
1. לפני שמתחילים
ב-Codelab הזה נסביר איך להעביר מסד נתונים יחיד של MySQL ב-Cloud SQL למסד נתונים של Cloud Spanner עם ניב GoogleSQL. המיקוד הוא בתהליך ההעברה הבסיסי מקצה לקצה, עם הדגמה של השלבים העיקריים. תשתמשו בשירותי Google Cloud, כולל Spanner Migration Tool (SMT), Dataflow, Datastream, PubSub ו-Google Cloud Storage.
מה תלמדו:
- איך מגדירים מכונות לדוגמה של Cloud SQL ו-Cloud Spanner.
- איך ממירים סכימת Cloud SQL MySQL לסכימה שתואמת ל-Spanner באמצעות Spanner Migration Tool (SMT).
- איך לבצע העברה של נתונים בכמות גדולה מ-Cloud SQL ל-Cloud Spanner באמצעות Dataflow.
- איך מגדירים שכפול רציף (CDC) מ-Cloud SQL ל-Cloud Spanner באמצעות Datastream ו-Dataflow.
- איך מגדירים שכפול הפוך מ-Cloud Spanner ל-Cloud SQL.
הנושאים שלא נכללים ב-Codelab הזה:
- העברות ממופעים עם שרדינג.
- ביצוע טרנספורמציות מורכבות של נתונים במהלך המיגרציה.
- טיפול מתקדם בשגיאות או תורים של הודעות שלא ניתן להעביר (DLQ).
- כוונון הביצועים של ההעברה.
- העברת אפליקציות: ה-Codelab הזה מתמקד בשכבת מסד הנתונים (סכימה ונתונים). היא לא כוללת את תהליך ההפעלה של פריסה מחדש או העברה של שירותי האפליקציה.
הדרישות
- פרויקט ב-Google Cloud שהחיוב בו מופעל.
- הרשאות IAM מספיקות כדי להפעיל ממשקי API וליצור ולנהל משאבי Cloud SQL, Spanner, Dataflow, Datastream ו-GCS. תפקיד
OwnerProject הוא הפשוט ביותר לשימוש ב-codelab, אבל נסביר על תפקידים ספציפיים יותר בקטע 'הגדרת הסביבה'. - דפדפן אינטרנט, כמו Google Chrome.
- היכרות בסיסית עם מסוף Google Cloud ועם כלי שורת הפקודה כמו
gcloud. - גישה לסביבת מעטפת. מומלץ להשתמש ב-Cloud Shell כי הוא כולל את
gcloud.
פרטים נוספים על ההגדרה שלמעלה מופיעים בקטע 'הגדרת הסביבה'.
2. הסבר על תהליך ההעברה
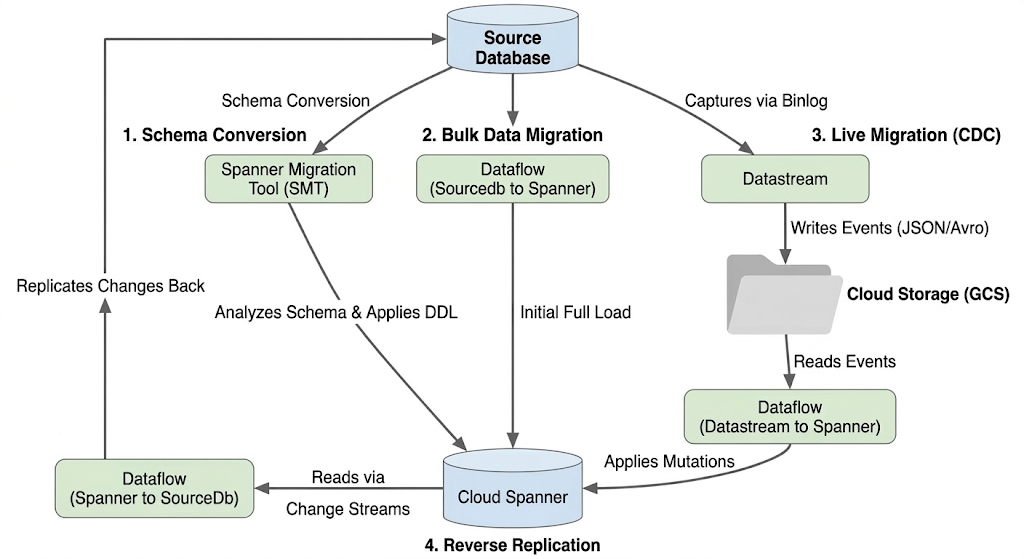
העברת מסד נתונים כוללת העברת נתונים ממכונת מסד הנתונים של CloudSQL אל מכונת Spanner. בקטע הזה מתוארת הארכיטקטורה וכלי המפתח שבהם נעשה שימוש בהעברה.
ארכיטקטורה של תהליך המיגרציה
תהליך ההעברה כולל את השלבים הבאים:
1. המרת סכימה:
- מטרה: המרת סכימת מסד הנתונים של המקור לסכימה תואמת של Cloud Spanner.
- כלי: הכלי להעברת נתונים ל-Spanner (SMT)
- תהליך: SMT מנתח את סכימת מסד הנתונים של המקור ומפיק את שפת הגדרת הנתונים (DDL) המקבילה של Spanner. במופע היעד של Spanner, נוצר מסד נתונים וה-DDL מוחל באופן אוטומטי.
2. העברת נתונים בכמות גדולה:
- מטרה: ביצוע טעינה ראשונית ומלאה של נתונים קיימים ממסד הנתונים של המקור לטבלאות Spanner שהוקצו.
