
1. Sebelum memulai
Codelab ini memandu Anda memigrasikan satu database MySQL di Cloud SQL ke database Cloud Spanner dengan dialek GoogleSQL. Fokusnya adalah alur migrasi end-to-end yang mendasar, yang menunjukkan langkah-langkah inti. Anda akan menggunakan layanan Google Cloud, termasuk Spanner Migration Tool (SMT), Dataflow, Datastream, PubSub, dan Google Cloud Storage.
Hal-hal yang akan Anda pelajari:
- Cara menyiapkan instance Cloud SQL dan Cloud Spanner contoh.
- Cara mengonversi skema Cloud SQL MySQL menjadi skema yang kompatibel dengan Spanner menggunakan Spanner Migration Tool (SMT).
- Cara melakukan migrasi data massal dari Cloud SQL ke Cloud Spanner menggunakan Dataflow.
- Cara menyiapkan replikasi berkelanjutan (CDC) dari Cloud SQL ke Cloud Spanner menggunakan Datastream dan Dataflow.
- Cara menyiapkan replikasi terbalik dari Cloud Spanner ke Cloud SQL.
Hal yang TIDAK dibahas dalam codelab ini:
- Migrasi dari instance yang di-shard.
- Transformasi data yang kompleks selama migrasi.
- Penanganan error lanjutan atau Dead Letter Queues (DLQ).
- Penyesuaian performa migrasi.
- Migrasi Aplikasi: Codelab ini berfokus pada lapisan database (skema dan data). Panduan ini tidak mencakup proses operasional untuk men-deploy ulang atau memigrasikan layanan aplikasi Anda.
Yang Anda butuhkan
- Project Google Cloud yang mengaktifkan penagihan.
- Izin IAM yang memadai untuk mengaktifkan API dan membuat/mengelola resource Cloud SQL, Spanner, Dataflow, Datastream, dan GCS. Meskipun peran Project
Owneradalah yang paling sederhana untuk codelab, peran yang lebih spesifik akan dibahas di "Penyiapan Lingkungan". - Browser web, seperti Google Chrome.
- Pemahaman dasar tentang Konsol Google Cloud dan alat command line seperti
gcloud. - Akses ke lingkungan shell. Cloud Shell direkomendasikan karena mencakup
gcloud.
Detail selengkapnya tentang penyiapan di atas dibahas di bagian Penyiapan Lingkungan.
2. Memahami Proses Migrasi
Memigrasikan database melibatkan migrasi data dari instance database CloudSQL sumber ke instance Spanner. Bagian ini menguraikan arsitektur dan alat utama yang digunakan dalam migrasi.
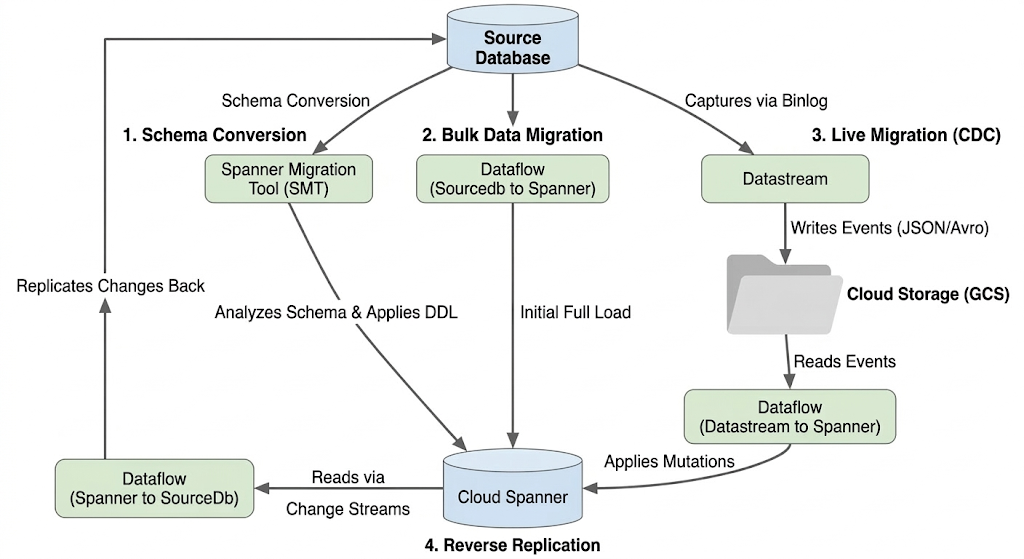
Arsitektur Alur Migrasi
Proses migrasi mencakup tahap-tahap berikut:
1. Konversi Skema:
- Tujuan: Mengonversi skema database sumber ke skema Cloud Spanner yang kompatibel.
- Alat: Alat Migrasi Spanner (SMT)
- Proses: SMT menganalisis skema database sumber dan menghasilkan Bahasa Definisi Data (DDL) Spanner yang setara. Di instance Spanner target, database dibuat dan DDL kemudian diterapkan secara otomatis.
2. Migrasi Data Massal:
- Tujuan: Untuk melakukan pemuatan penuh awal data yang ada dari database sumber ke tabel Spanner yang disediakan.
