
1. ALPHA-WORKSHOP
Link zum Workshop-Codelab: bit.ly/asm-workshop-jp
2. 概要
アーキテクチャ図
In diesem Workshop lernen Sie, wie Sie global verteilte Dienste in GCP für die Produktionsumgebung einrichten.Die wichtigsten Technologien, die wir verwenden, sind Google Kubernetes Engine (GKE) für die Rechenleistung und das Istio-Servicemesh für sichere Verbindungen, Beobachtbarkeit und erweiterte Traffic-Manipulationen.Alle in diesem Workshop verwendeten Praktiken und Tools sind dieselben, die auch in der Produktion verwendet werden.
Inhalt
TODO – mit der endgültigen Aufschlüsselung aktualisieren
前提条件
ワークショップを進める前に、下記の事項が必要となります:
- GCP組織リソース
- Rechnungskonto-ID (Sie müssen Administrator des Rechnungskontos für dieses Konto sein)
- IAM-Rolle „Organisationsadministrator“ auf Organisationsebene
3. Infrastruktur einrichten – Administratorworkflow
ワークショップ作成スクリプトの説明
Mit dem Skript bootstrap_workshop.sh wird die anfängliche Umgebung für den Workshop eingerichtet.Mit diesem Skript können Sie eine einzelne Umgebung für sich selbst oder mehrere Umgebungen für mehrere Nutzer einrichten.
Für das Skript zum Erstellen von Workshops sind die folgenden Informationen erforderlich:
- 組織名 (例.
yourcompany.com)- これはあなたがワークショップ環境を作成する組織の名称です。 - 請求先アカウントID (例.
12345-12345-12345) - Diese ID wird als Abrechnungskonto für alle im Workshop erstellten Ressourcen verwendet. - ワークショップ番号 (例.
01) – 2-stellige Zahl.これは、1日に複数のワークショップを行っており、それらを個別に管理したい場合に使用されます。Die Workshopnummer wird auch für die Benennung der Projekt-ID verwendet.Mit individuellen Workshopnummern erhalten Sie leichter jedes Mal eine eindeutige Projekt-ID.Zusätzlich zur Workshop-Nummer wird auch das aktuelle Datum (im Format JJMMTT) für die Projekt-ID verwendet.Durch die Kombination aus Datum und Workshopnummer wird eine eindeutige Projekt-ID erstellt. - ユーザーの開始番号 (例.
1) – Diese Nummer steht für die erste Nutzer-ID des Workshops.Wenn Sie beispielsweise einen Workshop für 10 Nutzer erstellen, ist die Startnummer des Nutzers 1 und die Endnummer des Nutzers 10. - ユーザーの終了番号 (例.
10) – Diese Nummer steht für die letzte Nutzer-ID des Workshops.Wenn Sie beispielsweise einen Workshop für 10 Nutzer erstellen, ist die Startnummer des Nutzers 1 und die Endnummer des Nutzers 10.Wenn Sie eine einzelne Umgebung (z. B. für sich selbst) erstellen, sind die Start- und Endnummer des Nutzers identisch.Dadurch wird eine einheitliche Umgebung geschaffen.
- 管理用 GCS バケット (例.
my-gcs-bucket-name) - このGCSバケットは、ワークショップ関連の情報を保存するために使用されます。Diese Informationen werden vom Skript cleanup_workshop.sh verwendet, um alle Ressourcen, die während des Skripts zum Erstellen des Workshops erstellt wurden, ordnungsgemäß zu entfernen.Administratoren, die Workshops erstellen, benötigen Lese-/Schreibberechtigungen für diesen Bucket.
Das Skript zum Erstellen von Workshops verwendet die oben genannten Werte und fungiert als Wrapper-Skript, das das Skript setup-terraform-admin-project.sh aufruft. Dieses Skript erstellt eine Workshop-Umgebung für einen einzelnen Nutzer.
管理者権限, die zum Erstellen von Workshops erforderlich sind
In diesem Workshop gibt es zwei Arten von Nutzern:1つめがこのワークショップのリソースを作成および削除する ADMIN_USER 、2番目は MY_USER で、ワークショップの手順を実行します。 MY_USER は、自身のリソースのみにアクセスできます。 ADMIN_USER hat Zugriff auf alle Nutzereinstellungen.Wenn Sie dieses Setup selbst erstellen, sind ADMIN_USER und MY_USER identisch.Wenn Sie ein Kursleiter sind, der diesen Workshop für mehrere Schüler erstellt, sind ADMIN_USER und MY_USER unterschiedlich.
ADMIN_USER には次の組織レベルの権限が必要です:
- オーナー: 組織内のすべてのプロジェクトに対するプロジェクトオーナーの権限。
- Ordneradministrator: Berechtigung zum Erstellen und Löschen von Ordnern in der Organisation.Alle Nutzer erhalten einen einzelnen Ordner mit allen Ressourcen im Projekt.
- 組織の管理者
- プロジェクト作成者: 組織内にプロジェクトを作成する権限。
- プロジェクトの削除: 組織内のプロジェクトを削除する権限。
- Projekt-IAM-Administrator: Berechtigung zum Erstellen von IAM-Regeln für alle Projekte in der Organisation.
Außerdem muss ADMIN_USER der Abrechnungsadministrator der im Workshop verwendeten Abrechnungskonto-ID sein.
ワークショップを実行するユーザースキーマと権限
Wenn Sie diesen Workshop für andere Nutzer in Ihrer Organisation erstellen, müssen Sie die spezifischen Namenskonventionen für Nutzer von MY_USER einhalten. Geben Sie während der Ausführung des Skripts „bootstrap_workshop.sh“ die Start- und Endnummer des Nutzers an.Diese Nummern werden verwendet, um Nutzernamen zu erstellen::
user<3桁のユーザー番号>@<組織名>
Wenn Sie beispielsweise das Skript zum Erstellen von Workshops für die Organisation „yourcompany.com“ mit der Startnummer 1 und der Endnummer 3 ausführen, werden Workshopumgebungen mit den folgenden Nutzernamen erstellt::
user001@yourcompany.comuser002@yourcompany.comuser003@yourcompany.com
これらのユーザー名には、setup_terraform_admin_project.shスクリプトで作成された特定のプロジェクトのプロジェクト所有者ロールが割り当てられます。Wenn Sie das Skript zum Erstellen von Workshops verwenden, müssen Sie diesem Benennungsschema für Nutzer folgen. 詳細は GSuiteで複数のユーザーを一度に追加する方法を参照してください。
ワークショップで必要なツール群
Dieser Workshop wird in Cloud Shell ausgeführt.Für den Workshop sind die folgenden Tools erforderlich:
- gcloud (Version >= 270)
- kubectl
- sed (funktioniert mit Cloud Shell / Linux-sed, nicht mit Mac OS)
- git (Achten Sie darauf, dass Sie die aktuelle Version verwenden.)
sudo apt updatesudo apt install git- jq
- envsubst
- kustomize
ワークショップのセットアップ (単一ユーザーセットアップ)
- Öffnen Sie Cloud Shell und führen Sie die folgenden Schritte dort aus.Klicken Sie auf den folgenden Link, um Cloud Shell zu öffnen.
- 想定している管理者ユーザーで gcloud にログインしていることを確認します。
gcloud config list
- Erstellen Sie einen
WORKDIR(Arbeitsordner) und klonen Sie das Workshop-Repository.
mkdir asm-workshop
cd asm-workshop
export WORKDIR=`pwd`
git clone https://github.com/GoogleCloudPlatform/anthos-service-mesh-workshop.git asm
- Definieren Sie den Organisationsnamen, die Abrechnungskonto-ID, die Workshopnummer und den GCS-Bucket für die Verwaltung, die für den Workshop verwendet werden sollen.In den oben genannten Abschnitten finden Sie die Berechtigungen, die für die Einrichtung eines Workshops erforderlich sind.
gcloud organizations list
export ORGANIZATION_NAME=<ORGANIZATION NAME>
gcloud beta billing accounts list
export ADMIN_BILLING_ID=<ADMIN_BILLING ID>
export WORKSHOP_NUMBER=<two digit number for example 01>
export ADMIN_STORAGE_BUCKET=<ADMIN CLOUD STORAGE BUCKET>
- Führen Sie das Skript „bootstrap_workshop.sh“ aus.Die Ausführung dieses Skripts kann einige Minuten dauern.
cd asm
./scripts/bootstrap_workshop.sh --org-name ${ORGANIZATION_NAME} --billing-id ${ADMIN_BILLING_ID} --workshop-num ${WORKSHOP_NUMBER} --admin-gcs-bucket ${ADMIN_STORAGE_BUCKET} --set-up-for-admin
Nach Abschluss des Skripts „bootstrap_workshop.sh“ wird für jeden Nutzer in der Organisation ein GCP-Ordner erstellt.Im Ordner wird ein Terraform-Verwaltungsprojekt erstellt. Das Terraform-Verwaltungsprojekt wird verwendet, um die verbleibenden GCP-Ressourcen zu erstellen, die für diesen Workshop erforderlich sind. terraform管理プロジェクトで必要なAPIを有効にします。 Cloud Buildを使用してTerraform planを適用します。 Cloud Build-Dienstkonto muss die entsprechenden IAM-Rollen haben, damit Ressourcen in GCP erstellt werden können.最後に、 Google Cloud Storage(GCS)バケットでリモートバックエンドを構成して、すべてのGCPリソースの Terraform statesを保存します。
Um Cloud Build-Aufgaben im Terraform-Verwaltungsprojekt aufzurufen, benötigen Sie die Terraform-Verwaltungsprojekt-ID.Dies wird im administrativen GCS-Bucket gespeichert, der im Skript zum Erstellen von Workshops angegeben ist.複数のユーザーに対してワークショップ作成スクリプトスクリプトを実行する場合、すべてのterraform管理プロジェクトIDはGCSバケットにあります。
- Rufen Sie die Datei „workshop.txt“ aus dem administrativen GCS-Bucket ab, um die Terraform-Projekt-ID zu erhalten.
export WORKSHOP_ID="$(date '+%y%m%d')-${WORKSHOP_NUMBER}"
gsutil cp gs://${ADMIN_STORAGE_BUCKET}/${ORGANIZATION_NAME}/${WORKSHOP_ID}/workshop.txt .
ワークショップのセットアップ (複数ユーザーセットアップ)
- Öffnen Sie Cloud Shell und führen Sie die folgenden Schritte dort aus.Klicken Sie auf den folgenden Link, um Cloud Shell zu öffnen.
- 想定している管理者ユーザーで gcloud にログインしていることを確認します。
gcloud config list
- Erstellen Sie ein WORKDIR (Arbeitsordner) und klonen Sie das Workshop-Repository.
mkdir asm-workshop
cd asm-workshop
export WORKDIR=`pwd`
git clone https://github.com/GoogleCloudPlatform/anthos-service-mesh-workshop.git asm
- Definieren Sie den Organisationsnamen, die Abrechnungskonto-ID, die Workshopnummer und den GCS-Bucket für die Verwaltung, die für den Workshop verwendet werden sollen.In den oben genannten Abschnitten finden Sie die Berechtigungen, die für die Einrichtung eines Workshops erforderlich sind.
gcloud organizations list
export ORGANIZATION_NAME=<ORGANIZATION NAME>
gcloud beta billing accounts list
export ADMIN_BILLING_ID=<BILLING ID>
export WORKSHOP_NUMBER=<two digit number for example 01>
export START_USER_NUMBER=<number for example 1>
export END_USER_NUMBER=<number greater or equal to START_USER_NUM>
export ADMIN_STORAGE_BUCKET=<ADMIN CLOUD STORAGE BUCKET>
- Führen Sie das Skript „bootstrap_workshop.sh“ aus.Die Ausführung dieses Skripts kann einige Minuten dauern.
cd asm
./scripts/bootstrap_workshop.sh --org-name ${ORGANIZATION_NAME} --billing-id ${ADMIN_BILLING_ID} --workshop-num ${WORKSHOP_NUMBER} --start-user-num ${START_USER_NUMBER} --end-user-num ${END_USER_NUMBER} --admin-gcs-bucket ${ADMIN_STORAGE_BUCKET}
- Rufen Sie die Datei „workshop.txt“ aus dem administrativen GCS-Bucket ab, um die Terraform-Projekt-ID zu erhalten.
export WORKSHOP_ID="$(date '+%y%m%d')-${WORKSHOP_NUMBER}"
gsutil cp gs://${ADMIN_STORAGE_BUCKET}/${ORGANIZATION_NAME}/${WORKSHOP_ID}/workshop.txt .
4. Infrastruktur einrichten – Nutzer-Workflow
所要時間: 1時間
Ziel: Infrastruktur und Istio-Installation bestätigen
- ワークショップで利用するツールをインストール
- ワークショップ用リポジトリをクローン
Infrastructureのインストールを確認k8s-repoのインストールを確認- Istio-Installation prüfen
ユーザー情報の取得
Administratoren, die Workshops einrichten, müssen den Nutzern die Informationen zu Nutzername und Passwort zur Verfügung stellen.Allen Nutzerprojekten wird ein Präfix mit dem Nutzernamen hinzugefügt, z. B. user001@yourcompany.com. Die Terraform-verwaltete Projekt-ID lautet dann user001-200131-01-tf-abcde.各ユーザーは、自分のワークショップ環境にのみアクセスできます。
ワークショップで必要なツール群
Dieser Workshop wird in Cloud Shell ausgeführt.Für den Workshop sind die folgenden Tools erforderlich:
- gcloud (Version >= 270)
- kubectl
- sed (funktioniert mit Cloud Shell / Linux-sed, nicht mit Mac OS)
- git (Achten Sie darauf, dass Sie die aktuelle Version verwenden.)
sudo apt updatesudo apt install git- jq
- envsubst
- kustomize
- pv
Zugriff auf das von Terraform verwaltete Projekt
Nach Abschluss des Skripts „bootstrap_workshop.sh“ wird für jeden Nutzer in der Organisation ein GCP-Ordner erstellt.Im Ordner wird ein Terraform-Verwaltungsprojekt erstellt. Das Terraform-Verwaltungsprojekt wird verwendet, um die verbleibenden GCP-Ressourcen zu erstellen, die für diesen Workshop erforderlich sind. setup-terraform-admin-project.shスクリプトは、terraform管理プロジェクトで必要なAPIを有効にします。 Cloud Build wird verwendet, um den Terraform-Plan anzuwenden.Mit dem Skript werden dem Cloud Build-Dienstkonto die entsprechenden IAM-Rollen zugewiesen, damit Ressourcen in GCP erstellt werden können.最後に、すべてのGCPリソースの Terraform stateを保存するために、リモートバックエンドが Google Cloud Storage(GCS)バケットに構成されます。
Um Cloud Build-Aufgaben im Terraform-Verwaltungsprojekt aufzurufen, benötigen Sie die Terraform-Verwaltungsprojekt-ID.Dies wird im administrativen GCS-Bucket gespeichert, der im Skript zum Erstellen von Workshops angegeben ist.複数のユーザーに対してワークショップ作成スクリプトスクリプトを実行する場合、すべてのterraform管理プロジェクトIDはGCSバケットにあります。
- Öffnen Sie Cloud Shell und führen Sie die folgenden Schritte dort aus.Klicken Sie auf den folgenden Link, um Cloud Shell zu öffnen.
- Installieren Sie kustomize in
$HOME/bin, falls es noch nicht installiert ist, und fügen Sie$HOME/binzu $PATH hinzu.
mkdir -p ${HOME}/bin
cd bin
curl -s "https://raw.githubusercontent.com/\
kubernetes-sigs/kustomize/master/hack/install_kustomize.sh" | bash
cd ${HOME}
export PATH=$PATH:${HOME}/bin
echo "export PATH=$PATH:${HOME}/bin" >> ~/.bashrc
- Installieren Sie pv und fügen Sie es
.customize_environmenthinzu, um die Einstellungen für die Sitzung beizubehalten.
sudo apt-get update && sudo apt-get -y install pv
echo -e '#!/bin/sh' >> $HOME/.customize_environment
echo -e "apt-get update" >> $HOME/.customize_environment
echo -e "apt-get -y install pv" >> $HOME/.customize_environment
- Prüfen Sie, ob der erwartete Nutzer in gcloud angemeldet ist.
gcloud config list
- Erstellen Sie ein WORKDIR (Arbeitsordner) und klonen Sie das Workshop-Repository.
mkdir asm-workshop
cd asm-workshop
export WORKDIR=`pwd`
git clone https://github.com/GoogleCloudPlatform/anthos-service-mesh-workshop.git asm
cd asm
- Terraform 管理プロジェクト ID を下記のコマンドで取得します。:
export TF_ADMIN=$(gcloud projects list | grep tf- | awk '{ print $1 }')
echo $TF_ADMIN
- Alle Ressourceninformationen für den Workshop werden als Variablen in der Datei „vars.sh“ gespeichert, die sich im GCS-Bucket des Terraform-Verwaltungsprojekts befindet. Rufen Sie die Datei „vars.sh“ des Terraform-Verwaltungsprojekts ab.
mkdir vars
gsutil cp gs://${TF_ADMIN}/vars/vars.sh ./vars/vars.sh
echo "export WORKDIR=${WORKDIR}" >> ./vars/vars.sh
- Klicken Sie auf den angezeigten Link, um die Cloud Build-Seite des Terraform-Verwaltungsprojekts zu öffnen.
source ./vars/vars.sh
echo "https://console.cloud.google.com/cloud-build/builds?project=${TF_ADMIN}"
- Die Seite Cloud Build wird angezeigt. Klicken Sie in der linken Navigationsleiste auf den Link Verlauf und dann auf den letzten Build, um die Details der ersten Terraform-Anwendung aufzurufen.Die folgenden Ressourcen werden als Teil des Terraform-Skripts erstellt.Das obige Architekturdiagramm kann Ihnen dabei helfen.
- Vier GCP-Projekte in der Organisation.各プロジェクトは提供された請求アカウントIDに紐付いています。
- Ein Projekt ist eine
network host project, für die eine gemeinsame VPC konfiguriert ist.Für dieses Projekt werden keine anderen Ressourcen erstellt. - Ein Projekt ist die
ops project, die für den GKE-Cluster der Istio-Steuerungsebene verwendet wird. - Die beiden anderen Projekte stehen für zwei verschiedene Entwicklungsteams, die an den jeweiligen Diensten arbeiten.
- In jedem der drei Projekte
ops,dev1unddev2werden zwei GKE-Cluster erstellt. - Es wird ein CSR-Repository mit dem Namen
k8s-repoerstellt, das sechs Ordner für Kubernetes-Manifestdateien enthält. Für jeden GKE-Cluster gibt es einen Ordner.Dieses Repository wird verwendet, um Kubernetes-Manifeste im GitOps-Stil in Clustern bereitzustellen. - Cloud Build-Trigger werden jedes Mal erstellt, wenn ein Commit für den Master-Branch von
k8s-repoerfolgt. Sie stellen Kubernetes-Manifeste aus den jeweiligen Ordnern in GKE-Clustern bereit.
- Wenn der Build im Terraform-Verwaltungsprojekt abgeschlossen ist, wird im Ops-Projekt ein weiterer Build gestartet.Klicken Sie auf den angezeigten Link, um die Cloud Build-Seite für das
ops-Projekt zu öffnen.
echo "https://console.cloud.google.com/cloud-build/builds?project=${TF_VAR_ops_project_name}"
インストールの確認
- Erstellen Sie eine kubeconfig-Datei, um alle Cluster zu verwalten.下記的スクリプトを実行します。
./scripts/setup-gke-vars-kubeconfig.sh
Dieses Skript erstellt eine neue kubeconfig-Datei mit dem Namen kubemesh im Ordner gke.
