
1. शुरू करने से पहले
इस कोडलैब में, Cloud SQL पर मौजूद किसी MySQL डेटाबेस को GoogleSQL डायलेक्ट वाले Cloud Spanner डेटाबेस पर माइग्रेट करने का तरीका बताया गया है. इसमें, माइग्रेशन के पूरे प्रोसेस पर फ़ोकस किया गया है. साथ ही, मुख्य चरणों के बारे में बताया गया है. आपको Google Cloud की सेवाओं का इस्तेमाल करना होगा. इनमें Spanner Migration Tool (SMT), Dataflow, Datastream, PubSub, और Google Cloud Storage शामिल हैं.
आपको यह जानकारी मिलेगी:
- Cloud SQL और Cloud Spanner के सैंपल इंस्टेंस सेट अप करने का तरीका.
- Spanner Migration Tool (SMT) का इस्तेमाल करके, Cloud SQL MySQL स्कीमा को Spanner के साथ काम करने वाले स्कीमा में बदलने का तरीका.
- Dataflow का इस्तेमाल करके, Cloud SQL से Cloud Spanner में डेटा को एक साथ कैसे माइग्रेट करें.
- Datastream और Dataflow का इस्तेमाल करके, Cloud SQL से Cloud Spanner में लगातार रेप्लिकेशन (सीडीसी) कैसे सेट अप करें.
- Cloud Spanner से Cloud SQL में रिवर्स रेप्लिकेशन सेट अप करने का तरीका.
इस कोडलैब में यह जानकारी शामिल नहीं है:
- शार्ड किए गए इंस्टेंस से माइग्रेशन.
- माइग्रेशन के दौरान डेटा में जटिल बदलाव करना.
- गड़बड़ी को बेहतर तरीके से मैनेज करने या डेड लेटर क्यू (डीएलक्यू) की सुविधा.
- माइग्रेशन की परफ़ॉर्मेंस को बेहतर बनाना.
- ऐप्लिकेशन माइग्रेशन: यह कोडलैब, डेटाबेस लेयर (स्कीमा और डेटा) पर फ़ोकस करता है. इसमें, ऐप्लिकेशन सेवाओं को फिर से डिप्लॉय करने या माइग्रेट करने की प्रोसेस शामिल नहीं है.
आपको किन चीज़ों की ज़रूरत होगी
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट.
- एपीआई चालू करने और Cloud SQL, Spanner, Dataflow, Datastream, और GCS संसाधन बनाने/मैनेज करने के लिए, आईएएम की ज़रूरी अनुमतियां. प्रोजेक्ट
Ownerकी भूमिका, कोडलैब के लिए सबसे आसान है. हालांकि, "एनवायरमेंट सेटअप" में ज़्यादा खास भूमिकाओं के बारे में बताया जाएगा. - कोई वेब ब्राउज़र, जैसे कि Google Chrome.
- Google Cloud Console और
gcloudजैसे कमांड-लाइन टूल के बारे में बुनियादी जानकारी होनी चाहिए. - शेल एनवायरमेंट का ऐक्सेस. हमारा सुझाव है कि आप Cloud Shell का इस्तेमाल करें, क्योंकि इसमें
gcloudशामिल है.
ऊपर दिए गए सेटअप के बारे में ज़्यादा जानकारी, एनवायरमेंट सेटअप सेक्शन में दी गई है.
2. माइग्रेशन की प्रोसेस के बारे में जानकारी
डेटाबेस माइग्रेट करने का मतलब है कि आपको अपने सोर्स CloudSQL डेटाबेस इंस्टेंस से डेटा को Spanner इंस्टेंस में माइग्रेट करना होगा. इस सेक्शन में, माइग्रेशन में इस्तेमाल किए गए आर्किटेक्चर और मुख्य टूल के बारे में बताया गया है.
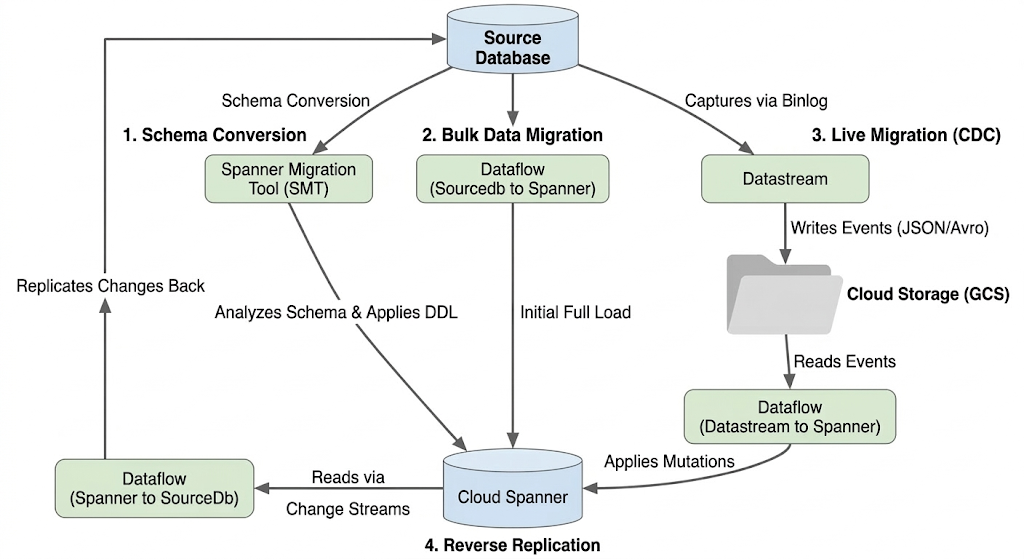
माइग्रेशन फ़्लो का आर्किटेक्चर
माइग्रेशन की प्रोसेस में ये चरण शामिल होते हैं:
1. स्कीमा कन्वर्ज़न:
- मकसद: सोर्स डेटाबेस के स्कीमा को Cloud Spanner के साथ काम करने वाले स्कीमा में बदलना.
- टूल: Spanner Migration Tool (SMT)
- प्रोसेस: एसएमटी, सोर्स डेटाबेस के स्कीमा का विश्लेषण करता है और उसके बराबर का Spanner डेटा डेफ़िनिशन लैंग्वेज (डीडीएल) जनरेट करता है. टारगेट Spanner इंस्टेंस में, एक डेटाबेस बनाया जाता है. इसके बाद, DDL अपने-आप लागू हो जाता है.
2. बल्क डेटा माइग्रेशन:
- मकसद: सोर्स डेटाबेस से, उपलब्ध कराई गई Spanner टेबल में मौजूदा डेटा को शुरुआती तौर पर पूरी तरह से लोड करना.
