
1. Прежде чем начать
Этот практический урок покажет вам, как перенести одну базу данных MySQL из Cloud SQL в базу данных Cloud Spanner с диалектом GoogleSQL. Основное внимание уделяется базовому сквозному процессу миграции и демонстрируются ключевые этапы. Вы будете использовать сервисы Google Cloud, включая инструмент миграции Spanner (SMT), Dataflow, Datastream, PubSub и Google Cloud Storage.
Что вы узнаете:
- Как настроить тестовые экземпляры Cloud SQL и Cloud Spanner.
- Как преобразовать схему Cloud SQL MySQL в схему, совместимую со Spanner, с помощью инструмента миграции Spanner (SMT).
- Как выполнить массовую миграцию данных из Cloud SQL в Cloud Spanner с помощью Dataflow.
- Как настроить непрерывную репликацию (CDC) из Cloud SQL в Cloud Spanner с использованием Datastream и Dataflow.
- Как настроить обратную репликацию с Cloud Spanner на Cloud SQL.
В этом практическом занятии НЕ рассматриваются следующие темы:
- Миграция с сегментированных экземпляров.
- Сложные преобразования данных в процессе миграции.
- Расширенная обработка ошибок или очереди недоставленных сообщений (DLQ).
- Оптимизация производительности миграции.
- Миграция приложений: Данный практический урок посвящен уровню базы данных (схема и данные). Он не охватывает операционный процесс повторного развертывания или миграции сервисов вашего приложения.
Что вам понадобится
- Проект Google Cloud с включенной функцией выставления счетов.
- Для работы с API и создания/управления ресурсами Cloud SQL, Spanner, Dataflow, Datastream и GCS необходимы достаточные права доступа IAM . Хотя роль
Ownerпроекта является наиболее простой для практического занятия, более специфические роли будут рассмотрены в разделе «Настройка среды». - Веб-браузер, например, Google Chrome.
- Базовые знания консоли Google Cloud и инструментов командной строки, таких как
gcloud. - Доступ к командной оболочке. Рекомендуется использовать Cloud Shell , поскольку она включает
gcloud.
Более подробная информация о вышеописанной настройке приведена в разделе «Настройка среды».
2. Понимание миграционного процесса
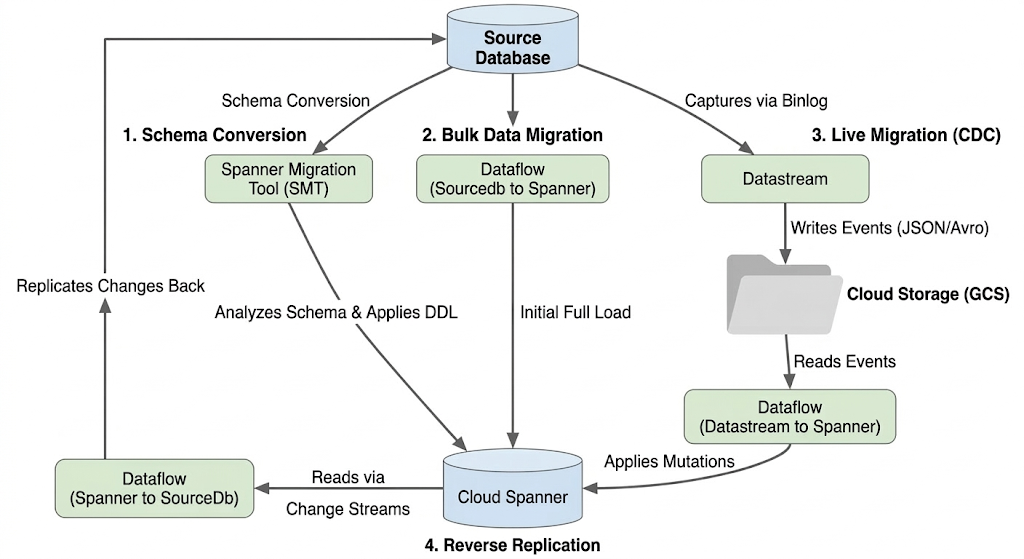
Миграция базы данных включает в себя перенос данных из исходного экземпляра базы данных CloudSQL в экземпляр Spanner. В этом разделе описывается архитектура и основные инструменты, используемые при миграции.
Архитектура потока миграции
Процесс миграции включает следующие этапы:
1. Преобразование схемы:
- Цель: Преобразовать схему исходной базы данных в совместимую схему Cloud Spanner.
