
1. 准备工作
此 Codelab 将指导您将 Cloud SQL 上的单个 MySQL 数据库迁移到使用 GoogleSQL 方言的 Cloud Spanner 数据库。重点是基本的端到端迁移流程,演示核心步骤。您将使用 Google Cloud 服务,包括 Spanner 迁移工具 (SMT)、Dataflow、Datastream、PubSub 和 Google Cloud Storage。
您将了解的内容:
- 如何设置 Cloud SQL 和 Cloud Spanner 示例实例。
- 如何使用 Spanner 迁移工具 (SMT) 将 Cloud SQL MySQL 架构转换为与 Spanner 兼容的架构。
- 如何使用 Dataflow 将数据从 Cloud SQL 批量迁移到 Cloud Spanner。
- 如何使用 Datastream 和 Dataflow 设置从 Cloud SQL 到 Cloud Spanner 的持续复制 (CDC)。
- 如何设置从 Cloud Spanner 到 Cloud SQL 的反向复制。
本 Codelab 不涵盖以下内容:
- 来自分片实例的迁移。
- 迁移期间的复杂数据转换。
- 高级错误处理或死信队列 (DLQ)。
- 迁移性能调优。
- 应用迁移:此 Codelab 侧重于数据库层(架构和数据)。它不涵盖重新部署或迁移应用服务的运营流程。
所需条件
- 启用了结算功能的 Google Cloud 项目。
- 具有足够的 IAM 权限,可用于启用 API 以及创建/管理 Cloud SQL、Spanner、Dataflow、Datastream 和 GCS 资源。虽然项目
Owner角色对于 Codelab 来说最简单,但“环境设置”中将介绍更具体的角色。 - 网络浏览器,例如 Google Chrome。
- 基本熟悉 Google Cloud 控制台和
gcloud等命令行工具。 - 对 shell 环境的访问权限。建议使用 Cloud Shell,因为它包含
gcloud。
有关上述设置的更多详细信息,请参阅“环境设置”部分。
2. 了解迁移过程
迁移数据库涉及将数据从源 Cloud SQL 数据库实例迁移到 Spanner 实例。本部分概述了迁移中使用的架构和关键工具。
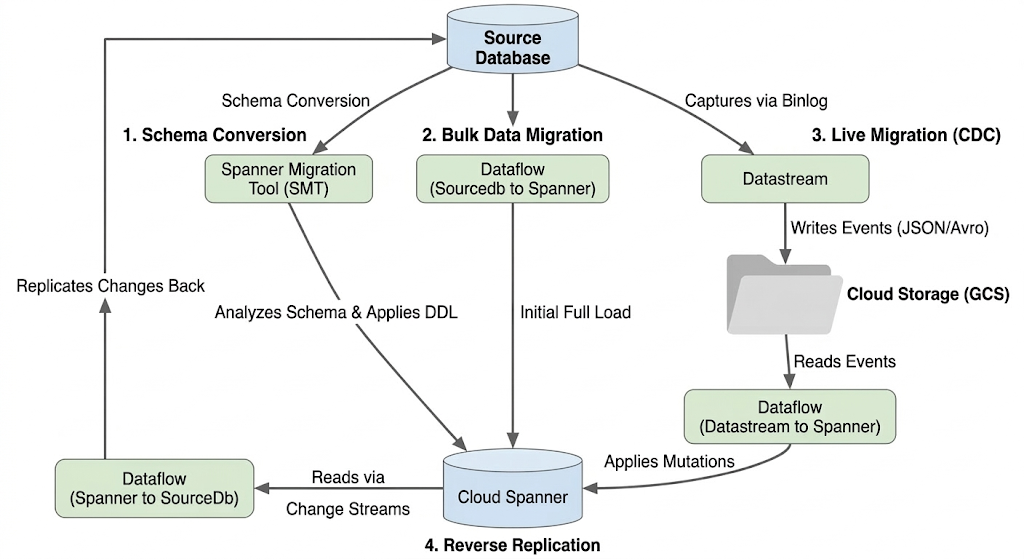
迁移流程架构
迁移过程包括以下阶段:
1. 架构转换:
- 用途:将源数据库架构转换为兼容的 Cloud Spanner 架构。
- 工具:Spanner 迁移工具 (SMT)
- 流程:SMT 会分析源数据库架构,并生成等效的 Spanner 数据定义语言 (DDL)。在目标 Spanner 实例中,系统会创建一个数据库,然后自动应用 DDL。
2. 批量数据迁移:
- 用途:用于将现有数据从源数据库初始完全加载到已预配的 Spanner 表中。
- 工具:Dataflow,使用 Google 提供的
Sourcedb to Spanner模板。 - 流程:此 Dataflow 作业会从指定的源表中读取所有数据,并将其写入相应的 Spanner 表中。此步骤在创建 Spanner 架构后完成。
3. 实时迁移 (CDC):
- 用途:近乎实时地捕获源数据库中的持续更改并将其应用到 Cloud Spanner,从而最大限度地缩短迁移期间的停机时间。
- 工具:
- Datastream:从源数据库捕获更改(插入、更新、删除),并将其写入 Cloud Storage (GCS)。
- Dataflow:使用
Datastream to Spanner模板从 GCS 读取更改事件,并将其应用到 Cloud Spanner。
4. 反向复制:
- 用途:将数据更改从 Cloud Spanner 复制回源数据库。这对于回退策略、分阶段迁移或在源中维护副本以用于特定应用场景非常有用。
- 工具:Dataflow,使用
Spanner to SourceDb模板。 - 处理:此作业利用 Spanner 变更数据流来捕获 Spanner 中的修改,并将其写回源数据库实例。
下图展示了组件和数据传输:
主要术语:
- Spanner 迁移工具 (SMT):一种用于评估 MySQL 架构、建议 Spanner 架构等效项并生成 Spanner 数据定义语言 (DDL) 的工具。
- 数据定义语言 (DDL):用于定义和修改数据库结构的语句,例如
CREATE TABLE语句。SMT 会根据 Cloud SQL 架构生成 Spanner DDL。 - Dataflow:一种全托管式无服务器数据处理服务。在此 Codelab 中,它用于运行 Google 提供的模板,以进行批量数据传输、应用 Datastream 更改和反向复制。
- Datastream:一种无服务器的变更数据捕获 (CDC) 和复制服务。在本 Codelab 中,它用于将更改从 Cloud SQL 流式传输到 Cloud Storage。
- Spanner 变更数据流:一种 Spanner 功能,可用于实时流式传输数据更改(插入、更新、删除),用作反向复制的来源。
- Pub/Sub:一种消息传递服务,用于将生成事件的服务与处理事件的服务分离开。在此 Codelab 中,每当 Datastream 将新的更改文件上传到 Cloud Storage 时,它都会触发 Dataflow 来处理更新。
3. 环境设置
在开始迁移之前,您需要设置 Google Cloud 项目并启用必要的服务。
1. 选择或创建 Google Cloud 项目
您需要一个启用了结算功能的 Google Cloud 项目才能使用本 Codelab 中的服务。
- 在 Google Cloud 控制台中,前往项目选择器页面:前往项目选择器
- 选择或创建 Google Cloud 项目。
- 确保您的项目已启用结算功能。 了解如何确认您的项目是否已启用结算功能。
2. 打开 Cloud Shell
