
1. Zanim zaczniesz
To ćwiczenie przeprowadzi Cię przez proces migracji pojedynczej bazy danych MySQL w Cloud SQL do bazy danych Cloud Spanner z dialektem GoogleSQL. Skupiamy się na podstawowym przepływie migracji od początku do końca, pokazującym najważniejsze kroki. Będziesz korzystać z usług Google Cloud, w tym z narzędzia do migracji Spanner (SMT), Dataflow, Datastream, PubSub i Google Cloud Storage.
Czego się dowiesz:
- Jak skonfigurować przykładowe instancje Cloud SQL i Cloud Spanner.
- Jak przekonwertować schemat Cloud SQL MySQL na schemat zgodny ze Spannerem za pomocą narzędzia Spanner Migration Tool (SMT).
- Jak przeprowadzić migrację zbiorczą danych z Cloud SQL do Cloud Spanner za pomocą Dataflow.
- Jak skonfigurować ciągłą replikację (CDC) z Cloud SQL do Cloud Spanner za pomocą Datastream i Dataflow.
- Jak skonfigurować replikację zwrotną z Cloud Spanner do Cloud SQL.
Czego nie obejmuje to ćwiczenie:
- Migracje z instancji podzielonych na fragmenty.
- skomplikowane przekształcenia danych podczas migracji;
- zaawansowaną obsługę błędów lub kolejki niedostarczonych komunikatów (DLQ);
- Dostrajanie wydajności migracji.
- Migracja aplikacji: ten przewodnik skupia się na warstwie bazy danych (schemat i dane). Nie obejmuje to procesu operacyjnego ponownego wdrażania ani migracji usług aplikacji.
Czego potrzebujesz
- Projekt Google Cloud z włączonymi płatnościami.
- Odpowiednie uprawnienia IAM do włączania interfejsów API oraz tworzenia zasobów Cloud SQL, Spanner, Dataflow, Datastream i GCS oraz zarządzania nimi. Rola Projektu
Ownerjest najprostsza w przypadku ćwiczenia w Codelabs, ale bardziej szczegółowe role zostaną omówione w sekcji „Konfiguracja środowiska”. - przeglądarkę, np. Google Chrome;
- Podstawowa znajomość konsoli Google Cloud i narzędzi wiersza poleceń, takich jak
gcloud. - Dostęp do środowiska powłoki. Zalecamy korzystanie z Cloud Shell, ponieważ zawiera ona
gcloud.
Więcej informacji o powyższej konfiguracji znajdziesz w sekcji Konfigurowanie środowiska.
2. Omówienie procesu migracji
Migracja bazy danych polega na przeniesieniu danych ze źródłowej instancji bazy danych Cloud SQL do instancji Spanner. W tej sekcji opisujemy architekturę i najważniejsze narzędzia używane podczas migracji.
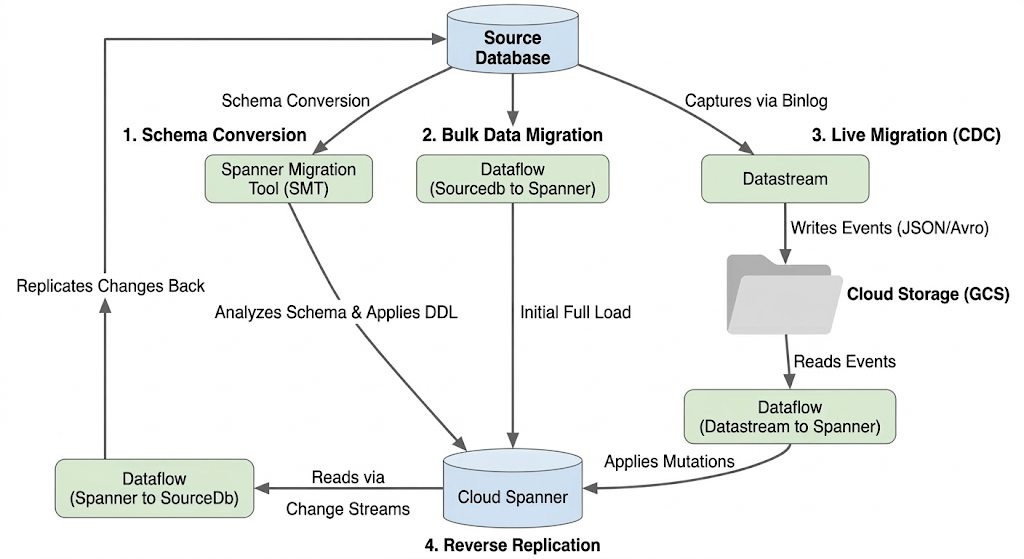
Architektura procesu migracji
Proces migracji obejmuje te etapy:
1. Konwersja schematu:
- Cel: przekonwertowanie schematu źródłowej bazy danych na zgodny schemat Cloud Spanner.
- Narzędzie: narzędzie do migracji usługi Spanner (SMT)
- Proces: SMT analizuje schemat źródłowej bazy danych i generuje odpowiedni język definiowania danych (DDL) w Spannerze. W docelowej instancji Spanner zostanie utworzona baza danych, a następnie automatycznie zastosowany DDL.
2. Migracja danych zbiorczych:
- Cel: przeprowadzenie wstępnego, pełnego wczytania istniejących danych ze źródłowej bazy danych do udostępnionych tabel Spanner.
