
۱. مقدمه

آخرین بهروزرسانی: ۱۴-۰۷-۲۰۲۲
قابلیت مشاهده برنامه
مشاهدهپذیری و پروفایلر پیوسته
قابلیت مشاهده اصطلاحی است که برای توصیف یک ویژگی از یک سیستم به کار میرود. سیستمی با قابلیت مشاهده به تیمها اجازه میدهد تا به طور فعال سیستم خود را اشکالزدایی کنند. در این زمینه، سه رکن قابلیت مشاهده؛ لاگها، معیارها و ردیابیها، ابزار اساسی برای سیستم جهت دستیابی به قابلیت مشاهده هستند.
همچنین علاوه بر سه رکن مشاهدهپذیری، پروفایلسازی مداوم یکی دیگر از مؤلفههای کلیدی برای مشاهدهپذیری است و در حال گسترش پایگاه کاربر در صنعت است. Cloud Profiler یکی از مبتکران این حوزه است و رابط کاربری آسانی را برای بررسی دقیقتر معیارهای عملکرد در پشتههای فراخوانی برنامه فراهم میکند.
این آزمایشگاه کد، بخش دوم این مجموعه است و به ابزار دقیق یک عامل پروفایلر پیوسته میپردازد. بخش اول، ردیابی توزیعشده با OpenTelemetry و Cloud Trace را پوشش میدهد و در بخش اول، اطلاعات بیشتری در مورد شناسایی بهتر گلوگاههای میکروسرویسها کسب خواهید کرد.
آنچه خواهید ساخت
در این آزمایشگاه کد، شما قرار است یک عامل پروفایلر پیوسته را در سرویس سرور "برنامه شکسپیر" (معروف به Shakesapp) که بر روی یک خوشه موتور Kubernetes گوگل اجرا میشود، پیادهسازی کنید. معماری Shakesapp به شرح زیر است:

- Loadgen یک رشته پرسوجو را به صورت HTTP به کلاینت ارسال میکند.
- کلاینتها در gRPC از طریق loadgen درخواست را به سرور ارسال میکنند.
- سرور، کوئری را از کلاینت میپذیرد، تمام آثار Shakespare را در قالب متن از Google Cloud Storage دریافت میکند، خطوطی را که شامل کوئری هستند جستجو میکند و شماره خطی را که با کوئری مطابقت دارد به کلاینت برمیگرداند.
در بخش اول، متوجه شدید که گلوگاه در جایی از سرویس سرور وجود دارد، اما نتوانستید علت دقیق آن را شناسایی کنید.
آنچه یاد خواهید گرفت
- نحوه جاسازی عامل پروفایلر
- چگونه گلوگاههای موجود در Cloud Profiler را بررسی کنیم؟
این آزمایشگاه کد توضیح میدهد که چگونه یک عامل پروفایلر پیوسته را در برنامه خود ابزاربندی کنید.
آنچه نیاز دارید
- دانش اولیه از Go
- دانش اولیه از Kubernetes
۲. تنظیمات و الزامات
تنظیم محیط خودتنظیم
اگر از قبل حساب گوگل (جیمیل یا برنامههای گوگل) ندارید، باید یکی ایجاد کنید . وارد کنسول پلتفرم ابری گوگل ( console.cloud.google.com ) شوید و یک پروژه جدید ایجاد کنید.
اگر از قبل پروژهای دارید، روی منوی کشویی انتخاب پروژه در سمت چپ بالای کنسول کلیک کنید:

و در پنجرهی باز شده روی دکمهی «پروژهی جدید» کلیک کنید تا یک پروژهی جدید ایجاد شود:

اگر از قبل پروژهای ندارید، باید پنجرهای مانند این را برای ایجاد اولین پروژه خود ببینید:

پنجرهی بعدیِ ایجاد پروژه به شما امکان میدهد جزئیات پروژهی جدید خود را وارد کنید:
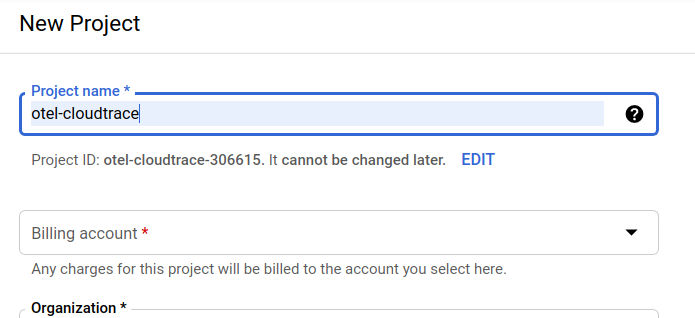
شناسه پروژه را به خاطر بسپارید، که یک نام منحصر به فرد در تمام پروژههای Google Cloud است (نام بالا قبلاً گرفته شده و برای شما کار نخواهد کرد، متاسفیم!). بعداً در این آزمایشگاه کد به آن PROJECT_ID گفته خواهد شد.
در مرحله بعد، اگر قبلاً این کار را نکردهاید، برای استفاده از منابع Google Cloud و فعال کردن Cloud Trace API ، باید صورتحساب را در کنسول توسعهدهندگان فعال کنید .