KUBECONFIG変数を新しい kubeconfig ファイルに変更します。
source ./vars/vars.sh
export KUBECONFIG=`pwd`/gke/kubemesh
- Fügen Sie var.sh zu .bashrc hinzu, damit sie immer geladen wird, wenn Cloud Shell neu gestartet wird.
echo "source ${WORKDIR}/asm/vars/vars.sh" >> ~/.bashrc
echo "export KUBECONFIG=${WORKDIR}/asm/gke/kubemesh" >> ~/.bashrc
- クラスタのコンテキストを取得します。Sie sollten sechs Cluster sehen.
kubectl config view -ojson | jq -r '.clusters[].name'
`出力結果(コピーしないでください)`
gke_tf05-01-ops_us-central1_gke-asm-2-r2-prod gke_tf05-01-ops_us-west1_gke-asm-1-r1-prod gke_tf05-02-dev1_us-west1-a_gke-1-apps-r1a-prod gke_tf05-02-dev1_us-west1-b_gke-2-apps-r1b-prod gke_tf05-03-dev2_us-central1-a_gke-3-apps-r2a-prod gke_tf05-03-dev2_us-central1-b_gke-4-apps-r2b-prod
Istio-Installation prüfen
- Prüfen Sie, ob alle Pods ausgeführt werden und der Job abgeschlossen ist. Prüfen Sie außerdem, ob Istio in beiden Clustern installiert ist.
kubectl --context ${OPS_GKE_1} get pods -n istio-system
kubectl --context ${OPS_GKE_2} get pods -n istio-system
`出力結果(コピーしないでください)`
NAME READY STATUS RESTARTS AGE grafana-5f798469fd-z9f98 1/1 Running 0 6m21s istio-citadel-568747d88-qdw64 1/1 Running 0 6m26s istio-egressgateway-8f454cf58-ckw7n 1/1 Running 0 6m25s istio-galley-6b9495645d-m996v 2/2 Running 0 6m25s istio-ingressgateway-5df799fdbd-8nqhj 1/1 Running 0 2m57s istio-pilot-67fd786f65-nwmcb 2/2 Running 0 6m24s istio-policy-74cf89cb66-4wrpl 2/2 Running 1 6m25s istio-sidecar-injector-759bf6b4bc-mw4vf 1/1 Running 0 6m25s istio-telemetry-77b6dfb4ff-zqxzz 2/2 Running 1 6m24s istio-tracing-cd67ddf8-n4d7k 1/1 Running 0 6m25s istiocoredns-5f7546c6f4-g7b5c 2/2 Running 0 6m39s kiali-7964898d8c-5twln 1/1 Running 0 6m23s prometheus-586d4445c7-xhn8d 1/1 Running 0 6m25s
`出力結果(コピーしないでください)`
NAME READY STATUS RESTARTS AGE grafana-5f798469fd-2s8k4 1/1 Running 0 59m istio-citadel-568747d88-87kdj 1/1 Running 0 59m istio-egressgateway-8f454cf58-zj9fs 1/1 Running 0 60m istio-galley-6b9495645d-qfdr6 2/2 Running 0 59m istio-ingressgateway-5df799fdbd-2c9rc 1/1 Running 0 60m istio-pilot-67fd786f65-nzhx4 2/2 Running 0 59m istio-policy-74cf89cb66-4bc7f 2/2 Running 3 59m istio-sidecar-injector-759bf6b4bc-grk24 1/1 Running 0 59m istio-telemetry-77b6dfb4ff-6zr94 2/2 Running 4 60m istio-tracing-cd67ddf8-grs9g 1/1 Running 0 60m istiocoredns-5f7546c6f4-gxd66 2/2 Running 0 60m kiali-7964898d8c-nhn52 1/1 Running 0 59m prometheus-586d4445c7-xr44v 1/1 Running 0 59m
- Istio muss auf beiden
dev1-Clustern installiert sein.dev1クラスターでは、Citadel、sidecar-injector、corednのみが実行されています。 ops-1クラスターで実行されているIstioのコントロールプレーンを共有します。
kubectl --context ${DEV1_GKE_1} get pods -n istio-system
kubectl --context ${DEV1_GKE_2} get pods -n istio-system
- Prüfen Sie, ob Istio in beiden
dev2-Clustern installiert ist.dev2クラスタでは、Citadel、sidecar-injector、corednのみが実行されています。 ops-2クラスタで実行されているIstioのコントロールプレーンを共有します。
kubectl --context ${DEV2_GKE_1} get pods -n istio-system
kubectl --context ${DEV2_GKE_2} get pods -n istio-system
`出力結果(コピーしないでください)`
NAME READY STATUS RESTARTS AGE istio-citadel-568747d88-4lj9b 1/1 Running 0 66s istio-sidecar-injector-759bf6b4bc-ks5br 1/1 Running 0 66s istiocoredns-5f7546c6f4-qbsqm 2/2 Running 0 78s
Dienstermittlung des freigegebenen Kontrollbereichs prüfen
- Optional können Sie prüfen, ob das Secret bereitgestellt wurde.
kubectl --context ${OPS_GKE_1} get secrets -l istio/multiCluster=true -n istio-system
kubectl --context ${OPS_GKE_2} get secrets -l istio/multiCluster=true -n istio-system
`出力結果(コピーしないでください)`
For OPS_GKE_1: NAME TYPE DATA AGE gke-1-apps-r1a-prod Opaque 1 8m7s gke-2-apps-r1b-prod Opaque 1 8m7s gke-3-apps-r2a-prod Opaque 1 44s gke-4-apps-r2b-prod Opaque 1 43s For OPS_GKE_2: NAME TYPE DATA AGE NAME TYPE DATA AGE gke-1-apps-r1a-prod Opaque 1 40s gke-2-apps-r1b-prod Opaque 1 40s gke-3-apps-r2a-prod Opaque 1 8m4s gke-4-apps-r2b-prod Opaque 1 8m4s
In diesem Workshop wird eine einzelne Shared VPC verwendet, in der alle GKE-Cluster erstellt werden.Um Dienste im gesamten Cluster zu erkennen, verwenden Sie die kubeconfig-Datei (für jeden Anwendungscluster), die als Secret im Ops-Cluster erstellt wurde.Pilot は、これらの Secret を使用して、アプリケーションクラスタの Kube API サーバー(上記の Secret を介して認証された)を照会することにより、サービスを検出します。Beide Ops-Cluster verwenden ein Secret, das mit kubeconfig erstellt wurde, um sich bei allen App-Clustern zu authentifizieren. Ops-Cluster können Dienste automatisch erkennen, indem sie die kubeconfig-Datei als Secret verwenden.Dazu muss der Pilot im Ops-Cluster auf die Kube API-Server aller anderen Cluster zugreifen können. Wenn Pilot den Kube-API-Server nicht erreichen kann, fügen Sie den Remote-Dienst manuell als ServiceEntries hinzu. ServiceEntries können als DNS-Einträge im Diensteregister betrachtet werden. ServiceEntries定義ieren Dienste mithilfe von vollständig qualifizierten DNS-Namen (FQDN) und erreichbaren IP-Adressen.Weitere Informationen finden Sie in der Istio Multicluster-Dokumentation.
5. Beschreibung des Infrastructure-Repositorys
Cloud Build für die Infrastruktur
Die GCP-Ressourcen für den Workshop werden mit Cloud Build und dem Infrastructure CSR-Repository erstellt.Führen Sie das Skript zum Erstellen von Workshops (scripts/bootstrap_workshop.sh) auf Ihrem lokalen Gerät aus.Das Skript zum Erstellen von Workshops erstellt die entsprechenden IAM-Berechtigungen für GCP-Ordner, das Terraform-Verwaltungsprojekt und das Cloud Build-Dienstkonto.Terraform-Verwaltungsprojekte werden zum Speichern von Terraform-Zuständen, Protokollen und anderen Skripts verwendet.Dort finden Sie die CSR-Repositories für infrastructure und k8s_repo.Diese Repositorys werden im nächsten Abschnitt genauer beschrieben. terraform管理プロジェクトには、他のワークショップリソースは組み込まれていません。 Das Cloud Build-Dienstkonto des Terraform-Verwaltungsprojekts wird zum Erstellen der Ressourcen für den Workshop verwendet.
Die Datei cloudbuild.yaml im Ordner Infrastructure wird verwendet, um die GCP-Ressourcen für den Workshop zu erstellen. Erstellen Sie ein benutzerdefiniertes Builder-Image mit allen Tools, die zum Erstellen von GCP-Ressourcen erforderlich sind.Zu diesen Tools gehören das gcloud SDK, Terraform und andere Dienstprogramme wie Python, Git und jq.カスタムビルダーイメージは、terraform plan を実行し、各リソースに apply します。Die Terraform-Dateien für die einzelnen Ressourcen befinden sich in separaten Ordnern (siehe nächsten Abschnitt).Ressourcen werden einzeln und in der Regel in der Reihenfolge erstellt, in der sie erstellt werden (z. B. wird ein GCP-Projekt erstellt, bevor Ressourcen im Projekt erstellt werden).Weitere Informationen finden Sie in der Datei cloudbuild.yaml.
Cloud Build wird bei jedem Commit in das infrastructure-Repository ausgelöst.Die an der Infrastruktur vorgenommenen Änderungen werden als Infrastructure as Code (IaC) gespeichert und im Repository committet.Der Status des Workshops wird immer in diesem Repository gespeichert.
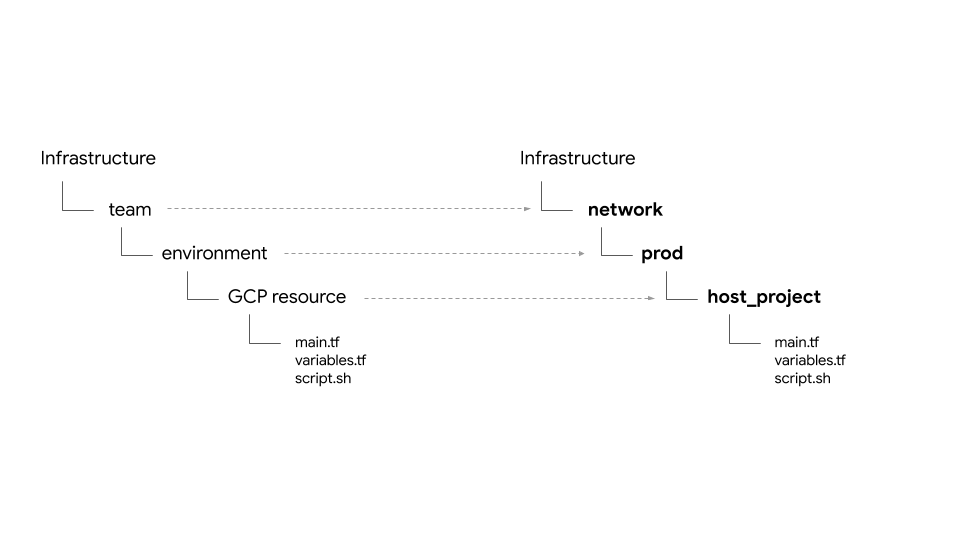
Ordnerstruktur – Teams, Umgebungen und Ressourcen
Das Infrastructure-Repository richtet die GCP-Infrastrukturressourcen für den Workshop ein.フォルダとサブフォルダに構造化されています。Der Basisordner in einem Repository stellt ein Team dar, das bestimmte GCP-Ressourcen besitzt.Die nächste Ebene der Ordner stellt die spezifische Umgebung des Teams dar, z. B. „dev“, „stage“ oder „prod“.Die nächste Ebene der Ordner in der Umgebung stellt bestimmte Ressourcen dar, z. B. host_project und gke_clusters.Die erforderlichen Skripts und Terraform-Dateien befinden sich im Ressourcenordner.
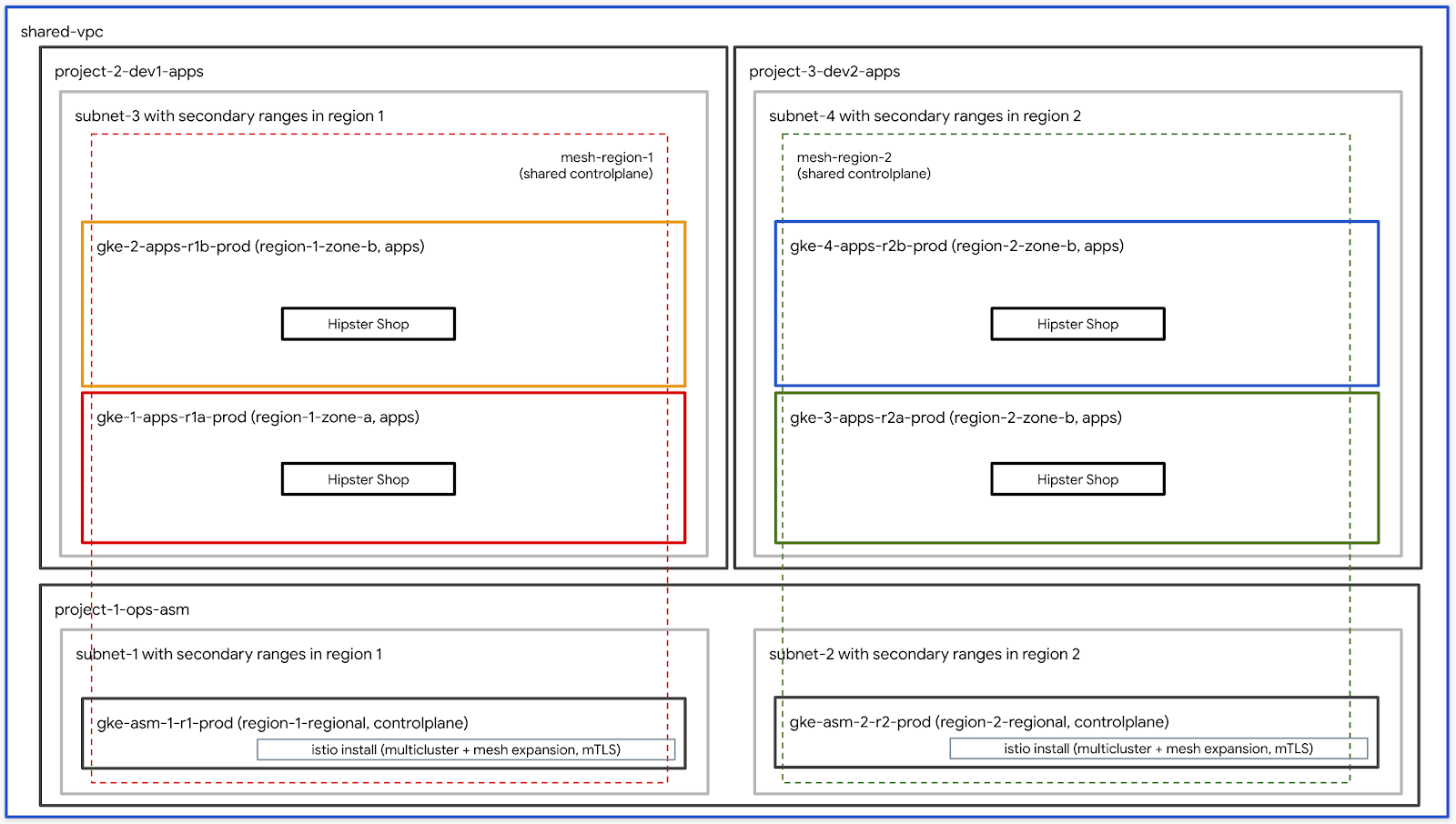
In diesem Workshop werden vier Arten von Teams vorgestellt::
- infrastructure: Stellt das Infrastrukturteam dar, das die Cloud verwaltet.他のすべてのチームのGCPリソースを作成する責任があります。Für Ressourcen wird ein von Terraform verwaltetes Projekt verwendet.Das Infrastruktur-Repository selbst befindet sich in der Terraform-Statusdatei (siehe unten).Diese Ressourcen werden während des Erstellungsprozesses des Workshops durch Bash-Skripts erstellt. Weitere Informationen finden Sie in Modul 0 – Infrastruktureinrichtung – Administratorworkflow.
- network: Steht für das Netzwerkteam. VPCと NetzwerkressourcenSie sind Inhaber der folgenden GCP-Ressourcen:
host project: Das Hostprojekt der freigegebenen VPC.shared VPC: Stellt freigegebene VPCs, Subnetze, sekundäre IP-Bereiche, Routinginformationen und Firewallregeln dar.- ops: Steht für das Betriebs- oder DevOps-Team.彼らは次のリソースを所有しています。
ops project: Stellt das Projekt für alle Ops-Ressourcen dar.gke clusters: Regionale GKE-Ops-Cluster.Außerdem wird die Istio-Steuerungsebene in jedem ops-GKE-Cluster installiert.k8s-repo: Das CSR-Repository mit GKE-Manifesten für alle GKE-Cluster.- apps: Steht für das Anwendungsteam.In diesem Workshop werden zwei Teams simuliert:
app1undapp2.彼らは次のリソースを所有しています。 app projects: Alle App-Teams haben eigene Projektsätze.So können Sie die Abrechnung und IAM für jedes Projekt steuern.gke clusters: Dies sind die Cluster für die Anwendung, in denen der Anwendungscontainer/ Pod ausgeführt wird.gce instances: Optional, wenn auf der GCE-Instanz eine Anwendung ausgeführt wird.In diesem Workshop hat app1 einige GCE-Instanzen, auf denen Teile der Anwendung ausgeführt werden.
In diesem Workshop verwenden wir dieselbe App („Hipster Shop“-App) für app1 und app2.
Provider, Status, Ausgabe – Backend, gemeinsamer Status
Die google- und google-beta-Anbieter befinden sich in gcp/[environment]/gcp/provider.tf. provider.tf ファイルは、すべてのリソースフォルダで シンボリックリンクされています。So können Sie Anbieter an einem zentralen Ort verwalten, anstatt für jede Ressource einzeln.
Alle Ressourcen enthalten eine backend.tf-Datei, in der der Speicherort der tfstate-Datei der Ressource definiert ist.Diese backend.tf-Datei wird mithilfe eines Skripts (in scripts/setup_terraform_admin_project) aus einer Vorlage (in templates/backend.tf_tmpl) generiert und in den jeweiligen Ressourcenordnern platziert. GCSバケットがファイル置き場として使われます。 GCS-Bucket-Ordnernamen stimmen mit den Ressourcennamen überein.Alle Ressourcen befinden sich im Terraform-verwalteten Projekt.
Ressourcen mit voneinander abhängigen Werten enthalten eine output.tf-Datei.Die erforderlichen Ausgabewerte werden in der tfstate-Datei gespeichert, die im Backend für die jeweilige Ressource definiert ist.Wenn Sie beispielsweise einen GKE-Cluster in einem Projekt erstellen möchten, benötigen Sie die Projekt-ID.Die Projekt-ID wird über die Datei „output.tf“ in die tfstate-Datei ausgegeben, die über die Datenquelle terraform_remote_state für GKE-Clusterressourcen verfügbar ist.
Die Datei „shared_state“ ist eine terraform_remote_state-Datenquelle, die auf die tfstate-Datei der Ressource verweist.shared_state_[resource_name].tf ファイルは、他のリソースからの出力を必要とするリソースフォルダに存在します。Beispielsweise enthält der Ordner ops_gke die Datei shared_state für die Ressourcen ops_project und shared_vpc.Das liegt daran, dass für die Erstellung eines GKE-Clusters in einem Ops-Projekt die Projekt-ID und VPC-Details erforderlich sind. Die Datei „shared_state“ wird mithilfe eines Skripts (in scripts/setup_terraform_admin_project) aus einer Vorlage (in templates/shared_state.tf_tmpl) generiert.Die shared_state-Datei für alle Ressourcen befindet sich im Ordner gcp/[environment]/shared_states.Die erforderlichen shared_state-Dateien sind in den jeweiligen Ressourcenordnern symbolisch verlinkt.Wenn Sie alle shared_state-Dateien in einem Ordner platzieren und sie mit dem entsprechenden Ressourcenordner verknüpfen, können Sie alle Statusdateien ganz einfach an einem Ort verwalten.
変数
Alle Ressourcenwerte werden als Umgebungsvariablen gespeichert.Diese Variablen werden in der Datei vars.sh im GCS-Bucket des Terraform-Administratorprojekts als Exportanweisungen gespeichert.Dazu gehören die Organisations-ID, das Abrechnungskonto, die Projekt-ID und die GKE-Clusterdetails.Sie können vars.sh auf ein beliebiges Gerät herunterladen und installieren, um die Einrichtungswerte abzurufen.
Terraform-Variablen werden als TF_VAR_[variable name] in vars.sh gespeichert.Diese Variablen werden verwendet, um die variables.tfvars-Datei in den jeweiligen Ressourcenordnern zu generieren. variables.tfvars Die Datei enthält alle Variablen und ihre Werte. variables.tfvars-Dateien werden mithilfe eines Skripts (scripts/setup_terraform_admin_project) aus den Vorlagendateien im selben Ordner generiert.
K8s リポジトリの説明
k8s_repo wird verwendet, um GKE-Manifeste in einem CSR-Repository (Certificate Signing Request, Zertifikatsignierungsanfrage) zu speichern und auf alle GKE-Cluster anzuwenden, das sich in einem von Terraform verwalteten Projekt befindet und sich vom Infrastruktur-Repository unterscheidet.k8s_repo wird von der Infrastruktur Cloud Build erstellt (siehe vorheriger Abschnitt).最初の Infrastruktur-Cloud Build-Prozess erstellt insgesamt sechs GKE-Cluster.k8s_repoには、6つのフォルダーが作成されます。Jeder Ordner (mit einem Namen, der mit dem GKE-Clusternamen übereinstimmt) entspricht einem GKE-Cluster, das die entsprechenden Ressourcenmanifestdateien enthält.Wie bei der Infrastruktur wird Cloud Build verwendet, um Kubernetes-Manifeste mithilfe von k8s_repo auf alle GKE-Cluster anzuwenden. Cloud Build wird jedes Mal ausgelöst, wenn ein Commit für das k8s_repo-Repository erfolgt.Wie bei der Infrastruktur werden alle Kubernetes-Manifeste als Code im k8s_repo-Repository gespeichert. Der Status jedes GKE-Clusters wird immer in seinem jeweiligen Ordner gespeichert.
