
1. Hinweis
In diesem Codelab wird beschrieben, wie Sie eine einzelne MySQL-Datenbank in Cloud SQL zu einer Cloud Spanner-Datenbank mit dem GoogleSQL-Dialekt migrieren. Der Fokus liegt auf dem grundlegenden End-to-End-Migrationsablauf, in dem die wichtigsten Schritte gezeigt werden. Sie verwenden Google Cloud-Dienste wie das Spanner Migration Tool (SMT), Dataflow, Datastream, PubSub und Google Cloud Storage.
Die Themen:
- So richten Sie Cloud SQL- und Cloud Spanner-Beispielinstanzen ein.
- Hier wird beschrieben, wie Sie ein Cloud SQL for MySQL-Schema mit dem Cloud Spanner-Migrationstool (SMT) in ein Spanner-kompatibles Schema konvertieren.
- Hier wird beschrieben, wie Sie mit Dataflow eine Bulk-Datenmigration von Cloud SQL zu Cloud Spanner durchführen.
- Einrichten der kontinuierlichen Replikation (CDC) von Cloud SQL zu Cloud Spanner mit Datastream und Dataflow
- So richten Sie die umgekehrte Replikation von Cloud Spanner zu Cloud SQL ein.
Was in diesem Codelab NICHT behandelt wird:
- Migrationen von shardbasierten Instanzen.
- Komplexe Datentransformationen während der Migration
- Erweiterte Fehlerbehandlung oder Dead-Letter-Warteschlangen.
- Leistungsoptimierung der Migration.
- Anwendungsmigration:In diesem Codelab geht es um die Datenbankebene (Schema und Daten). Der operative Prozess der erneuten Bereitstellung oder Migration Ihrer Anwendungsdienste wird nicht behandelt.
Voraussetzungen
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
- Ausreichende IAM-Berechtigungen zum Aktivieren von APIs und zum Erstellen/Verwalten von Cloud SQL-, Spanner-, Dataflow-, Datastream- und GCS-Ressourcen. Die Rolle „Projekt
Owner“ ist für ein Codelab am einfachsten. Spezifischere Rollen werden unter „Umgebung einrichten“ behandelt. - Ein Webbrowser wie Google Chrome.
- Grundlegende Vertrautheit mit der Google Cloud Console und Befehlszeilentools wie
gcloud. - Zugriff auf eine Shell-Umgebung. Wir empfehlen Cloud Shell, da
gclouddarin enthalten ist.
Weitere Informationen zur oben genannten Einrichtung finden Sie im Abschnitt „Umgebung einrichten“.
2. Migrationsprozess
Bei der Migration einer Datenbank werden Daten aus der Cloud SQL-Quelldatenbankinstanz in eine Spanner-Instanz migriert. In diesem Abschnitt werden die Architektur und die wichtigsten Tools beschrieben, die bei der Migration verwendet werden.
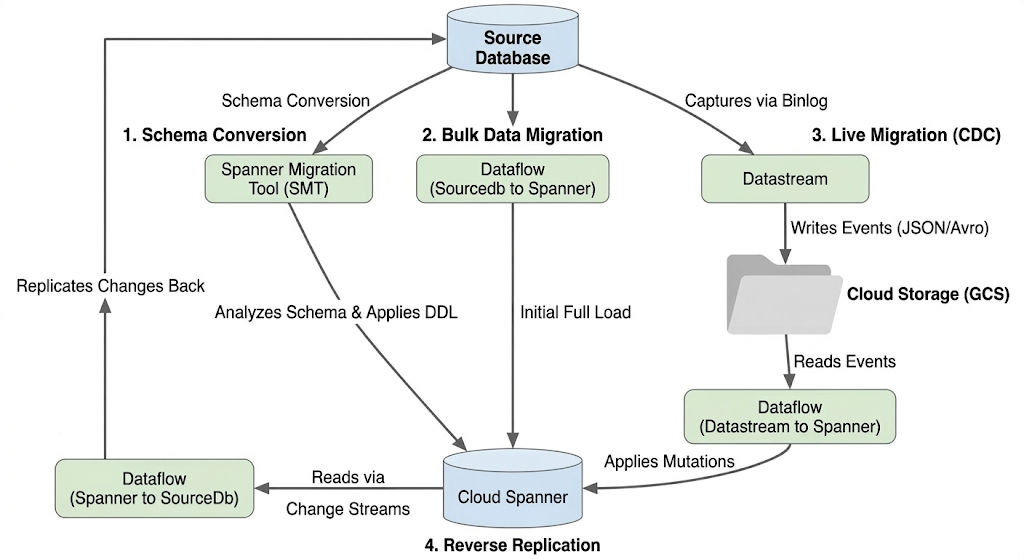
Architektur des Migrationsablaufs
Der Migrationsprozess umfasst die folgenden Phasen:
1. Schemakonvertierung:
- Zweck:Das Quelldatenbankschema in ein kompatibles Cloud Spanner-Schema konvertieren.
- Tool:Spanner-Migrationstool (SMT)
- Prozess:SMT analysiert das Quelldatenbankschema und generiert die entsprechende Spanner-Datendefinitionssprache (DDL). In der Ziel-Spanner-Instanz wird eine Datenbank erstellt und die DDL wird dann automatisch angewendet.