- Alat: Dataflow, menggunakan template
Sourcedb to Spanneryang disediakan Google. - Proses: Tugas Dataflow ini membaca semua data dari tabel sumber yang ditentukan dan menuliskannya ke tabel Spanner yang sesuai. Tindakan ini dilakukan setelah skema Spanner dibuat.
3. Migrasi Langsung (CDC):
- Tujuan: Untuk merekam dan menerapkan perubahan yang sedang berlangsung dari database sumber ke Cloud Spanner mendekati real time, sehingga meminimalkan periode nonaktif selama migrasi.
- Alat:
- Datastream: Merekam perubahan (Penyisipan, Pembaruan, Penghapusan) dari database sumber dan menuliskannya ke Cloud Storage (GCS).
- Dataflow: Menggunakan template
Datastream to Spanneruntuk membaca peristiwa perubahan dari GCS dan menerapkannya ke Cloud Spanner.
4. Replikasi Terbalik:
- Tujuan: Untuk mereplikasi perubahan data dari Cloud Spanner kembali ke database sumber. Hal ini dapat berguna untuk strategi penggantian, migrasi bertahap, atau mempertahankan replika di sumber untuk kasus penggunaan tertentu.
- Alat: Dataflow, menggunakan template
Spanner to SourceDb. - Proses: Tugas ini menggunakan aliran data perubahan Spanner untuk merekam modifikasi di Spanner dan menuliskannya kembali ke instance database sumber.
Diagram berikut menggambarkan komponen dan alur data:
Terminologi Utama:
- Alat Migrasi Spanner (SMT): Alat yang digunakan untuk menilai skema MySQL, menyarankan skema Spanner yang setara, dan membuat Bahasa Definisi Data (DDL) Spanner.
- Bahasa Definisi Data (DDL): Pernyataan yang digunakan untuk menentukan dan mengubah struktur database, seperti pernyataan
CREATE TABLE. SMT menghasilkan DDL Spanner berdasarkan skema Cloud SQL. - Dataflow: Layanan pemrosesan data serverless yang terkelola sepenuhnya. Dalam codelab ini, alat ini digunakan untuk menjalankan template yang disediakan Google untuk transfer data massal, menerapkan perubahan Datastream, dan replikasi terbalik.
- Datastream: Layanan replikasi dan Pengambilan Data Perubahan (CDC) serverless. Bucket ini digunakan untuk melakukan streaming perubahan dari Cloud SQL ke Cloud Storage dalam codelab ini.
- Aliran Data Perubahan Spanner: Fitur Spanner yang memungkinkan streaming perubahan pada data (penyisipan, pembaruan, penghapusan) secara real-time, yang digunakan sebagai sumber untuk replikasi terbalik.
- Pub/Sub: Layanan pesan yang digunakan untuk memisahkan layanan yang menghasilkan peristiwa dari layanan yang memprosesnya. Dalam codelab ini, Dataflow dipicu untuk memproses update setiap kali Datastream mengupload file perubahan baru ke Cloud Storage.
3. Penyiapan Lingkungan
Sebelum dapat memulai migrasi, Anda perlu menyiapkan project Google Cloud dan mengaktifkan layanan yang diperlukan.
1. Memilih atau Membuat Project Google Cloud
Anda memerlukan project Google Cloud dengan penagihan yang diaktifkan untuk menggunakan layanan dalam codelab ini.
- Di Konsol Google Cloud, buka halaman pemilih project: Buka Pemilih Project
- Pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Anda. Pelajari cara mengonfirmasi bahwa penagihan diaktifkan untuk project Anda.
2. Buka Cloud Shell
Cloud Shell adalah lingkungan command line yang berjalan di Google Cloud yang telah dilengkapi dengan gcloud CLI dan alat lain yang Anda perlukan.
- Klik tombol Activate Cloud Shell di kanan atas Konsol Google Cloud.
- Sesi Cloud Shell akan terbuka di dalam frame baru di bagian bawah konsol dan menampilkan perintah command-line.

3. Menetapkan Variabel Project dan Lingkungan
Di Cloud Shell, siapkan beberapa variabel lingkungan untuk project ID dan region yang akan Anda gunakan.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Mengaktifkan Google Cloud API yang Diperlukan
Aktifkan API yang diperlukan untuk Cloud Spanner, Dataflow, Datastream, dan layanan terkait lainnya.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Pemrosesan perintah ini mungkin membutuhkan waktu beberapa menit.
5. Mengonfigurasi Izin Akun Layanan
Tugas Dataflow dan Datastream memerlukan izin khusus untuk berinteraksi dengan layanan Google Cloud lainnya. Tugas Dataflow dalam codelab ini akan menggunakan akun layanan Compute Engine default.
Pertama, dapatkan Nomor Project Anda:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
Sekarang, berikan peran IAM yang diperlukan ke akun layanan default Compute Engine:
# Role for Dataflow to run jobs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.admin" \
--condition=None
# Roles for Dataflow workers
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.worker" \
--condition=None
# Role to connect to Cloud SQL instance
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudsql.client" \
--condition=None
# Role to read/write from Cloud Spanner
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/spanner.databaseUser" \
--condition=None
# Role to access GCS buckets (Datastream output, Dataflow temp, JDBC driver)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectAdmin" \
--condition=None
# Roles for Datastream and Pub/Sub (for CDC)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastream.viewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/pubsub.subscriber"
6. Membuat Bucket Cloud Storage
Buat bucket GCS di region yang sama dengan resource Anda yang lain. Bucket ini akan menyimpan driver JDBC, output Datastream, dan digunakan oleh Dataflow untuk file sementara.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
echo "Created bucket: gs://$BUCKET_NAME"
7. Menginstal Spanner Migration Tool (SMT)
Pastikan Spanner Migration Tool (SMT) diinstal di lingkungan Cloud Shell Anda.
