
1. Antes de comenzar
En este codelab, se explica cómo migrar una sola base de datos de MySQL en Cloud SQL a una base de datos de Cloud Spanner con el dialecto de GoogleSQL. El enfoque se centra en el flujo de migración fundamental de extremo a extremo, en el que se demuestran los pasos principales. Usarás los servicios de Google Cloud, incluidas las herramientas Spanner Migration Tool (SMT), Dataflow, Datastream, Pub/Sub y Google Cloud Storage.
Qué aprenderás:
- Cómo configurar instancias de muestra de Cloud SQL y Cloud Spanner
- Cómo convertir un esquema de Cloud SQL MySQL en un esquema compatible con Spanner usando Spanner Migration Tool (SMT).
- Cómo realizar la migración masiva de datos de Cloud SQL a Cloud Spanner con Dataflow
- Cómo configurar la replicación continua (CDC) de Cloud SQL a Cloud Spanner con Datastream y Dataflow
- Cómo configurar la replicación inversa de Cloud Spanner a Cloud SQL
Qué NO se aborda en este codelab:
- Son migraciones desde instancias fragmentadas.
- Transformaciones de datos complejas durante la migración
- Manejo de errores avanzado o colas de mensajes no entregados (DLQ)
- Ajuste del rendimiento de la migración
- Migración de la aplicación: Este codelab se enfoca en la capa de la base de datos (esquema y datos). No abarca el proceso operativo de volver a implementar o migrar tus servicios de aplicaciones.
Requisitos
- Un proyecto de Google Cloud con facturación habilitada.
- Permisos de IAM suficientes para habilitar APIs y crear o administrar recursos de Cloud SQL, Spanner, Dataflow, Datastream y GCS Si bien el rol de Project
Owneres el más simple para un codelab, en la sección "Configuración del entorno" se abordarán roles más específicos. - Un navegador web, como Google Chrome
- Conocimientos básicos de la consola de Google Cloud y herramientas de línea de comandos como
gcloud - Acceso a un entorno de shell Se recomienda Cloud Shell, ya que incluye
gcloud.
Encontrarás más detalles sobre la configuración anterior en la sección Configuración del entorno.
2. Información sobre el proceso de migración
La migración de una base de datos implica migrar datos de tu instancia de base de datos de Cloud SQL de origen a una instancia de Spanner. En esta sección, se describe la arquitectura y las herramientas clave que se usan en la migración.
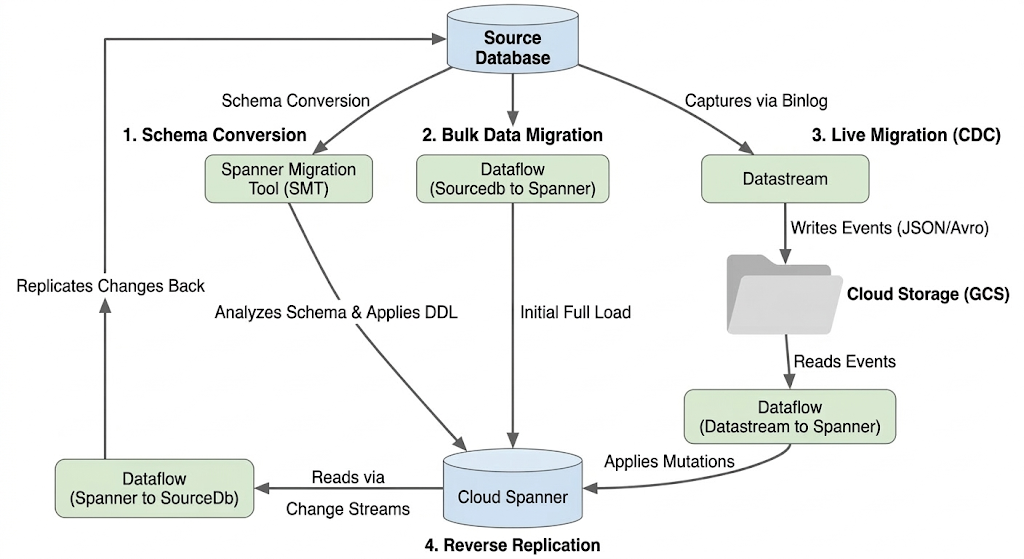
Arquitectura del flujo de migración
El proceso de migración incluye las siguientes etapas:
1. Conversión de esquemas:
- Propósito: Convertir el esquema de la base de datos de origen en un esquema compatible de Cloud Spanner
- Herramienta: Herramienta de migración de Spanner (SMT)
- Proceso: SMT analiza el esquema de la base de datos de origen y genera el lenguaje de definición de datos (DDL) de Spanner equivalente. En la instancia de Spanner de destino, se crea una base de datos y, luego, se aplica automáticamente el DDL.
2. Migración de datos masiva:
- Propósito: Realizar una carga inicial completa de los datos existentes desde la base de datos de origen a las tablas de Spanner aprovisionadas.
