
1. Prima di iniziare
Questo codelab ti guida nella migrazione di un singolo database MySQL su Cloud SQL a un database Cloud Spanner con il dialetto GoogleSQL. L'attenzione è rivolta al flusso di migrazione end-to-end fondamentale, che mostra i passaggi principali. Utilizzerai i servizi Google Cloud, tra cui Spanner Migration Tool (SMT), Dataflow, Datastream, Pub/Sub e Google Cloud Storage.
Cosa imparerai:
- Come configurare istanze Cloud SQL e Cloud Spanner di esempio.
- Come convertire uno schema Cloud SQL MySQL in uno schema compatibile con Spanner utilizzando Spanner Migration Tool (SMT).
- Come eseguire la migrazione collettiva dei dati da Cloud SQL a Cloud Spanner utilizzando Dataflow.
- Come configurare la replica continua (CDC) da Cloud SQL a Cloud Spanner utilizzando Datastream e Dataflow.
- Come configurare la replica inversa da Cloud Spanner a Cloud SQL.
Cosa NON copre questo codelab:
- Migrazioni da istanze partizionate.
- Trasformazioni complesse dei dati durante la migrazione.
- Gestione avanzata degli errori o code di messaggi non recapitabili (DLQ).
- Ottimizzazione del rendimento della migrazione.
- Migrazione delle applicazioni:questo codelab si concentra sul livello del database (schema e dati). Non copre la procedura operativa di ripristino o migrazione dei servizi applicativi.
Che cosa ti serve
- Un progetto Google Cloud con la fatturazione abilitata.
- Autorizzazioni IAM sufficienti per attivare le API e creare/gestire risorse Cloud SQL, Spanner, Dataflow, Datastream e GCS. Sebbene il ruolo Progetto
Ownersia il più semplice per un codelab, i ruoli più specifici verranno trattati nella sezione "Configurazione dell'ambiente". - Un browser web, ad esempio Google Chrome.
- Familiarità di base con la console Google Cloud e gli strumenti a riga di comando come
gcloud. - Accesso a un ambiente shell. Cloud Shell è consigliato perché include
gcloud.
Per maggiori dettagli sulla configurazione precedente, consulta la sezione Configurazione dell'ambiente.
2. Informazioni sul processo di migrazione
La migrazione di un database comporta la migrazione dei dati dall'istanza del database Cloud SQL di origine a un'istanza Spanner. Questa sezione descrive l'architettura e gli strumenti chiave utilizzati nella migrazione.
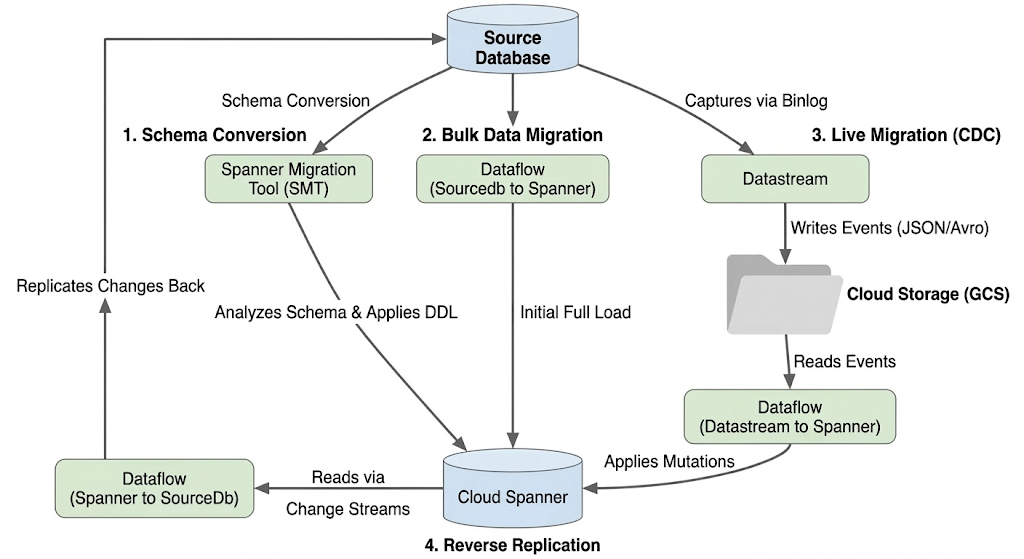
Architettura del flusso di migrazione
Il processo di migrazione prevede le seguenti fasi:
1. Conversione dello schema:
- Scopo:convertire lo schema del database di origine in uno schema Cloud Spanner compatibile.