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
Perintah ini akan menampilkan informasi bantuan untuk antarmuka web SMT, yang mengonfirmasi bahwa komponen gcloud telah diinstal. Codelab ini akan menggunakan fitur CLI SMT, yang merupakan bagian dari komponen yang sama.
4. Menyiapkan Database Cloud SQL Sumber
Di bagian ini, Anda akan membuat dan mengonfigurasi instance Cloud SQL untuk MySQL dengan IP Publik untuk berfungsi sebagai database sumber.
1. Membuat Instance Cloud SQL untuk MySQL
Jalankan perintah gcloud berikut di Cloud Shell untuk membuat instance MySQL 8.0. Logging biner diaktifkan (diperlukan untuk Datastream), dan instance dikonfigurasi dengan IP Publik.
export SQL_INSTANCE_NAME="source-mysql-instance"
export DB_ROOT_PASSWORD="Welcome@1" # Replace with a strong password if you prefer
gcloud sql instances create $SQL_INSTANCE_NAME \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=$REGION \
--root-password=$DB_ROOT_PASSWORD \
--enable-bin-log \
--assign-ip
--enable-bin-log: Diperlukan agar Datastream dapat merekam perubahan.--assign-ip: Memastikan instance mendapatkan alamat IP Publik.
Pembuatan instance memerlukan waktu beberapa menit. Anda dapat memeriksa apakah instance Anda dibuat di Halaman Instance Cloud SQL.
2. Mengonfigurasi Jaringan yang Diizinkan
Untuk terhubung ke instance melalui IP Publik, Anda harus menambahkan alamat IP ke daftar "Jaringan yang Diizinkan".
Dapatkan IP Cloud Shell Anda:
export CLOUD_SHELL_IP=$(curl -s ipinfo.io/ip)
echo "Your Cloud Shell IP: $CLOUD_SHELL_IP"
Memberikan Otorisasi pada IP Cloud Shell dan Akses Terbuka
Perintah berikut menambahkan IP Cloud Shell Anda. Tindakan ini juga menambahkan 0.0.0.0/0, yang memungkinkan akses dari alamat IP mana pun. Hal ini diperlukan untuk menyederhanakan koneksi dari pekerja Dataflow tanpa penyiapan jaringan yang rumit.
gcloud sql instances patch $SQL_INSTANCE_NAME \
--authorized-networks="${CLOUD_SHELL_IP}/32,0.0.0.0/0"
3. Menghubungkan ke Instance Cloud SQL dari Cloud Shell
Mengambil alamat IP Publik yang ditetapkan
export SQL_INSTANCE_IP=$(gcloud sql instances list --filter="name=$SQL_INSTANCE_NAME" --format="value(PRIMARY_ADDRESS)")
echo "Cloud SQL Public IP: $SQL_INSTANCE_IP"
Alamat IP ini akan digunakan untuk menghubungkan.
Menghubungkan ke Instance Cloud SQL dari Cloud Shell
Gunakan klien mysql standar untuk terhubung, menggunakan alamat IP Publik yang diperoleh:
mysql -h $SQL_INSTANCE_IP -u root -p
Saat diminta, masukkan sandi root yang Anda tetapkan (Welcome@1). Anda akan berada di perintah mysql>.
4. Membuat Database dan Data Contoh
Jalankan perintah SQL berikut dalam prompt mysql>:
CREATE DATABASE music_db;
USE music_db;
CREATE TABLE Singers (
SingerId BIGINT NOT NULL,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
BirthDate DATE,
AlbumCount BIGINT,
PRIMARY KEY (SingerId)
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY (SingerId, AlbumId),
CONSTRAINT FK_Albums_Singers FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
);
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES
(1, 'Marc', 'Richards', '1970-09-03', 2),
(2, 'Catalina', 'Smith', '1990-08-17', 1),
(3, 'Alice', 'Trentor', '1991-10-02', 3);
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle, ReleaseDate) VALUES
(1, 1, 'Total Junk', '2014-03-15'),
(1, 2, 'Go Go Go', '2016-11-01'),
(2, 1, 'Green', '2018-02-28'),
(3, 1, 'Blue', '2019-01-10'),
(3, 2, 'Red', '2020-05-22'),
(3, 3, 'Purple', '2022-11-11');
File dump untuk skema di atas dapat ditemukan di sini.
5. Memverifikasi Data
Periksa dengan cepat apakah data ada:
SELECT 'Singers music_db' as tbl, COUNT(*) FROM music_db.Singers
UNION ALL
SELECT 'Albums music_db', COUNT(*) FROM music_db.Albums;
EXIT;
Anda akan melihat jumlah untuk setiap tabel.
