
1. 始める前に
この Codelab では、Cloud SQL 上の単一の MySQL データベースを GoogleSQL 言語の Cloud Spanner データベースに移行する手順について説明します。ここでは、基本的なエンドツーエンドの移行フローに焦点を当て、コアステップを示します。Spanner Migration Tool(SMT)、Dataflow、Datastream、Pub/Sub、Google Cloud Storage などの Google Cloud サービスを使用します。
演習内容
- Cloud SQL と Cloud Spanner のサンプル インスタンスを設定する方法。
- Spanner 移行ツール(SMT)を使用して Cloud SQL MySQL スキーマを Spanner 互換スキーマに変換する方法。
- Dataflow を使用して Cloud SQL から Cloud Spanner にデータを一括移行する方法について説明します。
- Datastream と Dataflow を使用して Cloud SQL から Cloud Spanner への継続的レプリケーション(CDC)を設定する方法。
- Cloud Spanner から Cloud SQL へのリバース レプリケーションを設定する方法。
この Codelab で取り上げない内容:
- シャーディングされたインスタンスからの移行。
- 移行中の複雑なデータ変換。
- 高度なエラー処理またはデッドレター キュー(DLQ)。
- 移行のパフォーマンス チューニング。
- アプリケーションの移行: この Codelab では、データベース レイヤ(スキーマとデータ)に焦点を当てています。アプリケーション サービスの再デプロイまたは移行の運用プロセスについては説明していません。
必要なもの
- 課金を有効にした Google Cloud プロジェクト
- API を有効にして、Cloud SQL、Spanner、Dataflow、Datastream、GCS リソースを作成/管理するための十分な IAM 権限。この Codelab ではプロジェクトの
Ownerロールが最も簡単ですが、より具体的なロールについては「環境の設定」で説明します。 - ウェブブラウザ(Google Chrome など)。
- Google Cloud コンソールと
gcloudなどのコマンドライン ツールに関する基本的な知識。 - シェル環境へのアクセス。
gcloudが含まれているため、Cloud Shell をおすすめします。
上記の設定の詳細については、環境設定のセクションをご覧ください。
2. 移行プロセスについて
データベースの移行では、ソースの CloudSQL データベース インスタンスから Spanner インスタンスにデータを移行します。このセクションでは、移行で使用されるアーキテクチャと主要なツールについて説明します。
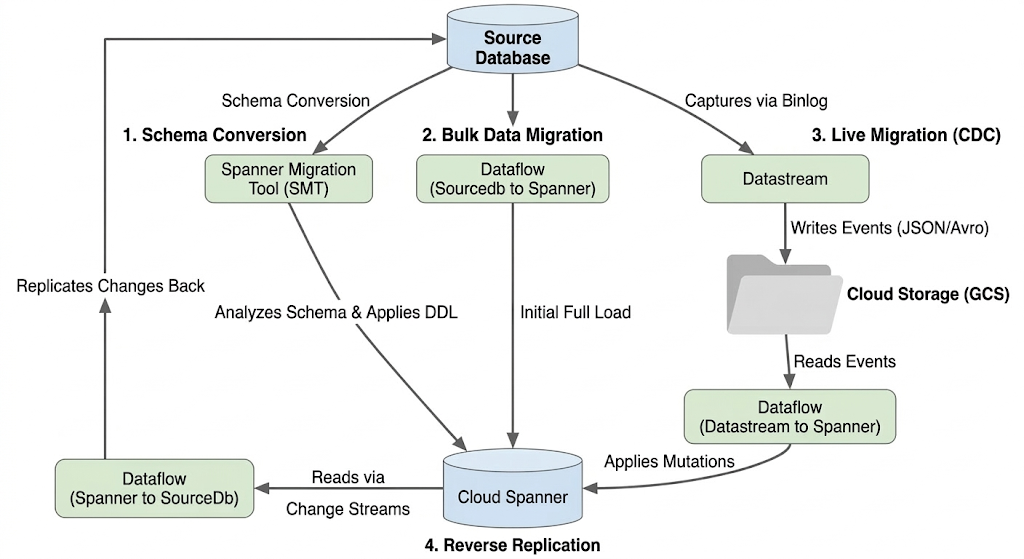
移行フローのアーキテクチャ
移行プロセスには次のステージがあります。
1. スキーマの変換:
- 目的: 移行元データベース スキーマを互換性のある Cloud Spanner スキーマに変換します。
- ツール: Spanner 移行ツール(SMT)
- プロセス: SMT は、ソース データベース スキーマを分析し、同等の Spanner データ定義言語(DDL)を生成します。移行先の Spanner インスタンスにデータベースが作成され、DDL が自動的に適用されます。
2. 一括データ移行:
- 目的: 移行元データベースからプロビジョニングされた Spanner テーブルに既存のデータの初期完全読み込みを実行します。
- ツール: Google 提供の
Sourcedb to Spannerテンプレートを使用する Dataflow。 - プロセス: この Dataflow ジョブは、指定されたソーステーブルからすべてのデータを読み取り、対応する Spanner テーブルに書き込みます。これは、Spanner スキーマの作成後に行われます。
3. ライブ マイグレーション(CDC):
- 目的: ソース データベースからの進行中の変更をほぼリアルタイムで Cloud Spanner にキャプチャして適用し、移行中のダウンタイムを最小限に抑えます。
- ツール:
- Datastream: ソース データベースから変更(挿入、更新、削除)をキャプチャし、Cloud Storage(GCS)に書き込みます。
- Dataflow:
Datastream to Spannerテンプレートを使用して、GCS から変更イベントを読み取り、Cloud Spanner に適用します。
4. リバース レプリケーション:
- 目的: Cloud Spanner から移行元データベースにデータ変更を複製します。これは、フォールバック戦略、段階的な移行、特定のユースケースのソースでレプリカを維持する場合に役立ちます。
- ツール:
Spanner to SourceDbテンプレートを使用する Dataflow。 - プロセス: このジョブは、Spanner 変更ストリームを使用して Spanner の変更をキャプチャし、ソース データベース インスタンスに書き戻します。
次の図は、コンポーネントとデータフローを示しています。
主な用語:
- Spanner 移行ツール(SMT): MySQL スキーマの評価、Spanner スキーマの同等物の提案、Spanner データ定義言語(DDL)の生成に使用されるツール。
- データ定義言語(DDL):
CREATE TABLEステートメントなど、データベース構造の定義と変更に使用されるステートメント。SMT は、Cloud SQL スキーマに基づいて Spanner DDL を生成します。 - Dataflow: フルマネージドのサーバーレス データ処理サービス。この Codelab では、一括データ転送、Datastream の変更の適用、逆レプリケーションのために Google 提供のテンプレートを実行するために使用されます。
- Datastream: サーバーレスの変更データ キャプチャ(CDC)とレプリケーション サービス。この Codelab では、Cloud SQL から Cloud Storage に変更をストリーミングするために使用します。
- Spanner 変更ストリーム: データの変更(挿入、更新、削除)をリアルタイムでストリーミングできる Spanner の機能。逆レプリケーションのソースとして使用されます。
- Pub/Sub: イベントを生成するサービスとイベントを処理するサービスを切り離すために使用されるメッセージング サービス。この Codelab では、Datastream が新しい変更ファイルを Cloud Storage にアップロードするたびに、Dataflow がトリガーされて更新が処理されます。