- Инструмент: Инструмент миграции Spanner (SMT)
- Процесс: SMT анализирует схему исходной базы данных и генерирует эквивалентный язык определения данных Spanner (DDL). В целевом экземпляре Spanner создается база данных, после чего DDL автоматически применяется.
2. Массовая миграция данных:
- Цель: Выполнить первоначальную полную загрузку существующих данных из исходной базы данных в подготовленные таблицы Spanner.
- Инструмент: Dataflow, с использованием предоставленного Google шаблона
Sourcedb to Spanner. - Процесс: Данное задание Dataflow считывает все данные из указанных исходных таблиц и записывает их в соответствующие таблицы Spanner. Это выполняется после создания схемы Spanner.
3. Живая миграция (CDC):
- Цель: Захват и применение текущих изменений из исходной базы данных в Cloud Spanner практически в режиме реального времени, минимизируя время простоя во время миграции.
- Инструменты:
- Datastream: Захватывает изменения (вставки, обновления, удаления) из исходной базы данных и записывает их в облачное хранилище (GCS).
- Dataflow: Использует шаблон
Datastream to Spannerдля чтения событий изменений из GCS и их применения к Cloud Spanner.
4. Обратная репликация:
- Назначение: Реплицировать изменения данных из Cloud Spanner обратно в исходную базу данных. Это может быть полезно для стратегий резервного копирования, поэтапной миграции или поддержания реплики в исходной базе данных для конкретных сценариев использования.
- Инструмент: Dataflow, с использованием шаблона
Spanner to SourceDb. - Процесс: В этой задаче используются потоки изменений Spanner для фиксации модификаций в Spanner и их записи обратно в исходный экземпляр базы данных.
Следующая диаграмма иллюстрирует компоненты и поток данных:
Ключевые термины:
- Инструмент миграции Spanner (SMT) : инструмент, используемый для оценки схем MySQL, предложения эквивалентов схем Spanner и генерации языка определения данных Spanner (DDL) .
- Язык определения данных (DDL): операторы, используемые для определения и изменения структуры базы данных, например, операторы
CREATE TABLE. SMT генерирует DDL Spanner на основе схемы Cloud SQL. - Dataflow : Полностью управляемый бессерверный сервис обработки данных. В этом практическом задании он используется для запуска предоставленных Google шаблонов для массовой передачи данных, применения изменений Dataflow и обратной репликации.
- Datastream : Бессерверный сервис для отслеживания изменений данных (CDC) и репликации. В этом практическом задании он используется для потоковой передачи изменений из Cloud SQL в Cloud Storage.
- Функция Spanner Change Streams : функция Spanner, позволяющая передавать изменения данных (вставки, обновления, удаления) в режиме реального времени, используемая в качестве источника для обратной репликации.
- Pub/Sub : служба обмена сообщениями, используемая для разделения служб, генерирующих события, от служб, обрабатывающих их. В этом практическом задании она запускает обработку обновлений Dataflow всякий раз, когда Datastream загружает новые файлы изменений в Cloud Storage.
3. Настройка среды
Прежде чем начать миграцию, необходимо настроить проект Google Cloud и включить необходимые сервисы.
1. Выберите или создайте проект Google Cloud.
Для использования сервисов в этом практическом задании вам потребуется проект Google Cloud с включенной функцией выставления счетов.
- В консоли Google Cloud перейдите на страницу выбора проекта: Перейти к выбору проекта
- Выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего проекта включена функция выставления счетов. Узнайте, как подтвердить включение этой функции для вашего проекта .
2. Open Cloud Shell
Cloud Shell — это среда командной строки, работающая в Google Cloud, которая поставляется с предустановленным CLI-интерфейсом gcloud и другими необходимыми инструментами.
- Нажмите кнопку «Активировать Cloud Shell» в правом верхнем углу консоли Google Cloud.
- В нижней части консоли открывается новая панель, в которой отображается приглашение командной строки.

3. Настройка переменных проекта и среды.
В Cloud Shell настройте несколько переменных среды для идентификатора вашего проекта и используемого региона.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Включите необходимые API Google Cloud.
Включите необходимые API для Cloud Spanner, Dataflow, Datastream и других связанных сервисов.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Выполнение этой команды может занять несколько минут.
5. Настройка прав доступа к учетной записи службы.
Для взаимодействия заданий Dataflow и Datastream с другими сервисами Google Cloud требуются определенные разрешения. В этом практическом занятии задания Dataflow будут использовать учетную запись службы Compute Engine по умолчанию.