- Strumento: Strumento di migrazione di Spanner (SMT)
- Procedura:SMT analizza lo schema del database di origine e genera il Data Definition Language (DDL) di Spanner equivalente. Nell'istanza Spanner di destinazione viene creato un database e la DDL viene applicata automaticamente.
2. Migrazione dei dati in blocco:
- Scopo:eseguire un caricamento completo iniziale dei dati esistenti dal database di origine alle tabelle Spanner di cui è stato eseguito il provisioning.
- Strumento:Dataflow, utilizzando il modello
Sourcedb to Spannerfornito da Google. - Procedura:questo job Dataflow legge tutti i dati dalle tabelle di origine specificate e li scrive nelle tabelle Spanner corrispondenti. Questa operazione viene eseguita dopo la creazione dello schema Spanner.
3. Migrazione live (CDC):
- Scopo:acquisire e applicare le modifiche in corso dal database di origine a Cloud Spanner quasi in tempo reale, riducendo al minimo i tempi di inattività durante la migrazione.
- Strumenti:
- Datastream:acquisisce le modifiche (inserimenti, aggiornamenti, eliminazioni) dal database di origine e le scrive in Cloud Storage (GCS).
- Dataflow:utilizza il modello
Datastream to Spannerper leggere gli eventi di modifica da GCS e applicarli a Cloud Spanner.
4. Replica inversa:
- Scopo:replicare le modifiche ai dati da Cloud Spanner al database di origine. Ciò può essere utile per le strategie di fallback, le migrazioni in più fasi o per mantenere una replica nell'origine per casi d'uso specifici.
- Strumento:Dataflow, utilizzando il modello
Spanner to SourceDb. - Processo:questo job utilizza i flussi di modifiche di Spanner per acquisire le modifiche in Spanner e riscriverle nell'istanza del database di origine.
Il seguente diagramma illustra i componenti e il flusso di dati:
Terminologia chiave:
- Strumento di migrazione Spanner (SMT): uno strumento utilizzato per valutare gli schemi MySQL, suggerire equivalenti dello schema Spanner e generare il Data Definition Language (DDL) di Spanner.
- Data Definition Language (DDL): istruzioni utilizzate per definire e modificare la struttura del database, ad esempio le istruzioni
CREATE TABLE. SMT genera il linguaggio DDL di Spanner in base allo schema Cloud SQL. - Dataflow: un servizio di elaborazione dei dati serverless completamente gestito. In questo codelab, viene utilizzato per eseguire modelli forniti da Google per il trasferimento collettivo dei dati, l'applicazione delle modifiche di Datastream e la replica inversa.
- Datastream: un servizio di replica e serverless Change Data Capture (CDC). Viene utilizzato per trasmettere in streaming le modifiche da Cloud SQL a Cloud Storage in questo codelab.
- Flussi di modifiche di Spanner: una funzionalità di Spanner che consente di trasmettere in streaming le modifiche ai dati (inserimenti, aggiornamenti, eliminazioni) in tempo reale, utilizzata come origine per la replica inversa.
- Pub/Sub: un servizio di messaggistica utilizzato per disaccoppiare i servizi che producono eventi da quelli che li elaborano. In questo codelab, attiva Dataflow per elaborare gli aggiornamenti ogni volta che Datastream carica nuovi file di modifiche in Cloud Storage.
3. Configurazione dell'ambiente
Prima di poter iniziare la migrazione, devi configurare il progetto Google Cloud e abilitare i servizi necessari.
1. Selezionare o creare un progetto Google Cloud
Per utilizzare i servizi in questo codelab, devi disporre di un progetto Google Cloud con la fatturazione abilitata.
- Nella console Google Cloud, vai alla pagina del selettore dei progetti: Vai al selettore dei progetti
- Seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto. Scopri come verificare che la fatturazione sia abilitata per il tuo progetto.
2. Apri Cloud Shell
Cloud Shell è un ambiente a riga di comando in esecuzione in Google Cloud che viene precaricato con l'interfaccia a riga di comando gcloud e altri strumenti necessari.
- Fai clic sul pulsante Attiva Cloud Shell in alto a destra nella console Google Cloud.
- All'interno di un nuovo frame nella parte inferiore della console si apre una sessione di Cloud Shell e viene visualizzato un prompt della riga di comando.

3. Imposta le variabili di progetto e di ambiente
In Cloud Shell, configura alcune variabili di ambiente per l'ID progetto e la regione che utilizzerai.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Abilita le API Google Cloud richieste
Abilita le API necessarie per Cloud Spanner, Dataflow, Datastream e altri servizi correlati.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Il completamento di questo comando potrebbe richiedere alcuni minuti.