2. Bulk-Datenmigration:
- Zweck:Führen Sie einen anfänglichen, vollständigen Ladevorgang für vorhandene Daten aus der Quelldatenbank in die bereitgestellten Spanner-Tabellen aus.
- Tool:Dataflow mit der von Google bereitgestellten Vorlage
Sourcedb to Spanner. - Prozess:Dieser Dataflow-Job liest alle Daten aus den angegebenen Quelltabellen und schreibt sie in die entsprechenden Spanner-Tabellen. Dies erfolgt nach der Erstellung des Spanner-Schemas.
3. Live-Migration (CDC):
- Zweck:Fortlaufende Änderungen aus der Quelldatenbank nahezu in Echtzeit in Cloud Spanner erfassen und anwenden, um Ausfallzeiten während der Migration zu minimieren.
- Optionen:
- Datastream:Erfasst Änderungen (Einfügungen, Aktualisierungen, Löschungen) aus der Quelldatenbank und schreibt sie in Cloud Storage (GCS).
- Dataflow:Verwendet die Vorlage
Datastream to Spanner, um die Änderungsereignisse aus GCS zu lesen und auf Cloud Spanner anzuwenden.
4. Rückwärtsreplikation:
- Zweck:Datenänderungen aus Cloud Spanner zurück in die Quelldatenbank replizieren. Das kann für Fallback-Strategien, schrittweise Migrationen oder die Aufrechterhaltung eines Replikats in der Quelle für bestimmte Anwendungsfälle nützlich sein.
- Tool:Dataflow mit der Vorlage
Spanner to SourceDb. - Verarbeiten:Bei diesem Job werden Spanner-Änderungsstreams verwendet, um Änderungen in Spanner zu erfassen und in die Quelldatenbankinstanz zurückzuschreiben.
Das folgende Diagramm veranschaulicht die Komponenten und den Datenfluss:
Wichtige Begriffe:
- Cloud Spanner-Migrationstool (SMT):Ein Tool zum Bewerten von MySQL-Schemas, zum Vorschlagen von Cloud Spanner-Schemaäquivalenten und zum Generieren der Datendefinitionssprache (DDL) von Cloud Spanner.
- Datendefinitionssprache (Data Definition Language, DDL): Anweisungen zum Definieren und Ändern der Datenbankstruktur, z. B.
CREATE TABLE-Anweisungen. SMT generiert Spanner-DDL basierend auf dem Cloud SQL-Schema. - Dataflow:Ein vollständig verwalteter, serverloser Dienst zur Datenverarbeitung. In diesem Codelab wird es verwendet, um von Google bereitgestellte Vorlagen für die Bulk-Datenübertragung, die Anwendung von Datastream-Änderungen und die Rückwärtsreplikation auszuführen.
- Datastream:Ein serverloser Dienst für Change Data Capture (CDC) und Replikation. In diesem Codelab wird damit ein Stream von Änderungen aus Cloud SQL in Cloud Storage erstellt.
- Spanner-Änderungsstreams:Eine Spanner-Funktion, mit der Änderungen an Daten (Einfügungen, Aktualisierungen, Löschungen) in Echtzeit gestreamt werden können. Sie wird als Quelle für die Reverse-Replikation verwendet.
- Pub/Sub:Ein Messaging-Dienst, der verwendet wird, um Dienste, die Ereignisse erzeugen, von Diensten zu entkoppeln, die sie verarbeiten. In diesem Codelab wird Dataflow ausgelöst, um Aktualisierungen zu verarbeiten, sobald Datastream neue Änderungsdateien in Cloud Storage hochlädt.
3. Umgebung einrichten
Bevor Sie mit der Migration beginnen können, müssen Sie Ihr Google Cloud-Projekt einrichten und die erforderlichen Dienste aktivieren.
1. Google Cloud-Projekt auswählen oder erstellen
Sie benötigen ein Google Cloud-Projekt mit aktivierter Abrechnung, um die Dienste in diesem Codelab verwenden zu können.
- Rufen Sie in der Google Cloud Console die Seite für die Projektauswahl auf: Zur Projektauswahl
- Wählen Sie ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für Ihr Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für Ihr Projekt aktiviert ist.
2. Cloud Shell öffnen
Cloud Shell ist eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und in der die gcloud CLI und andere benötigte Tools vorinstalliert sind.
- Klicken Sie rechts oben in der Google Cloud Console auf die Schaltfläche Cloud Shell aktivieren.
- Im unteren Bereich der Konsole wird ein neuer Frame für die Cloud Shell-Sitzung geöffnet, in dem eine Befehlszeilen-Eingabeaufforderung angezeigt wird.

3. Projekt- und Umgebungsvariablen festlegen
Richten Sie in Cloud Shell einige Umgebungsvariablen für Ihre Projekt-ID und die Region ein, die Sie verwenden möchten.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Erforderliche Google Cloud APIs aktivieren
Aktivieren Sie die APIs, die für Cloud Spanner, Dataflow, Datastream und andere zugehörige Dienste erforderlich sind.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Die Verarbeitung dieses Befehls kann einige Minuten dauern.