اجرای این آزمایشگاه کد نباید بیش از چند دلار برای شما هزینه داشته باشد، اما اگر تصمیم به استفاده از منابع بیشتر بگیرید یا اگر آنها را در حال اجرا رها کنید (به بخش "پاکسازی" در انتهای این سند مراجعه کنید)، میتواند بیشتر هزینه داشته باشد. قیمتهای Google Cloud Trace، Google Kubernetes Engine و Google Artifact Registry در اسناد رسمی ذکر شده است.
- قیمتگذاری مجموعه عملیات گوگل کلود | مجموعه عملیات
- قیمتگذاری | مستندات موتور Kubernetes
- قیمتگذاری ثبت آثار باستانی | مستندات ثبت آثار باستانی
کاربران جدید پلتفرم ابری گوگل واجد شرایط دریافت یک دوره آزمایشی رایگان ۳۰۰ دلاری هستند که این کدلب را کاملاً رایگان میکند.
راهاندازی پوسته ابری گوگل
اگرچه میتوان از راه دور و از طریق لپتاپ، Google Cloud و Google Cloud Trace را مدیریت کرد، اما در این آزمایشگاه کد، از Google Cloud Shell ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهیم کرد.
این ماشین مجازی مبتنی بر دبیان، تمام ابزارهای توسعه مورد نیاز شما را در خود جای داده است. این ماشین مجازی یک دایرکتوری خانگی ۵ گیگابایتی دائمی ارائه میدهد و در فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. این بدان معناست که تنها چیزی که برای این آزمایشگاه کد نیاز دارید یک مرورگر است (بله، روی کرومبوک هم کار میکند).
برای فعال کردن Cloud Shell از کنسول Cloud، کافیست روی Activate Cloud Shell کلیک کنید.  (فقط چند لحظه طول میکشد تا آماده شود و به محیط متصل شود).
(فقط چند لحظه طول میکشد تا آماده شود و به محیط متصل شود).

پس از اتصال به Cloud Shell، باید ببینید که از قبل احراز هویت شدهاید و پروژه از قبل روی PROJECT_ID شما تنظیم شده است.
gcloud auth list
خروجی دستور
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
خروجی دستور
[core] project = <PROJECT_ID>
اگر به هر دلیلی پروژه تنظیم نشده باشد، کافیست دستور زیر را اجرا کنید:
gcloud config set project <PROJECT_ID>
به دنبال PROJECT_ID خود هستید؟ بررسی کنید که در مراحل راهاندازی از چه شناسهای استفاده کردهاید یا آن را در داشبورد Cloud Console جستجو کنید:

Cloud Shell همچنین برخی از متغیرهای محیطی را به طور پیشفرض تنظیم میکند که ممکن است هنگام اجرای دستورات بعدی مفید باشند.
echo $GOOGLE_CLOUD_PROJECT
خروجی دستور
<PROJECT_ID>
در نهایت، منطقه پیشفرض و پیکربندی پروژه را تنظیم کنید.
gcloud config set compute/zone us-central1-f
شما میتوانید مناطق مختلفی را انتخاب کنید. برای اطلاعات بیشتر، به بخش مناطق و نواحی مراجعه کنید.
تنظیمات زبان برو
در این آزمایشگاه کد، ما از Go برای تمام کد منبع استفاده میکنیم. دستور زیر را روی Cloud Shell اجرا کنید و بررسی کنید که آیا نسخه Go 1.17+ است یا خیر.
go version
خروجی دستور
go version go1.18.3 linux/amd64
راهاندازی یک کلاستر گوگل کوبرنتیز
در این آزمایشگاه کد، شما یک کلاستر از میکروسرویسها را روی موتور کوبرنتیز گوگل (GKE) اجرا خواهید کرد. فرآیند این آزمایشگاه کد به شرح زیر است:
- پروژه پایه را در Cloud Shell دانلود کنید
- ساخت میکروسرویسها در کانتینرها
- کانتینرها را در فهرست آثار باستانی گوگل (GAR) بارگذاری کنید
- کانتینرها را روی GKE مستقر کنید
- کد منبع سرویسها را برای ابزار دقیق ردیابی تغییر دهید
- به مرحله ۲ بروید
فعال کردن موتور Kubernetes
ابتدا، ما یک کلاستر Kubernetes راهاندازی میکنیم که Shakesapp روی GKE اجرا میشود، بنابراین باید GKE را فعال کنیم. به منوی "Kubernetes Engine" بروید و دکمه ENABLE را فشار دهید.

اکنون آماده ایجاد یک خوشه Kubernetes هستید.
ایجاد خوشه Kubernetes
در Cloud Shell، دستور زیر را برای ایجاد یک کلاستر Kubernetes اجرا کنید. لطفاً تأیید کنید که مقدار منطقه، زیر منطقهای است که برای ایجاد مخزن Artifact Registry استفاده خواهید کرد. اگر منطقه مخزن شما منطقه را پوشش نمیدهد، مقدار منطقه را us-central1-f تغییر دهید.
gcloud container clusters create otel-trace-codelab2 \ --zone us-central1-f \ --release-channel rapid \ --preemptible \ --enable-autoscaling \ --max-nodes 8 \ --no-enable-ip-alias \ --scopes cloud-platform
خروجی دستور
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s). Creating cluster otel-trace-codelab2 in us-central1-f... Cluster is being health-checked (master is healthy)...done. Created [https://container.googleapis.com/v1/projects/development-215403/zones/us-central1-f/clusters/otel-trace-codelab2]. To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/workload_/gcloud/us-central1-f/otel-trace-codelab2?project=development-215403 kubeconfig entry generated for otel-trace-codelab2. NAME: otel-trace-codelab2 LOCATION: us-central1-f MASTER_VERSION: 1.23.6-gke.1501 MASTER_IP: 104.154.76.89 MACHINE_TYPE: e2-medium NODE_VERSION: 1.23.6-gke.1501 NUM_NODES: 3 STATUS: RUNNING
ثبت آثار باستانی و تنظیم اسکلت
اکنون یک کلاستر Kubernetes آماده برای استقرار داریم. در مرحله بعد، برای ثبت کانتینرها جهت ارسال و استقرار کانتینرها، آماده میشویم. برای این مراحل، باید یک ثبت مصنوعات (GAR) راهاندازی کنیم و آن را skaffold کنیم تا از آن استفاده شود.
تنظیم رجیستری مصنوعات
به منوی «ثبت آثار باستانی» بروید و دکمهی «فعالسازی» (ENABLE) را فشار دهید.

