
1. Trước khi bắt đầu
Lớp học lập trình này hướng dẫn bạn cách di chuyển một cơ sở dữ liệu MySQL duy nhất trên Cloud SQL sang cơ sở dữ liệu Cloud Spanner bằng phương ngữ GoogleSQL. Trọng tâm là quy trình di chuyển cơ bản từ đầu đến cuối, minh hoạ các bước cốt lõi. Bạn sẽ sử dụng các dịch vụ của Google Cloud, bao gồm cả Công cụ di chuyển Spanner (SMT), Dataflow, Datastream, PubSub và Google Cloud Storage.
Kiến thức bạn sẽ học được:
- Cách thiết lập các phiên bản Cloud SQL và Cloud Spanner mẫu.
- Cách chuyển đổi giản đồ Cloud SQL MySQL thành giản đồ tương thích với Spanner bằng Spanner Migration Tool (SMT).
- Cách thực hiện di chuyển hàng loạt dữ liệu từ Cloud SQL sang Cloud Spanner bằng Dataflow.
- Cách thiết lập tính năng sao chép liên tục (CDC) từ Cloud SQL sang Cloud Spanner bằng Datastream và Dataflow.
- Cách thiết lập quy trình sao chép ngược từ Cloud Spanner sang Cloud SQL.
Những nội dung KHÔNG có trong lớp học lập trình này:
- Di chuyển từ các phiên bản phân mảnh.
- Các phép biến đổi dữ liệu phức tạp trong quá trình di chuyển.
- Xử lý lỗi nâng cao hoặc Hàng đợi thư không gửi được (DLQ).
- Điều chỉnh hiệu suất di chuyển.
- Di chuyển ứng dụng: Lớp học lập trình này tập trung vào lớp cơ sở dữ liệu (giản đồ và dữ liệu). Tài liệu này không đề cập đến quy trình vận hành để triển khai lại hoặc di chuyển các dịch vụ ứng dụng của bạn.
Bạn cần có
- Một dự án trên Google Cloud đã bật tính năng thanh toán.
- Có đủ quyền IAM để bật API và tạo/quản lý tài nguyên Cloud SQL, Spanner, Dataflow, Datastream và GCS. Mặc dù vai trò Dự án
Ownerlà đơn giản nhất đối với một lớp học lập trình, nhưng các vai trò cụ thể hơn sẽ được đề cập trong phần "Thiết lập môi trường". - Một trình duyệt web, chẳng hạn như Google Chrome.
- Quen thuộc cơ bản với Google Cloud Console và các công cụ dòng lệnh như
gcloud. - Truy cập vào môi trường shell. Bạn nên dùng Cloud Shell vì công cụ này có
gcloud.
Thông tin chi tiết hơn về chế độ thiết lập nêu trên được trình bày trong phần Thiết lập môi trường.
2. Tìm hiểu quy trình di chuyển
Việc di chuyển cơ sở dữ liệu bao gồm việc di chuyển dữ liệu từ phiên bản cơ sở dữ liệu CloudSQL nguồn sang một phiên bản Spanner. Phần này trình bày tổng quan về cấu trúc và các công cụ chính được dùng trong quá trình di chuyển.
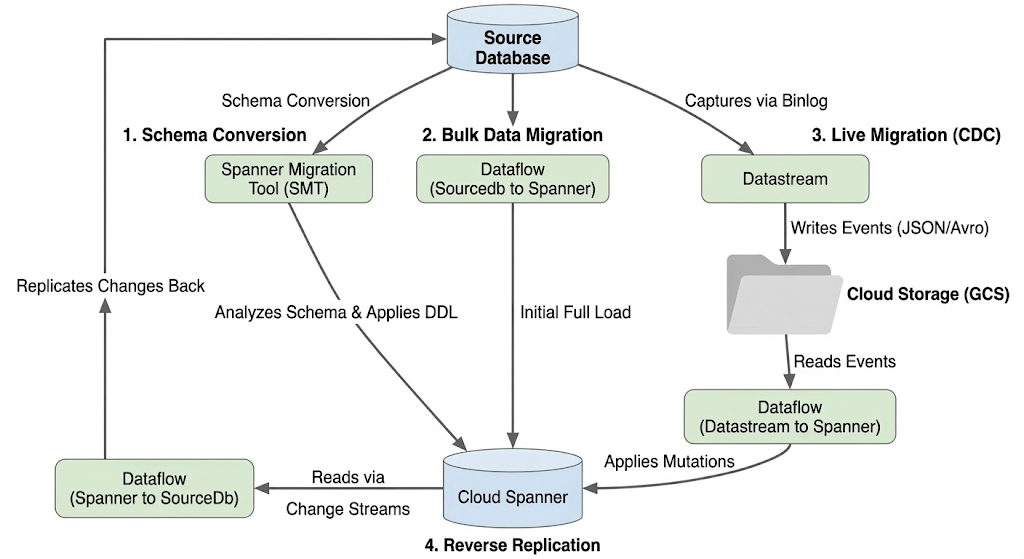
Kiến trúc luồng di chuyển
Quá trình di chuyển bao gồm các giai đoạn sau:
1. Chuyển đổi giản đồ:
- Mục đích: Chuyển đổi giản đồ cơ sở dữ liệu nguồn thành một giản đồ Cloud Spanner tương thích.
- Công cụ: Công cụ di chuyển Spanner (SMT)
- Quy trình: SMT phân tích giản đồ cơ sở dữ liệu nguồn và tạo Ngôn ngữ định nghĩa dữ liệu (DDL) tương đương của Spanner. Trong phiên bản Spanner mục tiêu, một cơ sở dữ liệu sẽ được tạo và DDL sau đó sẽ tự động được áp dụng.