3. 環境設定
移行を開始する前に、Google Cloud プロジェクトを設定し、必要なサービスを有効にする必要があります。
1. Google Cloud プロジェクトを選択または作成する
この Codelab のサービスを使用するには、課金が有効になっている Google Cloud プロジェクトが必要です。
- Google Cloud コンソールで、プロジェクト セレクタ ページに移動します。プロジェクト セレクタに移動
- Google Cloud プロジェクトを選択または作成します。
- プロジェクトに対して課金が有効になっていることを確認します。プロジェクトに対して課金が有効になっていることを確認する方法をご覧ください。
2. Cloud Shell を開く
Cloud Shell は、Google Cloud で実行されるコマンドライン環境です。gcloud CLI やその他の必要なツールがプリロードされています。
- Google Cloud コンソールの右上にある [Cloud Shell をアクティブにする] ボタンをクリックします。
- コンソールの下部の新しいフレーム内で Cloud Shell セッションが開き、コマンドライン プロンプトが表示されます。

3. プロジェクトと環境変数を設定する
Cloud Shell で、プロジェクト ID と使用するリージョンの環境変数を設定します。
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. 必要な Google Cloud APIs を有効にする
Cloud Spanner、Dataflow、Datastream、その他の関連サービスに必要な API を有効にします。
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
このコマンドが完了するまで数分かかる場合があります。
5. サービス アカウントの権限を構成する
Dataflow ジョブと Datastream が他の Google Cloud サービスとやり取りするには、特定の権限が必要です。この Codelab の Dataflow ジョブは、デフォルトの Compute Engine サービス アカウントを使用します。
まず、プロジェクト番号を取得します。
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
次に、Compute Engine のデフォルト サービス アカウントに必要な IAM ロールを付与します。
# Role for Dataflow to run jobs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.admin" \
--condition=None
# Roles for Dataflow workers
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.worker" \
--condition=None
# Role to connect to Cloud SQL instance
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudsql.client" \
--condition=None
# Role to read/write from Cloud Spanner
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/spanner.databaseUser" \
--condition=None
# Role to access GCS buckets (Datastream output, Dataflow temp, JDBC driver)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectAdmin" \
--condition=None
# Roles for Datastream and Pub/Sub (for CDC)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastream.viewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/pubsub.subscriber"
6. Cloud Storage バケットを作成する
他のリソースと同じリージョンに GCS バケットを作成します。このバケットには、JDBC ドライバと Datastream の出力が保存され、Dataflow で一時ファイルに使用されます。
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
echo "Created bucket: gs://$BUCKET_NAME"
7. Spanner 移行ツール(SMT)をインストールする
Cloud Shell 環境に Spanner 移行ツール(SMT)がインストールされていることを確認します。
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
このコマンドを実行すると、SMT ウェブ インターフェースのヘルプ情報が表示され、gcloud コンポーネントがインストールされていることを確認できます。この Codelab では、同じコンポーネントの一部である SMT の CLI 機能を使用します。
4. ソース Cloud SQL データベースを設定する
このセクションでは、ソース データベースとして機能する パブリック IP を使用して Cloud SQL for MySQL インスタンスを作成して構成します。
1. Cloud SQL for MySQL インスタンスを作成する
Cloud Shell で次の gcloud コマンドを実行して、MySQL 8.0 インスタンスを作成します。バイナリ ロギングが有効になっている(Datastream に必要)。インスタンスがパブリック IP で構成されている。
export SQL_INSTANCE_NAME="source-mysql-instance"
export DB_ROOT_PASSWORD="Welcome@1" # Replace with a strong password if you prefer
gcloud sql instances create $SQL_INSTANCE_NAME \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=$REGION \
