
1. Giới thiệu
Lần cập nhật gần đây nhất: ngày 14 tháng 7 năm 2022
Khả năng ghi nhận của ứng dụng
Khả năng quan sát và Trình phân tích tài nguyên liên tục
Khả năng ghi nhận là thuật ngữ dùng để mô tả một thuộc tính của hệ thống. Một hệ thống có khả năng quan sát cho phép các nhóm chủ động gỡ lỗi hệ thống của họ. Trong bối cảnh đó, 3 trụ cột của khả năng ghi nhận (nhật ký, chỉ số và dấu vết) là khả năng đo lường cơ bản để hệ thống có được khả năng ghi nhận.
Ngoài 3 trụ cột của khả năng ghi nhận, việc lập hồ sơ liên tục cũng là một thành phần quan trọng khác của khả năng ghi nhận và đang mở rộng cơ sở người dùng trong ngành. Cloud Profiler là một trong những công cụ khởi tạo và cung cấp một giao diện dễ dàng để đi sâu vào các chỉ số hiệu suất trong ngăn xếp lệnh gọi ứng dụng.
Đây là phần 2 của loạt lớp học lập trình này, trong đó trình bày cách đo lường một tác nhân trình phân tích tài nguyên liên tục. Phần 1 đề cập đến tính năng theo dõi phân tán bằng OpenTelemetry và Cloud Trace, đồng thời bạn sẽ tìm hiểu thêm về cách xác định điểm tắc nghẽn của các vi dịch vụ một cách hiệu quả hơn bằng phần 1.
Sản phẩm bạn sẽ tạo ra
Trong lớp học lập trình này, bạn sẽ đo lường tác nhân trình phân tích tài nguyên liên tục trong dịch vụ máy chủ của "ứng dụng Shakespeare" (còn gọi là Shakesapp) chạy trên một cụm Google Kubernetes Engine. Kiến trúc của Shakesapp như mô tả bên dưới:

- Loadgen gửi một chuỗi truy vấn đến máy khách trong HTTP
- Các ứng dụng truyền truy vấn từ loadgen đến máy chủ trong gRPC
- Máy chủ chấp nhận truy vấn từ máy khách, tìm nạp tất cả các tác phẩm của Shakespeare ở định dạng văn bản từ Google Cloud Storage, tìm kiếm các dòng có chứa truy vấn và trả về số dòng khớp với máy khách
Trong phần 1, bạn nhận thấy rằng có một điểm tắc nghẽn ở đâu đó trong dịch vụ máy chủ, nhưng bạn không thể xác định chính xác nguyên nhân.
Kiến thức bạn sẽ học được
- Cách nhúng tác nhân lập hồ sơ
- Cách điều tra nút thắt cổ chai trên Cloud Profiler
Lớp học lập trình này giải thích cách đo lường một tác nhân trình phân tích tài nguyên liên tục trong ứng dụng của bạn.
Bạn cần có
- Kiến thức cơ bản về Go
- Kiến thức cơ bản về Kubernetes
2. Thiết lập và yêu cầu
Thiết lập môi trường theo tốc độ của riêng bạn
Nếu chưa có Tài khoản Google (Gmail hoặc Google Apps), bạn phải tạo một tài khoản. Đăng nhập vào bảng điều khiển Google Cloud Platform ( console.cloud.google.com) rồi tạo một dự án mới.
Nếu bạn đã có dự án, hãy nhấp vào trình đơn thả xuống chọn dự án ở phía trên bên trái của bảng điều khiển:

rồi nhấp vào nút "DỰ ÁN MỚI" trong hộp thoại xuất hiện để tạo một dự án mới:

Nếu chưa có dự án, bạn sẽ thấy một hộp thoại như thế này để tạo dự án đầu tiên:

Hộp thoại tạo dự án tiếp theo cho phép bạn nhập thông tin chi tiết về dự án mới:
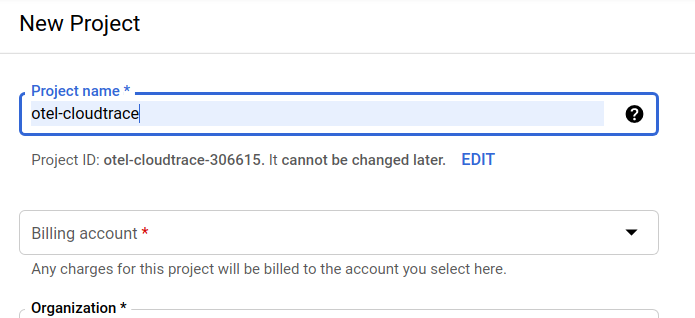
Hãy nhớ mã dự án. Đây là tên duy nhất trên tất cả các dự án Google Cloud (tên ở trên đã được sử dụng và sẽ không hoạt động đối với bạn, xin lỗi!). Sau này trong lớp học lập trình này, chúng ta sẽ gọi đó là PROJECT_ID.
Tiếp theo, nếu chưa làm, bạn cần phải bật tính năng thanh toán trong Play Console để sử dụng các tài nguyên của Google Cloud và bật Cloud Trace API.