2. Di chuyển dữ liệu hàng loạt:
- Mục đích: Để thực hiện thao tác tải đầy đủ ban đầu đối với dữ liệu hiện có từ cơ sở dữ liệu nguồn vào các bảng Spanner được cung cấp.
- Công cụ: Dataflow, sử dụng mẫu
Sourcedb to Spannerdo Google cung cấp. - Quy trình: Tác vụ Dataflow này đọc tất cả dữ liệu từ các bảng nguồn được chỉ định và ghi dữ liệu đó vào các bảng Spanner tương ứng. Việc này được thực hiện sau khi bạn tạo giản đồ Spanner.
3. Di chuyển trực tiếp (CDC):
- Mục đích: Để ghi lại và áp dụng các thay đổi liên tục từ cơ sở dữ liệu nguồn vào Cloud Spanner gần như theo thời gian thực, giảm thiểu thời gian ngừng hoạt động trong quá trình di chuyển.
- Công cụ:
- Datastream: Ghi lại các thay đổi (Chèn, Cập nhật, Xoá) từ cơ sở dữ liệu nguồn và ghi các thay đổi đó vào Cloud Storage (GCS).
- Dataflow: Sử dụng mẫu
Datastream to Spannerđể đọc các sự kiện thay đổi từ GCS và áp dụng các sự kiện đó cho Cloud Spanner.
4. Sao chép ngược:
- Mục đích: Sao chép các thay đổi về dữ liệu từ Cloud Spanner trở lại cơ sở dữ liệu nguồn. Điều này có thể hữu ích cho các chiến lược dự phòng, quá trình di chuyển theo giai đoạn hoặc duy trì bản sao trong nguồn cho các trường hợp sử dụng cụ thể.
- Công cụ: Dataflow, sử dụng mẫu
Spanner to SourceDb. - Quy trình: Tác vụ này sử dụng luồng thay đổi của Spanner để ghi lại các nội dung sửa đổi trong Spanner và ghi lại các nội dung đó vào phiên bản cơ sở dữ liệu nguồn.
Sơ đồ sau đây minh hoạ các thành phần và luồng dữ liệu:
Thuật ngữ chính:
- Công cụ di chuyển Spanner (SMT): Một công cụ dùng để đánh giá giản đồ MySQL, đề xuất các giản đồ tương đương của Spanner và tạo Ngôn ngữ định nghĩa dữ liệu (DDL) của Spanner.
- Ngôn ngữ định nghĩa dữ liệu (DDL): Các câu lệnh dùng để xác định và sửa đổi cấu trúc cơ sở dữ liệu, chẳng hạn như câu lệnh
CREATE TABLE. SMT tạo DDL Spanner dựa trên giản đồ Cloud SQL. - Dataflow: Một dịch vụ xử lý dữ liệu không máy chủ, được quản lý toàn diện. Trong lớp học lập trình này, bạn sẽ dùng công cụ này để chạy các mẫu do Google cung cấp cho hoạt động chuyển dữ liệu hàng loạt, áp dụng các thay đổi của Datastream và sao chép ngược.
- Datastream: Một dịch vụ sao chép và ghi nhận dữ liệu thay đổi (CDC) không cần máy chủ. Trong lớp học lập trình này, bạn sẽ dùng công cụ này để truyền trực tuyến các thay đổi từ Cloud SQL vào Cloud Storage.
- Luồng thay đổi của Spanner: Một tính năng của Spanner cho phép truyền trực tuyến các thay đổi đối với dữ liệu (thao tác chèn, cập nhật, xoá) theo thời gian thực, được dùng làm nguồn để sao chép ngược.
- Pub/Sub: Một dịch vụ nhắn tin được dùng để tách các dịch vụ tạo sự kiện khỏi các dịch vụ xử lý sự kiện. Trong lớp học lập trình này, bạn sẽ kích hoạt Dataflow để xử lý các bản cập nhật bất cứ khi nào Datastream tải tệp thay đổi mới lên Cloud Storage.
3. Thiết lập môi trường
Trước khi có thể bắt đầu di chuyển, bạn cần thiết lập dự án trên đám mây trên Google Cloud và bật các dịch vụ cần thiết.
1. Chọn hoặc tạo một dự án trên Google Cloud
Bạn cần có một dự án Google Cloud đã bật tính năng thanh toán để sử dụng các dịch vụ trong lớp học lập trình này.
- Trong Google Cloud Console, hãy chuyển đến trang chọn dự án: Chuyển đến trang chọn dự án
- Chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo bạn đã bật tính năng thanh toán cho dự án của mình. Tìm hiểu cách xác nhận rằng tính năng thanh toán đã được bật cho dự án của bạn.
2. Mở Cloud Shell
Cloud Shell là một môi trường dòng lệnh chạy trong Google Cloud, được tải sẵn gcloud CLI và các công cụ khác mà bạn cần.
- Nhấp vào nút Kích hoạt Cloud Shell ở trên cùng bên phải của Bảng điều khiển Google Cloud.
- Một phiên Cloud Shell sẽ mở ra trong một khung hình mới ở cuối bảng điều khiển và hiển thị một dấu nhắc dòng lệnh.

3. Đặt các biến môi trường và dự án
Trong Cloud Shell, hãy thiết lập một số biến môi trường cho mã dự án và khu vực mà bạn sẽ sử dụng.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Bật các API bắt buộc của Google Cloud
Bật các API cần thiết cho Cloud Spanner, Dataflow, Datastream và các dịch vụ liên quan khác.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Lệnh này có thể mất vài phút để hoàn tất.
5. Định cấu hình quyền cho tài khoản dịch vụ
Các công việc Dataflow và Datastream yêu cầu các quyền cụ thể để tương tác với các dịch vụ khác của Google Cloud. Các tác vụ Dataflow trong lớp học lập trình này sẽ sử dụng tài khoản dịch vụ Compute Engine mặc định.