- Herramienta: Dataflow, con la plantilla
Sourcedb to Spannerproporcionada por Google. - Proceso: Este trabajo de Dataflow lee todos los datos de las tablas de origen especificadas y los escribe en las tablas de Spanner correspondientes. Esto se realiza después de crear el esquema de Spanner.
3. Migración en vivo (CDC):
- Propósito: Capturar y aplicar cambios continuos de la base de datos de origen a Cloud Spanner casi en tiempo real, lo que minimiza el tiempo de inactividad durante la migración.
- Herramientas:
- Datastream: Captura los cambios (inserciones, actualizaciones y eliminaciones) de la base de datos de origen y los escribe en Cloud Storage (GCS).
- Dataflow: Usa la plantilla
Datastream to Spannerpara leer los eventos de cambio de GCS y aplicarlos a Cloud Spanner.
4. Replicación inversa:
- Propósito: Replicar los cambios de datos de Cloud Spanner a la base de datos de origen. Esto puede ser útil para las estrategias de respaldo, las migraciones por fases o el mantenimiento de una réplica en la fuente para casos de uso específicos.
- Herramienta: Dataflow, con la plantilla
Spanner to SourceDb. - Proceso: Este trabajo utiliza flujos de cambios de Spanner para capturar modificaciones en Spanner y volver a escribirlas en la instancia de la base de datos de origen.
En el siguiente diagrama, se ilustran los componentes y el flujo de datos:
Terminología clave:
- Herramienta de migración de Spanner (SMT): Es una herramienta que se usa para evaluar esquemas de MySQL, sugerir equivalentes de esquemas de Spanner y generar el lenguaje de definición de datos (DDL) de Spanner.
- Lenguaje de definición de datos (DDL): Son instrucciones que se usan para definir y modificar la estructura de la base de datos, como las instrucciones
CREATE TABLE. SMT genera DDL de Spanner en función del esquema de Cloud SQL. - Dataflow: Es un servicio de procesamiento de datos completamente administrado y sin servidores. En este codelab, se usa para ejecutar plantillas proporcionadas por Google para la transferencia de datos masiva, la aplicación de cambios de Datastream y la replicación inversa.
- Datastream: Es un servicio de replicación y captura de datos modificados (CDC) sin servidores. Se usa para transmitir cambios de Cloud SQL a Cloud Storage en este codelab.
- Flujos de cambios de Spanner: Es una función de Spanner que permite transmitir cambios en los datos (inserciones, actualizaciones y eliminaciones) en tiempo real, y se usa como fuente para la replicación inversa.
- Pub/Sub: Es un servicio de mensajería que se usa para separar los servicios que producen eventos de los servicios que los procesan. En este codelab, se activa Dataflow para procesar actualizaciones cada vez que Datastream sube archivos de cambios nuevos a Cloud Storage.
3. Configuración del entorno
Antes de comenzar la migración, debes configurar tu proyecto de Google Cloud y habilitar los servicios necesarios.
1. Selecciona o crea un proyecto de Google Cloud
Para usar los servicios de este codelab, necesitas un proyecto de Google Cloud con la facturación habilitada.
- En la consola de Google Cloud, ve a la página del selector de proyectos: Ir al selector de proyectos
- Selecciona o crea un proyecto de Google Cloud.
- Asegúrate de tener habilitada la facturación para tu proyecto. Obtén información para confirmar que tienes habilitada la facturación para tu proyecto.
2. Abre Cloud Shell
Cloud Shell es un entorno de línea de comandos que se ejecuta en Google Cloud y que viene precargado con la CLI de gcloud y otras herramientas que necesitas.
- Haz clic en el botón Activar Cloud Shell en la parte superior derecha de la consola de Google Cloud.
- Se abrirá una sesión de Cloud Shell en un marco nuevo en la parte inferior de la consola, que mostrará una línea de comandos.

3. Configura las variables de entorno y del proyecto
En Cloud Shell, configura algunas variables de entorno para el ID de tu proyecto y la región que usarás.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Habilita las APIs de Google Cloud requeridas
Habilita las APIs necesarias para Cloud Spanner, Dataflow, Datastream y otros servicios relacionados.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Este comando puede tardar unos minutos en completarse.
5. Configura los permisos de la cuenta de servicio
Los trabajos de Dataflow y Datastream requieren permisos específicos para interactuar con otros servicios de Google Cloud. Los trabajos de Dataflow en este codelab usarán la cuenta de servicio predeterminada de Compute Engine.
Primero, obtén tu número de proyecto:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
Ahora, otorga los roles de IAM necesarios a la cuenta de servicio predeterminada de Compute Engine:
# Role for Dataflow to run jobs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.admin" \
--condition=None
# Roles for Dataflow workers
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.worker" \
--condition=None
# Role to connect to Cloud SQL instance
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudsql.client" \
--condition=None
# Role to read/write from Cloud Spanner
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/spanner.databaseUser" \
--condition=None
# Role to access GCS buckets (Datastream output, Dataflow temp, JDBC driver)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectAdmin" \
--condition=None
# Roles for Datastream and Pub/Sub (for CDC)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastream.viewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/pubsub.subscriber"
6. Crea un bucket de Cloud Storage
Crea un bucket de GCS en la misma región que tus otros recursos. En este bucket, se almacenarán el controlador JDBC y el resultado de Datastream, y Dataflow lo usará para los archivos temporales.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
echo "Created bucket: gs://$BUCKET_NAME"
7. Instala Spanner Migration Tool (SMT)
Asegúrate de que la Herramienta de migración de Spanner (SMT) esté instalada en tu entorno de Cloud Shell.