- टूल: Google की ओर से उपलब्ध कराए गए
Sourcedb to Spannerटेंप्लेट का इस्तेमाल करके, Dataflow. - प्रोसेस: यह डेटाफ़्लो जॉब, बताई गई सोर्स टेबल से सारा डेटा पढ़ता है और उसे Spanner की संबंधित टेबल में लिखता है. यह काम, Spanner स्कीमा बनाने के बाद किया जाता है.
3. लाइव माइग्रेशन (सीडीसी):
- मकसद: सोर्स डेटाबेस में हो रहे बदलावों को रीयल टाइम में कैप्चर करना और उन्हें Cloud Spanner पर लागू करना. इससे माइग्रेशन के दौरान डाउनटाइम कम होता है.
- टूल:
- Datastream: यह सोर्स डेटाबेस में हुए बदलावों (डेटा डालना, अपडेट करना, मिटाना) को कैप्चर करता है और उन्हें Cloud Storage (GCS) में लिखता है.
- Dataflow: यह
Datastream to Spannerटेंप्लेट का इस्तेमाल करके, GCS से बदलाव वाले इवेंट को पढ़ता है और उन्हें Cloud Spanner पर लागू करता है.
4. रिवर्स रेप्लिकेशन:
- मकसद: Cloud Spanner से डेटा में हुए बदलावों को सोर्स डेटाबेस में वापस लाना. यह फ़ेलबैक रणनीतियों, चरणों में माइग्रेशन या इस्तेमाल के कुछ खास मामलों के लिए सोर्स में रेप्लिका बनाए रखने के लिए फ़ायदेमंद हो सकता है.
- टूल:
Spanner to SourceDbटेंप्लेट का इस्तेमाल करके डेटाफ़्लो. - प्रोसेस: यह जॉब, Spanner में किए गए बदलावों को कैप्चर करने के लिए Spanner की चेंज स्ट्रीम का इस्तेमाल करती है. साथ ही, इन बदलावों को सोर्स डेटाबेस इंस्टेंस में वापस लिखती है.
इस डायग्राम में कॉम्पोनेंट और डेटा फ़्लो दिखाया गया है:
मुख्य शब्दावली:
- Spanner Migration Tool (SMT): इस टूल का इस्तेमाल MySQL स्कीमा का आकलन करने, Spanner के मिलते-जुलते स्कीमा के सुझाव देने, और Spanner डेटा डेफ़िनिशन लैंग्वेज (डीडीएल) जनरेट करने के लिए किया जाता है.
- डेटा परिभाषा की भाषा (डीडीएल): डेटाबेस के स्ट्रक्चर को तय करने और उसमें बदलाव करने के लिए इस्तेमाल किए जाने वाले स्टेटमेंट, जैसे कि
CREATE TABLEस्टेटमेंट. एसएमटी, Cloud SQL स्कीमा के आधार पर Spanner DDL जनरेट करता है. - Dataflow: यह पूरी तरह से मैनेज की जाने वाली, बिना सर्वर वाली डेटा प्रोसेसिंग सेवा है. इस कोडलैब में, इसका इस्तेमाल एक साथ कई फ़ाइलों को ट्रांसफ़र करने, डेटा स्ट्रीम में बदलाव करने, और रिवर्स रेप्लिकेशन के लिए Google के उपलब्ध कराए गए टेंप्लेट को चलाने के लिए किया जाता है.
- Datastream: यह सर्वरलेस चेंज डेटा कैप्चर (सीडीसी) और रेप्लिकेशन सेवा है. इस कोड लैब में, इसका इस्तेमाल Cloud SQL से Cloud Storage में बदलावों को स्ट्रीम करने के लिए किया जाता है.
- Spanner की बदलाव स्ट्रीम: यह Spanner की एक सुविधा है. इसकी मदद से, डेटा में हुए बदलावों (डेटा डालना, अपडेट करना, मिटाना) को रीयल-टाइम में स्ट्रीम किया जा सकता है. इसका इस्तेमाल रिवर्स रेप्लिकेशन के सोर्स के तौर पर किया जाता है.
- Pub/Sub: यह एक मैसेज सेवा है. इसका इस्तेमाल, इवेंट जनरेट करने वाली सेवाओं को इवेंट प्रोसेस करने वाली सेवाओं से अलग करने के लिए किया जाता है. इस कोडलैब में, जब भी Datastream, Cloud Storage में बदलाव की नई फ़ाइलें अपलोड करता है, तब यह Dataflow को अपडेट प्रोसेस करने के लिए ट्रिगर करता है.
3. एनवायरमेंट सेटअप करना
माइग्रेशन शुरू करने से पहले, आपको अपना Google Cloud प्रोजेक्ट सेट अप करना होगा. साथ ही, ज़रूरी सेवाएं चालू करनी होंगी.
1. Google Cloud प्रोजेक्ट चुनें या बनाएं
इस कोडलैब में दी गई सेवाओं का इस्तेमाल करने के लिए, आपके पास ऐसा Google Cloud प्रोजेक्ट होना चाहिए जिसमें बिलिंग की सुविधा चालू हो.
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर जाएं: प्रोजेक्ट चुनने वाले पेज पर जाएं
- कोई Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके प्रोजेक्ट के लिए बिलिंग चालू हो. यह पुष्टि करने का तरीका जानें कि आपके प्रोजेक्ट के लिए बिलिंग चालू है या नहीं.
2. Cloud Shell खोलें
Cloud Shell, Google Cloud में चलने वाला कमांड-लाइन एनवायरमेंट है. इसमें gcloud CLI और अन्य ज़रूरी टूल पहले से लोड होते हैं.
- Google Cloud Console में सबसे ऊपर दाईं ओर मौजूद, Cloud Shell चालू करें बटन पर क्लिक करें.
- Cloud Shell सेशन, कंसोल में सबसे नीचे मौजूद नए फ़्रेम में खुलता है. इसमें कमांड-लाइन प्रॉम्प्ट दिखता है.

3. प्रोजेक्ट और एनवायरमेंट वैरिएबल सेट करना
Cloud Shell में, अपने प्रोजेक्ट आईडी और इस्तेमाल किए जाने वाले क्षेत्र के लिए कुछ एनवायरमेंट वैरिएबल सेट अप करें.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. ज़रूरी Google Cloud API चालू करना
Cloud Spanner, Dataflow, Datastream, और इनसे जुड़ी अन्य सेवाओं के लिए ज़रूरी एपीआई चालू करें.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
इस कमांड को पूरा होने में कुछ मिनट लग सकते हैं.
5. सेवा खाते की अनुमतियां कॉन्फ़िगर करना
Dataflow जॉब और Datastream को Google Cloud की अन्य सेवाओं के साथ इंटरैक्ट करने के लिए, कुछ खास अनुमतियों की ज़रूरत होती है. इस कोडलैब में मौजूद Dataflow जॉब, Compute Engine के डिफ़ॉल्ट सेवा खाते का इस्तेमाल करेंगी.