Trước tiên, hãy lấy Số dự án:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
Bây giờ, hãy cấp các vai trò IAM cần thiết cho tài khoản dịch vụ mặc định của Compute Engine:
# Role for Dataflow to run jobs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.admin" \
--condition=None
# Roles for Dataflow workers
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.worker" \
--condition=None
# Role to connect to Cloud SQL instance
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudsql.client" \
--condition=None
# Role to read/write from Cloud Spanner
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/spanner.databaseUser" \
--condition=None
# Role to access GCS buckets (Datastream output, Dataflow temp, JDBC driver)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectAdmin" \
--condition=None
# Roles for Datastream and Pub/Sub (for CDC)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastream.viewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/pubsub.subscriber"
6. Tạo một bộ chứa Cloud Storage
Tạo một bộ chứa GCS trong cùng vùng với các tài nguyên khác. Thùng này sẽ lưu trữ trình điều khiển JDBC, đầu ra Datastream và được Dataflow dùng cho các tệp tạm thời.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
echo "Created bucket: gs://$BUCKET_NAME"
7. Cài đặt Công cụ di chuyển Spanner (SMT)
Đảm bảo bạn đã cài đặt Công cụ di chuyển Spanner (SMT) trong môi trường Cloud Shell.
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
Lệnh này sẽ hiển thị thông tin trợ giúp cho giao diện web SMT, xác nhận rằng thành phần gcloud đã được cài đặt. Lớp học lập trình này sẽ sử dụng các tính năng CLI của SMT, vốn là một phần của cùng một thành phần.
4. Thiết lập cơ sở dữ liệu Cloud SQL nguồn
Trong phần này, bạn sẽ tạo và định cấu hình một phiên bản Cloud SQL cho MySQL có IP công khai để đóng vai trò là cơ sở dữ liệu nguồn.
1. Tạo một phiên bản Cloud SQL cho MySQL
Chạy lệnh gcloud sau đây trong Cloud Shell để tạo một thực thể MySQL 8.0. Tính năng ghi nhật ký nhị phân được bật (bắt buộc đối với Datastream) và phiên bản được định cấu hình bằng một IP công khai.
export SQL_INSTANCE_NAME="source-mysql-instance"
export DB_ROOT_PASSWORD="Welcome@1" # Replace with a strong password if you prefer
gcloud sql instances create $SQL_INSTANCE_NAME \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=$REGION \
--root-password=$DB_ROOT_PASSWORD \
--enable-bin-log \
--assign-ip
--enable-bin-log: Bắt buộc để Datastream ghi lại các thay đổi.--assign-ip: Đảm bảo phiên bản nhận được một địa chỉ IP công khai.
Quá trình tạo phiên bản sẽ mất vài phút. Bạn có thể kiểm tra xem phiên bản của mình có được tạo trên Trang phiên bản CloudSQL hay không.
2. Định cấu hình Mạng được uỷ quyền
Để kết nối với thực thể qua IP công khai, bạn cần thêm địa chỉ IP vào danh sách "Mạng được ủy quyền".
Lấy địa chỉ IP của Cloud Shell:
export CLOUD_SHELL_IP=$(curl -s ipinfo.io/ip)
echo "Your Cloud Shell IP: $CLOUD_SHELL_IP"
Uỷ quyền cho địa chỉ IP Cloud Shell và chế độ truy cập miễn phí
Lệnh sau đây sẽ thêm IP Cloud Shell của bạn. Thao tác này cũng thêm 0.0.0.0/0, cho phép truy cập từ mọi địa chỉ IP. Điều này là cần thiết để đơn giản hoá các kết nối từ các worker Dataflow mà không cần thiết lập mạng phức tạp.
gcloud sql instances patch $SQL_INSTANCE_NAME \
--authorized-networks="${CLOUD_SHELL_IP}/32,0.0.0.0/0"
3. Kết nối với phiên bản Cloud SQL từ Cloud Shell
Tìm nạp địa chỉ IP công khai được chỉ định
export SQL_INSTANCE_IP=$(gcloud sql instances list --filter="name=$SQL_INSTANCE_NAME" --format="value(PRIMARY_ADDRESS)")
echo "Cloud SQL Public IP: $SQL_INSTANCE_IP"
Địa chỉ IP này sẽ được dùng để kết nối.
Kết nối với phiên bản Cloud SQL từ Cloud Shell
Sử dụng ứng dụng mysql tiêu chuẩn để kết nối bằng địa chỉ IP công khai đã nhận được:
mysql -h $SQL_INSTANCE_IP -u root -p
Khi được nhắc, hãy nhập mật khẩu gốc mà bạn đã đặt (Welcome@1). Giờ đây, bạn sẽ thấy lời nhắc mysql>.
4. Tạo cơ sở dữ liệu và dữ liệu mẫu
Thực thi các lệnh SQL sau trong dấu nhắc mysql>:
CREATE DATABASE music_db;
USE music_db;
CREATE TABLE Singers (
SingerId BIGINT NOT NULL,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
BirthDate DATE,
AlbumCount BIGINT,
PRIMARY KEY (SingerId)
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY (SingerId, AlbumId),
CONSTRAINT FK_Albums_Singers FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
);
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES
(1, 'Marc', 'Richards', '1970-09-03', 2),
(2, 'Catalina', 'Smith', '1990-08-17', 1),
(3, 'Alice', 'Trentor', '1991-10-02', 3);
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle, ReleaseDate) VALUES
(1, 1, 'Total Junk', '2014-03-15'),
(1, 2, 'Go Go Go', '2016-11-01'),
(2, 1, 'Green', '2018-02-28'),
(3, 1, 'Blue', '2019-01-10'),
(3, 2, 'Red', '2020-05-22'),
(3, 3, 'Purple', '2022-11-11');
Bạn có thể tìm thấy tệp kết xuất cho giản đồ ở trên tại đây.