- כלי: Dataflow, באמצעות התבנית
Sourcedb to Spannerש-Google מספקת. - תהליך: משימת Dataflow הזו קוראת את כל הנתונים מטבלאות המקור שצוינו וכותבת אותם בטבלאות Spanner התואמות. הפעולה הזו מתבצעת אחרי שסכמת Spanner נוצרת.
3. מיגרציה פעילה (CDC):
- מטרה: לתעד ולהחיל שינויים שוטפים ממסד הנתונים של המקור ב-Cloud Spanner כמעט בזמן אמת, כדי למזער את זמן ההשבתה במהלך ההעברה.
- כלים:
- Datastream: מתעד שינויים (הוספות, עדכונים ומחיקות) ממסד הנתונים של המקור וכותב אותם ל-Cloud Storage (GCS).
- Dataflow: משתמש בתבנית
Datastream to Spannerכדי לקרוא את אירועי השינוי מ-GCS ולהחיל אותם על Cloud Spanner.
4. שכפול הפוך:
- מטרה: לשכפל שינויים בנתונים מ-Cloud Spanner בחזרה למסד הנתונים של המקור. האפשרות הזו יכולה להיות שימושית לאסטרטגיות גיבוי, להעברות מדורגות או לשמירה של העתק במקור לתרחישי שימוש ספציפיים.
- כלי: Dataflow, באמצעות התבנית
Spanner to SourceDb. - תהליך: העבודה הזו משתמשת בסנכרון שינויים בזרמי נתונים של Spanner כדי לתעד שינויים ב-Spanner ולכתוב אותם בחזרה למופע של מסד הנתונים של המקור.
התרשים הבא מדגים את הרכיבים ואת זרימת הנתונים:
הסברים על המונחים:
- Spanner Migration Tool (SMT): כלי שמשמש להערכת סכימות של MySQL, להצעת סכימות מקבילות של Spanner וליצירת Data Definition Language (DDL) של Spanner.
- שפת הגדרת נתונים (DDL): הצהרות שמשמשות להגדרה ולשינוי של מבנה מסד הנתונים, כמו הצהרות
CREATE TABLE. SMT יוצר DDL של Spanner על סמך הסכימה של Cloud SQL. - Dataflow: שירות מנוהל במלואו לעיבוד נתונים ללא שרתים (serverless). ב-codelab הזה, משתמשים בו כדי להריץ תבניות שסופקו על ידי Google להעברת נתונים בכמות גדולה, להחלת שינויים ב-Datastream ולשכפול הפוך.
- Datastream: שירות ללא שרת (serverless) לסימון נתונים שהשתנו (CDC) וליצירת רפליקות. ב-codelab הזה, משתמשים בו כדי להזרים שינויים מ-Cloud SQL אל Cloud Storage.
- Spanner Change Streams: תכונה של Spanner שמאפשרת להזרים שינויים בנתונים (הוספות, עדכונים, מחיקות) בזמן אמת, ומשמשת כמקור לשכפול הפוך.
- Pub/Sub: שירות העברת הודעות שמשמש להפרדה בין שירותים שמפיקים אירועים לבין שירותים שמעבדים אותם. ב-codelab הזה, מפעילים את Dataflow כדי לעבד עדכונים בכל פעם ש-Datastream מעלה קובצי שינויים חדשים ל-Cloud Storage.
3. הגדרת הסביבה
לפני שמתחילים במיגרציה, צריך להגדיר את הפרויקט בענן ב-Google Cloud ולהפעיל את השירותים הנדרשים.
1. בחירה או יצירה של פרויקט ב-Google Cloud
כדי להשתמש בשירותים ב-Codelab הזה, צריך פרויקט בענן ב-Google Cloud שמופעל בו חיוב.
- במסוף Google Cloud, עוברים לדף לבחירת הפרויקט: מעבר לדף לבחירת הפרויקט
- בוחרים פרויקט קיים או יוצרים פרויקט חדש ב-Google Cloud.
- מוודאים שהחיוב מופעל בפרויקט. איך מוודאים שהחיוב מופעל בפרויקט
2. פתיחת Cloud Shell
Cloud Shell היא סביבת שורת פקודה שפועלת ב-Google Cloud, וכוללת מראש את gcloud CLI וכלים אחרים שאתם צריכים.
- לוחצים על הלחצן Activate Cloud Shell (הפעלת Cloud Shell) בפינה הימנית העליונה של מסוף Google Cloud.
- בחלק התחתון של המסוף ייפתח סשן של Cloud Shell בתוך מסגרת חדשה ותופיע הודעה של שורת הפקודה.

3. הגדרת משתני סביבה ומשתני פרויקט
ב-Cloud Shell, מגדירים כמה משתני סביבה למזהה הפרויקט ולאזור שבו תשתמשו.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. הפעלה של ממשקי Google Cloud API הנדרשים
מפעילים את ממשקי ה-API שנדרשים ל-Cloud Spanner, ל-Dataflow, ל-Datastream ולשירותים קשורים אחרים.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
יכול להיות שיחלפו כמה דקות עד שהפקודה הזו תושלם.
5. הגדרת הרשאות לחשבון שירות
למשימות של Dataflow ול-Datastream נדרשות הרשאות ספציפיות כדי ליצור אינטראקציה עם שירותים אחרים של Google Cloud. הג'ובים של Dataflow ב-Codelab הזה ישתמשו בחשבון השירות שמוגדר כברירת מחדל ב-Compute Engine.