सबसे पहले, अपना प्रोजेक्ट नंबर पाएं:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
अब Compute Engine के डिफ़ॉल्ट सेवा खाते को ज़रूरी IAM भूमिकाएं असाइन करें:
# Role for Dataflow to run jobs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.admin" \
--condition=None
# Roles for Dataflow workers
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.worker" \
--condition=None
# Role to connect to Cloud SQL instance
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudsql.client" \
--condition=None
# Role to read/write from Cloud Spanner
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/spanner.databaseUser" \
--condition=None
# Role to access GCS buckets (Datastream output, Dataflow temp, JDBC driver)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectAdmin" \
--condition=None
# Roles for Datastream and Pub/Sub (for CDC)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastream.viewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/pubsub.subscriber"
6. Cloud Storage बकेट बनाना
अपने अन्य संसाधनों की तरह ही, उसी क्षेत्र में एक GCS बकेट बनाएं. इस बकेट में JDBC ड्राइवर और Datastream का आउटपुट सेव किया जाएगा. साथ ही, Dataflow इसका इस्तेमाल कुछ समय के लिए सेव की जाने वाली फ़ाइलों के लिए करेगा.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
echo "Created bucket: gs://$BUCKET_NAME"
7. Spanner Migration Tool (SMT) इंस्टॉल करना
पक्का करें कि आपके Cloud Shell एनवायरमेंट में Spanner Migration Tool (SMT) इंस्टॉल हो.
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
इस कमांड से, SMT वेब इंटरफ़ेस के लिए सहायता से जुड़ी जानकारी दिखनी चाहिए. इससे यह पुष्टि होती है कि gcloud कॉम्पोनेंट इंस्टॉल है. इस कोडलैब में, SMT की सीएलआई सुविधाओं का इस्तेमाल किया जाएगा. ये सुविधाएं, एक ही कॉम्पोनेंट का हिस्सा हैं.
4. सोर्स Cloud SQL डेटाबेस सेट अप करना
इस सेक्शन में, आपको सोर्स डेटाबेस के तौर पर काम करने के लिए, पब्लिक आईपी वाला Cloud SQL for MySQL इंस्टेंस बनाना और कॉन्फ़िगर करना होगा.
1. Cloud SQL for MySQL इंस्टेंस बनाना
MySQL 8.0 इंस्टेंस बनाने के लिए, Cloud Shell में यहां दिया गया gcloud कमांड चलाएं. बाइनरी लॉगिंग चालू हो (Datastream के लिए ज़रूरी है) और इंस्टेंस को सार्वजनिक आईपी के साथ कॉन्फ़िगर किया गया हो.
export SQL_INSTANCE_NAME="source-mysql-instance"
export DB_ROOT_PASSWORD="Welcome@1" # Replace with a strong password if you prefer
gcloud sql instances create $SQL_INSTANCE_NAME \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=$REGION \
--root-password=$DB_ROOT_PASSWORD \
--enable-bin-log \
--assign-ip
--enable-bin-log: Datastream को बदलावों को कैप्चर करने के लिए ज़रूरी है.--assign-ip: इससे यह पक्का किया जाता है कि इंस्टेंस को सार्वजनिक आईपी पता मिले.
इंस्टेंस बनाने में कुछ मिनट लगेंगे. CloudSQL इंस्टेंस पेज पर जाकर, यह देखा जा सकता है कि आपका इंस्टेंस बनाया गया है या नहीं.
2. भरोसेमंद नेटवर्क कॉन्फ़िगर करना
सार्वजनिक आईपी पते के ज़रिए इंस्टेंस से कनेक्ट करने के लिए, आपको आईपी पतों को "अनुमति वाले नेटवर्क" सूची में जोड़ना होगा.
Cloud Shell का आईपी पता पाने के लिए:
export CLOUD_SHELL_IP=$(curl -s ipinfo.io/ip)
echo "Your Cloud Shell IP: $CLOUD_SHELL_IP"
Cloud Shell के आईपी और ओपन ऐक्सेस को अनुमति देना
इस कमांड से, Cloud Shell का आईपी पता जुड़ जाता है. यह 0.0.0.0/0 भी जोड़ता है, जिससे किसी भी आईपी पते से ऐक्सेस किया जा सकता है. यह इसलिए ज़रूरी है, ताकि डेटाफ़्लो वर्कर के कनेक्शन को जटिल नेटवर्क सेटअप के बिना आसान बनाया जा सके.
gcloud sql instances patch $SQL_INSTANCE_NAME \
--authorized-networks="${CLOUD_SHELL_IP}/32,0.0.0.0/0"
3. Cloud Shell से Cloud SQL इंस्टेंस से कनेक्ट करना
असाइन किया गया सार्वजनिक आईपी पता फ़ेच करना
export SQL_INSTANCE_IP=$(gcloud sql instances list --filter="name=$SQL_INSTANCE_NAME" --format="value(PRIMARY_ADDRESS)")
echo "Cloud SQL Public IP: $SQL_INSTANCE_IP"
कनेक्ट करने के लिए, इस आईपी पते का इस्तेमाल किया जाएगा.
CloudShell से Cloud SQL इंस्टेंस से कनेक्ट करना
कनेक्ट करने के लिए, स्टैंडर्ड mysql क्लाइंट का इस्तेमाल करें. इसके लिए, मिला हुआ सार्वजनिक आईपी पता इस्तेमाल करें:
mysql -h $SQL_INSTANCE_IP -u root -p
जब कहा जाए, तब सेट किया गया रूट पासवर्ड (Welcome@1) डालें. अब आपको mysql> प्रॉम्प्ट दिखेगा.
4. डेटाबेस और सैंपल डेटा बनाना
mysql> प्रॉम्प्ट में, यहां दी गई एसक्यूएल कमांड चलाएं:
CREATE DATABASE music_db;
USE music_db;
CREATE TABLE Singers (
SingerId BIGINT NOT NULL,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
BirthDate DATE,
AlbumCount BIGINT,
PRIMARY KEY (SingerId)
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY (SingerId, AlbumId),
CONSTRAINT FK_Albums_Singers FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
);
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES
(1, 'Marc', 'Richards', '1970-09-03', 2),
(2, 'Catalina', 'Smith', '1990-08-17', 1),
(3, 'Alice', 'Trentor', '1991-10-02', 3);
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle, ReleaseDate) VALUES
(1, 1, 'Total Junk', '2014-03-15'),
(1, 2, 'Go Go Go', '2016-11-01'),
(2, 1, 'Green', '2018-02-28'),
(3, 1, 'Blue', '2019-01-10'),
(3, 2, 'Red', '2020-05-22'),
(3, 3, 'Purple', '2022-11-11');
ऊपर दिए गए स्कीमा की डंप फ़ाइल यहां देखी जा सकती है.