Для начала получите номер своего проекта:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
Теперь предоставьте необходимые роли IAM учетной записи службы Compute Engine по умолчанию:
# Role for Dataflow to run jobs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.admin" \
--condition=None
# Roles for Dataflow workers
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.worker" \
--condition=None
# Role to connect to Cloud SQL instance
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudsql.client" \
--condition=None
# Role to read/write from Cloud Spanner
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/spanner.databaseUser" \
--condition=None
# Role to access GCS buckets (Datastream output, Dataflow temp, JDBC driver)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectAdmin" \
--condition=None
# Roles for Datastream and Pub/Sub (for CDC)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastream.viewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/pubsub.subscriber"
6. Создайте сегмент облачного хранилища.
Создайте хранилище GCS в том же регионе, что и остальные ваши ресурсы. В этом хранилище будут храниться драйвер JDBC, выходные данные Datastream, а также оно будет использоваться Dataflow для временных файлов.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
echo "Created bucket: gs://$BUCKET_NAME"
7. Установите инструмент миграции Spanner (SMT).
Убедитесь, что инструмент миграции Spanner (SMT) установлен в вашей среде Cloud Shell.
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
Эта команда должна отобразить справочную информацию для веб-интерфейса SMT, подтверждая установку компонента gcloud . В этом практическом занятии будут использоваться функции командной строки SMT, которые являются частью того же компонента.
4. Настройка исходной облачной базы данных SQL.
В этом разделе вы создадите и настроите экземпляр Cloud SQL for MySQL с публичным IP-адресом , который будет использоваться в качестве исходной базы данных.
1. Создайте экземпляр Cloud SQL для MySQL.
Выполните следующую команду gcloud в Cloud Shell, чтобы создать экземпляр MySQL 8.0. Бинарное логирование включено (необходимо для Datastream), и экземпляр настроен с использованием публичного IP-адреса.
export SQL_INSTANCE_NAME="source-mysql-instance"
export DB_ROOT_PASSWORD="Welcome@1" # Replace with a strong password if you prefer
gcloud sql instances create $SQL_INSTANCE_NAME \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=$REGION \
--root-password=$DB_ROOT_PASSWORD \
--enable-bin-log \
--assign-ip
-
--enable-bin-log: Необходимо для того, чтобы Datastream фиксировал изменения. -
--assign-ip: Гарантирует, что экземпляр получит публичный IP-адрес.
Создание экземпляра займет несколько минут. Вы можете проверить, создан ли ваш экземпляр, на странице экземпляров CloudSQL.
2. Настройка авторизованных сетей
Для подключения к экземпляру по общедоступному IP-адресу необходимо добавить IP-адреса в список «Авторизованные сети».
Получите свой IP-адрес Cloud Shell:
export CLOUD_SHELL_IP=$(curl -s ipinfo.io/ip)
echo "Your Cloud Shell IP: $CLOUD_SHELL_IP"
Авторизация IP-адреса Cloud Shell и предоставление открытого доступа.
Следующая команда добавляет ваш IP-адрес Cloud Shell. Она также добавляет 0.0.0.0/0 , что позволяет получить доступ с любого IP-адреса. Это необходимо для упрощения подключений от рабочих процессов Dataflow без сложных сетевых настроек.
gcloud sql instances patch $SQL_INSTANCE_NAME \
--authorized-networks="${CLOUD_SHELL_IP}/32,0.0.0.0/0"
3. Подключитесь к экземпляру Cloud SQL из Cloud Shell.
Получите назначенный публичный IP-адрес.
export SQL_INSTANCE_IP=$(gcloud sql instances list --filter="name=$SQL_INSTANCE_NAME" --format="value(PRIMARY_ADDRESS)")
echo "Cloud SQL Public IP: $SQL_INSTANCE_IP"
Этот IP-адрес будет использоваться для подключения.
Подключитесь к экземпляру Cloud SQL из CloudShell.
Для подключения используйте стандартный клиент MySQL, используя полученный публичный IP-адрес:
mysql -h $SQL_INSTANCE_IP -u root -p
Когда появится запрос, введите установленный вами пароль root ( Welcome@1 ). Теперь вы окажетесь в командной строке mysql> .
4. Создайте базу данных и пример данных.