Việc thực hiện lớp học lập trình này sẽ không tốn của bạn quá vài đô la, nhưng có thể tốn nhiều hơn nếu bạn quyết định sử dụng nhiều tài nguyên hơn hoặc nếu bạn để các tài nguyên đó chạy (xem phần "dọn dẹp" ở cuối tài liệu này). Giá của Google Cloud Trace, Google Kubernetes Engine và Google Artifact Registry được ghi trong tài liệu chính thức.
- Giá của bộ công cụ vận hành của Google Cloud | Bộ công cụ vận hành
- Giá | Tài liệu về Kubernetes Engine
- Giá của Artifact Registry | Tài liệu về Artifact Registry
Người dùng mới của Google Cloud Platform đủ điều kiện dùng thử miễn phí trị giá 300 USD. Nhờ đó, bạn có thể hoàn toàn miễn phí tham gia lớp học lập trình này.
Thiết lập Google Cloud Shell
Mặc dù bạn có thể vận hành Google Cloud và Google Cloud Trace từ xa trên máy tính xách tay, nhưng trong lớp học lập trình này, chúng ta sẽ sử dụng Google Cloud Shell, một môi trường dòng lệnh chạy trên đám mây.
Máy ảo dựa trên Debian này được trang bị tất cả các công cụ phát triển mà bạn cần. Nền tảng này cung cấp một thư mục chính có dung lượng 5 GB và chạy trong Google Cloud, giúp tăng cường đáng kể hiệu suất mạng và hoạt động xác thực. Điều này có nghĩa là bạn chỉ cần một trình duyệt (có, trình duyệt này hoạt động trên Chromebook) cho lớp học lập trình này.
Để kích hoạt Cloud Shell từ Bảng điều khiển Cloud, bạn chỉ cần nhấp vào biểu tượng Kích hoạt Cloud Shell  (mất vài phút để cung cấp và kết nối với môi trường).
(mất vài phút để cung cấp và kết nối với môi trường).


Sau khi kết nối với Cloud Shell, bạn sẽ thấy rằng mình đã được xác thực và dự án đã được đặt thành PROJECT_ID.
gcloud auth list
Đầu ra của lệnh
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Đầu ra của lệnh
[core] project = <PROJECT_ID>
Nếu vì lý do nào đó mà dự án chưa được thiết lập, bạn chỉ cần đưa ra lệnh sau:
gcloud config set project <PROJECT_ID>
Bạn đang tìm PROJECT_ID? Kiểm tra mã nhận dạng bạn đã dùng trong các bước thiết lập hoặc tìm mã nhận dạng đó trong trang tổng quan của Cloud Console:

Cloud Shell cũng đặt một số biến môi trường theo mặc định, có thể hữu ích khi bạn chạy các lệnh trong tương lai.
echo $GOOGLE_CLOUD_PROJECT
Đầu ra của lệnh
<PROJECT_ID>
Cuối cùng, hãy đặt cấu hình dự án và vùng mặc định.
gcloud config set compute/zone us-central1-f
Bạn có thể chọn nhiều múi giờ khác nhau. Để biết thêm thông tin, hãy xem phần Khu vực và vùng.
Chuyển đến phần thiết lập ngôn ngữ
Trong lớp học lập trình này, chúng ta sử dụng Go cho tất cả mã nguồn. Chạy lệnh sau trên Cloud Shell và xác nhận xem phiên bản Go có phải là 1.17 trở lên hay không
go version
Đầu ra của lệnh
go version go1.18.3 linux/amd64
Thiết lập một Cụm Kubernetes của Google
Trong lớp học lập trình này, bạn sẽ chạy một cụm vi dịch vụ trên Google Kubernetes Engine (GKE). Quy trình của lớp học lập trình này như sau:
- Tải dự án cơ sở xuống Cloud Shell
- Tạo các vi dịch vụ vào vùng chứa
- Tải vùng chứa lên Google Artifact Registry (GAR)
- Triển khai vùng chứa trên GKE
- Sửa đổi mã nguồn của các dịch vụ để theo dõi khả năng đo lường
- Chuyển đến bước 2
Bật Kubernetes Engine
Trước tiên, chúng ta thiết lập một cụm Kubernetes nơi Shakesapp chạy trên GKE, vì vậy, chúng ta cần bật GKE. Chuyển đến trình đơn "Kubernetes Engine" rồi nhấn nút BẬT.
Bây giờ, bạn đã sẵn sàng tạo một cụm Kubernetes.
Tạo cụm Kubernetes
Trên Cloud Shell, hãy chạy lệnh sau để tạo một cụm Kubernetes. Vui lòng xác nhận giá trị của vùng nằm trong khu vực mà bạn sẽ dùng để tạo kho lưu trữ Artifact Registry. Thay đổi giá trị khu vực us-central1-f nếu khu vực kho lưu trữ của bạn không bao gồm khu vực đó.
gcloud container clusters create otel-trace-codelab2 \ --zone us-central1-f \ --release-channel rapid \ --preemptible \ --enable-autoscaling \ --max-nodes 8 \ --no-enable-ip-alias \ --scopes cloud-platform
Đầu ra của lệnh
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s). Creating cluster otel-trace-codelab2 in us-central1-f... Cluster is being health-checked (master is healthy)...done. Created [https://container.googleapis.com/v1/projects/development-215403/zones/us-central1-f/clusters/otel-trace-codelab2]. To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/workload_/gcloud/us-central1-f/otel-trace-codelab2?project=development-215403 kubeconfig entry generated for otel-trace-codelab2. NAME: otel-trace-codelab2 LOCATION: us-central1-f MASTER_VERSION: 1.23.6-gke.1501 MASTER_IP: 104.154.76.89 MACHINE_TYPE: e2-medium NODE_VERSION: 1.23.6-gke.1501 NUM_NODES: 3 STATUS: RUNNING
Thiết lập Artifact Registry và Skaffold
Giờ đây, chúng ta đã có một cụm Kubernetes sẵn sàng để triển khai. Tiếp theo, chúng ta chuẩn bị cho một sổ đăng ký vùng chứa để đẩy và triển khai vùng chứa. Đối với các bước này, chúng ta cần thiết lập Artifact Registry (GAR) và skaffold để sử dụng.
Thiết lập Artifact Registry
Chuyển đến trình đơn "Artifact Registry" rồi nhấn vào nút BẬT.

Sau vài phút, bạn sẽ thấy trình duyệt kho lưu trữ của GAR. Nhấp vào nút "TẠO KHO LƯU TRỮ" rồi nhập tên của kho lưu trữ.

