
1. Introduction
Dernière mise à jour : 14/07/2022
Observabilité de l'application
Observabilité et profileur continu
L'observabilité est un terme utilisé pour décrire un attribut d'un système. Un système avec observabilité permet aux équipes de déboguer activement leur système. Dans ce contexte, les trois piliers de l'observabilité (journaux, métriques et traces) sont l'instrumentation fondamentale permettant au système d'acquérir l'observabilité.
En plus des trois piliers de l'observabilité, le profilage continu est un autre élément clé de l'observabilité et élargit la base d'utilisateurs dans le secteur. Cloud Profiler est l'un des outils d'origine et fournit une interface simple pour examiner en détail les métriques de performances dans les piles d'appels d'application.
Cet atelier de programmation est la deuxième partie de la série. Il explique comment instrumenter un agent de profileur continu. La partie 1 couvre le traçage distribué avec OpenTelemetry et Cloud Trace. Vous en apprendrez davantage sur l'identification du goulot d'étranglement des microservices dans la partie 1.
Objectifs de l'atelier
Dans cet atelier de programmation, vous allez instrumenter l'agent de profileur continu dans le service de serveur de l'application Shakespeare (également appelée Shakesapp) qui s'exécute sur un cluster Google Kubernetes Engine. L'architecture de Shakesapp est décrite ci-dessous :

- Loadgen envoie une chaîne de requête au client en HTTP.
- Les clients transmettent la requête du générateur de charge au serveur dans gRPC.
- Le serveur accepte la requête du client, récupère toutes les œuvres de Shakespeare au format texte à partir de Google Cloud Storage, recherche les lignes contenant la requête et renvoie au client le numéro de la ligne correspondante.
Dans la partie 1, vous avez constaté que le goulot d'étranglement se trouvait quelque part dans le service de serveur, mais vous n'avez pas pu identifier la cause exacte.
Points abordés
- Intégrer l'agent Profiler
- Identifier le goulot d'étranglement dans Cloud Profiler
Cet atelier de programmation explique comment instrumenter un agent de profileur continu dans votre application.
Prérequis
- Connaissances de base de Go
- Connaissances de base de Kubernetes
2. Préparation
Configuration de l'environnement au rythme de chacun
Si vous ne possédez pas encore de compte Google (Gmail ou Google Apps), vous devez en créer un. Connectez-vous à la console Google Cloud Platform (console.cloud.google.com) et créez un projet.
Si vous avez déjà un projet, cliquez sur le menu déroulant de sélection du projet dans l'angle supérieur gauche de la console :
Cliquez ensuite sur le bouton "NEW PROJECT" (NOUVEAU PROJET) dans la boîte de dialogue qui s'affiche pour créer un projet :
Si vous n'avez pas encore de projet, une boîte de dialogue semblable à celle-ci apparaîtra pour vous permettre d'en créer un :
La boîte de dialogue de création de projet suivante vous permet de saisir les détails de votre nouveau projet :
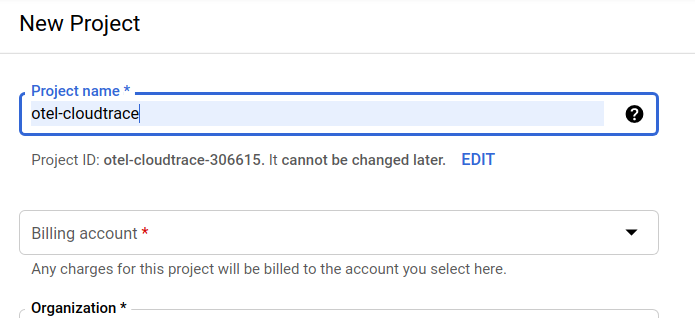
Notez l'ID du projet. Il s'agit d'un nom unique pour tous les projets Google Cloud, ce qui implique que le nom ci-dessus n'est plus disponible pour vous… Désolé ! Il sera désigné par le nom PROJECT_ID tout au long de cet atelier de programmation.
Ensuite, si ce n'est pas déjà fait, vous devez activer la facturation dans la console Développeurs afin de pouvoir utiliser les ressources Google Cloud, puis activer l'API Cloud Trace.
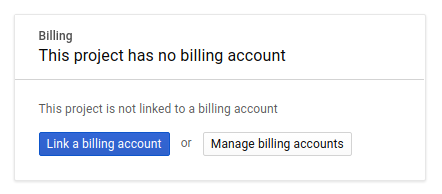
Suivre cet atelier de programmation ne devrait pas vous coûter plus d'un euro. Cependant, cela peut s'avérer plus coûteux si vous décidez d'utiliser davantage de ressources ou si vous n'interrompez pas les ressources (voir la section "Effectuer un nettoyage" à la fin du présent document). Les tarifs de Google Cloud Trace, Google Kubernetes Engine et Google Artifact Registry sont indiqués dans la documentation officielle.
- Tarifs de la suite Google Cloud Operations | Suite Operations
- Tarifs | Documentation Kubernetes Engine
- Tarifs d'Artifact Registry | Documentation Artifact Registry
Les nouveaux utilisateurs de Google Cloud Platform peuvent bénéficier d'un essai sans frais avec 300$de crédits afin de suivre sans frais le présent atelier.
Configuration de Google Cloud Shell
Bien que Google Cloud et Google Cloud Trace puissent être utilisés à distance depuis votre ordinateur portable, nous allons utiliser Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Cette machine virtuelle basée sur Debian contient tous les outils de développement dont vous aurez besoin. Elle intègre un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Cela signifie que tout ce dont vous avez besoin pour cet atelier de programmation est un navigateur (oui, tout fonctionne sur un Chromebook).
Pour activer Cloud Shell à partir de la console Cloud, cliquez simplement sur Activer Cloud Shell  (le provisionnement de l'environnement et la connexion ne devraient prendre que quelques minutes).
(le provisionnement de l'environnement et la connexion ne devraient prendre que quelques minutes).
Une fois connecté à Cloud Shell, vous êtes normalement déjà authentifié et le projet PROJECT_ID est sélectionné :
gcloud auth list
Résultat de la commande
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Résultat de la commande
[core] project = <PROJECT_ID>
Si, pour une raison quelconque, le projet n'est pas défini, exécutez simplement la commande suivante :
gcloud config set project <PROJECT_ID>
Vous recherchez votre PROJECT_ID ? Vérifiez l'ID que vous avez utilisé pendant les étapes de configuration ou recherchez-le dans le tableau de bord Cloud Console :
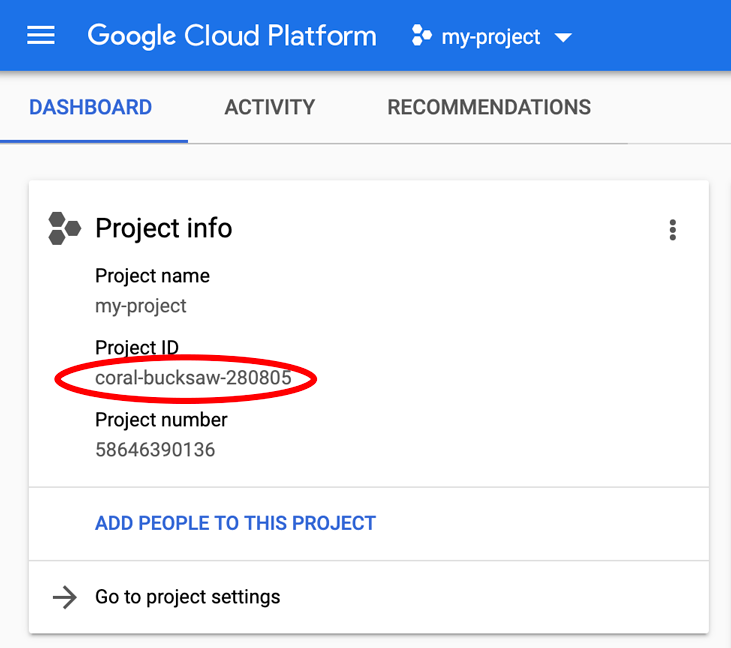
Par défaut, Cloud Shell définit certaines variables d'environnement qui pourront s'avérer utiles pour exécuter certaines commandes dans le futur.