5. Xác minh dữ liệu
Nhanh chóng kiểm tra để đảm bảo dữ liệu có xuất hiện:
SELECT 'Singers music_db' as tbl, COUNT(*) FROM music_db.Singers
UNION ALL
SELECT 'Albums music_db', COUNT(*) FROM music_db.Albums;
EXIT;
Bạn sẽ thấy số lượng cho từng bảng.
+------------------+----------+ | tbl | COUNT(*) | +------------------+----------+ | Singers music_db | 3 | | Albums music_db | 6 | +------------------+----------+
5. Thiết lập Cloud Spanner
Bây giờ, bạn sẽ thiết lập thực thể Cloud Spanner đích mà dữ liệu sẽ được di chuyển đến.
1. Tạo một phiên bản Cloud Spanner
Tạo một phiên bản Cloud Spanner ở cùng khu vực với phiên bản Cloud SQL. Lệnh này sẽ tạo một phiên bản nhỏ phù hợp với lớp học lập trình này, sử dụng 100 đơn vị xử lý.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="music-db-migrated"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
Quá trình tạo phiên bản có thể mất một hoặc hai phút.
6. Chuyển đổi giản đồ bằng Công cụ di chuyển Spanner (SMT)
Sử dụng SMT CLI để phân tích cơ sở dữ liệu MySQL (music_db) và tạo Ngôn ngữ định nghĩa giản đồ (DDL) của Spanner. Vì thực thể Cloud SQL được định cấu hình bằng IP công khai và các mạng được uỷ quyền thích hợp, nên SMT có thể kết nối trực tiếp.
1. Chuẩn bị môi trường cho SMT
Xác minh rằng các biến môi trường cần thiết đã được thiết lập từ các bước trước:
echo "Cloud SQL Instance Public IP: $SQL_INSTANCE_IP"
echo "Cloud SQL Root Password: $DB_ROOT_PASSWORD"
echo "Spanner Instance: $SPANNER_INSTANCE_NAME"
echo "Spanner Database: $SPANNER_DATABASE_NAME"
echo "Project ID: $PROJECT_ID"
2. Chạy tính năng Chuyển đổi giản đồ cho music_db
Thực thi lệnh SMT schema, kết nối trực tiếp với địa chỉ IP công khai của Cloud SQL:
gcloud alpha spanner migrate schema \
--source=mysql \
--source-profile="host=${SQL_INSTANCE_IP},port=3306,user=root,password=${DB_ROOT_PASSWORD},dbName=music_db" \
--target-profile="project=${PROJECT_ID},instance=${SPANNER_INSTANCE_NAME},dbName=${SPANNER_DATABASE_NAME}" \
--prefix="music-db"
Lệnh này kết nối với phiên bản Cloud SQL thông qua proxy và tạo các tệp giản đồ có tiền tố music-db.
3. Xem lại các tệp được tạo
SMT tạo một số tệp trong thư mục hiện tại của bạn. Sau đây là những điểm chính:
music-db.schema.ddl.txt: Các câu lệnh DDL của Spanner được tạo.music-db-.overrides.json: Tệp ghi đè giản đồ chứa các thay đổi về việc liên kết theo cách thủ công.music-db.session.json: Tệp phiên của quá trình di chuyển giản đồ.music-db.report.txt: Báo cáo đánh giá về việc chuyển đổi giản đồ.
Bạn có thể liệt kê các thẻ này bằng cách sử dụng ls music-db-*
4. Xác minh giản đồ trong Cloud Spanner
Kiểm tra để đảm bảo các bảng đã được tạo trong cơ sở dữ liệu Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Bạn sẽ thấy kết quả sau đây:
table_name: Albums table_name: Singers
Không bắt buộc: Nếu bạn muốn kiểm tra DDL của Spanner, hãy chạy lệnh sau:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
7. Khởi chạy tính năng Ghi lại dữ liệu thay đổi (CDC)
Trong phần này, bạn sẽ thiết lập "trình ghi" cho quá trình di chuyển. Bằng cách định cấu hình Datastream và Pub/Sub trước khi quá trình tải hàng loạt dữ liệu bắt đầu, bạn đảm bảo rằng mọi thay đổi đối với cơ sở dữ liệu nguồn đều được ghi lại và đưa vào hàng đợi, ngăn chặn mọi trường hợp mất dữ liệu trong quá trình chuyển đổi. Bạn phải thiết lập để sử dụng tính năng Di chuyển trực tiếp.
1. Tạo hồ sơ kết nối Datastream
Hồ sơ nguồn (Cloud SQL)
Hồ sơ này kết nối với IP công khai của thực thể Cloud SQL. Datastream sẽ sử dụng tính năng cho phép địa chỉ IP để kết nối.
export SQL_CP_NAME="mysql-src-cp"
gcloud datastream connection-profiles create $SQL_CP_NAME \
--location=$REGION \
--type=mysql \
--mysql-hostname=$SQL_INSTANCE_IP \
--mysql-port=3306 \
--mysql-username=root \
--mysql-password=$DB_ROOT_PASSWORD \
--display-name="Cloud SQL Source - Public IP"
Lưu ý: Kết nối này dựa vào Mạng được uỷ quyền của thực thể Cloud SQL để cho phép truy cập. Như đã định cấu hình trước đó bằng 0.0.0.0/0, các IP công khai của Datastream có thể kết nối. Trong môi trường sản xuất, bạn sẽ thay thế 0.0.0.0/0 bằng các dải IP cụ thể cho khu vực của mình được liệt kê trong Danh sách cho phép IP và khu vực của Datastream.