5. Dienstkontoberechtigungen konfigurieren
Dataflow-Jobs und Datastream benötigen bestimmte Berechtigungen, um mit anderen Google Cloud-Diensten interagieren zu können. Die Dataflow-Jobs in diesem Codelab verwenden das Compute Engine-Standarddienstkonto.
Rufen Sie zuerst Ihre Projektnummer ab:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
Weisen Sie dem Compute Engine-Standarddienstkonto nun die erforderlichen IAM-Rollen zu:
# Role for Dataflow to run jobs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.admin" \
--condition=None
# Roles for Dataflow workers
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.worker" \
--condition=None
# Role to connect to Cloud SQL instance
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudsql.client" \
--condition=None
# Role to read/write from Cloud Spanner
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/spanner.databaseUser" \
--condition=None
# Role to access GCS buckets (Datastream output, Dataflow temp, JDBC driver)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectAdmin" \
--condition=None
# Roles for Datastream and Pub/Sub (for CDC)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastream.viewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/pubsub.subscriber"
6. Cloud Storage-Bucket erstellen
Erstellen Sie einen GCS-Bucket in derselben Region wie Ihre anderen Ressourcen. In diesem Bucket werden der JDBC-Treiber und die Datastream-Ausgabe gespeichert. Außerdem wird er von Dataflow für temporäre Dateien verwendet.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
echo "Created bucket: gs://$BUCKET_NAME"
7. Spanner Migration Tool (SMT) installieren
Prüfen Sie, ob das Spanner Migration Tool (SMT) in Ihrer Cloud Shell-Umgebung installiert ist.
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
Mit diesem Befehl sollte die Hilfe für die SMT-Weboberfläche angezeigt werden. Das bestätigt, dass die gcloud-Komponente installiert ist. In diesem Codelab werden die CLI-Funktionen von SMT verwendet, die Teil derselben Komponente sind.
4. Cloud SQL-Quelldatenbank einrichten
In diesem Abschnitt erstellen und konfigurieren Sie eine Cloud SQL for MySQL-Instanz mit öffentlicher IP als Quelldatenbank.
1. Cloud SQL for MySQL-Instanz erstellen
Führen Sie den folgenden gcloud-Befehl in Cloud Shell aus, um eine MySQL 8.0-Instanz zu erstellen. Das Binärlogging ist aktiviert (für Datastream erforderlich) und die Instanz ist mit einer öffentlichen IP-Adresse konfiguriert.
export SQL_INSTANCE_NAME="source-mysql-instance"
export DB_ROOT_PASSWORD="Welcome@1" # Replace with a strong password if you prefer
gcloud sql instances create $SQL_INSTANCE_NAME \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=$REGION \
--root-password=$DB_ROOT_PASSWORD \
--enable-bin-log \
--assign-ip
--enable-bin-log: Erforderlich, damit Datastream Änderungen erfassen kann.--assign-ip: Sorgt dafür, dass die Instanz eine öffentliche IP-Adresse erhält.
Das Erstellen der Instanz kann einige Minuten dauern. Sie können auf der Seite „Cloud SQL-Instanzen“ prüfen, ob Ihre Instanz erstellt wurde.
2. Autorisierte Netzwerke konfigurieren
Wenn Sie über die öffentliche IP-Adresse eine Verbindung zur Instanz herstellen möchten, müssen Sie der Liste „Autorisierte Netzwerke“ IP-Adressen hinzufügen.
Cloud Shell-IP-Adresse abrufen:
export CLOUD_SHELL_IP=$(curl -s ipinfo.io/ip)
echo "Your Cloud Shell IP: $CLOUD_SHELL_IP"
Cloud Shell-IP und offenen Zugriff autorisieren
Mit dem folgenden Befehl wird Ihre Cloud Shell-IP-Adresse hinzugefügt. Außerdem wird 0.0.0.0/0 hinzugefügt, wodurch der Zugriff von jeder IP-Adresse möglich ist. Dies ist erforderlich, um Verbindungen von Dataflow-Workern ohne komplexe Netzwerkeinrichtungen zu vereinfachen.
gcloud sql instances patch $SQL_INSTANCE_NAME \
--authorized-networks="${CLOUD_SHELL_IP}/32,0.0.0.0/0"
3. Verbindung zur Cloud SQL-Instanz über Cloud Shell herstellen
Zugewiesene öffentliche IP-Adresse abrufen
export SQL_INSTANCE_IP=$(gcloud sql instances list --filter="name=$SQL_INSTANCE_NAME" --format="value(PRIMARY_ADDRESS)")
echo "Cloud SQL Public IP: $SQL_INSTANCE_IP"
Diese IP-Adresse wird für die Verbindung verwendet.
Verbindung zur Cloud SQL-Instanz über Cloud Shell herstellen
Verwenden Sie den Standard-MySQL-Client, um eine Verbindung über die erhaltene öffentliche IP-Adresse herzustellen:
mysql -h $SQL_INSTANCE_IP -u root -p
Geben Sie bei entsprechender Aufforderung das von Ihnen festgelegte Root-Passwort (Welcome@1) ein. Sie sehen jetzt den mysql>-Prompt.