echo $GOOGLE_CLOUD_PROJECT
Résultat de la commande
<PROJECT_ID>
Pour finir, définissez la configuration du projet et de la zone par défaut :
gcloud config set compute/zone us-central1-f
Vous pouvez choisir parmi différentes zones. Pour en savoir plus, consultez la page Régions et zones.
Configurer le langage Go
Dans cet atelier de programmation, nous utilisons Go pour tout le code source. Exécutez la commande suivante dans Cloud Shell et vérifiez si la version de Go est 1.17 ou ultérieure.
go version
Résultat de la commande
go version go1.18.3 linux/amd64
Configurer un cluster Google Kubernetes
Dans cet atelier de programmation, vous allez exécuter un cluster de microservices sur Google Kubernetes Engine (GKE). Voici le processus de cet atelier de programmation :
- Télécharger le projet de référence dans Cloud Shell
- Créer des microservices dans des conteneurs
- Importer des conteneurs dans Google Artifact Registry (GAR)
- Déployer des conteneurs sur GKE
- Modifier le code source des services pour l'instrumentation de trace
- Passez à l'étape 2.
Activer Kubernetes Engine
Nous allons d'abord configurer un cluster Kubernetes sur lequel Shakesapp s'exécute sur GKE. Nous devons donc activer GKE. Accédez au menu "Kubernetes Engine", puis cliquez sur le bouton "ACTIVER".
Vous êtes maintenant prêt à créer un cluster Kubernetes.
Créer un cluster Kubernetes
Dans Cloud Shell, exécutez la commande suivante pour créer un cluster Kubernetes. Veuillez confirmer que la valeur de la zone se trouve dans la région que vous utiliserez pour créer le dépôt Artifact Registry. Modifiez la valeur de la zone us-central1-f si la région de votre dépôt ne couvre pas la zone.
gcloud container clusters create otel-trace-codelab2 \ --zone us-central1-f \ --release-channel rapid \ --preemptible \ --enable-autoscaling \ --max-nodes 8 \ --no-enable-ip-alias \ --scopes cloud-platform
Résultat de la commande
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s). Creating cluster otel-trace-codelab2 in us-central1-f... Cluster is being health-checked (master is healthy)...done. Created [https://container.googleapis.com/v1/projects/development-215403/zones/us-central1-f/clusters/otel-trace-codelab2]. To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/workload_/gcloud/us-central1-f/otel-trace-codelab2?project=development-215403 kubeconfig entry generated for otel-trace-codelab2. NAME: otel-trace-codelab2 LOCATION: us-central1-f MASTER_VERSION: 1.23.6-gke.1501 MASTER_IP: 104.154.76.89 MACHINE_TYPE: e2-medium NODE_VERSION: 1.23.6-gke.1501 NUM_NODES: 3 STATUS: RUNNING
Configurer Artifact Registry et Skaffold
Nous disposons maintenant d'un cluster Kubernetes prêt pour le déploiement. Nous allons ensuite préparer un registre de conteneurs pour transférer et déployer des conteneurs. Pour ces étapes, nous devons configurer un registre d'artefacts (GAR) et skaffold pour l'utiliser.
Configurer Artifact Registry
Accédez au menu "Artifact Registry" et appuyez sur le bouton "ENABLE" (ACTIVER).

Au bout de quelques instants, le navigateur de dépôt de GAR s'affiche. Cliquez sur le bouton "CRÉER UN DÉPÔT", puis saisissez le nom du dépôt.
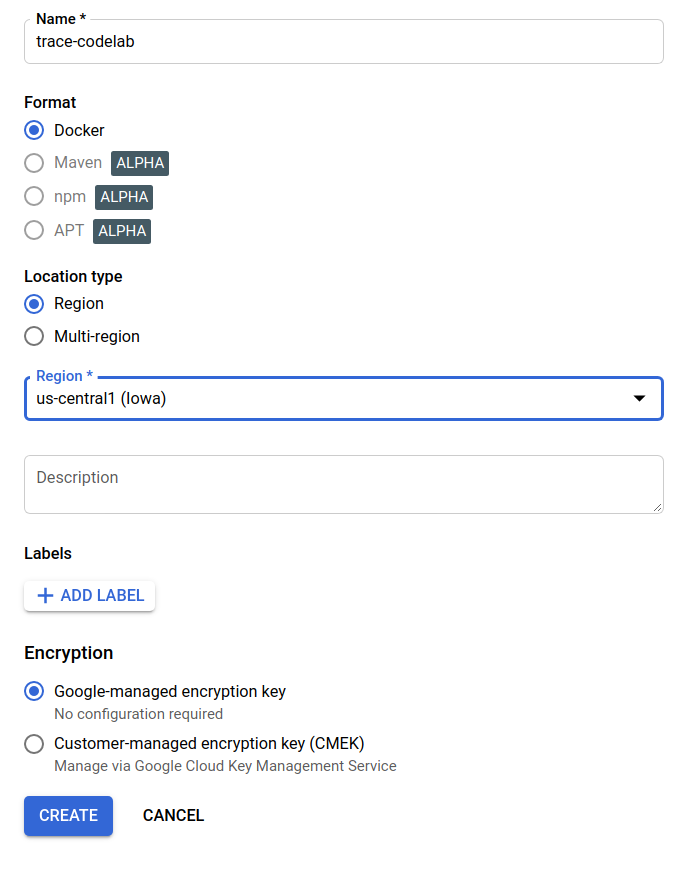
Dans cet atelier de programmation, je nomme le nouveau dépôt trace-codelab. Le format de l'artefact est "Docker" et le type d'emplacement est "Région". Choisissez la région proche de celle que vous avez définie pour la zone Google Compute Engine par défaut. Par exemple, l'exemple ci-dessus a choisi "us-central1-f", nous choisissons donc "us-central1 (Iowa)". Cliquez ensuite sur le bouton "CRÉER".
Vous voyez maintenant "trace-codelab" dans l'explorateur de dépôt.
Nous reviendrons ici plus tard pour vérifier le chemin d'accès au registre.
Configuration de Skaffold
Skaffold est un outil pratique lorsque vous créez des microservices qui s'exécutent sur Kubernetes. Il gère le workflow de création, de transfert et de déploiement des conteneurs d'applications avec un petit ensemble de commandes. Par défaut, Skaffold utilise Docker Registry comme registre de conteneurs. Vous devez donc configurer Skaffold pour qu'il reconnaisse GAR lors du transfert de conteneurs.
