
1. Antes de começar
Este codelab orienta você na migração de um único banco de dados MySQL no Cloud SQL para um banco de dados do Cloud Spanner com o dialeto GoogleSQL. O foco está no fluxo fundamental de migração de ponta a ponta, demonstrando as etapas principais. Você vai usar os serviços do Google Cloud, incluindo a ferramenta de migração do Spanner (SMT), o Dataflow, o Datastream, o Pub/Sub e o Google Cloud Storage.
Você vai saber:
- Como configurar instâncias de exemplo do Cloud SQL e do Cloud Spanner.
- Como converter um esquema do MySQL do Cloud SQL em um esquema compatível com o Spanner usando a ferramenta de migração do Spanner (SMT, na sigla em inglês).
- Como realizar a migração de dados em massa do Cloud SQL para o Cloud Spanner usando o Dataflow.
- Como configurar a replicação contínua (CDC) do Cloud SQL para o Cloud Spanner usando o Datastream e o Dataflow.
- Como configurar a replicação inversa do Cloud Spanner para o Cloud SQL.
O que este codelab NÃO aborda:
- Migrações de instâncias fragmentadas.
- Transformações complexas de dados durante a migração.
- Tratamento de erros avançado ou filas de mensagens inativas (DLQs).
- Ajuste de desempenho da migração.
- Migração de aplicativos:este codelab se concentra na camada de banco de dados (esquema e dados). Ele não aborda o processo operacional de reimplantação ou migração dos serviços de aplicativos.
O que é necessário
- Ter um projeto do Google Cloud com o faturamento ativado.
- Permissões do IAM suficientes para ativar APIs e criar/gerenciar recursos do Cloud SQL, Spanner, Dataflow, Datastream e GCS. Embora a função
Ownerdo projeto seja mais simples para um codelab, funções mais específicas serão abordadas na "Configuração do ambiente". - Um navegador da Web, como o Google Chrome.
- Familiaridade básica com o console do Google Cloud e ferramentas de linha de comando, como
gcloud. - Acesso a um ambiente shell. Recomendamos o Cloud Shell, porque ele inclui o
gcloud.
Mais detalhes sobre a configuração acima são abordados na seção "Configuração do ambiente".
2. Entender o processo de migração
A migração de um banco de dados envolve a migração de dados da instância de banco de dados de origem do Cloud SQL para uma instância do Spanner. Esta seção descreve a arquitetura e as principais ferramentas usadas na migração.
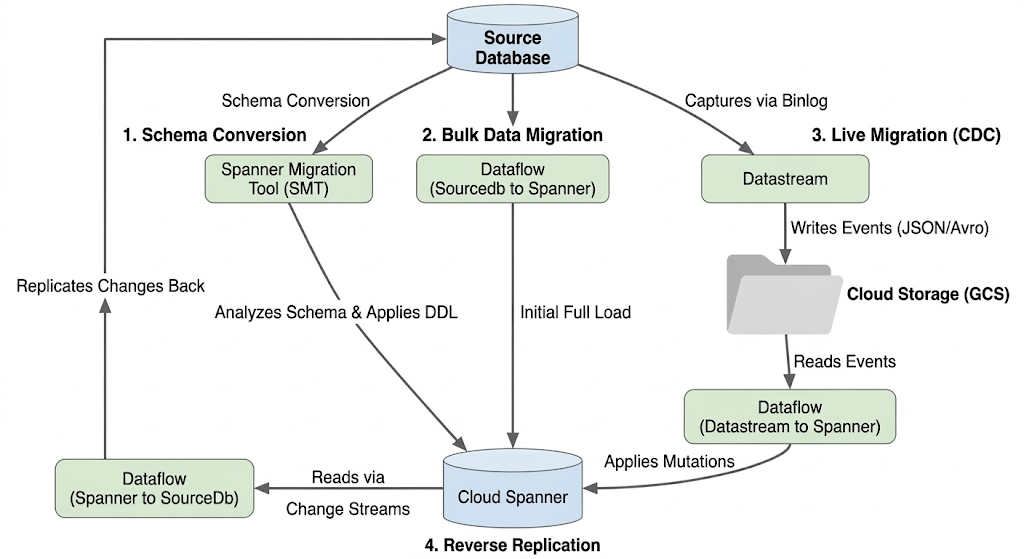
Arquitetura do fluxo de migração
O processo de migração envolve estas etapas:
1. Conversão de esquema:
- Finalidade:converter o esquema do banco de dados de origem em um esquema compatível do Cloud Spanner.
- Ferramenta:ferramenta de migração do Spanner (SMT, na sigla em inglês)
- Processo:o SMT analisa o esquema do banco de dados de origem e gera a Linguagem de definição de dados (DDL) equivalente do Spanner. Na instância de destino do Spanner, um banco de dados é criado e a DDL é aplicada automaticamente.
2. Migração de dados em massa:
- Objetivo:realizar uma carga inicial e completa dos dados atuais do banco de dados de origem para as tabelas provisionadas do Spanner.