קודם כל, צריך למצוא את מספר הפרויקט:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
עכשיו מקצים את תפקידי ה-IAM הנדרשים לחשבון השירות של Compute Engine שמוגדר כברירת מחדל:
# Role for Dataflow to run jobs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.admin" \
--condition=None
# Roles for Dataflow workers
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.worker" \
--condition=None
# Role to connect to Cloud SQL instance
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudsql.client" \
--condition=None
# Role to read/write from Cloud Spanner
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/spanner.databaseUser" \
--condition=None
# Role to access GCS buckets (Datastream output, Dataflow temp, JDBC driver)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectAdmin" \
--condition=None
# Roles for Datastream and Pub/Sub (for CDC)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastream.viewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/pubsub.subscriber"
6. יצירת קטגוריה של Cloud Storage
יוצרים קטגוריית GCS באותו אזור שבו נמצאים המשאבים האחרים. בקטגוריה הזו יישמרו מנהל ההתקן של JDBC, הפלט של Datastream והיא תשמש את Dataflow לקבצים זמניים.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
echo "Created bucket: gs://$BUCKET_NAME"
7. התקנת כלי ההעברה של Spanner (SMT)
מוודאים שכלי ההעברה של Spanner (SMT) מותקן בסביבת Cloud Shell.
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
הפקודה הזו אמורה להציג מידע עזרה לממשק האינטרנט של SMT, כדי לאשר שהרכיב gcloud מותקן. ב-Codelab הזה נשתמש בתכונות ה-CLI של SMT, שהן חלק מאותו רכיב.
4. הגדרת מסד הנתונים של Cloud SQL כמקור
בקטע הזה תיצרו ותגדירו מכונת Cloud SQL ל-MySQL עם כתובת IP ציבורית שתשמש כמסד נתונים של המקור.
1. יצירת מכונה של Cloud SQL ל-MySQL
מריצים את הפקודה gcloud הבאה ב-Cloud Shell כדי ליצור מכונת MySQL 8.0. הרישום ביומן בינארי מופעל (נדרש ל-Datastream), והמופע מוגדר עם כתובת IP ציבורית.
export SQL_INSTANCE_NAME="source-mysql-instance"
export DB_ROOT_PASSWORD="Welcome@1" # Replace with a strong password if you prefer
gcloud sql instances create $SQL_INSTANCE_NAME \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=$REGION \
--root-password=$DB_ROOT_PASSWORD \
--enable-bin-log \
--assign-ip
-
--enable-bin-log: נדרש כדי ש-Datastream יתעד שינויים. -
--assign-ip: מוודא שלמופע תוקצה כתובת IP ציבורית.
יצירת המופע תימשך כמה דקות. אפשר לבדוק אם המכונה נוצרה בדף 'מכונות של Cloud SQL'.
2. הגדרת רשתות מורשות
כדי להתחבר למופע באמצעות כתובת IP ציבורית, צריך להוסיף כתובות IP לרשימה 'רשתות מורשות'.
מקבלים את כתובת ה-IP של Cloud Shell:
export CLOUD_SHELL_IP=$(curl -s ipinfo.io/ip)
echo "Your Cloud Shell IP: $CLOUD_SHELL_IP"
אישור כתובת ה-IP של Cloud Shell וגישה פתוחה
הפקודה הבאה מוסיפה את כתובת ה-IP של Cloud Shell. היא גם מוסיפה את 0.0.0.0/0, שמאפשר גישה מכל כתובת IP. הפעולה הזו נדרשת כדי לפשט את החיבורים מעובדי Dataflow בלי הגדרות רשת מורכבות.
gcloud sql instances patch $SQL_INSTANCE_NAME \
--authorized-networks="${CLOUD_SHELL_IP}/32,0.0.0.0/0"
3. חיבור למכונה של Cloud SQL מ-Cloud Shell
אחזור כתובת ה-IP הציבורית שהוקצתה
export SQL_INSTANCE_IP=$(gcloud sql instances list --filter="name=$SQL_INSTANCE_NAME" --format="value(PRIMARY_ADDRESS)")
echo "Cloud SQL Public IP: $SQL_INSTANCE_IP"
כתובת ה-IP הזו תשמש לחיבור.
התחברות למכונה של Cloud SQL מ-CloudShell
משתמשים בלקוח mysql הרגיל כדי להתחבר באמצעות כתובת ה-IP הציבורית שהתקבלה:
mysql -h $SQL_INSTANCE_IP -u root -p
כשתתבקשו, תצטרכו להזין את סיסמת הבסיס שהגדרתם (Welcome@1). עכשיו תוצג בקשת mysql>.
4. יצירת מסד נתונים ונתונים לדוגמה
מריצים את פקודות ה-SQL הבאות בהנחיה mysql>:
CREATE DATABASE music_db;
USE music_db;
CREATE TABLE Singers (
SingerId BIGINT NOT NULL,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
BirthDate DATE,
AlbumCount BIGINT,
PRIMARY KEY (SingerId)
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY (SingerId, AlbumId),
CONSTRAINT FK_Albums_Singers FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
);
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES
(1, 'Marc', 'Richards', '1970-09-03', 2),
(2, 'Catalina', 'Smith', '1990-08-17', 1),
(3, 'Alice', 'Trentor', '1991-10-02', 3);
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle, ReleaseDate) VALUES
(1, 1, 'Total Junk', '2014-03-15'),
(1, 2, 'Go Go Go', '2016-11-01'),
(2, 1, 'Green', '2018-02-28'),
(3, 1, 'Blue', '2019-01-10'),
(3, 2, 'Red', '2020-05-22'),
(3, 3, 'Purple', '2022-11-11');
כאן אפשר למצוא את קובץ ה-dump של הסכימה שלמעלה.
5. אימות נתונים
כדי לבדוק במהירות שהנתונים קיימים:
SELECT 'Singers music_db' as tbl, COUNT(*) FROM music_db.Singers
UNION ALL
SELECT 'Albums music_db', COUNT(*) FROM music_db.Albums;
EXIT;
אמורים להופיע מספרים לכל טבלה.
