
1. Введение

Последнее обновление: 14.07.2022
Наблюдаемость приложения
Наблюдаемость и непрерывный профилировщик
Наблюдаемость — это термин, используемый для описания атрибута системы. Система, обладающая наблюдаемостью, позволяет командам активно отлаживать свою систему. В этом контексте три основных компонента наблюдаемости — журналы, метрики и трассировки — являются фундаментальными инструментами для обеспечения наблюдаемости системы.
Помимо трех основных составляющих — наблюдаемости, — непрерывный профилирование является еще одним ключевым компонентом , расширяющим базу пользователей в отрасли. Cloud Profiler — один из первопроходцев в этой области, предоставляющий простой интерфейс для детального анализа показателей производительности в стеках вызовов приложений.
Этот практический урок является частью 2 серии и посвящен настройке агента непрерывного профилирования. В части 1 рассматривается распределенная трассировка с помощью OpenTelemetry и Cloud Trace, а в части 1 вы узнаете больше о том, как лучше выявлять узкие места в микросервисах.
Что вы построите
В этом практическом задании вы настроите агент непрерывного профилирования в серверной службе приложения Shakespeare (также известного как Shakesapp), работающего в кластере Google Kubernetes Engine. Архитектура Shakesapp описана ниже:

- Loadgen отправляет клиенту строку запроса по протоколу HTTP.
- Клиенты передают запрос от генератора нагрузки на сервер по протоколу gRPC.
- Сервер принимает запрос от клиента, извлекает все произведения Шекспира в текстовом формате из Google Cloud Storage, ищет строки, содержащие запрос, и возвращает клиенту номер строки, которая соответствует запросу.
В первой части вы обнаружили, что узкое место находится где-то в серверной службе, но не смогли определить точную причину.
Что вы узнаете
- Как встроить агент профилирования
- Как выявить узкое место в Cloud Profiler
В этом практическом занятии объясняется, как внедрить в ваше приложение агент непрерывного профилирования.
Что вам понадобится
- Базовые знания игры Го.
- Базовые знания Kubernetes.
2. Настройка и требования
Настройка среды для самостоятельного обучения
Если у вас еще нет учетной записи Google (Gmail или Google Apps), вам необходимо ее создать . Войдите в консоль Google Cloud Platform ( console.cloud.google.com ) и создайте новый проект.
Если у вас уже есть проект, щелкните раскрывающееся меню выбора проекта в левом верхнем углу консоли:

и нажмите кнопку «СОЗДАТЬ ПРОЕКТ» в появившемся диалоговом окне, чтобы создать новый проект:

Если у вас ещё нет проекта, вы увидите диалоговое окно, подобное этому, для создания вашего первого проекта:
В появившемся диалоговом окне создания проекта вы можете ввести подробные сведения о вашем новом проекте:
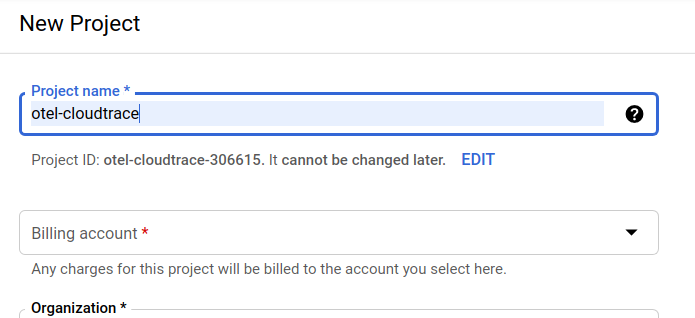
Запомните идентификатор проекта (Project ID), который является уникальным именем для всех проектов Google Cloud (указанное выше имя уже занято и вам не подойдёт, извините!). В дальнейшем в этом практическом занятии он будет обозначаться как PROJECT_ID.
Далее, если вы еще этого не сделали, вам необходимо включить оплату в консоли разработчика, чтобы использовать ресурсы Google Cloud и активировать API Cloud Trace .