- Ferramenta:Dataflow, usando o modelo
Sourcedb to Spannerfornecido pelo Google. - Processo:esse job do Dataflow lê todos os dados das tabelas de origem especificadas e os grava nas tabelas correspondentes do Spanner. Isso é feito depois que o esquema do Spanner é criado.
3. Migração em tempo real (CDC):
- Objetivo:capturar e aplicar mudanças contínuas do banco de dados de origem ao Cloud Spanner quase em tempo real, minimizando o tempo de inatividade durante a migração.
- Ferramentas:
- Datastream:captura mudanças (inserções, atualizações, exclusões) do banco de dados de origem e as grava no Cloud Storage (GCS).
- Dataflow:usa o modelo
Datastream to Spannerpara ler os eventos de mudança do GCS e aplicá-los ao Cloud Spanner.
4. Replicação reversa:
- Finalidade:replicar as mudanças de dados do Cloud Spanner de volta para o banco de dados de origem. Isso pode ser útil para estratégias de substituição, migrações graduais ou manutenção de uma réplica na origem para casos de uso específicos.
- Ferramenta:Dataflow, usando o modelo
Spanner to SourceDb. - Processo:esse job usa fluxos de alterações do Spanner para capturar modificações no Spanner e gravá-las de volta na instância do banco de dados de origem.
O diagrama a seguir ilustra os componentes e o fluxo de dados:
Terminologia importante:
- Ferramenta de migração do Spanner (SMT):uma ferramenta usada para avaliar esquemas do MySQL, sugerir equivalentes de esquema do Spanner e gerar a linguagem de definição de dados (DDL) do Spanner.
- Linguagem de definição de dados (DDL): instruções usadas para definir e modificar a estrutura do banco de dados, como instruções
CREATE TABLE. O SMT gera DDL do Spanner com base no esquema do Cloud SQL. - Dataflow:um serviço de processamento de dados sem servidor totalmente gerenciado. Neste codelab, ele é usado para executar modelos fornecidos pelo Google para transferência de dados em massa, aplicar mudanças do Datastream e fazer replicação inversa.
- Datastream:um serviço de replicação e captura de dados alterados (CDC) sem servidor. Ele é usado para transmitir mudanças do Cloud SQL para o Cloud Storage neste codelab.
- Fluxos de alterações do Spanner:um recurso do Spanner que permite transmitir alterações nos dados (inserções, atualizações, exclusões) em tempo real, usado como a origem da replicação inversa.
- Pub/Sub:um serviço de mensagens usado para separar serviços que produzem eventos daqueles que os processam. Neste codelab, ele aciona o Dataflow para processar atualizações sempre que o Datastream faz upload de novos arquivos de mudança para o Cloud Storage.
3. Configuração do ambiente
Antes de iniciar a migração, configure seu projeto na nuvem do Google Cloud e ative os serviços necessários.
1. Selecionar ou criar um projeto do Google Cloud
Você precisa de um projeto do Google Cloud com o faturamento ativado para usar os serviços neste codelab.
- No console do Google Cloud, acesse a página do seletor de projetos: Acessar o seletor de projetos
- Selecione ou crie um projeto do Google Cloud.
- Verifique se o faturamento foi ativado para o projeto. Saiba como confirmar se o faturamento está ativado para o projeto.
2. Abrir o Cloud Shell
O Cloud Shell é um ambiente de linha de comando em execução no Google Cloud que vem pré-carregado com a CLI gcloud e outras ferramentas necessárias.
- Clique no botão Ativar Cloud Shell no canto superior direito do console do Google Cloud.
- Uma sessão do Cloud Shell é aberta em um novo frame na parte inferior do console e um prompt de linha de comando é exibido.

3. Definir variáveis de ambiente e do projeto
No Cloud Shell, configure algumas variáveis de ambiente para o ID do projeto e a região que você vai usar.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Ativar as APIs obrigatórias do Cloud
Ative as APIs necessárias para o Cloud Spanner, o Dataflow, o Datastream e outros serviços relacionados.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Isso pode demorar alguns minutos.
5. Configurar permissões da conta de serviço
Os jobs do Dataflow e o Datastream exigem permissões específicas para interagir com outros serviços do Google Cloud. Os jobs do Dataflow neste codelab vão usar a conta de serviço padrão do Compute Engine.