Trong lớp học lập trình này, tôi đặt tên cho kho lưu trữ mới là trace-codelab. Định dạng của cấu phần phần mềm là "Docker" và loại vị trí là "Khu vực". Chọn khu vực gần với khu vực bạn đặt cho vùng mặc định của Google Compute Engine. Ví dụ: ví dụ này chọn "us-central1-f" ở trên, vì vậy ở đây chúng ta chọn "us-central1 (Iowa)". Sau đó, hãy nhấp vào nút "TẠO".

Giờ đây, bạn sẽ thấy "trace-codelab" trên trình duyệt kho lưu trữ.

Chúng ta sẽ quay lại đây sau để kiểm tra đường dẫn sổ đăng ký.
Thiết lập Skaffold
Skaffold là một công cụ hữu ích khi bạn làm việc để tạo các dịch vụ vi mô chạy trên Kubernetes. Công cụ này xử lý quy trình tạo, đẩy và triển khai các vùng chứa ứng dụng bằng một nhóm nhỏ các lệnh. Theo mặc định, Skaffold sử dụng Docker Registry làm sổ đăng ký vùng chứa, vì vậy, bạn cần định cấu hình Skaffold để nhận dạng GAR khi đẩy vùng chứa đến.
Mở lại Cloud Shell và xác nhận xem skaffold đã được cài đặt hay chưa. (Theo mặc định, Cloud Shell sẽ cài đặt skaffold vào môi trường.) Chạy lệnh sau và xem phiên bản skaffold.
skaffold version
Đầu ra của lệnh
v1.38.0
Giờ đây, bạn có thể đăng ký kho lưu trữ mặc định để skaffold sử dụng. Để lấy đường dẫn đăng ký, hãy chuyển đến trang tổng quan Artifact Registry rồi nhấp vào tên kho lưu trữ mà bạn vừa thiết lập ở bước trước.
Sau đó, bạn sẽ thấy đường dẫn breadcrumb ở đầu trang. Nhấp vào biểu tượng  để sao chép đường dẫn đăng ký vào bảng nhớ tạm.
để sao chép đường dẫn đăng ký vào bảng nhớ tạm.