Выполнение этого практического задания не должно обойтись вам дороже нескольких долларов, но может обойтись дороже, если вы решите использовать больше ресурсов или оставите их запущенными (см. раздел «очистка» в конце этого документа). Цены на Google Cloud Trace, Google Kubernetes Engine и Google Artifact Registry указаны в официальной документации.
- Цены на пакет инструментов для управления операциями Google Cloud | Operations Suite
- Цены | Документация Kubernetes Engine
- Цены на реестр артефактов | Документация по реестру артефактов
Новые пользователи Google Cloud Platform могут воспользоваться бесплатной пробной версией стоимостью 300 долларов , что сделает этот практический семинар совершенно бесплатным.
Настройка Google Cloud Shell
Хотя Google Cloud и Google Cloud Trace можно запускать удаленно с ноутбука, в этом практическом занятии мы будем использовать Google Cloud Shell — среду командной строки, работающую в облаке.
Эта виртуальная машина на базе Debian содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог размером 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Это означает, что для выполнения этого практического задания вам понадобится только браузер (да, он работает и на Chromebook).
Для активации Cloud Shell из консоли Cloud Console просто нажмите «Активировать Cloud Shell».  (На подготовку и подключение к среде должно уйти всего несколько минут).
(На подготовку и подключение к среде должно уйти всего несколько минут).
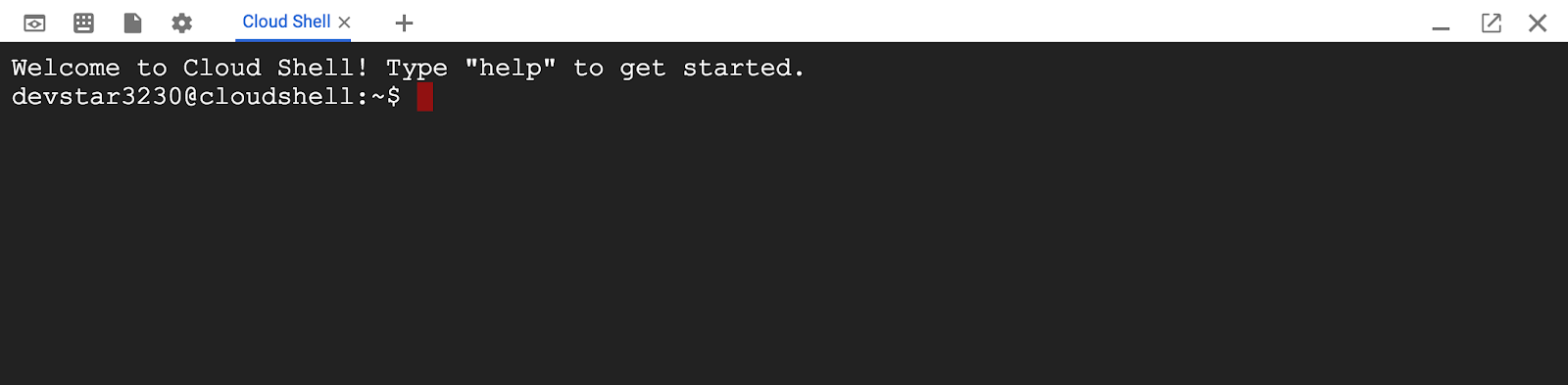
После подключения к Cloud Shell вы увидите, что ваша аутентификация пройдена и проект уже настроен на ваш PROJECT_ID .
gcloud auth list
вывод команды
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
вывод команды
[core] project = <PROJECT_ID>
Если по какой-либо причине проект не создан, просто выполните следующую команду:
gcloud config set project <PROJECT_ID>
Ищете свой PROJECT_ID ? Проверьте, какой ID вы использовали на этапах настройки, или найдите его на панели управления Cloud Console:

Cloud Shell также по умолчанию устанавливает некоторые переменные среды, которые могут быть полезны при выполнении будущих команд.
echo $GOOGLE_CLOUD_PROJECT
вывод команды
<PROJECT_ID>
Наконец, установите зону по умолчанию и конфигурацию проекта.
gcloud config set compute/zone us-central1-f
Вы можете выбрать различные зоны. Для получения дополнительной информации см. раздел «Регионы и зоны» .
Настройка языка Go
В этом практическом занятии мы используем Go для всего исходного кода. Выполните следующую команду в Cloud Shell и убедитесь, что версия Go — 1.17 или выше.
go version
вывод команды
go version go1.18.3 linux/amd64
Настройка кластера Google Kubernetes
В этом практическом занятии вы запустите кластер микросервисов на платформе Google Kubernetes Engine (GKE). Процесс выполнения этого практического занятия выглядит следующим образом:
- Загрузите базовый проект в Cloud Shell.
- Внедряйте микросервисы в контейнеры.
- Загрузите контейнеры в реестр артефактов Google (GAR).
- Развертывание контейнеров в GKE
- Измените исходный код сервисов для трассировочного мониторинга.
- Перейдите к шагу 2
Включить Kubernetes Engine
Сначала настроим кластер Kubernetes, в котором Shakesapp будет работать на GKE, поэтому нам нужно включить GKE. Перейдите в меню "Kubernetes Engine" и нажмите кнопку "Включить".

