
১. শুরু করার আগে
এই কোডল্যাবটি আপনাকে ক্লাউড এসকিউএল-এ থাকা একটিমাত্র মাইএসকিউএল (MySQL) ডেটাবেসকে গুগলএসকিউএল (GoogleSQL) ডায়ালেক্টসহ একটি ক্লাউড স্প্যানার (Cloud Spanner) ডেটাবেসে মাইগ্রেট করার প্রক্রিয়াটি ধাপে ধাপে দেখাবে। এর মূল লক্ষ্য হলো শুরু থেকে শেষ পর্যন্ত মাইগ্রেশনের মৌলিক প্রক্রিয়াটি দেখানো এবং এর প্রধান ধাপগুলো প্রদর্শন করা। আপনি স্প্যানার মাইগ্রেশন টুল (SMT), ডেটাফ্লো (Dataflow), ডেটাস্ট্রিম (Datastream), পাবসাব (PubSub) এবং গুগল ক্লাউড স্টোরেজ (Google Cloud Storage) সহ বিভিন্ন গুগল ক্লাউড পরিষেবা ব্যবহার করবেন।
আপনি যা শিখবেন:
- নমুনা ক্লাউড এসকিউএল এবং ক্লাউড স্প্যানার ইনস্ট্যান্স কীভাবে সেট আপ করবেন।
- স্প্যানার মাইগ্রেশন টুল (SMT) ব্যবহার করে কীভাবে একটি ক্লাউড SQL MySQL স্কিমা-কে স্প্যানার-উপযোগী স্কিমাতে রূপান্তর করা যায়।
- ডেটাফ্লো ব্যবহার করে ক্লাউড এসকিউএল থেকে ক্লাউড স্প্যানারে কীভাবে বাল্ক ডেটা মাইগ্রেশন করা যায়।
- Datastream এবং Dataflow ব্যবহার করে Cloud SQL থেকে Cloud Spanner-এ কীভাবে কন্টিনিউয়াস রেপ্লিকেশন (CDC) সেট আপ করবেন।
- ক্লাউড স্প্যানার থেকে ক্লাউড এসকিউএল-এ রিভার্স রেপ্লিকেশন কীভাবে সেট আপ করবেন
এই কোডল্যাবে যা অন্তর্ভুক্ত নয়:
- শার্ডেড ইনস্ট্যান্স থেকে মাইগ্রেশন।
- মাইগ্রেশনের সময় জটিল ডেটা রূপান্তর।
- উন্নত ত্রুটি ব্যবস্থাপনা বা ডেড লেটার কিউ (DLQ)।
- মাইগ্রেশন পারফরম্যান্স টিউনিং।
- অ্যাপ্লিকেশন মাইগ্রেশন: এই কোডল্যাবটি ডাটাবেস লেয়ারের (স্কিমা এবং ডেটা) উপর আলোকপাত করে। এটি আপনার অ্যাপ্লিকেশন সার্ভিসগুলো রিডিপ্লয় বা মাইগ্রেট করার অপারেশনাল প্রক্রিয়া অন্তর্ভুক্ত করে না।
আপনার যা যা লাগবে
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
- এপিআই (API) সক্রিয় করতে এবং ক্লাউড এসকিউএল (Cloud SQL), স্প্যানার (Spanner), ডেটাফ্লো (Dataflow), ডেটাস্ট্রিম (Datastream), ও জিসিএস (GCS) রিসোর্স তৈরি/পরিচালনা করার জন্য পর্যাপ্ত আইএএম (IAM) অনুমতি । যদিও একটি কোডল্যাবের জন্য প্রজেক্ট ওনার (Project
Ownerভূমিকাটি সবচেয়ে সহজ, আরও নির্দিষ্ট ভূমিকাগুলো 'এনভায়রনমেন্ট সেটআপ' (Environment Setup) অংশে আলোচনা করা হবে। - একটি ওয়েব ব্রাউজার, যেমন গুগল ক্রোম।
- গুগল ক্লাউড কনসোল এবং
gcloudমতো কমান্ড-লাইন টুল সম্পর্কে প্রাথমিক ধারণা থাকা। - শেল এনভায়রনমেন্টে অ্যাক্সেস। ক্লাউড শেল ব্যবহার করার পরামর্শ দেওয়া হচ্ছে, কারণ এতে
gcloudঅন্তর্ভুক্ত রয়েছে।
উপরোক্ত সেটআপ সম্পর্কে আরও বিস্তারিত তথ্য এনভায়রনমেন্ট সেটআপ বিভাগে আলোচনা করা হয়েছে।
২. অভিবাসন প্রক্রিয়া বোঝা
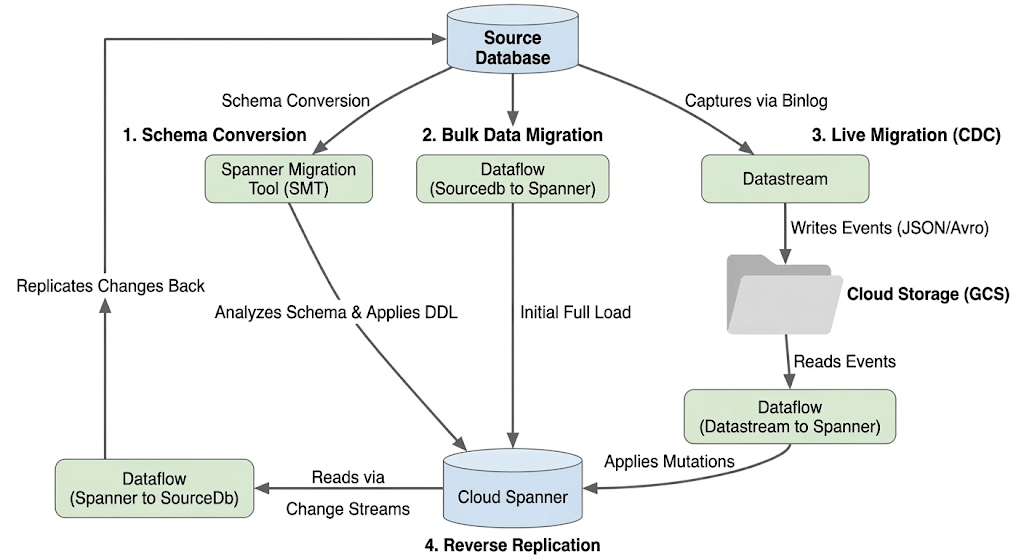
ডাটাবেস মাইগ্রেট করার অর্থ হলো আপনার সোর্স CloudSQL ডাটাবেস ইনস্ট্যান্স থেকে একটি স্প্যানার ইনস্ট্যান্সে ডেটা স্থানান্তর করা। এই বিভাগে মাইগ্রেশনে ব্যবহৃত আর্কিটেকচার এবং প্রধান টুলগুলোর রূপরেখা দেওয়া হয়েছে।
অভিবাসন প্রবাহ স্থাপত্য
স্থানান্তর প্রক্রিয়ার মধ্যে এই পর্যায়গুলো অন্তর্ভুক্ত:
১. স্কিমা রূপান্তর:
- উদ্দেশ্য: উৎস ডেটাবেস স্কিমাটিকে একটি সামঞ্জস্যপূর্ণ ক্লাউড স্প্যানার স্কিমাতে রূপান্তর করা।
- টুল: স্প্যানার মাইগ্রেশন টুল (SMT)
- প্রক্রিয়া: SMT উৎস ডেটাবেস স্কিমা বিশ্লেষণ করে এবং এর সমতুল্য স্প্যানার ডেটা ডেফিনিশন ল্যাঙ্গুয়েজ (DDL) তৈরি করে। টার্গেট স্প্যানার ইনস্ট্যান্সে একটি ডেটাবেস তৈরি করা হয় এবং তারপর DDL-টি স্বয়ংক্রিয়ভাবে প্রয়োগ করা হয়।
২. বৃহৎ ডেটা স্থানান্তর:
- উদ্দেশ্য: উৎস ডাটাবেস থেকে প্রোভিশন করা স্প্যানার টেবিলগুলিতে বিদ্যমান ডেটার একটি প্রাথমিক ও সম্পূর্ণ লোড সম্পাদন করা।
- টুল: ডেটাফ্লো, গুগল-প্রদত্ত
Sourcedb to Spannerটেমপ্লেট ব্যবহার করে। - প্রক্রিয়া: এই ডেটাফ্লো জবটি নির্দিষ্ট সোর্স টেবিলগুলো থেকে সমস্ত ডেটা পড়ে এবং সেগুলোকে সংশ্লিষ্ট স্প্যানার টেবিলগুলোতে লিখে দেয়। স্প্যানার স্কিমা তৈরি হওয়ার পর এই কাজটি করা হয়।
৩. জীবন্ত অভিবাসন (সিডিসি):
- উদ্দেশ্য: মাইগ্রেশন চলাকালীন ডাউনটাইম কমিয়ে, সোর্স ডাটাবেস থেকে ক্লাউড স্প্যানারে চলমান পরিবর্তনগুলো প্রায় রিয়েল-টাইমে গ্রহণ ও প্রয়োগ করা।
- সরঞ্জাম:
- ডেটাস্ট্রিম: উৎস ডেটাবেস থেকে পরিবর্তনসমূহ (সন্নিবেশ, হালনাগাদ, মুছে ফেলা) গ্রহণ করে এবং সেগুলোকে ক্লাউড স্টোরেজ (GCS)-এ লিখে রাখে।
- ডেটাফ্লো: GCS থেকে পরিবর্তনের ইভেন্টগুলো পড়তে এবং সেগুলোকে ক্লাউড স্প্যানারে প্রয়োগ করতে '
Datastream to Spannerটেমপ্লেট ব্যবহার করে।
৪. বিপরীত প্রতিলিপিকরণ:
- উদ্দেশ্য: ক্লাউড স্প্যানার থেকে ডেটার পরিবর্তনগুলো সোর্স ডেটাবেসে প্রতিলিপি করা। এটি ফলব্যাক কৌশল, পর্যায়ক্রমিক মাইগ্রেশন, অথবা নির্দিষ্ট ব্যবহারের ক্ষেত্রে সোর্সে একটি প্রতিলিপি রক্ষণাবেক্ষণের জন্য সহায়ক হতে পারে।
- টুল: ডেটাফ্লো,