5. डेटा की पुष्टि करना
जल्दी से यह जांचें कि डेटा मौजूद है या नहीं:
SELECT 'Singers music_db' as tbl, COUNT(*) FROM music_db.Singers
UNION ALL
SELECT 'Albums music_db', COUNT(*) FROM music_db.Albums;
EXIT;
आपको हर टेबल के लिए संख्याएं दिखनी चाहिए.
+------------------+----------+ | tbl | COUNT(*) | +------------------+----------+ | Singers music_db | 3 | | Albums music_db | 6 | +------------------+----------+
5. Cloud Spanner सेट अप करना
अब आपको टारगेट Cloud Spanner इंस्टेंस सेट अप करना होगा. डेटा को इसी इंस्टेंस में माइग्रेट किया जाएगा.
1. Cloud Spanner इंस्टेंस बनाना
Cloud SQL इंस्टेंस के लिए इस्तेमाल किए गए क्षेत्र में ही Cloud Spanner इंस्टेंस बनाएं. इस निर्देश से, इस कोडलैब के लिए एक छोटा इंस्टेंस बनाया जाता है. इसमें 100 प्रोसेसिंग यूनिट का इस्तेमाल किया जाता है.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="music-db-migrated"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
इंस्टेंस बनने में एक या दो मिनट लग सकते हैं.
6. Spanner Migration Tool (SMT) का इस्तेमाल करके, स्कीमा को बदलें
MySQL डेटाबेस (music_db) का विश्लेषण करने और Spanner स्कीमा डेफ़िनिशन लैंग्वेज (डीडीएल) जनरेट करने के लिए, SMT सीएलआई का इस्तेमाल करें. Cloud SQL इंस्टेंस को सार्वजनिक आईपी और ज़रूरी अनुमति वाले नेटवर्क के साथ कॉन्फ़िगर किया गया है. इसलिए, SMT सीधे तौर पर कनेक्ट हो सकता है.
1. एसएमटी के लिए एनवायरमेंट तैयार करना
पुष्टि करें कि पिछले चरणों में, ज़रूरी एनवायरमेंट वैरिएबल सेट किए गए हों:
echo "Cloud SQL Instance Public IP: $SQL_INSTANCE_IP"
echo "Cloud SQL Root Password: $DB_ROOT_PASSWORD"
echo "Spanner Instance: $SPANNER_INSTANCE_NAME"
echo "Spanner Database: $SPANNER_DATABASE_NAME"
echo "Project ID: $PROJECT_ID"
2. music_db के लिए स्कीमा कन्वर्ज़न चलाएं
SMT schema कमांड चलाएं. इससे सीधे Cloud SQL के सार्वजनिक आईपी पते से कनेक्ट किया जा सकता है:
gcloud alpha spanner migrate schema \
--source=mysql \
--source-profile="host=${SQL_INSTANCE_IP},port=3306,user=root,password=${DB_ROOT_PASSWORD},dbName=music_db" \
--target-profile="project=${PROJECT_ID},instance=${SPANNER_INSTANCE_NAME},dbName=${SPANNER_DATABASE_NAME}" \
--prefix="music-db"
यह कमांड, प्रॉक्सी के ज़रिए Cloud SQL इंस्टेंस से कनेक्ट होती है. साथ ही, music-db से प्रीफ़िक्स की गई स्कीमा फ़ाइलें जनरेट करती है.
3. जनरेट की गई फ़ाइलों की समीक्षा करना
SMT, आपकी मौजूदा डायरेक्ट्री में कुछ फ़ाइलें बनाता है. इनमें से मुख्य ये हैं:
music-db.schema.ddl.txt: जनरेट किए गए Spanner DDL स्टेटमेंट.music-db-.overrides.json: यह स्कीमा, मैन्युअल मैपिंग में किए गए बदलावों वाली फ़ाइल को बदलता है.music-db.session.json: स्कीमा माइग्रेशन की सेशन फ़ाइल.music-db.report.txt: स्कीमा कन्वर्ज़न की आकलन रिपोर्ट.
ls music-db-* का इस्तेमाल करके, उन्हें सूची में शामिल किया जा सकता है
4. Cloud Spanner में स्कीमा की पुष्टि करना
देखें कि Spanner डेटाबेस में टेबल बनाई गई हैं या नहीं.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
आपको यह आउटपुट दिखेगा:
table_name: Albums table_name: Singers
ज़रूरी नहीं: अगर आपको Spanner DDL की जांच करनी है, तो यह कमांड चलाएं:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
7. बदले गए डेटा को कैप्चर करने की सुविधा (सीडीसी) शुरू करना
इस सेक्शन में, आपको माइग्रेशन के लिए "रिकॉर्डर" सेट अप करना होगा. डेटा लोड करने की प्रोसेस शुरू होने से पहले, डेटास्ट्रीम और Pub/Sub को कॉन्फ़िगर करके, यह पक्का किया जा सकता है कि सोर्स डेटाबेस में किए गए हर बदलाव को कैप्चर और कतार में रखा जाए. इससे, ट्रांज़िशन के दौरान डेटा का नुकसान नहीं होता. लाइव माइग्रेशन के लिए, यह सेटअप ज़रूरी है.
1. डेटास्ट्रीम कनेक्शन प्रोफ़ाइलें बनाना
सोर्स प्रोफ़ाइल (Cloud SQL)
यह प्रोफ़ाइल, Cloud SQL इंस्टेंस के सार्वजनिक आईपी से कनेक्ट होती है. Datastream, कनेक्टिविटी के लिए आईपी पते को अनुमति देने की सुविधा का इस्तेमाल करेगा.
export SQL_CP_NAME="mysql-src-cp"
gcloud datastream connection-profiles create $SQL_CP_NAME \
--location=$REGION \
--type=mysql \
--mysql-hostname=$SQL_INSTANCE_IP \
--mysql-port=3306 \
--mysql-username=root \
--mysql-password=$DB_ROOT_PASSWORD \
--display-name="Cloud SQL Source - Public IP"
ध्यान दें: यह कनेक्शन, Cloud SQL इंस्टेंस के उन नेटवर्क पर काम करता है जिन्हें ऐक्सेस करने की अनुमति है. Datastream के सार्वजनिक आईपी, 0.0.0.0/0 के साथ पहले से कॉन्फ़िगर किए गए तरीके से कनेक्ट हो सकते हैं. प्रोडक्शन एनवायरमेंट में, 0.0.0.0/0 को डेटास्ट्रीम के आईपी पतों की अनुमति वाली सूचियों और क्षेत्रों में दिए गए, आपके क्षेत्र के लिए आईपी पतों की खास रेंज से बदलें.