Теперь вы готовы создать кластер Kubernetes.
Создание кластера Kubernetes
В Cloud Shell выполните следующую команду для создания кластера Kubernetes. Убедитесь, что значение зоны находится в регионе , который вы будете использовать для создания репозитория Artifact Registry. Измените значение зоны us-central1-f , если ваш регион репозитория не охватывает эту зону.
gcloud container clusters create otel-trace-codelab2 \ --zone us-central1-f \ --release-channel rapid \ --preemptible \ --enable-autoscaling \ --max-nodes 8 \ --no-enable-ip-alias \ --scopes cloud-platform
вывод команды
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s). Creating cluster otel-trace-codelab2 in us-central1-f... Cluster is being health-checked (master is healthy)...done. Created [https://container.googleapis.com/v1/projects/development-215403/zones/us-central1-f/clusters/otel-trace-codelab2]. To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/workload_/gcloud/us-central1-f/otel-trace-codelab2?project=development-215403 kubeconfig entry generated for otel-trace-codelab2. NAME: otel-trace-codelab2 LOCATION: us-central1-f MASTER_VERSION: 1.23.6-gke.1501 MASTER_IP: 104.154.76.89 MACHINE_TYPE: e2-medium NODE_VERSION: 1.23.6-gke.1501 NUM_NODES: 3 STATUS: RUNNING
Настройка реестра артефактов и Skaffold.
Теперь у нас есть кластер Kubernetes, готовый к развертыванию. Далее мы подготовим реестр контейнеров для отправки и развертывания контейнеров. Для этих шагов нам необходимо настроить реестр артефактов (GAR) и Skaffold для его использования.
Настройка реестра артефактов
Перейдите в меню «Реестр артефактов» и нажмите кнопку «Включить».

Через несколько мгновений вы увидите браузер репозиториев GAR. Нажмите кнопку "СОЗДАТЬ РЕПОЗИТОРИЙ" и введите имя репозитория.
В этом практическом занятии я называю новый репозиторий trace-codelab . Формат артефакта — "Docker", а тип местоположения — "Регион". Выберите регион, близкий к тому, который вы установили для зоны по умолчанию Google Compute Engine. Например, в этом примере был выбран "us-central1-f", поэтому здесь мы выберем "us-central1 (Айова)". Затем нажмите кнопку "СОЗДАТЬ".
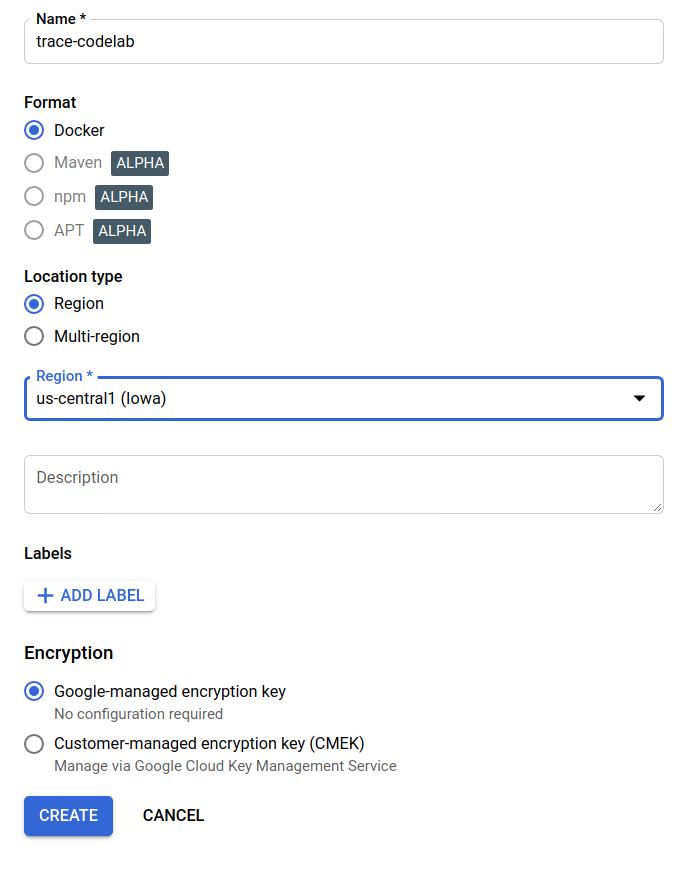
Теперь в браузере репозитория вы видите "trace-codelab".