Hồ sơ đích (Cloud Storage)
Chỉ đến gốc của nhóm.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
2. Tạo luồng Datastream
Tạo luồng để sao chép từ music_db.
export STREAM_NAME="mysql-to-spanner-stream"
export GCS_STREAM_PATH="data/${STREAM_NAME}"
gcloud datastream streams create $STREAM_NAME \
--location=$REGION \
--display-name="MySQL to Spanner CDC Stream" \
--source=$SQL_CP_NAME \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "
includeObjects:
mysqlDatabases:
- database: 'music_db'
") \
--gcs-destination-config=<(echo "
path: ${GCS_STREAM_PATH}
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}
") \
--backfill-none
- Datastream sẽ ghi các tệp trong
gs://${BUCKET_NAME}/${GCS_STREAM_PREFIX}/ - Datastream sẽ ghi các tệp ở định dạng Avro. Khi chạy lệnh di chuyển trực tiếp, chúng ta sẽ chỉ định inputFileFormat là avro để quy trình có thể xử lý tệp một cách chính xác.
- Việc sử dụng chế độ xoay vòng tệp nhỏ hơn sẽ giúp bạn thấy các thay đổi nhanh hơn trong lớp học lập trình.
Lệnh này có thể mất một chút thời gian để hoàn tất. Kiểm tra trạng thái: gcloud datastream streams describe $STREAM_NAME --location=$REGION.
3. Bắt đầu luồng Datastream
gcloud datastream streams update $STREAM_NAME \
--location=$REGION \
--state=RUNNING
Kiểm tra trạng thái: gcloud datastream streams describe $STREAM_NAME --location=$REGION. Trạng thái ban đầu sẽ là STARTING và sẽ chuyển thành RUNNING sau một thời gian. Chỉ chuyển sang bước tiếp theo sau khi bạn xác nhận rằng thiết bị đang ở trạng thái RUNNING.
4. Thiết lập Pub/Sub cho thông báo GCS
Tạo một chủ đề Pub/Sub:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
Tạo thông báo GCS
Thông báo khi tạo đối tượng trong tiền tố data/.
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Tạo gói thuê bao Pub/Sub
Thêm thời hạn xác nhận được đề xuất.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Di chuyển hàng loạt dữ liệu từ Cloud SQL sang Spanner
Sau khi thiết lập giản đồ Spanner, bạn sẽ sao chép dữ liệu hiện có từ cơ sở dữ liệu Cloud SQL music_db sang Cloud Spanner. Bạn sẽ sử dụng Sourcedb to Spanner Dataflow Flex Template, được thiết kế để sao chép hàng loạt dữ liệu từ các cơ sở dữ liệu có thể truy cập bằng JDBC sang Spanner.
1. Chạy lệnh di chuyển dữ liệu hàng loạt cho music_db
Thực thi lệnh sau trong Cloud Shell để bắt đầu quy trình Dataflow. Lệnh này sử dụng lệnh gcloud dataflow flex-template run, tham chiếu đến mẫu do Google cung cấp để di chuyển hàng loạt JDBC sang Spanner.
export JOB_NAME_MUSIC="mysql-music-db-to-spanner-bulk-$(date +%Y%m%d-%H%M%S)"
export MUSIC_DB_JDBC_URL="jdbc:mysql://${SQL_INSTANCE_IP}:3306/music_db"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration-output"
gcloud dataflow flex-template run $JOB_NAME_MUSIC \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL="$MUSIC_DB_JDBC_URL",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
outputDirectory="$OUTPUT_DIR/music_db",\
username="root",\
password="$DB_ROOT_PASSWORD",\
jdbcDriverClassName="com.mysql.cj.jdbc.Driver",\
jdbcDriverJars="gs://${BUCKET_NAME}/lib/mysql-connector-j-8.0.33.jar",\
spannerHost="https://batch-spanner.googleapis.com"
Giải thích về các thông số chính:
sourceConfigURL: Chuỗi kết nối JDBC cho nguồnmusic_db.instanceId,databaseId,projectId: Chỉ định cơ sở dữ liệu và phiên bản Cloud Spanner mục tiêu.outputDirectory: Đường dẫn Cloud Storage nơi Dataflow sẽ ghi thông tin về mọi bản ghi không di chuyển được.jdbcDriverClassName: Chỉ định trình điều khiển MySQL JDBC.jdbcDriverJars: Đường dẫn GCS đến JAR trình điều khiển JDBC đã ra mắt để thử nghiệm.spannerHost: Sử dụng điểm cuối được tối ưu hoá theo lô để ghi vào Spanner.maxWorkers,numWorkers: Kiểm soát việc mở rộng quy mô của công việc Dataflow. Được giữ ở mức thấp cho tập dữ liệu nhỏ này.
Lưu ý về mạng: Tác vụ này kết nối với thực thể Cloud SQL qua IP công khai của thực thể đó. Bạn làm được điều này vì trước đây bạn đã thêm 0.0.0.0/0 vào Mạng được uỷ quyền của phiên bản. Điều này cho phép các VM worker Dataflow (có IP bên ngoài) truy cập vào cơ sở dữ liệu.
2. Theo dõi Dataflow Job
Bạn có thể theo dõi tiến trình của công việc trong Bảng điều khiển Google Cloud:
- Chuyển đến trang Dataflow Jobs: Chuyển đến Dataflow Jobs
- Tìm việc làm có tên
mysql-music-db-to-spanner-bulk-...rồi nhấp vào việc làm đó. - Quan sát biểu đồ và chỉ số của công việc. Chờ trạng thái của lệnh chuyển thành Đã thành công. Quá trình này thường mất khoảng 5 đến 15 phút.