- Narzędzie: Dataflow z użyciem dostarczonego przez Google
Sourcedb to Spannerszablonu. - Proces: to zadanie Dataflow odczytuje wszystkie dane z określonych tabel źródłowych i zapisuje je w odpowiednich tabelach Spannera. Odbywa się to po utworzeniu schematu Spanner.
3. Migracja na żywo (CDC):
- Cel: rejestrowanie i stosowanie bieżących zmian z bazy danych źródłowej w Cloud Spanner w czasie zbliżonym do rzeczywistego, co minimalizuje czas przestoju podczas migracji.
- Narzędzia:
- Datastream: przechwytuje zmiany (wstawienia, aktualizacje, usunięcia) ze źródłowej bazy danych i zapisuje je w Cloud Storage (GCS).
- Dataflow: Używa szablonu
Datastream to Spannerdo odczytywania zdarzeń zmiany z GCS i stosowania ich w Cloud Spanner.
4. Replikacja odwrotna:
- Cel: replikowanie zmian danych z Cloud Spanner z powrotem do źródłowej bazy danych. Może to być przydatne w przypadku strategii rezerwowych, migracji etapowych lub utrzymywania repliki w źródle w określonych przypadkach użycia.
- Narzędzie: Dataflow, przy użyciu
Spanner to SourceDbszablonu. - Proces: to zadanie wykorzystuje strumienie zmian w usłudze Spanner do rejestrowania modyfikacji w usłudze Spanner i zapisywania ich z powrotem w instancji źródłowej bazy danych.
Ten diagram przedstawia komponenty i przepływ danych:
Kluczowe terminy:
- Narzędzie do migracji Spanner (SMT): narzędzie służące do oceny schematów MySQL, sugerowania odpowiedników schematów Spanner i generowania języka definiowania danych (DDL) Spanner.
- Język definiowania danych (DDL): instrukcje używane do definiowania i modyfikowania struktury bazy danych, np. instrukcje
CREATE TABLE. SMT generuje język DDL Spanner na podstawie schematu Cloud SQL. - Dataflow: usługa w pełni zarządzana i bezserwerowa do przetwarzania danych. W tym ćwiczeniu jest on używany do uruchamiania udostępnionych przez Google szablonów do przenoszenia danych zbiorczych, stosowania zmian w Datastream i replikacji zwrotnej.
- Datastream: bezserwerowa usługa do replikacji i przechwytywania zmian danych (CDC). W tym ćwiczeniu jest on używany do przesyłania strumieniowego zmian z Cloud SQL do Cloud Storage.
- Strumienie zmian w usłudze Spanner: funkcja Spannera, która umożliwia strumieniowe przesyłanie zmian danych (wstawień, aktualizacji i usunięć) w czasie rzeczywistym. Jest używana jako źródło replikacji zwrotnej.
- Pub/Sub: usługa do przesyłania wiadomości, która służy do oddzielania usług generujących zdarzenia od usług, które je przetwarzają. W tym ćwiczeniu w Codelabs wywołuje Dataflow do przetwarzania aktualizacji za każdym razem, gdy Datastream przesyła nowe pliki zmian do Cloud Storage.
3. Konfiguracja środowiska
Zanim rozpoczniesz migrację, musisz skonfigurować projekt Google Cloud i włączyć niezbędne usługi.
1. Wybieranie lub tworzenie projektu Google Cloud
Aby korzystać z usług w tym ćwiczeniu, musisz mieć projekt Google Cloud z włączonym rozliczeniem.
- W konsoli Google Cloud otwórz stronę selektora projektów: Otwórz selektor projektów
- Wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie włączone są płatności.
2. Otwieranie Cloud Shell
Cloud Shell to środowisko wiersza poleceń działające w Google Cloud, które zawiera zainstalowany interfejs gcloud i inne potrzebne narzędzia.
- W prawym górnym rogu konsoli Google Cloud kliknij przycisk Aktywuj Cloud Shell.
- Sesja Cloud Shell otworzy się w nowej ramce u dołu konsoli. Zostanie również wyświetlony monit wiersza poleceń.

3. Ustawianie zmiennych projektu i środowiska
W Cloud Shell skonfiguruj zmienne środowiskowe dla identyfikatora projektu i regionu, którego będziesz używać.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Włączanie wymaganych interfejsów Google Cloud API
Włącz interfejsy API niezbędne do korzystania z Cloud Spanner, Dataflow, Datastream i innych powiązanych usług.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Wykonanie tego polecenia może potrwać kilka minut.
5. Konfigurowanie uprawnień konta usługi
Zadania Dataflow i Datastream wymagają określonych uprawnień do interakcji z innymi usługami Google Cloud. Zadania Dataflow w tym ćwiczeniu będą korzystać z domyślnego konta usługi Compute Engine.
Najpierw uzyskaj numer projektu:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
Teraz przyznaj domyślnemu kontu usługi Compute Engine wymagane role uprawnień:
# Role for Dataflow to run jobs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.admin" \
--condition=None
# Roles for Dataflow workers
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.worker" \
--condition=None
# Role to connect to Cloud SQL instance
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudsql.client" \
--condition=None
# Role to read/write from Cloud Spanner
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/spanner.databaseUser" \
--condition=None
# Role to access GCS buckets (Datastream output, Dataflow temp, JDBC driver)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectAdmin" \
--condition=None
# Roles for Datastream and Pub/Sub (for CDC)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastream.viewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/pubsub.subscriber"
6. Tworzenie zasobnika Cloud Storage
Utwórz zasobnik GCS w tym samym regionie co inne zasoby. W tym zasobniku będą przechowywane sterownik JDBC i dane wyjściowe Datastream. Będzie on też używany przez Dataflow do przechowywania plików tymczasowych.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
echo "Created bucket: gs://$BUCKET_NAME"
7. Instalowanie narzędzia Spanner Migration Tool (SMT)
Sprawdź, czy narzędzie Spanner Migration Tool (SMT) jest zainstalowane w środowisku Cloud Shell.