بعد از چند لحظه، مرورگر مخزن GAR را مشاهده خواهید کرد. روی دکمه "ایجاد مخزن" کلیک کنید و نام مخزن را وارد کنید.
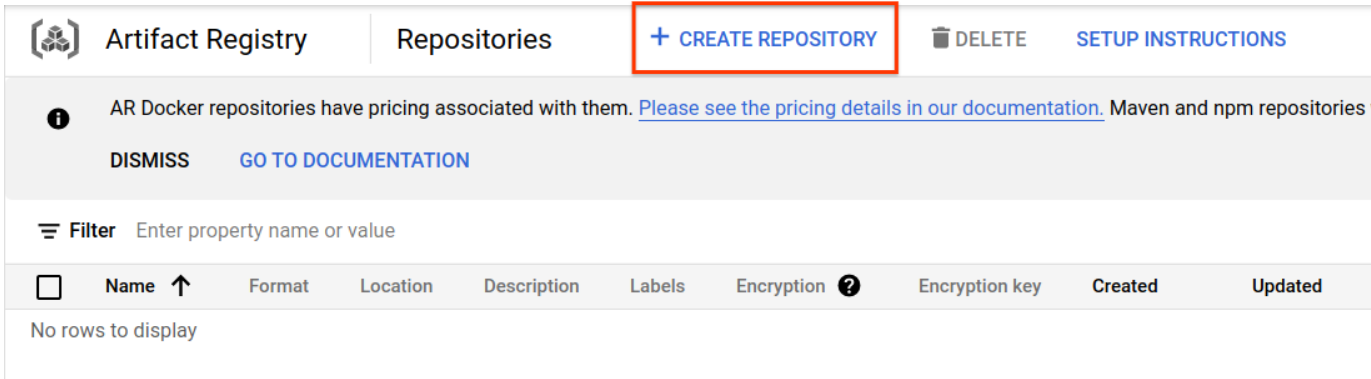
در این codelab، من مخزن جدید را trace-codelab نامگذاری میکنم. قالب مصنوع "Docker" و نوع مکان "Region" است. منطقهای را انتخاب کنید که به منطقهای که برای منطقه پیشفرض Google Compute Engine تعیین کردهاید، نزدیک باشد. برای مثال، در این مثال "us-central1-f" در بالا انتخاب شده است، بنابراین در اینجا "us-central1 (Iowa)" را انتخاب میکنیم. سپس روی دکمه "CREATE" کلیک کنید.

حالا عبارت "trace-codelab" را در مرورگر مخزن مشاهده میکنید.

بعداً برای بررسی مسیر رجیستری به اینجا برمیگردیم.
نصب اسکفولد
Skaffold ابزاری مفید برای ساخت میکروسرویسهایی است که روی Kubernetes اجرا میشوند. این ابزار گردش کار ساخت، ارسال و استقرار کانتینرهای برنامهها را با مجموعهای کوچک از دستورات مدیریت میکند. Skaffold به طور پیشفرض از Docker Registry به عنوان رجیستری کانتینر استفاده میکند، بنابراین باید Skaffold را طوری پیکربندی کنید که GAR را هنگام ارسال کانتینرها به آن تشخیص دهد.
دوباره Cloud Shell را باز کنید و تأیید کنید که آیا skaffold نصب شده است یا خیر. (Cloud Shell به طور پیشفرض skaffold را در محیط نصب میکند.) دستور زیر را اجرا کنید و نسخه skaffold را مشاهده کنید.
skaffold version
خروجی دستور
v1.38.0
اکنون میتوانید مخزن پیشفرض را برای استفاده skaffold ثبت کنید. برای به دست آوردن مسیر رجیستری، به داشبورد Artifact Registry بروید و روی نام مخزنی که در مرحله قبل تنظیم کردهاید کلیک کنید.
سپس مسیرهای breadcrumbs را در بالای صفحه مشاهده خواهید کرد. کلیک کنید  آیکون برای کپی کردن مسیر رجیستری به کلیپ بورد.
آیکون برای کپی کردن مسیر رجیستری به کلیپ بورد.