--root-password=$DB_ROOT_PASSWORD \
--enable-bin-log \
--assign-ip
--enable-bin-log: Datastream が変更をキャプチャするために必要です。--assign-ip: インスタンスにパブリック IP アドレスが割り当てられるようにします。
インスタンスの作成には数分かかります。インスタンスが作成されたかどうかは、CloudSQL インスタンス ページで確認できます。
2. 承認済みネットワークを構成する
パブリック IP 経由でインスタンスに接続するには、IP アドレスを [承認済みネットワーク] リストに追加する必要があります。
Cloud Shell の IP を取得します。
export CLOUD_SHELL_IP=$(curl -s ipinfo.io/ip)
echo "Your Cloud Shell IP: $CLOUD_SHELL_IP"
Cloud Shell IP を承認してオープン アクセスを許可する
次のコマンドは、Cloud Shell の IP を追加します。また、任意の IP アドレスからのアクセスを許可する 0.0.0.0/0 も追加します。これは、複雑なネットワーク設定なしで Dataflow ワーカーからの接続を簡素化するために必要です。
gcloud sql instances patch $SQL_INSTANCE_NAME \
--authorized-networks="${CLOUD_SHELL_IP}/32,0.0.0.0/0"
3. Cloud Shell から Cloud SQL インスタンスに接続する
割り当てられたパブリック IP アドレスを取得する
export SQL_INSTANCE_IP=$(gcloud sql instances list --filter="name=$SQL_INSTANCE_NAME" --format="value(PRIMARY_ADDRESS)")
echo "Cloud SQL Public IP: $SQL_INSTANCE_IP"
この IP アドレスは接続に使用されます。
CloudShell から Cloud SQL インスタンスに接続する
取得したパブリック IP アドレスを使用して、標準の MySQL クライアントを使用して接続します。
mysql -h $SQL_INSTANCE_IP -u root -p
プロンプトが表示されたら、設定した root パスワード(Welcome@1)を入力します。mysql> プロンプトが表示されます。
4. データベースとサンプルデータを作成する
mysql> プロンプトで次の SQL コマンドを実行します。
CREATE DATABASE music_db;
USE music_db;
CREATE TABLE Singers (
SingerId BIGINT NOT NULL,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
BirthDate DATE,
AlbumCount BIGINT,
PRIMARY KEY (SingerId)
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY (SingerId, AlbumId),
CONSTRAINT FK_Albums_Singers FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
);
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES
(1, 'Marc', 'Richards', '1970-09-03', 2),
(2, 'Catalina', 'Smith', '1990-08-17', 1),
(3, 'Alice', 'Trentor', '1991-10-02', 3);
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle, ReleaseDate) VALUES
(1, 1, 'Total Junk', '2014-03-15'),
(1, 2, 'Go Go Go', '2016-11-01'),
(2, 1, 'Green', '2018-02-28'),
(3, 1, 'Blue', '2019-01-10'),
(3, 2, 'Red', '2020-05-22'),
(3, 3, 'Purple', '2022-11-11');
上記のスキーマのダンプファイルはこちらで確認できます。
5. データを確認する
データが存在することをすばやく確認します。
SELECT 'Singers music_db' as tbl, COUNT(*) FROM music_db.Singers
UNION ALL
SELECT 'Albums music_db', COUNT(*) FROM music_db.Albums;
EXIT;
各テーブルのカウントが表示されます。
+------------------+----------+ | tbl | COUNT(*) | +------------------+----------+ | Singers music_db | 3 | | Albums music_db | 6 | +------------------+----------+
5. Cloud Spanner を設定する
次に、データの移行先となるターゲット Cloud Spanner インスタンスを設定します。
1. Cloud Spanner インスタンスを作成する
Cloud SQL インスタンスと同じリージョンに Cloud Spanner インスタンスを作成します。このコマンドは、100 処理単位を使用して、この Codelab に適した小規模なインスタンスを作成します。
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="music-db-migrated"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
インスタンスの作成には 1 ~ 2 分かかることがあります。
6. Spanner 移行ツール(SMT)を使用してスキーマを変換する
SMT CLI を使用して MySQL データベース(music_db)を分析し、Spanner スキーマ定義言語(DDL)を生成します。Cloud SQL インスタンスはパブリック IP と適切な承認済みネットワークで構成されているため、SMT は直接接続できます。