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
Este comando debería mostrar información de ayuda para la interfaz web de SMT, lo que confirma que el componente gcloud está instalado. En este codelab, se usarán las funciones de la CLI de SMT, que forman parte del mismo componente.
4. Configura la base de datos de Cloud SQL de origen
En esta sección, crearás y configurarás una instancia de Cloud SQL para MySQL con una IP pública para que funcione como la base de datos de origen.
1. Crea una instancia de Cloud SQL para MySQL
Ejecuta el siguiente comando gcloud en Cloud Shell para crear una instancia de MySQL 8.0. El registro binario está habilitado (obligatorio para Datastream) y la instancia está configurada con una IP pública.
export SQL_INSTANCE_NAME="source-mysql-instance"
export DB_ROOT_PASSWORD="Welcome@1" # Replace with a strong password if you prefer
gcloud sql instances create $SQL_INSTANCE_NAME \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=$REGION \
--root-password=$DB_ROOT_PASSWORD \
--enable-bin-log \
--assign-ip
--enable-bin-log: Se requiere para que Datastream capture los cambios.--assign-ip: Garantiza que la instancia obtenga una dirección IP pública.
La creación de la instancia tardará unos minutos. Puedes verificar si se creó tu instancia en la página Instancias de Cloud SQL.
2. Configura redes autorizadas
Para conectarte a la instancia a través de la IP pública, debes agregar direcciones IP a la lista de "Redes autorizadas".
Obtén tu IP de Cloud Shell:
export CLOUD_SHELL_IP=$(curl -s ipinfo.io/ip)
echo "Your Cloud Shell IP: $CLOUD_SHELL_IP"
Autoriza la IP de Cloud Shell y el acceso abierto
El siguiente comando agrega tu IP de Cloud Shell. También agrega 0.0.0.0/0, que permite el acceso desde cualquier dirección IP. Esto es necesario para simplificar las conexiones de los trabajadores de Dataflow sin configuraciones de red complejas.
gcloud sql instances patch $SQL_INSTANCE_NAME \
--authorized-networks="${CLOUD_SHELL_IP}/32,0.0.0.0/0"
3. Conéctate a la instancia de Cloud SQL desde Cloud Shell
Recupera la dirección IP pública asignada
export SQL_INSTANCE_IP=$(gcloud sql instances list --filter="name=$SQL_INSTANCE_NAME" --format="value(PRIMARY_ADDRESS)")
echo "Cloud SQL Public IP: $SQL_INSTANCE_IP"
Esta dirección IP se usará para la conexión.
Conéctate a la instancia de Cloud SQL desde Cloud Shell
Usa el cliente mysql estándar para conectarte con la dirección IP pública obtenida:
mysql -h $SQL_INSTANCE_IP -u root -p
Cuando se te solicite, ingresa la contraseña raíz que estableciste (Welcome@1). Ahora verás un mensaje de mysql>.
4. Crea una base de datos y datos de muestra
Ejecuta los siguientes comandos SQL en el mensaje de mysql>:
CREATE DATABASE music_db;
USE music_db;
CREATE TABLE Singers (
SingerId BIGINT NOT NULL,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
BirthDate DATE,
AlbumCount BIGINT,
PRIMARY KEY (SingerId)
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY (SingerId, AlbumId),
CONSTRAINT FK_Albums_Singers FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
);
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES
(1, 'Marc', 'Richards', '1970-09-03', 2),
(2, 'Catalina', 'Smith', '1990-08-17', 1),
(3, 'Alice', 'Trentor', '1991-10-02', 3);
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle, ReleaseDate) VALUES
(1, 1, 'Total Junk', '2014-03-15'),
(1, 2, 'Go Go Go', '2016-11-01'),
(2, 1, 'Green', '2018-02-28'),
(3, 1, 'Blue', '2019-01-10'),
(3, 2, 'Red', '2020-05-22'),
(3, 3, 'Purple', '2022-11-11');
El archivo de volcado del esquema anterior se puede encontrar aquí.
5. Verifica datos
Verifica rápidamente que los datos estén presentes:
SELECT 'Singers music_db' as tbl, COUNT(*) FROM music_db.Singers
UNION ALL
SELECT 'Albums music_db', COUNT(*) FROM music_db.Albums;
EXIT;
Deberías ver los recuentos de cada tabla.
+------------------+----------+ | tbl | COUNT(*) | +------------------+----------+ | Singers music_db | 3 | | Albums music_db | 6 | +------------------+----------+
5. Configura Cloud Spanner
Ahora, configurarás la instancia de Cloud Spanner de destino a la que se migrarán los datos.