डेस्टिनेशन प्रोफ़ाइल (Cloud Storage)
यह आपके बकेट के रूट को दिखाता है.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
2. डेटा स्ट्रीम स्ट्रीम बनाना
उस स्ट्रीम को बनाएं जिसे music_db से डुप्लीकेट करना है.
export STREAM_NAME="mysql-to-spanner-stream"
export GCS_STREAM_PATH="data/${STREAM_NAME}"
gcloud datastream streams create $STREAM_NAME \
--location=$REGION \
--display-name="MySQL to Spanner CDC Stream" \
--source=$SQL_CP_NAME \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "
includeObjects:
mysqlDatabases:
- database: 'music_db'
") \
--gcs-destination-config=<(echo "
path: ${GCS_STREAM_PATH}
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}
") \
--backfill-none
- डेटास्ट्रीम, फ़ाइलों को
gs://${BUCKET_NAME}/${GCS_STREAM_PREFIX}/में लिखेगा - Datastream, फ़ाइलों को Avro फ़ॉर्मैट में लिखेगा. लाइव माइग्रेशन कमांड चलाते समय, हम inputFileFormat को avro के तौर पर सेट करेंगे, ताकि पाइपलाइन फ़ाइल को सही तरीके से प्रोसेस कर सके.
- फ़ाइल रोटेशन की छोटी सेटिंग का इस्तेमाल करने से, कोडलैब में बदलावों को तेज़ी से देखा जा सकता है.
इस कमांड को पूरा होने में कुछ समय लग सकता है. स्टेटस देखें: gcloud datastream streams describe $STREAM_NAME --location=$REGION.
3. Datastream स्ट्रीम शुरू करना
gcloud datastream streams update $STREAM_NAME \
--location=$REGION \
--state=RUNNING
स्थिति देखें: gcloud datastream streams describe $STREAM_NAME --location=$REGION. शुरू में स्थिति STARTING होगी. कुछ समय बाद, यह RUNNING हो जाएगी. जब आपको यह पक्का हो जाए कि यह RUNNING स्थिति में है, तब अगले चरण पर जाएं.
4. GCS सूचनाओं के लिए Pub/Sub सेट अप करना
Pub/Sub विषय बनाएं:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
GCS सूचना बनाएं
data/ प्रीफ़िक्स के तहत ऑब्जेक्ट बनाने पर सूचना दें.
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Pub/Sub की सदस्यता बनाना
इसमें, सूचना देने की सुझाई गई समयसीमा शामिल करें.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Cloud SQL से Spanner में डेटा को एक साथ माइग्रेट करना
Spanner स्कीमा सेट अप करने के बाद, अब आपको Cloud SQL music_db डेटाबेस से मौजूदा डेटा को Cloud Spanner में कॉपी करना होगा. आपको Sourcedb to Spanner Dataflow फ़्लेक्स टेंप्लेट का इस्तेमाल करना होगा. इसे JDBC से ऐक्सेस किए जा सकने वाले डेटाबेस से Spanner में डेटा की बड़ी मात्रा में कॉपी करने के लिए डिज़ाइन किया गया है.
1. music_db के लिए, बल्क माइग्रेशन डेटाफ़्लो जॉब चलाना
Dataflow जॉब शुरू करने के लिए, Cloud Shell में यह कमांड चलाएं. यह कमांड, gcloud dataflow flex-template run कमांड का इस्तेमाल करती है. यह Google की ओर से उपलब्ध कराए गए टेंप्लेट का रेफ़रंस देती है. इस टेंप्लेट का इस्तेमाल, JDBC से Spanner में डेटा को एक साथ माइग्रेट करने के लिए किया जाता है.
export JOB_NAME_MUSIC="mysql-music-db-to-spanner-bulk-$(date +%Y%m%d-%H%M%S)"
export MUSIC_DB_JDBC_URL="jdbc:mysql://${SQL_INSTANCE_IP}:3306/music_db"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration-output"
gcloud dataflow flex-template run $JOB_NAME_MUSIC \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL="$MUSIC_DB_JDBC_URL",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
outputDirectory="$OUTPUT_DIR/music_db",\
username="root",\
password="$DB_ROOT_PASSWORD",\
jdbcDriverClassName="com.mysql.cj.jdbc.Driver",\
jdbcDriverJars="gs://${BUCKET_NAME}/lib/mysql-connector-j-8.0.33.jar",\
spannerHost="https://batch-spanner.googleapis.com"
मुख्य पैरामीटर के बारे में जानकारी:
sourceConfigURL: सोर्सmusic_dbके लिए JDBC कनेक्शन स्ट्रिंग.instanceId,databaseId,projectId: इससे टारगेट Cloud Spanner इंस्टेंस और डेटाबेस के बारे में पता चलता है.outputDirectory: यह Cloud Storage का वह पाथ है जहां Dataflow, उन सभी रिकॉर्ड के बारे में जानकारी लिखेगा जिन्हें माइग्रेट नहीं किया जा सका.jdbcDriverClassName: यह MySQL JDBC ड्राइवर के बारे में बताता है.jdbcDriverJars: स्टेज किए गए JDBC ड्राइवर JAR का GCS पाथ.spannerHost: Spanner में डेटा लिखने के लिए, बैच-ऑप्टिमाइज़ किए गए एंडपॉइंट का इस्तेमाल करता है.maxWorkers,numWorkers: इससे Dataflow जॉब की स्केलिंग को कंट्रोल किया जाता है. इस छोटे डेटासेट के लिए, इसे कम रखा गया है.
नेटवर्क से जुड़ी जानकारी: यह जॉब, Cloud SQL इंस्टेंस से उसके पब्लिक आईपी के ज़रिए कनेक्ट होती है. ऐसा इसलिए हो सकता है, क्योंकि आपने पहले 0.0.0.0/0 को इंस्टेंस के ऑथराइज़्ड नेटवर्क में जोड़ा था. इससे डेटाफ़्लो वर्कर वीएम को डेटाबेस तक पहुंचने की अनुमति मिलती है. इन वीएम के पास बाहरी आईपी होते हैं.
2. Dataflow जॉब की निगरानी करना
Google Cloud Console में जाकर, जॉब की प्रोग्रेस को ट्रैक किया जा सकता है:
- Dataflow Jobs पेज पर जाएं: Dataflow Jobs पर जाएं
mysql-music-db-to-spanner-bulk-...नाम की नौकरी ढूंढें और उस पर क्लिक करें.- जॉब ग्राफ़ और मेट्रिक देखें. जॉब का स्टेटस Succeeded में बदलने तक इंतज़ार करें. इसमें करीब 5 से 15 मिनट लगेंगे.