5. Configura le autorizzazioni degli account di servizio
I job Dataflow e Datastream richiedono autorizzazioni specifiche per interagire con altri servizi Google Cloud. I job Dataflow in questo codelab utilizzeranno il service account Compute Engine predefinito.
Per prima cosa, recupera il numero di progetto:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
Ora, concedi i ruoli IAM richiesti al service account predefinito di Compute Engine:
# Role for Dataflow to run jobs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.admin" \
--condition=None
# Roles for Dataflow workers
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.worker" \
--condition=None
# Role to connect to Cloud SQL instance
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudsql.client" \
--condition=None
# Role to read/write from Cloud Spanner
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/spanner.databaseUser" \
--condition=None
# Role to access GCS buckets (Datastream output, Dataflow temp, JDBC driver)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectAdmin" \
--condition=None
# Roles for Datastream and Pub/Sub (for CDC)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastream.viewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/pubsub.subscriber"
6. Crea un bucket Cloud Storage
Crea un bucket GCS nella stessa regione delle altre risorse. Questo bucket memorizzerà il driver JDBC, l'output di Datastream e verrà utilizzato da Dataflow per i file temporanei.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
echo "Created bucket: gs://$BUCKET_NAME"
7. Installa lo strumento di migrazione di Spanner (SMT)
Assicurati che lo strumento di migrazione Spanner (SMT) sia installato nel tuo ambiente Cloud Shell.
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
Questo comando dovrebbe visualizzare le informazioni della guida per l'interfaccia web SMT, confermando che il componente gcloud è installato. Questo codelab utilizzerà le funzionalità della CLI di SMT, che fanno parte dello stesso componente.
4. Configurare il database Cloud SQL di origine
In questa sezione, creerai e configurerai un'istanza Cloud SQL per MySQL con IP pubblico da utilizzare come database di origine.
1. Crea un'istanza Cloud SQL per MySQL
Esegui questo comando gcloud in Cloud Shell per creare un'istanza MySQL 8.0. Il logging binario è abilitato (obbligatorio per Datastream) e l'istanza è configurata con un IP pubblico.
export SQL_INSTANCE_NAME="source-mysql-instance"
export DB_ROOT_PASSWORD="Welcome@1" # Replace with a strong password if you prefer
gcloud sql instances create $SQL_INSTANCE_NAME \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=$REGION \
--root-password=$DB_ROOT_PASSWORD \
--enable-bin-log \
--assign-ip
--enable-bin-log: obbligatorio per Datastream per acquisire le modifiche.--assign-ip: garantisce che l'istanza riceva un indirizzo IP pubblico.
La creazione dell'istanza richiederà pochi minuti. Puoi verificare se l'istanza è stata creata nella pagina Istanze Cloud SQL.
2. Configura reti autorizzate
Per connetterti all'istanza tramite IP pubblico, devi aggiungere indirizzi IP all'elenco "Reti autorizzate".
Recupera l'IP di Cloud Shell:
export CLOUD_SHELL_IP=$(curl -s ipinfo.io/ip)
echo "Your Cloud Shell IP: $CLOUD_SHELL_IP"
Autorizza l'IP di Cloud Shell e l'accesso aperto
Il comando seguente aggiunge l'IP di Cloud Shell. Aggiunge anche 0.0.0.0/0, che consente l'accesso da qualsiasi indirizzo IP. Ciò è necessario per semplificare le connessioni dai worker di Dataflow senza configurazioni di rete complesse.
gcloud sql instances patch $SQL_INSTANCE_NAME \
--authorized-networks="${CLOUD_SHELL_IP}/32,0.0.0.0/0"
3. Connettiti all'istanza Cloud SQL da Cloud Shell
Recupera l'indirizzo IP pubblico assegnato
export SQL_INSTANCE_IP=$(gcloud sql instances list --filter="name=$SQL_INSTANCE_NAME" --format="value(PRIMARY_ADDRESS)")
echo "Cloud SQL Public IP: $SQL_INSTANCE_IP"
Questo indirizzo IP verrà utilizzato per la connessione.
Connettiti all'istanza Cloud SQL da Cloud Shell
Utilizza il client mysql standard per connetterti utilizzando l'indirizzo IP pubblico ottenuto:
mysql -h $SQL_INSTANCE_IP -u root -p
Quando richiesto, inserisci la password root che hai impostato (Welcome@1). Ora visualizzerai il prompt mysql>.
