
1. Введение
В этом практическом занятии вы научитесь создавать сложного ИИ-агента с помощью Google Agent Development Kit (ADK). Мы будем следовать естественному эволюционному пути, начиная с базового разговорного агента и постепенно добавляя специализированные возможности.
Создаваемый нами агент — это личный помощник руководителя, призванный помогать вам в повседневных задачах, таких как управление календарем, напоминания о задачах, проведение исследований и составление заметок. Все это разработано с нуля с использованием ADK, Gemini и Vertex AI.
По завершении этой лабораторной работы у вас будет полностью работоспособный агент, а также знания, необходимые для его расширения в соответствии с вашими собственными потребностями.
Предварительные требования
- Базовые знания языка программирования Python.
- Базовые знания консоли Google Cloud для управления облачными ресурсами.
Что вы узнаете
- Подготовка инфраструктуры Google Cloud для агентов искусственного интеллекта.
- Реализация устойчивой долговременной памяти с использованием Vertex AI Memory Bank.
- Построение иерархии специализированных суб-агентов.
- Интеграция внешних баз данных и экосистемы Google Workspace.
Что вам понадобится
Этот мастер-класс можно пройти полностью в среде Google Cloud Shell , в которой уже предустановлены все необходимые зависимости (gcloud CLI, редактор кода, Go, Gemini CLI).
В качестве альтернативы , если вы предпочитаете работать на собственном компьютере, вам потребуется следующее:
- Python (версия 3.12 или выше)
- Редактор кода или интегрированная среда разработки (например, VS Code или
vim). - Терминал для выполнения команд Python и
gcloud. - Рекомендуется использовать агент для управления кодом, например, Gemini CLI или Antigravity.
Ключевые технологии
Здесь вы найдете более подробную информацию о технологиях, которые мы будем использовать:
2. Настройка среды
Выберите один из следующих вариантов: Самостоятельная настройка среды, если вы хотите выполнить это практическое занятие на своем компьютере, или Запуск Cloud Shell, если вы хотите выполнить это практическое занятие полностью в облаке.
Настройка среды для самостоятельного обучения
- Войдите в консоль Google Cloud и создайте новый проект или используйте существующий. Если у вас еще нет учетной записи Gmail или Google Workspace, вам необходимо ее создать .

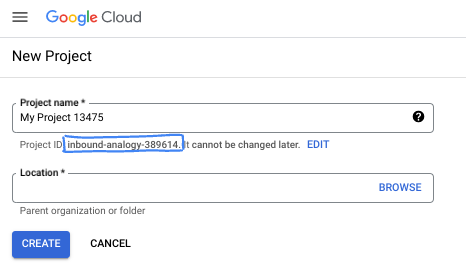
- Название проекта — это отображаемое имя участников данного проекта. Это строка символов, не используемая API Google. Вы всегда можете его изменить.
- Идентификатор проекта уникален для всех проектов Google Cloud и является неизменяемым (его нельзя изменить после установки). Консоль Cloud автоматически генерирует уникальную строку; обычно вам неважно, какая она. В большинстве практических заданий вам потребуется указать идентификатор вашего проекта (обычно обозначается как
PROJECT_ID). Если сгенерированный идентификатор вас не устраивает, вы можете сгенерировать другой случайный идентификатор. В качестве альтернативы вы можете попробовать свой собственный и посмотреть, доступен ли он. После этого шага его нельзя изменить, и он сохраняется на протяжении всего проекта. - К вашему сведению, существует третье значение — номер проекта , которое используется некоторыми API. Подробнее обо всех трех значениях можно узнать в документации .
- Далее вам потребуется включить оплату в консоли Cloud для использования ресурсов/API Cloud. Выполнение этого практического задания не потребует больших затрат, если вообще потребует. Чтобы отключить ресурсы и избежать дополнительных расходов после завершения этого урока, вы можете удалить созданные ресурсы или удалить проект. Новые пользователи Google Cloud имеют право на бесплатную пробную версию стоимостью 300 долларов США .
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
В консоли Google Cloud нажмите на значок Cloud Shell на панели инструментов в правом верхнем углу:
Подготовка и подключение к среде займут всего несколько минут. После завершения вы должны увидеть что-то подобное:

Эта виртуальная машина содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Вся работа в этом практическом задании может выполняться в браузере. Вам не нужно ничего устанавливать.
3. Настройка проекта
Прежде чем писать код, необходимо подготовить необходимую инфраструктуру и права доступа в Google Cloud.
Установка переменных среды
Откройте терминал и установите следующие переменные среды:
export PROJECT_ID=`gcloud config get project`
export LOCATION=us-central1
Включить необходимые API
Вашему агенту требуется доступ к нескольким сервисам Google Cloud. Выполните следующую команду, чтобы включить их:
gcloud services enable \
aiplatform.googleapis.com \
calendar-json.googleapis.com \
sqladmin.googleapis.com
Аутентификация с использованием учетных данных приложения по умолчанию.
Для связи со службами Google Cloud из вашей среды нам необходимо пройти аутентификацию с использованием учетных данных приложения по умолчанию (ADC).
Выполните следующую команду, чтобы убедиться, что ваши учетные данные по умолчанию для приложения активны и актуальны:
gcloud auth application-default login
4. Создайте базового агента.
Теперь нам нужно инициализировать каталог, где мы будем хранить исходный код проекта:
# setup project directory
mkdir -p adk_ea_codelab && cd adk_ea_codelab
# prepare virtual environment
uv init
# install dependencies
uv add google-adk google-api-python-client tzlocal python-dotenv
uv add cloud-sql-python-connector[pg8000] sqlalchemy
Начнем с определения личности агента и его основных навыков ведения диалога. В ADK класс Agent определяет образ агента и инструкции для него.
Сейчас самое время подумать о названии для агента. Мне нравится, когда у моих агентов есть настоящие имена, например, Аида или Шарон, так как, на мой взгляд, это помогает придать им "индивидуальность", но вы также можете просто называть агента по его роду деятельности, например, "помощник руководителя", "туристический агент" или "исполнитель кода".