1. Crea una instancia de Cloud Spanner
Crea una instancia de Cloud Spanner en la misma región que tu instancia de Cloud SQL. Con este comando, se crea una instancia pequeña adecuada para este codelab, con 100 unidades de procesamiento.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="music-db-migrated"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
La creación de la instancia puede tardar un minuto o dos.
6. Convierte el esquema con la herramienta de migración de Spanner (SMT)
Usa la CLI de SMT para analizar la base de datos de MySQL (music_db) y generar el lenguaje de definición de esquemas (DDL) de Spanner. Dado que la instancia de Cloud SQL está configurada con una IP pública y las redes autorizadas adecuadas, SMT puede conectarse directamente.
1. Prepara el entorno para SMT
Verifica que las variables de entorno necesarias estén configuradas desde los pasos anteriores:
echo "Cloud SQL Instance Public IP: $SQL_INSTANCE_IP"
echo "Cloud SQL Root Password: $DB_ROOT_PASSWORD"
echo "Spanner Instance: $SPANNER_INSTANCE_NAME"
echo "Spanner Database: $SPANNER_DATABASE_NAME"
echo "Project ID: $PROJECT_ID"
2. Ejecuta la conversión de esquemas para music_db
Ejecuta el comando schema de SMT y conéctate directamente a la dirección IP pública de Cloud SQL:
gcloud alpha spanner migrate schema \
--source=mysql \
--source-profile="host=${SQL_INSTANCE_IP},port=3306,user=root,password=${DB_ROOT_PASSWORD},dbName=music_db" \
--target-profile="project=${PROJECT_ID},instance=${SPANNER_INSTANCE_NAME},dbName=${SPANNER_DATABASE_NAME}" \
--prefix="music-db"
Este comando se conecta a la instancia de Cloud SQL a través del proxy y genera archivos de esquema con el prefijo music-db.
3. Revisa los archivos generados
SMT crea algunos archivos en tu directorio actual. Los principales son los siguientes:
music-db.schema.ddl.txt: Son las instrucciones DDL de Spanner generadas.music-db-.overrides.json: Archivo de anulaciones del esquema que contiene cambios de asignación manuales.music-db.session.json: Archivo de sesión de la migración del esquema.music-db.report.txt: Es un informe de evaluación de la conversión del esquema.
Puedes enumerarlos con ls music-db-*.
4. Verifica el esquema en Cloud Spanner
Verifica que se hayan creado las tablas en la base de datos de Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Deberías ver el siguiente resultado:
table_name: Albums table_name: Singers
Opcional: Si deseas verificar el DDL de Spanner, ejecuta el siguiente comando:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
7. Inicializa la captura de datos modificados (CDC)
En esta sección, configurarás el "grabador" para tu migración. Si configuras Datastream y Pub/Sub antes de que comience la carga de datos masiva, te aseguras de que se capture y se ponga en cola cada cambio realizado en la base de datos de origen, lo que evita la pérdida de datos durante la transición. Esta configuración es obligatoria para la migración en vivo.
1. Crea perfiles de conexión de Datastream
Perfil de origen (Cloud SQL)
Este perfil se conecta a la IP pública de la instancia de Cloud SQL. Datastream usará la lista de IPs permitidas para la conectividad.
export SQL_CP_NAME="mysql-src-cp"
gcloud datastream connection-profiles create $SQL_CP_NAME \
--location=$REGION \
--type=mysql \
--mysql-hostname=$SQL_INSTANCE_IP \
--mysql-port=3306 \
--mysql-username=root \
--mysql-password=$DB_ROOT_PASSWORD \
--display-name="Cloud SQL Source - Public IP"
Nota: Esta conexión depende de que las redes autorizadas de la instancia de Cloud SQL permitan el acceso. Como se configuró anteriormente con 0.0.0.0/0, las IPs públicas de Datastream pueden conectarse. En un entorno de producción, reemplazarías 0.0.0.0/0 por los rangos de IP específicos de tu región que se indican en Listas de IP permitidas y regiones de Datastream.
Perfil de destino (Cloud Storage)
Apunta a la raíz de tu bucket.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
2. Crea un flujo de Datastream
Crea la transmisión para replicar desde music_db.
export STREAM_NAME="mysql-to-spanner-stream"
export GCS_STREAM_PATH="data/${STREAM_NAME}"
gcloud datastream streams create $STREAM_NAME \
--location=$REGION \
--display-name="MySQL to Spanner CDC Stream" \
--source=$SQL_CP_NAME \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "
includeObjects:
mysqlDatabases:
- database: 'music_db'
") \
--gcs-destination-config=<(echo "
path: ${GCS_STREAM_PATH}
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}
") \
--backfill-none
- Datastream escribirá archivos en
gs://${BUCKET_NAME}/${GCS_STREAM_PREFIX}/ - Datastream escribirá los archivos en formato Avro. Cuando ejecutemos el comando de migración en vivo, especificaremos que inputFileFormat sea avro para que la canalización pueda procesar el archivo correctamente.