4. Crea database e dati di esempio
Esegui i seguenti comandi SQL all'interno del prompt mysql>:
CREATE DATABASE music_db;
USE music_db;
CREATE TABLE Singers (
SingerId BIGINT NOT NULL,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
BirthDate DATE,
AlbumCount BIGINT,
PRIMARY KEY (SingerId)
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY (SingerId, AlbumId),
CONSTRAINT FK_Albums_Singers FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
);
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES
(1, 'Marc', 'Richards', '1970-09-03', 2),
(2, 'Catalina', 'Smith', '1990-08-17', 1),
(3, 'Alice', 'Trentor', '1991-10-02', 3);
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle, ReleaseDate) VALUES
(1, 1, 'Total Junk', '2014-03-15'),
(1, 2, 'Go Go Go', '2016-11-01'),
(2, 1, 'Green', '2018-02-28'),
(3, 1, 'Blue', '2019-01-10'),
(3, 2, 'Red', '2020-05-22'),
(3, 3, 'Purple', '2022-11-11');
Il file di dump per lo schema riportato sopra è disponibile qui.
5. Verifica dei dati
Verifica rapidamente che i dati siano presenti:
SELECT 'Singers music_db' as tbl, COUNT(*) FROM music_db.Singers
UNION ALL
SELECT 'Albums music_db', COUNT(*) FROM music_db.Albums;
EXIT;
Dovresti visualizzare i conteggi per ogni tabella.
+------------------+----------+ | tbl | COUNT(*) | +------------------+----------+ | Singers music_db | 3 | | Albums music_db | 6 | +------------------+----------+
5. Configura Cloud Spanner
Ora configurerai l'istanza Cloud Spanner di destinazione in cui verranno migrati i dati.
1. Crea un'istanza Cloud Spanner
Crea un'istanza Cloud Spanner nella stessa regione dell'istanza Cloud SQL. Questo comando crea un'istanza piccola adatta a questo codelab, utilizzando 100 unità di elaborazione.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="music-db-migrated"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
La creazione dell'istanza potrebbe richiedere un paio di minuti.
6. Converti lo schema utilizzando lo strumento di migrazione di Spanner (SMT)
Utilizza la CLI SMT per analizzare il database MySQL (music_db) e generare il DDL (Schema Definition Language) di Spanner. Poiché l'istanza Cloud SQL è configurata con IP pubblico e reti autorizzate appropriate, SMT può connettersi direttamente.
1. Prepara l'ambiente per SMT
Verifica che le variabili di ambiente necessarie siano impostate dai passaggi precedenti:
echo "Cloud SQL Instance Public IP: $SQL_INSTANCE_IP"
echo "Cloud SQL Root Password: $DB_ROOT_PASSWORD"
echo "Spanner Instance: $SPANNER_INSTANCE_NAME"
echo "Spanner Database: $SPANNER_DATABASE_NAME"
echo "Project ID: $PROJECT_ID"
2. Esegui la conversione dello schema per music_db
Esegui il comando SMT schema, connettendoti direttamente all'indirizzo IP pubblico di Cloud SQL:
gcloud alpha spanner migrate schema \
--source=mysql \
--source-profile="host=${SQL_INSTANCE_IP},port=3306,user=root,password=${DB_ROOT_PASSWORD},dbName=music_db" \
--target-profile="project=${PROJECT_ID},instance=${SPANNER_INSTANCE_NAME},dbName=${SPANNER_DATABASE_NAME}" \
--prefix="music-db"
Questo comando si connette all'istanza Cloud SQL tramite il proxy e genera file di schema con il prefisso music-db.
3. Esame dei file generati
SMT crea alcuni file nella directory corrente. I principali sono:
music-db.schema.ddl.txt: le istruzioni DDL di Spanner generate.music-db-.overrides.json: Il file di override dello schema contenente le modifiche al mapping manuale.music-db.session.json: File di sessione della migrazione dello schema.music-db.report.txt: un report di valutazione della conversione dello schema.
Puoi elencarli utilizzando ls music-db-*
4. Verifica lo schema in Cloud Spanner
Verifica che le tabelle siano state create nel database Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Dovresti vedere l'output seguente:
table_name: Albums table_name: Singers
(Facoltativo) Se vuoi controllare Spanner DDL, esegui questo comando:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
7. Inizializza Change Data Capture (CDC)
In questa sezione configurerai il "registratore" per la migrazione. Configurando Datastream e Pub/Sub prima dell'inizio del caricamento collettivo dei dati, ti assicuri che ogni modifica apportata al database di origine venga acquisita e messa in coda, evitando qualsiasi perdita di dati durante la transizione. Questa configurazione è necessaria per la migrazione live.