Выполните команду adk create , чтобы запустить стандартный агент:
# replace with your desired agent name
uv run adk create executive_assistant
Пожалуйста, выберите gemini-2.5-flash в качестве модели и Vertex AI в качестве бэкенда. Дважды проверьте, совпадает ли предлагаемый идентификатор проекта с тем, который вы создали для этой лабораторной работы, и нажмите Enter для подтверждения. Для региона Google Cloud вы можете принять регион по умолчанию ( us-central1 ). Ваш терминал будет выглядеть примерно так:
daniela_petruzalek@cloudshell:~/adk_ea_codelab (your-project-id)$ uv run adk create executive_assistant Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [your-project-id]: Enter Google Cloud region [us-central1]: Agent created in /home/daniela_petruzalek/adk_ea_codelab/executive_assistant: - .env - __init__.py - agent.py daniela_petruzalek@cloudshell:~/adk_ea_codelab (your-project-id)$
После завершения выполнения предыдущей команды будет создана папка с именем агента (например, executive_assistant ), содержащая несколько файлов, в том числе файл agent.py с базовым определением агента:
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Чтобы взаимодействовать с этим агентом, вы можете запустить команду uv run adk web в командной строке и открыть пользовательский интерфейс для разработчиков в браузере. Вы увидите примерно следующее:
$ uv run adk web ... INFO: Started server process [1244] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
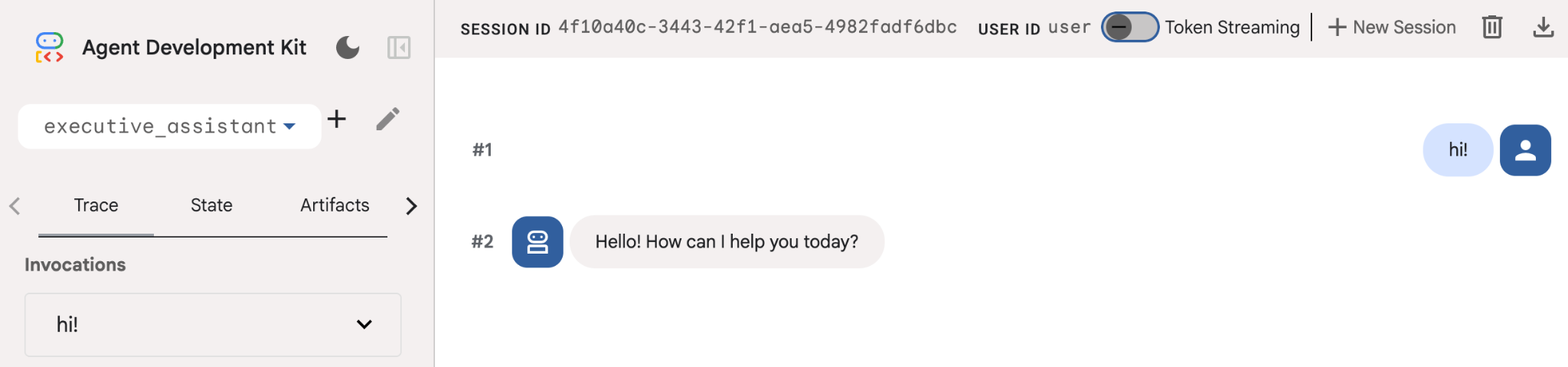
Даже если этот агент довольно простой, полезно хотя бы раз выполнить эту настройку, чтобы убедиться в её корректной работе, прежде чем приступать к редактированию агента. На скриншоте ниже показано простое взаимодействие с использованием пользовательского интерфейса для разработчиков:
Теперь давайте изменим определение агента, добавив в него нашего помощника руководителя. Скопируйте приведенный ниже код и замените им содержимое файла agent.py . Адаптируйте имя агента и его профиль в соответствии со своими предпочтениями.
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant',
instruction='''
You are an elite, warm, and highly efficient AI partner.
Your primary goal is to help the user manage their tasks, schedule, and research.
Always be direct, concise, and high-signal.
''',
)
Обратите внимание, что свойство name определяет внутреннее имя агента, хотя в инструкциях вы также можете указать более дружелюбное имя, отражающее его личные качества для взаимодействия с конечным пользователем. Внутреннее имя используется в основном для обеспечения наблюдаемости и передачи данных в многоагентных системах с помощью инструмента transfer_to_agent . Вам не нужно будет самостоятельно работать с этим инструментом, ADK автоматически регистрирует его при объявлении одного или нескольких субагентов.
Для запуска только что созданного агента используйте adk web:
uv run adk web
Откройте интерфейс ADK в браузере и поздоровайтесь со своим новым помощником!
5. Добавьте постоянную память с помощью Vertex AI Memory Bank.
Настоящий ассистент должен запоминать предпочтения и прошлые взаимодействия, чтобы обеспечить бесперебойный и персонализированный опыт. На этом этапе мы интегрируем Vertex AI Agent Engine Memory Bank — функцию Vertex AI, которая динамически генерирует долговременную память на основе разговоров с пользователем.
Memory Bank позволяет вашему агенту создавать персонализированную информацию, доступную в нескольких сессиях, обеспечивая непрерывность между сессиями. В фоновом режиме он управляет хронологической последовательностью сообщений в сессии и может использовать поиск по сходству, чтобы предоставить агенту наиболее релевантные воспоминания для текущего контекста.
Инициализация службы памяти
ADK использует Vertex AI для хранения и извлечения долговременной памяти. Вам необходимо инициализировать «Механизм памяти» в вашем проекте. По сути, это экземпляр Механизма рассуждений, настроенный для работы в качестве Банка памяти.
Создайте следующий скрипт под названием setup_memory.py :
setup_memory.py
import vertexai
import os
PROJECT_ID=os.getenv("PROJECT_ID")
LOCATION=os.getenv("LOCATION")
client = vertexai.Client(project=PROJECT_ID, location=LOCATION)
# Create Reasoning Engine for Memory Bank
agent_engine = client.agent_engines.create()
# You will need this resource name to give it to ADK
print(agent_engine.api_resource.name)
Теперь запустите setup_memory.py , чтобы выделить ресурсы для работы механизма рассуждений в банке памяти:
uv run python setup_memory.py
Результат должен выглядеть примерно так:
$ uv run python setup.py projects/1234567890/locations/us-central1/reasoningEngines/1234567890
Сохраните имя ресурса движка в переменной среды:
export ENGINE_ID="<insert the resource name above>"
Теперь нам нужно обновить код, чтобы он использовал постоянную память. Замените содержимое файла agent.py следующим:
agent.py
from google.adk.agents.llm_agent import Agent
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Update root_agent with memory tools and callback
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='Executive Assistant with Persistent Memory',
instruction='''
You are an elite AI partner with long-term memory.
Use load_memory to find context about the user when needed.
Always be direct, concise, and high-signal.