Ouvrez à nouveau Cloud Shell et vérifiez si Skaffold est installé. (Cloud Shell installe Skaffold dans l'environnement par défaut.) Exécutez la commande suivante pour afficher la version de Skaffold.
skaffold version
Résultat de la commande
v1.38.0
Vous pouvez maintenant enregistrer le dépôt par défaut que Skaffold doit utiliser. Pour obtenir le chemin d'accès au registre, accédez au tableau de bord Artifact Registry et cliquez sur le nom du dépôt que vous venez de configurer à l'étape précédente.
Un fil d'Ariane s'affiche en haut de la page. Cliquez sur l'icône  pour copier le chemin d'accès au registre dans le presse-papiers.
pour copier le chemin d'accès au registre dans le presse-papiers.
Lorsque vous cliquez sur le bouton "Copier", la boîte de dialogue s'affiche en bas du navigateur avec un message semblable à celui-ci :
"us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab" a été copié
Revenez à Cloud Shell. Exécutez la commande skaffold config set default-repo avec la valeur que vous venez de copier depuis le tableau de bord.
skaffold config set default-repo us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab
Résultat de la commande
set value default-repo to us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab for context gke_stackdriver-sandbox-3438851889_us-central1-b_stackdriver-sandbox
Vous devez également configurer le registre pour la configuration Docker. Exécutez la commande suivante :
gcloud auth configure-docker us-central1-docker.pkg.dev --quiet
Résultat de la commande
{
"credHelpers": {
"gcr.io": "gcloud",
"us.gcr.io": "gcloud",
"eu.gcr.io": "gcloud",
"asia.gcr.io": "gcloud",
"staging-k8s.gcr.io": "gcloud",
"marketplace.gcr.io": "gcloud",
"us-central1-docker.pkg.dev": "gcloud"
}
}
Adding credentials for: us-central1-docker.pkg.dev
Vous êtes maintenant prêt à passer à l'étape suivante pour configurer un conteneur Kubernetes sur GKE.
Résumé
Dans cette étape, vous allez configurer votre environnement d'atelier de programmation :
- Configurer Cloud Shell
- Création d'un dépôt Artifact Registry pour le registre de conteneurs
- Configurer Skaffold pour utiliser le registre de conteneurs
- Création d'un cluster Kubernetes dans lequel s'exécutent les microservices de l'atelier de programmation
Étape suivante
À l'étape suivante, vous instrumenterez l'agent de profileur continu dans le service de serveur.
3. Créer, transférer et déployer les microservices
Télécharger le matériel de l'atelier de programmation
À l'étape précédente, nous avons configuré tous les prérequis pour cet atelier de programmation. Vous êtes maintenant prêt à exécuter des microservices entiers par-dessus. Le contenu de l'atelier de programmation est hébergé sur GitHub. Téléchargez-le dans l'environnement Cloud Shell à l'aide de la commande git suivante.
cd ~ git clone https://github.com/ymotongpoo/opentelemetry-trace-codelab-go.git cd opentelemetry-trace-codelab-go
La structure de répertoire du projet est la suivante :
.
├── README.md
├── step0
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step1
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step2
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step3
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step4
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step5
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
└── step6
├── manifests
├── proto
├── skaffold.yaml
└── src
- manifests : fichiers manifestes Kubernetes
- proto : définition proto pour la communication entre le client et le serveur
- src : répertoires du code source de chaque service
- skaffold.yaml : fichier de configuration pour Skaffold
Dans cet atelier de programmation, vous allez mettre à jour le code source situé dans le dossier step4. Vous pouvez également consulter le code source dans les dossiers step[1-6] pour connaître les modifications depuis le début. (La partie 1 couvre les étapes 0 à 4, et la partie 2 couvre les étapes 5 et 6.)
Exécuter la commande skaffold
Vous êtes enfin prêt à créer, transférer et déployer l'intégralité du contenu sur le cluster Kubernetes que vous venez de créer. Cela semble contenir plusieurs étapes, mais en réalité, Skaffold fait tout pour vous. Essayons avec la commande suivante :
cd step4 skaffold dev
Dès que vous exécutez la commande, vous voyez le résultat du journal docker build et pouvez confirmer qu'ils ont bien été envoyés au registre.
Résultat de la commande
... ---> Running in c39b3ea8692b ---> 90932a583ab6 Successfully built 90932a583ab6 Successfully tagged us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice:step1 The push refers to repository [us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice] cc8f5a05df4a: Preparing 5bf719419ee2: Preparing 2901929ad341: Preparing 88d9943798ba: Preparing b0fdf826a39a: Preparing 3c9c1e0b1647: Preparing f3427ce9393d: Preparing 14a1ca976738: Preparing f3427ce9393d: Waiting 14a1ca976738: Waiting 3c9c1e0b1647: Waiting b0fdf826a39a: Layer already exists 88d9943798ba: Layer already exists f3427ce9393d: Layer already exists 3c9c1e0b1647: Layer already exists 14a1ca976738: Layer already exists 2901929ad341: Pushed 5bf719419ee2: Pushed cc8f5a05df4a: Pushed step1: digest: sha256:8acdbe3a453001f120fb22c11c4f6d64c2451347732f4f271d746c2e4d193bbe size: 2001
Une fois tous les conteneurs de service transférés, les déploiements Kubernetes démarrent automatiquement.
Résultat de la commande
sha256:b71fce0a96cea08075dc20758ae561cf78c83ff656b04d211ffa00cedb77edf8 size: 1997 Tags used in deployment: - serverservice -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice:step4@sha256:8acdbe3a453001f120fb22c11c4f6d64c2451347732f4f271d746c2e4d193bbe - clientservice -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/clientservice:step4@sha256:b71fce0a96cea08075dc20758ae561cf78c83ff656b04d211ffa00cedb77edf8 - loadgen -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/loadgen:step4@sha256:eea2e5bc8463ecf886f958a86906cab896e9e2e380a0eb143deaeaca40f7888a Starting deploy... - deployment.apps/clientservice created - service/clientservice created - deployment.apps/loadgen created - deployment.apps/serverservice created - service/serverservice created
Une fois le déploiement effectué, les journaux d'application réels émis sur stdout s'affichent dans chaque conteneur, comme suit :
Résultat de la commande
[client] 2022/07/14 06:33:15 {"match_count":3040}
[loadgen] 2022/07/14 06:33:15 query 'love': matched 3040
[client] 2022/07/14 06:33:15 {"match_count":3040}
[loadgen] 2022/07/14 06:33:15 query 'love': matched 3040
[client] 2022/07/14 06:33:16 {"match_count":3040}
[loadgen] 2022/07/14 06:33:16 query 'love': matched 3040
[client] 2022/07/14 06:33:19 {"match_count":463}
[loadgen] 2022/07/14 06:33:19 query 'tear': matched 463
[loadgen] 2022/07/14 06:33:20 query 'world': matched 728
[client] 2022/07/14 06:33:20 {"match_count":728}
[client] 2022/07/14 06:33:22 {"match_count":463}
[loadgen] 2022/07/14 06:33:22 query 'tear': matched 463
Notez qu'à ce stade, vous souhaitez voir tous les messages du serveur. Vous êtes enfin prêt à instrumenter votre application avec OpenTelemetry pour le traçage distribué des services.
Avant de commencer à instrumenter le service, veuillez arrêter votre cluster avec Ctrl+C.
Résultat de la commande
...
[client] 2022/07/14 06:34:57 {"match_count":1}
[loadgen] 2022/07/14 06:34:57 query 'what's past is prologue': matched 1
^CCleaning up...