Khi nhấp vào nút sao chép, bạn sẽ thấy hộp thoại ở cuối trình duyệt có thông báo như sau:
Đã sao chép "us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab"
Quay lại Cloud Shell. Chạy lệnh skaffold config set default-repo bằng giá trị mà bạn vừa sao chép từ trang tổng quan.
skaffold config set default-repo us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab
Đầu ra của lệnh
set value default-repo to us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab for context gke_stackdriver-sandbox-3438851889_us-central1-b_stackdriver-sandbox
Ngoài ra, bạn cần định cấu hình sổ đăng ký cho cấu hình Docker. Chạy lệnh sau:
gcloud auth configure-docker us-central1-docker.pkg.dev --quiet
Đầu ra của lệnh
{
"credHelpers": {
"gcr.io": "gcloud",
"us.gcr.io": "gcloud",
"eu.gcr.io": "gcloud",
"asia.gcr.io": "gcloud",
"staging-k8s.gcr.io": "gcloud",
"marketplace.gcr.io": "gcloud",
"us-central1-docker.pkg.dev": "gcloud"
}
}
Adding credentials for: us-central1-docker.pkg.dev
Giờ đây, bạn đã sẵn sàng chuyển sang bước tiếp theo để thiết lập một vùng chứa Kubernetes trên GKE.
Tóm tắt
Ở bước này, bạn sẽ thiết lập môi trường lớp học lập trình:
- Thiết lập Cloud Shell
- Đã tạo một kho lưu trữ Artifact Registry cho sổ đăng ký vùng chứa
- Thiết lập skaffold để sử dụng sổ đăng ký vùng chứa
- Tạo một cụm Kubernetes nơi các vi dịch vụ của lớp học lập trình chạy
Tiếp theo
Trong bước tiếp theo, bạn sẽ đo lường tác nhân trình phân tích tài nguyên liên tục trong dịch vụ máy chủ.
3. Tạo, chuyển và triển khai các vi dịch vụ
Tải tài liệu của lớp học lập trình xuống
Ở bước trước, chúng ta đã thiết lập tất cả các điều kiện tiên quyết cho lớp học lập trình này. Giờ đây, bạn đã sẵn sàng chạy toàn bộ các vi dịch vụ trên các vùng này. Tài liệu của lớp học lập trình được lưu trữ trên GitHub, vì vậy, hãy tải tài liệu xuống môi trường Cloud Shell bằng lệnh git sau.
cd ~ git clone https://github.com/ymotongpoo/opentelemetry-trace-codelab-go.git cd opentelemetry-trace-codelab-go
Cấu trúc thư mục của dự án như sau:
.
├── README.md
├── step0
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step1
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step2
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step3
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step4
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step5
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
└── step6
├── manifests
├── proto
├── skaffold.yaml
└── src
- manifests: Tệp kê khai Kubernetes
- proto: định nghĩa proto cho hoạt động giao tiếp giữa ứng dụng và máy chủ
- src: thư mục cho mã nguồn của từng dịch vụ
- skaffold.yaml: Tệp cấu hình cho skaffold
Trong lớp học lập trình này, bạn sẽ cập nhật mã nguồn nằm trong thư mục step4. Bạn cũng có thể tham khảo mã nguồn trong các thư mục step[1-6] để biết những thay đổi từ đầu. (Phần 1 bao gồm bước 0 đến bước 4, còn Phần 2 bao gồm bước 5 và 6)
Chạy lệnh skaffold
Cuối cùng, bạn đã sẵn sàng tạo, truyền và triển khai toàn bộ nội dung lên cụm Kubernetes mà bạn vừa tạo. Có vẻ như quy trình này có nhiều bước, nhưng thực tế là Skaffold sẽ làm mọi thứ cho bạn. Hãy thử làm việc đó bằng lệnh sau:
cd step4 skaffold dev
Ngay sau khi chạy lệnh, bạn sẽ thấy thông tin xuất trong nhật ký của docker build và có thể xác nhận rằng các thông tin này đã được chuyển thành công vào sổ đăng ký.
Đầu ra của lệnh
... ---> Running in c39b3ea8692b ---> 90932a583ab6 Successfully built 90932a583ab6 Successfully tagged us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice:step1 The push refers to repository [us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice] cc8f5a05df4a: Preparing 5bf719419ee2: Preparing 2901929ad341: Preparing 88d9943798ba: Preparing b0fdf826a39a: Preparing 3c9c1e0b1647: Preparing f3427ce9393d: Preparing 14a1ca976738: Preparing f3427ce9393d: Waiting 14a1ca976738: Waiting 3c9c1e0b1647: Waiting b0fdf826a39a: Layer already exists 88d9943798ba: Layer already exists f3427ce9393d: Layer already exists 3c9c1e0b1647: Layer already exists 14a1ca976738: Layer already exists 2901929ad341: Pushed 5bf719419ee2: Pushed cc8f5a05df4a: Pushed step1: digest: sha256:8acdbe3a453001f120fb22c11c4f6d64c2451347732f4f271d746c2e4d193bbe size: 2001
Sau khi đẩy tất cả các vùng chứa dịch vụ, các hoạt động triển khai Kubernetes sẽ tự động bắt đầu.
Đầu ra của lệnh
sha256:b71fce0a96cea08075dc20758ae561cf78c83ff656b04d211ffa00cedb77edf8 size: 1997 Tags used in deployment: - serverservice -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice:step4@sha256:8acdbe3a453001f120fb22c11c4f6d64c2451347732f4f271d746c2e4d193bbe - clientservice -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/clientservice:step4@sha256:b71fce0a96cea08075dc20758ae561cf78c83ff656b04d211ffa00cedb77edf8 - loadgen -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/loadgen:step4@sha256:eea2e5bc8463ecf886f958a86906cab896e9e2e380a0eb143deaeaca40f7888a Starting deploy... - deployment.apps/clientservice created - service/clientservice created - deployment.apps/loadgen created - deployment.apps/serverservice created - service/serverservice created
Sau khi triển khai, bạn sẽ thấy nhật ký ứng dụng thực tế được phát ra stdout trong mỗi vùng chứa như sau:
Đầu ra của lệnh
[client] 2022/07/14 06:33:15 {"match_count":3040}
[loadgen] 2022/07/14 06:33:15 query 'love': matched 3040
[client] 2022/07/14 06:33:15 {"match_count":3040}
[loadgen] 2022/07/14 06:33:15 query 'love': matched 3040
[client] 2022/07/14 06:33:16 {"match_count":3040}
[loadgen] 2022/07/14 06:33:16 query 'love': matched 3040
[client] 2022/07/14 06:33:19 {"match_count":463}
[loadgen] 2022/07/14 06:33:19 query 'tear': matched 463
[loadgen] 2022/07/14 06:33:20 query 'world': matched 728
[client] 2022/07/14 06:33:20 {"match_count":728}
[client] 2022/07/14 06:33:22 {"match_count":463}