Im Rahmen der anfänglichen Infrastruktur wird k8s_repo erstellt und Istio wird in allen Clustern installiert.
Projekte, GKE-Cluster und Namespaces
Die Ressourcen für diesen Workshop sind in verschiedene GCP-Projekte unterteilt.Projekte müssen mit der Organisations- oder Teamstruktur des Unternehmens übereinstimmen.Teams (innerhalb der Organisation), die für verschiedene Projekte, Produkte oder Ressourcen zuständig sind, verwenden verschiedene GCP-Projekte.Wenn Sie separate Projekte erstellen, können Sie separate IAM-Berechtigungen erstellen und die Abrechnung auf Projektebene verwalten.Außerdem werden Kontingente auf Projektebene verwaltet.
In diesem Workshop gibt es fünf Teams mit jeweils einem eigenen Projekt.
- GCPリソースを構築するインフラストラクチャチームは、Terraform管理プロジェクトを使用します。Sie verwalten die Infrastruktur als Code im CSR-Repository (
infrastructure) und speichern alle Terraform-Statusinformationen zu den in GCP erstellten Ressourcen in einem GCS-Bucket.Diese steuern den Zugriff auf das CSR-Repository und den GCS-Bucket für den Terraform-Status. - Das Netzwerkteam verwendet das
hostProjekt, um eine freigegebene VPC zu erstellen.Dieses Projekt enthält VPC, Subnetze, Routen und Firewallregeln.Mit einer freigegebenen VPC können Sie das Netzwerk Ihrer GCP-Ressourcen zentral verwalten.Alle Projekte verwenden diese einzelne freigegebene VPC für das Netzwerk. - Das Betriebs-/Plattformteam verwendet das
ops-Projekt, um GKE-Cluster und die ASM-/Istio-Steuerungsebene zu erstellen. GKEクラスターとサービスメッシュのライフサイクルを管理します。Diese sind für die Verbesserung von Clustern und die Verwaltung der Resilienz und Skalierung der Kubernetes-Plattform verantwortlich.In diesem Workshop verwenden wir die GitOps-Methode, um Ressourcen in Kubernetes bereitzustellen. Das CSR-Repository (k8s_repo) ist im Ops-Projekt vorhanden. - Schließlich verwenden die dev1- und dev2-Teams (die zwei Entwicklungsteams darstellen), die die Anwendung erstellen, eigene
dev1- unddev2-Projekte.Dies sind die Anwendungen und Dienste, die Sie Ihren Kunden anbieten.Diese werden auf Plattformen erstellt, die vom Betriebsteam verwaltet werden.Ressourcen (z. B. Bereitstellung, Dienst) werden ink8s_repoübertragen und im entsprechenden Cluster bereitgestellt.In diesem Workshop geht es nicht um CI / CD-Best Practices und ‑Tools. Cloud Build を使用して、GKEクラスターへのKubernetesリソースの展開を自動化します。In realen Einsatzszenarien stellen Sie Anwendungen mit einer geeigneten CI / CD-Lösung in GKE-Clustern bereit.
In diesem Workshop gibt es zwei Arten von GKE-Clustern.
- Ops-Cluster: Wird vom Ops-Team zum Ausführen von DevOps-Tools verwendet.In diesem Workshop führen Sie den ASM-/Istio-Kontrollbereich aus, um das Service-Mesh zu verwalten.
- Anwendungsgruppe: Wird vom Entwicklungsteam zum Ausführen der Anwendung verwendet.In diesem Workshop wird sie für die Hipster Shop-App verwendet.
Wenn Sie Ops-/Admin-Tools vom Cluster trennen, in dem die Anwendung ausgeführt wird, können Sie den Lebenszyklus der einzelnen Ressourcen separat verwalten. Die beiden Arten von Clustern sind auch in verschiedenen Projekten vorhanden, die mit den Teams / Produkten zusammenhängen, die sie verwenden.Dadurch lassen sich auch IAM-Berechtigungen leichter verwalten.
Insgesamt werden sechs GKE-Cluster angezeigt. In ops-Projekten werden zwei regionale ops-Cluster erstellt. ASM-/Istio-Kontrollebene wird in beiden Ops-Clustern installiert.各opsクラスターは異なるリージョンにあります。Außerdem gibt es vier Zonenanwendungsgruppen.Diese werden in separaten Projekten erstellt.In diesem Workshop werden zwei Entwicklungsteams mit jeweils eigenen Projekten simuliert.Jedes Projekt enthält zwei App-Cluster.App-Cluster sind Zonen-Cluster in verschiedenen Zonen. 4つのアプリクラスターは、2つのリージョンと4つのゾーンにあります。Dadurch wird Redundanz auf Regionen- und Zonenebene erreicht.
Die in diesem Workshop verwendete Anwendung, die Hipster Shop App, wird in allen vier App-Clustern bereitgestellt.各マイクロサービスは、すべてのアプリクラスターの個別の名前空間に存在します。Die Bereitstellung (Pod) der Hipster Shop-App erfolgt nicht im Ops-Cluster.Allerdings werden auch alle Namespace- und Serviceressourcen für die Mikroservices im Operations-Cluster erstellt.Das ASM-/Istio-Kontrollfeld verwendet die Kubernetes-Dienstregistrierung für die Dienstermittlung. Wenn keine Dienste im Operations-Cluster vorhanden sind, müssen Sie die ServiceEntries für jeden Dienst, der im App-Cluster ausgeführt wird, manuell erstellen.
In diesem Workshop stellen wir eine 10-schichtige Microservices-Anwendung bereit.Diese Anwendung ist eine webbasierte E-Commerce-App namens Hipster Shop, in der Nutzer Artikel ansehen, in den Warenkorb legen und kaufen können.
Kubernetes-Manifeste und k8s_repo
Mit k8s_repo können Sie allen GKE-Clustern Kubernetes-Ressourcen hinzufügen.Dazu kopieren Sie das Kubernetes-Manifest und committen es in k8s_repo. Alle Commits für k8s_repo lösen einen Cloud Build-Job aus, der die Kubernetes-Manifeste in den jeweiligen Clustern bereitstellt.Die Manifeste für die einzelnen Cluster befinden sich in einem separaten Ordner mit dem Namen des jeweiligen Clusters.
6つのクラスター名は下記になります:
- gke-asm-1-r1-prod: Regionaler Ops-Cluster in Region 1
- gke-asm-2-r2-prod: Regionaler Ops-Cluster in Region 2
- gke-1-apps-r1a-prod – App-Cluster in Zone a in Region 1
- gke-2-apps-r1b-prod: App-Cluster in Zone b in Region 1
- gke-3-apps-r2a-prod: App-Cluster in Zone a der Region 2
- gke-4-apps-r2b-prod: App-Cluster in Zone b von Region 2
k8s_repo には、これらの Clustern entsprechende Ordner.In diesen Ordnern platzierte Manifeste werden auf die entsprechenden GKE-Cluster angewendet.Die Manifeste für die einzelnen Cluster werden zur einfacheren Verwaltung in Unterordnern (im Hauptordner des Clusters) platziert.In diesem Workshop verwenden Sie Kustomize, um die bereitgestellten Ressourcen zu verfolgen.Weitere Informationen finden Sie in der offiziellen Kustomize-Dokumentation.
6. Beispiel-App bereitstellen
Ziel: Hipster Shop-App in einem Apps-Cluster bereitstellen
k8s-repoリポジトリをクローン- Hipsterショップのマニフェストを全てのappsクラスターにコピー
- HipsterショップアプリのためにServicesをopsクラスターに作成
- グローバルの接続性をテストするため
loadgeneratorをopsクラスターにセットアップ - Sichere Verbindung zur Hipster Shop App prüfen
ops プロジェクトのリポジトリ klonen
Im Rahmen der ersten Terraform-Infrastrukturerstellung wurde k8s-repo bereits im Ops-Projekt erstellt.
- Erstellen Sie unter WORKDIR einen leeren Ordner für das Repository.:
mkdir ${WORKDIR}/k8s-repo
cd ${WORKDIR}/k8s-repo
- git リポジトリとして初期化し、リモートのリポジトリとして追加、master ブランチを pull します:
git init && git remote add origin \
https://source.developers.google.com/p/${TF_VAR_ops_project_name}/r/k8s-repo
- git のローカル設定を行います。
git config --local user.email ${MY_USER}
git config --local user.name "K8s repo user"
git config --local \
credential.'https://source.developers.google.com'.helper gcloud.sh
git pull origin master
Manifest kopieren, committen und pushen
- Kopieren Sie das Hipster Shop-Manifest in das Quell-Repository für alle Cluster.
cd ${WORKDIR}/asm
cp -r k8s_manifests/prod/app/* ../k8s-repo/${DEV1_GKE_1_CLUSTER}/app/.
cp -r k8s_manifests/prod/app/* ../k8s-repo/${DEV1_GKE_2_CLUSTER}/app/.
cp -r k8s_manifests/prod/app/* ../k8s-repo/${DEV2_GKE_1_CLUSTER}/app/.
cp -r k8s_manifests/prod/app/* ../k8s-repo/${DEV2_GKE_2_CLUSTER}/app/.
cp -r k8s_manifests/prod/app/* ../k8s-repo/${OPS_GKE_1_CLUSTER}/app/.
cp -r k8s_manifests/prod/app/* ../k8s-repo/${OPS_GKE_2_CLUSTER}/app/.
- Der Hipster-Shop wird im Anwendungscluster und nicht im Ops-Cluster bereitgestellt. ops-Cluster werden nur mit der ASM-/Istio-Steuerungsebene verwendet. Entfernen Sie die Deployment-, PodSecurityPolicy- und RBAC-Manifeste für den Hipster Shop-Cluster.
rm -rf ../k8s-repo/${OPS_GKE_1_CLUSTER}/app/deployments
rm -rf ../k8s-repo/${OPS_GKE_2_CLUSTER}/app/deployments
rm -rf ../k8s-repo/${OPS_GKE_1_CLUSTER}/app/podsecuritypolicies
rm -rf ../k8s-repo/${OPS_GKE_2_CLUSTER}/app/podsecuritypolicies
rm -rf ../k8s-repo/${OPS_GKE_1_CLUSTER}/app/rbac
rm -rf ../k8s-repo/${OPS_GKE_2_CLUSTER}/app/rbac
- Entfernen Sie die cartservice-Bereitstellung, RBAC und PodSecurityPolicy aus allen Clustern außer einem dev-Cluster. Hipster Shop wurde nicht für die Bereitstellung in mehreren Clustern entwickelt. Wenn alle vier Bereitstellungen weiterhin ausgeführt werden, kann es zu Inkonsistenzen bei den Warenkorbinformationen kommen, je nachdem, auf welche Bereitstellung zugegriffen wird.
rm ../k8s-repo/${DEV1_GKE_2_CLUSTER}/app/deployments/app-cart-service.yaml
rm ../k8s-repo/${DEV1_GKE_2_CLUSTER}/app/podsecuritypolicies/cart-psp.yaml
rm ../k8s-repo/${DEV1_GKE_2_CLUSTER}/app/rbac/cart-rbac.yaml
rm ../k8s-repo/${DEV2_GKE_1_CLUSTER}/app/deployments/app-cart-service.yaml
rm ../k8s-repo/${DEV2_GKE_1_CLUSTER}/app/podsecuritypolicies/cart-psp.yaml
rm ../k8s-repo/${DEV2_GKE_1_CLUSTER}/app/rbac/cart-rbac.yaml
rm ../k8s-repo/${DEV2_GKE_2_CLUSTER}/app/deployments/app-cart-service.yaml
rm ../k8s-repo/${DEV2_GKE_2_CLUSTER}/app/podsecuritypolicies/cart-psp.yaml
rm ../k8s-repo/${DEV2_GKE_2_CLUSTER}/app/rbac/cart-rbac.yaml
- Fügen Sie die cartservice-Bereitstellung, RBAC und PodSecurityPolicy nur dem ersten Dev-Cluster in kustomization.yaml hinzu.
cd ../k8s-repo/${DEV1_GKE_1_CLUSTER}/app
cd deployments && kustomize edit add resource app-cart-service.yaml
cd ../podsecuritypolicies && kustomize edit add resource cart-psp.yaml
cd ../rbac && kustomize edit add resource cart-rbac.yaml
cd ${WORKDIR}/asm
- Entfernen Sie die Verzeichnisse „PodSecurityPolicies“, „deployment“ und „RBAC“ aus „kustomization.yaml“ des ops-Clusters.
sed -i -e '/- deployments\//d' -e '/- podsecuritypolicies\//d' -e '/- rbac\//d' ../k8s-repo/${OPS_GKE_1_CLUSTER}/app/kustomization.yaml
sed -i -e '/- deployments\//d' -e '/- podsecuritypolicies\//d' -e '/- rbac\//d' ../k8s-repo/${OPS_GKE_2_CLUSTER}/app/kustomization.yaml
- Ersetzen Sie PROJECT_ID im RBAC-Manifest.
sed -i 's/${PROJECT_ID}/'${TF_VAR_dev1_project_name}'/g' ../k8s-repo/${DEV1_GKE_1_CLUSTER}/app/rbac/*
sed -i 's/${PROJECT_ID}/'${TF_VAR_dev1_project_name}'/g' ../k8s-repo/${DEV1_GKE_2_CLUSTER}/app/rbac/*
sed -i 's/${PROJECT_ID}/'${TF_VAR_dev2_project_name}'/g' ../k8s-repo/${DEV2_GKE_1_CLUSTER}/app/rbac/*
sed -i 's/${PROJECT_ID}/'${TF_VAR_dev2_project_name}'/g' ../k8s-repo/${DEV2_GKE_2_CLUSTER}/app/rbac/*
- Kopieren Sie die IngressGateway- und VirtualService-Manifeste in das Quell-Repository des Ops-Clusters.
cp -r k8s_manifests/prod/app-ingress/* ../k8s-repo/${OPS_GKE_1_CLUSTER}/app-ingress/
cp -r k8s_manifests/prod/app-ingress/* ../k8s-repo/${OPS_GKE_2_CLUSTER}/app-ingress/
- Kopieren Sie Config Connector-Ressourcen in einen der Cluster in jedem Projekt.
cp -r k8s_manifests/prod/app-cnrm/* ../k8s-repo/${OPS_GKE_1_CLUSTER}/app-cnrm/
cp -r k8s_manifests/prod/app-cnrm/* ../k8s-repo/${DEV1_GKE_1_CLUSTER}/app-cnrm/
cp -r k8s_manifests/prod/app-cnrm/* ../k8s-repo/${DEV2_GKE_1_CLUSTER}/app-cnrm/
- Ersetzen Sie PROJECT_ID im Config Connector-Manifest.
sed -i 's/${PROJECT_ID}/'${TF_VAR_ops_project_name}'/g' ../k8s-repo/${OPS_GKE_1_CLUSTER}/app-cnrm/*
sed -i 's/${PROJECT_ID}/'${TF_VAR_dev1_project_name}'/g' ../k8s-repo/${DEV1_GKE_1_CLUSTER}/app-cnrm/*
sed -i 's/${PROJECT_ID}/'${TF_VAR_dev2_project_name}'/g' ../k8s-repo/${DEV2_GKE_1_CLUSTER}/app-cnrm/*
loadgeneratorマニフェスト(Deployment、PodSecurityPolicy、RBAC)をopsクラスターにコピーします。 Die Hipster Shop-App wird über einen globalen Google Cloud Load Balancer (GCLB) bereitgestellt. GCLB empfängt Client-Traffic (anfrontendgerichtet) und leitet ihn an die nächstgelegene Instanz des Dienstes weiter. Wenn Sieloadgeneratorin beiden Ops-Clustern bereitstellen, wird der Traffic an beide Istio-Ingress-Gateways gesendet, die in den Ops-Clustern ausgeführt werden.負荷分散については、次のセクションで詳しく説明します。
cp -r k8s_manifests/prod/app-loadgenerator/. ../k8s-repo/gke-asm-1-r1-prod/app-loadgenerator/.
cp -r k8s_manifests/prod/app-loadgenerator/. ../k8s-repo/gke-asm-2-r2-prod/app-loadgenerator/.
- Ersetzen Sie die Ops-Projekt-ID im
loadgenerator-Manifest beider Ops-Cluster.
sed -i 's/OPS_PROJECT_ID/'${TF_VAR_ops_project_name}'/g' ../k8s-repo/${OPS_GKE_1_CLUSTER}/app-loadgenerator/loadgenerator-deployment.yaml
sed -i 's/OPS_PROJECT_ID/'${TF_VAR_ops_project_name}'/g' ../k8s-repo/${OPS_GKE_1_CLUSTER}/app-loadgenerator/loadgenerator-rbac.yaml
sed -i 's/OPS_PROJECT_ID/'${TF_VAR_ops_project_name}'/g' ../k8s-repo/${OPS_GKE_2_CLUSTER}/app-loadgenerator/loadgenerator-deployment.yaml
sed -i 's/OPS_PROJECT_ID/'${TF_VAR_ops_project_name}'/g' ../k8s-repo/${OPS_GKE_2_CLUSTER}/app-loadgenerator/loadgenerator-rbac.yaml
- Fügen Sie der Datei „kustomization.yaml“ die
loadgenerator-Ressourcen beider Ops-Cluster hinzu.
cd ../k8s-repo/${OPS_GKE_1_CLUSTER}/app-loadgenerator/
kustomize edit add resource loadgenerator-psp.yaml
kustomize edit add resource loadgenerator-rbac.yaml
kustomize edit add resource loadgenerator-deployment.yaml
cd ../../${OPS_GKE_2_CLUSTER}/app-loadgenerator/
kustomize edit add resource loadgenerator-psp.yaml
kustomize edit add resource loadgenerator-rbac.yaml
kustomize edit add resource loadgenerator-deployment.yaml
k8s-repoにコミットします。
cd ${WORKDIR}/k8s-repo
git add . && git commit -am "create app namespaces and install hipster shop"
git push --set-upstream origin master
- Warten Sie, bis der Roll-out abgeschlossen ist.