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
To polecenie powinno wyświetlić informacje pomocy dotyczące interfejsu internetowego SMT, potwierdzając, że komponent gcloud jest zainstalowany. W tym ćwiczeniu w Codelabs użyjemy funkcji interfejsu wiersza poleceń SMT, które są częścią tego samego komponentu.
4. Konfigurowanie źródłowej bazy danych Cloud SQL
W tej sekcji utworzysz i skonfigurujesz instancję Cloud SQL for MySQL z publicznym adresem IP, która będzie służyć jako źródłowa baza danych.
1. Tworzenie instancji Cloud SQL for MySQL
Aby utworzyć instancję MySQL 8.0, uruchom w Cloud Shell to polecenie gcloud. Logowanie binarne jest włączone (wymagane w przypadku Datastream), a instancja jest skonfigurowana z publicznym adresem IP.
export SQL_INSTANCE_NAME="source-mysql-instance"
export DB_ROOT_PASSWORD="Welcome@1" # Replace with a strong password if you prefer
gcloud sql instances create $SQL_INSTANCE_NAME \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=$REGION \
--root-password=$DB_ROOT_PASSWORD \
--enable-bin-log \
--assign-ip
--enable-bin-log: wymagane, aby Datastream rejestrował zmiany.--assign-ip: zapewnia, że instancja otrzyma publiczny adres IP.
Tworzenie instancji potrwa kilka minut. Możesz sprawdzić, czy instancja została utworzona, na stronie Instancje Cloud SQL.
2. Konfigurowanie autoryzowanych sieci
Aby połączyć się z instancją za pomocą publicznego adresu IP, musisz dodać adresy IP do listy „Autoryzowane sieci”.
Uzyskaj adres IP Cloud Shell:
export CLOUD_SHELL_IP=$(curl -s ipinfo.io/ip)
echo "Your Cloud Shell IP: $CLOUD_SHELL_IP"
Autoryzowanie adresu IP Cloud Shell i otwartego dostępu
To polecenie dodaje adres IP Cloud Shell. Dodaje też 0.0.0.0/0, co umożliwia dostęp z dowolnego adresu IP. Jest to konieczne, aby uprościć połączenia z instancji roboczych Dataflow bez skomplikowanych konfiguracji sieci.
gcloud sql instances patch $SQL_INSTANCE_NAME \
--authorized-networks="${CLOUD_SHELL_IP}/32,0.0.0.0/0"
3. Nawiązywanie połączenia z instancją Cloud SQL z Cloud Shell
Pobieranie przypisanego publicznego adresu IP
export SQL_INSTANCE_IP=$(gcloud sql instances list --filter="name=$SQL_INSTANCE_NAME" --format="value(PRIMARY_ADDRESS)")
echo "Cloud SQL Public IP: $SQL_INSTANCE_IP"
Ten adres IP zostanie użyty do nawiązania połączenia.
Nawiązywanie połączenia z instancją Cloud SQL z Cloud Shell
Aby się połączyć, użyj standardowego klienta mysql, korzystając z uzyskanego publicznego adresu IP:
mysql -h $SQL_INSTANCE_IP -u root -p
Gdy pojawi się prośba, wpisz ustawione hasło roota (Welcome@1). Zobaczysz teraz wiersz poleceń mysql>.
4. Tworzenie bazy danych i przykładowych danych
W wierszu poleceń mysql> uruchom te polecenia SQL:
CREATE DATABASE music_db;
USE music_db;
CREATE TABLE Singers (
SingerId BIGINT NOT NULL,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
BirthDate DATE,
AlbumCount BIGINT,
PRIMARY KEY (SingerId)
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY (SingerId, AlbumId),
CONSTRAINT FK_Albums_Singers FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
);
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES
(1, 'Marc', 'Richards', '1970-09-03', 2),
(2, 'Catalina', 'Smith', '1990-08-17', 1),
(3, 'Alice', 'Trentor', '1991-10-02', 3);
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle, ReleaseDate) VALUES
(1, 1, 'Total Junk', '2014-03-15'),
(1, 2, 'Go Go Go', '2016-11-01'),
(2, 1, 'Green', '2018-02-28'),
(3, 1, 'Blue', '2019-01-10'),
(3, 2, 'Red', '2020-05-22'),
(3, 3, 'Purple', '2022-11-11');
Plik zrzutu dla powyższego schematu znajdziesz tutaj.
5. Weryfikacja danych
Szybko sprawdź, czy dane są dostępne:
SELECT 'Singers music_db' as tbl, COUNT(*) FROM music_db.Singers
UNION ALL
SELECT 'Albums music_db', COUNT(*) FROM music_db.Albums;
EXIT;
Powinny być widoczne liczby dla każdej tabeli.