با کلیک بر روی دکمه کپی، کادر محاورهای در پایین مرورگر با پیامی مانند زیر مشاهده خواهید کرد:
«us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab» کپی شده است
به پوسته ابری برگردید. دستور skaffold config set default-repo را با مقداری که از داشبورد کپی کردهاید، اجرا کنید.
skaffold config set default-repo us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab
خروجی دستور
set value default-repo to us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab for context gke_stackdriver-sandbox-3438851889_us-central1-b_stackdriver-sandbox
همچنین، باید رجیستری را با پیکربندی داکر پیکربندی کنید. دستور زیر را اجرا کنید:
gcloud auth configure-docker us-central1-docker.pkg.dev --quiet
خروجی دستور
{
"credHelpers": {
"gcr.io": "gcloud",
"us.gcr.io": "gcloud",
"eu.gcr.io": "gcloud",
"asia.gcr.io": "gcloud",
"staging-k8s.gcr.io": "gcloud",
"marketplace.gcr.io": "gcloud",
"us-central1-docker.pkg.dev": "gcloud"
}
}
Adding credentials for: us-central1-docker.pkg.dev
حالا میتوانید به مرحله بعدی بروید و یک کانتینر Kubernetes روی GKE راهاندازی کنید.
خلاصه
در این مرحله، محیط codelab خود را تنظیم میکنید:
- راهاندازی پوسته ابری
- یک مخزن Artifact Registry برای رجیستری کانتینر ایجاد کرد.
- تنظیم skaffold برای استفاده از رجیستری کانتینر
- یک کلاستر Kubernetes ایجاد کردیم که میکروسرویسهای codelab در آن اجرا میشوند.
بعدی
در مرحله بعد، شما عامل پروفایلر پیوسته را در سرویس سرور ابزاربندی خواهید کرد.
۳. ساخت، اجرا و استقرار میکروسرویسها
دانلود مطالب codelab
در مرحله قبل، تمام پیشنیازهای این codelab را تنظیم کردیم. اکنون آمادهاید تا کل میکروسرویسها را روی آنها اجرا کنید. مطالب codelab در GitHub میزبانی میشود، بنابراین آنها را با دستور git زیر در محیط Cloud Shell دانلود کنید.
cd ~ git clone https://github.com/ymotongpoo/opentelemetry-trace-codelab-go.git cd opentelemetry-trace-codelab-go
ساختار دایرکتوری پروژه به صورت زیر است:
.
├── README.md
├── step0
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step1
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step2
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step3
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step4
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step5
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
└── step6
├── manifests
├── proto
├── skaffold.yaml
└── src
- مانیفستها: فایلهای مانیفست Kubernetes
- proto: تعریف proto برای ارتباط بین کلاینت و سرور
- src: دایرکتوریهای مربوط به کد منبع هر سرویس
- skaffold.yaml: فایل پیکربندی برای skaffold
در این آزمایشگاه کد، کد منبع موجود در پوشه step4 را بهروزرسانی خواهید کرد. همچنین میتوانید برای مشاهده تغییرات از ابتدا، به کد منبع موجود در پوشههای step[1-6] مراجعه کنید. (بخش 1 مراحل 0 تا step4 و بخش 2 مراحل 5 و 6 را پوشش میدهد)
دستور skaffold را اجرا کنید
در نهایت، شما آمادهاید تا کل محتوا را روی کلاستر Kubernetes که ایجاد کردهاید، بسازید، بارگذاری کنید و مستقر کنید. به نظر میرسد که این شامل چندین مرحله است، اما در واقع skaffold همه چیز را برای شما انجام میدهد. بیایید این کار را با دستور زیر امتحان کنیم:
cd step4 skaffold dev
As soon as running the command, you see the log output of docker build and can confirm that they are successfully pushed to the registry.
خروجی دستور
... ---> Running in c39b3ea8692b ---> 90932a583ab6 Successfully built 90932a583ab6 Successfully tagged us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice:step1 The push refers to repository [us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice] cc8f5a05df4a: Preparing 5bf719419ee2: Preparing 2901929ad341: Preparing 88d9943798ba: Preparing b0fdf826a39a: Preparing 3c9c1e0b1647: Preparing f3427ce9393d: Preparing 14a1ca976738: Preparing f3427ce9393d: Waiting 14a1ca976738: Waiting 3c9c1e0b1647: Waiting b0fdf826a39a: Layer already exists 88d9943798ba: Layer already exists f3427ce9393d: Layer already exists 3c9c1e0b1647: Layer already exists 14a1ca976738: Layer already exists 2901929ad341: Pushed 5bf719419ee2: Pushed cc8f5a05df4a: Pushed step1: digest: sha256:8acdbe3a453001f120fb22c11c4f6d64c2451347732f4f271d746c2e4d193bbe size: 2001
پس از بارگذاری تمام کانتینرهای سرویس، استقرار Kubernetes به طور خودکار آغاز میشود.
خروجی دستور
sha256:b71fce0a96cea08075dc20758ae561cf78c83ff656b04d211ffa00cedb77edf8 size: 1997 Tags used in deployment: - serverservice -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice:step4@sha256:8acdbe3a453001f120fb22c11c4f6d64c2451347732f4f271d746c2e4d193bbe - clientservice -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/clientservice:step4@sha256:b71fce0a96cea08075dc20758ae561cf78c83ff656b04d211ffa00cedb77edf8 - loadgen -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/loadgen:step4@sha256:eea2e5bc8463ecf886f958a86906cab896e9e2e380a0eb143deaeaca40f7888a Starting deploy... - deployment.apps/clientservice created - service/clientservice created - deployment.apps/loadgen created - deployment.apps/serverservice created - service/serverservice created
پس از استقرار، گزارشهای واقعی برنامه را که به stdout در هر کانتینر ارسال میشوند، مانند این خواهید دید:
خروجی دستور
[client] 2022/07/14 06:33:15 {"match_count":3040}
[loadgen] 2022/07/14 06:33:15 query 'love': matched 3040
[client] 2022/07/14 06:33:15 {"match_count":3040}
[loadgen] 2022/07/14 06:33:15 query 'love': matched 3040
[client] 2022/07/14 06:33:16 {"match_count":3040}
[loadgen] 2022/07/14 06:33:16 query 'love': matched 3040
[client] 2022/07/14 06:33:19 {"match_count":463}
[loadgen] 2022/07/14 06:33:19 query 'tear': matched 463
[loadgen] 2022/07/14 06:33:20 query 'world': matched 728
[client] 2022/07/14 06:33:20 {"match_count":728}
[client] 2022/07/14 06:33:22 {"match_count":463}