''',
tools=[PreloadMemoryTool(), load_memory_tool],
after_agent_callback=auto_save_session_to_memory_callback,
)
Инструмент PreloadMemoryTool автоматически добавляет соответствующий контекст из прошлых разговоров в каждый запрос (используя поиск сходства), а load_memory_tool позволяет модели явно запрашивать данные из Memory Bank при необходимости. Эта комбинация обеспечивает вашему агенту глубокий и постоянный контекст!
Для запуска агента с поддержкой памяти необходимо передать ему параметр memory_service_uri при запуске веб-версии ADK:
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
Попробуйте рассказать агентам несколько фактов о себе, а затем вернитесь с другим вопросом, чтобы обсудить их. Например, назовите свое имя:
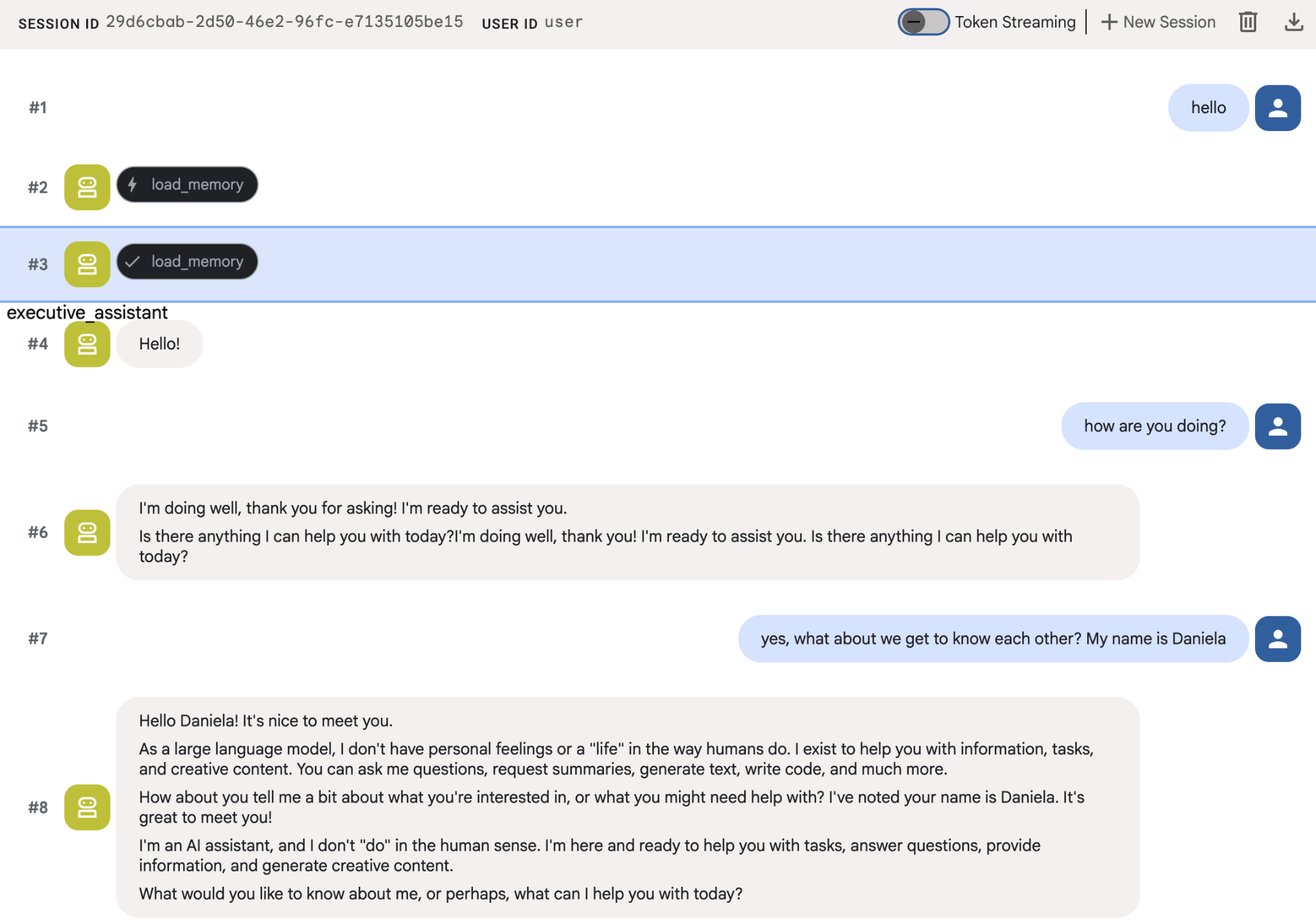
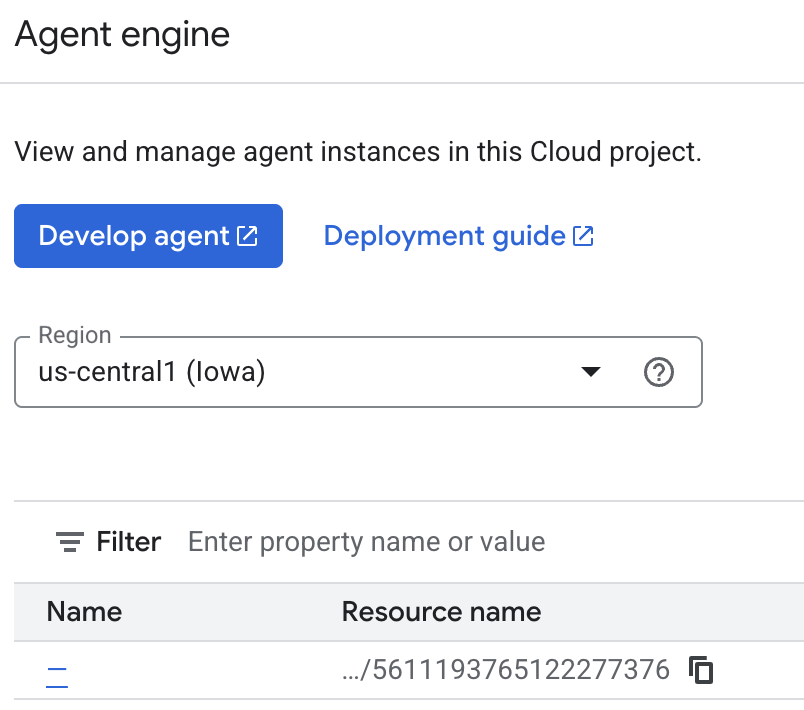
Вы можете просмотреть сохраненные агентом файлы в облачной консоли. Перейдите на страницу продукта "Agent Engine" (воспользуйтесь строкой поиска).