+------------------+----------+ | tbl | COUNT(*) | +------------------+----------+ | Singers music_db | 3 | | Albums music_db | 6 | +------------------+----------+
5. Konfigurowanie Cloud Spanner
Teraz skonfigurujesz docelową instancję Cloud Spanner, do której zostaną przeniesione dane.
1. Tworzenie instancji Cloud Spanner
Utwórz instancję Cloud Spanner w tym samym regionie co instancja Cloud SQL. To polecenie tworzy małą instancję odpowiednią do tego ćwiczenia, która wykorzystuje 100 jednostek przetwarzania.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="music-db-migrated"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
Tworzenie instancji może potrwać minutę lub dwie.
6. Konwertowanie schematu za pomocą narzędzia Spanner Migration Tool (SMT)
Użyj interfejsu SMT CLI, aby przeanalizować bazę danych MySQL (music_db) i wygenerować język definicji schematu Spanner (DDL). Instancja Cloud SQL jest skonfigurowana z publicznym adresem IP i odpowiednimi autoryzowanymi sieciami, więc SMT może łączyć się bezpośrednio.
1. Przygotowywanie środowiska pod kątem SMT
Sprawdź, czy zmienne środowiskowe zostały ustawione w poprzednich krokach:
echo "Cloud SQL Instance Public IP: $SQL_INSTANCE_IP"
echo "Cloud SQL Root Password: $DB_ROOT_PASSWORD"
echo "Spanner Instance: $SPANNER_INSTANCE_NAME"
echo "Spanner Database: $SPANNER_DATABASE_NAME"
echo "Project ID: $PROJECT_ID"
2. Uruchom konwersję schematu dla music_db
Wykonaj polecenie SMT schema, łącząc się bezpośrednio z publicznym adresem IP Cloud SQL:
gcloud alpha spanner migrate schema \
--source=mysql \
--source-profile="host=${SQL_INSTANCE_IP},port=3306,user=root,password=${DB_ROOT_PASSWORD},dbName=music_db" \
--target-profile="project=${PROJECT_ID},instance=${SPANNER_INSTANCE_NAME},dbName=${SPANNER_DATABASE_NAME}" \
--prefix="music-db"
To polecenie łączy się z instancją Cloud SQL za pomocą serwera proxy i generuje pliki schematu z prefiksem music-db.
3. Sprawdzanie wygenerowanych plików
Narzędzie SMT utworzy kilka plików w bieżącym katalogu. Najważniejsze z nich to:
music-db.schema.ddl.txt: wygenerowane instrukcje DDL usługi Spanner.music-db-.overrides.json: plik zastąpień schematu zawierający ręcznie wprowadzone zmiany mapowania.music-db.session.json: Plik sesji migracji schematu.music-db.report.txt: raport oceniający konwersję schematu.
Możesz je wyświetlić za pomocą ls music-db-*
4. Weryfikowanie schematu w Cloud Spanner
Sprawdź, czy tabele zostały utworzone w bazie danych Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Powinny się wyświetlić te dane wyjściowe:
table_name: Albums table_name: Singers
Opcjonalnie: jeśli chcesz sprawdzić język DDL Spanner, uruchom to polecenie:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
7. Inicjowanie przechwytywania zmian danych
W tej sekcji skonfigurujesz „rejestrator” migracji. Skonfiguruj Datastream i Pub/Sub, zanim rozpocznie się ładowanie zbiorcze danych. Dzięki temu każda zmiana wprowadzona w źródłowej bazie danych zostanie zarejestrowana i umieszczona w kolejce, co zapobiegnie utracie danych podczas przejścia. Ta konfiguracja jest wymagana w przypadku migracji na żywo.
1. Tworzenie profili połączeń Datastream
Profil źródłowy (Cloud SQL)
Ten profil łączy się z publicznym adresem IP instancji Cloud SQL. Datastream będzie używać list dozwolonych adresów IP do nawiązywania połączeń.
export SQL_CP_NAME="mysql-src-cp"
gcloud datastream connection-profiles create $SQL_CP_NAME \
--location=$REGION \
--type=mysql \
--mysql-hostname=$SQL_INSTANCE_IP \
--mysql-port=3306 \
--mysql-username=root \
--mysql-password=$DB_ROOT_PASSWORD \
--display-name="Cloud SQL Source - Public IP"
Uwaga: to połączenie zależy od tego, czy autoryzowane sieci instancji Cloud SQL zezwalają na dostęp. Zgodnie z wcześniejszą konfiguracją 0.0.0.0/0 publiczne adresy IP Datastream mogą się łączyć. W środowisku produkcyjnym zastąp 0.0.0.0/0 konkretnymi zakresami adresów IP dla Twojego regionu, które znajdziesz w artykule Listy dozwolonych adresów IP i regionów Datastream.
Profil miejsca docelowego (Cloud Storage)
Wskazuje katalog główny zasobnika.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
2. Tworzenie strumienia Datastream
Utwórz strumień do replikacji z music_db.
export STREAM_NAME="mysql-to-spanner-stream"
export GCS_STREAM_PATH="data/${STREAM_NAME}"
gcloud datastream streams create $STREAM_NAME \
--location=$REGION \
--display-name="MySQL to Spanner CDC Stream" \
--source=$SQL_CP_NAME \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "
includeObjects:
mysqlDatabases:
- database: 'music_db'
") \
--gcs-destination-config=<(echo "
path: ${GCS_STREAM_PATH}
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}
") \
--backfill-none
- Datastream będzie zapisywać pliki w folderze
gs://${BUCKET_NAME}/${GCS_STREAM_PREFIX}/. - Datastream będzie zapisywać pliki w formacie Avro. Podczas uruchamiania polecenia migracji na żywo określimy format inputFileFormat jako avro, aby potok mógł prawidłowo przetworzyć plik.