Primeiro, confira o número do projeto:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
Agora, conceda os papéis do IAM necessários à conta de serviço padrão do Compute Engine:
# Role for Dataflow to run jobs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.admin" \
--condition=None
# Roles for Dataflow workers
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.worker" \
--condition=None
# Role to connect to Cloud SQL instance
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudsql.client" \
--condition=None
# Role to read/write from Cloud Spanner
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/spanner.databaseUser" \
--condition=None
# Role to access GCS buckets (Datastream output, Dataflow temp, JDBC driver)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectAdmin" \
--condition=None
# Roles for Datastream and Pub/Sub (for CDC)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastream.viewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/pubsub.subscriber"
6. Crie um bucket do Cloud Storage
Crie um bucket do GCS na mesma região dos outros recursos. Esse bucket vai armazenar o driver JDBC, a saída do Datastream e será usado pelo Dataflow para arquivos temporários.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
echo "Created bucket: gs://$BUCKET_NAME"
7. Instalar a ferramenta de migração do Spanner (SMT)
Verifique se a ferramenta de migração do Spanner (SMT, na sigla em inglês) está instalada no ambiente shell do Cloud Shell.
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
Esse comando vai mostrar informações de ajuda para a interface da Web da SMT, confirmando que o componente gcloud está instalado. Este codelab vai usar os recursos da CLI do SMT, que fazem parte do mesmo componente.
4. Configurar o banco de dados de origem do Cloud SQL
Nesta seção, você vai criar e configurar uma instância do Cloud SQL para MySQL com IP público para servir como banco de dados de origem.
1. Criar uma instância do Cloud SQL para MySQL
Execute o seguinte comando gcloud no Cloud Shell para criar uma instância do MySQL 8.0. A geração de registros binários está ativada (necessária para o Datastream), e a instância está configurada com um IP público.
export SQL_INSTANCE_NAME="source-mysql-instance"
export DB_ROOT_PASSWORD="Welcome@1" # Replace with a strong password if you prefer
gcloud sql instances create $SQL_INSTANCE_NAME \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=$REGION \
--root-password=$DB_ROOT_PASSWORD \
--enable-bin-log \
--assign-ip
--enable-bin-log: obrigatório para que o Datastream capture as mudanças.--assign-ip: garante que a instância receba um endereço IP público.
A criação da instância levará alguns minutos. É possível verificar se a instância foi criada na página "Instâncias do Cloud SQL".
2. Configurar redes autorizadas
Para se conectar à instância por IP público, adicione endereços IP à lista "Redes autorizadas".
Confira o IP do Cloud Shell:
export CLOUD_SHELL_IP=$(curl -s ipinfo.io/ip)
echo "Your Cloud Shell IP: $CLOUD_SHELL_IP"
Autorizar o IP do Cloud Shell e o acesso aberto
O comando a seguir adiciona seu IP do Cloud Shell. Ele também adiciona 0.0.0.0/0, que permite o acesso de qualquer endereço IP. Isso é necessário para simplificar as conexões dos workers do Dataflow sem configurações de rede complexas.
gcloud sql instances patch $SQL_INSTANCE_NAME \
--authorized-networks="${CLOUD_SHELL_IP}/32,0.0.0.0/0"
3. Conectar-se à instância do Cloud SQL pelo Cloud Shell
Buscar o endereço IP público atribuído
export SQL_INSTANCE_IP=$(gcloud sql instances list --filter="name=$SQL_INSTANCE_NAME" --format="value(PRIMARY_ADDRESS)")
echo "Cloud SQL Public IP: $SQL_INSTANCE_IP"
Esse endereço IP será usado para a conexão.
Conectar-se à instância do Cloud SQL pelo Cloud Shell
Use o cliente mysql padrão para se conectar usando o endereço IP público obtido:
mysql -h $SQL_INSTANCE_IP -u root -p
Quando solicitado, digite a senha raiz que você definiu (Welcome@1). Agora você vai estar em um prompt mysql>.
4. Criar banco de dados e dados de amostra
Execute os seguintes comandos SQL no prompt mysql>:
CREATE DATABASE music_db;
USE music_db;
CREATE TABLE Singers (
SingerId BIGINT NOT NULL,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
BirthDate DATE,
AlbumCount BIGINT,
PRIMARY KEY (SingerId)
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY (SingerId, AlbumId),
CONSTRAINT FK_Albums_Singers FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
);
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES
(1, 'Marc', 'Richards', '1970-09-03', 2),
(2, 'Catalina', 'Smith', '1990-08-17', 1),
(3, 'Alice', 'Trentor', '1991-10-02', 3);
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle, ReleaseDate) VALUES
(1, 1, 'Total Junk', '2014-03-15'),
(1, 2, 'Go Go Go', '2016-11-01'),
(2, 1, 'Green', '2018-02-28'),
(3, 1, 'Blue', '2019-01-10'),
(3, 2, 'Red', '2020-05-22'),
(3, 3, 'Purple', '2022-11-11');
O arquivo dump do esquema acima pode ser encontrado aqui.
5. Verificar dados
Verifique rapidamente se os dados estão presentes:
SELECT 'Singers music_db' as tbl, COUNT(*) FROM music_db.Singers
UNION ALL
SELECT 'Albums music_db', COUNT(*) FROM music_db.Albums;
EXIT;
Você vai encontrar contagens para cada tabela.