1. Crea profili di connessione Datastream
Profilo di origine (Cloud SQL)
Questo profilo si connette all'IP pubblico dell'istanza Cloud SQL. Datastream utilizzerà la lista consentita IP per la connettività.
export SQL_CP_NAME="mysql-src-cp"
gcloud datastream connection-profiles create $SQL_CP_NAME \
--location=$REGION \
--type=mysql \
--mysql-hostname=$SQL_INSTANCE_IP \
--mysql-port=3306 \
--mysql-username=root \
--mysql-password=$DB_ROOT_PASSWORD \
--display-name="Cloud SQL Source - Public IP"
Nota:questa connessione si basa sull'accesso consentito dalle reti autorizzate dell'istanza Cloud SQL. Come configurato in precedenza con 0.0.0.0/0, gli IP pubblici di Datastream possono connettersi. In un ambiente di produzione, sostituiresti 0.0.0.0/0 con gli intervalli IP specifici per la tua regione elencati in Liste consentite e regioni IP di Datastream.
Profilo di destinazione (Cloud Storage)
Punta alla radice del bucket.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
2. Crea uno stream Datastream
Crea lo stream da replicare da music_db.
export STREAM_NAME="mysql-to-spanner-stream"
export GCS_STREAM_PATH="data/${STREAM_NAME}"
gcloud datastream streams create $STREAM_NAME \
--location=$REGION \
--display-name="MySQL to Spanner CDC Stream" \
--source=$SQL_CP_NAME \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "
includeObjects:
mysqlDatabases:
- database: 'music_db'
") \
--gcs-destination-config=<(echo "
path: ${GCS_STREAM_PATH}
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}
") \
--backfill-none
- Datastream scriverà i file in
gs://${BUCKET_NAME}/${GCS_STREAM_PREFIX}/ - Datastream scriverà i file in formato Avro. Durante l'esecuzione del comando di migrazione live, specificheremo che inputFileFormat deve essere avro in modo che la pipeline possa elaborare correttamente il file.
- L'utilizzo di impostazioni di rotazione dei file più piccole consente di visualizzare più rapidamente le modifiche nel codelab.
Il completamento di questo comando potrebbe richiedere un po' di tempo. Controlla lo stato: gcloud datastream streams describe $STREAM_NAME --location=$REGION.
3. Avvia lo stream Datastream
gcloud datastream streams update $STREAM_NAME \
--location=$REGION \
--state=RUNNING
Controlla lo stato: gcloud datastream streams describe $STREAM_NAME --location=$REGION. inizialmente lo stato sarà STARTING e dopo un po' diventerà RUNNING. Procedi al passaggio successivo solo dopo aver verificato che si trova nello stato RUNNING.
4. Configura Pub/Sub per le notifiche GCS
Crea un argomento Pub/Sub:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
Crea notifica GCS
Notifica alla creazione di oggetti con il prefisso data/.
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Crea una sottoscrizione Pub/Sub
Includi la scadenza della conferma consigliata.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Esegui la migrazione collettiva dei dati da Cloud SQL a Spanner
Ora che lo schema Spanner è in posizione, copia i dati esistenti dal database Cloud SQL music_db a Cloud Spanner. Utilizzerai il modello flessibile Dataflow Sourcedb to Spanner, progettato per copiare in blocco i dati dai database accessibili tramite JDBC a Spanner.
1. Esegui il job Dataflow di migrazione collettiva per music_db
Esegui questo comando in Cloud Shell per avviare il job Dataflow. Questo comando utilizza il comando gcloud dataflow flex-template run, facendo riferimento al modello fornito da Google per le migrazioni JDBC collettive a Spanner.
export JOB_NAME_MUSIC="mysql-music-db-to-spanner-bulk-$(date +%Y%m%d-%H%M%S)"
export MUSIC_DB_JDBC_URL="jdbc:mysql://${SQL_INSTANCE_IP}:3306/music_db"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration-output"
gcloud dataflow flex-template run $JOB_NAME_MUSIC \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL="$MUSIC_DB_JDBC_URL",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
outputDirectory="$OUTPUT_DIR/music_db",\
username="root",\
password="$DB_ROOT_PASSWORD",\
jdbcDriverClassName="com.mysql.cj.jdbc.Driver",\
jdbcDriverJars="gs://${BUCKET_NAME}/lib/mysql-connector-j-8.0.33.jar",\
spannerHost="https://batch-spanner.googleapis.com"
Spiegazione dei parametri chiave:
sourceConfigURL: la stringa di connessione JDBC per l'originemusic_db.instanceId,databaseId,projectId: specifica l'istanza e il database Cloud Spanner di destinazione.outputDirectory: un percorso Cloud Storage in cui Dataflow scriverà informazioni su tutti i record di cui non è stata eseguita la migrazione.jdbcDriverClassName: specifica il driver JDBC di MySQL.jdbcDriverJars: percorso GCS del file JAR del driver JDBC di staging.spannerHost: utilizza l'endpoint ottimizzato per i batch per le scritture di Spanner.maxWorkers,numWorkers: controlla lo scaling del job Dataflow. Mantenuto basso per questo piccolo set di dati.