Затем щелкните по названию вашего агента (убедитесь, что вы выбрали правильный регион):
А затем перейдите во вкладку «Воспоминания»:
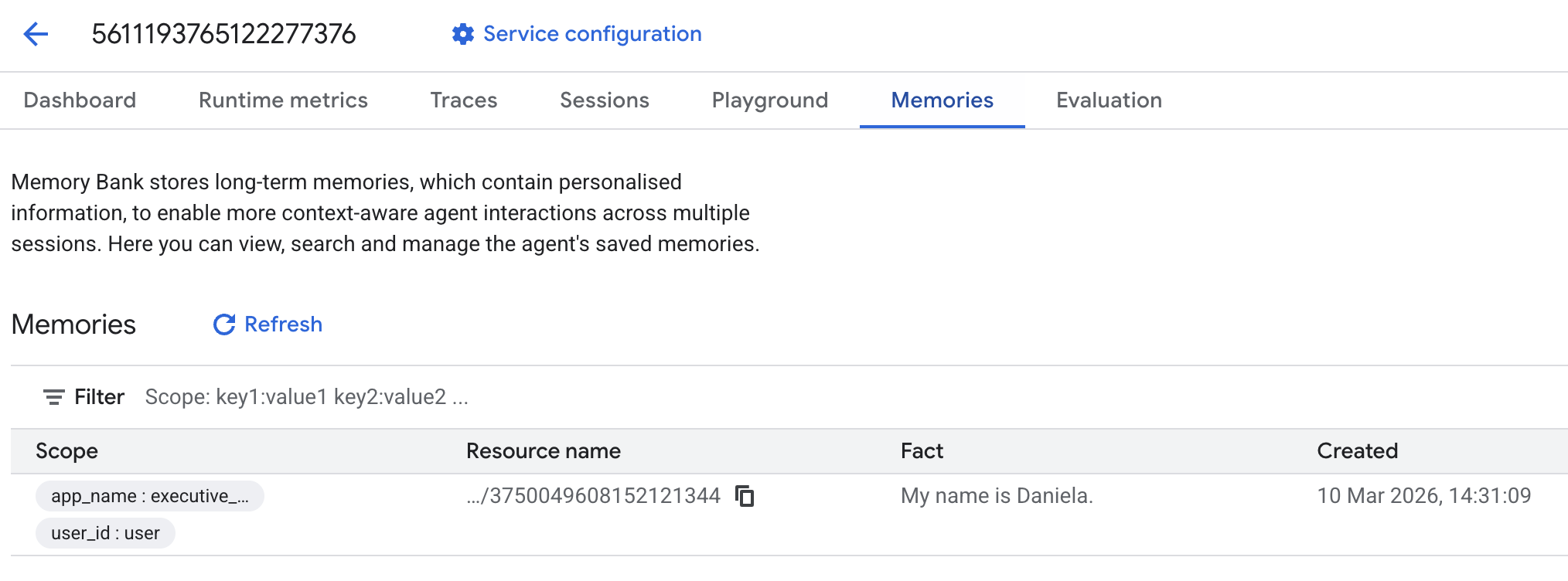
Вы должны увидеть, как добавляются некоторые воспоминания.
6. Добавить возможности веб-поиска.
Для предоставления высококачественной информации наш агент должен проводить углубленные исследования, выходящие за рамки одного поискового запроса. Делегируя исследования специализированному суб-агенту, мы сохраняем оперативность реагирования основного пользователя, в то время как исследователь занимается сложным сбором данных в фоновом режиме.
На этом этапе мы внедряем LoopAgent для достижения «глубины исследования», позволяя агенту итеративно искать, оценивать результаты и уточнять свои запросы до тех пор, пока не получит полную картину. Мы также обеспечиваем техническую строгость, требуя включения ссылок на источники в текст, гарантируя, что каждое утверждение подкреплено ссылкой на источник.
Создайте специалиста по исследованиям (research.py)
Здесь мы определяем базового агента, оснащенного инструментом поиска Google, и оборачиваем его в LoopAgent. Параметр max_iterations выступает в качестве регулятора, гарантируя, что агент будет выполнять поиск до 3 раз, если в его понимании остаются пробелы.
research.py
from google.adk.agents.llm_agent import Agent
from google.adk.agents.loop_agent import LoopAgent
from google.adk.tools.google_search_tool import GoogleSearchTool
from google.adk.tools.tool_context import ToolContext
def exit_loop(tool_context: ToolContext):
"""Call this function ONLY when no further research is needed, signaling the iterative process should end."""
print(f" [Tool Call] exit_loop triggered by {tool_context.agent_name}")
tool_context.actions.escalate = True
# Return empty dict as tools should typically return JSON-serializable output
return {}
# --- RESEARCH LOGIC ---
_research_worker = Agent(
model='gemini-2.5-flash',
name='research_worker',
description='Worker agent that performs a single research step.',
instruction='''
Use google_search to find facts and synthesize them for the user.
Critically evaluate your findings. If the data is incomplete or you need more context, prepare to search again in the next iteration.
You must include the links you found as references in your response, formatting them like citations in a research paper (e.g., [1], [2]).
Use the exit_loop tool to terminate the research early if no further research is needed.
If you need to ask the user for clarifications, call the exit_loop function early to interrupt the research cycle.
''',
tools=[GoogleSearchTool(bypass_multi_tools_limit=True), exit_loop],
)
# The LoopAgent iterates the worker up to 3 times for deeper research
research_agent = LoopAgent(
name='research_specialist',
description='Deep web research specialist.',
sub_agents=[_research_worker],
max_iterations=3,
)
Обновите корневой агент (agent.py)
Импортируйте research_agent и добавьте его в качестве инструмента для Sharon:
agent.py
from google.adk.agents.llm_agent import Agent
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import our new sub agent
from .research import research_agent
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Update root_agent with memory tools and callback
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='Executive Assistant with persistent memory and research capabilities',
instruction='''
You are an elite AI partner with long-term memory.
1. Use load_memory to recall facts.
2. Delegate research tasks to the research_specialist.
Always be direct, concise, and high-signal.
''',
tools=[PreloadMemoryTool(), load_memory_tool],
sub_agents=[research_agent],
after_agent_callback=auto_save_session_to_memory_callback,
)
Запустите веб-версию AdK еще раз, чтобы протестировать исследовательский агент.
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
Дайте задание на простое исследование, например: «Как написать хороший технический блог?»