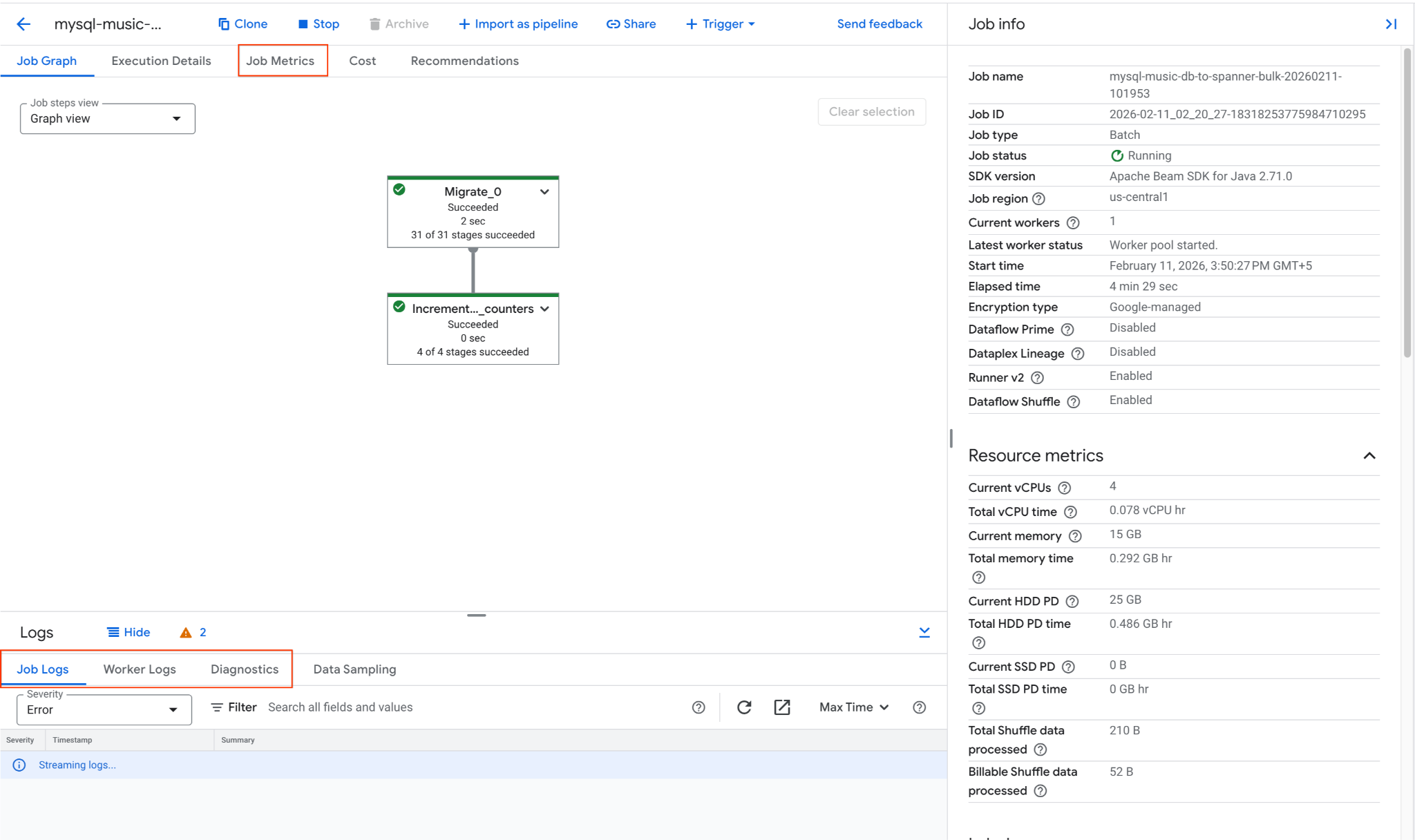
- अगर नौकरी में समस्याएं आती हैं, तो गड़बड़ी के मैसेज देखने के लिए, डेटाफ़्लो की नौकरी की जानकारी वाले पेज में मौजूद लॉग टैब देखें.
- जॉब मेट्रिक से, जॉब की प्रोग्रेस और संसाधन के इस्तेमाल के बारे में ज़्यादा जानकारी मिलती है. जैसे, थ्रूपुट और सीपीयू का इस्तेमाल.
3. Cloud Spanner में डेटा की पुष्टि करना
डेटाफ़्लो जॉब पूरा होने के बाद, पुष्टि करें कि डेटा को Spanner टेबल में कॉपी कर दिया गया है. Spanner डेटाबेस के बारे में क्वेरी करने के लिए, gcloud का इस्तेमाल करें:
# Verify row counts
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Singers"
# Expected output: 3
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Albums"
# Expected output: 6
# Inspect some data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT SingerId, FirstName, LastName FROM Singers ORDER BY SingerId"
अनुमानित आउटपुट:
row_count: 3 row_count: 6 SingerId: 1 FirstName: Marc LastName: Richards SingerId: 2 FirstName: Catalina LastName: Smith SingerId: 3 FirstName: Alice LastName: Trentor
Cloud SQL से Cloud Spanner में डेटा को एक साथ लोड करने की शुरुआती प्रोसेस अब पूरी हो गई है. अगला चरण, लाइव रेप्लिकेशन सेट अप करना है, ताकि मौजूदा बदलावों को कैप्चर किया जा सके.
9. लाइव माइग्रेशन (सीडीसी) शुरू करें
बल्क डेटा लोड होने के बाद, Datastream का इस्तेमाल करके लगातार रेप्लिकेशन स्ट्रीम सेट अप की जाएगी. इससे Cloud SQL से, बदलाव किए गए डेटा को कैप्चर करने वाले (सीडीसी) इवेंट कैप्चर किए जा सकेंगे. साथ ही, Dataflow स्ट्रीमिंग जॉब का इस्तेमाल करके, उन बदलावों को Cloud Spanner में रीयल-टाइम के आस-पास लागू किया जा सकेगा.