+------------------+----------+ | tbl | COUNT(*) | +------------------+----------+ | Singers music_db | 3 | | Albums music_db | 6 | +------------------+----------+
5. Configurar o Cloud Spanner
Agora, configure a instância de destino do Cloud Spanner em que os dados serão migrados.
1. Criar uma instância do Cloud Spanner
Crie uma instância do Cloud Spanner na mesma região da instância do Cloud SQL. Esse comando cria uma pequena instância adequada para este codelab, usando 100 unidades de processamento.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="music-db-migrated"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
A criação da instância pode levar alguns minutos.
6. Converter o esquema usando a ferramenta de migração do Spanner (SMT)
Use a CLI do SMT para analisar o banco de dados MySQL (music_db) e gerar a linguagem de definição de esquema (DDL) do Spanner. Como a instância do Cloud SQL está configurada com IP público e redes autorizadas adequadas, o SMT pode se conectar diretamente.
1. Preparar o ambiente para o SMT
Verifique se as variáveis de ambiente necessárias foram definidas nas etapas anteriores:
echo "Cloud SQL Instance Public IP: $SQL_INSTANCE_IP"
echo "Cloud SQL Root Password: $DB_ROOT_PASSWORD"
echo "Spanner Instance: $SPANNER_INSTANCE_NAME"
echo "Spanner Database: $SPANNER_DATABASE_NAME"
echo "Project ID: $PROJECT_ID"
2. Executar a conversão de esquema para music_db
Execute o comando SMT schema, conectando-se diretamente ao endereço IP público do Cloud SQL:
gcloud alpha spanner migrate schema \
--source=mysql \
--source-profile="host=${SQL_INSTANCE_IP},port=3306,user=root,password=${DB_ROOT_PASSWORD},dbName=music_db" \
--target-profile="project=${PROJECT_ID},instance=${SPANNER_INSTANCE_NAME},dbName=${SPANNER_DATABASE_NAME}" \
--prefix="music-db"
Esse comando se conecta à instância do Cloud SQL pelo proxy e gera arquivos de esquema com o prefixo music-db.
3. Revisar arquivos gerados
O SMT cria alguns arquivos no diretório atual. Os principais são:
music-db.schema.ddl.txt: as instruções DDL do Spanner geradas.music-db-.overrides.json: o arquivo de substituições de esquema que contém mudanças de mapeamento manual.music-db.session.json: arquivo de sessão da migração de esquema.music-db.report.txt: um relatório de avaliação da conversão de esquema.
É possível listar usando ls music-db-*
4. Verificar o esquema no Cloud Spanner
Verifique se as tabelas foram criadas no banco de dados do Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Você verá esta resposta:
table_name: Albums table_name: Singers
Opcional:se quiser verificar a DDL do Spanner, execute o seguinte comando:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
7. Inicializar a captura de dados alterados (CDC)
Nesta seção, você vai configurar o "gravador" para sua migração. Ao configurar o Datastream e o Pub/Sub antes do início do carregamento de dados em massa, você garante que todas as mudanças feitas no banco de dados de origem sejam capturadas e enfileiradas, evitando a perda de dados durante a transição. Essa configuração é obrigatória para a migração dinâmica.
1. Criar perfis de conexão do Datastream
Perfil de origem (Cloud SQL)
Esse perfil se conecta ao IP público da instância do Cloud SQL. O Datastream vai usar a lista de permissões de IP para conectividade.
export SQL_CP_NAME="mysql-src-cp"
gcloud datastream connection-profiles create $SQL_CP_NAME \
--location=$REGION \
--type=mysql \
--mysql-hostname=$SQL_INSTANCE_IP \
--mysql-port=3306 \
--mysql-username=root \
--mysql-password=$DB_ROOT_PASSWORD \
--display-name="Cloud SQL Source - Public IP"
Observação:essa conexão depende de as redes autorizadas da instância do Cloud SQL permitirem o acesso. Conforme configurado anteriormente com 0.0.0.0/0, os IPs públicos do Datastream podem se conectar. Em um ambiente de produção, substitua 0.0.0.0/0 pelos intervalos de IP específicos da sua região listados em Regiões e listas de permissões de IP do Datastream.
Perfil de destino (Cloud Storage)
Aponta para a raiz do seu bucket.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
2. Criar um stream do Datastream
Crie o stream para replicar de music_db.
export STREAM_NAME="mysql-to-spanner-stream"
export GCS_STREAM_PATH="data/${STREAM_NAME}"
gcloud datastream streams create $STREAM_NAME \
--location=$REGION \
--display-name="MySQL to Spanner CDC Stream" \
--source=$SQL_CP_NAME \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "
includeObjects:
mysqlDatabases:
- database: 'music_db'
") \
--gcs-destination-config=<(echo "
path: ${GCS_STREAM_PATH}
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}
") \
--backfill-none
- O Datastream vai gravar arquivos em
gs://${BUCKET_NAME}/${GCS_STREAM_PREFIX}/. - O Datastream vai gravar os arquivos no formato Avro. Ao executar o comando de migração em tempo real, vamos especificar o inputFileFormat como avro para que o pipeline possa processar o arquivo corretamente.