Cloud Shell 是在 Google Cloud 中运行的命令行环境,预加载了 gcloud CLI 和您需要的其他工具。
- 点击 Google Cloud 控制台右上角的激活 Cloud Shell 按钮。
- 一个 Cloud Shell 会话随即会在控制台底部的新框架内打开,并显示命令行提示符。

3. 设置项目变量和环境变量
在 Cloud Shell 中,为您的项目 ID 和要使用的区域设置一些环境变量。
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. 启用必需的 Google Cloud API
启用 Cloud Spanner、Dataflow、Datastream 和其他相关服务所需的 API。
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
此命令可能需要几分钟时间才能完成。
5. 配置服务账号权限
Dataflow 作业和 Datastream 需要特定权限才能与其他 Google Cloud 服务进行交互。此 Codelab 中的 Dataflow 作业将使用默认的 Compute Engine 服务账号。
首先,获取您的项目编号:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
现在,向 Compute Engine 默认服务账号授予所需的 IAM 角色:
# Role for Dataflow to run jobs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.admin" \
--condition=None
# Roles for Dataflow workers
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.worker" \
--condition=None
# Role to connect to Cloud SQL instance
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudsql.client" \
--condition=None
# Role to read/write from Cloud Spanner
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/spanner.databaseUser" \
--condition=None
# Role to access GCS buckets (Datastream output, Dataflow temp, JDBC driver)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectAdmin" \
--condition=None
# Roles for Datastream and Pub/Sub (for CDC)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastream.viewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/pubsub.subscriber"
6. 创建 Cloud Storage 存储桶
在与其他资源相同的区域中创建 GCS 存储分区。此存储分区将存储 JDBC 驱动程序、Datastream 输出,并供 Dataflow 用于临时文件。
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
echo "Created bucket: gs://$BUCKET_NAME"
7. 安装 Spanner 迁移工具 (SMT)
确保在 Cloud Shell 环境中安装了 Spanner 迁移工具 (SMT)。
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
此命令应显示 SMT Web 界面的帮助信息,从而确认 gcloud 组件已安装。此 Codelab 将使用 SMT 的 CLI 功能,这些功能属于同一组件。
4. 设置源 Cloud SQL 数据库
在本部分中,您将创建并配置一个具有公共 IP 的 Cloud SQL for MySQL 实例,以用作源数据库。
1. 创建 Cloud SQL for MySQL 实例
在 Cloud Shell 中运行以下 gcloud 命令,以创建 MySQL 8.0 实例。已启用二进制日志记录(Datastream 所需),并且实例已配置公共 IP。
export SQL_INSTANCE_NAME="source-mysql-instance"
export DB_ROOT_PASSWORD="Welcome@1" # Replace with a strong password if you prefer
gcloud sql instances create $SQL_INSTANCE_NAME \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=$REGION \
--root-password=$DB_ROOT_PASSWORD \
--enable-bin-log \
--assign-ip
--enable-bin-log:Datastream 捕获更改时需要此参数。--assign-ip:确保实例获得公共 IP 地址。
创建实例需要几分钟时间。您可以在“Cloud SQL 实例”页面上查看实例是否已创建。
2. 配置已获授权的网络
如需通过公共 IP 连接到实例,您需要将 IP 地址添加到“已获授权的网络”列表中。
获取 Cloud Shell IP:
export CLOUD_SHELL_IP=$(curl -s ipinfo.io/ip)