Nota di rete: questo job si connette all'istanza Cloud SQL tramite il relativo IP pubblico. Ciò è possibile perché in precedenza hai aggiunto 0.0.0.0/0 alle reti autorizzate dell'istanza. In questo modo, le VM worker Dataflow, che hanno IP esterni, possono raggiungere il database.
2. Monitora il job Dataflow
Puoi monitorare l'avanzamento del job nella console Google Cloud:
- Vai alla pagina Job Dataflow: Vai a Job Dataflow
- Individua il job denominato
mysql-music-db-to-spanner-bulk-...e fai clic su di esso. - Osserva il grafico del job e le metriche. Attendi che lo stato del job cambi in Riuscito. L'operazione dovrebbe richiedere circa 5-15 minuti.
- Se il job riscontra problemi, esamina la scheda Log nella pagina dei dettagli del job Dataflow per i messaggi di errore.
- Metriche del job fornisce maggiori informazioni sullo stato di avanzamento del job e sul consumo di risorse come velocità effettiva e utilizzo della CPU.
3. Verifica dei dati in Cloud Spanner
Una volta completato correttamente il job Dataflow, verifica che i dati siano stati copiati nelle tabelle Spanner. Utilizza gcloud per eseguire query sul database Spanner:
# Verify row counts
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Singers"
# Expected output: 3
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Albums"
# Expected output: 6
# Inspect some data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT SingerId, FirstName, LastName FROM Singers ORDER BY SingerId"
Output previsto:
row_count: 3 row_count: 6 SingerId: 1 FirstName: Marc LastName: Richards SingerId: 2 FirstName: Catalina LastName: Smith SingerId: 3 FirstName: Alice LastName: Trentor
Il caricamento collettivo iniziale dei dati da Cloud SQL a Cloud Spanner è ora completato. Il passaggio successivo consiste nel configurare la replica in tempo reale per acquisire le modifiche in corso.
9. Avvia migrazione live (CDC)
Ora che il caricamento collettivo dei dati è completato, configurerai un flusso di replica continuo utilizzando Datastream per acquisire gli eventi Change Data Capture (CDC) da Cloud SQL e un job di streaming Dataflow per applicare queste modifiche a Cloud Spanner quasi in tempo reale.
1. Esegui il job Dataflow di migrazione live
Avvia il job Dataflow di streaming per leggere da GCS e scrivere in Spanner. Questo modello utilizzerà le notifiche GCS Pub/Sub per elaborare immediatamente i nuovi file.
export JOB_NAME_CDC="datastream-to-spanner-cdc-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR="gs://${BUCKET_NAME}/dlq"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
deadLetterQueueDirectory="$DLQ_DIR",\
streamName="projects/${PROJECT_ID}/locations/${REGION}/streams/${STREAM_NAME}"
Parametri chiave
gcsPubSubSubscription: l'abbonamento Pub/Sub che ascolta le notifiche di nuovi file da GCS. In questo modo, il job può elaborare le modifiche istantaneamente man mano che Datastream le scrive.inputFileFormat="avro": indica a Dataflow di prevedere file Avro da Datastream. Questo valore deve corrispondere alla configurazione della "Destinazione" di Datastream (ad es.avroFileFormatanzichéjsonFileFormat).deadLetterQueueDirectory: un percorso GCS in cui il job archivia i record che non sono stati elaborati (ad es. a causa di mancata corrispondenza dello schema) per una revisione manuale successiva.streamName: il percorso completo della risorsa dello stream Datastream, che consente al job Dataflow di monitorare lo stato e i metadati della replica.
Monitora l'avvio del job nella console Dataflow Jobs.
2. Testare la migrazione live
Applica le modifiche all'origine Cloud SQL music_db per testare la pipeline CDC.