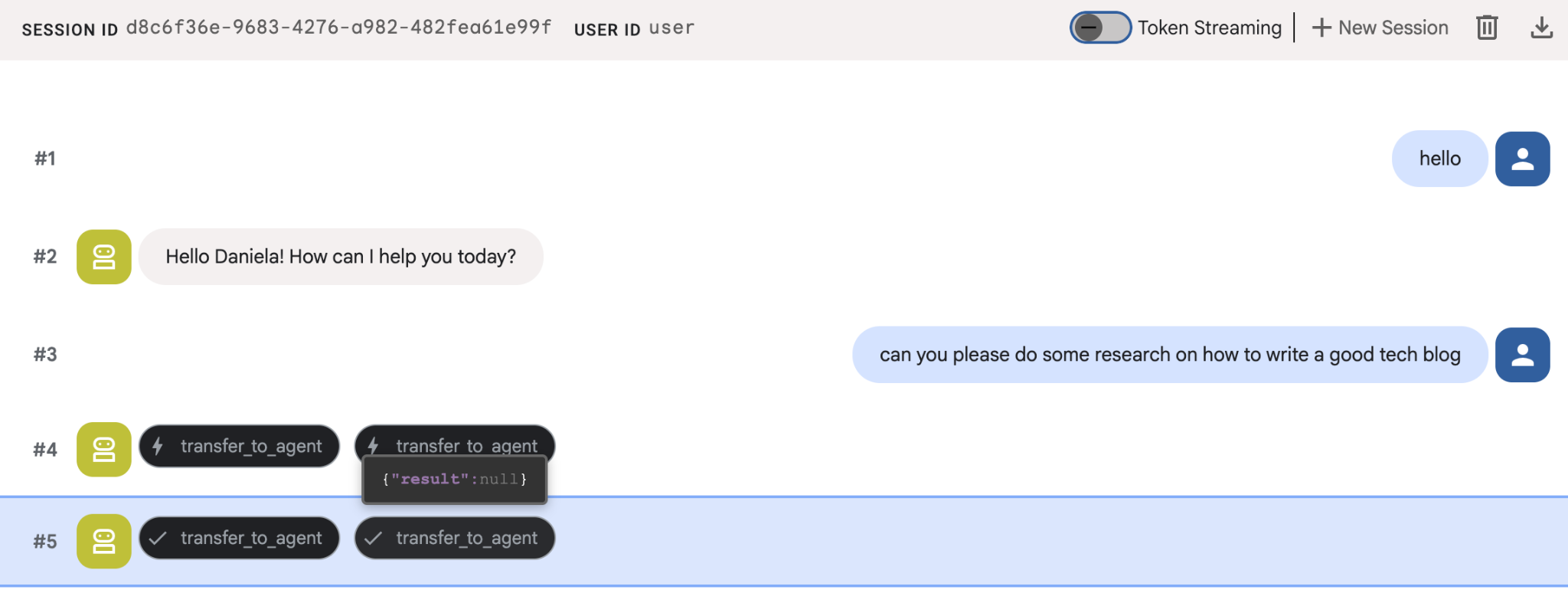
Возможно, вы заметили, что агент запомнил мое имя, хотя это новая сессия. Обратите также внимание на вызов инструмента "transfer_to_agent": именно этот инструмент передает задачу нашему новому исследовательскому агенту.

Теперь перейдём к управлению задачами.
7. Добавьте управление задачами с помощью Cloud SQL.
Хотя агент обладает долговременной памятью, он не подходит для обработки детализированных структурированных данных, таких как список дел. Для задач мы используем традиционную реляционную базу данных. Мы будем использовать SQLAlchemy и базу данных Google Cloud SQL (PostgreSQL). Прежде чем писать код, необходимо подготовить инфраструктуру.
Обеспечение инфраструктуры
Выполните эти команды для создания базы данных. Примечание: создание экземпляра занимает около 5–10 минут. Вы можете перейти к следующему шагу, пока процесс выполняется в фоновом режиме.
# 1. Define instance variables
export INSTANCE_NAME="assistant-db"
export USER_EMAIL=$(gcloud config get-value account)
# 2. Create the Cloud SQL instance
gcloud sql instances create $INSTANCE_NAME \
--database-version=POSTGRES_18 \
--tier=db-f1-micro \
--region=us-central1 \
--edition=ENTERPRISE
# 3. Create the database for our tasks
gcloud sql databases create tasks --instance=$INSTANCE_NAME
Подготовка экземпляра базы данных займет несколько минут. Возможно, сейчас самое время выпить чашечку кофе или чая, или обновить код, пока вы ждете завершения процесса, только не забудьте вернуться и завершить настройку контроля доступа!
Настройка контроля доступа
Теперь нам нужно настроить вашу учетную запись пользователя для доступа к базе данных. Выполните следующие команды в терминале:
# change this to your favorite password
export DB_PASS="correct-horse-battery-staple"
# Create a regular database user
gcloud sql users create assistant_user \
--instance=$INSTANCE_NAME \
--password=$DB_PASS
Обновите конфигурацию среды.
ADK загружает конфигурацию из файла .env во время выполнения. Обновите среду вашего агента, указав данные для подключения к базе данных.
# Retrieve the unique connection name
export DB_CONN=$(gcloud sql instances describe $INSTANCE_NAME --format='value(connectionName)')
# Append configuration to your .env file
cat <<EOF >> executive_assistant/.env
DB_CONNECTION_NAME=$DB_CONN
DB_USER=assistant_user
DB_PASSWORD=$DB_PASS
DB_NAME=tasks
EOF
Теперь перейдём к внесению изменений в код.
Создайте специалиста по задачам (todo.py)
Аналогично агенту-исследователю, давайте создадим нашего специалиста по спискам задач в отдельном файле. Создайте todo.py :
todo.py
import os
import uuid
import sqlalchemy
from datetime import datetime
from typing import Optional, List
from sqlalchemy import (
Column,
String,
DateTime,
Enum,
select,
delete,
update,
)
from sqlalchemy.orm import declarative_base, Session
from google.cloud.sql.connector import Connector
from google.adk.agents.llm_agent import Agent
# --- DATABASE LOGIC ---
Base = declarative_base()
connector = Connector()
def getconn():
db_connection_name = os.environ.get("DB_CONNECTION_NAME")
db_user = os.environ.get("DB_USER")
db_password = os.environ.get("DB_PASSWORD")
db_name = os.environ.get("DB_NAME", "tasks")
return connector.connect(
db_connection_name,
"pg8000",
user=db_user,
password=db_password,
db=db_name,
)
engine = sqlalchemy.create_engine(
"postgresql+pg8000://",
creator=getconn,
)
class Todo(Base):
__tablename__ = "todos"
id = Column(String(36), primary_key=True, default=lambda: str(uuid.uuid4()))
title = Column(String(255), nullable=False)
priority = Column(
Enum("high", "medium", "low", name="priority_levels"), nullable=False, default="medium"
)
due_date = Column(DateTime, nullable=True)
status = Column(Enum("pending", "done", name="status_levels"), default="pending")
created_at = Column(DateTime, default=datetime.utcnow)
def init_db():
"""Builds the table if it's missing."""