- Usar configurações menores de rotação de arquivos ajuda a ver as mudanças mais rápido no codelab.
Esse comando pode levar algum tempo para ser concluído. Verifique o status: gcloud datastream streams describe $STREAM_NAME --location=$REGION.
3. Iniciar o stream do Datastream
gcloud datastream streams update $STREAM_NAME \
--location=$REGION \
--state=RUNNING
Verifique o status: gcloud datastream streams describe $STREAM_NAME --location=$REGION.. O estado será STARTING inicialmente e se tornará RUNNING depois de algum tempo. Siga para a próxima etapa somente depois de confirmar que ele está no estado RUNNING.
4. Configurar o Pub/Sub para notificações do GCS
Crie um tópico do Pub/Sub:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
Criar notificação do GCS
Notificar na criação de objetos com o prefixo data/.
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Crie uma assinatura do Pub/Sub
Inclua o prazo de confirmação recomendado.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Migrar dados em massa do Cloud SQL para o Spanner
Com o esquema do Spanner no lugar, agora você vai copiar os dados atuais do banco de dados music_db do Cloud SQL para o Cloud Spanner. Você vai usar o modelo flex do Dataflow Sourcedb to Spanner, que foi projetado para copiar dados em massa de bancos de dados acessíveis por JDBC para o Spanner.
1. Executar o job do Dataflow de migração em massa para music_db
Execute o comando a seguir no Cloud Shell para iniciar o job do Dataflow. Esse comando usa o comando gcloud dataflow flex-template run, referenciando o modelo fornecido pelo Google para migrações JDBC em massa para o Spanner.
export JOB_NAME_MUSIC="mysql-music-db-to-spanner-bulk-$(date +%Y%m%d-%H%M%S)"
export MUSIC_DB_JDBC_URL="jdbc:mysql://${SQL_INSTANCE_IP}:3306/music_db"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration-output"
gcloud dataflow flex-template run $JOB_NAME_MUSIC \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL="$MUSIC_DB_JDBC_URL",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
outputDirectory="$OUTPUT_DIR/music_db",\
username="root",\
password="$DB_ROOT_PASSWORD",\
jdbcDriverClassName="com.mysql.cj.jdbc.Driver",\
jdbcDriverJars="gs://${BUCKET_NAME}/lib/mysql-connector-j-8.0.33.jar",\
spannerHost="https://batch-spanner.googleapis.com"
Explicação dos principais parâmetros:
sourceConfigURL: a string de conexão JDBC para a origemmusic_db.instanceId,databaseId,projectId: especifica a instância e o banco de dados de destino do Cloud Spanner.outputDirectory: um caminho do Cloud Storage em que o Dataflow vai gravar informações sobre os registros que não foram migrados.jdbcDriverClassName: especifica o driver JDBC do MySQL.jdbcDriverJars: caminho do GCS para o JAR do driver JDBC preparado.spannerHost: usa o endpoint otimizado para lotes em gravações do Spanner.maxWorkers,numWorkers: controla o escalonamento do job do Dataflow. Mantido baixo para esse conjunto de dados pequeno.
Observação sobre a rede:esse job se conecta à instância do Cloud SQL pelo IP público dela. Isso é possível porque você adicionou 0.0.0.0/0 às redes autorizadas da instância. Isso permite que as VMs de worker do Dataflow, que têm IPs externos, alcancem o banco de dados.
2. Monitorar o job do Dataflow
É possível acompanhar o progresso do job no console do Google Cloud:
- Acesse a página "Jobs do Dataflow": Acessar Jobs do Dataflow
- Localize o job chamado
mysql-music-db-to-spanner-bulk-...e clique nele. - Observe o gráfico e as métricas do job. Aguarde o status do job mudar para Concluído. Esse processo leva de 5 a 15 minutos.