1. SMT の環境を準備する
前の手順で必要な環境変数が設定されていることを確認します。
echo "Cloud SQL Instance Public IP: $SQL_INSTANCE_IP"
echo "Cloud SQL Root Password: $DB_ROOT_PASSWORD"
echo "Spanner Instance: $SPANNER_INSTANCE_NAME"
echo "Spanner Database: $SPANNER_DATABASE_NAME"
echo "Project ID: $PROJECT_ID"
2. music_db のスキーマ変換を実行する
SMT schema コマンドを実行して、Cloud SQL パブリック IP アドレスに直接接続します。
gcloud alpha spanner migrate schema \
--source=mysql \
--source-profile="host=${SQL_INSTANCE_IP},port=3306,user=root,password=${DB_ROOT_PASSWORD},dbName=music_db" \
--target-profile="project=${PROJECT_ID},instance=${SPANNER_INSTANCE_NAME},dbName=${SPANNER_DATABASE_NAME}" \
--prefix="music-db"
このコマンドは、プロキシ経由で Cloud SQL インスタンスに接続し、music-db という接頭辞が付いたスキーマ ファイルを生成します。
3. 生成されたファイルを確認する
SMT は、現在のディレクトリにいくつかのファイルを作成します。主なものは次のとおりです。
music-db.schema.ddl.txt: 生成された Spanner DDL ステートメント。music-db-.overrides.json: 手動マッピングの変更を含むスキーマ オーバーライド ファイル。music-db.session.json: スキーマ移行のセッション ファイル。music-db.report.txt: スキーマ変換の評価レポート。
ls music-db-* を使用して一覧表示できます。
4. Cloud Spanner でスキーマを確認する
テーブルが Spanner データベースに作成されていることを確認します。
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
次の出力が表示されます。
table_name: Albums table_name: Singers
省略可: Spanner DDL を確認する場合は、次のコマンドを実行します。
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
7. 変更データ キャプチャ(CDC)を初期化します。
このセクションでは、移行の「レコーダー」を設定します。一括データ読み込みを開始する前に Datastream と Pub/Sub を構成することで、移行中にデータが失われないように、ソース データベースに加えられたすべての変更がキャプチャされてキューに登録されます。この設定はライブ マイグレーションに必要です。
1. Datastream 接続プロファイルを作成する
ソース プロファイル(Cloud SQL)
このプロファイルは、Cloud SQL インスタンスのパブリック IP に接続します。Datastream は接続に IP 許可リストを使用します。
export SQL_CP_NAME="mysql-src-cp"
gcloud datastream connection-profiles create $SQL_CP_NAME \
--location=$REGION \
--type=mysql \
--mysql-hostname=$SQL_INSTANCE_IP \
--mysql-port=3306 \
--mysql-username=root \
--mysql-password=$DB_ROOT_PASSWORD \
--display-name="Cloud SQL Source - Public IP"
注: この接続は、Cloud SQL インスタンスの承認済みネットワークがアクセスを許可していることを前提としています。0.0.0.0/0 で構成したように、Datastream のパブリック IP を接続できます。本番環境では、0.0.0.0/0 を Datastream の IP 許可リストとリージョンに記載されているリージョンの特定の IP 範囲に置き換えます。
宛先プロファイル(Cloud Storage)
バケットのルートを指します。
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
2. Datastream ストリームを作成する
music_db から複製するストリームを作成します。
export STREAM_NAME="mysql-to-spanner-stream"
export GCS_STREAM_PATH="data/${STREAM_NAME}"
gcloud datastream streams create $STREAM_NAME \
--location=$REGION \
--display-name="MySQL to Spanner CDC Stream" \
--source=$SQL_CP_NAME \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "
includeObjects:
mysqlDatabases:
- database: 'music_db'
") \
--gcs-destination-config=<(echo "
path: ${GCS_STREAM_PATH}
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}
") \
--backfill-none
- Datastream は
gs://${BUCKET_NAME}/${GCS_STREAM_PREFIX}/にファイルを書き込みます。 - Datastream は Avro 形式でファイルを書き込みます。ライブ マイグレーション コマンドの実行時に、inputFileFormat を avro に指定して、パイプラインがファイルを正しく処理できるようにします。
- ファイル ローテーションの設定を小さくすると、コードラボで変更をすばやく確認できます。