../asm/scripts/stream_logs.sh $TF_VAR_ops_project_name
アプリケーションの展開を確認する
- Prüfen Sie, ob alle Pods im Namespace der Anwendung (mit Ausnahme des Warenkorbs) in allen Entwicklerclustern den Status „Running“ (Wird ausgeführt) haben.
for ns in ad checkout currency email frontend payment product-catalog recommendation shipping; do
kubectl --context ${DEV1_GKE_1} get pods -n ${ns};
kubectl --context ${DEV1_GKE_2} get pods -n ${ns};
kubectl --context ${DEV2_GKE_1} get pods -n ${ns};
kubectl --context ${DEV2_GKE_2} get pods -n ${ns};
done;
出力結果(コピーしないでください)
NAME READY STATUS RESTARTS AGE currencyservice-5c5b8876db-pvc6s 2/2 Running 0 13m NAME READY STATUS RESTARTS AGE currencyservice-5c5b8876db-xlkl9 2/2 Running 0 13m NAME READY STATUS RESTARTS AGE currencyservice-5c5b8876db-zdjkg 2/2 Running 0 115s NAME READY STATUS RESTARTS AGE currencyservice-5c5b8876db-l748q 2/2 Running 0 82s NAME READY STATUS RESTARTS AGE emailservice-588467b8c8-gk92n 2/2 Running 0 13m NAME READY STATUS RESTARTS AGE emailservice-588467b8c8-rvzk9 2/2 Running 0 13m NAME READY STATUS RESTARTS AGE emailservice-588467b8c8-mt925 2/2 Running 0 117s NAME READY STATUS RESTARTS AGE emailservice-588467b8c8-klqn7 2/2 Running 0 84s NAME READY STATUS RESTARTS AGE frontend-64b94cf46f-kkq7d 2/2 Running 0 13m NAME READY STATUS RESTARTS AGE frontend-64b94cf46f-lwskf 2/2 Running 0 13m NAME READY STATUS RESTARTS AGE frontend-64b94cf46f-zz7xs 2/2 Running 0 118s NAME READY STATUS RESTARTS AGE frontend-64b94cf46f-2vtw5 2/2 Running 0 85s NAME READY STATUS RESTARTS AGE paymentservice-777f6c74f8-df8ml 2/2 Running 0 13m NAME READY STATUS RESTARTS AGE paymentservice-777f6c74f8-bdcvg 2/2 Running 0 13m NAME READY STATUS RESTARTS AGE paymentservice-777f6c74f8-jqf28 2/2 Running 0 117s NAME READY STATUS RESTARTS AGE paymentservice-777f6c74f8-95x2m 2/2 Running 0 86s NAME READY STATUS RESTARTS AGE productcatalogservice-786dc84f84-q5g9p 2/2 Running 0 13m NAME READY STATUS RESTARTS AGE productcatalogservice-786dc84f84-n6lp8 2/2 Running 0 13m NAME READY STATUS RESTARTS AGE productcatalogservice-786dc84f84-gf9xl 2/2 Running 0 119s NAME READY STATUS RESTARTS AGE productcatalogservice-786dc84f84-v7cbr 2/2 Running 0 86s NAME READY STATUS RESTARTS AGE recommendationservice-5fdf959f6b-2ltrk 2/2 Running 0 13m NAME READY STATUS RESTARTS AGE recommendationservice-5fdf959f6b-dqd55 2/2 Running 0 13m NAME READY STATUS RESTARTS AGE recommendationservice-5fdf959f6b-jghcl 2/2 Running 0 119s NAME READY STATUS RESTARTS AGE recommendationservice-5fdf959f6b-kkspz 2/2 Running 0 87s NAME READY STATUS RESTARTS AGE shippingservice-7bd5f569d-qqd9n 2/2 Running 0 13m NAME READY STATUS RESTARTS AGE shippingservice-7bd5f569d-xczg5 2/2 Running 0 13m NAME READY STATUS RESTARTS AGE shippingservice-7bd5f569d-wfgfr 2/2 Running 0 2m NAME READY STATUS RESTARTS AGE shippingservice-7bd5f569d-r6t8v 2/2 Running 0 88s
- Prüfen Sie, ob der Pod im Namespace „cart“ nur im ersten Entwicklercluster ausgeführt wird.
kubectl --context ${DEV1_GKE_1} get pods -n cart;
出力結果(コピーしないでください)
NAME READY STATUS RESTARTS AGE cartservice-659c9749b4-vqnrd 2/2 Running 0 17m
Zugriff auf die Hipster Shop-App
グローバル負荷分散
Die Hipster Shop-App wurde jetzt in allen vier App-Clustern bereitgestellt.Diese Cluster befinden sich in zwei Regionen und vier Zonen.クライアントは、frontendサービスにアクセスしてHipsterショップアプリにアクセスできます。frontend-Dienste werden in allen vier App-Clustern ausgeführt. Mit Google Cloud Load Balancer (GCLB) wird Client-Traffic an alle vier Instanzen des frontend-Dienstes weitergeleitet.
Istio Ingress-Gateways werden nur im Ops-Cluster ausgeführt und fungieren als regionaler Load Balancer für die beiden zonenbasierten Anwendungscluster in der Region.GCLB verwendet zwei Istio-Ingress-Gateways (die in zwei Ops-Clustern ausgeführt werden) als Backends für den globalen Frontend-Dienst. Das Istio-Ingress-Gateway empfängt Client-Traffic von GCLB und leitet ihn an die Frontend-Pods weiter, die im Anwendungscluster ausgeführt werden.
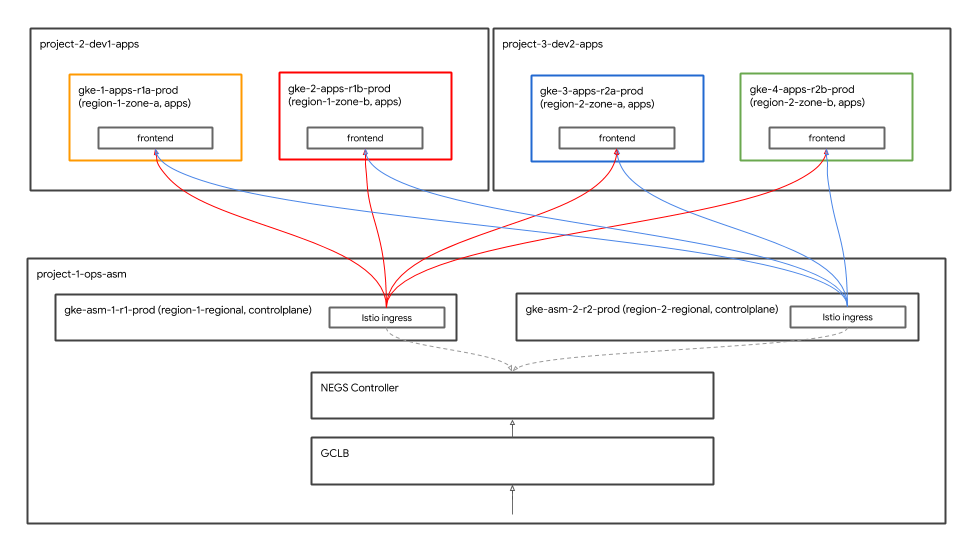
Außerdem können Sie Istio Ingress-Gateways direkt im Anwendungscluster bereitstellen und GCLB kann sie als Back-Ends verwenden.
GKE Autoneg-Controller
Istio IngressゲートウェイKubernetes Serviceは、 ネットワークエンドポイントグループ(NEG)を使用して、GCLBのバックエンドとして自身を登録します。 Mit NEG können Sie containerbasierten Lastenausgleich mit GCLB nutzen. NEGはKubernetes-Diensten mit einer speziellen Annotation erstellt, sodass sich der NEG-Controller selbst registrieren kann. Der Autoneg-Controller ist ein spezieller GKE-Controller, der die Erstellung von NEG automatisiert und sie mithilfe von Service-Annotationen als Backends für GCLBs zuweist. Die Istio-Steuerungsebene, einschließlich des Istio-Ingress-Gateways, wird in der anfänglichen Infrastruktur von Terraform Cloud Build bereitgestellt. Die Konfiguration von GCLB und Autoneg erfolgt als Teil des ersten Cloud Build-Vorgangs der Terraform-Infrastruktur.
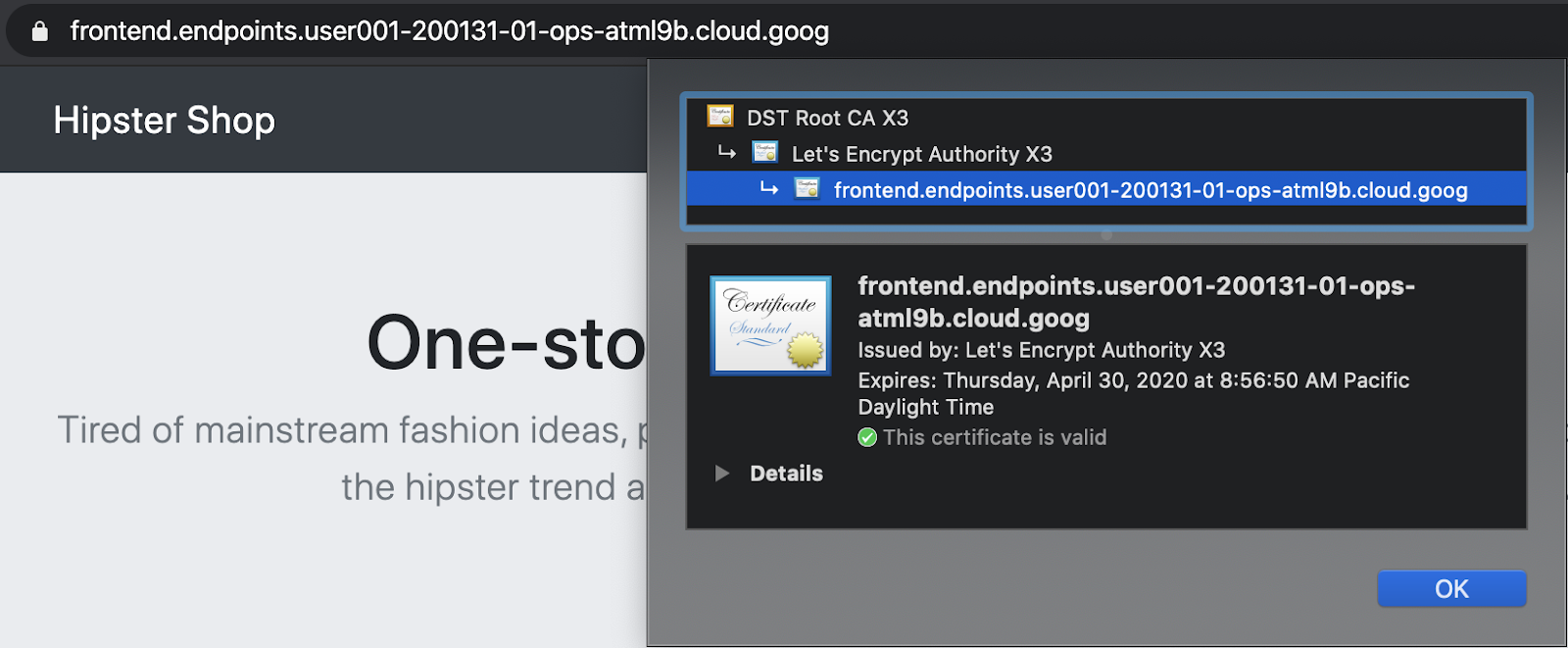
Cloud Endpointsとマネージド証明書を使ったセキュアなIngress
GCPマネージド証明書は、frontend GCLBサービスへのクライアントトラフィックを保護するために使用されます。 GCLBは、グローバルfrontendサービスにマネージド証明書を使用し、SSLはGCLBで終端されます。In diesem Workshop verwenden wir Cloud Endpoints als Domain für verwaltete Zertifikate.Alternativ können Sie ein von GCP verwaltetes Zertifikat mit der Domain und dem DNS-Namen von frontend erstellen.
- Hipsterショップにアクセスするために、下記のコマンドで出力されるリンクをクリックします。
echo "https://frontend.endpoints.${TF_VAR_ops_project_name}.cloud.goog"
- Sie können prüfen, ob das Zertifikat gültig ist, indem Sie in der URL-Leiste des Chrome-Tabs auf das Schloss-Symbol klicken.
Globale Lastverteilung prüfen
Im Rahmen der Anwendungsbereitstellung wurde die Funktion zur Generierung von Last auf beiden Ops-Clustern bereitgestellt, um Testtraffic an die Cloud Endpoints-Links von GCLB Hipster Shop zu senden. Prüfen Sie, ob GCLB Traffic empfängt und an beide Istio Ingress-Gateways sendet.
- Rufen Sie den Link GCLB > Monitoring des Ops-Projekts ab, in dem der Hipster Shop-GCLB erstellt wurde.
echo "https://console.cloud.google.com/net-services/loadbalancing/details/http/istio-ingressgateway?project=${TF_VAR_ops_project_name}&cloudshell=false&tab=monitoring&duration=PT1H"
- Ändern Sie im Backend-Dropdown-Menü All backends in istio-ingressgateway, wie unten dargestellt:
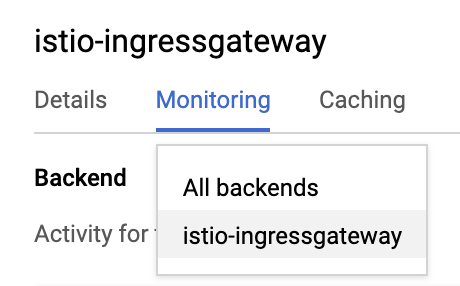
- Sehen Sie sich den Traffic für beide
istio-ingressgatewaysan.

istio-ingressgatewayごとに3つのNEGが作成されます。 Da es sich bei ops-Clustern um regionale Cluster handelt, wird für jede Zone in der Region ein NEG erstellt.istio-ingressgatewayPods werden jedoch in einer einzelnen Zone pro Region ausgeführt. Hier sehen Sie den Traffic, der an den istio-ingressgatewayPod gesendet wird.
Die Funktion zum Generieren von Last wird in beiden Ops-Clustern ausgeführt, um Client-Traffic aus zwei Regionen zu simulieren.opsクラスターリージョン1で生成された負荷は、リージョン2のistio-ingressgatewayに送信されます。Ebenso wird die in der ops-Clusterregion 2 generierte Last an istio-ingressgateway in Region 1 gesendet.
7. Stackdriverによる可観測性
目標: IstioのテレメトリデータをStackdriverに連携し、確認する
istio-telemetryリソースをインストール- Istio Servicesのダッシュボードを作成/更新
- Containerlogs ansehen
- Stackdriverで分散トレーシング情報を表示
Eine der wichtigsten Funktionen von Istio ist die integrierte Observability („o11y“).Das bedeutet, dass der Betreiber den Traffic, der in diese Container ein- und ausgeht, beobachten und den Kunden Dienste anbieten kann, auch wenn es sich um Blackbox-Container ohne Funktionen handelt.Diese Beobachtung kann in Form von Metriken, Protokollen und Traces erfolgen.
Außerdem wird die in den Hipster-Shop integrierte Funktion zur Generierung von Last verwendet.Da die Beobachtbarkeit in statischen Systemen ohne Traffic nicht gut funktioniert, ist die Erzeugung von Last hilfreich, um die Funktionsweise zu überprüfen.負荷生成はすでに実行されているので、簡単に確認可能です。
- istioをstackdriverの構成ファイルにインストールします。
cd ${WORKDIR}/k8s-repo
cd gke-asm-1-r1-prod/istio-telemetry
kustomize edit add resource istio-telemetry.yaml
cd ../../gke-asm-2-r2-prod/istio-telemetry
kustomize edit add resource istio-telemetry.yaml
- k8s-repoにコミットします。
cd ../../
git add . && git commit -am "Install istio to stackdriver configuration"
git push
- Warten Sie, bis der Roll-out abgeschlossen ist.
../asm/scripts/stream_logs.sh $TF_VAR_ops_project_name
- Istio→Stackdriverの連携を確認します。Stackdriver Handler CRDを取得します。
kubectl --context ${OPS_GKE_1} get handler -n istio-system
In der Ausgabe sollte ein Handler mit dem Namen „stackdriver“ angezeigt werden:
NAME AGE kubernetesenv 12d prometheus 12d stackdriver 69s
IstioのメトリックスがStackdriverにエクスポートされていることを確認します。Klicken Sie auf den Link, der durch diesen Befehl ausgegeben wird.:
echo "https://console.cloud.google.com/monitoring/metrics-explorer?cloudshell=false&project=${TF_VAR_ops_project_name}"
Sie werden aufgefordert, einen neuen Arbeitsbereich zu erstellen, der nach dem Ops-Projekt benannt ist. Wählen Sie dazu „OK“ aus.Wenn Sie aufgefordert werden, die neue Benutzeroberfläche zu verwenden, schließen Sie das Dialogfeld.
Klicken Sie im Messwert-Explorer auf „Datensatztyp“ und geben Sie „istio“ ein.Für den Ressourcentyp „Kubernetes Pod“ sind Optionen wie „Server Request Count“ (Anzahl der Serveranfragen) verfügbar.これは、メトリックがメッシュからStackdriverに流れていることを示しています。
(以下の行を表示する場合は、destination_service_nameでグループ化する必要があります。)
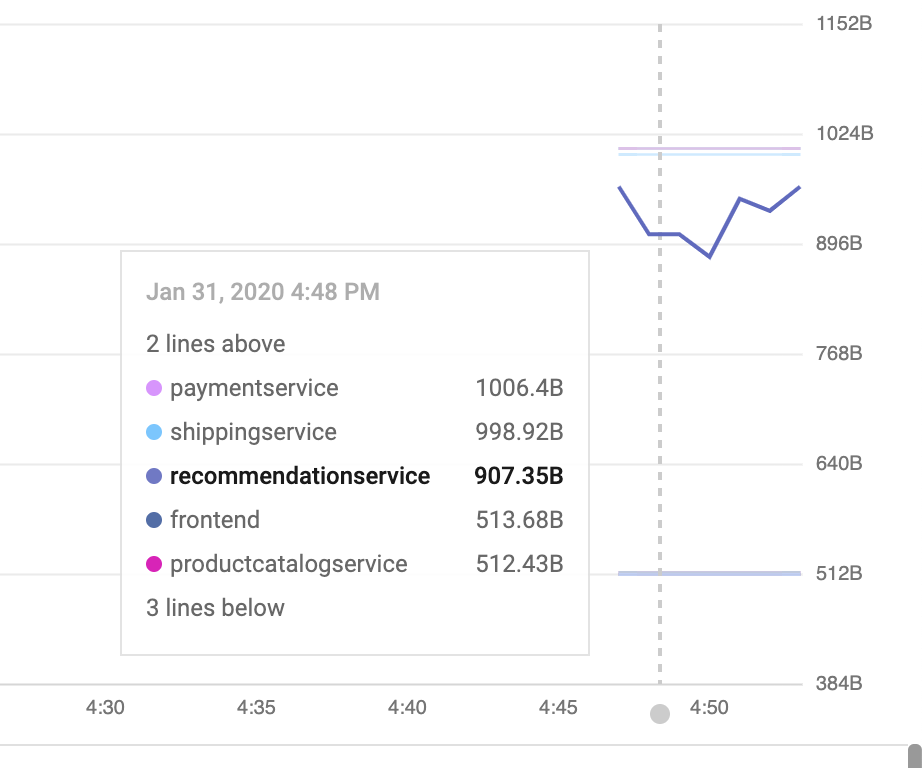
Messwerte im Dashboard visualisieren:
メトリックがStackdriver APMシステムにあるので、それらを視覚化する方法が必要です。In diesem Abschnitt installieren Sie ein vordefiniertes Dashboard, auf dem drei der vier Golden Signals für Messwerte zu sehen sind.Traffic (Anzahl der Anfragen pro Sekunde), Latenz (in diesem Fall das 99. und 50. Perzentil) und Fehler (in diesem Beispiel wird Sättigung ausgeschlossen).
Der Envoy-Proxy von Istio bietet einige Messwerte, die sich gut für den Einstieg eignen. Eine vollständige Liste finden Sie hier.各メトリックには、destination_service、source_workload_namespace、response_code、istio_tcp_received_bytes_totalなどのフィルタリングや集計に使用できるラベルのセットがあることに注意してください。
- Als Nächstes fügen wir ein vordefiniertes Dashboard mit Messwerten hinzu. Dashboard APIを直接使用します。Dies ist normalerweise nicht erforderlich, wenn Sie API-Aufrufe manuell generieren.なんらかの自動化システムの一部であるか、Web UIでダッシュボードを手動で作成します。So können Sie sofort loslegen.:
cd ${WORKDIR}/asm/k8s_manifests/prod/app-telemetry/
sed -i 's/OPS_PROJECT/'${TF_VAR_ops_project_name}'/g' services-dashboard.json
OAUTH_TOKEN=$(gcloud auth application-default print-access-token)
curl -X POST -H "Authorization: Bearer $OAUTH_TOKEN" -H "Content-Type: application/json" \
https://monitoring.googleapis.com/v1/projects/${TF_VAR_ops_project_name}/dashboards \
-d @services-dashboard.json
- 以下の ausgegebenen Links aufrufen, um die neu hinzugefügten Dashboards aufzurufen.
echo "https://console.cloud.google.com/monitoring/dashboards/custom/servicesdash?cloudshell=false&project=${TF_VAR_ops_project_name}"
Sie können das Dashboard auch über die Benutzeroberfläche bearbeiten. In diesem Fall fügen wir jedoch schnell neue Diagramme über die API hinzu.Dazu müssen Sie die aktuelle Version des Dashboards abrufen, die Änderungen anwenden und dann die HTTP PATCH-Methode verwenden, um die Änderungen zu übertragen.
- Mit der Monitoring API können Sie vorhandene Dashboards abrufen.Ruft ein gerade hinzugefügtes Dashboard ab.:
curl -X GET -H "Authorization: Bearer $OAUTH_TOKEN" -H "Content-Type: application/json" \
https://monitoring.googleapis.com/v1/projects/${TF_VAR_ops_project_name}/dashboards/servicesdash > sd-services-dashboard.json
- Neues Diagramm hinzufügen (50th%ile latency): [API-Referenz] Damit können Sie dem Dashboard jetzt ein neues Diagramm-Widget per Code hinzufügen.Diese Änderung wird von einem Peer überprüft und in das Versionsverwaltungssystem eingecheckt.Das zusätzliche Widget weist eine Latenz von 50 % (Median) auf.