Connettiti a Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
Inserisci la password (Welcome@1) e seleziona il database:
USE music_db;
-- INSERT
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (4, 'Elena', 'Nadal', '1985-05-30', 0);
SELECT * FROM Singers WHERE SingerId = 4;
-- UPDATE
UPDATE Singers SET LastName = 'Richards-Smith' WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- DELETE
DELETE FROM Albums WHERE SingerId = 2;
DELETE FROM Singers WHERE SingerId = 2;
SELECT * FROM Singers WHERE SingerId = 2;
EXIT;
Verifica in Spanner (dopo alcuni istanti):
# Verify INSERT: This should return the new row for Elena Nadal.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 4"
# Verify UPDATE: This should show LastName as Richards-Smith.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName FROM Singers WHERE SingerId = 1"
# Verify DELETE: This should now return 0 rows.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Albums WHERE SingerId = 2"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 2"
Output previsto:
SingerId: 4 FirstName: Elena LastName: Nadal BirthDate: 1985-05-30 AlbumCount: 0 SingerId: 1 FirstName: Marc LastName: Richards-Smith
3. Verifica finale in Spanner
Controlla lo stato generale della tabella Singers in Spanner:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId"
Output previsto:
SingerId: 1 FirstName: Marc LastName: Richards-Smith AlbumCount: 2 SingerId: 3 FirstName: Alice LastName: Trentor AlbumCount: 3 SingerId: 4 FirstName: Elena LastName: Nadal AlbumCount: 0
10. Configura la replica inversa (da Spanner a Cloud SQL)
Per gestire scenari in cui potrebbe essere necessario eseguire il rollback o mantenere sincronizzato il database Cloud SQL con Spanner per un periodo di tempo, puoi configurare la replica inversa. Questa pipeline utilizza Spanner Change Streams per acquisire le modifiche in Spanner e le riscrive in Cloud SQL music_db.
1. Crea un flusso di modifiche Spanner
Innanzitutto, devi creare un flusso di modifiche nel database Spanner per monitorare le modifiche nelle tabelle Singers e Albums.
export CHANGE_STREAM_NAME="MusicDBChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Singers, Albums"
Questo flusso di modifiche ora registrerà tutte le modifiche ai dati apportate alle tabelle specificate.
2. Crea un database Spanner per i metadati Dataflow
Il modello Dataflow Spanner to SourceDB richiede un database Spanner separato per archiviare i metadati per la gestione del consumo dello stream delle modifiche.
export SPANNER_METADATA_DB_NAME="reverse-replication-metadata"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Prepara la configurazione della connessione Cloud SQL per Dataflow
Il modello Dataflow richiede un file JSON in Cloud Storage contenente i dettagli di connessione per il database Cloud SQL di destinazione.
Crea un file locale denominato shard_config.json:
cat << EOF > shard_config.json
[
{
"logicalShardId": "mysql_shard",
"host": "${SQL_INSTANCE_IP}",
"port": "3306",
"user": "root",
"password": "${DB_ROOT_PASSWORD}",
"dbName": "music_db"
}
]
EOF
Carica questo file nel tuo bucket GCS:
export SHARD_CONFIG_FILE="gs://${BUCKET_NAME}/shard_config.json"
gcloud storage cp shard_config.json $SHARD_CONFIG_FILE
4. Esegui il job Dataflow di replica inversa
Avvia il job Dataflow utilizzando il Spanner_to_SourceDb modello flessibile.
export JOB_NAME_REVERSE="spanner-to-mysql-reverse-$(date +%Y%m%d-%H%M%S)"
export REVERSE_DLQ_DIR="gs://${BUCKET_NAME}/reverse-dlq"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$SHARD_CONFIG_FILE",\
deadLetterQueueDirectory="$REVERSE_DLQ_DIR"
Parametri chiave
changeStreamName: il nome dello stream di modifiche di Spanner da cui leggere.metadataInstance, metadataDatabase: l'istanza/il database Spanner in cui archiviare i metadati utilizzati dal connettore per controllare il consumo dei dati dell'API change stream.sourceShardsFilePath: il percorso GCS del tuoshard_config.json.filtrationMode: specifica come eliminare determinati record in base a un criterio. Il valore predefinito èforward_migration(filtra i record scritti utilizzando la pipeline di migrazione in avanti)
Nota di rete:i worker Dataflow si connetteranno all'istanza Cloud SQL utilizzando l'IP pubblico specificato in shard_config.json. Questa connessione è consentita grazie alla voce 0.0.0.0/0 nelle reti autorizzate dell'istanza Cloud SQL.
Monitora l'avvio del job nella console Dataflow Jobs.