4. Datenbank und Beispieldaten erstellen
Führen Sie die folgenden SQL-Befehle in der Eingabeaufforderung mysql> aus:
CREATE DATABASE music_db;
USE music_db;
CREATE TABLE Singers (
SingerId BIGINT NOT NULL,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
BirthDate DATE,
AlbumCount BIGINT,
PRIMARY KEY (SingerId)
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY (SingerId, AlbumId),
CONSTRAINT FK_Albums_Singers FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
);
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES
(1, 'Marc', 'Richards', '1970-09-03', 2),
(2, 'Catalina', 'Smith', '1990-08-17', 1),
(3, 'Alice', 'Trentor', '1991-10-02', 3);
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle, ReleaseDate) VALUES
(1, 1, 'Total Junk', '2014-03-15'),
(1, 2, 'Go Go Go', '2016-11-01'),
(2, 1, 'Green', '2018-02-28'),
(3, 1, 'Blue', '2019-01-10'),
(3, 2, 'Red', '2020-05-22'),
(3, 3, 'Purple', '2022-11-11');
Die Dump-Datei für das obige Schema finden Sie hier.
5. Daten prüfen
Prüfen Sie schnell, ob die Daten vorhanden sind:
SELECT 'Singers music_db' as tbl, COUNT(*) FROM music_db.Singers
UNION ALL
SELECT 'Albums music_db', COUNT(*) FROM music_db.Albums;
EXIT;
Sie sollten Zählungen für jede Tabelle sehen.
+------------------+----------+ | tbl | COUNT(*) | +------------------+----------+ | Singers music_db | 3 | | Albums music_db | 6 | +------------------+----------+
5. Cloud Spanner einrichten
Als Nächstes richten Sie die Cloud Spanner-Zielinstanz ein, in die die Daten migriert werden.
1. Cloud Spanner-Instanz erstellen
Erstellen Sie eine Cloud Spanner-Instanz in derselben Region wie Ihre Cloud SQL-Instanz. Mit diesem Befehl wird eine kleine Instanz mit 100 Verarbeitungseinheiten erstellt, die für dieses Codelab geeignet ist.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="music-db-migrated"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
Das Erstellen der Instanz kann ein oder zwei Minuten dauern.
6. Schema mit dem Cloud Spanner-Migrationstool (SMT) konvertieren
Verwenden Sie die SMT-Befehlszeile, um die MySQL-Datenbank zu analysieren (music_db) und die Spanner-Schemadefinitionssprache (DDL) zu generieren. Da die Cloud SQL-Instanz mit einer öffentlichen IP-Adresse und den entsprechenden autorisierten Netzwerken konfiguriert ist, kann SMT direkt eine Verbindung herstellen.
1. Umgebung für SMT vorbereiten
Prüfen Sie, ob die erforderlichen Umgebungsvariablen aus den vorherigen Schritten festgelegt sind:
echo "Cloud SQL Instance Public IP: $SQL_INSTANCE_IP"
echo "Cloud SQL Root Password: $DB_ROOT_PASSWORD"
echo "Spanner Instance: $SPANNER_INSTANCE_NAME"
echo "Spanner Database: $SPANNER_DATABASE_NAME"
echo "Project ID: $PROJECT_ID"
2. Schemakonvertierung für music_db ausführen
Führen Sie den SMT-Befehl schema aus, um eine direkte Verbindung zur öffentlichen IP-Adresse von Cloud SQL herzustellen:
gcloud alpha spanner migrate schema \
--source=mysql \
--source-profile="host=${SQL_INSTANCE_IP},port=3306,user=root,password=${DB_ROOT_PASSWORD},dbName=music_db" \
--target-profile="project=${PROJECT_ID},instance=${SPANNER_INSTANCE_NAME},dbName=${SPANNER_DATABASE_NAME}" \
--prefix="music-db"
Mit diesem Befehl wird über den Proxy eine Verbindung zur Cloud SQL-Instanz hergestellt und Schemadateien mit dem Präfix music-db generiert.
3. Generierte Dateien überprüfen
Mit dem SMT werden einige Dateien in Ihrem aktuellen Verzeichnis erstellt. Die wichtigsten sind:
music-db.schema.ddl.txt: Die generierten Spanner-DDL-Anweisungen.music-db-.overrides.json: Die Datei mit Schemaüberschreibungen, die manuelle Zuordnungsänderungen enthält.music-db.session.json: Sitzungsdatei der Schemamigration.music-db.report.txt: Ein Bewertungsbericht zur Schemaumstellung.
Sie können sie mit ls music-db-* auflisten.
4. Schema in Cloud Spanner überprüfen
Prüfen Sie, ob die Tabellen in der Spanner-Datenbank erstellt wurden.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Es sollte folgende Ausgabe angezeigt werden:
table_name: Albums table_name: Singers
Optional:Wenn Sie die Spanner-DDL prüfen möchten, führen Sie den folgenden Befehl aus:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
7. Change Data Capture (CDC) initialisieren
In diesem Abschnitt richten Sie den „Recorder“ für die Migration ein. Wenn Sie Datastream und Pub/Sub konfigurieren, bevor der Bulk-Datenladevorgang beginnt, wird jede Änderung an der Quelldatenbank erfasst und in die Warteschlange gestellt. So wird ein Datenverlust während der Umstellung verhindert. Diese Einrichtung ist für die Live-Migration erforderlich.