echo "Your Cloud Shell IP: $CLOUD_SHELL_IP"
授权 Cloud Shell IP 和开放访问权限
以下命令会添加您的 Cloud Shell IP。它还添加了 0.0.0.0/0,允许从任何 IP 地址访问。这对于简化 Dataflow 工作器的连接(无需复杂的网络设置)是必要的。
gcloud sql instances patch $SQL_INSTANCE_NAME \
--authorized-networks="${CLOUD_SHELL_IP}/32,0.0.0.0/0"
3. 从 Cloud Shell 连接到 Cloud SQL 实例
提取分配的公共 IP 地址
export SQL_INSTANCE_IP=$(gcloud sql instances list --filter="name=$SQL_INSTANCE_NAME" --format="value(PRIMARY_ADDRESS)")
echo "Cloud SQL Public IP: $SQL_INSTANCE_IP"
此 IP 地址将用于连接。
从 CloudShell 连接到 Cloud SQL 实例
使用标准 mysql 客户端进行连接,使用获得的公共 IP 地址:
mysql -h $SQL_INSTANCE_IP -u root -p
出现提示时,输入您设置的 root 密码 (Welcome@1)。现在,您将看到 mysql> 提示。
4. 创建数据库和示例数据
在 mysql> 提示符下,执行以下 SQL 命令:
CREATE DATABASE music_db;
USE music_db;
CREATE TABLE Singers (
SingerId BIGINT NOT NULL,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
BirthDate DATE,
AlbumCount BIGINT,
PRIMARY KEY (SingerId)
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY (SingerId, AlbumId),
CONSTRAINT FK_Albums_Singers FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
);
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES
(1, 'Marc', 'Richards', '1970-09-03', 2),
(2, 'Catalina', 'Smith', '1990-08-17', 1),
(3, 'Alice', 'Trentor', '1991-10-02', 3);
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle, ReleaseDate) VALUES
(1, 1, 'Total Junk', '2014-03-15'),
(1, 2, 'Go Go Go', '2016-11-01'),
(2, 1, 'Green', '2018-02-28'),
(3, 1, 'Blue', '2019-01-10'),
(3, 2, 'Red', '2020-05-22'),
(3, 3, 'Purple', '2022-11-11');
您可以在此处找到上述架构的转储文件。
5. 验证数据
快速检查数据是否存在:
SELECT 'Singers music_db' as tbl, COUNT(*) FROM music_db.Singers
UNION ALL
SELECT 'Albums music_db', COUNT(*) FROM music_db.Albums;
EXIT;
您应该会看到每个表的数量。
+------------------+----------+ | tbl | COUNT(*) | +------------------+----------+ | Singers music_db | 3 | | Albums music_db | 6 | +------------------+----------+
5. 设置 Cloud Spanner
现在,您将设置要将数据迁移到的目标 Cloud Spanner 实例。
1. 创建 Cloud Spanner 实例
在 Cloud SQL 实例所在的区域中创建一个 Cloud Spanner 实例。此命令使用 100 个处理单元创建一个适合此 Codelab 的小型实例。
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="music-db-migrated"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
创建实例可能需要一到两分钟。
6. 使用 Spanner 迁移工具 (SMT) 转换架构
使用 SMT CLI 分析 MySQL 数据库 (music_db) 并生成 Spanner 架构定义语言 (DDL)。由于 Cloud SQL 实例配置了公共 IP 和适当的已获授权网络,因此 SMT 可以直接连接。
1. 为 SMT 准备环境
验证是否已在之前的步骤中设置必要的环境变量:
echo "Cloud SQL Instance Public IP: $SQL_INSTANCE_IP"
echo "Cloud SQL Root Password: $DB_ROOT_PASSWORD"
echo "Spanner Instance: $SPANNER_INSTANCE_NAME"
echo "Spanner Database: $SPANNER_DATABASE_NAME"
echo "Project ID: $PROJECT_ID"