Base.metadata.create_all(bind=engine)
def add_todo(
title: str, priority: str = "medium", due_date: Optional[str] = None
) -> dict:
"""
Adds a new task to the list.
Args:
title (str): The description of the task.
priority (str): The urgency level. Must be one of: 'high', 'medium', 'low'.
due_date (str, optional): The due date in ISO format (YYYY-MM-DD or YYYY-MM-DDTHH:MM:SS).
Returns:
dict: A dictionary containing the new task's ID and a status message.
"""
init_db()
with Session(engine) as session:
due = datetime.fromisoformat(due_date) if due_date else None
item = Todo(
title=title,
priority=priority.lower(),
due_date=due,
)
session.add(item)
session.commit()
return {"id": item.id, "status": f"Task added ✅"}
def list_todos(status: str = "pending") -> list:
"""
Lists tasks from the database, optionally filtering by status.
Args:
status (str, optional): The status to filter by. 'pending', 'done', or 'all'.
"""
init_db()
with Session(engine) as session:
query = select(Todo)
s_lower = status.lower()
if s_lower != "all":
query = query.where(Todo.status == s_lower)
query = query.order_by(Todo.priority, Todo.created_at)
results = session.execute(query).scalars().all()
return [
{
"id": t.id,
"task": t.title,
"priority": t.priority,
"status": t.status,
}
for t in results
]
def complete_todo(task_id: str) -> str:
"""Marks a specific task as 'done'."""
init_db()
with Session(engine) as session:
session.execute(update(Todo).where(Todo.id == task_id).values(status="done"))
session.commit()
return f"Task {task_id} marked as done."
def delete_todo(task_id: str) -> str:
"""Permanently removes a task from the database."""
init_db()
with Session(engine) as session:
session.execute(delete(Todo).where(Todo.id == task_id))
session.commit()
return f"Task {task_id} deleted."
# --- TODO SPECIALIST AGENT ---
todo_agent = Agent(
model='gemini-2.5-flash',
name='todo_specialist',
description='A specialist agent that manages a structured SQL task list.',
instruction='''
You manage the user's task list using a PostgreSQL database.
- Use add_todo when the user wants to remember something. If no priority is mentioned, mark it as 'medium'.
- Use list_todos to show tasks.
- Use complete_todo to mark a task as finished.
- Use delete_todo to remove a task entirely.
When marking a task as complete or deleting it, if the user doesn't provide the ID,
use list_todos first to find the correct ID for the task they described.
''',
tools=[add_todo, list_todos, complete_todo, delete_todo],
)
Приведенный выше код отвечает за две основные задачи: подключение к базе данных Cloud SQL и предоставление списка инструментов для всех распространенных операций в списке дел, включая добавление, удаление и пометку их как выполненных.
Поскольку эта логика очень специфична для агента задач, и нас не обязательно интересует такое детальное управление с точки зрения исполнительного помощника (корневого агента), мы будем оформлять этого агента как " AgentTool ", а не как подагента.
Чтобы решить, использовать ли AgentTool или субагента, следует учесть, нужно ли им обмениваться контекстной информацией:
- Используйте AgentTool, когда вашему агенту не нужно обмениваться контекстом с корневым агентом.
- Используйте дочернего агента, если хотите, чтобы ваш основной агент обменивался контекстом с корневым агентом.
В случае с агентом-исследователем обмен контекстной информацией может быть полезен, но для простого агента, отслеживающего задачи, это не принесет большой пользы.
Давайте реализуем AgentTool в agent.py .
Обновите корневой агент (agent.py)
Теперь импортируйте todo_agent в основной файл и прикрепите его как инструмент:
agent.py
import os
from datetime import datetime
from google.adk.agents.llm_agent import Agent
from google.adk.tools.agent_tool import AgentTool
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import our specialized sub-agents
from .research import research_agent
from .todo import todo_agent
# Callback for persistent memory storage
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# --- ROOT AGENT DEFINITION ---
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant with memory and specialized tools.',
instruction='''
You are an elite, high-signal AI Executive Assistant.
Your goal is to help the user manage their knowledge, tasks, and research.
## Your Capabilities:
1. Memory: Use load_memory to recall personal facts or past context about the user.
2. Research: Delegate complex web-based investigations to the research_specialist.
3. Tasks: Delegate all to-do list management (adding, listing, or completing tasks) to the todo_specialist.
Always be direct and professional. If a task is successful, provide a brief confirmation.
''',
tools=[
PreloadMemoryTool(),
load_memory_tool,
AgentTool(todo_agent) # Exposes the Todo Specialist as a tool
],
sub_agents=[research_agent], # Exposes the Research Specialist for direct handover
after_agent_callback=auto_save_session_to_memory_callback,
)
Запустите adk web еще раз, чтобы протестировать новую функцию:
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
И попробуйте создать задание:
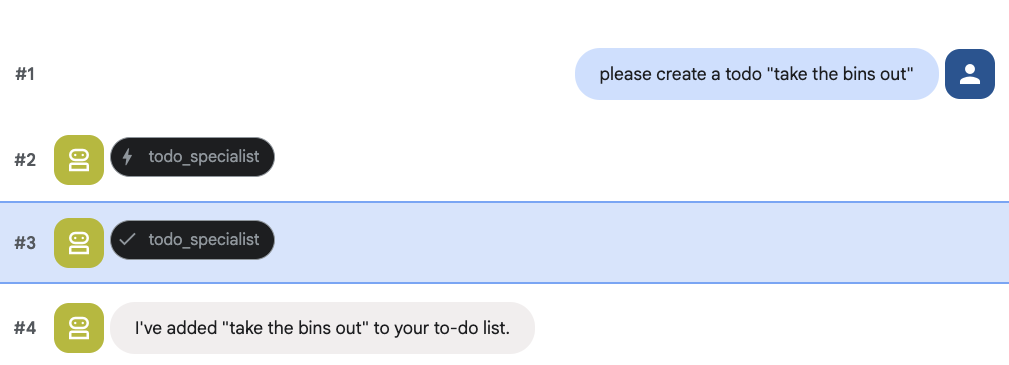
8. Добавьте управление календарем.