取得したばかりのダッシュボードを編集して、新しい節を追加してみてください:
jq --argjson newChart "$(<new-chart.json)" '.gridLayout.widgets += [$newChart]' sd-services-dashboard.json > patched-services-dashboard.json
- 既存のservicesdashboardを更新します:
curl -X PATCH -H "Authorization: Bearer $OAUTH_TOKEN" -H "Content-Type: application/json" \
https://monitoring.googleapis.com/v1/projects/${TF_VAR_ops_project_name}/dashboards/servicesdash \
-d @patched-services-dashboard.json
- Rufen Sie den folgenden Link auf, um das aktualisierte Dashboard aufzurufen:
echo "https://console.cloud.google.com/monitoring/dashboards/custom/servicesdash?cloudshell=false&project=${TF_VAR_ops_project_name}"
- 簡単なログ分析を行います。
Istio bietet eine Reihe von strukturierten Logs für den gesamten In-Mesh-Netzwerktraffic, die in Stackdriver Logging hochgeladen werden können, um die clusterübergreifende Analyse in einem leistungsstarken Tool zu ermöglichen.Den Logs werden Metadaten auf Dienstebene wie Cluster, Container, App und connection_id hinzugefügt.
Beispiel für einen Logeintrag (in diesem Fall das Envoy-Proxy-Accesslog)::
logName: "projects/PROJECTNAME-11932-01-ops/logs/server-tcp-accesslog-stackdriver.instance.istio-system"
labels: {
connection_id: "fbb46826-96fd-476c-ac98-68a9bd6e585d-1517191"
destination_app: "redis-cart"
destination_ip: "10.16.1.7"
destination_name: "redis-cart-6448dcbdcc-cj52v"
destination_namespace: "cart"
destination_owner: "kubernetes://apis/apps/v1/namespaces/cart/deployments/redis-cart"
destination_workload: "redis-cart"
source_ip: "10.16.2.8"
total_received_bytes: "539"
total_sent_bytes: "569"
...
}
Hier werden die Logs angezeigt.:
echo "https://console.cloud.google.com/logs/viewer?cloudshell=false&project=${TF_VAR_ops_project_name}"
So rufen Sie die Istio-Kontrollebenenlogs auf: Wählen Sie „Ressourcen“ > „Kubernetes-Container“ aus und suchen Sie nach „Pilot“.
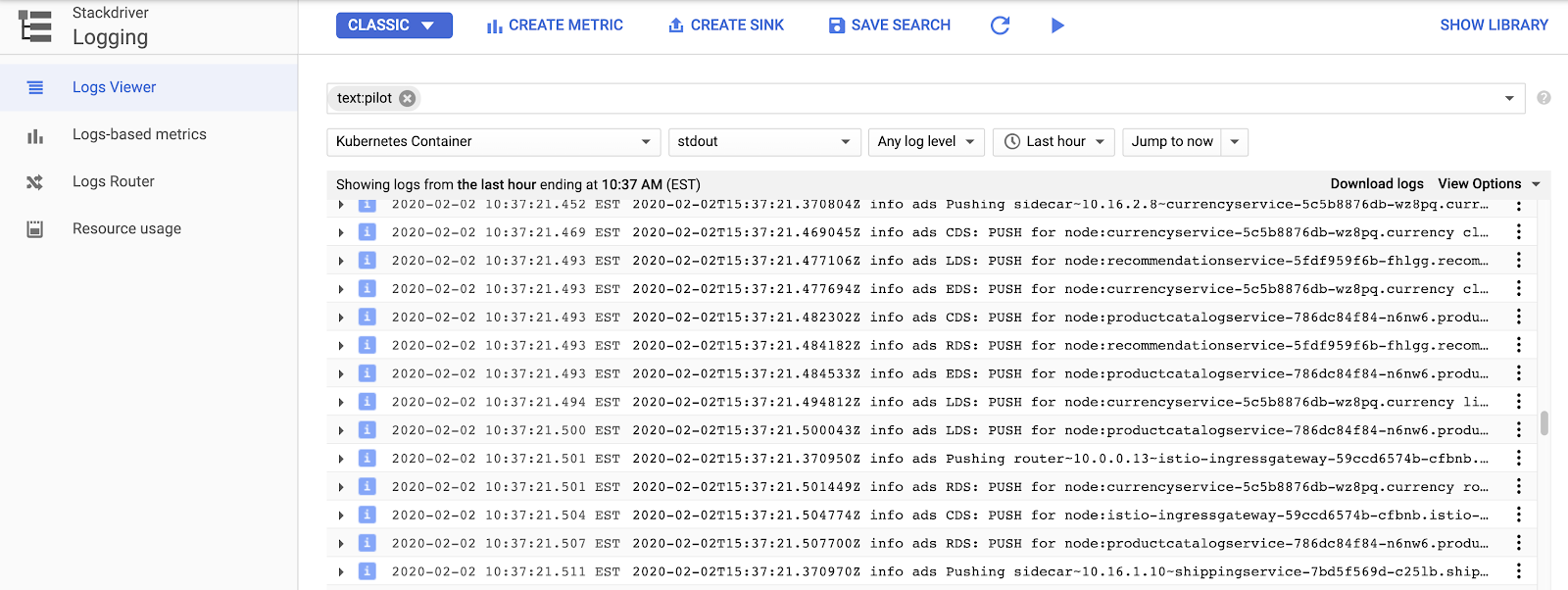
Hier sehen Sie den Istio-Kontrollbereich, der die Proxyeinstellungen für die einzelnen Beispiel-App-Dienste überträgt. „CDS“, „LDS“ und „RDS“ stehen für verschiedene Envoy-APIs (weitere Informationen).
Über Istio-Logs hinaus können Sie Containerlogs sowie Infrastruktur- oder andere GCP-Servicelogs über dieselbe Schnittstelle aufrufen. Hier sind einige Beispiel-Logabfragen für GKE:Im Log Viewer können Sie auch Messwerte aus Logs erstellen, z. B. „Alle Fehler zählen, die mit einem String übereinstimmen“.Sie können im Dashboard oder als Teil von Benachrichtigungen verwendet werden.Die Logs können auch in andere Analysetools wie BigQuery gestreamt werden.
Hier sind einige Beispielfilter für Hipster-Shops:
resource.type="k8s_container" labels.destination_app="productcatalogservice"
resource.type="k8s_container" resource.labels.namespace_name="cart"
- 分散トレーシングを確認します。
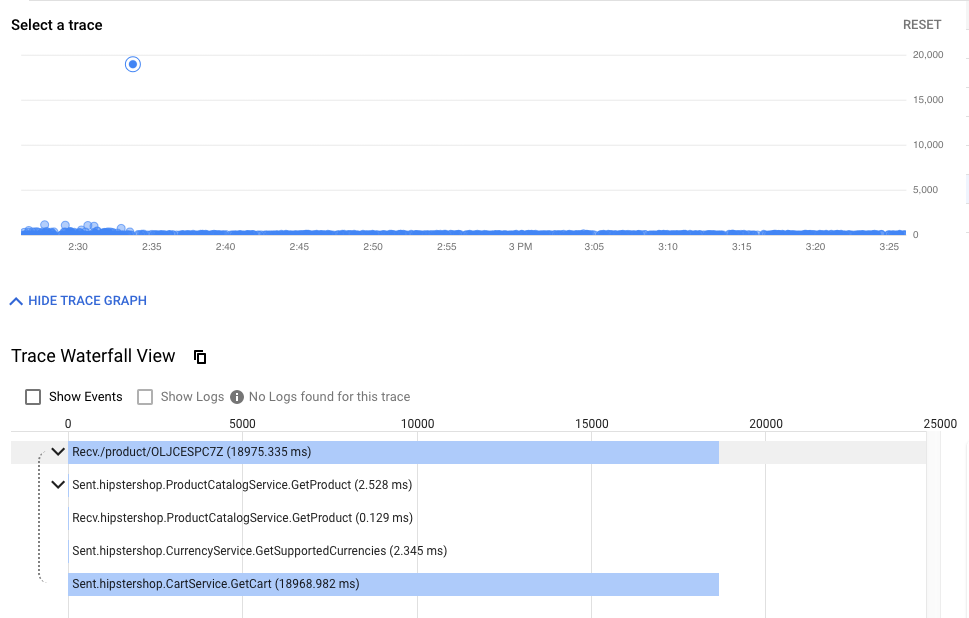
Da wir ein verteiltes System verwenden, ist für das Debugging ein neues Tool erforderlich: verteilte Traces.Mit diesem Tool können Sie Statistiken zur Interaktion von Diensten aufrufen, z. B. die Erkennung ungewöhnlich langsamer Ereignisse im folgenden Diagramm, oder sich rohe Beispiel-Traces ansehen, um herauszufinden, was tatsächlich passiert.
In der Zeitachse werden alle Anfragen in chronologischer Reihenfolge angezeigt, bis der Endnutzer eine Antwort erhält.Die Wartezeit oder die Zeit vom ersten bis zum ersten Hipster-Stack-Request wird grafisch dargestellt.Je höher die Punktzahl, desto langsamer ist die Nutzererfahrung (und desto unzufriedener sind die Nutzer).)。
Wenn Sie auf einen Punkt klicken, wird eine detaillierte Wasserfallansicht für die entsprechende Anfrage angezeigt.Diese Funktion, mit der Sie die rohen Details für bestimmte Anfragen finden können (nicht nur die aggregierten Statistiken), ist unerlässlich, um die Interaktionen zwischen Diensten zu verstehen, insbesondere um seltene, aber schlechte Interaktionen zwischen Diensten zu finden.
Die Wasserfallansicht ist jedem bekannt, der schon einmal den Debugger verwendet hat. In diesem Fall wird jedoch nicht die Zeit angezeigt, die für die verschiedenen Prozesse einer einzelnen Anwendung aufgewendet wurde, sondern die Zeit, die für die Überquerung des Mesh zwischen Diensten und die Ausführung in separaten Containern aufgewendet wurde.
Hier finden Sie die Traces.:
echo "https://console.cloud.google.com/traces/overview?cloudshell=false&project=${TF_VAR_ops_project_name}"
Beispiel für einen Screenshot eines Tools:
- Veröffentlichen Sie die beobachtbaren Tools im Cluster.
Prometheus und Grafana sind Open-Source-Tools für die Beobachtbarkeit, die als Teil der Istio-Steuerungsebene für den Ops-Cluster bereitgestellt werden.Diese werden in Ops-Clustern ausgeführt und können verwendet werden, um den Status des Mesh oder des Hipster-Shops selbst weiter zu untersuchen.
Um diese Tools aufzurufen, führen Sie einfach den folgenden Befehl in Cloud Shell aus (Prometheus wird übersprungen, da es nicht viel zu sehen gibt):
kubectl --context ${OPS_GKE_1} -n istio-system port-forward svc/grafana 3000:3000 >> /dev/null &
Öffnen Sie als Nächstes den veröffentlichten Dienst (3000) auf dem Cloud Shell-Webvorschau-Tab.
- https://ssh.cloud.google.com/devshell/proxy?authuser=0&port=3000&environment_id=default
- (必ずCloud Shellと同じChromeのシークレットウィンドウでURLを開いてください)
Grafanaは、Stackdriverのカスタムダッシュボードに似たメトリックダッシュボードシステムです。 Für die Installation von Istio sind mehrere integrierte Dashboards enthalten, mit denen Sie die Messwerte der in einem bestimmten Istio-Mesh ausgeführten Dienste und Arbeitslasten sowie den Zustand der Istio-Steuerungsebene selbst ansehen können.
8. 相互TLS認証
Ziel: Sichere Verbindungen zwischen Microservices einrichten(Authentifizierung)
- mTLS für das gesamte Mesh aktivieren
- 調査ログを使いmTLSを確認
Nachdem die App installiert wurde und die Beobachtbarkeit gewährleistet ist, müssen Sie die Verbindung zwischen den Diensten schützen und dafür sorgen, dass sie weiterhin funktioniert.
Beispielsweise können Sie im Kiali-Dashboard sehen, ob ein Dienst kein mTLS verwendet (kein Schloss-Symbol).しかし、トラフィックは流れており、システムは正常に動作しています。 Das Stackdriver-Dashboard für Gold-Messwerte gibt Ihnen die Gewissheit, dass Ihr System insgesamt funktioniert.
- opsクラスターのMeshPolicyを確認します。Hinweis: mTLS ist dauerhaft und lässt sowohl verschlüsselten als auch nicht verschlüsselten Traffic zu.
kubectl --context ${OPS_GKE_1} get MeshPolicy -o yaml
kubectl --context ${OPS_GKE_2} get MeshPolicy -o yaml
`出力結果(コピーしないでください)`
spec:
peers:
- mtls:
mode: PERMISSIVE
- mTLSをオンにします。 Der Istio Operator-Controller wird ausgeführt und Sie können die Istio-Konfiguration ändern, indem Sie die IstioControlPlane-Ressource bearbeiten oder ersetzen.コントローラーは変更を検出し、それに応じてIstioインストール状態を更新することで対応します。Aktivieren Sie mTLS in beiden IstioControlPlane-Ressourcen, sowohl im freigegebenen als auch im replizierten Kontrollbereich.Dadurch wird MeshPolicy auf ISTIO_MUTUAL festgelegt und die Standard-DestinationRule wird erstellt.
cd ${WORKDIR}/asm
sed -i '/global:/a\ \ \ \ \ \ mtls:\n\ \ \ \ \ \ \ \ enabled: true' ../k8s-repo/${OPS_GKE_1_CLUSTER}/istio-controlplane/istio-replicated-controlplane.yaml
sed -i '/global:/a\ \ \ \ \ \ mtls:\n\ \ \ \ \ \ \ \ enabled: true' ../k8s-repo/${OPS_GKE_2_CLUSTER}/istio-controlplane/istio-replicated-controlplane.yaml
sed -i '/global:/a\ \ \ \ \ \ mtls:\n\ \ \ \ \ \ \ \ enabled: true' ../k8s-repo/${DEV1_GKE_1_CLUSTER}/istio-controlplane/istio-shared-controlplane.yaml
sed -i '/global:/a\ \ \ \ \ \ mtls:\n\ \ \ \ \ \ \ \ enabled: true' ../k8s-repo/${DEV1_GKE_2_CLUSTER}/istio-controlplane/istio-shared-controlplane.yaml
sed -i '/global:/a\ \ \ \ \ \ mtls:\n\ \ \ \ \ \ \ \ enabled: true' ../k8s-repo/${DEV2_GKE_1_CLUSTER}/istio-controlplane/istio-shared-controlplane.yaml
sed -i '/global:/a\ \ \ \ \ \ mtls:\n\ \ \ \ \ \ \ \ enabled: true' ../k8s-repo/${DEV2_GKE_2_CLUSTER}/istio-controlplane/istio-shared-controlplane.yaml
- k8s-repo にコミットします。
cd ${WORKDIR}/k8s-repo
git add . && git commit -am "turn mTLS on"
git push
- Warten Sie, bis der Roll-out abgeschlossen ist.
${WORKDIR}/asm/scripts/stream_logs.sh $TF_VAR_ops_project_name
mTLSの動作確認
- opsクラスターでMeshPolicyをもう一度確認します。注. Nicht verschlüsselter Traffic ist nicht zulässig. Es ist nur mTLS-Traffic zulässig.
kubectl --context ${OPS_GKE_1} get MeshPolicy -o json | jq .items[].spec
kubectl --context ${OPS_GKE_2} get MeshPolicy -o json | jq .items[].spec
Ausgabe (nicht kopieren):
{
"peers": [
{
"mtls": {}
}
]
}
- Istioオペレーターコントローラーによって作成されたDestinationRuleを確認します。
kubectl --context ${OPS_GKE_1} get DestinationRule default -n istio-system -o yaml
kubectl --context ${OPS_GKE_2} get DestinationRule default -n istio-system -o yaml
Ausgabe (nicht kopieren):
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: default
namespace: istio-system
spec:
host: '*.local'
trafficPolicy:
tls:
mode: ISTIO_MUTUAL
Außerdem können Sie in den Logs nachsehen, ob die Migration von HTTP zu HTTPS erfolgt ist. Wenn Sie dieses bestimmte Feld in den UI-Logs veröffentlichen möchten, klicken Sie auf einen Logeintrag und dann auf den Wert des Felds, das Sie anzeigen möchten.Klicken Sie in diesem Fall neben „Protokoll“ auf „http“.:
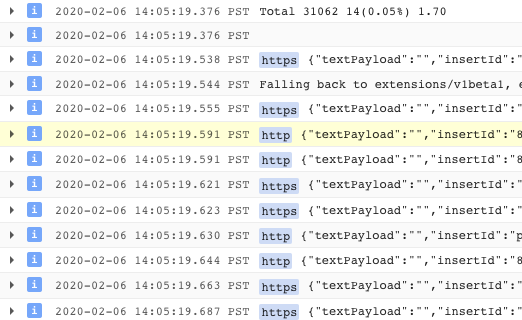
So lässt sich gut prüfen, ob mTLS aktiviert ist.:
Außerdem können Sie Logeinträge in Messwerte umwandeln und Zeitreihendiagramme anzeigen lassen.:
TODO(smcghee)
9. Canary-Deployment
Ziel: Neue Version des Frontend-Dienstes einführen
Frontend-v2(次のプロダクションバージョン)サービスを1リージョンにロールアウトDestinationRulesとVirtualServicesを使い徐々にトラフィックをfrontend-v2に転送- Mehrere Commits in
k8s-repoausführen und die GitOps-Bereitstellungspipeline prüfen
カナリアデプロイメントは、新しいサービスの段階的なロールアウト手法です。Beim Canary-Deployment wird der Traffic zur neuen Version erhöht, während der Rest des Traffics an die aktuelle Version gesendet wird.Ein gängiges Muster besteht darin, in jeder Phase der Traffic-Aufteilung eine Canary-Analyse durchzuführen und die neuen Versionen der „Golden Signals“ (Latenz, Fehlerrate, Sättigung) mit der Baseline zu vergleichen.So können Sie Dienstunterbrechungen vermeiden und die Stabilität des neuen Dienstes „v2“ in allen Phasen der Traffic-Aufteilung sicherstellen.
In diesem Abschnitt erfahren Sie, wie Sie mit Cloud Build und Istio-Traffic-Richtlinien ein einfaches Canary-Deployment für eine neue Version des frontend-Dienstes erstellen.
Zuerst führen Sie die Canary-Pipeline in der **DEV1-Region (us-west1)**aus und stellen die Frontend-Version 2 in beiden Clustern in dieser Region bereit.次に、**DEV2リージョン(us-central)**でカナリアパイプラインを実行し、そのリージョンの両方のクラスターにv2を展開します。Die Ausführung der Pipelines nacheinander für jede Region anstatt parallel für alle Regionen kann dazu beitragen, globale Ausfälle zu vermeiden, die durch eine falsche Konfiguration oder Fehler in der V2-App selbst verursacht werden.
Hinweis: Die Canary-Pipeline wird in beiden Regionen manuell ausgelöst. In der Produktionsumgebung wird sie jedoch automatisch ausgelöst, z. B. basierend auf einem neuen Docker-Image-Tag, das in die Registry gepusht wird.
- Wechseln Sie in Cloud Shell in das Canary-Verzeichnis.:
CANARY_DIR="${WORKDIR}/asm/k8s_manifests/prod/app-canary/"
K8S_REPO="${WORKDIR}/k8s-repo"
- Führen Sie das Skript „repo_setup.sh“ aus, um das Baseline-Manifest in das K8s-Repository zu kopieren.
cd $CANARY_DIR
./repo-setup.sh
Die folgenden Manifeste werden kopiert::
- frontend-v2-Deployment
- frontend-v1-Patch (Container-Images mit dem Label „v1“ und dem Endpunkt „/version“ einschließen)
- respy: Ein kleiner Pod, mit dem die Verteilung von HTTP-Antworten exportiert und Canary-Bereitstellungen in Echtzeit visualisiert werden können.
- frontend Istio DestinationRule: Der Frontend-Kubernetes-Dienst wird basierend auf dem Bereitstellungslabel „version“ in zwei Teilmengen unterteilt: v1 und v2.
- frontend Istio VirtualService: Leitet 100 % des Traffics an frontend v1 weiter.Dadurch wird das standardmäßige Round-Robin-Verhalten von Kubernetes-Diensten überschrieben und 50 % des gesamten Dev1-Region-Traffics werden sofort an „frontend v2“ gesendet.