- Usar parámetros de configuración de rotación de archivos más pequeños ayuda a ver los cambios más rápido en el codelab.
Este comando puede tardar un tiempo en completarse. Verifica el estado: gcloud datastream streams describe $STREAM_NAME --location=$REGION.
3. Inicia la transmisión de Datastream
gcloud datastream streams update $STREAM_NAME \
--location=$REGION \
--state=RUNNING
Verifica el estado: gcloud datastream streams describe $STREAM_NAME --location=$REGION. El estado será STARTING inicialmente y se convertirá en RUNNING después de un tiempo. Continúa con el siguiente paso solo después de confirmar que está en estado RUNNING.
4. Configura Pub/Sub para las notificaciones de GCS
Crea un tema de Pub/Sub:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
Crea una notificación de GCS
Notifica la creación de objetos con el prefijo data/.
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Cree una suscripción a Pub/Sub
Incluye el plazo de confirmación recomendado.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Migra datos de forma masiva de Cloud SQL a Spanner
Con el esquema de Spanner implementado, ahora copiarás los datos existentes de tu base de datos music_db de Cloud SQL a Cloud Spanner. Usarás la plantilla de Flex de Sourcedb to Spanner Dataflow, que está diseñada para copiar de forma masiva datos de bases de datos accesibles a través de JDBC a Spanner.
1. Ejecuta el trabajo de Dataflow de migración masiva para music_db
Ejecuta el siguiente comando en Cloud Shell para iniciar el trabajo de Dataflow. Este comando utiliza el comando gcloud dataflow flex-template run, que hace referencia a la plantilla proporcionada por Google para las migraciones masivas de JDBC a Spanner.
export JOB_NAME_MUSIC="mysql-music-db-to-spanner-bulk-$(date +%Y%m%d-%H%M%S)"
export MUSIC_DB_JDBC_URL="jdbc:mysql://${SQL_INSTANCE_IP}:3306/music_db"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration-output"
gcloud dataflow flex-template run $JOB_NAME_MUSIC \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL="$MUSIC_DB_JDBC_URL",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
outputDirectory="$OUTPUT_DIR/music_db",\
username="root",\
password="$DB_ROOT_PASSWORD",\
jdbcDriverClassName="com.mysql.cj.jdbc.Driver",\
jdbcDriverJars="gs://${BUCKET_NAME}/lib/mysql-connector-j-8.0.33.jar",\
spannerHost="https://batch-spanner.googleapis.com"
Explicación de los parámetros clave:
sourceConfigURL: Es la cadena de conexión JDBC para la fuentemusic_db.instanceId,databaseId,projectId: Especifica la instancia y la base de datos de Cloud Spanner de destino.outputDirectory: Es una ruta de acceso de Cloud Storage en la que Dataflow escribirá información sobre los registros que no se pudieron migrar.jdbcDriverClassName: Especifica el controlador JDBC de MySQL.jdbcDriverJars: Es la ruta de acceso de GCS al archivo JAR del controlador JDBC transferido.spannerHost: Usa el extremo optimizado por lotes para las escrituras de Spanner.maxWorkers,numWorkers: Controla el ajuste de escala del trabajo de Dataflow. Se mantiene bajo para este conjunto de datos pequeño.
Nota sobre la red: Este trabajo se conecta a la instancia de Cloud SQL a través de su IP pública. Esto es posible porque anteriormente agregaste 0.0.0.0/0 a las redes autorizadas de la instancia. Esto permite que las VMs de trabajador de Dataflow, que tienen IPs externas, lleguen a la base de datos.
2. Supervisa el trabajo de Dataflow
Puedes hacer un seguimiento del progreso del trabajo en la consola de Google Cloud:
- Navega a la página Trabajos de Dataflow: Ir a Trabajos de Dataflow
- Ubica el trabajo llamado
mysql-music-db-to-spanner-bulk-...y haz clic en él. - Observa el gráfico y las métricas del trabajo. Espera a que el estado del trabajo cambie a Completado. Este proceso debería tardar entre 5 y 15 minutos aproximadamente.