[loadgen] 2022/07/14 06:33:22 query 'tear': matched 463
Xin lưu ý rằng tại thời điểm này, bạn muốn xem mọi thông báo từ máy chủ. Được rồi, cuối cùng bạn đã sẵn sàng bắt đầu đo lường ứng dụng của mình bằng OpenTelemetry để theo dõi phân tán các dịch vụ.
Trước khi bắt đầu đo lường dịch vụ, vui lòng tắt cụm bằng Ctrl-C.
Đầu ra của lệnh
...
[client] 2022/07/14 06:34:57 {"match_count":1}
[loadgen] 2022/07/14 06:34:57 query 'what's past is prologue': matched 1
^CCleaning up...
- W0714 06:34:58.464305 28078 gcp.go:120] WARNING: the gcp auth plugin is deprecated in v1.22+, unavailable in v1.25+; use gcloud instead.
- To learn more, consult https://cloud.google.com/blog/products/containers-kubernetes/kubectl-auth-changes-in-gke
- deployment.apps "clientservice" deleted
- service "clientservice" deleted
- deployment.apps "loadgen" deleted
- deployment.apps "serverservice" deleted
- service "serverservice" deleted
Tóm tắt
Ở bước này, bạn đã chuẩn bị tài liệu của lớp học lập trình trong môi trường của mình và xác nhận rằng skaffold chạy như mong đợi.
Tiếp theo
Trong bước tiếp theo, bạn sẽ sửa đổi mã nguồn của dịch vụ loadgen để đo lường thông tin theo dõi.
4. Khả năng đo lường của nhân viên hỗ trợ Cloud Profiler
Khái niệm về lập hồ sơ liên tục
Trước khi giải thích khái niệm về việc lập hồ sơ liên tục, chúng ta cần hiểu rõ khái niệm về việc lập hồ sơ. Lập hồ sơ là một trong những cách để phân tích ứng dụng một cách linh hoạt (phân tích chương trình linh hoạt) và thường được thực hiện trong quá trình phát triển ứng dụng trong quá trình kiểm thử tải, v.v. Đây là một hoạt động đơn lẻ để đo lường các chỉ số hệ thống, chẳng hạn như mức sử dụng CPU và bộ nhớ, trong một khoảng thời gian cụ thể. Sau khi thu thập dữ liệu hồ sơ, nhà phát triển sẽ phân tích dữ liệu đó bên ngoài mã.
Lập hồ sơ liên tục là phương pháp mở rộng của việc lập hồ sơ thông thường: Phương pháp này chạy các hồ sơ cửa sổ ngắn đối với ứng dụng chạy trong thời gian dài theo định kỳ và thu thập một loạt dữ liệu hồ sơ. Sau đó, công cụ này sẽ tự động tạo phân tích thống kê dựa trên một thuộc tính nhất định của ứng dụng, chẳng hạn như số phiên bản, vùng triển khai, thời gian đo lường, v.v. Bạn sẽ tìm thấy thêm thông tin chi tiết về khái niệm này trong tài liệu của chúng tôi.
Vì đích đến là một ứng dụng đang chạy, nên có một cách để định kỳ thu thập dữ liệu hồ sơ và gửi dữ liệu đó đến một số phần phụ trợ xử lý dữ liệu thống kê sau. Đó là tác nhân Cloud Profiler và bạn sẽ sớm nhúng tác nhân này vào dịch vụ máy chủ.
Nhúng tác nhân Cloud Profiler
Mở Cloud Shell Editor bằng cách nhấn vào nút  ở trên cùng bên phải của Cloud Shell. Mở
ở trên cùng bên phải của Cloud Shell. Mở step4/src/server/main.go trong trình khám phá ở ngăn bên trái và tìm hàm chính.
step4/src/server/main.go
func main() {
...
// step2. setup OpenTelemetry
tp, err := initTracer()
if err != nil {
log.Fatalf("failed to initialize TracerProvider: %v", err)
}
defer func() {
if err := tp.Shutdown(context.Background()); err != nil {
log.Fatalf("error shutting down TracerProvider: %v", err)
}
}()
// step2. end setup
svc := NewServerService()
// step2: add interceptor
interceptorOpt := otelgrpc.WithTracerProvider(otel.GetTracerProvider())
srv := grpc.NewServer(
grpc.UnaryInterceptor(otelgrpc.UnaryServerInterceptor(interceptorOpt)),
grpc.StreamInterceptor(otelgrpc.StreamServerInterceptor(interceptorOpt)),
)
// step2: end adding interceptor
shakesapp.RegisterShakespeareServiceServer(srv, svc)
healthpb.RegisterHealthServer(srv, svc)
if err := srv.Serve(lis); err != nil {
log.Fatalf("error serving server: %v", err)
}
}
Trong hàm main, bạn sẽ thấy một số mã thiết lập cho OpenTelemetry và gRPC. Mã này đã được thực hiện trong phần 1 của lớp học lập trình. Bây giờ, bạn sẽ thêm khả năng đo lường cho tác nhân Cloud Profiler tại đây. Giống như những gì chúng ta đã làm cho initTracer(), bạn có thể viết một hàm có tên là initProfiler() để dễ đọc.
step4/src/server/main.go
import (
...
"cloud.google.com/go/profiler" // step5. add profiler package
"cloud.google.com/go/storage"
...
)
// step5: add Profiler initializer
func initProfiler() {
cfg := profiler.Config{
Service: "server",
ServiceVersion: "1.0.0",
NoHeapProfiling: true,
NoAllocProfiling: true,
NoGoroutineProfiling: true,
NoCPUProfiling: false,
}
if err := profiler.Start(cfg); err != nil {
log.Fatalf("failed to launch profiler agent: %v", err)
}
}
Hãy xem xét kỹ các lựa chọn được chỉ định trong đối tượng profiler.Config{}.
- Dịch vụ: Tên dịch vụ mà bạn có thể chọn và bật trên trang tổng quan của trình phân tích tài nguyên
- ServiceVersion: Tên phiên bản dịch vụ. Bạn có thể so sánh các tập dữ liệu hồ sơ dựa trên giá trị này.
- NoHeapProfiling: tắt chế độ phân tích mức tiêu thụ bộ nhớ
- NoAllocProfiling: tắt tính năng phân bổ bộ nhớ
- NoGoroutineProfiling: tắt tính năng lập hồ sơ goroutine
- NoCPUProfiling: tắt tính năng lập hồ sơ CPU
Trong lớp học lập trình này, chúng ta chỉ bật tính năng lập hồ sơ CPU.
Bây giờ, bạn chỉ cần gọi hàm này trong hàm main. Nhớ nhập gói Cloud Profiler vào khối nhập.
step4/src/server/main.go
func main() {
...
defer func() {
if err := tp.Shutdown(context.Background()); err != nil {
log.Fatalf("error shutting down TracerProvider: %v", err)
}
}()
// step2. end setup
// step5. start profiler
go initProfiler()
// step5. end
svc := NewServerService()
// step2: add interceptor
...
}
Xin lưu ý rằng bạn đang gọi hàm initProfiler() bằng từ khoá go. Vì profiler.Start() chặn nên bạn cần chạy mã này trong một goroutine khác. Giờ đây, bạn đã sẵn sàng xây dựng. Hãy nhớ chạy go mod tidy trước khi triển khai.
go mod tidy
Bây giờ, hãy triển khai cụm bằng dịch vụ máy chủ mới.
skaffold dev
Thường thì bạn sẽ thấy biểu đồ ngọn lửa trên Cloud Profiler sau vài phút. Nhập "profiler" vào hộp tìm kiếm ở trên cùng rồi nhấp vào biểu tượng của Profiler.