- W0714 06:34:58.464305 28078 gcp.go:120] WARNING: the gcp auth plugin is deprecated in v1.22+, unavailable in v1.25+; use gcloud instead.
- To learn more, consult https://cloud.google.com/blog/products/containers-kubernetes/kubectl-auth-changes-in-gke
- deployment.apps "clientservice" deleted
- service "clientservice" deleted
- deployment.apps "loadgen" deleted
- deployment.apps "serverservice" deleted
- service "serverservice" deleted
Résumé
Dans cette étape, vous avez préparé le contenu de l'atelier de programmation dans votre environnement et vérifié que Skaffold s'exécute comme prévu.
Étape suivante
À l'étape suivante, vous allez modifier le code source du service loadgen pour instrumenter les informations de trace.
4. Instrumentation de l'agent Cloud Profiler
Concept de profilage continu
Avant d'expliquer le concept de profilage continu, nous devons d'abord comprendre celui du profilage. Le profilage est l'une des méthodes d'analyse dynamique des applications (analyse dynamique des programmes). Il est généralement effectué lors du développement des applications, au cours des tests de charge, etc. Il s'agit d'une activité ponctuelle permettant de mesurer les métriques système, telles que l'utilisation du processeur et de la mémoire, au cours d'une période spécifique. Une fois les données de profil collectées, les développeurs les analysent en dehors du code.
Le profilage continu est une approche étendue du profilage normal : il exécute périodiquement des profils de courte durée sur l'application de longue durée et collecte un ensemble de données de profil. Il génère ensuite automatiquement l'analyse statistique en fonction d'un certain attribut de l'application, tel que le numéro de version, la zone de déploiement, le temps de mesure, etc. Pour en savoir plus sur ce concept, consultez notre documentation.
Comme la cible est une application en cours d'exécution, il est possible de collecter des données de profil de manière périodique et de les envoyer à un backend qui post-traite les données statistiques. Il s'agit de l'agent Cloud Profiler, que vous allez bientôt intégrer au service de serveur.
Intégrer l'agent Cloud Profiler
Ouvrez l'éditeur Cloud Shell en cliquant sur le bouton  en haut à droite de Cloud Shell. Ouvrez
en haut à droite de Cloud Shell. Ouvrez step4/src/server/main.go à partir de l'explorateur dans le volet de gauche, puis recherchez la fonction principale.
step4/src/server/main.go
func main() {
...
// step2. setup OpenTelemetry
tp, err := initTracer()
if err != nil {
log.Fatalf("failed to initialize TracerProvider: %v", err)
}
defer func() {
if err := tp.Shutdown(context.Background()); err != nil {
log.Fatalf("error shutting down TracerProvider: %v", err)
}
}()
// step2. end setup
svc := NewServerService()
// step2: add interceptor
interceptorOpt := otelgrpc.WithTracerProvider(otel.GetTracerProvider())
srv := grpc.NewServer(
grpc.UnaryInterceptor(otelgrpc.UnaryServerInterceptor(interceptorOpt)),
grpc.StreamInterceptor(otelgrpc.StreamServerInterceptor(interceptorOpt)),
)
// step2: end adding interceptor
shakesapp.RegisterShakespeareServiceServer(srv, svc)
healthpb.RegisterHealthServer(srv, svc)
if err := srv.Serve(lis); err != nil {
log.Fatalf("error serving server: %v", err)
}
}
Dans la fonction main, vous trouverez du code de configuration pour OpenTelemetry et gRPC, qui a été effectué dans la partie 1 de l'atelier de programmation. Vous allez maintenant ajouter l'instrumentation pour l'agent Cloud Profiler. Comme nous l'avons fait pour initTracer(), vous pouvez écrire une fonction appelée initProfiler() pour plus de lisibilité.
step4/src/server/main.go
import (
...
"cloud.google.com/go/profiler" // step5. add profiler package
"cloud.google.com/go/storage"
...
)
// step5: add Profiler initializer
func initProfiler() {
cfg := profiler.Config{
Service: "server",
ServiceVersion: "1.0.0",
NoHeapProfiling: true,
NoAllocProfiling: true,
NoGoroutineProfiling: true,
NoCPUProfiling: false,
}
if err := profiler.Start(cfg); err != nil {
log.Fatalf("failed to launch profiler agent: %v", err)
}
}
Examinons de plus près les options spécifiées dans l'objet profiler.Config{}.
- Service : nom du service que vous pouvez sélectionner et activer dans le tableau de bord du profileur
- ServiceVersion : nom de la version du service. Vous pouvez comparer des ensembles de données de profil en fonction de cette valeur.
- NoHeapProfiling : désactiver le profilage de la consommation de mémoire
- NoAllocProfiling : désactiver le profilage de l'allocation de mémoire
- NoGoroutineProfiling : désactive le profilage des goroutines.
- NoCPUProfiling : désactiver le profilage du processeur
Dans cet atelier de programmation, nous n'activons que le profilage du processeur.
Il vous suffit maintenant d'appeler cette fonction dans la fonction main. Veillez à importer le package Cloud Profiler dans le bloc d'importation.
step4/src/server/main.go
func main() {
...
defer func() {
if err := tp.Shutdown(context.Background()); err != nil {
log.Fatalf("error shutting down TracerProvider: %v", err)
}
}()
// step2. end setup
// step5. start profiler
go initProfiler()
// step5. end
svc := NewServerService()
// step2: add interceptor
...
}
Notez que vous appelez la fonction initProfiler() avec le mot clé go. Étant donné que profiler.Start() bloque, vous devez l'exécuter dans une autre goroutine. Vous êtes maintenant prêt à créer. Veillez à exécuter go mod tidy avant le déploiement.
go mod tidy
Déployez maintenant votre cluster avec votre nouveau service de serveur.