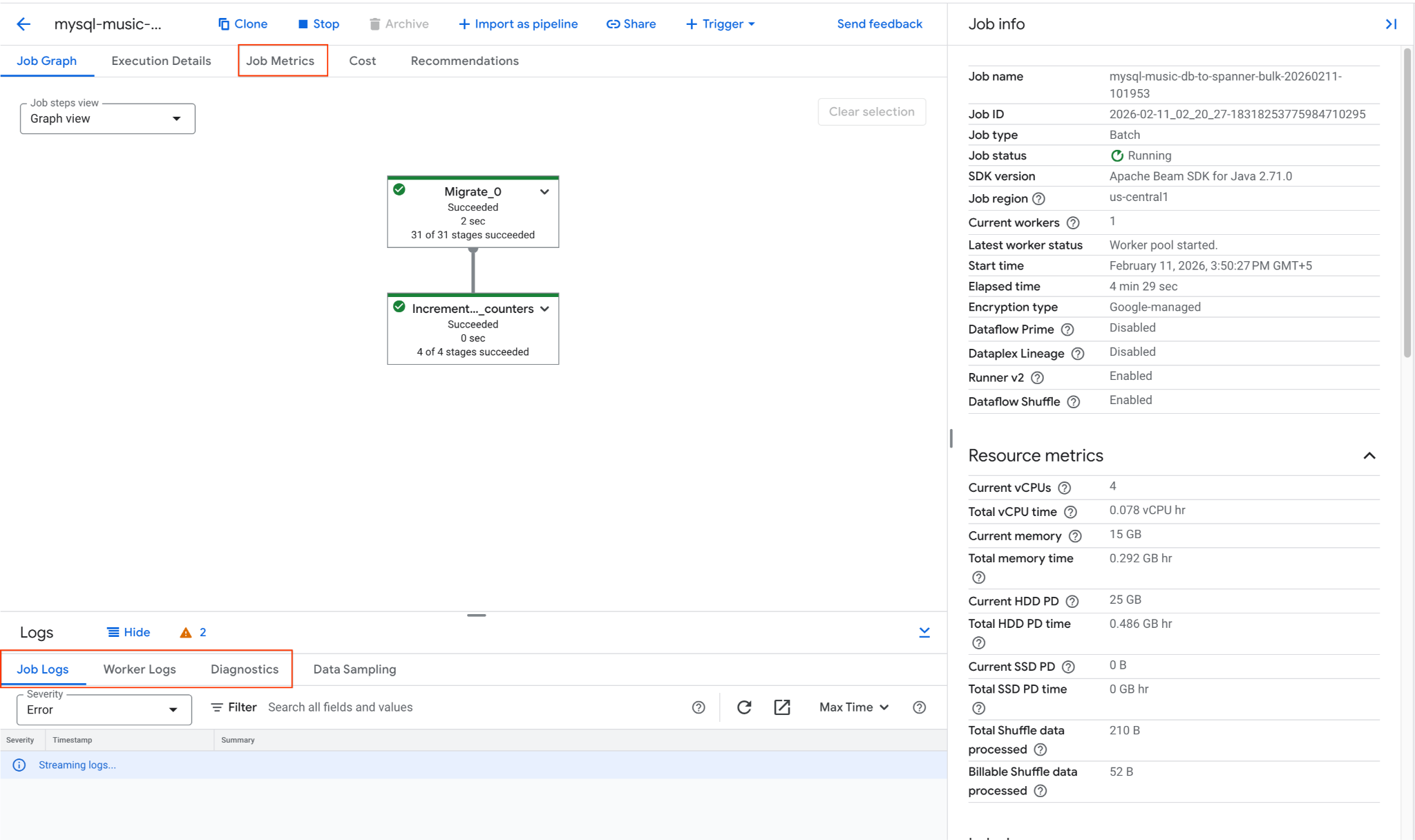
- Si el trabajo tiene problemas, revisa la pestaña Registros en la página de detalles del trabajo de Dataflow para ver los mensajes de error.
- Métricas del trabajo proporciona más información sobre el progreso del trabajo y el consumo de recursos, como el rendimiento y el uso de CPU.
3. Verifica los datos en Cloud Spanner
Una vez que el trabajo de Dataflow se complete correctamente, confirma que los datos se hayan copiado en las tablas de Spanner. Usa gcloud para consultar la base de datos de Spanner:
# Verify row counts
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Singers"
# Expected output: 3
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Albums"
# Expected output: 6
# Inspect some data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT SingerId, FirstName, LastName FROM Singers ORDER BY SingerId"
Resultado esperado:
row_count: 3 row_count: 6 SingerId: 1 FirstName: Marc LastName: Richards SingerId: 2 FirstName: Catalina LastName: Smith SingerId: 3 FirstName: Alice LastName: Trentor
Se completó la carga masiva inicial de datos de Cloud SQL a Cloud Spanner. El siguiente paso es configurar la replicación en vivo para capturar los cambios en curso.
9. Iniciar la migración en vivo (CDC)
Ahora que se completó la carga masiva de datos, configurarás un flujo de replicación continua con Datastream para capturar eventos de captura de datos modificados (CDC) de Cloud SQL y un trabajo de transmisión de Dataflow para aplicar esos cambios a Cloud Spanner casi en tiempo real.
1. Ejecuta el trabajo de Dataflow de migración en vivo
Inicia el trabajo de transmisión de Dataflow para leer desde GCS y escribir en Spanner. Esta plantilla usará las notificaciones de Pub/Sub de GCS para procesar archivos nuevos de forma instantánea.
export JOB_NAME_CDC="datastream-to-spanner-cdc-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR="gs://${BUCKET_NAME}/dlq"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
deadLetterQueueDirectory="$DLQ_DIR",\
streamName="projects/${PROJECT_ID}/locations/${REGION}/streams/${STREAM_NAME}"
Parámetros clave
gcsPubSubSubscription: Es la suscripción de Pub/Sub que escucha las notificaciones de archivos nuevos de GCS. Esto permite que el trabajo procese los cambios de inmediato a medida que Datastream los escribe.inputFileFormat="avro": Indica a Dataflow que espere archivos Avro de Datastream. Debe coincidir con la configuración del "Destino" de tu flujo de datos (p. ej.,avroFileFormatfrente ajsonFileFormat).deadLetterQueueDirectory: Es una ruta de acceso de GCS en la que el trabajo almacena los registros que no se pudieron procesar (p.ej., debido a discrepancias en el esquema) para su revisión manual posterior.streamName: Es la ruta de acceso completa al recurso del flujo de Datastream, que permite que el trabajo de Dataflow haga un seguimiento del estado de replicación y los metadatos.