Выполните следующие SQL-команды в командной строке mysql> :
CREATE DATABASE music_db;
USE music_db;
CREATE TABLE Singers (
SingerId BIGINT NOT NULL,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
BirthDate DATE,
AlbumCount BIGINT,
PRIMARY KEY (SingerId)
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY (SingerId, AlbumId),
CONSTRAINT FK_Albums_Singers FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
);
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES
(1, 'Marc', 'Richards', '1970-09-03', 2),
(2, 'Catalina', 'Smith', '1990-08-17', 1),
(3, 'Alice', 'Trentor', '1991-10-02', 3);
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle, ReleaseDate) VALUES
(1, 1, 'Total Junk', '2014-03-15'),
(1, 2, 'Go Go Go', '2016-11-01'),
(2, 1, 'Green', '2018-02-28'),
(3, 1, 'Blue', '2019-01-10'),
(3, 2, 'Red', '2020-05-22'),
(3, 3, 'Purple', '2022-11-11');
Файл дампа для указанной выше схемы можно найти здесь .
5. Проверка данных
Быстро проверьте наличие данных:
SELECT 'Singers music_db' as tbl, COUNT(*) FROM music_db.Singers
UNION ALL
SELECT 'Albums music_db', COUNT(*) FROM music_db.Albums;
EXIT;
Вы должны увидеть количество записей в каждой таблице.
+------------------+----------+ | tbl | COUNT(*) | +------------------+----------+ | Singers music_db | 3 | | Albums music_db | 6 | +------------------+----------+
5. Настройка Cloud Spanner
Теперь вам нужно настроить целевой экземпляр Cloud Spanner, куда будут перенесены данные.
1. Создайте экземпляр Cloud Spanner.
Создайте экземпляр Cloud Spanner в том же регионе, что и ваш экземпляр Cloud SQL. Эта команда создаст небольшой экземпляр, подходящий для данного практического занятия, с использованием 100 вычислительных блоков.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="music-db-migrated"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
Создание экземпляра может занять одну-две минуты.
6. Преобразуйте схему с помощью инструмента миграции Spanner (SMT).
Используйте интерфейс командной строки SMT для анализа базы данных MySQL ( music_db ) и генерации языка определения схемы Spanner (DDL). Поскольку экземпляр Cloud SQL настроен с использованием публичного IP-адреса и соответствующих авторизованных сетей, SMT может подключаться напрямую.
1. Подготовка среды для SMT.
Убедитесь, что необходимые переменные среды установлены на предыдущих шагах:
echo "Cloud SQL Instance Public IP: $SQL_INSTANCE_IP"
echo "Cloud SQL Root Password: $DB_ROOT_PASSWORD"
echo "Spanner Instance: $SPANNER_INSTANCE_NAME"
echo "Spanner Database: $SPANNER_DATABASE_NAME"
echo "Project ID: $PROJECT_ID"
2. Выполните преобразование схемы для music_db
Выполните команду SMT schema , подключившись напрямую к публичному IP-адресу Cloud SQL:
gcloud alpha spanner migrate schema \
--source=mysql \
--source-profile="host=${SQL_INSTANCE_IP},port=3306,user=root,password=${DB_ROOT_PASSWORD},dbName=music_db" \
--target-profile="project=${PROJECT_ID},instance=${SPANNER_INSTANCE_NAME},dbName=${SPANNER_DATABASE_NAME}" \
--prefix="music-db"
Эта команда подключается к экземпляру Cloud SQL через прокси и генерирует файлы схемы с префиксом music-db .
3. Проверка сгенерированных файлов
SMT создаёт несколько файлов в текущей директории. Ключевые из них:
-
music-db.schema.ddl.txt: Сгенерированные операторы DDL Spanner. -
music-db-.overrides.json: Файл переопределений схемы, содержащий изменения сопоставления, внесенные вручную. -
music-db.session.json: Файл сессии миграции схемы. -
music-db.report.txt: Отчет об оценке преобразования схемы.
Вы можете вывести их список с помощью ls music-db-*
4. Проверьте схему в Cloud Spanner.
Убедитесь, что таблицы созданы в базе данных Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Вы должны увидеть следующий результат:
table_name: Albums table_name: Singers
(Необязательно) Если вы хотите проверить DDL-скрипт Spanner, выполните следующую команду:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
7. Инициализация системы отслеживания изменений данных (CDC)
В этом разделе вы настроите «регистратор» для миграции. Настроив Datastream и Pub/Sub до начала массовой загрузки данных, вы гарантируете, что каждое изменение, внесенное в исходную базу данных, будет зафиксировано и поставлено в очередь, предотвращая потерю данных во время перехода. Эта настройка необходима для миграции в реальном времени.