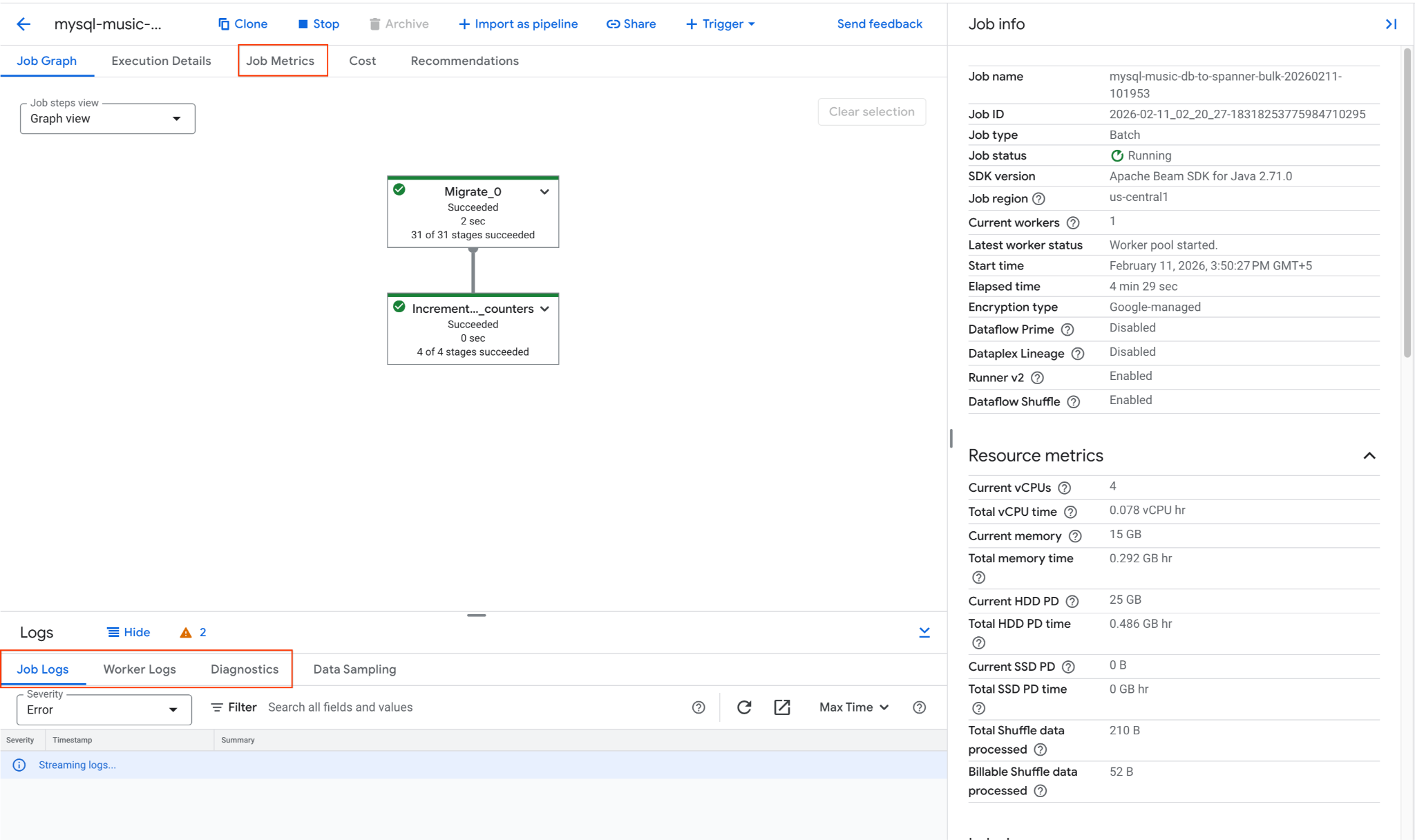
- Nếu công việc gặp vấn đề, hãy xem thẻ Nhật ký trong trang thông tin chi tiết về công việc Dataflow để biết thông báo lỗi.
- Chỉ số về công việc cung cấp thêm thông tin về tiến trình của công việc và mức tiêu thụ tài nguyên, chẳng hạn như thông lượng và mức sử dụng CPU.
3. Xác minh dữ liệu trong Cloud Spanner
Sau khi Dataflow hoàn tất thành công, hãy xác nhận rằng dữ liệu đã được sao chép vào các bảng Spanner. Sử dụng gcloud để truy vấn cơ sở dữ liệu Spanner:
# Verify row counts
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Singers"
# Expected output: 3
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Albums"
# Expected output: 6
# Inspect some data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT SingerId, FirstName, LastName FROM Singers ORDER BY SingerId"
Kết quả đầu ra dự kiến:
row_count: 3 row_count: 6 SingerId: 1 FirstName: Marc LastName: Richards SingerId: 2 FirstName: Catalina LastName: Smith SingerId: 3 FirstName: Alice LastName: Trentor
Quá trình tải hàng loạt dữ liệu ban đầu từ Cloud SQL lên Cloud Spanner hiện đã hoàn tất. Bước tiếp theo là thiết lập tính năng sao chép trực tiếp để ghi lại những thay đổi đang diễn ra.
9. Bắt đầu di chuyển trực tiếp (CDC)
Sau khi hoàn tất quá trình tải hàng loạt dữ liệu, bạn sẽ thiết lập một luồng sao chép liên tục bằng Datastream để ghi lại các sự kiện CDC (Change Data Capture) từ Cloud SQL và một công việc truyền trực tuyến Dataflow để áp dụng những thay đổi đó cho Cloud Spanner gần như theo thời gian thực.