+------------------+----------+ | tbl | COUNT(*) | +------------------+----------+ | Singers music_db | 3 | | Albums music_db | 6 | +------------------+----------+
5. הגדרה של Cloud Spanner
עכשיו מגדירים את מכונת היעד של Cloud Spanner שאליה יועברו הנתונים.
1. יצירת מכונה של Cloud Spanner
יוצרים מכונה של Cloud Spanner באותו אזור שבו נמצאת המכונה של Cloud SQL. הפקודה הזו יוצרת מכונה קטנה שמתאימה ל-Codelab הזה, באמצעות 100 יחידות עיבוד.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="music-db-migrated"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
יצירת המכונה עשויה להימשך דקה או שתיים.
6. המרת הסכימה באמצעות הכלי להעברה ל-Spanner (SMT)
משתמשים ב-SMT CLI כדי לנתח את מסד הנתונים של MySQL (music_db) וליצור את שפת הגדרת הסכימה (DDL) של Spanner. מכיוון שמכונת Cloud SQL מוגדרת עם כתובת IP ציבורית ורשתות מורשות מתאימות, כלי SMT יכול להתחבר ישירות.
1. הכנת הסביבה ל-SMT
מוודאים שמשתני הסביבה הנדרשים מוגדרים מהשלבים הקודמים:
echo "Cloud SQL Instance Public IP: $SQL_INSTANCE_IP"
echo "Cloud SQL Root Password: $DB_ROOT_PASSWORD"
echo "Spanner Instance: $SPANNER_INSTANCE_NAME"
echo "Spanner Database: $SPANNER_DATABASE_NAME"
echo "Project ID: $PROJECT_ID"
2. הפעלת המרת סכימה עבור music_db
מריצים את הפקודה schema של SMT, ומתחברים ישירות לכתובת ה-IP הציבורית של Cloud SQL:
gcloud alpha spanner migrate schema \
--source=mysql \
--source-profile="host=${SQL_INSTANCE_IP},port=3306,user=root,password=${DB_ROOT_PASSWORD},dbName=music_db" \
--target-profile="project=${PROJECT_ID},instance=${SPANNER_INSTANCE_NAME},dbName=${SPANNER_DATABASE_NAME}" \
--prefix="music-db"
הפקודה הזו מתחברת למופע Cloud SQL דרך ה-proxy ויוצרת קובצי סכימה עם הקידומת music-db.
3. בדיקת קבצים שנוצרו
הכלי SMT יוצר כמה קבצים בספרייה הנוכחית. העיקריים שבהם הם:
-
music-db.schema.ddl.txt: הצהרות ה-DDL שנוצרו ב-Spanner. -
music-db-.overrides.json: קובץ שינויים בסכימה שמכיל שינויים במיפוי שבוצעו באופן ידני. -
music-db.session.json: קובץ הסשן של העברת הסכימה. -
music-db.report.txt: דוח הערכה של המרת הסכימה.
אפשר לראות את הרשימה שלהם באמצעות ls music-db-*
4. אימות הסכימה ב-Cloud Spanner
בודקים שהטבלאות נוצרו במסד הנתונים של Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
הפלט הבא אמור להתקבל:
table_name: Albums table_name: Singers
אופציונלי: כדי לבדוק את Spanner DDL, מריצים את הפקודה הבאה:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
7. הפעלה של סימון נתונים שהשתנו (CDC)
בקטע הזה מגדירים את הכלי 'הקלטה' להעברה. אם תגדירו את Datastream ואת Pub/Sub לפני שתתחילו להעמיס את הנתונים בכמות גדולה, תוכלו לוודא שכל שינוי במסד הנתונים של המקור יתועד ויוכנס לתור, וכך למנוע אובדן נתונים במהלך המעבר. ההגדרה הזו נדרשת להעברה הפעילה.
1. יצירת פרופילים של חיבורי Datastream
פרופיל מקור (Cloud SQL)
הפרופיל הזה מתחבר לכתובת ה-IP הציבורית של מכונת Cloud SQL. Datastream ישתמש בהוספה לרשימת ההיתרים של כתובות IP לצורך קישוריות.
export SQL_CP_NAME="mysql-src-cp"
gcloud datastream connection-profiles create $SQL_CP_NAME \
--location=$REGION \
--type=mysql \
--mysql-hostname=$SQL_INSTANCE_IP \
--mysql-port=3306 \
--mysql-username=root \
--mysql-password=$DB_ROOT_PASSWORD \
--display-name="Cloud SQL Source - Public IP"
הערה: החיבור הזה מסתמך על רשתות מורשות של מופע Cloud SQL שמאפשרות גישה. כמו שהגדרנו קודם עם 0.0.0.0/0, כתובות ה-IP הציבוריות של Datastream יכולות להתחבר. בסביבת ייצור, מחליפים את 0.0.0.0/0 בטווחים הספציפיים של כתובות ה-IP באזור שלכם, שמופיעים במאמר רשימות ההיתרים של כתובות IP ואזורים ב-Datastream.
פרופיל יעד (Cloud Storage)
מצביע על קטגוריית הבסיס.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
2. יצירת מקור נתונים ב-Datastream
יוצרים את הזרם לשכפול מ-music_db.
export STREAM_NAME="mysql-to-spanner-stream"
export GCS_STREAM_PATH="data/${STREAM_NAME}"
gcloud datastream streams create $STREAM_NAME \
--location=$REGION \
--display-name="MySQL to Spanner CDC Stream" \
--source=$SQL_CP_NAME \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "
includeObjects:
mysqlDatabases:
- database: 'music_db'
") \
--gcs-destination-config=<(echo "
path: ${GCS_STREAM_PATH}
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}
") \
--backfill-none
- Datastream יכתוב קבצים בתיקייה
gs://${BUCKET_NAME}/${GCS_STREAM_PREFIX}/ - Datastream יכתוב את הקבצים בפורמט Avro. כשמריצים את פקודת המיגרציה הפעילה, צריך לציין את inputFileFormat כ-avro כדי שצינור הנתונים יוכל לעבד את הקובץ בצורה נכונה.