skaffold dev
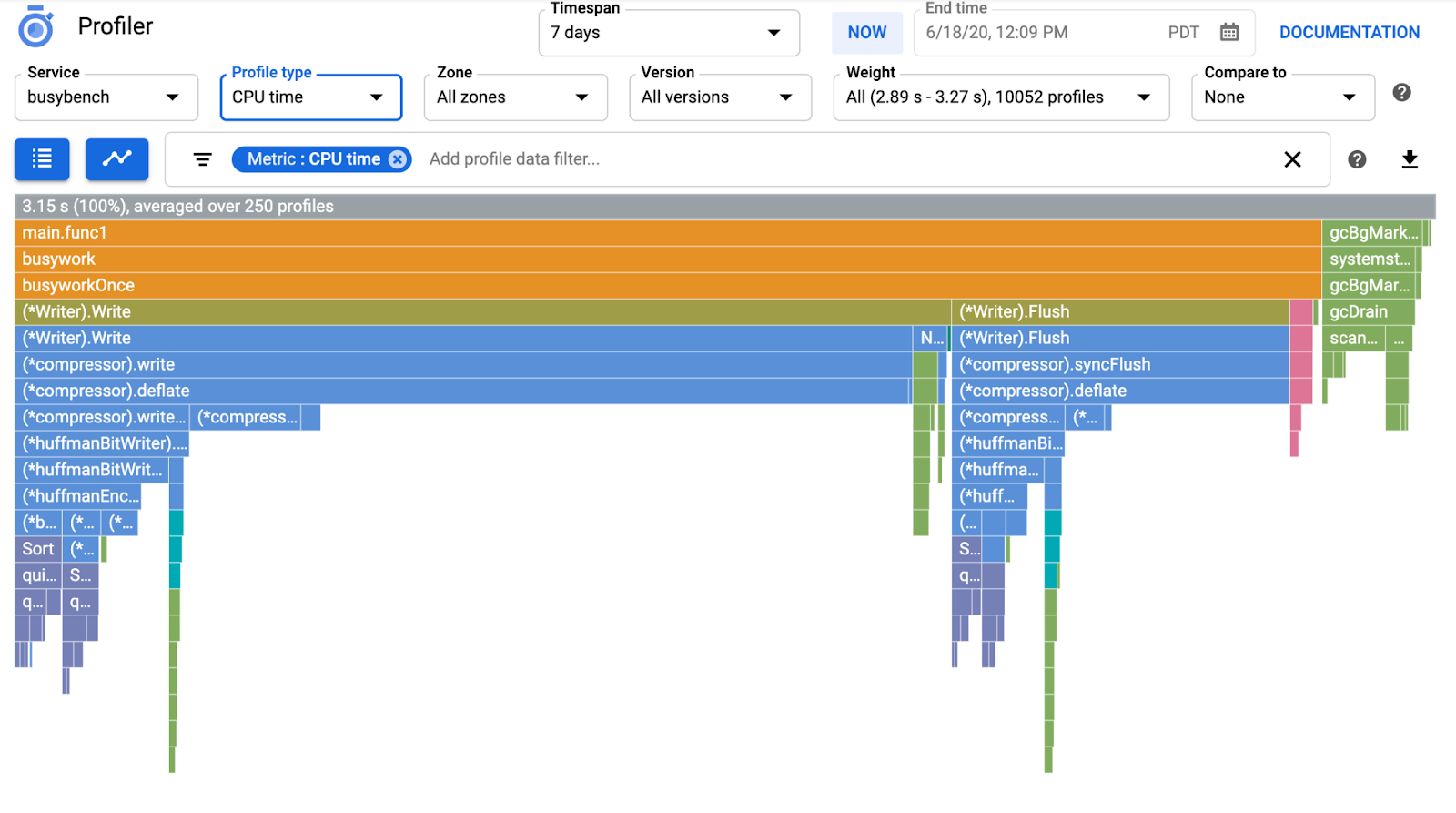
Il faut généralement quelques minutes pour que le graphique en flammes s'affiche dans Cloud Profiler. Saisissez "profiler" dans le champ de recherche en haut de l'écran, puis cliquez sur l'icône de Profiler.

Le graphique de type "flamme" suivant s'affiche.
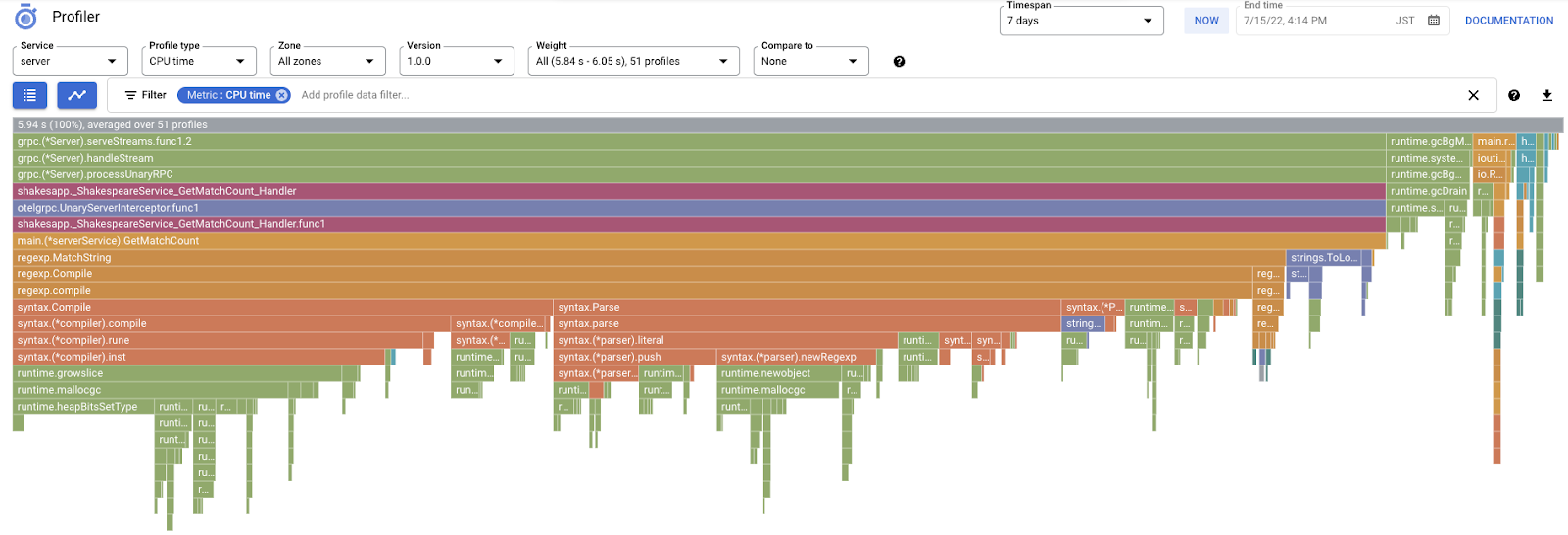
Résumé
Au cours de cette étape, vous avez intégré l'agent Cloud Profiler au service de serveur et vérifié qu'il générait un graphique en flammes.
Étape suivante
À l'étape suivante, vous allez examiner la cause du goulot d'étranglement dans l'application à l'aide du graphique en flammes.
5. Analyser le graphique de type "flamme" Cloud Profiler
Qu'est-ce qu'un graphique de type "flamme" ?
Le graphique de type "flamme" est l'une des façons de visualiser les données de profil. Pour en savoir plus, veuillez consulter notre document. Voici un bref résumé :
- Chaque barre représente l'appel de méthode/fonction dans l'application.
- La direction verticale correspond à la pile d'appel, qui s'étend de haut en bas.
- La direction horizontale correspond à l'utilisation des ressources. Plus la barre est longue, plus la situation est mauvaise.
Cela étant dit, examinons le graphique de type "flamme" obtenu.
Analyser un graphique de flammes
Dans la section précédente, vous avez appris que chaque barre du graphique en flammes représente l'appel de fonction/méthode, et que sa longueur indique l'utilisation des ressources dans la fonction/méthode. Le graphique en flammes de Cloud Profiler trie les barres par ordre décroissant de longueur, de gauche à droite. Vous pouvez commencer par examiner le coin supérieur gauche du graphique.
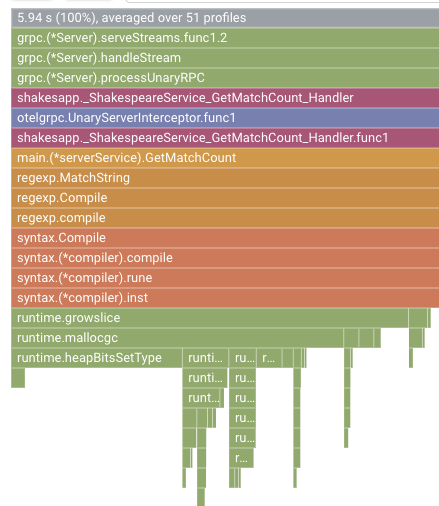
Dans notre cas, il est explicite que grpc.(*Server).serveStreams.func1.2 consomme la majeure partie du temps CPU. En examinant la pile d'appels de haut en bas, on constate que la majeure partie du temps est passée dans main.(*serverService).GetMatchCount, qui est le gestionnaire de serveur gRPC dans le service de serveur.