1. Chạy lệnh Live Migration Dataflow Job
Khởi chạy đối tượng công việc Dataflow truyền trực tuyến để đọc từ GCS và ghi vào Spanner. Mẫu này sẽ sử dụng thông báo Pub/Sub của GCS để xử lý ngay các tệp mới.
export JOB_NAME_CDC="datastream-to-spanner-cdc-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR="gs://${BUCKET_NAME}/dlq"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
deadLetterQueueDirectory="$DLQ_DIR",\
streamName="projects/${PROJECT_ID}/locations/${REGION}/streams/${STREAM_NAME}"
Thông số chính
gcsPubSubSubscription: Đăng ký Pub/Sub để nhận thông báo về tệp mới từ GCS. Điều này cho phép tác vụ xử lý các thay đổi ngay lập tức khi Datastream ghi các thay đổi đó.inputFileFormat="avro": Yêu cầu Dataflow dự kiến các tệp Avro từ Datastream. Giá trị này phải khớp với cấu hình "Đích đến" của Luồng dữ liệu (ví dụ:avroFileFormatso vớijsonFileFormat).deadLetterQueueDirectory: Đường dẫn GCS nơi lưu trữ các bản ghi không xử lý được (ví dụ: do không khớp lược đồ) để xem xét thủ công sau này.streamName: Đường dẫn đầy đủ đến tài nguyên của luồng Datastream, cho phép tác vụ Dataflow theo dõi trạng thái sao chép và siêu dữ liệu.
Theo dõi quá trình khởi động tác vụ trong Bảng điều khiển tác vụ Dataflow.
2. Kiểm thử tính năng Di chuyển trực tiếp
Áp dụng các thay đổi cho Cloud SQL nguồn music_db để kiểm thử quy trình CDC.
Kết nối với Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
Nhập mật khẩu (Welcome@1) rồi chọn cơ sở dữ liệu:
USE music_db;
-- INSERT
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (4, 'Elena', 'Nadal', '1985-05-30', 0);
SELECT * FROM Singers WHERE SingerId = 4;
-- UPDATE
UPDATE Singers SET LastName = 'Richards-Smith' WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- DELETE
DELETE FROM Albums WHERE SingerId = 2;
DELETE FROM Singers WHERE SingerId = 2;
SELECT * FROM Singers WHERE SingerId = 2;
EXIT;
Xác minh trong Spanner (sau vài phút):
# Verify INSERT: This should return the new row for Elena Nadal.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 4"
# Verify UPDATE: This should show LastName as Richards-Smith.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName FROM Singers WHERE SingerId = 1"
# Verify DELETE: This should now return 0 rows.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Albums WHERE SingerId = 2"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 2"
Kết quả đầu ra dự kiến:
SingerId: 4 FirstName: Elena LastName: Nadal BirthDate: 1985-05-30 AlbumCount: 0 SingerId: 1 FirstName: Marc LastName: Richards-Smith
3. Xác minh cuối cùng trong Spanner
Kiểm tra trạng thái tổng thể của bảng Singers trong Spanner:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId"
Kết quả đầu ra dự kiến:
SingerId: 1 FirstName: Marc LastName: Richards-Smith AlbumCount: 2 SingerId: 3 FirstName: Alice LastName: Trentor AlbumCount: 3 SingerId: 4 FirstName: Elena LastName: Nadal AlbumCount: 0
10. Thiết lập tính năng sao chép ngược (Spanner sang Cloud SQL)
Để xử lý các trường hợp mà bạn có thể cần khôi phục hoặc giữ cho cơ sở dữ liệu Cloud SQL đồng bộ hoá với Spanner trong một khoảng thời gian, bạn có thể thiết lập tính năng sao chép ngược. Quy trình này sử dụng Luồng thay đổi của Spanner để ghi lại các thay đổi trong Spanner và ghi các thay đổi đó trở lại music_db của Cloud SQL.
1. Tạo một luồng thay đổi Spanner
Trước tiên, bạn cần tạo một luồng thay đổi trong cơ sở dữ liệu Spanner để theo dõi các thay đổi trên bảng Singers và Albums.
export CHANGE_STREAM_NAME="MusicDBChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Singers, Albums"
Luồng thay đổi này sẽ ghi lại tất cả các nội dung sửa đổi dữ liệu đối với các bảng được chỉ định.
2. Tạo cơ sở dữ liệu Spanner cho siêu dữ liệu Dataflow
Mẫu Dataflow Spanner to SourceDB yêu cầu phải có một cơ sở dữ liệu Spanner riêng biệt để lưu trữ siêu dữ liệu nhằm quản lý việc sử dụng luồng thay đổi.
export SPANNER_METADATA_DB_NAME="reverse-replication-metadata"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Chuẩn bị cấu hình kết nối Cloud SQL cho Dataflow
Mẫu Dataflow cần một tệp JSON trong Cloud Storage chứa thông tin chi tiết về kết nối cho cơ sở dữ liệu Cloud SQL mục tiêu.
Tạo một tệp cục bộ có tên shard_config.json:
cat << EOF > shard_config.json
[
{
"logicalShardId": "mysql_shard",
"host": "${SQL_INSTANCE_IP}",
"port": "3306",
"user": "root",
"password": "${DB_ROOT_PASSWORD}",
"dbName": "music_db"
}
]
EOF
Tải tệp này lên bộ chứa GCS của bạn:
export SHARD_CONFIG_FILE="gs://${BUCKET_NAME}/shard_config.json"
gcloud storage cp shard_config.json $SHARD_CONFIG_FILE
4. Chạy công việc Dataflow sao chép ngược
Khởi chạy công việc Dataflow bằng cách sử dụng Spanner_to_SourceDb Flex Template.
export JOB_NAME_REVERSE="spanner-to-mysql-reverse-$(date +%Y%m%d-%H%M%S)"
export REVERSE_DLQ_DIR="gs://${BUCKET_NAME}/reverse-dlq"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$SHARD_CONFIG_FILE",\
deadLetterQueueDirectory="$REVERSE_DLQ_DIR"
Tham số chính
changeStreamName: Tên của luồng thay đổi Spanner cần đọc.metadataInstance, metadataDatabase: Phiên bản/cơ sở dữ liệu Spanner để lưu trữ siêu dữ liệu mà trình kết nối dùng để kiểm soát mức tiêu thụ dữ liệu API luồng thay đổi.sourceShardsFilePath: Đường dẫn GCS đếnshard_config.json.filtrationMode: Chỉ định cách loại bỏ một số bản ghi dựa trên một tiêu chí. Mặc định làforward_migration(lọc các bản ghi được ghi bằng quy trình di chuyển chuyển tiếp)
Lưu ý về mạng: Các worker Dataflow sẽ kết nối với thực thể Cloud SQL bằng IP công khai được chỉ định trong shard_config.json. Kết nối này được phép do mục 0.0.0.0/0 trong Mạng được uỷ quyền của phiên bản Cloud SQL.
