", credentials=impersonated)
# 3. Create the calendar
print("Creating independent Service Account calendar...")
calendar = service.calendars().insert(body={
"summary": "AI Assistant (SA Owned)",
"description": "An independent calendar managed purely by the AI."
}).execute()
calendar_id = calendar['id']
# 4. Save the ID
with open("executive_assistant/.env", "a") as f:
f.write(f"\nCALENDAR_ID={calendar_id}\n")
print(f"Setup complete! CALENDAR_ID {calendar_id} added to .env")
if __name__ == "__main__":
setup_sa_calendar()
Execute o script no terminal:
uv run python setup_calendar.py
Criar o especialista em Agenda (calendar.py)
Agora vamos falar sobre o especialista em Agenda. Vamos equipar esse agente com um conjunto completo de ferramentas de agenda: listar, criar, atualizar, excluir e até mesmo um recurso de "adição rápida" que entende a linguagem natural.
Copie o código abaixo para calendar.py.
calendar.py
import os
from datetime import datetime, timedelta, timezone
import google.auth
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from google.adk.agents.llm_agent import Agent
def _get_calendar_service():
"""Build the Google Calendar API service using Service Account Impersonation."""
from google.auth.transport.requests import Request
from google.auth import impersonated_credentials
target_principal = os.environ.get("SERVICE_ACCOUNT_EMAIL")
if not target_principal:
raise ValueError("SERVICE_ACCOUNT_EMAIL environment variable is missing.")
base_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
creds, _ = google.auth.default(scopes=base_scopes)
creds.refresh(Request())
target_scopes = ["https://www.googleapis.com/auth/calendar"]
impersonated = impersonated_credentials.Credentials(
source_credentials=creds,
target_principal=target_principal,
target_scopes=target_scopes,
)
return build("calendar", "v3", credentials=impersonated)
def _format_event(event: dict) -> dict:
"""Format a raw Calendar API event into a clean dict for the LLM."""
start = event.get("start", {})
end = event.get("end", {})
return {
"id": event.get("id"),
"title": event.get("summary", "(No title)"),
"start": start.get("dateTime", start.get("date")),
"end": end.get("dateTime", end.get("date")),
"location": event.get("location", ""),
"description": event.get("description", ""),
"attendees": [
{"email": a["email"], "status": a.get("responseStatus", "unknown")}
for a in event.get("attendees", [])
],
"link": event.get("htmlLink", ""),
"conference_link": (
event.get("conferenceData", {}).get("entryPoints", [{}])[0].get("uri", "")
if event.get("conferenceData")
else ""
),
"status": event.get("status", ""),
}
def list_events(days_ahead: int = 7) -> dict:
"""List upcoming calendar events."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
now = datetime.now(timezone.utc).isoformat()
end = (datetime.now(timezone.utc) + timedelta(days=days_ahead)).isoformat()
events_result = service.events().list(
calendarId=calendar_id, timeMin=now, timeMax=end,
maxResults=50, singleEvents=True, orderBy="startTime"
).execute()
events = events_result.get("items", [])
if not events:
return {"status": "success", "count": 0, "events": []}
return {"status": "success", "count": len(events), "events": [_format_event(e) for e in events]}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def create_event(title: str, start_time: str, end_time: str, description: str = "", location: str = "", attendees: str = "", add_google_meet: bool = False) -> dict:
"""Create a new calendar event."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
event_body = {
"summary": title,
"start": {"dateTime": start_time},
"end": {"dateTime": end_time},
}
if description: event_body["description"] = description
if location: event_body["location"] = location
if attendees:
email_list = [e.strip() for e in attendees.split(",") if e.strip()]
event_body["attendees"] = [{"email": e} for e in email_list]
conference_version = 0
if add_google_meet:
event_body["conferenceData"] = {
"createRequest": {"requestId": f"event-{datetime.now().strftime('%Y%m%d%H%M%S')}", "conferenceSolutionKey": {"type": "hangoutsMeet"}}
}
conference_version = 1
event = service.events().insert(calendarId=calendar_id, body=event_body, conferenceDataVersion=conference_version).execute()
return {"status": "success", "message": f"Event created ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def update_event(event_id: str, title: str = "", start_time: str = "", end_time: str = "", description: str = "") -> dict:
"""Update an existing calendar event."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
patch_body = {}
if title: patch_body["summary"] = title
if start_time: patch_body["start"] = {"dateTime": start_time}
if end_time: patch_body["end"] = {"dateTime": end_time}
if description: patch_body["description"] = description
if not patch_body: return {"status": "error", "message": "No fields to update."}
event = service.events().patch(calendarId=calendar_id, eventId=event_id, body=patch_body).execute()
return {"status": "success", "message": "Event updated ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def delete_event(event_id: str) -> dict:
"""Delete a calendar event by its ID."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
service.events().delete(calendarId=calendar_id, eventId=event_id).execute()
return {"status": "success", "message": f"Event '{event_id}' deleted ✅"}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def quick_add_event(text: str) -> dict:
"""Create an event using natural language (e.g. 'Lunch with Sarah next Monday noon')."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
event = service.events().quickAdd(calendarId=calendar_id, text=text).execute()
return {"status": "success", "message": "Event created from text ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
calendar_agent = Agent(
model='gemini-2.5-flash',
name='calendar_specialist',
description='Manages the user schedule and calendar events.',
instruction='''
You manage the user's Google Calendar.