Sous GetMatchCount, vous voyez une série de fonctions regexp : regexp.MatchString et regexp.Compile. Ils proviennent du package standard, c'est-à-dire qu'ils doivent être bien testés sous de nombreux angles, y compris en termes de performances. Toutefois, le résultat montre ici que l'utilisation des ressources de temps CPU est élevée dans regexp.MatchString et regexp.Compile. Compte tenu de ces faits, l'hypothèse ici est que l'utilisation de regexp.MatchString a quelque chose à voir avec les problèmes de performances. Lisons donc le code source où la fonction est utilisée.
step4/src/server/main.go
func (s *serverService) GetMatchCount(ctx context.Context, req *shakesapp.ShakespeareRequest) (*shakesapp.ShakespeareResponse, error) {
resp := &shakesapp.ShakespeareResponse{}
texts, err := readFiles(ctx, bucketName, bucketPrefix)
if err != nil {
return resp, fmt.Errorf("fails to read files: %s", err)
}
for _, text := range texts {
for _, line := range strings.Split(text, "\n") {
line, query := strings.ToLower(line), strings.ToLower(req.Query)
isMatch, err := regexp.MatchString(query, line)
if err != nil {
return resp, err
}
if isMatch {
resp.MatchCount++
}
}
}
return resp, nil
}
C'est l'endroit où regexp.MatchString est appelé. En lisant le code source, vous remarquerez peut-être que la fonction est appelée à l'intérieur de la boucle for imbriquée. L'utilisation de cette fonction peut donc être incorrecte. Consultons la documentation GoDoc de regexp.

Selon le document, regexp.MatchString compile le modèle d'expression régulière à chaque appel. La cause de la forte consommation de ressources semble être la suivante.
Résumé
Au cours de cette étape, vous avez émis une hypothèse sur la cause de la consommation de ressources en analysant le graphique de type "flamme".
Étape suivante
À l'étape suivante, vous allez mettre à jour le code source du service de serveur et confirmer la modification à partir de la version 1.0.0.
6. Mettre à jour le code source et comparer les graphiques en flammes
Mettre à jour le code source
À l'étape précédente, vous avez supposé que l'utilisation de regexp.MatchString avait un lien avec la forte consommation de ressources. Résolvons ce problème. Ouvrez le code et modifiez légèrement cette partie.
step4/src/server/main.go
func (s *serverService) GetMatchCount(ctx context.Context, req *shakesapp.ShakespeareRequest) (*shakesapp.ShakespeareResponse, error) {
resp := &shakesapp.ShakespeareResponse{}
texts, err := readFiles(ctx, bucketName, bucketPrefix)
if err != nil {
return resp, fmt.Errorf("fails to read files: %s", err)
}
// step6. considered the process carefully and naively tuned up by extracting
// regexp pattern compile process out of for loop.
query := strings.ToLower(req.Query)
re := regexp.MustCompile(query)
for _, text := range texts {
for _, line := range strings.Split(text, "\n") {
line = strings.ToLower(line)
isMatch := re.MatchString(line)
// step6. done replacing regexp with strings
if isMatch {
resp.MatchCount++
}
}
}
return resp, nil
}
Comme vous pouvez le voir, le processus de compilation du modèle d'expression régulière est maintenant extrait de regexp.MatchString et déplacé hors de la boucle for imbriquée.
Avant de déployer ce code, veillez à mettre à jour la chaîne de version dans la fonction initProfiler().
step4/src/server/main.go
func initProfiler() {
cfg := profiler.Config{
Service: "server",
ServiceVersion: "1.1.0", // step6. update version
NoHeapProfiling: true,
NoAllocProfiling: true,
NoGoroutineProfiling: true,
NoCPUProfiling: false,
}
if err := profiler.Start(cfg); err != nil {
log.Fatalf("failed to launch profiler agent: %v", err)
}
}
Voyons maintenant comment cela fonctionne. Déployez le cluster avec la commande skaffold.
skaffold dev
Après un certain temps, actualisez le tableau de bord Cloud Profiler et voyez à quoi il ressemble.
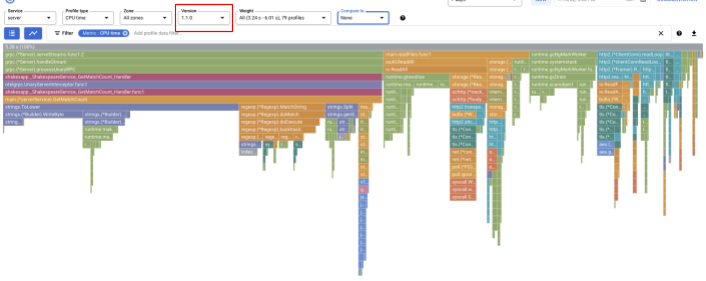
Veillez à remplacer la version par "1.1.0" afin de n'afficher que les profils de la version 1.1.0. Comme vous pouvez le voir, la longueur de la barre GetMatchCount a diminué, tout comme le taux d'utilisation du temps CPU (c'est-à-dire que la barre est devenue plus courte).

Vous pouvez non seulement examiner le graphique en flammes d'une seule version, mais aussi comparer les différences entre deux versions.

Définissez la valeur de la liste déroulante "Comparer à" sur "Version", puis définissez la valeur de "Version comparée" sur "1.0.0", la version d'origine.
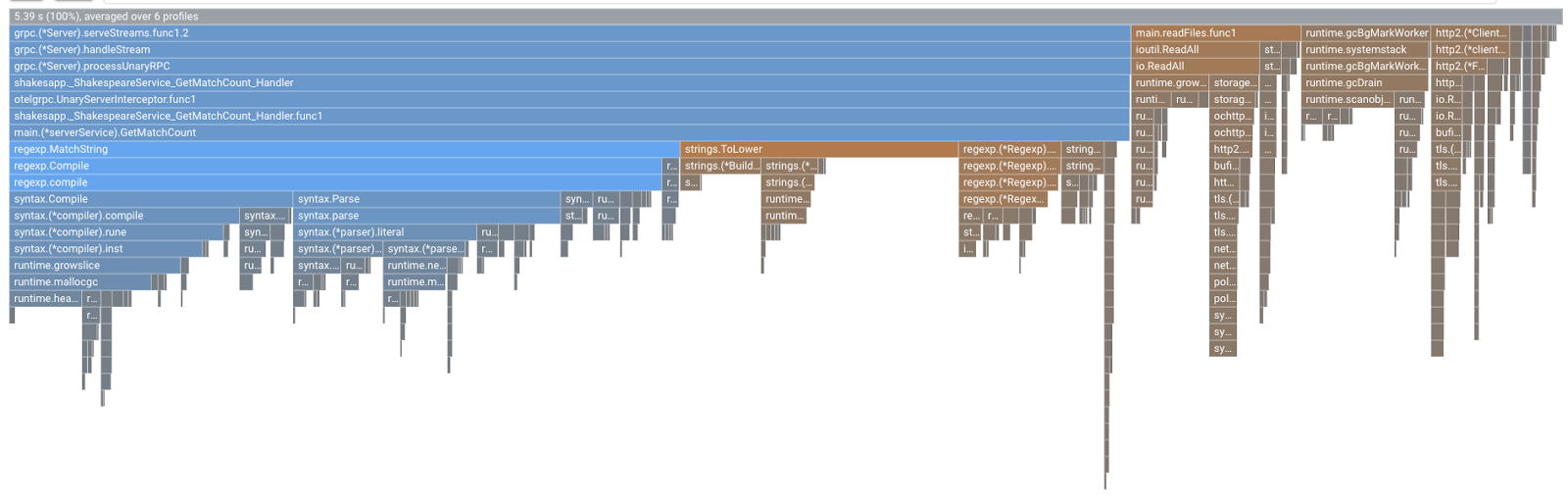
Vous verrez ce type de graphique de flamme. La forme du graphique est la même que celle de 1.1.0, mais la couleur est différente. En mode Comparaison, la signification des couleurs est la suivante :
- Bleu : valeur (consommation de ressources) réduite
- Orange : valeur (consommation de ressources) gagnée
- Gris : neutre
Examinons de plus près la fonction à l'aide de la légende. Cliquez sur la barre sur laquelle vous souhaitez effectuer un zoom avant pour afficher plus de détails dans la pile. Veuillez cliquer sur la barre main.(*serverService).GetMatchCount. Vous pouvez également pointer sur la barre pour afficher les détails de la comparaison.