Spanner to SourceDbটেমপ্লেট ব্যবহার করে। - প্রক্রিয়া: এই কাজটি স্প্যানারের পরিবর্তনগুলো ধারণ করতে এবং সেগুলোকে উৎস ডাটাবেস ইনস্ট্যান্সে পুনরায় লিখে দিতে স্প্যানার চেঞ্জ স্ট্রিম ব্যবহার করে।
নিম্নলিখিত ডায়াগ্রামটি উপাদান এবং ডেটা প্রবাহ চিত্রিত করে:
মূল পরিভাষা:
- স্প্যানার মাইগ্রেশন টুল (SMT) : একটি টুল যা MySQL স্কিমা মূল্যায়ন করতে, স্প্যানার স্কিমার সমতুল্য বিকল্পের পরামর্শ দিতে এবং স্প্যানার ডেটা ডেফিনিশন ল্যাঙ্গুয়েজ (DDL) তৈরি করতে ব্যবহৃত হয়।
- ডেটা ডেফিনিশন ল্যাঙ্গুয়েজ (DDL): ডাটাবেসের কাঠামো নির্ধারণ ও পরিবর্তন করতে ব্যবহৃত স্টেটমেন্ট, যেমন
CREATE TABLEস্টেটমেন্ট। SMT, ক্লাউড SQL স্কিমার উপর ভিত্তি করে স্প্যানার DDL তৈরি করে। - ডেটাফ্লো : একটি সম্পূর্ণভাবে পরিচালিত, সার্ভারবিহীন ডেটা প্রসেসিং পরিষেবা। এই কোডল্যাবে, এটি গুগল-প্রদত্ত টেমপ্লেটগুলো চালানোর জন্য ব্যবহৃত হয়, যার মধ্যে রয়েছে বাল্ক ডেটা ট্রান্সফার, ডেটাস্ট্রিম পরিবর্তন প্রয়োগ এবং রিভার্স রেপ্লিকেশন।
- ডেটাস্ট্রিম : একটি সার্ভারবিহীন চেঞ্জ ডেটা ক্যাপচার (CDC) এবং রেপ্লিকেশন সার্ভিস। এই কোডল্যাবে ক্লাউড SQL থেকে ক্লাউড স্টোরেজে পরিবর্তনসমূহ স্ট্রিম করতে এটি ব্যবহৃত হয়।
- স্প্যানার চেঞ্জ স্ট্রিমস : স্প্যানারের একটি ফিচার যা ডেটার পরিবর্তন (ইনসার্ট, আপডেট, ডিলিট) রিয়েল-টাইমে স্ট্রিম করার সুযোগ দেয় এবং এটি রিভার্স রেপ্লিকেশনের উৎস হিসেবে ব্যবহৃত হয়।
- পাব/সাব : একটি মেসেজিং পরিষেবা যা ইভেন্ট তৈরি করে এমন পরিষেবাগুলিকে সেই ইভেন্ট প্রক্রিয়াকারী পরিষেবাগুলি থেকে বিচ্ছিন্ন করতে ব্যবহৃত হয়। এই কোডল্যাবে, যখনই ডেটাস্ট্রিম ক্লাউড স্টোরেজে নতুন পরিবর্তন ফাইল আপলোড করে, তখন এটি আপডেটগুলি প্রক্রিয়া করার জন্য ডেটাফ্লোকে ট্রিগার করে।
৩. পরিবেশ সেটআপ
মাইগ্রেশন শুরু করার আগে, আপনাকে আপনার গুগল ক্লাউড প্রজেক্ট সেট আপ করতে হবে এবং প্রয়োজনীয় সার্ভিসগুলো চালু করতে হবে।
১. একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন
এই কোডল্যাবের পরিষেবাগুলো ব্যবহার করার জন্য আপনার বিলিং চালু করা একটি গুগল ক্লাউড প্রজেক্ট প্রয়োজন।
- Google Cloud Console-এ, প্রজেক্ট সিলেক্টর পেজে যান: প্রজেক্ট সিলেক্টরে যান
- একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। আপনার প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা কীভাবে নিশ্চিত করবেন তা জানুন।
২. ক্লাউড শেল খুলুন
ক্লাউড শেল হলো গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ, যা gcloud CLI এবং আপনার প্রয়োজনীয় অন্যান্য টুলসহ আগে থেকেই লোড করা থাকে।
- গুগল ক্লাউড কনসোলের উপরের ডানদিকে থাকা ‘Activate Cloud Shell’ বোতামটিতে ক্লিক করুন।
- কনসোলের নীচে একটি নতুন ফ্রেমে একটি ক্লাউড শেল সেশন খোলে এবং একটি কমান্ড-লাইন প্রম্পট প্রদর্শন করে।

৩. প্রজেক্ট এবং এনভায়রনমেন্ট ভেরিয়েবল সেট করুন
ক্লাউড শেলে, আপনার প্রজেক্ট আইডি এবং ব্যবহৃত অঞ্চলের জন্য কিছু এনভায়রনমেন্ট ভেরিয়েবল সেট আপ করুন।
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
৪. প্রয়োজনীয় গুগল ক্লাউড এপিআইগুলো সক্রিয় করুন
Cloud Spanner, Dataflow, Datastream এবং অন্যান্য সংশ্লিষ্ট পরিষেবাগুলির জন্য প্রয়োজনীয় API গুলি সক্রিয় করুন।
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
এই কমান্ডটি সম্পন্ন হতে কয়েক মিনিট সময় লাগতে পারে।
৫. পরিষেবা অ্যাকাউন্টের অনুমতি কনফিগার করুন
অন্যান্য গুগল ক্লাউড পরিষেবার সাথে সংযোগ স্থাপনের জন্য ডেটাফ্লো জব এবং ডেটাস্ট্রিমের নির্দিষ্ট অনুমতির প্রয়োজন হয়। এই কোডল্যাবের ডেটাফ্লো জবগুলো ডিফল্ট কম্পিউট ইঞ্জিন সার্ভিস অ্যাকাউন্ট ব্যবহার করবে।
প্রথমে, আপনার প্রজেক্ট নম্বরটি সংগ্রহ করুন:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
এখন, Compute Engine ডিফল্ট পরিষেবা অ্যাকাউন্টকে প্রয়োজনীয় IAM ভূমিকাগুলি প্রদান করুন:
# Role for Dataflow to run jobs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.admin" \
--condition=None
# Roles for Dataflow workers
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.worker" \
--condition=None
# Role to connect to Cloud SQL instance
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudsql.client" \
--condition=None
# Role to read/write from Cloud Spanner
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/spanner.databaseUser" \
--condition=None
# Role to access GCS buckets (Datastream output, Dataflow temp, JDBC driver)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectAdmin" \
--condition=None
# Roles for Datastream and Pub/Sub (for CDC)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastream.viewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/pubsub.subscriber"
৬. একটি ক্লাউড স্টোরেজ বাকেট তৈরি করুন