1. Создание профилей подключения к потоку данных
Профиль источника (Cloud SQL)
Этот профиль подключается к публичному IP-адресу экземпляра Cloud SQL. Datastream будет использовать список разрешенных IP-адресов для подключения.
export SQL_CP_NAME="mysql-src-cp"
gcloud datastream connection-profiles create $SQL_CP_NAME \
--location=$REGION \
--type=mysql \
--mysql-hostname=$SQL_INSTANCE_IP \
--mysql-port=3306 \
--mysql-username=root \
--mysql-password=$DB_ROOT_PASSWORD \
--display-name="Cloud SQL Source - Public IP"
Примечание: Это соединение зависит от разрешения доступа со стороны авторизованных сетей экземпляра Cloud SQL. Как было настроено ранее с 0.0.0.0/0 , публичные IP-адреса Datastream могут подключаться. В производственной среде следует заменить 0.0.0.0/0 на конкретные диапазоны IP-адресов для вашего региона, указанные в списках разрешенных IP-адресов и регионах Datastream .
Профиль назначения (облачное хранилище)
Указывает на основание вашего ведра.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
2. Создайте поток данных.
Создайте поток для репликации из music_db .
export STREAM_NAME="mysql-to-spanner-stream"
export GCS_STREAM_PATH="data/${STREAM_NAME}"
gcloud datastream streams create $STREAM_NAME \
--location=$REGION \
--display-name="MySQL to Spanner CDC Stream" \
--source=$SQL_CP_NAME \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "
includeObjects:
mysqlDatabases:
- database: 'music_db'
") \
--gcs-destination-config=<(echo "
path: ${GCS_STREAM_PATH}
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}
") \
--backfill-none
- Datastream будет записывать файлы в каталог
gs://${BUCKET_NAME}/${GCS_STREAM_PREFIX}/ - Datastream будет записывать файлы в формате Avro. При выполнении команды миграции в реальном времени мы укажем inputFileFormat как avro, чтобы конвейер мог корректно обработать файл.
- Использование меньших значений поворота файлов помогает быстрее увидеть изменения в практическом задании.
Выполнение этой команды может занять некоторое время. Проверьте статус: gcloud datastream streams describe $STREAM_NAME --location=$REGION .
3. Запустите поток данных.
gcloud datastream streams update $STREAM_NAME \
--location=$REGION \
--state=RUNNING
Проверка статуса: gcloud datastream streams describe $STREAM_NAME --location=$REGION. Первоначально состояние будет STARTING , а через некоторое время изменится RUNNING . Переходите к следующему шагу только после того, как убедитесь, что состояние RUNNING .
4. Настройка механизма публикации/подписки для уведомлений GCS.
Создайте тему для публикации/подписки:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
Создать уведомление GCS
Уведомление о создании объекта с префиксом data/ .
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Создать подписку Pub/Sub
Укажите рекомендуемый срок подтверждения получения.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Массовая миграция данных из Cloud SQL в Spanner.
После настройки схемы Spanner, вы сможете скопировать существующие данные из вашей базы данных Cloud SQL music_db в Cloud Spanner. Для этого используйте гибкий шаблон потока данных Sourcedb to Spanner , предназначенный для массового копирования данных из баз данных, доступных по JDBC, в Spanner.
1. Запустите задачу массовой миграции данных для music_db
Выполните следующую команду в Cloud Shell, чтобы запустить задание Dataflow. Эта команда использует команду gcloud dataflow flex-template run , ссылаясь на предоставленный Google шаблон для массовой миграции JDBC в Spanner.
export JOB_NAME_MUSIC="mysql-music-db-to-spanner-bulk-$(date +%Y%m%d-%H%M%S)"
export MUSIC_DB_JDBC_URL="jdbc:mysql://${SQL_INSTANCE_IP}:3306/music_db"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration-output"
gcloud dataflow flex-template run $JOB_NAME_MUSIC \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL="$MUSIC_DB_JDBC_URL",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
outputDirectory="$OUTPUT_DIR/music_db",\
username="root",\
password="$DB_ROOT_PASSWORD",\
jdbcDriverClassName="com.mysql.cj.jdbc.Driver",\
jdbcDriverJars="gs://${BUCKET_NAME}/lib/mysql-connector-j-8.0.33.jar",\
spannerHost="https://batch-spanner.googleapis.com"
Ключевые параметры объяснены:
-
sourceConfigURL: Строка подключения JDBC к источникуmusic_db. -
instanceId,databaseId,projectId: Указывает целевой экземпляр Cloud Spanner и базу данных. -
outputDirectory: Путь в Cloud Storage, куда Dataflow будет записывать информацию о любых записях, которые не удалось перенести. -
jdbcDriverClassName: Указывает драйвер JDBC для MySQL. -
jdbcDriverJars: Путь GCS к подготовленному JAR-файлу драйвера JDBC. -
spannerHost: Использует оптимизированную для пакетной обработки конечную точку для записи в Spanner. -
maxWorkers,numWorkers: Управляет масштабированием задачи Dataflow. Для этого небольшого набора данных установите низкое значение.