- 変更内容をk8s_repoにコミットします。:
cd $K8S_REPO
git add . && git commit -am "frontend canary setup"
git push
cd $CANARY_DIR
- Rufen Sie in der Konsole für das Ops1-Projekt Cloud Build auf. Warten Sie, bis die Cloud Build-Pipeline abgeschlossen ist, und rufen Sie dann die Pods im Frontend-Namespace beider DEV1-Cluster ab.以下が表示されるはずです。:
watch -n 1 kubectl --context ${DEV1_GKE_1} get pods -n frontend
出力結果(コピーしないでください)
NAME READY STATUS RESTARTS AGE frontend-578b5c5db6-h9567 2/2 Running 0 59m frontend-v2-54b74fc75b-fbxhc 2/2 Running 0 2m26s respy-5f4664b5f6-ff22r 2/2 Running 0 2m26s
- 別のCloud Shellセッションを開きます。 DEV1_GKE_1で実行されている新しいRespy Podに入ります。
RESPY_POD=$(kubectl --context ${DEV1_GKE_1} get pod -n frontend | grep respy | awk '{ print $1 }')
kubectl --context ${DEV1_GKE_1} exec -n frontend -it $RESPY_POD -c respy /bin/sh
- Führen Sie den Befehl „watch“ aus, um die Verteilung der HTTP-Antworten des Frontend-Dienstes zu prüfen.Der gesamte Traffic wird an die Frontend v1-Bereitstellung weitergeleitet, die im neuen VirtualService definiert ist.
watch -n 1 ./respy --u http://frontend:80/version --c 10 --n 500
出力結果(コピーしないでください)
500 requests to http://frontend:80/version... +----------+-------------------+ | RESPONSE | % OF 500 REQUESTS | +----------+-------------------+ | v1 | 100.0% | | | | +----------+-------------------+
- Zurück zur vorherigen Cloud Shell-Sitzung und Ausführen der Canary-Pipeline in der Region „Dev2“ Hier finden Sie ein Skript, mit dem Sie den Anteil des Frontend v2-Traffics für einen VirtualService aktualisieren können (Gewichtung auf 20 %, 50 %, 80 % und 100 % aktualisieren).Zwischen den einzelnen Updates wartet das Skript, bis die Cloud Build-Pipeline abgeschlossen ist. Führen Sie das Canary-Bereitstellungsskript für die Dev1-Region aus.Hinweis: Die Ausführung dieses Skripts dauert etwa 10 Minuten.
cd ${CANARY_DIR}
K8S_REPO=${K8S_REPO} CANARY_DIR=${CANARY_DIR} OPS_DIR=${OPS_GKE_1_CLUSTER} OPS_CONTEXT=${OPS_GKE_1} ./auto-canary.sh
Während dieses Skript ausgeführt wird, können Sie zum zweiten Cloud Shell-Fenster wechseln, in dem der Befehl „respy“ ausgeführt wird, um die Traffic-Aufteilung in Echtzeit zu sehen.Beispiel: Bei 20 % sieht das so aus:
出力結果(コピーしないでください)
500 requests to http://frontend:80/version... +----------+-------------------+ | RESPONSE | % OF 500 REQUESTS | +----------+-------------------+ | v1 | 79.4% | | | | | v2 | 20.6% | | | | +----------+-------------------+
- frontend v2のDev1ロールアウトが完了すると、スクリプトの最後に成功メッセージが表示されます。
出力結果(コピーしないでください)
✅ 100% successfully deployed 🌈 frontend-v2 Canary Complete for gke-asm-1-r1-prod
- Außerdem muss der gesamte Frontend-Traffic von Dev1 Pod an Frontend v2 weitergeleitet werden.:
出力結果(コピーしないでください)
500 requests to http://frontend:80/version... +----------+-------------------+ | RESPONSE | % OF 500 REQUESTS | +----------+-------------------+ | v2 | 100.0% | | | | +----------+-------------------+
- **Cloud Source Repos > k8s_repoに移動します。**Für jeden Anteil des Traffics wird ein separater Commit angezeigt. Der neueste Commit wird oben in der Liste aufgeführt.:

- Dev1でrespy Podを終了します。Als Nächstes rufen Sie den respy-Pod auf, der in der Dev2-Region ausgeführt wird.
RESPY_POD=$(kubectl --context ${DEV2_GKE_1} get pod -n frontend | grep respy | awk '{ print $1 }')
kubectl --context ${DEV2_GKE_1} exec -n frontend -it $RESPY_POD -c respy /bin/sh
- respyコマンドを再度実行します。:
watch -n 1 ./respy --u http://frontend:80/version --c 10 --n 500
出力結果(コピーしないでください)
500 requests to http://frontend:80/version... +----------+-------------------+ | RESPONSE | % OF 500 REQUESTS | +----------+-------------------+ | v1 | 100.0% | | | | +----------+-------------------+
*Die Dev2-Region ist in Version 1 noch gesperrt.*Das liegt daran, dass im Baseline-Skript „repo_setup“ der VirtualService gepusht wurde, um den gesamten Traffic explizit an v1 zu senden.Auf diese Weise konnten wir regionale Kanarienvogeltests auf Dev1 sicher durchführen und prüfen, ob die neue Version ordnungsgemäß ausgeführt wurde, bevor wir sie weltweit bereitgestellt haben.
- Dev2リージョンで自動カナリアスクリプトを実行します。
K8S_REPO=${K8S_REPO} CANARY_DIR=${CANARY_DIR} OPS_DIR=${OPS_GKE_2_CLUSTER} OPS_CONTEXT=${OPS_GKE_2} ./auto-canary.sh
- Sehen Sie sich den Respy-Pod von Dev2 an. Der Traffic wird nach und nach von Frontend v1 zu Frontend v2 verschoben.スクリプトが完了すると、次のように表示されます。:
出力結果(コピーしないでください)
500 requests to http://frontend:80/version... +----------+-------------------+ | RESPONSE | % OF 500 REQUESTS | +----------+-------------------+ | v2 | 100.0% | | | | +----------+-------------------+
In diesem Abschnitt haben wir gezeigt, wie Sie Istio für regionale Canary-Bereitstellungen verwenden.In der Produktionsumgebung können Sie dieses Canary-Script als Cloud Build-Pipeline automatisch auslösen lassen. Dazu verwenden Sie Trigger wie neue getaggte Container-Images, die in die Container-Registry gepusht werden, anstelle von manuellen Skripts.Außerdem können Sie zwischen den einzelnen Schritten eine Kanarienvogel-Analyse einfügen, um die Latenz und Fehlerrate von Version 2 anhand vordefinierter Sicherheitsschwellen zu analysieren, bevor Sie Traffic senden.
10. 認可ポリシー
Ziel: RBAC zwischen Microservices einrichten (Autorisierung)
AuthorizationPolicyを作成し、マイクロサービスへのアクセスを拒否する- Mit
AuthorizationPolicyden Zugriff auf bestimmte Microservices zulassen
Anders als bei monolithischen Anwendungen, die an einem Ort ausgeführt werden können, werden bei global verteilten Microservice-Apps Aufrufe über die Netzwerkgrenzen hinweg ausgeführt.Das bedeutet, dass es mehr Einstiegspunkte für die Anwendung gibt und somit mehr Möglichkeiten für böswillige Angriffe.Außerdem haben Kubernetes-Pods temporäre IP-Adressen, sodass herkömmliche IP-Adressen-basierte Firewallregeln nicht ausreichen, um den Zugriff zwischen Arbeitslasten zu schützen.In einer Microservices-Architektur ist ein neuer Ansatz für die Sicherheit erforderlich. Basierend auf Kubernetes-Sicherheitsbausteinen wie Dienstkonten bietet Istio eine flexible Reihe von Sicherheitsrichtlinien für Anwendungen.
Istio-Richtlinien decken sowohl die Authentifizierung als auch die Autorisierung ab.認証はIDを検証し(このサーバーは本人であると言っていますか?)、認可は権限を検証します(このクライアントは許可されていますか?)。モジュール1(MeshPolicy)の相互TLSセクションでIstio認証について説明しました。In diesem Abschnitt erfahren Sie, wie Sie den Zugriff auf eine der Anwendungs-Workloads, den currencyservice, mit Istio-Autorisierungsrichtlinien steuern.
Zuerst stellen wir AuthorizationPolicy für alle vier Dev-Cluster bereit, um den gesamten Zugriff auf „currencyservice“ zu blockieren und Fehler im Frontend auszulösen.Als Nächstes sorgen wir dafür, dass nur der Frontend-Dienst auf den Währungsdienst zugreifen kann.
- Wechseln Sie zum Beispielverzeichnis für die Autorisierung.
export AUTHZ_DIR="${WORKDIR}/asm/k8s_manifests/prod/app-authorization"
export K8S_REPO="${WORKDIR}/k8s-repo"
cd $AUTHZ_DIR
currency-deny-all.yamlの内容を見てみます。Diese Richtlinie schränkt den Zugriff auf den Währungsservice mithilfe von Deployment-Label-Selektoren ein.specフィールドがないことに注意してください-これは、このポリシーが選択したサービスへのすべての アクセスを拒否することを意味します。
cat currency-deny-all.yaml
出力結果(コピーしないでください)
apiVersion: "security.istio.io/v1beta1"
kind: "AuthorizationPolicy"
metadata:
name: "currency-policy"
namespace: currency
spec:
selector:
matchLabels:
app: currencyservice
- Kopieren Sie die Währungsrichtlinie für beide Regions-Ops-Cluster in das K8s-Repository.
mkdir -p ${K8S_REPO}/${OPS_GKE_1_CLUSTER}/app-authorization/
sed -i '/ - app-ingress\//a\ \ - app-authorization\/' ${K8S_REPO}/${OPS_GKE_1_CLUSTER}/kustomization.yaml
cp currency-deny-all.yaml ${K8S_REPO}/${OPS_GKE_1_CLUSTER}/app-authorization/currency-policy.yaml
cd ${K8S_REPO}/${OPS_GKE_1_CLUSTER}/app-authorization/; kustomize create --autodetect
cd $AUTHZ_DIR
mkdir -p ${K8S_REPO}/${OPS_GKE_2_CLUSTER}/app-authorization/
sed -i '/ - app-ingress\//a\ \ - app-authorization\/' ${K8S_REPO}/${OPS_GKE_2_CLUSTER}/kustomization.yaml
cp currency-deny-all.yaml ${K8S_REPO}/${OPS_GKE_2_CLUSTER}/app-authorization/currency-policy.yaml
cd ${K8S_REPO}/${OPS_GKE_2_CLUSTER}/app-authorization/; kustomize create --autodetect
- Änderungen pushen
cd $K8S_REPO
git add . && git commit -am "AuthorizationPolicy - currency: deny all"
git push
cd $AUTHZ_DIR
- ブラウザでHipsterショップアプリのfrontendにアクセスしてみてください:
echo "https://frontend.endpoints.${TF_VAR_ops_project_name}.cloud.goog"
currencyserviceから認可エラーが表示されるはずです:
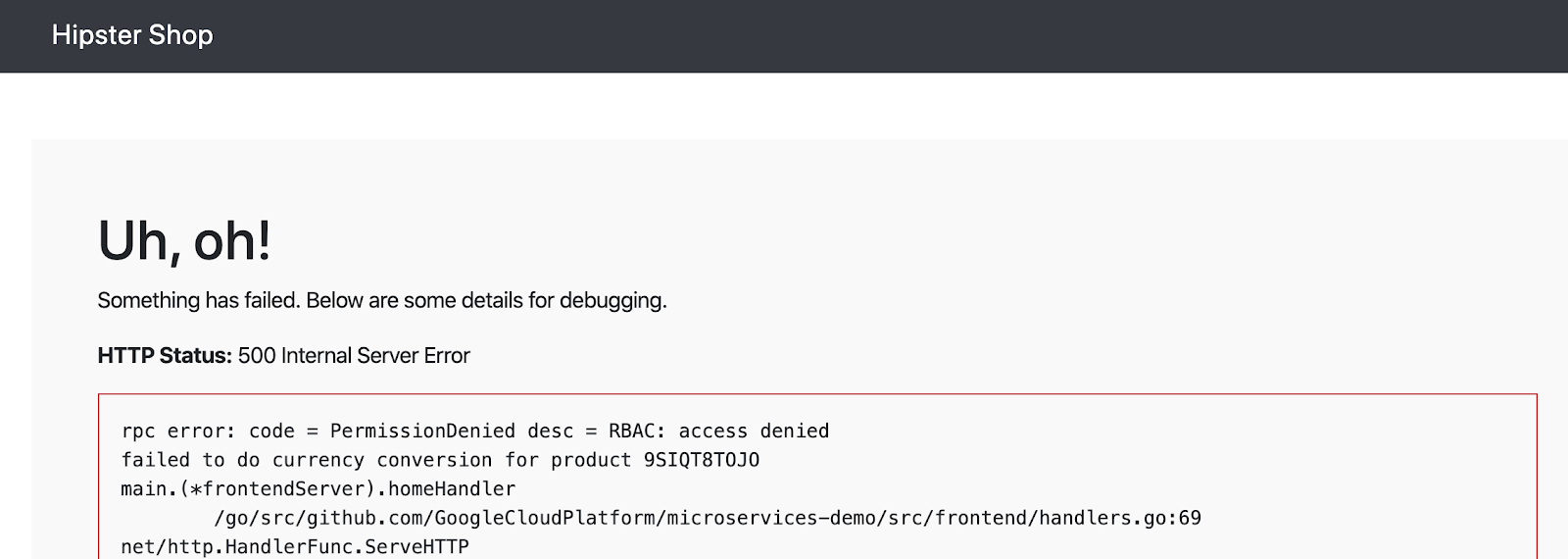
- Sehen wir uns an, wie der currency-Dienst diese AuthorizationPolicy anwendet.Zuerst müssen Sie Protokolle auf Trace-Ebene in einem der Envoy-Proxys des Währungspods aktivieren, da blockierte Autorisierungsaufrufe standardmäßig nicht protokolliert werden.
CURRENCY_POD=$(kubectl --context ${DEV1_GKE_2} get pod -n currency | grep currency| awk '{ print $1 }')
kubectl --context ${DEV1_GKE_2} exec -it $CURRENCY_POD -n currency -c istio-proxy /bin/sh
curl -X POST "http://localhost:15000/logging?level=trace"; exit
- currencyサービスのサイドカープロキシからRBAC(認可)ログを取得します。 Sie sollten eine Meldung mit dem Hinweis „Forced Reject“ (Erzwungene Ablehnung) sehen, die darauf hinweist, dass currencyservice so konfiguriert ist, dass alle eingehenden Anfragen blockiert werden.
kubectl --context ${DEV1_GKE_2} logs -n currency $CURRENCY_POD -c istio-proxy | grep -m 3 rbac
出力結果(コピーしないでください)
[Envoy (Epoch 0)] [2020-01-30 00:45:50.815][22][debug][rbac] [external/envoy/source/extensions/filters/http/rbac/rbac_filter.cc:67] checking request: remoteAddress: 10.16.5.15:37310, localAddress: 10.16.3.8:7000, ssl: uriSanPeerCertificate: spiffe://cluster.local/ns/frontend/sa/frontend, subjectPeerCertificate: , headers: ':method', 'POST' [Envoy (Epoch 0)] [2020-01-30 00:45:50.815][22][debug][rbac] [external/envoy/source/extensions/filters/http/rbac/rbac_filter.cc:118] enforced denied [Envoy (Epoch 0)] [2020-01-30 00:45:50.815][22][debug][http] [external/envoy/source/common/http/conn_manager_impl.cc:1354] [C115][S17310331589050212978] Sending local reply with details rbac_access_denied
- Als Nächstes sorgen Sie dafür, dass das Frontend auf den Währungsservice zugreifen kann, jedoch nicht von anderen Backend-Diensten aus.
currency-allow-frontend.yamlを開き、その内容を調べます。次のルールを追加したことに確認してください。:
cat currency-allow-frontend.yaml
出力結果(コピーしないでください)
rules:
- from:
- source:
principals: ["cluster.local/ns/frontend/sa/frontend"]
Hier wird ein bestimmter source.principal (Client) auf die Whitelist gesetzt, um auf den currency-Dienst zuzugreifen.Diese source.principal wird durch das Kubernetes-Dienstkonto definiert.In diesem Fall ist das Dienstkonto, das auf die Zulassungsliste gesetzt werden soll, das Frontend-Dienstkonto des Frontend-Namespace.
Hinweis: Wenn Sie Kubernetes-Dienstkonten mit Istio AuthorizationPolicies verwenden, müssen Sie zuerst die clusterweite gegenseitige TLS-Authentifizierung aktivieren, wie in Modul 1 beschrieben.Dies ist erforderlich, damit die Anmeldedaten des Dienstkontos in die Anfrage eingebunden werden.
- Aktualisierte Währungsrichtlinie kopieren
cp $AUTHZ_DIR/currency-allow-frontend.yaml ${K8S_REPO}/${OPS_GKE_1_CLUSTER}/app-authorization/currency-policy.yaml
cp $AUTHZ_DIR/currency-allow-frontend.yaml ${K8S_REPO}/${OPS_GKE_2_CLUSTER}/app-authorization/currency-policy.yaml
- 更新をプッシュします。
cd $K8S_REPO
git add . && git commit -am "AuthorizationPolicy - currency: allow frontend"
git push
cd $AUTHZ_DIR
- Warten Sie, bis Cloud Build abgeschlossen ist.
- Öffnen Sie das Frontend der Hipster Shop-App noch einmal.Diesmal sollten keine Fehler auf der Startseite angezeigt werden.これは、frontendが現在のサービスにアクセスすることを明示的に許可しているためです。
- 次に、カートにアイテムを追加し、"place order"をクリックして、チェックアウトを実行してください。今回は、currencyサービスから価格変換エラーが表示されるはずです。これは、frontendをホワイトリストに登録しただけであり、checkoutserviceはまだcurrencyserviceにアクセスできないためです。
- 最後に fügen Sie der AuthorizationPolicy eine weitere Regel hinzu, damit der Checkout-Dienst auf den Währungsservice zugreifen kann.Beachten Sie, dass nur der Zugriff auf den Währungsservice von den beiden Diensten „Frontend“ und „Checkout“ aus möglich ist.Andere Backend-Dienste werden weiterhin blockiert.
currency-allow-frontend-checkout.yamlを開き、その内容を見てみます。Die Liste der Regeln funktioniert als logisches ODER.currency serviceは、これら2つのサービスアカウントのいずれかを持つワークロードからの要求のみを受け入れます。
cat currency-allow-frontend-checkout.yaml
出力結果(コピーしないでください)
apiVersion: "security.istio.io/v1beta1"
kind: "AuthorizationPolicy"
metadata:
name: "currency-policy"
namespace: currency
spec:
selector:
matchLabels:
app: currencyservice
rules:
- from:
- source:
principals: ["cluster.local/ns/frontend/sa/frontend"]
- from:
- source:
principals: ["cluster.local/ns/checkout/sa/checkout"]
- Kopieren Sie die endgültigen Autorisierungsrichtlinien in das k8s-Repository.
cp $AUTHZ_DIR/currency-allow-frontend-checkout.yaml ${K8S_REPO}/${OPS_GKE_1_CLUSTER}/app-authorization/currency-policy.yaml
cp $AUTHZ_DIR/currency-allow-frontend-checkout.yaml ${K8S_REPO}/${OPS_GKE_2_CLUSTER}/app-authorization/currency-policy.yaml
- 更新をプッシュします。
cd $K8S_REPO
git add . && git commit -am "AuthorizationPolicy - currency: allow frontend and checkout"
git push
- Warten Sie, bis Cloud Build abgeschlossen ist.
- チェックアウトを実行してみてください。正常に動作するはずです。
In diesem Abschnitt haben wir beschrieben, wie Sie mit Istio-Autorisierungsrichtlinien eine detaillierte Zugriffssteuerung auf Dienstebene implementieren können.In der Produktionsumgebung erstellen Sie für jeden Dienst eine AuthorizationPolicy und verwenden beispielsweise die allow-all-Richtlinie, damit alle Arbeitslasten im selben Namespace aufeinander zugreifen können.