Supervisa el inicio del trabajo en la consola de trabajos de Dataflow.
2. Prueba de migración en vivo
Aplica cambios a la instancia de Cloud SQL de origen music_db para probar la canalización de CDC.
Conéctate a Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
Ingresa la contraseña (Welcome@1) y selecciona la base de datos:
USE music_db;
-- INSERT
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (4, 'Elena', 'Nadal', '1985-05-30', 0);
SELECT * FROM Singers WHERE SingerId = 4;
-- UPDATE
UPDATE Singers SET LastName = 'Richards-Smith' WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- DELETE
DELETE FROM Albums WHERE SingerId = 2;
DELETE FROM Singers WHERE SingerId = 2;
SELECT * FROM Singers WHERE SingerId = 2;
EXIT;
Verificación en Spanner (después de unos momentos):
# Verify INSERT: This should return the new row for Elena Nadal.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 4"
# Verify UPDATE: This should show LastName as Richards-Smith.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName FROM Singers WHERE SingerId = 1"
# Verify DELETE: This should now return 0 rows.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Albums WHERE SingerId = 2"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 2"
Resultado esperado:
SingerId: 4 FirstName: Elena LastName: Nadal BirthDate: 1985-05-30 AlbumCount: 0 SingerId: 1 FirstName: Marc LastName: Richards-Smith
3. Verificación final en Spanner
Verifica el estado general de la tabla Singers en Spanner:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId"
Resultado esperado:
SingerId: 1 FirstName: Marc LastName: Richards-Smith AlbumCount: 2 SingerId: 3 FirstName: Alice LastName: Trentor AlbumCount: 3 SingerId: 4 FirstName: Elena LastName: Nadal AlbumCount: 0
10. Configura la replicación inversa (de Spanner a Cloud SQL)
Para controlar situaciones en las que es posible que debas revertir o mantener la base de datos de Cloud SQL sincronizada con Spanner durante un período, puedes configurar la replicación inversa. Esta canalización usa flujos de cambios de Spanner para capturar cambios en Spanner y volver a escribirlos en music_db de Cloud SQL.
1. Crea un flujo de cambios de Spanner
Primero, debes crear un flujo de cambios en tu base de datos de Spanner para hacer un seguimiento de los cambios en las tablas Singers y Albums.
export CHANGE_STREAM_NAME="MusicDBChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Singers, Albums"
Este flujo de cambios ahora registrará todas las modificaciones de datos en las tablas especificadas.
2. Crea una base de datos de Spanner para los metadatos de Dataflow
La plantilla de Spanner to SourceDB Dataflow requiere una base de datos de Spanner independiente para almacenar metadatos y administrar el consumo del flujo de cambios.
export SPANNER_METADATA_DB_NAME="reverse-replication-metadata"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Prepara la configuración de la conexión de Cloud SQL para Dataflow
La plantilla de Dataflow necesita un archivo JSON en Cloud Storage que contenga los detalles de conexión de la base de datos de Cloud SQL de destino.
Crea un archivo local llamado shard_config.json:
cat << EOF > shard_config.json
[
{
"logicalShardId": "mysql_shard",
"host": "${SQL_INSTANCE_IP}",
"port": "3306",
"user": "root",
"password": "${DB_ROOT_PASSWORD}",
"dbName": "music_db"
}
]
EOF
Sube este archivo a tu bucket de GCS:
export SHARD_CONFIG_FILE="gs://${BUCKET_NAME}/shard_config.json"
gcloud storage cp shard_config.json $SHARD_CONFIG_FILE
4. Ejecuta el trabajo de Dataflow de replicación inversa
Inicia el trabajo de Dataflow con la plantilla de Flex Spanner_to_SourceDb.
export JOB_NAME_REVERSE="spanner-to-mysql-reverse-$(date +%Y%m%d-%H%M%S)"
export REVERSE_DLQ_DIR="gs://${BUCKET_NAME}/reverse-dlq"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$SHARD_CONFIG_FILE",\
deadLetterQueueDirectory="$REVERSE_DLQ_DIR"
Parámetros clave
changeStreamName: Es el nombre del flujo de cambios de Spanner desde el que se leerá.metadataInstance, metadataDatabase: Instancia o base de datos de Spanner para almacenar los metadatos que usa el conector para controlar el consumo de los datos de la API de flujo de cambios.sourceShardsFilePath: Es la ruta de acceso a tushard_config.jsonen GCS.filtrationMode: Especifica cómo descartar ciertos registros según un criterio. El valor predeterminado esforward_migration(filtra los registros escritos con la canalización de migración hacia adelante).