[loadgen] 2022/07/14 06:33:22 query 'tear': matched 463
توجه داشته باشید که در این مرحله، میخواهید هرگونه پیامی را از سرور مشاهده کنید. بسیار خب، بالاخره آمادهاید تا برنامه خود را با OpenTelemetry برای ردیابی توزیعشده سرویسها تجهیز کنید.
قبل از شروع به ابزاربندی سرویس، لطفاً کلاستر خود را با Ctrl-C خاموش کنید.
خروجی دستور
...
[client] 2022/07/14 06:34:57 {"match_count":1}
[loadgen] 2022/07/14 06:34:57 query 'what's past is prologue': matched 1
^CCleaning up...
- W0714 06:34:58.464305 28078 gcp.go:120] WARNING: the gcp auth plugin is deprecated in v1.22+, unavailable in v1.25+; use gcloud instead.
- To learn more, consult https://cloud.google.com/blog/products/containers-kubernetes/kubectl-auth-changes-in-gke
- deployment.apps "clientservice" deleted
- service "clientservice" deleted
- deployment.apps "loadgen" deleted
- deployment.apps "serverservice" deleted
- service "serverservice" deleted
خلاصه
در این مرحله، شما مواد codelab را در محیط خود آماده کردهاید و تأیید کردهاید که skaffold مطابق انتظار اجرا میشود.
بعدی
در مرحله بعد، کد منبع سرویس loadgen را برای ابزار دقیق اطلاعات ردیابی تغییر خواهید داد.
۴. ابزار دقیق عامل Cloud Profiler
مفهوم پروفایلینگ پیوسته
قبل از توضیح مفهوم پروفایلینگ مداوم، ابتدا باید مفهوم پروفایلینگ را درک کنیم. پروفایلینگ یکی از راههای تجزیه و تحلیل پویای برنامه (تجزیه و تحلیل پویای برنامه) است و معمولاً در طول توسعه برنامه در فرآیند تست بار و غیره انجام میشود. این یک فعالیت تک مرحلهای برای اندازهگیری معیارهای سیستم، مانند میزان استفاده از CPU و حافظه، در طول دوره خاص است. پس از جمعآوری دادههای پروفایل، توسعهدهندگان آنها را از روی کد تجزیه و تحلیل میکنند.
پروفایلسازی مداوم، رویکرد توسعهیافتهی پروفایلسازی معمولی است: این پروفایلها، پروفایلهای پنجرهی کوتاه را به صورت دورهای در برابر برنامهی طولانیمدت اجرا میکنند و مجموعهای از دادههای پروفایل را جمعآوری میکنند. سپس به طور خودکار تجزیه و تحلیل آماری را بر اساس یک ویژگی خاص از برنامه، مانند شماره نسخه، منطقهی استقرار، زمان اندازهگیری و غیره، تولید میکنند. جزئیات بیشتر این مفهوم را در مستندات ما خواهید یافت.
از آنجا که هدف یک برنامه در حال اجرا است، راهی برای جمعآوری دادههای پروفایل به صورت دورهای و ارسال آنها به یک backend وجود دارد که دادههای آماری را پس پردازش میکند. این عامل Cloud Profiler است و شما به زودی آن را در سرویس سرور جاسازی خواهید کرد.
عامل Cloud Profiler را جاسازی کنید
با فشار دادن دکمه، ویرایشگر Cloud Shell را باز کنید  در بالا سمت راست Cloud Shell. از پنجره اکسپلورر در سمت چپ،
در بالا سمت راست Cloud Shell. از پنجره اکسپلورر در سمت چپ، step4/src/server/main.go را باز کنید و تابع main را پیدا کنید.
مرحله ۴/src/server/main.go
func main() {
...
// step2. setup OpenTelemetry
tp, err := initTracer()
if err != nil {
log.Fatalf("failed to initialize TracerProvider: %v", err)
}
defer func() {
if err := tp.Shutdown(context.Background()); err != nil {
log.Fatalf("error shutting down TracerProvider: %v", err)
}
}()
// step2. end setup
svc := NewServerService()
// step2: add interceptor
interceptorOpt := otelgrpc.WithTracerProvider(otel.GetTracerProvider())
srv := grpc.NewServer(
grpc.UnaryInterceptor(otelgrpc.UnaryServerInterceptor(interceptorOpt)),
grpc.StreamInterceptor(otelgrpc.StreamServerInterceptor(interceptorOpt)),
)
// step2: end adding interceptor
shakesapp.RegisterShakespeareServiceServer(srv, svc)
healthpb.RegisterHealthServer(srv, svc)
if err := srv.Serve(lis); err != nil {
log.Fatalf("error serving server: %v", err)
}
}
در تابع main ، شما تعدادی کد راهاندازی برای OpenTelemetry و gRPC میبینید که در بخش اول codelab انجام شده است. اکنون ابزار دقیق را برای عامل Cloud Profiler در اینجا اضافه خواهید کرد. مانند کاری که برای initTracer() انجام دادیم، میتوانید تابعی به نام initProfiler() برای خوانایی بیشتر بنویسید.
مرحله ۴/src/server/main.go
import (
...
"cloud.google.com/go/profiler" // step5. add profiler package
"cloud.google.com/go/storage"
...
)
// step5: add Profiler initializer
func initProfiler() {
cfg := profiler.Config{
Service: "server",
ServiceVersion: "1.0.0",
NoHeapProfiling: true,
NoAllocProfiling: true,
NoGoroutineProfiling: true,
NoCPUProfiling: false,
}
if err := profiler.Start(cfg); err != nil {
log.Fatalf("failed to launch profiler agent: %v", err)
}
}
بیایید نگاهی دقیقتر به گزینههای مشخص شده در شیء profiler.Config{} بیندازیم.
- سرویس : نام سرویسی که میتوانید انتخاب کنید و در داشبورد پروفایلر فعال کنید
- ServiceVersion : نام نسخه سرویس. میتوانید مجموعه دادههای پروفایل را بر اساس این مقدار مقایسه کنید.
- NoHeapProfiling : غیرفعال کردن پروفایل مصرف حافظه
- NoAllocProfiling : غیرفعال کردن پروفایل تخصیص حافظه
- NoGoroutineProfiling : غیرفعال کردن پروفایلبندی گوروتین
- NoCPUProfiling : غیرفعال کردن پروفایل CPU
در این آزمایشگاه کد، ما فقط پروفایلبندی CPU را فعال میکنیم.
حالا کاری که باید انجام دهید این است که این تابع را در تابع main فراخوانی کنید. مطمئن شوید که پکیج Cloud Profiler را در بلوک import وارد کردهاید.
مرحله ۴/src/server/main.go
func main() {
...
defer func() {
if err := tp.Shutdown(context.Background()); err != nil {
log.Fatalf("error shutting down TracerProvider: %v", err)
}
}()
// step2. end setup
// step5. start profiler
go initProfiler()
// step5. end
svc := NewServerService()
// step2: add interceptor
...
}
توجه داشته باشید که شما تابع initProfiler() را با کلمه کلیدی go فراخوانی میکنید. از آنجا که profiler.Start() بلوکبندی میکند، باید آن را در یک goroutine دیگر اجرا کنید. اکنون آماده ساخت است. قبل از استقرار، حتماً go mod tidy را اجرا کنید.
go mod tidy
اکنون کلاستر خود را با سرویس سرور جدید خود مستقر کنید.
skaffold dev
معمولاً چند دقیقه طول میکشد تا نمودار شعلهای را در Cloud Profiler مشاهده کنید. در کادر جستجو در بالا، عبارت "profiler" را تایپ کنید و روی نماد Profiler کلیک کنید.