Наконец, мы интегрируем Google Календарь, чтобы агент мог управлять встречами. В рамках этого практического занятия, вместо того чтобы предоставлять агенту доступ к вашему личному календарю, что может быть потенциально опасно, если это сделано неправильно, мы создадим независимый календарь, которым агент сможет управлять самостоятельно.
Сначала мы создадим выделенную учетную запись службы , которая будет использоваться в качестве идентификатора агента. Затем мы программно создадим календарь агента, используя эту учетную запись службы.
Создайте учетную запись службы.
Откройте терминал и выполните следующие команды, чтобы создать учетную запись и предоставить вашей личной учетной записи разрешение на использование ее в качестве вашей личности:
export SA_NAME="ea-agent"
export SA_EMAIL="${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"
# Create the service account
gcloud iam service-accounts create $SA_NAME \
--display-name="Executive Assistant Agent"
# Allow your local user to impersonate it
gcloud iam service-accounts add-iam-policy-binding $SA_EMAIL \
--member="user:$(gcloud config get-value account)" \
--role="roles/iam.serviceAccountTokenCreator"
# Save it to the agent's environment
echo "SERVICE_ACCOUNT_EMAIL=$SA_EMAIL" >> executive_assistant/.env
Создать календарь программно
Давайте напишем скрипт, который сообщит учетной записи службы о необходимости создания календаря. Создайте новый файл с именем setup_calendar.py в корневой директории вашего проекта (рядом с setup_memory.py ):
setup_calendar.py
import os
import google.auth
from googleapiclient.discovery import build
from google.auth.transport.requests import Request
from google.auth import impersonated_credentials
from dotenv import load_dotenv
load_dotenv('executive_assistant/.env')
SA_EMAIL = os.environ.get("SERVICE_ACCOUNT_EMAIL")
def setup_sa_calendar():
print(f"Authenticating to impersonate {SA_EMAIL}...")
# 1. Base credentials
creds, _ = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
creds.refresh(Request())
# 2. Impersonate the Service Account
impersonated = impersonated_credentials.Credentials(
source_credentials=creds,
target_principal=SA_EMAIL,
target_scopes=["https://www.googleapis.com/auth/calendar"],
)
service = build("calendar", "v3", credentials=impersonated)
# 3. Create the calendar
print("Creating independent Service Account calendar...")
calendar = service.calendars().insert(body={
"summary": "AI Assistant (SA Owned)",
"description": "An independent calendar managed purely by the AI."
}).execute()
calendar_id = calendar['id']
# 4. Save the ID
with open("executive_assistant/.env", "a") as f:
f.write(f"\nCALENDAR_ID={calendar_id}\n")
print(f"Setup complete! CALENDAR_ID {calendar_id} added to .env")
if __name__ == "__main__":
setup_sa_calendar()
Запустите скрипт из терминала:
uv run python setup_calendar.py
Создайте специалиста по календарям (файл calendar.py).
Теперь давайте сосредоточимся на специалисте по календарям. Мы оснастим этого агента полным набором инструментов для работы с календарями: составление списков, создание, обновление, удаление и даже функция «быстрого добавления», которая распознает естественный язык.
Скопируйте приведенный ниже код в calendar.py .
календарь.py
import os
from datetime import datetime, timedelta, timezone
import google.auth
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from google.adk.agents.llm_agent import Agent
def _get_calendar_service():
"""Build the Google Calendar API service using Service Account Impersonation."""
from google.auth.transport.requests import Request
from google.auth import impersonated_credentials
target_principal = os.environ.get("SERVICE_ACCOUNT_EMAIL")
if not target_principal:
raise ValueError("SERVICE_ACCOUNT_EMAIL environment variable is missing.")
base_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
creds, _ = google.auth.default(scopes=base_scopes)
creds.refresh(Request())
target_scopes = ["https://www.googleapis.com/auth/calendar"]
impersonated = impersonated_credentials.Credentials(
source_credentials=creds,
target_principal=target_principal,
target_scopes=target_scopes,
)
return build("calendar", "v3", credentials=impersonated)
def _format_event(event: dict) -> dict:
"""Format a raw Calendar API event into a clean dict for the LLM."""
start = event.get("start", {})
end = event.get("end", {})
return {
"id": event.get("id"),
"title": event.get("summary", "(No title)"),
"start": start.get("dateTime", start.get("date")),
"end": end.get("dateTime", end.get("date")),
"location": event.get("location", ""),
"description": event.get("description", ""),
"attendees": [
{"email": a["email"], "status": a.get("responseStatus", "unknown")}
for a in event.get("attendees", [])
],
"link": event.get("htmlLink", ""),
"conference_link": (
event.get("conferenceData", {}).get("entryPoints", [{}])[0].get("uri", "")
if event.get("conferenceData")
else ""
),
"status": event.get("status", ""),
}
def list_events(days_ahead: int = 7) -> dict:
"""List upcoming calendar events."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
now = datetime.now(timezone.utc).isoformat()
end = (datetime.now(timezone.utc) + timedelta(days=days_ahead)).isoformat()
events_result = service.events().list(
calendarId=calendar_id, timeMin=now, timeMax=end,
maxResults=50, singleEvents=True, orderBy="startTime"
).execute()
events = events_result.get("items", [])
if not events:
return {"status": "success", "count": 0, "events": []}
return {"status": "success", "count": len(events), "events": [_format_event(e) for e in events]}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def create_event(title: str, start_time: str, end_time: str, description: str = "", location: str = "", attendees: str = "", add_google_meet: bool = False) -> dict:
"""Create a new calendar event."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
event_body = {
"summary": title,
"start": {"dateTime": start_time},
"end": {"dateTime": end_time},
}
if description: event_body["description"] = description
if location: event_body["location"] = location
if attendees:
email_list = [e.strip() for e in attendees.split(",") if e.strip()]
event_body["attendees"] = [{"email": e} for e in email_list]
conference_version = 0
if add_google_meet:
event_body["conferenceData"] = {
"createRequest": {"requestId": f"event-{datetime.now().strftime('%Y%m%d%H%M%S')}", "conferenceSolutionKey": {"type": "hangoutsMeet"}}
}
conference_version = 1
event = service.events().insert(calendarId=calendar_id, body=event_body, conferenceDataVersion=conference_version).execute()
return {"status": "success", "message": f"Event created ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def update_event(event_id: str, title: str = "", start_time: str = "", end_time: str = "", description: str = "") -> dict:
"""Update an existing calendar event."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
patch_body = {}
if title: patch_body["summary"] = title
if start_time: patch_body["start"] = {"dateTime": start_time}
if end_time: patch_body["end"] = {"dateTime": end_time}
if description: patch_body["description"] = description
if not patch_body: return {"status": "error", "message": "No fields to update."}
event = service.events().patch(calendarId=calendar_id, eventId=event_id, body=patch_body).execute()
return {"status": "success", "message": "Event updated ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def delete_event(event_id: str) -> dict:
"""Delete a calendar event by its ID."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
service.events().delete(calendarId=calendar_id, eventId=event_id).execute()
return {"status": "success", "message": f"Event '{event_id}' deleted ✅"}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
def quick_add_event(text: str) -> dict:
"""Create an event using natural language (e.g. 'Lunch with Sarah next Monday noon')."""