11. Infrastrukturskalierung
Ziel: Neue Regionen, Projekte und Cluster hinzufügen und die Infrastruktur skalieren
infrastructureリポジトリをクローン- 新しいリソースを作成するため、terraformファイルを更新
- Zwei Subnetze in der neuen Region (eines für das Ops-Projekt und eines für das neue Projekt)
- 新しいリージョンに新しいopsクラスター (新しいサブネット内に)
- Neue Istio-Steuerungsebene in neuen Regionen
- Neue Projekt mit zwei App-Clustern in einer neuen Region
infrastructureリポジトリにコミット- セットアップを確認
Es gibt verschiedene Möglichkeiten, eine Plattform zu skalieren.既存のクラスターにノードを追加することにより、さらに計算リソースを追加できます。Sie können der Region weitere Cluster hinzufügen.Sie können der Plattform auch weitere Regionen hinzufügen.Welche Aspekte der Plattform erweitert werden sollen, hängt von den Anforderungen ab.Wenn Sie beispielsweise in allen drei Zonen einer Region Cluster haben, reicht es wahrscheinlich aus, den vorhandenen Clustern Knoten (oder Knotenpools) hinzuzufügen.Wenn jedoch in zwei der drei Zonen einer Region Cluster vorhanden sind, können Sie durch Hinzufügen eines neuen Clusters in der dritten Zone die Skalierung und eine zusätzliche Fehlerdomain (d. h. die neue Zone) erreichen.Ein weiterer Grund, einer Region neue Cluster hinzuzufügen, sind regulatorische oder Compliance-Gründe, z. B. wenn ein einzelner Mandantencluster für PCI- oder PII-Informationen (personenbezogene Daten) erforderlich ist.ビジネスとサービスが拡大するにつれて、クライアントにより近くでサービスを提供するために新しいリージョンを追加することが避けられなくなります。
Die aktuelle Plattform besteht aus zwei Regionen und einem Cluster mit zwei Zonen in jeder Region.プラットフォームのスケーリング kann auf zwei Arten erfolgen::
- Vertikal: Fügt der Region mehr Rechenleistung hinzu.Dies geschieht durch Hinzufügen von Knoten (oder Knotenpools) zu einem vorhandenen Cluster oder durch Hinzufügen eines neuen Clusters in einer Region.これは、
infrastructureリポジトリを介して行われます。Die einfachste Methode ist, einem vorhandenen Cluster einen Knoten hinzuzufügen.追加の構成は必要ありません。Zum Hinzufügen eines neuen Clusters müssen Sie möglicherweise zusätzliche Subnetze (und sekundäre Bereiche) hinzufügen, geeignete Firewallregeln hinzufügen, den neuen Cluster der ASM-/Istio-Service-Mesh-Steuerungsebene der Region hinzufügen und Anwendungsressourcen im neuen Cluster bereitstellen. - Horizontal: Es werden weitere Regionen hinzugefügt.Die aktuelle Plattform bietet Vorlagen für Regionen. ASM / Istio-Steuerungsebenen bestehen aus einem regionalen Ops-Cluster, in dem die Steuerungsebene gehostet wird, und zwei oder mehr zonenbasierten Anwendungsclustern, in denen die Anwendungsressourcen bereitgestellt werden.
In diesem Workshop werden auch Schritte für vertikale Anwendungsfälle behandelt, sodass die Plattform horizontal skaliert wird.Um die Plattform zu skalieren, indem Sie der Plattform horizontal eine neue Region (r3) hinzufügen, müssen Sie die folgenden Ressourcen hinzufügen::
- Neue Vorgänge und Anwendungscluster – Subnetz des Hostprojekts in der freigegebenen VPC in Region r3
- Regionaler Ops-Cluster in Region r3 mit ASM-/Istio-Steuerungsebene
- 2つのゾーンアプリケーションクラスター(リージョンr3の2つのゾーンにある)
- k8s-repoへの更新:
- ASM-/Istio-Kontrollebenenressourcen in Ops-Cluster in Region r3 bereitstellen
- ASM / Istio共有-Kontrollebene-Ressourcen in App-Cluster in Region r3 bereitstellen
- Sie müssen kein neues Projekt erstellen. In der Anleitung für den Workshop wird jedoch gezeigt, wie Sie ein neues Projekt dev3 hinzufügen, um den Anwendungsfall abzudecken, in dem Sie der Plattform ein neues Team hinzufügen.
Das infrastructure-Repository wird verwendet, um die oben genannten neuen Ressourcen hinzuzufügen.
- Cloud Shellで、WORKDIRに移動し、
infrastructureリポジトリのクローンを作成します。
cd ${WORKDIR}
mkdir -p ${WORKDIR}/infra-repo
cd ${WORKDIR}/infra-repo
git init && git remote add origin https://source.developers.google.com/p/${TF_ADMIN}/r/infrastructure
git config --local user.email ${MY_USER} && git config --local user.name "infra repo user"
git config --local credential.'https://source.developers.google.com'.helper gcloud.sh
git pull origin master
- Checken Sie den
add-proj-Branch aus dem asm-Repository (Haupt-Workshop) aus.add-projブランチには、このセクションの変更内容が含まれています。
cd ${WORKDIR}/asm
git checkout add-proj
cd ${WORKDIR}
- Kopieren Sie neue und geänderte Ressourcen aus dem
add-proj-Branch des Haupt-Workshops in dasinfrastructure-Repository.
cp -r asm/infrastructure/apps/prod/app3 ./infra-repo/apps/prod/.
cp -r asm/infrastructure/cloudbuild.yaml ./infra-repo/cloudbuild.yaml
cp -r asm/infrastructure/network/prod/shared_vpc/main.tf ./infra-repo/network/prod/shared_vpc/main.tf
cp -r asm/infrastructure/network/prod/shared_vpc/variables.tf ./infra-repo/network/prod/shared_vpc/variables.tf
cp -r asm/infrastructure/ops/prod/cloudbuild/config/cloudbuild.tpl.yaml ./infra-repo/ops/prod/cloudbuild/config/cloudbuild.tpl.yaml
cp -r asm/infrastructure/ops/prod/cloudbuild/main.tf ./infra-repo/ops/prod/cloudbuild/main.tf
cp -r asm/infrastructure/ops/prod/cloudbuild/shared_state_app3_project.tf ./infra-repo/ops/prod/cloudbuild/shared_state_app3_project.tf
cp -r asm/infrastructure/ops/prod/cloudbuild/shared_state_app3_gke.tf ./infra-repo/ops/prod/cloudbuild/shared_state_app3_gke.tf
cp -r asm/infrastructure/ops/prod/k8s_repo/build_repo.sh ./infra-repo/ops/prod/k8s_repo/build_repo.sh
cp -r asm/infrastructure/ops/prod/k8s_repo/config/make_multi_cluster_config.sh ./infra-repo/ops/prod/k8s_repo/config/make_multi_cluster_config.sh
cp -r asm/infrastructure/ops/prod/k8s_repo/main.tf ./infra-repo/ops/prod/k8s_repo/main.tf
cp -r asm/infrastructure/ops/prod/k8s_repo/shared_state_app3_project.tf ./infra-repo/ops/prod/k8s_repo/shared_state_app3_project.tf
cp -r asm/infrastructure/ops/prod/k8s_repo/shared_state_app3_gke.tf ./infra-repo/ops/prod/k8s_repo/shared_state_app3_gke.tf
cp -r asm/infrastructure/ops/prod/ops_gke/main.tf ./infra-repo/ops/prod/ops_gke/main.tf
cp -r asm/infrastructure/ops/prod/ops_gke/outputs.tf ./infra-repo/ops/prod/ops_gke/outputs.tf
cp -r asm/infrastructure/ops/prod/ops_gke/variables.tf ./infra-repo/ops/prod/ops_gke/variables.tf
cp -r asm/infrastructure/ops/prod/ops_project/main.tf ./infra-repo/ops/prod/ops_project/main.tf
add-project.shスクリプトを実行します。Dieses Skript erstellt das Backend für die neuen Ressourcen, aktualisiert die Terraform-Variablen und committet die Änderungen iminfrastructure-Repository.
./asm/scripts/add-project.sh
- Durch den Commit wird das
infrastructure-Repository ausgelöst und die Infrastruktur mit neuen Ressourcen bereitgestellt.Klicken Sie auf die Ausgabe des folgenden Links, um oben zum neuesten Build zu gelangen und den Fortschritt von Cloud Build zu sehen.
echo "https://console.cloud.google.com/cloud-build/builds?project=${TF_ADMIN}"
Infrastructure Im letzten Schritt von Cloud Build werden in k8s-repo neue Kubernetes-Ressourcen erstellt.Dadurch wird Cloud Build in k8s-repo (im Ops-Projekt) ausgelöst.Die neuen Kubernetes-Ressourcen sind für die drei neuen Cluster, die im vorherigen Schritt hinzugefügt wurden. ASM-/Istio-Steuerungsebene und freigegebene Steuerungsebenenressourcen werden mit k8s-repo Cloud Build in neuen Clustern bereitgestellt.
infrastructureWenn Cloud Build erfolgreich abgeschlossen wurde, klicken Sie auf den ausgegebenen Link, um zur neuesten Cloud Build-Ausführung vonk8s-repozu gelangen.
echo "https://console.cloud.google.com/cloud-build/builds?project=${TF_VAR_ops_project_name}"
- Führen Sie das folgende Skript aus, um den neuen Cluster den Dateien „vars“ und „kubeconfig“ hinzuzufügen.
chmod +x ./asm/scripts/setup-gke-vars-kubeconfig-add-proj.sh
./asm/scripts/setup-gke-vars-kubeconfig-add-proj.sh
KUBECONFIG変数を ändern, sodass sie auf die neue kubeconfig-Datei verweisen.
source ${WORKDIR}/asm/vars/vars.sh
export KUBECONFIG=${WORKDIR}/asm/gke/kubemesh
- Listet den Clusterkontext auf. Es sollten acht Cluster angezeigt werden.
kubectl config view -ojson | jq -r '.clusters[].name'
`出力結果(コピーしないでください)`
gke_user001-200204-05-dev1-49tqc4_us-west1-a_gke-1-apps-r1a-prod gke_user001-200204-05-dev1-49tqc4_us-west1-b_gke-2-apps-r1b-prod gke_user001-200204-05-dev2-49tqc4_us-central1-a_gke-3-apps-r2a-prod gke_user001-200204-05-dev2-49tqc4_us-central1-b_gke-4-apps-r2b-prod gke_user001-200204-05-dev3-49tqc4_us-east1-b_gke-5-apps-r3b-prod gke_user001-200204-05-dev3-49tqc4_us-east1-c_gke-6-apps-r3c-prod gke_user001-200204-05-ops-49tqc4_us-central1_gke-asm-2-r2-prod gke_user001-200204-05-ops-49tqc4_us-east1_gke-asm-3-r3-prod gke_user001-200204-05-ops-49tqc4_us-west1_gke-asm-1-r1-prod
Istio-Installation prüfen
- Prüfen Sie, ob alle Pods ausgeführt werden und der Job abgeschlossen ist. Prüfen Sie außerdem, ob Istio im neuen Ops-Cluster installiert ist.
kubectl --context ${OPS_GKE_3} get pods -n istio-system
`出力結果(コピーしないでください)`
NAME READY STATUS RESTARTS AGE grafana-5f798469fd-72g6w 1/1 Running 0 5h12m istio-citadel-7d8595845-hmmvj 1/1 Running 0 5h12m istio-egressgateway-779b87c464-rw8bg 1/1 Running 0 5h12m istio-galley-844ddfc788-zzpkl 2/2 Running 0 5h12m istio-ingressgateway-59ccd6574b-xfj98 1/1 Running 0 5h12m istio-pilot-7c8989f5cf-5plsg 2/2 Running 0 5h12m istio-policy-6674bc7678-2shrk 2/2 Running 3 5h12m istio-sidecar-injector-7795bb5888-kbl5p 1/1 Running 0 5h12m istio-telemetry-5fd7cbbb47-c4q7b 2/2 Running 2 5h12m istio-tracing-cd67ddf8-2qwkd 1/1 Running 0 5h12m istiocoredns-5f7546c6f4-qhj9k 2/2 Running 0 5h12m kiali-7964898d8c-l74ww 1/1 Running 0 5h12m prometheus-586d4445c7-x9ln6 1/1 Running 0 5h12m
- Istio muss auf beiden
dev3-Clustern installiert sein.dev3クラスターで実行されるのは、Citadel、sidecar-injector、corednのみです。ops-3クラスターで実行されているIstioコントロールプレーンを共有します。
kubectl --context ${DEV3_GKE_1} get pods -n istio-system
kubectl --context ${DEV3_GKE_2} get pods -n istio-system
`出力結果(コピーしないでください)`
NAME READY STATUS RESTARTS AGE istio-citadel-568747d88-4lj9b 1/1 Running 0 66s istio-sidecar-injector-759bf6b4bc-ks5br 1/1 Running 0 66s istiocoredns-5f7546c6f4-qbsqm 2/2 Running 0 78s
Dienstermittlung für die gemeinsame Steuerungsebene prüfen
- Optional können Sie prüfen, ob das Secret in allen Ops-Clustern der sechs Anwendungscluster bereitgestellt wurde.
kubectl --context ${OPS_GKE_1} get secrets -l istio/multiCluster=true -n istio-system
kubectl --context ${OPS_GKE_2} get secrets -l istio/multiCluster=true -n istio-system
kubectl --context ${OPS_GKE_3} get secrets -l istio/multiCluster=true -n istio-system
`出力結果(コピーしないでください)`
NAME TYPE DATA AGE gke-1-apps-r1a-prod Opaque 1 14h gke-2-apps-r1b-prod Opaque 1 14h gke-3-apps-r2a-prod Opaque 1 14h gke-4-apps-r2b-prod Opaque 1 14h gke-5-apps-r3b-prod Opaque 1 5h12m gke-6-apps-r3c-prod Opaque 1 5h12m
12. サーキットブレーカー
目標: サーキットブレーカーをshippingサービスに実装
shippingにサーキットブレーカーを実装するためDestinationRuleを作成fortio(負荷生成ユーティリティ)を使用して、強制的に負荷をかけることにより、shippingサービスのサーキットブレーカーを検証
Nachdem Sie die grundlegenden Strategien für die Überwachung und Fehlerbehebung von Istio-kompatiblen Diensten kennengelernt haben, sehen wir uns an, wie Istio die Resilienz von Diensten verbessert und die Menge an Fehlerbehebung reduziert, die Sie anfangs durchführen müssen.
Die Mikroservicearchitektur birgt das Risiko von kaskadierenden Fehlern, bei denen sich der Fehler eines Dienstes auf seine Abhängigkeiten und die Abhängigkeiten seiner Abhängigkeiten auswirkt und so zu einem „Ripple-Effekt“ führt, der sich auf Endnutzer auswirken kann. Istio bietet Circuit Breaker-Traffic-Richtlinien, mit denen Dienste isoliert werden können. So wird verhindert, dass Downstream-Dienste (Clientseite) auf fehlerhafte Dienste warten, und Upstream-Dienste (Serverseite) werden vor plötzlichen Spitzen des Downstream-Traffics geschützt.Insgesamt können Sie mit Circuit Breakern verhindern, dass alle Dienste aufgrund eines hängenden Back-End-Dienstes gegen das SLO verstoßen.
Das Circuit Breaker-Muster ist nach einem elektrischen Schalter benannt, der bei zu hohem Stromfluss „auslöst“ und das Gerät vor Überlastung schützt. Im Istio-Setup ist Envoy der Circuit Breaker, der die Anzahl der ausstehenden Anfragen an einen Dienst verfolgt.In diesem Standardstatus „Geschlossen“ werden Anfragen von Envoy ohne Unterbrechung weitergeleitet.
Wenn die Anzahl der ausstehenden Anfragen jedoch einen vordefinierten Schwellenwert überschreitet, wird der Sicherungsautomat ausgelöst (geöffnet) und Envoy gibt sofort einen Fehler zurück.Dadurch wird der Server sofort für den Client nicht mehr erreichbar und der Serveranwendungscode kann bei Überlastung keine Clientanfragen mehr empfangen.
Als Nächstes wechselt Envoy nach dem definierten Zeitlimit in den halb offenen Zustand.サーバーは試用的な方法でリクエストの受信を再開できます。Wenn die Anfrage erfolgreich beantwortet werden kann, wird der Leistungsschalter wieder geschlossen und Anfragen an den Server werden wieder gesendet.
Abbildung 1 fasst das Istio-Circuit-Breaker-Muster zusammen.Das blaue Rechteck steht für Envoy, der blaue Kreis für den Client und der weiße Kreis für den Servercontainer.
Mit Istio-DestinationRules können Sie Circuit Breaker-Richtlinien definieren.In diesem Abschnitt wird beschrieben, wie die folgenden Richtlinien angewendet werden, um Unterbrecher für Versanddienste zu implementieren.:
出力結果(コピーしないでください)
apiVersion: "networking.istio.io/v1alpha3"
kind: "DestinationRule"
metadata:
name: "shippingservice-shipping-destrule"
namespace: "shipping"
spec:
host: "shippingservice.shipping.svc.cluster.local"
trafficPolicy:
tls:
mode: ISTIO_MUTUAL
connectionPool:
tcp:
maxConnections: 1
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
outlierDetection:
consecutiveErrors: 1
interval: 1s
baseEjectionTime: 10s
maxEjectionPercent: 100
Hier sind zwei DestinationRule-Felder zu beachten: **connectionPool**definiert die Anzahl der Verbindungen, die für diesen Dienst zulässig sind. Das Feld „outlierDetection“ ist der Ort, an dem Sie konfigurieren, wie Envoy den Schwellenwert für das Öffnen des Leistungsschalters bestimmt.Hier zählt Envoy die Anzahl der Fehler, die pro Sekunde (Intervall) vom Servercontainer empfangen werden. Wenn der **consecutiveErrors**-Grenzwert überschritten wird, löst der Envoy-Leistungsschalter aus und 100 % der productcatalog-Pods werden 10 Sekunden lang vor neuen Clientanfragen geschützt. Wenn der Envoy-Circuit Breaker geöffnet (aktiv) ist, erhält der Client den Fehler 503 (Service Unavailable).Sehen wir uns das einmal an.
- Gehen Sie zum Verzeichnis des Leistungsschalters.
export K8S_REPO="${WORKDIR}/k8s-repo"
export ASM="${WORKDIR}/asm"
- Aktualisieren Sie die DestinationRule für den Versanddienst in beiden Ops-Clustern.
cp $ASM/k8s_manifests/prod/istio-networking/app-shipping-circuit-breaker.yaml ${K8S_REPO}/${OPS_GKE_1_CLUSTER}/istio-networking/app-shipping-circuit-breaker.yaml
cp $ASM/k8s_manifests/prod/istio-networking/app-shipping-circuit-breaker.yaml ${K8S_REPO}/${OPS_GKE_2_CLUSTER}/istio-networking/app-shipping-circuit-breaker.yaml
cd ${K8S_REPO}/${OPS_GKE_1_CLUSTER}/istio-networking/; kustomize edit add resource app-shipping-circuit-breaker.yaml
cd ${K8S_REPO}/${OPS_GKE_2_CLUSTER}/istio-networking/; kustomize edit add resource app-shipping-circuit-breaker.yaml
- Kopieren Sie den Fortio-Pod zur Lastgenerierung in den GKE_1-Cluster in der Dev1-Region.Dies ist der Client-Pod, der zum „Auslösen“ des Circuit Breaker für den Versanddienst verwendet wird.
cp $ASM/k8s_manifests/prod/app/deployments/app-fortio.yaml ${K8S_REPO}/${DEV1_GKE_1_CLUSTER}/app/deployments/
cd ${K8S_REPO}/${DEV1_GKE_1_CLUSTER}/app/deployments; kustomize edit add resource app-fortio.yaml
- Änderungen werden übernommen.
cd $K8S_REPO
git add . && git commit -am "Circuit Breaker: shippingservice"
git push
cd $ASM
- Warten Sie, bis Cloud Build abgeschlossen ist.
- Kehren Sie zu Cloud Shell zurück und senden Sie mit dem fortio-Pod gRPC-Traffic mit einer gleichzeitigen Verbindung an den shippingService.(合計1000リクエスト)
connectionPoolDie Einstellungen wurden noch nicht überschritten, daher wird der Leistungsschalter nicht ausgelöst.