- שימוש בהגדרות קטנות יותר של רוטציה של קבצים עוזר לראות שינויים מהר יותר ב-codelab.
יכול להיות שיעבור קצת זמן עד להשלמת הפקודה. בדיקת הסטטוס: gcloud datastream streams describe $STREAM_NAME --location=$REGION.
3. התחלת השידור של Datastream
gcloud datastream streams update $STREAM_NAME \
--location=$REGION \
--state=RUNNING
בדיקת הסטטוס: gcloud datastream streams describe $STREAM_NAME --location=$REGION. הסטטוס יהיה STARTING בהתחלה, ויהפוך ל-RUNNING אחרי זמן מה. אפשר להמשיך לשלב הבא רק אחרי שמאשרים שהמצב הוא RUNNING.
4. הגדרת Pub/Sub להתראות GCS
יצירת נושא Pub/Sub:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
יצירת התראה ב-GCS
התראה על יצירת אובייקט תחת הקידומת data/.
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
יצירת מינוי ל-Pub/Sub
צריך לכלול את המועד האחרון המומלץ לאישור.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. העברה בכמות גדולה של נתונים מ-Cloud SQL ל-Spanner
אחרי שיוצרים את הסכימה ב-Spanner, מעתיקים את הנתונים הקיימים ממסד הנתונים music_db ב-Cloud SQL אל Cloud Spanner. תשתמשו בSourcedb to Spanner תבנית Flex של Dataflow, שנועדה להעתקת נתונים בכמות גדולה ממסדי נתונים שאפשר לגשת אליהם באמצעות JDBC אל Spanner.
1. הפעלת משימת Dataflow להעברת נתונים בכמות גדולה עבור music_db
מריצים את הפקודה הבאה ב-Cloud Shell כדי להפעיל את משימת Dataflow. הפקודה הזו משתמשת בפקודה gcloud dataflow flex-template run, עם הפניה לתבנית ש-Google מספקת להעברות בכמות גדולה מ-JDBC ל-Spanner.
export JOB_NAME_MUSIC="mysql-music-db-to-spanner-bulk-$(date +%Y%m%d-%H%M%S)"
export MUSIC_DB_JDBC_URL="jdbc:mysql://${SQL_INSTANCE_IP}:3306/music_db"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration-output"
gcloud dataflow flex-template run $JOB_NAME_MUSIC \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL="$MUSIC_DB_JDBC_URL",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
outputDirectory="$OUTPUT_DIR/music_db",\
username="root",\
password="$DB_ROOT_PASSWORD",\
jdbcDriverClassName="com.mysql.cj.jdbc.Driver",\
jdbcDriverJars="gs://${BUCKET_NAME}/lib/mysql-connector-j-8.0.33.jar",\
spannerHost="https://batch-spanner.googleapis.com"
הסבר על הפרמטרים העיקריים:
-
sourceConfigURL: מחרוזת החיבור של JDBC למקורmusic_db. -
instanceId,databaseId,projectId: מציינים את מסד הנתונים ואת מכונת היעד של Cloud Spanner. -
outputDirectory: נתיב ב-Cloud Storage שבו Dataflow יכתוב מידע על רשומות שלא הצליחו לעבור מיגרציה. -
jdbcDriverClassName: ציון מנהל ההתקן של MySQL JDBC. -
jdbcDriverJars: נתיב GCS לקובץ ה-JAR של מנהל התקן JDBC שהועבר להמתנה. -
spannerHost: משתמש בנקודת הקצה (endpoint) של כתיבה ב-Spanner שעברה אופטימיזציה עבור אצווה. -
maxWorkers, numWorkers: שולט בהתאמת הגודל של משימת Dataflow. הערך נשאר נמוך בגלל שמערך הנתונים קטן.
הערה לגבי הרשת: העבודה הזו מתחברת למופע Cloud SQL דרך כתובת ה-IP הציבורית שלו. האפשרות הזו קיימת כי הוספתם בעבר את 0.0.0.0/0 לרשתות המורשות של המופע. כך מכונות וירטואליות של Dataflow Worker עם כתובות IP חיצוניות יכולות להגיע למסד הנתונים.
2. מעקב אחרי משימת Dataflow
אפשר לעקוב אחרי התקדמות העבודה במסוף Google Cloud:
- עוברים לדף 'משימות Dataflow': מעבר אל 'משימות Dataflow'
- מאתרים את המשרה בשם
mysql-music-db-to-spanner-bulk-...ולוחצים עליה. - בודקים את תרשים המשימה ואת המדדים. מחכים שסטטוס העבודה ישתנה להצלחה. התהליך יימשך כ-5 עד 15 דקות.