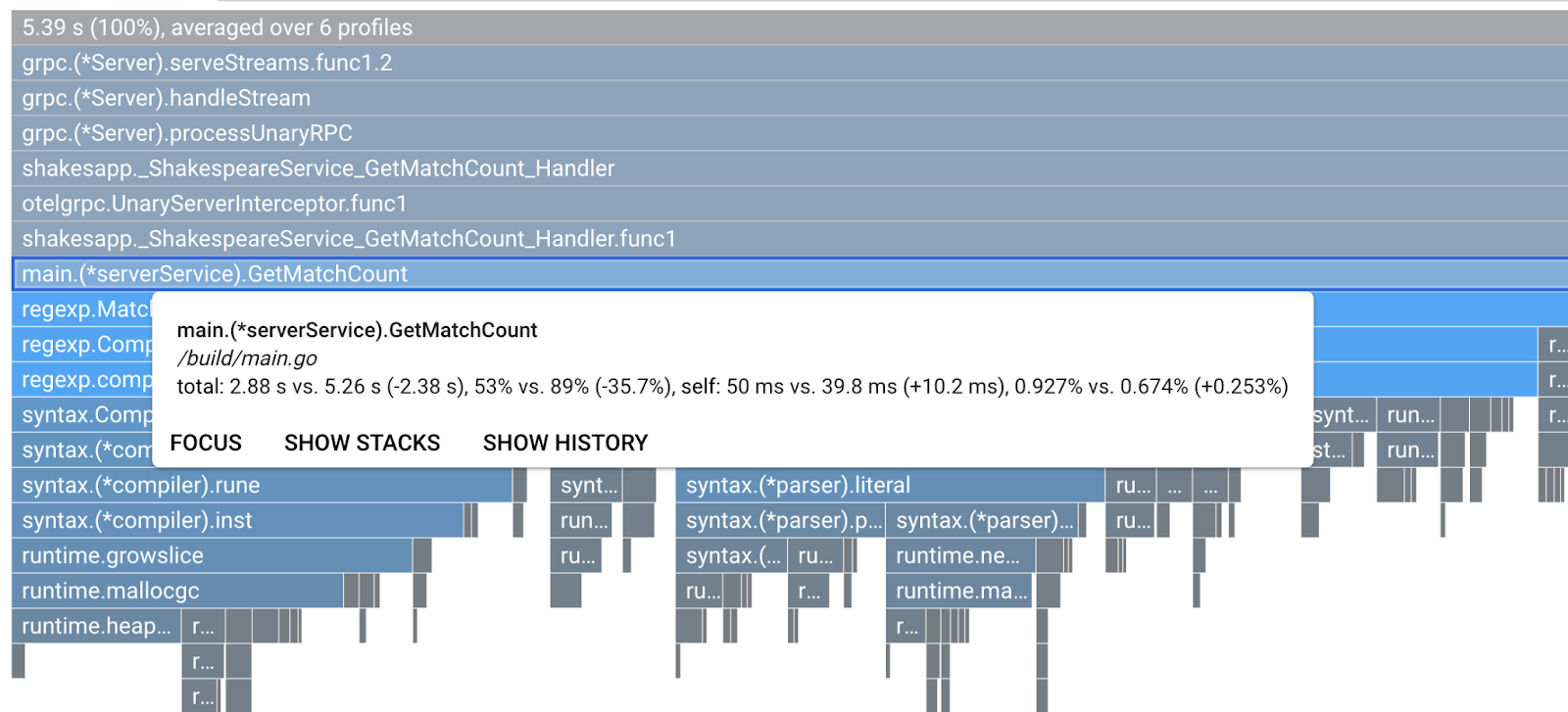
Il indique que le temps CPU total est réduit de 5,26 s à 2,88 s (le total est de 10 s, soit la fenêtre d'échantillonnage). C'est une énorme amélioration !
Vous pouvez désormais améliorer les performances de votre application à partir de l'analyse des données de profil.
Résumé
Au cours de cette étape, vous avez modifié le service de serveur et confirmé l'amélioration dans le mode Comparaison de Cloud Profiler.
Étape suivante
À l'étape suivante, vous allez mettre à jour le code source du service de serveur et confirmer la modification à partir de la version 1.0.0.
7. Étape supplémentaire : confirmez l'amélioration dans le graphique en cascade Trace
Différence entre le traçage distribué et le profilage continu
Dans la partie 1 de l'atelier de programmation, vous avez confirmé que vous pouviez identifier le service à l'origine du goulot d'étranglement dans les microservices d'un chemin de requête, mais que vous ne pouviez pas déterminer la cause exacte du goulot d'étranglement dans le service spécifique. Dans cet atelier de programmation de la partie 2, vous avez appris que le profilage continu vous permet d'identifier le goulot d'étranglement à l'intérieur du service unique à partir des piles d'appels.
Dans cette étape, examinons le graphique en cascade de la trace distribuée (Cloud Trace) et comparons-le au profilage continu.
Ce graphique en cascade correspond à l'une des traces avec la requête "love". Cela prend environ 6,7 s (6 700 ms) au total.