Nota sobre la red: Los trabajadores de Dataflow se conectarán a la instancia de Cloud SQL con la IP pública especificada en shard_config.json. Esta conexión se permite debido a la entrada 0.0.0.0/0 en las redes autorizadas de la instancia de Cloud SQL.
Supervisa el inicio del trabajo en la consola de trabajos de Dataflow.
5. Prueba la replicación inversa
Ahora, realiza cambios directamente en Cloud Spanner y verifica que se reflejen en Cloud SQL. Hazlo solo una vez que el trabajo de Dataflow se haya iniciado y esté en estado de procesamiento.
Prueba INSERT, UPDATE y DELETE
# INSERT: Insert a new singer (SingerId 5) into Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (5, 'David', 'Chen', '1995-02-18', 0)"
# UPDATE: Update SingerId 3's AlbumCount in Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Singers SET AlbumCount = 5 WHERE SingerId = 3"
# DELETE: Delete SingerId 1 from Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Albums WHERE SingerId = 1"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Singers WHERE SingerId = 1"
Verificación en Cloud SQL (después de unos momentos):
Conéctate a Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
Cuando se te solicite, ingresa la contraseña (Welcome@1) y, luego, ejecuta los siguientes comandos de SQL en el mensaje mysql>.
USE music_db;
-- Verify INSERT: This should show the new row for David Chen
SELECT * FROM Singers WHERE SingerId = 5;
-- Verify UPDATE: This should show AlbumCount as 5.
SELECT SingerId, FirstName, AlbumCount FROM Singers WHERE SingerId = 3;
-- Verify DELETE: This should return an empty set.
SELECT * FROM Albums WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- Final Verification
SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId;
EXIT;
El resultado esperado en Cloud SQL debe reflejar los cambios realizados en Spanner.
+----------+-----------+----------------+------------+ | SingerId | FirstName | LastName | AlbumCount | +----------+-----------+----------------+------------+ | 3 | Alice | Trentor | 5 | | 4 | Elena | Nadal | 0 | | 5 | David | Chen | 0 | +----------+-----------+----------------+------------+
Esto confirma que la canalización de replicación inversa funciona y sincroniza los cambios de Spanner a Cloud SQL.
11. Limpia los recursos
Para evitar que se apliquen cargos adicionales a tu cuenta de Google Cloud, borra los recursos que creaste durante este codelab.
Configura las variables de entorno (si es necesario)
Comprueba si las variables de entorno están configuradas correctamente:
echo "PROJECT_ID: $PROJECT_ID"
echo "REGION: $REGION"
echo "SQL_INSTANCE_NAME: $SQL_INSTANCE_NAME"
echo "SPANNER_INSTANCE_NAME: $SPANNER_INSTANCE_NAME"
echo "BUCKET_NAME: $BUCKET_NAME"
echo "STREAM_NAME: $STREAM_NAME"
echo "SQL_CP_NAME: $SQL_CP_NAME"
echo "GCS_CP_NAME: $GCS_CP_NAME"
echo "PUBSUB_SUBSCRIPTION: $PUBSUB_SUBSCRIPTION"
echo "PUBSUB_TOPIC: $PUBSUB_TOPIC"
echo "CHANGE_STREAM_NAME: $CHANGE_STREAM_NAME"
Enumera tus trabajos para encontrar los IDs de los trabajos de Dataflow en ejecución. Exporta JOB_ID_CDC y JOB_ID_REVERSE según corresponda.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Si estás en una sesión nueva de Cloud Shell, vuelve a exportar las variables de entorno clave:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or the region you used
export SQL_INSTANCE_NAME="source-mysql-instance"
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export STREAM_NAME="mysql-to-spanner-stream"
export SQL_CP_NAME="mysql-src-cp"
export GCS_CP_NAME="gcs-dest-cp"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CHANGE_STREAM_NAME="MusicDBChangeStream"
Detén los trabajos de transmisión de Dataflow
Cancela el trabajo de Datastream to Spanner (migración en vivo):
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
Cancela el trabajo de Spanner to Cloud SQL (replicación inversa):
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Borra recursos de transmisiones de datos
Detén y borra la transmisión:
gcloud datastream streams update $STREAM_NAME \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Borrar perfiles de conexión
gcloud datastream connection-profiles delete $SQL_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Borra recursos de Pub/Sub
Borra la suscripción:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Borrar tema:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Borra la instancia de Cloud SQL
Esto borrará automáticamente las bases de datos (music_db) que contiene.
gcloud sql instances delete $SQL_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Borra la instancia de Cloud Spanner
También se borrarán las bases de datos (music-db-migrated y reverse-replication-metadata) que contiene.
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Borra el bucket y el contenido de GCS
gcloud storage rm --recursive gs://${BUCKET_NAME}
Borrar archivos locales
Quita los archivos generados en tu directorio principal de Cloud Shell:
rm -f music-db* shard_config.json
Ahora, limpiaste los recursos creados para este codelab.