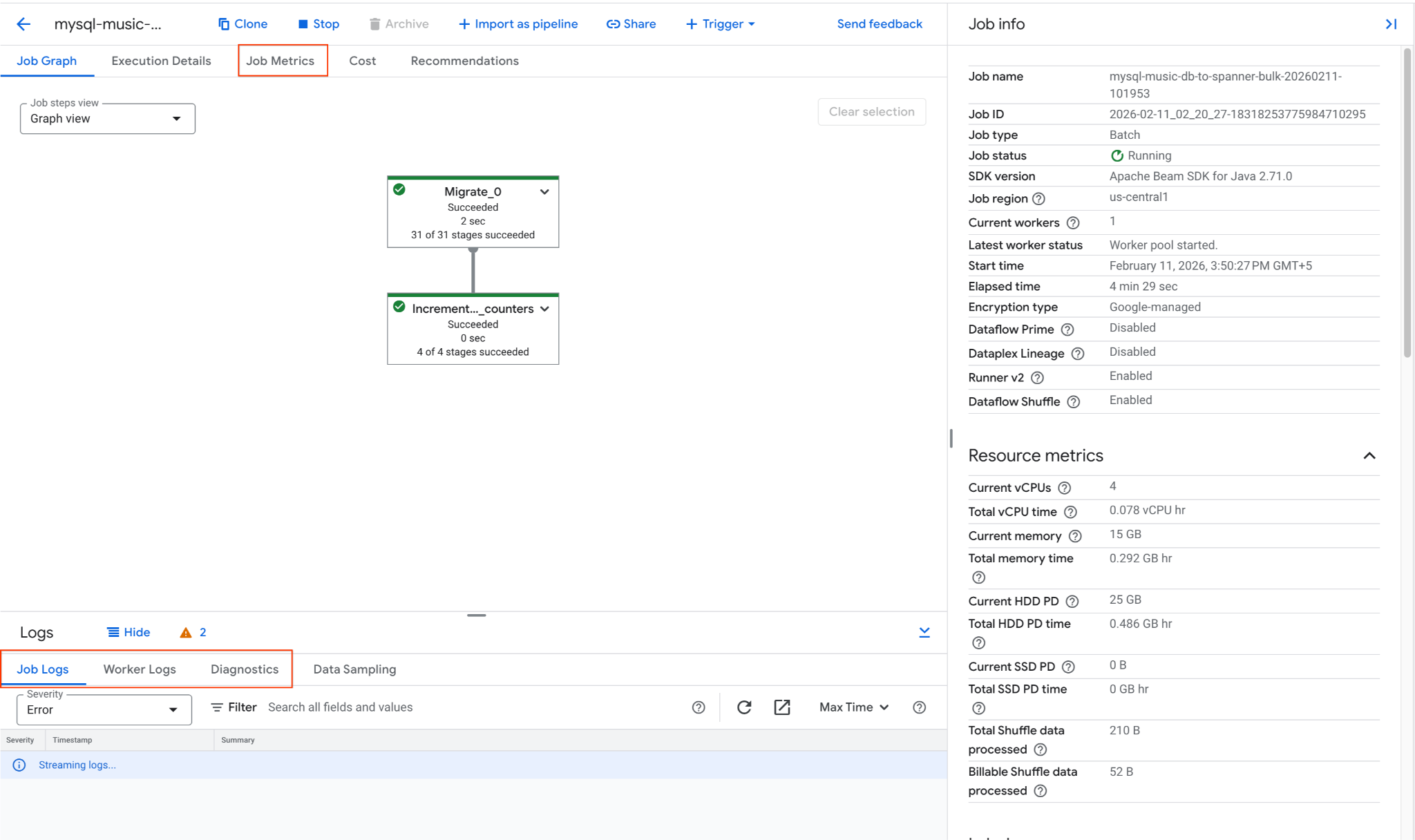
- Se o job encontrar problemas, revise a guia Registros na página de detalhes do job do Dataflow para ver mensagens de erro.
- As métricas de job oferecem mais informações sobre o progresso do job e o consumo de recursos, como taxa de transferência e uso da CPU.
3. Verificar dados no Cloud Spanner
Depois que o job do Dataflow for concluído, confirme se os dados foram copiados para as tabelas do Spanner. Use gcloud para consultar o banco de dados do Spanner:
# Verify row counts
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Singers"
# Expected output: 3
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Albums"
# Expected output: 6
# Inspect some data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT SingerId, FirstName, LastName FROM Singers ORDER BY SingerId"
Saída esperada:
row_count: 3 row_count: 6 SingerId: 1 FirstName: Marc LastName: Richards SingerId: 2 FirstName: Catalina LastName: Smith SingerId: 3 FirstName: Alice LastName: Trentor
O carregamento em massa inicial de dados do Cloud SQL para o Cloud Spanner foi concluído. A próxima etapa é configurar a replicação ativa para capturar as mudanças em andamento.
9. Iniciar migração em tempo real (CDC)
Agora que a carga de dados em massa foi concluída, você vai configurar um fluxo de replicação contínua usando o Datastream para capturar eventos de captura de dados alterados (CDC) do Cloud SQL e um job de streaming do Dataflow para aplicar essas mudanças ao Cloud Spanner quase em tempo real.
1. Executar o job do Dataflow de migração em tempo real
Inicie o job de streaming do Dataflow para ler do GCS e gravar no Spanner. Esse modelo usa notificações do Pub/Sub do GCS para processar novos arquivos instantaneamente.
export JOB_NAME_CDC="datastream-to-spanner-cdc-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR="gs://${BUCKET_NAME}/dlq"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
deadLetterQueueDirectory="$DLQ_DIR",\
streamName="projects/${PROJECT_ID}/locations/${REGION}/streams/${STREAM_NAME}"
Parâmetros principais
gcsPubSubSubscription: a assinatura do Pub/Sub que detecta novas notificações de arquivos do GCS. Isso permite que o job processe as mudanças instantaneamente à medida que o Datastream as grava.inputFileFormat="avro": informa ao Dataflow que ele deve esperar arquivos Avro do Datastream. Isso precisa corresponder à configuração de "Destino" do Datastream (por exemplo,avroFileFormatxjsonFileFormat).deadLetterQueueDirectory: um caminho do GCS em que o job armazena registros que não foram processados (por exemplo, devido a incompatibilidades de esquema) para revisão manual posterior.streamName: o caminho completo do recurso do stream do Datastream, que permite que o job do Dataflow rastreie o estado e os metadados da replicação.