このコマンドが完了するまでに時間がかかることがあります。ステータスを確認します: gcloud datastream streams describe $STREAM_NAME --location=$REGION。
3. Datastream ストリームを開始する
gcloud datastream streams update $STREAM_NAME \
--location=$REGION \
--state=RUNNING
ステータスを確認する: gcloud datastream streams describe $STREAM_NAME --location=$REGION. 状態は最初は STARTING になり、しばらくすると RUNNING になります。RUNNING 状態であることを確認してから、次の手順に進みます。
4. GCS 通知用に Pub/Sub を設定する
Pub/Sub トピックを作成します。
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
GCS 通知を作成する
data/ 接頭辞でオブジェクトが作成されたときに通知します。
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Pub/Sub サブスクリプションを作成する
推奨される確認応答期限を含めます。
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Cloud SQL から Spanner へのデータの一括移行
Spanner スキーマが作成されたので、Cloud SQL music_db データベースから Cloud Spanner に既存のデータをコピーします。ここでは、JDBC アクセス可能なデータベースから Spanner にデータを一括コピーするように設計された Sourcedb to Spanner Dataflow Flex テンプレートを使用します。
1. music_db の一括移行 Dataflow ジョブを実行する
Cloud Shell で次のコマンドを実行して、Dataflow ジョブを開始します。このコマンドは gcloud dataflow flex-template run コマンドを利用し、JDBC から Spanner への一括移行用に Google が提供するテンプレートを参照します。
export JOB_NAME_MUSIC="mysql-music-db-to-spanner-bulk-$(date +%Y%m%d-%H%M%S)"
export MUSIC_DB_JDBC_URL="jdbc:mysql://${SQL_INSTANCE_IP}:3306/music_db"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration-output"
gcloud dataflow flex-template run $JOB_NAME_MUSIC \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL="$MUSIC_DB_JDBC_URL",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
outputDirectory="$OUTPUT_DIR/music_db",\
username="root",\
password="$DB_ROOT_PASSWORD",\
jdbcDriverClassName="com.mysql.cj.jdbc.Driver",\
jdbcDriverJars="gs://${BUCKET_NAME}/lib/mysql-connector-j-8.0.33.jar",\
spannerHost="https://batch-spanner.googleapis.com"
主なパラメータの説明:
sourceConfigURL: ソースmusic_dbの JDBC 接続文字列。instanceId、databaseId、projectId: ターゲットの Cloud Spanner インスタンスとデータベースを指定します。outputDirectory: 移行に失敗したレコードに関する情報を Dataflow が書き込む Cloud Storage パス。jdbcDriverClassName: MySQL JDBC ドライバを指定します。jdbcDriverJars: ステージングされた JDBC ドライバ JAR の GCS パス。spannerHost: Spanner 書き込みにバッチ最適化エンドポイントを使用します。maxWorkers、numWorkers: Dataflow ジョブのスケーリングを制御します。この小さなデータセットでは低く保たれています。
ネットワークに関する注: このジョブは、パブリック IP 経由で Cloud SQL インスタンスに接続します。これは、以前に 0.0.0.0/0 をインスタンスの承認済みネットワークに追加したためです。これにより、外部 IP を持つ Dataflow ワーカー VM がデータベースにアクセスできるようになります。
2. Dataflow ジョブをモニタリングする
ジョブの進行状況は Google Cloud コンソールで確認できます。
- Dataflow の [ジョブ] ページに移動します。[Dataflow ジョブ] に移動
mysql-music-db-to-spanner-bulk-...という名前のジョブを見つけてクリックします。- ジョブグラフと指標を確認します。ジョブ ステータスが [完了] に変わるまで待ちます。これには約 5 ~ 15 分かかります。
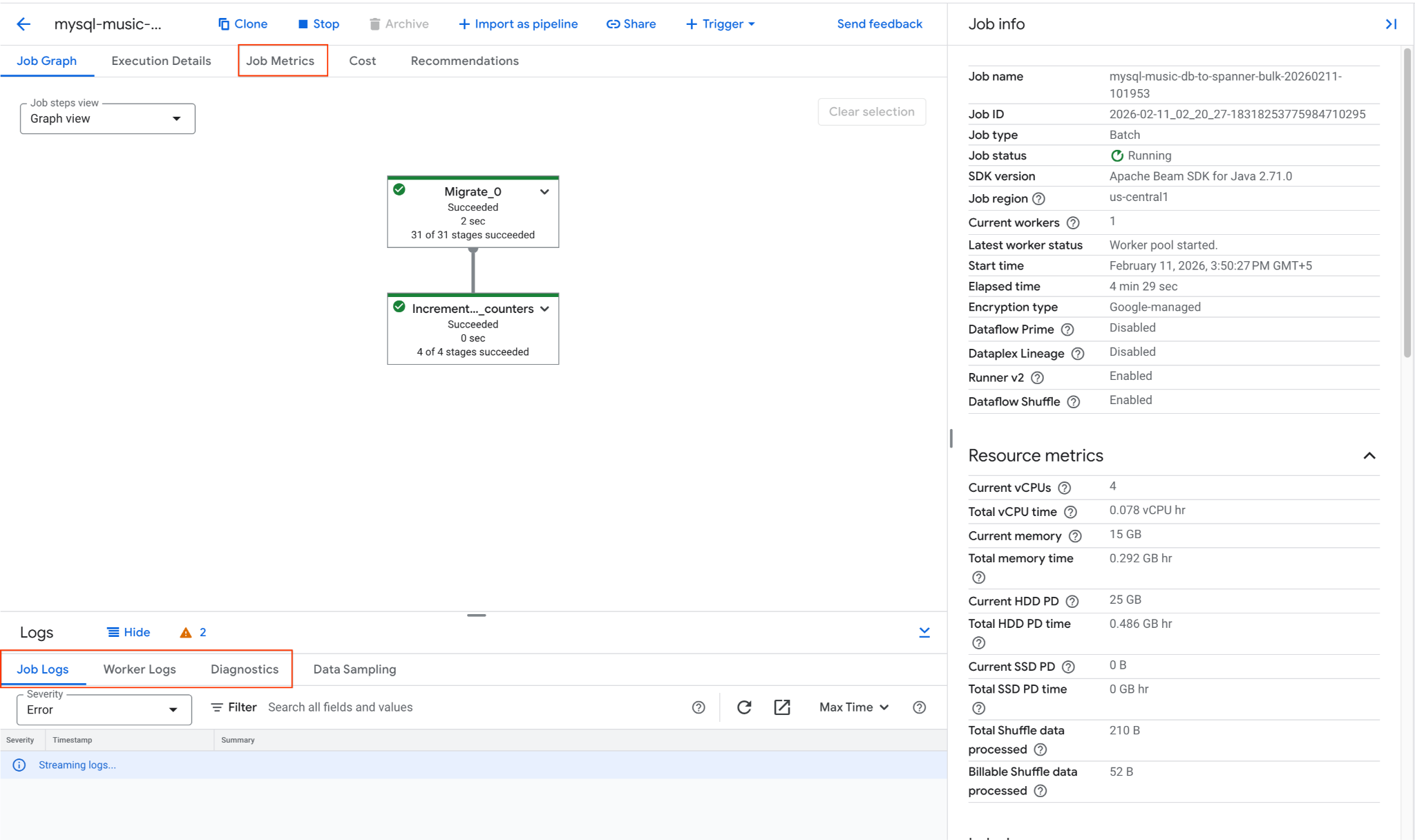
- ジョブで問題が発生した場合は、Dataflow ジョブの詳細ページの [ログ] タブでエラー メッセージを確認します。
- ジョブ指標には、ジョブの進行状況と、スループットや CPU 使用率などのリソース消費量に関する詳細情報が表示されます。
3. Cloud Spanner のデータを確認する
Dataflow ジョブが正常に完了したら、データが Spanner テーブルにコピーされたことを確認します。gcloud を使用して Spanner データベースにクエリを実行します。
# Verify row counts
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Singers"
# Expected output: 3
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Albums"