Примечание по сети: Это задание подключается к экземпляру Cloud SQL через его публичный IP-адрес. Это возможно, потому что вы ранее добавили 0.0.0.0/0 в список авторизованных сетей экземпляра. Это позволяет виртуальным машинам Dataflow, имеющим внешние IP-адреса, подключаться к базе данных.
2. Мониторинг задания потока данных.
Вы можете отслеживать ход выполнения задания в консоли Google Cloud:
- Перейдите на страницу заданий Dataflow: Перейдите в раздел «Задания Dataflow».
- Найдите задание с именем
mysql-music-db-to-spanner-bulk-...и щелкните по нему. - Проанализируйте график выполнения задания и показатели. Дождитесь, пока статус задания изменится на «Успешно» . Это займет приблизительно 5-15 минут.
- Если в процессе выполнения задания возникнут проблемы, просмотрите вкладку «Журналы» на странице сведений о задании Dataflow, чтобы ознакомиться с сообщениями об ошибках.
- Метрики задания предоставляют более подробную информацию о ходе выполнения задания и потреблении ресурсов, таких как пропускная способность и загрузка ЦП.
3. Проверьте данные в Cloud Spanner.
После успешного завершения задания Dataflow убедитесь, что данные скопированы в таблицы Spanner. Используйте gcloud для запроса к базе данных Spanner:
# Verify row counts
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Singers"
# Expected output: 3
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Albums"
# Expected output: 6
# Inspect some data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT SingerId, FirstName, LastName FROM Singers ORDER BY SingerId"
Ожидаемый результат:
row_count: 3 row_count: 6 SingerId: 1 FirstName: Marc LastName: Richards SingerId: 2 FirstName: Catalina LastName: Smith SingerId: 3 FirstName: Alice LastName: Trentor
Первоначальная массовая загрузка данных из Cloud SQL в Cloud Spanner завершена. Следующий шаг — настройка репликации в реальном времени для фиксации текущих изменений.
9. Начать миграцию в реальном времени (CDC)
Теперь, когда загрузка больших объемов данных завершена, вам нужно будет настроить непрерывный поток репликации с использованием Datastream для захвата событий Change Data Capture (CDC) из Cloud SQL и задание потоковой передачи Dataflow для применения этих изменений в Cloud Spanner практически в режиме реального времени.
1. Запустите задание потока данных для миграции в реальном времени.
Запустите потоковое задание Dataflow для чтения из GCS и записи в Spanner. Этот шаблон будет использовать уведомления GCS Pub/Sub для мгновенной обработки новых файлов.
export JOB_NAME_CDC="datastream-to-spanner-cdc-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR="gs://${BUCKET_NAME}/dlq"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
deadLetterQueueDirectory="$DLQ_DIR",\
streamName="projects/${PROJECT_ID}/locations/${REGION}/streams/${STREAM_NAME}"
Ключевые параметры
-
gcsPubSubSubscription: Подписка Pub/Sub, которая отслеживает уведомления о новых файлах от GCS. Это позволяет заданию обрабатывать изменения мгновенно по мере их записи в Datastream. -
inputFileFormat="avro": Указывает Dataflow ожидать файлы Avro из Datastream. Это должно соответствовать конфигурации "Destination" вашего Datastream (например,avroFileFormatилиjsonFileFormat). -
deadLetterQueueDirectory: Путь в GCS, куда задание сохраняет записи, обработка которых не удалась (например, из-за несоответствия схемы), для последующей ручной проверки. -
streamName: Полный путь к ресурсу потока Datastream, позволяющий заданию Dataflow отслеживать состояние репликации и метаданные.
Отслеживайте запуск задания в консоли заданий Dataflow .
2. Тестирование миграции в рабочую среду.
Внесите изменения в исходную базу данных Cloud SQL music_db , чтобы протестировать конвейер CDC.