2. 为 music_db 运行架构转换
执行 SMT schema 命令,直接连接到 Cloud SQL 公共 IP 地址:
gcloud alpha spanner migrate schema \
--source=mysql \
--source-profile="host=${SQL_INSTANCE_IP},port=3306,user=root,password=${DB_ROOT_PASSWORD},dbName=music_db" \
--target-profile="project=${PROJECT_ID},instance=${SPANNER_INSTANCE_NAME},dbName=${SPANNER_DATABASE_NAME}" \
--prefix="music-db"
此命令通过代理连接到 Cloud SQL 实例,并生成以 music-db 为前缀的架构文件。
3. 查看生成的文件
SMT 会在当前目录中创建一些文件。以下是关键的广告资源:
music-db.schema.ddl.txt:生成的 Spanner DDL 语句。music-db-.overrides.json:包含手动映射更改的架构替换文件。music-db.session.json:架构迁移的会话文件。music-db.report.txt:架构转换的评估报告。
您可以使用 ls music-db-* 列出这些资源
4. 验证 Cloud Spanner 中的架构
检查 Spanner 数据库中是否已创建表。
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
您应该会看到以下输出内容:
table_name: Albums table_name: Singers
可选:如果您想检查 Spanner DDL,请运行以下命令:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
7. 初始化变更数据捕获 (CDC)
在本部分中,您将为迁移设置“记录器”。通过在批量数据加载开始之前配置 Datastream 和 Pub/Sub,您可以确保捕获并排队源数据库中的每一项更改,从而防止在过渡期间丢失任何数据。实时迁移需要此设置。
1. 创建 Datastream 连接配置文件
来源配置文件 (Cloud SQL)
此配置文件连接到 Cloud SQL 实例的公共 IP。Datastream 将使用 IP 许可名单进行连接。
export SQL_CP_NAME="mysql-src-cp"
gcloud datastream connection-profiles create $SQL_CP_NAME \
--location=$REGION \
--type=mysql \
--mysql-hostname=$SQL_INSTANCE_IP \
--mysql-port=3306 \
--mysql-username=root \
--mysql-password=$DB_ROOT_PASSWORD \
--display-name="Cloud SQL Source - Public IP"
注意:此连接依赖于 Cloud SQL 实例的已授权网络,后者允许访问。如之前使用 0.0.0.0/0 配置的那样,Datastream 的公共 IP 可以连接。在生产环境中,您需要将 0.0.0.0/0 替换为 Datastream IP 许可名单和地区中列出的您所在地区的特定 IP 范围。
目标配置文件 (Cloud Storage)
指向存储分区的根目录。
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
2. 创建 Datastream 数据流
创建要从 music_db 复制的流。
export STREAM_NAME="mysql-to-spanner-stream"
export GCS_STREAM_PATH="data/${STREAM_NAME}"
gcloud datastream streams create $STREAM_NAME \
--location=$REGION \
--display-name="MySQL to Spanner CDC Stream" \
--source=$SQL_CP_NAME \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "
includeObjects:
mysqlDatabases:
- database: 'music_db'
") \
--gcs-destination-config=<(echo "
path: ${GCS_STREAM_PATH}
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}
") \
--backfill-none
- Datastream 会将文件写入
gs://${BUCKET_NAME}/${GCS_STREAM_PREFIX}/下 - Datastream 将以 Avro 格式写入文件。运行实时迁移命令时,我们将指定 inputFileFormat 为 avro,以便流水线正确处理文件。
- 使用较小的文件轮换设置有助于在 Codelab 中更快地看到更改。
此命令可能需要一些时间才能完成。查看状态:gcloud datastream streams describe $STREAM_NAME --location=$REGION。
3. 启动 Datastream 流
gcloud datastream streams update $STREAM_NAME \
--location=$REGION \
--state=RUNNING