আপনার অন্যান্য রিসোর্সগুলোর মতো একই অঞ্চলে একটি GCS বাকেট তৈরি করুন। এই বাকেটটি JDBC ড্রাইভার ও ডেটাস্ট্রিম আউটপুট সংরক্ষণ করবে এবং ডেটাফ্লো দ্বারা অস্থায়ী ফাইলের জন্য ব্যবহৃত হবে।
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
echo "Created bucket: gs://$BUCKET_NAME"
৭. স্প্যানার মাইগ্রেশন টুল (SMT) ইনস্টল করুন।
আপনার ক্লাউড শেল পরিবেশে স্প্যানার মাইগ্রেশন টুল (SMT) ইনস্টল করা আছে কিনা তা নিশ্চিত করুন।
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
এই কমান্ডটি SMT ওয়েব ইন্টারফেসের জন্য সাহায্য তথ্য প্রদর্শন করবে, যা gcloud কম্পোনেন্টটি ইনস্টল করা আছে কিনা তা নিশ্চিত করবে। এই কোডল্যাবে SMT-এর CLI বৈশিষ্ট্যগুলো ব্যবহার করা হবে, যা একই কম্পোনেন্টের অংশ।
৪. সোর্স ক্লাউড SQL ডেটাবেস সেট আপ করুন
এই অংশে, আপনি সোর্স ডাটাবেস হিসেবে ব্যবহারের জন্য পাবলিক আইপি সহ একটি ক্লাউড এসকিউএল ফর মাইএসকিউএল (Cloud SQL for MySQL) ইনস্ট্যান্স তৈরি ও কনফিগার করবেন।
১. একটি ক্লাউড এসকিউএল ফর মাইএসকিউএল ইনস্ট্যান্স তৈরি করুন
একটি MySQL 8.0 ইনস্ট্যান্স তৈরি করতে ক্লাউড শেলে নিম্নলিখিত gcloud কমান্ডটি চালান। বাইনারি লগিং সক্রিয় করা আছে (ডেটাস্ট্রিমের জন্য আবশ্যক), এবং ইনস্ট্যান্সটি একটি পাবলিক আইপি দিয়ে কনফিগার করা হয়েছে।
export SQL_INSTANCE_NAME="source-mysql-instance"
export DB_ROOT_PASSWORD="Welcome@1" # Replace with a strong password if you prefer
gcloud sql instances create $SQL_INSTANCE_NAME \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=$REGION \
--root-password=$DB_ROOT_PASSWORD \
--enable-bin-log \
--assign-ip
-
--enable-bin-log: ডেটাস্ট্রিমের পরিবর্তনসমূহ ধারণ করার জন্য এটি আবশ্যক। -
--assign-ip: এটি নিশ্চিত করে যে ইনস্ট্যান্সটি একটি পাবলিক আইপি অ্যাড্রেস পাবে।
ইনস্ট্যান্স তৈরি হতে কয়েক মিনিট সময় লাগবে। আপনার ইনস্ট্যান্সটি তৈরি হয়েছে কিনা, তা আপনি ক্লাউডএসকিউএল ইনস্ট্যান্সেস পেজে দেখতে পারেন।
২. অনুমোদিত নেটওয়ার্কগুলি কনফিগার করুন
পাবলিক আইপি-র মাধ্যমে ইনস্ট্যান্সে সংযোগ করতে, আপনাকে "অনুমোদিত নেটওয়ার্ক" তালিকায় আইপি অ্যাড্রেস যোগ করতে হবে।
আপনার ক্লাউড শেল আইপি সংগ্রহ করুন:
export CLOUD_SHELL_IP=$(curl -s ipinfo.io/ip)
echo "Your Cloud Shell IP: $CLOUD_SHELL_IP"
ক্লাউড শেল আইপি এবং উন্মুক্ত অ্যাক্সেস অনুমোদন করুন
নিম্নলিখিত কমান্ডটি আপনার ক্লাউড শেল আইপি যোগ করে। এটি 0.0.0.0/0 যোগ করে, যা যেকোনো আইপি অ্যাড্রেস থেকে অ্যাক্সেসের সুযোগ দেয়। জটিল নেটওয়ার্ক সেটআপ ছাড়াই ডেটাফ্লো ওয়ার্কারদের থেকে সংযোগ সহজ করার জন্য এটি প্রয়োজনীয়।
gcloud sql instances patch $SQL_INSTANCE_NAME \
--authorized-networks="${CLOUD_SHELL_IP}/32,0.0.0.0/0"
৩. ক্লাউড শেল থেকে ক্লাউড এসকিউএল ইনস্ট্যান্সে সংযোগ করুন
বরাদ্দকৃত পাবলিক আইপি ঠিকানাটি আনুন।
export SQL_INSTANCE_IP=$(gcloud sql instances list --filter="name=$SQL_INSTANCE_NAME" --format="value(PRIMARY_ADDRESS)")
echo "Cloud SQL Public IP: $SQL_INSTANCE_IP"
সংযোগ করার জন্য এই আইপি ঠিকানাটি ব্যবহার করা হবে।
CloudShell থেকে Cloud SQL ইনস্ট্যান্সে সংযোগ করুন
প্রাপ্ত পাবলিক আইপি অ্যাড্রেসটি ব্যবহার করে স্ট্যান্ডার্ড mysql ক্লায়েন্টের মাধ্যমে সংযোগ করুন:
mysql -h $SQL_INSTANCE_IP -u root -p
অনুরোধ করা হলে, আপনার সেট করা রুট পাসওয়ার্ডটি ( Welcome@1 ) দিন। এখন আপনি mysql> প্রম্পটে থাকবেন।
৪. ডেটাবেস এবং নমুনা ডেটা তৈরি করুন
mysql> প্রম্পটে নিম্নলিখিত SQL কমান্ডগুলো চালান:
CREATE DATABASE music_db;
USE music_db;
CREATE TABLE Singers (
SingerId BIGINT NOT NULL,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
BirthDate DATE,
AlbumCount BIGINT,
PRIMARY KEY (SingerId)
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY (SingerId, AlbumId),
CONSTRAINT FK_Albums_Singers FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
);
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES
(1, 'Marc', 'Richards', '1970-09-03', 2),
(2, 'Catalina', 'Smith', '1990-08-17', 1),
(3, 'Alice', 'Trentor', '1991-10-02', 3);
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle, ReleaseDate) VALUES
(1, 1, 'Total Junk', '2014-03-15'),
(1, 2, 'Go Go Go', '2016-11-01'),
(2, 1, 'Green', '2018-02-28'),
(3, 1, 'Blue', '2019-01-10'),
(3, 2, 'Red', '2020-05-22'),
(3, 3, 'Purple', '2022-11-11');
উপরোক্ত স্কিমার ডাম্প ফাইলটি এখানে পাওয়া যাবে।
৫. ডেটা যাচাই করুন
ডেটা উপস্থিত আছে কিনা দ্রুত যাচাই করুন:
SELECT 'Singers music_db' as tbl, COUNT(*) FROM music_db.Singers
UNION ALL