Theo dõi quá trình khởi động tác vụ trong Bảng điều khiển tác vụ Dataflow.
5. Kiểm thử tính năng Sao chép ngược
Bây giờ, hãy thực hiện các thay đổi trực tiếp trong Cloud Spanner và xác minh rằng các thay đổi đó được phản ánh trong Cloud SQL. Chỉ thực hiện việc này khi công việc luồng dữ liệu đã bắt đầu và đang ở trạng thái xử lý.
Kiểm thử INSERT, UPDATE và DELETE
# INSERT: Insert a new singer (SingerId 5) into Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (5, 'David', 'Chen', '1995-02-18', 0)"
# UPDATE: Update SingerId 3's AlbumCount in Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Singers SET AlbumCount = 5 WHERE SingerId = 3"
# DELETE: Delete SingerId 1 from Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Albums WHERE SingerId = 1"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Singers WHERE SingerId = 1"
Xác minh trong Cloud SQL (sau vài phút):
Kết nối với Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
Nhập mật khẩu (Welcome@1) khi được nhắc, sau đó chạy các lệnh SQL sau tại dấu nhắc mysql>.
USE music_db;
-- Verify INSERT: This should show the new row for David Chen
SELECT * FROM Singers WHERE SingerId = 5;
-- Verify UPDATE: This should show AlbumCount as 5.
SELECT SingerId, FirstName, AlbumCount FROM Singers WHERE SingerId = 3;
-- Verify DELETE: This should return an empty set.
SELECT * FROM Albums WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- Final Verification
SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId;
EXIT;
Đầu ra dự kiến trong Cloud SQL phải phản ánh những thay đổi được thực hiện trong Spanner.
+----------+-----------+----------------+------------+ | SingerId | FirstName | LastName | AlbumCount | +----------+-----------+----------------+------------+ | 3 | Alice | Trentor | 5 | | 4 | Elena | Nadal | 0 | | 5 | David | Chen | 0 | +----------+-----------+----------------+------------+
Điều này xác nhận rằng quy trình sao chép ngược đang hoạt động, đồng bộ hoá các thay đổi từ Spanner trở lại Cloud SQL.
11. Dọn dẹp tài nguyên
Để tránh phát sinh thêm các khoản phí cho tài khoản Google Cloud của bạn, hãy xoá các tài nguyên đã tạo trong lớp học lập trình này.
Đặt các biến môi trường (nếu cần)
Kiểm tra xem các biến môi trường có được thiết lập đúng cách hay không:
echo "PROJECT_ID: $PROJECT_ID"
echo "REGION: $REGION"
echo "SQL_INSTANCE_NAME: $SQL_INSTANCE_NAME"
echo "SPANNER_INSTANCE_NAME: $SPANNER_INSTANCE_NAME"
echo "BUCKET_NAME: $BUCKET_NAME"
echo "STREAM_NAME: $STREAM_NAME"
echo "SQL_CP_NAME: $SQL_CP_NAME"
echo "GCS_CP_NAME: $GCS_CP_NAME"
echo "PUBSUB_SUBSCRIPTION: $PUBSUB_SUBSCRIPTION"
echo "PUBSUB_TOPIC: $PUBSUB_TOPIC"
echo "CHANGE_STREAM_NAME: $CHANGE_STREAM_NAME"
Liệt kê các công việc để tìm mã công việc của các công việc luồng dữ liệu đang chạy. Xuất JOB_ID_CDC và JOB_ID_REVERSE cho phù hợp.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Nếu bạn đang ở trong một phiên Cloud Shell mới, hãy xuất lại các biến môi trường khoá:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or the region you used
export SQL_INSTANCE_NAME="source-mysql-instance"
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export STREAM_NAME="mysql-to-spanner-stream"
export SQL_CP_NAME="mysql-src-cp"
export GCS_CP_NAME="gcs-dest-cp"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CHANGE_STREAM_NAME="MusicDBChangeStream"
Dừng các công việc truyền trực tuyến Dataflow
Huỷ lệnh Datastream to Spanner (Di chuyển trực tiếp):
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
Huỷ lệnh Spanner to Cloud SQL (Sao chép đảo ngược):
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Xoá tài nguyên Datastream
Dừng và xoá luồng dữ liệu:
gcloud datastream streams update $STREAM_NAME \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Xoá hồ sơ kết nối
gcloud datastream connection-profiles delete $SQL_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Xoá tài nguyên Pub/Sub
Xoá gói thuê bao:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Xoá chủ đề:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Xoá phiên bản Cloud SQL
Thao tác này sẽ tự động xoá các cơ sở dữ liệu (music_db) trong đó.
gcloud sql instances delete $SQL_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Xoá phiên bản Cloud Spanner
Thao tác này cũng sẽ xoá các cơ sở dữ liệu (music-db-migrated và reverse-replication-metadata) trong đó.
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Xoá bộ chứa và nội dung trên Google Cloud Storage
gcloud storage rm --recursive gs://${BUCKET_NAME}
Xoá tệp trên thiết bị
Xoá mọi tệp được tạo trong thư mục chính của Cloud Shell:
rm -f music-db* shard_config.json
Giờ đây, bạn đã dọn dẹp các tài nguyên được tạo cho lớp học lập trình này.