Sau đó, bạn sẽ thấy biểu đồ ngọn lửa sau.

Tóm tắt
Trong bước này, bạn đã nhúng tác nhân Cloud Profiler vào dịch vụ máy chủ và xác nhận rằng tác nhân này tạo ra biểu đồ ngọn lửa.
Tiếp theo
Trong bước tiếp theo, bạn sẽ tìm hiểu nguyên nhân gây ra tình trạng tắc nghẽn trong ứng dụng bằng biểu đồ hình ngọn lửa.
5. Phân tích biểu đồ hình ngọn lửa của Cloud Profiler
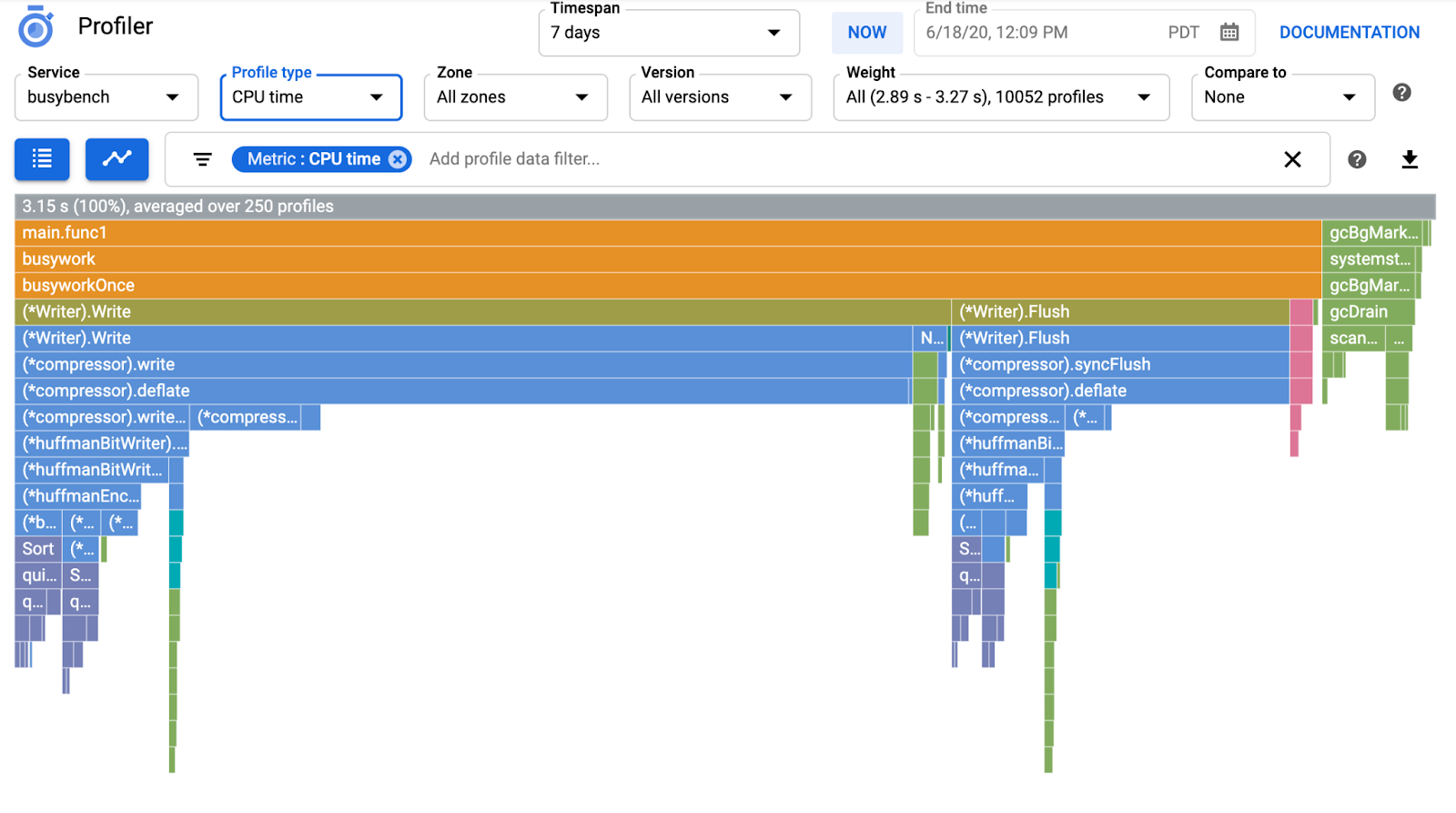
Biểu đồ hình ngọn lửa là gì?
Biểu đồ ngọn lửa là một trong những cách để trực quan hoá dữ liệu hồ sơ. Để biết nội dung giải thích chi tiết, vui lòng tham khảo tài liệu của chúng tôi, nhưng nội dung tóm tắt ngắn gọn là:
- Mỗi thanh biểu thị lệnh gọi phương thức/hàm trong ứng dụng
- Hướng dọc là ngăn xếp lệnh gọi; ngăn xếp lệnh gọi tăng từ trên xuống dưới
- Hướng ngang là mức sử dụng tài nguyên; càng dài thì càng tệ.
Hãy xem biểu đồ hình ngọn lửa thu được.
Phân tích biểu đồ ngọn lửa
Trong phần trước, bạn đã biết rằng mỗi thanh trong biểu đồ ngọn lửa thể hiện lệnh gọi hàm/lệnh gọi phương thức và độ dài của thanh đó có nghĩa là mức sử dụng tài nguyên trong hàm/phương thức. Biểu đồ ngọn lửa của Cloud Profiler sắp xếp các thanh theo thứ tự giảm dần hoặc độ dài từ trái sang phải, bạn có thể bắt đầu xem ở phía trên cùng bên trái của biểu đồ trước.
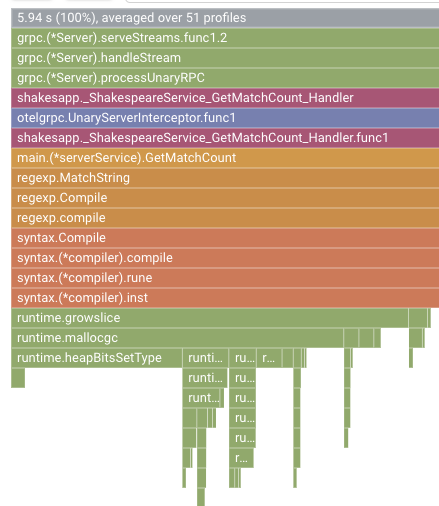
Trong trường hợp này, rõ ràng là grpc.(*Server).serveStreams.func1.2 đang tiêu tốn phần lớn thời gian CPU và bằng cách xem xét ngăn xếp lệnh gọi từ trên xuống, phần lớn thời gian được sử dụng trong main.(*serverService).GetMatchCount, đây là trình xử lý máy chủ gRPC trong dịch vụ máy chủ.
Trong GetMatchCount, bạn sẽ thấy một loạt hàm regexp: regexp.MatchString và regexp.Compile. Chúng thuộc gói tiêu chuẩn, tức là chúng phải được kiểm thử kỹ lưỡng ở nhiều khía cạnh, bao gồm cả hiệu suất. Nhưng kết quả ở đây cho thấy mức sử dụng tài nguyên thời gian CPU cao trong regexp.MatchString và regexp.Compile. Với những dữ kiện đó, giả định ở đây là việc sử dụng regexp.MatchString có liên quan đến các vấn đề về hiệu suất. Vì vậy, hãy đọc mã nguồn nơi hàm này được dùng.
step4/src/server/main.go
func (s *serverService) GetMatchCount(ctx context.Context, req *shakesapp.ShakespeareRequest) (*shakesapp.ShakespeareResponse, error) {
resp := &shakesapp.ShakespeareResponse{}
texts, err := readFiles(ctx, bucketName, bucketPrefix)
if err != nil {
return resp, fmt.Errorf("fails to read files: %s", err)
}
for _, text := range texts {
for _, line := range strings.Split(text, "\n") {
line, query := strings.ToLower(line), strings.ToLower(req.Query)
isMatch, err := regexp.MatchString(query, line)
if err != nil {
return resp, err
}
if isMatch {
resp.MatchCount++
}
}
}
return resp, nil
}
Đây là nơi gọi regexp.MatchString. Bằng cách đọc mã nguồn, bạn có thể nhận thấy rằng hàm này được gọi bên trong vòng lặp for lồng nhau. Vì vậy, việc sử dụng hàm này có thể không chính xác. Hãy tìm GoDoc của regexp.