1. लाइव माइग्रेशन डेटाफ़्लो जॉब चलाना
GCS से डेटा पढ़ने और Spanner में डेटा लिखने के लिए, स्ट्रीमिंग Dataflow जॉब लॉन्च करें. यह टेंप्लेट, नई फ़ाइलों को तुरंत प्रोसेस करने के लिए GCS Pub/Sub सूचनाओं का इस्तेमाल करेगा.
export JOB_NAME_CDC="datastream-to-spanner-cdc-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR="gs://${BUCKET_NAME}/dlq"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
deadLetterQueueDirectory="$DLQ_DIR",\
streamName="projects/${PROJECT_ID}/locations/${REGION}/streams/${STREAM_NAME}"
मुख्य पैरामीटर
gcsPubSubSubscription: यह Pub/Sub सदस्यता, GCS से नई फ़ाइल की सूचनाएं पाने के लिए होती है. इससे, Datastream के डेटा लिखने के साथ ही, जॉब में बदलावों को तुरंत प्रोसेस किया जा सकता है.inputFileFormat="avro": इससे Dataflow को यह पता चलता है कि Datastream से Avro फ़ाइलें मिलेंगी. यह आपके डेटास्ट्रीम के "डेस्टिनेशन" कॉन्फ़िगरेशन से मेल खाना चाहिए. उदाहरण के लिए,avroFileFormatबनामjsonFileFormat.deadLetterQueueDirectory: यह एक GCS पाथ होता है. इसमें नौकरी से जुड़े उन रिकॉर्ड को सेव किया जाता है जिन्हें प्रोसेस नहीं किया जा सका. जैसे, स्कीमा के मेल न खाने की वजह से. ऐसा इसलिए किया जाता है, ताकि बाद में उनकी मैन्युअल तरीके से समीक्षा की जा सके.streamName: Datastream स्ट्रीम का पूरा रिसॉर्स पाथ. इससे Dataflow जॉब को रेप्लिकेशन की स्थिति और मेटाडेटा को ट्रैक करने की अनुमति मिलती है.
Dataflow Jobs Console में जाकर, नौकरी के शुरू होने की प्रोसेस पर नज़र रखें.
2. लाइव माइग्रेशन की जांच करना
सीडीसी पाइपलाइन की जांच करने के लिए, सोर्स Cloud SQL music_db में बदलाव लागू करें.
Cloud SQL से कनेक्ट करने के लिए:
mysql -h $SQL_INSTANCE_IP -u root -p
पासवर्ड (Welcome@1) डालें और डेटाबेस चुनें:
USE music_db;
-- INSERT
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (4, 'Elena', 'Nadal', '1985-05-30', 0);
SELECT * FROM Singers WHERE SingerId = 4;
-- UPDATE
UPDATE Singers SET LastName = 'Richards-Smith' WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- DELETE
DELETE FROM Albums WHERE SingerId = 2;
DELETE FROM Singers WHERE SingerId = 2;
SELECT * FROM Singers WHERE SingerId = 2;
EXIT;
Spanner में पुष्टि (कुछ समय बाद):
# Verify INSERT: This should return the new row for Elena Nadal.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 4"
# Verify UPDATE: This should show LastName as Richards-Smith.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName FROM Singers WHERE SingerId = 1"
# Verify DELETE: This should now return 0 rows.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Albums WHERE SingerId = 2"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 2"
अनुमानित आउटपुट:
SingerId: 4 FirstName: Elena LastName: Nadal BirthDate: 1985-05-30 AlbumCount: 0 SingerId: 1 FirstName: Marc LastName: Richards-Smith
3. Spanner में पुष्टि की आखिरी प्रोसेस
Spanner में Singers टेबल की पूरी स्थिति देखें:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId"
अनुमानित आउटपुट:
SingerId: 1 FirstName: Marc LastName: Richards-Smith AlbumCount: 2 SingerId: 3 FirstName: Alice LastName: Trentor AlbumCount: 3 SingerId: 4 FirstName: Elena LastName: Nadal AlbumCount: 0
10. रिवर्स रेप्लिकेशन सेट अप करना (Spanner से Cloud SQL)
ऐसे मामलों में जहां आपको Cloud SQL डेटाबेस को कुछ समय के लिए Spanner के साथ सिंक रखना हो या रोलबैक करना हो, रिवर्स रेप्लिकेशन सेट अप किया जा सकता है. यह पाइपलाइन, Spanner में हुए बदलावों को कैप्चर करने के लिए Spanner Change Streams का इस्तेमाल करती है. साथ ही, इन बदलावों को Cloud SQL music_db में वापस लिखती है.
1. Spanner की बदलाव वाली स्ट्रीम बनाना
सबसे पहले, आपको अपने Spanner डेटाबेस में बदलाव की स्ट्रीम बनानी होगी, ताकि Singers और Albums टेबल में हुए बदलावों को ट्रैक किया जा सके.
export CHANGE_STREAM_NAME="MusicDBChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Singers, Albums"
यह बदलाव स्ट्रीम, अब चुनी गई टेबल में किए गए सभी बदलावों को रिकॉर्ड करेगी.
2. Dataflow के मेटाडेटा के लिए Spanner डेटाबेस बनाना
Spanner to SourceDB Dataflow टेंप्लेट को एक अलग Spanner डेटाबेस की ज़रूरत होती है. इससे बदलाव के स्ट्रीम के इस्तेमाल से जुड़े मेटाडेटा को सेव किया जा सकता है.
export SPANNER_METADATA_DB_NAME="reverse-replication-metadata"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Dataflow के लिए Cloud SQL कनेक्शन कॉन्फ़िगरेशन तैयार करना
Dataflow टेंप्लेट को Cloud Storage में मौजूद एक JSON फ़ाइल की ज़रूरत होती है. इसमें टारगेट Cloud SQL डेटाबेस के कनेक्शन की जानकारी होती है.
shard_config.json नाम की लोकल फ़ाइल बनाएं:
cat << EOF > shard_config.json
[
{
"logicalShardId": "mysql_shard",
"host": "${SQL_INSTANCE_IP}",
"port": "3306",
"user": "root",
"password": "${DB_ROOT_PASSWORD}",
"dbName": "music_db"
}
]
EOF
इस फ़ाइल को अपने GCS बकेट में अपलोड करें:
export SHARD_CONFIG_FILE="gs://${BUCKET_NAME}/shard_config.json"
gcloud storage cp shard_config.json $SHARD_CONFIG_FILE
4. रिवर्स रेप्लिकेशन डेटाफ़्लो जॉब चलाना
Spanner_to_SourceDb फ़्लेक्स टेंप्लेट का इस्तेमाल करके, डेटाफ़्लो जॉब लॉन्च करें.
export JOB_NAME_REVERSE="spanner-to-mysql-reverse-$(date +%Y%m%d-%H%M%S)"
export REVERSE_DLQ_DIR="gs://${BUCKET_NAME}/reverse-dlq"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$SHARD_CONFIG_FILE",\
deadLetterQueueDirectory="$REVERSE_DLQ_DIR"
मुख्य पैरामीटर
changeStreamName: उस Spanner चेंज स्ट्रीम का नाम जिससे डेटा पढ़ना है.metadataInstance, metadataDatabase: यह Spanner इंस्टेंस/डेटाबेस है. इसमें कनेक्टर इस्तेमाल किया गया मेटाडेटा सेव किया जाता है. इससे, बदलाव के स्ट्रीम एपीआई डेटा के इस्तेमाल को कंट्रोल किया जा सकता है.sourceShardsFilePath: आपकेshard_config.jsonका GCS पाथ.filtrationMode: इससे यह तय होता है कि किसी शर्त के आधार पर कुछ रिकॉर्ड कैसे हटाए जाएं. डिफ़ॉल्ट रूप से, यहforward_migrationपर सेट होता है. इसका मतलब है कि फ़ॉरवर्ड माइग्रेशन पाइपलाइन का इस्तेमाल करके लिखे गए रिकॉर्ड को फ़िल्टर किया जाता है
नेटवर्क से जुड़ी जानकारी: Dataflow वर्कर, shard_config.json में दिए गए सार्वजनिक आईपी का इस्तेमाल करके Cloud SQL इंस्टेंस से कनेक्ट होंगे. Cloud SQL इंस्टेंस के अनुमति वाले नेटवर्क में 0.0.0.0/0 एंट्री की वजह से, इस कनेक्शन को अनुमति दी गई है.