# Expected output: 6
# Inspect some data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT SingerId, FirstName, LastName FROM Singers ORDER BY SingerId"
予想される出力:
row_count: 3 row_count: 6 SingerId: 1 FirstName: Marc LastName: Richards SingerId: 2 FirstName: Catalina LastName: Smith SingerId: 3 FirstName: Alice LastName: Trentor
Cloud SQL から Cloud Spanner へのデータの初期一括読み込みが完了しました。次のステップでは、進行中の変更をキャプチャするようにライブ レプリケーションを設定します。
9. ライブ マイグレーション(CDC)を開始する
一括データ読み込みが完了したので、Datastream を使用して継続的なレプリケーション ストリームを設定し、Cloud SQL から変更データ キャプチャ(CDC)イベントをキャプチャします。また、Dataflow ストリーミング ジョブを使用して、これらの変更をほぼリアルタイムで Cloud Spanner に適用します。
1. ライブ マイグレーション Dataflow ジョブを実行する
ストリーミング Dataflow ジョブを起動して、GCS から読み取り、Spanner に書き込みます。このテンプレートは、GCS Pub/Sub 通知を使用して新しいファイルを即座に処理します。
export JOB_NAME_CDC="datastream-to-spanner-cdc-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR="gs://${BUCKET_NAME}/dlq"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
deadLetterQueueDirectory="$DLQ_DIR",\
streamName="projects/${PROJECT_ID}/locations/${REGION}/streams/${STREAM_NAME}"
主なパラメータ
gcsPubSubSubscription: GCS からの新しいファイル通知をリッスンする Pub/Sub サブスクリプション。これにより、Datastream が変更を書き込むと、ジョブは変更を即座に処理できます。inputFileFormat="avro": Datastream から Avro ファイルが送信されることを Dataflow に伝えます。これは、Datastream の [宛先] 構成(avroFileFormatとjsonFileFormatなど)と一致している必要があります。deadLetterQueueDirectory: ジョブが処理に失敗したレコード(スキーマの不一致など)を保存し、後で手動で確認するための GCS パス。streamName: Datastream ストリームの完全なリソースパス。これにより、Dataflow ジョブはレプリケーションの状態とメタデータを追跡できます。
Dataflow ジョブ コンソールでジョブの起動をモニタリングします。
2. ライブ マイグレーションをテストする
ソース Cloud SQL music_db に変更を適用して、CDC パイプラインをテストします。
Cloud SQL に接続します。
mysql -h $SQL_INSTANCE_IP -u root -p
パスワード(Welcome@1)を入力して、データベースを選択します。
USE music_db;
-- INSERT
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (4, 'Elena', 'Nadal', '1985-05-30', 0);
SELECT * FROM Singers WHERE SingerId = 4;
-- UPDATE
UPDATE Singers SET LastName = 'Richards-Smith' WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- DELETE
DELETE FROM Albums WHERE SingerId = 2;
DELETE FROM Singers WHERE SingerId = 2;
SELECT * FROM Singers WHERE SingerId = 2;
EXIT;
Spanner での検証(数分後):
# Verify INSERT: This should return the new row for Elena Nadal.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 4"
# Verify UPDATE: This should show LastName as Richards-Smith.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName FROM Singers WHERE SingerId = 1"
# Verify DELETE: This should now return 0 rows.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Albums WHERE SingerId = 2"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 2"
予想される出力:
SingerId: 4 FirstName: Elena LastName: Nadal BirthDate: 1985-05-30 AlbumCount: 0 SingerId: 1 FirstName: Marc LastName: Richards-Smith
3. Spanner での最終確認
Spanner の Singers テーブルの全体的な状態を確認します。
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId"
予想される出力:
SingerId: 1 FirstName: Marc LastName: Richards-Smith AlbumCount: 2 SingerId: 3 FirstName: Alice LastName: Trentor AlbumCount: 3 SingerId: 4 FirstName: Elena LastName: Nadal AlbumCount: 0