+------------------+----------+ | tbl | COUNT(*) | +------------------+----------+ | Singers music_db | 3 | | Albums music_db | 6 | +------------------+----------+
5. Menyiapkan Cloud Spanner
Sekarang, Anda akan menyiapkan instance Cloud Spanner target tempat data akan dimigrasikan.
1. Membuat Instance Cloud Spanner
Buat instance Cloud Spanner di region yang sama dengan instance Cloud SQL Anda. Perintah ini membuat instance kecil yang cocok untuk codelab ini, menggunakan 100 unit pemrosesan.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="music-db-migrated"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
Pembuatan instance mungkin memerlukan waktu satu atau dua menit.
6. Mengonversi Skema menggunakan Alat Migrasi Spanner (SMT)
Gunakan SMT CLI untuk menganalisis database MySQL (music_db) dan membuat Spanner Schema Definition Language (DDL). Karena instance Cloud SQL dikonfigurasi dengan IP Publik dan jaringan yang diizinkan yang sesuai, SMT dapat terhubung secara langsung.
1. Menyiapkan Lingkungan untuk SMT
Pastikan variabel lingkungan yang diperlukan telah ditetapkan dari langkah-langkah sebelumnya:
echo "Cloud SQL Instance Public IP: $SQL_INSTANCE_IP"
echo "Cloud SQL Root Password: $DB_ROOT_PASSWORD"
echo "Spanner Instance: $SPANNER_INSTANCE_NAME"
echo "Spanner Database: $SPANNER_DATABASE_NAME"
echo "Project ID: $PROJECT_ID"
2. Menjalankan Konversi Skema untuk music_db
Jalankan perintah SMT schema, yang terhubung langsung ke alamat IP Publik Cloud SQL:
gcloud alpha spanner migrate schema \
--source=mysql \
--source-profile="host=${SQL_INSTANCE_IP},port=3306,user=root,password=${DB_ROOT_PASSWORD},dbName=music_db" \
--target-profile="project=${PROJECT_ID},instance=${SPANNER_INSTANCE_NAME},dbName=${SPANNER_DATABASE_NAME}" \
--prefix="music-db"
Perintah ini terhubung ke instance Cloud SQL melalui proxy dan menghasilkan file skema dengan awalan music-db.
3. Meninjau File yang Dibuat
SMT membuat beberapa file di direktori Anda saat ini. Yang utama adalah:
music-db.schema.ddl.txt: Pernyataan DDL Spanner yang dihasilkan.music-db-.overrides.json: File penggantian skema yang berisi perubahan pemetaan manual.music-db.session.json: File Sesi migrasi skema.music-db.report.txt: Laporan penilaian konversi skema.
Anda dapat mencantumkannya menggunakan ls music-db-*
4. Memverifikasi Skema di Cloud Spanner
Pastikan bahwa tabel telah dibuat di database Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Anda akan melihat output berikut:
table_name: Albums table_name: Singers
Opsional: Jika Anda ingin memeriksa DDL Spanner, jalankan perintah berikut:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
7. Menginisialisasi Pengambilan Data Perubahan (CDC)
Di bagian ini, Anda akan menyiapkan "perekam" untuk migrasi. Dengan mengonfigurasi Datastream dan Pub/Sub sebelum pemuatan data massal dimulai, Anda memastikan bahwa setiap perubahan yang dilakukan pada database sumber dicatat dan dimasukkan dalam antrean, sehingga mencegah kehilangan data selama transisi. Penyiapan ini diperlukan untuk Migrasi Langsung.
1. Membuat Profil Koneksi Datastream
Profil Sumber (Cloud SQL)
Profil ini terhubung ke IP Publik instance Cloud SQL. Datastream akan menggunakan Daftar IP yang Diizinkan untuk konektivitas.
export SQL_CP_NAME="mysql-src-cp"
gcloud datastream connection-profiles create $SQL_CP_NAME \
--location=$REGION \
--type=mysql \
--mysql-hostname=$SQL_INSTANCE_IP \
--mysql-port=3306 \
--mysql-username=root \
--mysql-password=$DB_ROOT_PASSWORD \
--display-name="Cloud SQL Source - Public IP"
Catatan: Koneksi ini mengandalkan Jaringan yang Diizinkan instance Cloud SQL untuk mengizinkan akses. Seperti yang dikonfigurasi sebelumnya dengan 0.0.0.0/0, IP publik Datastream dapat terhubung. Di lingkungan produksi, Anda akan mengganti 0.0.0.0/0 dengan rentang IP spesifik untuk region Anda yang tercantum dalam Daftar yang diberi akses dan region IP Datastream.
Profil Tujuan (Cloud Storage)
Menunjuk ke root bucket Anda.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
2. Membuat Aliran Datastream
Buat aliran yang akan direplikasi dari music_db.
export STREAM_NAME="mysql-to-spanner-stream"
export GCS_STREAM_PATH="data/${STREAM_NAME}"
gcloud datastream streams create $STREAM_NAME \
--location=$REGION \
--display-name="MySQL to Spanner CDC Stream" \
--source=$SQL_CP_NAME \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "
includeObjects:
mysqlDatabases:
- database: 'music_db'
") \
--gcs-destination-config=<(echo "
path: ${GCS_STREAM_PATH}
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}
") \
--backfill-none
- Datastream akan menulis file di
gs://${BUCKET_NAME}/${GCS_STREAM_PREFIX}/ - Datastream akan menulis file dalam format Avro. Saat menjalankan perintah migrasi langsung, kita akan menentukan inputFileFormat sebagai avro sehingga pipeline dapat memproses file dengan benar.