سپس نمودار شعلهای زیر را مشاهده خواهید کرد.

خلاصه
در این مرحله، شما عامل Cloud Profiler را در سرویس سرور تعبیه کردید و تأیید کردید که نمودار شعلهای تولید میکند.
بعدی
در مرحله بعد، با استفاده از نمودار شعلهای، علت گلوگاه در برنامه را بررسی خواهید کرد.
۵. نمودار شعلهای Cloud Profiler را تحلیل کنید
نمودار شعلهای چیست؟
نمودار شعلهای یکی از راههای تجسم دادههای پروفایل است. برای توضیح بیشتر، لطفاً به سند ما مراجعه کنید، اما خلاصه آن به شرح زیر است:
- هر نوار، فراخوانی متد/تابع در برنامه را بیان میکند.
- جهت عمودی، پشته فراخوانی است؛ پشته فراخوانی از بالا به پایین رشد میکند.
- جهت افقی، میزان استفاده از منابع است؛ هر چه طولانیتر، بدتر.
با توجه به این موضوع، بیایید به نمودار شعلهای بهدستآمده نگاهی بیندازیم.
تحلیل نمودار شعلهای
در بخش قبل، یاد گرفتید که هر نوار در نمودار شعلهای، فراخوانی تابع/متد را بیان میکند و طول آن به معنای میزان استفاده از منابع در تابع/متد است. نمودار شعلهای Cloud Profiler نوار را به ترتیب نزولی یا بر اساس طول از چپ به راست مرتب میکند، میتوانید ابتدا از بالا سمت چپ نمودار شروع به بررسی کنید.

در مورد ما، واضح است که grpc.(*Server).serveStreams.func1.2 بیشترین زمان CPU را مصرف میکند، و با نگاه کردن به پشته فراخوانی از بالا به پایین، این زمان بیشتر در main.(*serverService).GetMatchCount صرف میشود، که هندلر سرور gRPC در سرویس سرور است.
در زیر GetMatchCount، مجموعهای از توابع regexp را مشاهده میکنید: regexp.MatchString و regexp.Compile . آنها از بسته استاندارد هستند: یعنی باید از بسیاری از دیدگاهها، از جمله عملکرد، به خوبی آزمایش شوند. اما نتیجه اینجا نشان میدهد که استفاده از منابع زمانی CPU در regexp.MatchString و regexp.Compile زیاد است. با توجه به این حقایق، فرض اینجا این است که استفاده از regexp.MatchString ارتباطی با مشکلات عملکرد دارد. بنابراین بیایید کد منبعی را که این تابع در آن استفاده شده است، بخوانیم.
مرحله ۴/src/server/main.go
func (s *serverService) GetMatchCount(ctx context.Context, req *shakesapp.ShakespeareRequest) (*shakesapp.ShakespeareResponse, error) {
resp := &shakesapp.ShakespeareResponse{}
texts, err := readFiles(ctx, bucketName, bucketPrefix)
if err != nil {
return resp, fmt.Errorf("fails to read files: %s", err)
}
for _, text := range texts {
for _, line := range strings.Split(text, "\n") {
line, query := strings.ToLower(line), strings.ToLower(req.Query)
isMatch, err := regexp.MatchString(query, line)
if err != nil {
return resp, err
}
if isMatch {
resp.MatchCount++
}
}
}
return resp, nil
}
این جایی است که regexp.MatchString فراخوانی میشود. با خواندن کد منبع، ممکن است متوجه شوید که این تابع درون حلقه for تو در تو فراخوانی میشود. بنابراین استفاده از این تابع ممکن است نادرست باشد. بیایید GoDoc مربوط به regexp را بررسی کنیم.