SELECT 'Albums music_db', COUNT(*) FROM music_db.Albums;
EXIT;
আপনার প্রতিটি টেবিলের সংখ্যা দেখা উচিত।
+------------------+----------+ | tbl | COUNT(*) | +------------------+----------+ | Singers music_db | 3 | | Albums music_db | 6 | +------------------+----------+
৫. ক্লাউড স্প্যানার সেট আপ করুন
এখন, আপনি সেই টার্গেট ক্লাউড স্প্যানার ইনস্ট্যান্সটি সেট আপ করবেন যেখানে ডেটা মাইগ্রেট করা হবে।
১. একটি ক্লাউড স্প্যানার ইনস্ট্যান্স তৈরি করুন
আপনার Cloud SQL ইনস্ট্যান্সের একই অঞ্চলে একটি Cloud Spanner ইনস্ট্যান্স তৈরি করুন। এই কমান্ডটি ১০০টি প্রসেসিং ইউনিট ব্যবহার করে এই কোডল্যাবের জন্য উপযুক্ত একটি ছোট ইনস্ট্যান্স তৈরি করে।
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="music-db-migrated"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
ইনস্ট্যান্স তৈরি হতে এক বা দুই মিনিট সময় লাগতে পারে।
৬. স্প্যানার মাইগ্রেশন টুল (SMT) ব্যবহার করে স্কিমা রূপান্তর করুন।
SMT CLI ব্যবহার করে MySQL ডাটাবেস ( music_db ) বিশ্লেষণ করুন এবং স্প্যানার স্কিমা ডেফিনিশন ল্যাঙ্গুয়েজ (DDL) তৈরি করুন। যেহেতু ক্লাউড SQL ইনস্ট্যান্সটি পাবলিক আইপি এবং উপযুক্ত অনুমোদিত নেটওয়ার্ক দিয়ে কনফিগার করা আছে, SMT সরাসরি সংযোগ করতে পারে।
১. এসএমটি-এর জন্য পরিবেশ প্রস্তুত করুন
পূর্ববর্তী ধাপগুলো থেকে প্রয়োজনীয় এনভায়রনমেন্ট ভেরিয়েবলগুলো সেট করা আছে কিনা তা যাচাই করুন:
echo "Cloud SQL Instance Public IP: $SQL_INSTANCE_IP"
echo "Cloud SQL Root Password: $DB_ROOT_PASSWORD"
echo "Spanner Instance: $SPANNER_INSTANCE_NAME"
echo "Spanner Database: $SPANNER_DATABASE_NAME"
echo "Project ID: $PROJECT_ID"
২. music_db এর জন্য স্কিমা রূপান্তর চালান
সরাসরি ক্লাউড এসকিউএল পাবলিক আইপি অ্যাড্রেসে সংযোগ করে SMT schema কমান্ডটি চালান:
gcloud alpha spanner migrate schema \
--source=mysql \
--source-profile="host=${SQL_INSTANCE_IP},port=3306,user=root,password=${DB_ROOT_PASSWORD},dbName=music_db" \
--target-profile="project=${PROJECT_ID},instance=${SPANNER_INSTANCE_NAME},dbName=${SPANNER_DATABASE_NAME}" \
--prefix="music-db"
এই কমান্ডটি প্রক্সির মাধ্যমে ক্লাউড এসকিউএল ইনস্ট্যান্সের সাথে সংযোগ স্থাপন করে এবং music-db উপসর্গযুক্ত স্কিমা ফাইল তৈরি করে।
৩. তৈরি করা ফাইলগুলো পর্যালোচনা করুন
SMT আপনার বর্তমান ডিরেক্টরিতে কয়েকটি ফাইল তৈরি করে। প্রধান ফাইলগুলো হলো:
-
music-db.schema.ddl.txt: তৈরি হওয়া স্প্যানার ডিডিএল স্টেটমেন্টগুলো। -
music-db-.overrides.json: এই স্কিমা ওভাররাইড ফাইলটিতে হাতে করা ম্যাপিং পরিবর্তনগুলো থাকে। -
music-db.session.json: স্কিমা মাইগ্রেশনের সেশন ফাইল। -
music-db.report.txt: স্কিমা রূপান্তরের একটি মূল্যায়ন প্রতিবেদন।
আপনি ls music-db-* ব্যবহার করে সেগুলোর তালিকা দেখতে পারেন।
৪. ক্লাউড স্প্যানারে স্কিমা যাচাই করুন
স্প্যানার ডেটাবেসে টেবিলগুলো তৈরি হয়েছে কিনা তা যাচাই করুন।
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
আপনি নিম্নলিখিত আউটপুট দেখতে পাবেন:
table_name: Albums table_name: Singers
ঐচ্ছিক: আপনি যদি স্প্যানার ডিডিএল (Spanner DDL) পরীক্ষা করতে চান, তাহলে নিম্নলিখিত কমান্ডটি চালান:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
৭. চেঞ্জ ডেটা ক্যাপচার (CDC) চালু করুন
এই অংশে, আপনি আপনার মাইগ্রেশনের জন্য 'রেকর্ডার' সেট আপ করবেন। বাল্ক ডেটা লোড শুরু হওয়ার আগে ডেটাস্ট্রিম এবং পাব/সাব কনফিগার করার মাধ্যমে, আপনি নিশ্চিত করেন যে সোর্স ডেটাবেসে করা প্রতিটি পরিবর্তন ক্যাপচার এবং কিউতে যুক্ত হয়, যা স্থানান্তরের সময় ডেটা হারানোর ঝুঁকি প্রতিরোধ করে। লাইভ মাইগ্রেশনের জন্য এই সেটআপটি আবশ্যক।
১. ডেটাস্ট্রিম সংযোগ প্রোফাইল তৈরি করুন
উৎস প্রোফাইল (ক্লাউড এসকিউএল)
এই প্রোফাইলটি ক্লাউড SQL ইনস্ট্যান্সের পাবলিক আইপি-র সাথে সংযুক্ত হয়। ডেটাস্ট্রিম সংযোগের জন্য আইপি অ্যালাওলিস্টিং ব্যবহার করবে।
export SQL_CP_NAME="mysql-src-cp"
gcloud datastream connection-profiles create $SQL_CP_NAME \
--location=$REGION \
--type=mysql \
--mysql-hostname=$SQL_INSTANCE_IP \
--mysql-port=3306 \
--mysql-username=root \
--mysql-password=$DB_ROOT_PASSWORD \
--display-name="Cloud SQL Source - Public IP"
দ্রষ্টব্য: এই সংযোগটি ক্লাউড SQL ইনস্ট্যান্সের অনুমোদিত নেটওয়ার্কগুলোর অ্যাক্সেসের অনুমতির উপর নির্ভরশীল। পূর্বে 0.0.0.0/0 দিয়ে কনফিগার করা থাকায়, ডেটাস্ট্রিমের পাবলিক আইপিগুলো সংযোগ করতে পারে। একটি প্রোডাকশন পরিবেশে, আপনাকে 0.0.0.0/0 পরিবর্তে ডেটাস্ট্রিম আইপি অ্যালাওলিস্ট এবং রিজিয়নস- এ তালিকাভুক্ত আপনার অঞ্চলের নির্দিষ্ট আইপি রেঞ্জগুলো ব্যবহার করতে হবে।