检查状态:gcloud datastream streams describe $STREAM_NAME --location=$REGION. 状态最初为 STARTING,过一段时间后会变为 RUNNING。仅当您确认其处于 RUNNING 状态后,才继续执行下一步。
4. 为 GCS 通知设置 Pub/Sub
创建 Pub/Sub 主题:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
创建 GCS 通知
在 data/ 前缀下创建对象时发送通知。
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
创建 Pub/Sub 订阅
包含建议的确认截止时间。
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. 将数据从 Cloud SQL 批量迁移到 Spanner
在 Spanner 架构就绪后,您现在需要将 Cloud SQL music_db 数据库中的现有数据复制到 Cloud Spanner。您将使用 Sourcedb to Spanner Dataflow Flex 模板,该模板旨在将数据从可通过 JDBC 访问的数据库批量复制到 Spanner。
1. 为 music_db 运行批量迁移 Dataflow 作业
在 Cloud Shell 中执行以下命令,以启动 Dataflow 作业。此命令使用 gcloud dataflow flex-template run 命令,引用 Google 提供的用于将 JDBC 数据批量迁移到 Spanner 的模板。
export JOB_NAME_MUSIC="mysql-music-db-to-spanner-bulk-$(date +%Y%m%d-%H%M%S)"
export MUSIC_DB_JDBC_URL="jdbc:mysql://${SQL_INSTANCE_IP}:3306/music_db"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration-output"
gcloud dataflow flex-template run $JOB_NAME_MUSIC \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL="$MUSIC_DB_JDBC_URL",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
outputDirectory="$OUTPUT_DIR/music_db",\
username="root",\
password="$DB_ROOT_PASSWORD",\
jdbcDriverClassName="com.mysql.cj.jdbc.Driver",\
jdbcDriverJars="gs://${BUCKET_NAME}/lib/mysql-connector-j-8.0.33.jar",\
spannerHost="https://batch-spanner.googleapis.com"
关键参数说明:
sourceConfigURL:来源music_db的 JDBC 连接字符串。instanceId、databaseId、projectId:指定目标 Cloud Spanner 实例和数据库。outputDirectory:一个 Cloud Storage 路径,Dataflow 会将未能成功迁移的任何记录的相关信息写入该路径。jdbcDriverClassName:指定 MySQL JDBC 驱动程序。jdbcDriverJars:已暂存的 JDBC 驱动程序 JAR 的 GCS 路径。spannerHost:使用针对 Spanner 写入操作进行了批量优化的端点。maxWorkers、numWorkers:控制 Dataflow 作业的扩缩。对于此小型数据集,保持较低值。
网络注意事项:此作业通过 Cloud SQL 实例的公共 IP 连接到该实例。之所以能够这么做,是因为您之前已将 0.0.0.0/0 添加到实例的授权网络。这样,具有外部 IP 的 Dataflow 工作器虚拟机便可访问数据库。
2. 监控 Dataflow 作业
您可以在 Google Cloud 控制台中跟踪作业的进度:
- 前往 Dataflow 作业页面:前往 Dataflow 作业
- 找到名为
mysql-music-db-to-spanner-bulk-...的作业,然后点击它。 - 查看作业图和指标。等待作业状态变为成功。此过程大约需要 5-15 分钟。
- 如果作业遇到问题,请查看 Dataflow 作业详情页面中的日志标签页,了解错误消息。
- 作业指标可提供有关作业进度和资源消耗(例如吞吐量和 CPU 利用率)的更多信息。
3. 验证 Cloud Spanner 中的数据
Dataflow 作业成功完成后,请确认数据已复制到 Spanner 表中。使用 gcloud 查询 Spanner 数据库:
# Verify row counts
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Singers"
# Expected output: 3
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Albums"
# Expected output: 6
# Inspect some data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT SingerId, FirstName, LastName FROM Singers ORDER BY SingerId"
预期输出:
row_count: 3 row_count: 6 SingerId: 1 FirstName: Marc LastName: Richards SingerId: 2 FirstName: Catalina LastName: Smith SingerId: 3 FirstName: Alice LastName: Trentor