calendar_id = os.environ.get("CALENDAR_ID")
try:
service = _get_calendar_service()
event = service.events().quickAdd(calendarId=calendar_id, text=text).execute()
return {"status": "success", "message": "Event created from text ✅", "event": _format_event(event)}
except HttpError as e:
return {"status": "error", "message": f"Calendar API error: {e}"}
calendar_agent = Agent(
model='gemini-2.5-flash',
name='calendar_specialist',
description='Manages the user schedule and calendar events.',
instruction='''
You manage the user's Google Calendar.
- Use list_events to check the schedule.
- Use quick_add_event for simple, conversational scheduling requests (e.g., "Lunch tomorrow at noon").
- Use create_event for complex meetings that require attendees, specific durations, or Google Meet links.
- Use update_event to change details of an existing event.
- Use delete_event to cancel or remove an event.
CRITICAL: For update_event and delete_event, you must provide the exact `event_id`.
If the user does not provide the ID, you MUST call list_events first to find the correct `event_id` before attempting the update or deletion.
Always use the current date/time context provided by the root agent to resolve relative dates like "tomorrow".
''',
tools=[list_events, create_event, update_event, delete_event, quick_add_event],
)
Завершить настройку корневого агента (agent.py)
Обновите файл agent.py , добавив следующий код:
agent.py
import os
from datetime import datetime
from zoneinfo import ZoneInfo
from google.adk.agents.llm_agent import Agent
from google.adk.tools.agent_tool import AgentTool
from google.adk.tools.preload_memory_tool import PreloadMemoryTool
from google.adk.tools.load_memory_tool import load_memory_tool
# Import all our specialized sub-agents
from .research import research_agent
from .todo import todo_agent
from .calendar import calendar_agent
import tzlocal
# Automatically detect the local system timezone
TIMEZONE = tzlocal.get_localzone_name()
# Callback for persistent memory storage
async def auto_save_session_to_memory_callback(callback_context):
await callback_context._invocation_context.memory_service.add_session_to_memory(
callback_context._invocation_context.session)
# Callback to inject the current time into the prompt
async def setup_agent_context(callback_context, **kwargs):
now = datetime.now(ZoneInfo(TIMEZONE))
callback_context.state["current_time"] = now.strftime("%A, %Y-%m-%d %I:%M %p")
callback_context.state["timezone"] = TIMEZONE
# --- ROOT AGENT DEFINITION ---
root_agent = Agent(
model='gemini-2.5-flash',
name='executive_assistant',
description='A professional AI Executive Assistant with memory and specialized tools.',
instruction='''
You are an elite, high-signal AI Executive Assistant.
Your goal is to help the user manage their knowledge, tasks, research, and schedule.
## Your Capabilities:
1. Memory: Use load_memory to recall personal facts.
2. Research: Delegate complex web investigations to the research_specialist.
3. Tasks: Delegate all to-do list management to the todo_specialist.
4. Scheduling: Delegate all calendar queries to the calendar_specialist.
## 🕒 Current State
- Time: {current_time?}
- Timezone: {timezone?}
Always be direct and professional.
''',
tools=[
PreloadMemoryTool(),
load_memory_tool,
AgentTool(todo_agent),
AgentTool(calendar_agent)
],
sub_agents=[research_agent],
before_agent_callback=[setup_agent_context],
after_agent_callback=[auto_save_session_to_memory_callback],
)
Обратите внимание, что помимо инструмента календаря, мы также добавили новую функцию обратного вызова перед запуском агента : setup_agent_context . Эта функция предоставляет агенту информацию о текущей дате, времени и часовом поясе, что позволяет ему более эффективно использовать календарь. Она работает путем установки переменных состояния сессии — особого типа памяти агента, предназначенной для кратковременного сохранения данных.
Запустите adk web еще раз, чтобы протестировать агент полностью!
uv run adk web --memory_service_uri="agentengine://$ENGINE_ID"
Состояние сессии можно проверить на вкладке «Состояние» в пользовательском интерфейсе разработчика:
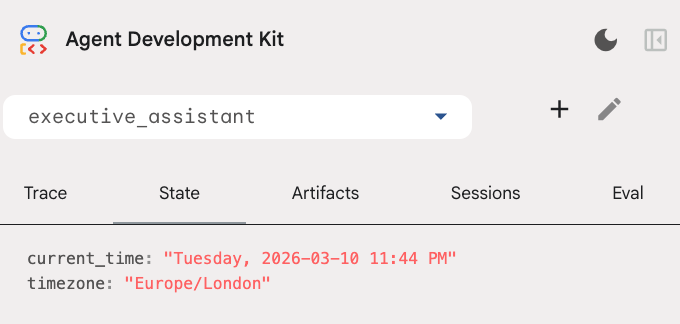
Теперь у вас есть агент, который может отслеживать события календаря, списки дел, проводить исследования и обладает долговременной памятью!
Уборка после работы в лаборатории
9. Заключение
Поздравляем! Вы успешно разработали многофункциональный ИИ-помощник для руководителей, пройдя 5 этапов эволюции.
Что мы обсудили
- Обеспечение инфраструктуры для агентов искусственного интеллекта.
- Реализация постоянной памяти и специализированных субагентов с использованием встроенных функций ADK.
- Интеграция внешних баз данных и API для повышения производительности.
Следующие шаги
Вы можете продолжить обучение, изучая другие практические задания на этой платформе или самостоятельно улучшая работу помощника руководителя.
Если вам нужны идеи для улучшений, вы можете попробовать следующее:
- Внедрите сжатие событий для оптимизации производительности при длительных диалогах.
- Добавьте службу обработки артефактов, чтобы агент мог делать заметки за вас и сохранять их в виде файлов.
- Разверните своего агента в качестве серверной службы, используя Google Cloud Run.
После завершения тестирования не забудьте очистить среду, чтобы избежать непредвиденных расходов на вашем платежном счете.
Удачного программирования!