- Use list_events to check the schedule.
- Use quick_add_event for simple, conversational scheduling requests (e.g., "Lunch tomorrow at noon").
- Use create_event for complex meetings that require attendees, specific durations, or Google Meet links.
- Use update_event to change details of an existing event.
- Use delete_event to cancel or remove an event.
CRITICAL: For update_event and delete_event, you must provide the exact `event_id`.
If the user does not provide the ID, you MUST call list_events first to find the correct `event_id` before attempting the update or deletion.
Always use the current date/time context provided by the root agent to resolve relative dates like "tomorrow".
''',
tools=[list_events, create_event, update_event, delete_event, quick_add_event],
)
Finalizar o agente raiz (agent.py)
Atualize o arquivo agent.py com o código abaixo:
agent.py
import os
from datetime import datetime
from zoneinfo import ZoneInfo
from google.adk.agents.llm_agent import Agent
from google.adk.tools.agent_tool import AgentTool
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import all our specialized sub-agents
from .research import research_agent
from .todo import todo_agent
from .calendar import calendar_agent
import tzlocal
# Automatically detect the local system timezone
TIMEZONE = tzlocal.get_localzone_name()
# Callback for persistent memory storage
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Callback to inject the current time into the prompt
async def setup_agent_context(callback_context, **kwargs):
now = datetime.now(ZoneInfo(TIMEZONE))
callback_context.state["current_time"] = now.strftime("%A, %Y-%m-%d %I:%M %p")
callback_context.state["timezone"] = TIMEZONE
# --- ROOT AGENT DEFINITION ---
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant with memory and specialized tools.',
instruction='''
You are an elite, high-signal AI Executive Assistant.
Your goal is to help the user manage their knowledge, tasks, research, and schedule.
## Your Capabilities:
1. Memory: Use load_memory to recall personal facts.
2. Research: Delegate complex web investigations to the research_specialist.
3. Tasks: Delegate all to-do list management to the todo_specialist.
4. Scheduling: Delegate all calendar queries to the calendar_specialist.
## 🕒 Current State
- Time: {current_time?}
- Timezone: {timezone?}
Always be direct and professional.
''',
tools=[
PreloadMemoryTool(),
load_memory_tool,
AgentTool(todo_agent),
AgentTool(calendar_agent)
],
sub_agents=[research_agent],
before_agent_callback=[setup_agent_context],
after_agent_callback=[auto_save_session_to_memory_callback],
)
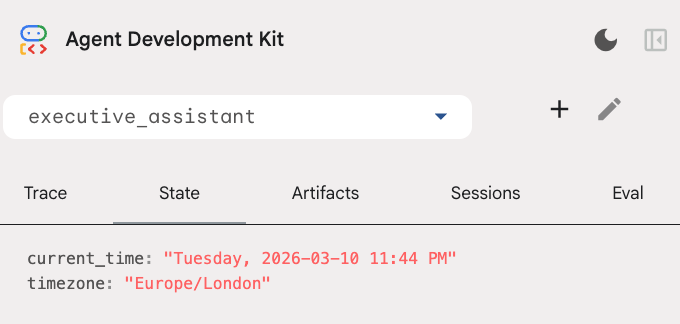
Além da ferramenta de calendário, também adicionamos uma nova função de callback antes do agente: setup_agent_context. Essa função permite que o agente saiba a data, a hora e o fuso horário atuais para usar a agenda de forma mais eficiente. Ele funciona definindo variáveis de estado da sessão, um tipo diferente de memória do agente projetado para persistência de curto prazo.
Execute o ADK web pela última vez para testar o agente completo.
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
É possível inspecionar o estado da sessão na guia "Estado" da interface do desenvolvedor:
Agora você tem um agente que pode acompanhar eventos da agenda, listas de tarefas, fazer pesquisas e tem memória de longo prazo.
Limpeza após o laboratório
9. Conclusão
Parabéns! Você criou um assistente executivo de IA multifuncional em cinco estágios evolutivos.
O que discutimos
- Provisionamento de infraestrutura para agentes de IA.
- Implementar memória persistente e subagentes especializados usando recursos integrados do ADK.
- Integração de bancos de dados externos e APIs de produtividade.
Próximas etapas
Para continuar aprendendo, confira outros codelabs nesta plataforma ou faça melhorias no assistente executivo por conta própria.
Se você precisar de ideias para melhorias, tente:
- Implemente a compactação de eventos para otimizar a performance em conversas longas.
- Adicione um serviço de artefato para permitir que o agente faça anotações para você e salve como arquivos
- Implante seu agente como um serviço de back-end usando o Google Cloud Run.
Depois de concluir o teste, limpe o ambiente para não gerar cobranças inesperadas na sua conta de faturamento.
Divirta-se com os códigos!