Подключение к Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
Введите пароль ( Welcome@1 ) и выберите базу данных:
USE music_db;
-- INSERT
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (4, 'Elena', 'Nadal', '1985-05-30', 0);
SELECT * FROM Singers WHERE SingerId = 4;
-- UPDATE
UPDATE Singers SET LastName = 'Richards-Smith' WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- DELETE
DELETE FROM Albums WHERE SingerId = 2;
DELETE FROM Singers WHERE SingerId = 2;
SELECT * FROM Singers WHERE SingerId = 2;
EXIT;
Проверка в Spanner (через несколько мгновений):
# Verify INSERT: This should return the new row for Elena Nadal.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 4"
# Verify UPDATE: This should show LastName as Richards-Smith.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName FROM Singers WHERE SingerId = 1"
# Verify DELETE: This should now return 0 rows.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Albums WHERE SingerId = 2"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 2"
Ожидаемый результат:
SingerId: 4 FirstName: Elena LastName: Nadal BirthDate: 1985-05-30 AlbumCount: 0 SingerId: 1 FirstName: Marc LastName: Richards-Smith
3. Окончательная проверка в гаечном ключе
Проверьте общее состояние таблицы Singers в Spanner:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId"
Ожидаемый результат:
SingerId: 1 FirstName: Marc LastName: Richards-Smith AlbumCount: 2 SingerId: 3 FirstName: Alice LastName: Trentor AlbumCount: 3 SingerId: 4 FirstName: Elena LastName: Nadal AlbumCount: 0
10. Настройка обратной репликации (Spanner к Cloud SQL)
Для обработки сценариев, когда может потребоваться откат или синхронизация базы данных Cloud SQL со Spanner в течение определенного периода, можно настроить обратную репликацию. Этот конвейер использует потоки изменений Spanner для захвата изменений в Spanner и записи их обратно в базу данных Cloud SQL music_db .
1. Создайте поток изменений гаечного ключа.
Во-первых, вам необходимо создать поток изменений в вашей базе данных Spanner для отслеживания изменений в таблицах Singers и Albums .
export CHANGE_STREAM_NAME="MusicDBChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Singers, Albums"
Теперь в этот поток изменений будут записываться все изменения данных в указанных таблицах.
2. Создайте базу данных Spanner для метаданных потока данных.
Для использования шаблона Spanner to SourceDB Dataflow требуется отдельная база данных Spanner для хранения метаданных, необходимых для управления потоком изменений.
export SPANNER_METADATA_DB_NAME="reverse-replication-metadata"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Подготовка конфигурации подключения Cloud SQL для Dataflow.
Для работы шаблона Dataflow требуется JSON-файл в Cloud Storage, содержащий данные для подключения к целевой базе данных Cloud SQL.
Создайте локальный файл с именем shard_config.json :
cat << EOF > shard_config.json
[
{
"logicalShardId": "mysql_shard",
"host": "${SQL_INSTANCE_IP}",
"port": "3306",
"user": "root",
"password": "${DB_ROOT_PASSWORD}",
"dbName": "music_db"
}
]
EOF
Загрузите этот файл в свой бакет GCS:
export SHARD_CONFIG_FILE="gs://${BUCKET_NAME}/shard_config.json"
gcloud storage cp shard_config.json $SHARD_CONFIG_FILE
4. Запустите задание обратной репликации потока данных.
Запустите задание Dataflow, используя гибкий шаблон Spanner_to_SourceDb .
export JOB_NAME_REVERSE="spanner-to-mysql-reverse-$(date +%Y%m%d-%H%M%S)"
export REVERSE_DLQ_DIR="gs://${BUCKET_NAME}/reverse-dlq"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$SHARD_CONFIG_FILE",\
deadLetterQueueDirectory="$REVERSE_DLQ_DIR"
Ключевые параметры
-
changeStreamName: Имя потока изменений Spanner, из которого нужно считывать данные. -
metadataInstance, metadataDatabase: Экземпляр/база данных Spanner для хранения метаданных, используемых коннектором для управления потреблением данных API потока изменений. -
sourceShardsFilePath: Путь кshard_config.jsonв системе GCS. -
filtrationMode: Определяет, как удалять определенные записи на основе заданных критериев. По умолчанию используетсяforward_migration(фильтрация записей, созданных с помощью конвейера прямой миграции).
Примечание по сети: Рабочие процессы Dataflow будут подключаться к экземпляру Cloud SQL, используя публичный IP-адрес, указанный в файле shard_config.json . Это подключение разрешено благодаря записи 0.0.0.0/0 в списке авторизованных сетей экземпляра Cloud SQL.
Отслеживайте запуск задания в консоли заданий Dataflow .