Theo tài liệu này, regexp.MatchString sẽ biên dịch mẫu biểu thức chính quy trong mọi lệnh gọi. Vì vậy, nguyên nhân dẫn đến mức tiêu thụ tài nguyên lớn có vẻ như sau.
Tóm tắt
Trong bước này, bạn đã giả định nguyên nhân tiêu thụ tài nguyên bằng cách phân tích biểu đồ hình ngọn lửa.
Tiếp theo
Trong bước tiếp theo, bạn sẽ cập nhật mã nguồn của dịch vụ máy chủ và xác nhận thay đổi từ phiên bản 1.0.0.
6. Cập nhật mã nguồn và so sánh các biểu đồ ngọn lửa
Cập nhật mã nguồn
Ở bước trước, bạn đã giả định rằng việc sử dụng regexp.MatchString có liên quan đến mức tiêu thụ tài nguyên lớn. Vậy hãy giải quyết vấn đề này. Mở mã và thay đổi một chút phần đó.
step4/src/server/main.go
func (s *serverService) GetMatchCount(ctx context.Context, req *shakesapp.ShakespeareRequest) (*shakesapp.ShakespeareResponse, error) {
resp := &shakesapp.ShakespeareResponse{}
texts, err := readFiles(ctx, bucketName, bucketPrefix)
if err != nil {
return resp, fmt.Errorf("fails to read files: %s", err)
}
// step6. considered the process carefully and naively tuned up by extracting
// regexp pattern compile process out of for loop.
query := strings.ToLower(req.Query)
re := regexp.MustCompile(query)
for _, text := range texts {
for _, line := range strings.Split(text, "\n") {
line = strings.ToLower(line)
isMatch := re.MatchString(line)
// step6. done replacing regexp with strings
if isMatch {
resp.MatchCount++
}
}
}
return resp, nil
}
Như bạn thấy, hiện tại quy trình biên dịch mẫu biểu thức chính quy được trích xuất từ regexp.MatchString và được di chuyển ra khỏi vòng lặp for lồng nhau.
Trước khi triển khai mã này, hãy nhớ cập nhật chuỗi phiên bản trong hàm initProfiler().
step4/src/server/main.go
func initProfiler() {
cfg := profiler.Config{
Service: "server",
ServiceVersion: "1.1.0", // step6. update version
NoHeapProfiling: true,
NoAllocProfiling: true,
NoGoroutineProfiling: true,
NoCPUProfiling: false,
}
if err := profiler.Start(cfg); err != nil {
log.Fatalf("failed to launch profiler agent: %v", err)
}
}
Bây giờ, hãy xem cách hoạt động của tính năng này. Triển khai cụm bằng lệnh skaffold.
skaffold dev
Sau một lúc, hãy tải lại trang tổng quan Cloud Profiler và xem trang này trông như thế nào.

Hãy nhớ thay đổi phiên bản thành "1.1.0" để bạn chỉ thấy các hồ sơ từ phiên bản 1.1.0. Như bạn có thể thấy, độ dài của thanh GetMatchCount đã giảm và tỷ lệ sử dụng thời gian CPU cũng giảm (tức là thanh ngắn hơn).

Không chỉ xem biểu đồ ngọn lửa của một phiên bản, bạn cũng có thể so sánh sự khác biệt giữa hai phiên bản.

Thay đổi giá trị của danh sách thả xuống "So sánh với" thành "Phiên bản" và thay đổi giá trị của "Phiên bản được so sánh" thành "1.0.0", phiên bản ban đầu.

Bạn sẽ thấy biểu đồ ngọn lửa như thế này. Hình dạng của biểu đồ giống như 1.1.0 nhưng màu sắc thì khác. Trong chế độ so sánh, ý nghĩa của màu sắc là:
- Màu xanh dương: giá trị (mức tiêu thụ tài nguyên) giảm
- Màu cam: giá trị (mức tiêu thụ tài nguyên) đạt được
- Xám: trung tính
Dựa vào chú thích, hãy xem xét kỹ hơn về chức năng này. Khi nhấp vào thanh mà bạn muốn phóng to, bạn có thể xem thêm thông tin chi tiết bên trong ngăn xếp. Vui lòng nhấp vào thanh main.(*serverService).GetMatchCount. Ngoài ra, khi di chuột lên cột, bạn sẽ thấy thông tin chi tiết về kết quả so sánh.