从 Cloud SQL 到 Cloud Spanner 的初始批量数据加载现已完成。下一步是设置实时复制,以捕获持续发生的变化。
9. 开始实时迁移 (CDC)
现在,批量数据加载已完成,接下来您将使用 Datastream 设置一个持续复制流,以捕获来自 Cloud SQL 的变更数据捕获 (CDC) 事件,并使用 Dataflow 流式作业近乎实时地将这些变更应用到 Cloud Spanner。
1. 运行实时迁移 Dataflow 作业
启动流式 Dataflow 作业,以从 GCS 读取数据并写入 Spanner。此模板将使用 GCS Pub/Sub 通知来立即处理新文件。
export JOB_NAME_CDC="datastream-to-spanner-cdc-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR="gs://${BUCKET_NAME}/dlq"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
deadLetterQueueDirectory="$DLQ_DIR",\
streamName="projects/${PROJECT_ID}/locations/${REGION}/streams/${STREAM_NAME}"
关键形参
gcsPubSubSubscription:用于监听来自 GCS 的新文件通知的 Pub/Sub 订阅。这样,作业就可以在 Datastream 写入更改时立即处理这些更改。inputFileFormat="avro":告知 Dataflow 预期会收到来自 Datastream 的 Avro 文件。此值必须与 Datastream“目标”配置(例如,avroFileFormat与jsonFileFormat)相匹配。deadLetterQueueDirectory:一个 GCS 路径,作业会将未能处理的记录(例如,由于架构不匹配)存储在该路径中,以供日后手动审核。streamName:Datastream 流的完整资源路径,用于让 Dataflow 作业跟踪复制状态和元数据。
在 Dataflow 作业控制台中监控作业启动情况。
2. 测试实时迁移
对源 Cloud SQL music_db 应用更改,以测试 CDC 流水线。
连接到 Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
输入密码 (Welcome@1),然后选择数据库:
USE music_db;
-- INSERT
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (4, 'Elena', 'Nadal', '1985-05-30', 0);
SELECT * FROM Singers WHERE SingerId = 4;
-- UPDATE
UPDATE Singers SET LastName = 'Richards-Smith' WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- DELETE
DELETE FROM Albums WHERE SingerId = 2;
DELETE FROM Singers WHERE SingerId = 2;
SELECT * FROM Singers WHERE SingerId = 2;
EXIT;
在 Spanner 中进行验证(过一会儿):
# Verify INSERT: This should return the new row for Elena Nadal.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 4"
# Verify UPDATE: This should show LastName as Richards-Smith.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName FROM Singers WHERE SingerId = 1"
# Verify DELETE: This should now return 0 rows.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Albums WHERE SingerId = 2"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 2"
预期输出:
SingerId: 4 FirstName: Elena LastName: Nadal BirthDate: 1985-05-30 AlbumCount: 0 SingerId: 1 FirstName: Marc LastName: Richards-Smith
3. 在 Spanner 中进行最终验证
检查 Spanner 中 Singers 表的总体状态:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId"
预期输出:
SingerId: 1 FirstName: Marc LastName: Richards-Smith AlbumCount: 2 SingerId: 3 FirstName: Alice LastName: Trentor AlbumCount: 3 SingerId: 4 FirstName: Elena LastName: Nadal AlbumCount: 0
10. 设置反向复制(从 Spanner 到 Cloud SQL)