- Menggunakan setelan rotasi file yang lebih kecil membantu melihat perubahan lebih cepat di codelab.
Pemrosesan perintah ini mungkin memerlukan waktu beberapa saat. Periksa status: gcloud datastream streams describe $STREAM_NAME --location=$REGION.
3. Mulai Aliran Datastream
gcloud datastream streams update $STREAM_NAME \
--location=$REGION \
--state=RUNNING
Periksa status: gcloud datastream streams describe $STREAM_NAME --location=$REGION. Status awalnya adalah STARTING, dan akan menjadi RUNNING setelah beberapa waktu. Lanjutkan ke langkah berikutnya hanya setelah Anda mengonfirmasi bahwa statusnya adalah RUNNING.
4. Menyiapkan Pub/Sub untuk Notifikasi GCS
Buat Topik Pub/Sub:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
Membuat Notifikasi GCS
Memberi tahu saat pembuatan objek dengan awalan data/.
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Buat Langganan Pub/Sub
Sertakan batas waktu konfirmasi yang direkomendasikan.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Memigrasikan Data dalam Jumlah Besar dari Cloud SQL ke Spanner
Setelah skema Spanner diterapkan, Anda akan menyalin data yang ada dari database music_db Cloud SQL ke Cloud Spanner. Anda akan menggunakan Sourcedb to Spanner Template Fleksibel Dataflow, yang dirancang untuk menyalin data dalam jumlah besar dari database yang dapat diakses JDBC ke Spanner.
1. Menjalankan Tugas Dataflow Migrasi Massal untuk music_db
Jalankan perintah berikut di Cloud Shell untuk memulai tugas Dataflow. Perintah ini menggunakan perintah gcloud dataflow flex-template run, yang mereferensikan template yang disediakan Google untuk migrasi JDBC ke Spanner secara massal.
export JOB_NAME_MUSIC="mysql-music-db-to-spanner-bulk-$(date +%Y%m%d-%H%M%S)"
export MUSIC_DB_JDBC_URL="jdbc:mysql://${SQL_INSTANCE_IP}:3306/music_db"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration-output"
gcloud dataflow flex-template run $JOB_NAME_MUSIC \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL="$MUSIC_DB_JDBC_URL",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
outputDirectory="$OUTPUT_DIR/music_db",\
username="root",\
password="$DB_ROOT_PASSWORD",\
jdbcDriverClassName="com.mysql.cj.jdbc.Driver",\
jdbcDriverJars="gs://${BUCKET_NAME}/lib/mysql-connector-j-8.0.33.jar",\
spannerHost="https://batch-spanner.googleapis.com"
Penjelasan Parameter Utama:
sourceConfigURL: String koneksi JDBC untukmusic_dbsumber.instanceId,databaseId,projectId: Menentukan instance dan database Cloud Spanner target.outputDirectory: Jalur Cloud Storage tempat Dataflow akan menulis informasi tentang semua data yang gagal dimigrasikan.jdbcDriverClassName: Menentukan driver JDBC MySQL.jdbcDriverJars: Jalur GCS ke JAR driver JDBC yang di-stage.spannerHost: Menggunakan endpoint yang dioptimalkan untuk batch bagi penulisan Spanner.maxWorkers,numWorkers: Mengontrol penskalaan tugas Dataflow. Tetap rendah untuk set data kecil ini.
Catatan Jaringan: Tugas ini terhubung ke instance Cloud SQL melalui IP Publiknya. Hal ini memungkinkan karena sebelumnya Anda menambahkan 0.0.0.0/0 ke Jaringan yang Diizinkan instance. Hal ini memungkinkan VM worker Dataflow, yang memiliki IP eksternal, untuk menjangkau database.
2. Memantau Tugas Dataflow
Anda dapat melacak progres tugas di Konsol Google Cloud:
- Buka halaman Dataflow Jobs: Buka Dataflow Jobs
- Temukan tugas bernama
mysql-music-db-to-spanner-bulk-..., lalu klik. - Amati grafik dan metrik tugas. Tunggu hingga status tugas berubah menjadi Succeeded. Proses ini akan memakan waktu sekitar 5-15 menit.