FORTIO_POD=$(kubectl --context ${DEV1_GKE_1} get pod -n shipping | grep fortio | awk '{ print $1 }')
kubectl --context ${DEV1_GKE_1} exec -it $FORTIO_POD -n shipping -c fortio /usr/bin/fortio -- load -grpc -c 1 -n 1000 -qps 0 shippingservice.shipping.svc.cluster.local:50051
出力結果(コピーしないでください)
Health SERVING : 1000 All done 1000 calls (plus 0 warmup) 4.968 ms avg, 201.2 qps
- Hier führen wir fortio noch einmal aus und erhöhen die Anzahl der gleichzeitigen Verbindungen auf 2, während die Gesamtzahl der Anfragen gleich bleibt.Aufgrund eines Leistungsschalters wird bei bis zu zwei Dritteln der Anfragen der Fehler „Überlauf“ zurückgegeben.In der definierten Richtlinie ist nur eine gleichzeitige Verbindung pro Sekunde zulässig.
kubectl --context ${DEV1_GKE_1} exec -it $FORTIO_POD -n shipping -c fortio /usr/bin/fortio -- load -grpc -c 2 -n 1000 -qps 0 shippingservice.shipping.svc.cluster.local:50051
出力結果(コピーしないでください)
18:46:16 W grpcrunner.go:107> Error making grpc call: rpc error: code = Unavailable desc = upstream connect error or disconnect/reset before headers. reset reason: overflow ... Health ERROR : 625 Health SERVING : 375 All done 1000 calls (plus 0 warmup) 12.118 ms avg, 96.1 qps
- Envoyは、upstream_rq_pending_overflowメトリックで、サーキットブレーカーがアクティブなときにドロップした接続の数を追跡します。これをfortio Podで見つけましょう。:
kubectl --context ${DEV1_GKE_1} exec -it $FORTIO_POD -n shipping -c istio-proxy -- sh -c 'curl localhost:15000/stats' | grep shipping | grep pending
出力結果(コピーしないでください)
cluster.outbound|50051||shippingservice.shipping.svc.cluster.local.circuit_breakers.default.rq_pending_open: 0 cluster.outbound|50051||shippingservice.shipping.svc.cluster.local.circuit_breakers.high.rq_pending_open: 0 cluster.outbound|50051||shippingservice.shipping.svc.cluster.local.upstream_rq_pending_active: 0 cluster.outbound|50051||shippingservice.shipping.svc.cluster.local.upstream_rq_pending_failure_eject: 9 cluster.outbound|50051||shippingservice.shipping.svc.cluster.local.upstream_rq_pending_overflow: 565 cluster.outbound|50051||shippingservice.shipping.svc.cluster.local.upstream_rq_pending_total: 1433
- Wir entfernen die Circuit Breaker-Richtlinie aus beiden Regionen, um sie zu bereinigen.
kubectl --context ${OPS_GKE_1} delete destinationrule shippingservice-circuit-breaker -n shipping
rm ${K8S_REPO}/${OPS_GKE_1_CLUSTER}/istio-networking/app-shipping-circuit-breaker.yaml
cd ${K8S_REPO}/${OPS_GKE_1_CLUSTER}/istio-networking/; kustomize edit remove resource app-shipping-circuit-breaker.yaml
kubectl --context ${OPS_GKE_2} delete destinationrule shippingservice-circuit-breaker -n shipping
rm ${K8S_REPO}/${OPS_GKE_2_CLUSTER}/istio-networking/app-shipping-circuit-breaker.yaml
cd ${K8S_REPO}/${OPS_GKE_2_CLUSTER}/istio-networking/; kustomize edit remove resource app-shipping-circuit-breaker.yaml
cd $K8S_REPO; git add .; git commit -m "Circuit Breaker: cleanup"; git push origin master
In diesem Abschnitt haben wir gezeigt, wie Sie eine einzelne Unterbrecherrichtlinie für einen Dienst festlegen.Die Best Practice besteht darin, für Upstream-Dienste (Backend) Circuit Breakers zu konfigurieren, die möglicherweise hängen bleiben. Durch die Anwendung von Istio-Unterbrecherrichtlinien können Sie Mikroservices isolieren, Fehlertoleranz in die Architektur einbauen und das Risiko von kaskadierenden Fehlern bei hoher Last verringern.
13. Fehlereinschleusung (Fault Injection)
Ziel: Die Robustheit des Empfehlungsdienstes testen, indem absichtlich Verzögerungen eingeführt werden (bevor die Änderungen in die Produktionsumgebung übertragen werden).
recommendationサービスのVirtualServiceを作成し5秒の遅延を発生させるfortio負荷発生ツールで遅延をテスト- 遅延を取り除き、確認
VirtualService
Das Hinzufügen einer Circuit Breaker-Richtlinie zu einem Dienst ist eine Möglichkeit, die Resilienz für einen laufenden Dienst zu erhöhen.Allerdings kann ein Circuit Breaker zu Fehlern führen, die möglicherweise auf Nutzerseite auftreten. Das ist nicht ideal.Um diese Fehler zu vermeiden, können Sie in der Staging-Umgebung Chaos-Tests durchführen, um genauer vorherzusagen, wie Downstream-Dienste reagieren, wenn das Backend einen Fehler zurückgibt.Chaos-Tests sind eine Methode, um Schwachstellen in einem System zu analysieren und die Fehlertoleranz zu verbessern, indem Dienste absichtlich unterbrochen werden.Mit Chaos-Tests lässt sich beispielsweise auch ermitteln, wie sich die Fehlermeldungen für Nutzer reduzieren lassen, wenn im Backend ein Fehler auftritt, indem beispielsweise gecachte Ergebnisse im Frontend angezeigt werden.
Wenn Sie Istio für die Fehlerinjektion verwenden, können Sie Fehler auf der Netzwerkebene hinzufügen, indem Sie das Image für die Betriebsversion verwenden, anstatt den Quellcode zu ändern.In der Produktionsumgebung können Sie mit Chaos-Testtools die Resilienz in der Netzwerkebene sowie in der Kubernetes-/Compute-Ebene testen.
Durch Anwenden des Felds „fault“ auf VirtualService kann Istio für Chaos-Tests verwendet werden. Istio unterstützt zwei Arten von Fehlern: 遅延フォールト(タイムアウトを挿入)と アボートフォールト(HTTPエラーを挿入)です。In diesem Beispiel wird ein Verzögerungsfehler von 5 Sekunden in den Empfehlungsdienst eingefügt.In diesem Fall verwenden wir jedoch einen Circuit Breaker, um für diesen hängenden Dienst „fail fast“ zu verwenden, anstatt dass Downstream-Dienste ein vollständiges Zeitlimit überschreiten.
- Wechseln Sie zum Verzeichnis für die Fehlerinjektion.
export K8S_REPO="${WORKDIR}/k8s-repo"
export ASM="${WORKDIR}/asm/"
cd $ASM
k8s_manifests / prod / istio-networking / app-recommendation-vs-fault.yamlを開いてその内容を検査します。 Istioには、リクエストのパーセンテージにフォールトを挿入するオプションがあることに注意してください。Hier fügen wir ein Zeitlimit für alle „recommendationservice“-Anfragen ein.
出力結果(コピーしないでください)
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: recommendation-delay-fault
spec:
hosts:
- recommendationservice.recommendation.svc.cluster.local
http:
- route:
- destination:
host: recommendationservice.recommendation.svc.cluster.local
fault:
delay:
percentage:
value: 100
fixedDelay: 5s
- Kopieren Sie VirtualService in k8s_repo.グローバルに障害を挿入するため両方のリージョンに設定を行います。
cp $ASM/k8s_manifests/prod/istio-networking/app-recommendation-vs-fault.yaml ${K8S_REPO}/${OPS_GKE_1_CLUSTER}/istio-networking/app-recommendation-vs-fault.yaml
cd ${K8S_REPO}/${OPS_GKE_1_CLUSTER}/istio-networking/; kustomize edit add resource app-recommendation-vs-fault.yaml
cp $ASM/k8s_manifests/prod/istio-networking/app-recommendation-vs-fault.yaml ${K8S_REPO}/${OPS_GKE_2_CLUSTER}/istio-networking/app-recommendation-vs-fault.yaml
cd ${K8S_REPO}/${OPS_GKE_2_CLUSTER}/istio-networking/; kustomize edit add resource app-recommendation-vs-fault.yaml
- Änderungen pushen
cd $K8S_REPO
git add . && git commit -am "Fault Injection: recommendationservice"
git push
cd $ASM
- Warten Sie, bis Cloud Build abgeschlossen ist.
- Gehen Sie zum Abschnitt „Circuit Breaker“ (Sicherung) und stellen Sie eine Verbindung zum bereitgestellten Fortio-Pod her, um etwas Traffic an den Empfehlungsservice zu senden.
FORTIO_POD=$(kubectl --context ${DEV1_GKE_1} get pod -n shipping | grep fortio | awk '{ print $1 }')
kubectl --context ${DEV1_GKE_1} exec -it $FORTIO_POD -n shipping -c fortio /usr/bin/fortio -- load -grpc -c 100 -n 100 -qps 0 recommendationservice.recommendation.svc.cluster.local:8080
fortioコマンドが完了すると、応答に平均5秒かかっていることが表示されます。
出力結果(コピーしないでください)
Ended after 5.181367359s : 100 calls. qps=19.3 Aggregated Function Time : count 100 avg 5.0996506 +/- 0.03831 min 5.040237641 max 5.177559818 sum 509.965055
- Eine weitere Möglichkeit, die in der Aktion eingefügten Fehler zu prüfen, besteht darin, das Frontend in einem Webbrowser zu öffnen und auf ein beliebiges Produkt zu klicken.Die Produktseite benötigt weitere 5 Sekunden zum Laden, da die Empfehlungen am unteren Seitenrand abgerufen werden.
- Entfernen Sie den Fault Injection-Dienst aus beiden Ops-Clustern, um sie zu bereinigen.
kubectl --context ${OPS_GKE_1} delete virtualservice recommendation-delay-fault -n recommendation
rm ${K8S_REPO}/${OPS_GKE_1_CLUSTER}/istio-networking/app-recommendation-vs-fault.yaml
cd ${K8S_REPO}/${OPS_GKE_1_CLUSTER}/istio-networking/; kustomize edit remove resource app-recommendation-vs-fault.yaml
kubectl --context ${OPS_GKE_2} delete virtualservice recommendation-delay-fault -n recommendation
rm ${K8S_REPO}/${OPS_GKE_2_CLUSTER}/istio-networking/app-recommendation-vs-fault.yaml
cd ${K8S_REPO}/${OPS_GKE_2_CLUSTER}/istio-networking/; kustomize edit remove resource app-recommendation-vs-fault.yaml
- Änderungen pushen
cd $K8S_REPO
git add . && git commit -am "Fault Injection cleanup / restore"
git push
cd $ASM
14. Istio-Steuerungsebene überwachen
ASMは、Pilot、Mixer、Galley、Citadelの4つの重要なコントロールプレーンコンポーネントをインストールします。それぞれが関連する監視メトリックをPrometheusに送信します。ASMにはGrafanaダッシュボードが付属しており、オペレータはこの監視データを視覚化し、コントロールプレーンの健全性とパフォーマンスを評価できます。
ダッシュボードを表示する
- Istioと共にインストールされたGrafanaサービスをポートフォワードします。
kubectl --context ${OPS_GKE_1} -n istio-system port-forward svc/grafana 3001:3000 >> /dev/null
- Öffnen Sie Grafana in einem Browser.
- Klicken Sie in der Cloud Shell-Konsole rechts oben auf das Symbol „Webvorschau“.
- Klicken Sie auf „Vorschau“ unter Port 3000. Hinweis: Wenn der Port nicht 3000 ist, klicken Sie auf „Port ändern“ und wählen Sie Port 3000 aus.
- Dadurch wird im Browser ein Tab mit einer URL wie BASE_URL/?orgId=1&authuser=0&environment_id=default geöffnet.
- 利用可能なダッシュボードを表示します
- URLを次のように変更します" BASE_URL/dashboard"
- Klicken Sie auf den Ordner „istio“, um die verfügbaren Dashboards aufzurufen.
- Klicken Sie auf eines dieser Dashboards, um die Leistung der entsprechenden Komponente aufzurufen.Im nächsten Abschnitt sehen wir uns die wichtigsten Messwerte für die einzelnen Komponenten an.
Pilot-Überwachung
Pilotは、データプレーン(Envoyプロキシ)にネットワークとポリシーの構成を配布するコントロールプレーンコンポーネントです。Pilot wird in der Regel entsprechend der Anzahl der Arbeitslasten und Bereitstellungen skaliert, aber nicht unbedingt entsprechend der Menge des Traffics zu diesen Arbeitslasten.正常ではないPilotは次のようになり得ます:
- 必要以上のリソースを消費します (CPU と/または RAM)
- 更新された構成情報をEnvoyにプッシュする際に遅延が生じます
Hinweis: Auch wenn der Pilot ausgefallen ist oder es zu Verzögerungen kommt, werden die Arbeitslasten weiterhin Traffic verarbeiten.
- Öffnen Sie im Browser BASE_URL/dashboard/db/istio-pilot-dashboard, um die Pilot-Messwerte aufzurufen.
Wichtige Überwachungs-Messwerte
リソース使用量
Verwenden Sie die Seite zu Leistung und Skalierbarkeit von Istio als Richtlinie für die verfügbare Nutzung.Wenn Sie deutlich mehr Ressourcen verwenden, wenden Sie sich bitte an den GCP-Support.
Pilotのプッシュ情報
In diesem Abschnitt wird die Konfiguration von Pilot-Pushs an Envoy-Proxys überwacht.
- Pilot Pushes gibt den Typ der Einstellungen an, die per Push übertragen werden.
- ADS Monitoring zeigt die Anzahl der virtuellen Dienste, Dienste und verbundenen Endpunkte im System an.
- Cluster ohne bekannte Endpunkte zeigen Endpunkte an, die konfiguriert sind, aber keine laufenden Instanzen haben. Dies kann auf externe Dienste wie *.googleapis.com hinweisen.
- Pilot Errors(Pilotfehler) gibt die Anzahl der Fehler an, die im Laufe der Zeit aufgetreten sind.
- Conflicts gibt die Anzahl der mehrdeutigen Konflikte in der Zuhörerkonfiguration an.
Wenn Fehler oder Konflikte auftreten, ist die Konfiguration von mindestens einem Dienst nicht korrekt oder nicht konsistent.Weitere Informationen finden Sie unter „Fehlerbehebung für die Datenebene“.
Envoy情報
Dieser Abschnitt enthält Informationen zu Envoy-Proxys, die eine Verbindung zum Kontroll-Layer herstellen.Wenn wiederholt XDS-Verbindungsfehler auftreten, wenden Sie sich bitte an den GCP-Support.
Mixer-Überwachung
Mixer ist eine Komponente, die Telemetrie vom Envoy-Proxy an ein Telemetrie-Backend (in der Regel Prometheus, Stackdriver usw.) weiterleitet.Diese Kapazität ist nicht im Daten-Tarif enthalten. Sie werden als zwei Kubernetes-Jobs (Mixer genannt) mit zwei verschiedenen Dienstnamen (istio-telemetry und istio-policy) bereitgestellt.
Mixerを使用して、ポリシーシステムと統合することもできます。Diese Funktion wirkt sich auf die Datenebene aus.これは、サービスへのアクセスのブロックに失敗したポリシーがMixerにチェックするためです。
Mixerは、トラフィックの量に応じてスケーリングする傾向があります。
- Öffnen Sie im Browser BASE_URL/dashboard/db/istio-mixer-dashboard, um die Mixer-Messwerte aufzurufen.
Wichtige Überwachungs-Messwerte
リソース使用量
Verwenden Sie die Seite „Istio-Leistung und ‑Skalierbarkeit“ als Richtlinie für die verfügbare Nutzung.Wenn Sie deutlich mehr Ressourcen verwenden, wenden Sie sich bitte an den GCP-Support.
Mixer概要
- Die **Antwortdauer**ist ein wichtiger Messwert. Berichte für die Mixer-Telemetrie sind nicht im Datenpfad enthalten. Wenn diese Latenzen jedoch hoch sind, wird die Leistung des Sidecar-Proxys beeinträchtigt. Das 90. Perzentil sollte im einstelligen Millisekundenbereich liegen und das 99. Perzentil sollte unter 100 Millisekunden liegen.
- Adapter Dispatch Duration gibt die Latenz an, die auftritt, wenn Mixer einen Adapter aufruft. Sie wird verwendet, um Informationen an Telemetrie- und Protokollierungssysteme zu senden.Wenn die Wartezeit hier lang ist, hat das einen direkten Einfluss auf die Leistung des Mesh.Nochmal: Die P90-Latenz muss unter 10 Millisekunden liegen.
Galleyの監視
Galley ist die Komponente, die die Konfiguration von Istio validiert, aufnimmt, verarbeitet und verteilt.Die Konfiguration wird vom Kubernetes API-Server an Pilot übergeben. Wie bei Pilot skaliert die Anzahl der Dienste und Endpunkte im System.
- Öffnen Sie im Browser BASE_URL/dashboard/db/istio-galley-dashboard, um die Galley-Messwerte aufzurufen.
Wichtige Überwachungs-Messwerte
リソース検証
Dies ist die wichtigste Messgröße, da sie die Anzahl der verschiedenen Ressourcentypen wie Zielregeln, Gateways und Serviceeinträge angibt, die die Validierung bestanden oder nicht bestanden haben.
接続されたクライアント
Galleyに接続されているクライアントの数を示します。Normalerweise sind es 3 (Pilot, istio-telemetry, istio-policy), die mit der Skalierung dieser Komponenten skaliert werden.
15. Istio-Fehlerbehebung
Fehlerbehebung für die Datenebene
Wenn im Pilot-Dashboard Probleme mit der Konfiguration angezeigt werden, müssen Sie die Pilot-Logs untersuchen oder „istioctl“ verwenden, um Konfigurationsprobleme zu finden.
Um Pilot-Logs zu untersuchen, führen Sie einen Befehl wie kubectl -n istio-system logs istio-pilot-69db46c598-45m44 discovery aus.Ersetzen Sie „istio-pilot“ durch die Pod-Kennung der Pilot-Instanz, bei der Sie die Fehlerbehebung durchführen möchten.
Suchen Sie im Ergebnislog nach der Meldung Push-Status.Beispiel:
2019-11-07T01:16:20.451967Z info ads Push Status: {
"ProxyStatus": {
"pilot_conflict_outbound_listener_tcp_over_current_tcp": {
"0.0.0.0:443": {
"proxy": "cartservice-7555f749f-k44dg.hipster",
"message": "Listener=0.0.0.0:443 AcceptedTCP=accounts.google.com,*.googleapis.com RejectedTCP=edition.cnn.com TCPServices=2"
}
},
"pilot_duplicate_envoy_clusters": {
"outbound|15443|httpbin|istio-egressgateway.istio-system.svc.cluster.local": {
"proxy": "sleep-6c66c7765d-9r85f.default",
"message": "Duplicate cluster outbound|15443|httpbin|istio-egressgateway.istio-system.svc.cluster.local found while pushing CDS"
},
"outbound|443|httpbin|istio-egressgateway.istio-system.svc.cluster.local": {
"proxy": "sleep-6c66c7765d-9r85f.default",
"message": "Duplicate cluster outbound|443|httpbin|istio-egressgateway.istio-system.svc.cluster.local found while pushing CDS"
},
"outbound|80|httpbin|istio-egressgateway.istio-system.svc.cluster.local": {
"proxy": "sleep-6c66c7765d-9r85f.default",
"message": "Duplicate cluster outbound|80|httpbin|istio-egressgateway.istio-system.svc.cluster.local found while pushing CDS"
}
},
"pilot_eds_no_instances": {
"outbound_.80_._.frontend-external.hipster.svc.cluster.local": {},
"outbound|443||*.googleapis.com": {},
"outbound|443||accounts.google.com": {},
"outbound|443||metadata.google.internal": {},
"outbound|80||*.googleapis.com": {},
"outbound|80||accounts.google.com": {},
"outbound|80||frontend-external.hipster.svc.cluster.local": {},
"outbound|80||metadata.google.internal": {}
},
"pilot_no_ip": {
"loadgenerator-778c8489d6-bc65d.hipster": {
"proxy": "loadgenerator-778c8489d6-bc65d.hipster"
}
}
},
"Version": "o1HFhx32U4s="
}
Der Push-Status gibt an, welche Probleme beim Versuch aufgetreten sind, die Konfiguration an den Envoy-Proxy zu übertragen.In diesem Fall sehen Sie mehrere Meldungen vom Typ „Cluster-Duplizierung“, die auf doppelte Upstream-Ziele hinweisen.
問題の診断に関するサポートについては、Google Cloudサポートにお問い合わせください。
設定エラーの発見
Mit dem Befehl istioctl experimental analyze -k --context $ OPS_GKE_1 können Sie die Konfiguration mit istioctl analysieren.Dadurch wird die Konfiguration des Systems analysiert und Probleme werden zusammen mit vorgeschlagenen Änderungen angezeigt.Eine vollständige Liste der Konfigurationsfehler, die mit diesem Befehl erkannt werden können, finden Sie in der Dokumentation.
16. Bereinigen
Der Administrator führt das Skript „cleanup_workshop.sh“ aus, um die vom Skript „bootstrap_workshop.sh“ erstellten Ressourcen zu entfernen.クリーンアップスクリプトを実行するには、次の情報が必要です。
- Organisationsname – z. B.
yourcompany.com - ワークショップID -
YYMMDD-NN**形式。**Beispiel:200131-01 - Administrativer GCS-Bucket – im Workshop-Erstellungsskript definiert
- Öffnen Sie Cloud Shell und führen Sie alle folgenden Aktionen darin aus.Klicken Sie auf den Link unten.
- 想定している管理者ユーザーでgcloudにログインしていることを確認します。
gcloud config list
- Gehen Sie zum asm-Ordner.
cd ${WORKDIR}/asm
- 削除する組織名とワークショップIDを定義します。
export ORGANIZATION_NAME=<ORGANIZATION NAME>
export ASM_WORKSHOP_ID=<WORKSHOP ID>
export ADMIN_STORAGE_BUCKET=<ADMIN CLOUD STORAGE BUCKET>
- So führen Sie das Bereinigungsskript aus:
./scripts/cleanup_workshop.sh --workshop-id ${ASM_WORKSHOP_ID} --admin-gcs-bucket ${ADMIN_STORAGE_BUCKET} --org-name ${ORGANIZATION_NAME}