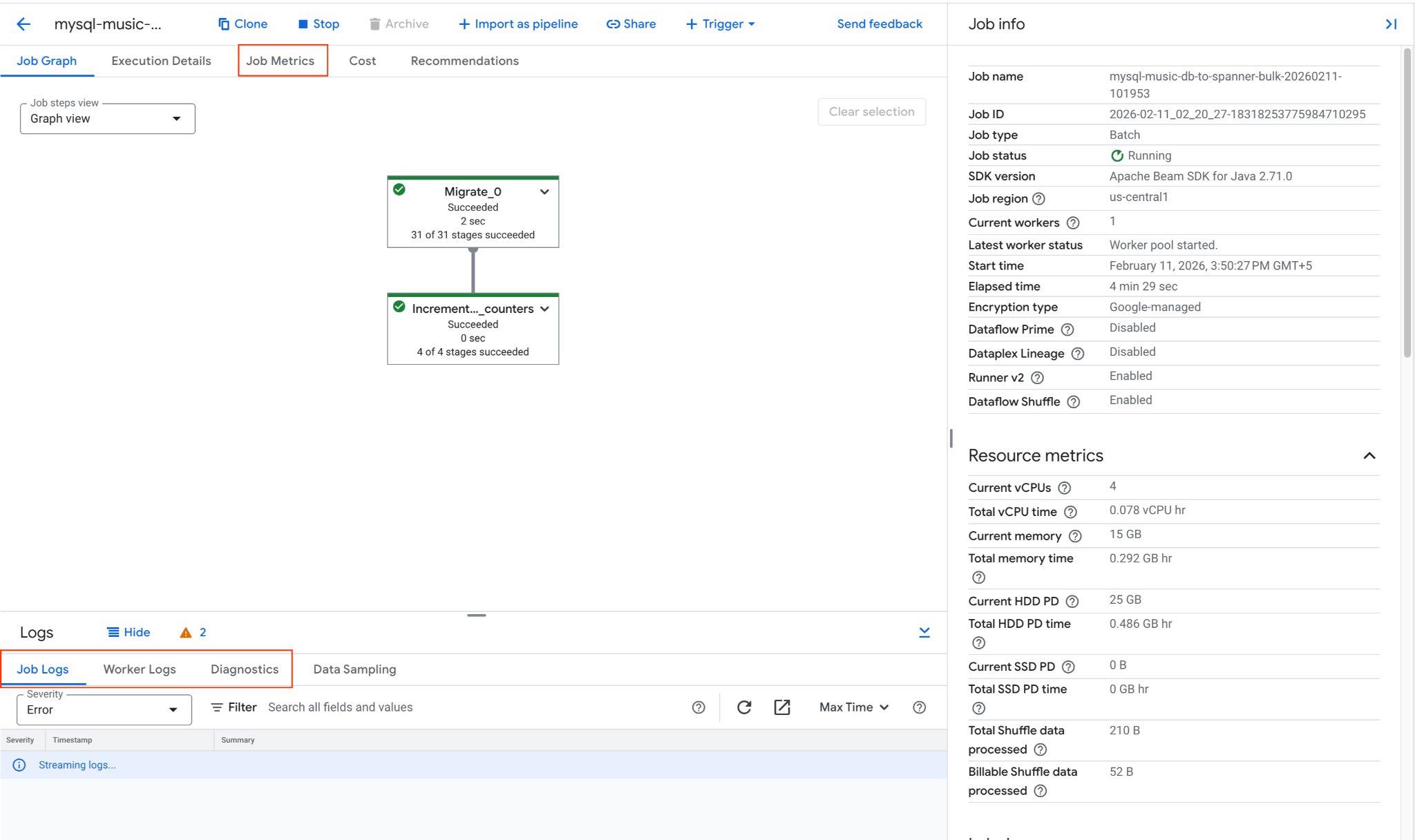
- אם נתקלים בבעיות בעבודה, אפשר לעיין בכרטיסייה Logs (יומנים) בדף הפרטים של עבודת Dataflow כדי למצוא הודעות שגיאה.
- מדדי עבודה מספקים מידע נוסף על התקדמות העבודה ועל צריכת המשאבים, כמו קצב העברת הנתונים וניצול המעבד.
3. אימות הנתונים ב-Cloud Spanner
אחרי שמשימת Dataflow מסתיימת בהצלחה, צריך לוודא שהנתונים הועתקו לטבלאות Spanner. משתמשים ב-gcloud כדי לשלוח שאילתה למסד הנתונים של Spanner:
# Verify row counts
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Singers"
# Expected output: 3
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Albums"
# Expected output: 6
# Inspect some data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT SingerId, FirstName, LastName FROM Singers ORDER BY SingerId"
הפלט הצפוי:
row_count: 3 row_count: 6 SingerId: 1 FirstName: Marc LastName: Richards SingerId: 2 FirstName: Catalina LastName: Smith SingerId: 3 FirstName: Alice LastName: Trentor
הטעינה הראשונית של נתונים מ-Cloud SQL ל-Cloud Spanner הסתיימה. השלב הבא הוא להגדיר שכפול בזמן אמת כדי לתעד שינויים שמתבצעים באופן שוטף.
9. התחלת העברה פעילה (CDC)
עכשיו, אחרי שטעינת הנתונים בכמות גדולה הסתיימה, תגדירו זרם רפליקציה רציף באמצעות Datastream כדי לתעד אירועים של סימון נתונים שהשתנו (CDC) מ-Cloud SQL, ומשימת סטרימינג של Dataflow כדי להחיל את השינויים האלה על Cloud Spanner כמעט בזמן אמת.