Мы вернемся сюда позже, чтобы проверить путь в реестре.
установка строительных лесов
Skaffold — удобный инструмент при работе над созданием микросервисов, работающих на Kubernetes. Он управляет процессом сборки, отправки и развертывания контейнеров приложений с помощью небольшого набора команд. По умолчанию Skaffold использует Docker Registry в качестве реестра контейнеров, поэтому вам необходимо настроить Skaffold для распознавания GAR при отправке контейнеров.
Откройте Cloud Shell еще раз и убедитесь, что skaffold установлен. (Cloud Shell устанавливает skaffold в среду по умолчанию.) Выполните следующую команду, чтобы увидеть версию skaffold.
skaffold version
вывод команды
v1.38.0
Теперь вы можете зарегистрировать репозиторий по умолчанию для использования skaffold. Чтобы получить путь к реестру, перейдите на панель управления Реестр артефактов и щелкните имя репозитория, который вы только что настроили на предыдущем шаге.
Затем вы увидите дорожки с хлебными крошками в верхней части страницы. Нажмите на них.  значок для копирования пути к файлу реестра в буфер обмена.
значок для копирования пути к файлу реестра в буфер обмена.

При нажатии на кнопку копирования внизу браузера появится диалоговое окно с сообщением следующего вида:
"us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab" был скопирован.
Вернитесь в облачную оболочку. Выполните команду ` skaffold config set default-repo , указав значение, которое вы только что скопировали с панели управления.
skaffold config set default-repo us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab
вывод команды
set value default-repo to us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab for context gke_stackdriver-sandbox-3438851889_us-central1-b_stackdriver-sandbox
Кроме того, необходимо настроить реестр для работы с Docker. Выполните следующую команду:
gcloud auth configure-docker us-central1-docker.pkg.dev --quiet
вывод команды
{
"credHelpers": {
"gcr.io": "gcloud",
"us.gcr.io": "gcloud",
"eu.gcr.io": "gcloud",
"asia.gcr.io": "gcloud",
"staging-k8s.gcr.io": "gcloud",
"marketplace.gcr.io": "gcloud",
"us-central1-docker.pkg.dev": "gcloud"
}
}
Adding credentials for: us-central1-docker.pkg.dev
Теперь вы можете перейти к следующему шагу — настройке контейнера Kubernetes в GKE.
Краткое содержание
На этом этапе вы настраиваете среду для работы с кодовой лабораторией:
- Настройка Cloud Shell
- Создан репозиторий Artifact Registry для реестра контейнеров.
- Настройте Skaffold для использования реестра контейнеров.
- Создан кластер Kubernetes, в котором работают микросервисы из Codelab.
Далее
На следующем этапе вы внедрите агент непрерывного профилирования в серверную службу.
3. Создайте, разверните и реализуйте микросервисы.
Скачайте материалы для практического занятия.
На предыдущем шаге мы подготовили все необходимые условия для этого практического занятия. Теперь вы готовы запустить на их основе целые микросервисы. Материалы для практического занятия размещены на GitHub, поэтому загрузите их в среду Cloud Shell с помощью следующей команды git.
cd ~ git clone https://github.com/ymotongpoo/opentelemetry-trace-codelab-go.git cd opentelemetry-trace-codelab-go
Структура каталогов проекта выглядит следующим образом:
.
├── README.md
├── step0
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step1
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step2
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step3
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step4
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step5
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
└── step6
├── manifests
├── proto
├── skaffold.yaml
└── src
- манифесты: файлы манифестов Kubernetes
- proto: определение протокола для обмена данными между клиентом и сервером.
- src: каталоги с исходным кодом каждого сервиса
- skaffold.yaml: Конфигурационный файл для skaffold
В этом практическом задании вы обновите исходный код, расположенный в папке step4 . Вы также можете обратиться к исходному коду в папках step[1-6] для ознакомления с изменениями с самого начала. (Часть 1 охватывает шаги с step0 по step4, а Часть 2 — шаги 5 и 6)
Выполните команду skaffold
Наконец, вы готовы собрать, отправить и развернуть весь контент в только что созданном кластере Kubernetes. Кажется, что это включает в себя несколько шагов, но на самом деле Skaffold делает всё за вас. Давайте попробуем это сделать с помощью следующей команды:
cd step4 skaffold dev
Сразу после выполнения команды вы увидите лог-вывод команды docker build и сможете убедиться, что файлы успешно загружены в реестр.
вывод команды
... ---> Running in c39b3ea8692b ---> 90932a583ab6 Successfully built 90932a583ab6 Successfully tagged us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice:step1 The push refers to repository [us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice] cc8f5a05df4a: Preparing 5bf719419ee2: Preparing 2901929ad341: Preparing 88d9943798ba: Preparing b0fdf826a39a: Preparing 3c9c1e0b1647: Preparing f3427ce9393d: Preparing 14a1ca976738: Preparing f3427ce9393d: Waiting 14a1ca976738: Waiting 3c9c1e0b1647: Waiting b0fdf826a39a: Layer already exists 88d9943798ba: Layer already exists f3427ce9393d: Layer already exists 3c9c1e0b1647: Layer already exists 14a1ca976738: Layer already exists 2901929ad341: Pushed 5bf719419ee2: Pushed cc8f5a05df4a: Pushed step1: digest: sha256:8acdbe3a453001f120fb22c11c4f6d64c2451347732f4f271d746c2e4d193bbe size: 2001
После отправки всех контейнеров сервисов развертывание Kubernetes запускается автоматически.
вывод команды
sha256:b71fce0a96cea08075dc20758ae561cf78c83ff656b04d211ffa00cedb77edf8 size: 1997 Tags used in deployment: - serverservice -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice:step4@sha256:8acdbe3a453001f120fb22c11c4f6d64c2451347732f4f271d746c2e4d193bbe - clientservice -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/clientservice:step4@sha256:b71fce0a96cea08075dc20758ae561cf78c83ff656b04d211ffa00cedb77edf8 - loadgen -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/loadgen:step4@sha256:eea2e5bc8463ecf886f958a86906cab896e9e2e380a0eb143deaeaca40f7888a Starting deploy... - deployment.apps/clientservice created - service/clientservice created - deployment.apps/loadgen created - deployment.apps/serverservice created - service/serverservice created
После развертывания вы увидите фактические логи приложения, выводимые в стандартный поток вывода каждого контейнера, примерно такого вида:
вывод команды
[client] 2022/07/14 06:33:15 {"match_count":3040}
[loadgen] 2022/07/14 06:33:15 query 'love': matched 3040
[client] 2022/07/14 06:33:15 {"match_count":3040}
[loadgen] 2022/07/14 06:33:15 query 'love': matched 3040
[client] 2022/07/14 06:33:16 {"match_count":3040}
[loadgen] 2022/07/14 06:33:16 query 'love': matched 3040
[client] 2022/07/14 06:33:19 {"match_count":463}
[loadgen] 2022/07/14 06:33:19 query 'tear': matched 463
[loadgen] 2022/07/14 06:33:20 query 'world': matched 728
[client] 2022/07/14 06:33:20 {"match_count":728}
[client] 2022/07/14 06:33:22 {"match_count":463}
[loadgen] 2022/07/14 06:33:22 query 'tear': matched 463
Обратите внимание, что на данном этапе вам необходимо видеть все сообщения с сервера. Итак, наконец, вы готовы начать инструментирование вашего приложения с помощью OpenTelemetry для распределенной трассировки сервисов.
Перед началом мониторинга сервиса, пожалуйста, выключите кластер с помощью Ctrl-C.
вывод команды
...
[client] 2022/07/14 06:34:57 {"match_count":1}
[loadgen] 2022/07/14 06:34:57 query 'what's past is prologue': matched 1
^CCleaning up...
- W0714 06:34:58.464305 28078 gcp.go:120] WARNING: the gcp auth plugin is deprecated in v1.22+, unavailable in v1.25+; use gcloud instead.
- To learn more, consult https://cloud.google.com/blog/products/containers-kubernetes/kubectl-auth-changes-in-gke
- deployment.apps "clientservice" deleted
- service "clientservice" deleted
- deployment.apps "loadgen" deleted
- deployment.apps "serverservice" deleted
- service "serverservice" deleted
Краткое содержание
На этом этапе вы подготовили материалы для лабораторной работы в своей среде и подтвердили, что Skaffold работает должным образом.
Далее
На следующем шаге вы измените исходный код службы loadgen, чтобы добавить инструменты для сбора информации трассировки.
4. Инструментация агента Cloud Profiler
Концепция непрерывного профилирования
Прежде чем объяснить концепцию непрерывного профилирования, необходимо сначала понять, что такое профилирование. Профилирование — это один из способов динамического анализа приложения (динамический анализ программы), который обычно выполняется в процессе разработки приложения, например, при нагрузочном тестировании и т.д. Это разовая операция по измерению системных метрик, таких как использование ЦП и памяти, в течение определенного периода времени. После сбора данных профилирования разработчики анализируют их вне кода.