- Używanie mniejszych ustawień rotacji plików pomaga szybciej zobaczyć zmiany w ćwiczeniu w Codelabs.
Wykonanie tego polecenia może trochę potrwać. Sprawdź stan: gcloud datastream streams describe $STREAM_NAME --location=$REGION.
3. Uruchamianie strumienia Datastream
gcloud datastream streams update $STREAM_NAME \
--location=$REGION \
--state=RUNNING
Sprawdź stan: gcloud datastream streams describe $STREAM_NAME --location=$REGION. początkowo stan będzie STARTING, a po pewnym czasie zmieni się na RUNNING. Przejdź do następnego kroku dopiero po potwierdzeniu, że jest w stanie RUNNING.
4. Konfigurowanie Pub/Sub na potrzeby powiadomień GCS
Utwórz temat Pub/Sub:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
Tworzenie powiadomienia GCS
Powiadamianie o tworzeniu obiektów z prefiksem data/.
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Tworzenie subskrypcji Pub/Sub
Podaj zalecany termin potwierdzenia.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Zbiorcza migracja danych z Cloud SQL do Spanner
Po utworzeniu schematu Spanner skopiujesz istniejące dane z bazy danych Cloud SQLmusic_db do Cloud Spanner. Użyjesz Sourcedb to Spanner elastycznego szablonu Dataflow, który jest przeznaczony do kopiowania zbiorczego danych z baz danych dostępnych przez JDBC do Spannera.
1. Uruchomienie zadania Dataflow do migracji zbiorczej w przypadku music_db
Aby uruchomić zadanie Dataflow, wykonaj w Cloud Shell to polecenie: To polecenie korzysta z polecenia gcloud dataflow flex-template run, które odwołuje się do udostępnionego przez Google szablonu migracji zbiorczych z JDBC do Spannera.
export JOB_NAME_MUSIC="mysql-music-db-to-spanner-bulk-$(date +%Y%m%d-%H%M%S)"
export MUSIC_DB_JDBC_URL="jdbc:mysql://${SQL_INSTANCE_IP}:3306/music_db"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration-output"
gcloud dataflow flex-template run $JOB_NAME_MUSIC \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL="$MUSIC_DB_JDBC_URL",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
outputDirectory="$OUTPUT_DIR/music_db",\
username="root",\
password="$DB_ROOT_PASSWORD",\
jdbcDriverClassName="com.mysql.cj.jdbc.Driver",\
jdbcDriverJars="gs://${BUCKET_NAME}/lib/mysql-connector-j-8.0.33.jar",\
spannerHost="https://batch-spanner.googleapis.com"
Wyjaśnienie kluczowych parametrów:
sourceConfigURL: ciąg znaków połączenia JDBC dla źródłamusic_db.instanceId,databaseId,projectId: określa docelową instancję i bazę danych Cloud Spanner.outputDirectory: ścieżka w Cloud Storage, w której Dataflow będzie zapisywać informacje o rekordach, których nie udało się przenieść.jdbcDriverClassName: określa sterownik JDBC MySQL.jdbcDriverJars: ścieżka GCS do przygotowanego pliku JAR sterownika JDBC.spannerHost: używa punktu końcowego zoptymalizowanego pod kątem przetwarzania wsadowego do zapisów w Spannerze.maxWorkers,numWorkers: kontroluje skalowanie zadania Dataflow. W przypadku tego małego zbioru danych jest ona niska.
Uwaga dotycząca sieci: to zadanie łączy się z instancją Cloud SQL za pomocą publicznego adresu IP. Jest to możliwe, ponieważ wcześniej dodano 0.0.0.0/0 do autoryzowanych sieci instancji. Umożliwia to maszynom wirtualnym Dataflow z zewnętrznymi adresami IP dostęp do bazy danych.
2. Monitorowanie zadania Dataflow
Postęp zadania możesz śledzić w konsoli Google Cloud:
- Otwórz stronę Zadania Dataflow: Otwórz stronę Zadania Dataflow
- Znajdź zadanie o nazwie
mysql-music-db-to-spanner-bulk-...i kliknij je. - Przyjrzyj się wykresowi zadania i jego danym. Poczekaj, aż stan zadania zmieni się na Ukończono. Powinno to zająć około 5–15 minut.