গন্তব্য প্রোফাইল (ক্লাউড স্টোরেজ)
আপনার বালতির মূলের দিকে নির্দেশ করে।
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
২. একটি ডেটাস্ট্রিম তৈরি করুন
music_db থেকে প্রতিলিপি করার জন্য স্ট্রিমটি তৈরি করুন।
export STREAM_NAME="mysql-to-spanner-stream"
export GCS_STREAM_PATH="data/${STREAM_NAME}"
gcloud datastream streams create $STREAM_NAME \
--location=$REGION \
--display-name="MySQL to Spanner CDC Stream" \
--source=$SQL_CP_NAME \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "
includeObjects:
mysqlDatabases:
- database: 'music_db'
") \
--gcs-destination-config=<(echo "
path: ${GCS_STREAM_PATH}
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}
") \
--backfill-none
- ডেটাস্ট্রিম
gs://${BUCKET_NAME}/${GCS_STREAM_PREFIX}/এর অধীনে ফাইলগুলি লিখবে। - ডেটাস্ট্রিম ফাইলগুলো অ্যাভ্রো ফরম্যাটে লিখবে। লাইভ মাইগ্রেশন কমান্ড চালানোর সময় আমরা ইনপুট ফাইল ফরম্যাট (inputFileFormat) অ্যাভ্রো হিসেবে নির্দিষ্ট করে দেব, যাতে পাইপলাইনটি ফাইলটি সঠিকভাবে প্রসেস করতে পারে।
- ফাইল রোটেশনের সেটিং ছোট করলে কোডল্যাবে পরিবর্তনগুলো দ্রুত দেখা যায়।
এই কমান্ডটি সম্পন্ন হতে কিছুটা সময় লাগতে পারে। স্ট্যাটাস চেক করুন: gcloud datastream streams describe $STREAM_NAME --location=$REGION .
৩. ডেটাস্ট্রিমটি চালু করুন
gcloud datastream streams update $STREAM_NAME \
--location=$REGION \
--state=RUNNING
স্ট্যাটাস চেক করুন: gcloud datastream streams describe $STREAM_NAME --location=$REGION. শুরুতে এর স্টেট STARTING থাকবে এবং কিছুক্ষণ পর RUNNING হয়ে যাবে। এটি RUNNING স্টেটে আছে তা নিশ্চিত করার পরেই পরবর্তী ধাপে যান।
৪. GCS নোটিফিকেশনের জন্য Pub/Sub সেট আপ করুন
একটি পাব/সাব টপিক তৈরি করুন:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
GCS বিজ্ঞপ্তি তৈরি করুন
data/ প্রিফিক্সের অধীনে অবজেক্ট তৈরি হলে অবহিত করুন।
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
একটি পাব/সাব সাবস্ক্রিপশন তৈরি করুন
প্রাপ্তিস্বীকারের প্রস্তাবিত শেষ তারিখ অন্তর্ভুক্ত করুন।
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
৮. ক্লাউড এসকিউএল থেকে স্প্যানারে ডেটা একযোগে স্থানান্তর করুন
স্প্যানার স্কিমাটি প্রস্তুত হয়ে গেলে, আপনি এখন আপনার ক্লাউড SQL music_db ডাটাবেস থেকে বিদ্যমান ডেটা ক্লাউড স্প্যানারে কপি করবেন। এর জন্য আপনি Sourcedb to Spanner Dataflow Flex Template ব্যবহার করবেন, যা JDBC-অ্যাক্সেসযোগ্য ডাটাবেস থেকে স্প্যানারে একসাথে অনেক ডেটা কপি করার জন্য ডিজাইন করা হয়েছে।
১. music_db এর জন্য বাল্ক মাইগ্রেশন ডেটাফ্লো জব চালান
ডেটাফ্লো জবটি শুরু করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান। এই কমান্ডটি gcloud dataflow flex-template run কমান্ডটি ব্যবহার করে, যা বাল্ক JDBC থেকে স্প্যানার মাইগ্রেশনের জন্য গুগল-প্রদত্ত টেমপ্লেটকে রেফারেন্স করে।
export JOB_NAME_MUSIC="mysql-music-db-to-spanner-bulk-$(date +%Y%m%d-%H%M%S)"
export MUSIC_DB_JDBC_URL="jdbc:mysql://${SQL_INSTANCE_IP}:3306/music_db"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration-output"
gcloud dataflow flex-template run $JOB_NAME_MUSIC \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL="$MUSIC_DB_JDBC_URL",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
outputDirectory="$OUTPUT_DIR/music_db",\
username="root",\
password="$DB_ROOT_PASSWORD",\
jdbcDriverClassName="com.mysql.cj.jdbc.Driver",\
jdbcDriverJars="gs://${BUCKET_NAME}/lib/mysql-connector-j-8.0.33.jar",\
spannerHost="https://batch-spanner.googleapis.com"
মূল প্যারামিটারগুলোর ব্যাখ্যা:
-
sourceConfigURL:music_dbসোর্সের জন্য JDBC সংযোগ স্ট্রিং। -
instanceId,databaseId,projectId: লক্ষ্য ক্লাউড স্প্যানার ইনস্ট্যান্স এবং ডাটাবেস নির্দিষ্ট করে। -
outputDirectory: একটি ক্লাউড স্টোরেজ পাথ যেখানে ডেটাফ্লো মাইগ্রেট করতে ব্যর্থ হওয়া রেকর্ডগুলোর তথ্য লিখবে। -
jdbcDriverClassName: MySQL JDBC ড্রাইভার নির্দিষ্ট করে। -
jdbcDriverJars: স্টেজড JDBC ড্রাইভার JAR-এর GCS পাথ। -
spannerHost: স্প্যানার রাইটের জন্য ব্যাচ-অপ্টিমাইজড এন্ডপয়েন্ট ব্যবহার করে। -
maxWorkers,numWorkers: ডেটাফ্লো জবের স্কেলিং নিয়ন্ত্রণ করে। এই ছোট ডেটাসেটের জন্য এর মান কম রাখা হয়েছে।
নেটওয়ার্ক নোট: এই জবটি ক্লাউড SQL ইনস্ট্যান্সের পাবলিক আইপি-র মাধ্যমে এর সাথে সংযোগ স্থাপন করে। এটি সম্ভব হয়েছে কারণ আপনি পূর্বে ইনস্ট্যান্সটির অনুমোদিত নেটওয়ার্কের তালিকায় 0.0.0.0/0 যোগ করেছেন। এর ফলে ডেটাফ্লো ওয়ার্কার ভিএমগুলো, যাদের এক্সটার্নাল আইপি রয়েছে, তারা ডাটাবেসে পৌঁছাতে পারে।