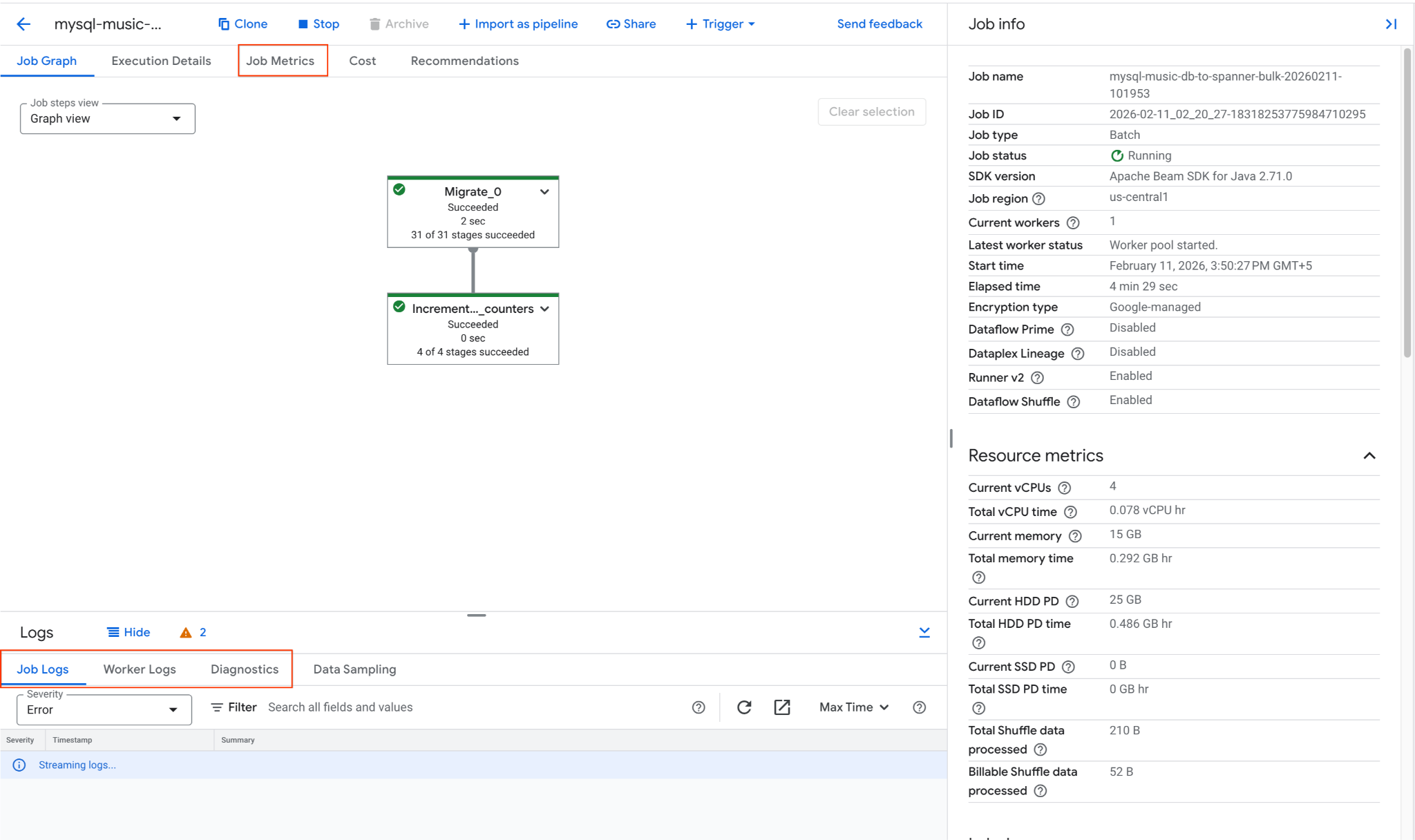
- Jika tugas mengalami masalah, tinjau tab Log di halaman detail tugas Dataflow untuk melihat pesan error.
- Metrik Tugas memberikan informasi selengkapnya mengenai progres tugas dan penggunaan resource seperti throughput dan pemakaian CPU.
3. Memverifikasi Data di Cloud Spanner
Setelah tugas Dataflow berhasil diselesaikan, pastikan data telah disalin ke tabel Spanner. Gunakan gcloud untuk membuat kueri database Spanner:
# Verify row counts
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Singers"
# Expected output: 3
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Albums"
# Expected output: 6
# Inspect some data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT SingerId, FirstName, LastName FROM Singers ORDER BY SingerId"
Output yang Diharapkan:
row_count: 3 row_count: 6 SingerId: 1 FirstName: Marc LastName: Richards SingerId: 2 FirstName: Catalina LastName: Smith SingerId: 3 FirstName: Alice LastName: Trentor
Pemuatan data massal awal dari Cloud SQL ke Cloud Spanner kini telah selesai. Langkah selanjutnya adalah menyiapkan replikasi langsung untuk merekam perubahan yang sedang berlangsung.
9. Mulai Migrasi Langsung (CDC)
Setelah pemuatan data massal selesai, Anda akan menyiapkan aliran replikasi berkelanjutan menggunakan Datastream untuk merekam peristiwa Pengambilan Data Perubahan (CDC) dari Cloud SQL dan tugas streaming Dataflow untuk menerapkan perubahan tersebut ke Cloud Spanner dalam waktu yang mendekati real-time.
1. Menjalankan Tugas Dataflow Migrasi Langsung
Luncurkan tugas Dataflow streaming untuk membaca dari GCS dan menulis ke Spanner. Template ini akan menggunakan notifikasi Pub/Sub GCS untuk memproses file baru secara instan.
export JOB_NAME_CDC="datastream-to-spanner-cdc-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR="gs://${BUCKET_NAME}/dlq"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
deadLetterQueueDirectory="$DLQ_DIR",\
streamName="projects/${PROJECT_ID}/locations/${REGION}/streams/${STREAM_NAME}"
Parameter Utama
gcsPubSubSubscription: Langganan Pub/Sub yang memproses notifikasi file baru dari GCS. Hal ini memungkinkan tugas memproses perubahan secara instan saat Datastream menuliskannya.inputFileFormat="avro": Memberi tahu Dataflow untuk mengharapkan file Avro dari Datastream. Ini harus cocok dengan konfigurasi "Tujuan" Aliran Data Anda (misalnya,avroFileFormatvs.jsonFileFormat).deadLetterQueueDirectory: Jalur GCS tempat tugas menyimpan data yang gagal diproses (misalnya, karena ketidakcocokan skema) untuk ditinjau secara manual nanti.streamName: Jalur resource lengkap dari aliran Datastream, yang memungkinkan tugas Dataflow melacak status dan metadata replikasi.