Непрерывное профилирование — это расширенный подход к обычному профилированию: оно периодически запускает короткие профилирования для длительно работающего приложения и собирает множество данных профилирования. Затем оно автоматически генерирует статистический анализ на основе определенного атрибута приложения, такого как номер версии, зона развертывания, время измерения и т. д. Более подробную информацию о концепции вы найдете в нашей документации .
Поскольку целевым объектом является запущенное приложение, существует способ периодически собирать данные профилирования и отправлять их на серверную часть, которая обрабатывает статистические данные. Это агент Cloud Profiler, и вскоре вы интегрируете его в серверную службу.
Встроить агент Cloud Profiler
Откройте редактор Cloud Shell, нажав кнопку.  В правом верхнем углу Cloud Shell откройте
В правом верхнем углу Cloud Shell откройте step4/src/server/main.go в обозревателе в левой панели и найдите функцию main.
step4/src/server/main.go
func main() {
...
// step2. setup OpenTelemetry
tp, err := initTracer()
if err != nil {
log.Fatalf("failed to initialize TracerProvider: %v", err)
}
defer func() {
if err := tp.Shutdown(context.Background()); err != nil {
log.Fatalf("error shutting down TracerProvider: %v", err)
}
}()
// step2. end setup
svc := NewServerService()
// step2: add interceptor
interceptorOpt := otelgrpc.WithTracerProvider(otel.GetTracerProvider())
srv := grpc.NewServer(
grpc.UnaryInterceptor(otelgrpc.UnaryServerInterceptor(interceptorOpt)),
grpc.StreamInterceptor(otelgrpc.StreamServerInterceptor(interceptorOpt)),
)
// step2: end adding interceptor
shakesapp.RegisterShakespeareServiceServer(srv, svc)
healthpb.RegisterHealthServer(srv, svc)
if err := srv.Serve(lis); err != nil {
log.Fatalf("error serving server: %v", err)
}
}
В main функции вы увидите код настройки для OpenTelemetry и gRPC, который был выполнен в первой части практического занятия. Теперь вы добавите сюда инструментарий для агента Cloud Profiler. Как и в случае с initTracer() для удобства чтения можно написать функцию с именем initProfiler() .
step4/src/server/main.go
import (
...
"cloud.google.com/go/profiler" // step5. add profiler package
"cloud.google.com/go/storage"
...
)
// step5: add Profiler initializer
func initProfiler() {
cfg := profiler.Config{
Service: "server",
ServiceVersion: "1.0.0",
NoHeapProfiling: true,
NoAllocProfiling: true,
NoGoroutineProfiling: true,
NoCPUProfiling: false,
}
if err := profiler.Start(cfg); err != nil {
log.Fatalf("failed to launch profiler agent: %v", err)
}
}
Давайте внимательно рассмотрим параметры, указанные в объекте profiler.Config{} .
- Сервис : Название сервиса, которое можно выбрать и включить на панели мониторинга профилировщика.
- ServiceVersion : Название версии сервиса. Вы можете сравнивать наборы данных профиля на основе этого значения.
- NoHeapProfiling : отключить профилирование потребления памяти
- NoAllocProfiling : отключить профилирование выделения памяти
- NoGoroutineProfiling : отключить профилирование горутин
- NoCPUProfiling : отключить профилирование ЦП
В этом практическом занятии мы включаем только профилирование ЦП.
Теперь вам нужно просто вызвать эту функцию в main функции. Убедитесь, что вы импортировали пакет Cloud Profiler в блоке импорта.
step4/src/server/main.go
func main() {
...
defer func() {
if err := tp.Shutdown(context.Background()); err != nil {
log.Fatalf("error shutting down TracerProvider: %v", err)
}
}()
// step2. end setup
// step5. start profiler
go initProfiler()
// step5. end
svc := NewServerService()
// step2: add interceptor
...
}
Обратите внимание, что вы вызываете функцию initProfiler() с ключевым словом go . Поскольку profiler.Start() блокирует выполнение, вам нужно запустить её в другой горутине. Теперь сборка готова. Перед развертыванием обязательно запустите команду go mod tidy .
go mod tidy
Теперь разверните свой кластер с помощью новой серверной службы.
skaffold dev
Обычно требуется несколько минут, чтобы увидеть график пламени в Cloud Profiler. Введите «profiler» в поле поиска вверху и щелкните значок Profiler.