২. ডেটাফ্লো জবটি মনিটর করুন
আপনি গুগল ক্লাউড কনসোলে কাজটি അവതരിക്കിക്കുന്ന
- ডেটাফ্লো জবস পৃষ্ঠায় যান: ডেটাফ্লো জবস-এ যান
-
mysql-music-db-to-spanner-bulk-...নামের জবটি খুঁজুন এবং সেটিতে ক্লিক করুন। - জব গ্রাফ এবং মেট্রিক্স পর্যবেক্ষণ করুন। জবের স্ট্যাটাস 'সফল' ( Succeeded) হওয়া পর্যন্ত অপেক্ষা করুন। এতে আনুমানিক ৫-১৫ মিনিট সময় লাগতে পারে।
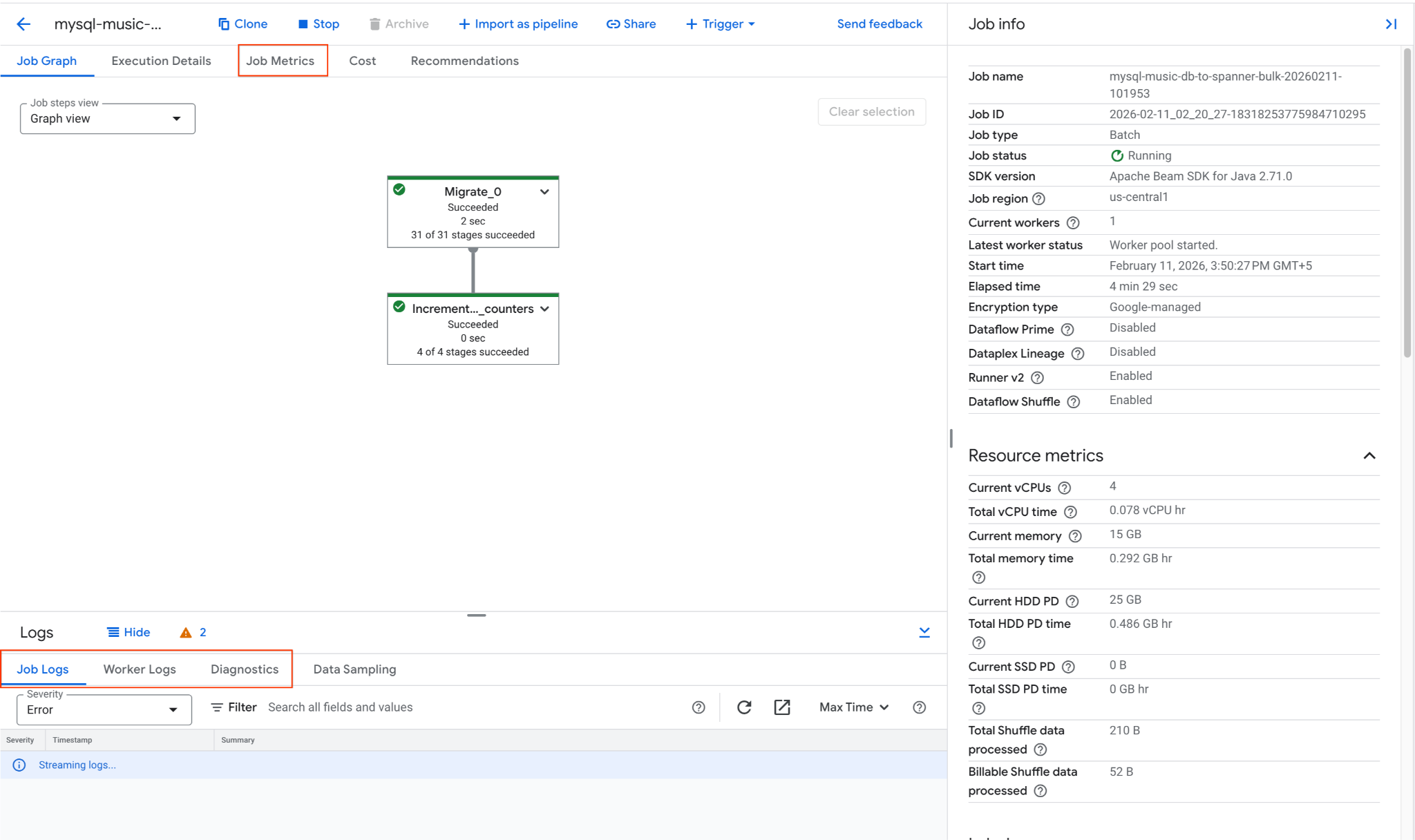
- জবটিতে কোনো সমস্যা দেখা দিলে, ত্রুটির বার্তাগুলোর জন্য ডেটাফ্লো জব ডিটেইলস পেজের মধ্যে থাকা লগস ট্যাবটি পর্যালোচনা করুন।
- জব মেট্রিক্স কাজের অগ্রগতি এবং থ্রুপুট ও সিপিইউ ইউটিলাইজেশনের মতো রিসোর্স ব্যবহার সম্পর্কে আরও তথ্য প্রদান করে।
৩. ক্লাউড স্প্যানারে ডেটা যাচাই করুন
ডেটাফ্লো জবটি সফলভাবে সম্পন্ন হলে, ডেটা স্প্যানার টেবিলগুলিতে কপি হয়েছে কিনা তা নিশ্চিত করুন। স্প্যানার ডাটাবেস কোয়েরি করতে gcloud ব্যবহার করুন:
# Verify row counts
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Singers"
# Expected output: 3
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Albums"
# Expected output: 6
# Inspect some data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT SingerId, FirstName, LastName FROM Singers ORDER BY SingerId"
প্রত্যাশিত আউটপুট:
row_count: 3 row_count: 6 SingerId: 1 FirstName: Marc LastName: Richards SingerId: 2 FirstName: Catalina LastName: Smith SingerId: 3 FirstName: Alice LastName: Trentor
ক্লাউড এসকিউএল থেকে ক্লাউড স্প্যানারে ডেটার প্রাথমিক বাল্ক লোড এখন সম্পন্ন হয়েছে। পরবর্তী পদক্ষেপ হলো চলমান পরিবর্তনগুলো ক্যাপচার করার জন্য লাইভ রেপ্লিকেশন সেট আপ করা।
৯. লাইভ মাইগ্রেশন শুরু করুন (সিডিসি)
বাল্ক ডেটা লোড সম্পন্ন হয়ে গেলে, আপনি ক্লাউড এসকিউএল (Cloud SQL) থেকে চেঞ্জ ডেটা ক্যাপচার (CDC) ইভেন্টগুলো ক্যাপচার করার জন্য ডেটাস্ট্রিম (Datastream) ব্যবহার করে একটি নিরবচ্ছিন্ন রেপ্লিকেশন স্ট্রিম এবং প্রায় রিয়েল-টাইমে ক্লাউড স্প্যানারে (Cloud Spanner) সেই পরিবর্তনগুলো প্রয়োগ করার জন্য একটি ডেটাফ্লো (Dataflow) স্ট্রিমিং জব সেট আপ করবেন।
১. লাইভ মাইগ্রেশন ডেটাফ্লো জবটি চালান
GCS থেকে ডেটা পড়তে এবং স্প্যানারে লিখতে স্ট্রিমিং ডেটাফ্লো জবটি চালু করুন। এই টেমপ্লেটটি নতুন ফাইলগুলোকে তাৎক্ষণিকভাবে প্রসেস করার জন্য GCS পাব/সাব নোটিফিকেশন ব্যবহার করবে।
export JOB_NAME_CDC="datastream-to-spanner-cdc-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR="gs://${BUCKET_NAME}/dlq"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
deadLetterQueueDirectory="$DLQ_DIR",\
streamName="projects/${PROJECT_ID}/locations/${REGION}/streams/${STREAM_NAME}"
মূল পরামিতি
-
gcsPubSubSubscription: এটি সেই পাব/সাব সাবস্ক্রিপশন যা GCS থেকে নতুন ফাইলের নোটিফিকেশন শোনে। এর ফলে, ডেটাস্ট্রিম পরিবর্তনগুলো লেখার সাথে সাথেই জবটি তা তাৎক্ষণিকভাবে প্রসেস করতে পারে। -
inputFileFormat="avro": এটি Dataflow-কে জানায় যে Datastream থেকে Avro ফাইল আশা করতে হবে। এটি অবশ্যই আপনার Datastream-এর 'Destination' কনফিগারেশনের সাথে মিলতে হবে (যেমন,avroFileFormatবনামjsonFileFormat)। -
deadLetterQueueDirectory: একটি GCS পাথ যেখানে জবটি সেই রেকর্ডগুলি সংরক্ষণ করে যেগুলি প্রসেস হতে ব্যর্থ হয়েছে (যেমন, স্কিমা অমিলের কারণে), পরবর্তী ম্যানুয়াল পর্যালোচনার জন্য। -
streamName: ডেটাস্ট্রিম-এর সম্পূর্ণ রিসোর্স পাথ, যা ডেটাফ্লো জবকে রেপ্লিকেশন স্টেট এবং মেটাডেটা ট্র্যাক করতে সাহায্য করে।
ডেটাফ্লো জবস কনসোলে জবটির সূচনা পর্যবেক্ষণ করুন।
২. লাইভ মাইগ্রেশন পরীক্ষা করুন
সিডিসি পাইপলাইন পরীক্ষা করার জন্য উৎস ক্লাউড এসকিউএল music_db তে পরিবর্তনগুলো প্রয়োগ করুন।
ক্লাউড এসকিউএল-এর সাথে সংযোগ করুন:
mysql -h $SQL_INSTANCE_IP -u root -p
পাসওয়ার্ড ( Welcome@1 ) প্রবেশ করান এবং ডাটাবেস নির্বাচন করুন:
USE music_db;
-- INSERT
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (4, 'Elena', 'Nadal', '1985-05-30', 0);
SELECT * FROM Singers WHERE SingerId = 4;
-- UPDATE
UPDATE Singers SET LastName = 'Richards-Smith' WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- DELETE
DELETE FROM Albums WHERE SingerId = 2;
DELETE FROM Singers WHERE SingerId = 2;
SELECT * FROM Singers WHERE SingerId = 2;
EXIT;
স্প্যানারে যাচাইকরণ (কিছুক্ষণ পর):
# Verify INSERT: This should return the new row for Elena Nadal.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 4"
# Verify UPDATE: This should show LastName as Richards-Smith.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName FROM Singers WHERE SingerId = 1"
# Verify DELETE: This should now return 0 rows.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Albums WHERE SingerId = 2"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 2"
প্রত্যাশিত আউটপুট:
SingerId: 4 FirstName: Elena LastName: Nadal BirthDate: 1985-05-30 AlbumCount: 0 SingerId: 1 FirstName: Marc LastName: Richards-Smith
৩. স্প্যানারে চূড়ান্ত যাচাইকরণ
স্প্যানারে Singers টেবিলের সার্বিক অবস্থা পরীক্ষা করুন:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId"
প্রত্যাশিত আউটপুট:
SingerId: 1 FirstName: Marc LastName: Richards-Smith AlbumCount: 2 SingerId: 3 FirstName: Alice LastName: Trentor AlbumCount: 3 SingerId: 4 FirstName: Elena LastName: Nadal AlbumCount: 0
১০. রিভার্স রেপ্লিকেশন সেট আপ করুন (স্প্যানার থেকে ক্লাউড এসকিউএল)
এমন পরিস্থিতি সামাল দিতে, যেখানে আপনার রোলব্যাক করার প্রয়োজন হতে পারে অথবা কিছু সময়ের জন্য ক্লাউড এসকিউএল ডাটাবেসকে স্প্যানারের সাথে সিঙ্ক করে রাখার দরকার হতে পারে, আপনি রিভার্স রেপ্লিকেশন সেট আপ করতে পারেন। এই পাইপলাইনটি স্প্যানারের পরিবর্তনগুলো ক্যাপচার করতে স্প্যানার চেঞ্জ স্ট্রিম ব্যবহার করে এবং সেগুলোকে ক্লাউড এসকিউএল-এর music_db তে পুনরায় লিখে দেয়।
১. একটি স্প্যানার পরিবর্তন স্ট্রিম তৈরি করুন
প্রথমে, Singers এবং Albums টেবিলের পরিবর্তনগুলো ট্র্যাক করার জন্য আপনাকে আপনার Spanner ডেটাবেসে একটি চেঞ্জ স্ট্রিম তৈরি করতে হবে।
export CHANGE_STREAM_NAME="MusicDBChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Singers, Albums"
এই পরিবর্তন প্রবাহটি এখন নির্দিষ্ট টেবিলগুলিতে হওয়া সমস্ত ডেটা পরিবর্তন রেকর্ড করবে।
২. ডেটাফ্লো মেটাডেটার জন্য একটি স্প্যানার ডেটাবেস তৈরি করুন
চেঞ্জ স্ট্রিম কনসাম্পশন পরিচালনার জন্য মেটাডেটা সংরক্ষণ করতে Spanner to SourceDB ডেটাফ্লো টেমপ্লেটটির একটি পৃথক স্প্যানার ডেটাবেস প্রয়োজন।
export SPANNER_METADATA_DB_NAME="reverse-replication-metadata"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
৩. ডেটাফ্লো-এর জন্য ক্লাউড এসকিউএল সংযোগ কনফিগারেশন প্রস্তুত করুন।
ডেটাফ্লো টেমপ্লেটটির জন্য ক্লাউড স্টোরেজে একটি JSON ফাইল প্রয়োজন, যেটিতে টার্গেট ক্লাউড SQL ডেটাবেসের সংযোগের বিবরণ থাকবে।
shard_config.json নামে একটি স্থানীয় ফাইল তৈরি করুন:
cat << EOF > shard_config.json
[
{
"logicalShardId": "mysql_shard",
"host": "${SQL_INSTANCE_IP}",
"port": "3306",
"user": "root",
"password": "${DB_ROOT_PASSWORD}",
"dbName": "music_db"
}
]
EOF
এই ফাইলটি আপনার GCS বাকেটে আপলোড করুন:
export SHARD_CONFIG_FILE="gs://${BUCKET_NAME}/shard_config.json"
gcloud storage cp shard_config.json $SHARD_CONFIG_FILE
৪. রিভার্স রেপ্লিকেশন ডেটাফ্লো জবটি চালান।
Spanner_to_SourceDb ফ্লেক্স টেমপ্লেটটি ব্যবহার করে ডেটাফ্লো জবটি চালু করুন।
export JOB_NAME_REVERSE="spanner-to-mysql-reverse-$(date +%Y%m%d-%H%M%S)"
export REVERSE_DLQ_DIR="gs://${BUCKET_NAME}/reverse-dlq"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$SHARD_CONFIG_FILE",\
deadLetterQueueDirectory="$REVERSE_DLQ_DIR"
মূল পরামিতি
-
changeStreamName: যে স্প্যানার চেঞ্জ স্ট্রিম থেকে ডেটা পড়তে হবে তার নাম। -
metadataInstance, metadataDatabase: চেঞ্জ স্ট্রিম এপিআই ডেটার ব্যবহার নিয়ন্ত্রণের জন্য কানেক্টর কর্তৃক ব্যবহৃত মেটাডেটা সংরক্ষণের স্প্যানার ইনস্ট্যান্স/ডাটাবেস। -
sourceShardsFilePath: আপনারshard_config.jsonGCS পাথ। -
filtrationMode: একটি নির্দিষ্ট মানদণ্ডের উপর ভিত্তি করে কীভাবে কিছু রেকর্ড বাদ দেওয়া হবে তা নির্ধারণ করে। ডিফল্ট হলোforward_migration(ফরওয়ার্ড মাইগ্রেশন পাইপলাইন ব্যবহার করে লেখা রেকর্ড ফিল্টার করে)।
নেটওয়ার্ক নোট: ডেটাফ্লো ওয়ার্কাররা shard_config.json এ উল্লেখিত পাবলিক আইপি ব্যবহার করে ক্লাউড এসকিউএল ইনস্ট্যান্সের সাথে সংযুক্ত হবে। ক্লাউড এসকিউএল ইনস্ট্যান্সের অনুমোদিত নেটওয়ার্কের তালিকায় 0.0.0.0/0 এন্ট্রিটি থাকায় এই সংযোগের অনুমতি রয়েছে।
ডেটাফ্লো জবস কনসোলে জবটির সূচনা পর্যবেক্ষণ করুন।
৫. বিপরীত প্রতিলিপি পরীক্ষা করুন
এখন, সরাসরি ক্লাউড স্প্যানারে পরিবর্তনগুলি করুন এবং যাচাই করুন যে সেগুলি ক্লাউড এসকিউএল-এ প্রতিফলিত হয়েছে। ডেটাফ্লো জবটি শুরু হয়ে প্রসেসিং অবস্থায় থাকলেই কেবল এটি করুন।
INSERT , UPDATE এবং DELETE পরীক্ষা করুন
# INSERT: Insert a new singer (SingerId 5) into Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (5, 'David', 'Chen', '1995-02-18', 0)"
# UPDATE: Update SingerId 3's AlbumCount in Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Singers SET AlbumCount = 5 WHERE SingerId = 3"
# DELETE: Delete SingerId 1 from Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Albums WHERE SingerId = 1"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Singers WHERE SingerId = 1"
ক্লাউড এসকিউএল-এ যাচাইকরণ (কিছুক্ষণ পর):