10. 逆レプリケーションを設定する(Spanner から Cloud SQL)
ロールバックが必要になるシナリオや、Cloud SQL データベースを Spanner と一定期間同期する必要があるシナリオに対応するには、逆レプリケーションを設定します。このパイプラインは、Spanner Change Streams を使用して Spanner の変更をキャプチャし、Cloud SQL music_db に書き戻します。
1. Spanner 変更ストリームを作成する
まず、Spanner データベースに Singers テーブルと Albums テーブルの変更を追跡する変更ストリームを作成する必要があります。
export CHANGE_STREAM_NAME="MusicDBChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Singers, Albums"
この変更ストリームは、指定されたテーブルに対するすべてのデータ変更を記録するようになります。
2. Dataflow メタデータ用の Spanner データベースを作成する
Spanner to SourceDB Dataflow テンプレートでは、変更ストリームの使用量を管理するためのメタデータを保存するために、別の Spanner データベースが必要です。
export SPANNER_METADATA_DB_NAME="reverse-replication-metadata"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Dataflow 用の Cloud SQL 接続構成を準備する
Dataflow テンプレートには、ターゲット Cloud SQL データベースの接続詳細を含む Cloud Storage 内の JSON ファイルが必要です。
shard_config.json という名前のローカル ファイルを作成します。
cat << EOF > shard_config.json
[
{
"logicalShardId": "mysql_shard",
"host": "${SQL_INSTANCE_IP}",
"port": "3306",
"user": "root",
"password": "${DB_ROOT_PASSWORD}",
"dbName": "music_db"
}
]
EOF
このファイルを GCS バケットにアップロードします。
export SHARD_CONFIG_FILE="gs://${BUCKET_NAME}/shard_config.json"
gcloud storage cp shard_config.json $SHARD_CONFIG_FILE
4. リバース レプリケーションの Dataflow ジョブを実行する
Spanner_to_SourceDb Flex テンプレートを使用して Dataflow ジョブを起動します。
export JOB_NAME_REVERSE="spanner-to-mysql-reverse-$(date +%Y%m%d-%H%M%S)"
export REVERSE_DLQ_DIR="gs://${BUCKET_NAME}/reverse-dlq"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$SHARD_CONFIG_FILE",\
deadLetterQueueDirectory="$REVERSE_DLQ_DIR"
主なパラメータ
changeStreamName: 読み取る Spanner 変更ストリームの名前。metadataInstance, metadataDatabase: コネクタが変更ストリーム API データの使用量を制御するために使用するメタデータを保存する Spanner インスタンス/データベース。sourceShardsFilePath:shard_config.jsonの GCS パス。filtrationMode: 条件に基づいて特定のレコードを削除する方法を指定します。デフォルトはforward_migration(前方移行パイプラインを使用して書き込まれたレコードをフィルタする)です。
ネットワークに関する注: Dataflow ワーカーは、shard_config.json で指定されたパブリック IP を使用して Cloud SQL インスタンスに接続します。この接続は、Cloud SQL インスタンスの承認済みネットワークの 0.0.0.0/0 エントリによって許可されています。
Dataflow ジョブ コンソールでジョブの起動をモニタリングします。
5. リバース レプリケーションをテストする
次に、Cloud Spanner で直接変更を行い、その変更が Cloud SQL に反映されていることを確認します。これは、Dataflow ジョブが開始され、処理状態になった場合にのみ行います。
INSERT、UPDATE、DELETE をテストする
# INSERT: Insert a new singer (SingerId 5) into Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (5, 'David', 'Chen', '1995-02-18', 0)"
# UPDATE: Update SingerId 3's AlbumCount in Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Singers SET AlbumCount = 5 WHERE SingerId = 3"
# DELETE: Delete SingerId 1 from Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Albums WHERE SingerId = 1"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Singers WHERE SingerId = 1"
Cloud SQL での確認(数分後):
Cloud SQL に接続します。
mysql -h $SQL_INSTANCE_IP -u root -p
プロンプトが表示されたらパスワード(Welcome@1)を入力し、mysql> プロンプトで次の SQL コマンドを実行します。
USE music_db;
-- Verify INSERT: This should show the new row for David Chen
SELECT * FROM Singers WHERE SingerId = 5;
-- Verify UPDATE: This should show AlbumCount as 5.