Затем вы увидите следующий график пламени.

Краткое содержание
На этом этапе вы встроили агент Cloud Profiler в серверную службу и подтвердили, что он генерирует график пламени.
Далее
На следующем этапе вы с помощью графика пламени исследуете причину возникновения «узкого места» в приложении.
5. Анализ графика пламени Cloud Profiler.
Что такое пламенная диаграмма?
Пламенная диаграмма — один из способов визуализации данных профиля. Для более подробного объяснения обратитесь к нашей документации , но вкратце она выглядит следующим образом:
- Каждый столбик отображает вызов метода/функции в приложении.
- Вертикальное направление — это стек вызовов; стек вызовов растет сверху вниз.
- Горизонтальное направление отражает использование ресурсов; чем длиннее, тем хуже.
Исходя из этого, давайте посмотрим на полученный график пламени.
Анализ графика пламени
В предыдущем разделе вы узнали, что каждый столбик на графике пламени отображает вызов функции/метода, а его длина означает использование ресурсов в функции/методе. График пламени Cloud Profiler сортирует столбики в порядке убывания или по длине слева направо, поэтому вы можете начать с верхнего левого угла графика.

В нашем случае очевидно, что grpc.(*Server).serveStreams.func1.2 потребляет больше всего процессорного времени, и, проанализировав стек вызовов сверху вниз, можно увидеть, что большая часть времени тратится в main.(*serverService).GetMatchCount , который является обработчиком gRPC-сервера в службе сервера.
В функции GetMatchCount вы видите ряд функций для работы с регулярными выражениями : regexp.MatchString и regexp.Compile . Они входят в стандартный пакет, то есть должны быть хорошо протестированы с разных точек зрения, включая производительность. Но результат показывает, что использование ресурсов ЦП в функциях regexp.MatchString и regexp.Compile велико. Учитывая эти факты, можно предположить, что использование regexp.MatchString как-то связано с проблемами производительности. Поэтому давайте прочитаем исходный код, где используется эта функция.
step4/src/server/main.go
func (s *serverService) GetMatchCount(ctx context.Context, req *shakesapp.ShakespeareRequest) (*shakesapp.ShakespeareResponse, error) {
resp := &shakesapp.ShakespeareResponse{}
texts, err := readFiles(ctx, bucketName, bucketPrefix)
if err != nil {
return resp, fmt.Errorf("fails to read files: %s", err)
}
for _, text := range texts {
for _, line := range strings.Split(text, "\n") {
line, query := strings.ToLower(line), strings.ToLower(req.Query)
isMatch, err := regexp.MatchString(query, line)
if err != nil {
return resp, err
}
if isMatch {
resp.MatchCount++
}
}
}
return resp, nil
}
Здесь вызывается функция regexp.MatchString . Прочитав исходный код, вы можете заметить, что функция вызывается внутри вложенного цикла for. Поэтому её использование может быть некорректным. Давайте посмотрим документацию GoDoc по функции regexp .

Согласно документации, regexp.MatchString компилирует шаблон регулярного выражения при каждом вызове. Поэтому причиной большого потребления ресурсов, по всей видимости, является следующее.
Краткое содержание
На этом этапе вы сделали предположение о причине потребления ресурсов, проанализировав график пламени.
Далее
На следующем шаге вам нужно будет обновить исходный код серверной службы и подтвердить изменения по сравнению с версией 1.0.0.
6. Обновите исходный код и сравните графики пламени.
Обновите исходный код
На предыдущем шаге вы предположили, что использование regexp.MatchString связано с большим потреблением ресурсов. Давайте это исправим. Откройте код и немного измените эту часть.
step4/src/server/main.go
func (s *serverService) GetMatchCount(ctx context.Context, req *shakesapp.ShakespeareRequest) (*shakesapp.ShakespeareResponse, error) {
resp := &shakesapp.ShakespeareResponse{}
texts, err := readFiles(ctx, bucketName, bucketPrefix)
if err != nil {
return resp, fmt.Errorf("fails to read files: %s", err)
}
// step6. considered the process carefully and naively tuned up by extracting
// regexp pattern compile process out of for loop.
query := strings.ToLower(req.Query)
re := regexp.MustCompile(query)
for _, text := range texts {
for _, line := range strings.Split(text, "\n") {
line = strings.ToLower(line)
isMatch := re.MatchString(line)
// step6. done replacing regexp with strings
if isMatch {
resp.MatchCount++
}
}
}
return resp, nil
}
Как видите, теперь процесс компиляции шаблонов регулярных выражений вынесен из функции regexp.MatchString и перемещен за пределы вложенного цикла for.
Перед развертыванием этого кода обязательно обновите строку версии в функции initProfiler() .
step4/src/server/main.go
func initProfiler() {
cfg := profiler.Config{
Service: "server",
ServiceVersion: "1.1.0", // step6. update version
NoHeapProfiling: true,
NoAllocProfiling: true,
NoGoroutineProfiling: true,
NoCPUProfiling: false,
}
if err := profiler.Start(cfg); err != nil {
log.Fatalf("failed to launch profiler agent: %v", err)
}
}
Теперь давайте посмотрим, как это работает. Разверните кластер с помощью команды skaffold.
skaffold dev
А через некоторое время перезагрузите панель мониторинга Cloud Profiler и посмотрите, что получится.

Обязательно измените версию на "1.1.0" , чтобы отображались только профили из версии 1.1.0. Как видите, длина полосы GetMatchCount уменьшилась, а коэффициент использования процессорного времени (то есть полоса стала короче) снизился.

Сравнивать различия между двумя версиями можно не только по графику пламени одной версии.

Измените значение в выпадающем списке «Сравнить с» на «Версия», а значение в поле «Сравнимая версия» — на «1.0.0», то есть на исходную версию.