1. Datastream-Verbindungsprofile erstellen
Quellprofil (Cloud SQL)
Dieses Profil stellt eine Verbindung zur öffentlichen IP-Adresse der Cloud SQL-Instanz her. Datastream verwendet IP-Zulassungslisten für die Verbindung.
export SQL_CP_NAME="mysql-src-cp"
gcloud datastream connection-profiles create $SQL_CP_NAME \
--location=$REGION \
--type=mysql \
--mysql-hostname=$SQL_INSTANCE_IP \
--mysql-port=3306 \
--mysql-username=root \
--mysql-password=$DB_ROOT_PASSWORD \
--display-name="Cloud SQL Source - Public IP"
Hinweis:Für diese Verbindung muss der Zugriff über die autorisierten Netzwerke der Cloud SQL-Instanz erlaubt sein. Wie zuvor mit 0.0.0.0/0 konfiguriert, können die öffentlichen IP-Adressen von Datastream eine Verbindung herstellen. In einer Produktionsumgebung würden Sie 0.0.0.0/0 durch die spezifischen IP-Bereiche für Ihre Region ersetzen, die in Datastream-IP-Zulassungslisten und ‑Regionen aufgeführt sind.
Zielprofil (Cloud Storage)
Verweist auf das Stammverzeichnis Ihres Buckets.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
2. Datastream-Stream erstellen
Erstellen Sie den Stream, der aus music_db repliziert werden soll.
export STREAM_NAME="mysql-to-spanner-stream"
export GCS_STREAM_PATH="data/${STREAM_NAME}"
gcloud datastream streams create $STREAM_NAME \
--location=$REGION \
--display-name="MySQL to Spanner CDC Stream" \
--source=$SQL_CP_NAME \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "
includeObjects:
mysqlDatabases:
- database: 'music_db'
") \
--gcs-destination-config=<(echo "
path: ${GCS_STREAM_PATH}
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}
") \
--backfill-none
- Der Datenstream schreibt Dateien unter
gs://${BUCKET_NAME}/${GCS_STREAM_PREFIX}/. - Datastream schreibt die Dateien im Avro-Format. Beim Ausführen des Live-Migrationsbefehls geben wir das inputFileFormat als „avro“ an, damit die Pipeline die Datei korrekt verarbeiten kann.
- Wenn Sie kleinere Einstellungen für die Dateirotation verwenden, sind Änderungen im Codelab schneller sichtbar.
Die Ausführung dieses Befehls kann einige Zeit in Anspruch nehmen. Status prüfen: gcloud datastream streams describe $STREAM_NAME --location=$REGION.
3. Datastream-Stream starten
gcloud datastream streams update $STREAM_NAME \
--location=$REGION \
--state=RUNNING
Status prüfen: gcloud datastream streams describe $STREAM_NAME --location=$REGION. Der Status ist anfangs STARTING und ändert sich nach einiger Zeit zu RUNNING. Fahren Sie erst mit dem nächsten Schritt fort, wenn Sie bestätigt haben, dass sich das Gerät im Status RUNNING befindet.
4. Pub/Sub für GCS-Benachrichtigungen einrichten
Pub/Sub-Thema erstellen:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
GCS-Benachrichtigung erstellen
Benachrichtigung bei der Erstellung von Objekten unter dem Präfix data/.
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Pub/Sub-Abo erstellen
Geben Sie die empfohlene Bestätigungsfrist an.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Daten aus Cloud SQL zu Spanner migrieren
Nachdem das Spanner-Schema eingerichtet ist, kopieren Sie die vorhandenen Daten aus Ihrer Cloud SQL-Datenbank music_db nach Cloud Spanner. Sie verwenden die flexible Dataflow-Vorlage Sourcedb to Spanner, die für das Bulk-Kopieren von Daten aus JDBC-zugänglichen Datenbanken nach Spanner entwickelt wurde.
1. Dataflow-Job für die Bulk-Migration für music_db ausführen
Führen Sie den folgenden Befehl in Cloud Shell aus, um den Dataflow-Job zu starten. In diesem Befehl wird der Befehl gcloud dataflow flex-template run verwendet, der auf die von Google bereitgestellte Vorlage für die Migration von JDBC zu Spanner verweist.
export JOB_NAME_MUSIC="mysql-music-db-to-spanner-bulk-$(date +%Y%m%d-%H%M%S)"
export MUSIC_DB_JDBC_URL="jdbc:mysql://${SQL_INSTANCE_IP}:3306/music_db"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration-output"
gcloud dataflow flex-template run $JOB_NAME_MUSIC \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL="$MUSIC_DB_JDBC_URL",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
outputDirectory="$OUTPUT_DIR/music_db",\
username="root",\
password="$DB_ROOT_PASSWORD",\
jdbcDriverClassName="com.mysql.cj.jdbc.Driver",\
jdbcDriverJars="gs://${BUCKET_NAME}/lib/mysql-connector-j-8.0.33.jar",\
spannerHost="https://batch-spanner.googleapis.com"
Erklärung der wichtigsten Parameter:
sourceConfigURL: Der JDBC-Verbindungsstring für die Quellemusic_db.instanceId,databaseId,projectId: Gibt die Cloud Spanner-Zielinstanz und -Datenbank an.outputDirectory: Ein Cloud Storage-Pfad, in den Dataflow Informationen zu Datensätzen schreibt, die nicht migriert werden konnten.jdbcDriverClassName: Gibt den MySQL-JDBC-Treiber an.jdbcDriverJars: GCS-Pfad zur bereitgestellten JDBC-Treiber-JAR-Datei.spannerHost: Verwendet den batchoptimierten Endpunkt für Cloud Spanner-Schreibvorgänge.maxWorkers,numWorkers: Steuert die Skalierung des Dataflow-Jobs. Für dieses kleine Dataset wurde er niedrig gehalten.