ক্লাউড এসকিউএল-এর সাথে সংযোগ করুন:
mysql -h $SQL_INSTANCE_IP -u root -p
অনুরোধ করা হলে পাসওয়ার্ড ( Welcome@1 ) দিন, তারপর mysql> প্রম্পটে নিম্নলিখিত SQL কমান্ডগুলি চালান।
USE music_db;
-- Verify INSERT: This should show the new row for David Chen
SELECT * FROM Singers WHERE SingerId = 5;
-- Verify UPDATE: This should show AlbumCount as 5.
SELECT SingerId, FirstName, AlbumCount FROM Singers WHERE SingerId = 3;
-- Verify DELETE: This should return an empty set.
SELECT * FROM Albums WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- Final Verification
SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId;
EXIT;
ক্লাউড এসকিউএল-এ প্রত্যাশিত আউটপুটে স্প্যানারে করা পরিবর্তনগুলো প্রতিফলিত হওয়া উচিত।
+----------+-----------+----------------+------------+ | SingerId | FirstName | LastName | AlbumCount | +----------+-----------+----------------+------------+ | 3 | Alice | Trentor | 5 | | 4 | Elena | Nadal | 0 | | 5 | David | Chen | 0 | +----------+-----------+----------------+------------+
এটি নিশ্চিত করে যে রিভার্স রেপ্লিকেশন পাইপলাইনটি কাজ করছে এবং স্প্যানার থেকে ক্লাউড এসকিউএল-এ পরিবর্তনগুলো সিঙ্ক্রোনাইজ করছে।
১১. সম্পদ পরিষ্কার করুন
আপনার গুগল ক্লাউড অ্যাকাউন্টে অতিরিক্ত চার্জ এড়াতে, এই কোডল্যাব চলাকালীন তৈরি করা রিসোর্সগুলো মুছে ফেলুন।
পরিবেশ ভেরিয়েবল সেট করুন (প্রয়োজন হলে)
পরিবেশ ভেরিয়েবলগুলো সঠিকভাবে সেট করা আছে কিনা তা পরীক্ষা করুন:
echo "PROJECT_ID: $PROJECT_ID"
echo "REGION: $REGION"
echo "SQL_INSTANCE_NAME: $SQL_INSTANCE_NAME"
echo "SPANNER_INSTANCE_NAME: $SPANNER_INSTANCE_NAME"
echo "BUCKET_NAME: $BUCKET_NAME"
echo "STREAM_NAME: $STREAM_NAME"
echo "SQL_CP_NAME: $SQL_CP_NAME"
echo "GCS_CP_NAME: $GCS_CP_NAME"
echo "PUBSUB_SUBSCRIPTION: $PUBSUB_SUBSCRIPTION"
echo "PUBSUB_TOPIC: $PUBSUB_TOPIC"
echo "CHANGE_STREAM_NAME: $CHANGE_STREAM_NAME"
চলমান ডেটাফ্লো জবগুলোর জব আইডি খুঁজে পেতে আপনার জবগুলোর তালিকা তৈরি করুন। সেই অনুযায়ী JOB_ID_CDC এবং JOB_ID_REVERSE এক্সপোর্ট করুন।
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
আপনি যদি একটি নতুন ক্লাউড শেল সেশনে থাকেন, তাহলে মূল এনভায়রনমেন্ট ভেরিয়েবলগুলো পুনরায় এক্সপোর্ট করুন:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or the region you used
export SQL_INSTANCE_NAME="source-mysql-instance"
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export STREAM_NAME="mysql-to-spanner-stream"
export SQL_CP_NAME="mysql-src-cp"
export GCS_CP_NAME="gcs-dest-cp"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CHANGE_STREAM_NAME="MusicDBChangeStream"
ডেটাফ্লো স্ট্রিমিং জব বন্ধ করুন
Datastream to Spanner (Live Migration) জবটি বাতিল করুন:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
Spanner to Cloud SQL (রিভার্স রেপ্লিকেশন) জবটি বাতিল করুন:
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
ডেটাস্ট্রিম রিসোর্সগুলি মুছে ফেলুন
স্ট্রিমটি বন্ধ করুন এবং মুছে ফেলুন:
gcloud datastream streams update $STREAM_NAME \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
সংযোগ প্রোফাইলগুলি মুছুন
gcloud datastream connection-profiles delete $SQL_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
পাব/সাব রিসোর্স মুছে ফেলুন
সাবস্ক্রিপশন মুছুন:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
বিষয়টি মুছে ফেলুন:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
ক্লাউড SQL ইনস্ট্যান্স মুছে ফেলুন
এটি স্বয়ংক্রিয়ভাবে এর ভেতরের ডেটাবেসগুলো ( music_db ) মুছে ফেলবে।
gcloud sql instances delete $SQL_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
ক্লাউড স্প্যানার ইনস্ট্যান্স মুছুন
এর ফলে এর অন্তর্ভুক্ত ডেটাবেসগুলোও ( music-db-migrated এবং reverse-replication-metadata ) মুছে যাবে।
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
GCS বাকেট এবং এর ভেতরের বিষয়বস্তু মুছে ফেলুন
gcloud storage rm --recursive gs://${BUCKET_NAME}
স্থানীয় ফাইলগুলি মুছুন
আপনার ক্লাউড শেল হোম ডিরেক্টরিতে তৈরি হওয়া যেকোনো ফাইল মুছে ফেলুন:
rm -f music-db* shard_config.json
আপনি এখন এই কোডল্যাবের জন্য তৈরি করা রিসোর্সগুলো পরিষ্কার করেছেন।