5. Testa la replica inversa
Ora, apporta modifiche direttamente in Cloud Spanner e verifica che vengano riflesse in Cloud SQL. Esegui questa operazione solo dopo l'avvio del job Dataflow e quando è in stato di elaborazione.
Test INSERT, UPDATE e DELETE
# INSERT: Insert a new singer (SingerId 5) into Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (5, 'David', 'Chen', '1995-02-18', 0)"
# UPDATE: Update SingerId 3's AlbumCount in Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Singers SET AlbumCount = 5 WHERE SingerId = 3"
# DELETE: Delete SingerId 1 from Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Albums WHERE SingerId = 1"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Singers WHERE SingerId = 1"
Verifica in Cloud SQL (dopo alcuni istanti):
Connettiti a Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
Inserisci la password (Welcome@1) quando richiesto, quindi esegui i seguenti comandi SQL al prompt mysql>.
USE music_db;
-- Verify INSERT: This should show the new row for David Chen
SELECT * FROM Singers WHERE SingerId = 5;
-- Verify UPDATE: This should show AlbumCount as 5.
SELECT SingerId, FirstName, AlbumCount FROM Singers WHERE SingerId = 3;
-- Verify DELETE: This should return an empty set.
SELECT * FROM Albums WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- Final Verification
SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId;
EXIT;
L'output previsto in Cloud SQL deve riflettere le modifiche apportate in Spanner.
+----------+-----------+----------------+------------+ | SingerId | FirstName | LastName | AlbumCount | +----------+-----------+----------------+------------+ | 3 | Alice | Trentor | 5 | | 4 | Elena | Nadal | 0 | | 5 | David | Chen | 0 | +----------+-----------+----------------+------------+
Ciò conferma che la pipeline di replica inversa funziona, sincronizzando le modifiche da Spanner a Cloud SQL.
11. Esegui la pulizia delle risorse
Per evitare ulteriori addebiti al tuo account Google Cloud, elimina le risorse create durante questo codelab.
Imposta le variabili di ambiente (se necessario)
Controlla se le variabili di ambiente sono impostate correttamente:
echo "PROJECT_ID: $PROJECT_ID"
echo "REGION: $REGION"
echo "SQL_INSTANCE_NAME: $SQL_INSTANCE_NAME"
echo "SPANNER_INSTANCE_NAME: $SPANNER_INSTANCE_NAME"
echo "BUCKET_NAME: $BUCKET_NAME"
echo "STREAM_NAME: $STREAM_NAME"
echo "SQL_CP_NAME: $SQL_CP_NAME"
echo "GCS_CP_NAME: $GCS_CP_NAME"
echo "PUBSUB_SUBSCRIPTION: $PUBSUB_SUBSCRIPTION"
echo "PUBSUB_TOPIC: $PUBSUB_TOPIC"
echo "CHANGE_STREAM_NAME: $CHANGE_STREAM_NAME"
Elenca i tuoi job per trovare gli ID job dei job Dataflow in esecuzione. Esporta JOB_ID_CDC e JOB_ID_REVERSE di conseguenza.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Se ti trovi in una nuova sessione di Cloud Shell, riesporta le variabili di ambiente della chiave:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or the region you used
export SQL_INSTANCE_NAME="source-mysql-instance"
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export STREAM_NAME="mysql-to-spanner-stream"
export SQL_CP_NAME="mysql-src-cp"
export GCS_CP_NAME="gcs-dest-cp"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CHANGE_STREAM_NAME="MusicDBChangeStream"
Arresta i job Dataflow Streaming
Annulla il job Datastream to Spanner (migrazione live):
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
Annulla il job Spanner to Cloud SQL (replica inversa):
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Elimina risorse Datastream
Interrompi ed elimina lo stream:
gcloud datastream streams update $STREAM_NAME \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Elimina profili di connessione
gcloud datastream connection-profiles delete $SQL_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Elimina risorse Pub/Sub
Elimina abbonamento:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Elimina argomento:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Elimina l'istanza Cloud SQL
In questo modo, i database (music_db) al suo interno verranno eliminati automaticamente.
gcloud sql instances delete $SQL_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Elimina istanza Cloud Spanner
Verranno eliminati anche i database (music-db-migrated e reverse-replication-metadata) al suo interno.
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Eliminazione del bucket GCS e dei relativi contenuti
gcloud storage rm --recursive gs://${BUCKET_NAME}
Elimina file locali
Rimuovi tutti i file generati nella home directory di Cloud Shell:
rm -f music-db* shard_config.json
Ora hai eseguito la pulizia delle risorse create per questo codelab.