Вы увидите подобный график пламени. Форма графика такая же, как в версии 1.1.0, но цветовая гамма другая. В режиме сравнения цвет означает следующее:
- Синий цвет : значение (потребление ресурсов) уменьшилось.
- Апельсин : полученная ценность (потребление ресурсов).
- Серый : нейтральный
Учитывая легенду, давайте подробнее рассмотрим функцию. Щелкнув по нужной полосе, вы сможете увидеть более подробную информацию внутри стека. Пожалуйста, щелкните по полосе main.(*serverService).GetMatchCount . Также, наведя курсор на эту полосу, вы увидите подробности сравнения.

В сообщении говорится, что общее время работы процессора сократилось с 5,26 с до 2,88 с (общая продолжительность окна выборки составляет 10 с). Это огромное улучшение!
Теперь вы можете улучшить производительность своего приложения, проанализировав данные профиля.
Краткое содержание
На этом этапе вы внесли изменения в серверную службу и подтвердили улучшение в режиме сравнения Cloud Profiler.
Далее
На следующем шаге вам нужно будет обновить исходный код серверной службы и подтвердить изменения по сравнению с версией 1.0.0.
7. Дополнительный шаг: Подтвердите улучшение в каскадной модели трассировки.
Разница между распределенным трассировочным и непрерывным профилированием.
В первой части практического занятия вы подтвердили, что можете определить узкое место в работе микросервисов на определенном пути запроса, но не можете точно определить причину этого узкого места в конкретном сервисе. Во второй части вы узнали, что непрерывное профилирование позволяет выявлять узкое место внутри отдельного сервиса на основе стека вызовов.
На этом этапе давайте рассмотрим график водопада, полученный в результате распределенной трассировки (Cloud Trace), и сравним его с графиком, полученным в результате непрерывного профилирования.
Этот график в виде водопада — один из результатов обработки запроса "любовь". Его выполнение занимает около 6,7 секунд (6700 мс).

И это после улучшения обработки того же запроса. Как вы и сказали, общая задержка теперь составляет 1,5 секунды (1500 мс), что является огромным улучшением по сравнению с предыдущей реализацией.

Важный момент здесь заключается в том, что на диаграмме каскадной трассировки распределенного режима информация о стеке вызовов недоступна, если не инструментировать трассировку по всему периметру системы. Кроме того, распределенная трассировка фокусируется только на задержке между сервисами, тогда как непрерывное профилирование фокусируется на вычислительных ресурсах (ЦП, память, потоки ОС) отдельного сервиса.
С другой стороны, распределенная трассировка представляет собой базу событий, а непрерывный профиль — статистический. Каждая трассировка имеет свой собственный график задержки, и для получения тенденции изменения задержки требуется разный формат, например, распределение .
Краткое содержание
На этом этапе вы проверили разницу между распределенной трассировкой и непрерывным профилированием.
8. Поздравляем!
Вы успешно создали распределенную трассировку с помощью OpenTelemery и подтвердили задержки запросов в микросервисе в Google Cloud Trace.
Для более развернутых упражнений вы можете самостоятельно изучить следующие темы.
- Текущая реализация отправляет все трассировки, сгенерированные проверкой работоспособности (
grpc.health.v1.Health/Check). Как отфильтровать эти трассировки из Cloud Traces? Подсказка здесь . - Сопоставьте журналы событий с данными о сегментах сети и посмотрите, как это работает в Google Cloud Trace и Google Cloud Logging. Подсказка здесь .
- Замените какой-либо сервис на сервис на другом языке и попробуйте использовать для его работы OpenTelemetry для этого языка.
Также, если после этого вы захотите узнать больше о профилировщике, пожалуйста, перейдите ко второй части. В этом случае вы можете пропустить раздел об очистке, расположенный ниже.
Уборка
После выполнения этого практического задания остановите кластер Kubernetes и обязательно удалите проект, чтобы избежать непредвиденных расходов на Google Kubernetes Engine, Google Cloud Trace и Google Artifact Registry.
Сначала удалите кластер. Если вы запускаете кластер с помощью skaffold dev , просто нажмите Ctrl-C. Если вы запускаете кластер с помощью skaffold run , выполните следующую команду:
skaffold delete
вывод команды
Cleaning up... - deployment.apps "clientservice" deleted - service "clientservice" deleted - deployment.apps "loadgen" deleted - deployment.apps "serverservice" deleted - service "serverservice" deleted
После удаления кластера в панели меню выберите «IAM и администрирование» > «Настройки», а затем нажмите кнопку «Выключить».

Затем введите идентификатор проекта (а не название проекта) в форму в диалоговом окне и подтвердите завершение работы.