Hinweis zum Netzwerk:Dieser Job stellt über die öffentliche IP-Adresse eine Verbindung zur Cloud SQL-Instanz her. Das ist möglich, weil Sie 0.0.0.0/0 zuvor den autorisierten Netzwerken der Instanz hinzugefügt haben. So können die Dataflow-Worker-VMs, die externe IPs haben, auf die Datenbank zugreifen.
2. Dataflow-Job überwachen
Sie können den Fortschritt des Jobs in der Google Cloud Console verfolgen:
- Rufen Sie die Seite „Dataflow-Jobs“ auf: Zur Seite „Dataflow-Jobs“
- Suchen Sie den Job mit dem Namen
mysql-music-db-to-spanner-bulk-...und klicken Sie darauf. - Jobgrafik und Messwerte ansehen Warten Sie, bis sich der Jobstatus in Erfolgreich ändert. Dies dauert etwa 5–15 Minuten.
- Wenn beim Job Probleme auftreten, sehen Sie sich auf der Seite mit den Dataflow-Jobdetails den Tab Logs an, um Fehlermeldungen zu finden.
- Unter Job-Messwerte finden Sie weitere Informationen zum Fortschritt des Jobs und zum Ressourcenverbrauch, z. B. Durchsatz und CPU-Auslastung.
3. Daten in Cloud Spanner prüfen
Wenn der Dataflow-Job erfolgreich abgeschlossen wurde, prüfen Sie, ob die Daten in die Spanner-Tabellen kopiert wurden. Verwenden Sie gcloud, um die Spanner-Datenbank abzufragen:
# Verify row counts
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Singers"
# Expected output: 3
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Albums"
# Expected output: 6
# Inspect some data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT SingerId, FirstName, LastName FROM Singers ORDER BY SingerId"
Erwartete Ausgabe:
row_count: 3 row_count: 6 SingerId: 1 FirstName: Marc LastName: Richards SingerId: 2 FirstName: Catalina LastName: Smith SingerId: 3 FirstName: Alice LastName: Trentor
Der erste Bulk-Upload von Daten aus Cloud SQL in Cloud Spanner ist jetzt abgeschlossen. Im nächsten Schritt richten Sie die Live-Replikation ein, um laufende Änderungen zu erfassen.
9. Live-Migration (CDC) starten
Nachdem der Bulk-Datenladevorgang abgeschlossen ist, richten Sie einen kontinuierlichen Replikationsstream mit Datastream ein, um CDC-Ereignisse (Change Data Capture) aus Cloud SQL zu erfassen, und einen Dataflow-Streamingjob, um diese Änderungen nahezu in Echtzeit auf Cloud Spanner anzuwenden.
1. Dataflow-Job für die Live-Migration ausführen
Starten Sie den Streaming-Dataflow-Job, um Daten aus GCS zu lesen und in Spanner zu schreiben. Bei dieser Vorlage werden GCS Pub/Sub-Benachrichtigungen verwendet, um neue Dateien sofort zu verarbeiten.
export JOB_NAME_CDC="datastream-to-spanner-cdc-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR="gs://${BUCKET_NAME}/dlq"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
deadLetterQueueDirectory="$DLQ_DIR",\
streamName="projects/${PROJECT_ID}/locations/${REGION}/streams/${STREAM_NAME}"
Wichtige Parameter
gcsPubSubSubscription: Das Pub/Sub-Abo, das auf Benachrichtigungen zu neuen Dateien von GCS wartet. So kann der Job Änderungen sofort verarbeiten, wenn Datastream sie schreibt.inputFileFormat="avro": Gibt an, dass Dataflow Avro-Dateien von Datastream erwartet. Dies muss mit der Konfiguration des Datastreams für das Ziel übereinstimmen (z. B.avroFileFormatim Vergleich zujsonFileFormat).deadLetterQueueDirectory: Ein GCS-Pfad, in dem der Job Datensätze speichert, die nicht verarbeitet werden konnten (z.B. aufgrund von Schemaabweichungen), damit sie später manuell überprüft werden können.streamName: Der vollständige Ressourcenpfad des Datastream-Streams, über den der Dataflow-Job den Replikationsstatus und die Metadaten verfolgen kann.
Überwachen Sie den Jobstart in der Dataflow-Jobs-Konsole.
2. Live-Migration testen
Nehmen Sie Änderungen an der Cloud SQL-Quellinstanz music_db vor, um die CDC-Pipeline zu testen.