为了应对可能需要回滚或在一段时间内保持 Cloud SQL 数据库与 Spanner 同步的场景,您可以设置反向复制。此流水线使用 Spanner 变更数据流来捕获 Spanner 中的更改,并将其写回 Cloud SQL music_db。
1. 创建 Spanner 变更数据流
首先,您需要在 Spanner 数据库中创建一个变更数据流,以跟踪 Singers 和 Albums 表中的变更。
export CHANGE_STREAM_NAME="MusicDBChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Singers, Albums"
此变更数据流现在将记录对指定表的所有数据修改。
2. 为 Dataflow 元数据创建 Spanner 数据库
Spanner to SourceDB Dataflow 模板需要单独的 Spanner 数据库来存储元数据,以便管理变更数据流使用情况。
export SPANNER_METADATA_DB_NAME="reverse-replication-metadata"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. 为 Dataflow 准备 Cloud SQL 连接配置
Dataflow 模板需要 Cloud Storage 中的一个 JSON 文件,其中包含目标 Cloud SQL 数据库的连接详细信息。
创建名为 shard_config.json 的本地文件:
cat << EOF > shard_config.json
[
{
"logicalShardId": "mysql_shard",
"host": "${SQL_INSTANCE_IP}",
"port": "3306",
"user": "root",
"password": "${DB_ROOT_PASSWORD}",
"dbName": "music_db"
}
]
EOF
将此文件上传到您的 GCS 存储分区:
export SHARD_CONFIG_FILE="gs://${BUCKET_NAME}/shard_config.json"
gcloud storage cp shard_config.json $SHARD_CONFIG_FILE
4. 运行反向复制 Dataflow 作业
使用 Spanner_to_SourceDb Flex 模板启动 Dataflow 作业。
export JOB_NAME_REVERSE="spanner-to-mysql-reverse-$(date +%Y%m%d-%H%M%S)"
export REVERSE_DLQ_DIR="gs://${BUCKET_NAME}/reverse-dlq"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$SHARD_CONFIG_FILE",\
deadLetterQueueDirectory="$REVERSE_DLQ_DIR"
关键形参
changeStreamName:要从中读取数据的 Spanner 变更数据流的名称。metadataInstance, metadataDatabase:用于存储元数据的 Spanner 实例/数据库,连接器使用这些元数据来控制变更数据流 API 数据的使用。sourceShardsFilePath:shard_config.json的 GCS 路径。filtrationMode:指定如何根据条件舍弃某些记录。默认值为forward_migration(过滤使用正向迁移流水线写入的记录)
网络注意事项:Dataflow 工作器将使用 shard_config.json 中指定的公共 IP 连接到 Cloud SQL 实例。由于 Cloud SQL 实例的“已获授权的网络”中存在 0.0.0.0/0 条目,因此允许此连接。
在 Dataflow 作业控制台中监控作业启动情况。
5. 测试反向复制
现在,直接在 Cloud Spanner 中进行更改,并验证这些更改是否反映在 Cloud SQL 中。仅当 Dataflow 作业已启动并处于处理状态时,才执行此操作。
测试 INSERT、UPDATE 和 DELETE
# INSERT: Insert a new singer (SingerId 5) into Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (5, 'David', 'Chen', '1995-02-18', 0)"
# UPDATE: Update SingerId 3's AlbumCount in Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Singers SET AlbumCount = 5 WHERE SingerId = 3"
# DELETE: Delete SingerId 1 from Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Albums WHERE SingerId = 1"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Singers WHERE SingerId = 1"
Cloud SQL 中的验证(过一会儿):
连接到 Cloud SQL:
mysql -h $SQL_INSTANCE_IP -u root -p
在系统提示时输入密码 (Welcome@1),然后在 mysql> 提示符处运行以下 SQL 命令。
USE music_db;
-- Verify INSERT: This should show the new row for David Chen
SELECT * FROM Singers WHERE SingerId = 5;
-- Verify UPDATE: This should show AlbumCount as 5.