Monitore a inicialização do job no console de jobs do Dataflow.
2. Testar a migração em tempo real
Aplique mudanças ao Cloud SQL de origem music_db para testar o pipeline de CDC.
Conecte-se ao Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
Insira a senha (Welcome@1) e selecione o banco de dados:
USE music_db;
-- INSERT
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (4, 'Elena', 'Nadal', '1985-05-30', 0);
SELECT * FROM Singers WHERE SingerId = 4;
-- UPDATE
UPDATE Singers SET LastName = 'Richards-Smith' WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- DELETE
DELETE FROM Albums WHERE SingerId = 2;
DELETE FROM Singers WHERE SingerId = 2;
SELECT * FROM Singers WHERE SingerId = 2;
EXIT;
Verificação no Spanner (após alguns instantes):
# Verify INSERT: This should return the new row for Elena Nadal.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 4"
# Verify UPDATE: This should show LastName as Richards-Smith.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName FROM Singers WHERE SingerId = 1"
# Verify DELETE: This should now return 0 rows.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Albums WHERE SingerId = 2"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 2"
Saída esperada:
SingerId: 4 FirstName: Elena LastName: Nadal BirthDate: 1985-05-30 AlbumCount: 0 SingerId: 1 FirstName: Marc LastName: Richards-Smith
3. Verificação final no Spanner
Verifique o estado geral da tabela Singers no Spanner:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId"
Saída esperada:
SingerId: 1 FirstName: Marc LastName: Richards-Smith AlbumCount: 2 SingerId: 3 FirstName: Alice LastName: Trentor AlbumCount: 3 SingerId: 4 FirstName: Elena LastName: Nadal AlbumCount: 0
10. Configurar a replicação inversa (Spanner para Cloud SQL)
Para lidar com cenários em que talvez seja necessário fazer um rollback ou manter o banco de dados do Cloud SQL sincronizado com o Spanner por um período, configure a replicação inversa. Esse pipeline usa fluxos de alterações do Spanner para capturar mudanças no Spanner e as grava de volta no music_db do Cloud SQL.
1. Criar um fluxo de alterações do Spanner
Primeiro, crie um fluxo de mudanças no banco de dados do Spanner para rastrear as mudanças nas tabelas Singers e Albums.
export CHANGE_STREAM_NAME="MusicDBChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Singers, Albums"
Esse fluxo de alterações agora vai registrar todas as modificações de dados nas tabelas especificadas.
2. Criar um banco de dados do Spanner para metadados do Dataflow
O modelo do Dataflow Spanner to SourceDB exige um banco de dados do Spanner separado para armazenar metadados e gerenciar o consumo do fluxo de alterações.
export SPANNER_METADATA_DB_NAME="reverse-replication-metadata"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Preparar a configuração de conexão do Cloud SQL para o Dataflow
O modelo do Dataflow precisa de um arquivo JSON no Cloud Storage com os detalhes da conexão do banco de dados de destino do Cloud SQL.
Crie um arquivo local chamado shard_config.json:
cat << EOF > shard_config.json
[
{
"logicalShardId": "mysql_shard",
"host": "${SQL_INSTANCE_IP}",
"port": "3306",
"user": "root",
"password": "${DB_ROOT_PASSWORD}",
"dbName": "music_db"
}
]
EOF
Faça upload deste arquivo para o bucket do GCS:
export SHARD_CONFIG_FILE="gs://${BUCKET_NAME}/shard_config.json"
gcloud storage cp shard_config.json $SHARD_CONFIG_FILE
4. Executar o job do Dataflow de replicação inversa
Inicie o job do Dataflow usando o modelo Flex Spanner_to_SourceDb.
export JOB_NAME_REVERSE="spanner-to-mysql-reverse-$(date +%Y%m%d-%H%M%S)"
export REVERSE_DLQ_DIR="gs://${BUCKET_NAME}/reverse-dlq"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$SHARD_CONFIG_FILE",\
deadLetterQueueDirectory="$REVERSE_DLQ_DIR"
Parâmetros principais
changeStreamName: o nome do fluxo de alterações a ser lido pelo Spanner.metadataInstance, metadataDatabase: a instância/o banco de dados do Spanner para armazenar os metadados usados pelo conector para controlar o consumo dos dados da API Change Stream.sourceShardsFilePath: o caminho do GCS para seushard_config.json.filtrationMode: especifica como descartar determinados registros com base em um critério. O padrão éforward_migration(filtra registros gravados usando o pipeline de migração direta).