Verbindung zu Cloud SQL herstellen:
mysql -h $SQL_INSTANCE_IP -u root -p
Geben Sie das Passwort (Welcome@1) ein und wählen Sie die Datenbank aus:
USE music_db;
-- INSERT
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (4, 'Elena', 'Nadal', '1985-05-30', 0);
SELECT * FROM Singers WHERE SingerId = 4;
-- UPDATE
UPDATE Singers SET LastName = 'Richards-Smith' WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- DELETE
DELETE FROM Albums WHERE SingerId = 2;
DELETE FROM Singers WHERE SingerId = 2;
SELECT * FROM Singers WHERE SingerId = 2;
EXIT;
Bestätigung in Spanner (nach einigen Augenblicken):
# Verify INSERT: This should return the new row for Elena Nadal.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 4"
# Verify UPDATE: This should show LastName as Richards-Smith.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName FROM Singers WHERE SingerId = 1"
# Verify DELETE: This should now return 0 rows.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Albums WHERE SingerId = 2"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 2"
Erwartete Ausgabe:
SingerId: 4 FirstName: Elena LastName: Nadal BirthDate: 1985-05-30 AlbumCount: 0 SingerId: 1 FirstName: Marc LastName: Richards-Smith
3. Endgültige Bestätigung in Spanner
Prüfen Sie den Gesamtstatus der Tabelle Singers in Spanner:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId"
Erwartete Ausgabe:
SingerId: 1 FirstName: Marc LastName: Richards-Smith AlbumCount: 2 SingerId: 3 FirstName: Alice LastName: Trentor AlbumCount: 3 SingerId: 4 FirstName: Elena LastName: Nadal AlbumCount: 0
10. Reverse Replication einrichten (Spanner zu Cloud SQL)
Um Szenarien zu bewältigen, in denen Sie die Cloud SQL-Datenbank möglicherweise zurücksetzen oder für einen bestimmten Zeitraum mit Spanner synchronisieren müssen, können Sie die umgekehrte Replikation einrichten. In dieser Pipeline werden Spanner-Änderungsstreams verwendet, um Änderungen in Spanner zu erfassen und in die Cloud SQL-music_db zurückzuschreiben.
1. Spanner-Änderungsstream erstellen
Zuerst müssen Sie einen Änderungsstream in Ihrer Spanner-Datenbank erstellen, um Änderungen an den Tabellen Singers und Albums zu verfolgen.
export CHANGE_STREAM_NAME="MusicDBChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Singers, Albums"
In diesem Änderungsstream werden jetzt alle Datenänderungen an den angegebenen Tabellen aufgezeichnet.
2. Spanner-Datenbank für Dataflow-Metadaten erstellen
Für die Dataflow-Vorlage Spanner to SourceDB ist eine separate Spanner-Datenbank erforderlich, in der Metadaten zum Verwalten der Änderungsstream-Nutzung gespeichert werden.
export SPANNER_METADATA_DB_NAME="reverse-replication-metadata"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Cloud SQL-Verbindungskonfiguration für Dataflow vorbereiten
Für die Dataflow-Vorlage ist eine JSON-Datei in Cloud Storage erforderlich, die die Verbindungsdetails für die Cloud SQL-Zieldatenbank enthält.
Erstellen Sie eine lokale Datei mit dem Namen shard_config.json:
cat << EOF > shard_config.json
[
{
"logicalShardId": "mysql_shard",
"host": "${SQL_INSTANCE_IP}",
"port": "3306",
"user": "root",
"password": "${DB_ROOT_PASSWORD}",
"dbName": "music_db"
}
]
EOF
Laden Sie diese Datei in Ihren GCS-Bucket hoch:
export SHARD_CONFIG_FILE="gs://${BUCKET_NAME}/shard_config.json"
gcloud storage cp shard_config.json $SHARD_CONFIG_FILE
4. Dataflow-Job für die Rückwärtsreplikation ausführen
Starten Sie den Dataflow-Job mit der Spanner_to_SourceDb-Flex-Vorlage.
export JOB_NAME_REVERSE="spanner-to-mysql-reverse-$(date +%Y%m%d-%H%M%S)"
export REVERSE_DLQ_DIR="gs://${BUCKET_NAME}/reverse-dlq"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$SHARD_CONFIG_FILE",\
deadLetterQueueDirectory="$REVERSE_DLQ_DIR"
Wichtige Parameter
changeStreamName: Der Name des Spanner-Änderungsstreams, aus dem gelesen werden soll.metadataInstance, metadataDatabase: Die Spanner-Instanz bzw. -Datenbank zum Speichern der Metadaten, die vom Connector verwendet werden, um die Nutzung der Änderungsstream-API-Daten zu steuern.sourceShardsFilePath: Der GCS-Pfad zu Ihremshard_config.json.filtrationMode: Gibt an, wie bestimmte Datensätze anhand eines Kriteriums gelöscht werden sollen. Standardmäßig wirdforward_migrationverwendet (Datensätze filtern, die mit der Forward-Migrationspipeline geschrieben wurden).
Hinweis zum Netzwerk:Die Dataflow-Worker stellen über die in shard_config.json angegebene öffentliche IP-Adresse eine Verbindung zur Cloud SQL-Instanz her. Diese Verbindung ist aufgrund des 0.0.0.0/0-Eintrags in den autorisierten Netzwerken der Cloud SQL-Instanz zulässig.
Überwachen Sie den Jobstart in der Dataflow-Jobs-Konsole.