Pantau mulai tugas di Konsol Tugas Dataflow.
2. Menguji Migrasi Langsung
Terapkan perubahan pada Cloud SQL music_db sumber untuk menguji pipeline CDC.
Hubungkan ke Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
Masukkan sandi (Welcome@1) dan pilih database:
USE music_db;
-- INSERT
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (4, 'Elena', 'Nadal', '1985-05-30', 0);
SELECT * FROM Singers WHERE SingerId = 4;
-- UPDATE
UPDATE Singers SET LastName = 'Richards-Smith' WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- DELETE
DELETE FROM Albums WHERE SingerId = 2;
DELETE FROM Singers WHERE SingerId = 2;
SELECT * FROM Singers WHERE SingerId = 2;
EXIT;
Verifikasi di Spanner (setelah beberapa saat):
# Verify INSERT: This should return the new row for Elena Nadal.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 4"
# Verify UPDATE: This should show LastName as Richards-Smith.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName FROM Singers WHERE SingerId = 1"
# Verify DELETE: This should now return 0 rows.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Albums WHERE SingerId = 2"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 2"
Output yang Diharapkan:
SingerId: 4 FirstName: Elena LastName: Nadal BirthDate: 1985-05-30 AlbumCount: 0 SingerId: 1 FirstName: Marc LastName: Richards-Smith
3. Verifikasi Akhir di Spanner
Periksa status keseluruhan tabel Singers di Spanner:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId"
Output yang diharapkan:
SingerId: 1 FirstName: Marc LastName: Richards-Smith AlbumCount: 2 SingerId: 3 FirstName: Alice LastName: Trentor AlbumCount: 3 SingerId: 4 FirstName: Elena LastName: Nadal AlbumCount: 0
10. Menyiapkan Replikasi Terbalik (Spanner ke Cloud SQL)
Untuk menangani skenario saat Anda mungkin perlu melakukan rollback atau menjaga sinkronisasi database Cloud SQL dengan Spanner selama jangka waktu tertentu, Anda dapat menyiapkan replikasi terbalik. Pipeline ini menggunakan Aliran Perubahan Spanner untuk merekam perubahan di Spanner dan menuliskannya kembali ke Cloud SQL music_db.
1. Membuat Aliran Data Perubahan Spanner
Pertama, Anda perlu membuat aliran perubahan di database Spanner untuk melacak perubahan pada tabel Singers dan Albums.
export CHANGE_STREAM_NAME="MusicDBChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Singers, Albums"
Aliran perubahan ini kini akan mencatat semua modifikasi data ke tabel yang ditentukan.
2. Membuat Database Spanner untuk Metadata Dataflow
Template Dataflow Spanner to SourceDB memerlukan database Spanner terpisah untuk menyimpan metadata guna mengelola penggunaan aliran perubahan.
export SPANNER_METADATA_DB_NAME="reverse-replication-metadata"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Menyiapkan Konfigurasi Koneksi Cloud SQL untuk Dataflow
Template Dataflow memerlukan file JSON di Cloud Storage yang berisi detail koneksi untuk database Cloud SQL target.
Buat file lokal bernama shard_config.json:
cat << EOF > shard_config.json
[
{
"logicalShardId": "mysql_shard",
"host": "${SQL_INSTANCE_IP}",
"port": "3306",
"user": "root",
"password": "${DB_ROOT_PASSWORD}",
"dbName": "music_db"
}
]
EOF
Upload file ini ke bucket GCS Anda:
export SHARD_CONFIG_FILE="gs://${BUCKET_NAME}/shard_config.json"
gcloud storage cp shard_config.json $SHARD_CONFIG_FILE
4. Menjalankan Tugas Dataflow Replikasi Terbalik
Luncurkan tugas Dataflow menggunakan Spanner_to_SourceDb Template Flex.
export JOB_NAME_REVERSE="spanner-to-mysql-reverse-$(date +%Y%m%d-%H%M%S)"
export REVERSE_DLQ_DIR="gs://${BUCKET_NAME}/reverse-dlq"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$SHARD_CONFIG_FILE",\
deadLetterQueueDirectory="$REVERSE_DLQ_DIR"
Parameter Utama
changeStreamName: Nama aliran data perubahan Spanner yang akan dibaca.metadataInstance, metadataDatabase: Instance/database Spanner untuk menyimpan metadata yang digunakan oleh konektor untuk mengontrol penggunaan data Change Stream API.sourceShardsFilePath: Jalur GCS keshard_config.jsonAnda.filtrationMode: Menentukan cara menghilangkan rekaman tertentu berdasarkan kriteria. Defaultnya adalahforward_migration(memfilter data yang ditulis menggunakan pipeline migrasi penerusan)
Catatan Jaringan: Pekerja Dataflow akan terhubung ke instance Cloud SQL menggunakan IP Publik yang ditentukan di shard_config.json. Koneksi ini diizinkan karena adanya entri 0.0.0.0/0 di Jaringan yang Diizinkan pada instance Cloud SQL.