1. הפעלת משימת Dataflow של העברה פעילה
מפעילים את משימת הסטרימינג של Dataflow כדי לקרוא מ-GCS ולכתוב ל-Spanner. התבנית הזו תשתמש בהתראות GCS Pub/Sub כדי לעבד קבצים חדשים באופן מיידי.
export JOB_NAME_CDC="datastream-to-spanner-cdc-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR="gs://${BUCKET_NAME}/dlq"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
deadLetterQueueDirectory="$DLQ_DIR",\
streamName="projects/${PROJECT_ID}/locations/${REGION}/streams/${STREAM_NAME}"
פרמטרים מרכזיים
-
gcsPubSubSubscription: מינוי Pub/Sub שמקשיב להתראות על קבצים חדשים מ-GCS. כך העבודה יכולה לעבד את השינויים באופן מיידי בזמן ש-Datastream כותב אותם. -
inputFileFormat="avro": מציין ל-Dataflow לצפות לקובצי Avro מ-Datastream. הערך הזה צריך להיות זהה להגדרת ה'יעד' במקור הנתונים (לדוגמה,avroFileFormatלעומתjsonFileFormat). -
deadLetterQueueDirectory: נתיב GCS שבו המשימה מאחסנת רשומות שלא הצליחו לעבור עיבוד (למשל, בגלל חוסר התאמה לסכימה) לצורך בדיקה ידנית מאוחר יותר. -
streamName: נתיב המשאב המלא של הזרם ב-Datastream, שמאפשר למשימת Dataflow לעקוב אחרי מצב השכפול והמטא-נתונים.
עוקבים אחרי הפעלת המשימה ב-Dataflow Jobs Console.
2. בדיקת מיגרציה פעילה
מחילים שינויים על Cloud SQL music_db כדי לבדוק את צינור ה-CDC.
מתחברים ל-Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
מזינים את הסיסמה (Welcome@1) ובוחרים את מסד הנתונים:
USE music_db;
-- INSERT
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (4, 'Elena', 'Nadal', '1985-05-30', 0);
SELECT * FROM Singers WHERE SingerId = 4;
-- UPDATE
UPDATE Singers SET LastName = 'Richards-Smith' WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- DELETE
DELETE FROM Albums WHERE SingerId = 2;
DELETE FROM Singers WHERE SingerId = 2;
SELECT * FROM Singers WHERE SingerId = 2;
EXIT;
אימות ב-Spanner (אחרי כמה רגעים):
# Verify INSERT: This should return the new row for Elena Nadal.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 4"
# Verify UPDATE: This should show LastName as Richards-Smith.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName FROM Singers WHERE SingerId = 1"
# Verify DELETE: This should now return 0 rows.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Albums WHERE SingerId = 2"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 2"
הפלט הצפוי:
SingerId: 4 FirstName: Elena LastName: Nadal BirthDate: 1985-05-30 AlbumCount: 0 SingerId: 1 FirstName: Marc LastName: Richards-Smith
3. אימות סופי ב-Spanner
בודקים את המצב הכולל של הטבלה Singers ב-Spanner:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId"
הפלט אמור להיראות כך:
SingerId: 1 FirstName: Marc LastName: Richards-Smith AlbumCount: 2 SingerId: 3 FirstName: Alice LastName: Trentor AlbumCount: 3 SingerId: 4 FirstName: Elena LastName: Nadal AlbumCount: 0
10. הגדרת שכפול הפוך (מ-Spanner ל-Cloud SQL)
כדי לטפל בתרחישים שבהם יכול להיות שתצטרכו לבטל את השינויים או לשמור על סנכרון של מסד הנתונים של Cloud SQL עם Spanner למשך תקופה מסוימת, אתם יכולים להגדיר שכפול הפוך. פייפליין זה משתמש בזרמי שינויים ב-Spanner כדי לתעד שינויים ב-Spanner ולכתוב אותם בחזרה ל-Cloud SQL music_db.
1. יצירת שינוי בשידור חי ב-Spanner
קודם כול, צריך ליצור מקור לשינויים במסד הנתונים של Spanner כדי לעקוב אחרי שינויים בטבלאות Singers ו-Albums.
export CHANGE_STREAM_NAME="MusicDBChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Singers, Albums"
מעכשיו, בזרם השינויים הזה יתועדו כל שינויי הנתונים בטבלאות שצוינו.
2. יצירת מסד נתונים של Spanner למטא-נתונים של Dataflow
Spanner to SourceDB תבנית Dataflow דורשת מסד נתונים נפרד של Spanner לאחסון מטא-נתונים לניהול הצריכה של זרם השינויים.
export SPANNER_METADATA_DB_NAME="reverse-replication-metadata"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. הכנת הגדרת חיבור Cloud SQL ל-Dataflow
תבנית Dataflow צריכה קובץ JSON ב-Cloud Storage שמכיל את פרטי החיבור למסד הנתונים של Cloud SQL.
יוצרים קובץ מקומי בשם shard_config.json:
cat << EOF > shard_config.json
[
{
"logicalShardId": "mysql_shard",
"host": "${SQL_INSTANCE_IP}",
"port": "3306",
"user": "root",
"password": "${DB_ROOT_PASSWORD}",
"dbName": "music_db"
}
]
EOF
מעלים את הקובץ הזה לקטגוריה של GCS:
export SHARD_CONFIG_FILE="gs://${BUCKET_NAME}/shard_config.json"
gcloud storage cp shard_config.json $SHARD_CONFIG_FILE
4. הפעלת משימת Dataflow של שכפול הפוך
מפעילים את משימת Dataflow באמצעות Spanner_to_SourceDb תבנית Flex.
export JOB_NAME_REVERSE="spanner-to-mysql-reverse-$(date +%Y%m%d-%H%M%S)"
export REVERSE_DLQ_DIR="gs://${BUCKET_NAME}/reverse-dlq"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$SHARD_CONFIG_FILE",\
deadLetterQueueDirectory="$REVERSE_DLQ_DIR"
פרמטרים מרכזיים
-
changeStreamName: השם של זרם השינויים ב-Spanner שממנו רוצים לקרוא. -
metadataInstance, metadataDatabase: מופע או מסד נתונים של Spanner לאחסון המטא-נתונים שמשמשים את המחבר לשליטה בצריכת הנתונים של Change Stream API. -
sourceShardsFilePath: הנתיב ב-GCS אלshard_config.json. -
filtrationMode: מציין איך להשמיט רשומות מסוימות על סמך קריטריון. ברירת המחדל היאforward_migration(סינון רשומות שנכתבו באמצעות צינור ההעברה קדימה)
הערה לגבי הרשת: העובדים של Dataflow יתחברו למופע Cloud SQL באמצעות כתובת ה-IP הציבורית שצוינה ב-shard_config.json. החיבור הזה מותר בגלל הרשומה 0.0.0.0/0 ברשתות המורשות של מופע Cloud SQL.