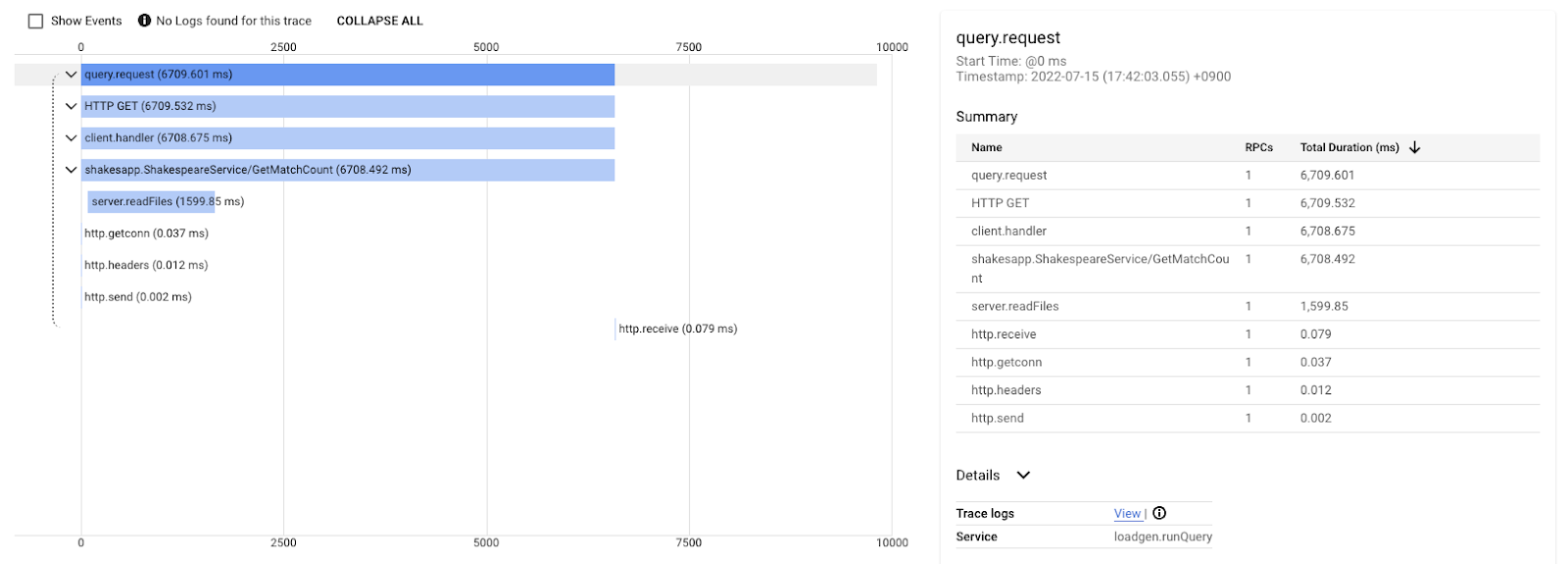
Et ce, après l'amélioration pour la même requête. Comme vous pouvez le voir, la latence totale est désormais de 1,5 s (1 500 ms), ce qui représente une amélioration considérable par rapport à l'implémentation précédente.
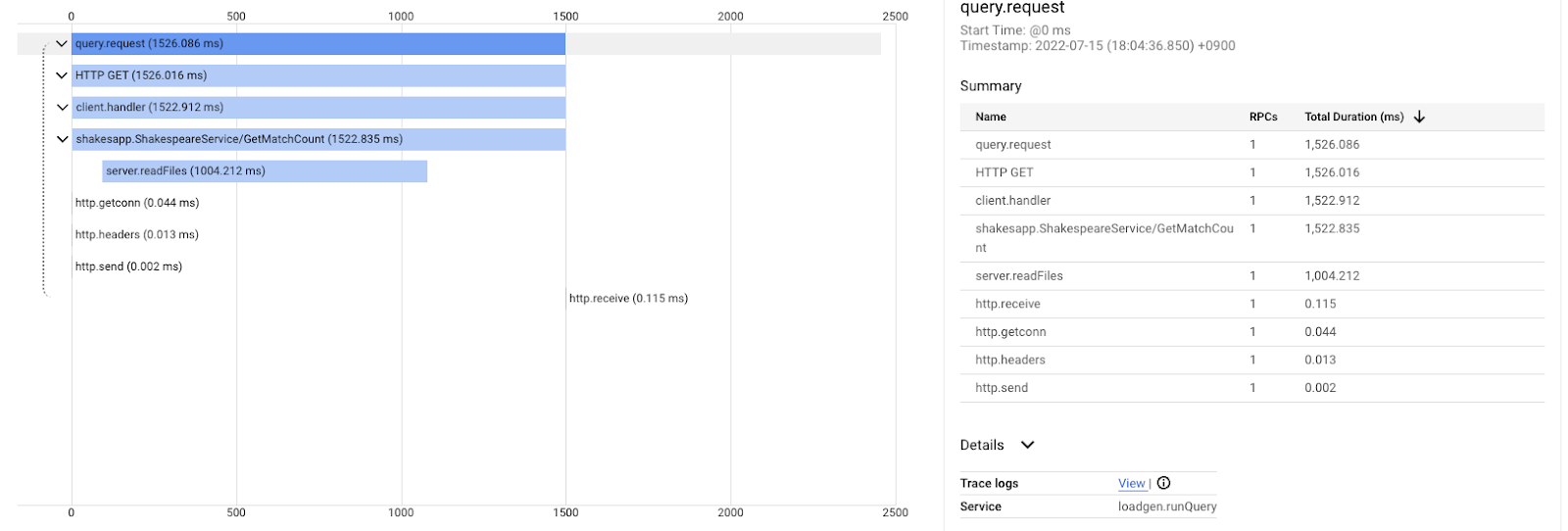
Le point important ici est que dans le graphique en cascade de trace distribuée, les informations de la pile d'appels ne sont pas disponibles, sauf si vous instrumentez les spans partout. De plus, les traces distribuées se concentrent uniquement sur la latence entre les services, tandis que le profilage continu se concentre sur les ressources de calcul (processeur, mémoire, threads OS) d'un seul service.
Dans un autre aspect, la trace distribuée est la base d'événements, tandis que le profil continu est statistique. Chaque trace possède un graphique de latence différent. Vous avez besoin d'un format différent, tel que distribution, pour obtenir la tendance des changements de latence.
Résumé
Au cours de cette étape, vous avez vérifié la différence entre le traçage distribué et le profilage continu.
8. Félicitations
Vous avez créé des traces distribuées avec OpenTelemetry et confirmé les latences des requêtes dans le microservice sur Google Cloud Trace.
Pour des exercices plus complets, vous pouvez essayer les thèmes suivants par vous-même.
- L'implémentation actuelle envoie toutes les portées générées par la vérification de l'état. (
grpc.health.v1.Health/Check) Comment filtrer ces spans dans Cloud Trace ? Cliquez ici pour obtenir un indice. - Corrélez les journaux d'événements avec les spans et découvrez comment cela fonctionne dans Google Cloud Trace et Google Cloud Logging. Cliquez ici pour obtenir un indice.
- Remplacez un service par celui d'une autre langue et essayez de l'instrumenter avec OpenTelemetry pour cette langue.
Si vous souhaitez en savoir plus sur le profileur après cela, passez à la partie 2. Dans ce cas, vous pouvez ignorer la section sur le nettoyage ci-dessous.
Nettoyage
Après cet atelier de programmation, veuillez arrêter le cluster Kubernetes et veillez à supprimer le projet afin d'éviter des frais inattendus sur Google Kubernetes Engine, Google Cloud Trace et Google Artifact Registry.
Commencez par supprimer le cluster. Si vous exécutez le cluster avec skaffold dev, il vous suffit d'appuyer sur Ctrl+C. Si vous exécutez le cluster avec skaffold run, exécutez la commande suivante :
skaffold delete
Résultat de la commande
Cleaning up... - deployment.apps "clientservice" deleted - service "clientservice" deleted - deployment.apps "loadgen" deleted - deployment.apps "serverservice" deleted - service "serverservice" deleted
Après avoir supprimé le cluster, dans le volet de menu, sélectionnez "IAM et administration" > "Paramètres", puis cliquez sur le bouton "ARRÊTER".
Saisissez ensuite l'ID du projet (et non son nom) dans le formulaire de la boîte de dialogue, puis confirmez l'arrêt.