Pantau mulai tugas di Konsol Tugas Dataflow.
5. Menguji Replikasi Terbalik
Sekarang, buat perubahan langsung di Cloud Spanner dan pastikan perubahan tersebut tercermin di Cloud SQL. Lakukan ini hanya setelah tugas alur data dimulai dan dalam status pemrosesan.
Uji INSERT, UPDATE, dan DELETE
# INSERT: Insert a new singer (SingerId 5) into Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (5, 'David', 'Chen', '1995-02-18', 0)"
# UPDATE: Update SingerId 3's AlbumCount in Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Singers SET AlbumCount = 5 WHERE SingerId = 3"
# DELETE: Delete SingerId 1 from Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Albums WHERE SingerId = 1"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Singers WHERE SingerId = 1"
Verifikasi di Cloud SQL (setelah beberapa saat):
Hubungkan ke Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
Masukkan sandi (Welcome@1) saat diminta, lalu jalankan perintah SQL berikut di prompt mysql>.
USE music_db;
-- Verify INSERT: This should show the new row for David Chen
SELECT * FROM Singers WHERE SingerId = 5;
-- Verify UPDATE: This should show AlbumCount as 5.
SELECT SingerId, FirstName, AlbumCount FROM Singers WHERE SingerId = 3;
-- Verify DELETE: This should return an empty set.
SELECT * FROM Albums WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- Final Verification
SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId;
EXIT;
Output yang diharapkan di Cloud SQL harus mencerminkan perubahan yang dilakukan di Spanner.
+----------+-----------+----------------+------------+ | SingerId | FirstName | LastName | AlbumCount | +----------+-----------+----------------+------------+ | 3 | Alice | Trentor | 5 | | 4 | Elena | Nadal | 0 | | 5 | David | Chen | 0 | +----------+-----------+----------------+------------+
Hal ini mengonfirmasi bahwa pipeline replikasi terbalik berfungsi, menyinkronkan perubahan dari Spanner kembali ke Cloud SQL.
11. Membersihkan Resource
Agar tidak menimbulkan biaya lebih lanjut pada akun Google Cloud Anda, hapus resource yang dibuat selama codelab ini.
Menetapkan Variabel Lingkungan (jika diperlukan)
Periksa apakah variabel lingkungan sudah ditetapkan dengan benar:
echo "PROJECT_ID: $PROJECT_ID"
echo "REGION: $REGION"
echo "SQL_INSTANCE_NAME: $SQL_INSTANCE_NAME"
echo "SPANNER_INSTANCE_NAME: $SPANNER_INSTANCE_NAME"
echo "BUCKET_NAME: $BUCKET_NAME"
echo "STREAM_NAME: $STREAM_NAME"
echo "SQL_CP_NAME: $SQL_CP_NAME"
echo "GCS_CP_NAME: $GCS_CP_NAME"
echo "PUBSUB_SUBSCRIPTION: $PUBSUB_SUBSCRIPTION"
echo "PUBSUB_TOPIC: $PUBSUB_TOPIC"
echo "CHANGE_STREAM_NAME: $CHANGE_STREAM_NAME"
Buat daftar tugas Anda untuk menemukan ID Tugas dari tugas Dataflow yang sedang berjalan. Ekspor JOB_ID_CDC dan JOB_ID_REVERSE dengan tepat.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Jika Anda berada di sesi Cloud Shell baru, ekspor ulang variabel lingkungan kunci:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or the region you used
export SQL_INSTANCE_NAME="source-mysql-instance"
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export STREAM_NAME="mysql-to-spanner-stream"
export SQL_CP_NAME="mysql-src-cp"
export GCS_CP_NAME="gcs-dest-cp"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CHANGE_STREAM_NAME="MusicDBChangeStream"
Menghentikan Tugas Streaming Dataflow
Batalkan tugas Datastream to Spanner (Migrasi Langsung):
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
Membatalkan tugas Spanner to Cloud SQL (Replikasi Terbalik):
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Menghapus Resource Datastream
Hentikan dan Hapus Aliran Data:
gcloud datastream streams update $STREAM_NAME \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Menghapus Profil Koneksi
gcloud datastream connection-profiles delete $SQL_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Menghapus Resource Pub/Sub
Menghapus Langganan:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Menghapus Topik:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Menghapus Instance Cloud SQL
Tindakan ini akan otomatis menghapus database (music_db) di dalamnya.
gcloud sql instances delete $SQL_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Menghapus Instance Cloud Spanner
Tindakan ini juga akan menghapus database (music-db-migrated dan reverse-replication-metadata) di dalamnya.
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Menghapus Bucket dan Konten GCS
gcloud storage rm --recursive gs://${BUCKET_NAME}
Menghapus File Lokal
Hapus semua file yang dibuat di direktori beranda Cloud Shell Anda:
rm -f music-db* shard_config.json
Anda kini telah membersihkan resource yang dibuat untuk codelab ini.