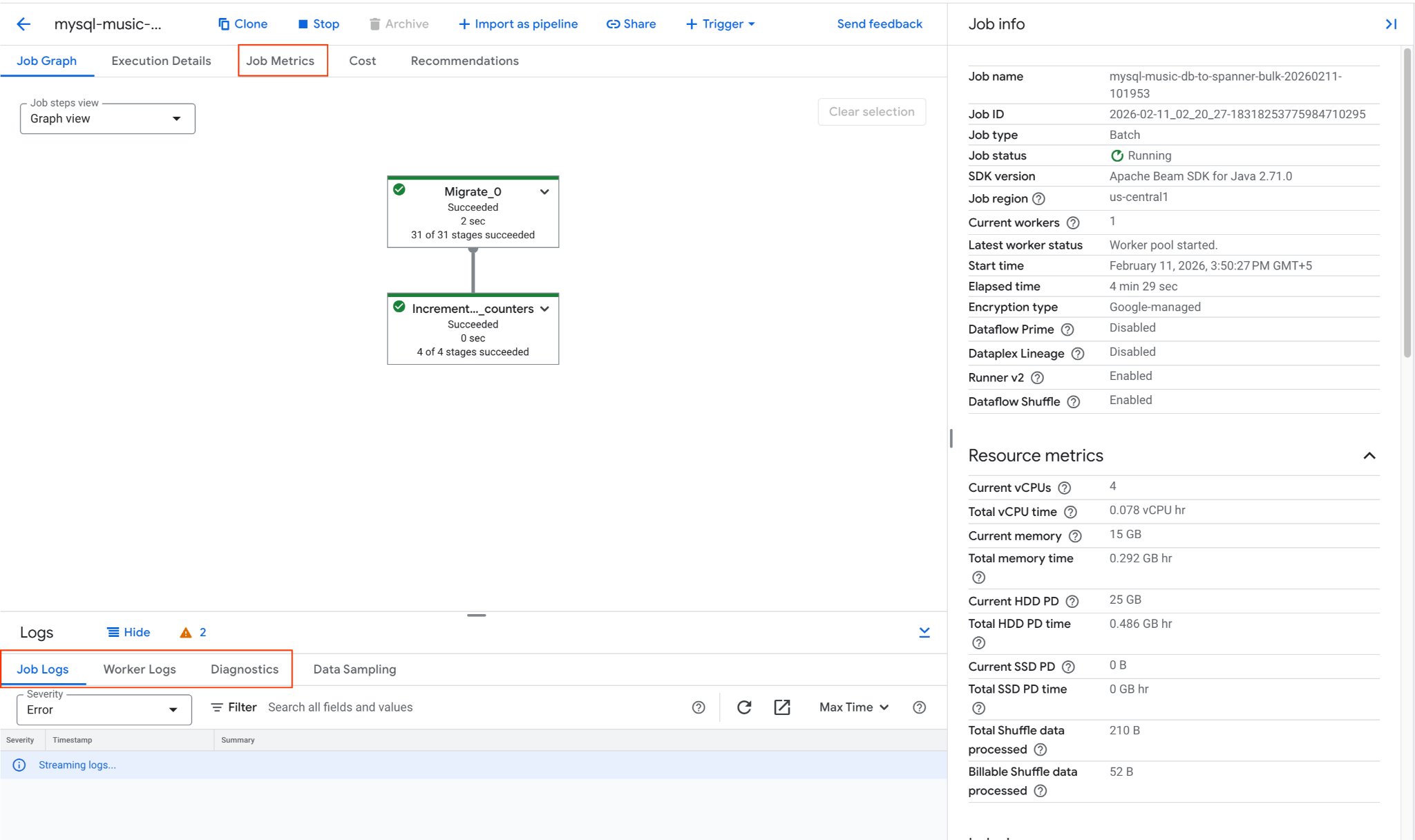
- Jeśli zadanie napotka problemy, na karcie Logi na stronie szczegółów zadania Dataflow sprawdź komunikaty o błędach.
- Dane zadania zawierają więcej informacji o postępach zadania i zużyciu zasobów, takich jak przepustowość i wykorzystanie procesora.
3. Weryfikowanie danych w Cloud Spanner
Po pomyślnym zakończeniu zadania Dataflow sprawdź, czy dane zostały skopiowane do tabel Spanner. Użyj gcloud, aby wysłać zapytanie do bazy danych Spanner:
# Verify row counts
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Singers"
# Expected output: 3
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Albums"
# Expected output: 6
# Inspect some data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT SingerId, FirstName, LastName FROM Singers ORDER BY SingerId"
Oczekiwane dane wyjściowe:
row_count: 3 row_count: 6 SingerId: 1 FirstName: Marc LastName: Richards SingerId: 2 FirstName: Catalina LastName: Smith SingerId: 3 FirstName: Alice LastName: Trentor
Początkowe wczytywanie zbiorcze danych z Cloud SQL do Cloud Spanner zostało zakończone. Następnym krokiem jest skonfigurowanie replikacji na żywo, aby rejestrować bieżące zmiany.
9. Rozpocznij migrację na żywo (CDC)
Po zakończeniu wczytywania danych zbiorczych skonfigurujesz ciągły strumień replikacji za pomocą Datastream, aby przechwytywać zdarzenia przechwytywania zmian danych (CDC) z Cloud SQL, oraz zadanie przesyłania strumieniowego Dataflow, aby wprowadzać te zmiany w Cloud Spanner w czasie zbliżonym do rzeczywistego.
1. Uruchamianie zadania Dataflow migracji na żywo
Uruchom strumieniowe zadanie Dataflow, aby odczytywać dane z GCS i zapisywać je w Spannerze. Ten szablon będzie używać powiadomień GCS Pub/Sub do natychmiastowego przetwarzania nowych plików.
export JOB_NAME_CDC="datastream-to-spanner-cdc-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR="gs://${BUCKET_NAME}/dlq"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
deadLetterQueueDirectory="$DLQ_DIR",\
streamName="projects/${PROJECT_ID}/locations/${REGION}/streams/${STREAM_NAME}"
Kluczowe parametry
gcsPubSubSubscription: subskrypcja Pub/Sub, która nasłuchuje powiadomień o nowych plikach z GCS. Dzięki temu zadanie może przetwarzać zmiany natychmiast po ich zapisaniu przez Datastream.inputFileFormat="avro": informuje Dataflow, że ma oczekiwać plików Avro z Datastream. Musi to być zgodne z konfiguracją „Miejsca docelowego” w Datastream (np.avroFileFormatvs.jsonFileFormat).deadLetterQueueDirectory: ścieżka GCS, w której zadanie przechowuje rekordy, których nie udało się przetworzyć (np. z powodu niezgodności schematu), aby można je było później sprawdzić ręcznie.streamName: pełna ścieżka zasobu strumienia Datastream, która umożliwia zadaniu Dataflow śledzenie stanu replikacji i metadanych.