עוקבים אחרי הפעלת המשימה ב-Dataflow Jobs Console.
5. בדיקת שכפול הפוך
עכשיו, מבצעים שינויים ישירות ב-Cloud Spanner ומוודאים שהם משתקפים ב-Cloud SQL. צריך לעשות את זה רק אחרי שתהליך העבודה של העברת הנתונים התחיל והוא במצב עיבוד.
בדיקה של INSERT, UPDATE ו-DELETE
# INSERT: Insert a new singer (SingerId 5) into Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (5, 'David', 'Chen', '1995-02-18', 0)"
# UPDATE: Update SingerId 3's AlbumCount in Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Singers SET AlbumCount = 5 WHERE SingerId = 3"
# DELETE: Delete SingerId 1 from Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Albums WHERE SingerId = 1"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Singers WHERE SingerId = 1"
אימות ב-Cloud SQL (אחרי כמה רגעים):
מתחברים ל-Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
מזינים את הסיסמה (Welcome@1) כשמתבקשים, ואז מריצים את פקודות ה-SQL הבאות בהנחיה mysql>.
USE music_db;
-- Verify INSERT: This should show the new row for David Chen
SELECT * FROM Singers WHERE SingerId = 5;
-- Verify UPDATE: This should show AlbumCount as 5.
SELECT SingerId, FirstName, AlbumCount FROM Singers WHERE SingerId = 3;
-- Verify DELETE: This should return an empty set.
SELECT * FROM Albums WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- Final Verification
SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId;
EXIT;
הפלט הצפוי ב-Cloud SQL צריך לשקף את השינויים שבוצעו ב-Spanner.
+----------+-----------+----------------+------------+ | SingerId | FirstName | LastName | AlbumCount | +----------+-----------+----------------+------------+ | 3 | Alice | Trentor | 5 | | 4 | Elena | Nadal | 0 | | 5 | David | Chen | 0 | +----------+-----------+----------------+------------+
הפעולה הזו מאשרת שפייפליין הרפליקציה ההפוכה פועל ומסנכרן שינויים מ-Spanner בחזרה ל-Cloud SQL.
11. מחיקת משאבי הבדיקה
כדי להימנע מחיובים נוספים בחשבון Google Cloud, מוחקים את המשאבים שנוצרו במהלך ה-codelab הזה.
הגדרת משתני סביבה (אם צריך)
בודקים אם משתני הסביבה מוגדרים בצורה נכונה:
echo "PROJECT_ID: $PROJECT_ID"
echo "REGION: $REGION"
echo "SQL_INSTANCE_NAME: $SQL_INSTANCE_NAME"
echo "SPANNER_INSTANCE_NAME: $SPANNER_INSTANCE_NAME"
echo "BUCKET_NAME: $BUCKET_NAME"
echo "STREAM_NAME: $STREAM_NAME"
echo "SQL_CP_NAME: $SQL_CP_NAME"
echo "GCS_CP_NAME: $GCS_CP_NAME"
echo "PUBSUB_SUBSCRIPTION: $PUBSUB_SUBSCRIPTION"
echo "PUBSUB_TOPIC: $PUBSUB_TOPIC"
echo "CHANGE_STREAM_NAME: $CHANGE_STREAM_NAME"
מציגים את רשימת המשימות כדי למצוא את מזהי המשימות של משימות ה-Dataflow שפועלות. מייצאים את JOB_ID_CDC וJOB_ID_REVERSE בהתאם.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
אם אתם בסשן חדש של Cloud Shell, מייצאים מחדש את משתני הסביבה של המפתח:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or the region you used
export SQL_INSTANCE_NAME="source-mysql-instance"
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export STREAM_NAME="mysql-to-spanner-stream"
export SQL_CP_NAME="mysql-src-cp"
export GCS_CP_NAME="gcs-dest-cp"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CHANGE_STREAM_NAME="MusicDBChangeStream"
הפסקת משימות סטרימינג של Dataflow
ביטול המשימה Datastream to Spanner (מיגרציה פעילה):
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
מבטלים את המשימה Spanner to Cloud SQL (שכפול הפוך):
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
מחיקה של משאבים ב-Datastream
עצירה ומחיקה של השידור:
gcloud datastream streams update $STREAM_NAME \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
מחיקת פרופילי קישור
gcloud datastream connection-profiles delete $SQL_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
מחיקת משאבי Pub/Sub
מחיקת מינוי:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
מחיקת נושא:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
מחיקת מכונה של Cloud SQL
הפעולה הזו תמחק באופן אוטומטי את מסדי הנתונים (music_db) שכלולים בה.
gcloud sql instances delete $SQL_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
מחיקה של מופע Cloud Spanner
גם מסדי הנתונים (music-db-migrated ו-reverse-replication-metadata) בתוכה יימחקו.
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
מחיקה של קטגוריית GCS ותוכן
gcloud storage rm --recursive gs://${BUCKET_NAME}
מחיקת קבצים מקומיים
מסירים את כל הקבצים שנוצרו בספריית הבית של Cloud Shell:
rm -f music-db* shard_config.json
הסרתם את המשאבים שנוצרו ל-Codelab הזה.