Theo đó, tổng thời gian CPU giảm từ 5,26 giây xuống 2,88 giây (tổng thời gian là 10 giây = cửa sổ lấy mẫu). Đây là một bước tiến lớn!
Giờ đây, bạn có thể cải thiện hiệu suất ứng dụng thông qua việc phân tích dữ liệu hồ sơ.
Tóm tắt
Trong bước này, bạn đã chỉnh sửa dịch vụ máy chủ và xác nhận sự cải thiện ở chế độ so sánh của Cloud Profiler.
Tiếp theo
Trong bước tiếp theo, bạn sẽ cập nhật mã nguồn của dịch vụ máy chủ và xác nhận thay đổi từ phiên bản 1.0.0.
7. Bước bổ sung: Xác nhận mức độ cải thiện trong thác nước Dấu vết
Sự khác biệt giữa tính năng theo dõi phân tán và tính năng lập hồ sơ liên tục
Trong phần 1 của lớp học lập trình, bạn đã xác nhận rằng bạn có thể tìm ra điểm tắc nghẽn dịch vụ trong các dịch vụ vi mô cho một đường dẫn yêu cầu và bạn không thể tìm ra nguyên nhân chính xác gây tắc nghẽn trong dịch vụ cụ thể. Trong lớp học lập trình phần 2 này, bạn đã tìm hiểu rằng việc lập hồ sơ liên tục cho phép bạn xác định điểm tắc nghẽn bên trong một dịch vụ duy nhất từ các ngăn xếp lệnh gọi.
Trong bước này, hãy xem xét biểu đồ thác nước từ dấu vết phân tán (Cloud Trace) và xem sự khác biệt so với việc lập hồ sơ liên tục.
Biểu đồ thác nước này là một trong những dấu vết có truy vấn "love". Tổng thời gian là khoảng 6,7 giây (6700 mili giây).

Đây là sau khi cải thiện cho cùng một cụm từ tìm kiếm. Như bạn thấy, tổng độ trễ hiện là 1,5 giây (1.500 mili giây), đây là một bước cải thiện lớn so với cách triển khai trước đó.

Điểm quan trọng ở đây là trong biểu đồ thác nước dấu vết phân tán, thông tin ngăn xếp lệnh gọi sẽ không có sẵn trừ phi bạn đo lường các khoảng ở mọi nơi. Ngoài ra, các dấu vết phân tán chỉ tập trung vào độ trễ trên các dịch vụ, trong khi hoạt động lập hồ sơ liên tục tập trung vào tài nguyên máy tính (CPU, bộ nhớ, luồng hệ điều hành) của một dịch vụ.
Về một khía cạnh khác, dấu vết phân tán là cơ sở sự kiện, hồ sơ liên tục là thống kê. Mỗi dấu vết có một biểu đồ độ trễ riêng và bạn cần một định dạng khác, chẳng hạn như phân phối để nắm được xu hướng thay đổi độ trễ.
Tóm tắt
Trong bước này, bạn đã kiểm tra sự khác biệt giữa tính năng theo dõi phân tán và tính năng lập hồ sơ liên tục.
8. Xin chúc mừng
Bạn đã tạo thành công các dấu vết phân tán bằng OpenTelemetry và xác nhận độ trễ của yêu cầu trên các vi dịch vụ trên Google Cloud Trace.
Đối với các bài tập mở rộng, bạn có thể tự mình thử các chủ đề sau.
- Quy trình triển khai hiện tại sẽ gửi tất cả các khoảng thời gian do quy trình kiểm tra tình trạng tạo ra. (
grpc.health.v1.Health/Check) Làm cách nào để lọc những khoảng thời gian đó khỏi Cloud Trace? Gợi ý tại đây. - Tương quan nhật ký sự kiện với khoảng thời gian và xem cách hoạt động của nhật ký trên Google Cloud Trace và Google Cloud Logging. Gợi ý tại đây.
- Thay thế một số dịch vụ bằng dịch vụ bằng ngôn ngữ khác và thử đo lường dịch vụ đó bằng OpenTelemetry cho ngôn ngữ đó.
Ngoài ra, nếu bạn muốn tìm hiểu về trình phân tích tài nguyên sau phần này, vui lòng chuyển sang phần 2. Trong trường hợp đó, bạn có thể bỏ qua phần dọn dẹp bên dưới.
Dọn dẹp
Sau khi hoàn thành lớp học lập trình này, vui lòng dừng cụm Kubernetes và nhớ xoá dự án để bạn không bị tính phí ngoài dự kiến trên Google Kubernetes Engine, Google Cloud Trace, Google Artifact Registry.
Trước tiên, hãy xoá cụm ảnh. Nếu đang chạy cụm bằng skaffold dev, bạn chỉ cần nhấn Ctrl-C. Nếu bạn đang chạy cụm bằng skaffold run, hãy chạy lệnh sau:
skaffold delete
Đầu ra của lệnh
Cleaning up... - deployment.apps "clientservice" deleted - service "clientservice" deleted - deployment.apps "loadgen" deleted - deployment.apps "serverservice" deleted - service "serverservice" deleted
Sau khi xoá cụm, trên ngăn trình đơn, hãy chọn "IAM & Admin" (IAM và Quản trị) > "Settings" (Cài đặt), rồi nhấp vào nút "SHUT DOWN" (TẮT).
Sau đó, hãy nhập Mã dự án (không phải Tên dự án) vào biểu mẫu trong hộp thoại rồi xác nhận tắt.