Monitoruj uruchamianie zadania w konsoli zadań Dataflow.
2. Testowanie migracji na żywo
Zastosuj zmiany w źródłowej bazie danych Cloud SQL music_db, aby przetestować potok CDC.
Połącz się z Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
Wpisz hasło (Welcome@1) i wybierz bazę danych:
USE music_db;
-- INSERT
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (4, 'Elena', 'Nadal', '1985-05-30', 0);
SELECT * FROM Singers WHERE SingerId = 4;
-- UPDATE
UPDATE Singers SET LastName = 'Richards-Smith' WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- DELETE
DELETE FROM Albums WHERE SingerId = 2;
DELETE FROM Singers WHERE SingerId = 2;
SELECT * FROM Singers WHERE SingerId = 2;
EXIT;
Weryfikacja w Spannerze (po chwili):
# Verify INSERT: This should return the new row for Elena Nadal.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 4"
# Verify UPDATE: This should show LastName as Richards-Smith.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName FROM Singers WHERE SingerId = 1"
# Verify DELETE: This should now return 0 rows.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Albums WHERE SingerId = 2"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 2"
Oczekiwane dane wyjściowe:
SingerId: 4 FirstName: Elena LastName: Nadal BirthDate: 1985-05-30 AlbumCount: 0 SingerId: 1 FirstName: Marc LastName: Richards-Smith
3. Weryfikacja końcowa w Spannerze
Sprawdź ogólny stan tabeli Singers w usłudze Spanner:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId"
Oczekiwane dane wyjściowe:
SingerId: 1 FirstName: Marc LastName: Richards-Smith AlbumCount: 2 SingerId: 3 FirstName: Alice LastName: Trentor AlbumCount: 3 SingerId: 4 FirstName: Elena LastName: Nadal AlbumCount: 0
10. Konfigurowanie replikacji zwrotnej (Spanner do Cloud SQL)
Aby obsługiwać scenariusze, w których może być konieczne wycofanie zmian lub utrzymywanie synchronizacji bazy danych Cloud SQL z bazą danych Spanner przez pewien czas, możesz skonfigurować replikację zwrotną. Ten potok korzysta ze strumieni zmian Spanner, aby przechwytywać zmiany w Spanner i zapisywać je z powrotem w Cloud SQLmusic_db.
1. Tworzenie strumienia zmian w Spannerze
Najpierw musisz utworzyć strumień zmian w bazie danych Spanner, aby śledzić zmiany w tabelach Singers i Albums.
export CHANGE_STREAM_NAME="MusicDBChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Singers, Albums"
Ten strumień zmian będzie teraz rejestrować wszystkie modyfikacje danych w określonych tabelach.
2. Tworzenie bazy danych Spanner na potrzeby metadanych Dataflow
Spanner to SourceDB Szablon Dataflow wymaga osobnej bazy danych Spanner do przechowywania metadanych na potrzeby zarządzania wykorzystaniem strumienia zmian.
export SPANNER_METADATA_DB_NAME="reverse-replication-metadata"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Przygotowywanie konfiguracji połączenia z Cloud SQL na potrzeby Dataflow
Szablon Dataflow wymaga pliku JSON w Cloud Storage zawierającego szczegóły połączenia z docelową bazą danych Cloud SQL.
Utwórz plik lokalny o nazwie shard_config.json:
cat << EOF > shard_config.json
[
{
"logicalShardId": "mysql_shard",
"host": "${SQL_INSTANCE_IP}",
"port": "3306",
"user": "root",
"password": "${DB_ROOT_PASSWORD}",
"dbName": "music_db"
}
]
EOF
Prześlij ten plik do zasobnika GCS:
export SHARD_CONFIG_FILE="gs://${BUCKET_NAME}/shard_config.json"
gcloud storage cp shard_config.json $SHARD_CONFIG_FILE
4. Uruchamianie zadania Dataflow replikacji zwrotnej
Uruchom zadanie Dataflow za pomocą szablonu Flex Spanner_to_SourceDb.
export JOB_NAME_REVERSE="spanner-to-mysql-reverse-$(date +%Y%m%d-%H%M%S)"
export REVERSE_DLQ_DIR="gs://${BUCKET_NAME}/reverse-dlq"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$SHARD_CONFIG_FILE",\
deadLetterQueueDirectory="$REVERSE_DLQ_DIR"
Kluczowe parametry
changeStreamName: nazwa strumienia zmian w Spannerze, z którego mają być odczytywane dane.metadataInstance, metadataDatabase: instancja lub baza danych Spanner do przechowywania metadanych używanych przez łącznik do kontrolowania wykorzystania danych interfejsu Change Stream API.sourceShardsFilePath: ścieżka GCS do Twojegoshard_config.json.filtrationMode: określa, jak usuwać określone rekordy na podstawie kryteriów. Domyślnieforward_migration(filtruje rekordy zapisane za pomocą potoku migracji do przodu)
Uwaga dotycząca sieci: instancje robocze Dataflow będą łączyć się z instancją Cloud SQL przy użyciu publicznego adresu IP określonego w shard_config.json. To połączenie jest dozwolone ze względu na wpis 0.0.0.0/0 w sekcji Autoryzowane sieci instancji Cloud SQL.