Observação sobre a rede:os workers do Dataflow se conectarão à instância do Cloud SQL usando o IP público especificado em shard_config.json. Essa conexão é permitida devido à entrada 0.0.0.0/0 nas redes autorizadas da instância do Cloud SQL.
Monitore a inicialização do job no console de jobs do Dataflow.
5. Testar a replicação reversa
Agora, faça mudanças diretamente no Cloud Spanner e verifique se elas são refletidas no Cloud SQL. Faça isso somente depois que o job do Dataflow for iniciado e estiver em estado de processamento.
Testar INSERT, UPDATE e DELETE
# INSERT: Insert a new singer (SingerId 5) into Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (5, 'David', 'Chen', '1995-02-18', 0)"
# UPDATE: Update SingerId 3's AlbumCount in Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Singers SET AlbumCount = 5 WHERE SingerId = 3"
# DELETE: Delete SingerId 1 from Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Albums WHERE SingerId = 1"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Singers WHERE SingerId = 1"
Verificação no Cloud SQL (após alguns instantes):
Conecte-se ao Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
Insira a senha (Welcome@1) quando solicitado e execute os seguintes comandos SQL no prompt mysql>.
USE music_db;
-- Verify INSERT: This should show the new row for David Chen
SELECT * FROM Singers WHERE SingerId = 5;
-- Verify UPDATE: This should show AlbumCount as 5.
SELECT SingerId, FirstName, AlbumCount FROM Singers WHERE SingerId = 3;
-- Verify DELETE: This should return an empty set.
SELECT * FROM Albums WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- Final Verification
SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId;
EXIT;
A saída esperada no Cloud SQL deve refletir as mudanças feitas no Spanner.
+----------+-----------+----------------+------------+ | SingerId | FirstName | LastName | AlbumCount | +----------+-----------+----------------+------------+ | 3 | Alice | Trentor | 5 | | 4 | Elena | Nadal | 0 | | 5 | David | Chen | 0 | +----------+-----------+----------------+------------+
Isso confirma que o pipeline de replicação inversa está funcionando, sincronizando as mudanças do Spanner de volta para o Cloud SQL.
11. Limpar recursos
Para evitar mais cobranças na sua conta do Google Cloud, exclua os recursos criados durante este codelab.
Definir variáveis de ambiente (se necessário)
Verifique se as variáveis de ambiente estão definidas corretamente:
echo "PROJECT_ID: $PROJECT_ID"
echo "REGION: $REGION"
echo "SQL_INSTANCE_NAME: $SQL_INSTANCE_NAME"
echo "SPANNER_INSTANCE_NAME: $SPANNER_INSTANCE_NAME"
echo "BUCKET_NAME: $BUCKET_NAME"
echo "STREAM_NAME: $STREAM_NAME"
echo "SQL_CP_NAME: $SQL_CP_NAME"
echo "GCS_CP_NAME: $GCS_CP_NAME"
echo "PUBSUB_SUBSCRIPTION: $PUBSUB_SUBSCRIPTION"
echo "PUBSUB_TOPIC: $PUBSUB_TOPIC"
echo "CHANGE_STREAM_NAME: $CHANGE_STREAM_NAME"
Liste seus jobs para encontrar os IDs dos jobs do Dataflow em execução. Exporte JOB_ID_CDC e JOB_ID_REVERSE de acordo com a necessidade.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Se você estiver em uma nova sessão do Cloud Shell, exporte novamente as variáveis de ambiente principais:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or the region you used
export SQL_INSTANCE_NAME="source-mysql-instance"
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export STREAM_NAME="mysql-to-spanner-stream"
export SQL_CP_NAME="mysql-src-cp"
export GCS_CP_NAME="gcs-dest-cp"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CHANGE_STREAM_NAME="MusicDBChangeStream"
Interromper jobs de streaming do Dataflow
Cancele o job de Datastream to Spanner (migração dinâmica):
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
Cancele o job de Spanner to Cloud SQL (replicação inversa):
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Excluir recursos do Datastream
Parar e excluir o stream:
gcloud datastream streams update $STREAM_NAME \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Excluir perfis de conexão
gcloud datastream connection-profiles delete $SQL_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Excluir recursos do Pub/Sub
Excluir assinatura:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Excluir tema:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Excluir instância do Cloud SQL
Isso vai excluir automaticamente os bancos de dados (music_db) dentro dela.
gcloud sql instances delete $SQL_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Excluir instância do Cloud Spanner
Isso também vai excluir os bancos de dados (music-db-migrated e reverse-replication-metadata) dentro dele.
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Excluir bucket e conteúdo do GCS
gcloud storage rm --recursive gs://${BUCKET_NAME}
Excluir arquivos locais
Remova todos os arquivos gerados no diretório inicial do Cloud Shell:
rm -f music-db* shard_config.json
Agora você limpou os recursos criados para este codelab.