Dataflow Jobs Console में जाकर, नौकरी के शुरू होने की प्रोसेस पर नज़र रखें.
5. उलटे क्रम में जवाब देने की सुविधा की जांच करना
अब Cloud Spanner में सीधे तौर पर बदलाव करें और पुष्टि करें कि वे Cloud SQL में दिख रहे हैं. ऐसा सिर्फ़ तब करें, जब डेटाफ़्लो जॉब शुरू हो गई हो और प्रोसेस हो रही हो.
INSERT, UPDATE, और DELETE की जांच करें
# INSERT: Insert a new singer (SingerId 5) into Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (5, 'David', 'Chen', '1995-02-18', 0)"
# UPDATE: Update SingerId 3's AlbumCount in Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Singers SET AlbumCount = 5 WHERE SingerId = 3"
# DELETE: Delete SingerId 1 from Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Albums WHERE SingerId = 1"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Singers WHERE SingerId = 1"
Cloud SQL में पुष्टि (कुछ समय बाद):
Cloud SQL से कनेक्ट करने के लिए:
mysql -h $SQL_INSTANCE_IP -u root -p
जब आपसे पासवर्ड (Welcome@1) मांगा जाए, तब उसे डालें. इसके बाद, mysql> प्रॉम्प्ट पर यहां दी गई एसक्यूएल कमांड चलाएं.
USE music_db;
-- Verify INSERT: This should show the new row for David Chen
SELECT * FROM Singers WHERE SingerId = 5;
-- Verify UPDATE: This should show AlbumCount as 5.
SELECT SingerId, FirstName, AlbumCount FROM Singers WHERE SingerId = 3;
-- Verify DELETE: This should return an empty set.
SELECT * FROM Albums WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- Final Verification
SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId;
EXIT;
Cloud SQL में दिखने वाला आउटपुट, Spanner में किए गए बदलावों के मुताबिक होना चाहिए.
+----------+-----------+----------------+------------+ | SingerId | FirstName | LastName | AlbumCount | +----------+-----------+----------------+------------+ | 3 | Alice | Trentor | 5 | | 4 | Elena | Nadal | 0 | | 5 | David | Chen | 0 | +----------+-----------+----------------+------------+
इससे पुष्टि होती है कि रिवर्स रेप्लिकेशन पाइपलाइन काम कर रही है और Spanner से Cloud SQL में बदलावों को सिंक कर रही है.
11. संसाधन मिटाना
अपने Google Cloud खाते पर ज़्यादा शुल्क लगने से बचने के लिए, इस कोडलैब के दौरान बनाई गई संसाधनों को मिटा दें.
ज़रूरत पड़ने पर, एनवायरमेंट वैरिएबल सेट करें
देखें कि एनवायरमेंट वैरिएबल सही तरीके से सेट किए गए हैं या नहीं:
echo "PROJECT_ID: $PROJECT_ID"
echo "REGION: $REGION"
echo "SQL_INSTANCE_NAME: $SQL_INSTANCE_NAME"
echo "SPANNER_INSTANCE_NAME: $SPANNER_INSTANCE_NAME"
echo "BUCKET_NAME: $BUCKET_NAME"
echo "STREAM_NAME: $STREAM_NAME"
echo "SQL_CP_NAME: $SQL_CP_NAME"
echo "GCS_CP_NAME: $GCS_CP_NAME"
echo "PUBSUB_SUBSCRIPTION: $PUBSUB_SUBSCRIPTION"
echo "PUBSUB_TOPIC: $PUBSUB_TOPIC"
echo "CHANGE_STREAM_NAME: $CHANGE_STREAM_NAME"
डेटाफ़्लो की चालू नौकरियों के जॉब आईडी ढूंढने के लिए, अपनी नौकरियां लिस्ट करें. इसके बाद, JOB_ID_CDC और JOB_ID_REVERSE को एक्सपोर्ट करें.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
अगर आप नए Cloud Shell सेशन में हैं, तो कुंजी वाले एनवायरमेंट वैरिएबल को फिर से एक्सपोर्ट करें:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or the region you used
export SQL_INSTANCE_NAME="source-mysql-instance"
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export STREAM_NAME="mysql-to-spanner-stream"
export SQL_CP_NAME="mysql-src-cp"
export GCS_CP_NAME="gcs-dest-cp"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CHANGE_STREAM_NAME="MusicDBChangeStream"
डेटाफ़्लो स्ट्रीमिंग जॉब बंद करना
Datastream to Spanner (लाइव माइग्रेशन) जॉब रद्द करें:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
Spanner to Cloud SQL (रिवर्स रेप्लिकेशन) जॉब रद्द करें:
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Datastream संसाधन मिटाना
स्ट्रीम बंद करना और मिटाना:
gcloud datastream streams update $STREAM_NAME \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
कनेक्शन प्रोफ़ाइलें मिटाएं
gcloud datastream connection-profiles delete $SQL_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Pub/Sub संसाधन मिटाना
सदस्यता मिटाना:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
विषय मिटाएं:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Cloud SQL इंस्टेंस मिटाना
इससे डेटाबेस (music_db) अपने-आप मिट जाएंगे.
gcloud sql instances delete $SQL_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Cloud Spanner इंस्टेंस मिटाना
इससे, इसमें मौजूद डेटाबेस (music-db-migrated और reverse-replication-metadata) भी मिट जाएंगे.
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
GCS बकेट और कॉन्टेंट मिटाना
gcloud storage rm --recursive gs://${BUCKET_NAME}
डिवाइस पर मौजूद फ़ाइलें मिटाना
Cloud Shell की होम डायरेक्ट्री में जनरेट की गई सभी फ़ाइलें हटाएं:
rm -f music-db* shard_config.json
आपने इस कोडलैब के लिए बनाए गए संसाधनों को अब हटा दिया है.