Monitoruj uruchamianie zadania w konsoli zadań Dataflow.
5. Testowanie replikacji zwrotnej
Teraz wprowadź zmiany bezpośrednio w Cloud Spanner i sprawdź, czy są one odzwierciedlone w Cloud SQL. Zrób to dopiero po uruchomieniu zadania Dataflow i przejściu do stanu przetwarzania.
Testuj INSERT, UPDATE i DELETE
# INSERT: Insert a new singer (SingerId 5) into Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (5, 'David', 'Chen', '1995-02-18', 0)"
# UPDATE: Update SingerId 3's AlbumCount in Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Singers SET AlbumCount = 5 WHERE SingerId = 3"
# DELETE: Delete SingerId 1 from Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Albums WHERE SingerId = 1"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Singers WHERE SingerId = 1"
Weryfikacja w Cloud SQL (po chwili):
Połącz się z Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
Gdy pojawi się prośba, wpisz hasło (Welcome@1), a potem w wierszu poleceń mysql> uruchom te polecenia SQL.
USE music_db;
-- Verify INSERT: This should show the new row for David Chen
SELECT * FROM Singers WHERE SingerId = 5;
-- Verify UPDATE: This should show AlbumCount as 5.
SELECT SingerId, FirstName, AlbumCount FROM Singers WHERE SingerId = 3;
-- Verify DELETE: This should return an empty set.
SELECT * FROM Albums WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- Final Verification
SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId;
EXIT;
Oczekiwane dane wyjściowe w Cloud SQL powinny odzwierciedlać zmiany wprowadzone w Spannerze.
+----------+-----------+----------------+------------+ | SingerId | FirstName | LastName | AlbumCount | +----------+-----------+----------------+------------+ | 3 | Alice | Trentor | 5 | | 4 | Elena | Nadal | 0 | | 5 | David | Chen | 0 | +----------+-----------+----------------+------------+
Potwierdza to, że potok replikacji zwrotnej działa i synchronizuje zmiany z Spanner z powrotem do Cloud SQL.
11. Usuwanie zasobów
Aby uniknąć dalszych opłat na koncie Google Cloud, usuń zasoby utworzone podczas tego ćwiczenia.
Ustawianie zmiennych środowiskowych (w razie potrzeby)
Sprawdź, czy zmienne środowiskowe są prawidłowo ustawione:
echo "PROJECT_ID: $PROJECT_ID"
echo "REGION: $REGION"
echo "SQL_INSTANCE_NAME: $SQL_INSTANCE_NAME"
echo "SPANNER_INSTANCE_NAME: $SPANNER_INSTANCE_NAME"
echo "BUCKET_NAME: $BUCKET_NAME"
echo "STREAM_NAME: $STREAM_NAME"
echo "SQL_CP_NAME: $SQL_CP_NAME"
echo "GCS_CP_NAME: $GCS_CP_NAME"
echo "PUBSUB_SUBSCRIPTION: $PUBSUB_SUBSCRIPTION"
echo "PUBSUB_TOPIC: $PUBSUB_TOPIC"
echo "CHANGE_STREAM_NAME: $CHANGE_STREAM_NAME"
Wyświetl listę zadań, aby znaleźć identyfikatory uruchomionych zadań Dataflow. Wyeksportuj odpowiednio JOB_ID_CDC i JOB_ID_REVERSE.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Jeśli jesteś w nowej sesji Cloud Shell, ponownie wyeksportuj kluczowe zmienne środowiskowe:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or the region you used
export SQL_INSTANCE_NAME="source-mysql-instance"
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export STREAM_NAME="mysql-to-spanner-stream"
export SQL_CP_NAME="mysql-src-cp"
export GCS_CP_NAME="gcs-dest-cp"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CHANGE_STREAM_NAME="MusicDBChangeStream"
Zatrzymywanie zadań strumieniowych Dataflow
Anuluj zadanie Datastream to Spanner (migracja na żywo):
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
Anuluj zadanie Spanner to Cloud SQL (replikacja zwrotna):
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Usuwanie zasobów strumienia danych
Zatrzymaj i usuń strumień:
gcloud datastream streams update $STREAM_NAME \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Usuwanie profili połączeń
gcloud datastream connection-profiles delete $SQL_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Usuwanie zasobów Pub/Sub
Usuń subskrypcję:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Usuń temat:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Usuwanie instancji Cloud SQL
Spowoduje to automatyczne usunięcie baz danych (music_db) w tym projekcie.
gcloud sql instances delete $SQL_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Usuwanie instancji Cloud Spanner
Spowoduje to również usunięcie baz danych (music-db-migrated i reverse-replication-metadata) w tym systemie.
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Usuwanie zasobnika GCS i jego zawartości
gcloud storage rm --recursive gs://${BUCKET_NAME}
Usuwanie plików lokalnych
Usuń wszystkie pliki wygenerowane w katalogu domowym Cloud Shell:
rm -f music-db* shard_config.json
Zasoby utworzone na potrzeby tego ćwiczenia zostały usunięte.