SELECT SingerId, FirstName, AlbumCount FROM Singers WHERE SingerId = 3;
-- Verify DELETE: This should return an empty set.
SELECT * FROM Albums WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- Final Verification
SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId;
EXIT;
Cloud SQL の出力は、Spanner で行われた変更を反映している必要があります。
+----------+-----------+----------------+------------+ | SingerId | FirstName | LastName | AlbumCount | +----------+-----------+----------------+------------+ | 3 | Alice | Trentor | 5 | | 4 | Elena | Nadal | 0 | | 5 | David | Chen | 0 | +----------+-----------+----------------+------------+
これにより、リバース レプリケーション パイプラインが機能し、Spanner から Cloud SQL に変更が同期されていることを確認できます。
11. リソースをクリーンアップする
Google Cloud アカウントに課金されないようにするには、この Codelab で作成したリソースを削除します。
環境変数を設定する(必要な場合)
環境変数が正しく設定されているかどうかを確認します。
echo "PROJECT_ID: $PROJECT_ID"
echo "REGION: $REGION"
echo "SQL_INSTANCE_NAME: $SQL_INSTANCE_NAME"
echo "SPANNER_INSTANCE_NAME: $SPANNER_INSTANCE_NAME"
echo "BUCKET_NAME: $BUCKET_NAME"
echo "STREAM_NAME: $STREAM_NAME"
echo "SQL_CP_NAME: $SQL_CP_NAME"
echo "GCS_CP_NAME: $GCS_CP_NAME"
echo "PUBSUB_SUBSCRIPTION: $PUBSUB_SUBSCRIPTION"
echo "PUBSUB_TOPIC: $PUBSUB_TOPIC"
echo "CHANGE_STREAM_NAME: $CHANGE_STREAM_NAME"
ジョブを一覧表示して、実行中の Dataflow ジョブのジョブ ID を確認します。必要に応じて JOB_ID_CDC と JOB_ID_REVERSE をエクスポートします。
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
新しい Cloud Shell セッションの場合は、キー環境変数を再度エクスポートします。
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or the region you used
export SQL_INSTANCE_NAME="source-mysql-instance"
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export STREAM_NAME="mysql-to-spanner-stream"
export SQL_CP_NAME="mysql-src-cp"
export GCS_CP_NAME="gcs-dest-cp"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CHANGE_STREAM_NAME="MusicDBChangeStream"
Dataflow ストリーミング ジョブを停止する
Datastream to Spanner(ライブ マイグレーション)ジョブをキャンセルします。
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
Spanner to Cloud SQL(逆レプリケーション)ジョブをキャンセルします。
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Datastream リソースを削除する
ストリームを停止して削除します。
gcloud datastream streams update $STREAM_NAME \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
接続プロファイルを削除する
gcloud datastream connection-profiles delete $SQL_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Pub/Sub リソースを削除する
サブスクリプションの削除:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
トピックを削除:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Cloud SQL インスタンスを削除する
これにより、その中のデータベース(music_db)が自動的に削除されます。
gcloud sql instances delete $SQL_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Cloud Spanner インスタンスを削除する
この操作を行うと、その中のデータベース(music-db-migrated と reverse-replication-metadata)も削除されます。
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
GCS バケットとコンテンツを削除する
gcloud storage rm --recursive gs://${BUCKET_NAME}
ローカル ファイルを削除する
Cloud Shell ホーム ディレクトリに生成されたファイルを削除します。
rm -f music-db* shard_config.json
これで、この Codelab で作成したリソースをクリーンアップしました。