5. Тестирование обратной репликации
Теперь внесите изменения непосредственно в Cloud Spanner и убедитесь, что они отражены в Cloud SQL. Делайте это только после того, как задание потока данных запустится и перейдет в состояние обработки.
Проверьте работу INSERT , UPDATE и DELETE
# INSERT: Insert a new singer (SingerId 5) into Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (5, 'David', 'Chen', '1995-02-18', 0)"
# UPDATE: Update SingerId 3's AlbumCount in Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Singers SET AlbumCount = 5 WHERE SingerId = 3"
# DELETE: Delete SingerId 1 from Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Albums WHERE SingerId = 1"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Singers WHERE SingerId = 1"
Проверка в Cloud SQL (через несколько мгновений):
Подключение к Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
Введите пароль ( Welcome@1 ), когда появится соответствующий запрос, затем выполните следующие команды SQL в командной строке mysql> .
USE music_db;
-- Verify INSERT: This should show the new row for David Chen
SELECT * FROM Singers WHERE SingerId = 5;
-- Verify UPDATE: This should show AlbumCount as 5.
SELECT SingerId, FirstName, AlbumCount FROM Singers WHERE SingerId = 3;
-- Verify DELETE: This should return an empty set.
SELECT * FROM Albums WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- Final Verification
SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId;
EXIT;
Ожидаемый результат в Cloud SQL должен отражать изменения, внесенные в Spanner.
+----------+-----------+----------------+------------+ | SingerId | FirstName | LastName | AlbumCount | +----------+-----------+----------------+------------+ | 3 | Alice | Trentor | 5 | | 4 | Elena | Nadal | 0 | | 5 | David | Chen | 0 | +----------+-----------+----------------+------------+
Это подтверждает, что конвейер обратной репликации функционирует, синхронизируя изменения из Spanner обратно в Cloud SQL.
11. Ресурсы для уборки
Чтобы избежать дополнительных расходов на ваш аккаунт Google Cloud, удалите ресурсы, созданные в ходе этого практического занятия.
Установите переменные среды (при необходимости).
Проверьте правильность установки переменных среды:
echo "PROJECT_ID: $PROJECT_ID"
echo "REGION: $REGION"
echo "SQL_INSTANCE_NAME: $SQL_INSTANCE_NAME"
echo "SPANNER_INSTANCE_NAME: $SPANNER_INSTANCE_NAME"
echo "BUCKET_NAME: $BUCKET_NAME"
echo "STREAM_NAME: $STREAM_NAME"
echo "SQL_CP_NAME: $SQL_CP_NAME"
echo "GCS_CP_NAME: $GCS_CP_NAME"
echo "PUBSUB_SUBSCRIPTION: $PUBSUB_SUBSCRIPTION"
echo "PUBSUB_TOPIC: $PUBSUB_TOPIC"
echo "CHANGE_STREAM_NAME: $CHANGE_STREAM_NAME"
Чтобы найти идентификаторы запущенных заданий потока данных, выведите список заданий. Экспортируйте соответствующие поля JOB_ID_CDC и JOB_ID_REVERSE .
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Если вы находитесь в новой сессии Cloud Shell, повторно экспортируйте ключевые переменные среды:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or the region you used
export SQL_INSTANCE_NAME="source-mysql-instance"
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export STREAM_NAME="mysql-to-spanner-stream"
export SQL_CP_NAME="mysql-src-cp"
export GCS_CP_NAME="gcs-dest-cp"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CHANGE_STREAM_NAME="MusicDBChangeStream"
Остановить потоковые задания Dataflow
Отмените задачу Datastream to Spanner (миграция в реальном времени):
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
Отмените задание Spanner to Cloud SQL (обратная репликация):
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Удалить ресурсы потока данных
Остановить и удалить поток:
gcloud datastream streams update $STREAM_NAME \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Удаление профилей подключения
gcloud datastream connection-profiles delete $SQL_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Удалить ресурсы Pub/Sub
Удалить подписку:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Удалить тему:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Удаление экземпляра Cloud SQL
Это автоматически удалит базы данных ( music_db ) внутри неё.
gcloud sql instances delete $SQL_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Удалить экземпляр Cloud Spanner
Это также приведет к удалению баз данных ( music-db-migrated и reverse-replication-metadata ) внутри него.
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Удалить корзину и содержимое GCS.
gcloud storage rm --recursive gs://${BUCKET_NAME}
Удалить локальные файлы
Удалите все файлы, созданные в домашнем каталоге Cloud Shell:
rm -f music-db* shard_config.json
Вы завершили очистку ресурсов, созданных для этого практического занятия.