طبق این سند، regexp.MatchString الگوی عبارت منظم را در هر فراخوانی کامپایل میکند. بنابراین علت مصرف زیاد منابع به این شکل به نظر میرسد.
خلاصه
در این مرحله، شما با تحلیل نمودار شعلهای، فرض علت مصرف منابع را مطرح کردید.
بعدی
در مرحله بعد، کد منبع سرویس سرور را بهروزرسانی کرده و تغییر از نسخه ۱.۰.۰ را تأیید خواهید کرد.
۶. کد منبع را بهروزرسانی کنید و نمودارهای flame را تغییر دهید
کد منبع را بهروزرسانی کنید
در مرحله قبل، شما این فرض را مطرح کردید که استفاده از regexp.MatchString به نحوی با مصرف زیاد منابع مرتبط است. پس بیایید این مشکل را حل کنیم. کد را باز کنید و آن بخش را کمی تغییر دهید.
مرحله ۴/src/server/main.go
func (s *serverService) GetMatchCount(ctx context.Context, req *shakesapp.ShakespeareRequest) (*shakesapp.ShakespeareResponse, error) {
resp := &shakesapp.ShakespeareResponse{}
texts, err := readFiles(ctx, bucketName, bucketPrefix)
if err != nil {
return resp, fmt.Errorf("fails to read files: %s", err)
}
// step6. considered the process carefully and naively tuned up by extracting
// regexp pattern compile process out of for loop.
query := strings.ToLower(req.Query)
re := regexp.MustCompile(query)
for _, text := range texts {
for _, line := range strings.Split(text, "\n") {
line = strings.ToLower(line)
isMatch := re.MatchString(line)
// step6. done replacing regexp with strings
if isMatch {
resp.MatchCount++
}
}
}
return resp, nil
}
همانطور که میبینید، اکنون فرآیند کامپایل الگوی regexp از regexp.MatchString استخراج شده و از حلقه for تو در تو خارج میشود.
قبل از استقرار این کد، مطمئن شوید که رشته نسخه را در تابع initProfiler() بهروزرسانی کردهاید.
مرحله ۴/src/server/main.go
func initProfiler() {
cfg := profiler.Config{
Service: "server",
ServiceVersion: "1.1.0", // step6. update version
NoHeapProfiling: true,
NoAllocProfiling: true,
NoGoroutineProfiling: true,
NoCPUProfiling: false,
}
if err := profiler.Start(cfg); err != nil {
log.Fatalf("failed to launch profiler agent: %v", err)
}
}
حالا بیایید ببینیم چگونه کار میکند. کلاستر را با دستور skaffold مستقر کنید.
skaffold dev
و بعد از مدتی، داشبورد Cloud Profiler را دوباره بارگذاری کنید و ببینید که چگونه است.

مطمئن شوید که نسخه را به "1.1.0" تغییر میدهید تا فقط پروفایلهای نسخه 1.1.0 را ببینید. همانطور که میبینید، طول نوار GetMatchCount کاهش یافته و نسبت استفاده از زمان CPU نیز کمتر شده است (یعنی نوار کوتاهتر شده است).

نه تنها با نگاه کردن به نمودار شعلهای یک نسخه واحد، بلکه میتوانید تفاوتهای بین دو نسخه را نیز مقایسه کنید.

مقدار لیست کشویی "مقایسه با" را به "نسخه" تغییر دهید و مقدار "نسخه مقایسه شده" را به "1.0.0"، نسخه اصلی، تغییر دهید.

شما این نوع نمودار شعلهای را خواهید دید. شکل نمودار مشابه ۱.۱.۰ است اما رنگآمیزی آن متفاوت است. در حالت مقایسه ، معنی رنگ به شرح زیر است:
- آبی : مقدار (مصرف منابع) کاهش یافته
- نارنجی : ارزش (مصرف منابع) به دست آمده
- خاکستری : خنثی
با توجه به توضیحات، بیایید نگاه دقیقتری به تابع بیندازیم. با کلیک روی نواری که میخواهید بزرگنمایی کنید، میتوانید جزئیات بیشتری را درون پشته مشاهده کنید. لطفاً روی نوار main.(*serverService).GetMatchCount کلیک کنید. همچنین با نگه داشتن نشانگر ماوس روی نوار، جزئیات مقایسه را مشاهده خواهید کرد.

میگوید کل زمان CPU از ۵.۲۶ ثانیه به ۲.۸۸ ثانیه کاهش یافته است (مجموع ۱۰ ثانیه = پنجره نمونهبرداری). این یک پیشرفت بزرگ است!
اکنون میتوانید عملکرد برنامه خود را از تجزیه و تحلیل دادههای پروفایل بهبود بخشید.
خلاصه
در این مرحله، شما ویرایشی را در سرویس سرور انجام دادید و بهبود حالت مقایسه Cloud Profiler را تأیید کردید.
بعدی
در مرحله بعد، کد منبع سرویس سرور را بهروزرسانی کرده و تغییر از نسخه ۱.۰.۰ را تأیید خواهید کرد.
۷. مرحله اضافی: تأیید بهبود در آبشار Trace
تفاوت بین ردیابی توزیعشده و پروفایل پیوسته
در بخش اول آزمایشگاه کد، شما تأیید کردید که میتوانید گلوگاه سرویس را در سراسر میکروسرویسها برای یک مسیر درخواست تشخیص دهید و نمیتوانید علت دقیق گلوگاه را در سرویس خاص تشخیص دهید. در این آزمایشگاه کد بخش دوم، یاد گرفتید که پروفایلسازی مداوم به شما امکان میدهد گلوگاه را در داخل یک سرویس واحد از طریق پشتههای فراخوانی شناسایی کنید.
در این مرحله، بیایید نمودار آبشاری حاصل از ردیابی توزیعشده (Cloud Trace) را بررسی کنیم و تفاوت آن را با پروفایلسازی پیوسته ببینیم.
این نمودار آبشاری، یکی از مسیرهای جستجو با عبارت جستجو شده "love" است. در مجموع حدود ۶.۷ ثانیه (۶۷۰۰ میلیثانیه) طول میکشد.