5. Rückwärtsreplikation testen
Nehmen Sie nun Änderungen direkt in Cloud Spanner vor und prüfen Sie, ob sie in Cloud SQL übernommen werden. Führen Sie diesen Schritt erst aus, wenn der Dataflow-Job gestartet wurde und sich im Verarbeitungsstatus befindet.
INSERT, UPDATE und DELETE testen
# INSERT: Insert a new singer (SingerId 5) into Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (5, 'David', 'Chen', '1995-02-18', 0)"
# UPDATE: Update SingerId 3's AlbumCount in Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Singers SET AlbumCount = 5 WHERE SingerId = 3"
# DELETE: Delete SingerId 1 from Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Albums WHERE SingerId = 1"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Singers WHERE SingerId = 1"
Bestätigung in Cloud SQL (nach einigen Augenblicken):
Verbindung zu Cloud SQL herstellen:
mysql -h $SQL_INSTANCE_IP -u root -p
Geben Sie bei entsprechender Aufforderung das Passwort (Welcome@1) ein und führen Sie dann am mysql>-Prompt die folgenden SQL-Befehle aus.
USE music_db;
-- Verify INSERT: This should show the new row for David Chen
SELECT * FROM Singers WHERE SingerId = 5;
-- Verify UPDATE: This should show AlbumCount as 5.
SELECT SingerId, FirstName, AlbumCount FROM Singers WHERE SingerId = 3;
-- Verify DELETE: This should return an empty set.
SELECT * FROM Albums WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- Final Verification
SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId;
EXIT;
Die erwartete Ausgabe in Cloud SQL sollte die in Spanner vorgenommenen Änderungen widerspiegeln.
+----------+-----------+----------------+------------+ | SingerId | FirstName | LastName | AlbumCount | +----------+-----------+----------------+------------+ | 3 | Alice | Trentor | 5 | | 4 | Elena | Nadal | 0 | | 5 | David | Chen | 0 | +----------+-----------+----------------+------------+
So können Sie bestätigen, dass die Pipeline für die umgekehrte Replikation funktioniert und Änderungen von Spanner zurück zu Cloud SQL synchronisiert werden.
11. Ressourcen bereinigen
Löschen Sie die in diesem Codelab erstellten Ressourcen, um zu vermeiden, dass Ihrem Google Cloud-Konto weitere Kosten in Rechnung gestellt werden.
Umgebungsvariablen festlegen (falls erforderlich)
Prüfen Sie, ob die Umgebungsvariablen richtig festgelegt sind:
echo "PROJECT_ID: $PROJECT_ID"
echo "REGION: $REGION"
echo "SQL_INSTANCE_NAME: $SQL_INSTANCE_NAME"
echo "SPANNER_INSTANCE_NAME: $SPANNER_INSTANCE_NAME"
echo "BUCKET_NAME: $BUCKET_NAME"
echo "STREAM_NAME: $STREAM_NAME"
echo "SQL_CP_NAME: $SQL_CP_NAME"
echo "GCS_CP_NAME: $GCS_CP_NAME"
echo "PUBSUB_SUBSCRIPTION: $PUBSUB_SUBSCRIPTION"
echo "PUBSUB_TOPIC: $PUBSUB_TOPIC"
echo "CHANGE_STREAM_NAME: $CHANGE_STREAM_NAME"
Listen Sie Ihre Jobs auf, um die Job-IDs der laufenden Dataflow-Jobs zu finden. Exportieren Sie JOB_ID_CDC und JOB_ID_REVERSE entsprechend.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Wenn Sie sich in einer neuen Cloud Shell-Sitzung befinden, exportieren Sie die wichtigsten Umgebungsvariablen noch einmal:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or the region you used
export SQL_INSTANCE_NAME="source-mysql-instance"
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export STREAM_NAME="mysql-to-spanner-stream"
export SQL_CP_NAME="mysql-src-cp"
export GCS_CP_NAME="gcs-dest-cp"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CHANGE_STREAM_NAME="MusicDBChangeStream"
Dataflow-Streamingjobs beenden
Brechen Sie den Job Datastream to Spanner (Live-Migration) ab:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
Brechen Sie den Job Spanner to Cloud SQL (Reverse Replication) ab:
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Datastream-Ressourcen löschen
Stream beenden und löschen:
gcloud datastream streams update $STREAM_NAME \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Verbindungsprofile löschen
gcloud datastream connection-profiles delete $SQL_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Pub/Sub-Ressourcen löschen
Abo löschen:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Thema löschen:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Cloud SQL-Instanz löschen
Dadurch werden die Datenbanken (music_db) darin automatisch gelöscht.
gcloud sql instances delete $SQL_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Cloud Spanner-Instanz löschen
Dadurch werden auch die Datenbanken (music-db-migrated und reverse-replication-metadata) darin gelöscht.
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
GCS-Bucket und ‑Inhalte löschen
gcloud storage rm --recursive gs://${BUCKET_NAME}
Lokale Dateien löschen
Entfernen Sie alle Dateien, die in Ihrem Cloud Shell-Basisverzeichnis generiert wurden:
rm -f music-db* shard_config.json
Sie haben jetzt die Ressourcen bereinigt, die für dieses Codelab erstellt wurden.