SELECT SingerId, FirstName, AlbumCount FROM Singers WHERE SingerId = 3;
-- Verify DELETE: This should return an empty set.
SELECT * FROM Albums WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- Final Verification
SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId;
EXIT;
Cloud SQL 中的预期输出应反映在 Spanner 中所做的更改。
+----------+-----------+----------------+------------+ | SingerId | FirstName | LastName | AlbumCount | +----------+-----------+----------------+------------+ | 3 | Alice | Trentor | 5 | | 4 | Elena | Nadal | 0 | | 5 | David | Chen | 0 | +----------+-----------+----------------+------------+
这会确认反向复制流水线是否正常运行,是否能将 Spanner 中的更改同步回 Cloud SQL。
11. 清理资源
为避免您的 Google Cloud 账号产生进一步费用,请删除在此 Codelab 期间创建的资源。
设置环境变量(如果需要)
检查环境变量是否已正确设置:
echo "PROJECT_ID: $PROJECT_ID"
echo "REGION: $REGION"
echo "SQL_INSTANCE_NAME: $SQL_INSTANCE_NAME"
echo "SPANNER_INSTANCE_NAME: $SPANNER_INSTANCE_NAME"
echo "BUCKET_NAME: $BUCKET_NAME"
echo "STREAM_NAME: $STREAM_NAME"
echo "SQL_CP_NAME: $SQL_CP_NAME"
echo "GCS_CP_NAME: $GCS_CP_NAME"
echo "PUBSUB_SUBSCRIPTION: $PUBSUB_SUBSCRIPTION"
echo "PUBSUB_TOPIC: $PUBSUB_TOPIC"
echo "CHANGE_STREAM_NAME: $CHANGE_STREAM_NAME"
列出您的作业,以查找正在运行的 Dataflow 作业的作业 ID。相应地导出 JOB_ID_CDC 和 JOB_ID_REVERSE。
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
如果您处于新的 Cloud Shell 会话中,请重新导出关键环境变量:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or the region you used
export SQL_INSTANCE_NAME="source-mysql-instance"
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export STREAM_NAME="mysql-to-spanner-stream"
export SQL_CP_NAME="mysql-src-cp"
export GCS_CP_NAME="gcs-dest-cp"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CHANGE_STREAM_NAME="MusicDBChangeStream"
停止 Dataflow 流式处理作业
取消 Datastream to Spanner(实时迁移)作业:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
取消 Spanner to Cloud SQL(反向复制)作业:
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
删除 Datastream 资源
停止并删除数据流:
gcloud datastream streams update $STREAM_NAME \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
删除连接配置文件
gcloud datastream connection-profiles delete $SQL_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
删除 Pub/Sub 资源
删除订阅:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
删除主题:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
删除 Cloud SQL 实例
系统会自动删除其中的数据库 (music_db)。
gcloud sql instances delete $SQL_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
删除 Cloud Spanner 实例
这也会删除其中的数据库(music-db-migrated 和 reverse-replication-metadata)。
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
删除 GCS 存储分区和内容
gcloud storage rm --recursive gs://${BUCKET_NAME}
删除本地文件
移除 Cloud Shell 主目录中生成的所有文件:
rm -f music-db* shard_config.json
您现在已清理为此 Codelab 创建的资源。