و این بعد از بهبود برای همان پرس و جو است. همانطور که گفتید، کل تأخیر اکنون ۱.۵ ثانیه (۱۵۰۰ میلیثانیه) است که بهبود بزرگی نسبت به پیادهسازی قبلی است.
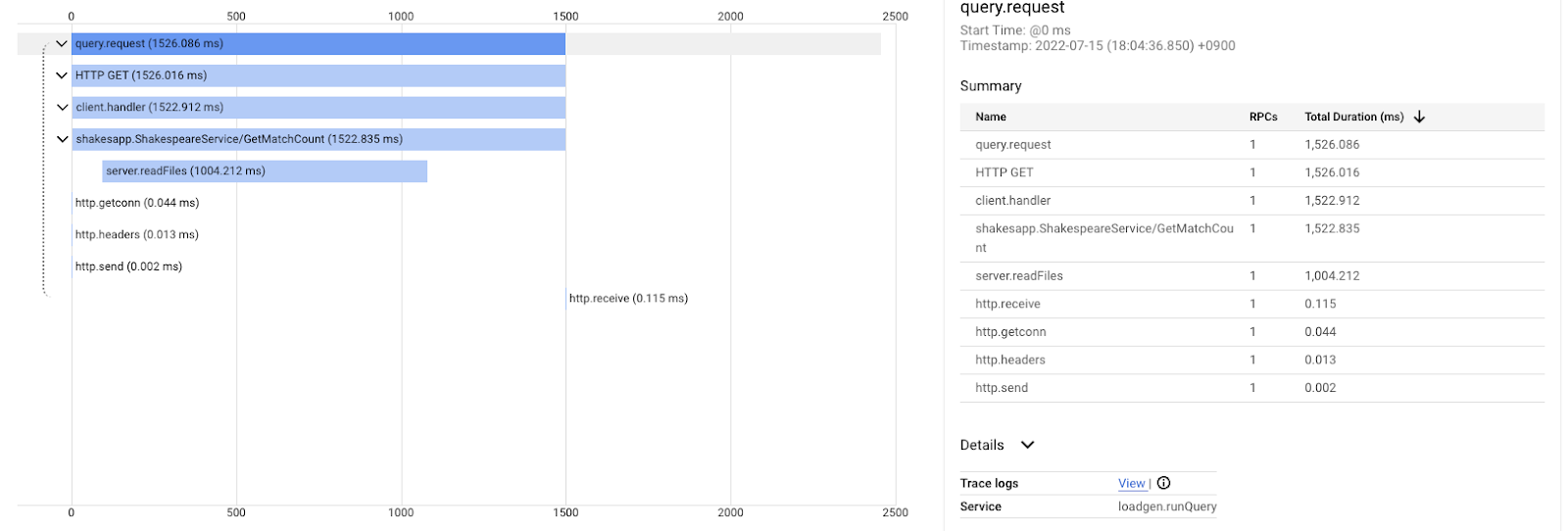
نکته مهم اینجاست که در نمودار آبشاری ردیابی توزیعشده، اطلاعات پشته فراخوانی در دسترس نیست مگر اینکه ابزار شما همه جا را پوشش دهد. همچنین ردیابیهای توزیعشده فقط بر تأخیر در سرویسها تمرکز میکنند در حالی که پروفایلینگ پیوسته بر منابع رایانهای (پردازنده، حافظه، نخهای سیستم عامل) یک سرویس واحد تمرکز دارد.
از جنبهای دیگر، رد توزیعشده، مبنای رویداد است، و نمایه پیوسته، آماری است. هر رد، نمودار تأخیر متفاوتی دارد و برای دریافت روند تغییرات تأخیر، به قالب متفاوتی مانند توزیع نیاز دارید.
خلاصه
در این مرحله، تفاوت بین ردیابی توزیعشده و پروفایلسازی پیوسته را بررسی کردید.
۸. تبریک
شما با موفقیت ردیابیهای توزیعشده را با OpenTelemery ایجاد کردید و تأخیر درخواستها را در سراسر میکروسرویس در Google Cloud Trace تأیید کردید.
برای تمرینهای طولانیتر، میتوانید خودتان موضوعات زیر را امتحان کنید.
- پیادهسازی فعلی تمام span های تولید شده توسط بررسی سلامت را ارسال میکند. (
grpc.health.v1.Health/Check) چگونه میتوان آن span ها را از Cloud Traces فیلتر کرد؟ راهنمایی اینجا است. - گزارشهای رویداد را با spanها مرتبط کنید و ببینید که چگونه در Google Cloud Trace و Google Cloud Logging کار میکند. راهنمایی اینجا است.
- یک سرویس را با سرویسی به زبان دیگر جایگزین کنید و سعی کنید آن را با OpenTelemetry برای آن زبان تجهیز کنید.
همچنین، اگر مایلید پس از این درباره پروفایلر اطلاعات بیشتری کسب کنید، لطفاً به بخش ۲ بروید. در این صورت میتوانید از بخش پاکسازی زیر صرف نظر کنید.
تمیز کردن
پس از این آزمایش کد، لطفاً خوشه Kubernetes را متوقف کنید و حتماً پروژه را حذف کنید تا هزینههای غیرمنتظرهای روی Google Kubernetes Engine، Google Cloud Trace و Google Artifact Registry دریافت نکنید.
ابتدا، کلاستر را حذف کنید. اگر کلاستر را با skaffold dev اجرا میکنید، فقط باید Ctrl-C را فشار دهید. اگر کلاستر را با skaffold run اجرا میکنید، دستور زیر را اجرا کنید:
skaffold delete
خروجی دستور
Cleaning up... - deployment.apps "clientservice" deleted - service "clientservice" deleted - deployment.apps "loadgen" deleted - deployment.apps "serverservice" deleted - service "serverservice" deleted
پس از حذف کلاستر، از قسمت منو، گزینه "IAM & Admin" > "Settings" را انتخاب کرده و سپس روی دکمه "SHUT DOWN" کلیک کنید.
سپس شناسه پروژه (نه نام پروژه) را در فرم موجود در کادر محاورهای وارد کنید و خاموش شدن را تأیید کنید.